Lesen Sie Excel-Dateien mit Python
Inhaltsverzeichnis
Mit Pip installieren
pip install Spire.XLS
verwandte Links
Excel-Dateien (Tabellenkalkulationen) werden von Menschen weltweit zum Organisieren, Analysieren und Speichern tabellarischer Daten verwendet. Aufgrund ihrer Beliebtheit geraten Entwickler häufig in Situationen, in denen sie Daten aus Excel extrahieren oder Berichte im Excel-Format erstellen müssen. Fähig sein zu Lesen Sie Excel-Dateien mit Python eröffnet umfassende Möglichkeiten der Datenverarbeitung und Automatisierung. In diesem Artikel erfahren Sie, wie das geht Lesen Sie Daten (Text- oder Zahlenwerte) aus einer Zelle, einem Zellbereich oder einem gesamten Arbeitsblatt durch Verwendung der Spire.XLS for Python-Bibliothek
- Lesen Sie Daten einer bestimmten Zelle in Python
- Lesen Sie Daten aus einem Zellbereich in Python
- Lesen Sie Daten aus einem Excel-Arbeitsblatt in Python
- Lesen Sie in Python einen Wert statt einer Formel in einer Zelle
Python-Bibliothek zum Lesen von Excel
Spire.XLS for Python ist eine zuverlässige Python-Bibliothek auf Unternehmensebene zum Erstellen, Schreiben, Lesen und Bearbeiten von Excel-Dokumenten (XLS, XLSX, XLSB, XLSM, ODS) in einer Python-Anwendung. Es bietet einen umfassenden Satz an Schnittstellen, Klassen und Eigenschaften, die es Programmierern ermöglichen, Excel -Dateien problemlos zu lesen und zu schreiben. Insbesondere kann mit der Worksheet.Range-Eigenschaft auf eine Zelle in einer Arbeitsmappe zugegriffen werden und der Wert der Zelle kann mit der CellRange.Value-Eigenschaft abgerufen werden.
Die Bibliothek lässt sich einfach installieren, indem Sie den folgenden pip-Befehl ausführen. Wenn Sie die erforderlichen Abhängigkeiten manuell importieren möchten, lesen Sie weiter So installieren Sie Spire.XLS for Python in VS Code
pip install Spire.XLS
Klassen und Eigenschaften in Spire.XLS for die Python-API
- Arbeitsmappenklasse: Stellt ein Excel-Arbeitsmappenmodell dar, mit dem Sie eine Arbeitsmappe von Grund auf erstellen oder ein vorhandenes Excel-Dokument laden und Änderungen daran vornehmen können.
- Arbeitsblattklasse: Stellt ein Arbeitsblatt in einer Arbeitsmappe dar.
- CellRange-Klasse: Stellt eine bestimmte Zelle oder einen Zellbereich in einer Arbeitsmappe dar.
- Worksheet.Range-Eigenschaft: Ruft eine Zelle oder einen Bereich ab und gibt ein Objekt der CellRange-Klasse zurück.
- Worksheet.AllocatedRange-Eigenschaft: Ruft den Zellbereich mit Daten ab und gibt ein Objekt der CellRange-Klasse zurück.
- CellRange.Value-Eigenschaft: Ruft den Zahlenwert oder Textwert einer Zelle ab. Wenn eine Zelle jedoch eine Formel enthält, gibt diese Eigenschaft die Formel anstelle des Ergebnisses der Formel zurück.
Lesen Sie Daten einer bestimmten Zelle in Python
Mit Spire.XLS for Python können Sie mithilfe der CellRange.Value-Eigenschaft ganz einfach den Wert einer bestimmten Zelle ermitteln. Die Schritte zum Lesen von Daten einer bestimmten Excel-Zelle in Python sind wie folgt.
- Arbeitsmappenklasse instanziieren
- Laden Sie ein Excel-Dokument mit der LoadFromFile-Methode.
- Rufen Sie ein bestimmtes Arbeitsblatt mit der Eigenschaft Workbook.Worksheets[index] ab.
- Rufen Sie eine bestimmte Zelle mithilfe der Worksheet.Range-Eigenschaft ab.
- Rufen Sie den Wert der Zelle mithilfe der CellRange.Value-Eigenschaft ab
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
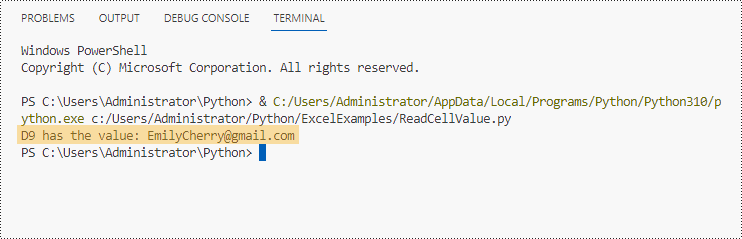
certainCell = sheet.Range["D9"]
# Get the value of the cell
print("D9 has the value: " + certainCell.Value)
Lesen Sie Daten aus einem Zellbereich in Python
Wir wissen bereits, wie man den Wert einer Zelle erhält, um die Werte eines Zellbereichs, wie z. B. bestimmter Zeilen oder Spalten, zu erhalten. Wir müssen lediglich Schleifenanweisungen verwenden, um die Zellen zu durchlaufen und sie dann einzeln zu extrahieren. Die Schritte zum Lesen von Daten aus einem Excel-Zellenbereich in Python sind wie folgt.
- Arbeitsmappenklasse instanziieren
- Laden Sie ein Excel-Dokument mit der LoadFromFile-Methode.
- Rufen Sie ein bestimmtes Arbeitsblatt mit der Eigenschaft Workbook.Worksheets[index] ab.
- Rufen Sie mithilfe der Worksheet.Range-Eigenschaft einen bestimmten Zellbereich ab.
