Python: Add Comments in Excel
Comment in Excel is a function that allows users to add extra details or remarks as explanatory notes. Comments can be in the form of text or images. It enables users to provide additional information to explain or supplement the data in specified cells. After adding a comment, users can view the content of the comment by hovering the mouse over the cell with the comment. This feature enhances the readability and comprehensibility of the document, helping readers better understand and handle the data in Excel. In this article, we will show you how to add comments in Excel by using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Add Comment with Text in Excel
Spire.XLS for Python allows users to add comment with text in Excel by calling CellRange.AddComment() method. The following are detailed steps.
- Create an object of Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get the first worksheet of this file using Workbook.Worksheets[] property.
- Get the specified cell by using Worksheet.Range[] property.
- Set the author and content of the comment and add them to the obtained cell using CellRange.AddComment() method.
- Set the font of the comment.
- Save the result file using Workbook.SaveToFile() method.
- Python
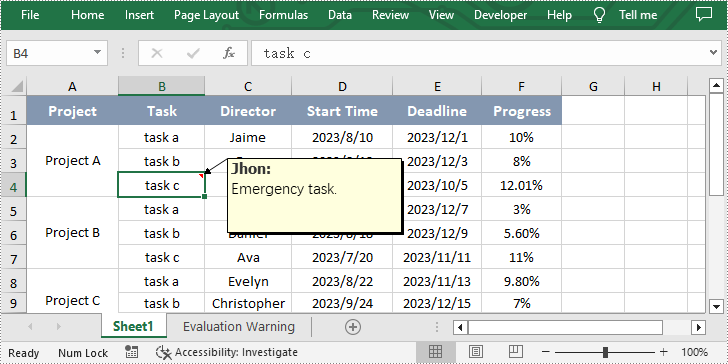
from spire.xls import * from spire.xls.common import * inputFile = "sample.xlsx" outputFile = "CommentWithAuthor.xlsx" #Create an object of Workbook class workbook = Workbook() #Load the sample file from disk workbook.LoadFromFile(inputFile) #Get the first worksheet sheet = workbook.Worksheets[0] #Get the specified cell range = sheet.Range["B4"] #Set the author and content of the comment author = "Jhon" text = "Emergency task." #Add comment to the obtained cell comment = range.AddComment() comment.Width = 200 comment.Visible = True comment.Text = author + ":\n" + text #Set the font of the comment font = workbook.CreateFont() font.FontName = "Tahoma" font.KnownColor = ExcelColors.Black font.IsBold = True comment.RichText.SetFont(0, len(author), font) #Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2013) workbook.Dispose()
Add Comment with Picture in Excel
Additionally, Spire.XLS for Python also enable users to add comment with picture to the specified cell in Excel by using CellRange.AddComment() and ExcelCommentObject.Fill.CustomPicture() methods. The following are detailed steps.
- Create an object of Workbook class.
- Get the first worksheet using Workbook.Worksheets[] property.
- Get the specified cell by using Worksheet.Range[] property and set text for it.
- Add comment to the obtained cell by using CellRange.AddComment() method.
- Load an image and fill the comment with it by calling ExcelCommentObject.Fill.CustomPicture() method.
- Set the height and width of the comment.
- Save the result file using Workbook.SaveToFile() method.
- Python
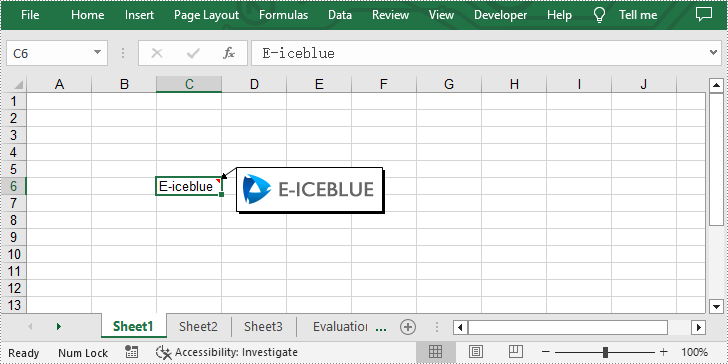
from spire.xls import * from spire.xls.common import * inputFile = "logo.png" outputFile = "CommentWithPicture.xlsx" #Create an object of Workbook class workbook = Workbook() #Get the first worksheet sheet = workbook.Worksheets[0] #Get the specified cell and set text for it range = sheet.Range["C6"] range.Text = "E-iceblue" #Add comment to the obtained cell comment = range["C6"].AddComment() #Load an image file and fill the comment with it image = Image.FromFile(inputFile) comment.Fill.CustomPicture(image, "logo.png") #Set the height and width of the comment comment.Height = image.Height comment.Width = image.Width comment.Visible = True #Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2010) workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Extract Text and Images from Word Documents
By extracting text from Word documents, you can effortlessly obtain the written information contained within them. This allows for easier manipulation, analysis, and organization of textual content, enabling tasks such as text mining, sentiment analysis, and natural language processing. Extracting images, on the other hand, provides access to visual elements embedded within Word documents, which can be crucial for tasks like image recognition, content extraction, or creating image databases. In this article, you will learn how to extract text and images from a Word document in Python using Spire.Doc for Python.
- Extract Text from a Specific Paragraph in Python
- Extract Text from an Entire Word Document in Python
- Extract Images from an Entire Word Document in Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Extract Text from a Specific Paragraph in Python
To get a certain paragraph from a section, use Section.Paragraphs[index] property. Then, you can get the text of the paragraph through Paragraph.Text property. The detailed steps are as follows.
- Create a Document object.
- Load a Word file using Document.LoadFromFile() method.
- Get a specific section through Document.Sections[index] property.
- Get a specific paragraph through Section.Paragraphs[index] property.
- Get text from the paragraph through Paragraph.Text property.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Get a specific section
section = doc.Sections.get_Item(0)
# Get a specific paragraph
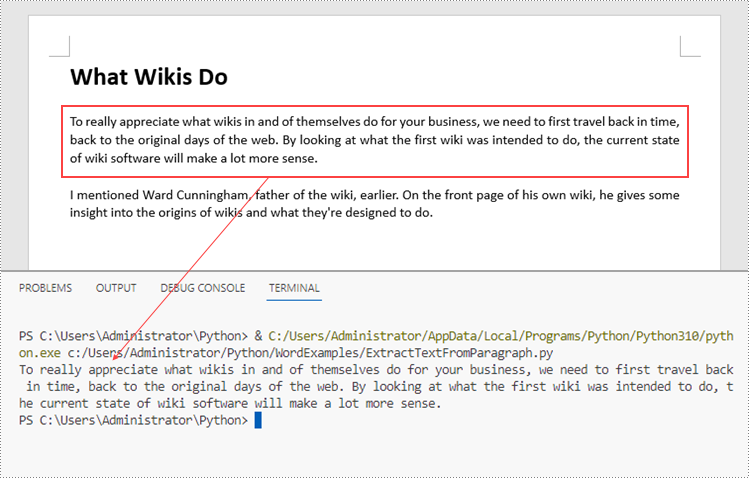
paragraph = section.Paragraphs.get_Item(2)
# Get text from the paragraph
str = paragraph.Text
# Print result
print(str)
Extract Text from an Entire Word Document in Python
If you want to get text from a whole document, you can simply use Document.GetText() method. Below are the steps.
- Create a Document object.
- Load a Word file using Document.LoadFromFile() method.
- Get text from the document using Document.GetText() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Get text from the entire document
str = doc.GetText()
# Print result
print(str)

Extract Images from an Entire Word Document in Python
Spire.Doc for Python does not provide a straightforward method to get images from a Word document. You need to iterate through the child objects in the document, and determine if a certain a child object is a DocPicture. If yes, you get the image data using DocPicture.ImageBytes property and then save it as a popular image format file. The main steps are as follows.
- Create a Document object.
- Load a Word file using Document.LoadFromFile() method.
- Loop through the child objects in the document.
- Determine if a specific child object is a DocPicture. If yes, get the image data through DocPicture.ImageBytes property.
- Write the image data as a PNG file.
