
PDFs sind großartig, um Dokumentenlayouts zu erhalten, aber das Extrahieren von tabellarischen Daten daraus kann frustrierend sein. Der Hauptgrund dafür ist, dass PDFs für eine konsistente visuelle Darstellung über verschiedene Geräte hinweg konzipiert sind und nicht für die Extraktion strukturierter Daten. Infolgedessen können Tabellen in digitalen PDFs als auswählbarer Text oder in gescannten Dateien als Bilder vorliegen, wobei die Strukturen stark variieren.
Glücklicherweise gibt es mehrere praktische Möglichkeiten, Tabellen aus PDFs zu extrahieren, abhängig von Ihren Bedürfnissen und Ihrem technischen Komfortniveau. In diesem Leitfaden führen wir Sie durch vier effektive Methoden, von einfachen No-Code-Tools wie Excel und Google Docs bis hin zu einer leistungsstarken Python-basierten Lösung für volle Kontrolle und Automatisierung.
Methodenübersicht:
- Methode 1: Microsoft Excel (Integrierter PDF-Import)
- Methode 2: Google Docs (Kostenlos & Einfach)
- Methode 3: Adobe Acrobat Pro (Exportfunktion)
- Methode 4: Python (Volle Kontrolle & Automatisierung)
Methode 1: Microsoft Excel (Integrierter PDF-Import)
Am besten geeignet für: Windows-Benutzer mit Microsoft Office 365 oder Excel 2016+ (nur Windows).
Microsoft Excel verfügt über eine native PDF-Importfunktion, die für digitale PDFs überraschend gut funktioniert. Sie verbindet sich direkt mit der Datei und versucht, Tabellen zu erkennen und zu konvertieren.
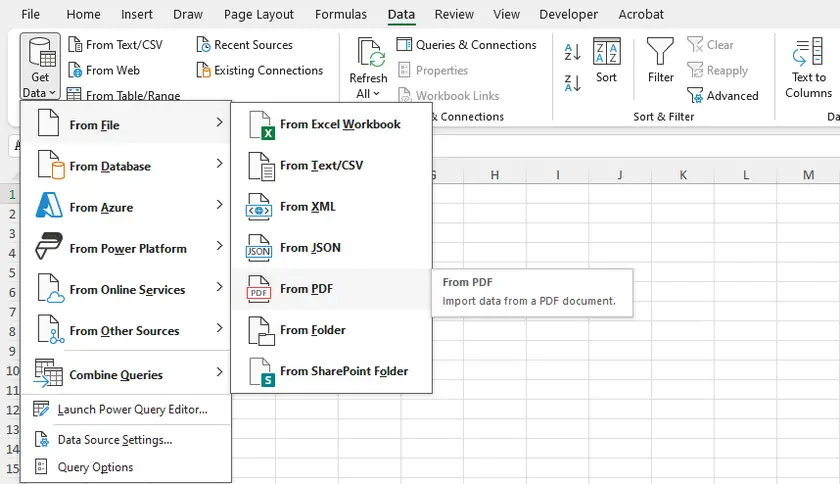
Schritt-für-Schritt-Anleitung
- Öffnen Sie Microsoft Excel.
- Gehen Sie zu Daten → Daten abrufen → Aus Datei → Aus PDF.
- Durchsuchen und wählen Sie Ihre PDF-Datei aus.
- Ein Navigator-Fenster wird angezeigt, das alle erkannten Tabellen und Seiten auflistet.
- Wählen Sie die gewünschte(n) Tabelle(n) aus und klicken Sie auf Laden (zum direkten Import) oder Daten transformieren (zum Bereinigen vor dem Laden).
- Excel importiert die Tabelle in ein Arbeitsblatt und behält die Zeilen-/Spaltenstruktur einigermaßen gut bei.
Vorteile & Nachteile
| Vorteile | Nachteile |
|---|---|
| Keine zusätzliche Software erforderlich (mit Office) | Nur Windows |
| Numerische Formate werden beibehalten | Schwierigkeiten mit verbundenen Zellen |
| Gut für digitale, textbasierte PDFs | Kein OCR für gescannte PDFs |
| Daten können aktualisiert werden, wenn sich das PDF ändert | Kann bei großen PDFs langsam sein |
Methode 2: Google Docs (Kostenlos & Einfach)
Am besten geeignet für: Schnelle, einmalige Extraktionen, wenn Sie kein Excel oder kostenpflichtige Tools haben.
Google Docs bietet eine versteckte, aber kostenlose Methode zum Extrahieren von Tabellen aus PDFs. Es funktioniert, indem das gesamte PDF in ein bearbeitbares Google Doc konvertiert wird, wo Tabellen zu textbasierten Gittern werden.
