
Knowledgebase (2344)
Children categories
Convert Markdown to HTML in C# .NET (Strings, Files & Batch)
2025-09-11 06:35:13 Written by zaki zou
Markdown (md) is a widely adopted lightweight markup language known for its simplicity and readability. Developers, technical writers, and content creators often use it for documentation, README files, blogs, and technical notes. While Markdown is easy to write and read in its raw form, displaying it on websites or integrating it into web applications requires HTML. Converting Markdown to HTML is therefore a fundamental task for developers working with content management systems, documentation pipelines, or web-based applications.
In this tutorial, you will learn how to convert Markdown to HTML in C#. The guide covers converting both Markdown strings and files to HTML, as well as batch processing multiple Markdown documents efficiently. By the end, you’ll have practical, ready-to-use examples that you can apply directly to real-world projects.
Table of Contents
- Understanding Markdown and HTML: Key Differences and Use Cases
- C# Library for Markdown to HTML Conversion
- Convert a Markdown String to HTML in C# (Step-by-Step)
- Convert a Single Markdown File to HTML in C# (Step-by-Step)
- Batch Convert Multiple Markdown Files to HTML in C#
- Additional Tips for Efficient Markdown to HTML Conversion in C#
- Conclusion
- FAQs
Understanding Markdown and HTML: Key Differences and Use Cases
What is Markdown?
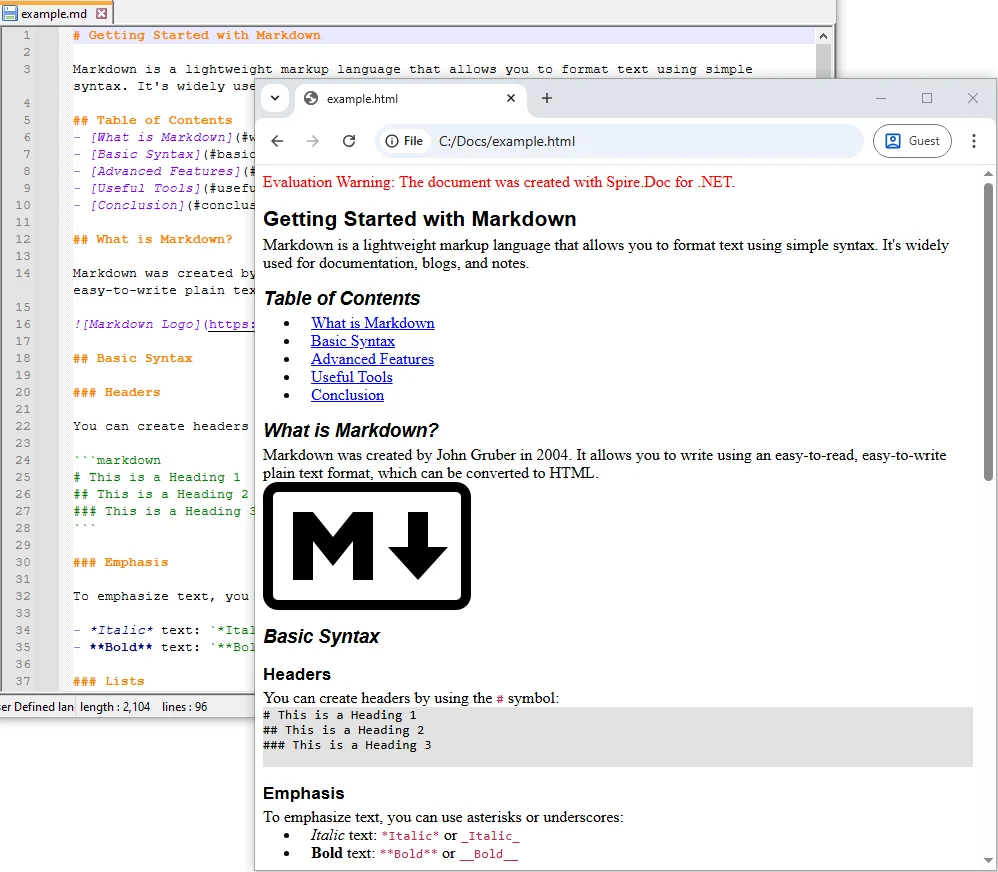
Markdown is a lightweight markup language that allows developers and writers to create structured documents using plain text. It uses straightforward syntax for headings, lists, links, images, code blocks, and more. Its readability in raw form makes it ideal for writing documentation, README files, technical blogs, and collaborative notes.
