
Imagine o seguinte: você finalmente localiza o relatório de pesquisa exato, o contrato comercial ou o whitepaper cheio de dados de que precisa, mas ele está preso em um PDF. Ao tentar copiar e colar seu conteúdo, você se depara com formatação confusa, texto não selecionável ou blocos frustrantes de proteção de conteúdo. A questão é universal: como extrair texto de arquivos PDF sem redigitação manual ou software caro?
Neste guia abrangente, exploraremos as melhores maneiras de extrair texto de PDF gratuitamente (incluindo PDFs digitalizados com OCR). Seja você um estudante, um profissional de negócios ou um desenvolvedor, encontrará o método perfeito para extrair texto de PDF com precisão e eficiência.
- Por que extrair texto de PDF pode ser complicado?
- O truque mais simples – Copiar e colar
- Principais ferramentas online gratuitas para extrair texto de PDF
- Ferramentas gratuitas de extração de texto de PDF para desktop do PDF24 Creator
- Ferramenta de desenvolvedor gratuita para extrair texto de PDF em C#
- Perguntas Frequentes (FAQ)
Por que extrair texto de PDF pode ser complicado?
Os PDFs armazenam texto de uma forma que prioriza a consistência visual. Isso significa que o texto pode ser armazenado como blocos fragmentados, em uma ordem incomum ou, pior, como parte de uma imagem. Existem dois tipos principais de PDFs, cada um com desafios de extração exclusivos:
- PDFs digitais: eles contêm texto selecionável, mas layouts complexos como artigos de várias colunas ou tabelas podem confundir ações simples de copiar e colar.
- PDFs digitalizados: são essencialmente imagens de páginas. Para extrair texto de um PDF digitalizado, você precisa da tecnologia OCR (Reconhecimento Óptico de Caracteres), que analisa a imagem e reconhece as formas das letras.
Felizmente, as ferramentas gratuitas abaixo lidam com os dois tipos com facilidade.
O truque mais simples – Copiar e colar
Se você tem um PDF digital simples e precisa apenas de uma pequena seção de texto, não ignore o básico. É a maneira mais rápida de obter texto de um PDF para pequenas tarefas.
- Abra o PDF: use um visualizador padrão como o Adobe Acrobat Reader, um navegador da web (como Chrome ou Edge) ou um aplicativo de visualização.
- Selecione e copie: destaque o texto que deseja, clique com o botão direito e selecione "Copiar" ou use os atalhos de teclado “Ctrl+C” (Windows) ou “Command+C” (Mac).
- Cole: abra um editor de texto (como o Bloco de Notas ou o TextEdit) ou um documento do Word e cole o texto com “Ctrl+V” ou “Command+V”.
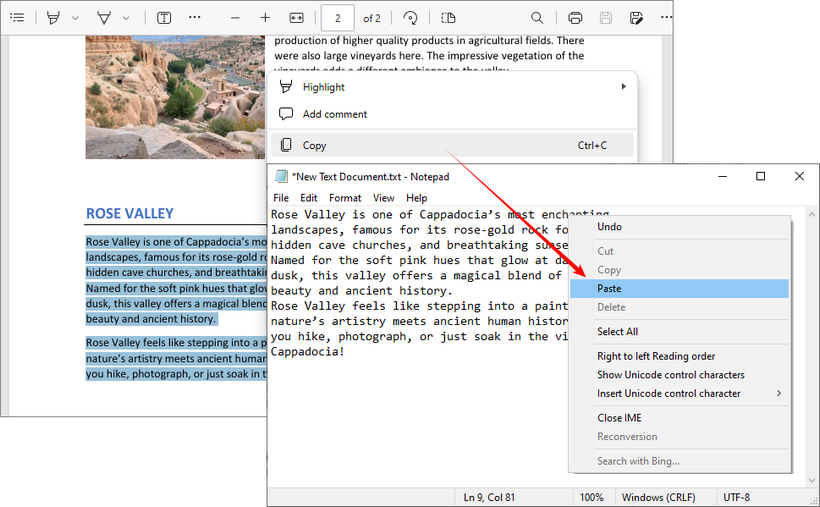
A ressalva: este método falha para documentos digitalizados, PDFs protegidos ou quando você precisa preservar formatação complexa. Para estes, use as ferramentas gratuitas dedicadas abaixo ou consulte nosso guia sobre como copiar texto de um PDF protegido.
