
Os PDFs são ótimos para preservar layouts de documentos, mas extrair dados tabulares deles pode ser frustrante. A principal razão é que os PDFs são projetados para renderização visual consistente em diferentes dispositivos, não para extração de dados estruturados. Como resultado, as tabelas podem existir como texto selecionável em PDFs digitais ou como imagens em arquivos digitalizados, com estruturas variando amplamente.
Felizmente, existem várias maneiras práticas de extrair tabelas de PDFs, dependendo de suas necessidades e nível de conforto técnico. Neste guia, abordaremos quatro métodos eficazes, desde ferramentas simples sem código como Excel e Google Docs até uma poderosa solução baseada em Python para controle total e automação.
Visão geral dos métodos:
- Método 1: Microsoft Excel (Importação de PDF Integrada)
- Método 2: Google Docs (Gratuito e Simples)
- Método 3: Adobe Acrobat Pro (Funcionalidade de Exportação)
- Método 4: Python (Controle Total e Automação)
Método 1: Microsoft Excel (Importação de PDF Integrada)
Ideal para: Usuários do Windows com Microsoft Office 365 ou Excel 2016+ (apenas Windows).
O Microsoft Excel possui um recurso nativo de importação de PDF que funciona surpreendentemente bem para PDFs digitais. Ele se conecta diretamente ao arquivo e tenta detectar e converter tabelas.
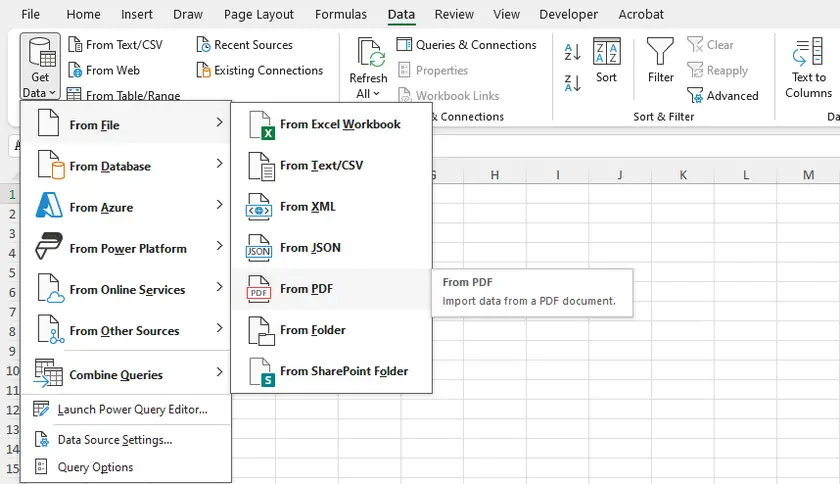
Instruções Passo a Passo
- Abra o Microsoft Excel.
- Vá para Dados → Obter Dados → De Arquivo → De PDF.
- Navegue e selecione seu arquivo PDF.
- Uma janela do navegador aparecerá mostrando todas as tabelas e páginas detectadas.
- Selecione as tabelas que você deseja e clique em Carregar (para importar diretamente) ou Transformar Dados (para limpar antes de carregar).
- O Excel importará a tabela para uma planilha, preservando a estrutura de linha/coluna razoavelmente bem.
Prós e Contras
| Prós | Contras |
|---|---|
| Não é necessário software adicional (com Office) | Apenas para Windows |
| Preserva formatos numéricos | Dificuldade com células mescladas |
| Bom para PDFs digitais baseados em texto | Sem OCR para PDFs digitalizados |
| Pode atualizar dados se o PDF for atualizado | Pode ser lento em PDFs grandes |
Método 2: Google Docs (Gratuito e Simples)
Ideal para: Extrações rápidas e pontuais quando você não tem Excel ou ferramentas pagas.
O Google Docs oferece um método oculto, mas gratuito, para extrair tabelas de PDFs. Ele funciona convertendo todo o PDF em um Google Doc editável, onde as tabelas se tornam grades baseadas em texto.
