
Java (483)
Adding, inserting, and deleting pages in a Word document are crucial steps in managing and presenting content. By adding or inserting new pages, you can expand the document to accommodate more content, making it more organized and readable. Deleting pages helps simplify the document by removing unnecessary or erroneous information. These operations can enhance the overall quality and clarity of the document. This article will demonstrate how to use Spire.Doc for Java to add, insert, and delete pages in a Word document within a Java project.
- Add a Page in a Word Document in Java
- Insert a Page in a Word Document in Java
- Delete a Page from a Word Document in Java
Install Spire.Doc for Java
First, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.6.0</version>
</dependency>
</dependencies>
Add a Page in a Word Document in Java
The steps to add a new page at the end of a Word document include locating the last section, and then inserting a page break at the end of that section's last paragraph. This way ensures that any content added subsequently will start displaying on a new page, maintaining the clarity and coherence of the document structure. The detailed steps are as follows:
- Create a Document object.
- Load a Word document using the Document.loadFromFile() method.
- Get the body of the last section of the document using Document.getLastSection().getBody().
- Add a page break by calling Paragraph.appendBreak(BreakType.Page_Break) method.
- Create a new paragraph style ParagraphStyle object.
- Add the new paragraph style to the document's style collection using Document.getStyles().add(paragraphStyle) method.
- Create a new paragraph Paragraph object and set the text content.
- Apply the previously created paragraph style to the new paragraph using Paragraph.applyStyle(paragraphStyle.getName()) method.
- Add the new paragraph to the document using Body.getChildObjects().add(paragraph) method.
- Save the resulting document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class AddOnePage {
public static void main(String[] args) {
// Create a new document object
Document document = new Document();
// Load a sample document from a file
document.loadFromFile("Sample.docx");
// Get the body of the last section of the document
Body body = document.getLastSection().getBody();
// Insert a page break after the last paragraph in the body
body.getLastParagraph().appendBreak(BreakType.Page_Break);
// Create a new paragraph style
ParagraphStyle paragraphStyle = new ParagraphStyle(document);
paragraphStyle.setName("CustomParagraphStyle1");
paragraphStyle.getParagraphFormat().setLineSpacing(12);
paragraphStyle.getParagraphFormat().setAfterSpacing(8);
paragraphStyle.getCharacterFormat().setFontName("Microsoft YaHei");
paragraphStyle.getCharacterFormat().setFontSize(12);
// Add the paragraph style to the document's style collection
document.getStyles().add(paragraphStyle);
// Create a new paragraph and set the text content
Paragraph paragraph = new Paragraph(document);
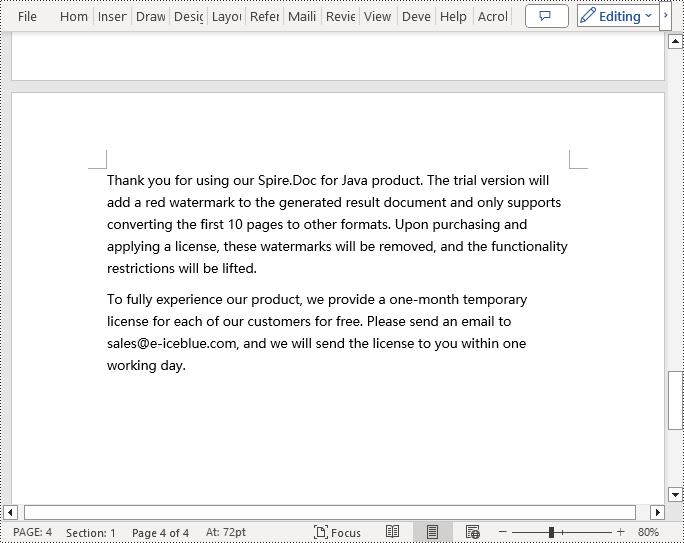
paragraph.appendText("Thank you for using our Spire.Doc for Java product. The trial version will add a red watermark to the generated result document and only supports converting the first 10 pages to other formats. Upon purchasing and applying a license, these watermarks will be removed, and the functionality restrictions will be lifted.");
// Apply the paragraph style
paragraph.applyStyle(paragraphStyle.getName());
// Add the paragraph to the body's content collection
body.getChildObjects().add(paragraph);
// Create another new paragraph and set the text content
paragraph = new Paragraph(document);
paragraph.appendText("To fully experience our product, we provide a one-month temporary license for each of our customers for free. Please send an email to sales@e-iceblue.com, and we will send the license to you within one working day.");
// Apply the paragraph style
paragraph.applyStyle(paragraphStyle.getName());
// Add the paragraph to the body's content collection
body.getChildObjects().add(paragraph);
// Save the document to a specified path
document.saveToFile("Add a Page.docx", FileFormat.Docx);
// Close the document
document.close();
// Dispose of the document object's resources
document.dispose();
}
}
Insert a Page in a Word Document in Java
Before inserting a new page, it is necessary to determine the ending position index of the specified page content within the section, and then add the content of the new page to the document one by one. To ensure that the content is separated from the subsequent pages, page breaks need to be inserted at appropriate positions. The detailed steps are as follows:
- Create a Document object.
