
DBF와 같은 레거시 데이터베이스 형식으로 작업하는 것은 여전히 일반적이지만 이러한 파일은 데이터 분석, 보고 또는 시스템 통합과 같은 최신 워크플로우에 적합하지 않습니다. 많은 경우 데이터를 더 쉽게 사용, 공유 또는 처리하기 위해 DBF 파일을 Excel 파일로 변환해야 할 수 있습니다. Excel이나 온라인 변환기와 같은 도구는 DBF 파일을 열 수 있지만 특히 대용량 데이터 세트나 반복 가능한 작업을 처리할 때 자동화, 유연성 및 안정성이 부족합니다.
Python은 더 확장 가능한 솔루션을 제공합니다. DBF 파일을 Excel로 변환할 수 있을 뿐만 아니라 데이터를 정리하고 구조를 표준화하며 프로세스를 자동화된 워크플로우에 통합할 수 있습니다.
이 가이드에서는 재사용 가능한 명령을 구축하고 실제 사용을 위해 구조화된 Excel 출력을 생성하는 것을 포함하여 DBF-Excel 변환에 대한 실용적인 접근 방식을 다룹니다.
빠른 탐색
- DBF를 Excel로 변환하는 이유
- Python을 사용한 기본 DBF-Excel 변환
- DBF 파일에서 서식 있는 Excel 출력 생성
- 일괄 변환 및 자동 서식 지정
- DBF-Excel 변환을 위한 명령줄 도구
- 방법 비교
- 모범 사례 및 팁
- 자주 묻는 질문
DBF를 Excel로 변환하는 이유 및 일반적인 변환 방법
DBF 파일은 구조화된 데이터를 저장하지만 몇 가지 제한 사항이 있습니다.
- 레거시 인코딩 형식(종종 문자 문제 발생)
- 최신 도구와의 제한된 호환성
- 서식 또는 보고 지원 없음
DBF를 Excel(XLS/XLSX)로 변환하면 다음을 수행할 수 있습니다.
- 최신 데이터 파이프라인과 통합
- 가독성 및 사용성 향상
- 구조화된 보고 및 분석 활성화
일반적인 DBF-Excel 변환 방법
DBF 파일을 Excel 파일로 변환하는 방법에는 여러 가지가 있습니다.
- Excel에서 직접 DBF 열기
- 온라인 변환기 사용
- 레거시 데이터베이스 도구를 통해 내보내기
그러나 이러한 방법에는 명확한 한계가 있습니다.
- ❌ 자동화 없음
- ❌ 낮은 확장성
- ❌ 출력에 대한 제한된 제어
- ❌ 구조화된 보고 지원 없음
개발자 및 프로덕션 워크플로우의 경우 이러한 접근 방식으로는 충분하지 않습니다.
Python은 완전한 제어, 자동화 및 확장성을 지원하므로 더 실용적인 솔루션입니다.
Python에서 DBF를 Excel로 변환 (기본 변환)
Python에서 기본 DBF-Excel 변환을 수행하는 프로세스는 간단합니다. DBF 파일을 구조화된 형식으로 읽은 다음 Excel 파일(XLSX)로 내보냅니다.
이 워크플로우에서:
- dbf 라이브러리는 레거시 형식을 포함하여 DBF 파일을 읽고 구문 분석하는 데 사용됩니다.
- 데이터는 pandas와 같은 라이브러리(Excel 쓰기 엔진으로 openpyxl 사용)를 사용하여 구성되고 내보내집니다.
이 접근 방식은 최소한의 설정으로 DBF 파일을 Excel로 변환하는 간단하고 실용적인 방법을 제공합니다.
1단계: 종속성 설치
pip를 사용하여 필요한 라이브러리를 설치할 수 있습니다.
pip install dbf pandas openpyxl
2단계: DBF 파일 읽기
import dbf
import pandas as pd
table = dbf.Table("business_demo.dbf")
table.open()
data = [{field: record[field] for field in dbf.field_names(table)} for record in table]
df = pd.DataFrame(data)
이 단계는 DBF 레코드를 구조화된 Excel 호환 형식으로 변환합니다.
3단계: DBF를 Excel로 내보내기
df.to_excel("output.xlsx", index=False)
이 단계에서 DBF 데이터는 표준 Excel 파일(XLSX 형식)에 기록되어 기본 DBF-XLSX 변환을 완료합니다.
