
Knowledgebase (2344)
Children categories
How to Convert Markdown to HTML in Python: Step-by-Step Guide
2025-09-05 02:05:04 Written by Administrator
Markdown (.md) is widely used in web development, documentation, and technical writing. Its simple syntax makes content easy to write and read. However, web browsers do not render Markdown directly. Converting Markdown to HTML ensures your content is structured, readable, and compatible with web platforms.
In this step-by-step guide, you will learn how to efficiently convert Markdown (.md) files into HTML using Python and Spire.Doc for Python, complete with practical code examples, clear instructions, and best practices for both single-file and batch conversions.
Table of Contents
- What is Markdown
- Why Convert Markdown to HTML
- Introducing Spire.Doc for Python
- Step-by-Step Guide: Converting Markdown to HTML in Python
- Automating Batch Conversion
- Best Practices for Markdown to HTML Conversion
- Conclusion
- FAQs
What is Markdown?
Markdown is a lightweight markup language designed for readability and ease of writing. Unlike HTML, which can be verbose and harder to write by hand, Markdown uses simple syntax to indicate headings, lists, links, images, and more.
Example Markdown:
# This is a Heading
This is a paragraph with \*\*bold text\*\* and \*italic text\*.
- Item 1
- Item 2
Even in its raw form, Markdown is easy to read, which makes it popular for documentation, blogging, README files, and technical writing.
For more on Markdown syntax, see the Markdown Guide.
Why Convert Markdown to HTML?
While Markdown is excellent for authoring content, web browsers cannot render it natively. Converting Markdown to HTML allows you to:
- Publish content on websites – Most CMS platforms require HTML for web pages.
- Enhance styling – HTML supports CSS and JavaScript for advanced formatting and interactivity.
- Maintain compatibility – HTML is universally supported by browsers, ensuring content displays correctly everywhere.
- Integrate with web frameworks – Frameworks like React, Vue, and Angular require HTML as the base for rendering components.
Introducing Spire.Doc for Python
Spire.Doc for Python is a robust library for handling multiple document formats. It supports reading and writing Word documents, Markdown files, and exporting content to HTML. The library allows developers to convert Markdown directly to HTML with minimal code, preserving proper formatting and structure.
In addition to HTML, Spire.Doc for Python also allows you to convert Markdown to Word in Python or convert Markdown to PDF in Python, making it particularly useful for developers who want a unified tool for handling Markdown across different output formats.
Benefits of Using Spire.Doc for Python for Markdown to HTML Conversion
- Easy-to-use API – Simple, intuitive methods that reduce development effort.
- Accurate formatting – Preserves all Markdown elements such as headings, lists, links, and emphasis in HTML.
- No extra dependencies – Eliminates the need for manual parsing or third-party libraries.
- Flexible usage – Supports both single-file conversion and automated batch processing.
Step-by-Step Guide: Converting Markdown to HTML in Python
Now that you understand the purpose and benefits of converting Markdown to HTML, let’s walk through a clear, step-by-step process to transform your Markdown files into structured, web-ready HTML.