- Load a Word document using the Document.loadFromFile() method.
- Create a FixedLayoutDocument object.
- Obtain the FixedLayoutPage object of a page in the document.
- Get the index position of the last paragraph on the page within the section.
- Create a new paragraph style ParagraphStyle object.
- Add the new paragraph style to the document using the Document.getStyles().add(paragraphStyle) method.
- Create a new paragraph Paragraph object and set the text content.
- Apply the previously created paragraph style to the new paragraph using the Paragraph.applyStyle(paragraphStyle.getName()) method.
- Insert the new paragraph at the specified position using the Body.getChildObjects().insert(index, Paragraph) method.
- Create another new paragraph object, set its text content, add a page break by calling the Paragraph.appendBreak(BreakType.Page_Break) method, apply the previously created paragraph style, and finally insert this paragraph into the document.
- Save the resulting document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
import com.spire.doc.pages.*;
import com.spire.doc.documents.*;
public class InsertOnePage {
public static void main(String[] args) {
// Create a new document object
Document document = new Document();
// Load a sample document from a file
document.loadFromFile("Sample.docx");
// Create a fixed layout document object
FixedLayoutDocument layoutDoc = new FixedLayoutDocument(document);
// Get the first page
FixedLayoutPage page = layoutDoc.getPages().get(0);
// Get the body of the document
Body body = page.getSection().getBody();
// Get the paragraph at the end of the current page
Paragraph paragraphEnd = page.getColumns().get(0).getLines().getLast().getParagraph();
// Initialize the end index
int endIndex = 0;
if (paragraphEnd != null) {
// Get the index of the last paragraph
endIndex = body.getChildObjects().indexOf(paragraphEnd);
}
// Create a new paragraph style
ParagraphStyle paragraphStyle = new ParagraphStyle(document);
paragraphStyle.setName("CustomParagraphStyle1");
paragraphStyle.getParagraphFormat().setLineSpacing(12);
paragraphStyle.getParagraphFormat().setAfterSpacing(8);
paragraphStyle.getCharacterFormat().setFontName("Microsoft YaHei");
paragraphStyle.getCharacterFormat().setFontSize(12);
// Add the style to the document
document.getStyles().add(paragraphStyle);
// Create a new paragraph and set the text content
Paragraph paragraph = new Paragraph(document);
paragraph.appendText("Thank you for using our Spire.Doc for Java product. The trial version will add a red watermark to the generated result document and only supports converting the first 10 pages to other formats. Upon purchasing and applying a license, these watermarks will be removed, and the functionality restrictions will be lifted.");
// Apply the paragraph style
paragraph.applyStyle(paragraphStyle.getName());
// Insert the paragraph at the specified position
body.getChildObjects().insert(endIndex + 1, paragraph);
// Create another new paragraph and set the text content
paragraph = new Paragraph(document);
paragraph.appendText("To fully experience our product, we provide a one-month temporary license for each of our customers for free. Please send an email to sales@e-iceblue.com, and we will send the license to you within one working day.");
// Apply the paragraph style
paragraph.applyStyle(paragraphStyle.getName());
// Add a page break
paragraph.appendBreak(BreakType.Page_Break);
// Insert the paragraph at the specified position
body.getChildObjects().insert(endIndex + 2, paragraph);
// Save the document to a specified path
document.saveToFile("Insert a New Page after a Specified Page.docx", FileFormat.Docx);
// Close and dispose of the document object's resources
document.close();
document.dispose();
}
}

Delete a Page from a Word Document in Java
To delete the content of a page, you first need to find the position index of the starting and ending elements of that page in the document. Then, by looping through, you can remove these elements one by one to delete the entire content of the page. The detailed steps are as follows:
- Create a Document object.