아래는 생성된 Excel 파일을 보여주는 이미지입니다.
이렇게 하면 직접 사용하거나 필요한 경우 추가 처리할 수 있는 깨끗하고 구조화된 데이터 세트가 생성됩니다.
이 방법이 작동하는 이유
이 방법은 변환 프로세스를 간단하고 안정적으로 유지하기 때문에 일반적으로 사용됩니다.
- DBF 레코드를 구조화된 테이블 형식으로 변환
- 필드 이름 및 데이터 구성 유지
- 다양한 DBF 변형(dBase, FoxPro 등)에서 작동
- 변환을 완료하는 데 최소한의 코드 필요
결과적으로 빠른 .dbf 파일에서 .xlsx 파일로의 작업 및 자동화된 워크플로우에 적합합니다.
이 접근 방식은 기본 변환에는 잘 작동하지만 원시 Excel 데이터만 생성하고 서식, 레이아웃 또는 보고서 구조에 대한 제어를 제공하지 않습니다.
CSV, JSON 및 XML과 같은 다른 데이터 소스에서 Excel 파일을 생성하는 작업도 하는 경우 자세한 지침은 Python으로 Excel 파일로 데이터 가져오기 방법을 참조할 수 있습니다.
기본 변환의 한계
이 기본 변환 접근 방식은 빠르고 간단한 변환에 강력하지만 Excel 파일을 내보낼 때 한계가 있습니다.
- 스타일링 또는 서식 없음
- 레이아웃 제어 없음
- 보고서 구조 없음
- 비즈니스용 출력에 대한 제한된 사용성
결과는 세련된 보고서가 아닌 원시 데이터 세트입니다.
DBF 데이터에서 전문적인 Excel 보고서 생성
기본 DBF-Excel 변환은 원시 데이터 세트만 생성합니다. 그러나 실제 시나리오에서 Excel 파일은 종종 보고, 프레젠테이션 및 의사 결정에 사용됩니다. 단순한 데이터 내보내기를 넘어 구조화된 비즈니스용 출력을 생성하려면 Spire.XLS for Python을 사용할 수 있습니다.
일반적인 프로덕션 워크플로우는 다음과 같습니다.
- dbf로 DBF 데이터 읽기
- Spire.XLS로 구조화된 Excel 데이터 쓰기
- 서식 및 레이아웃 적용
- 필요에 따라 차트 및 기타 보고서 요소 추가
이 접근 방식을 사용하면 기본 테이블에서 시각적 요소가 포함된 완전한 서식의 보고서로 Excel 파일을 점진적으로 향상시킬 수 있습니다.
1단계: 라이브러리 설치
pip를 사용하여 라이브러리를 설치할 수 있습니다.
pip install spire.xls dbf
2단계: DBF 데이터 읽기 및 Excel에 쓰기
from spire.xls import *
import dbf
table = dbf.Table("business_demo.dbf")
table.open()
data = [{field: record[field] for field in dbf.field_names(table)} for record in table]
field_names = list(dbf.field_names(table))
workbook = Workbook()
workbook.Worksheets.Clear()
sheet = workbook.Worksheets.Add("Data")
# 헤더 쓰기
for j, col in enumerate(field_names):
sheet.Range[1, j+1].Value = col
# 데이터 쓰기
for i, record in enumerate(data, start=2):
for j, col in enumerate(field_names):
sheet.Range[i, j+1].Value = str(record[col])
이 단계에서 DBF 파일은 구조화된 Excel 데이터 세트로 변환되었습니다.
3단계: 스타일 적용 및 Excel 파일로 저장
데이터가 작성되면 스타일 및 레이아웃 조정을 적용하여 가독성을 향상시킬 수 있습니다.
# 헤더 스타일링
header = sheet.Range[1, 1, 1, sheet.LastColumn]
header.Style.Font.Bold = True
header.Style.Font.Size = 12
header.Style.Color = Color.get_LightGray()
# 데이터 테두리
data_range = sheet.Range[1, 1, sheet.LastRow, sheet.LastColumn]
data_range.BorderAround(LineStyleType.Thin, ExcelColors.Black)
data_range.BorderInside(LineStyleType.Thin, ExcelColors.Black)
# 전역 글꼴
sheet.AllocatedRange.Style.Font.Name = "Arial"
# 열 자동 맞춤
sheet.AllocatedRange.AutoFitColumns()
# 통합 문서를 파일에 저장
workbook.SaveToFile("output.xlsx", ExcelVersion.Version2016)
생성된 Excel 파일은 다음과 같습니다.