Step 1: Install Spire.Doc for Python
First, ensure that Spire.Doc for Python is installed in your environment. You can install it directly from PyPI using pip:
pip install spire.doc
Step 2: Prepare Your Markdown File
Next, create a sample Markdown file that you want to convert. For example, example.md:
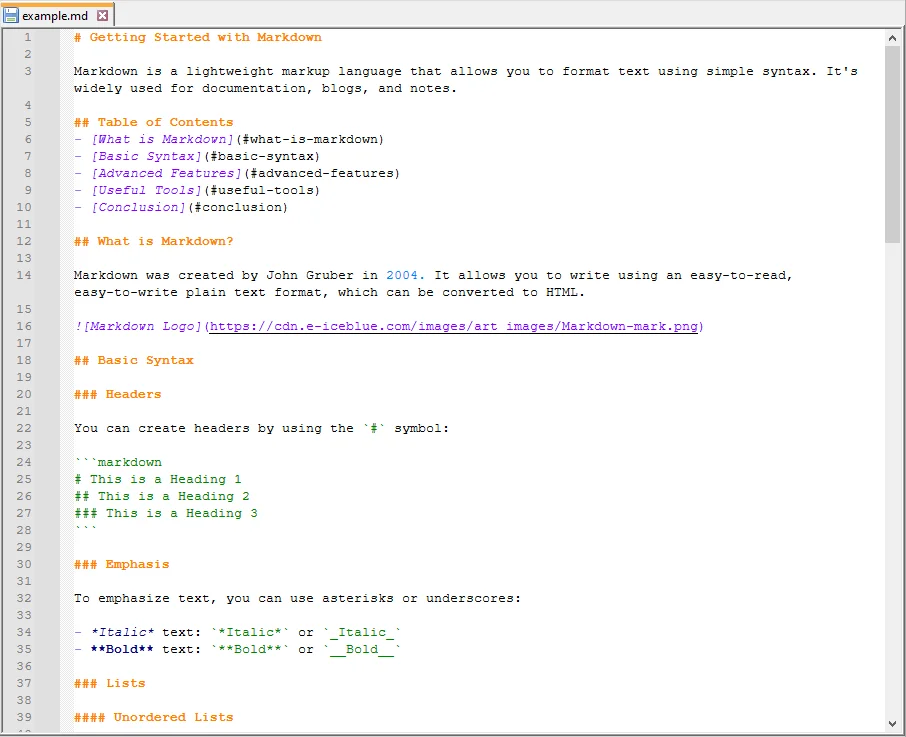
Step 3: Write the Python Script
Now, write a Python script that loads the Markdown file and converts it to HTML:
from spire.doc import *
# Create a Document object
doc = Document()
# Load the Markdown file
doc.LoadFromFile("example.md", FileFormat.Markdown)
# Save the document as HTML
doc.SaveToFile("example.html", FileFormat.Html)
# Close the document
doc.Close()
Explanation of the code:
- Document() initializes a new document object.
- LoadFromFile("example.md", FileFormat.Markdown) loads the Markdown file into memory.
- SaveToFile("example.html", FileFormat.Html) converts the loaded content into HTML and saves it to disk.
- doc.Close() ensures resources are released properly, which is particularly important when processing multiple files or running batch operations.
Step 4: Verify the HTML Output
Finally, open the generated example.html file in a web browser or HTML editor. Verify that the Markdown content has been correctly converted.

Automating Batch Conversion
You can convert multiple Markdown files in a folder automatically:
import os
from spire.doc import *
# Set the folder containing Markdown files
input_folder = "markdown_files"
# Set the folder where HTML files will be saved
output_folder = "html_files"
# Create the output folder if it doesn't exist
os.makedirs(output_folder, exist_ok=True)
# Loop through all files in the input folder
for filename in os.listdir(input_folder):
# Process only Markdown files
if filename.endswith(".md"):
# Create a new Document object for each file
doc = Document()
# Load the Markdown file into the Document object
doc.LoadFromFile(os.path.join(input_folder, filename), FileFormat.Markdown)
# Construct the output file path by replacing .md extension with .html
output_file = os.path.join(output_folder, filename.replace(".md", ".html"))
# Save the loaded Markdown content as HTML
doc.SaveToFile(output_file, FileFormat.Html)
# Close the document to release resources
doc.Close()
This approach allows you to process multiple Markdown files efficiently and generate corresponding HTML files automatically.
Best Practices for Markdown to HTML Conversion
While the basic steps are enough to complete a Markdown-to-HTML conversion, following a few best practices will help you avoid common pitfalls, improve compatibility, and ensure your output is both clean and professional:
- Use proper Markdown syntax – Ensure headings, lists, links, and emphasis are correctly written.
- Use UTF-8 Encoding: Always save your Markdown files in UTF-8 encoding to avoid issues with special characters or non-English text.
- Batch Processing: If you need to convert multiple files, wrap your script in a loop and process entire folders. This saves time and ensures consistent formatting across documents.