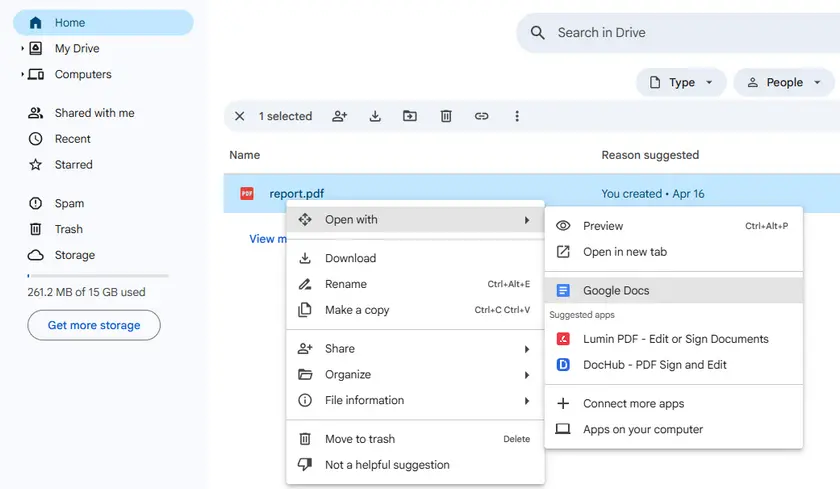
Schritt-für-Schritt-Anleitung
- Laden Sie das PDF in Google Drive hoch.
- Klicken Sie mit der rechten Maustaste auf das PDF → Öffnen mit → Google Docs.
- Warten Sie, bis Google Docs die Datei verarbeitet hat.
- Scrollen Sie, um die Tabelle zu finden. Sie wird als textbasiertes Gitter angezeigt (Zeilen und Spalten, getrennt durch Leerzeichen oder Tabulatoren).
- Kopieren Sie den Tabellenbereich und fügen Sie ihn in Google Sheets oder Microsoft Excel ein.
Vorteile & Nachteile
| Vorteile | Nachteile |
|---|---|
| Völlig kostenlos | Keine echte Tabellenerkennung (nur Textausrichtung) |
| Keine Softwareinstallation | Unordentliche Ergebnisse bei komplexen Tabellen |
| Funktioniert auf jedem Betriebssystem mit einem Browser | Schlechte Handhabung von verbundenen Zellen oder mehrzeiligen Zellen |
| Verarbeitet einfache Tabellen zuverlässig | Kein OCR (gescannte PDFs erscheinen als Bilder) |
Methode 3: Adobe Acrobat Pro (Exportfunktion)
Am besten geeignet für: Profis, die bereits Acrobat Pro besitzen und zuverlässige Exporte aus digitalen PDFs benötigen.
Adobe Acrobat Pro (nicht der kostenlose Reader) verfügt über eine integrierte Exportfunktion, die PDF-Tabellen direkt in Excel oder CSV konvertiert. Sie behält mehr Formatierungen bei als kostenlose Tools.
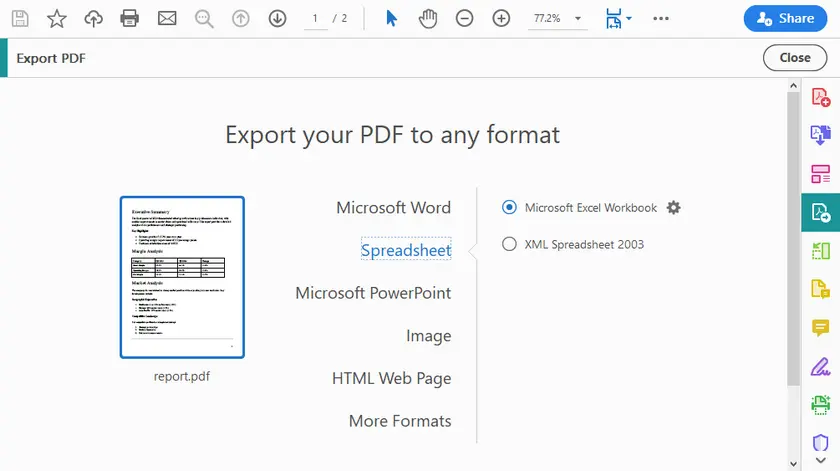
Schritt-für-Schritt-Anleitung
- Öffnen Sie das PDF in Adobe Acrobat Pro.
- Klicken Sie auf PDF exportieren (rechte Werkzeugleiste).
- Wählen Sie Tabellenkalkulation → Microsoft Excel-Arbeitsmappe (oder CSV).
- Klicken Sie auf Exportieren.
- Wählen Sie einen Speicherort und speichern Sie.
- Öffnen Sie die generierte Excel-Datei und überprüfen Sie die Tabellen.
Zusätzliche Tipps
- Verwenden Sie zuerst die Option Text erkennen (OCR), wenn Sie mit gescannten PDFs arbeiten.