Example Markdown:
# Project Title
This is a **bold** statement.
- Feature 1
- Feature 2
What is HTML?
HTML (HyperText Markup Language) is the foundational language of the web. Unlike Markdown, HTML provides precise control over document structure, formatting, multimedia embedding, and web interactivity. While Markdown focuses on simplicity, HTML is indispensable for web pages and application content.
Example HTML Output:
<h1>Project Title</h1>
<p>This is a <strong>bold</strong> statement.</p>
<ul>
<li>Feature 1</li>
<li>Feature 2</li>
</ul>
Key Differences and Use Cases
| Feature | Markdown | HTML |
|---|---|---|
| Complexity | Simple, minimal syntax | More detailed, verbose |
| Readability | Readable in raw form | Harder to read directly |
| Use Cases | Documentation, readmes, blogs | Websites, web apps, emails |
Use Case Tip: Use Markdown for author-friendly writing, then convert it to HTML for web display, automated documentation pipelines, or content management systems.
C# Library for Markdown to HTML Conversion
For C# developers, one of the most practical libraries for Markdown-to-HTML conversion is Spire.Doc for .NET. This library offers robust document processing capabilities, supporting not only loading Markdown files and converting content to HTML, but also extending to other formats, such as Markdown to Word and PDF. With this flexibility, developers can easily choose the output format that best fits their project needs.
Key Features
- Load Markdown files and convert to HTML
- Preserve headings, lists, links, images, and other Markdown formatting in HTML output
- Batch process multiple Markdown documents efficiently
- Integrate seamlessly with .NET applications without requiring Microsoft Office
- Compatible with .NET Framework and .NET Core
Installation
You can easily add the required library to your C# project in two ways:
- Using NuGet (Recommended)
Run the following command in your Package Manager Console:
This method ensures that the library and its dependencies are automatically downloaded and integrated into your project.Install-Package Spire.Doc - Manual Installation
Alternatively, you can download the library DLL and manually add it as a reference in your project. This approach is useful if you need offline installation or prefer direct control over the library files.
Tip: Using NuGet is generally recommended for faster setup and easier version management.
Convert a Markdown String to HTML in C# (Step-by-Step)
In many applications, Markdown content may be generated dynamically or stored in a database as a string. This section demonstrates how you can convert a Markdown string into a fully formatted HTML file using C#.
Steps to Convert a Markdown String to HTML
- Prepare the Markdown string that you want to convert.
- Save the Markdown string to a .md file with WriteAllText.
- Load the Markdown file into a Document object using LoadFromFile with FileFormat.Markdown.
- Save the document as an HTML file using SaveToFile with FileFormat.Html.
Example Code
using Spire.Doc;
using System;
using System.IO;
namespace MarkdownToHtml
{
internal class Program
{
static void Main(string[] args)
{
// Define the markdown string
string markdown = @"
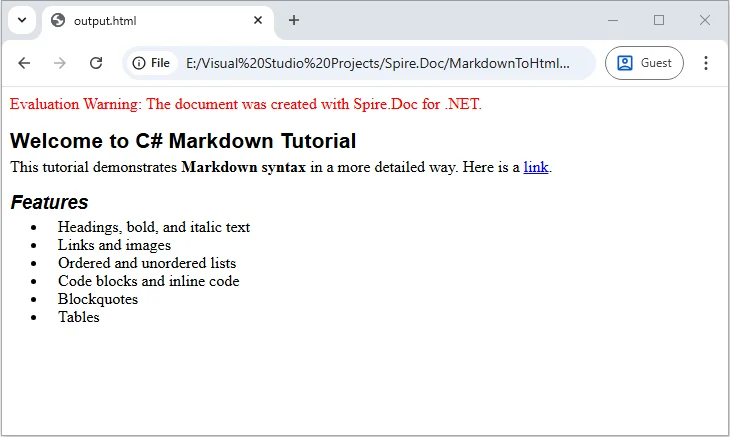
# Welcome to C# Markdown Tutorial
This tutorial demonstrates **Markdown syntax** in a more detailed way.
Here is a [link](https://example.com).