- Load a Word document using the Document.loadFromFile() method.
- Create a FixedLayoutDocument object.
- Obtain the FixedLayoutPage object of the first page in the document.
- Use the FixedLayoutPage.getSection() method to get the section where the page is located.
- Get the index position of the first paragraph on the page within the section.
- Get the index position of the last paragraph on the page within the section.
- Use a for loop to remove the content of the page one by one.
- Save the resulting document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
import com.spire.doc.pages.*;
import com.spire.doc.documents.*;
public class RemoveOnePage {
public static void main(String[] args) {
// Create a new document object
Document document = new Document();
// Load a sample document from a file
document.loadFromFile("Sample.docx");
// Create a fixed layout document object
FixedLayoutDocument layoutDoc = new FixedLayoutDocument(document);
// Get the second page
FixedLayoutPage page = layoutDoc.getPages().get(1);
// Get the section of the page
Section section = page.getSection();
// Get the first paragraph on the first page
Paragraph paragraphStart = page.getColumns().get(0).getLines().getFirst().getParagraph();
int startIndex = 0;
if (paragraphStart != null) {
// Get the index of the starting paragraph
startIndex = section.getBody().getChildObjects().indexOf(paragraphStart);
}
// Get the last paragraph on the last page
Paragraph paragraphEnd = page.getColumns().get(0).getLines().getLast().getParagraph();
int endIndex = 0;
if (paragraphEnd != null) {
// Get the index of the ending paragraph
endIndex = section.getBody().getChildObjects().indexOf(paragraphEnd);
}
// Remove paragraphs within the specified range
for (int i = 0; i <= (endIndex - startIndex); i++) {
section.getBody().getChildObjects().removeAt(startIndex);
}
// Save the document to a specified path
document.saveToFile("Delete a Page.docx", FileFormat.Docx);
// Close and dispose of the document object's resources
document.close();
document.dispose();
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Captions play multiple important roles in a document. They not only provide explanations for images or tables but also help in organizing the document structure, referencing specific content, and ensuring consistency and standardization. They serve as guides, summaries, and emphasis within the document, enhancing readability and assisting readers in better understanding and utilizing the information presented in the document. This article will demonstrate how to use Spire.Doc for Java to add or remove captions in Word documents within a Java project.
- Add Image Captions to a Word document in Java
- Add Table Captions to a Word document in Java
- Remove Captions from a Word document in Java
Install Spire.Doc for Java
First, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.6.0</version>
</dependency>
</dependencies>
Add Image Captions to a Word document in Java
By using the DocPicture.addCaption(String name, CaptionNumberingFormat format, CaptionPosition captionPosition) method, you can easily add descriptive captions to images within a Word document. The following are the detailed steps:
- Create an object of the Document class.
- Use the Document.addSection() method to add a section.
- Add a paragraph using Section.addParagraph() method.
- Use the Paragraph.appendPicture(String filePath) method to add a DocPicture image object to the paragraph.
- Add a caption using the DocPicture.addCaption(String name, CaptionNumberingFormat format, CaptionPosition captionPosition) method, numbering the captions in CaptionNumberingFormat.Number format.
- Update all fields using the Document.isUpdateFields(true) method.