- Python
import queue
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Create a Queue object
nodes = queue.Queue()
nodes.put(doc)
# Create a list
images = []
while nodes.qsize() > 0:
node = nodes.get()
# Loop through the child objects in the document
for i in range(node.ChildObjects.Count):
child = node.ChildObjects.get_Item(i)
# Determine if a child object is a picture
if child.DocumentObjectType == DocumentObjectType.Picture:
picture = child if isinstance(child, DocPicture) else None
dataBytes = picture.ImageBytes
# Add the image data to the list
images.append(dataBytes)
elif isinstance(child, ICompositeObject):
nodes.put(child if isinstance(child, ICompositeObject) else None)
# Loop through the images in the list
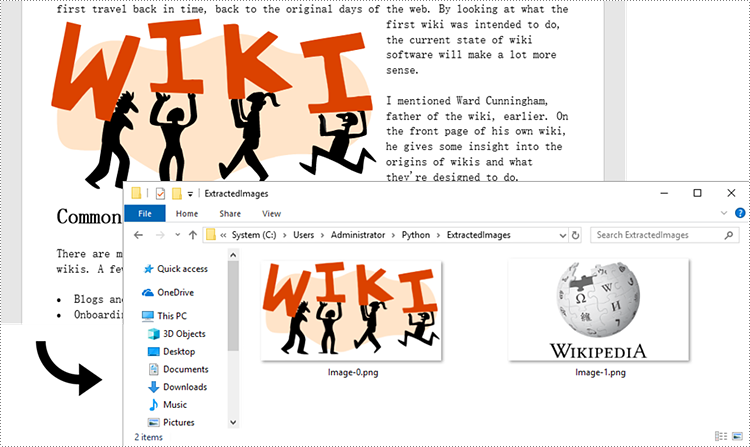
for i, item in enumerate(images):
fileName = "Image-{}.png".format(i)
with open("ExtractedImages/"+fileName,'wb') as imageFile:
# Write the image to a specified path
imageFile.write(item)
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Create, Read, or Update a Word Document
Creating, reading, and updating Word documents is a common need for many developers working with the Python programming language. Whether it's generating reports, manipulating existing documents, or automating document creation processes, having the ability to work with Word documents programmatically can greatly enhance productivity and efficiency. In this article, you will learn how to create, read, or update Word documents in Python using Spire.Doc for Python.
- Create a Word Document from Scratch in Python
- Read Text of a Word Document in Python
- Update a Word Document in Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Create a Word Document from Scratch in Python
Spire.Doc for Python offers the Document class to represent a Word document model. A document must contain at least one section (represented by the Section class) and each section is a container for various elements such as paragraphs, tables, charts, and images. This example shows you how to create a simple Word document containing several paragraphs using Spire.Doc for Python.
- Create a Document object.
- Add a section using Document.AddSection() method.
- Set the page margins through Section.PageSetUp.Margins property.
- Add several paragraphs to the section using Section.AddParagraph() method.
- Add text to the paragraphs using Paragraph.AppendText() method.
- Create a ParagraphStyle object, and apply it to a specific paragraph using Paragraph.ApplyStyle() method.
- Save the document to a Word file using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Add a section
section = doc.AddSection()
# Set the page margins
section.PageSetup.Margins.All = 40
# Add a title
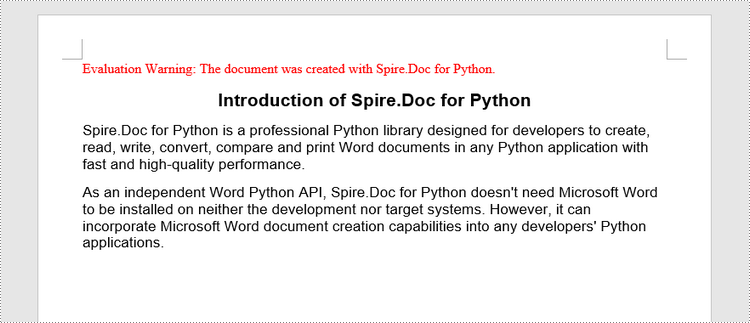
titleParagraph = section.AddParagraph()
titleParagraph.AppendText("Introduction of Spire.Doc for Python")
# Add two paragraphs
bodyParagraph_1 = section.AddParagraph()
bodyParagraph_1.AppendText("Spire.Doc for Python is a professional Python library designed for developers to " +
"create, read, write, convert, compare and print Word documents in any Python application " +
"with fast and high-quality performance.")
bodyParagraph_2 = section.AddParagraph()
bodyParagraph_2.AppendText("As an independent Word Python API, Spire.Doc for Python doesn't need Microsoft Word to " +
"be installed on neither the development nor target systems. However, it can incorporate Microsoft Word " +
"document creation capabilities into any developers' Python applications.")
# Apply heading1 to the title
titleParagraph.ApplyStyle(BuiltinStyle.Heading1)
# Create a style for the paragraphs
style2 = ParagraphStyle(doc)
style2.Name = "paraStyle"
style2.CharacterFormat.FontName = "Arial"
style2.CharacterFormat.FontSize = 13
doc.Styles.Add(style2)
bodyParagraph_1.ApplyStyle("paraStyle")
bodyParagraph_2.ApplyStyle("paraStyle")
# Set the horizontal alignment of the paragraphs
titleParagraph.Format.HorizontalAlignment = HorizontalAlignment.Center
bodyParagraph_1.Format.HorizontalAlignment = HorizontalAlignment.Left
bodyParagraph_2.Format.HorizontalAlignment = HorizontalAlignment.Left
# Set the after spacing
titleParagraph.Format.AfterSpacing = 10
bodyParagraph_1.Format.AfterSpacing = 10
# Save to file
doc.SaveToFile("output/WordDocument.docx", FileFormat.Docx2019)
Read Text of a Word Document in Python
To get the text of an entire Word document, you could simply use Document.GetText() method. The following are the detailed steps.
- Create a Document object.
- Load a Word document using Document.LoadFromFile() method.
- Get text from the entire document using Document.GetText() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
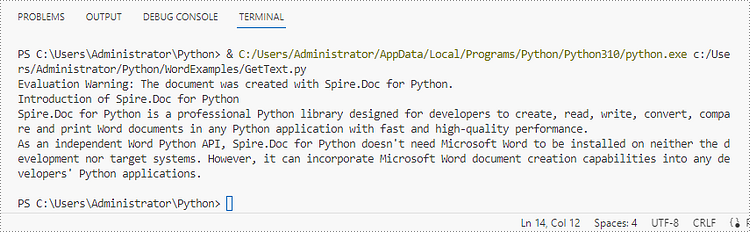
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\WordDocument.docx")
# Get text from the entire document
text = doc.GetText()
# Print text
print(text)
Update a Word Document in Python
To access a specific paragraph, you can use the Section.Paragraphs[index] property. If you want to modify the text of the paragraph, you can reassign text to the paragraph through the Paragraph.Text property. The following are the detailed steps.
- Create a Document object.
- Load a Word document using Document.LoadFromFile() method.
- Get a specific section through Document.Sections[index] property.
- Get a specific paragraph through Section.Paragraphs[index] property.
- Change the text of the paragraph through Paragraph.Text property.
- Save the document to another Word file using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\WordDocument.docx")
# Get a specific section
section = doc.Sections.get_Item(0)
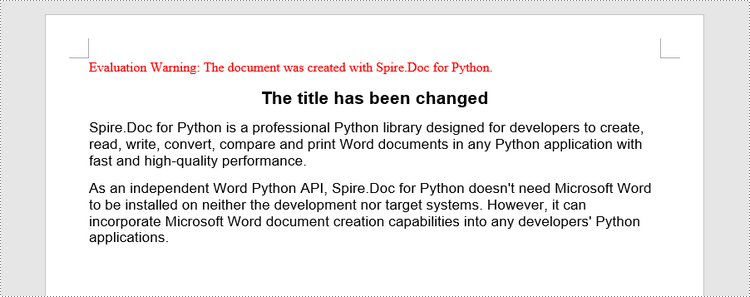
# Get a specific paragraph
paragraph = section.Paragraphs.get_Item(1)
# Change the text of the paragraph
paragraph.Text = "The title has been changed"
# Save to file
doc.SaveToFile("output/Updated.docx", FileFormat.Docx2019)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C#/VB.NET: Change or Delete Hyperlinks in PDF
Hyperlinks in PDF documents allow users to jump to pages or open documents, making PDF files more interactive and easier to use. However, if the target site of the link has been changed or the link points to the wrong page, it may cause trouble or misunderstanding to the document users. Therefore, it is very important to change or remove wrong or invalid hyperlinks in PDF documents to ensure the accuracy and usability of the hyperlinks, so as to provide a better reading experience for users. This article will introduce how to change or remove hyperlinks in PDF documents through .NET programs using Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Change the URL of a Hyperlink in PDF
To change the URL of a hyperlink on a PDF page, it is necessary to get the hyperlink annotation widget and use the PdfUriAnnotationWidget.Uri property to reset the URL. The detailed steps are as follows:
- Create an object of PdfDocument class.
- Load a PDF file using PdfDocument.LoadFromFIle() method.
- Get the first page of the document using PdfDocument.Pages[] property.
- Get the first hyperlink widget on the page using PdfPageBase.AnnotationsWidget[] property.
- Reset the URL of the hyperlink using PdfUriAnnotationWidget.Uri property.