## Features
- Headings, bold, and italic text
- Links and images
- Ordered and unordered lists
- Code blocks and inline code
- Blockquotes
- Tables
";
// Define the file paths
string markdownFilePath = "example.md"; // Path to save the Markdown file
string outputHtmlPath = "output.html"; // Path to save the converted HTML file
// Create a Markdown file from the markdown string
File.WriteAllText(markdownFilePath, markdown);
// Load the Markdown file
Document document = new Document();
document.LoadFromFile(markdownFilePath, FileFormat.Markdown);
// Save as HTML
document.SaveToFile(outputHtmlPath, FileFormat.Html);
// Close the document
document.Close();
Console.WriteLine($"Markdown string converted to HTML at: {outputHtmlPath}");
}
}
}
Convert a Single Markdown File to HTML in C# (Step-by-Step)
If you have a Markdown file ready, converting it to HTML for web pages or email templates is straightforward. With Spire.Doc, you can load your Markdown file and export it as a fully formatted HTML document, preserving all styling, including headings, lists, links, images, and other formatting elements.
Steps to Convert a Markdown File to HTML
- Prepare the Markdown file you want to convert.
- Load the file into a Document object using LoadFromFile with the FileFormat.Markdown parameter.
- Save the loaded document as HTML using SaveToFile with FileFormat.Html.
Example Code
using Spire.Doc;
using System;
namespace MarkdownToHtml
{
internal class Program
{
static void Main(string[] args)
{
// Path to the Markdown file
string markdownFile = @"C:\Docs\example.md";
// Path to save the converted HTML file
string htmlFile = @"C:\Docs\example.html";
// Load the Markdown file
Document document = new Document();
document.LoadFromFile(markdownFile, FileFormat.Markdown);
// Save as HTML file
document.SaveToFile(htmlFile, FileFormat.Html);
// Close the document
document.Close();
Console.WriteLine($"Converted '{markdownFile}' to HTML successfully!");
}
}
}
Batch Convert Multiple Markdown Files to HTML in C#
If you have a collection of Markdown files that need to be converted at once, you can use the following C# example to batch process and convert them into HTML.
Example Code
using Spire.Doc;
using System;
using System.IO;
namespace MarkdownToHtml
{
internal class Program
{
static void Main(string[] args)
{
// Define the input folder containing Markdown files
string inputFolder = @"C:\Docs\MarkdownFiles";
// Define the output folder where converted HTML files will be saved
string outputFolder = @"C:\Docs\HtmlFiles";
// Create the output folder if it does not already exist
Directory.CreateDirectory(outputFolder);
// Loop through all Markdown (.md) files in the input folder
foreach (string file in Directory.GetFiles(inputFolder, "*.md"))
{
// Load the Markdown file into a Document object
Document doc = new Document();
doc.LoadFromFile(file, FileFormat.Markdown);
// Get the file name without extension
string fileName = Path.GetFileNameWithoutExtension(file);
// Build the output path with .html extension
string outputPath = Path.Combine(outputFolder, fileName + ".html");
// Save the document as an HTML file
doc.SaveToFile(outputPath, FileFormat.Html);
// Print a confirmation message for each converted file
Console.WriteLine($"Converted {file} to HTML.");
}
// Print a final message when batch conversion is complete
Console.WriteLine("Batch conversion complete.");
}
}
}
Additional Tips for Efficient Markdown to HTML Conversion in C#
Converting Markdown to HTML is straightforward, but applying a few practical strategies can help handle advanced scenarios, improve performance, and ensure your HTML output is clean and consistent. Here are some key tips to enhance your conversion workflow:
-
Implement Error Handling When processing multiple files, wrap your conversion logic in try-catch blocks to handle invalid Markdown, missing files, or access permission issues. This ensures your batch conversion won’t fail entirely due to a single problematic file.
try { Document doc = new Document(); doc.LoadFromFile(filePath, FileFormat.Markdown); doc.SaveToFile(outputPath, FileFormat.Html); } catch (Exception ex) { Console.WriteLine($"Failed to convert {filePath}: {ex.Message}"); } -
Optimize Batch Conversion Performance
For large numbers of Markdown files, consider using asynchronous or parallel processing. This reduces conversion time and avoids high memory usage:Parallel.ForEach(Directory.GetFiles(inputFolder, "*.md"), file => { // Conversion logic }); -
Post-Process HTML Output
After conversion, you can enhance the HTML by injecting CSS styles, adding custom attributes, or minifying the output. This is especially useful when integrating HTML into web pages or applications.string htmlContent = File.ReadAllText(outputPath); htmlContent = "<link rel='stylesheet' href='https://cdn.e-iceblue.com/style.css'>" + htmlContent; File.WriteAllText(outputPath, htmlContent); -
Maintain UTF-8 Encoding
Always save Markdown and HTML files with UTF-8 encoding to preserve special characters, symbols, and multilingual content, ensuring consistent rendering across browsers and devices.