- Save the resulting document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
public class addPictureCaption {
public static void main(String[] args) {
// Create a Word document object
Document document = new Document();
// Add a section to the document
Section section = document.addSection();
// Add a new paragraph and insert an image into it
Paragraph pictureParagraphCaption = section.addParagraph();
pictureParagraphCaption.getFormat().setAfterSpacing(10);
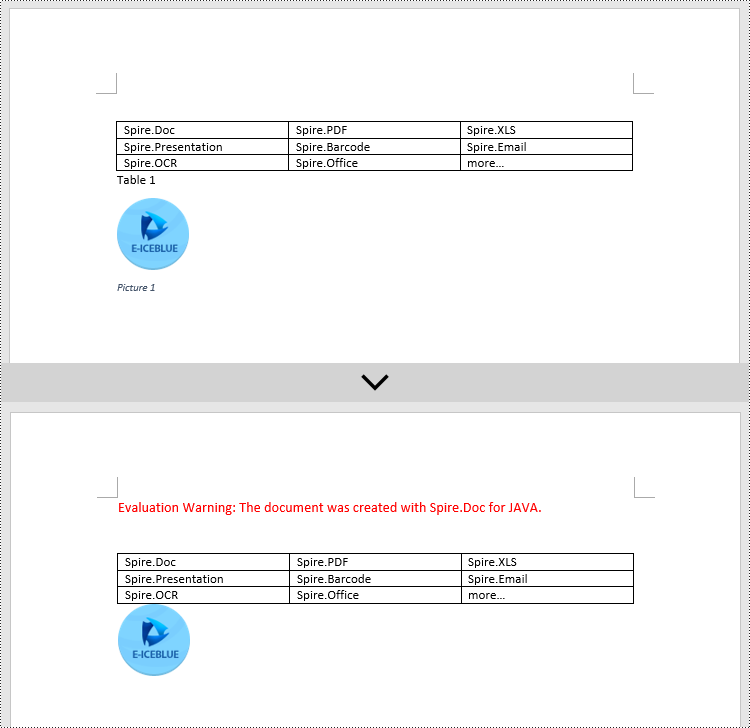
DocPicture pic1 = pictureParagraphCaption.appendPicture("Data\\1.png");
pic1.setHeight(100);
pic1.setWidth(100);
// Add a caption to the image
CaptionNumberingFormat format = CaptionNumberingFormat.Number;
pic1.addCaption("Image", format, CaptionPosition.Below_Item);
// Add another paragraph and insert another image into it
pictureParagraphCaption = section.addParagraph();
DocPicture pic2 = pictureParagraphCaption.appendPicture("Data\\2.png");
pic2.setHeight(100);
pic2.setWidth(100);
// Add a caption to the second image
pic2.addCaption("Image", format, CaptionPosition.Below_Item);
// Update all fields in the document
document.isUpdateFields(true);
// Save the document as a docx file
String result = "AddImageCaption.docx";
document.saveToFile(result, FileFormat.Docx_2016);
// Close and dispose the document object to release resources
document.close();
document.dispose();
}
}

Add Table Captions to a Word document in Java
Similar to adding captions to images, to add a caption to a table, you need to call the Table.addCaption(String name, CaptionNumberingFormat format, CaptionPosition captionPosition) method. The detailed steps are as follows:
- Create an object of the Document class.
- Use the Document.addSection() method to add a section.
- Create a Table object and add it to the specified section in the document.
- Use the Table.resetCells(int rowsNum, int columnsNum) method to set the number of rows and columns in the table.
- Add a caption using the Table.addCaption(String name, CaptionNumberingFormat format, CaptionPosition captionPosition) method, numbering the captions in CaptionNumberingFormat.Number format.
- Update all fields using the Document.isUpdateFields(true) method.