- Save the document using PdfDocument.SaveToFile() method.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Annotations;
using System;
namespace ChangeHyperlink
{
internal class Program
{
static void Main(string[] args)
{
//Cretae an object of PdfDocument
PdfDocument pdf = new PdfDocument();
//Load a PDF file
pdf.LoadFromFile("Sample.pdf");
//Get the first page
PdfPageBase page = pdf.Pages[0];
//Get the first hyperlink
PdfUriAnnotationWidget url = (PdfUriAnnotationWidget)page.Annotations[0];
//Reset the url of the hyperlink
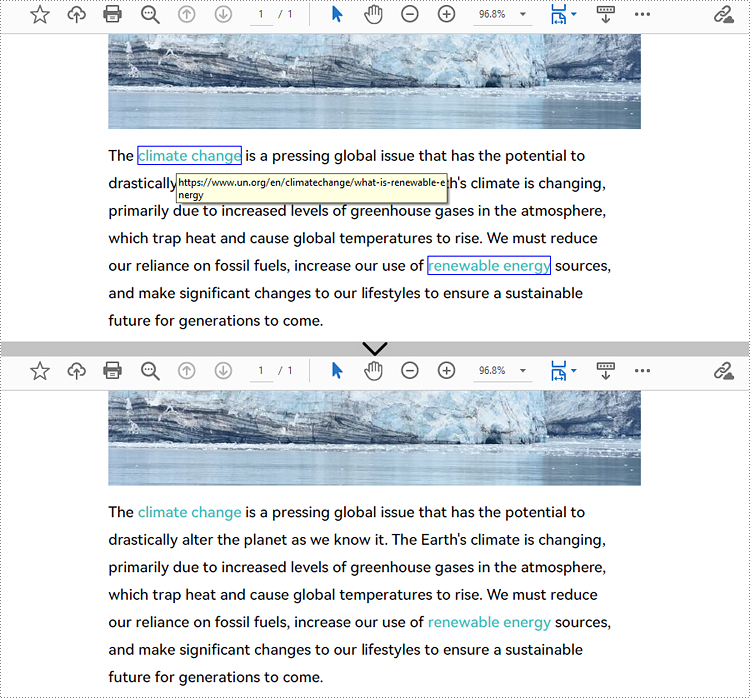
url.Uri = "https://en.wikipedia.org/wiki/Climate_change";
//Save the PDF file
pdf.SaveToFile("ChangeHyperlink.pdf");
pdf.Dispose();
}
}
}
Remove Hyperlinks from PDF
Spire.PDF for .NET provides the PdfPageBase.AnnotationsWidget.RemoveAt() method to remove a hyperlink on a PDF page by its index. Eliminating all hyperlinks from a PDF document requires iterating through the pages, obtaining the annotation widgets of each page, verifying whether an annotation is an instance of the PdfUriAnnotationWidget class, and deleting the annotation if it is. The following are the detailed steps:
- Create an object of PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFIle() method.
- To remove a specific hyperlink, get the page containing the hyperlink and remove the hyperlink by its index using PdfPageBase.AnnotationsWidget.RemoveAt() method.
- To remove all hyperlinks, loop through the pages in the document to get the annotation collection of each page using PdfPageBase.AnnotationsWidget property.
- Check if an annotation widget is an instance of PdfUriAnnotationWidget class and remove the annotation widget using PdfAnnotationCollection.Remove(PdfUriAnnotationWidget) method if it is.
- Save the document using PdfDocument.SaveToFIle() method.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Annotations;
using System;
using System.Dynamic;
namespace DeleteHyperlink
{
internal class Program
{
static void Main(string[] args)
{
//Cretae an object of PdfDocument
PdfDocument pdf = new PdfDocument();
//Load a PDF file
pdf.LoadFromFile("Sample.pdf");
//Remove the second hyperlink in the fisrt page
//PdfPageBase page = pdf.Pages[0];
//page.AnnotationsWidget.RemoveAt(1);
//Remove all hyperlinks in the document
//Loop through pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Get the annotation collection of a page
PdfAnnotationCollection collection = page.Annotations;
for (int i = collection.Count - 1; i >= 0; i--)
{
PdfAnnotation annotation = collection[i];
//Check if an annotation is an instance of PdfUriAnnotationWidget
if (annotation is PdfUriAnnotationWidget)
{
PdfUriAnnotationWidget url = (PdfUriAnnotationWidget)annotation;
//Remove the hyperlink
collection.Remove(url);
}
}
}
//Save the document
pdf.SaveToFile("DeleteHyperlink.pdf");
pdf.Dispose();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
How to Print Word Documents in C#: The Ultimate Guide

Printing Word documents programmatically in C# can streamline business workflows, automate reporting, and enhance document management systems. This comprehensive guide explores how to print Word documents in C# using Spire.Doc for .NET, covering everything from basic printing to advanced customization techniques. We'll walk through practical code examples for each scenario, ensuring you can implement these solutions in real-world applications.
- .NET Library for Printing Word Documents
- Print Word Documents in C#
- Customize Printing Options
- Silently Print Word Documents
- Print Multiple Pages on One Sheet
- Conclusion
- FAQs
.NET Library for Printing Word Documents
Spire.Doc for .NET is a robust, standalone library that supports comprehensive Word document processing without requiring Microsoft Office to be installed. It provides intuitive APIs for loading, editing, and printing Word files (DOC/DOCX) while maintaining perfect formatting fidelity.
To get started, install the library via NuGet Package Manager:
Install-Package Spire.DocAlternatively, you can download Spire.Doc for .NET from our official website and reference the DLL file manually.
Print Word Documents in C#
The foundation of Word document printing in C# involves three key steps demonstrated in the following code. First, we create a Document object to represent our Word file, then load the actual document, and finally access the printing functionality through the PrintDocument class.
- C#
using Spire.Doc;
using System.Drawing.Printing;
namespace PrintWordDocument
{
internal class Program
{
static void Main(string[] args)
{
// Initialize a new Document instance
Document doc = new Document();
// Load the Word file from specified path
doc.LoadFromFile("Input.docx");
// Access the PrintDocument object for printing operations
PrintDocument printDoc = doc.PrintDocument;
// Send document to default printer
printDoc.Print();
}
}
}This basic implementation handles the entire printing process, from document loading to physical printing, with just a few lines of code. The PrintDocument object abstracts all the underlying printing operations, making the process straightforward for developers.
Customize Printing Options
Beyond basic printing, Spire.Doc offers extensive customization via the PrinterSettings class, providing developers with granular control over the printing process. These settings allow you to tailor the output to specific needs, such as selecting particular pages or configuring advanced printer features.
To obtain the PrinterSettings object associated with the current document, use the following line of code:
- C#
PrinterSettings settings = printDoc.PrinterSettings;Now, let’s explore the specific settings.
1. Specify the Printer Name
- C#
settings.PrinterName = "Your Printer Name";This code snippet demonstrates how to target a specific printer in environments with multiple installed printers. The PrinterName property accepts the exact name of the printer as it appears in the system's printer list.
2. Specify Pages to Print
- C#
settings.FromPage = 1;
settings.ToPage = 5;These settings are particularly useful when dealing with large documents, allowing you to print only the relevant sections and conserve resources.
3. Specify Number of Copies to Print
- C#
settings.Copies = 2;The Copies property controls how many duplicates of the document will be printed, with the printer handling the duplication process efficiently.
4. Enable Duplex Printing
- C#
if (settings.CanDuplex)
{
settings.Duplex = Duplex.Default;
}This example first checks for duplex printing support before enabling two-sided printing, ensuring compatibility across different printer hardware.
5. Print on a Custom Paper Size
- C#
settings.DefaultPageSettings.PaperSize = new PaperSize("custom", 800, 500);Here we create a custom paper size (800x500 units) for specialized printing requirements, demonstrating Spire.Doc's flexibility in handling non-standard document formats.
6. Print Word to File
- C#
settings.PrintToFile = true;
settings.PrinterName = "Microsoft Print to PDF";
settings.PrintFileName = @"C:\Output.pdf";This configuration uses the system's PDF virtual printer to create a PDF file instead of physical printing, showcasing how Spire.Doc can be used for document conversion as well.
Silently Print Word Documents
In automated environments, you may need to print documents without any user interaction or visible dialogs. The following implementation achieves silent printing by using the StandardPrintController.
- C#
using Spire.Doc;
using System.Drawing.Printing;
namespace SilentlyPrintWord
{
class Program
{
static void Main(string[] args)
{
// Initialize a new Document instance
Document doc = new Document();
// Load the Word file from specified path
doc.LoadFromFile("Input.docx");
// Access the PrintDocument object for printing operations
PrintDocument printDoc = doc.PrintDocument;
// Disable the print dialog
printDoc.PrintController = new StandardPrintController();
// Exexute printing
printDoc.Print();
}
}
}The key to silent printing lies in assigning the StandardPrintController to the PrintController property, which suppresses all printing-related dialogs and progress indicators. This approach is ideal for server-side applications or batch processing scenarios where user interaction is not possible or desired.