- Enhance Styling: Remember that HTML gives you the flexibility to add CSS and JavaScript for custom layouts, responsive design, and interactivity—something not possible in raw Markdown.
Conclusion
Converting Markdown to HTML using Python with Spire.Doc is simple, reliable, and efficient. It preserves formatting, supports automation, and produces clean HTML output ready for web use. By following this guide, you can implement a smooth Markdown to HTML workflow for both single documents and batch operations.
FAQs
Q1: Can I convert multiple Markdown files to HTML in Python?
A1: Yes, you can automate batch conversions by iterating through Markdown files in a directory and applying the conversion logic to each file.
Q2: Will the HTML preserve all Markdown formatting?
A2: Yes, Spire.Doc effectively preserves all essential Markdown formatting, including headings, lists, bold and italic text, links, and more.
Q3: Is there a way to handle images in Markdown during conversion?
A3: Yes, Spire.Doc supports the conversion of images embedded in Markdown, ensuring they are included in the resulting HTML.
Q4: Do I need additional libraries besides Spire.Doc?
A4: No additional libraries are required. Spire.Doc for Python provides a comprehensive solution for converting Markdown to HTML without any external dependencies.
Q5: Can I use the generated HTML in web frameworks?
A5: Yes, the HTML produced is fully compatible with popular web frameworks such as React, Vue, and Angular, making integration seamless.
C# Write to Excel Guide: Insert Data into Worksheets Easily
2025-09-04 09:05:06 Written by Administrator
Excel remains one of the most widely used tools for managing and analyzing data due to its powerful features and user-friendly interface. In C# applications, developers often need to generate reports, export database results, or automate tasks by writing directly to Excel files.
To achieve this efficiently, developers often turn to third-party libraries. Spire.XLS for .NET makes it simple to write to Excel programmatically without relying on Microsoft Excel. With Spire.XLS, you can insert text, numbers, dates, formulas, or even bulk datasets such as arrays, DataTables, and lists into Excel worksheets. This provides a fast, flexible, and reliable way to automate Excel writing in C# applications.
On this page:
- Getting Started with Spire.XLS for .NET
- How to Create a New Excel File in C#
- Write Different Data Types to Excel Cells
- Write Bulk Data to Excel Sheets
- Save and Export Excel Files
- Common Issues and Solutions
- Conclusion
- FAQs
Getting Started with Spire.XLS for .NET
What’s Spire.XLS for .NET
Spire.XLS for .NET is a professional .NET Excel library developed by E-iceblue. It allows developers to write to Excel files in C# and perform a wide range of operations including creating, editing, reading, and exporting Excel documents—without requiring Microsoft Excel to be installed.
Key features include:
- Write and update Excel files programmatically.
- Support for Excel formats (XLS, XLSX, CSV, ODS).
- Advanced features such as formulas, charts, pivot tables, and data validation.
- Export Excel to PDF, HTML, and image formats.
- High performance with large datasets, suitable for desktop, server, and web applications.
How to Install Spire.XLS for .NET
Option 1: Install via NuGet (recommended)
- Open Visual Studio.
- Navigate to Tools > NuGet Package Manager > Manage NuGet Packages for Solution.
- Search for Spire.XLS and install it.
Or, install it directly using the Package Manager Console :
PM> Install-Package Spire.XLS
Option 2: Manual installation
- Download the Spire.XLS package from our official website
- Add a reference to Spire.Xls.dll in your project.
Once installed, you’re ready to start writing to Excel in C#.
How to Create a New Excel File in C#
The first step is to create a new workbook and add a worksheet. Here’s how:
using Spire.Xls;
namespace CreateNewExcel
{
class Program
{
static void Main(string[] args)
{
// Create a new workbook
Workbook workbook = new Workbook();
// Remove default worksheets
workbook.Worksheets.Clear();
// Add a worksheet
Worksheet sheet = workbook.Worksheets.Add("Report");
// Save the empty Excel file
workbook.SaveToFile("NewExcelFile.xlsx", ExcelVersion.Version2016);
workbook.Dispose();
}
}
}
At this point, you have created an empty Excel file with a worksheet named “Report”. Next, let’s write data into it.