Conclusion
In this tutorial, you learned how to convert Markdown to HTML in C#, covering single Markdown strings, individual files, and batch processing multiple documents.
These examples provide a solid foundation for integrating Markdown to HTML conversion into various .NET applications, including documentation systems, blogs, and other content-driven projects. By applying these methods, you can efficiently manage Markdown content and produce consistent, well-structured HTML output.
FAQs
Q1: Can I convert Markdown with images and links using Spire.Doc in C#?
A1: Yes. The library allows you to convert Markdown files that include images, hyperlinks, headings, lists, and code blocks into fully formatted HTML. This ensures the output closely matches your source content.
Q2: Do I need Microsoft Office installed to convert Markdown to HTML in C#?
A2: No. Spire.Doc is a standalone library for .NET, so you can convert Markdown to HTML in C# without Microsoft Office, making it easy to integrate into both desktop and web applications.
Q3: How can I batch convert multiple Markdown files to HTML in C# efficiently?
A3: You can loop through all Markdown files in a folder and convert them using Spire.Doc’s Document.LoadFromFile and SaveToFile methods. This approach allows batch conversion of Markdown documents to HTML in .NET quickly and reliably.
Q4: Can I convert Markdown to HTML dynamically in an ASP.NET application using C#?
A4: Yes. You can dynamically convert Markdown content stored as strings or files to HTML in ASP.NET using Spire.Doc, which is useful for web apps, blogs, or CMS platforms.
Q5: Is Spire.Doc compatible with .NET Core and .NET 6 for Markdown to HTML conversion?
A5: Yes. It supports .NET Framework, .NET Core, .NET 5, and .NET 6+, making it ideal for modern C# projects that require Markdown to HTML conversion.
Q6: Can I customize the HTML output after converting Markdown in C#?
A6: Yes. After conversion, you can add CSS, modify HTML tags, or inject styles programmatically in C# to match your website or application’s design requirements.
Q7: Can Spire.Doc convert other document formats besides Markdown?
A7: Yes. It can convert a wide range of formats, such as Word to PDF or Word to HTML, giving you flexibility to manage different document types in C# projects.
Q8: How do I preserve special characters and encoding when converting Markdown to HTML in C#?
A8: Always save your Markdown files with UTF-8 encoding to ensure special characters, symbols, and multilingual content are preserved during Markdown to HTML conversion.
.NET PDF to JPG Converter: Convert PDF Pages to Images in C#
2025-09-10 03:20:19 Written by Administrator
Working with PDF documents is a common requirement in modern applications. Whether you are building a document management system , an ASP.NET web service , or a desktop viewer application , there are times when you need to display a PDF page as an image. Instead of embedding the full PDF viewer, you can convert PDF pages to JPG images and use them wherever images are supported.
In this guide, we will walk through a step-by-step tutorial on how to convert PDF files to JPG images using Spire.PDF for .NET. We’ll cover the basics of converting a single page, handling multiple pages, adjusting resolution and quality, saving images to streams, and even batch converting entire folders of PDFs.
By the end, you’ll have a clear understanding of how to implement PDF-to-image conversion in your .NET projects.
Table of Contents:
- Install .NET PDF-to-JPG Converter Library
- Core Method: SaveAsImage
- Steps to Convert PDF to JPG in C# .NET
- Convert a Single Page to JPG
- Convert Multiple Pages (All or Range)
- Advanced Conversion Options
- Troubleshooting & Best Practices
- Conclusion
- FAQs
Install .NET PDF-to-JPG Converter Library
To perform the conversion, we’ll use Spire.PDF for .NET , a library designed for developers who need full control over PDFs in C#. It supports reading, editing, and converting PDFs without requiring Adobe Acrobat or any third-party dependencies.
Installation via NuGet
You can install Spire.PDF directly into your project using NuGet Package Manager Console:
Install-Package Spire.PDF
Alternatively, open NuGet Package Manager in Visual Studio, search for Spire.PDF , and click Install.
Licensing Note
Spire.PDF offers a free version with limitations, allowing conversion of only the first few pages. For production use, a commercial license unlocks the full feature set.
Core Method: SaveAsImage
The heart of PDF-to-image conversion in Spire.PDF lies in the SaveAsImage() method provided by the PdfDocument class.