API 참고
Spire.XLS는 범위 기반 스타일링 모델을 제공하여 개별 셀 대신 전체 영역에 서식을 적용할 수 있습니다.
- Range[row, col] → 특정 셀 또는 영역에 액세스
- Style.Font → 크기, 굵게, 글꼴 모음과 같은 글꼴 속성 제어
- BorderAround / BorderInside → 내부 및 외부 테두리 추가
- AllocatedRange → 데이터가 있는 모든 셀을 포함하는 워크시트에서 사용된 범위를 참조합니다.
- AutoFitColumns / AutoFitRows → 범위 내에서 열 및 행 너비 자동 조정
- SaveToFile → 지정된 형식으로 통합 문서를 파일에 저장
참고: SaveToFile 메서드의 경우 두 번째 인수는 파일 형식을 지정합니다. FileFormat.Version97to2003은 .xls 형식을 나타내고 FileFormat.Version2007 이상은 .xlsx 형식을 나타냅니다.
이 접근 방식은 최소한의 코드로 대용량 데이터 세트를 효율적으로 서식 지정할 수 있게 해줍니다.
이 시점에서 Excel 파일은 더 이상 원시 데이터가 아니며 깨끗하고 읽기 쉬운 테이블로 변환되었습니다. 그러나 여전히 완전한 보고서가 아닌 서식 있는 데이터 세트입니다.
보고서 요소 추가 (점진적 향상)
출력을 더욱 향상시키기 위해 분석 및 시각적 요소를 추가할 수 있습니다.
예제 1: 차트 추가
# REGION별 데이터 집계 (차트 작성 목적)
region_sales = defaultdict(float)
for record in data:
region = record["REGION"]
sales = float(record["SALES"])
region_sales[region] += sales
# 집계된 데이터에 대한 요약 시트 만들기
summary_sheet = workbook.Worksheets.Add("Summary")
# 요약 헤더 쓰기
summary_sheet.Range[1, 1].Value = "Region"
summary_sheet.Range[1, 2].Value = "Total Sales"
# 집계된 결과 쓰기
for i, (region, total) in enumerate(region_sales.items(), start=2):
summary_sheet.Range[i, 1].Value = region
summary_sheet.Range[i, 2].Value = total
summary_sheet.Range[2, 2, summary_sheet.LastRow, 2].NumberFormat = "$#,##0.00"
# 집계된 데이터를 기반으로 차트 만들기
chart = summary_sheet.Charts.Add()
chart.ChartType = ExcelChartType.ColumnClustered
# 데이터 범위 설정 (지역 + 총 매출)
chart.DataRange = summary_sheet.Range[
"A1:B{}".format(len(region_sales) + 1)
]
# 워크시트에 차트 배치
chart.LeftColumn = 4
chart.TopRow = 2
chart.RightColumn = 10
chart.BottomRow = 20
# 차트 제목 설정
chart.ChartTitle = "지역별 매출"
아래는 Excel 시트에 추가된 차트의 미리보기입니다.
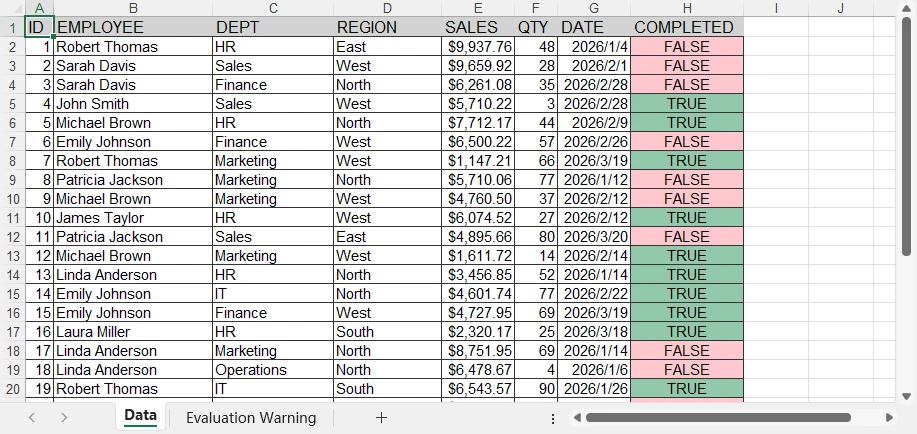
Spire.XLS를 사용하면 원형 차트 및 막대 차트와 같은 다양한 유형의 차트를 Excel 워크시트에서 만들 수 있습니다. 데이터 및 요구 사항에 따라 적절한 차트 유형을 선택하십시오.
