
Les PDF sont parfaits pour préserver la mise en page des documents, mais l'extraction de données tabulaires à partir d'eux peut être frustrante. La raison principale est que les PDF sont conçus pour un rendu visuel cohérent sur différents appareils, et non pour l'extraction de données structurées. Par conséquent, les tableaux peuvent exister sous forme de texte sélectionnable dans les PDF numériques ou sous forme d'images dans les fichiers numérisés, avec des structures très variables.
Heureusement, il existe plusieurs façons pratiques d'extraire des tableaux de PDF, en fonction de vos besoins et de votre niveau de confort technique. Dans ce guide, nous allons passer en revue quatre méthodes efficaces, des outils simples sans code comme Excel et Google Docs à une solution puissante basée sur Python pour un contrôle total et une automatisation.
Aperçu des méthodes :
- Méthode 1 : Microsoft Excel (Importation PDF intégrée)
- Méthode 2 : Google Docs (Gratuit et simple)
- Méthode 3 : Adobe Acrobat Pro (Fonction d'exportation)
- Méthode 4 : Python (Contrôle total et automatisation)
Méthode 1 : Microsoft Excel (Importation PDF intégrée)
Idéal pour : Les utilisateurs Windows disposant de Microsoft Office 365 ou Excel 2016+ (Windows uniquement).
Microsoft Excel dispose d'une fonctionnalité d'importation PDF native qui fonctionne étonnamment bien pour les PDF numériques. Elle se connecte directement au fichier et tente de détecter et de convertir les tableaux.
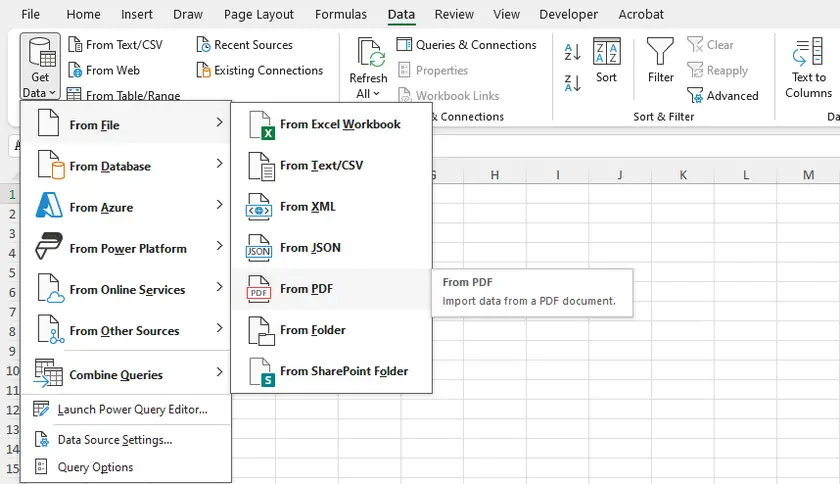
Instructions étape par étape
- Ouvrez Microsoft Excel.
- Allez dans Données → Obtenir les données → À partir d'un fichier → À partir d'un PDF.
- Parcourez et sélectionnez votre fichier PDF.
- Une fenêtre de navigateur apparaîtra, montrant tous les tableaux et pages détectés.
- Sélectionnez les tableaux que vous souhaitez et cliquez sur Charger (pour importer directement) ou sur Transformer les données (pour nettoyer avant de charger).
- Excel importera le tableau dans une feuille de calcul, en préservant raisonnablement bien la structure des lignes/colonnes.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Aucun logiciel supplémentaire requis (avec Office) | Windows uniquement |
| Préserve les formats numériques | Difficultés avec les cellules fusionnées |
| Bon pour les PDF numériques basés sur du texte | Pas d'OCR pour les PDF numérisés |
| Peut actualiser les données si le PDF est mis à jour | Peut être lent sur les PDF volumineux |
Méthode 2 : Google Docs (Gratuit et simple)
Idéal pour : Les extractions rapides et ponctuelles lorsque vous n'avez pas Excel ou d'outils payants.
Google Docs offre une méthode cachée mais gratuite pour extraire des tableaux de PDF. Elle fonctionne en convertissant l'intégralité du PDF en un Google Doc modifiable, où les tableaux deviennent des grilles textuelles.