Principais ferramentas online gratuitas para extrair texto de PDF
Para a maioria dos usuários, as ferramentas online gratuitas são a maneira mais rápida e fácil de extrair texto de PDF gratuitamente. Elas funcionam diretamente no seu navegador, não exigem instalação e muitas agora incluem recursos poderosos de OCR. Abaixo estão as duas principais opções para diferentes casos de uso - desde a extração básica de texto até o OCR multilíngue.
CLOUDXDOCS - A ferramenta gratuita mais simples para PDFs digitais
Se você precisa de uma ferramenta simples e sem anúncios para extrair texto de PDFs baseados em texto (não digitalizados), o CLOUDXDOCS é ideal. É 100% gratuito, não requer registro e funciona com um clique - perfeito para pegar texto de arquivos PDF em segundos.
Passos para extrair texto de PDF online:
- Visite o Conversor Gratuito de PDF para Texto do CLOUDXDOCS.
- Carregue seu arquivo PDF arrastando e soltando ou clicando para navegar.
- Aguarde a ferramenta processar seu arquivo.
- Baixe o texto extraído como um arquivo TXT.
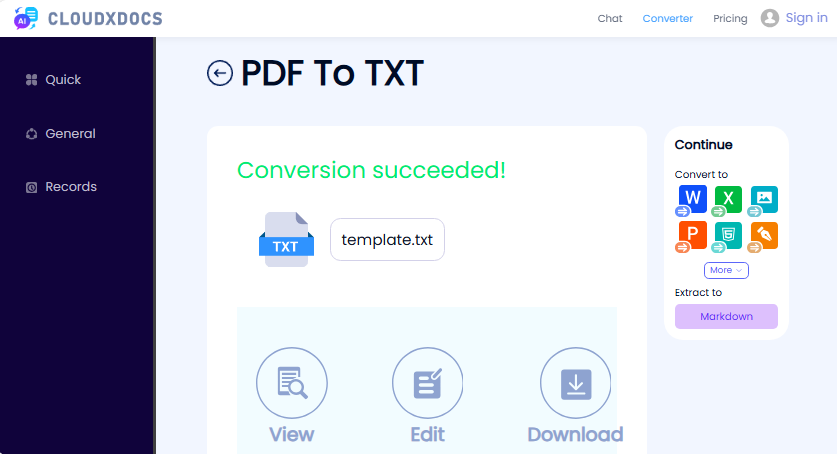
✔ Prós: Sem inscrição, sem anúncios, interface simples.
✘ Contras: Sem OCR (não funciona para PDFs digitalizados).
i2OCR - Ferramenta de OCR gratuita para PDFs digitalizados
O i2OCR é uma ferramenta online gratuita especializada em OCR para imagens e PDFs digitalizados, suportando mais de 100 idiomas - perfeito para PDFs que não estão em inglês. É gratuito para uso de página única e oferece vários formatos de saída.
Passos para extrair texto de PDF digitalizado online gratuitamente:
- Visite a ferramenta de OCR de PDF do i2OCR.
- Selecione o idioma de reconhecimento e o mecanismo de OCR de sua preferência.
- Clique em “Selecionar PDF” para carregar seu PDF digitalizado.
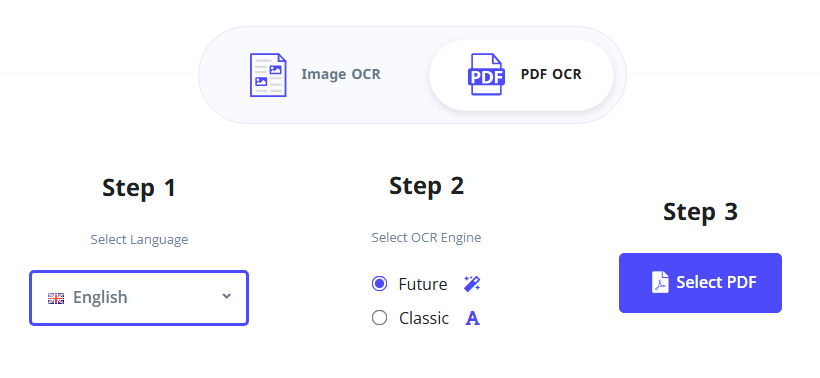
- Clique em “Iniciar OCR” e aguarde a ferramenta processar a digitalização.