예제 2: 조건부 서식 추가
# 지정된 범위에 조건부 서식 만들기
conditions = sheet.ConditionalFormats.Add()
conditions.AddRange(sheet.Range[2, 8, sheet.LastRow, 8])
# 조건부 서식에 규칙 추가
condition1 = conditions.AddCondition()
condition1.FormatType = ConditionalFormatType.ContainsText;
condition1.FirstFormula = "TRUE"
condition1.BackColor = Color.FromRgb(144, 200, 172)
# 조건부 서식에 다른 규칙 추가
condition2 = conditions.AddCondition()
condition2.FormatType = ConditionalFormatType.ContainsText
condition2.FirstFormula = "FALSE"
condition2.BackColor = Color.FromRgb(255, 199, 206)
아래는 조건부 서식이 적용된 생성된 Excel 파일의 미리보기입니다.
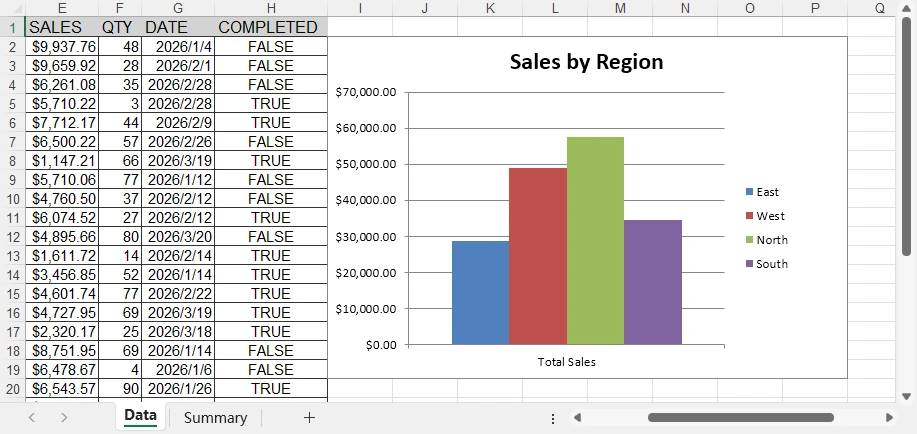
조건부 서식을 사용하면 Excel 시트에서 다양한 특수 효과를 얻을 수 있습니다. 자세한 내용은 Python을 사용하여 Excel 시트에 조건부 서식 적용 방법을 참조하십시오.
이것이 중요한 이유
이러한 향상 기능은 Excel 파일을 단순한 내보내기에서 보고 도구로 변환합니다.
이제 다음을 수행할 수 있습니다.
- 구조화된 데이터를 명확하게 제시
- 주요 정보 강조
- 차트로 추세 시각화
구조화된 데이터 처리와 고급 Excel 기능을 결합하여 레거시 DBF 파일을 최신 사용 가능한 보고서로 전환할 수 있습니다. 이 수준의 기능은 비즈니스 워크플로우, 대시보드 및 자동화된 보고 시스템에 필수적입니다.
고급 변환: 일괄 처리 및 자동 서식 지정
실제 워크플로우의 경우 DBF-Excel 변환은 종종 일회성 작업이 아닙니다. 대신 데이터 마이그레이션이나 예약된 작업과 같은 시나리오에서 특히 여러 파일을 자동으로 처리해야 할 수 있습니다.
Python을 사용하면 단일 파일에서 일괄 처리로 DBF-Excel 변환을 쉽게 확장할 수 있습니다.
DBF 파일을 Excel 파일로 일괄 변환
기본 Excel 파일만 생성해야 하는 경우 변환 논리를 os 모듈과 결합하여 디렉토리의 모든 DBF 파일을 처리할 수 있습니다.
import os
import dbf
import pandas as pd
input_folder = "dbf_files"
output_folder = "excel_files"
for file in os.listdir(input_folder):
if file.endswith(".dbf"):
table = dbf.Table(os.path.join(input_folder, file))
table.open()
df = pd.DataFrame([dict(record) for record in table])
output_file = file.replace(".dbf", ".xlsx")
df.to_excel(os.path.join(output_folder, output_file), index=False)
이 접근 방식은 여러 파일에 걸쳐 자동화된 DBF-Excel 내보내기를 가능하게 하며 다음에 적합합니다.
