
Java (483)

Converting HTML to Word in Java is essential for developers building reporting tools, content management systems, and enterprise applications. While HTML powers web content, Word documents offer professional formatting, offline accessibility, and easy editing, making them ideal for reports, invoices, contracts, and formal submissions.
This comprehensive guide demonstrates how to use Java and Spire.Doc for Java to convert HTML to Word. It covers everything from converting HTML files and strings, batch processing multiple files, and preserving formatting and images.
Table of Contents
- Why Convert HTML to Word in Java
- Set Up Spire.Doc for Java
- Convert HTML File to Word in Java
- Convert HTML String to Word in Java
- Batch Conversion of Multiple HTML Files to Word in Java
- Best Practices for HTML to Word Conversion
- Conclusion
- FAQs
Why Convert HTML to Word in Java?
Converting HTML to Word offers several advantages:
- Flexible editing – Add comments, track changes, and review content easily.
- Consistent formatting – Preserve layouts, fonts, and styles across documents.
- Professional appearance – DOCX files look polished and ready to share.
- Offline access – Word files can be opened without an internet connection.
- Integration – Word is widely supported across tools and industries.
Common use cases: exporting HTML reports from web apps, archiving dynamic content in editable formats, and generating formal reports, invoices, or contracts.
Set Up Spire.Doc for Java
Spire.Doc for Java is a robust library that enables developers to create Word documents, edit existing Word documents, and read and convert Word documents in Java without requiring Microsoft Word to be installed.
Before you can convert HTML content into Word documents, it’s essential to properly install and configure Spire.Doc for Java in your development environment.
1. Java Version Requirement
Ensure that your development environment is running Java 6 (JDK 1.6) or a higher version.
2. Installation
Option 1: Using Maven
For projects managed with Maven, you can add the repository and dependency to your pom.xml:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.6.0</version>
</dependency>
</dependencies>
For a step-by-step guide on Maven installation and configuration, refer to our article**:** How to Install Spire Series Products for Java from Maven Repository.
Option 2. Manual JAR Installation
For projects without Maven, you can manually add the library:
- Download Spire.Doc.jar from the official website.
- Add it to your project classpath.
Convert HTML File to Word in Java
If you already have an existing HTML file, converting it into a Word document is straightforward and efficient. This method is ideal for situations where HTML reports, templates, or web content need to be transformed into professionally formatted, editable Word files.
By using Spire.Doc for Java, you can preserve the original layout, text formatting, tables, lists, images, and hyperlinks, ensuring that the converted document remains faithful to the source. The process is simple, requiring only a few lines of code while giving you full control over page settings and document structure.
Conversion Steps:
- Create a new Document object.
- Load the HTML file with loadFromFile().
- Adjust settings like page margins.
- Save the output as a Word document with saveToFile().
Example:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.XHTMLValidationType;
public class ConvertHtmlFileToWord {
public static void main(String[] args) {
// Create a Document object
Document document = new Document();
// Load an HTML file
document.loadFromFile("C:\\Users\\Administrator\\Desktop\\sample.html",
FileFormat.Html,
XHTMLValidationType.None);
// Adjust margins
Section section = document.getSections().get(0);
section.getPageSetup().getMargins().setAll(2);
// Save as Word file
document.saveToFile("output/FromHtmlFile.docx", FileFormat.Docx);
// Release resources
document.dispose();
System.out.println("HTML file successfully converted to Word!");
}
}
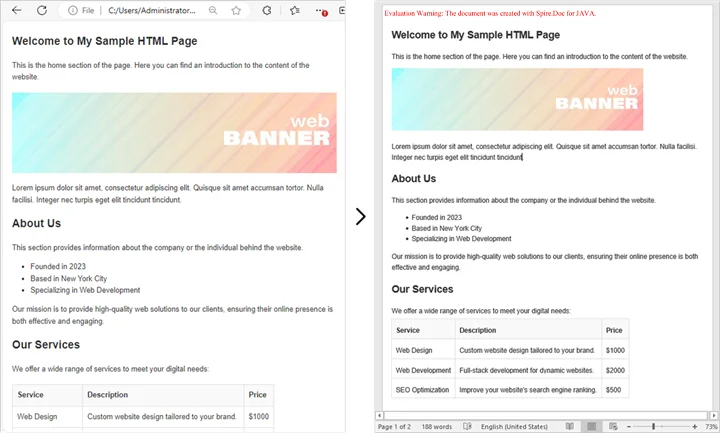
You may also be interested in: Java: Convert Word to HTML
Convert HTML String to Word in Java
In many real-world applications, HTML content is generated dynamically - whether it comes from user input, database records, or template engines. Converting these HTML strings directly into Word documents allows developers to create professional, editable reports, invoices, or documents on the fly without relying on pre-existing HTML files.