Print Multiple Pages on One Sheet
For economizing paper usage or creating compact document versions, Spire.Doc supports printing multiple document pages on a single physical sheet. The PrintMultipageToOneSheet method simplifies this process with predefined layout options.
- C#
using Spire.Doc;
using Spire.Doc.Printing;
using System.Drawing.Printing;
namespace PrintMultiplePagesOnOneSheet
{
internal class Program
{
static void Main(string[] args)
{
// Initialize a new Document instance
Document doc = new Document();
// Load the Word file from specified path
doc.LoadFromFile("Input.docx");
// Configure 2-page-per-sheet printing and execute printing
doc.PrintMultipageToOneSheet(PagesPerSheet.TwoPages, false);
}
}
}The PagesPreSheet enumeration offers several layout options (OnePage, TwoPages, FourPages, etc.), while the boolean parameter determines whether to include a page border on the printed sheet. This feature is particularly valuable for creating booklet layouts or draft versions of documents.
P.S. This scenario works only with .NET Framework versions earlier than 5.0.
Conclusion
This guide has demonstrated how Spire.Doc for .NET provides a comprehensive solution for Word document printing in C#. It simplifies the process with features such as:
- Basic & silent printing.
- Customizable print settings (printer selection, duplex, copies).
- Multi-page per sheet printing to reduce paper usage.
By integrating these techniques, developers can efficiently automate document printing in enterprise applications, enhancing productivity and reducing manual effort. Overall, Spire.Doc empowers developers to create robust printing solutions that meet diverse business requirements.
FAQs
Q1. Can I print encrypted or password-protected Word files?
A: Yes, Spire.Doc supports printing password-protected documents after loading them with the correct password:
- C#
doc.LoadFromFile("Protected.docx", FileFormat.Docx, "password");After successful loading, you can print it like any other document, with all the same customization options available.
Q2. How can I print only selected text from a Word document?
A: You can extract specific content by accessing document sections and paragraphs:
- C#
Section section = doc.Sections[0];
Paragraph paragraph = section.Paragraphs[0];
// Create new document with selected content
Document newDoc = new Document();
newDoc.Sections.Add(section.Clone());
newDoc.Print();This approach gives you precise control over which document portions get printed.
Q3. Can I print documents in landscape mode or adjust margins programmatically?
A: Yes! Modify the DefaultPageSettings properties:
- C#
printDoc.DefaultPageSettings.Landscape = true;
printDoc.DefaultPageSettings.Margins = new Margins(50, 50, 50, 50);Q4. Can I print other file formats (e.g., PDF, Excel) using Spire.Doc?
A: Spire.Doc is designed for Word files (DOC/DOCX). For PDFs, use Spire.PDF; for Excel, use Spire.XLS.
Get a Free License
To fully experience the capabilities of Spire.Doc for Python without any evaluation limitations, you can request a free 30-day trial license.
Java: Insert Repeating Watermarks into Word Documents
Repeating watermarks, also called multi-line watermarks, are a type of watermark that appears multiple times on a page of a Word document at regular intervals. Compared with single watermarks, repeating watermarks are more difficult to remove or obscure, thus offering a better deterrent to unauthorized copying and distribution. This article is going to show how to insert repeating text and image watermarks into Word documents programmatically using Spire.Doc for Java.
- Add Repeating Text Watermarks to Word Documents in Java
- Add Repeating Picture Watermarks to Word Documents in Java
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.6.0</version>
</dependency>
</dependencies>
Add Repeating Text Watermarks to Word Documents in Java
We can insert repeating text watermarks to Word documents by adding repeating WordArt to the headers of a document at specified intervals. The detailed steps are as follows:
- Create an object of Document class.
- Load a Word document using Document.loadFromFile() method.
- Create an object of ShapeObject class and set the WordArt text using ShapeObject.getWordArt().setText() method.
- Specify the rotation angle and the number of vertical repetitions and horizontal repetitions.
- Set the format of the shape using methods under ShapeObject class.
- Loop through the sections in the document to insert repeating watermarks to each section by adding the WordArt shape to the header of each section multiple times at specified intervals using Paragraph.getChildObjects().add(ShapeObject) method.
- Save the document using Document.saveToFile() method.
- Java
import com.spire.doc.Document;
import com.spire.doc.HeaderFooter;
import com.spire.doc.Section;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.ShapeLineStyle;
import com.spire.doc.documents.ShapeType;
import com.spire.doc.fields.ShapeObject;
import java.awt.*;
public class insertRepeatingTextWatermark {
public static void main(String[] args) {
//Create an object of Document class
Document doc = new Document();
//Load a Word document
doc.loadFromFile("Sample.docx");
//Create an object of ShapeObject class and set the WordArt text
ShapeObject shape = new ShapeObject(doc, ShapeType.Text_Plain_Text);
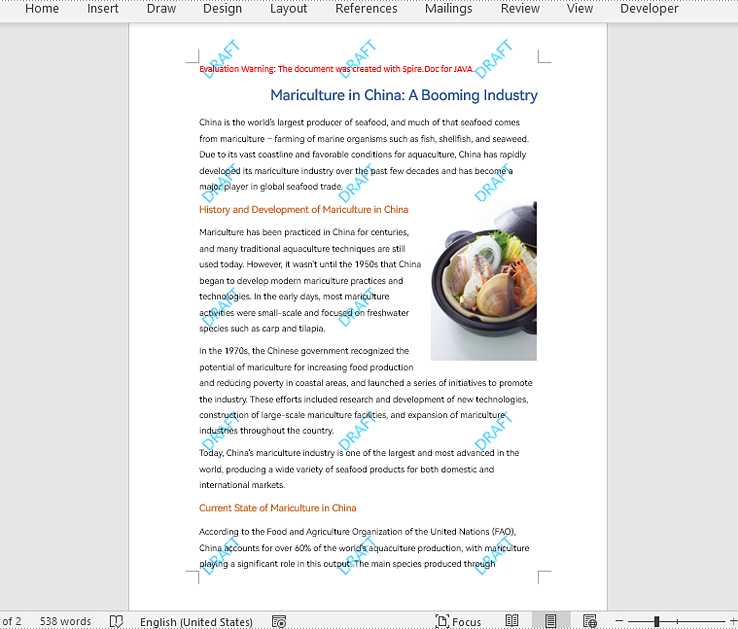
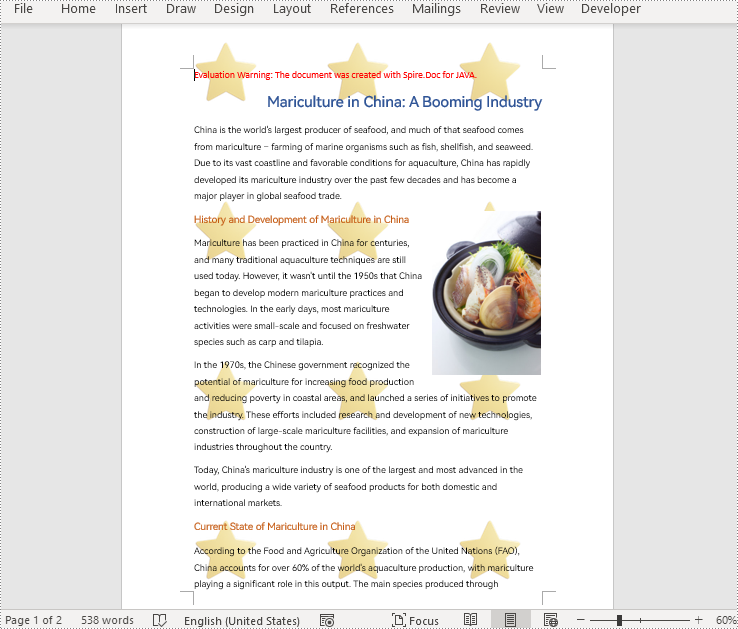
shape.getWordArt().setText("DRAFT");
//Specify the watermark rotating angle and the number of vertical repetitions and horizontal repetitions
double rotation = 315;
int ver = 5;
int hor = 3;
//Set the format of the WordArt shape
shape.setWidth(60);
shape.setHeight(20);
shape.setVerticalPosition(30);
shape.setHorizontalPosition(20);
shape.setRotation(rotation);
shape.setFillColor(Color.BLUE);
shape.setLineStyle(ShapeLineStyle.Single);
shape.setStrokeColor(Color.CYAN);
shape.setStrokeWeight(1);
//Loop through the sections in the document
for (Section section : (Iterable<Section>) doc.getSections()) {
//Get the header of a section
HeaderFooter header = section.getHeadersFooters().getHeader();
//Add paragraphs to the header
Paragraph paragraph = header.addParagraph();
for (int i = 0; i < ver; i++) {
for (int j = 0; j < hor; j++) {
//Add the WordArt shape to the header
shape = (ShapeObject) shape.deepClone();
shape.setVerticalPosition((float) (section.getPageSetup().getPageSize().getHeight()/ver * i + Math.sin(rotation) * shape.getWidth()/2));
shape.setHorizontalPosition((float) ((section.getPageSetup().getPageSize().getWidth()/hor - shape.getWidth()/2) * j));
paragraph.getChildObjects().add(shape);
}
}
}
//Save the document
doc.saveToFile("RepeatingTextWatermark.docx");
doc.dispose();
}
}
Add Repeating Picture Watermarks to Word Documents in Java
Similarly, we can insert repeating image watermarks into Word documents by adding repeating pictures to headers at regular intervals. The detailed steps are as follows:
- Create an object of Document class.