- 레거시 시스템 마이그레이션
- 데이터 동기화
- 예약된 ETL 워크플로우
자동 서식 지정을 사용한 일괄 변환
비즈니스 데이터로 작업할 때 원시 Excel 파일을 내보내는 것만으로는 충분하지 않은 경우가 많습니다. 생성된 모든 파일에 걸쳐 일관된 서식과 구조화된 출력이 필요할 수도 있습니다.
Spire.XLS for Python을 사용하면 일괄 변환 중에 자동으로 서식을 적용할 수 있습니다.
import os
import dbf
from spire.xls import *
input_folder = "dbf_files"
output_folder = "formatted_reports"
for file in os.listdir(input_folder):
if file.endswith(".dbf"):
table = dbf.Table(os.path.join(input_folder, file))
table.open()
data = [{field: record[field] for field in dbf.field_names(table)} for record in table]
field_names = list(dbf.field_names(table))
workbook = Workbook()
workbook.Worksheets.Clear()
sheet = workbook.Worksheets.Add("Data")
# 헤더 쓰기
for j, col in enumerate(field_names):
sheet.Range[1, j+1].Value = col
# 데이터 쓰기
for i, record in enumerate(data, start=2):
for j, col in enumerate(field_names):
sheet.Range[i, j+1].Value = str(record[col])
# 기본 제공 스타일로 테이블 만들기
table_range = sheet.AllocatedRange
table_obj = sheet.ListObjects.Create("Data", table_range)
table_obj.BuiltInTableStyle = TableBuiltInStyles.TableStyleMedium13
# 레이아웃 자동 맞춤
sheet.AllocatedRange.AutoFitColumns()
# 파일 저장
output_file = file.replace(".dbf", ".xlsx")
workbook.SaveToFile(os.path.join(output_folder, output_file), FileFormat.Version2016)
workbook.Dispose()
아래는 데이터에 적용된 기본 제공 테이블 스타일의 미리보기입니다.
이 접근 방식이 중요한 이유
일괄 처리와 자동 서식 지정을 결합하면 다음을 수행할 수 있습니다.
- 하나의 워크플로우에서 여러 DBF 파일을 Excel로 변환
- 모든 출력에서 일관된 구조 및 스타일링 보장
- 보고서 생성 시 수동 작업 감소
- 자동화된 파이프라인에 변환 통합
이렇게 하면 간단한 DBF 파일-Excel 변환 작업이 확장 가능하고 프로덕션에 즉시 사용 가능한 솔루션으로 바뀝니다.
Spire.XLS를 사용하면 Excel 파일과 데이터베이스 간에 데이터를 쉽게 전송할 수 있습니다. 자세한 내용은 Python에서 Excel과 데이터베이스 간의 데이터 전송을 참조하십시오.
DBF-Excel 변환을 위한 명령줄 도구
일괄 처리 외에도 변환 논리를 재사용 가능한 명령줄 도구로 전환하여 자동화를 더욱 향상시킬 수 있습니다.
이를 통해 터미널에서 직접 DBF-Excel 변환을 실행할 수 있으므로 스크립트, 예약된 작업 및 백엔드 워크플로우에 적합합니다.
명령줄 인터페이스 만들기
변환 논리를 입력 및 출력 경로를 인수로 받는 Python 스크립트로 래핑할 수 있습니다.
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
명령 사용
스크립트가 준비되면 명령줄에서 실행할 수 있습니다.
python convert.py data.dbf output.xlsx
이 접근 방식을 사용하면 다양한 환경에서 동일한 변환 논리를 재사용하고 최소한의 노력으로 변환을 자동화된 워크플로우에 통합할 수 있습니다.
기본 변환 대 Spire.XLS for Python
DBF 파일을 Excel로 변환할 때 접근 방식의 선택은 목표에 따라 다릅니다.
| 기능 | 기본 변환 (예: pandas 및 dbf) | Spire.XLS for Python 및 dbf |
|---|---|---|
| DBF-Excel 내보내기 | ✅ | ✅ |
| 일괄 처리 | ✅ | ✅ |
| 서식 및 스타일링 | ❌ | ✅ |
| 보고서 구조 | ❌ | ✅ |
| 차트 및 시각화 | ❌ | ✅ |
각 접근 방식을 사용해야 하는 경우
다음과 같은 경우 기본 변환을 사용하십시오.
