Comment supprimer des images d'un PDF (Un guide complet pour 2026)

Parfois, un PDF qui semble parfait devient difficile à partager en raison de grandes images intégrées. Vous pourriez rencontrer des limites de taille de pièces jointes d'e-mail, des téléchargements lents ou un gonflement inutile du fichier lorsque vous travaillez avec des rapports ou des documents numérisés. Dans ces cas, savoir comment supprimer des images des documents PDF peut vous aider à réduire rapidement la taille du fichier et à simplifier le contenu.
Dans ce guide, nous vous présenterons des moyens pratiques de supprimer des images de fichiers PDF, des outils manuels aux solutions Python automatisées.
- Supprimer des images des fichiers PDF avec Adobe Acrobat
- Supprimer des images des PDF avec des outils PDF en ligne
- Supprimer automatiquement toutes les images d'un PDF avec Python
- Dépannage et FAQ
- Conclusion
Méthode 1 : Supprimer des images des fichiers PDF avec Adobe Acrobat
Lorsqu'il s'agit de supprimer des images de documents PDF, le premier outil qui peut vous venir à l'esprit est Adobe Acrobat. En tant qu'éditeur PDF professionnel, il offre un environnement faisant autorité et sécurisé, ce qui signifie que vous n'avez pas à confier vos données sensibles à des installations tierces ou à des serveurs Web inconnus. Adobe Acrobat offre un contrôle précis sur les éléments PDF, garantissant que lorsque vous supprimez des images de fichiers PDF, le texte et la mise en page d'origine restent parfaitement intacts.
Voici les étapes pour supprimer une image d'un PDF à l'aide d'Adobe Acrobat :
- Étape 1. Ouvrez votre fichier et accédez à l'outil Modifier le PDF dans le volet de droite.
- Étape 2. Cliquez sur l'image que vous souhaitez supprimer. Une boîte de délimitation apparaîtra.
- Étape 3. Appuyez sur la touche Supprimer de votre clavier.
- Étape 4. Enregistrez votre document.
Bien qu'Adobe Acrobat soit l'outil le plus fiable pour le traitement des PDF, il nécessite un abonnement premium, ce qui peut ne pas être idéal pour une solution unique. Si vous recherchez des résultats professionnels sans l'écosystème Adobe, des outils comme Nitro PDF ou Foxit Editor offrent des modes d'édition similaires qui sont parfaits pour une inspection manuelle. Mais si vous recherchez un moyen plus économique ou automatisé de supprimer des images de fichiers PDF, les outils en ligne et les solutions Python abordés ci-dessous peuvent être une option plus appropriée.
Méthode 2 : Supprimer des images des PDF avec des outils PDF en ligne
Si vous n'avez besoin de traiter un fichier qu'occasionnellement, il n'est pas nécessaire de vous abonner à Adobe Acrobat pour une seule tâche. Au lieu de cela, les éditeurs PDF en ligne gratuits offrent une alternative beaucoup plus pratique. Des plateformes comme Sejda offrent de puissantes fonctionnalités d'édition directement dans votre navigateur sans installation. Téléchargez simplement votre document et vous pouvez supprimer des images de fichiers PDF instantanément, où que vous soyez.
Voici comment supprimer une image d'un PDF en ligne en utilisant Sejda comme exemple :
- Étape 1. Téléchargez votre document dans l'éditeur en ligne Sejda.
- Étape 2. Cliquez sur la flèche déroulante à côté du bouton Images dans la barre d'outils supérieure.
- Étape 3. Sélectionnez l'option Supprimer l'image existante dans la liste.
- Étape 4. Localisez l'image que vous souhaitez supprimer et cliquez sur l'icône Supprimer qui apparaît dans son coin supérieur gauche.

Bien que Sejda soit puissant, il a ses limites. La version gratuite vous limite à trois tâches par jour et a des limites sur la taille des fichiers et le nombre de pages. Pour les utilisateurs qui traitent de grands volumes de documents ou des données hautement confidentielles, ces contraintes en ligne et ces risques de confidentialité pourraient faire de la solution Python automatisée ci-dessous un meilleur choix.
Astuce : Si votre objectif n'est pas de vous débarrasser de ces images mais de les enregistrer pour d'autres projets, consultez notre guide sur la façon d'extraire des images PDF à l'aide des meilleurs outils gratuits disponibles.
Méthode 3 : Supprimer automatiquement toutes les images d'un PDF avec Python
Si vous traitez des centaines de fichiers, le clic manuel est une perte de temps. Vous pouvez apprendre à supprimer toutes les images des documents PDF par programmation à l'aide de Python. Nous utiliserons la bibliothèque Free Spire.PDF for Python car elle est puissante et gère efficacement les ressources PDF complexes sans Adobe Acrobat.
Configuration de l'environnement
Tout d'abord, installez la bibliothèque à l'aide de pip :
pip install Spire.Pdf.Free
Comment fonctionne le script
Le script Python supprime les images des fichiers PDF en appelant la classe PdfImageHelper pour scanner le dictionnaire des ressources internes de chaque page. Cette méthode identifie les objets image et les supprime complètement du document. Nous supprimons ces objets dans l'ordre inverse pour garantir que l'indexation interne du document reste stable jusqu'à ce que la page soit complètement effacée.
Le code Python
from spire.pdf.common import *
from spire.pdf import *
# Créer une instance de PdfDocument
doc = PdfDocument()
# Charger le document PDF
doc.LoadFromFile("/input/Sample.pdf")
# Initialiser l'aide d'image
image_helper = PdfImageHelper()
# Itérer sur chaque page du document
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
# Obtenir toutes les informations d'image de la page actuelle
image_infos = image_helper.GetImagesInfo(page)
# Si des images sont trouvées, les supprimer dans l'ordre inverse
if image_infos:
for j in range(len(image_infos) - 1, -1, -1):
image_helper.DeleteImage(image_infos[j])
# Enregistrer le résultat dans un nouveau fichier
doc.SaveToFile("/output/no images.pdf", FileFormat.PDF)
doc.Dispose()
Voici l'aperçu du fichier d'origine et du fichier PDF de sortie :
Cette approche programmatique est idéale pour les flux de travail de niveau entreprise où vous devez traiter des volumes massifs de fichiers avec une vitesse et une cohérence élevées. En intégrant cela dans votre travail, vous pouvez automatiser la génération de versions de documents uniquement textuelles en quelques secondes.
Vous pourriez aimer : Python : définir la transparence des images PDF
Dépannage et FAQ
Q : Pourquoi y a-t-il un espace blanc vide là où se trouvait l'image ?
R : Les PDF sont construits en couches. Lorsque vous supprimez une image, vous supprimez l'objet, mais le texte ne "s'écoule" pas automatiquement vers le haut pour combler le vide comme il le fait dans un document Word.
Q : Pourquoi ne puis-je pas sélectionner l'image ?
R : Si vous ne pouvez pas cliquer dessus, l'"image" pourrait en fait faire partie d'une page numérisée (toute la page est une grande image) ou d'un graphique vectoriel composé de milliers de petits tracés.
Q : La suppression d'images affectera-t-elle la mise en forme du texte ?
R : Généralement, non. Tant que vous utilisez un éditeur PDF approprié ou la méthode Python ci-dessus, les coordonnées du texte restent fixes.
Conclusion
Le choix du bon outil pour supprimer des images de fichiers PDF dépend finalement de vos besoins spécifiques en matière de précision, de vitesse et de volume. Pour les tâches ponctuelles nécessitant de la précision, Adobe Acrobat reste le choix professionnel, tandis que Sejda offre une alternative pratique sans installation pour des modifications rapides sur le pouce. Cependant, pour les tâches impliquant des lots de fichiers massifs, l'automatisation Python via Free Spire.PDF offre une vitesse et une confidentialité des données inégalées. En sélectionnant la méthode qui correspond à votre flux de travail, vous pouvez réduire efficacement la taille des fichiers et protéger les informations sensibles en quelques secondes.
À lire également :
Cómo eliminar imágenes de un PDF (Guía completa para 2026)
Tabla de Contenidos
A veces, un PDF que parece perfectamente bien se vuelve difícil de compartir debido a imágenes incrustadas grandes. Puede encontrarse con límites de tamaño de archivo adjunto de correo electrónico, cargas lentas o un inflado innecesario del archivo al trabajar con informes o documentos escaneados. En estos casos, saber cómo eliminar imágenes de documentos PDF puede ayudarle a reducir rápidamente el tamaño del archivo y simplificar el contenido.
En esta guía, le mostraremos formas prácticas de eliminar imágenes de archivos PDF, desde herramientas manuales hasta soluciones automatizadas con Python.
- Eliminar imágenes de archivos PDF con Adobe Acrobat
- Eliminar imágenes de PDF con herramientas PDF en línea
- Eliminar todas las imágenes de PDF automáticamente con Python
- Solución de problemas y preguntas frecuentes
- Conclusión
Método 1: Eliminar imágenes de archivos PDF con Adobe Acrobat
Cuando se trata de eliminar imágenes de documentos PDF, la primera herramienta que puede venirle a la mente es Adobe Acrobat. Como editor profesional de PDF, ofrece un entorno autoritario y seguro, lo que significa que no tiene que confiar sus datos confidenciales a instalaciones de terceros o servidores web desconocidos. Adobe Acrobat proporciona un control preciso sobre los elementos del PDF, asegurando que cuando elimine imágenes de los archivos PDF, el texto y el diseño originales permanezcan perfectamente intactos.
Aquí están los pasos para eliminar una imagen de un PDF usando Adobe Acrobat:
- Paso 1. Abra su archivo y navegue a la herramienta Editar PDF en el panel derecho.
- Paso 2. Haga clic en la imagen que desea eliminar. Aparecerá un cuadro delimitador.
- Paso 3. Presione la tecla Eliminar en su teclado.
- Paso 4. Guarde su documento.
Si bien Adobe Acrobat es la herramienta más confiable para el procesamiento de PDF, requiere una suscripción premium, que podría no ser ideal para una solución única. Si busca resultados profesionales sin el ecosistema de Adobe, herramientas como Nitro PDF o Foxit Editor ofrecen modos de edición similares que son perfectos para la inspección manual. Pero si busca una forma más rentable o automatizada de eliminar imágenes de archivos PDF, las herramientas en línea y las soluciones de Python que se analizan a continuación pueden ser una opción más adecuada.
Método 2: Eliminar imágenes de PDF con herramientas PDF en línea
Si solo necesita procesar un archivo ocasionalmente, no hay necesidad de suscribirse a Adobe Acrobat para una sola tarea. En su lugar, los editores de PDF en línea gratuitos ofrecen una alternativa mucho más conveniente. Plataformas como Sejda proporcionan potentes funciones de edición directamente en su navegador sin necesidad de instalación. Simplemente cargue su documento y podrá eliminar imágenes de archivos PDF al instante mientras viaja.
Así es como se elimina una imagen de un PDF en línea usando Sejda como ejemplo:
- Paso 1. Cargue su documento en el editor en línea de Sejda.
- Paso 2. Haga clic en la flecha desplegable junto al botón Imágenes en la barra de herramientas superior.
- Paso 3. Seleccione la opción Eliminar imagen existente de la lista.
- Paso 4. Localice la imagen que desea eliminar y haga clic en el icono Eliminar que aparece en su esquina superior izquierda.
Si bien Sejda es potente, tiene sus limitaciones. La versión gratuita le limita a tres tareas por día y tiene límites en el tamaño del archivo y el número de páginas. Para los usuarios que manejan grandes volúmenes de documentos o datos altamente confidenciales, estas limitaciones en línea y los riesgos de privacidad podrían hacer que la solución automatizada de Python a continuación sea un mejor ajuste.
Consejo: Si su objetivo no es deshacerse de estas imágenes, sino guardarlas para otros proyectos, consulte nuestra guía sobre cómo extraer imágenes de PDF utilizando las mejores herramientas gratuitas disponibles.
Método 3: Eliminar todas las imágenes de PDF automáticamente con Python
Si está tratando con cientos de archivos, hacer clic manualmente es una pérdida de tiempo. Puede aprender a eliminar todas las imágenes de documentos PDF mediante programación usando Python. Utilizaremos la biblioteca Free Spire.PDF for Python porque es potente y maneja recursos PDF complejos de manera eficiente sin Adobe Acrobat.
Configuración del entorno
Primero, instale la biblioteca usando pip:
pip install Spire.Pdf.Free
Cómo funciona el script
El script de Python elimina imágenes de archivos PDF llamando a la clase PdfImageHelper para escanear el diccionario de recursos internos de cada página. Este método identifica los objetos de imagen y los elimina por completo del documento. Eliminamos estos objetos en orden inverso para garantizar que el índice interno del documento permanezca estable hasta que la página se limpie por completo.
El código Python
from spire.pdf.common import *
from spire.pdf import *
# Crear una instancia de PdfDocument
doc = PdfDocument()
# Cargar el documento PDF
doc.LoadFromFile("/input/Sample.pdf")
# Inicializar el Ayudante de Imágenes
image_helper = PdfImageHelper()
# Iterar a través de cada página del documento
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
# Obtener toda la información de imágenes de la página actual
image_infos = image_helper.GetImagesInfo(page)
# Si se encuentran imágenes, elimínelas en orden inverso
if image_infos:
for j in range(len(image_infos) - 1, -1, -1):
image_helper.DeleteImage(image_infos[j])
# Guardar el resultado en un nuevo archivo
doc.SaveToFile("/output/no images.pdf", FileFormat.PDF)
doc.Dispose()
Aquí está la vista previa del archivo original y el archivo PDF de salida:
Este enfoque programático es ideal para flujos de trabajo a nivel empresarial donde necesita procesar grandes volúmenes de archivos con alta velocidad y consistencia. Al integrar esto en su trabajo, puede automatizar la generación de versiones de documentos solo de texto en solo unos segundos.
Puede que le interese: Python: Establecer la transparencia de las imágenes PDF
Solución de problemas y preguntas frecuentes
P: ¿Por qué hay un espacio en blanco donde estaba la imagen?
R: Los PDF se construyen en capas. Cuando elimina una imagen, está eliminando el objeto, pero el texto no se "desborda" automáticamente hacia arriba para llenar el espacio como lo hace en un documento de Word.
P: ¿Por qué no puedo seleccionar la imagen?
R: Si no puede hacer clic en ella, la "imagen" podría ser en realidad parte de una página escaneada (toda la página es una imagen grande) o un gráfico vectorial hecho de miles de pequeños trazados.
P: ¿Eliminar imágenes afectará el formato del texto?
R: Generalmente, no. Siempre que utilice un editor de PDF adecuado o el método de Python anterior, las coordenadas del texto permanecen fijas.
Conclusión
La elección de la herramienta adecuada para eliminar imágenes de archivos PDF depende en última instancia de sus necesidades específicas de precisión, velocidad y volumen. Para tareas únicas que requieren precisión, Adobe Acrobat sigue siendo la opción profesional, mientras que Sejda ofrece una alternativa conveniente y sin instalación para ediciones rápidas sobre la marcha. Sin embargo, para tareas que involucran lotes masivos de archivos, la automatización con Python a través de Free Spire.PDF proporciona una velocidad y privacidad de datos inigualables. Al seleccionar el método que se adapta a su flujo de trabajo, puede reducir eficientemente el tamaño de los archivos y proteger la información confidencial en segundos.