Here’s what you need to know:
-
Syntax (overload 1):
-
Image SaveAsImage(int pageIndex, PdfImageType imageType);
- pageIndex: The zero-based index of the PDF page you want to convert.
- imageType: The type of image to generate, typically PdfImageType.Bitmap.
-
Syntax (overload 2 with resolution):
-
Image SaveAsImage(int pageIndex, PdfImageType imageType, int dpiX, int dpiY);
- dpiX, dpiY: Horizontal and vertical resolution (dots per inch).
Higher DPI = better quality but larger file size.
Supported PdfImageType Values
- Bitmap → returns a raw image.
- Metafile → returns a vector image (less common for JPG export).
Most developers use Bitmap when exporting to JPG.
Steps to Convert PDF to JPG in C# .NET
- Import the Spire.Pdf and System.Drawing namespaces.
- Create a new PdfDocument instance.
- Load the PDF file from the specified path.
- Use SaveAsImage() to convert one or more pages into images.
- Save the generated image(s) in JPG format.
Convert a Single Page to JPG
Here’s a simple workflow to convert a single PDF page to a JPG image:
using Spire.Pdf.Graphics;
using Spire.Pdf;
using System.Drawing.Imaging;
using System.Drawing;
namespace ConvertSpecificPageToPng
{
class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a sample PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\sample.pdf");
// Convert a specific page to a bitmap image
Image image = doc.SaveAsImage(0, PdfImageType.Bitmap);
// Save the image as a JPG file
image.Save("ToJPG.jpg", ImageFormat.Jpeg);
// Disposes resources
doc.Dispose();
}
}
}
Output:
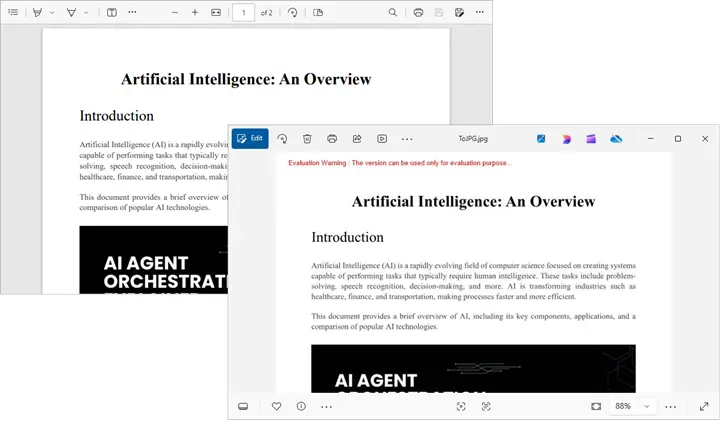
Spire.PDF supports converting PDF to various other image formats like PNG, BMP, SVG, and TIFF. For more details, refer to the documentation: Convert PDF to Image in C#.
Convert Multiple Pages (All or Range)
Convert All Pages
The following loop iterates over all pages, converts each one into an image, and saves it to disk with page numbers in the filename.
for (int i = 0; i < doc.Pages.Count; i++)
{
Image image = doc.SaveAsImage(i, PdfImageType.Bitmap);
string fileName = string.Format("Output\\ToJPG-{0}.jpg", i);
image.Save(fileName, ImageFormat.Jpeg);
}
Convert a Range of Pages
To convert a specific range of pages (e.g., pages 2 to 4), modify the for loop as follows:
for (int i = 1; i <= 3; i++)
{
Image image = doc.SaveAsImage(i, PdfImageType.Bitmap);
string fileName = string.Format("Output\\ToJPG-{0}.jpg", i);
image.Save(fileName, ImageFormat.Jpeg);
}
Advanced Conversion Options
Set Image Resolution/Quality
By default, the output resolution might be too low for printing or detailed analysis. You can set DPI explicitly:
Image image = doc.SaveAsImage(0, PdfImageType.Bitmap, 300, 300);
image.Save("ToJPG.jpg", ImageFormat.Jpeg);
Tips:
- 72 DPI : Default, screen quality.
- 150 DPI : Good for previews and web.
- 300 DPI : High quality, suitable for printing.
Higher DPI results in sharper images but also increases memory and file size.
Save the Converted Images as Stream
Instead of writing directly to disk, you can store the output in memory streams. This is useful in:
- ASP.NET applications returning images to browsers.
- Web APIs sending images as HTTP responses.
