Python: Add, Edit, or Delete Bookmarks in PDF
PDF bookmarks are navigational aids that allow users to quickly locate and jump to specific sections or pages in a PDF document. Through a simple click, users can arrive at the target location, which eliminates the need to manually scroll or search for specific content in a lengthy document. In this article, you will learn how to programmatically add, modify and delete bookmarks in PDF files using Spire.PDF for Python.
- Add Bookmarks to a PDF Document
- Edit Bookmarks in a PDF Document
- Delete Bookmarks from a PDF Document
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Add Bookmarks to a PDF Document in Python
Spire.PDF for Python provides a method to add bookmarks to a PDF document: PdfDocument. Bookmarks.Add(). You can use this method to create primary bookmarks for the PDF document and use the PdfBookmarkCollection.Add() method to add sub-bookmarks to the primary bookmarks. Additionally, the PdfBookmark class offers other methods to set properties such as destination, text color, and text style for the bookmarks. The following are the detailed steps for adding bookmarks to a PDF document.
- Create a PdfDocument class instance.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Add a parent bookmark to the document using PdfDocument.Bookmarks.Add() method.
- Create a PdfDestination class object and set the destination of the parent bookmark using PdfBookmark.Action property.
- Set the text color and style of the parent bookmark.
- Create a PdfBookmarkCollection class object to add sub-bookmark to the parent bookmark using PdfBookmarkCollection.Add() method.
- Use the above methods to set the destination, text color, and text style of the sub-bookmark.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Terms of service.pdf")
# Loop through the pages in the PDF file
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
# Set the title and destination for the bookmark
bookmarkTitle = "Bookmark-{0}".format(i+1)
bookmarkDest = PdfDestination(page, PointF(0.0, 0.0))
# Create and configure the bookmark
bookmark = doc.Bookmarks.Add(bookmarkTitle)
bookmark.Color = PdfRGBColor(Color.get_SaddleBrown())
bookmark.DisplayStyle = PdfTextStyle.Bold
bookmark.Action = PdfGoToAction(bookmarkDest)
# Create a collection to hold child bookmarks
bookmarkColletion = PdfBookmarkCollection(bookmark)
# Set the title and destination for the child bookmark
childBookmarkTitle = "Sub-Bookmark-{0}".format(i+1)
childBookmarkDest = PdfDestination(page, PointF(0.0, 100.0))
# Create and configure the child bookmark
childBookmark = bookmarkColletion.Add(childBookmarkTitle)
childBookmark.Color = PdfRGBColor(Color.get_Coral())
childBookmark.DisplayStyle = PdfTextStyle.Italic
childBookmark.Action = PdfGoToAction(childBookmarkDest)
# Save the PDF file
outputFile = "Bookmark.pdf"
doc.SaveToFile(outputFile)
# Close the document
doc.Close()
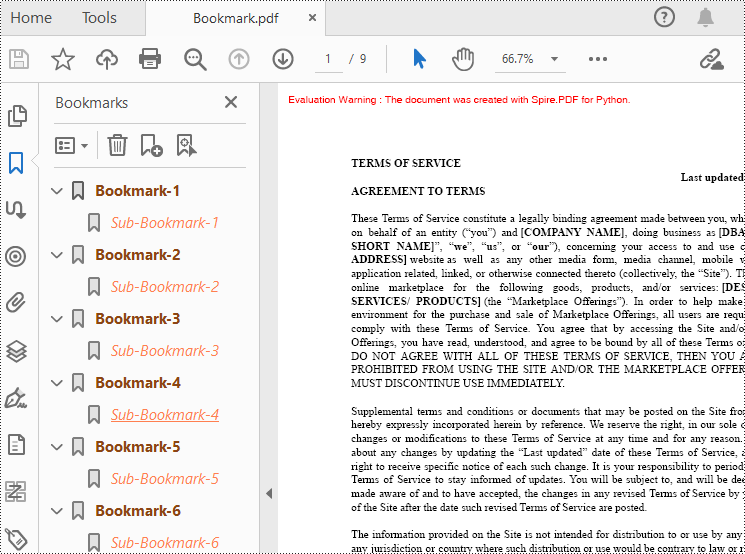
Edit Bookmarks in a PDF Document
If you need to update the existing bookmarks, you can use the methods of PdfBookmark class to rename the bookmarks and change their text color, text style. The following are the detailed steps.
- Create a PdfDocument class instance.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get a specified bookmark using PdfDocument.Bookmarks[] property.
- Change the title of the bookmark using PdfBookmark.Title property.
- Change the font color of the bookmark using PdfBookmark.Color property.
- Change the text style of the bookmark using PdfBookmark.DisplayStyle property.
- Change the text color and style of the sub-bookmark using the above methods.
- Save the result document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Bookmark.pdf")
# Get the first bookmark
bookmark = doc.Bookmarks.get_Item(0)
# Change the title of the bookmark
bookmark.Title = "Modified BookMark"
# Set the color of the bookmark
bookmark.Color = PdfRGBColor(Color.get_Black())
# Set the outline text style of the bookmark
bookmark.DisplayStyle = PdfTextStyle.Bold
# Edit child bookmarks of the parent bookmark
pBookmark = PdfBookmarkCollection(bookmark)
for i in range(pBookmark.Count):
childBookmark = pBookmark.get_Item(i)
childBookmark.Color = PdfRGBColor(Color.get_Blue())
childBookmark.DisplayStyle = PdfTextStyle.Regular
# Save the PDF document
outputFile = "EditBookmark.pdf"
# Close the document
doc.SaveToFile(outputFile)
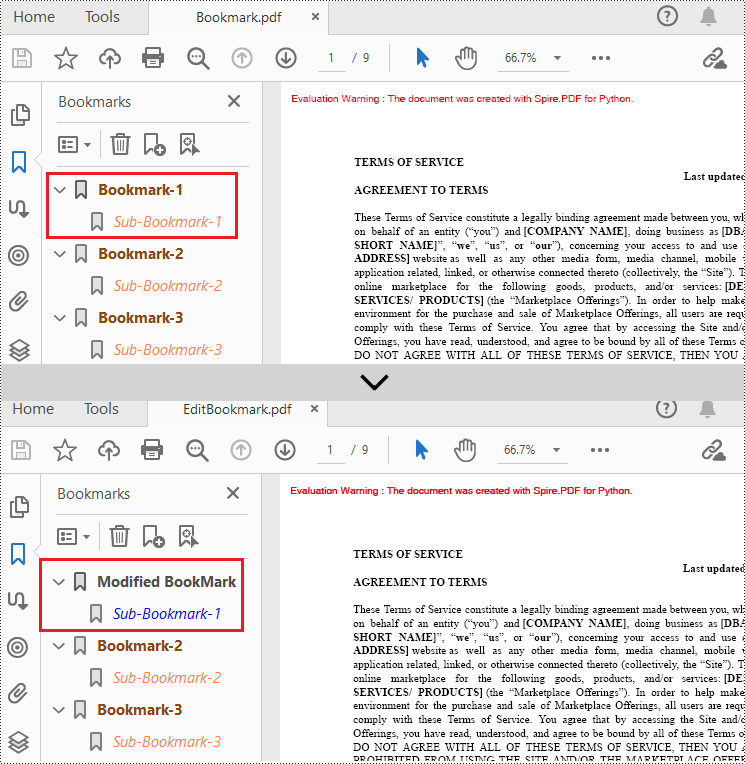
Delete Bookmarks from a PDF Document
Spire.PDF for Python also provides methods to delete any bookmark in a PDF document. PdfDocument.Bookmarks.RemoveAt() method is used to remove a specific primary bookmark, PdfDocument.Bookmarks.Clear() method is used to remove all bookmarks, and PdfBookmarkCollection.RemoveAt() method is used to remove a specific sub-bookmark of a primary bookmark. The detailed steps of removing bookmarks form a PDF document are as follows.
- Create a PdfDocument class instance.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the first bookmark using PdfDocument.Bookmarks[] property.
- Remove a specified sub-bookmark of the first bookmark using PdfBookmarkCollection.RemoveAt() method.
- Remove a specified bookmark including its sub-bookmarks using PdfDocument.Bookmarks.RemoveAt() method.