- Copie o texto extraído ou baixe-o como TXT, Word ou HTML.
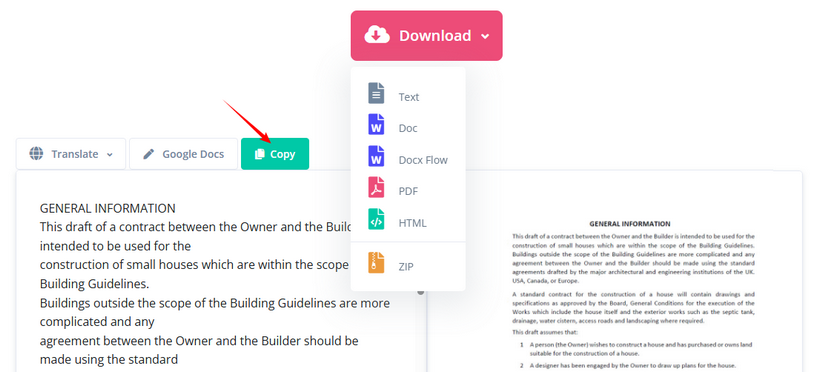
✔ Prós: Suporte para mais de 100 idiomas, OCR gratuito, vários formatos de saída, sem inscrição.
✘ Contras: O plano gratuito suporta apenas uma página por vez.
Além de texto, os PDFs geralmente contêm imagens, gráficos ou diagramas valiosos - descubra como extrair imagens incorporadas em seu documento PDF.
Ferramentas gratuitas de extração de texto de PDF para desktop do PDF24 Creator
Se você trabalha com PDFs com frequência, precisa de acesso offline ou tem arquivos em massa para processar, o PDF24 Creator é a escolha ideal. Esta ferramenta de desktop gratuita exclusiva para Windows oferece recursos abrangentes de manuseio de PDF - incluindo extração de texto, OCR para PDFs digitalizados e processamento em lote - tudo isso mantendo seus arquivos locais para máxima privacidade.
Extrair texto de um PDF digital (selecionável)
- Vá para a página de download oficial do PDF24 Creator e baixe a versão apropriada para o seu sistema Windows.
- Instale e inicie o PDF24. Você verá a Caixa de Ferramentas do PDF24 (um painel com muitas ferramentas de PDF).
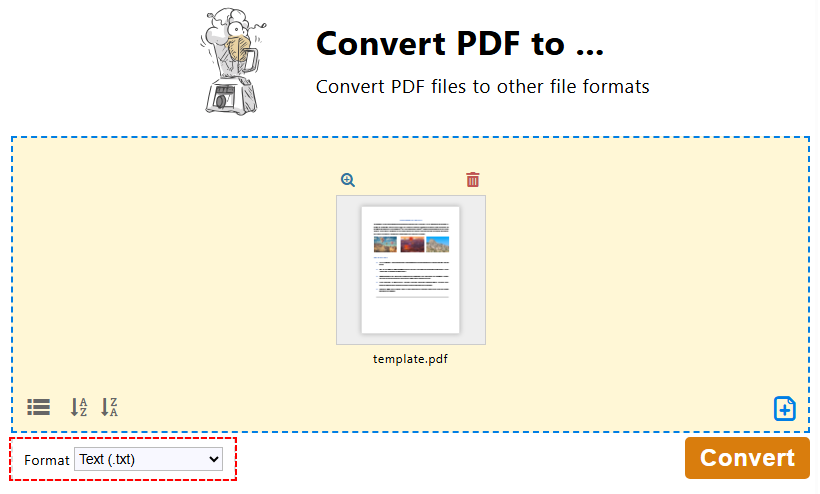
- Na Caixa de Ferramentas do PDF24, clique em "Converter PDF para…".
- Clique em "Escolher arquivos" ou arraste e solte para carregar seu arquivo PDF.
- Escolha “Texto (.txt)” como formato de saída e clique em "Converter".
- Salve o arquivo de texto extraído em seu dispositivo.