- Database storage for binary blobs.
using (MemoryStream ms = new MemoryStream())
{
pdf.SaveAsImage(0, PdfImageType.Bitmap, 300, 300).Save(ms, ImageFormat.Jpeg);
byte[] imageBytes = ms.ToArray();
}
Here, the JPG image is stored as a byte array , ready for further processing.
Batch Conversion (Multiple PDFs)
In scenarios where you need to process multiple PDF documents at once, you can apply batch conversion as shown below:
string[] files = Directory.GetFiles("InputPDFs", "*.pdf");
foreach (string file in files)
{
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(file);
for (int i = 0; i < doc.Pages.Count; i++)
{
Image image = doc.SaveAsImage(i, PdfImageType.Bitmap);
string fileName = Path.GetFileNameWithoutExtension(file);
image.Save($"Output\\{fileName}-Page{i + 1}.jpg", ImageFormat.Jpeg);
}
doc.Dispose();
}
Troubleshooting & Best Practices
Working with PDF-to-image conversion in .NET can come with challenges. Here’s how to address them:
- Large PDFs consume memory
- Use lower DPI (e.g., 150 instead of 300).
- Process in chunks rather than loading everything at once.
- Images are blurry or low quality
- Increase DPI.
- Consider using PNG instead of JPG for sharp diagrams or text.
- File paths cause errors
- Always check that the output directory exists.
- Use Path.Combine() for cross-platform paths.
- Handling password-protected PDFs
- Provide the password when loading:
doc.LoadFromFile("secure.pdf", "password123");
- Dispose objects
- Always call Dispose() on PdfDocument and Image objects to release memory.
Conclusion
Converting PDF to JPG in .NET is straightforward with Spire.PDF for .NET . The library provides the SaveAsImage() method, allowing you to convert a single page or an entire document with just a few lines of code. With options for custom resolution, stream handling, and batch conversion , you can adapt the workflow to desktop apps, web services, or cloud platforms.
By following best practices like managing memory and adjusting resolution, you can ensure efficient, high-quality output that fits your project’s requirements.
If you’re exploring more advanced document processing, Spire also offers libraries for Word, Excel, and PowerPoint, enabling a complete .NET document solution.
FAQs
Q1. Can I convert PDFs to formats other than JPG?
Yes. Spire.PDF supports PNG, BMP, SVG, and other common formats.
Q2. What DPI should I use?
- 72 DPI for thumbnails.
- 150 DPI for web previews.
- 300 DPI for print quality.
Q3. Does Spire.PDF support encrypted PDFs?
Yes, but you need to provide the correct password when loading the file.
Q4. Can I integrate this in ASP.NET?
Yes. You can save images to memory streams and return them as HTTP responses.
Q5. Can I convert images back to PDF?
Yes. You can load JPG, PNG, or BMP files and insert them into PDF pages, effectively converting images back into a PDF.
Get a Free License
To fully experience the capabilities of Spire.PDF for .NET without any evaluation limitations, you can request a free 30-day trial license.
Converting HTML to RTF in C# is a key task for developers working with web content that needs to be transformed into editable, universally compatible documents. HTML excels at web display with dynamic styles and structure, while RTF is ideal for shareable, editable files in tools like Word or WordPad.
For .NET developers, using libraries like Spire.Doc can streamline the process. In this tutorial, we'll explore how to use C# to convert HTML to RTF, covering everything from basic implementations to advanced scenarios such as handling HTML images, batch conversion.
- Why Use Spire.Doc for HTML to RTF Conversion?
- Getting Started
- Convert HTML to RTF (C# Code Examples)
- Advanced Conversion Scenarios
- Final Thoughts
- Common Questions
Why Use Spire.Doc for HTML to RTF Conversion?
Spire.Doc for .NET is a lightweight, feature-rich library for creating, editing, and converting Word and RTF documents in .NET applications (supports .NET Framework, .NET Core, and .NET 5+). For HTML to rich text conversion, it offers key benefits:
- Preserves HTML formatting (fonts, colors, links, lists, tables).
- Supports loading HTML from strings or local files.
- No dependency on Microsoft Word or other third-party software.
- Intuitive API with minimal code required.
Getting Started
1. Create a C# Project
If you’re starting from scratch, create a new Console App (.NET Framework/.NET Core) project in Visual Studio. This example uses a console app for simplicity, but the code works in WinForms, WPF, or ASP.NET projects too.
2. Install Spire.Doc via NuGet
The fastest way to add Spire.Doc to your C# project is through NuGet Package Manager:
- Open your C# project in Visual Studio.