- Verwenden Sie for-Schleifenanweisungen, um jede Zelle im Bereich abzurufen und den Wert einer bestimmten Zelle mithilfe der CellRange.Value-Eigenschaft abzurufen
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a cell range
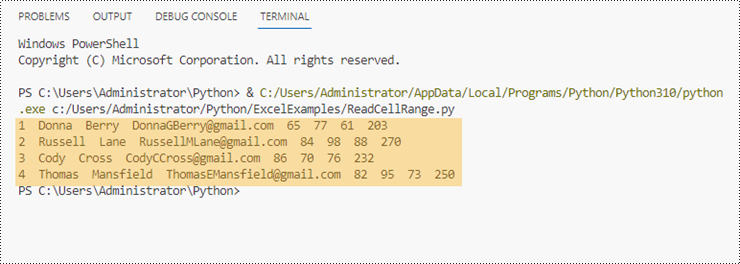
cellRange = sheet.Range["A2:H5"]
# Iterate through the rows
for i in range(len(cellRange.Rows)):
# Iterate through the columns
for j in range(len(cellRange.Rows[i].Columns)):
# Get data of a specific cell
print(cellRange[i + 2, j + 1].Value + " ", end='')
print("")
Lesen Sie Daten aus einem Excel-Arbeitsblatt in Python
Spire.XLS for Python offers bietet die Worksheet.AllocatedRange-Eigenschaft, um automatisch den Zellbereich abzurufen, der Daten aus einem Arbeitsblatt enthält. Anschließend durchlaufen wir die Zellen innerhalb des Zellbereichs und nicht das gesamte Arbeitsblatt und rufen die Zellwerte einzeln ab. Im Folgenden finden Sie die Schritte zum Lesen von Daten aus einem Excel-Arbeitsblatt in Python.
- Arbeitsmappenklasse instanziieren
- Laden Sie ein Excel-Dokument mit der LoadFromFile-Methode.
- Rufen Sie ein bestimmtes Arbeitsblatt mit der Eigenschaft Workbook.Worksheets[index] ab.
- Rufen Sie mithilfe der Worksheet.AllocatedRange-Eigenschaft den Zellbereich mit Daten aus dem Arbeitsblatt ab.
- Verwenden Sie for-Schleifenanweisungen, um jede Zelle im Bereich abzurufen und den Wert einer bestimmten Zelle mithilfe der CellRange.Value-Eigenschaft abzurufen
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get the first worksheet
sheet = wb.Worksheets[0]
# Get the cell range containing data
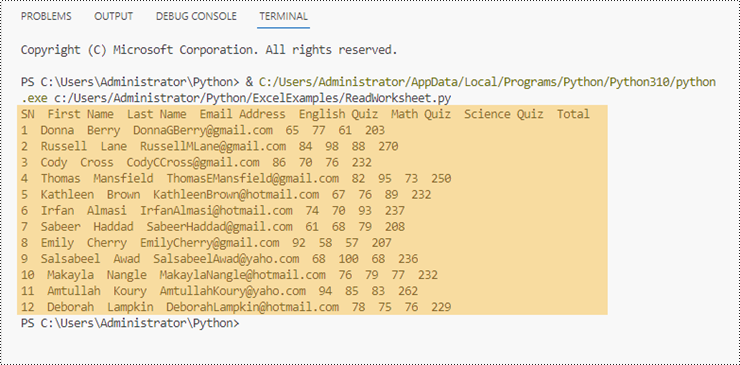
locatedRange = sheet.AllocatedRange
# Iterate through the rows
for i in range(len(sheet.Rows)):
# Iterate through the columns
for j in range(len(locatedRange.Rows[i].Columns)):
# Get data of a specific cell
print(locatedRange[i + 1, j + 1].Value + " ", end='')
print("")
Lesen Sie in Python einen Wert statt einer Formel in einer Zelle
Wie bereits erwähnt, gibt die CellRange.Value-Eigenschaft die Formel selbst zurück, wenn eine Zelle eine Formel enthält, nicht den Wert der Formel. Wenn wir den Wert erhalten möchten, müssen wir die Methode str(CellRange.FormulaValue) verwenden. Im Folgenden finden Sie die Schritte zum Lesen von Werten anstelle von Formeln in einer Excel-Zelle in Python.
- Arbeitsmappenklasse instanziieren
- Laden Sie ein Excel-Dokument mit der LoadFromFile-Methode.
- Rufen Sie ein bestimmtes Arbeitsblatt mit der Eigenschaft Workbook.Worksheets[index] ab.
- Rufen Sie eine bestimmte Zelle mithilfe der Worksheet.Range-Eigenschaft ab.
- Bestimmen Sie mithilfe der CellRange.HasFormula-Eigenschaft, ob die Zelle über eine Formel verfügt.
- Rufen Sie den Formelwert der Zelle mit der Methode str(CellRange.FormulaValue) ab
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Formula.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
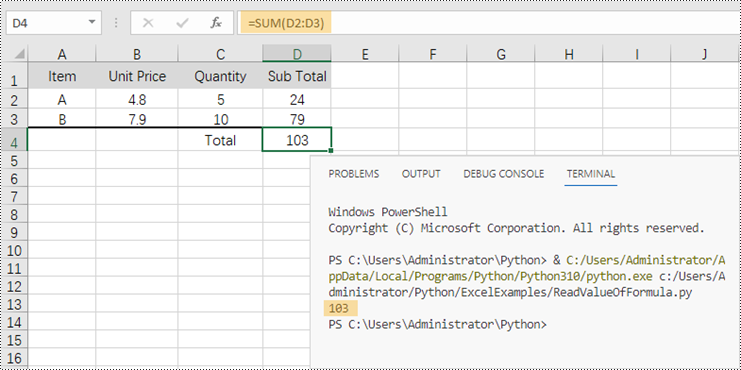
certainCell = sheet.Range["D4"]
# Determine if the cell has formula
if(certainCell.HasFormula):
# Get the formula value of the cell
print(str(certainCell.FormulaValue))
Abschluss
In diesem Blogbeitrag haben wir gelernt, wie man mithilfe der Spire.XLS for Python-API Daten aus Zellen, Zellregionen und Arbeitsblättern in Python liest. Wir haben auch besprochen, wie man ermittelt, ob eine Zelle eine Formel hat und wie man den Wert der Formel erhält. Diese Bibliothek unterstützt die Extraktion vieler anderer Elemente in Excel wie Bilder, Hyperlinks und OEL-Objekte. Weitere Tutorials finden Sie in unserer Online-Dokumentation. Wenn Sie Fragen haben, kontaktieren Sie uns bitte per E-Mail oder im Forum.
