
PDF는 문서 레이아웃을 보존하는 데 뛰어나지만, 거기서 표 형식의 데이터를 추출하는 것은 좌절스러울 수 있습니다. 주된 이유는 PDF가 장치 간 일관된 시각적 렌더링을 위해 설계되었지, 구조화된 데이터 추출을 위해 설계되지 않았기 때문입니다. 결과적으로 표는 디지털 PDF에서는 선택 가능한 텍스트로 존재하거나 스캔된 파일에서는 이미지로 존재할 수 있으며, 구조는 매우 다양합니다.
다행히도 필요와 기술적 숙련도에 따라 PDF에서 표를 추출하는 몇 가지 실용적인 방법이 있습니다. 이 가이드에서는 간단한 노코드 도구인 Excel 및 Google Docs부터 완전한 제어 및 자동화를 위한 강력한 Python 기반 솔루션까지 네 가지 효과적인 방법을 안내해 드립니다.
방법 개요:
- 방법 1: Microsoft Excel (내장 PDF 가져오기)
- 방법 2: Google Docs (무료 및 간단)
- 방법 3: Adobe Acrobat Pro (내보내기 기능)
- 방법 4: Python (완전한 제어 및 자동화)
방법 1: Microsoft Excel (내장 PDF 가져오기)
최적: Microsoft Office 365 또는 Excel 2016+ (Windows만 해당)를 사용하는 Windows 사용자.
Microsoft Excel에는 디지털 PDF에 대해 놀라울 정도로 잘 작동하는 기본 PDF 가져오기 기능이 있습니다. 파일에 직접 연결하여 표를 감지하고 변환하려고 시도합니다.
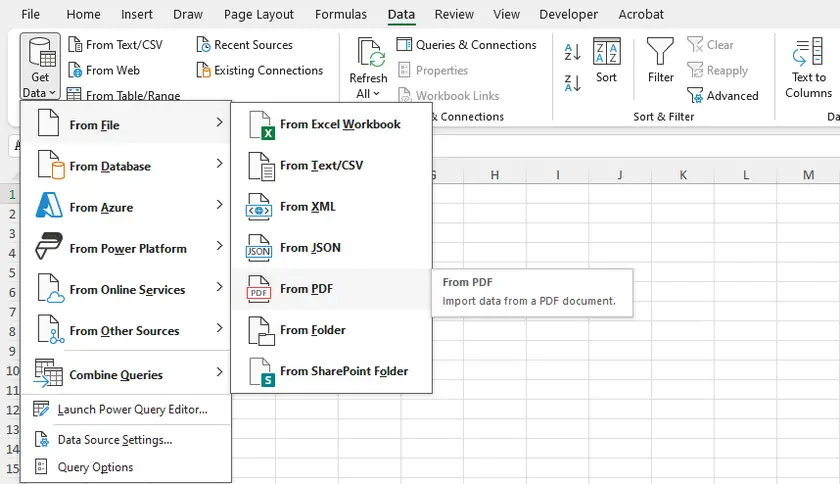
단계별 지침
- Microsoft Excel을 엽니다.
- 데이터 → 데이터 가져오기 → 파일에서 → PDF에서로 이동합니다.
- PDF 파일을 찾아 선택합니다.
- 감지된 모든 표와 페이지를 보여주는 탐색기 창이 나타납니다.
- 원하는 표를 선택하고 로드 (직접 가져오기) 또는 데이터 변환 (로드 전 정리)을 클릭합니다.
- Excel은 표를 워크시트로 가져오며 행/열 구조를 합리적으로 잘 유지합니다.
장점 및 단점
| 장점 | 단점 |
|---|---|
| 추가 소프트웨어 불필요 (Office 포함) | Windows 전용 |
| 숫자 형식 유지 | 병합된 셀에 어려움 |
| 디지털, 텍스트 기반 PDF에 적합 | 스캔된 PDF용 OCR 없음 |
| PDF 업데이트 시 데이터 새로 고침 가능 | 대용량 PDF에서 느릴 수 있음 |
방법 2: Google Docs (무료 및 간단)
최적: Excel이나 유료 도구가 없을 때 빠르고 일회성으로 추출해야 하는 경우.
Google Docs는 PDF에서 표를 추출하는 숨겨진 무료 방법을 제공합니다. 전체 PDF를 편집 가능한 Google 문서로 변환하여 표가 텍스트 기반 그리드로 표시됩니다.
