
Los PDF son excelentes para preservar el diseño de los documentos, pero extraer datos tabulares de ellos puede ser frustrante. La razón principal es que los PDF están diseñados para una representación visual consistente en diferentes dispositivos, no para la extracción de datos estructurados. Como resultado, las tablas pueden existir como texto seleccionable en PDF digitales o como imágenes en archivos escaneados, con estructuras que varían ampliamente.
Afortunadamente, existen varias formas prácticas de extraer tablas de PDF, dependiendo de tus necesidades y nivel de comodidad técnica. En esta guía, recorreremos cuatro métodos efectivos, desde herramientas sencillas sin código como Excel y Google Docs hasta una potente solución basada en Python para un control total y automatización.
Resumen de métodos:
- Método 1: Microsoft Excel (Importación de PDF integrada)
- Método 2: Google Docs (Gratis y Sencillo)
- Método 3: Adobe Acrobat Pro (Función de Exportación)
- Método 4: Python (Control Total y Automatización)
Método 1: Microsoft Excel (Importación de PDF integrada)
Ideal para: Usuarios de Windows con Microsoft Office 365 o Excel 2016+ (solo Windows).
Microsoft Excel tiene una función de importación de PDF nativa que funciona sorprendentemente bien para PDF digitales. Se conecta directamente al archivo e intenta detectar y convertir tablas.
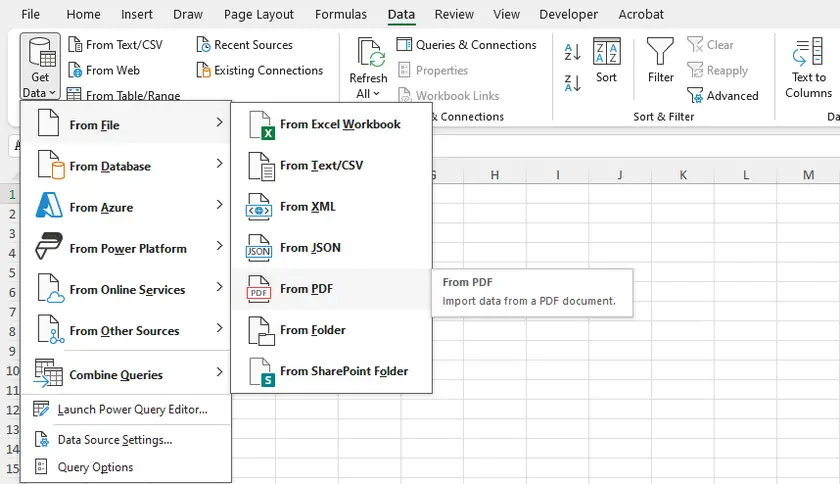
Instrucciones Paso a Paso
- Abre Microsoft Excel.
- Ve a Datos → Obtener datos → Desde archivo → Desde PDF.
- Busca y selecciona tu archivo PDF.
- Aparecerá una ventana del navegador que muestra todas las tablas y páginas detectadas.
- Selecciona las tablas que deseas y haz clic en Cargar (para importar directamente) o Transformar datos (para limpiar antes de cargar).
- Excel importará la tabla a una hoja de cálculo, conservando la estructura de filas/columnas de manera razonable.
Pros y Contras
| Pros | Contras |
|---|---|
| No se necesita software adicional (con Office) | Solo para Windows |
| Conserva formatos numéricos | Lucha con celdas combinadas |
| Bueno para PDF digitales basados en texto | Sin OCR para PDF escaneados |
| Puede actualizar datos si el PDF cambia | Puede ser lento en PDF grandes |
Método 2: Google Docs (Gratis y Sencillo)
Ideal para: Extracciones rápidas y únicas cuando no tienes Excel o herramientas de pago.
Google Docs ofrece un método oculto pero gratuito para extraer tablas de PDF. Funciona convirtiendo todo el PDF en un Google Doc editable, donde las tablas se convierten en cuadrículas basadas en texto.