Write Different Data Types to Excel Cells in C#
Spire.XLS allows you to write various data types directly to Excel cells. Below are common examples:
Write Text Values
sheet.Range["A1"].Text = "Hello Excel!";
Write Numeric Values
sheet.Range["A2"].NumberValue = 123.45;
Write Date and Time
sheet.Range["A3"].DateTimeValue = DateTime.Now;
sheet.Range["A3"].NumberFormat = "yyyy-mm-dd hh:mm";
Write Boolean Values
sheet.Range["A4"].BooleanValue = true;
Write TimeSpan Values
sheet.Range["A5"].TimeSpanValue = new TimeSpan(2, 30, 0); // 2 hours 30 minutes;
sheet.Range["A5"].NumberFormat = "[h]:mm:ss";
Insert Formulas
sheet.Range["A6"].Formula = "=SUM(A2,100)";
Insert HTML Formatted Strings
string htmlText = "<span style=\"font-family: Times New Roman; color: blue; font-size: 15pt;\">Hello
<strong>Spire.XLS</strong></span>";
sheet.Range["A7"].HtmlString = htmlText;
Write General Values Without Specific Type
sheet.Range["A8"].Value = "General Value";
Output:

You might also be interested in: How to Read Excel Files in C#
Write Bulk Data to Excel Sheets in C#
When dealing with larger datasets, writing values cell by cell isn’t efficient. Spire.XLS provides methods to insert arrays , and DataTables directly. Other data structures can be converted to arrays or DataTables before being written to the Excel sheet.
Write Arrays to Excel
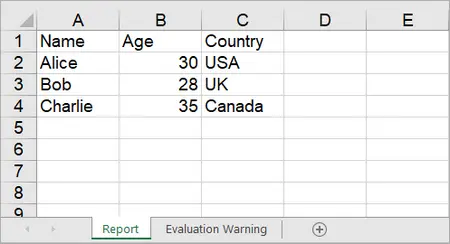
Spire.XLS provides the Worksheet.InsertArray(string[] stringArray, int firstRow, int firstColumn, bool isVertical) method, allowing developers to insert one-dimensional or two-dimensional arrays into a specified range of cells in a worksheet.
string[,] data = {
{ "Name", "Age", "Country" },
{ "Alice", "30", "USA" },
{ "Bob", "28", "UK" },
{ "Charlie", "35", "Canada" }
};
sheet.InsertArray(data, 1, 1);
Output:
Write DataTables to Excel
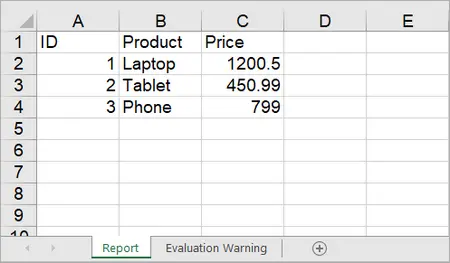
To import data from a DataTable to a worksheet, use the Worksheet.InsertDataTable(DataTable dataTable, bool columnHeaders, int firstRow, int firstColumn, bool transTypes) method.
using System.Data;
DataTable dt = new DataTable();
dt.Columns.Add("ID", typeof(int));
dt.Columns.Add("Product", typeof(string));
dt.Columns.Add("Price", typeof(double));
// Add rows
dt.Rows.Add(1, "Laptop", 1200.5);
dt.Rows.Add(2, "Tablet", 450.99);
dt.Rows.Add(3, "Phone", 799.0);
// Insert DataTable starting at cell A1
sheet.InsertDataTable(dt, true, 1, 1, true);
Output:
On the contrary, you can export data from Excel to DataTable by using the ExportDataTable method of the Worksheet class.