Using Spire.Doc for Java, you can render rich HTML content, including headings, lists, tables, images, hyperlinks, and more, directly into a Word document while preserving formatting and layout.
Conversion Steps:
- Create a new Document object.
- Add a section and adjust settings like page margins.
- Add a paragraph.
- Add the HTML string to the paragraph using appendHTML().
- Save the output as a Word document with saveToFile().
Example:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.Paragraph;
public class ConvertHtmlStringToWord {
public static void main(String[] args) {
// Sample HTML string
String htmlString = "<h1>Java HTML to Word Conversion</h1>" +
"<p><b>Spire.Doc</b> allows you to convert HTML content into Word documents seamlessly. " +
"This includes support for headings, paragraphs, lists, tables, links, and images.</p>" +
"<h2>Features</h2>" +
"<ul>" +
"<li>Preserve text formatting such as <i>italic</i>, <u>underline</u>, and <b>bold</b></li>" +
"<li>Support for ordered and unordered lists</li>" +
"<li>Insert tables with multiple rows and columns</li>" +
"<li>Add hyperlinks and bookmarks</li>" +
"<li>Embed images from URLs or base64 strings</li>" +
"</ul>" +
"<h2>Example Table</h2>" +
"<table border='1' style='border-collapse:collapse;'>" +
"<tr><th>Item</th><th>Description</th><th>Quantity</th></tr>" +
"<tr><td>Notebook</td><td>Spire.Doc Java Guide</td><td>10</td></tr>" +
"<tr><td>Pen</td><td>Blue Ink</td><td>20</td></tr>" +
"<tr><td>Marker</td><td>Permanent Marker</td><td>5</td></tr>" +
"</table>" +
"<h2>Links and Images</h2>" +
"<p>Visit <a href='https://www.e-iceblue.com/'>E-iceblue Official Site</a> for more resources.</p>" +
"<p>Sample Image:</p>" +
"<img src='https://www.e-iceblue.com/images/intro_pic/Product_Logo/doc-j.png' alt='Product Logo' width='150' height='150'/>" +
"<h2>Conclusion</h2>" +
"<p>Using Spire.Doc, Java developers can easily generate Word documents from rich HTML content while preserving formatting and layout.</p>";
// Create a Document
Document document = new Document();
// Add section and paragraph
Section section = document.addSection();
section.getPageSetup().getMargins().setAll(72);
Paragraph paragraph = section.addParagraph();
// Render HTML string
paragraph.appendHTML(htmlString);
// Save as Word
document.saveToFile("output/FromHtmlString.docx", FileFormat.Docx);
document.dispose();
System.out.println("HTML string successfully converted to Word!");
}
}

Batch Conversion of Multiple HTML Files to Word in Java
Sometimes you may need to convert hundreds of HTML files into Word documents. Here’s how to batch process them in Java.
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.documents.XHTMLValidationType;
import java.io.File;
public class BatchConvertHtmlToWord {
public static void main(String[] args) {
File folder = new File("C:\\Users\\Administrator\\Desktop\\HtmlFiles");
for (File file : folder.listFiles()) {
if (file.getName().endsWith(".html") || file.getName().endsWith(".htm")) {
Document document = new Document();
document.loadFromFile(file.getAbsolutePath(), FileFormat.Html, XHTMLValidationType.None);
String outputPath = "output/" + file.getName().replace(".html", ".docx");
document.saveToFile(outputPath, FileFormat.Docx);
document.dispose();
System.out.println(file.getName() + " converted to Word!");
}
}
}
}
This approach is great for reporting systems where multiple HTML reports are generated daily.
Best Practices for HTML to Word Conversion
- Use Inline CSS for Reliable Styling
Inline CSS ensures that fonts, colors, and spacing are preserved during conversion. External stylesheets may not always render correctly, especially if they are not accessible at runtime. - Validate HTML Structure
Well-formed HTML with proper nesting and closed tags helps render tables, lists, and headings accurately. - Optimize Images
Use absolute URLs or embed images as base64. Resize large images to fit Word layouts and reduce file size. - Manage Resources in Batch Conversion
When processing multiple files, convert them one by one and call dispose() after each document to prevent memory issues. - Preserve Page Layouts
Set page margins, orientation, and paper size to ensure the Word document looks professional, especially for reports and formal documents.
Conclusion
Converting HTML to Word in Java is an essential feature for many enterprise applications. Using Spire.Doc for Java, you can:
- Convert HTML files into Word documents.