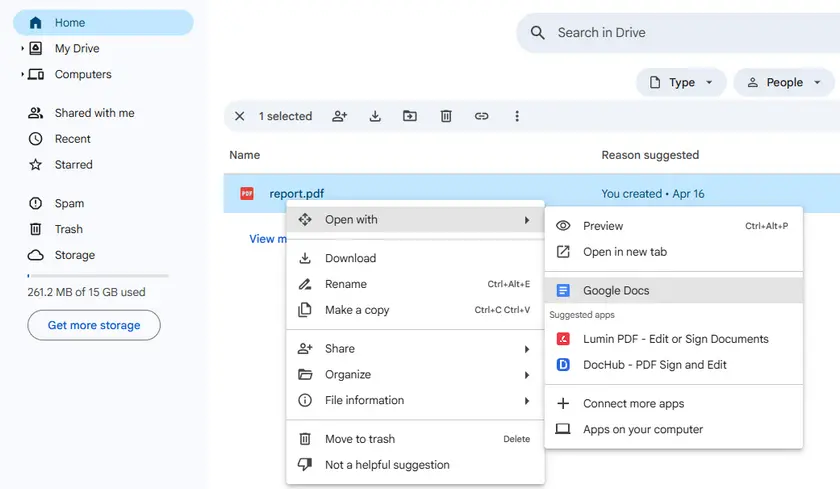
Instrucciones Paso a Paso
- Sube el PDF a Google Drive.
- Haz clic derecho en el PDF → Abrir con → Google Docs.
- Espera a que Google Docs procese el archivo.
- Desplázate para encontrar la tabla. Aparecerá como una cuadrícula basada en texto (filas y columnas separadas por espacios o tabulaciones).
- Copia el área de la tabla y pégala en Google Sheets o Microsoft Excel.
Pros y Contras
| Pros | Contras |
|---|---|
| Completamente gratis | Sin detección real de tablas (solo alineación de texto) |
| Sin instalación de software | Resultados desordenados con tablas complejas |
| Funciona en cualquier SO con un navegador | Manejo deficiente de celdas combinadas o celdas multilínea |
| Maneja tablas simples de manera confiable | Sin OCR (los PDF escaneados aparecen como imágenes) |
Método 3: Adobe Acrobat Pro (Función de Exportación)
Ideal para: Profesionales que ya tienen Acrobat Pro y necesitan exportaciones confiables de PDF digitales.
Adobe Acrobat Pro (no el Reader gratuito) tiene una función de exportación integrada que convierte tablas de PDF directamente a Excel o CSV. Conserva más formato que las herramientas gratuitas.
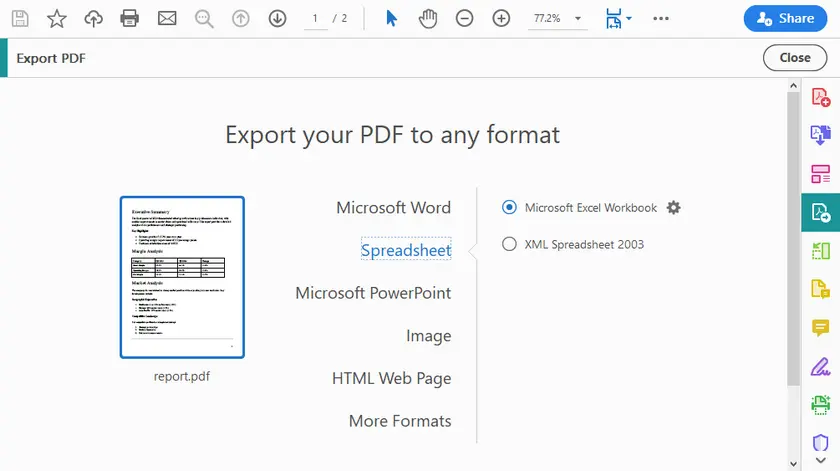
Instrucciones Paso a Paso
- Abre el PDF en Adobe Acrobat Pro.
- Haz clic en Exportar PDF (barra de herramientas derecha).
- Selecciona Hoja de cálculo → Libro de Microsoft Excel (o CSV).
- Haz clic en Exportar.
- Elige una ubicación y guarda.
- Abre el archivo Excel generado y verifica las tablas.