- Bei mehrseitigen Tabellen fasst Acrobat diese oft intelligent zusammen.
- Sie können nur ausgewählte Seiten exportieren, um Zeit zu sparen.
Vorteile & Nachteile
| Vorteile | Nachteile |
|---|---|
| Hohe Genauigkeit für digitale PDFs | Teuer (Abonnement erforderlich) |
| Verarbeitet mehrseitige Tabellen gut | Keine feingranulare Kontrolle über die Extraktion |
| Behält Formeln und Zahlen bei | Schwierigkeiten mit sehr komplexen verschachtelten Tabellen |
| Stapelverarbeitung verfügbar | Nur Windows/macOS (keine Webversion) |
Methode 4: Python (Volle Kontrolle & Automatisierung)
Am besten geeignet für: Entwickler, Datenwissenschaftler und fortgeschrittene Benutzer, die maximale Flexibilität benötigen, gescannte PDFs verarbeiten oder Stapeldateien verarbeiten müssen.
Python gibt Ihnen die vollständige Kontrolle über den Extraktionsprozess. Sie können digitale PDFs mit Bibliotheken wie pdfplumber, camelot oder Spire.PDF for Python (eine kommerzielle Bibliothek mit einer kostenlosen Version) verarbeiten. Nachfolgend finden Sie ein praktisches Beispiel mit Spire.PDF zum Extrahieren von Tabellen und deren Speichern als saubere Textdateien.
Installation
pip install spire.pdf
Vollständiges Codebeispiel (Tabellen in TXT-Dateien extrahieren)
Der folgende Code extrahiert alle Tabellen von einer bestimmten PDF-Seite und speichert jede Tabelle als separate Textdatei im CSV-ähnlichen Format:
from spire.pdf.common import *
from spire.pdf import *
# Erstellen Sie ein PdfDocument-Objekt
doc = PdfDocument()
# Laden Sie eine PDF-Datei
doc.LoadFromFile("report.pdf")
# Erstellen Sie ein PdfTableExtractor-Objekt
extractor = PdfTableExtractor(doc)
# Extrahieren Sie Tabellen von einer bestimmten Seite (Seitenindex beginnt bei 0)
tableList = extractor.ExtractTable(0)
# Bestimmen Sie, ob die Tabellenliste nicht leer ist
if tableList is not None:
# Schleife durch die Tabellen auf der Seite
for i in range(len(tableList)):
# Erstellen Sie eine neue Liste, um Daten für diese Tabelle zu speichern
builder = []
# Holen Sie sich eine bestimmte Tabelle
table = tableList[i]
# Holen Sie sich die Zeilen- und Spaltenanzahl
row = table.GetRowCount()
column = table.GetColumnCount()
# Schleife durch jede Zeile und Spalte
for m in range(row):
for n in range(column):
# Holen Sie sich den Text aus der spezifischen Zelle
text = table.GetText(m, n)
# Fügen Sie den Text gefolgt von einem Komma (CSV-Stil) hinzu
builder.append(text + ",")
builder.append("\n") # Ende der Zeile
builder.append("\n") # Leerzeile zwischen den Tabellen
# Schreiben Sie den Inhalt in eine Textdatei
with open(f"output/Table-{i + 1}.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))
# Schließen Sie das Dokument
doc.Close()
Ausgabe:
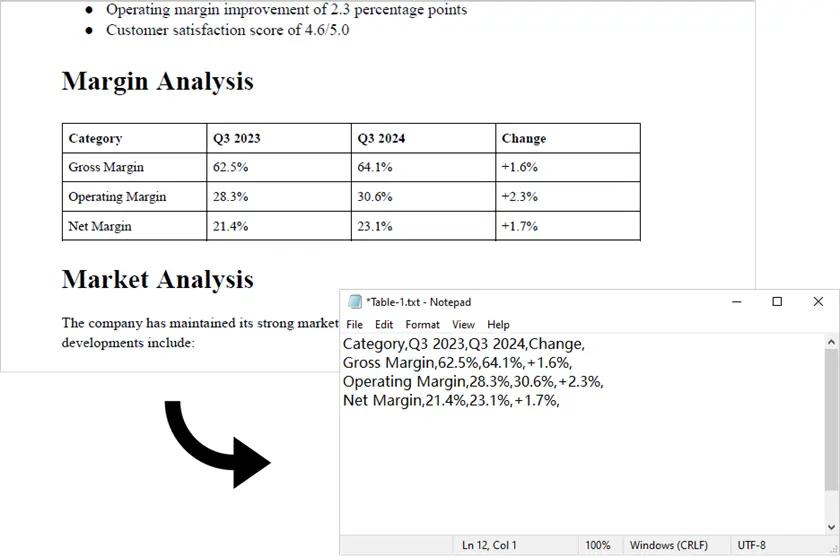
Hinweis: Dieses Skript funktioniert nur mit digital generierten PDFs (textbasiert). Für gescannte PDFs reicht Spire.PDF allein nicht aus. In solchen Fällen können Sie das PDF zuerst mit Spire.PDF in Bilder konvertieren und dann eine OCR-Engine wie pytesseract zusammen mit zusätzlicher Verarbeitungslogik anwenden, um Tabellendaten zu erkennen und zu extrahieren.