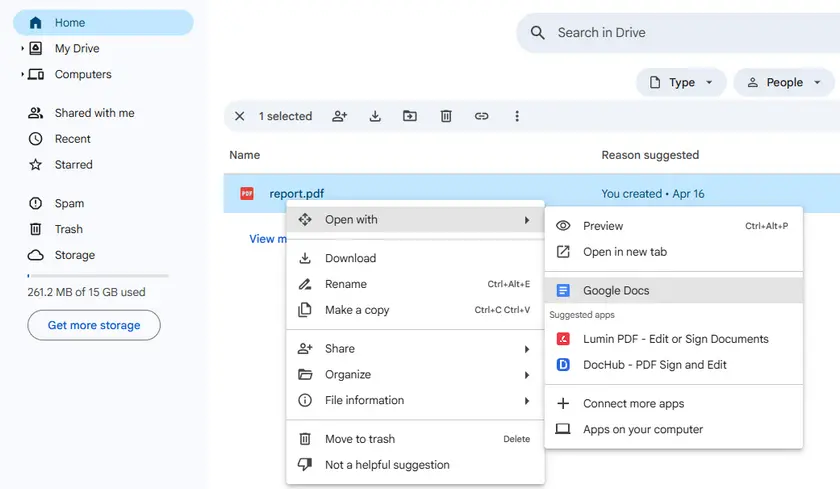
Instruções Passo a Passo
- Carregue o PDF no Google Drive.
- Clique com o botão direito no PDF → Abrir com → Google Docs.
- Aguarde o Google Docs processar o arquivo.
- Role para encontrar a tabela. Ela aparecerá como uma grade baseada em texto (linhas e colunas separadas por espaços ou tabulações).
- Copie a área da tabela e cole-a no Google Sheets ou Microsoft Excel.
Prós e Contras
| Prós | Contras |
|---|---|
| Completamente gratuito | Sem detecção real de tabela (apenas alinhamento de texto) |
| Sem instalação de software | Resultados confusos com tabelas complexas |
| Funciona em qualquer sistema operacional com um navegador | Mau manuseio de células mescladas ou células de várias linhas |
| Lida com tabelas simples de forma confiável | Sem OCR (PDFs digitalizados aparecem como imagens) |
Método 3: Adobe Acrobat Pro (Funcionalidade de Exportação)
Ideal para: Profissionais que já possuem o Acrobat Pro e precisam de exportações confiáveis de PDFs digitais.
Adobe Acrobat Pro (não o Reader gratuito) possui uma função de exportação integrada que converte tabelas de PDF diretamente para Excel ou CSV. Ele preserva mais formatação do que ferramentas gratuitas.
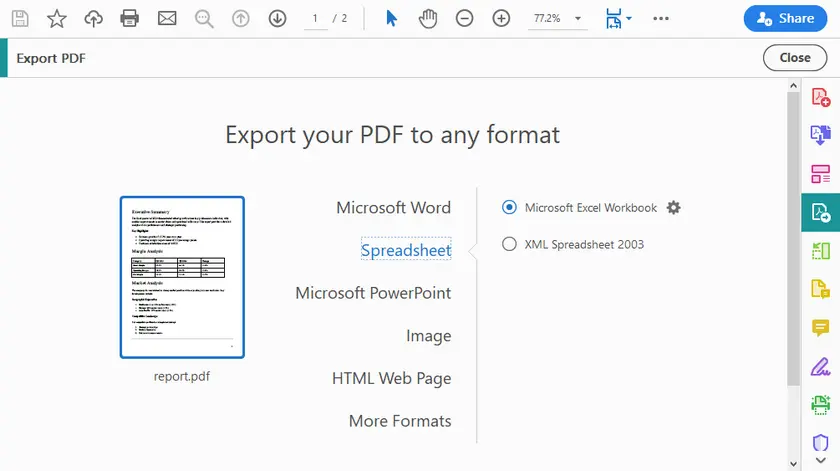
Instruções Passo a Passo
- Abra o PDF no Adobe Acrobat Pro.
- Clique em Exportar PDF (barra lateral direita).
- Selecione Planilha → Pasta de Trabalho do Microsoft Excel (ou CSV).
- Clique em Exportar.
- Escolha um local e salve.
- Abra o arquivo Excel gerado e verifique as tabelas.