- Remove all bookmarks in the PDF file using PdfDocument.Bookmarks.Clear() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Bookmark.pdf")
# # Delete the first bookmark
# doc.Bookmarks.RemoveAt(0)
# # Get the first bookmark
# bookmark = doc.Bookmarks.get_Item(0)
# # Remove the first child bookmark from first parent bookmark
# pBookmark = PdfBookmarkCollection(bookmark)
# pBookmark.RemoveAt(0)
#Remove all bookmarks
doc.Bookmarks.Clear()
# Save the PDF document
output = "DeleteAllBookmarks.pdf"
doc.SaveToFile(output)
# Close the document
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
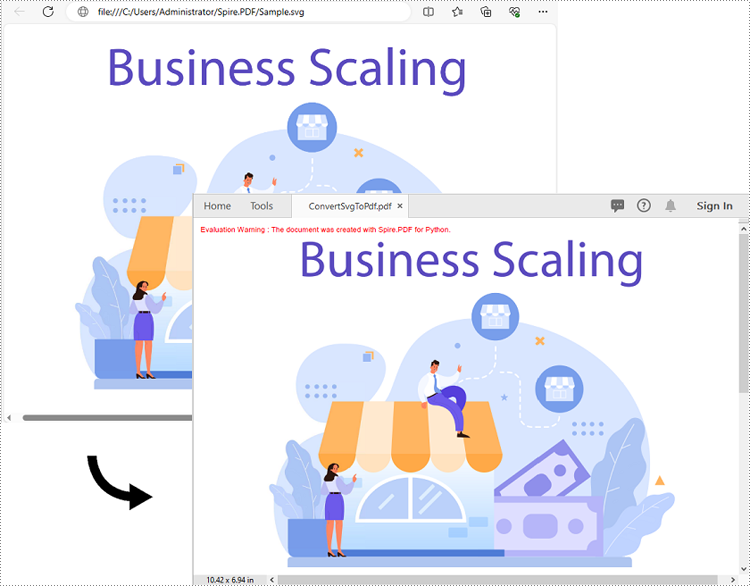
Python: Convert SVG to PDF
SVG files are commonly used for web graphics and vector-based illustrations because they can be scaled and adjusted easily. PDF, on the other hand, is a versatile format widely supported across different devices and operating systems. Converting SVG to PDF allows for easy sharing of graphics and illustrations, ensuring that recipients can open and view the files without requiring specialized software or worrying about browser compatibility issues. In this article, we will demonstrate how to convert SVG files to PDF format in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert SVG to PDF in Python
Spire.PDF for Python provides the PdfDocument.LoadFromSvg() method, which allows users to load an SVG file. Once loaded, users can use the PdfDocument.SaveToFile() method to save the SVG file as a PDF file. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load an SVG file using PdfDocument.LoadFromSvg() method.
- Save the SVG file to PDF format using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load an SVG file
doc.LoadFromSvg("Sample.svg")
# Save the SVG file to PDF format
doc.SaveToFile("ConvertSvgToPdf.pdf", FileFormat.PDF)
# Close the PdfDocument object
doc.Close()
Add SVG to PDF in Python
In addition to converting SVG to PDF directly, Spire.PDF for Python also supports adding SVG files to specific locations in PDF. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load an SVG file using PdfDocument.LoadFromSvg() method.
- Create a template based on the content of the SVG file using PdfDocument. Pages[].CreateTemplate() method.
- Get the width and height of the template.
- Create another object of the PdfDocument class and load a PDF file using PdfDocument.LoadFromFile() method.
- Draw the template with a custom size at a specific location in the PDF file using PdfDocument.Pages[].Canvas.DrawTemplate() method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc1 = PdfDocument()
# Load an SVG file
doc1.LoadFromSvg("Sample.svg")
# Create a template based on the content of the SVG
template = doc1.Pages.get_Item(0).CreateTemplate()
# Get the width and height of the template
width = template.Width
height = template.Height
# Create another PdfDocument object
doc2 = PdfDocument()
# Load a PDF file
doc2.LoadFromFile(""Sample.pdf"")
# Draw the template with a custom size at a specific location on the first page of the loaded PDF file
doc2.Pages.get_Item(0).Canvas.DrawTemplate(template, PointF(10.0, 100.0), SizeF(width*0.8, height*0.8))
# Save the result file
doc2.SaveToFile("AddSvgToPdf.pdf", FileFormat.PDF)
# Close the PdfDocument objects
doc2.Close()
doc1.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Edit or Remove Comments in Excel
Comment in Excel is primarily used to add additional instructions or notes to cells. With this feature, users can add relevant content next to a specific cell to explain the data, provide contextual information, or give instructions. It also helps users to better organize and manage the data in the Excel workbook and improve the understanding and readability of the data. Spire.XLS for Python supports adding comments to Excel files. If necessary, you can also use this library to edit the content of the comments or delete unnecessary comments. In this article, we will show you how to edit or remove existing comments in Excel on Python platforms using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Edit Existing Comments in Excel Using Python
Spire.XLS for Python allows users to edit existing comments in Excel, including setting new text or changing comment box size. The following are detailed steps.
- Create a Workbook instance.
- Load an Excel file from disk using Workbook.LoadFromFile() method.
- Get the first worksheet of the Excel file using Workbook.Worksheets[] property.
- Set new text for the existing comments using Worksheet.Range[].Comment.Text property.
- Set the height and width of the existing comment by using Worksheet.Range[].Comment.Height and Worksheet.Range[].Comment.Width properties.
- Automatically adapt to the size of the comment by setting the Worksheet.Range.Comment.AutoSize property to "True".
- Save the result file using Workbook.SaveToFile() method.
- Python
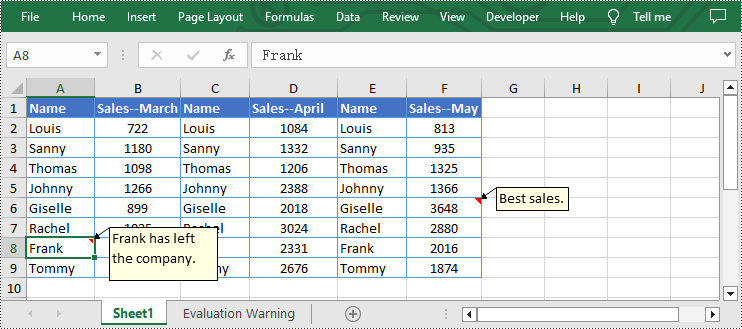
from spire.xls import * from spire.xls.common import * inputFile = "C:/Users/Administrator/Desktop/Sample.xlsx" outputFile = "C:/Users/Administrator/Desktop/EditExcelComment.xlsx" # Create a Workbook instance workbook = Workbook() # Load an Excel file from disk workbook.LoadFromFile(inputFile) # Get the first worksheet of this file sheet = workbook.Worksheets[0] # Set new text for the existing comments sheet.Range["A8"].Comment.Text = "Frank has left the company." sheet.Range["F6"].Comment.Text = "Best sales." # Set the height and width of the comment of A8 sheet.Range["A8"].Comment.Height = 60 sheet.Range["A8"].Comment.Width = 100 # Automatically adapt to the size of the comment of F6 sheet.Range["F6"].Comment.AutoSize = True # Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2013) workbook.Dispose()
Remove Existing Comments from Excel Using Python
The Worksheet.Range[].Comment.Remove() method offered by Spire.XLS for Python allows users to remove a specified comment easily. The detailed steps are as follows.
- Create a Workbook instance.
- Load an Excel file from disk using Workbook.LoadFromFile() method.
- Get the first worksheet of the Excel file using Workbook.Worksheets[] property.
- Remove the comment by using Worksheet.Range[].Comment.Remove() method.
- Save the document to another file using Workbook.SaveToFile() method.
