
PDF-файлы отлично подходят для сохранения макетов документов, но извлечение табличных данных из них может быть утомительным. Основная причина заключается в том, что PDF-файлы разработаны для последовательного визуального отображения на разных устройствах, а не для извлечения структурированных данных. В результате таблицы могут существовать в виде выбираемого текста в цифровых PDF-файлах или в виде изображений в отсканированных файлах, причем структуры сильно различаются.
К счастью, существует несколько практических способов извлечения таблиц из PDF, в зависимости от ваших потребностей и уровня технической подготовки. В этом руководстве мы рассмотрим четыре эффективных метода, от простых инструментов без кода, таких как Excel и Google Docs, до мощного решения на основе Python для полного контроля и автоматизации.
Обзор методов:
- Метод 1: Microsoft Excel (встроенный импорт PDF)
- Метод 2: Google Документы (бесплатно и просто)
- Метод 3: Adobe Acrobat Pro (функция экспорта)
- Метод 4: Python (полный контроль и автоматизация)
Метод 1: Microsoft Excel (встроенный импорт PDF)
Лучше всего подходит для: пользователей Windows с Microsoft Office 365 или Excel 2016+ (только для Windows).
Microsoft Excel имеет встроенную функцию импорта PDF, которая удивительно хорошо работает с цифровыми PDF-файлами. Она напрямую подключается к файлу и пытается обнаружить и преобразовать таблицы.
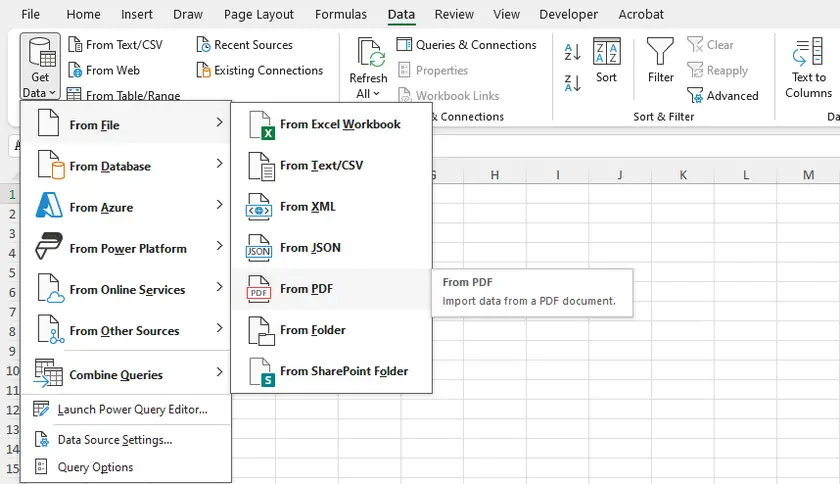
Пошаговые инструкции
- Откройте Microsoft Excel.
- Перейдите в раздел Данные → Получить данные → Из файла → Из PDF.
- Найдите и выберите ваш PDF-файл.
- Появится окно навигатора, показывающее все обнаруженные таблицы и страницы.
- Выберите таблицы, которые вы хотите импортировать, и нажмите Загрузить (для прямого импорта) или Преобразовать данные (для очистки перед загрузкой).
- Excel импортирует таблицу в рабочий лист, сохраняя структуру строк/столбцов достаточно хорошо.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Не требуется дополнительное программное обеспечение (с Office) | Только для Windows |
| Сохраняет числовые форматы | Проблемы со слитыми ячейками |
| Хорошо подходит для цифровых, текстовых PDF | Нет OCR для отсканированных PDF |
| Можно обновлять данные, если PDF обновляется | Может быть медленным для больших PDF |
Метод 2: Google Документы (бесплатно и просто)
Лучше всего подходит для: быстрого разового извлечения, когда у вас нет Excel или платных инструментов.
Google Документы предлагает скрытый, но бесплатный способ извлечения таблиц из PDF-файлов. Он работает путем преобразования всего PDF в редактируемый документ Google, где таблицы становятся сетками на основе текста.