Dicas Adicionais
- Use a opção Reconhecer Texto (OCR) primeiro se estiver lidando com PDFs digitalizados.
- Para tabelas de várias páginas, o Acrobat geralmente as concatena de forma inteligente.
- Você pode exportar apenas páginas selecionadas para economizar tempo.
Prós e Contras
| Prós | Contras |
|---|---|
| Alta precisão para PDFs digitais | Caro (assinatura necessária) |
| Lida bem com tabelas de várias páginas | Sem controle granular sobre a extração |
| Preserva fórmulas e números | Ainda tem dificuldade com tabelas aninhadas muito complexas |
| Processamento em lote disponível | Apenas Windows/macOS (sem versão web) |
Método 4: Python (Controle Total e Automação)
Ideal para: Desenvolvedores, cientistas de dados e usuários avançados que precisam de flexibilidade máxima, lidam com PDFs digitalizados ou processam arquivos em lote.
O Python oferece controle total sobre o processo de extração. Você pode lidar com PDFs digitais com bibliotecas como pdfplumber, camelot ou Spire.PDF for Python (uma biblioteca comercial com uma versão gratuita disponível). Abaixo está um exemplo prático usando Spire.PDF para extrair tabelas e salvá-las como arquivos de texto limpos.
Instalação
pip install spire.pdf
Exemplo de Código Completo (Extrair Tabelas para Arquivos TXT)
O código a seguir extrai todas as tabelas de uma página PDF específica e salva cada tabela como um arquivo de texto separado em formato semelhante a CSV:
from spire.pdf.common import *
from spire.pdf import *
# Criar um objeto PdfDocument
doc = PdfDocument()
# Carregar um arquivo PDF
doc.LoadFromFile("report.pdf")
# Criar um objeto PdfTableExtractor
extractor = PdfTableExtractor(doc)
# Extrair tabelas de uma página específica (o índice da página começa em 0)
tableList = extractor.ExtractTable(0)
# Determinar se a lista de tabelas não está vazia
if tableList is not None:
# Loop através das tabelas na página
for i in range(len(tableList)):
# Criar uma nova lista para armazenar dados desta tabela
builder = []
# Obter uma tabela específica
table = tableList[i]
# Obter o número de linhas e colunas
row = table.GetRowCount()
column = table.GetColumnCount()
# Loop através de cada linha e coluna
for m in range(row):
for n in range(column):
# Obter texto da célula específica
text = table.GetText(m, n)
# Adicionar o texto seguido por uma vírgula (estilo CSV)
builder.append(text + ",")
builder.append("\n") # Fim da linha
builder.append("\n") # Linha em branco entre as tabelas
# Escrever o conteúdo em um arquivo de texto
with open(f"output/Table-{i + 1}.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))
# Fechar o documento
doc.Close()
Saída:
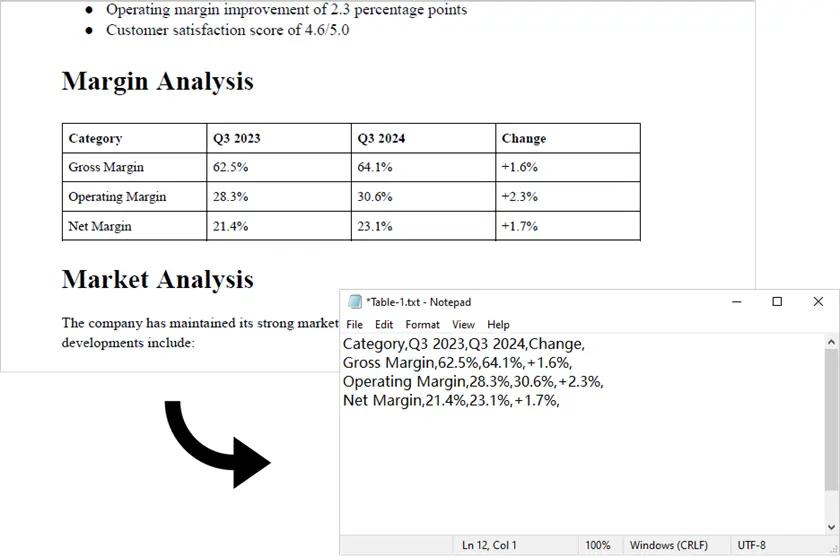
Observação: Este script funciona apenas com PDFs gerados digitalmente (baseados em texto). Para PDFs digitalizados, o Spire.PDF sozinho não é suficiente. Nesses casos, você pode primeiro converter o PDF em imagens usando Spire.PDF, depois aplicar um mecanismo de OCR como pytesseract junto com lógica de processamento adicional para detectar e extrair dados de tabelas.