Python: Merge Word Documents
Table of Contents
Install with Pip
pip install Spire.Doc
Related Links
Dealing with a large number of Word documents can be very challenging. Whether it's editing or reviewing a large number of documents, there's a lot of time wasted on opening and closing documents. What's more, sharing and receiving a large number of separate Word documents can be annoying, as it may require a lot of repeated sending and receiving operations by both the sharer and the receiver. Therefore, in order to enhance efficiency and save time, it is advisable to merge related Word documents into a single file. From this article, you will know how to use Spire.Doc for Python to easily merge Word documents through Python programs.
- Merge Word Documents by Inserting Files with Python
- Merge Word Documents by Cloning Contents with Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your VS Code through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python in VS Code
Merge Word Documents by Inserting Files with Python
The method Document.insertTextFromFile() is used to insert other Word documents to the current one, and the inserted content will start from a new page. The detailed steps for merging Word documents by inserting are as follows:
- Create an object of Document class and load a Word document using Document.LoadFromFile() method.
- Insert the content from another document to it using Document.InsertTextFromFile() method.
- Save the document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document class and load a Word document
doc = Document()
doc.LoadFromFile("Sample1.docx")
# Insert the content from another Word document to this one
doc.InsertTextFromFile("Sample2.docx", FileFormat.Auto)
# Save the document
doc.SaveToFile("output/InsertDocuments.docx")
doc.Close()

Merge Word Documents by Cloning Contents with Python
Merging Word documents can also be achieved by cloning contents from one Word document to another. This method maintains the formatting of the original document, and content cloned from another document continues at the end of the current document without starting a new Page. The detailed steps are as follows:
- Create two objects of Document class and load two Word documents using Document.LoadFromFile() method.
- Get the last section of the destination document using Document.Sections.get_Item() method.
- Loop through the sections in the document to be cloned and then loop through the child objects of the sections.
- Get a section child object using Section.Body.ChildObjects.get_Item() method.
- Add the child object to the last section of the destination document using Section.Body.ChildObjects.Add() method.
- Save the result document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create two objects of Document class and load two Word documents
doc1 = Document()
doc1.LoadFromFile("Sample1.docx")
doc2 = Document()
doc2.LoadFromFile("Sample2.docx")
# Get the last section of the first document
lastSection = doc1.Sections.get_Item(doc1.Sections.Count - 1)
# Loop through the sections in the second document
for i in range(doc2.Sections.Count):
section = doc2.Sections.get_Item(i)
# Loop through the child objects in the sections
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
# Add the child objects from the second document to the last section of the first document
lastSection.Body.ChildObjects.Add(obj.Clone())
# Save the result document
doc1.SaveToFile("output/MergeByCloning.docx")
doc1.Close()
doc2.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: mesclar documentos do Word
Índice
Instalar com Pip
pip install Spire.Doc
Links Relacionados
Lidar com um grande número de documentos do Word pode ser muito desafiador. Seja editando ou revisando um grande número de documentos, há muito tempo perdido abrindo e fechando documentos. Além do mais, compartilhar e receber um grande número de documentos Word separados pode ser irritante, pois pode exigir muitas operações repetidas de envio e recebimento tanto por parte do compartilhador quanto do destinatário. Portanto, para aumentar a eficiência e economizar tempo, é aconselhável mesclar documentos do Word relacionados em um único arquivo. Neste artigo, você saberá como usar Spire.Doc for Python para facilmente mesclar documentos do Word através de programas Python.
- Mesclar documentos do Word inserindo arquivos com Python
- Mesclar documentos do Word clonando conteúdo com Python
Instale Spire.Doc for Python
Este cenário requer Spire.Doc for Python e plum-dispatch v1.7.4. Eles podem ser facilmente instalados em seu VS Code por meio do seguinte comando pip.
pip install Spire.Doc
Se você não tiver certeza de como instalar, consulte este tutorial: Como instalar Spire.Doc for Python no código VS
Mesclar documentos do Word inserindo arquivos com Python
O método Document.insertTextFromFile() é usado para inserir outros documentos do Word ao atual, e o conteúdo inserido começará a partir de uma nova página. As etapas detalhadas para mesclar documentos do Word por inserção são as seguintes:
- Crie um objeto da classe Document e carregue um documento Word usando o método Document.LoadFromFile().
- Insira o conteúdo de outro documento nele usando o método Document.InsertTextFromFile().
- Save the document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document class and load a Word document
doc = Document()
doc.LoadFromFile("Sample1.docx")
# Insert the content from another Word document to this one
doc.InsertTextFromFile("Sample2.docx", FileFormat.Auto)
# Save the document
doc.SaveToFile("output/InsertDocuments.docx")
doc.Close()
Mesclar documentos do Word clonando conteúdo com Python
A mesclagem de documentos do Word também pode ser obtida clonando o conteúdo de um documento do Word para outro. Este método mantém a formatação do documento original e o conteúdo clonado de outro documento continua no final do documento atual sem iniciar uma nova página. As etapas detalhadas são as seguintes:
- Crie dois objetos da classe Document e carregue dois documentos do Word usando o método Document.LoadFromFile().
- Obtenha a última seção do documento de destino usando o método Document.Sections.get_Item().
- Percorra as seções do documento a ser clonado e, em seguida, percorra os objetos filhos das seções.
- Obtenha um objeto filho de seção usando o método Section.Body.ChildObjects.get_Item().
- Adicione o objeto filho à última seção do documento de destino usando o método Section.Body.ChildObjects.Add().
- Salve o documento resultante usando o método Document.SaveToFile().
- Python
from spire.doc import *
from spire.doc.common import *
# Create two objects of Document class and load two Word documents
doc1 = Document()
doc1.LoadFromFile("Sample1.docx")
doc2 = Document()
doc2.LoadFromFile("Sample2.docx")
# Get the last section of the first document
lastSection = doc1.Sections.get_Item(doc1.Sections.Count - 1)
# Loop through the sections in the second document
for i in range(doc2.Sections.Count):
section = doc2.Sections.get_Item(i)
# Loop through the child objects in the sections
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
# Add the child objects from the second document to the last section of the first document
lastSection.Body.ChildObjects.Add(obj.Clone())
# Save the result document
doc1.SaveToFile("output/MergeByCloning.docx")
doc1.Close()
doc2.Close()
Solicite uma licença temporária
Se desejar remover a mensagem de avaliação dos documentos gerados ou se livrar das limitações de função, por favor solicite uma licença de teste de 30 dias para você mesmo.