- Load a Word document using Document.loadFromFile() method.
- Load a picture using DocPicture.loadImage() method.
- Set the text wrapping style of the picture as Behind using DocPicture.setTextWrappingStyle(TextWrappingStyle.Behind) method.
- Specify the number of vertical repetitions and horizontal repetitions.
- Loop through the sections in the document to insert repeating picture watermarks to the document by adding a picture to the header of each section at specified intervals using Paragraph.getChildObjects().add(DocPicture) method.
- Save the document using Document.saveToFile() method.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.HeaderFooter;
import com.spire.doc.Section;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.TextWrappingStyle;
import com.spire.doc.fields.DocPicture;
public class insertRepeatingPictureWatermark {
public static void main(String[] args) {
//Create an object of Document class
Document doc = new Document();
//Load a Word document
doc.loadFromFile("Sample.docx");
//Load a picture
DocPicture pic = new DocPicture(doc);
pic.loadImage("watermark.png");
//Set the text wrapping style of the picture as Behind
pic.setTextWrappingStyle(TextWrappingStyle.Behind);
//Specify the number of vertical repetitions and horizontal repetitions
int ver = 4;
int hor = 3;
//Loop through the sections in the document
for (Section section : (Iterable<Section>) doc.getSections()) {
//Get the header of a section
HeaderFooter header = section.getHeadersFooters().getHeader();
//Add a paragraph to the section
Paragraph paragraph = header.addParagraph();
for (int i = 0; i < ver; i++) {
for (int j = 0; j < hor; j++) {
//Add the picture to the header
pic = (DocPicture) pic.deepClone();
pic.setVerticalPosition((float) ((section.getPageSetup().getPageSize().getHeight()/ver) * i));
pic.setHorizontalPosition((float) (section.getPageSetup().getPageSize().getWidth()/hor - pic.getWidth()/2) * j);
paragraph.getChildObjects().add(pic);
}
}
}
//Save the document
doc.saveToFile("RepeatingPictureWatermark.docx", FileFormat.Auto);
doc.dispose();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C++: Merge or Unmerge Cells in Excel
Merging and unmerging cells are two essential features in Microsoft Excel that allow users to create a more organized and visually appealing spreadsheet. Merging cells enables users to combine adjacent cells to create a single cell that spans multiple columns or rows. This feature is particularly useful for creating headers, titles, or labels for tables, as well as for combining data into a more concise format.
Unmerging cells, on the other hand, is the process of separating a merged cell back into individual cells. This feature is useful when users need to apply different formatting or styles to individual cells within a merged cell or when they want to separate data that were previously combined.
In this article, we will demonstrate how to merge or unmerge cells in an Excel file in C++ using Spire.XLS for C++ library.
- Merge Specific Cells in Excel in C++
- Unmerge Specific Merged Cells in Excel in C++
- Unmerge All Merged Cells in Excel in C++
Install Spire.XLS for C++
There are two ways to integrate Spire.XLS for C++ into your application. One way is to install it through NuGet, and the other way is to download the package from our website and copy the libraries into your program. Installation via NuGet is simpler and more recommended. You can find more details by visiting the following link.
Integrate Spire.XLS for C++ in a C++ Application
Merge Specific Cells in Excel in C++
You can easily use the IXLSRange->Merge() method provided by Spire.XLS for C++ to merge a specific range of cells into a single cell. The detailed steps are as follows:
- Initialize an instance of the Workbook instance.
- Load an Excel file using the Workbook->LoadFromFile(LPCWSTR_S fileName) method.
- Get a specific worksheet of the file using the Workbbok->GetWorksheets()->Get(int index) method.
- Get the cell range that you want to merge using the Worksheet->GetRange(LPCWSTR_S name) method.
- Merge the cell range using the IXLSRange->Merge() method.
- Center the text in the merged cell using the IXLSRange->GetStyle()->SetHorizontalAlignment(HorizontalAlignType::Center) method.
- Save the result file to a specific location using the Workbook->SaveToFile(LPCWSTR_S fileName, ExcelVersion version) method.
- C++
#include "Spire.Xls.o.h";
using namespace Spire::Xls;
using namespace std;
int main()
{
//Specify the input and output file paths
wstring inputFile = L"Template.xlsx";
wstring outputFile = L"MergeCells.xlsx";
//Initialize an instance of the Workbook instance
intrusive_ptr<Workbook> workbook = new Workbook();
//Load an Excel file
workbook->LoadFromFile(inputFile.c_str());
//Get the first worksheet of the file
intrusive_ptr<Worksheet> sheet = dynamic_pointer_cast<Worksheet>(workbook->GetWorksheets()->Get(0));
//Merge a particular range of cells in the worksheet
intrusive_ptr<IXLSRange> range = sheet->GetRange(L"A1:D1");
range->Merge();
//Center the text in the merged cell
range->GetStyle()->SetHorizontalAlignment(HorizontalAlignType::Center);
//Save the result file to the specific path
workbook->SaveToFile(outputFile.c_str(), ExcelVersion::Version2013);
workbook->Dispose();
}
Unmerge Specific Merged Cells in Excel in C++
To unmerge merged cells, you can use the IXLSRange->UnMerge() method. The detailed steps are as follows:
- Initialize an instance of the Workbook instance.
- Load an Excel file using the Workbook->LoadFromFile(LPCWSTR_S fileName) method.
- Get a specific worksheet of the file using the Workbbok->GetWorksheets()->Get(int index) method.
- Get the cell that you want to unmerge using the Worksheet->GetRange(LPCWSTR_S name) method.
- Unmerge the cell using the IXLSRange->UnMerge() method.
- Save the result file to a specific location using the Workbook->SaveToFile(LPCWSTR_S fileName, ExcelVersion version) method.
- C++
#include "Spire.Xls.o.h";
using namespace Spire::Xls;
using namespace std;
int main()
{
//Specify the input and output file paths
wstring inputFile = L"MergeCells.xlsx";
wstring outputFile = L"UnmergeCells.xlsx";
//Initialize an instance of the Workbook instance
intrusive_ptr<Workbook> workbook = new Workbook();
//Load an Excel file
workbook->LoadFromFile(inputFile.c_str());
//Get the first worksheet of the file
intrusive_ptr<Worksheet> sheet = dynamic_pointer_cast<Worksheet>(workbook->GetWorksheets()->Get(0));
//Unmerge a specific merged cell in the worksheet
intrusive_ptr<IXLSRange> range = sheet->GetRange(L"A1");
range->UnMerge();
//Save the result file to the specific path
workbook->SaveToFile(outputFile.c_str(), ExcelVersion::Version2013);
workbook->Dispose();
}
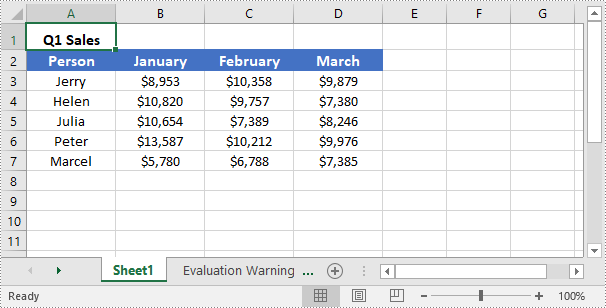
Unmerge All Merged Cells in Excel in C++
Spire.XLS for C++ provides the Worksheet->GetMergedCells() method which enables you to obtain all merged cells in a specific worksheet. Once the merged cells are obtained, you can use the IXLSRange->UnMerge() method to unmerge them. The detailed steps are as follows:
- Initialize an instance of the Workbook instance.
- Load an Excel file using the Workbook->LoadFromFile(LPCWSTR_S fileName) method.
- Get a specific worksheet of the file using the Workbbok->GetWorksheets()->Get(int index) method.
- Get the merged cells in the worksheet using the Worksheet->GetMergedCells() method.
- Iterate through all the merged cells, then unmerge each merged cell using the IXLSRange->UnMerge() method.
- Save the result file to a specific location using the Workbook->SaveToFile(LPCWSTR_S fileName, ExcelVersion version) method.