- DBF를 Excel로 변환하기만 하면 됩니다.
- 출력은 저장 또는 추가 처리에 사용됩니다.
- 서식이나 보고가 필요하지 않습니다.
다음과 같은 경우 Spire.XLS for Python 및 dbf를 사용하십시오.
- 구조화된 Excel 보고서가 필요합니다.
- 서식과 레이아웃이 중요합니다.
- 차트나 시각적 요소를 포함하고 싶습니다.
올바른 접근 방식을 선택하면 특히 간단한 .dbf 파일에서 .xlsx 파일로의 변환에서 자동화된 보고 워크플로우로 이동할 때 효율성과 출력 품질을 모두 크게 향상시킬 수 있습니다.
DBF-Excel 변환을 위한 모범 사례
인코딩을 신중하게 처리
table = dbf.Table("file.dbf", codepage="cp1252")
DBF 파일은 소스에 따라 다른 인코딩을 사용할 수 있습니다. 문자 손상을 방지하려면 항상 올바른 코드 페이지를 확인하십시오.
데이터 유형 확인
DBF 필드가 항상 Excel 형식에 깔끔하게 매핑되는 것은 아닙니다. 내보내기 전에 숫자, 날짜 및 부울 값을 확인하여 정확성을 보장하십시오.
대용량 파일 최적화
대용량 데이터 세트로 작업할 때:
- 데이터를 청크 단위로 처리
- 모든 레코드를 한 번에 메모리에 로드하지 마십시오.
변환 및 보고 분리
더 나은 유연성과 유지 관리를 위해:
- DBF-Excel 변환에 간단한 접근 방식 사용
- 필요할 때만 서식 및 보고서 요소 적용
결론
DBF 파일을 Excel로 변환하는 것은 종종 단순한 형식 변경 그 이상입니다. 레거시 데이터를 더 쉽게 사용, 공유 및 분석할 수 있도록 만드는 것입니다.
Python을 사용하면 간단한 DBF-Excel 변환으로 시작하여 일괄 처리 및 자동화된 워크플로우로 확장할 수 있습니다. 기본 요구 사항의 경우 가벼운 접근 방식이 잘 작동합니다. 그러나 구조화된 레이아웃, 일관된 서식 또는 시각적 요소가 필요한 경우 고급 Excel 기능이 중요해집니다.
전문적이고 보고서에 즉시 사용 가능한 Excel 파일을 생성하려는 경우 Spire.XLS for Python을 사용해 볼 수 있습니다. 무료 30일 라이선스가 제공되어 실제 시나리오에서 전체 기능을 탐색할 수 있습니다.
자주 묻는 질문
Python에서 DBF 파일을 Excel로 변환하려면 어떻게 해야 합니까?
Python 기반 접근 방식을 사용하여 DBF 데이터를 읽고 Excel로 내보냅니다. 예를 들어 dbf를 pandas와 같은 도구와 결합하여 빠른 DBF 파일-Excel 파일 변환을 수행할 수 있습니다.
DBF를 XLSX로 변환하는 가장 좋은 방법은 무엇입니까?
요구 사항에 따라 다릅니다.
- 간단한 변환의 경우 → 기본 Python 접근 방식 사용
- 서식 있는 보고서의 경우 → Spire.XLS for Python 사용
DBF 파일을 Excel로 직접 가져올 수 있습니까?
예, 하지만 자동화나 대용량 데이터 세트에는 적합하지 않습니다. Python은 더 안정적이고 확장 가능한 솔루션을 제공합니다.
내 Excel 파일에 서식이 지정되지 않은 이유는 무엇입니까?
기본 변환 방법은 스타일링 없이 원시 데이터만 내보냅니다. 서식 있는 Excel 보고서를 생성하려면 Spire.XLS for Python과 같이 레이아웃 및 스타일링을 지원하는 도구가 필요합니다.
DBF를 Excel로 변환하는 명령을 만들려면 어떻게 해야 합니까?
변환 논리를 스크립트로 래핑하고 입력/출력 경로를 인수로 전달합니다. 이를 통해 명령줄에서 직접 DBF-Excel 변환을 실행할 수 있습니다.