- Python
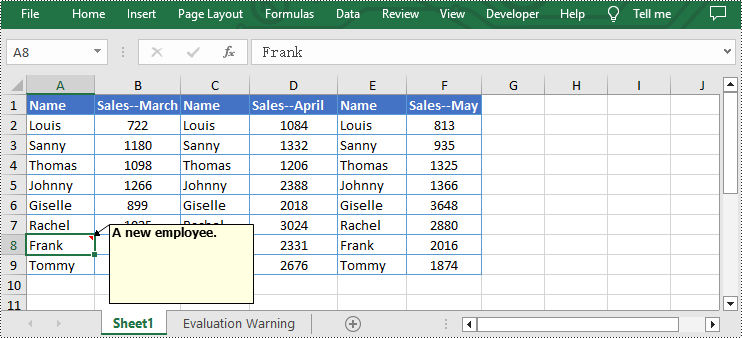
from spire.xls import * from spire.xls.common import * inputFile = "C:/Users/Administrator/Desktop/Sample.xlsx" outputFile = "C:/Users/Administrator/Desktop/RemoveExcelComment.xlsx" # Create a Workbook instance workbook = Workbook() # Load an Excel file from disk workbook.LoadFromFile(inputFile) # Get the first worksheet of this file sheet = workbook.Worksheets[0] # Remove the comment from the sheet sheet.Range["F6"].Comment.Remove() # Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2013) workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Create a Bar Chart in Excel
A bar chart is a type of graph that represents categorical data using rectangular bars. It is somewhat like a column chart, but with bars that extend horizontally from the Y-axis. The length of each bar corresponds to the value represented by a particular category or group, and changes, trends, or rankings can be quickly identified by comparing the lengths of the bars. In this article, you will learn how to create a clustered or stacked bar chart in Excel in Python using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Create a Clustered Bar Chart in Excel in Python
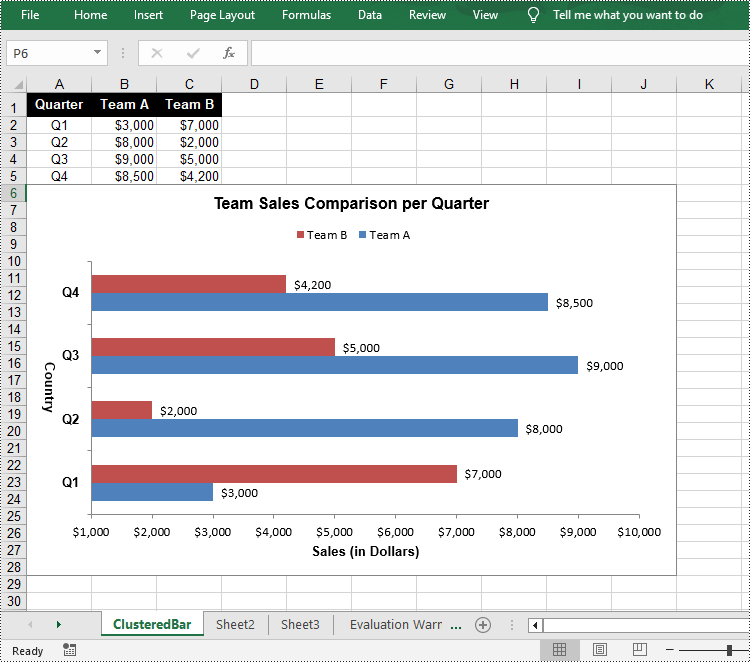
The Worksheet.Chart.Add(ExcelChartType chartType) method provided by Spire.XLS for Python allows to add a chart to a worksheet. To add a clustered bar chart in Excel, you can set the chart type to BarClustered. The following are the steps.
- Create a Workbook object.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Add chart data to specified cells and set the cell styles.
- Add a clustered bar char to the worksheet using Worksheet.Chart.Add(ExcelChartType.BarClustered) method.
- Set data range for the chart using Chart.DataRange property.
- Set position, title, category axis and value axis for the chart.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
# Create a Workbook instance
workbook = Workbook()
# Get the first sheet and set its name
sheet = workbook.Worksheets[0]
sheet.Name = "ClusteredBar"
# Add chart data to specified cells
sheet.Range["A1"].Value = "Quarter"
sheet.Range["A2"].Value = "Q1"
sheet.Range["A3"].Value = "Q2"
sheet.Range["A4"].Value = "Q3"
sheet.Range["A5"].Value = "Q4"
sheet.Range["B1"].Value = "Team A"
sheet.Range["B2"].NumberValue = 3000
sheet.Range["B3"].NumberValue = 8000
sheet.Range["B4"].NumberValue = 9000
sheet.Range["B5"].NumberValue = 8500
sheet.Range["C1"].Value = "Team B"
sheet.Range["C2"].NumberValue = 7000
sheet.Range["C3"].NumberValue = 2000
sheet.Range["C4"].NumberValue = 5000
sheet.Range["C5"].NumberValue = 4200
# Set cell style
sheet.Range["A1:C1"].RowHeight = 18
sheet.Range["A1:C1"].Style.Color = Color.get_Black()
sheet.Range["A1:C1"].Style.Font.Color = Color.get_White()
sheet.Range["A1:C1"].Style.Font.IsBold = True
sheet.Range["A1:C1"].Style.VerticalAlignment = VerticalAlignType.Center
sheet.Range["A1:C1"].Style.HorizontalAlignment = HorizontalAlignType.Center
sheet.Range["A2:A5"].Style.HorizontalAlignment = HorizontalAlignType.Center
sheet.Range["B2:C5"].Style.NumberFormat = "\"$\"#,##0"
# Add a clustered bar chart to the sheet
chart = sheet.Charts.Add(ExcelChartType.BarClustered)
# Set data range of the chart
chart.DataRange = sheet.Range["A1:C5"]
chart.SeriesDataFromRange = False
# Set position of the chart
chart.LeftColumn = 1
chart.TopRow = 6
chart.RightColumn = 11
chart.BottomRow = 29
# Set and format chart title
chart.ChartTitle = "Team Sales Comparison per Quarter"
chart.ChartTitleArea.IsBold = True
chart.ChartTitleArea.Size = 12
# Set and format category axis
chart.PrimaryCategoryAxis.Title = "Country"
chart.PrimaryCategoryAxis.Font.IsBold = True
chart.PrimaryCategoryAxis.TitleArea.IsBold = True
chart.PrimaryCategoryAxis.TitleArea.TextRotationAngle = 90
# Set and format value axis
chart.PrimaryValueAxis.Title = "Sales (in Dollars)"
chart.PrimaryValueAxis.HasMajorGridLines = False
chart.PrimaryValueAxis.MinValue = 1000
chart.PrimaryValueAxis.TitleArea.IsBold = True
# Show data labels for data points
for cs in chart.Series:
cs.Format.Options.IsVaryColor = True
cs.DataPoints.DefaultDataPoint.DataLabels.HasValue = True
# Set legend position
chart.Legend.Position = LegendPositionType.Top
#Save the result file
workbook.SaveToFile("ClusteredBarChart.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
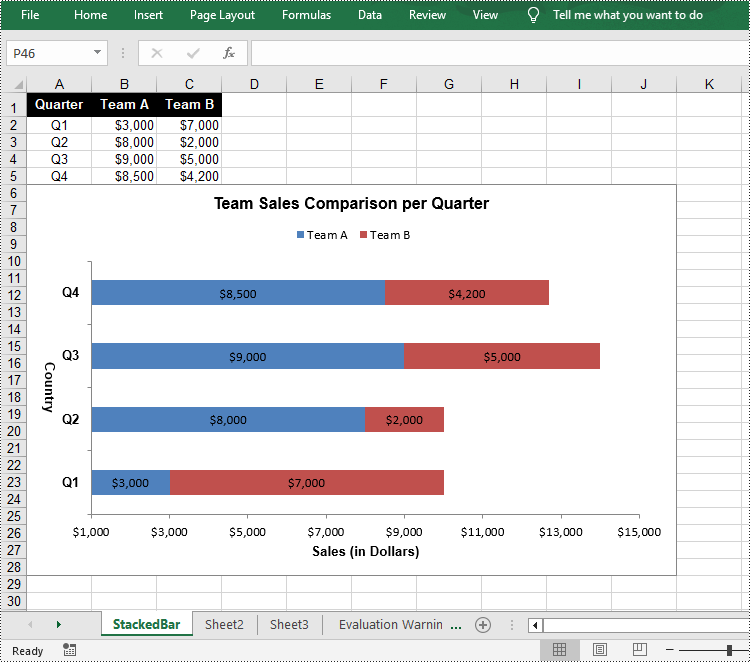
Create a Stacked Bar Chart in Excel in Python
To create a stacked bar chart, you just need to change the Excel chart type to BarStacked. The following are the steps.
- Create a Workbook object.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Add chart data to specified cells and set the cell styles.
- Add a clustered bar char to the worksheet using Worksheet.Chart.Add(ExcelChartType.BarStacked) method.
- Set data range for the chart using Chart.DataRange property.