Python: объединить документы Word
Оглавление
Установить с помощью Пипа
pip install Spire.Doc
Ссылки по теме
Работа с большим количеством документов Word может быть очень сложной задачей. Будь то редактирование или просмотр большого количества документов, на открытие и закрытие документов тратится много времени. Более того, совместное использование и получение большого количества отдельных документов Word может раздражать, поскольку для этого может потребоваться множество повторяющихся операций отправки и получения как отправителем, так и получателем. Поэтому для повышения эффективности и экономии времени рекомендуется объединить связанные документы Word в один файл. Из этой статьи вы узнаете, как легко использовать Spire.Doc for Python объединить документы Word через программы Python.
- Объединение документов Word путем вставки файлов с помощью Python
- Объединение документов Word путем клонирования содержимого с помощью Python
Установите Spire.Doc for Python
Для этого сценария требуется Spire.Doc for Python и Plum-Dispatch v1.7.4. Их можно легко установить в ваш VS Code с помощью следующей команды pip.
pip install Spire.Doc
Если вы не знаете, как установить, обратитесь к этому руководству: Как установить Spire.Doc for Python в VS Code
Объединение документов Word путем вставки файлов с помощью Python
Метод Document.insertTextFromFile() используется для вставки других документов Word в текущий, при этом вставленное содержимое начинается с новой страницы. Подробные шаги по объединению документов Word путем вставки следующие:
- Создайте объект класса Document и загрузите документ Word с помощью метода Document.LoadFromFile().
- Вставьте в него содержимое из другого документа с помощью метода Document.InsertTextFromFile().
- Сохраните документ, используя метод Document.SaveToFile().
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document class and load a Word document
doc = Document()
doc.LoadFromFile("Sample1.docx")
# Insert the content from another Word document to this one
doc.InsertTextFromFile("Sample2.docx", FileFormat.Auto)
# Save the document
doc.SaveToFile("output/InsertDocuments.docx")
doc.Close()
Объединение документов Word путем клонирования содержимого с помощью Python
Объединение документов Word также может быть достигнуто путем клонирования содержимого одного документа Word в другой. Этот метод сохраняет форматирование исходного документа, а контент, клонированный из другого документа, продолжается в конце текущего документа, не начиная новую страницу. Подробные шаги следующие:
- Создайте два объекта класса Document и загрузите два документа Word с помощью метода Document.LoadFromFile().
- Получите последний раздел целевого документа, используя метод Document.Sections.get_Item().
- Прокрутите разделы документа, которые нужно клонировать, а затем просмотрите дочерние объекты разделов.
- Получите дочерний объект раздела, используя метод Раздел.Body.ChildObjects.get_Item().
- Добавьте дочерний объект в последний раздел целевого документа с помощью метода Раздел.Body.ChildObjects.Add().
- Сохраните полученный документ с помощью метода Document.SaveToFile().
- Python
from spire.doc import *
from spire.doc.common import *
# Create two objects of Document class and load two Word documents
doc1 = Document()
doc1.LoadFromFile("Sample1.docx")
doc2 = Document()
doc2.LoadFromFile("Sample2.docx")
# Get the last section of the first document
lastSection = doc1.Sections.get_Item(doc1.Sections.Count - 1)
# Loop through the sections in the second document
for i in range(doc2.Sections.Count):
section = doc2.Sections.get_Item(i)
# Loop through the child objects in the sections
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
# Add the child objects from the second document to the last section of the first document
lastSection.Body.ChildObjects.Add(obj.Clone())
# Save the result document
doc1.SaveToFile("output/MergeByCloning.docx")
doc1.Close()
doc2.Close()
Подать заявку на временную лицензию
Если вы хотите удалить сообщение об оценке из сгенерированных документов или избавиться от ограничений функции, пожалуйста запросите 30-дневную пробную лицензию для себя.
Python: Word-Dokumente zusammenführen
Inhaltsverzeichnis
Mit Pip installieren
pip install Spire.Doc
verwandte Links
Der Umgang mit einer großen Anzahl von Word-Dokumenten kann eine große Herausforderung sein. Unabhängig davon, ob es darum geht, eine große Anzahl von Dokumenten zu bearbeiten oder zu überprüfen, wird beim Öffnen und Schließen von Dokumenten viel Zeit verschwendet. Darüber hinaus kann das Teilen und Empfangen einer großen Anzahl separater Word-Dokumente lästig sein, da es viele wiederholte Sende- und Empfangsvorgänge sowohl seitens des Teilenden als auch des Empfängers erfordern kann. Um die Effizienz zu steigern und Zeit zu sparen, ist es daher ratsam, dies zu tun Zusammenführen zusammengehöriger Word-Dokumente in eine einzige Datei. In diesem Artikel erfahren Sie, wie Sie Spire.Doc for Python ganz einfach verwenden Word-Dokumente zusammenführen durch Python-Programme.
- Führen Sie Word-Dokumente zusammen, indem Sie Dateien mit Python einfügen
- Führen Sie Word-Dokumente zusammen, indem Sie Inhalte mit Python klonen
Installieren Sie Spire.Doc for Python
Dieses Szenario erfordert Spire.Doc for Python und plum-dispatch v1.7.4. Sie können mit dem folgenden pip-Befehl einfach in Ihrem VS-Code installiert werden.
pip install Spire.Doc
Wenn Sie sich bei der Installation nicht sicher sind, lesen Sie bitte dieses Tutorial: So installieren Sie Spire.Doc for Python in VS Code
Führen Sie Word-Dokumente zusammen, indem Sie Dateien mit Python einfügen
Die Methode Document.insertTextFromFile() wird verwendet, um andere Word-Dokumente in das aktuelle einzufügen, und der eingefügte Inhalt beginnt auf einer neuen Seite. Die detaillierten Schritte zum Zusammenführen von Word-Dokumenten durch Einfügen sind wie folgt:
- Erstellen Sie ein Objekt der Document-Klasse und laden Sie ein Word-Dokument mit der Methode Document.LoadFromFile().
- Fügen Sie den Inhalt eines anderen Dokuments mit der Methode Document.InsertTextFromFile() ein.
- Speichern Sie das Dokument mit der Methode Document.SaveToFile().