- Right-click the project in the Solution Explorer → Select Manage NuGet Packages.
- Search for Spire.Doc and click Install to add the latest version to your project.
Alternatively, use the NuGet Package Manager Console with this command:
Install-Package Spire.Doc
Convert HTML to RTF (C# Code Examples)
Spire.Doc’s Document class handles HTML loading and RTF saving. Below are two common scenarios:
Scenario 1: Convert HTML String to RTF in C#
Use this when HTML content is dynamic (e.g., from user input, APIs, or databases).
using Spire.Doc;
using Spire.Doc.Documents;
namespace HtmlToRtfConverter
{
class Program
{
static void Main(string[] args)
{
// Create a Document object
Document doc = new Document();
// Define your HTML content
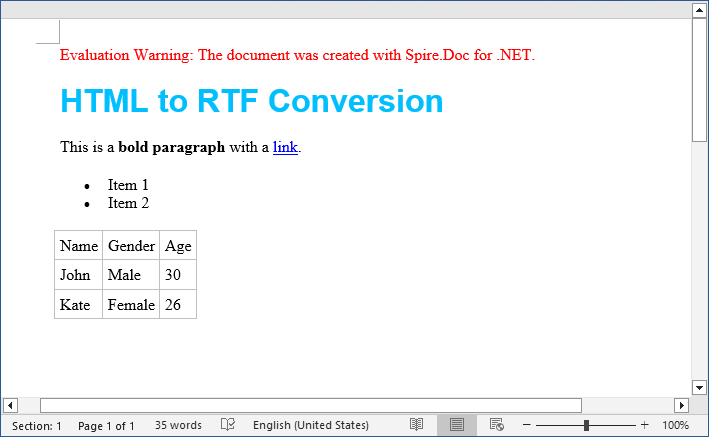
string htmlString = @"
<html>
<body>
<h1 style='color: #00BFFF; font-family: Arial'>HTML to RTF Conversion</h1>
<p>This is a <b>bold paragraph</b> with a <a href='https://www.e-iceblue.com'>link</a>.</p>
<ul>
<li>Item 1 </li>
<li>Item 2</li>
</ul>
<table border='1' cellpadding='5'>
<tr><td>Name</td><td>Gender</td><td>Age</td></tr>
<tr><td>John</td><td>Male</td><td>30</td></tr>
<tr><td>Kate</td><td>Female</td><td>26</td></tr>
</table>
</body>
</html>";
// Add a paragraph in Word
Paragraph para = doc.AddSection().AddParagraph();
// Append the HTML string to the paragraph
para.AppendHTML(htmlString);
// Save the document as RTF
doc.SaveToFile("HtmlStringToRtf.rtf", FileFormat.Rtf);
doc.Dispose();
}
}
}
In this code:
- Document Object: Represents an empty document.
- HTML String: You can customize this to include any valid HTML (styles, media, or dynamic content from databases/APIs).
- AppendHTML(): Parses HTML tags (e.g.,
<h1>,<table>,<a>) and inserts them into a paragraph. - SaveToFile(): Writes the converted content to an RTF file.
Output:
The SaveToFile method accepts different FileFormat parameters. You can change it to implement HTML to Word conversion in C#.
Scenario 2: Convert HTML File to RTF File
For static HTML files (e.g., templates or saved web pages), use LoadFromFile with parameter FileFormat.Html:
using Spire.Doc;
namespace ConvertHtmlToRTF
{
class Program
{
static void Main()
{
// Create a Document object
Document doc = new Document();
// Load an HTML file
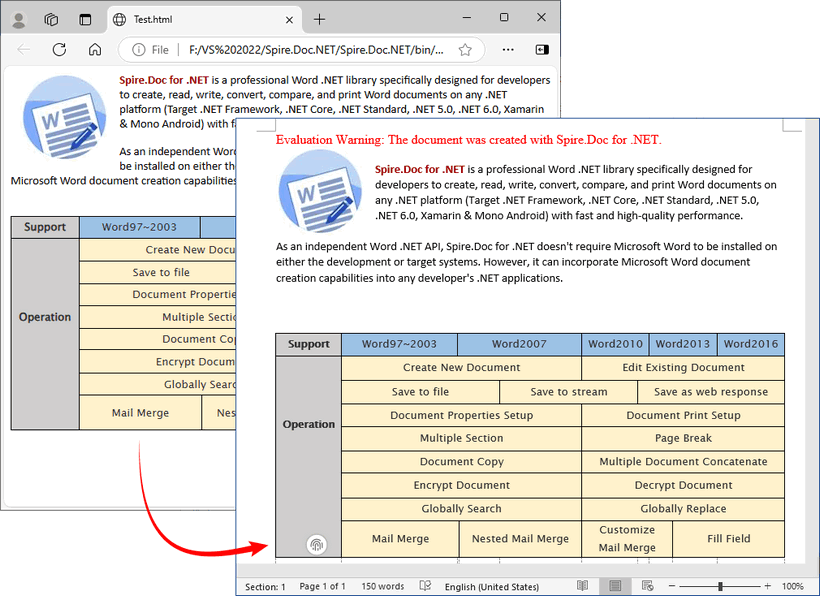
doc.LoadFromFile("Test.html", FileFormat.Html);
// Save the HTML file as rtf format
doc.SaveToFile("HTMLtoRTF.rtf", FileFormat.Rtf);
doc.Dispose();
}
}
}
This code simplifies HTML-to-RTF conversion into three core steps:
- Creates a Document object.