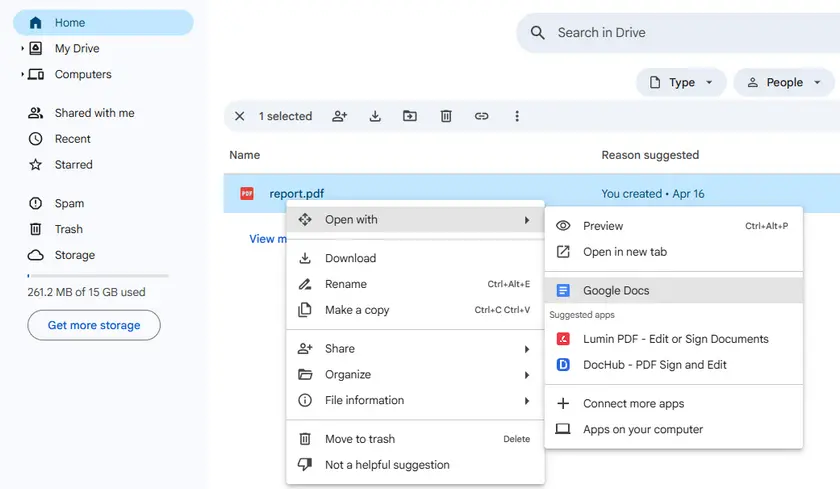
Пошаговые инструкции
- Загрузите PDF в Google Диск.
- Щелкните правой кнопкой мыши по PDF → Открыть с помощью → Google Документы.
- Дождитесь обработки файла Google Документами.
- Прокрутите, чтобы найти таблицу. Она появится в виде сетки на основе текста (строки и столбцы разделены пробелами или табуляцией).
- Скопируйте область таблицы и вставьте ее в Google Таблицы или Microsoft Excel.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Полностью бесплатно | Нет реального обнаружения таблиц (только выравнивание текста) |
| Не требуется установка программного обеспечения | Неаккуратные результаты со сложными таблицами |
| Работает на любой ОС с браузером | Плохая обработка слитых ячеек или многострочных ячеек |
| Надежно обрабатывает простые таблицы | Нет OCR (отсканированные PDF отображаются как изображения) |
Метод 3: Adobe Acrobat Pro (функция экспорта)
Лучше всего подходит для: профессионалов, у которых уже есть Acrobat Pro и которым требуется надежный экспорт из цифровых PDF.
Adobe Acrobat Pro (не бесплатный Reader) имеет встроенную функцию экспорта, которая преобразует таблицы PDF напрямую в Excel или CSV. Он сохраняет больше форматирования, чем бесплатные инструменты.
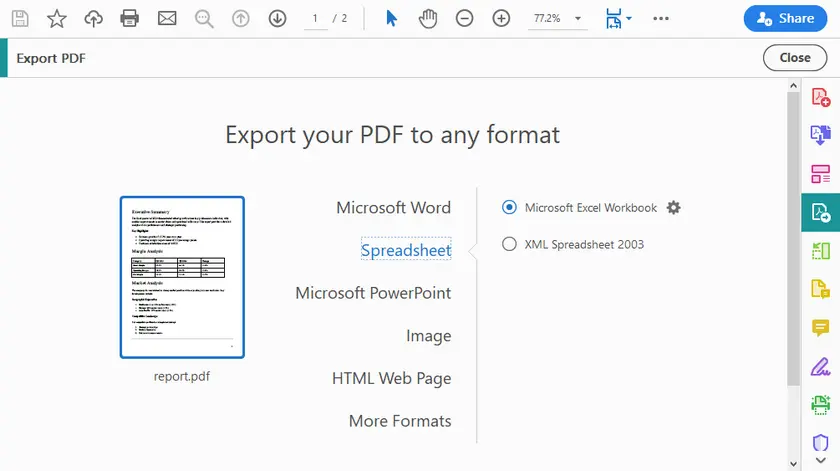
Пошаговые инструкции
- Откройте PDF в Adobe Acrobat Pro.
- Нажмите Экспорт PDF (панель инструментов справа).
- Выберите Электронная таблица → Книга Microsoft Excel (или CSV).
- Нажмите Экспорт.
- Выберите местоположение и сохраните.