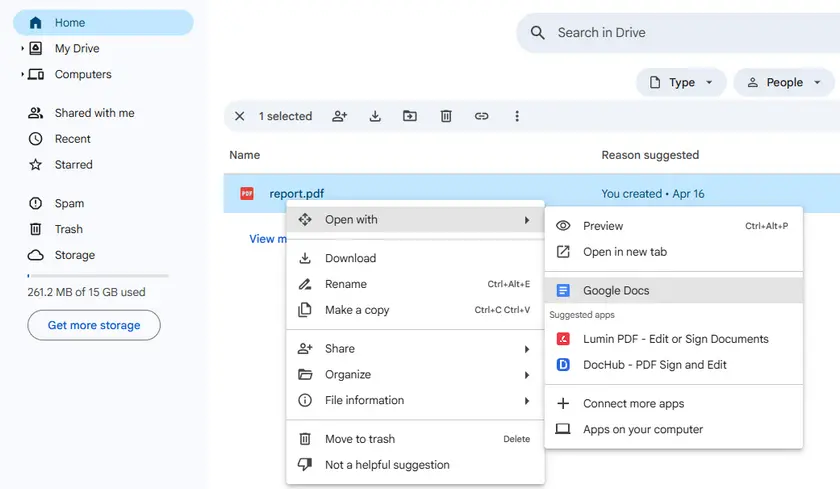
단계별 지침
- PDF를 Google Drive에 업로드합니다.
- PDF를 마우스 오른쪽 버튼으로 클릭 → 다음으로 열기 → Google Docs를 선택합니다.
- Google Docs가 파일을 처리할 때까지 기다립니다.
- 스크롤하여 표를 찾습니다. 표는 텍스트 기반 그리드 (공백 또는 탭으로 구분된 행과 열)로 표시됩니다.
- 표 영역을 복사하여 Google Sheets 또는 Microsoft Excel에 붙여넣습니다.
장점 및 단점
| 장점 | 단점 |
|---|---|
| 완전히 무료 | 진정한 표 감지 없음 (텍스트 정렬만) |
| 소프트웨어 설치 불필요 | 복잡한 표의 경우 결과가 지저분함 |
| 브라우저가 있는 모든 OS에서 작동 | 병합된 셀 또는 여러 줄 셀 처리 능력 부족 |
| 간단한 표를 안정적으로 처리 | OCR 없음 (스캔된 PDF는 이미지로 표시됨) |
방법 3: Adobe Acrobat Pro (내보내기 기능)
최적: 이미 Acrobat Pro를 사용 중이며 디지털 PDF에서 안정적인 내보내기가 필요한 전문가.
Adobe Acrobat Pro (무료 Reader 아님)에는 PDF 표를 Excel 또는 CSV로 직접 변환하는 내장 내보내기 기능이 있습니다. 무료 도구보다 더 많은 서식을 유지합니다.
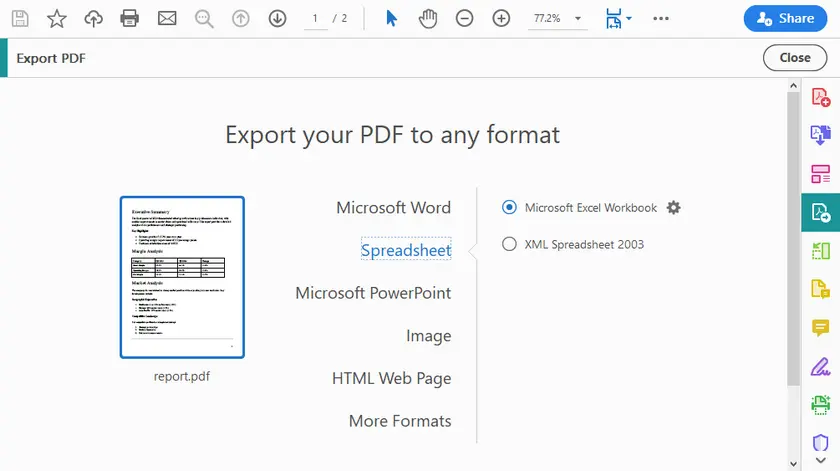
단계별 지침
- Adobe Acrobat Pro에서 PDF를 엽니다.
- PDF 내보내기 (오른쪽 도구 모음)를 클릭합니다.
- 스프레드시트 → Microsoft Excel 통합 문서 (또는 CSV)를 선택합니다.
- 내보내기를 클릭합니다.
- 위치를 선택하고 저장합니다.
- 생성된 Excel 파일을 열고 표를 확인합니다.
추가 팁
- 스캔된 PDF를 다루는 경우 먼저 텍스트 인식 (OCR) 옵션을 사용하십시오.