Extrair texto de um PDF digitalizado (usando OCR)
Para PDFs digitalizados/baseados em imagem, use o OCR integrado do PDF24 para reconhecer texto de digitalizações de PDF e convertê-los em texto editável ou PDFs pesquisáveis:
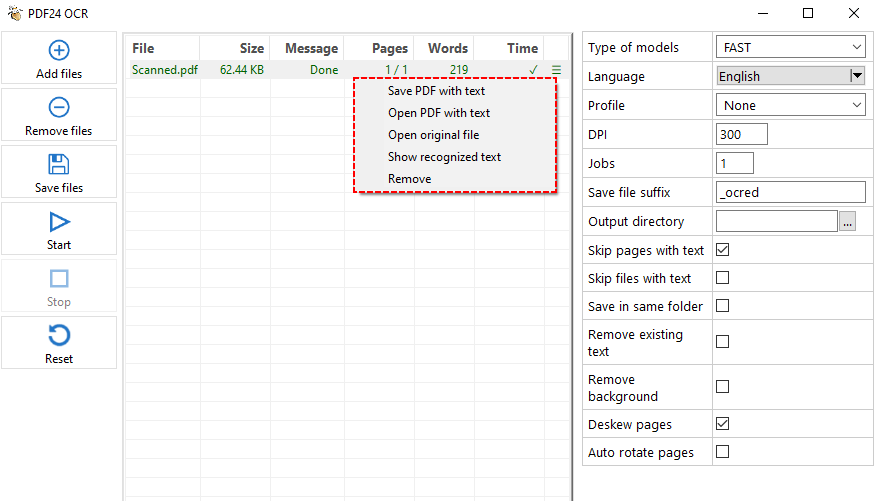
- Na Caixa de Ferramentas do PDF24, clique em "OCR de PDF".
- Clique em "Adicionar arquivo(s)" e selecione seu PDF digitalizado.
- No painel de configurações à direita, selecione o modo de reconhecimento de texto, idioma, DPI, diretório de saída, etc.
- Clique no botão "Iniciar" para processar o PDF.
- O PDF24 processará cada página, reconhecerá o texto e o salvará em um arquivo de texto ou em um PDF pesquisável.
Dica profissional para usuários da Adobe:
Se você tiver o Adobe Acrobat Pro (pago), poderá extrair texto indo para a ferramenta “Exportar PDF” e selecionando “Texto (Simples)” como formato de saída. O Acrobat salvará o arquivo como um documento .txt instantaneamente.
Ferramenta de desenvolvedor gratuita para extrair texto de PDF em C#
Se você é um desenvolvedor, Free Spire.PDF for .NET é uma biblioteca gratuita e sem dependências para ler texto de PDF programaticamente. É rápido, leve e perfeito para integrar a extração de texto de PDF em seus projetos.
Código C# para extrair texto de PDF
O código itera por cada página em um arquivo PDF digital e extrai todo o texto do PDF. As principais classes e métodos de extração de texto incluem:
- PdfTextExtractor: uma classe de utilitário especializada que extrai texto de uma única página de PDF (uma página por vez).
- PdfTextExtractOptions: uma classe de configuração para extração de texto. Define regras como se deve extrair todo o texto.