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document class and load a Word document
doc = Document()
doc.LoadFromFile("Sample1.docx")
# Insert the content from another Word document to this one
doc.InsertTextFromFile("Sample2.docx", FileFormat.Auto)
# Save the document
doc.SaveToFile("output/InsertDocuments.docx")
doc.Close()
Führen Sie Word-Dokumente zusammen, indem Sie Inhalte mit Python klonen
Das Zusammenführen von Word-Dokumenten kann auch durch das Klonen von Inhalten von einem Word-Dokument in ein anderes erreicht werden. Diese Methode behält die Formatierung des Originaldokuments bei und der aus einem anderen Dokument geklonte Inhalt wird am Ende des aktuellen Dokuments fortgesetzt, ohne eine neue Seite zu beginnen. Die detaillierten Schritte sind wie folgt:
- Erstellen Sie zwei Objekte der Document-Klasse und laden Sie zwei Word-Dokumente mit der Methode Document.LoadFromFile().
- Rufen Sie den letzten Abschnitt des Zieldokuments mit der Methode Document.Sections.get_Item() ab.
- Durchlaufen Sie die Abschnitte im Dokument, die geklont werden sollen, und durchlaufen Sie dann die untergeordneten Objekte der Abschnitte.
- Rufen Sie ein untergeordnetes Abschnittsobjekt mit der Methode Section.Body.ChildObjects.get_Item() ab.
- Fügen Sie das untergeordnete Objekt mit der Methode Section.Body.ChildObjects.Add() zum letzten Abschnitt des Zieldokuments hinzu.
- Speichern Sie das Ergebnisdokument mit der Methode Document.SaveToFile().
- Python
from spire.doc import *
from spire.doc.common import *
# Create two objects of Document class and load two Word documents
doc1 = Document()
doc1.LoadFromFile("Sample1.docx")
doc2 = Document()
doc2.LoadFromFile("Sample2.docx")
# Get the last section of the first document
lastSection = doc1.Sections.get_Item(doc1.Sections.Count - 1)
# Loop through the sections in the second document
for i in range(doc2.Sections.Count):
section = doc2.Sections.get_Item(i)
# Loop through the child objects in the sections
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
# Add the child objects from the second document to the last section of the first document
lastSection.Body.ChildObjects.Add(obj.Clone())
# Save the result document
doc1.SaveToFile("output/MergeByCloning.docx")
doc1.Close()
doc2.Close()
Beantragen Sie eine temporäre Lizenz
Wenn Sie die Bewertungsmeldung aus den generierten Dokumenten entfernen oder die Funktionseinschränkungen beseitigen möchten, wenden Sie sich bitte an uns Fordern Sie eine 30-Tage-Testlizenz an für sich selbst.
Python: fusionar documentos de Word
Tabla de contenido
Instalar con Pip
pip install Spire.Doc
enlaces relacionados
Manejar una gran cantidad de documentos de Word puede resultar un gran desafío. Ya sea editando o revisando una gran cantidad de documentos, se pierde mucho tiempo abriendo y cerrando documentos. Es más, compartir y recibir una gran cantidad de documentos de Word separados puede resultar molesto, ya que puede requerir muchas operaciones repetidas de envío y recepción tanto por parte del que comparte como del receptor. Por lo tanto, para mejorar la eficiencia y ahorrar tiempo, es aconsejable fusionar documentos de Word relacionados en un solo archivo. A partir de este artículo, sabrás cómo usar Spire.Doc for Python para fácilmente fusionar documentos de Word a través de programas Python.
- Fusionar documentos de Word insertando archivos con Python
- Fusionar documentos de Word clonando contenidos con Python
Instalar Spire.Doc for Python
Este escenario requiere Spire.Doc for Python y plum-dispatch v1.7.4. Se pueden instalar fácilmente en su código VS mediante el siguiente comando pip.
pip install Spire.Doc
Si no está seguro de cómo instalarlo, consulte este tutorial: Cómo instalar Spire.Doc for Python en VS Code
Fusionar documentos de Word insertando archivos con Python
El método Document.insertTextFromFile() se utiliza para insertar otros documentos de Word en el actual, y el contenido insertado comenzará desde una nueva página. Los pasos detallados para fusionar documentos de Word mediante inserción son los siguientes:
- Cree un objeto de la clase Documento y cargue un documento de Word usando el método Document.LoadFromFile().
- Inserte el contenido de otro documento utilizando el método Document.InsertTextFromFile().
- Guarde el documento utilizando el método Document.SaveToFile().
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document class and load a Word document
doc = Document()
doc.LoadFromFile("Sample1.docx")
# Insert the content from another Word document to this one
doc.InsertTextFromFile("Sample2.docx", FileFormat.Auto)
# Save the document
doc.SaveToFile("output/InsertDocuments.docx")
doc.Close()
Fusionar documentos de Word clonando contenidos con Python
También se puede fusionar documentos de Word clonando el contenido de un documento de Word a otro. Este método mantiene el formato del documento original y el contenido clonado de otro documento continúa al final del documento actual sin iniciar una nueva página. Los pasos detallados son los siguientes:
- Cree dos objetos de la clase Documento y cargue dos documentos de Word utilizando el método Document.LoadFromFile().
- Obtenga la última sección del documento de destino utilizando el método Document.Sections.get_Item().
- Recorra las secciones del documento que se van a clonar y luego recorra los objetos secundarios de las secciones.
- Obtenga un objeto secundario de sección utilizando el método Sección.Body.ChildObjects.get_Item().
- Agregue el objeto secundario a la última sección del documento de destino utilizando el método Sección.Body.ChildObjects.Add().
- Guarde el documento resultante utilizando el método Document.SaveToFile().
- Python
from spire.doc import *
from spire.doc.common import *
# Create two objects of Document class and load two Word documents
doc1 = Document()
doc1.LoadFromFile("Sample1.docx")
doc2 = Document()
doc2.LoadFromFile("Sample2.docx")
# Get the last section of the first document
lastSection = doc1.Sections.get_Item(doc1.Sections.Count - 1)
# Loop through the sections in the second document
for i in range(doc2.Sections.Count):
section = doc2.Sections.get_Item(i)
# Loop through the child objects in the sections
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
# Add the child objects from the second document to the last section of the first document
lastSection.Body.ChildObjects.Add(obj.Clone())
# Save the result document
doc1.SaveToFile("output/MergeByCloning.docx")
doc1.Close()
doc2.Close()
Solicitar una licencia temporal
Si desea eliminar el mensaje de evaluación de los documentos generados o deshacerse de las limitaciones de la función, por favor solicitar una licencia de prueba de 30 días para ti.