También lea:
So entfernen Sie Bilder aus PDF (Ein vollständiger Leitfaden für 2026)
Manchmal wird eine PDF-Datei, die perfekt aussieht, schwer zu teilen, da sie große eingebettete Bilder enthält. Sie können E-Mail-Anhangslimits, langsame Uploads oder unnötige Dateigrößenüberschreitungen bei der Arbeit mit Berichten oder gescannten Dokumenten haben. In diesen Fällen kann die Kenntnis, wie man Bilder aus PDF-Dokumenten entfernt, Ihnen helfen, die Dateigröße schnell zu reduzieren und den Inhalt zu vereinfachen.
In diesem Leitfaden führen wir Sie durch praktische Möglichkeiten, Bilder aus PDF-Dateien zu löschen, von manuellen Tools bis hin zu automatisierten Python-Lösungen.
- Bilder aus PDF-Dateien mit Adobe Acrobat entfernen
- Bilder mit Online-PDF-Tools aus PDF löschen
- Alle Bilder automatisch mit Python aus PDF entfernen
- Fehlerbehebung & FAQs
- Fazit
Methode 1: Bilder aus PDF-Dateien mit Adobe Acrobat entfernen
Wenn es darum geht, Bilder aus PDF-Dokumenten zu entfernen, ist das erste Werkzeug, das Ihnen vielleicht einfällt, Adobe Acrobat. Als professioneller PDF-Editor bietet er eine autoritative und sichere Umgebung, was bedeutet, dass Sie Ihre sensiblen Daten keinen Drittanbieterinstallationen oder unbekannten Webservern anvertrauen müssen. Adobe Acrobat bietet präzise Kontrolle über PDF-Elemente und stellt sicher, dass beim Entfernen von Bildern aus PDF-Dateien der ursprüngliche Text und das Layout perfekt erhalten bleiben.
Hier sind die Schritte zum Entfernen eines Bildes aus einer PDF-Datei mit Adobe Acrobat:
- Schritt 1. Öffnen Sie Ihre Datei und navigieren Sie zum Werkzeug PDF bearbeiten im rechten Bereich.
- Schritt 2. Klicken Sie auf das Bild, das Sie entfernen möchten. Ein Begrenzungsrahmen wird angezeigt.
- Schritt 3. Drücken Sie die Taste Entf auf Ihrer Tastatur.
- Schritt 4. Speichern Sie Ihr Dokument.
Obwohl Adobe Acrobat das vertrauenswürdigste Werkzeug für die PDF-Verarbeitung ist, erfordert es ein Premium-Abonnement, was für eine einmalige Lösung möglicherweise nicht ideal ist. Wenn Sie professionelle Ergebnisse ohne das Adobe-Ökosystem suchen, bieten Tools wie Nitro PDF oder Foxit Editor ähnliche Bearbeitungsmodi, die sich perfekt für die manuelle Überprüfung eignen. Wenn Sie jedoch nach einer kostengünstigeren oder automatisierten Möglichkeit suchen, Bilder aus PDF-Dateien zu löschen, sind die unten beschriebenen Online-Tools und Python-Lösungen möglicherweise eine geeignetere Option.
Methode 2: Bilder mit Online-PDF-Tools aus PDF löschen
Wenn Sie eine Datei nur gelegentlich bearbeiten müssen, gibt es keinen Grund, Adobe Acrobat für eine einzelne Aufgabe zu abonnieren. Stattdessen bieten kostenlose Online-PDF-Editoren eine viel bequemere Alternative. Plattformen wie Sejda bieten leistungsstarke Bearbeitungsfunktionen direkt in Ihrem Browser ohne Installation. Laden Sie einfach Ihr Dokument hoch, und Sie können Bilder aus PDF-Dateien sofort unterwegs entfernen.
So entfernen Sie ein Bild aus einer PDF-Datei online mit Sejda als Beispiel:
- Schritt 1. Laden Sie Ihr Dokument in den Sejda Online-Editor hoch.
- Schritt 2. Klicken Sie auf den Dropdown-Pfeil neben der Schaltfläche Bilder in der oberen Symbolleiste.
- Schritt 3. Wählen Sie aus der Liste die Option Vorhandenes Bild löschen.
- Schritt 4. Suchen Sie das Bild, das Sie entfernen möchten, und klicken Sie auf das Löschen-Symbol, das in der oberen linken Ecke erscheint.
Obwohl Sejda leistungsstark ist, hat es seine Grenzen. Die kostenlose Version beschränkt Sie auf drei Aufgaben pro Tag und hat Einschränkungen bei Dateigröße und Seitenzahl. Für Benutzer, die große Mengen an Dokumenten oder hochvertrauliche Daten verarbeiten, könnten diese Online-Beschränkungen und Datenschutzrisiken die unten beschriebene automatisierte Python-Lösung besser geeignet machen.
Tipp: Wenn Ihr Ziel nicht darin besteht, diese Bilder zu entfernen, sondern sie für andere Projekte zu speichern, lesen Sie unseren Leitfaden, wie Sie PDF-Bilder extrahieren mit den besten kostenlosen Tools.
Methode 3: Alle Bilder automatisch mit Python aus PDF entfernen
Wenn Sie Hunderte von Dateien bearbeiten, ist manuelles Klicken Zeitverschwendung. Sie können lernen, wie Sie alle Bilder aus PDF-Dokumenten programmatisch mit Python entfernen. Wir werden die Bibliothek Free Spire.PDF for Python verwenden, da sie leistungsstark ist und komplexe PDF-Ressourcen effizient ohne Adobe Acrobat verarbeitet.
Umgebungssetup
Installieren Sie zuerst die Bibliothek mit pip:
pip install Spire.Pdf.Free
Wie das Skript funktioniert
Das Python-Skript entfernt Bilder aus PDF-Dateien, indem es die Klasse PdfImageHelper aufruft, um das interne Ressourcenverzeichnis jeder Seite zu scannen. Diese Methode identifiziert Bildobjekte und entfernt sie vollständig aus dem Dokument. Wir löschen diese Objekte in umgekehrter Reihenfolge, um sicherzustellen, dass die interne Indizierung des Dokuments stabil bleibt, bis die Seite vollständig gelöscht ist.
Der Python-Code
from spire.pdf.common import *
from spire.pdf import *
# Erstellen Sie eine PdfDocument-Instanz
doc = PdfDocument()
# Laden Sie das PDF-Dokument
doc.LoadFromFile("/input/Sample.pdf")
# Initialisieren Sie den Image Helper
image_helper = PdfImageHelper()
# Iterieren Sie durch jede Seite im Dokument
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
# Rufen Sie alle Bildinformationen von der aktuellen Seite ab
image_infos = image_helper.GetImagesInfo(page)
# Wenn Bilder gefunden werden, löschen Sie sie in umgekehrter Reihenfolge
if image_infos:
for j in range(len(image_infos) - 1, -1, -1):
image_helper.DeleteImage(image_infos[j])
# Speichern Sie das Ergebnis in einer neuen Datei
doc.SaveToFile("/output/no images.pdf", FileFormat.PDF)
doc.Dispose()
Hier ist die Vorschau der Originaldatei und der Ausgabe-PDF-Datei:
Dieser programmatische Ansatz ist ideal für unternehmensweite Workflows, bei denen Sie riesige Mengen an Dateien mit hoher Geschwindigkeit und Konsistenz verarbeiten müssen. Durch die Integration in Ihre Arbeit können Sie die Erstellung von reinen Textversionen von Dokumenten in nur wenigen Sekunden automatisieren.
Vielleicht gefällt Ihnen: Python: Transparenz von PDF-Bildern festlegen
Fehlerbehebung & FAQs
F: Warum ist dort ein leerer weißer Bereich, wo das Bild war?
A: PDFs sind in Ebenen aufgebaut. Wenn Sie ein Bild löschen, entfernen Sie das Objekt, aber der Text fließt nicht automatisch nach oben, um die Lücke zu füllen, wie es in einem Word-Dokument geschieht.
F: Warum kann ich das Bild nicht auswählen?
A: Wenn Sie nicht darauf klicken können, ist das "Bild" möglicherweise Teil einer gescannten Seite (die gesamte Seite ist ein großes Bild) oder eine Vektorgrafik aus Tausenden von winzigen Pfaden.
F: Beeinträchtigt das Entfernen von Bildern die Textformatierung?
A: Im Allgemeinen nein. Solange Sie einen ordnungsgemäßen PDF-Editor oder die obige Python-Methode verwenden, bleiben die Textkoordinaten unverändert.
Fazit
Die Wahl des richtigen Werkzeugs zum Entfernen von Bildern aus PDF-Dateien hängt letztendlich von Ihren spezifischen Anforderungen an Präzision, Geschwindigkeit und Volumen ab. Für einmalige Aufgaben, die Genauigkeit erfordern, bleibt Adobe Acrobat die professionelle Wahl, während Sejda eine bequeme, installationsfreie Alternative für schnelle Bearbeitungen unterwegs bietet. Für Aufgaben, die riesige Dateibatchs beinhalten, bietet die Python-Automatisierung über Free Spire.PDF jedoch unübertroffene Geschwindigkeit und Datenschutz. Indem Sie die Methode wählen, die zu Ihrem Workflow passt, können Sie die Dateigrößen effizient reduzieren und sensible Informationen in Sekundenschnelle schützen.
Lesen Sie auch:
Как удалить изображения из PDF (полное руководство на 2026 год)
Содержание
Иногда PDF-файл, который выглядит совершенно нормально, становится трудно передать из-за больших встроенных изображений. Вы можете столкнуться с ограничениями на размер вложений электронной почты, медленной загрузкой или ненужным раздуванием файла при работе с отчетами или отсканированными документами. В таких случаях знание того, как удалить изображения из PDF-документов, поможет вам быстро уменьшить размер файла и упростить содержимое.
В этом руководстве мы расскажем о практических способах удаления изображений из PDF-файлов, от ручных инструментов до автоматизированных решений на Python.
- Удаление изображений из PDF-файлов с помощью Adobe Acrobat
- Удаление изображений из PDF с помощью онлайн-инструментов для работы с PDF
- Автоматическое удаление всех изображений из PDF с помощью Python
- Устранение неполадок и ответы на часто задаваемые вопросы
- Заключение
Метод 1: Удаление изображений из PDF-файлов с помощью Adobe Acrobat
Когда речь заходит об удалении изображений из PDF-документов, первым инструментом, который может прийти на ум, является Adobe Acrobat. Как профессиональный редактор PDF, он предлагает авторитетную и безопасную среду, что означает, что вам не придется доверять свои конфиденциальные данные сторонним установкам или неизвестным веб-серверам. Adobe Acrobat обеспечивает точный контроль над элементами PDF, гарантируя, что при удалении изображений из PDF-файлов исходный текст и макет останутся идеально нетронутыми.
Вот шаги по удалению изображения из PDF с помощью Adobe Acrobat:
- Шаг 1. Откройте файл и перейдите к инструменту Редактировать PDF в правой панели.
- Шаг 2. Щелкните изображение, которое вы хотите удалить. Появится ограничивающая рамка.
- Шаг 3. Нажмите клавишу Delete на клавиатуре.
- Шаг 4. Сохраните документ.
Хотя Adobe Acrobat является наиболее надежным инструментом для обработки PDF, он требует премиум-подписки, что может быть неидеально для одноразового исправления. Если вы ищете профессиональные результаты без экосистемы Adobe, такие инструменты, как Nitro PDF или Foxit Editor, предлагают аналогичные режимы редактирования, которые идеально подходят для ручной проверки. Но если вы ищете более экономичный или автоматизированный способ удаления изображений из PDF-файлов, онлайн-инструменты и решения на Python, обсуждаемые ниже, могут быть более подходящим вариантом.
Метод 2: Удаление изображений из PDF с помощью онлайн-инструментов для работы с PDF
Если вам нужно обрабатывать файл только время от времени, нет необходимости подписываться на Adobe Acrobat для одной задачи. Вместо этого бесплатные онлайн-редакторы PDF предлагают гораздо более удобную альтернативу. Платформы, такие как Sejda, предоставляют мощные функции редактирования прямо в вашем браузере без установки. Просто загрузите свой документ, и вы сможете мгновенно удалять изображения из PDF-файлов на ходу.
Вот как удалить изображение из PDF онлайн, используя Sejda в качестве примера:
- Шаг 1. Загрузите свой документ в онлайн-редактор Sejda.
- Шаг 2. Нажмите на стрелку раскрывающегося списка рядом с кнопкой Изображения в верхней панели инструментов.
- Шаг 3. Выберите опцию Удалить существующее изображение из списка.
- Шаг 4. Найдите изображение, которое вы хотите удалить, и нажмите значок Удалить, который появляется в его верхнем левом углу.
Хотя Sejda мощный, у него есть свои ограничения. Бесплатная версия ограничивает вас тремя задачами в день и имеет ограничения по размеру файла и количеству страниц. Для пользователей, работающих с большими объемами документов или высококонфиденциальными данными, эти онлайн-ограничения и риски конфиденциальности могут сделать автоматизированное решение на Python, описанное ниже, более подходящим.
Совет: Если ваша цель не избавиться от этих изображений, а сохранить их для других проектов, ознакомьтесь с нашим руководством о том, как извлекать изображения из PDF с помощью лучших бесплатных инструментов.
Метод 3: Автоматическое удаление всех изображений из PDF с помощью Python
Если вы работаете с сотнями файлов, ручное нажатие — пустая трата времени. Вы можете научиться удалять все изображения из PDF-документов программно с помощью Python. Мы будем использовать библиотеку Free Spire.PDF for Python, потому что она мощная и эффективно обрабатывает сложные ресурсы PDF без Adobe Acrobat.
Настройка среды
Сначала установите библиотеку с помощью pip:
pip install Spire.Pdf.Free
Как работает скрипт
Python-скрипт удаляет изображения из PDF-файлов, вызывая класс PdfImageHelper для сканирования словаря внутренних ресурсов каждой страницы. Этот метод идентифицирует объекты изображений и полностью удаляет их из документа. Мы удаляем эти объекты в обратном порядке, чтобы обеспечить стабильность внутреннего индексирования документа до полного очистки страницы.
Python-код
from spire.pdf.common import *
from spire.pdf import *
# Создать экземпляр PdfDocument
doc = PdfDocument()
# Загрузить PDF-документ
doc.LoadFromFile("/input/Sample.pdf")
# Инициализировать Image Helper
image_helper = PdfImageHelper()
# Пройти по каждой странице документа
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
# Получить всю информацию об изображениях с текущей страницы
image_infos = image_helper.GetImagesInfo(page)
# Если изображения найдены, удалить их в обратном порядке
if image_infos:
for j in range(len(image_infos) - 1, -1, -1):
image_helper.DeleteImage(image_infos[j])
# Сохранить результат в новый файл
doc.SaveToFile("/output/no images.pdf", FileFormat.PDF)
doc.Dispose()
Вот предварительный просмотр исходного файла и выходного PDF-файла:
Этот программный подход идеально подходит для корпоративных рабочих процессов, где вам нужно обрабатывать огромные объемы файлов с высокой скоростью и согласованностью. Интегрируя это в свою работу, вы можете автоматизировать создание версий документов только с текстом всего за несколько секунд.