- C++
#include ""Spire.Xls.o.h"";
using namespace Spire::Xls;
using namespace std;
int main()
{
//Specify the input and output file paths
wstring inputFile = L""MergeCells.xlsx"";
wstring outputFile = L""UnmergeAllCells.xlsx"";
//Initialize an instance of the Workbook class
intrusive_ptr<Workbook> workbook = new Workbook();
//Load an Excel file
workbook->LoadFromFile(inputFile.c_str());
//Get the first worksheet
intrusive_ptr<Worksheet> sheet = dynamic_pointer_cast<Worksheet>(workbook->GetWorksheets()->Get(0));
//Get the merged cell ranges in the first worksheet
intrusive_ptr<Spire::Xls::IList<XlsRange>> range = dynamic_pointer_cast<Spire::Xls::IList<XlsRange>>(sheet->GetMergedCells());
//Iterate through the merged cells
for (int i = 0; i < range->GetCount(); i++)
{
intrusive_ptr<XlsRange> cell = range->GetItem(i);
//Unmerge each merged cell
cell->UnMerge();
}
//Save the result file to the specific path
workbook->SaveToFile(outputFile.c_str(), ExcelVersion::Version2013);
workbook->Dispose();
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C++: Split a PDF File into Multiple PDFs
When dealing with large PDF files, splitting them into multiple separate files is a useful operation to streamline your work. By doing this, you can get the specific parts you need, or get smaller PDF files that are easy to upload to a website, send via email, etc. In this article, you will learn how to split a PDF into multiple files in C++ using Spire.PDF for C++.
Install Spire.PDF for C++
There are two ways to integrate Spire.PDF for C++ into your application. One way is to install it through NuGet, and the other way is to download the package from our website and copy the libraries into your program. Installation via NuGet is simpler and more recommended. You can find more details by visiting the following link.
Integrate Spire.PDF for C++ in a C++ Application
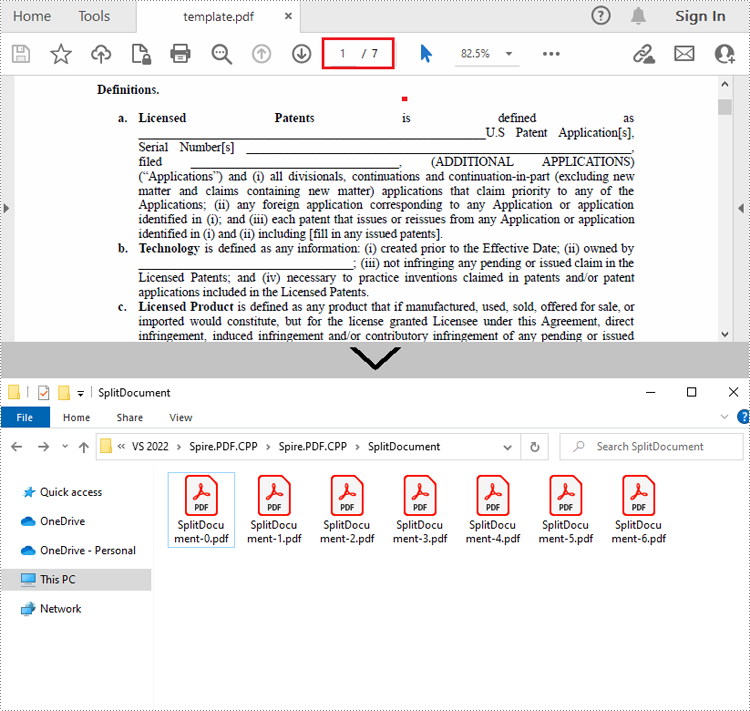
Split a PDF File into Multiple Single-Page PDFs in C++
Spire.PDF for C++ offers the PdfDocument->Split() method to divide a multipage PDF document into multiple single-page files. The following are the detailed steps.
- Create a PdfDcoument instance.
- Load a sample PDF document using PdfDocument->LoadFromFile() method.
- Split the document into one-page PDFs using PdfDocument->Split() method.
- C++
#include "Spire.Pdf.o.h";
using namespace Spire::Pdf;
int main()
{
//Specify the input and output files
std::wstring inputFile = L"Data\\template.pdf";
std::wstring outputFile = L"SplitDocument/";
std::wstring pattern = outputFile + L"SplitDocument-{0}.pdf";
//Create a PdfDocument instance
intrusive_ptr<PdfDocument> pdf = new PdfDocument();
//Load a sample PDF file
pdf->LoadFromFile(inputFile.c_str());
//Split the PDF to one-page PDFs
pdf->Split(pattern.c_str());
pdf->Close();
}
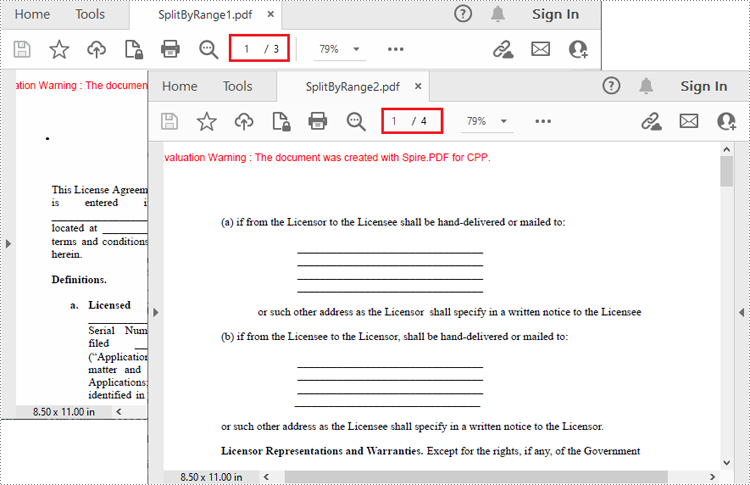
Split a PDF File by Page Ranges in C++
There's no straightforward way to split PDF documents by page ranges. To do so, you can create two or more new PDF documents and then use the PdfPageBase->CreateTemplate()->Draw() method to draw the contents of the specified pages in the input PDF file onto the pages of the new PDFs. The following are the detailed steps.
- Create a PdfDocument instance and load a sample PDF file.
- Create a new PDF document, and then Initialize a new instance of PdfPageBase class.
- Iterate through the first several pages in the sample PDF file.
- Create a new page with specified size and margins in the new PDF document
- Get the specified page in the sample PDF using PdfDocument->GetPages()->GetItem() method, and then draw the contents of the specified page onto the new page using PdfPageBase->CreateTemplate()->Draw() method.
- Save the first new PDF document using PdfDocument->SaveToFile() method.
- Create another new PDF document and then draw the remaining pages of the sample PDF file into it.
- Save the second new PDF document.
- C++
#include "Spire.Pdf.o.h";
using namespace Spire::Pdf;
int main()
{
//Create a PdfDocument instance and load a sample PDF file
intrusive_ptr<PdfDocument> oldPdf = new PdfDocument();
oldPdf->LoadFromFile(L"Data\\template.pdf");
//Create a new PDF document
intrusive_ptr<PdfDocument> newPdf1 = new PdfDocument();
//Initialize a new instance of PdfPageBase class
intrusive_ptr<PdfPageBase> page;
//Draw the first three pages of the sample file into the new PDF document
for (int i = 0; i < 3; i++)
{
//Create a new page with specified size and margin in the new PDF document
intrusive_ptr<PdfMargins> tempVar = new PdfMargins(0);
page = newPdf1->GetPages()->Add(oldPdf->GetPages()->GetItem(i)->GetSize(), tempVar);
//Draw the contents of a specified page in the sample file onto the new page
oldPdf->GetPages()->GetItem(i)->CreateTemplate()->Draw(page, new PointF(0, 0));
}
//Save the first PDF document
newPdf1->SaveToFile(L"SplitByRange1.pdf");
newPdf1->Close();
//Create another new PDF document
intrusive_ptr<PdfDocument> newPdf2 = new PdfDocument();
//Draw the rest pages of the sample file into the new PDF document
for (int i = 3; i < oldPdf->GetPages()->GetCount(); i++)
{
//Create a new page with specified size and margin in the new PDF document
intrusive_ptr<PdfMargins> tempVar = new PdfMargins(0);
page = newPdf2->GetPages()->Add(oldPdf->GetPages()->GetItem(i)->GetSize(), tempVar);
// Draw the contents of a specified page in the sample file onto the new page
oldPdf->GetPages()->GetItem(i)->CreateTemplate()->Draw(page, new PointF(0, 0));
}
//Save the second PDF document
newPdf2->SaveToFile(L"SplitByRange2.pdf");
newPdf2->Close();
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C++: Create a PDF Document from Scratch
PDF documents generated through code are consistent in terms of formatting, layout, and content, ensuring a professional look. Automating the creation of PDF documents reduces the time and effort required to produce them manually. Nowadays, most invoices, receipts and other financial documents are generated programmatically. In this article, you will learn how to create PDF documents from scratch in C++ using Spire.PDF for C++.