- Откройте сгенерированный файл Excel и проверьте таблицы.
Дополнительные советы
- Используйте опцию Распознать текст (OCR), если работаете с отсканированными PDF.
- Для многостраничных таблиц Acrobat часто разумно объединяет их.
- Вы можете экспортировать только выбранные страницы, чтобы сэкономить время.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Высокая точность для цифровых PDF | Дорого (требуется подписка) |
| Хорошо обрабатывает многостраничные таблицы | Нет детального контроля над извлечением |
| Сохраняет формулы и числа | Все еще проблемы с очень сложными вложенными таблицами |
| Доступна пакетная обработка | Только для Windows/macOS (нет веб-версии) |
Метод 4: Python (полный контроль и автоматизация)
Лучше всего подходит для: разработчиков, специалистов по данным и продвинутых пользователей, которым требуется максимальная гибкость, работа с отсканированными PDF или пакетная обработка файлов.
Python предоставляет полный контроль над процессом извлечения. Вы можете работать с цифровыми PDF с помощью таких библиотек, как pdfplumber, camelot или Spire.PDF for Python (коммерческая библиотека с доступной бесплатной версией). Ниже приведен практический пример использования Spire.PDF для извлечения таблиц и сохранения их в виде чистых текстовых файлов.
Установка
pip install spire.pdf
Полный пример кода (извлечение таблиц в файлы TXT)
Следующий код извлекает все таблицы с указанной страницы PDF и сохраняет каждую таблицу в отдельный текстовый файл в формате, похожем на CSV:
from spire.pdf.common import *
from spire.pdf import *
# Создать объект PdfDocument
doc = PdfDocument()
# Загрузить PDF-файл
doc.LoadFromFile("report.pdf")
# Создать объект PdfTableExtractor
extractor = PdfTableExtractor(doc)
# Извлечь таблицы с определенной страницы (индекс страницы начинается с 0)
tableList = extractor.ExtractTable(0)
# Определить, не пуст ли список таблиц
if tableList is not None:
# Пройти по таблицам на странице
for i in range(len(tableList)):
# Создать новый список для хранения данных этой таблицы
builder = []
# Получить конкретную таблицу
table = tableList[i]
# Получить количество строк и столбцов
row = table.GetRowCount()
column = table.GetColumnCount()
# Пройти по каждой строке и столбцу
for m in range(row):
for n in range(column):
# Получить текст из конкретной ячейки
text = table.GetText(m, n)
# Добавить текст, за которым следует запятая (в стиле CSV)
builder.append(text + ",")
builder.append("\n") # Конец строки
builder.append("\n") # Пустая строка между таблицами
# Записать содержимое в текстовый файл
with open(f"output/Table-{i + 1}.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))
# Закрыть документ
doc.Close()
Вывод:
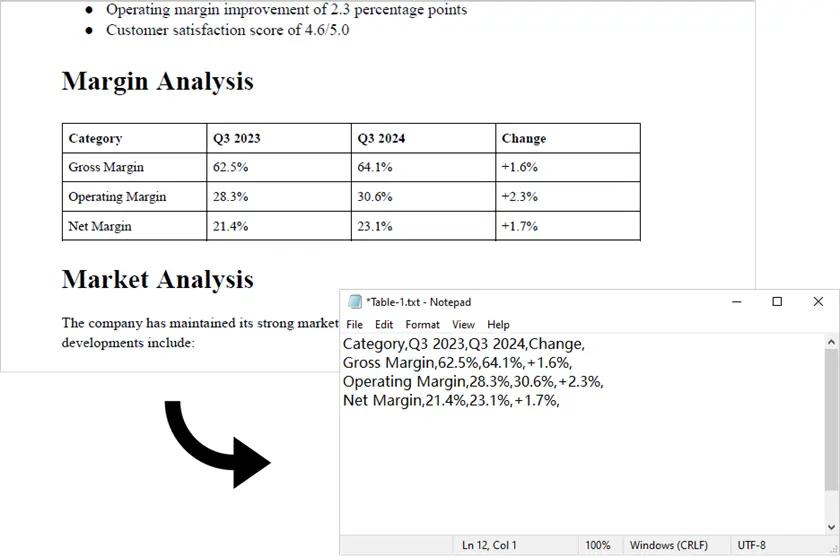
Примечание: Этот скрипт работает только с цифровыми PDF (текстовыми). Для отсканированных PDF одного Spire.PDF недостаточно. В таких случаях вы можете сначала преобразовать PDF в изображения с помощью Spire.PDF, а затем применить движок OCR, такой как pytesseract, вместе с дополнительной логикой обработки для обнаружения и извлечения табличных данных.