- ExtractText(): executa a extração de texto na página do PDF e retorna a string de texto extraída.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Text;
namespace ExtractAllTextFromPDF
{
internal class Program
{
static void Main(string[] args)
{
// Crie uma instância de documento PDF
PdfDocument pdf = new PdfDocument();
// Carregue o arquivo PDF
pdf.LoadFromFile("SamplePDF.pdf");
// Inicialize um StringBuilder para conter o texto extraído
StringBuilder extractedText = new StringBuilder();
// Percorra cada página do PDF
foreach (PdfPageBase page in pdf.Pages)
{
// Crie um PdfTextExtractor para a página atual
PdfTextExtractor extractor = new PdfTextExtractor(page);
// Definir opções de extração
PdfTextExtractOptions option = new PdfTextExtractOptions
{
IsExtractAllText = true
};
// Extraia o texto da página atual
string text = extractor.ExtractText(option);
// Anexe o texto extraído ao StringBuilder
extractedText.AppendLine(text);
}
// Salve o texto extraído em um arquivo de texto
File.WriteAllText("ExtractedText.txt", extractedText.ToString());
// Feche o documento PDF
pdf.Close();
}
}
}
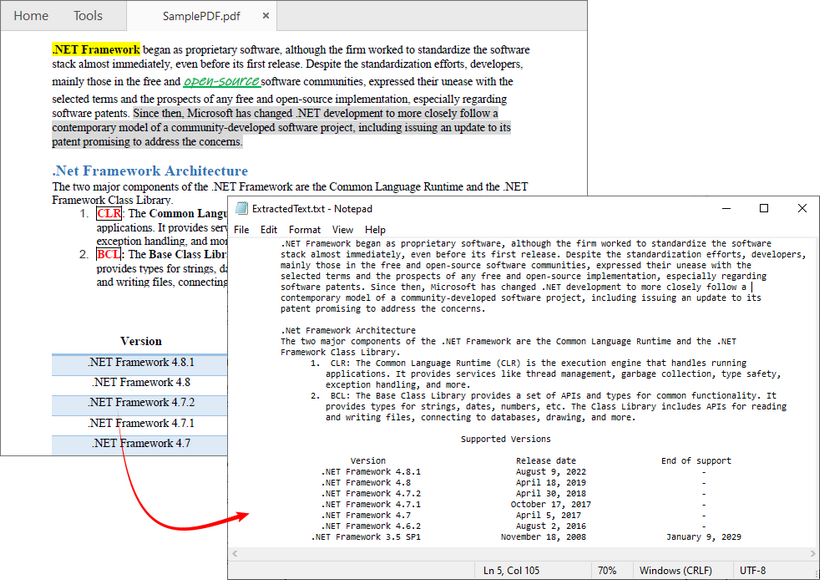
Além de extrair todo o texto, o Free Spire.PDF também permite extrair texto de uma única página ou de uma área especificada. O resultado da extração é mostrado abaixo:
Dica profissional: para extrair texto de um PDF digitalizado em C#, siga o guia oficial: Realizar OCR em PDFs digitalizados em C# para extração de texto
Perguntas Frequentes (FAQ)
P1: Como posso extrair texto de um PDF digitalizado gratuitamente?
R: Ferramentas como o i2OCR e o PDF24 oferecem opções de OCR gratuitas. Basta carregar seu PDF digitalizado e ativar a configuração de OCR antes de extrair.
P2: As ferramentas gratuitas suportam a extração de texto em massa?
R: Sim, mas o método é importante. A maioria das ferramentas online gratuitas tem limites de volume, mas você pode usar uma ferramenta de desktop offline como o PDF24 Creator ou uma solução programática para processar vários PDFs em massa.
P3: Qual é a melhor maneira de extrair tabelas de um PDF?
R: Extrair tabelas para texto simples é notoriamente difícil, pois a estrutura tabular é perdida. Sua melhor aposta é usar uma ferramenta que possa converter o PDF para Excel (XLSX) ou CSV. Isso tentará colocar os dados em células, preservando a estrutura.
P4: Como extraio texto de um PDF e mantenho a formatação?
R: Texto simples (.txt) não pode preservar a formatação como negrito, itálico ou tamanhos de fonte. Para manter a formatação, você deve converter seu PDF para um documento do Word (.docx).
Resumo
Este artigo apresenta várias maneiras confiáveis de extrair texto de PDF gratuitamente, independentemente do seu nível de habilidade técnica ou da complexidade do documento.
Para uma tarefa rápida e única, uma ferramenta online confiável como o CLOUDXDOCS é sua melhor aposta. Para trabalhos recorrentes ou informações confidenciais, recorra a um software offline como o PDF24. E se você deseja construir um pipeline de conteúdo automatizado de ponta, explorar uma solução de código como o Free Spire.PDF pode revolucionar seu fluxo de trabalho.
Com este guia, você agora está equipado para desbloquear o texto oculto em qualquer PDF e colocá-lo para trabalhar para você.
Veja também
- Converter tabelas de PDF para CSV: manual, online e automatizado
- Como desproteger um PDF (com ou sem senha)
- Como extrair páginas de um PDF gratuitamente - sem necessidade de Adobe
- Extrair texto de PDF em Python: um guia completo com exemplos de código práticos
- PDF para texto em Java: extraia texto de PDFs (baseados em texto e digitalizados)