Warum Python?
- Verarbeitet sowohl digitale als auch gescannte PDFs (mit OCR-Integration)
- Stapelverarbeitung von Hunderten von Dateien
- Anpassbare Nachbearbeitung (Bereinigung, Zusammenführung, Validierung)
- Kann in Web-Apps, APIs oder ETL-Pipelines integriert werden
- Sie kontrollieren genau, wie Tabellen formatiert und gespeichert werden
Als umfassende PDF-Bibliothek extrahiert Spire.PDF for Python nicht nur Tabellen aus PDFs, sondern unterstützt auch das Extrahieren von Bildern, Metadaten und Anhängen. Darüber hinaus kann es ganze Dokumente in Formate wie Word, Excel und TXT exportieren.
Vorteile & Nachteile
| Vorteile | Nachteile |
|---|---|
| Volle Kontrolle über die Extraktionslogik | Erfordert Programmierkenntnisse |
| Verarbeitet komplexe und mehrseitige Tabellen | Steilere Lernkurve |
| Stapelverarbeitung von Tausenden von Dateien | Spire.PDF erfordert eine Lizenz für die kommerzielle Nutzung (kostenlos für private Zwecke) |
| Saubere, reproduzierbare Ergebnisse | Die Tabellenerkennung ist nicht bei allen PDFs perfekt |
| Einfache Integration mit pandas, Excel oder Datenbanken |
Vergleichstabelle: Die richtige Methode wählen
| Methode | Benutzerfreundlichkeit | Verarbeitet gescannte PDFs | Stapelverarbeitung | Kosten | Am besten geeignet für |
|---|---|---|---|---|---|
| Excel | Mittel | x | x | Erfordert Office | Schnelle, einmalige digitale Tabellen |
| Google Docs | Hoch | x | x | Kostenlos | Einfache Tabellen, keine Software |
| Adobe Acrobat Pro | Hoch | √ | x | Kostenpflichtig | Professionelle, nicht-technische Benutzer |
| Python | Niedrig | √ | √ | Kostenlos / Kostenpflichtig | Maximale Flexibilität, groß angelegte, gescannte PDFs |
Fazit
Das Extrahieren von Tabellen aus PDFs muss kein Kopfzerbrechen bereiten. Die richtige Methode hängt vollständig von Ihrer spezifischen Situation ab:
- Für eine einmalige, einfache Tabelle → Versuchen Sie zuerst Google Docs oder ein Online-Tool.
- Für professionelle, polierte Ergebnisse → Verwenden Sie Excel oder Adobe Acrobat Pro, wenn Sie Zugriff darauf haben.
- Für maximale Kontrolle, komplexe Tabellen oder gescannte Dokumente → Python ist Ihre beste Wahl.
Beginnen Sie mit der einfachsten Methode, die Ihren Anforderungen entspricht. Wenn Ihre Anforderungen wachsen (mehr Dateien, gescannte Dokumente, benutzerdefinierte Bereinigung), können Sie jederzeit zu leistungsfähigeren Tools wie Python wechseln. Der Schlüssel ist zu erkennen, dass Tabellenextraktion kein Einheits problem ist – und jetzt haben Sie vier Möglichkeiten, es zu lösen.
FAQs
F1. Warum ist es schwierig, Tabellen aus PDFs zu extrahieren?
Da PDFs Inhalte als positionierten Text und nicht als strukturierte Datentabellen speichern, ist die Extraktion weniger einfach.
F2. Welche Methode liefert die genauesten Ergebnisse?
Adobe Acrobat Pro bietet im Allgemeinen die beste Genauigkeit für komplexe Tabellen.
F3. Kann ich Tabellen aus gescannten PDFs extrahieren?
Ja, aber es erfordert OCR (Optical Character Recognition). Tools wie Adobe Acrobat oder Spire.PDF (mit einer OCR-Komponente) können gescannte Bilder in maschinenlesbaren Text umwandeln, danach können Tabellendaten erkannt und extrahiert werden.
F4. Ist Python besser als andere Methoden?
Das kommt darauf an. Python ist am besten für Automatisierung und groß angelegte Verarbeitung, aber für einmalige Aufgaben übertrieben.
F5. Kann ich extrahierte Tabellen direkt in Excel konvertieren?
Ja. Die meisten Tools (Excel, Acrobat) unterstützen den direkten Export nach .xlsx, und Python kann erweitert werden, um dasselbe zu tun.