Почему Python?
- Обрабатывает как цифровые, так и отсканированные PDF (с интеграцией OCR)
- Пакетная обработка сотен файлов
- Настраиваемая постобработка (очистка, объединение, проверка)
- Может быть интегрирован в веб-приложения, API или конвейеры ETL
- Вы точно контролируете, как таблицы форматируются и сохраняются
Как комплексная библиотека для работы с PDF, Spire.PDF for Python не только извлекает таблицы из PDF, но также поддерживает извлечение изображений, метаданных и вложений. Кроме того, он может экспортировать целые документы в такие форматы, как Word, Excel и TXT.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Полный контроль над логикой извлечения | Требует знаний программирования |
| Обрабатывает сложные и многостраничные таблицы | Более крутая кривая обучения |
| Пакетная обработка тысяч файлов | Spire.PDF требует лицензии для коммерческого использования (бесплатно для личного) |
| Чистые, воспроизводимые результаты | Обнаружение таблиц не идеально для всех PDF |
| Легко интегрируется с pandas, Excel или базами данных |
Сравнительная таблица: выбор правильного метода
| Метод | Простота использования | Обрабатывает отсканированные PDF | Пакетная обработка | Стоимость | Лучше всего подходит для |
|---|---|---|---|---|---|
| Excel | Средняя | x | x | Требуется Office | Быстрые, разовые цифровые таблицы |
| Google Docs | Высокая | x | x | Бесплатно | Простые таблицы, без ПО |
| Adobe Acrobat Pro | Высокая | √ | x | Платно | Профессиональные, нетехнические пользователи |
| Python | Низкая | √ | √ | Бесплатно / Платно | Максимальная гибкость, крупномасштабные, отсканированные PDF |
Заключение
Извлечение таблиц из PDF не обязательно должно быть головной болью. Правильный метод полностью зависит от вашей конкретной ситуации:
- Для одноразовой простой таблицы → Сначала попробуйте Google Документы или онлайн-инструмент.
- Для профессиональных, отполированных результатов → Используйте Excel или Adobe Acrobat Pro, если у вас есть доступ.
- Для максимального контроля, сложных таблиц или отсканированных документов → Python — ваш лучший выбор.
Начните с самого простого метода, который соответствует вашим потребностям. По мере роста ваших требований (больше файлов, отсканированные документы, пользовательская очистка) вы всегда можете перейти на более мощные инструменты, такие как Python. Ключ в том, чтобы признать, что извлечение таблиц не является универсальной проблемой, и теперь у вас есть четыре способа ее решить.
Часто задаваемые вопросы
В1. Почему сложно извлекать таблицы из PDF?
Потому что PDF хранят контент как позиционированный текст, а не как структурированные табличные данные, что делает извлечение менее простым.
В2. Какой метод дает наиболее точные результаты?
Adobe Acrobat Pro обычно обеспечивает наилучшую точность для сложных таблиц.
В3. Могу ли я извлекать таблицы из отсканированных PDF?
Да, но это требует OCR (оптического распознавания символов). Инструменты, такие как Adobe Acrobat или Spire.PDF (с компонентом OCR), могут преобразовывать отсканированные изображения в машиночитаемый текст, после чего можно обнаруживать и извлекать табличные данные.
В4. Лучше ли Python, чем другие методы?
Зависит от ситуации. Python лучше всего подходит для автоматизации и крупномасштабной обработки, но избыточен для разовых задач.
В5. Могу ли я напрямую преобразовывать извлеченные таблицы в Excel?
Да. Большинство инструментов (Excel, Acrobat) поддерживают прямой экспорт в .xlsx, а Python может быть расширен для выполнения того же.