Write Lists to Excel
While Spire.XLS does not provide a direct method for writing lists to Excel, you can convert lists to a DataTable and then use the InsertDataTable method to write the DataTable to Excel.
using Spire.Xls;
using System.Data;
namespace WriteListToExcel
{
class Program
{
static void Main(string[] args)
{
// Create a Workbook instance
Workbook workbook = new Workbook();
// Remove default worksheets
workbook.Worksheets.Clear();
// Add a worksheet and name it
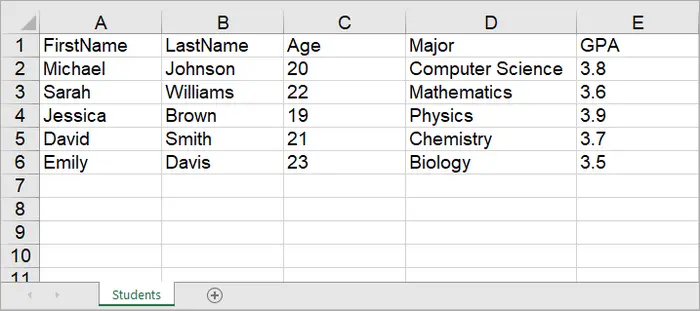
Worksheet worksheet = workbook.Worksheets.Add("Students");
// Create a list with student data
List<Student> students = new List<Student>
{
new Student("Michael", "Johnson", 20, "Computer Science", 3.8),
new Student("Sarah", "Williams", 22, "Mathematics", 3.6),
new Student("Jessica", "Brown", 19, "Physics", 3.9),
new Student("David", "Smith", 21, "Chemistry", 3.7),
new Student("Emily", "Davis", 23, "Biology", 3.5)
};
// Convert the list to DataTable
DataTable dataTable = ConvertListToDataTable(students);
// Write DataTable to the worksheet
worksheet.InsertDataTable(dataTable, true, 1, 1, true);
// Set column width
worksheet.AllocatedRange.ColumnWidth = 12;
// Align content to left
worksheet.AllocatedRange.HorizontalAlignment = HorizontalAlignType.Left;
// Save to an Excel file
workbook.SaveToFile("InsertStudents.xlsx", ExcelVersion.Version2016);
// Dispose resources
workbook.Dispose();
}
static DataTable ConvertListToDataTable(List<Student> students)
{
DataTable dataTable = new DataTable();
// Add columns
dataTable.Columns.Add("FirstName", typeof(string));
dataTable.Columns.Add("LastName", typeof(string));
dataTable.Columns.Add("Age", typeof(int));
dataTable.Columns.Add("Major", typeof(string));
dataTable.Columns.Add("GPA", typeof(double));
// Add rows
foreach (var student in students)
{
DataRow row = dataTable.NewRow();
row["FirstName"] = student.FirstName;
row["LastName"] = student.LastName;
row["Age"] = student.Age;
row["Major"] = student.Major;
row["GPA"] = student.GPA;
dataTable.Rows.Add(row);
}
return dataTable;
}
}
class Student
{
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; }
public string Major { get; set; }
public double GPA { get; set; }
public Student(string firstName, string lastName, int age, string major, double gpa)
{
FirstName = firstName;
LastName = lastName;
Age = age;
Major = major;
GPA = gpa;
}
}
}
Output:
Save and Export Excel Files
After writing data, you’ll want to save or export the Excel file. Spire.XLS supports multiple formats including XLSX, CSV, and PDF .
// Save as XLSX
workbook.SaveToFile("Output.xlsx", ExcelVersion.Version2016);
// Save as CSV
workbook.SaveToFile("Output.csv", ",", Encoding.UTF8);
// Export as PDF
workbook.SaveToFile("Output.pdf", FileFormat.PDF);
For web applications, you can also save to a MemoryStream :
using (MemoryStream ms = new MemoryStream())
{
workbook.SaveToStream(ms, FileFormat.Version2016);
// Write to Response in ASP.NET if needed
}
Common Issues and Solutions
1. Incorrect Date or Time Format
Issue: Dates/times appear as serial numbers.