- Set position, title, category axis and value axis for the chart.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
# Create a Workbook instance
workbook = Workbook()
# Get the first sheet and set its name
sheet = workbook.Worksheets[0]
sheet.Name = "StackedBar"
# Add chart data to specified cells
sheet.Range["A1"].Value = "Quarter"
sheet.Range["A2"].Value = "Q1"
sheet.Range["A3"].Value = "Q2"
sheet.Range["A4"].Value = "Q3"
sheet.Range["A5"].Value = "Q4"
sheet.Range["B1"].Value = "Team A"
sheet.Range["B2"].NumberValue = 3000
sheet.Range["B3"].NumberValue = 8000
sheet.Range["B4"].NumberValue = 9000
sheet.Range["B5"].NumberValue = 8500
sheet.Range["C1"].Value = "Team B"
sheet.Range["C2"].NumberValue = 7000
sheet.Range["C3"].NumberValue = 2000
sheet.Range["C4"].NumberValue = 5000
sheet.Range["C5"].NumberValue = 4200
# Set cell style
sheet.Range["A1:C1"].RowHeight = 18
sheet.Range["A1:C1"].Style.Color = Color.get_Black()
sheet.Range["A1:C1"].Style.Font.Color = Color.get_White()
sheet.Range["A1:C1"].Style.Font.IsBold = True
sheet.Range["A1:C1"].Style.VerticalAlignment = VerticalAlignType.Center
sheet.Range["A1:C1"].Style.HorizontalAlignment = HorizontalAlignType.Center
sheet.Range["A2:A5"].Style.HorizontalAlignment = HorizontalAlignType.Center
sheet.Range["B2:C5"].Style.NumberFormat = "\"$\"#,##0"
# Add a clustered bar chart to the sheet
chart = sheet.Charts.Add(ExcelChartType.BarStacked)
# Set data range of the chart
chart.DataRange = sheet.Range["A1:C5"]
chart.SeriesDataFromRange = False
# Set position of the chart
chart.LeftColumn = 1
chart.TopRow = 6
chart.RightColumn = 11
chart.BottomRow = 29
# Set and format chart title
chart.ChartTitle = "Team Sales Comparison per Quarter"
chart.ChartTitleArea.IsBold = True
chart.ChartTitleArea.Size = 12
# Set and format category axis
chart.PrimaryCategoryAxis.Title = "Country"
chart.PrimaryCategoryAxis.Font.IsBold = True
chart.PrimaryCategoryAxis.TitleArea.IsBold = True
chart.PrimaryCategoryAxis.TitleArea.TextRotationAngle = 90
# Set and format value axis
chart.PrimaryValueAxis.Title = "Sales (in Dollars)"
chart.PrimaryValueAxis.HasMajorGridLines = False
chart.PrimaryValueAxis.MinValue = 1000
chart.PrimaryValueAxis.TitleArea.IsBold = True
# Show data labels for data points
for cs in chart.Series:
cs.Format.Options.IsVaryColor = True
cs.DataPoints.DefaultDataPoint.DataLabels.HasValue = True
# Set legend position
chart.Legend.Position = LegendPositionType.Top
#Save the result file
workbook.SaveToFile("StackedBarChart.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Find and Replace Data in Excel
The Find and Replace feature in Excel allows you to quickly find specific values and perform targeted replacements based on specific requirements. With it, all occurrences of a specific value can be updated at once, which can significantly improve productivity when working with large data sets. In this article, you will learn how to programmatically find and replace data in Excel in Python using Spire.XLS for Python.
- Find and Replace Data in a Worksheet in Excel
- Find and Replace Data in a Specific Cell Range in Excel
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Find and Replace Data in an Excel Worksheet in Python
Spire.XLS for Python offers the Worksheet.FindAllString() method to find the cells containing specific data values in an Excel worksheet. Once the cells are found, you can use the CellRange.Text property to update their values with new values. The detailed steps are as follows:
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[] property.
- Find the cells containing a specific value in the worksheet using Worksheet.FindAllString() method.
- Iterate through the found cells.
- Replace the value of each found cell with another value using CellRange.Text property.
- Set a background color to highlight the cell using CellRange.Style.Color property.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel document from disk
workbook.LoadFromFile("input.xlsx")
# Get the first worksheet
worksheet = workbook.Worksheets[0]
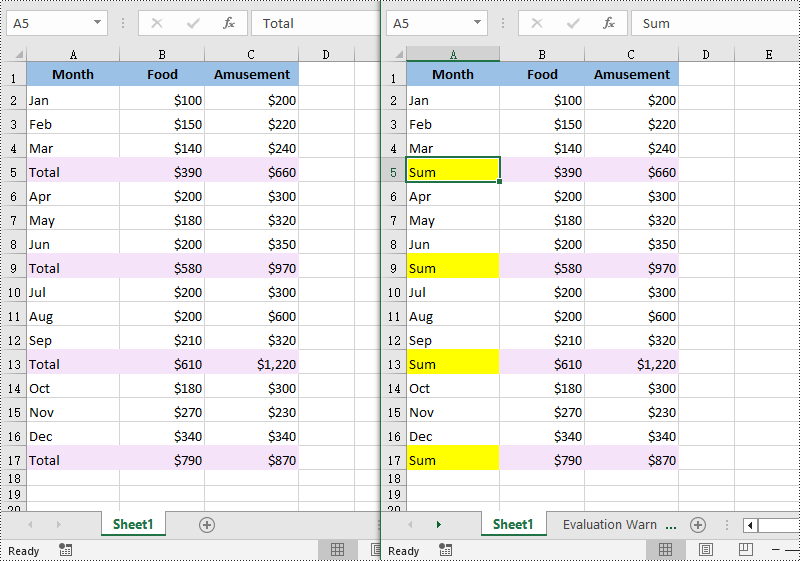
# Find the cells with the specific string value “Total” in the worksheet
ranges = worksheet.FindAllString("Total", False, False)
# Iterate through the found cells
for range in ranges:
# Replace the value of the cell with another value
range.Text = "Sum"
# Set a background color for the cell
range.Style.Color = Color.get_Yellow()
# Save the result file
workbook.SaveToFile("FindAndReplaceData.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
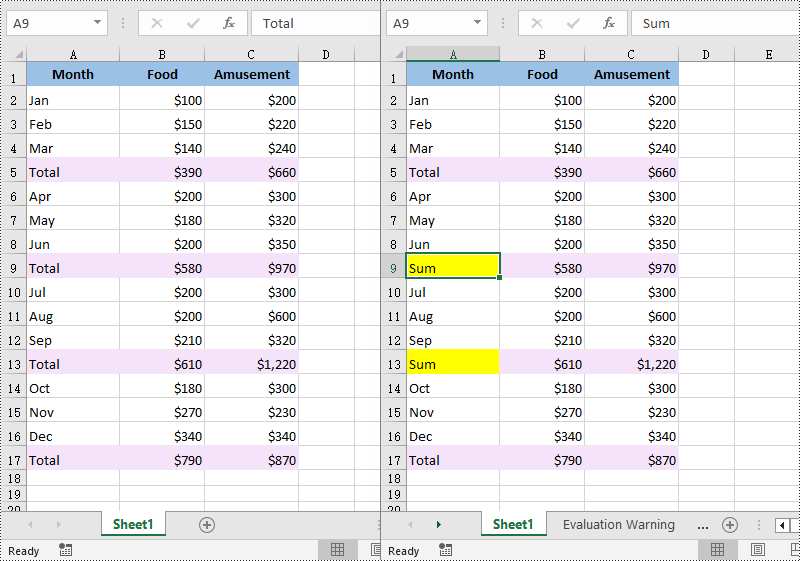
Find and Replace Data in a Specific Cell Range in Excel in Python
Spire.XLS for Python also allows you to find the cells containing a specific value in a cell range through the CellRange.FindAllString() method. Then you can update the value of each found cell with another value using the CellRange.Text property. The detailed steps are as follows:
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[] property.
- Get a specific cell range of the worksheet using Worksheet.Range[] property.
- Find the cells with a specific value in the cell range using CellRange.FindAllString() method.
- Iterate through the found cells.
- Replace the value of each found cell with another value using CellRange.Text property.