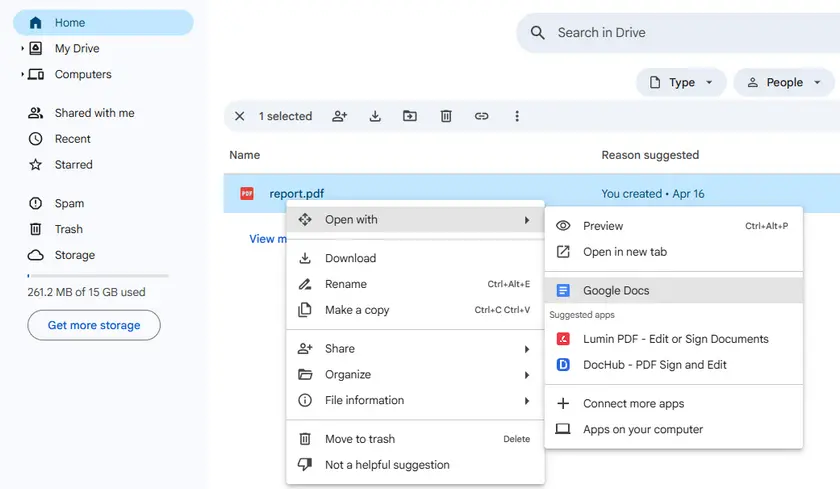
Instructions étape par étape
- Téléchargez le PDF sur Google Drive.
- Cliquez avec le bouton droit sur le PDF → Ouvrir avec → Google Docs.
- Attendez que Google Docs traite le fichier.
- Faites défiler pour trouver le tableau. Il apparaîtra sous forme de grille textuelle (lignes et colonnes séparées par des espaces ou des tabulations).
- Copiez la zone du tableau et collez-la dans Google Sheets ou Microsoft Excel.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Entièrement gratuit | Pas de détection de tableau réelle (juste alignement du texte) |
| Aucune installation de logiciel | Résultats désordonnés avec des tableaux complexes |
| Fonctionne sur n'importe quel système d'exploitation avec un navigateur | Mauvaise gestion des cellules fusionnées ou des cellules multi-lignes |
| Gère de manière fiable les tableaux simples | Pas d'OCR (les PDF numérisés apparaissent comme des images) |
Méthode 3 : Adobe Acrobat Pro (Fonction d'exportation)
Idéal pour : Les professionnels qui possèdent déjà Acrobat Pro et ont besoin d'exportations fiables à partir de PDF numériques.
Adobe Acrobat Pro (pas le lecteur gratuit) dispose d'une fonction d'exportation intégrée qui convertit les tableaux PDF directement en Excel ou CSV. Il préserve plus de formatage que les outils gratuits.
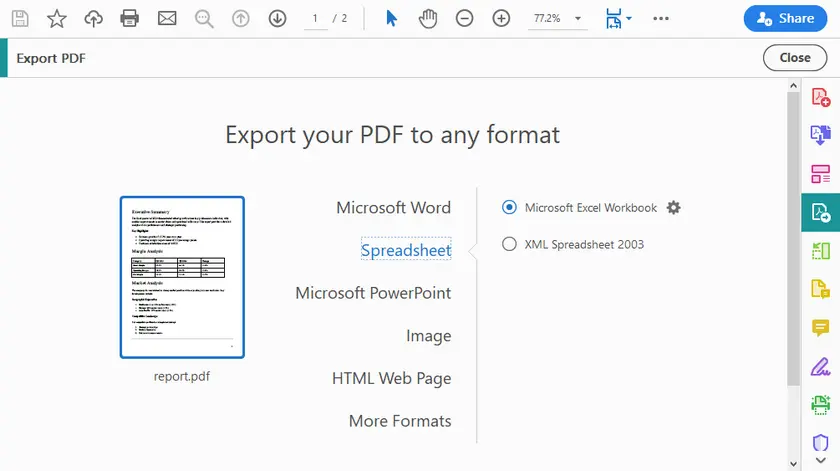
Instructions étape par étape
- Ouvrez le PDF dans Adobe Acrobat Pro.
- Cliquez sur Exporter le PDF (barre d'outils de droite).
- Sélectionnez Feuille de calcul → Classeur Microsoft Excel (ou CSV).
- Cliquez sur Exporter.
- Choisissez un emplacement et enregistrez.
- Ouvrez le fichier Excel généré et vérifiez les tableaux.