- Render HTML strings directly into DOCX.
- Handle batch processing for multiple files.
- Preserve images, tables, and styles with ease.
By following the examples and best practices above, you can integrate HTML to Word conversion seamlessly into your Java applications.
FAQs (Frequently Asked Questions)
Q1. Can Java convert multiple HTML files into one Word document?
A1: Yes. Instead of saving each file separately, you can load multiple HTML contents into the same Document and then save it once.
Q2. How to preserve CSS styles during HTML to Word conversion?
A2: Inline CSS will be preserved; external stylesheets can also be applied if they’re accessible at run time.
Q3. Can I generate a Word document directly from a web page?
A3: Yes. You can fetch the HTML using an HTTP client in Java, then pass it into the conversion method.
Q4. What Word formats are supported for saving the converted document?
A4: You can save as DOCX, DOC, or other Word-compatible formats supported by Spire.Doc. DOCX is recommended for modern applications due to its compatibility and smaller file size.
When working with PDF files, you may need to adjust the page size to emphasize important content, remove extra white space, or fit specific printing and display requirements. Cropping PDF pages helps streamline the document layout, making the content more readable and well-organized. It also reduces file size, improving both accessibility and sharing. Additionally, precise cropping enhances the document's visual appeal, giving it a more polished and professional look. This article will demonstrate how to crop PDF pages in Java using the Spire.PDF for Java library.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.6.4</version>
</dependency>
</dependencies>
Crop a PDF Page in Java
Spire.PDF for Java provides the PdfPageBase.setCropBox(Rectangle2D rect) method to set the crop area for a PDF page. The detailed steps are as follows.
- Create an instance of the PdfDocument class.
- Load a PDF document using the PdfDocument.loadFromFile() method.
- Get a specific page from the PDF using the PdfDocument.getPages().get(int pageIndex) method.
- Create an instance of the Rectangle2D class to define the crop area.
- Use the PdfPageBase.setCropBox(Rectangle2D rect) method to set the crop area for the page.
- Save the cropped PDF using the PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import java.awt.geom.Rectangle2D;
public class CropPdfPage {
public static void main(String[] args) {
// Create an instance of the PdfDocument class
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.loadFromFile("example.pdf");
// Get the first page of the PDF
PdfPageBase page = pdf.getPages().get(0);
// Define the crop area (parameters: x, y, width, height)
Rectangle2D rectangle = new Rectangle2D.Float(0, 40, 600, 360);
// Set the crop area for the page
page.setCropBox(rectangle);
// Save the cropped PDF
pdf.saveToFile("cropped.pdf");
// Close the document and release resources
pdf.close();
}
}
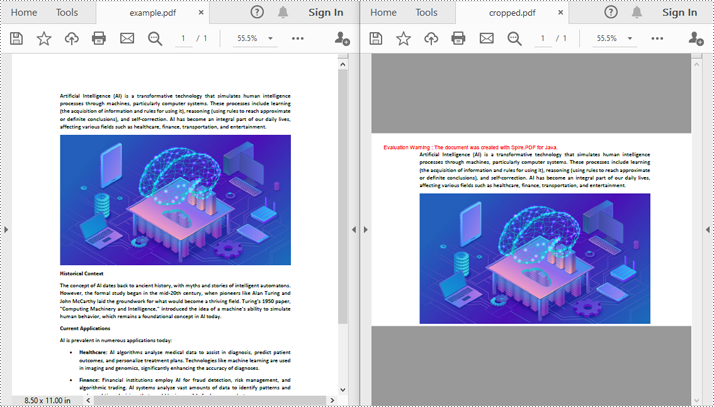
Crop a PDF page and Export the Result as an Image in Java
After cropping a PDF page, developers can use the PdfDocument.saveAsImage(int pageIndex, PdfImageType type) method to export the result as an image. The detailed steps are as follows.
- Create an instance of the PdfDocument class.
- Load a PDF document using the PdfDocument.loadFromFile() class.
- Get a specific page from the PDF using the PdfDocument.getPages().get(int pageIndex) mthod.
- Create an instance of the Rectangle2D class to define the crop area.
- Use the PdfPageBase.setCropBox(Rectangle2D rect) method to set the crop area for the page.
- Use the PdfDocument.saveAsImage(int pageIndex, PdfImageType type) method to export the cropped page as an image.