Consejos Adicionales
- Usa la opción Reconocer texto (OCR) primero si trabajas con PDF escaneados.
- Para tablas de varias páginas, Acrobat a menudo las concatena de forma inteligente.
- Puedes exportar solo páginas seleccionadas para ahorrar tiempo.
Pros y Contras
| Pros | Contras |
|---|---|
| Alta precisión para PDF digitales | Caro (se requiere suscripción) |
| Maneja bien tablas de varias páginas | Sin control detallado sobre la extracción |
| Conserva fórmulas y números | Todavía tiene problemas con tablas anidadas muy complejas |
| Procesamiento por lotes disponible | Solo Windows/macOS (sin versión web) |
Método 4: Python (Control Total y Automatización)
Ideal para: Desarrolladores, científicos de datos y usuarios avanzados que necesitan la máxima flexibilidad, manejan PDF escaneados o procesan archivos por lotes.
Python te da control total sobre el proceso de extracción. Puedes manejar PDF digitales con bibliotecas como pdfplumber, camelot o Spire.PDF para Python (una biblioteca comercial con una versión gratuita disponible). A continuación, se muestra un ejemplo práctico utilizando Spire.PDF para extraer tablas y guardarlas como archivos de texto limpios.
Instalación
pip install spire.pdf
Ejemplo de Código Completo (Extraer Tablas a Archivos TXT)
El siguiente código extrae todas las tablas de una página PDF específica y guarda cada tabla como un archivo de texto separado en formato similar a CSV:
from spire.pdf.common import *
from spire.pdf import *
# Crear un objeto PdfDocument
doc = PdfDocument()
# Cargar un archivo PDF
doc.LoadFromFile("report.pdf")
# Crear un objeto PdfTableExtractor
extractor = PdfTableExtractor(doc)
# Extraer tablas de una página específica (el índice de página comienza en 0)
tableList = extractor.ExtractTable(0)
# Determinar si la lista de tablas no está vacía
if tableList is not None:
# Recorrer las tablas de la página
for i in range(len(tableList)):
# Crear una nueva lista para almacenar datos de esta tabla
builder = []
# Obtener una tabla específica
table = tableList[i]
# Obtener el número de filas y columnas
row = table.GetRowCount()
column = table.GetColumnCount()
# Recorrer cada fila y columna
for m in range(row):
for n in range(column):
# Obtener texto de la celda específica
text = table.GetText(m, n)
# Agregar el texto seguido de una coma (estilo CSV)
builder.append(text + ",")
builder.append("\n") # Fin de fila
builder.append("\n") # Línea en blanco entre tablas
# Escribir el contenido en un archivo de texto
with open(f"output/Table-{i + 1}.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))
# Cerrar el documento
doc.Close()
Salida:
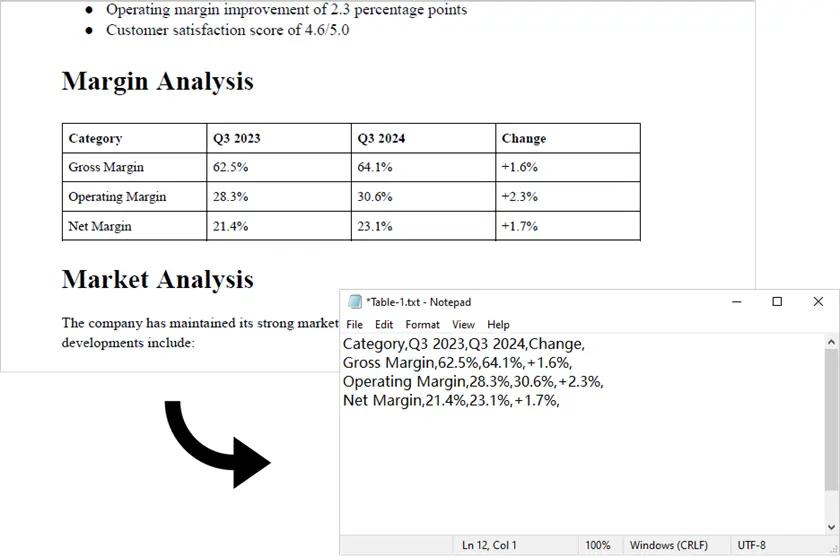
Nota: Este script solo funciona con PDF generados digitalmente (basados en texto). Para PDF escaneados, Spire.PDF por sí solo no es suficiente. En tales casos, primero puedes convertir el PDF a imágenes usando Spire.PDF, luego aplicar un motor OCR como pytesseract junto con lógica de procesamiento adicional para detectar y extraer datos de tablas.