Вам может понравиться: Python: установка прозрачности изображений PDF
Устранение неполадок и ответы на часто задаваемые вопросы
В: Почему там, где было изображение, осталось пустое белое пространство?
О: PDF-файлы построены по слоям. Когда вы удаляете изображение, вы удаляете объект, но текст автоматически не «перетекает» вверх, чтобы заполнить пробел, как это происходит в документе Word.
В: Почему я не могу выбрать изображение?
О: Если вы не можете щелкнуть его, «изображение» может быть частью отсканированной страницы (вся страница — это одно большое изображение) или векторной графикой, состоящей из тысяч крошечных путей.
В: Повлияет ли удаление изображений на форматирование текста?
О: Обычно нет. Пока вы используете правильный редактор PDF или приведенный выше метод Python, координаты текста остаются фиксированными.
Заключение
Выбор правильного инструмента для удаления изображений из PDF-файлов в конечном итоге зависит от ваших конкретных потребностей в точности, скорости и объеме. Для разовых задач, требующих точности, Adobe Acrobat остается профессиональным выбором, в то время как Sejda предлагает удобную альтернативу без установки для быстрых правок на ходу. Однако для задач, связанных с большими пакетами файлов, автоматизация Python через Free Spire.PDF обеспечивает непревзойденную скорость и конфиденциальность данных. Выбрав метод, соответствующий вашему рабочему процессу, вы сможете эффективно уменьшить размер файлов и защитить конфиденциальную информацию за считанные секунды.
Также читайте:
Como remover o fundo no PowerPoint: 5 maneiras fáceis
Sumário
- Resposta Rápida: Como Remover o Fundo no PowerPoint
- Método 1. Remover Fundo do Slide do PowerPoint (Formatar Plano de Fundo)
- Método 2. Excluir Fundo de Todos os Slides do PowerPoint Rapidamente (Slide Mestre)
- Método 3. Remover Fundo de Imagem no PowerPoint (Ferramenta Remover Fundo)
- Método 4. Limpar Fundo no PowerPoint Automaticamente com VBA
- Método 5. Remover Fundo em Lote no PowerPoint com Python
- Comparação: Qual Método Escolher?
- Por Que Remover o Fundo no PowerPoint
- Problemas Comuns de Remoção de Fundo e Soluções
- FAQs: Como Remover o Fundo no PowerPoint

Fundos confusos ou que distraem no PowerPoint podem, às vezes, fazer com que suas apresentações pareçam pouco profissionais, difíceis de ler e diminuir o engajamento da audiência. Aprender como remover o fundo no PowerPoint ajuda você a limpar rapidamente os slides, melhorar a legibilidade e manter uma aparência consistente e profissional.
Neste guia, mostraremos 5 métodos práticos para remover o fundo no PowerPoint - cobrindo slides individuais, imagens, apresentações inteiras e até mesmo vários arquivos - para que você possa criar slides limpos e polidos de forma mais eficiente.
Visão Geral dos Conteúdos
- Resposta Rápida: Como Remover o Fundo no PowerPoint
- Método 1. Remover Fundo do Slide do PowerPoint (Formatar Plano de Fundo)
- Método 2. Excluir Fundo de Todos os Slides do PowerPoint Rapidamente (Slide Mestre)
- Método 3. Remover Fundo de Imagem no PowerPoint (Ferramenta Remover Fundo)
- Método 4. Limpar Fundo no PowerPoint Automaticamente com VBA
- Método 5. Remover Fundo em Lote no PowerPoint com Python
- Comparação: Qual Método Escolher?
- Por Que Remover o Fundo no PowerPoint
- Problemas Comuns de Remoção de Fundo e Soluções
- FAQs: Como Remover o Fundo no PowerPoint
Resposta Rápida: Como Remover o Fundo no PowerPoint
Se você deseja remover o fundo no PowerPoint rapidamente, aqui estão os métodos mais fáceis:
- Use Formatar Plano de Fundo - melhor para slides individuais.
- Use Slide Mestre - melhor para todos os slides.
- Use Remover Fundo - melhor para imagens.
Continue lendo para obter instruções passo a passo e métodos avançados como VBA e Python.
Método 1. Remover Fundo do Slide do PowerPoint (Formatar Plano de Fundo)
Se você deseja remover o fundo de um slide rapidamente, o recurso Formatar Plano de Fundo é a opção mais direta. Ele permite limpar o fundo existente sem afetar texto ou outros elementos. Este método funciona melhor quando você precisa limpar um ou alguns slides.
Passos:
-
Selecione o slide do qual você deseja remover o fundo.
-
Vá para a guia Design e clique em Formatar Plano de Fundo (ou clique com o botão direito no slide e escolha Formatar Plano de Fundo).

-
No painel Formatar Plano de Fundo, selecione Preenchimento sólido.
-
Clique no botão Cor e escolha a cor branca no menu suspenso. O fundo agora foi removido dos slides selecionados.
Dica Pro: Se você quiser que essa alteração se aplique a todos os slides da sua apresentação, clique em Aplicar a Todos na parte inferior do painel Formatar Plano de Fundo.
Quando usar: Use-o quando você precisar limpar apenas slides individuais sem afetar o restante da apresentação.
Se você quiser alterar ou personalizar fundos em vez de removê-los, veja nosso guia sobre alterar fundos de slides do PowerPoint.
Método 2. Excluir Fundo de Todos os Slides do PowerPoint Rapidamente (Slide Mestre)
Quando você precisa remover o fundo de todos os slides no PowerPoint, usar o Slide Mestre é a abordagem mais eficiente. Ele permite limpar configurações de fundo em vários slides de uma vez a partir de um único local. Este método é ideal para eliminar fundos indesejados, mantendo os slides consistentes sem editá-los um por um.
Passos:
-
Navegue até a guia Exibir e selecione Slide Mestre no grupo Modos de Exibição Mestre.
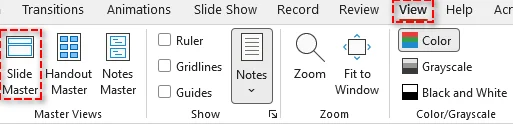
-
No painel esquerdo, escolha o slide mestre ou o layout específico que você deseja editar.
-
No grupo Plano de Fundo, clique em Estilos de Plano de Fundo > Formatar Plano de Fundo.
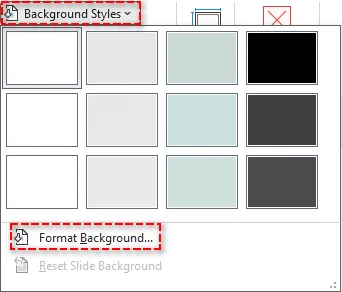
-
No painel Formatar Plano de Fundo, selecione Preenchimento sólido e escolha a cor branca no seletor de cores.
-
Clique em Fechar Slide Mestre para aplicar as alterações a todos os slides relacionados.
Dica: Se você tiver vários layouts usando o mesmo fundo, certifique-se de atualizar cada layout no Slide Mestre.
Quando usar: Use-o para aplicar a remoção consistente de fundo em toda a apresentação.
Solução de Problemas de Fundos Persistentes
Se os elementos de fundo ainda aparecerem após a remoção, eles geralmente fazem parte do tema do slide ou estão armazenados no Slide Mestre. Use os métodos abaixo para ocultá-los ou removê-los.
1. Ocultar Gráficos de Fundo do Tema
-
Abra o painel Formatar Plano de Fundo.
-
Marque a caixa Ocultar gráficos de plano de fundo para ocultar elementos baseados no tema, como linhas decorativas, formas ou logotipos.
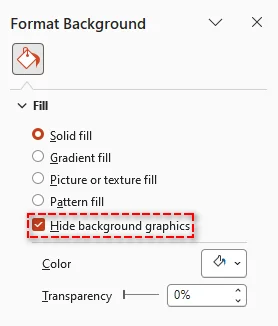
Observação: Isso apenas oculta elementos herdados do Slide Mestre. Não remove imagens ou objetos que foram adicionados manualmente ao slide.
2. Remover Elementos de Fundo via Slide Mestre
- Vá para a guia Exibir e selecione Slide Mestre.
- No painel esquerdo, selecione o slide mestre (pai) superior ou o layout específico.
- Clique no gráfico de fundo ou logotipo que você deseja remover e pressione Excluir.
- Clique em Fechar Modo de Exibição Mestre para aplicar as alterações.
Método 3. Remover Fundo de Imagem no PowerPoint (Ferramenta Remover Fundo)
Se você precisar remover o fundo de uma imagem no PowerPoint, a ferramenta integrada Remover Fundo oferece uma solução rápida e eficaz. Ela detecta automaticamente o assunto principal e remove áreas indesejadas com ajuste manual mínimo. Este método é ideal para limpar imagens diretamente em seus slides sem usar ferramentas externas.
Passos:
-
Selecione a imagem da qual você deseja remover o fundo.
-
Vá para a guia Formato de Imagem.
-
Selecione Remover Fundo. O PowerPoint destacará o fundo em roxo.

-
Ajuste a seleção usando Marcar Áreas para Manter ou Marcar Áreas para Remover, se necessário.
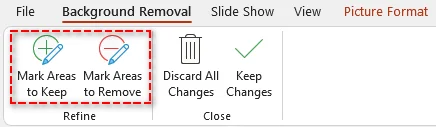
-
Clique em Manter Alterações para aplicar a remoção de fundo.
Dicas e Observações:
- Este método funciona melhor quando há um contraste claro entre o assunto e o fundo.
- O recurso Remover Fundo está disponível em versões recentes para desktop, como PowerPoint para Microsoft 365, 2024 e 2021, mas pode não ser suportado em algumas versões web.
- Para imagens com um fundo de cor sólida, vá para Formato de Imagem > Cor > Definir Cor Transparente e clique no fundo para torná-lo transparente rapidamente.
Quando usar: Use-o para remover fundos de imagens, mantendo o assunto principal.
Método 4. Limpar Fundo no PowerPoint Automaticamente com VBA
Se você precisar realizar tarefas repetitivas de remoção de fundo, o VBA oferece uma maneira de automatizar o processo dentro do PowerPoint. Ao executar uma macro simples, você pode atualizar vários slides sem trabalho manual. Este método é útil para usuários familiarizados com scripts básicos.
Macro VBA para Remover Fundos de Todos os Slides
Este script percorre cada slide na apresentação ativa, desabilita o fundo mestre e limpa os elementos de fundo automaticamente.
Sub RemoveAllBackgrounds()
Dim sld As Slide
' Loop through each slide in the presentation
For Each sld In ActivePresentation.Slides
' Follow Master Background: Set to False to customize
sld.FollowMasterBackground = msoFalse
' Set the background fill to visible = false (Transparent/No Fill)
sld.Background.Fill.Visible = msoFalse
' Alternatively, hide background graphics (like logos/themes)
sld.DisplayMasterShapes = msoFalse
Next sld
MsgBox "All slide backgrounds have been removed!", vbInformation
End Sub
Propriedades Chave Explicadas:
- FollowMasterBackground: Definido como msoFalse para substituir o fundo do Slide Mestre.
- DisplayMasterShapes: Oculta elementos de fundo como logotipos ou formas de design do Slide Mestre.
- Background.Fill.Visible: Controla se o preenchimento do fundo é visível.
Como usar o script:
- Pressione Alt + F11 para abrir o Editor VBA.
- Vá para Inserir > Módulo.
- Cole o código na janela do módulo.
- Pressione F5 ou clique no botão Executar para executar a macro.
Observações:
- Este método não remove imagens inseridas como formas. Se o seu fundo for um objeto de imagem, você precisará de um script separado para excluir essas formas.
- Sempre salve uma cópia da sua apresentação antes de executar macros, pois as ações do VBA não podem ser desfeitas.
- Se as macros estiverem desabilitadas, vá para Arquivo > Opções > Central de Confiabilidade > Configurações da Central de Confiabilidade > Configurações de Macro para habilitá-las.
Quando Usar: Ideal para automatizar tarefas repetitivas de remoção de fundo dentro do PowerPoint.
Método 5. Remover Fundo em Lote no PowerPoint com Python
Para tarefas em larga escala envolvendo vários arquivos do PowerPoint, usar Python pode melhorar significativamente a eficiência. Com a biblioteca certa, como Spire.Presentation for Python, você pode automatizar a remoção de fundo entre apresentações sem abrir o PowerPoint manualmente. Este método é ideal para processamento em lote e fluxos de trabalho de back-end.
Guia Passo a Passo:
-
Instale a biblioteca via pip:
pip install spire.presentation -
Escreva o Script Python:
O exemplo a seguir mostra como remover o fundo de slides em lote de vários arquivos .pptx do PowerPoint:
from spire.presentation import * import os # Folder containing the PPTX files to process input_folder = "presentations" # Folder with all the PPTX files output_folder = "processed" # Folder to save processed files # Create output folder if it doesn't exist if not os.path.exists(output_folder): os.makedirs(output_folder) # Loop through all PPTX files in the input folder for filename in os.listdir(input_folder): if filename.lower().endswith(".pptx"): input_path = os.path.join(input_folder, filename) output_path = os.path.join(output_folder, f"RemoveBackground_{filename}") # Load the presentation presentation = Presentation() presentation.LoadFromFile(input_path) # Loop through each slide and remove background for slide in presentation.Slides: slide.SlideBackground.Type = BackgroundType.none # Save the modified presentation presentation.SaveToFile(output_path, FileFormat.Pptx2010) presentation.Dispose() print(f"Processed: {filename} → {output_path}") print("All presentations have been processed successfully.")
Dica: Além de remover o fundo dos slides, você também pode remover o fundo dos slides mestres.
Quando usar: Ideal para processar vários arquivos do PowerPoint em lote de forma eficiente.
Comparação: Qual Método Escolher?
Escolher a maneira certa de remover o fundo no PowerPoint depende de quantos slides você está trabalhando e se você precisa de automação.
Aqui está uma comparação rápida dos cinco métodos:
| Método | Melhor para | Escopo | Nível de Habilidade |
|---|---|---|---|
| Formatar Plano de Fundo | Limpeza rápida de slides | Slides individuais / poucos | Iniciante |
| Slide Mestre | Consistência em toda a apresentação | Apresentação inteira | Iniciante |
| Remover Fundo (Imagem) | Edição de imagem | Imagens individuais | Iniciante |
| VBA | Tarefas repetitivas dentro do PowerPoint | Vários slides | Intermediário |
| Python | Processamento em lote | Várias apresentações | Avançado |
Recomendação Rápida:
- Para a maioria dos usuários, Formatar Plano de Fundo e Slide Mestre são suficientes para tarefas diárias.