- Save the resulting document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
public class addTableCaption {
public static void main(String[] args) {
// Create a Word document object
Document document = new Document();
// Add a section to the document
Section section = document.addSection();
// Add a table to the section
Table tableCaption = section.addTable(true);
tableCaption.resetCells(3, 2);
// Add a caption to the table
tableCaption.addCaption("Table", CaptionNumberingFormat.Number, CaptionPosition.Below_Item);
// Add another table to the section
tableCaption = section.addTable(true);
tableCaption.resetCells(2, 3);
// Add a caption to the second table
tableCaption.addCaption("Table", CaptionNumberingFormat.Number, CaptionPosition.Below_Item);
// Update all fields in the document
document.isUpdateFields(true);
// Save the document as a docx file
String result = "AddTableCaption.docx";
document.saveToFile(result, FileFormat.Docx_2016);
// Close and dispose the document object to release resources
document.close();
document.dispose();
}
}

Remove Captions from a Word document in Java
In addition to adding captions, Spire.Doc for Java also supports deleting captions from a Word document. The steps involved are as follows:
- Create an object of the Document class.
- Use the Document.loadFromFile() method to load a Word document.
- Create a custom method named DetectCaptionParagraph(Paragraph paragraph), to determine if the paragraph contains a caption.
- Iterate through all the Paragraph objects in the document using a loop and use the custom method, DetectCaptionParagraph(Paragraph paragraph), to identify the paragraphs that contain captions and delete them.
- Save the resulting document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
public class deleteCaptions {
public static void main(String[] args) {
// Create a Word document object
Document document = new Document();
// Load the sample.docx file
document.loadFromFile("Data/sample.docx");
Section section;
// Iterate through all sections
for (int i = 0; i < document.getSections().getCount(); i++) {
section = document.getSections().get(i);
// Iterate through paragraphs in reverse order
for (int j = section.getBody().getParagraphs().getCount() - 1; j >= 0; j--) {
// Check if the paragraph is a caption paragraph
if (DetectCaptionParagraph(section.getBody().getParagraphs().get(j))) {
// If it is a caption paragraph, remove it
section.getBody().getParagraphs().removeAt(j);
}
}
}
// Save the document after removing captions
String result = "RemoveCaptions.docx";
document.saveToFile(result, FileFormat.Docx_2016);
// Close and dispose the document object to release resources
document.close();
document.dispose();
}
// Method to detect if a paragraph is a caption paragraph
static Boolean DetectCaptionParagraph(Paragraph paragraph) {
Boolean tag = false;
Field field;
// Iterate through child objects of the paragraph
for (int i = 0; i < paragraph.getChildObjects().getCount(); i++) {
if (paragraph.getChildObjects().get(i).getDocumentObjectType().equals(DocumentObjectType.Field)) {
// Check if the child object is of type Field
field = (Field) paragraph.getChildObjects().get(i);
if (field.getType().equals(FieldType.Field_Sequence)) {
// Check if the Field type is FieldSequence, indicating a caption field
return true;
}
}
}
return tag;
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
OCR (Optical Character Recognition) technology is the primary method to extract text from images. Spire.OCR for Java provides developers with a quick and efficient solution to scan and extract text from images in Java projects. This article will guide you on how to use Spire.OCR for Java to recognize and extract text from images in Java projects.
Obtaining Spire.OCR for Java
To scan and recognize text in images using Spire.OCR for Java, you need to first import the Spire.OCR.jar file along with other relevant dependencies into your Java project.
You can download Spire.OCR for Java from our website. If you are using Maven, you can add the following code to your project's pom.xml file to import the JAR file into your application.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.ocr</artifactId>
<version>2.1.5</version>
</dependency>
</dependencies>
Please download the other dependencies based on your operating system:
Install Dependencies
Step 1: Create a Java project in IntelliJ IDEA.