- Set a background color to highlight the cell using CellRange.Style.Color property.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel document from disk
workbook.LoadFromFile("input.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get a specific cell range
range = sheet.Range["A6:C13"]
# Find the cells with the specific value "Total" in the cell range
cells = range.FindAllString("Total", False, False)
# Iterate through the found cells
for cell in cells:
# Replace the value of the cell with another value
cell.Text = "Sum"
# Set a background color for the cell
cell.Style.Color = Color.get_Yellow()
# Save the result file
workbook.SaveToFile("ReplaceDataInCellRange.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Insert Headers and Footers in Word
Headers and footers in Word are sections at the top and bottom margins of each page. They can contain additional information such as page numbers, document titles, dates, author names, and other identifying details. By default, the headers or footers on all pages are the same, but in certain scenarios, you can also insert different headers or footers on the first page, odd pages, or even pages. This article will demonstrate how to insert headers and footers into a Word document in Python using Spire.Doc for Python.
- Insert Headers and Footers into a Word Document
- Add Different Headers and Footers for the First Page and Other Pages
- Add Different Headers and Footers for Odd and Even Pages
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Insert Headers and Footers into a Word Document in Python
To insert a header or a footer into a Word document, you first need to get them through the Section.HeadersFooters.Header and Section.HeadersFooters.Footer properties, and then add paragraphs to them to insert pictures, text, page numbers, dates, or other information.
The following are steps to add headers and footers in Word:
- Create a Document object.
- Load a Word document using Document.LoadFromFile() method.
- Get a specified section using Document.Sections[] property.
- Add Header
- Get header using Section.HeadersFooters.Header property.
- Add a paragraph to the header using HeaderFooter.AddParagraph() method and set paragraph alignment.
- Add an image to the header paragraph using Paragraph.AppendPicture() method, and then set the text wrapping style and position of the image.
- Add text to the header paragraph using Paragraph.AppendText() method, and then set the font name, size, color, etc.
- Add Footer
- Get footer using Section.HeadersFooters.Footer property.
- Add a paragraph to the footer and then add text to the footer paragraph.
- Get the borders of the footer paragraph using Paragraph.Format.Borders property, and then set the top border style and space.
- Save the result document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load a Word document
document.LoadFromFile("Sample.docx")
# Get a specific section
section = document.Sections.get_Item(0)
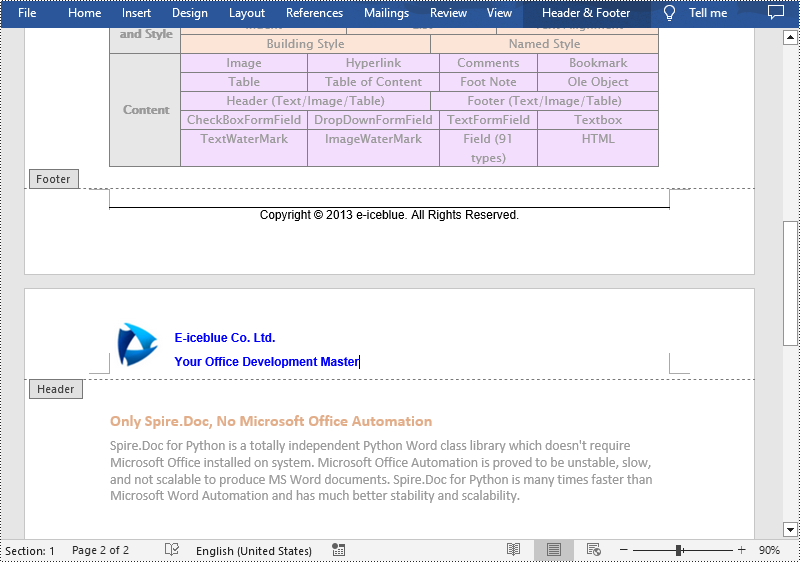
# Get header
header = section.HeadersFooters.Header
# Add a paragraph to the header and set its alignment style
headerParagraph = header.AddParagraph()
headerParagraph.Format.HorizontalAlignment = HorizontalAlignment.Left
# Add an image to the header paragraph and set its text wrapping style, position
headerPicture = headerParagraph.AppendPicture("Logo.png")
headerPicture.TextWrappingStyle = TextWrappingStyle.Square
headerPicture.VerticalOrigin = VerticalOrigin.Line
headerPicture.VerticalAlignment = ShapeVerticalAlignment.Center
# Add text to the header paragraph and set its font style
text = headerParagraph.AppendText("E-iceblue Co. Ltd."+ "\nYour Office Development Master")
text.CharacterFormat.FontName = "Arial"
text.CharacterFormat.FontSize = 10
text.CharacterFormat.Bold = True
text.CharacterFormat.TextColor = Color.get_Blue()
# Get footer
footer = section.HeadersFooters.Footer
# Add a paragraph to the footer paragraph and set its alignment style
footerParagraph = footer.AddParagraph()
footerParagraph.Format.HorizontalAlignment = HorizontalAlignment.Center
# Add text to the footer paragraph and set its font style
text = footerParagraph.AppendText("Copyright © 2013 e-iceblue. All Rights Reserved.")
text.CharacterFormat.FontName = "Arial"
text.CharacterFormat.FontSize = 10
# Set the border of the footer paragraph
footerParagraph.Format.Borders.Top.BorderType = BorderStyle.Single
footerParagraph.Format.Borders.Top.Space = 0.05
# Save the result file
document.SaveToFile("HeaderAndFooter.docx", FileFormat.Docx)
document.Close()
Add Different Headers and Footers for the First Page and Other Pages in Word in Python
Sometimes you may need to insert a header and footer only on the first page, or you may want the header and footer on the first page different from other pages.
Spire.Doc for Python offers the Section.PageSetup.DifferentFirstPageHeaderFooter property to enable a different first page header or footer. The following are the detailed steps to accomplish the task.
- Create a Document object.
- Load a Word document using Document.LoadFromFile() method.
- Get a specified section using Document.Sections[] property.
- Enable different headers and footers for the first page and other pages by setting the Section.PageSetup.DifferentFirstPageHeaderFooter property to True.
- Get the first page header using Section.HeadersFooters.FirstPageHeader property.
- Add a paragraph to the first page header and then add an image to the header paragraph.
- Get the first page footer using Section.HeadersFooters.FirstPageFooter property.
- Add a paragraph to the first page footer and then add text to the footer paragraph.
- Set headers and footers for other pages. (There's no need to set this if you only need the header & footer for the first page.)
- Save the result document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word document
doc.LoadFromFile("Sample.docx")
# Get a specific section
section = document.Sections.get_Item(0)
# Enable different headers and footers for the first page and other pages
section.PageSetup.DifferentFirstPageHeaderFooter = True
# Add a paragraph to the first page header and set its alignment style
headerParagraph = section.HeadersFooters.FirstPageHeader.AddParagraph()
headerParagraph.Format.HorizontalAlignment = HorizontalAlignment.Right
# Add an image to the header paragraph
headerimage = headerParagraph.AppendPicture("E-iceblue.png")
# Add a paragraph to the first page footer and set its alignment style
footerParagraph = section.HeadersFooters.FirstPageFooter.AddParagraph()
footerParagraph.Format.HorizontalAlignment = HorizontalAlignment.Center
# Add text to the footer paragraph and set its font style
text = footerParagraph.AppendText("Different First Page Footer")
text.CharacterFormat.FontSize = 11
# Set the header & footer for other pages. If you only headers & footers for the first page, don't set this.
para = section.HeadersFooters.Header.AddParagraph()
para.Format.HorizontalAlignment = HorizontalAlignment.Left
paraText = para.AppendText("A Professional Word Python API")
paraText.CharacterFormat.FontSize = 12
paraText.CharacterFormat.TextColor = Color.get_DeepPink()
para.Format.Borders.Bottom.BorderType = BorderStyle.Single
para.Format.Borders.Bottom.Space = 0.05
paragraph = section.HeadersFooters.Footer.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paraText = paragraph.AppendText("E-iceblue Co. Ltd.")
paraText.CharacterFormat.FontSize = 12
paraText.CharacterFormat.Bold = True
paraText.CharacterFormat.TextColor = Color.get_DodgerBlue()
# Save the result document
doc.SaveToFile("DifferentFirstPage.docx", FileFormat.Docx)
doc.Close()

Add Different Headers and Footers for Odd and Even Pages in Word in Python
To have different headers and footers on odd and even pages, Spire.Doc for Python provides the Section.PageSetup.DifferentOddAndEvenPagesHeaderFooter property. The following are the detailed steps.
- Create a Document object.
- Load a Word document using Document.LoadFromFile() method.
- Get a specified section using Document.Sections[] property.