- Use VBA se você precisar automatizar ações repetidas dentro do PowerPoint.
- Escolha Python se você precisar processar vários arquivos ou criar fluxos de trabalho automatizados.
Por Que Remover o Fundo no PowerPoint
Remover fundos no PowerPoint não é apenas uma questão de limpeza visual - pode melhorar significativamente a aparência e o desempenho da sua apresentação. Aqui estão os principais benefícios:
- Melhor Clareza Visual: Remova elementos distrativos que competem com seu conteúdo.
- Consistência de Marca: Elimine fundos inconsistentes ou indesejados.
- Melhor Legibilidade: Fundos limpos ajudam o texto a se destacar com mais clareza.
- Design Simplificado: Remova visuais desnecessários e concentre-se nas informações principais.
- Qualidade Profissional: Crie apresentações limpas e sem distrações.
Problemas Comuns de Remoção de Fundo e Soluções
- Gráficos de fundo ou logotipos ainda visíveis - Esses elementos geralmente fazem parte do Slide Mestre. Para removê-los, vá para Exibir > Slide Mestre, selecione o slide pai ou os layouts afetados, exclua os elementos e, em seguida, feche o Modo de Exibição Mestre.
- Não é possível remover o fundo - A apresentação pode estar protegida ou restrita. Verifique as permissões de edição do arquivo e habilite a edição, se necessário, antes de fazer alterações.
- As alterações não se aplicam a todos os slides - Remover o fundo em um slide não afeta os outros. Use Aplicar a Todos no painel Formatar Plano de Fundo ou atualize o Slide Mestre para aplicar as alterações em toda a apresentação.
FAQs: Como Remover o Fundo no PowerPoint
Q1: Posso remover fundos de todos os slides de uma vez?
R1: Sim, usando Slide Mestre, VBA ou automação com Python, você pode remover fundos em toda a apresentação ou em vários arquivos.
Q2: Posso remover fundos sem o PowerPoint?
R2: Sim, bibliotecas Python como Spire.Presentation permitem a remoção de fundos sem o Microsoft PowerPoint instalado.
Q3: Remover o fundo afetará imagens ou texto nos meus slides?
R3: Não, remover o fundo do slide geralmente não afeta outro conteúdo do slide, como caixas de texto ou imagens. No entanto, sempre crie um backup antes de usar ferramentas automatizadas como scripts VBA ou Python para evitar alterações acidentais.
Q4: O VBA é seguro para usar na remoção de fundo do PowerPoint?
R4: Sim, desde que você habilite macros apenas de fontes confiáveis e salve um backup antes de executar o script.
Veja Também
PowerPoint에서 배경을 제거하는 방법: 5가지 쉬운 방법
목차
- 빠른 답변: PowerPoint에서 배경을 제거하는 방법
- 방법 1. PowerPoint 슬라이드 배경 제거 (배경 서식)
- 방법 2. 모든 PowerPoint 슬라이드 배경 빠르게 삭제 (슬라이드 마스터)
- 방법 3. PowerPoint에서 이미지 배경 제거 (배경 제거 도구)
- 방법 4. VBA를 사용하여 PowerPoint 배경 자동 삭제
- 방법 5. Python을 사용하여 PowerPoint에서 일괄 배경 제거
- 비교: 어떤 방법을 선택해야 할까요?
- PowerPoint에서 배경을 제거하는 이유
- 일반적인 배경 제거 문제 및 해결 방법
- 자주 묻는 질문: PowerPoint에서 배경을 제거하는 방법
PowerPoint에서 산만하거나 주의를 산만하게 하는 배경은 프레젠테이션을 비전문적으로 보이게 하고, 읽기 어렵게 만들며, 청중의 참여를 줄일 수 있습니다. PowerPoint에서 배경을 제거하는 방법을 배우면 슬라이드를 빠르게 정리하고, 가독성을 개선하며, 일관되고 전문적인 모양을 유지하는 데 도움이 됩니다.
이 가이드에서는 단일 슬라이드, 이미지, 전체 프레젠테이션 및 여러 파일에 걸쳐 PowerPoint에서 배경을 제거하는 5가지 실용적인 방법을 보여드리겠습니다. 이를 통해 더 효율적으로 깔끔하고 세련된 슬라이드를 만들 수 있습니다.
콘텐츠 개요
- 빠른 답변: PowerPoint에서 배경을 제거하는 방법
- 방법 1. PowerPoint 슬라이드 배경 제거 (배경 서식)
- 방법 2. 모든 PowerPoint 슬라이드 배경 빠르게 삭제 (슬라이드 마스터)
- 방법 3. PowerPoint에서 이미지 배경 제거 (배경 제거 도구)
- 방법 4. VBA를 사용하여 PowerPoint 배경 자동 삭제
- 방법 5. Python을 사용하여 PowerPoint에서 일괄 배경 제거
- 비교: 어떤 방법을 선택해야 할까요?
- PowerPoint에서 배경을 제거하는 이유
- 일반적인 배경 제거 문제 및 해결 방법
- 자주 묻는 질문: PowerPoint에서 배경을 제거하는 방법
빠른 답변: PowerPoint에서 배경을 제거하는 방법
PowerPoint에서 배경을 빠르게 제거하려면 다음이 가장 쉬운 방법입니다.
- 배경 서식 사용 - 단일 슬라이드에 가장 적합합니다.
- 슬라이드 마스터 사용 - 모든 슬라이드에 가장 적합합니다.
- 배경 제거 사용 - 이미지에 가장 적합합니다.
단계별 지침과 VBA 및 Python과 같은 고급 방법을 계속 읽어보세요.
방법 1. PowerPoint 슬라이드 배경 제거 (배경 서식)
슬라이드에서 배경을 빠르게 제거하려면 배경 서식 기능이 가장 간단한 옵션입니다. 텍스트나 다른 요소에 영향을 주지 않고 기존 배경을 지울 수 있습니다. 이 방법은 하나 또는 몇 개의 슬라이드를 정리해야 할 때 가장 잘 작동합니다.
단계:
-
배경을 제거하려는 슬라이드를 선택합니다.
-
디자인 탭으로 이동하여 배경 서식을 클릭합니다 (또는 슬라이드를 마우스 오른쪽 버튼으로 클릭하고 배경 서식을 선택합니다).
-
배경 서식 창에서 단색 채우기를 선택합니다.
-
색 버튼을 클릭하고 드롭다운에서 흰색을 선택합니다. 이제 선택한 슬라이드에서 배경이 제거되었습니다.
전문가 팁: 이 변경 사항을 프레젠테이션의 모든 슬라이드에 적용하려면 배경 서식 창 하단의 모두 적용을 클릭합니다.
사용 시기: 프레젠테이션의 나머지 부분에 영향을 주지 않고 개별 슬라이드만 정리해야 할 때 사용합니다.
배경을 제거하는 대신 배경을 변경하거나 사용자 지정하려면 PowerPoint 슬라이드 배경 변경에 대한 가이드를 참조하세요.
방법 2. 모든 PowerPoint 슬라이드 배경 빠르게 삭제 (슬라이드 마스터)
PowerPoint의 모든 슬라이드에서 배경을 제거해야 할 때 슬라이드 마스터를 사용하는 것이 가장 효율적인 접근 방식입니다. 이를 통해 단일 위치에서 한 번에 여러 슬라이드의 배경 설정을 지울 수 있습니다. 이 방법은 슬라이드를 하나씩 편집하지 않고 원치 않는 배경을 제거하는 데 이상적입니다.
단계:
-
보기 탭으로 이동하여 마스터 보기 그룹에서 슬라이드 마스터를 선택합니다.
-
왼쪽 창에서 편집하려는 마스터 슬라이드 또는 특정 레이아웃을 선택합니다.
-
배경 그룹에서 배경 스타일 > 배경 서식을 클릭합니다.
-
배경 서식 창에서 단색 채우기를 선택하고 색상 선택기에서 흰색을 선택합니다.
-
슬라이드 마스터 닫기를 클릭하여 변경 사항을 관련 슬라이드에 적용합니다.
팁: 동일한 배경을 사용하는 여러 레이아웃이 있는 경우 각 레이아웃을 슬라이드 마스터에서 업데이트해야 합니다.
사용 시기: 전체 프레젠테이션에 걸쳐 일관된 배경 제거를 적용하는 데 사용합니다.
까다로운 배경 문제 해결
제거 후에도 배경 요소가 계속 표시되면 일반적으로 슬라이드 테마의 일부이거나 슬라이드 마스터에 저장된 것입니다. 아래 방법을 사용하여 숨기거나 제거합니다.
1. 테마 배경 그래픽 숨기기
-
배경 서식 창을 엽니다.
-
배경 그래픽 숨기기 확인란을 선택하여 장식 선, 모양 또는 로고와 같은 테마 기반 요소를 숨깁니다.
참고: 이 기능은 슬라이드 마스터에서 상속된 요소만 숨깁니다. 슬라이드에 수동으로 추가된 이미지나 개체는 제거하지 않습니다.
2. 슬라이드 마스터를 통해 배경 요소 제거
- 보기 탭으로 이동하여 슬라이드 마스터를 선택합니다.
- 왼쪽 창에서 최상위 (부모) 마스터 슬라이드 또는 특정 레이아웃을 선택합니다.
- 제거하려는 배경 그래픽 또는 로고를 클릭하고 Delete 키를 누릅니다.
- 마스터 보기 닫기를 클릭하여 변경 사항을 적용합니다.
방법 3. PowerPoint에서 이미지 배경 제거 (배경 제거 도구)
PowerPoint에서 이미지 배경을 제거해야 하는 경우 내장된 배경 제거 도구를 사용하면 빠르고 효과적인 솔루션을 제공합니다. 주요 개체를 자동으로 감지하고 최소한의 수동 조정으로 원치 않는 영역을 제거합니다. 이 방법은 외부 도구를 사용하지 않고 슬라이드 내에서 직접 이미지를 정리하는 데 이상적입니다.
단계:
-
배경을 제거하려는 이미지를 선택합니다.
-
그림 서식 탭으로 이동합니다.
-
배경 제거를 선택합니다. PowerPoint가 배경을 보라색으로 강조 표시합니다.
-
필요한 경우 유지할 영역 표시 또는 제거할 영역 표시를 사용하여 선택 영역을 조정합니다.
-
변경 내용 유지를 클릭하여 배경 제거를 적용합니다.
팁 및 참고 사항:
- 이 방법은 개체와 배경 사이에 명확한 대비가 있을 때 가장 잘 작동합니다.
- 배경 제거 기능은 PowerPoint for Microsoft 365, 2024, 2021과 같은 최신 데스크톱 버전에서 사용할 수 있지만 일부 웹 버전에서는 지원되지 않을 수 있습니다.
- 단색 배경이 있는 이미지의 경우 그림 서식 > 색 > 투명색 설정으로 이동한 다음 배경을 클릭하여 빠르게 투명하게 만듭니다.
사용 시기: 주요 개체를 유지하면서 이미지에서 배경을 제거하는 데 사용합니다.
방법 4. VBA를 사용하여 PowerPoint 배경 자동 삭제
반복적인 배경 제거 작업을 수행해야 하는 경우 VBA를 사용하면 PowerPoint 내에서 프로세스를 자동화할 수 있습니다. 간단한 매크로를 실행하여 수동 작업 없이 여러 슬라이드를 업데이트할 수 있습니다. 이 방법은 기본 스크립팅에 익숙한 사용자에게 유용합니다.
모든 슬라이드에서 배경을 제거하는 VBA 매크로
이 스크립트는 활성 프레젠테이션의 각 슬라이드를 반복하고, 마스터 배경을 비활성화하고, 배경 요소를 자동으로 지웁니다.
Sub RemoveAllBackgrounds()
Dim sld As Slide
' 프레젠테이션의 각 슬라이드를 반복합니다.
For Each sld In ActivePresentation.Slides
' 마스터 배경 따르기: 사용자 지정하려면 False로 설정합니다.
sld.FollowMasterBackground = msoFalse
' 배경 채우기를 표시=false (투명/채우기 없음)로 설정합니다.
sld.Background.Fill.Visible = msoFalse
' 또는 배경 그래픽 (로고/테마 등)을 숨깁니다.
sld.DisplayMasterShapes = msoFalse
Next sld
MsgBox "모든 슬라이드 배경이 제거되었습니다!", vbInformation
End Sub
주요 속성 설명:
- FollowMasterBackground: 슬라이드 마스터 배경을 재정의하려면 msoFalse로 설정합니다.
- DisplayMasterShapes: 슬라이드 마스터의 로고 또는 디자인 모양과 같은 배경 요소를 숨깁니다.
- Background.Fill.Visible: 배경 채우기가 표시되는지 여부를 제어합니다.
스크립트 사용 방법:
- Alt + F11을 눌러 VBA 편집기를 엽니다.
- 삽입 > 모듈로 이동합니다.
- 모듈 창에 코드를 붙여넣습니다.
- F5를 누르거나 실행 버튼을 클릭하여 매크로를 실행합니다.
참고 사항:
- 이 방법은 이미지로 삽입된 모양은 제거하지 않습니다. 배경이 그림 개체인 경우 해당 모양을 삭제하려면 별도의 스크립트가 필요합니다.
- 항상 매크로를 실행하기 전에 프레젠테이션 사본을 저장하십시오. VBA 작업은 실행 취소할 수 없습니다.
- 매크로가 비활성화된 경우 파일 > 옵션 > 보안 센터 > 보안 센터 설정 > 매크로 설정으로 이동하여 활성화합니다.
사용 시기: PowerPoint 내에서 반복적인 배경 제거 작업을 자동화하는 데 이상적입니다.
방법 5. Python을 사용하여 PowerPoint에서 일괄 배경 제거
여러 PowerPoint 파일을 포함하는 대규모 작업의 경우 Python을 사용하면 효율성을 크게 향상시킬 수 있습니다. Spire.Presentation for Python과 같은 올바른 라이브러리를 사용하면 PowerPoint를 수동으로 열지 않고도 프레젠테이션 전반에 걸쳐 배경 제거를 자동화할 수 있습니다. 이 방법은 일괄 처리 및 백엔드 워크플로에 이상적입니다.
단계별 가이드:
-
pip를 통해 라이브러리를 설치합니다.
pip install spire.presentation -
Python 스크립트 작성:
다음 예는 여러 PowerPoint .pptx 파일에서 슬라이드 배경을 일괄 제거하는 방법을 보여줍니다.
from spire.presentation import * import os # 처리할 PPTX 파일이 포함된 폴더 input_folder = "presentations" # 모든 PPTX 파일이 있는 폴더 output_folder = "processed" # 처리된 파일을 저장할 폴더 # 출력 폴더가 없으면 생성합니다. if not os.path.exists(output_folder): os.makedirs(output_folder) # 입력 폴더의 모든 PPTX 파일을 반복합니다. for filename in os.listdir(input_folder): if filename.lower().endswith(".pptx"): input_path = os.path.join(input_folder, filename) output_path = os.path.join(output_folder, f"RemoveBackground_{filename}") # 프레젠테이션 로드 presentation = Presentation() presentation.LoadFromFile(input_path) # 각 슬라이드를 반복하고 배경 제거 for slide in presentation.Slides: slide.SlideBackground.Type = BackgroundType.none # 수정된 프레젠테이션 저장 presentation.SaveToFile(output_path, FileFormat.Pptx2010) presentation.Dispose() print(f"처리됨: {filename} → {output_path}") print("모든 프레젠테이션이 성공적으로 처리되었습니다.")