Python: Word 문서 병합
핍으로 설치
pip install Spire.Doc
관련된 링크들
많은 수의 Word 문서를 처리하는 것은 매우 어려울 수 있습니다. 많은 양의 문서를 편집하거나 검토하는 경우 문서를 열고 닫는 데 많은 시간이 낭비됩니다. 더욱이, 다수의 개별 Word 문서를 공유하고 수신하는 것은 공유자와 수신자 모두의 반복적인 전송 및 수신 작업을 많이 요구할 수 있기 때문에 성가신 일이 될 수 있습니다. 따라서 효율성을 높이고 시간을 절약하려면 다음을 수행하는 것이 좋습니다 관련 Word 문서 병합 단일 파일로. 이 기사를 통해 Spire.Doc for Python 쉽게 사용하는 방법을 알게 될 것입니다 Word 문서 병합 Python 프로그램을 통해
Spire.Doc for Python 설치
이 시나리오에는 Spire.Doc for Python 및 Plum-dispatch v1.7.4가 필요합니다. 다음 pip 명령을 통해 VS Code에 쉽게 설치할 수 있습니다.
pip install Spire.Doc
설치 방법을 잘 모르는 경우 다음 튜토리얼을 참조하세요: VS Code에서 Spire.Doc for Python를 설치하는 방법
Python으로 파일을 삽입하여 Word 문서 병합
Document.insertTextFromFile() 메소드는 다른 Word 문서를 현재 문서에 삽입하는 데 사용되며 삽입된 내용은 새 페이지에서 시작됩니다. Word 문서를 삽입하여 병합하는 자세한 단계는 다음과 같습니다.
- Document 클래스의 객체를 생성하고 Document.LoadFromFile() 메서드를 사용하여 Word 문서를 로드합니다.
- Document.InsertTextFromFile() 메서드를 사용하여 다른 문서의 내용을 해당 문서에 삽입합니다.
- Document.SaveToFile() 메서드를 사용하여 문서를 저장합니다.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document class and load a Word document
doc = Document()
doc.LoadFromFile("Sample1.docx")
# Insert the content from another Word document to this one
doc.InsertTextFromFile("Sample2.docx", FileFormat.Auto)
# Save the document
doc.SaveToFile("output/InsertDocuments.docx")
doc.Close()
Python으로 내용을 복제하여 Word 문서 병합
Word 문서 병합은 한 Word 문서의 내용을 다른 Word 문서로 복제하여 수행할 수도 있습니다. 이 방법은 원본 문서의 서식을 유지하며 다른 문서에서 복제된 내용은 새 페이지를 시작하지 않고 현재 문서의 끝 부분에서 계속됩니다. 자세한 단계는 다음과 같습니다.
- Document 클래스의 두 개체를 만들고 Document.LoadFromFile() 메서드를 사용하여 두 개의 Word 문서를 로드합니다.
- Document.Sections.get_Item() 메서드를 사용하여 대상 문서의 마지막 섹션을 가져옵니다.
- 복제할 문서의 섹션을 반복한 다음 섹션의 하위 개체를 반복합니다.
- Section.Body.ChildObjects.get_Item() 메서드를 사용하여 섹션 하위 개체를 가져옵니다.
- Section.Body.ChildObjects.Add() 메서드를 사용하여 대상 문서의 마지막 섹션에 하위 개체를 추가합니다.
- Document.SaveToFile() 메서드를 사용하여 결과 문서를 저장합니다.
- Python
from spire.doc import *
from spire.doc.common import *
# Create two objects of Document class and load two Word documents
doc1 = Document()
doc1.LoadFromFile("Sample1.docx")
doc2 = Document()
doc2.LoadFromFile("Sample2.docx")
# Get the last section of the first document
lastSection = doc1.Sections.get_Item(doc1.Sections.Count - 1)
# Loop through the sections in the second document
for i in range(doc2.Sections.Count):
section = doc2.Sections.get_Item(i)
# Loop through the child objects in the sections
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
# Add the child objects from the second document to the last section of the first document
lastSection.Body.ChildObjects.Add(obj.Clone())
# Save the result document
doc1.SaveToFile("output/MergeByCloning.docx")
doc1.Close()
doc2.Close()
임시 라이센스 신청
생성된 문서에서 평가 메시지를 제거하고 싶거나, 기능 제한을 없애고 싶다면 30일 평가판 라이센스 요청 자신을 위해.
Python: unisci documenti Word
Sommario
Installa con Pip
pip install Spire.Doc
Link correlati
Gestire un gran numero di documenti Word può essere molto impegnativo. Che si tratti di modificare o rivedere un gran numero di documenti, si perde molto tempo nell'apertura e chiusura dei documenti. Inoltre, condividere e ricevere un gran numero di documenti Word separati può essere fastidioso, poiché potrebbe richiedere molte operazioni ripetute di invio e ricezione sia da parte di chi condivide che di chi riceve. Pertanto, per migliorare l'efficienza e risparmiare tempo, è consigliabile farlo unire documenti Word correlati in un unico file. Da questo articolo imparerai come utilizzare Spire.Doc for Python in modo semplice unire documenti Word attraverso programmi Python.
- Unisci documenti Word inserendo file con Python
- Unisci documenti Word clonando i contenuti con Python
Installa Spire.Doc for Python
Questo scenario richiede Spire.Doc for Python e plum-dispatch v1.7.4. Possono essere facilmente installati nel tuo VS Code tramite il seguente comando pip.
pip install Spire.Doc
Se non sei sicuro su come installare, fai riferimento a questo tutorial: Come installare Spire.Doc for Python in VS Code
Unisci documenti Word inserendo file con Python
Il metodo Document.insertTextFromFile() viene utilizzato per inserire altri documenti Word in quello corrente e il contenuto inserito inizierà da una nuova pagina. I passaggi dettagliati per unire documenti Word mediante inserimento sono i seguenti:
- Crea un oggetto della classe Document e carica un documento Word utilizzando il metodo Document.LoadFromFile().
- Inserisci il contenuto di un altro documento utilizzando il metodo Document.InsertTextFromFile().
- Salva il documento utilizzando il metodo Document.SaveToFile() .