- Enable different headers and footers for the odd and even pages by setting the Section.PageSetup.DifferentOddAndEvenPagesHeaderFooter property to True.
- Get the header and footer of odd pages using Section.HeadersFooters.OddHeader and Section.HeadersFooters.OddFooter properties.
- Add paragraphs to the header and footer of odd pages and then add text to them.
- Get the header and footer of even pages using Section.HeadersFooters.EvenHeader and Section.HeadersFooters.EvenFooter properties.
- Add paragraphs to the header and footer of even pages and then add text to them.
- Save the result document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word document
doc.LoadFromFile("Sample.docx")
# Get a specific section
section = document.Sections.get_Item(0)
# Enable different headers and footers for the odd and even pages
section.PageSetup.DifferentOddAndEvenPagesHeaderFooter = True
# Add headers and footers to odd pages
OHpara = section.HeadersFooters.OddHeader.AddParagraph()
OHtext = OHpara.AppendText("Odd Page Header")
OHpara.Format.HorizontalAlignment = HorizontalAlignment.Center
OHtext.CharacterFormat.FontName = "Arial"
OHtext.CharacterFormat.FontSize = 12
OHtext.CharacterFormat.TextColor = Color.get_Red()
OFpara = section.HeadersFooters.OddFooter.AddParagraph()
OFtext = OFpara.AppendText("Odd Page Footer")
OFpara.Format.HorizontalAlignment = HorizontalAlignment.Center
OFtext.CharacterFormat.FontName = "Arial"
OFtext.CharacterFormat.FontSize = 12
OFtext.CharacterFormat.TextColor = Color.get_Red()
# Add headers and footers to even pages
EHpara = section.HeadersFooters.EvenHeader.AddParagraph()
EHtext = EHpara.AppendText("Even Page Header")
EHpara.Format.HorizontalAlignment = HorizontalAlignment.Center
EHtext.CharacterFormat.FontName = "Arial"
EHtext.CharacterFormat.FontSize = 12
EHtext.CharacterFormat.TextColor = Color.get_Blue()
EFpara = section.HeadersFooters.EvenFooter.AddParagraph()
EFtext = EFpara.AppendText("Even Page Footer")
EFpara.Format.HorizontalAlignment = HorizontalAlignment.Center
EFtext.CharacterFormat.FontName = "Arial"
EFtext.CharacterFormat.FontSize = 12
EFtext.CharacterFormat.TextColor = Color.get_Blue()
# Save the result document
doc.SaveToFile("OddAndEvenHeaderFooter.docx", FileFormat.Docx)
doc.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Set or Change Fonts in PowerPoint
In a PowerPoint document, the choice of fonts plays a significant role in enhancing the overall visual appeal and effectiveness of the presentation. Different fonts can be used to establish a visual hierarchy, allowing you to emphasize key points, headings, or subheadings in your presentation and guide the audience's attention. This article introduces how to set or change fonts in a PowerPoint document in Python using Spire.Presentation for Python.
- Set Fonts when Creating a New PowerPoint Document in Python
- Change Fonts in an Existing PowerPoint Document in Python
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Set Fonts when Creating a New PowerPoint Document in Python
Spire.Presentation for Python offers the TextRange class to represent a range of text. A paragraph can consist of one or more text ranges. To apply font formatting to the characters in a text range, you can use the properties like LatinFont, IsBold, IsItalic, and FontHeight of the TextRange class. The following are the steps to set fonts when creating a new PowerPoint document in Python.
- Create a Presentation object.
- Get the first slide through Presentation.Slides[0] property.
- Add a shape to the slide using ISlide.Shapes.AppendShape() method.
- Add text to the shape using IAutoShape.AppendTextFrame() method.
- Get TextRange object through IAutoShape.TextFrame.TextRange property.
- Set the font information such as font name, font size, bold, italic, underline, and text color through the properties under the TextRange object.
- Save the presentation to a PPTX file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
import math
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Set slide size type
presentation.SlideSize.Type = SlideSizeType.Screen16x9
# Add a shape to the first slide
rec = RectangleF.FromLTRB (30, 100, 900, 250)
shape = presentation.Slides[0].Shapes.AppendShape(ShapeType.Rectangle, rec)
# Set line color and fill type of the shape
shape.ShapeStyle.LineColor.Color = Color.get_Transparent()
shape.Fill.FillType = FillFormatType.none
# Add text to the shape
shape.AppendTextFrame("Spire.Presentation for Python is a professional presentation processing API that \
is highly compatible with PowerPoint. It is a completely independent class library that developers can \
use to create, edit, convert, and save PowerPoint presentations efficiently without installing Microsoft PowerPoint.")
# Get text of the shape as a text range
textRange = shape.TextFrame.TextRange
# Set font name
textRange.LatinFont = TextFont("Times New Roman")
# Set font style (bold & italic)
textRange.IsBold = TriState.TTrue
textRange.IsItalic = TriState.TTrue
# Set underline type
textRange.TextUnderlineType = TextUnderlineType.Single
# Set font size
textRange.FontHeight = 22
# Set text color
textRange.Fill.FillType = FillFormatType.Solid
textRange.Fill.SolidColor.Color = Color.get_CadetBlue()
# Set alignment
textRange.Paragraph.Alignment = TextAlignmentType.Left
# Set line spacing
textRange.LineSpacing = 0.5
# Save to file
presentation.SaveToFile("output/SetFont.pptx", FileFormat.Pptx2019)
presentation.Dispose()
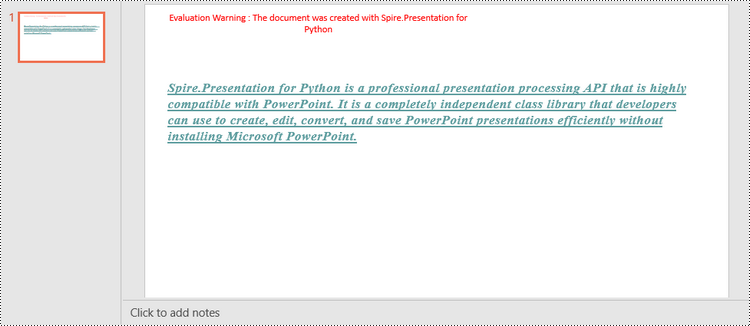
Change Fonts in an Existing PowerPoint Document in Python
To change the font for a specific paragraph, we need to get the paragraph from the document. Then, iterate through the text ranges in the paragraph and reset the font information for each text range. Below are the steps to change the font of a paragraph in an existing PowerPoint document using Spire.Presentation for Python.
- Create a Presentation object.
- Get a specific slide through Presentation.Slides[index] property.
- Get a specific shape through ISlide.Shapes[index] property.
- Get a specific paragraph of the shape through IAutoShape.TextFrame.Paragraphs[index] property.
- Iterate through the text ranges in the paragraph.
- Set the font information such as font name, font size, bold, italic, underline, and text color of a specific text range through the properties under the TextRange object.
- Save the presentation to a PPTX file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Load a PowerPoint file
presentation.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.pptx")
# Get the first slide
slide = presentation.Slides[0]
"# Get the first shape on the slide
shape = (IAutoShape)(slide.Shapes[0])
# Get the first paragraph of the shape
paragraph = shape.TextFrame.Paragraphs[0]
# Get the first paragraph of the shape
paragraph = shape.TextFrame.Paragraphs[0]
# Create a font
newFont = TextFont("Times New Roman")
# Loop through the text ranges in the paragraph
for textRange in paragraph.TextRanges:
# Apply font to a specific text range
textRange.LatinFont = newFont
# Set font to Italic
textRange.Format.IsItalic = TriState.TTrue
# Set font size
textRange.FontHeight = 25
# Set font color
textRange.Fill.FillType = FillFormatType.Solid
textRange.Fill.SolidColor.Color = Color.get_Purple()
# Save to file
presentation.SaveToFile("output/ChangeFont.pptx", FileFormat.Pptx2019)
presentation.Dispose()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Add Hyperlinks to PDF
Hyperlinks in PDF are interactive elements that, when clicked, can jump to a specific location in the document, to an external website, or to other resources. By inserting hyperlinks in a PDF document, you can provide supplementary information and enhance the overall integrity of the document. This article will demonstrate how to add hyperlinks to PDF files in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDFIf you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Add Hyperlinks to a PDF Document in Python
With Spire.PDF for Python, you can add web links, email links and file links to a PDF document. The following are the detailed steps:
- Create a pdf document and add a page to it.