Solution :
- Apply a proper number format to the cell:
sheet.Range["A1"].DateTimeValue = DateTime.Now;
sheet.Range["A1"].NumberFormat = "yyyy-mm-dd hh:mm";
2. Data Overwriting or Misaligned
Issue : Writing arrays or DataTables overwrites existing data unintentionally.
Solution :
- Check firstRow and firstColumn parameters in InsertArray() or InsertDataTable().
- Use separate worksheets or offset ranges if necessary.
3. Large Dataset Performance Issues
Issue : Writing thousands of rows is slow.
Solution :
- Use bulk writing methods instead of looping cell by cell.
- Apply styles after inserting data to avoid repeated formatting overhead.
4. Formula Not Calculating Correctly
Issue : Excel formulas inserted via sheet.Range["A1"].Formula do not return expected results.
Solution :
- Ensure the formula syntax is correct for Excel (e.g., =SUM(A2:A10)).
- Call workbook.CalculateAllValue() to update all formulas before saving if needed.
Conclusion
Writing to Excel in C# doesn’t have to be complex. With Spire.XLS for .NET , you can seamlessly write different data types—whether individual values or large datasets—into Excel worksheets. The library also provides support for styling, formulas, and advanced formatting, ensuring your Excel files are not only accurate but also presentation-ready.
By using efficient bulk-writing techniques like arrays and DataTables, you can handle both small and large data operations with ease. If your goal is to write to Excel files quickly and reliably , Spire.XLS gives you the tools you need—without the overhead of Microsoft Excel.
FAQs
Q1. Can I write to an existing Excel file with Spire.XLS?
Yes. Use workbook.LoadFromFile("file.xlsx") to open an existing file, then modify and save it.
Q2. Does Spire.XLS require Microsoft Excel to be installed?
No. It’s a standalone library that works without Excel.
Q3. Can Spire.XLS handle large Excel files with thousands of rows?
Yes. It’s optimized for high performance with large datasets.
Q4. How do I format cells while writing data?
You can style cells using properties like font, color, borders, and alignment:
sheet.Range["A1"].Style.Font.IsBold = true;
sheet.Range["A1"].Style.Color = Color.Yellow;
sheet.Range["A1"].Style.HorizontalAlignment = HorizontalAlignType.Left;
Get a Free License
To fully experience the capabilities of Spire.XLS for .NET without any evaluation limitations, you can request a free 30-day trial license.

Creating PDFs in ASP.NET applications is a common requirement, whether you're generating invoices, reports, forms, or exporting dynamic content. To streamline this process, you can utilize Spire.PDF for .NET, a professional and lightweight library that enables developers to easily create and manipulate PDF documents programmatically, without the need for complex APIs or third-party printer drivers.
In this tutorial, we’ll show you how to create PDF documents in an ASP.NET Core Web application using Spire.PDF for .NET, with examples of creating a PDF from scratch and converting HTML to PDF.
On this page:
- Why Use Spire.PDF for .NET?
- Step-by-Step: Generate PDF in ASP.NET Core Web App
- Create PDF from HTML in ASP.NET Core
- Best Practices for ASP.NET PDF Generation
- Conclusion
- FAQs
Why Use Spire.PDF for .NET?
There are many ways to create PDF in ASP.NET, but most involve trade-offs: some depend on printer drivers, others have limited layout control, and many require heavy third-party frameworks. Spire.PDF for .NET offers a more streamlined approach. It’s a dedicated .NET library that handles the majority of PDF creation and manipulation tasks on its own, without external tools.
Key advantages include:
- No Adobe dependency – Generate and manage PDFs without Acrobat installed.
- Full-featured PDF toolkit – Beyond creation, you can edit, merge, split, protect, or annotate PDFs.
- High-fidelity rendering – Preserve fonts, CSS, images, and layouts when exporting content.
- ASP.NET ready – Compatible with both ASP.NET Web Forms/MVC and ASP.NET Core projects.
- Flexible generation options – Create PDFs from scratch, images, or streams.
(Note: HTML-to-PDF conversion requires a lightweight external plugin such as Qt WebEngine.)