팁: 슬라이드 배경을 제거하는 것 외에도 슬라이드 마스터의 배경을 제거할 수도 있습니다.
사용 시기: 여러 PowerPoint 파일을 효율적으로 일괄 처리하는 데 이상적입니다.
비교: 어떤 방법을 선택해야 할까요?
PowerPoint에서 배경을 제거하는 올바른 방법을 선택하는 것은 작업 중인 슬라이드 수와 자동화가 필요한지에 따라 달라집니다.
다섯 가지 방법의 빠른 비교입니다.
| 방법 | 가장 적합한 경우 | 범위 | 기술 수준 |
|---|---|---|---|
| 배경 서식 | 빠른 슬라이드 정리 | 단일 / 소수 슬라이드 | 초급 |
| 슬라이드 마스터 | 프레젠테이션 전체 일관성 | 전체 프레젠테이션 | 초급 |
| 배경 제거 (이미지) | 이미지 편집 | 개별 이미지 | 초급 |
| VBA | PowerPoint 내 반복 작업 | 여러 슬라이드 | 중급 |
| Python | 일괄 처리 | 여러 프레젠테이션 | 고급 |
빠른 권장 사항:
- 대부분의 사용자의 경우 배경 서식 및 슬라이드 마스터가 일상적인 작업에 충분합니다.
- PowerPoint 내에서 반복적인 작업을 자동화해야 하는 경우 VBA를 사용합니다.
- 여러 파일을 처리하거나 자동화된 워크플로를 구축해야 하는 경우 Python을 선택합니다.
PowerPoint에서 배경을 제거하는 이유
PowerPoint에서 배경을 제거하는 것은 단순히 시각적인 정리를 넘어 프레젠테이션의 모양과 성능을 크게 향상시킬 수 있습니다. 주요 이점은 다음과 같습니다.
- 향상된 시각적 명확성: 콘텐츠와 경쟁하는 산만 한 요소를 제거합니다.
- 브랜드 일관성: 일관되지 않거나 원치 않는 배경을 제거합니다.
- 가독성 향상: 깔끔한 배경은 텍스트를 더 명확하게 돋보이게 합니다.
- 간소화된 디자인: 불필요한 시각 요소를 제거하고 핵심 정보에 집중합니다.
- 전문적인 품질: 깔끔하고 산만 하지 않은 프레젠테이션을 만듭니다.
일반적인 배경 제거 문제 및 해결 방법
- 배경 그래픽 또는 로고가 계속 표시됨 - 이러한 요소는 종종 슬라이드 마스터의 일부입니다. 이를 제거하려면 보기 > 슬라이드 마스터로 이동하여 부모 슬라이드 또는 영향을 받는 레이아웃을 선택하고 요소를 삭제한 다음 마스터 보기 닫기를 클릭합니다.
- 배경을 제거할 수 없음 - 프레젠테이션이 보호되거나 제한되었을 수 있습니다. 파일의 편집 권한을 확인하고 변경하기 전에 필요한 경우 편집을 활성화합니다.
- 변경 사항이 모든 슬라이드에 적용되지 않음 - 한 슬라이드에서 배경을 제거해도 다른 슬라이드에는 영향을 주지 않습니다. 배경 서식 창에서 모두 적용을 사용하거나 슬라이드 마스터를 업데이트하여 전체 프레젠테이션에 변경 사항을 적용합니다.
자주 묻는 질문: PowerPoint에서 배경을 제거하는 방법
Q1: 모든 슬라이드의 배경을 한 번에 제거할 수 있습니까?
A1: 예, 슬라이드 마스터, VBA 또는 Python 자동화를 사용하여 전체 프레젠테이션 또는 여러 파일에 걸쳐 배경을 제거할 수 있습니다.
Q2: PowerPoint 없이 배경을 제거할 수 있습니까?
A2: 예, Spire.Presentation과 같은 Python 라이브러리를 사용하면 Microsoft PowerPoint가 설치되지 않은 상태에서도 배경을 제거할 수 있습니다.
Q3: 배경을 제거하면 슬라이드의 이미지나 텍스트에 영향을 미칩니까?
A3: 아니요, 슬라이드 배경을 제거해도 일반적으로 텍스트 상자나 이미지와 같은 다른 슬라이드 콘텐츠에는 영향을 주지 않습니다. 그러나 VBA 또는 Python 스크립트와 같은 자동화 도구를 사용하기 전에 항상 백업을 만들어 우발적인 변경을 방지하십시오.
Q4: VBA를 PowerPoint 배경 제거에 안전하게 사용할 수 있습니까?
A4: 예, 신뢰할 수 있는 소스의 매크로만 활성화하고 스크립트를 실행하기 전에 백업을 저장하는 한 안전합니다.
참고 자료
Come rimuovere lo sfondo in PowerPoint: 5 modi semplici
Indice
- Risposta rapida: Come rimuovere lo sfondo in PowerPoint
- Metodo 1. Rimuovi lo sfondo da una diapositiva di PowerPoint (Formato sfondo)
- Metodo 2. Elimina rapidamente lo sfondo da tutte le diapositive di PowerPoint (Master diapositive)
- Metodo 3. Rimuovi lo sfondo di un'immagine in PowerPoint (Strumento Rimuovi sfondo)
- Metodo 4. Cancella lo sfondo in PowerPoint automaticamente con VBA
- Metodo 5. Rimuovi in blocco lo sfondo in PowerPoint con Python
- Confronto: Quale metodo dovresti scegliere?
- Perché rimuovere lo sfondo in PowerPoint
- Problemi comuni di rimozione dello sfondo e soluzioni
- FAQ: Come rimuovere lo sfondo in PowerPoint
Gli sfondi disordinati o distraenti in PowerPoint possono a volte rendere le tue presentazioni poco professionali, difficili da leggere e ridurre il coinvolgimento del pubblico. Imparare come rimuovere lo sfondo in PowerPoint ti aiuta a ripulire rapidamente le diapositive, migliorare la leggibilità e mantenere un aspetto coerente e professionale.
In questa guida, ti mostreremo 5 metodi pratici per rimuovere lo sfondo in PowerPoint, coprendo singole diapositive, immagini, intere presentazioni e persino più file, in modo da poter creare diapositive pulite e curate in modo più efficiente.
Panoramica dei contenuti
- Risposta rapida: Come rimuovere lo sfondo in PowerPoint
- Metodo 1. Rimuovi lo sfondo da una diapositiva di PowerPoint (Formato sfondo)
- Metodo 2. Elimina rapidamente lo sfondo da tutte le diapositive di PowerPoint (Master diapositive)
- Metodo 3. Rimuovi lo sfondo di un'immagine in PowerPoint (Strumento Rimuovi sfondo)
- Metodo 4. Cancella lo sfondo in PowerPoint automaticamente con VBA
- Metodo 5. Rimuovi in blocco lo sfondo in PowerPoint con Python
- Confronto: Quale metodo dovresti scegliere?
- Perché rimuovere lo sfondo in PowerPoint
- Problemi comuni di rimozione dello sfondo e soluzioni
- FAQ: Come rimuovere lo sfondo in PowerPoint
Risposta rapida: Come rimuovere lo sfondo in PowerPoint
Se vuoi rimuovere rapidamente lo sfondo in PowerPoint, ecco i metodi più semplici:
- Usa Formato sfondo - ideale per singole diapositive.
- Usa Master diapositive - ideale per tutte le diapositive.
- Usa Rimuovi sfondo - ideale per le immagini.
Continua a leggere per istruzioni passo passo e metodi avanzati come VBA e Python.
Metodo 1. Rimuovi lo sfondo da una diapositiva di PowerPoint (Formato sfondo)
Se vuoi rimuovere lo sfondo da una diapositiva rapidamente, la funzionalità Formato sfondo è l'opzione più semplice. Ti consente di cancellare lo sfondo esistente senza influenzare testo o altri elementi. Questo metodo funziona meglio quando devi ripulire una o poche diapositive.
Passaggi:
-
Seleziona la diapositiva da cui vuoi rimuovere lo sfondo.
-
Vai alla scheda Progettazione e fai clic su Formato sfondo (oppure fai clic con il pulsante destro del mouse sulla diapositiva e scegli Formato sfondo).
-
Nel riquadro Formato sfondo, seleziona Riempimento a tinta unita.
-
Fai clic sul pulsante Colore e scegli il colore bianco dal menu a discesa. Lo sfondo è ora rimosso dalle diapositive selezionate.
Suggerimento Pro: Se desideri che questa modifica si applichi a tutte le diapositive della tua presentazione, fai clic su Applica a tutte nella parte inferiore del riquadro Formato sfondo.
Quando usarlo: Usalo quando devi ripulire solo singole diapositive senza influenzare il resto della presentazione.
Se desideri cambiare o personalizzare gli sfondi invece di rimuoverli, consulta la nostra guida su come cambiare gli sfondi delle diapositive di PowerPoint.
Metodo 2. Elimina rapidamente lo sfondo da tutte le diapositive di PowerPoint (Master diapositive)
Quando è necessario rimuovere lo sfondo da tutte le diapositive in PowerPoint, l'uso del Master diapositive è l'approccio più efficiente. Ti consente di cancellare le impostazioni dello sfondo su più diapositive contemporaneamente da un unico posto. Questo metodo è ideale per eliminare sfondi indesiderati mantenendo le diapositive coerenti senza doverle modificare una per una.
Passaggi:
-
Vai alla scheda Visualizza e seleziona Master diapositive nel gruppo Visualizzazioni master.
-
Nel riquadro sinistro, scegli il master diapositiva o il layout specifico che desideri modificare.
-
Nel gruppo Sfondo, fai clic su Stili sfondo > Formato sfondo.
-
Nel riquadro Formato sfondo, seleziona Riempimento a tinta unita e scegli il colore bianco dal selettore di colori.
-
Fai clic su Chiudi master diapositive per applicare le modifiche a tutte le diapositive correlate.
Suggerimento: Se hai più layout che utilizzano lo stesso sfondo, assicurati di aggiornare ogni layout nel Master diapositive.
Quando usarlo: Usalo per applicare una rimozione coerente dello sfondo in tutta la presentazione.
Risoluzione dei problemi di sfondi ostinati
Se gli elementi di sfondo appaiono ancora dopo la rimozione, fanno solitamente parte del tema della diapositiva o sono memorizzati nel Master diapositive. Usa i metodi seguenti per nasconderli o rimuoverli.
1. Nascondi grafica di sfondo del tema
-
Apri il riquadro Formato sfondo.
-
Seleziona la casella Nascondi grafica di sfondo per nascondere elementi basati sul tema come linee decorative, forme o loghi.
Nota: Questo nasconde solo gli elementi ereditati dal Master diapositive. Non rimuove immagini o oggetti aggiunti manualmente alla diapositiva.
2. Rimuovi elementi di sfondo tramite Master diapositive
- Vai alla scheda Visualizza e seleziona Master diapositive.
- Nel riquadro sinistro, seleziona il master diapositiva principale o il layout specifico.
- Fai clic sulla grafica di sfondo o sul logo che desideri rimuovere e premi Elimina.
- Fai clic su Chiudi visualizzazione master per applicare le modifiche.
Metodo 3. Rimuovi lo sfondo di un'immagine in PowerPoint (Strumento Rimuovi sfondo)
Se hai bisogno di rimuovere lo sfondo da un'immagine in PowerPoint, lo strumento integrato Rimuovi sfondo offre una soluzione rapida ed efficace. Rileva automaticamente il soggetto principale e rimuove le aree indesiderate con un minimo aggiustamento manuale. Questo metodo è ideale per ripulire le immagini direttamente nelle tue diapositive senza utilizzare strumenti esterni.
Passaggi:
-
Seleziona l'immagine da cui vuoi rimuovere lo sfondo.
-
Vai alla scheda Formato immagine.
-
Seleziona Rimuovi sfondo. PowerPoint evidenzierà lo sfondo in viola.
-
Regola la selezione usando Segna aree da mantenere o Segna aree da rimuovere, se necessario.
-
Fai clic su Mantieni modifiche per applicare la rimozione dello sfondo.
Suggerimenti e note:
- Questo metodo funziona meglio quando c'è un chiaro contrasto tra il soggetto e lo sfondo.
- La funzionalità Rimuovi sfondo è disponibile nelle versioni desktop recenti, come PowerPoint per Microsoft 365, 2024 e 2021, ma potrebbe non essere supportata in alcune versioni web.
- Per le immagini con uno sfondo a tinta unita, vai su Formato immagine > Colore > Imposta colore trasparente, quindi fai clic sullo sfondo per renderlo trasparente rapidamente.
Quando usarlo: Usalo per rimuovere sfondi dalle immagini mantenendo il soggetto principale.
Metodo 4. Cancella lo sfondo in PowerPoint automaticamente con VBA
Se hai bisogno di eseguire attività ripetitive di rimozione dello sfondo, VBA offre un modo per automatizzare il processo all'interno di PowerPoint. Eseguendo una semplice macro, puoi aggiornare più diapositive senza lavoro manuale. Questo metodo è utile per gli utenti che hanno familiarità con lo scripting di base.
Macro VBA per rimuovere gli sfondi da tutte le diapositive
Questo script scorre ogni diapositiva nella presentazione attiva, disabilita lo sfondo del master e cancella automaticamente gli elementi di sfondo.
Sub RemoveAllBackgrounds()
Dim sld As Slide
' Loop through each slide in the presentation
For Each sld In ActivePresentation.Slides
' Follow Master Background: Set to False to customize
sld.FollowMasterBackground = msoFalse
' Set the background fill to visible = false (Transparent/No Fill)
sld.Background.Fill.Visible = msoFalse
' Alternatively, hide background graphics (like logos/themes)
sld.DisplayMasterShapes = msoFalse
Next sld
MsgBox "All slide backgrounds have been removed!", vbInformation
End Sub
Proprietà chiave spiegate:
- FollowMasterBackground: Impostato su msoFalse per sovrascrivere lo sfondo del Master diapositive.
- DisplayMasterShapes: Nasconde gli elementi di sfondo come loghi o forme di progettazione dal Master diapositive.
- Background.Fill.Visible: Controlla se il riempimento dello sfondo è visibile.
Come usare lo script:
- Premi Alt + F11 per aprire l'Editor VBA.
- Vai su Inserisci > Modulo.
- Incolla il codice nella finestra del modulo.
- Premi F5 o fai clic sul pulsante Esegui per eseguire la macro.
Note:
- Questo metodo non rimuove le immagini inserite come forme. Se il tuo sfondo è un oggetto immagine, avrai bisogno di uno script separato per eliminare tali forme.