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document class and load a Word document
doc = Document()
doc.LoadFromFile("Sample1.docx")
# Insert the content from another Word document to this one
doc.InsertTextFromFile("Sample2.docx", FileFormat.Auto)
# Save the document
doc.SaveToFile("output/InsertDocuments.docx")
doc.Close()
Unisci documenti Word clonando i contenuti con Python
L'unione di documenti Word può essere ottenuta anche clonando i contenuti da un documento Word a un altro. Questo metodo mantiene la formattazione del documento originale e il contenuto clonato da un altro documento continua alla fine del documento corrente senza iniziare una nuova pagina. I passaggi dettagliati sono i seguenti:
- Crea due oggetti della classe Document e carica due documenti Word utilizzando il metodo Document.LoadFromFile().
- Ottieni l'ultima sezione del documento di destinazione utilizzando il metodo Document.Sections.get_Item().
- Passare in rassegna le sezioni del documento da clonare, quindi scorrere gli oggetti figlio delle sezioni.
- Ottieni un oggetto figlio della sezione utilizzando il metodo Sezione.Body.ChildObjects.get_Item().
- Aggiungi l'oggetto figlio all'ultima sezione del documento di destinazione utilizzando il metodo Sezione.Body.ChildObjects.Add().
- Salvare il documento risultante utilizzando il metodo Document.SaveToFile().
- Python
from spire.doc import *
from spire.doc.common import *
# Create two objects of Document class and load two Word documents
doc1 = Document()
doc1.LoadFromFile("Sample1.docx")
doc2 = Document()
doc2.LoadFromFile("Sample2.docx")
# Get the last section of the first document
lastSection = doc1.Sections.get_Item(doc1.Sections.Count - 1)
# Loop through the sections in the second document
for i in range(doc2.Sections.Count):
section = doc2.Sections.get_Item(i)
# Loop through the child objects in the sections
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
# Add the child objects from the second document to the last section of the first document
lastSection.Body.ChildObjects.Add(obj.Clone())
# Save the result document
doc1.SaveToFile("output/MergeByCloning.docx")
doc1.Close()
doc2.Close()
Richiedi una licenza temporanea
Se desideri rimuovere il messaggio di valutazione dai documenti generati o eliminare le limitazioni della funzione, per favore richiedere una licenza di prova di 30 giorni per te.
Python : fusionner des documents Word
Table des matières
Installer avec Pip
pip install Spire.Doc
Liens connexes
Traiter un grand nombre de documents Word peut s’avérer très difficile. Qu'il s'agisse d'éditer ou de réviser un grand nombre de documents, on perd beaucoup de temps à ouvrir et fermer des documents. De plus, partager et recevoir un grand nombre de documents Word distincts peut être ennuyeux, car cela peut nécessiter de nombreuses opérations d'envoi et de réception répétées de la part du partageur et du destinataire. Par conséquent, afin d’améliorer l’efficacité et de gagner du temps, il est conseillé de fusionner des documents Word associés dans un seul fichier. À partir de cet article, vous saurez comment utiliser Spire.Doc for Python pour facilement fusionner des documents Word via des programmes Python.
- Fusionner des documents Word en insérant des fichiers avec Python
- Fusionner des documents Word en clonant le contenu avec Python
Installer Spire.Doc for Python
Ce scénario nécessite Spire.Doc for Python et plum-dispatch v1.7.4. Ils peuvent être facilement installés dans votre VS Code via la commande pip suivante.
pip install Spire.Doc
Si vous ne savez pas comment procéder à l'installation, veuillez vous référer à ce tutoriel : Comment installer Spire.Doc for Python dans VS Code
Fusionner des documents Word en insérant des fichiers avec Python
La méthode Document.insertTextFromFile() est utilisée pour insérer d'autres documents Word dans le document actuel, et le contenu inséré démarrera à partir d'une nouvelle page. Les étapes détaillées pour fusionner des documents Word par insertion sont les suivantes :
- Créez un objet de la classe Document et chargez un document Word à l'aide de la méthode Document.LoadFromFile().
- Insérez-y le contenu d'un autre document à l'aide de la méthode Document.InsertTextFromFile().
- Enregistrez le document à l'aide de la méthode Document.SaveToFile().
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document class and load a Word document
doc = Document()
doc.LoadFromFile("Sample1.docx")
# Insert the content from another Word document to this one
doc.InsertTextFromFile("Sample2.docx", FileFormat.Auto)
# Save the document
doc.SaveToFile("output/InsertDocuments.docx")
doc.Close()
Fusionner des documents Word en clonant le contenu avec Python
La fusion de documents Word peut également être réalisée en clonant le contenu d'un document Word à un autre. Cette méthode conserve le formatage du document d'origine et le contenu cloné à partir d'un autre document continue à la fin du document en cours sans démarrer une nouvelle page. Les étapes détaillées sont les suivantes :
- Créez deux objets de la classe Document et chargez deux documents Word à l'aide de la méthode Document.LoadFromFile().
- Obtenez la dernière section du document de destination à l’aide de la méthode Document.Sections.get_Item().
- Parcourez les sections du document à cloner, puis parcourez les objets enfants des sections.
- Obtenez un objet enfant de section à l’aide de la méthode Section.Body.ChildObjects.get_Item().
- Ajoutez l'objet enfant à la dernière section du document de destination à l'aide de la méthode Section.Body.ChildObjects.Add().
- Enregistrez le document résultat à l'aide de la méthode Document.SaveToFile().
- Python
from spire.doc import *
from spire.doc.common import *
# Create two objects of Document class and load two Word documents
doc1 = Document()
doc1.LoadFromFile("Sample1.docx")
doc2 = Document()
doc2.LoadFromFile("Sample2.docx")
# Get the last section of the first document
lastSection = doc1.Sections.get_Item(doc1.Sections.Count - 1)
# Loop through the sections in the second document
for i in range(doc2.Sections.Count):
section = doc2.Sections.get_Item(i)
# Loop through the child objects in the sections
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
# Add the child objects from the second document to the last section of the first document
lastSection.Body.ChildObjects.Add(obj.Clone())
# Save the result document
doc1.SaveToFile("output/MergeByCloning.docx")
doc1.Close()
doc2.Close()
Demander une licence temporaire
Si vous souhaitez supprimer le message d'évaluation des documents générés ou vous débarrasser des limitations fonctionnelles, veuillez demander une licence d'essai de 30 jours pour toi.