- Save the image as an image file.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImageType;
import javax.imageio.ImageIO;
import java.awt.geom.Rectangle2D;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class CropPdfPageAndSaveAsImage {
public static void main(String[] args) {
// Create an instance of the PdfDocument class
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.loadFromFile("example.pdf");
// Get the first page of the PDF
PdfPageBase page = pdf.getPages().get(0);
// Define the crop area (parameters: x, y, width, height)
Rectangle2D rectangle = new Rectangle2D.Float(0, 40, 600, 360);
// Set the crop area for the page
page.setCropBox(rectangle);
// Export the cropped page as an image
BufferedImage image = pdf.saveAsImage(0, PdfImageType.Bitmap);
// Save the image as a PNG file
File outputFile = new File("cropped.png");
try {
ImageIO.write(image, "PNG", outputFile);
System.out.println("Cropped page saved as: " + outputFile.getAbsolutePath());
} catch (IOException e) {
System.err.println("Error saving image: " + e.getMessage());
}
// Close the document and release resources
pdf.close();
}
}
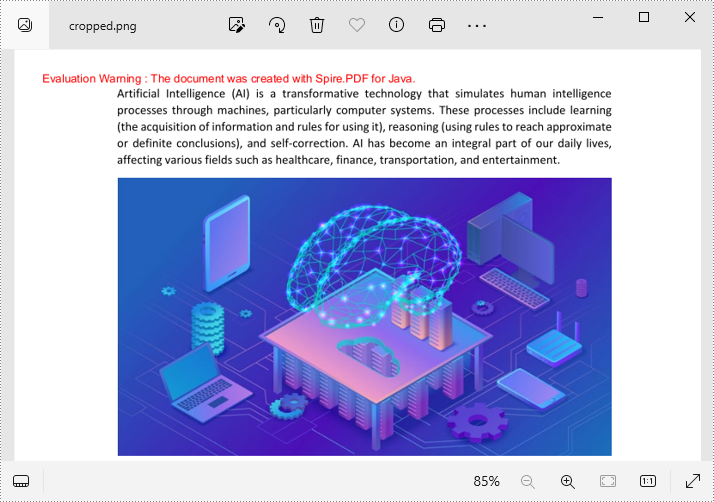
Get a Free License
To fully experience the capabilities of Spire.PDF for Java without any evaluation limitations, you can request a free 30-day trial license.
Comments in Word documents often hold valuable information, such as feedback, suggestions, and notes. Unfortunately, editors like Microsoft Word lack a built-in feature for batch-extracting comments, leaving users to rely on cumbersome methods like copying and pasting or using VBA macros. To simplify this process, this article demonstrates how to use Java to extract comments from Word documents with Spire.Doc for Java. With a streamlined approach, you can easily retrieve all comment text and images in a single operation—quickly, efficiently, and error-free. Let's explore how it’s done.
- Extract Comments Text from Word Documents in Java
- Extract Comment Images from Word Documents in Java
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.6.0</version>
</dependency>
</dependencies>
Extract Comments Text from Word Documents in Java
Using Java to extract all comment text is easy and quick. Firstly, loop through all comments in the Word file and get the current comment using the Document.getComments().get() method offered by Spire.Doc for Java. Then iterate through all paragraphs in the comment body and get the current paragraph. Finally, text from comment paragraphs will be extracted using the Paragraph.getText() method. Let's dive into the detailed steps.
Steps to extract comment text from Word files:
- Create an object of Document class.
- Load a Word document from files using Document.loadFromFile() method.
- Iterate through all comments in the Word file.
- Get the current comment with Document.getComments().get() method.
- Loop through paragraphs in the comment and access the current paragraph through Comment.getBody().getParagraphs().get() method.
- Extract the text of the paragraphs in comments by calling Paragraph.getText() method.
- Get the current comment with Document.getComments().get() method.
- Save the extracted comments.