- Specify a URL address and draw it directly on the page using PdfPageBase.Canvas.DrawString() method.
- Create a PdfTextWebLink object.
- Set the link's display text, URL address, and the font and brush used to draw it using properties of PdfTextWebLink class.
- Draw the link on the page using PdfTextWebLink.DrawTextWebLink() method.
- Create a PdfFileLinkAnnotation object and with a specified file.
- Add the file link to the page annotations using PdfPageBase.AnnotationsWidget.Add(PdfFileLinkAnnotation) method.
- Draw hypertext of the file link using PdfPageBase.Canvas.DrawString() method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Add a page
page = pdf.Pages.Add()
# Initialize x, y coordinates
y = 30.0
x = 10.0
# Create true type fonts
font = PdfTrueTypeFont("Arial", 14.0,PdfFontStyle.Regular,True)
font1 = PdfTrueTypeFont("Arial", 14.0, PdfFontStyle.Underline,True)
# Add a simply link
label = "Simple Text Link: "
format = PdfStringFormat()
format.MeasureTrailingSpaces = True
page.Canvas.DrawString(label, font, PdfBrushes.get_Orange(), 0.0, y, format)
x = font.MeasureString(label, format).Width
url = "http://www.e-iceblue.com"
page.Canvas.DrawString(url, font1, PdfBrushes.get_Blue(), x, y)
y = y + 28
# Add a hypertext link
label = "Hypertext Link: "
page.Canvas.DrawString(label, font, PdfBrushes.get_Orange(), 0.0, y, format)
x = font.MeasureString(label, format).Width
webLink = PdfTextWebLink()
webLink.Text = "Home Page"
webLink.Url = url
webLink.Font = font1
webLink.Brush = PdfBrushes.get_Blue()
webLink.DrawTextWebLink(page.Canvas, PointF(x, y))
y = y + 28
# Add an Email link
label = "Email Link: "
page.Canvas.DrawString(label, font, PdfBrushes.get_Orange(), 0.0, y, format)
x = font.MeasureString(label, format).Width
link = PdfTextWebLink()
link.Text = "Contact Us"
link.Url = "mailto:support@e-iceblue.com"
link.Font = font1
link.Brush = PdfBrushes.get_Blue()
link.DrawTextWebLink(page.Canvas, PointF(x, y))
y = y + 28
# Add a file link
label = "Document Link: "
page.Canvas.DrawString(label, font, PdfBrushes.get_Orange(), 0.0, y, format)
x = font.MeasureString(label, format).Width
text = "Open File"
location = PointF(x, y)
size = font1.MeasureString(text)
linkBounds = RectangleF(location, size)
fileLink = PdfFileLinkAnnotation(linkBounds,"C:\\Users\\Administrator\\Desktop\\Report.xlsx")
fileLink.Border = PdfAnnotationBorder(0.0)
page.AnnotationsWidget.Add(fileLink)
page.Canvas.DrawString(text, font1, PdfBrushes.get_Blue(), x, y)
#Save the result pdf file
pdf.SaveToFile("AddLinkstoPDF.pdf")
pdf.Close()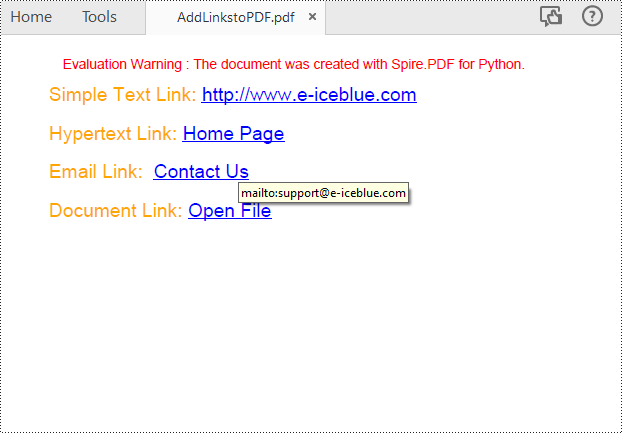
Insert Hyperlinks into Existing Text in PDF in Python
Adding a hyperlink to existing text in a PDF document requires locating the text first. Once the location has been obtained, an object of PdfUriAnnotation class with the link can be created and added to the position. The following are the detailed steps:
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the first page using PdfDocument.Pages.get_Item() method.
- Create a PdfTextFinder object for the page and set the search parameter using finds.Options.Parameter.
- Find all occurrences of the specified text on the page using PdfTextFinder.Find() method.
- Loop through all occurrences of the found text and create a PdfUriAnnotation instance based on the bounds of each occurrence.
- Set the hyperlink URL, border, and border color using properties under PdfUriAnnotation class.
- Insert the hyperlink to the page annotations using PdfPageBase.AnnotationsWidget.Add(PdfUriAnnotation) method.
- Save the PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("input.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Create a PdfTextFinder object for the current page
finds = PdfTextFinder(page)
# Set the search parameter to find exact matches
finds.Options.Parameter = TextFindParameter.IgnoreCase
# Find all occurrences of the specified text in the page
fragments = finds.Find("big O notation")
# Iterate through the found text fragments and create hyperlink annotations for each occurrence
for fragment in fragments:
# Get the bounds of the found text
bounds = fragment.Bounds
for bound in bounds:
# Create a PdfUriAnnotation for the found text and set its properties
uri = PdfUriAnnotation(bound)
uri.Uri = "https://en.wikipedia.org/wiki/Big_O_notation"
uri.Border = PdfAnnotationBorder(1.0)
uri.Color = PdfRGBColor(Color.get_Blue())
page.AnnotationsWidget.Add(uri)
#Save the result file
pdf.SaveToFile("SearchTextAndAddHyperlink1.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Add, Hide, or Remove Layers in PDF
Layers in PDF are similar to layers in image editing software, where different elements of a document can be organized and managed separately. Each layer can contain different content, such as text, images, graphics, or annotations, and can be shown or hidden independently. PDF layers are often used to control the visibility and positioning of specific elements within a document, making it easier to manage complex layouts, create dynamic designs, or control the display of information. In this article, you will learn how to add, hide, remove layers in a PDF document in Python using Spire.PDF for Python.
- Add a Layer to PDF in Python
- Set Visibility of a Layer in PDF in Python
- Remove a Layer from PDF in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Add a Layer to PDF in Python
A layer can be added to a PDF document using the Document.Layers.AddLayer() method. After the layer object is created, you can draw text, images, fields, or other elements on it to form its appearance. The detailed steps to add a layer to PDF using Spire.PDF for Java are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Create a layer using Document.Layers.AddLayer() method.
- Get a specific page through PdfDocument.Pages[index] property.
- Create a canvas for the layer based on the page using PdfLayer.CreateGraphics() method.