Conseils supplémentaires
- Utilisez d'abord l'option Reconnaître le texte (OCR) si vous traitez des PDF numérisés.
- Pour les tableaux multi-pages, Acrobat les concatène souvent intelligemment.
- Vous pouvez exporter uniquement des pages sélectionnées pour gagner du temps.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Haute précision pour les PDF numériques | Coûteux (abonnement requis) |
| Gère bien les tableaux multi-pages | Pas de contrôle granulaire sur l'extraction |
| Préserve les formules et les nombres | Rencontre toujours des difficultés avec les tableaux imbriqués très complexes |
| Traitement par lots disponible | Windows/macOS uniquement (pas de version web) |
Méthode 4 : Python (Contrôle total et automatisation)
Idéal pour : Les développeurs, les scientifiques des données et les utilisateurs avancés qui ont besoin d'une flexibilité maximale, traitent des PDF numérisés ou traitent des fichiers par lots.
Python vous donne un contrôle total sur le processus d'extraction. Vous pouvez traiter des PDF numériques avec des bibliothèques comme pdfplumber, camelot ou Spire.PDF pour Python (une bibliothèque commerciale avec une version gratuite disponible). Vous trouverez ci-dessous un exemple pratique utilisant Spire.PDF pour extraire des tableaux et les enregistrer sous forme de fichiers texte propres.
Installation
pip install spire.pdf
Exemple de code complet (Extraction de tableaux vers des fichiers TXT)
Le code suivant extrait tous les tableaux d'une page PDF spécifique et enregistre chaque tableau sous forme de fichier texte distinct au format CSV :
from spire.pdf.common import *
from spire.pdf import *
# Créer un objet PdfDocument
doc = PdfDocument()
# Charger un fichier PDF
doc.LoadFromFile("report.pdf")
# Créer un objet PdfTableExtractor
extractor = PdfTableExtractor(doc)
# Extraire les tableaux d'une page spécifique (l'index de page commence à 0)
tableList = extractor.ExtractTable(0)
# Déterminer si la liste de tableaux n'est pas vide
if tableList is not None:
# Parcourir les tableaux de la page
for i in range(len(tableList)):
# Créer une nouvelle liste pour stocker les données de ce tableau
builder = []
# Obtenir un tableau spécifique
table = tableList[i]
# Obtenir le nombre de lignes et le nombre de colonnes
row = table.GetRowCount()
column = table.GetColumnCount()
# Parcourir chaque ligne et colonne
for m in range(row):
for n in range(column):
# Obtenir le texte de la cellule spécifique
text = table.GetText(m, n)
# Ajouter le texte suivi d'une virgule (style CSV)
builder.append(text + ",")
builder.append("\n") # Fin de ligne
builder.append("\n") # Ligne vide entre les tableaux
# Écrire le contenu dans un fichier texte
with open(f"output/Table-{i + 1}.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))
# Fermer le document
doc.Close()
Sortie :
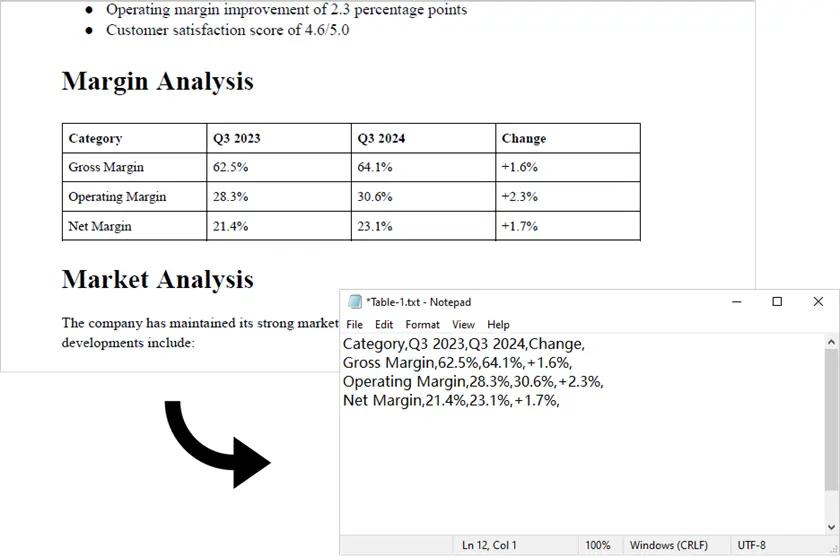
Remarque : Ce script ne fonctionne qu'avec les PDF générés numériquement (basés sur du texte). Pour les PDF numérisés, Spire.PDF seul n'est pas suffisant. Dans de tels cas, vous pouvez d'abord convertir le PDF en images à l'aide de Spire.PDF, puis appliquer un moteur OCR comme pytesseract ainsi qu'une logique de traitement supplémentaire pour détecter et extraire les données tabulaires.