Install Spire.PDF for C++
There are two ways to integrate Spire.PDF for C++ into your application. One way is to install it through NuGet, and the other way is to download the package from our website and copy the libraries into your program. Installation via NuGet is simpler and more recommended. You can find more details by visiting the following link.
Integrate Spire.PDF for C++ in a C++ Application
Background Knowledge
A page in Spire.PDF for C++ (represented by PdfPageBase class) consists of client area and margins all around. The content area is for users to write various contents, and the margins are usually blank edges.
As shown in the figure below, the origin of the coordinate system on the page is located at the top left corner of the client area, with the x-axis extending horizontally to the right and the y-axis extending vertically down. All elements added to the client area must be based on the specified coordinates.
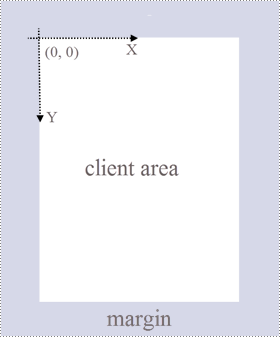
In addition, the following table lists the important classes and methods, which can help you easily understand the code snippet provided in the following section.
| Member | Description |
| PdfDocument class | Represents a PDF document model. |
| PdfPageBase class | Represents a page in a PDF document. |
| PdfSolidBrush class | Represents a brush that fills any object with a solid color. |
| PdfTrueTypeFont class | Represents a true type font. |
| PdfStringFormat class | Represents text format information, such as alignment, characters spacing and indent. |
| PdfTextWidget class | Represents the text area with the ability to span several pages. |
| PdfTextLayout class | Represents the text layout information. |
| PdfDocument->GetPages()->Add() method | Adds a page to a PDF document. |
| PdfPageBase->GetCanvas()->DrawString() method | Draws string on a page at the specified location with specified font and brush objects. |
| PdfLayoutWidget->Draw() method | Draws widget on a page at the specified location. |
| PdfDocument->Save() method | Saves the document to a PDF file. |
Create a PDF Document from Scratch in C++
Despite the fact that Spire.PDF for C++ enables users to add various elements to PDF documents, this article demonstrates how to create a simple PDF document with only plain text. The following are the detailed steps.
- Create a PdfDocument object.
- Add a page using PdfDocument->GetPages()->Add() method.
- Create brush and font objects.
- Draw string on the page at a specified coordinate using PdfPageBase->GetCanvas()->DrawString() method.
- Create a PdfTextWidget object to hold a chunk of text.
- Convert the text widget to an object of PdfLayoutWidget class and draw it on the page using PdfLayoutWidget->Draw() method
- Save the document to a PDF file using PdfDocument->Save() method.
- C++
#include "Spire.Pdf.o.h";
using namespace Spire::Pdf;
using namespace std;
wstring readFileIntoWstring(const string& path) {
ifstream input_file(path);
if (!input_file.is_open()) {
cerr << "Could not open the file - '"
<< path << "'" << endl;
exit(EXIT_FAILURE);
}
string s1 = string((std::istreambuf_iterator<char>(input_file)), std::istreambuf_iterator<char>());
wstring ws(s1.begin(), s1.end());
return ws;
}
int main() {
//Create a PdfDocument object
intrusive_ptr<PdfDocument> doc = new PdfDocument();
//Add a page
intrusive_ptr<PdfPageBase> page = doc->GetPages()->Add(PdfPageSize::A4(), new PdfMargins(35));
//Specify title text
wstring titleText = L"What is MySQL";
//Create solid brushes
intrusive_ptr<PdfSolidBrush> titleBrush = new PdfSolidBrush(new PdfRGBColor(Color::GetPurple()));
intrusive_ptr<PdfSolidBrush> paraBrush = new PdfSolidBrush(new PdfRGBColor(Color::GetBlack()));
//Create true type fonts
intrusive_ptr<PdfTrueTypeFont> titleFont = new PdfTrueTypeFont(L"Times New Roman", 18, PdfFontStyle::Bold, true);
intrusive_ptr<PdfTrueTypeFont> paraFont = new PdfTrueTypeFont(L"Times New Roman", 12, PdfFontStyle::Regular, true);
//Set the text alignment via PdfStringFormat class
intrusive_ptr<PdfStringFormat> format = new PdfStringFormat();
format->SetAlignment(PdfTextAlignment::Center);
//Draw title on the page
page->GetCanvas()->DrawString(titleText.c_str(), titleFont, titleBrush, page->GetClientSize()->GetWidth() / 2, 20, format);
//Get paragraph text from a .txt file
wstring paraText = readFileIntoWstring("C:\\Users\\Administrator\\Desktop\\content.txt");
//Create a PdfTextWidget object to hold the paragraph content
intrusive_ptr<PdfTextWidget> widget = new PdfTextWidget(paraText.c_str(), paraFont, paraBrush);
//Create a rectangle where the paragraph content will be placed
intrusive_ptr<RectangleF> rect = new RectangleF(0, 50, (float)page->GetClientSize()->GetWidth(), (float)page->GetClientSize()->GetHeight());
//Set the PdfLayoutType to Paginate to make the content paginated automatically
intrusive_ptr<PdfTextLayout> layout = new PdfTextLayout();
layout->SetLayout(PdfLayoutType::Paginate);
//Draw paragraph text on the page
Object::Convert<PdfLayoutWidget>(widget)->Draw(page, rect, layout);
//Save to file
doc->SaveToFile(L"output/CreatePdfDocument.pdf");
doc->Dispose();
}
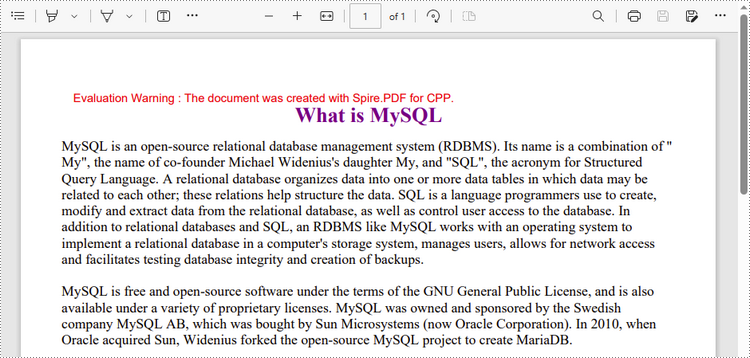
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C++: Apply or Remove Data Validation in Excel
Data validation in Excel controls what types of information can be entered into a cell. Using it, you can restrict only specific data types such as numbers or dates to be in a cell, or limit numbers to a certain range and text to a certain length. In addition, it also allows you to present a list of predefined values in a drop-down menu for users to choose from. In this article, you will learn how to apply or remove data validation in Excel in C++ using Spire.XLS for C++.
Install Spire.XLS for C++
There are two ways to integrate Spire.XLS for C++ into your application. One way is to install it through NuGet, and the other way is to download the package from our website and copy the libraries into your program. Installation via NuGet is simpler and more recommended. You can find more details by visiting the following link.
Integrate Spire.XLS for C++ in a C++ Application
Apply Data Validation to Excel Cells in C++
Spire.XLS for C++ allows you to create validation rules for numbers, dates, text values, lists, etc. The following are the steps to apply different data validation types to specified cells in Excel.
- Create a Workbook object.
- Get a specified worksheet using Workbook->GetWorksheets()->Get() method.
- Get a specific cell using Worksheet->GetRange() method.
- Set the data type allowed in the cell using CellRange->GetDataValidation()->SetAllowType() method. You can select different data type such as Decimal, Time, Date, TextLength and Integer.
- Set the comparison operator using CellRange->GetDataValidation()->SetCompareOperator() method. The comparison operators include Between, NotBetween, Less, Greater, and Equal.
- Set one or two formulas for the data validation using CellRange->GetDataValidation()->SetFormula1() and CellRange->GetDataValidation()->SetFormula2() methods.
- Set the input prompt using CellRange->GetDataValidation()->SetInputMessage() method.
- Set the error message using CellRange->GetDataValidation()->SetErrorMessage() method.
- Set to show the error alert and set its alert style when invalid data is entered.
- Save the result document using Workbook->SaveToFile() method.