Python: Create, Read, or Update a Word Document
Table of Contents
Install with Pip
pip install Spire.Doc
Related Links
Creating, reading, and updating Word documents is a common need for many developers working with the Python programming language. Whether it's generating reports, manipulating existing documents, or automating document creation processes, having the ability to work with Word documents programmatically can greatly enhance productivity and efficiency. In this article, you will learn how to create, read, or update Word documents in Python using Spire.Doc for Python.
- Create a Word Document from Scratch in Python
- Read Text of a Word Document in Python
- Update a Word Document in Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your VS Code through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python in VS Code
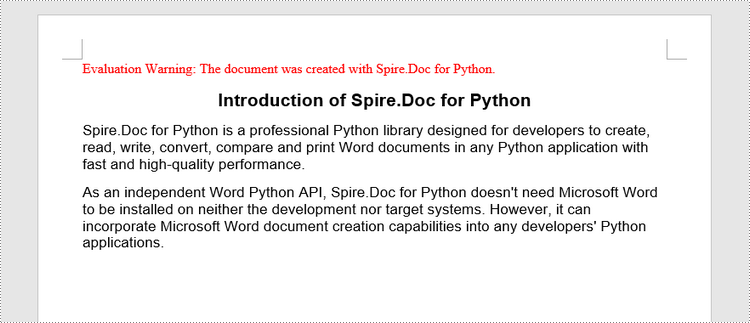
Create a Word Document from Scratch in Python
Spire.Doc for Python offers the Document class to represent a Word document model. A document must contain at least one section (represented by the Section class) and each section is a container for various elements such as paragraphs, tables, charts, and images. This example shows you how to create a simple Word document containing several paragraphs using Spire.Doc for Python.
- Create a Document object.
- Add a section using Document.AddSection() method.
- Set the page margins through Section.PageSetUp.Margins property.
- Add several paragraphs to the section using Section.AddParagraph() method.
- Add text to the paragraphs using Paragraph.AppendText() method.
- Create a ParagraphStyle object, and apply it to a specific paragraph using Paragraph.ApplyStyle() method.
- Save the document to a Word file using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Add a section
section = doc.AddSection()
# Set the page margins
section.PageSetup.Margins.All = 40
# Add a title
titleParagraph = section.AddParagraph()
titleParagraph.AppendText("Introduction of Spire.Doc for Python")
# Add two paragraphs
bodyParagraph_1 = section.AddParagraph()
bodyParagraph_1.AppendText("Spire.Doc for Python is a professional Python library designed for developers to " +
"create, read, write, convert, compare and print Word documents in any Python application " +
"with fast and high-quality performance.")
bodyParagraph_2 = section.AddParagraph()
bodyParagraph_2.AppendText("As an independent Word Python API, Spire.Doc for Python doesn't need Microsoft Word to " +
"be installed on neither the development nor target systems. However, it can incorporate Microsoft Word " +
"document creation capabilities into any developers' Python applications.")
# Apply heading1 to the title
titleParagraph.ApplyStyle(BuiltinStyle.Heading1)
# Create a style for the paragraphs
style2 = ParagraphStyle(doc)
style2.Name = "paraStyle"
style2.CharacterFormat.FontName = "Arial"
style2.CharacterFormat.FontSize = 13
doc.Styles.Add(style2)
bodyParagraph_1.ApplyStyle("paraStyle")
bodyParagraph_2.ApplyStyle("paraStyle")
# Set the horizontal alignment of the paragraphs
titleParagraph.Format.HorizontalAlignment = HorizontalAlignment.Center
bodyParagraph_1.Format.HorizontalAlignment = HorizontalAlignment.Left
bodyParagraph_2.Format.HorizontalAlignment = HorizontalAlignment.Left
# Set the after spacing
titleParagraph.Format.AfterSpacing = 10
bodyParagraph_1.Format.AfterSpacing = 10
# Save to file
doc.SaveToFile("output/WordDocument.docx", FileFormat.Docx2019)
Read Text of a Word Document in Python
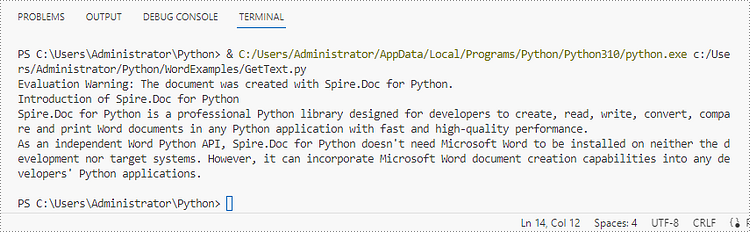
To get the text of an entire Word document, you could simply use Document.GetText() method. The following are the detailed steps.
- Create a Document object.
- Load a Word document using Document.LoadFromFile() method.
- Get text from the entire document using Document.GetText() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\WordDocument.docx")
# Get text from the entire document
text = doc.GetText()
# Print text
print(text)
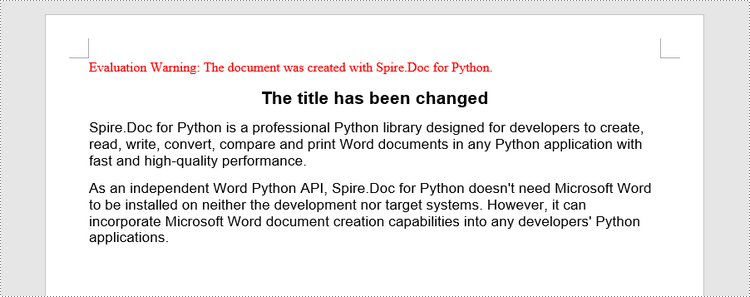
Update a Word Document in Python
To access a specific paragraph, you can use the Section.Paragraphs[index] property. If you want to modify the text of the paragraph, you can reassign text to the paragraph through the Paragraph.Text property. The following are the detailed steps.
- Create a Document object.
- Load a Word document using Document.LoadFromFile() method.
- Get a specific section through Document.Sections[index] property.
- Get a specific paragraph through Section.Paragraphs[index] property.
- Change the text of the paragraph through Paragraph.Text property.
- Save the document to another Word file using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\WordDocument.docx")
# Get a specific section
section = doc.Sections[0]
# Get a specific paragraph
paragraph = section.Paragraphs[1]
# Change the text of the paragraph
paragraph.Text = "The title has been changed"
# Save to file
doc.SaveToFile("output/Updated.docx", FileFormat.Docx2019)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.