Pourquoi Python ?
- Gère les PDF numériques et numérisés (avec intégration OCR)
- Traitement par lots de centaines de fichiers
- Post-traitement personnalisable (nettoyage, fusion, validation)
- Peut être intégré dans des applications web, des API ou des pipelines ETL
- Vous contrôlez exactement comment les tableaux sont formatés et enregistrés
En tant que bibliothèque PDF complète, Spire.PDF pour Python n'extrait pas seulement des tableaux de PDF, mais prend également en charge l'extraction d'images, de métadonnées et de pièces jointes. De plus, il peut exporter des documents entiers vers des formats tels que Word, Excel et TXT.
Avantages et inconvénients
| Avantages | Inconvénients |
|---|---|
| Contrôle total sur la logique d'extraction | Nécessite des connaissances en programmation |
| Gère les tableaux complexes et multi-pages | Courbe d'apprentissage plus raide |
| Traitement par lots de milliers de fichiers | Spire.PDF nécessite une licence pour un usage commercial (gratuit pour un usage personnel) |
| Résultats propres et reproductibles | La détection de tableaux n'est pas parfaite sur tous les PDF |
| Facile à intégrer avec pandas, Excel ou des bases de données |
Tableau comparatif : Choisir la bonne méthode
| Méthode | Facilité d'utilisation | Gère les PDF numérisés | Traitement par lots | Coût | Idéal pour |
|---|---|---|---|---|---|
| Excel | Moyen | x | x | Nécessite Office | Tableaux numériques rapides et ponctuels |
| Google Docs | Élevé | x | x | Gratuit | Tableaux simples, sans logiciel |
| Adobe Acrobat Pro | Élevé | √ | x | Payant | Utilisateurs professionnels non techniques |
| Python | Faible | √ | √ | Gratuit / Payant | Flexibilité maximale, à grande échelle, PDF numérisés |
Conclusion
L'extraction de tableaux de PDF ne doit pas être un casse-tête. La bonne méthode dépend entièrement de votre situation spécifique :
- Pour un tableau simple et unique → Essayez d'abord Google Docs ou un outil en ligne.
- Pour des résultats professionnels et soignés → Utilisez Excel ou Adobe Acrobat Pro si vous y avez accès.
- Pour un contrôle maximal, des tableaux complexes ou des documents numérisés → Python est votre meilleure option.
Commencez par la méthode la plus simple qui répond à vos besoins. À mesure que vos exigences augmentent (plus de fichiers, documents numérisés, nettoyage personnalisé), vous pouvez toujours passer à des outils plus puissants comme Python. L'essentiel est de reconnaître que l'extraction de tableaux n'est pas un problème universel, et vous disposez maintenant de quatre façons de le résoudre.
FAQ
Q1. Pourquoi est-il difficile d'extraire des tableaux de PDF ?
Parce que les PDF stockent le contenu sous forme de texte positionné plutôt que de tableaux de données structurées, ce qui rend l'extraction moins simple.
Q2. Quelle méthode donne les résultats les plus précis ?
Adobe Acrobat Pro offre généralement la meilleure précision pour les tableaux complexes.
Q3. Puis-je extraire des tableaux de PDF numérisés ?
Oui, mais cela nécessite l'OCR (reconnaissance optique de caractères). Des outils comme Adobe Acrobat ou Spire.PDF (avec un composant OCR) peuvent convertir des images numérisées en texte lisible par machine, après quoi les données tabulaires peuvent être détectées et extraites.
Q4. Python est-il meilleur que les autres méthodes ?
Cela dépend. Python est idéal pour l'automatisation et le traitement à grande échelle, mais excessif pour les tâches uniques.
Q5. Puis-je convertir directement les tableaux extraits en Excel ?
Oui. La plupart des outils (Excel, Acrobat) prennent en charge l'exportation directe au format .xlsx, et Python peut être étendu pour faire de même.