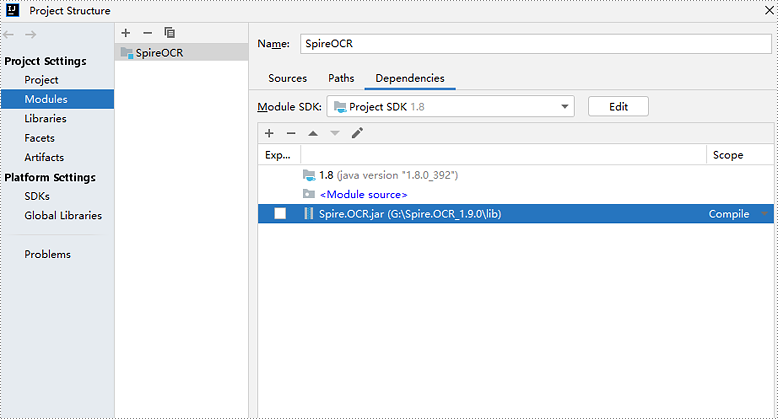
Step 2: Go to File > Project Structure > Modules > Dependencies in the menu and add Spire.OCR.jar as a project dependency.
Step 3: Download and extract the other dependency files. Copy all the files from the extracted "dependencies" folder to your project directory.
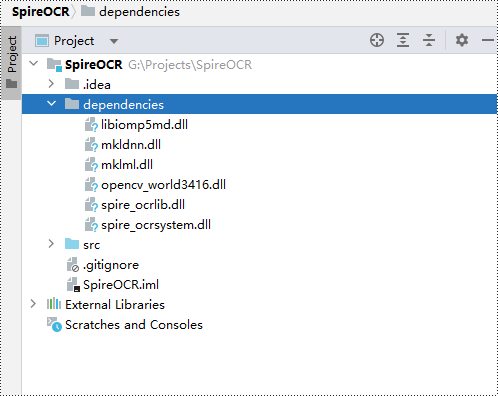
Scanning and Recognizing Text from a Local Image
- Java
import com.spire.ocr.OcrScanner;
import java.io.*;
public class ScanLocalImage {
public static void main(String[] args) throws Exception {
// Specify the path to the dependency files
String dependencies = "dependencies/";
// Specify the path to the image file to be scanned
String imageFile = "data/Sample.png";
// Specify the path to the output file
String outputFile = "ScanLocalImage_out.txt";
// Create an OcrScanner object
OcrScanner scanner = new OcrScanner();
// Set the dependency file path for the OcrScanner object
scanner.setDependencies(dependencies);
// Use the OcrScanner object to scan the specified image file
scanner.scan(imageFile);
// Get the scanned text content
String scannedText = scanner.getText().toString();
// Create an output file object
File output = new File(outputFile);
// If the output file already exists, delete it
if (output.exists()) {
output.delete();
}
// Create a BufferedWriter object to write content to the output file
BufferedWriter writer = new BufferedWriter(new FileWriter(outputFile));
// Write the scanned text content to the output file
writer.write(scannedText);
// Close the BufferedWriter object to release resources
writer.close();
}
}
Specify the Language File to Scan and Recognize Text from an Image
- Java
import com.spire.ocr.OcrScanner;
import java.io.*;
public class ScanImageWithLanguageSelection {
public static void main(String[] args) throws Exception {
// Specify the path to the dependency files
String dependencies = "dependencies/";
// Specify the path to the language file
String languageFile = "data/japandata";
// Specify the path to the image file to be scanned
String imageFile = "data/JapaneseSample.png";
// Specify the path to the output file
String outputFile = "ScanImageWithLanguageSelection_out.txt";
// Create an OcrScanner object
OcrScanner scanner = new OcrScanner();
// Set the dependency file path for the OcrScanner object
scanner.setDependencies(dependencies);
// Load the specified language file
scanner.loadLanguageFile(languageFile);
// Use the OcrScanner object to scan the specified image file
scanner.scan(imageFile);
// Get the scanned text content
String scannedText = scanner.getText().toString();
// Create an output file object
File output = new File(outputFile);
// If the output file already exists, delete it
if (output.exists()) {
output.delete();
}
// Create a BufferedWriter object to write content to the output file
BufferedWriter writer = new BufferedWriter(new FileWriter(outputFile));
// Write the scanned text content to the output file
writer.write(scannedText);
// Close the BufferedWriter object to release resources
writer.close();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