- Salva sempre una copia della tua presentazione prima di eseguire macro, poiché le azioni VBA non possono essere annullate.
- Se le macro sono disabilitate, vai su File > Opzioni > Centro protezione > Impostazioni Centro protezione > Impostazioni macro per abilitarle.
Quando usarlo: Ideale per automatizzare attività ripetitive di rimozione dello sfondo all'interno di PowerPoint.
Metodo 5. Rimuovi in blocco lo sfondo in PowerPoint con Python
Per attività su larga scala che coinvolgono più file di PowerPoint, l'uso di Python può migliorare significativamente l'efficienza. Con la libreria giusta come Spire.Presentation per Python, puoi automatizzare la rimozione dello sfondo tra le presentazioni senza aprire PowerPoint manualmente. Questo metodo è ideale per l'elaborazione in blocco e i flussi di lavoro backend.
Guida passo passo:
-
Installa la libreria tramite pip:
pip install spire.presentation -
Scrivi lo script Python:
Il seguente esempio mostra come rimuovere in blocco lo sfondo delle diapositive da più file .pptx di PowerPoint:
from spire.presentation import * import os # Folder containing the PPTX files to process input_folder = "presentations" # Folder with all the PPTX files output_folder = "processed" # Folder to save processed files # Create output folder if it doesn't exist if not os.path.exists(output_folder): os.makedirs(output_folder) # Loop through all PPTX files in the input folder for filename in os.listdir(input_folder): if filename.lower().endswith(".pptx"): input_path = os.path.join(input_folder, filename) output_path = os.path.join(output_folder, f"RemoveBackground_{filename}") # Load the presentation presentation = Presentation() presentation.LoadFromFile(input_path) # Loop through each slide and remove background for slide in presentation.Slides: slide.SlideBackground.Type = BackgroundType.none # Save the modified presentation presentation.SaveToFile(output_path, FileFormat.Pptx2010) presentation.Dispose() print(f"Processed: {filename} → {output_path}") print("All presentations have been processed successfully.")
Suggerimento: Oltre a rimuovere lo sfondo dalle diapositive, puoi anche rimuovere lo sfondo dai master diapositive.
Quando usarlo: Ideale per l'elaborazione in blocco di più file di PowerPoint in modo efficiente.
Confronto: Quale metodo dovresti scegliere?
Scegliere il modo giusto per rimuovere lo sfondo in PowerPoint dipende da quante diapositive stai elaborando e se hai bisogno di automazione.
Ecco un rapido confronto dei cinque metodi:
| Metodo | Ideale per | Ambito | Livello di competenza |
|---|---|---|---|
| Formato sfondo | Pulizia rapida delle diapositive | Singole / poche diapositive | Principiante |
| Master diapositive | Coerenza a livello di presentazione | Intera presentazione | Principiante |
| Rimuovi sfondo (Immagine) | Modifica immagini | Singole immagini | Principiante |
| VBA | Attività ripetitive all'interno di PowerPoint | Più diapositive | Intermedio |
| Python | Elaborazione in blocco | Più presentazioni | Avanzato |
Raccomandazione rapida:
- Per la maggior parte degli utenti, Formato sfondo e Master diapositive sono sufficienti per le attività quotidiane.
- Usa VBA se hai bisogno di automatizzare azioni ripetute all'interno di PowerPoint.
- Scegli Python se hai bisogno di elaborare più file o creare flussi di lavoro automatizzati.
Perché rimuovere lo sfondo in PowerPoint
Rimuovere gli sfondi in PowerPoint non è solo una questione di pulizia visiva, ma può migliorare significativamente l'aspetto e le prestazioni della tua presentazione. Ecco i principali vantaggi:
- Migliore chiarezza visiva: Rimuovi elementi distraenti che competono con il tuo contenuto.
- Coerenza del marchio: Elimina sfondi incoerenti o indesiderati.
- Migliore leggibilità: Gli sfondi puliti aiutano il testo a risaltare più chiaramente.
- Design semplificato: Rimuovi elementi visivi non necessari e concentrati sulle informazioni chiave.
- Qualità professionale: Crea presentazioni pulite e prive di distrazioni.
Problemi comuni di rimozione dello sfondo e soluzioni
- Grafica di sfondo o loghi ancora visibili - Questi elementi fanno spesso parte del Master diapositive. Per rimuoverli, vai su Visualizza > Master diapositive, seleziona la diapositiva principale o i layout interessati, elimina gli elementi, quindi chiudi la visualizzazione master.
- Impossibile rimuovere lo sfondo - La presentazione potrebbe essere protetta o limitata. Controlla le autorizzazioni di modifica del file e abilita la modifica se necessario prima di apportare modifiche.
- Le modifiche non si applicano a tutte le diapositive - La rimozione dello sfondo su una diapositiva non influisce sulle altre. Usa Applica a tutte nel riquadro Formato sfondo o aggiorna il Master diapositive per applicare le modifiche all'intera presentazione.
FAQ: Come rimuovere lo sfondo in PowerPoint
D1: Posso rimuovere gli sfondi da tutte le diapositive contemporaneamente?
R1: Sì, utilizzando Master diapositive, VBA o automazione Python, puoi rimuovere gli sfondi in tutta la presentazione o in più file.
D2: Posso rimuovere gli sfondi senza PowerPoint?
R2: Sì, le librerie Python come Spire.Presentation consentono la rimozione degli sfondi senza che Microsoft PowerPoint sia installato.
D3: La rimozione dello sfondo influenzerà le immagini o il testo nelle mie diapositive?
R3: No, la rimozione dello sfondo della diapositiva in genere non influisce su altri contenuti della diapositiva come caselle di testo o immagini. Tuttavia, crea sempre un backup prima di utilizzare strumenti automatizzati come script VBA o Python per evitare modifiche accidentali.
D4: È sicuro usare VBA per la rimozione dello sfondo di PowerPoint?
R4: Sì, a condizione che tu abiliti le macro solo da fonti attendibili e salvi un backup prima di eseguire lo script.
Vedi anche
Comment supprimer l'arrière-plan dans PowerPoint : 5 méthodes simples
Table des matières
- Réponse rapide : Comment supprimer l'arrière-plan dans PowerPoint
- Méthode 1. Supprimer l'arrière-plan d'une diapositive PowerPoint (Format d'arrière-plan)
- Méthode 2. Supprimer rapidement l'arrière-plan de toutes les diapositives PowerPoint (Masque de diapositives)
- Méthode 3. Supprimer l'arrière-plan d'une image dans PowerPoint (Outil Supprimer l'arrière-plan)
- Méthode 4. Effacer l'arrière-plan dans PowerPoint automatiquement avec VBA
- Méthode 5. Supprimer l'arrière-plan par lots dans PowerPoint avec Python
- Comparaison : Quelle méthode choisir ?
- Pourquoi supprimer l'arrière-plan dans PowerPoint
- Problèmes courants de suppression d'arrière-plan et solutions
- FAQ : Comment supprimer l'arrière-plan dans PowerPoint
Les arrière-plans encombrés ou distrayants dans PowerPoint peuvent parfois rendre vos présentations peu professionnelles, difficiles à lire et réduire l'engagement du public. Apprendre comment supprimer l'arrière-plan dans PowerPoint vous aide à nettoyer rapidement les diapositives, à améliorer la lisibilité et à maintenir un aspect cohérent et professionnel.
Dans ce guide, nous vous présenterons 5 méthodes pratiques pour supprimer l'arrière-plan dans PowerPoint - couvrant les diapositives uniques, les images, les présentations entières, et même plusieurs fichiers - afin que vous puissiez créer des diapositives propres et soignées plus efficacement.
Aperçu du contenu
- Réponse rapide : Comment supprimer l'arrière-plan dans PowerPoint
- Méthode 1. Supprimer l'arrière-plan d'une diapositive PowerPoint (Format d'arrière-plan)
- Méthode 2. Supprimer rapidement l'arrière-plan de toutes les diapositives PowerPoint (Masque de diapositives)
- Méthode 3. Supprimer l'arrière-plan d'une image dans PowerPoint (Outil Supprimer l'arrière-plan)
- Méthode 4. Effacer l'arrière-plan dans PowerPoint automatiquement avec VBA
- Méthode 5. Supprimer l'arrière-plan par lots dans PowerPoint avec Python
- Comparaison : Quelle méthode choisir ?
- Pourquoi supprimer l'arrière-plan dans PowerPoint
- Problèmes courants de suppression d'arrière-plan et solutions
- FAQ : Comment supprimer l'arrière-plan dans PowerPoint
Réponse rapide : Comment supprimer l'arrière-plan dans PowerPoint
Si vous souhaitez supprimer rapidement l'arrière-plan dans PowerPoint, voici les méthodes les plus simples :
- Utiliser Format d'arrière-plan - idéal pour les diapositives uniques.
- Utiliser le Masque de diapositives - idéal pour toutes les diapositives.
- Utiliser Supprimer l'arrière-plan - idéal pour les images.
Continuez à lire pour obtenir des instructions étape par étape et des méthodes avancées comme VBA et Python.
Méthode 1. Supprimer l'arrière-plan d'une diapositive PowerPoint (Format d'arrière-plan)
Si vous souhaitez supprimer rapidement l'arrière-plan d'une diapositive, la fonctionnalité Format d'arrière-plan est l'option la plus simple. Elle vous permet d'effacer l'arrière-plan existant sans affecter le texte ou d'autres éléments. Cette méthode fonctionne mieux lorsque vous devez nettoyer une ou quelques diapositives.
Étapes :
-
Sélectionnez la diapositive dont vous souhaitez supprimer l'arrière-plan.
-
Accédez à l'onglet Création et cliquez sur Format d'arrière-plan (ou faites un clic droit sur la diapositive et choisissez Format d'arrière-plan).
-
Dans le volet Format d'arrière-plan, sélectionnez Remplissage uni.
-
Cliquez sur le bouton Couleur et choisissez la couleur blanche dans la liste déroulante. L'arrière-plan est maintenant supprimé des diapositives sélectionnées.
Astuce de pro : Si vous souhaitez que cette modification s'applique à toutes les diapositives de votre présentation, cliquez sur Appliquer partout en bas du volet Format d'arrière-plan.
Quand l'utiliser : Utilisez-la lorsque vous avez seulement besoin de nettoyer des diapositives individuelles sans affecter le reste de la présentation.
Si vous souhaitez modifier ou personnaliser les arrière-plans au lieu de les supprimer, consultez notre guide sur la modification des arrière-plans des diapositives PowerPoint.
Méthode 2. Supprimer rapidement l'arrière-plan de toutes les diapositives PowerPoint (Masque de diapositives)
Lorsque vous devez supprimer l'arrière-plan de toutes les diapositives dans PowerPoint, l'utilisation du Masque de diapositives est l'approche la plus efficace. Il vous permet d'effacer les paramètres d'arrière-plan sur plusieurs diapositives à la fois à partir d'un seul endroit. Cette méthode est idéale pour éliminer les arrière-plans indésirables tout en maintenant la cohérence des diapositives sans les modifier une par une.
Étapes :
-
Accédez à l'onglet Affichage et sélectionnez Masque de diapositives dans le groupe Vues Masque.
-
Dans le volet de gauche, choisissez le masque de diapositives ou la mise en page spécifique que vous souhaitez modifier.
-
Dans le groupe Arrière-plan, cliquez sur Styles d'arrière-plan > Format d'arrière-plan.
-
Dans le volet Format d'arrière-plan, sélectionnez Remplissage uni et choisissez la couleur blanche dans le sélecteur de couleurs.
-
Cliquez sur Fermer le masque de diapositives pour appliquer les modifications à toutes les diapositives associées.
Astuce : Si plusieurs mises en page utilisent le même arrière-plan, assurez-vous de mettre à jour chaque mise en page dans le Masque de diapositives.
Quand l'utiliser : Utilisez-la pour appliquer une suppression d'arrière-plan cohérente sur l'ensemble d'une présentation.
Dépannage des arrière-plans récalcitrants
Si des éléments d'arrière-plan apparaissent toujours après la suppression, ils font généralement partie du thème de la diapositive ou sont stockés dans le Masque de diapositives. Utilisez les méthodes ci-dessous pour les masquer ou les supprimer.
1. Masquer les graphiques d'arrière-plan du thème
-
Ouvrez le volet Format d'arrière-plan.
-
Cochez la case Masquer les graphiques d'arrière-plan pour masquer les éléments basés sur le thème tels que les lignes décoratives, les formes ou les logos.
Remarque : Cela ne masque que les éléments hérités du Masque de diapositives. Cela ne supprime pas les images ou les objets qui ont été ajoutés manuellement à la diapositive.
2. Supprimer les éléments d'arrière-plan via le Masque de diapositives
- Accédez à l'onglet Affichage et sélectionnez Masque de diapositives.
- Dans le volet de gauche, sélectionnez le masque parent (supérieur) ou la mise en page spécifique.
- Cliquez sur le graphique d'arrière-plan ou le logo que vous souhaitez supprimer et appuyez sur Supprimer.
- Cliquez sur Fermer la vue Masque pour appliquer les modifications.
Méthode 3. Supprimer l'arrière-plan d'une image dans PowerPoint (Outil Supprimer l'arrière-plan)
Si vous avez besoin de supprimer l'arrière-plan d'une image dans PowerPoint, l'outil intégré Supprimer l'arrière-plan offre une solution rapide et efficace. Il détecte automatiquement le sujet principal et supprime les zones indésirables avec un minimum d'ajustements manuels. Cette méthode est idéale pour nettoyer les images directement dans vos diapositives sans utiliser d'outils externes.
Étapes :
-
Sélectionnez l'image dont vous souhaitez supprimer l'arrière-plan.
-
Accédez à l'onglet Format de l'image.
-
Sélectionnez Supprimer l'arrière-plan. PowerPoint mettra en surbrillance l'arrière-plan en violet.
-
Ajustez la sélection en utilisant Marquer les zones à conserver ou Marquer les zones à supprimer si nécessaire.
-
Cliquez sur Conserver les modifications pour appliquer la suppression de l'arrière-plan.
Conseils et notes :
- Cette méthode fonctionne mieux lorsqu'il y a un contraste clair entre le sujet et l'arrière-plan.
- La fonctionnalité Supprimer l'arrière-plan est disponible dans les versions de bureau récentes, comme PowerPoint pour Microsoft 365, 2024 et 2021, mais peut ne pas être prise en charge dans certaines versions web.
- Pour les images avec un arrière-plan de couleur unie, accédez à Format de l'image > Couleur > Définir la couleur transparente, puis cliquez sur l'arrière-plan pour le rendre transparent rapidement.
Quand l'utiliser : Utilisez-la pour supprimer les arrière-plans des images tout en conservant le sujet principal.
Méthode 4. Effacer l'arrière-plan dans PowerPoint automatiquement avec VBA
Si vous avez besoin d'effectuer des tâches répétitives de suppression d'arrière-plan, VBA offre un moyen d'automatiser le processus dans PowerPoint. En exécutant une macro simple, vous pouvez mettre à jour plusieurs diapositives sans travail manuel. Cette méthode est utile pour les utilisateurs familiers avec les scripts de base.