- 여러 페이지에 걸친 표의 경우 Acrobat은 종종 지능적으로 연결합니다.
- 시간을 절약하기 위해 선택한 페이지만 내보낼 수 있습니다.
장점 및 단점
| 장점 | 단점 |
|---|---|
| 디지털 PDF에 대한 높은 정확도 | 비쌈 (구독 필요) |
| 여러 페이지 표를 잘 처리 | 추출에 대한 세부적인 제어 없음 |
| 수식 및 숫자 유지 | 매우 복잡한 중첩 표에는 여전히 어려움 |
| 배치 처리 가능 | Windows/macOS 전용 (웹 버전 없음) |
방법 4: Python (완전한 제어 및 자동화)
최적: 최대의 유연성이 필요하고, 스캔된 PDF를 처리하거나, 배치 파일을 처리해야 하는 개발자, 데이터 과학자 및 고급 사용자.
Python은 추출 프로세스를 완벽하게 제어할 수 있게 해줍니다. pdfplumber, camelot 또는 Spire.PDF for Python (무료 버전도 제공되는 상용 라이브러리)과 같은 라이브러리를 사용하여 디지털 PDF를 처리할 수 있습니다. 아래는 Spire.PDF를 사용하여 표를 추출하고 깔끔한 텍스트 파일로 저장하는 실용적인 예입니다.
설치
pip install spire.pdf
전체 코드 예제 (표를 TXT 파일로 추출)
다음 코드는 특정 PDF 페이지에서 모든 표를 추출하여 각 표를 별도의 텍스트 파일로 CSV와 유사한 형식으로 저장합니다.
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument 객체 생성
doc = PdfDocument()
# PDF 파일 로드
doc.LoadFromFile("report.pdf")
# PdfTableExtractor 객체 생성
extractor = PdfTableExtractor(doc)
# 특정 페이지에서 표 추출 (페이지 인덱스는 0부터 시작)
tableList = extractor.ExtractTable(0)
# 표 목록이 비어 있지 않은지 확인
if tableList is not None:
# 페이지의 표들을 반복
for i in range(len(tableList)):
# 이 표의 데이터를 저장할 새 목록 생성
builder = []
# 특정 표 가져오기
table = tableList[i]
# 행 수와 열 수 가져오기
row = table.GetRowCount()
column = table.GetColumnCount()
# 각 행과 열을 반복
for m in range(row):
for n in range(column):
# 특정 셀에서 텍스트 가져오기
text = table.GetText(m, n)
# 텍스트 뒤에 쉼표 추가 (CSV 스타일)
builder.append(text + ",")
builder.append("\n") # 행 끝
builder.append("\n") # 표 간 빈 줄
# 내용을 텍스트 파일에 쓰기
with open(f"output/Table-{i + 1}.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))
# 문서 닫기
doc.Close()
출력:
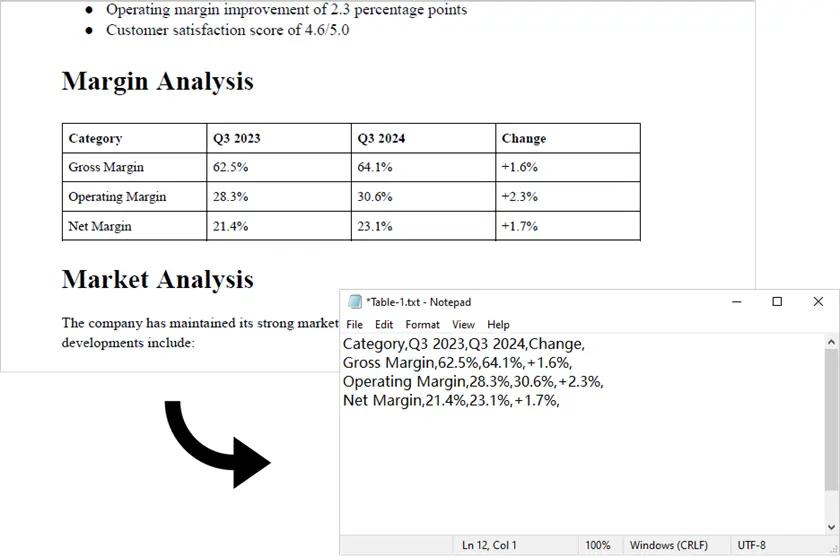
참고: 이 스크립트는 디지털로 생성된 PDF (텍스트 기반)에서만 작동합니다. 스캔된 PDF의 경우 Spire.PDF만으로는 충분하지 않습니다. 이러한 경우 Spire.PDF를 사용하여 PDF를 이미지로 먼저 변환한 다음, pytesseract와 같은 OCR 엔진과 추가 처리 로직을 적용하여 표 데이터를 감지하고 추출할 수 있습니다.