- Draw text on the canvas using PdfCanvas.DrawString() method.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
def AddLayerWatermark(doc):
# Create a layer named "Watermark"
layer = doc.Layers.AddLayer("Watermark")
# Create a font
font = PdfTrueTypeFont("Bodoni MT Black", 50.0, 1, True)
# Specify watermark text
watermarkText = "DO NOT COPY"
# Get text size
fontSize = font.MeasureString(watermarkText)
# Get page count
pageCount = doc.Pages.Count
# Loop through the pages
for i in range(0, pageCount):
# Get a specific page
page = doc.Pages.get_Item(i)
# Create canvas for layer
canvas = layer.CreateGraphics(page.Canvas)
# Draw sting on the graphics
canvas.DrawString(watermarkText, font, PdfBrushes.get_Gray(), (canvas.Size.Width - fontSize.Width)/2, (canvas.Size.Height - fontSize.Height)/2 )
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.pdf")
# Invoke AddLayerWatermark method to add a layer
AddLayerWatermark(doc)
# Save to file
doc.SaveToFile("output/AddLayer.pdf", FileFormat.PDF)
doc.Close()
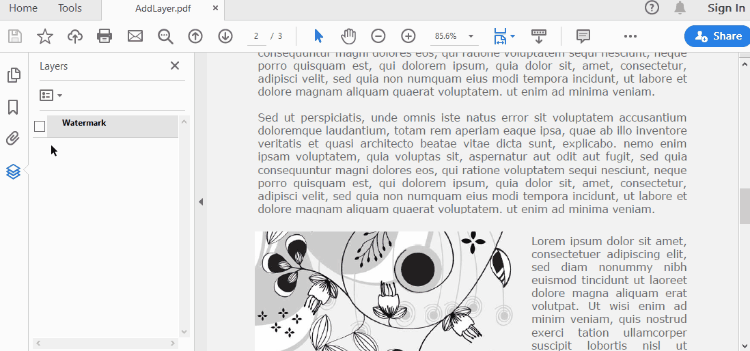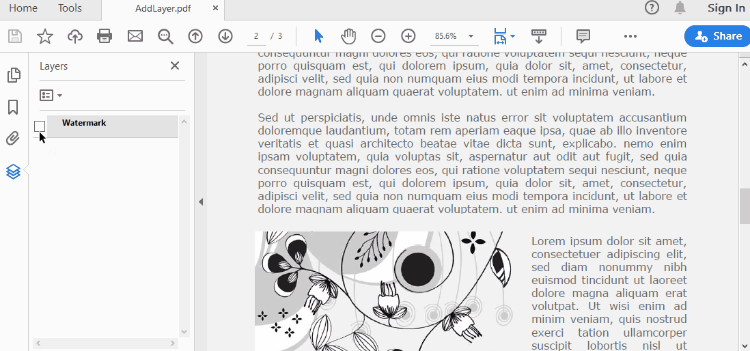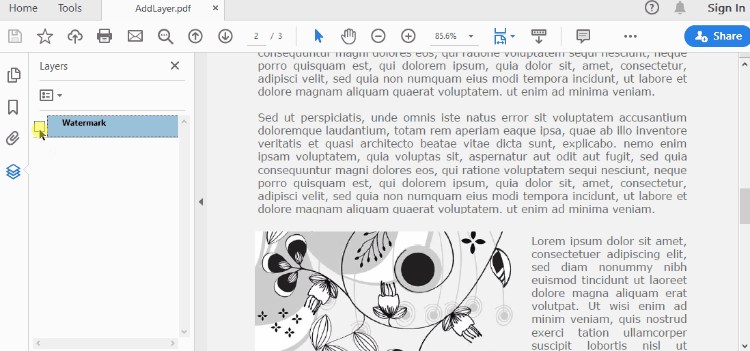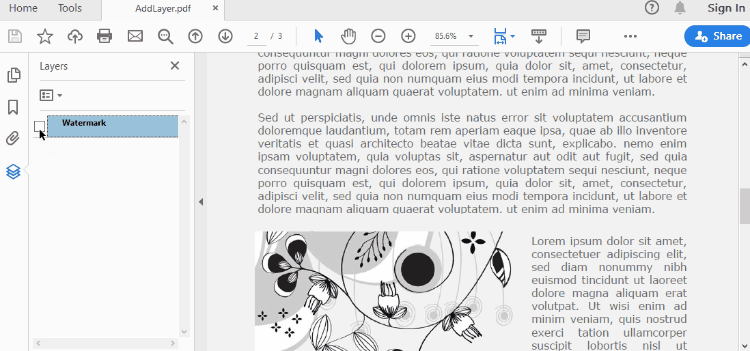
Set Visibility of a Layer in PDF in Python
To control the visibility of layers in a PDF document, you can use the PdfDocument.Layers[index].Visibility property. Set it to off to hide a layer, or set it to on to unhide a layer. The detailed steps are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Set the visibility of a certain layer through Document.Layers[index].Visibility property.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Layer.pdf")
# Hide a layer by setting the visibility to off
doc.Layers.get_Item(0).Visibility = PdfVisibility.Off
# Save to file
doc.SaveToFile("output/HideLayer.pdf", FileFormat.PDF)
doc.Close()
Remove a Layer from PDF in Python
If a layer is no more wanted, you can remove it using the PdfDocument.Layers.RmoveLayer() method. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specific layer through PdfDocument.Layers[index] property.
- Remove the layer from the document using PdfDcument.Layers.RemoveLayer(PdfLayer.Name) method.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Layer.pdf")
# Delete the specific layer
doc.Layers.RemoveLayer(doc.Layers.get_Item(0).Name)
# Save to file
doc.SaveToFile("output/RemoveLayer.pdf", FileFormat.PDF)
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Find and Highlight Text in PDF
Highlighting important text with vibrant colors is a commonly employed method for navigating and emphasizing content in PDF documents. Particularly in lengthy PDFs, emphasizing key information aids readers swiftly comprehending the document content, thereby enhancing reading efficiency. Utilizing Python programs enables document creators to effortlessly and expeditiously execute the highlighting process. This article will explain how to use Spire.PDF for Python to find and highlight text in PDF documents with Python programs.
- Find and Highlight Specific Text in PDF with Python
- Find and Highlight Text in a Specified PDF Page Area with Python
- Find and Highlight Text in PDF using Regular Expression with Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDFIf you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Find and Highlight Specific Text in PDF with Python
Spire.PDF for Python enables developers to find all occurrences of specific text on a page with PdfTextFinder class and apply highlight color to an occurrence with HighLight() method. Below is an example of using Spire.PDF for Python to highlight all occurrence of specific text:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Loop through the pages in the document.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create a PdfTextFinder object for the current page.
- Set the search parameter using finds.Options.Parameter.
- Find all occurrences of specific text on the page using PdfTextFinder.Find() method.
- Loop through the occurrences and apply a highlight color to each occurrence using HighLight() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Iterate through each page in the PDF
for i in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(i)
# Create a PdfTextFinder object for the current page
finds = PdfTextFinder(page)
# Set the search parameter to find exact matches
finds.Options.Parameter = TextFindParameter.IgnoreCase
# Find all occurrences of specific text on the page
result = finds.Find("cloud server")
# Iterate through each instance of the word "science" found on the page
for find in result:
# Highlight the searched text
find.HighLight(Color.get_Cyan())
# Save the modified document to a new file
pdf.SaveToFile("output/FindHighlight.pdf", FileFormat.PDF)
pdf.Close()
Find and Highlight Text in a Specified PDF Page Area with Python
In addition to finding and highlighting specified text on the entire PDF page, Spire.PDF for Python also supports finding and highlighting specified text in specified areas on the page by setting the finds.Options.Area property of PdfTextFinder class to a RectangleF instance. The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get the first page of the document using PdfDocument.Pages.get_Item() method.
- Define a rectangular area using RectangleF.
- Create a PdfTextFinder object for the page and set the search parameter using finds.Options.Parameter.
- Set the search area to the defined rectangle using finds.Options.Area.
- Find all occurrences of specific text in the specified rectangular area using PdfTextFinder.Find() method.
- Loop through the occurrences and apply a highlight color to each occurrence using HighLight() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an objetc of PdfDocument and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Get a page
pdfPageBase = pdf.Pages.get_Item(0)
# Define a rectangular area
rctg = RectangleF(0.0, 0.0, pdfPageBase.ActualSize.Width, 300.0)
# Create a PdfTextFinder object for the page
finds = PdfTextFinder(pdfPageBase)
# Set the search parameter to find exact matches
finds.Options.Parameter = TextFindParameter.IgnoreCase
# Set the search area to the defined rectangle
finds.Options.Area = rctg
# Find all occurrences of specific text on the page
result = finds.Find("cloud server")
# Find text in the rectangle
for find in result:
#Highlight searched text
find.HighLight(Color.get_Green())
# Save the document
pdf.SaveToFile("output/FindHighlightArea.pdf")
pdf.Close()
Find and Highlight Text in PDF using Regular Expression with Python
Sometimes the text that needs to be highlighted is not exactly the same words. In this case, the use of regular expressions allows more flexibility in text search. By setting finds.Options.Parameter to TextFindParameter.Regex, we can find text using regular expression with PdfTextFinder class. The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Specify the regular expression.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create a PdfTextFinder object for the page and set the search parameter to TextFindParameter.Regex.
- Find matched text with the regular expression on the page using PdfTextFinder.Find() method.
- Loop through the matched text and apply Highlight color to the text using HighLight() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import*
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Specify the regular expression that matches two words after *
regex = "\\*(\\w+\\s+\\w+)"
# Get the second page
page = pdf.Pages.get_Item(1)
# Find matched text on the page using regular expression
finds = PdfTextFinder(page)
finds.Options.Parameter =TextFindParameter.Regex
result = finds.Find(regex)
# Highlight the matched text
for text in result:
text.HighLight(Color.get_DeepPink())
# Save the document
pdf.SaveToFile("output/FindHighlightRegex.pdf")
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.