- Loads an existing HTML file using LoadFromFile() with the FileFormat.Html parameter.
- Saves the loaded HTML as an RTF format using SaveToFile() with the FileFormat.Rtf parameter.
Output:
Spire.Doc supports bidirectional conversion, so you can convert the RTF file back to HTML in C# when needed.
Advanced Conversion Scenarios
1. Handling Images in HTML
Spire.Doc preserves images embedded in HTML (via <img> tags). For local images, ensure the src path is correct. For remote images (URLs), Spire.Doc automatically downloads and embeds them.
// HTML with local and remote images
string htmlWithImages = @"<html>
<body>
<h3>HTML with Images</h3>
<p>Local image: <img src='https://cdn.e-iceblue.com/C:\Users\Administrator\Desktop\HelloWorld.png' alt='Sample Image' width='200'></p>
<p>Remote image: <img src='https://www.e-iceblue.com/images/art_images/csharp-html-to-rtf.png' alt='Online Image'></p>
</body>
</html>";
// Append the HTML string to a paragraph
Paragraph para = doc.AddSection().AddParagraph();
para.AppendHTML(htmlWithImages);
// Save the document as RTF
doc.SaveToFile("HtmlWithImage.rtf", FileFormat.Rtf);
2. Batch Conversion of Multiple HTML Files
Process an entire directory of HTML files with a loop:
string inputDir = @"C:\Input\HtmlFiles";
string outputDir = @"C:\Output\RtfFiles";
// Create output directory if it doesn't exist
Directory.CreateDirectory(outputDir);
// Get all .html files in input directory
foreach (string htmlFile in Directory.EnumerateFiles(inputDir, "*.html"))
{
using (Document doc = new Document())
{
doc.LoadFromFile(htmlFile, FileFormat.Html, XHTMLValidationType.None);
// Use the same filename but with .rtf extension
string fileName = Path.GetFileNameWithoutExtension(htmlFile) + ".rtf";
string outputPath = Path.Combine(outputDir, fileName);
doc.SaveToFile(outputPath, FileFormat.Rtf);
Final Thoughts
Converting HTML to RTF in C# is straightforward with Spire.Doc for .NET. This library eliminates the need for manual parsing and ensures consistent formatting across outputs. Whether you’re working with HTML strings or files, this article provides practical code examples to handle both scenarios.
For further exploration, refer to the Spire.Doc documentation.
Common Questions
Q1: Is Spire.Doc free to use?
A: For large-scale projects, you can request a free 30-day trial license to fully evaluate it. Alternatively, Spire.Doc offers a free community edition without any watermarks (but with certain page/functionality limits).
Q2: Does Spire.Doc preserve HTML hyperlinks, images, and tables in the RTF output?
A: Yes. Spire.Doc retains most HTML elements:
- Hyperlinks:
<a>tags are converted to clickable links in RTF. - Images: Local (
<img src="/path">) and remote (<img src="/URL">) images are embedded in the RTF. - Tables: HTML tables (with border, cellpadding, etc.) are converted to RTF tables with preserved structure.
Q3: Can I style the RTF output further after loading the HTML?
A: Absolutely. After loading the HTML content into the Document object, you can use the full Spire.Doc API to programmatically modify the document before saving it as RTF.
Q4: Can I convert HTML to other formats with Spire.Doc?
A: Yes. Apart from converting to RTF, the library also supports converting HTML to Word, HTML to XML, and HTML to images, etc.