- C++
#include "Spire.Xls.o.h";
using namespace Spire::Xls;
int main() {
//Specify the output file
std::wstring outputFile = L"DataValidation.xlsx";
//Create a Workbook object
intrusive_ptr<Workbook> workbook = new Workbook();
//Get the first worksheet
intrusive_ptr<Worksheet> sheet = dynamic_pointer_cast<Worksheet>(workbook->GetWorksheets()->Get(0));
//Insert text in specified cells
dynamic_pointer_cast<CellRange>(sheet->GetRange(L"B2"))->SetText(L"Number Validation: ");
dynamic_pointer_cast<CellRange>(sheet->GetRange(L"B4"))->SetText(L"Date Validation: ");
dynamic_pointer_cast<CellRange>(sheet->GetRange(L"B6"))->SetText(L"Text Length Validation: ");
dynamic_pointer_cast<CellRange>(sheet->GetRange(L"B8"))->SetText(L"List Validation: ");
dynamic_pointer_cast<CellRange>(sheet->GetRange(L"B10"))->SetText(L"Time Validation: ");
//Add a number validation to C2
intrusive_ptr<CellRange> rangeNumber = dynamic_pointer_cast<CellRange>(sheet->GetRange(L"C2"));
rangeNumber->GetDataValidation()->SetAllowType(CellDataType::Decimal);
rangeNumber->GetDataValidation()->SetCompareOperator(ValidationComparisonOperator::Between);
rangeNumber->GetDataValidation()->SetFormula1(L"3");
rangeNumber->GetDataValidation()->SetFormula2(L"6");
rangeNumber->GetDataValidation()->SetInputMessage(L"Enter a number between 1 and 10");
rangeNumber->GetDataValidation()->SetErrorMessage(L"Please input correct number!");
rangeNumber->GetDataValidation()->SetShowError(true);
rangeNumber->GetDataValidation()->SetAlertStyle(AlertStyleType::Warning);
rangeNumber->GetStyle()->SetKnownColor(ExcelColors::Gray25Percent);
//Add a date validation to C4
intrusive_ptr<CellRange> rangeDate = dynamic_pointer_cast<CellRange>(sheet->GetRange(L"C4"));
rangeDate->GetDataValidation()->SetAllowType(CellDataType::Date);
rangeDate->GetDataValidation()->SetCompareOperator(ValidationComparisonOperator::Between);
rangeDate->GetDataValidation()->SetFormula1(L"1/1/2021");
rangeDate->GetDataValidation()->SetFormula2(L"12/31/2021");
rangeDate->GetDataValidation()->SetInputMessage(L"Enter a date between 1/1/2021 and 12/31/2021");
rangeDate->GetStyle()->SetKnownColor(ExcelColors::Gray25Percent);
//Add a text length validation to C6
intrusive_ptr<CellRange> rangeTextLength = dynamic_pointer_cast<CellRange>(sheet->GetRange(L"C6"));
rangeTextLength->GetDataValidation()->SetAllowType(CellDataType::TextLength);
rangeTextLength->GetDataValidation()->SetCompareOperator(ValidationComparisonOperator::LessOrEqual);
rangeTextLength->GetDataValidation()->SetFormula1(L"5");
rangeTextLength->GetDataValidation()->SetErrorMessage(L"Enter a Valid String!");
rangeTextLength->GetDataValidation()->SetShowError(true);
rangeTextLength->GetDataValidation()->SetAlertStyle(AlertStyleType::Stop);
rangeTextLength->GetStyle()->SetKnownColor(ExcelColors::Gray25Percent);
//Apply a list validation to C8
intrusive_ptr<CellRange> rangeList = dynamic_pointer_cast<CellRange>(sheet->GetRange(L"C8"));
std::vector<LPCWSTR_S> files = { L"United States", L"Canada", L"United Kingdom" };
rangeList->GetDataValidation()->SetValues(files);
rangeList->GetDataValidation()->SetIsSuppressDropDownArrow(false);
rangeList->GetDataValidation()->SetInputMessage(L"Choose an item from the list");
rangeList->GetStyle()->SetKnownColor(ExcelColors::Gray25Percent);
//Apply a time validation to C10
intrusive_ptr<CellRange> rangeTime = dynamic_pointer_cast<CellRange>(sheet->GetRange(L"C10"));
rangeTime->GetDataValidation()->SetAllowType(CellDataType::Time);
rangeTime->GetDataValidation()->SetCompareOperator(ValidationComparisonOperator::Between);
rangeTime->GetDataValidation()->SetFormula1(L"9:00");
rangeTime->GetDataValidation()->SetFormula2(L"12:00");
rangeTime->GetDataValidation()->SetInputMessage(L"Enter a time between 9:00 and 12:00");
rangeTime->GetStyle()->SetKnownColor(ExcelColors::Gray25Percent);
//Auto fit width of column 2
sheet->AutoFitColumn(2);
//Set the width of column 3
sheet->GetColumns()->GetItem(2)->SetColumnWidth(20);
//Save the result document
workbook->SaveToFile(outputFile.c_str(), ExcelVersion::Version2016);
workbook->Dispose();
}
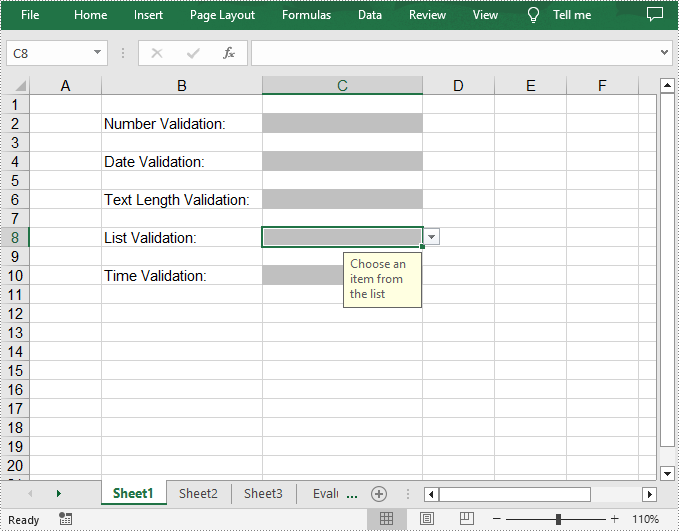
Remove Data Validation from Excel Cells in C++
To remove data validation applied to the cells, Spire.XLS for C++ provides the Worksheet->GetDVTable()->Remove() method. The following are the detailed steps.
- Create a Workbook object.
- Load a sample Excel document containing data validation using Workbook->LoadFromFile() method.
- Get a specified worksheet using Workbook->GetWorksheets()->Get() method.
- Create an array of rectangles, which is used to locate the cells where the validation will be removed.
- Remove the data validation from the selected cells using Worksheet->GetDVTable()->Remove() method.
- Save the result document using Workbook->SaveToFile() method.
- C++
#include "Spire.Xls.o.h";
using namespace Spire::Xls;
int main() {
//Specify the input and output files
std::wstring inputFile = L"DataValidation.xlsx";
std::wstring outputFile = L"RemoveDataValidation.xlsx";
//Create a Workbook object
intrusive_ptr<Workbook> workbook = new Workbook();
//Load a sample Excel document from disk
workbook->LoadFromFile(inputFile.c_str());
//Get the first worksheet
intrusive_ptr<Worksheet> sheet = dynamic_pointer_cast<Worksheet>(workbook->GetWorksheets()->Get(0));
//Create an array of rectangles, which is used to locate the ranges in worksheet
std::vector<intrusive_ptr<Spire::Xls::Rectangle>> rectangles(1);
//Assign value to the first element of the array. A rectangle specifies a cell range
rectangles[0] = Spire::Xls::Rectangle::FromLTRB(0, 0, 2, 9);
//Remove validations in the ranges represented by rectangles
sheet->GetDVTable()->Remove(rectangles);
//Save the result document
workbook->SaveToFile(outputFile.c_str(), ExcelVersion::Version2016);
workbook->Dispose();
}
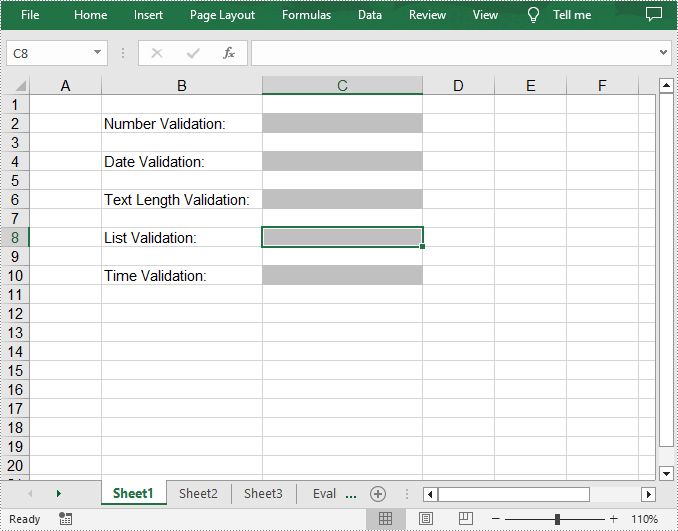
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.