Macro VBA pour supprimer les arrière-plans de toutes les diapositives
Ce script parcourt chaque diapositive de la présentation active, désactive l'arrière-plan du masque et efface automatiquement les éléments d'arrière-plan.
Sub RemoveAllBackgrounds()
Dim sld As Slide
' Parcourir chaque diapositive de la présentation
For Each sld In ActivePresentation.Slides
' Suivre l'arrière-plan du masque : définir sur False pour personnaliser
sld.FollowMasterBackground = msoFalse
' Définir le remplissage de l'arrière-plan sur visible = false (Transparent/Aucun remplissage)
sld.Background.Fill.Visible = msoFalse
' Alternativement, masquer les graphiques d'arrière-plan (logos/thèmes)
sld.DisplayMasterShapes = msoFalse
Next sld
MsgBox "Tous les arrière-plans des diapositives ont été supprimés !", vbInformation
End Sub
Propriétés clés expliquées :
- FollowMasterBackground : Défini sur msoFalse pour remplacer l'arrière-plan du Masque de diapositives.
- DisplayMasterShapes : Masque les éléments d'arrière-plan tels que les logos ou les formes de conception du Masque de diapositives.
- Background.Fill.Visible : Contrôle la visibilité du remplissage de l'arrière-plan.
Comment utiliser le script :
- Appuyez sur Alt + F11 pour ouvrir l'éditeur VBA.
- Accédez à Insertion > Module.
- Collez le code dans la fenêtre du module.
- Appuyez sur F5 ou cliquez sur le bouton Exécuter pour exécuter la macro.
Remarques :
- Cette méthode ne supprime pas les images insérées sous forme de formes. Si votre arrière-plan est un objet image, vous aurez besoin d'un script séparé pour supprimer ces formes.
- Sauvegardez toujours une copie de votre présentation avant d'exécuter des macros, car les actions VBA ne peuvent pas être annulées.
- Si les macros sont désactivées, accédez à Fichier > Options > Centre de gestion de la confidentialité > Paramètres du Centre de gestion de la confidentialité > Paramètres des macros pour les activer.
Quand l'utiliser : Idéal pour automatiser les tâches répétitives de suppression d'arrière-plan dans PowerPoint.
Méthode 5. Supprimer l'arrière-plan par lots dans PowerPoint avec Python
Pour les tâches à grande échelle impliquant plusieurs fichiers PowerPoint, l'utilisation de Python peut améliorer considérablement l'efficacité. Avec la bonne bibliothèque comme Spire.Presentation pour Python, vous pouvez automatiser la suppression d'arrière-plan dans les présentations sans ouvrir PowerPoint manuellement. Cette méthode est idéale pour le traitement par lots et les flux de travail backend.
Guide étape par étape :
-
Installez la bibliothèque via pip :
pip install spire.presentation -
Écrire un script Python :
L'exemple suivant montre comment supprimer par lots l'arrière-plan des diapositives de plusieurs fichiers .pptx PowerPoint :
from spire.presentation import * import os # Dossier contenant les fichiers PPTX à traiter input_folder = "presentations" # Dossier avec tous les fichiers PPTX output_folder = "processed" # Dossier pour enregistrer les fichiers traités # Créer le dossier de sortie s'il n'existe pas if not os.path.exists(output_folder): os.makedirs(output_folder) # Parcourir tous les fichiers PPTX dans le dossier d'entrée for filename in os.listdir(input_folder): if filename.lower().endswith(".pptx"): input_path = os.path.join(input_folder, filename) output_path = os.path.join(output_folder, f"RemoveBackground_{filename}") # Charger la présentation presentation = Presentation() presentation.LoadFromFile(input_path) # Parcourir chaque diapositive et supprimer l'arrière-plan for slide in presentation.Slides: slide.SlideBackground.Type = BackgroundType.none # Enregistrer la présentation modifiée presentation.SaveToFile(output_path, FileFormat.Pptx2010) presentation.Dispose() print(f"Traité : {filename} → {output_path}") print("Toutes les présentations ont été traitées avec succès.")
Astuce : En plus de supprimer l'arrière-plan des diapositives, vous pouvez également supprimer l'arrière-plan des masques de diapositives.
Quand l'utiliser : Idéal pour traiter efficacement plusieurs fichiers PowerPoint par lots.
Comparaison : Quelle méthode choisir ?
Choisir la bonne façon de supprimer l'arrière-plan dans PowerPoint dépend du nombre de diapositives sur lesquelles vous travaillez et si vous avez besoin d'automatisation.
Voici une comparaison rapide des cinq méthodes :
| Méthode | Idéal pour | Portée | Niveau de compétence |
|---|---|---|---|
| Format d'arrière-plan | Nettoyage rapide de diapositives | Diapositives uniques / quelques-unes | Débutant |
| Masque de diapositives | Cohérence à l'échelle de la présentation | Présentation entière | Débutant |
| Supprimer l'arrière-plan (Image) | Édition d'images | Images individuelles | Débutant |
| VBA | Tâches répétitives dans PowerPoint | Plusieurs diapositives | Intermédiaire |
| Python | Traitement par lots | Plusieurs présentations | Avancé |
Recommandation rapide :
- Pour la plupart des utilisateurs, Format d'arrière-plan et Masque de diapositives suffisent pour les tâches quotidiennes.
- Utilisez VBA si vous avez besoin d'automatiser des actions répétées dans PowerPoint.
- Choisissez Python si vous avez besoin de traiter plusieurs fichiers ou de créer des flux de travail automatisés.
Pourquoi supprimer l'arrière-plan dans PowerPoint
Supprimer les arrière-plans dans PowerPoint ne se limite pas à un nettoyage visuel - cela peut améliorer considérablement l'apparence et les performances de votre présentation. Voici les principaux avantages :
- Clarté visuelle améliorée : Supprimez les éléments distrayants qui rivalisent avec votre contenu.
- Cohérence de la marque : Éliminez les arrière-plans incohérents ou indésirables.
- Lisibilité améliorée : Les arrière-plans clairs aident le texte à ressortir plus nettement.
- Conception simplifiée : Retirez les visuels inutiles et concentrez-vous sur les informations clés.
- Qualité professionnelle : Créez des présentations propres et sans distraction.
Problèmes courants de suppression d'arrière-plan et solutions
- Les graphiques d'arrière-plan ou les logos sont toujours visibles - Ces éléments font souvent partie du Masque de diapositives. Pour les supprimer, accédez à Affichage > Masque de diapositives, sélectionnez le masque parent ou les mises en page affectées, supprimez les éléments, puis fermez la vue Masque.
- Impossible de supprimer l'arrière-plan - La présentation peut être protégée ou restreinte. Vérifiez les autorisations de modification du fichier et activez la modification si nécessaire avant d'apporter des modifications.
- Les modifications ne s'appliquent pas à toutes les diapositives - La suppression de l'arrière-plan sur une diapositive n'affecte pas les autres. Utilisez Appliquer partout dans le volet Format d'arrière-plan ou mettez à jour le Masque de diapositives pour appliquer les modifications à l'ensemble de la présentation.
FAQ : Comment supprimer l'arrière-plan dans PowerPoint
Q1 : Puis-je supprimer les arrière-plans de toutes les diapositives en une seule fois ?
R1 : Oui, en utilisant le Masque de diapositives, VBA ou l'automatisation Python, vous pouvez supprimer les arrière-plans sur l'ensemble d'une présentation ou sur plusieurs fichiers.
Q2 : Puis-je supprimer les arrière-plans sans PowerPoint ?
R2 : Oui, les bibliothèques Python comme Spire.Presentation permettent de supprimer les arrière-plans sans avoir Microsoft PowerPoint installé.
Q3 : La suppression de l'arrière-plan affectera-t-elle les images ou le texte de mes diapositives ?
R3 : Non, la suppression de l'arrière-plan de la diapositive n'affecte généralement pas le contenu des autres diapositives comme les zones de texte ou les images. Cependant, créez toujours une sauvegarde avant d'utiliser des outils automatisés comme les scripts VBA ou Python pour éviter les modifications accidentelles.
Q4 : Est-il sûr d'utiliser VBA pour supprimer l'arrière-plan de PowerPoint ?
R4 : Oui, à condition d'activer les macros uniquement à partir de sources fiables et de sauvegarder une copie avant d'exécuter le script.
Voir aussi
Cómo quitar el fondo en PowerPoint: 5 formas sencillas
Tabla de Contenidos
- Respuesta Rápida: Cómo Eliminar Fondo en PowerPoint
- Método 1. Eliminar Fondo de Diapositiva de PowerPoint (Formato de Fondo)
- Método 2. Eliminar Fondo de Todas las Diapositivas de PowerPoint Rápidamente (Patrón de Diapositivas)
- Método 3. Eliminar Fondo de Imagen en PowerPoint (Herramienta Eliminar Fondo)
- Método 4. Borrar Fondo en PowerPoint Automáticamente con VBA
- Método 5. Eliminar Fondo en Lote en PowerPoint con Python
- Comparación: ¿Qué Método Deberías Elegir?
- Por Qué Eliminar Fondo en PowerPoint
- Problemas Comunes de Eliminación de Fondo y Soluciones
- Preguntas Frecuentes: Cómo Eliminar Fondo en PowerPoint
Los fondos desordenados o que distraen en PowerPoint a veces pueden hacer que tus presentaciones parezcan poco profesionales, difíciles de leer y reducir la participación de la audiencia. Aprender cómo eliminar fondo en PowerPoint te ayuda a limpiar diapositivas rápidamente, mejorar la legibilidad y mantener un aspecto consistente y profesional.
En esta guía, te mostraremos 5 métodos prácticos para eliminar fondo en PowerPoint, cubriendo diapositivas individuales, imágenes, presentaciones completas e incluso múltiples archivos, para que puedas crear diapositivas limpias y pulidas de manera más eficiente.
Resumen de Contenidos
- Respuesta Rápida: Cómo Eliminar Fondo en PowerPoint
- Método 1. Eliminar Fondo de Diapositiva de PowerPoint (Formato de Fondo)
- Método 2. Eliminar Fondo de Todas las Diapositivas de PowerPoint Rápidamente (Patrón de Diapositivas)
- Método 3. Eliminar Fondo de Imagen en PowerPoint (Herramienta Eliminar Fondo)
- Método 4. Borrar Fondo en PowerPoint Automáticamente con VBA
- Método 5. Eliminar Fondo en Lote en PowerPoint con Python
- Comparación: ¿Qué Método Deberías Elegir?
- Por Qué Eliminar Fondo en PowerPoint
- Problemas Comunes de Eliminación de Fondo y Soluciones
- Preguntas Frecuentes: Cómo Eliminar Fondo en PowerPoint
Respuesta Rápida: Cómo Eliminar Fondo en PowerPoint
Si deseas eliminar el fondo en PowerPoint rápidamente, aquí tienes los métodos más fáciles:
- Usar Formato de Fondo - mejor para diapositivas individuales.
- Usar Patrón de Diapositivas - mejor para todas las diapositivas.
- Usar Eliminar Fondo - mejor para imágenes.
Sigue leyendo para obtener instrucciones paso a paso y métodos avanzados como VBA y Python.
Método 1. Eliminar Fondo de Diapositiva de PowerPoint (Formato de Fondo)
Si deseas eliminar el fondo de una diapositiva rápidamente, la función Formato de Fondo es la opción más directa. Te permite borrar el fondo existente sin afectar el texto u otros elementos. Este método funciona mejor cuando necesitas limpiar una o pocas diapositivas.
Pasos:
-
Selecciona la diapositiva de la que deseas eliminar el fondo.
-
Ve a la pestaña Diseño y haz clic en Formato de Fondo (o haz clic derecho en la diapositiva y elige Formato de Fondo).
-
En el panel Formato de Fondo, selecciona Relleno sólido.
-
Haz clic en el botón Color y elige el color blanco del menú desplegable. El fondo ahora se ha eliminado de las diapositivas seleccionadas.
Consejo Profesional: Si deseas que este cambio se aplique a todas las diapositivas de tu presentación, haz clic en Aplicar a todas en la parte inferior del panel Formato de Fondo.
Cuándo usar: Úsalo cuando solo necesites limpiar diapositivas individuales sin afectar el resto de la presentación.
Si deseas cambiar o personalizar fondos en lugar de eliminarlos, consulta nuestra guía sobre cambiar fondos de diapositivas de PowerPoint.
Método 2. Eliminar Fondo de Todas las Diapositivas de PowerPoint Rápidamente (Patrón de Diapositivas)
Cuando necesites eliminar el fondo de todas las diapositivas en PowerPoint, usar Patrón de Diapositivas es el enfoque más eficiente. Te permite borrar configuraciones de fondo en múltiples diapositivas a la vez desde un solo lugar. Este método es ideal para eliminar fondos no deseados manteniendo las diapositivas consistentes sin editarlas una por una.
Pasos:
-
Navega a la pestaña Vista y selecciona Patrón de Diapositivas en el grupo Vistas Patrón.
-
En el panel izquierdo, elige el patrón de diapositiva o el diseño específico que deseas editar.
-
En el grupo Fondo, haz clic en Estilos de Fondo > Formato de Fondo.
-
En el panel Formato de Fondo, selecciona Relleno sólido y elige el color blanco del selector de color.
-
Haz clic en Cerrar Patrón de Diapositivas para aplicar los cambios a todas las diapositivas relacionadas.
Consejo: Si tienes varios diseños que usan el mismo fondo, asegúrate de actualizar cada diseño en el Patrón de Diapositivas.
Cuándo usar: Úsalo para aplicar la eliminación de fondo consistente en toda una presentación.
Solución de Problemas de Fondos Rebeldes
Si los elementos de fondo aún aparecen después de la eliminación, generalmente forman parte del tema de la diapositiva o se almacenan en el Patrón de Diapositivas. Usa los métodos a continuación para ocultarlos o eliminarlos.
1. Ocultar Gráficos de Fondo del Tema
-
Abre el panel Formato de Fondo.
-
Marca la casilla Ocultar gráficos de fondo para ocultar elementos basados en el tema, como líneas decorativas, formas o logotipos.
Nota: Esto solo oculta elementos heredados del Patrón de Diapositivas. No elimina imágenes u objetos que se agregaron manualmente a la diapositiva.
2. Eliminar Elementos de Fondo a través del Patrón de Diapositivas
- Ve a la pestaña Vista y selecciona Patrón de Diapositivas.
- En el panel izquierdo, selecciona el patrón principal (superior) o el diseño específico.
- Haz clic en el gráfico de fondo o logotipo que deseas eliminar y presiona Eliminar.
- Haz clic en Cerrar Vista de Patrón para aplicar los cambios.
Método 3. Eliminar Fondo de Imagen en PowerPoint (Herramienta Eliminar Fondo)
Si necesitas eliminar el fondo de una imagen en PowerPoint, la herramienta integrada Eliminar Fondo proporciona una solución rápida y efectiva. Detecta automáticamente el sujeto principal y elimina las áreas no deseadas con un ajuste manual mínimo. Este método es ideal para limpiar imágenes directamente en tus diapositivas sin usar herramientas externas.