Python을 사용하는 이유?
- 디지털 및 스캔된 PDF 모두 처리 (OCR 통합 포함)
- 수백 개의 파일을 배치 처리
- 사용자 정의 가능한 후처리 (정리, 병합, 검증)
- 웹 앱, API 또는 ETL 파이프라인에 통합 가능
- 표가 어떻게 형식화되고 저장되는지 정확하게 제어
포괄적인 PDF 라이브러리인 Spire.PDF for Python은 PDF에서 표를 추출할 뿐만 아니라 이미지, 메타데이터 및 첨부 파일 추출도 지원합니다. 또한 전체 문서를 Word, Excel 및 TXT와 같은 형식으로 내보낼 수 있습니다.
장점 및 단점
| 장점 | 단점 |
|---|---|
| 추출 로직에 대한 완전한 제어 | 프로그래밍 지식 필요 |
| 복잡하고 여러 페이지에 걸친 표 처리 | 가파른 학습 곡선 |
| 수천 개의 파일을 배치 처리 | Spire.PDF는 상업적 사용 시 라이선스가 필요합니다 (개인용 무료). |
| 깔끔하고 재현 가능한 결과 | 모든 PDF에서 표 감지가 완벽하지는 않음 |
| pandas, Excel 또는 데이터베이스와 쉽게 통합 가능 |
비교표: 적합한 방법 선택
| 방법 | 사용 편의성 | 스캔된 PDF 처리 | 배치 처리 | 비용 | 최적 |
|---|---|---|---|---|---|
| Excel | 중간 | x | x | Office 필요 | 빠르고 일회성 디지털 표 |
| Google Docs | 높음 | x | x | 무료 | 간단한 표, 소프트웨어 불필요 |
| Adobe Acrobat Pro | 높음 | √ | x | 유료 | 전문가, 비기술 사용자 |
| Python | 낮음 | √ | √ | 무료 / 유료 | 최대 유연성, 대규모, 스캔된 PDF |
결론
PDF에서 표를 추출하는 것이 더 이상 골칫거리가 될 필요는 없습니다. 적합한 방법은 전적으로 특정 상황에 따라 달라집니다.
- 일회성의 간단한 표의 경우 → 먼저 Google Docs 또는 온라인 도구를 사용해 보세요.
- 전문적이고 세련된 결과를 얻으려면 → 액세스할 수 있다면 Excel 또는 Adobe Acrobat Pro를 사용하십시오.
- 최대 제어, 복잡한 표 또는 스캔된 문서의 경우 → Python이 가장 좋습니다.
필요에 맞는 가장 간단한 방법부터 시작하세요. 요구 사항이 늘어남에 따라 (더 많은 파일, 스캔된 문서, 사용자 정의 정리) 더 강력한 도구인 Python으로 전환할 수 있습니다. 핵심은 표 추출이 모든 경우에 적용되는 단일 문제가 아니라는 것을 인식하는 것입니다. 이제 이를 해결할 네 가지 방법을 알게 되었습니다.
자주 묻는 질문
Q1. PDF에서 표를 추출하기 어려운 이유는 무엇인가요?
PDF는 구조화된 데이터 표가 아닌 위치 지정된 텍스트로 콘텐츠를 저장하기 때문에 추출이 덜 간단합니다.
Q2. 어떤 방법이 가장 정확한 결과를 제공하나요?
Adobe Acrobat Pro는 일반적으로 복잡한 표에 대해 가장 좋은 정확도를 제공합니다.
Q3. 스캔된 PDF에서 표를 추출할 수 있나요?
예, 하지만 OCR (광학 문자 인식)이 필요합니다. Adobe Acrobat 또는 Spire.PDF (OCR 구성 요소 포함)와 같은 도구는 스캔된 이미지를 기계가 읽을 수 있는 텍스트로 변환할 수 있으며, 그 후 표 데이터를 감지하고 추출할 수 있습니다.
Q4. Python이 다른 방법보다 더 나은가요?
상황에 따라 다릅니다. Python은 자동화 및 대규모 처리에 가장 적합하지만, 일회성 작업에는 과도할 수 있습니다.
Q5. 추출된 표를 Excel로 직접 변환할 수 있나요?
예. 대부분의 도구 (Excel, Acrobat)는 .xlsx로 직접 내보내기를 지원하며, Python은 이를 수행하도록 확장할 수 있습니다.