The code example below demonstrates how to extract all comment text from a Word document:
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
import java.io.*;
public class ExtractComments {
public static void main(String[] args) throws IOException {
// Create a new Document instance
Document doc = new Document();
// Load the document from the specified input file
doc.loadFromFile("/comments.docx");
// Iterate over each comment in the document
for (int i = 0; i < doc.getComments().getCount(); i++) {
// Get the comment at the current index
Comment comment = doc.getComments().get(i);
// Iterate over each paragraph in the comment's body
for (int j = 0; j < comment.getBody().getParagraphs().getCount(); j++) {
// Get the paragraph at the current index
Paragraph para = comment.getBody().getParagraphs().get(j);
// Get the text of the paragraph and append a line break
String result = para.getText() + "\r\n";
// Write the extracted comment a text file
writeStringToTxt(result, "/commenttext.txt");
}
}
// Dispose of the document resources
doc.dispose();
}
// Custom method to write a string to a text file
public static void writeStringToTxt(String content, String txtFileName) throws IOException {
FileWriter fWriter = new FileWriter(txtFileName, true);
try {
// Write the content to the text file
fWriter.write(content);
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
// Flush and close the FileWriter
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
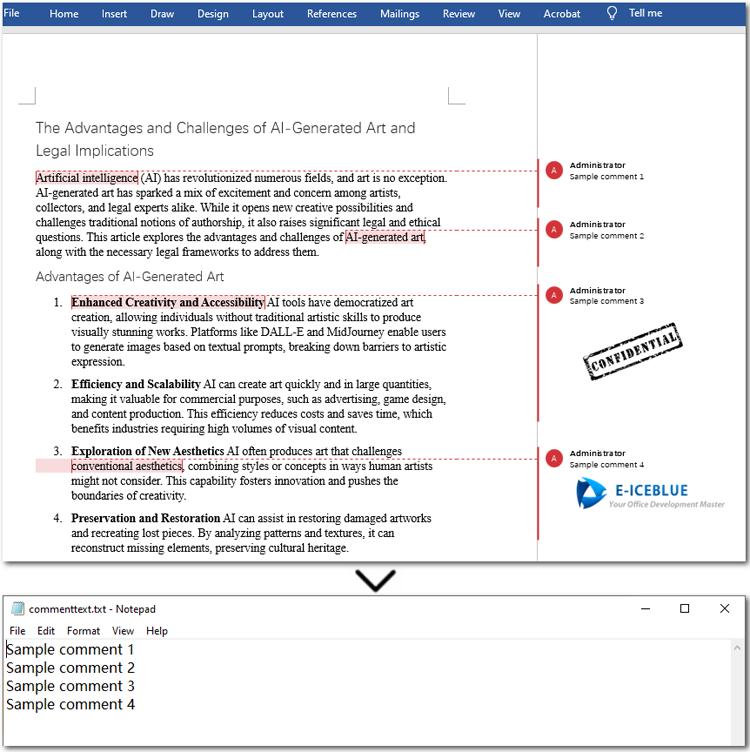
Extract Comments Images from Word Documents with Java
Sometimes, comments in a document may contain not only text but also images. With the methods provided by Spire.Doc for Java, you can easily extract all images from comments in bulk. The process is similar to extracting text: you need to iterate through each comment, the paragraphs in the comment body, and the child objects of each paragraph. Then, check if the object is a DocPicture. If it is, use the DocPicture.getImageBytes() method to extract the image.
Steps to extract comment images from Word documents:
- Create an instance of Document class.
- Specify the file path to load a source Word file through Document.loadFromFile() method.
- Create a list to store extracted data.
- Loop through comments in the Word file and get the current comment using Document.getComments().get() method.
- Loop through all paragraphs in a comment, and get the current paragraph with Comment.getBody().getParagraphs().get() method.
- Iterate through each child object of a paragraph, and access a child object through Paragraph.getChildObjects().get() method.
- Check if the child object is DocPicture, if it is, get the image data using DocPicture.getImageBytes() method.
- Loop through all paragraphs in a comment, and get the current paragraph with Comment.getBody().getParagraphs().get() method.
- Add the image data to the list and save it as image files.
Here is the code example of extracting all comment images from a Word file:
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
import java.io.*;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
public class ExtractCommentImages {
public static void main(String[] args) {
// Create an object of the Document class
Document document = new Document();
// Load a Word document with comments
document.loadFromFile("/comments.docx");
// Create a list to store the extracted image data
List<byte[]> images = new ArrayList<>();
// Loop through the comments in the document
for (int i = 0; i < document.getComments().getCount(); i++) {
Comment comment = document.getComments().get(i);
// Iterate through the paragraphs in the comment body
for (int j = 0; j < comment.getBody().getParagraphs().getCount(); j++) {
Paragraph paragraph = comment.getBody().getParagraphs().get(j);
// Loop through the child objects in the paragraph
for (int k = 0; k < paragraph.getChildObjects().getCount(); k++) {
DocumentObject obj = paragraph.getChildObjects().get(k);
// Check if it is a picture
if (obj instanceof DocPicture) {
DocPicture picture = (DocPicture) obj;
// Get the image date and add it to the list
images.add(picture.getImageBytes());
}
}
}
}
// Specify the output file path
String outputDir = "/comment_images/";
new File(outputDir).mkdirs();
// Save the image data as image files
for (int i = 0; i < images.size(); i++) {
String fileName = String.format("comment-image-%d.png", i);
Path filePath = Paths.get(outputDir, fileName);
try (FileOutputStream fos = new FileOutputStream(filePath.toFile())) {
fos.write(images.get(i));
} catch (IOException e) {
e.printStackTrace();
}
}
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