Por que Python?
- Lida com PDFs digitais e digitalizados (com integração de OCR)
- Processamento em lote de centenas de arquivos
- Pós-processamento personalizável (limpeza, mesclagem, validação)
- Pode ser integrado em aplicativos web, APIs ou pipelines ETL
- Você controla exatamente como as tabelas são formatadas e salvas
Como uma biblioteca PDF abrangente, o Spire.PDF for Python não apenas extrai tabelas de PDFs, mas também suporta a extração de imagens, metadados e anexos. Além disso, ele pode exportar documentos inteiros para formatos como Word, Excel e TXT.
Prós e Contras
| Prós | Contras |
|---|---|
| Controle total sobre a lógica de extração | Requer conhecimento de programação |
| Lida com tabelas complexas e de várias páginas | Curva de aprendizado mais acentuada |
| Processamento em lote de milhares de arquivos | Spire.PDF requer uma licença para uso comercial (gratuito para uso pessoal) |
| Resultados limpos e reproduzíveis | A detecção de tabelas não é perfeita em todos os PDFs |
| Fácil de integrar com pandas, Excel ou bancos de dados |
Tabela Comparativa: Escolhendo o Método Certo
| Método | Facilidade de Uso | Lida com PDFs Digitalizados | Processamento em Lote | Custo | Ideal Para |
|---|---|---|---|---|---|
| Excel | Médio | x | x | Requer Office | Tabelas digitais rápidas e pontuais |
| Google Docs | Alto | x | x | Gratuito | Tabelas simples, sem software |
| Adobe Acrobat Pro | Alto | √ | x | Pago | Usuários profissionais não técnicos |
| Python | Baixo | √ | √ | Gratuito / Pago | Flexibilidade máxima, larga escala, PDFs digitalizados |
Conclusão
Extrair tabelas de PDFs não precisa ser uma dor de cabeça. O método certo depende inteiramente da sua situação específica:
- Para uma tabela simples e única → Tente o Google Docs ou uma ferramenta online primeiro.
- Para resultados profissionais e polidos → Use Excel ou Adobe Acrobat Pro se tiver acesso.
- Para controle máximo, tabelas complexas ou documentos digitalizados → Python é sua melhor opção.
Comece com o método mais simples que atenda às suas necessidades. À medida que seus requisitos aumentam (mais arquivos, documentos digitalizados, limpeza personalizada), você sempre pode migrar para ferramentas mais poderosas como Python. A chave é reconhecer que a extração de tabelas não é um problema único para todos – e agora você tem quatro maneiras de resolvê-lo.
Perguntas Frequentes
P1. Por que é difícil extrair tabelas de PDFs?
Porque os PDFs armazenam conteúdo como texto posicionado em vez de tabelas de dados estruturadas, tornando a extração menos direta.
P2. Qual método oferece os resultados mais precisos?
O Adobe Acrobat Pro geralmente oferece a melhor precisão para tabelas complexas.
P3. Posso extrair tabelas de PDFs digitalizados?
Sim, mas requer OCR (Reconhecimento Óptico de Caracteres). Ferramentas como Adobe Acrobat ou Spire.PDF (com um componente de OCR) podem converter imagens digitalizadas em texto legível por máquina, após o qual os dados da tabela podem ser detectados e extraídos.
P4. Python é melhor do que outros métodos?
Depende. Python é melhor para automação e processamento em larga escala, mas excessivo para tarefas pontuais.
P5. Posso converter tabelas extraídas diretamente para o Excel?
Sim. A maioria das ferramentas (Excel, Acrobat) suporta exportação direta para .xlsx, enquanto Python pode ser estendido para fazer o mesmo.