Step-by-Step: Generate PDF in ASP.NET Core Web App
Step 1. Create a New ASP.NET Core Web App
- Open Visual Studio .
- Select Create a new project .
- Choose ASP.NET Core Web App (Model-View-Controller) → Click Next .
- Enter a project name, e.g., PdfDemoApp.
- Select your target framework (e.g., . NET 6 , 7 , or 8 ).
- Click Create .
Step 2. Install Spire.PDF via NuGet
- Right-click on your project → Manage NuGet Packages .
- Search for Spire.PDF .
- Install the package Spire.PDF (latest stable version).
Or install using the Package Manager Console :
Install-Package Spire.PDF
Step 3. Add a Controller for PDF Generation
- Right-click on the Controllers folder → Add → Controller → MVC Controller – Empty .
- Name it: PdfController.cs.
- Replace the default code with this:
using Microsoft.AspNetCore.Mvc;
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace PdfDemoApp.Controllers
{
public class PdfController : Controller
{
public IActionResult CreatePdf()
{
// Create a new PDF document
PdfDocument doc = new PdfDocument();
PdfPageBase page = doc.Pages.Add(PdfPageSize.A4, new PdfMargins(40));
// Draw text on the page
PdfFont font = new PdfFont(PdfFontFamily.Helvetica, 25f);
PdfSolidBrush brush = new PdfSolidBrush(Color.Black);
page.Canvas.DrawString("Hello from ASP.NET Core!", font, brush, 10, 50);
// Save to memory stream
using (MemoryStream ms = new MemoryStream())
{
doc.SaveToStream(ms);
doc.Close();
ms.Position = 0;
// Return PDF file
return File(ms.ToArray(), "application/pdf", "Generated.pdf");
}
}
}
}
Step 4: (Optional) Add a Button or Link in Your View
Open Views/Home/Index.cshtml (or whichever view is your homepage).
Add a button or link like this:
<div>
<a asp-controller="Pdf" asp-action="CreatePdf" class="btn btn-primary">
Create PDF from Scratch
</a>
</div>
This uses ASP.NET Core tag helpers to generate the correct route (/Pdf/CreatePdf).
Step 5. Run and Test
- Press F5 to run your app.
- On the home page, click the "Create PDF from Scratch" button. This will call the CreatePdf method in PdfController and trigger a download of the generated PDF.
- If you didn’t add the button, you can still run the CreatePdf method directly by visiting this URL in your browser:
https://localhost:xxxx/Pdf/CreatePdf
(where xxxx is your local port number).
Output:

In addition to text, Spire.PDF supports adding a wide range of elements to PDF, such as images, shapes, tables, lists, hyperlinks, annotations, and watermarks. For more details and advanced usage, check the .NET PDF Tutorials.
Create PDF from HTML in ASP.NET Core
Spire.PDF allows you to convert HTML content directly into PDF files. This feature is particularly useful for generating invoices, reports, receipts, or exporting styled web pages with consistent formatting.
To render HTML as PDF, Spire.PDF relies on an external rendering engine. You can choose between Qt WebEngine or Google Chrome . In this guide, we’ll use Qt WebEngine .
Setup the Qt plugin:
-
Download the Qt WebEngine plugin for your operating system:
-
Extract the package to obtain the plugins directory, e.g.: C:\plugins-windows-x64\plugins
-
Register the plugin path inyour code:
HtmlConverter.PluginPath = @"C:\plugins-windows-x64\plugins";
Once the plugin is ready, you can follow the steps from the previous section and add the code snippet below to your controller to generate PDF output from HTML content.