¿Por qué Python?
- Maneja PDF digitales y escaneados (con integración OCR)
- Procesamiento por lotes de cientos de archivos
- Post-procesamiento personalizable (limpieza, fusión, validación)
- Se puede integrar en aplicaciones web, API o pipelines ETL
- Controlas exactamente cómo se formatean y guardan las tablas
Como biblioteca PDF completa, Spire.PDF para Python no solo extrae tablas de PDF, sino que también admite la extracción de imágenes, metadatos y adjuntos. Además, puede exportar documentos completos a formatos como Word, Excel y TXT.
Pros y Contras
| Pros | Contras |
|---|---|
| Control total sobre la lógica de extracción | Requiere conocimientos de programación |
| Maneja tablas complejas y de varias páginas | Curva de aprendizaje más pronunciada |
| Procesamiento por lotes de miles de archivos | Spire.PDF requiere una licencia para uso comercial (gratis para uso personal) |
| Resultados limpios y reproducibles | La detección de tablas no es perfecta en todos los PDF |
| Fácil de integrar con pandas, Excel o bases de datos |
Tabla Comparativa: Eligiendo el Método Adecuado
| Método | Facilidad de Uso | Maneja PDF Escaneados | Procesamiento por Lotes | Costo | Ideal para |
|---|---|---|---|---|---|
| Excel | Medio | x | x | Requiere Office | Tablas digitales rápidas y únicas |
| Google Docs | Alto | x | x | Gratis | Tablas simples, sin software |
| Adobe Acrobat Pro | Alto | √ | x | De pago | Usuarios profesionales no técnicos |
| Python | Bajo | √ | √ | Gratis / De pago | Máxima flexibilidad, a gran escala, PDF escaneados |
Conclusión
Extraer tablas de PDF no tiene por qué ser un dolor de cabeza. El método adecuado depende completamente de tu situación específica:
- Para una tabla simple y única → Prueba Google Docs o una herramienta en línea primero.
- Para resultados profesionales y pulidos → Usa Excel o Adobe Acrobat Pro si tienes acceso.
- Para máximo control, tablas complejas o documentos escaneados → Python es tu mejor opción.
Comienza con el método más sencillo que satisfaga tus necesidades. A medida que tus requisitos crezcan (más archivos, documentos escaneados, limpieza personalizada), siempre puedes pasar a herramientas más potentes como Python. La clave es reconocer que la extracción de tablas no es un problema único para todos, ¡y ahora tienes cuatro formas de resolverlo!
Preguntas Frecuentes
P1. ¿Por qué es difícil extraer tablas de los PDF?
Porque los PDF almacenan el contenido como texto posicionado en lugar de tablas de datos estructuradas, lo que hace que la extracción sea menos sencilla.
P2. ¿Qué método ofrece los resultados más precisos?
Adobe Acrobat Pro generalmente ofrece la mejor precisión para tablas complejas.
P3. ¿Puedo extraer tablas de PDF escaneados?
Sí, pero requiere OCR (Reconocimiento Óptico de Caracteres). Herramientas como Adobe Acrobat o Spire.PDF (con un componente OCR) pueden convertir imágenes escaneadas en texto legible por máquina, después de lo cual los datos de la tabla pueden ser detectados y extraídos.
P4. ¿Es Python mejor que otros métodos?
Depende. Python es mejor para la automatización y el procesamiento a gran escala, pero es excesivo para tareas únicas.
P5. ¿Puedo convertir tablas extraídas directamente a Excel?
Sí. La mayoría de las herramientas (Excel, Acrobat) admiten la exportación directa a .xlsx, y Python se puede extender para hacer lo mismo.