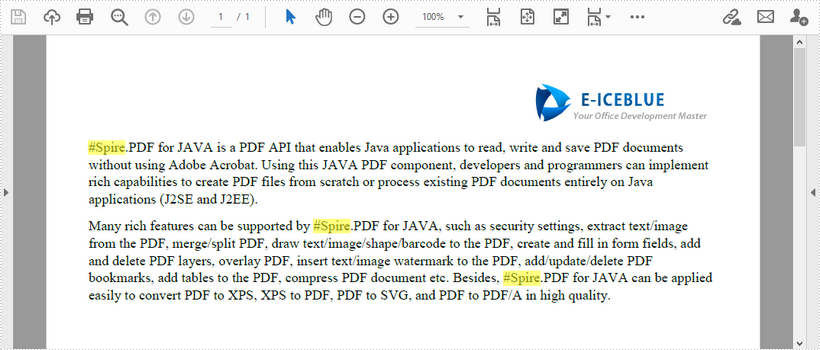
This article demonstrates how to find the text that matches a specific regular expression in a PDF document using Spire.PDF for Java.
import com.spire.pdf.*;
import com.spire.pdf.texts.*;
import java.awt.*;
import java.util.*;
import java.util.List;
public class FindText {
public static void main(String[] args) {
//Load a PDF document
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("C:\\Users\\Administrator\\Desktop\\test.pdf");
//Create a object of PdfTextFind collection
PdfTextFindOptions findOptions = new PdfTextFindOptions();
//Loop through the pages
for (Object page : (Iterable) pdf.getPages()) {
PdfPageBase pageBase = (PdfPageBase) page;
//Define a regular expression
String pattern = "\\#\\w+\\b";
// Set search parameter to use regular expression
findOptions.setTextFindParameter(EnumSet.of(TextFindParameter.Regex));
// Create a text finder object for the page
PdfTextFinder textFinder = new PdfTextFinder(pageBase);
// Find text fragments that match the pattern
List<PdfTextFragment> finds = textFinder.find(pattern, findOptions);
//Highlight the search results with yellow
for (PdfTextFragment find : finds) {
find.highLight(Color.yellow);
}
}
//Save to file
pdf.saveToFile("FindByPattern.pdf");
}
}