using Microsoft.AspNetCore.Mvc;
using Spire.Additions.Qt;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace PdfDemoApp.Controllers
{
public class PdfController : Controller
{
[HttpGet]
public IActionResult HtmlToPdf()
{
// Example HTML string
string html = @"
<html>
<head>
<style>
body { font-family: Arial, sans-serif; }
h1 { color: #2563eb; }
</style>
</head>
<body>
<h1>ASP.NET Core: Create PDF from HTML</h1>
<p>This PDF was generated using the Qt-based converter.</p>
</body>
</html>";
// Path to the Qt plugin folder
// ⚠️ Ensure this folder exists on your server/deployment environment
string pluginPath = @"C:\plugins-windows-x64\plugins";
HtmlConverter.PluginPath = pluginPath;
// Create a temp file path (on server side)
string tempFile = Path.GetTempFileName();
// Convert HTML string → PDF using Qt
HtmlConverter.Convert(
html,
tempFile,
enableJavaScript: true,
timeout: 100000, // milliseconds
pageSize: new SizeF(595, 842), // A4 page size in points
margins: new PdfMargins(40), // 40pt margins
LoadHtmlType.SourceCode // Load from HTML string
);
// Read the generated PDF into memory
byte[] fileBytes = System.IO.File.ReadAllBytes(tempFile);
// Clean up temp file
System.IO.File.Delete(tempFile);
// Return PDF to browser as download
return File(fileBytes, "application/pdf", "HtmlToPdf.pdf");
}
}
}
Output:
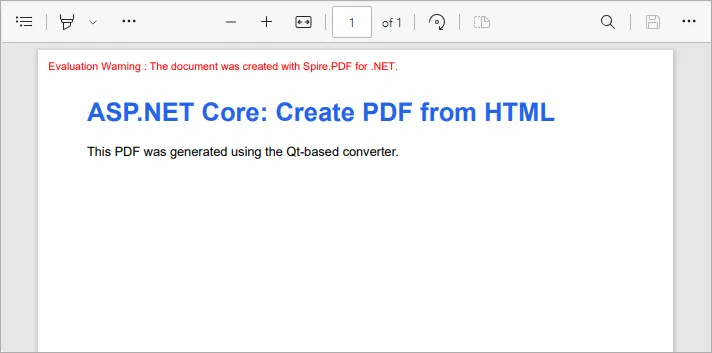
This example converts inline HTML into a properly formatted PDF. You can also load external HTML files or URLs - see our detailed guide on Convert HTML to PDF in C# for more information.
Best Practices for ASP.NET PDF Generation
- Use memory streams instead of disk storage for performance and scalability.
- Cache static PDFs (like terms & conditions or forms) to reduce server load.
- Use HTML-to-PDF for dynamic reports with CSS styling.
- Consider templates (like Word-to-PDF with Spire.Doc) when documents have complex layouts.
- Secure sensitive PDFs with password protection or access permissions.
Conclusion
With Spire.PDF for .NET, you can easily generate PDF in ASP.NET Core applications. Whether you’re creating PDFs from scratch or performing HTML-to-PDF conversion in C# , Spire.PDF provides a reliable, developer-friendly solution—no external dependencies required.
If you also need to generate PDFs from Word documents, that feature is available via Spire.Doc for .NET, another product in the Spire family. Together, they cover the full range of PDF document generation scenarios.
By integrating these tools, developers can streamline workflows, reduce reliance on Adobe or other third-party components, and ensure consistent, professional-quality output. This makes your ASP.NET PDF solutions more scalable, maintainable, and ready for enterprise use.
FAQs
Q1. Do I need Adobe Acrobat installed on the server?
No. Spire.PDF is a standalone library and works independently of Adobe Acrobat.
Q2. Can I generate PDFs from both raw content and HTML?
Yes. You can build documents programmatically (drawing text, shapes, tables) or convert HTML pages to PDF.
Q3. Can I convert Word documents to PDF with Spire.PDF?
No. Word-to-PDF is supported by Spire.Doc for .NET, not Spire.PDF. You can use them together if your project requires it.
Q4. How can I protect generated PDFs?
Spire.PDF supports setting passwords, permissions, and digital signatures for document security.
Q5. Does Spire.PDF support ASP.NET Framework?
Yes. It works with both ASP.NET Core and ASP.NET Framework.
Get a Free License
To fully experience the capabilities of Spire.PDF for .NET without any evaluation limitations, you can request a free 30-day trial license.