Pasos:
-
Selecciona la imagen de la que deseas eliminar el fondo.
-
Ve a la pestaña Formato de imagen.
-
Selecciona Eliminar Fondo. PowerPoint resaltará el fondo en púrpura.
-
Ajusta la selección usando Marcar áreas para mantener o Marcar áreas para eliminar si es necesario.
-
Haz clic en Mantener cambios para aplicar la eliminación del fondo.
Consejos y Notas:
- Este método funciona mejor cuando hay un claro contraste entre el sujeto y el fondo.
- La función Eliminar Fondo está disponible en versiones de escritorio recientes, como PowerPoint para Microsoft 365, 2024 y 2021, pero puede no ser compatible con algunas versiones web.
- Para imágenes con un fondo de color sólido, ve a Formato de imagen > Color > Establecer color transparente, luego haz clic en el fondo para hacerlo transparente rápidamente.
Cuándo usar: Úsalo para eliminar fondos de imágenes manteniendo el sujeto principal.
Método 4. Borrar Fondo en PowerPoint Automáticamente con VBA
Si necesitas realizar tareas repetitivas de eliminación de fondo, VBA ofrece una forma de automatizar el proceso dentro de PowerPoint. Al ejecutar una macro simple, puedes actualizar múltiples diapositivas sin trabajo manual. Este método es útil para usuarios familiarizados con scripting básico.
Macro VBA para Eliminar Fondos de Todas las Diapositivas
Este script recorre cada diapositiva en la presentación activa, deshabilita el fondo del patrón y borra los elementos de fondo automáticamente.
Sub RemoveAllBackgrounds()
Dim sld As Slide
' Recorre cada diapositiva de la presentación
For Each sld In ActivePresentation.Slides
' Seguir Fondo del Patrón: Establecer a False para personalizar
sld.FollowMasterBackground = msoFalse
' Establecer el relleno del fondo a visible = falso (Transparente/Sin Relleno)
sld.Background.Fill.Visible = msoFalse
' Alternativamente, ocultar gráficos de fondo (como logotipos/temas)
sld.DisplayMasterShapes = msoFalse
Next sld
MsgBox "¡Se han eliminado todos los fondos de las diapositivas!", vbInformation
End Sub
Propiedades Clave Explicadas:
- FollowMasterBackground: Establecido a msoFalse para anular el fondo del Patrón de Diapositivas.
- DisplayMasterShapes: Oculta elementos de fondo como logotipos o formas de diseño del Patrón de Diapositivas.
- Background.Fill.Visible: Controla si el relleno del fondo es visible.
Cómo usar el script:
- Presiona Alt + F11 para abrir el Editor de VBA.
- Ve a Insertar > Módulo.
- Pega el código en la ventana del módulo.
- Presiona F5 o haz clic en el botón Ejecutar para ejecutar la macro.
Notas:
- Este método no elimina imágenes insertadas como formas. Si tu fondo es un objeto de imagen, necesitarás un script separado para eliminar esas formas.
- Siempre guarda una copia de tu presentación antes de ejecutar macros, ya que las acciones de VBA no se pueden deshacer.
- Si las macros están deshabilitadas, ve a Archivo > Opciones > Centro de confianza > Configuración del Centro de confianza > Configuración de macros para habilitarlas.
Cuándo Usar: Ideal para automatizar tareas repetitivas de eliminación de fondo dentro de PowerPoint.
Método 5. Eliminar Fondo en Lote en PowerPoint con Python
Para tareas a gran escala que involucran múltiples archivos de PowerPoint, usar Python puede mejorar significativamente la eficiencia. Con la biblioteca adecuada como Spire.Presentation para Python, puedes automatizar la eliminación de fondo en presentaciones sin abrir PowerPoint manualmente. Este método es ideal para procesamiento por lotes y flujos de trabajo de backend.
Guía Paso a Paso:
-
Instala la biblioteca a través de pip:
pip install spire.presentation -
Escribe el Script de Python:
El siguiente ejemplo muestra cómo eliminar el fondo de diapositivas en lote de múltiples archivos .pptx de PowerPoint:
from spire.presentation import * import os # Carpeta que contiene los archivos PPTX a procesar input_folder = "presentations" # Carpeta con todos los archivos PPTX output_folder = "processed" # Carpeta para guardar los archivos procesados # Crea la carpeta de salida si no existe if not os.path.exists(output_folder): os.makedirs(output_folder) # Recorre todos los archivos PPTX en la carpeta de entrada for filename in os.listdir(input_folder): if filename.lower().endswith(".pptx"): input_path = os.path.join(input_folder, filename) output_path = os.path.join(output_folder, f"RemoveBackground_{filename}") # Carga la presentación presentation = Presentation() presentation.LoadFromFile(input_path) # Recorre cada diapositiva y elimina el fondo for slide in presentation.Slides: slide.SlideBackground.Type = BackgroundType.none # Guarda la presentación modificada presentation.SaveToFile(output_path, FileFormat.Pptx2010) presentation.Dispose() print(f"Procesado: {filename} → {output_path}") print("Todas las presentaciones han sido procesadas con éxito.")
Consejo: Además de eliminar el fondo de las diapositivas, también puedes eliminar el fondo de los patrones de diapositivas.
Cuándo usar: Ideal para procesar múltiples archivos de PowerPoint de manera eficiente en lote.
Comparación: ¿Qué Método Deberías Elegir?
Elegir la forma correcta de eliminar el fondo en PowerPoint depende de cuántas diapositivas estés trabajando y si necesitas automatización.
Aquí tienes una comparación rápida de los cinco métodos:
| Método | Mejor para | Alcance | Nivel de Habilidad |
|---|---|---|---|
| Formato de Fondo | Limpieza rápida de diapositivas | Diapositivas individuales / pocas | Principiante |
| Patrón de Diapositivas | Consistencia en toda la presentación | Presentación completa | Principiante |
| Eliminar Fondo (Imagen) | Edición de imágenes | Imágenes individuales | Principiante |
| VBA | Tareas repetitivas dentro de PowerPoint | Múltiples diapositivas | Intermedio |
| Python | Procesamiento por lotes | Múltiples presentaciones | Avanzado |
Recomendación Rápida:
- Para la mayoría de los usuarios, Formato de Fondo y Patrón de Diapositivas son suficientes para tareas cotidianas.
- Usa VBA si necesitas automatizar acciones repetidas dentro de PowerPoint.
- Elige Python si necesitas procesar múltiples archivos o construir flujos de trabajo automatizados.
Por Qué Eliminar Fondo en PowerPoint
Eliminar fondos en PowerPoint no es solo una cuestión de limpieza visual, puede mejorar significativamente la apariencia y el rendimiento de tu presentación. Aquí están los principales beneficios:
- Claridad Visual Mejorada: Elimina elementos distractores que compiten con tu contenido.
- Consistencia de Marca: Elimina fondos inconsistentes o no deseados.
- Legibilidad Mejorada: Los fondos limpios ayudan a que el texto resalte más claramente.
- Diseño Simplificado: Elimina elementos visuales innecesarios y enfócate en la información clave.
- Calidad Profesional: Crea presentaciones limpias y sin distracciones.
Problemas Comunes de Eliminación de Fondo y Soluciones
- Gráficos de fondo o logotipos aún visibles - Estos elementos a menudo forman parte del Patrón de Diapositivas. Para eliminarlos, ve a Vista > Patrón de Diapositivas, selecciona el patrón principal o los diseños afectados, elimina los elementos y luego cierra la Vista de Patrón.
- No se puede eliminar el fondo - La presentación puede estar protegida o restringida. Verifica los permisos de edición del archivo y habilita la edición si es necesario antes de realizar cambios.
- Los cambios no se aplican a todas las diapositivas - Eliminar el fondo en una diapositiva no afecta a las demás. Usa Aplicar a todas en el panel Formato de Fondo o actualiza el Patrón de Diapositivas para aplicar los cambios en toda la presentación.
Preguntas Frecuentes: Cómo Eliminar Fondo en PowerPoint
P1: ¿Puedo eliminar fondos de todas las diapositivas a la vez?
R1: Sí, usando Patrón de Diapositivas, VBA o automatización con Python, puedes eliminar fondos en toda una presentación o en múltiples archivos.
P2: ¿Puedo eliminar fondos sin PowerPoint?
R2: Sí, las bibliotecas de Python como Spire.Presentation permiten eliminar fondos sin tener Microsoft PowerPoint instalado.
P3: ¿Eliminar el fondo afectará las imágenes o el texto de mis diapositivas?
R3: No, eliminar el fondo de la diapositiva generalmente no afecta a otro contenido de la diapositiva como cuadros de texto o imágenes. Sin embargo, siempre crea una copia de seguridad antes de usar herramientas automatizadas como scripts de VBA o Python para evitar cambios accidentales.
P4: ¿Es seguro usar VBA para eliminar fondos de PowerPoint?
R4: Sí, siempre y cuando habilite las macros solo de fuentes confiables y guardes una copia de seguridad antes de ejecutar el script.
Ver También
Hintergrund in PowerPoint entfernen: 5 einfache Möglichkeiten
Inhaltsverzeichnis
- Schnelle Antwort: Hintergrund in PowerPoint entfernen
- Methode 1. Hintergrund von PowerPoint-Folie entfernen (Hintergrund formatieren)
- Methode 2. Hintergrund schnell von allen PowerPoint-Folien löschen (Folienmaster)
- Methode 3. Bildhintergrund in PowerPoint entfernen (Werkzeug Hintergrund entfernen)
- Methode 4. Hintergrund in PowerPoint automatisch mit VBA löschen
- Methode 5. Hintergrundstapelverarbeitung in PowerPoint mit Python
- Vergleich: Welche Methode sollten Sie wählen?
- Warum Hintergrund in PowerPoint entfernen
- Häufige Probleme bei der Hintergrundentfernung und Lösungen
- FAQs: Hintergrund in PowerPoint entfernen
Unübersichtliche oder ablenkende Hintergründe in PowerPoint können Ihre Präsentationen manchmal unprofessionell aussehen lassen, die Lesbarkeit erschweren und das Engagement des Publikums verringern. Zu lernen, wie man den Hintergrund in PowerPoint entfernt, hilft Ihnen, Folien schnell aufzuräumen, die Lesbarkeit zu verbessern und ein konsistentes, professionelles Erscheinungsbild beizubehalten.
In dieser Anleitung zeigen wir Ihnen 5 praktische Methoden, um Hintergründe in PowerPoint zu entfernen – für einzelne Folien, Bilder, ganze Präsentationen und sogar mehrere Dateien –, damit Sie sauberere, poliertere Folien effizienter erstellen können.
Übersicht der Inhalte
- Schnelle Antwort: Hintergrund in PowerPoint entfernen
- Methode 1. Hintergrund von PowerPoint-Folie entfernen (Hintergrund formatieren)
- Methode 2. Hintergrund schnell von allen PowerPoint-Folien löschen (Folienmaster)
- Methode 3. Bildhintergrund in PowerPoint entfernen (Werkzeug Hintergrund entfernen)
- Methode 4. Hintergrund in PowerPoint automatisch mit VBA löschen
- Methode 5. Hintergrundstapelverarbeitung in PowerPoint mit Python
- Vergleich: Welche Methode sollten Sie wählen?
- Warum Hintergrund in PowerPoint entfernen
- Häufige Probleme bei der Hintergrundentfernung und Lösungen
- FAQs: Hintergrund in PowerPoint entfernen
Schnelle Antwort: Hintergrund in PowerPoint entfernen
Wenn Sie den Hintergrund in PowerPoint schnell entfernen möchten, sind hier die einfachsten Methoden:
- Hintergrund formatieren verwenden – am besten für einzelne Folien.
- Folienmaster verwenden – am besten für alle Folien.
- Hintergrund entfernen verwenden – am besten für Bilder.
Lesen Sie weiter für Schritt-für-Schritt-Anleitungen und fortgeschrittene Methoden wie VBA und Python.
Methode 1. Hintergrund von PowerPoint-Folie entfernen (Hintergrund formatieren)
Wenn Sie den Hintergrund einer Folie schnell entfernen möchten, ist die Funktion „Hintergrund formatieren“ die einfachste Option. Sie ermöglicht es Ihnen, den vorhandenen Hintergrund zu löschen, ohne Text oder andere Elemente zu beeinträchtigen. Diese Methode eignet sich am besten, wenn Sie eine oder wenige Folien bereinigen müssen.
Schritte:
-
Wählen Sie die Folie aus, von der Sie den Hintergrund entfernen möchten.
-
Gehen Sie zur Registerkarte Entwurf und klicken Sie auf Hintergrund formatieren (oder klicken Sie mit der rechten Maustaste auf die Folie und wählen Sie Hintergrund formatieren).
-
Wählen Sie im Bereich Hintergrund formatieren die Option Vollfarbfläche.
-
Klicken Sie auf die Schaltfläche Farbe und wählen Sie aus dem Dropdown-Menü die Farbe Weiß. Der Hintergrund wurde nun von den ausgewählten Folien entfernt.
Profi-Tipp: Wenn diese Änderung für alle Folien in Ihrer Präsentation gelten soll, klicken Sie am unteren Rand des Bereichs „Hintergrund formatieren“ auf Übernehmen für alle.
Wann verwenden: Verwenden Sie es, wenn Sie nur einzelne Folien bereinigen müssen, ohne den Rest der Präsentation zu beeinträchtigen.
Wenn Sie Hintergründe ändern oder anpassen möchten, anstatt sie zu entfernen, lesen Sie unsere Anleitung zum Ändern von PowerPoint-Folienhintergründen.
Methode 2. Hintergrund schnell von allen PowerPoint-Folien löschen (Folienmaster)
Wenn Sie den Hintergrund von allen Folien in PowerPoint entfernen müssen, ist die Verwendung des Folienmasters der effizienteste Ansatz. Er ermöglicht es Ihnen, Hintergrundeinstellungen auf mehreren Folien gleichzeitig von einem einzigen Ort aus zu löschen. Diese Methode ist ideal, um unerwünschte Hintergründe zu entfernen und gleichzeitig die Konsistenz der Folien zu wahren, ohne sie einzeln bearbeiten zu müssen.
Schritte:
-
Navigieren Sie zur Registerkarte Ansicht und wählen Sie im Gruppenbereich Masteransichten Folienmaster.
-
Wählen Sie im linken Bereich den Master oder das Layout aus, das Sie bearbeiten möchten.
-
Klicken Sie in der Gruppe Hintergrund auf Hintergrundformate > Hintergrund formatieren.
-
Wählen Sie im Bereich Hintergrund formatieren Vollfarbfläche und wählen Sie Weiß aus dem Farbwähler.
-
Klicken Sie auf Masteransicht schließen, um die Änderungen auf alle zugehörigen Folien anzuwenden.
Tipp: Wenn mehrere Layouts denselben Hintergrund verwenden, stellen Sie sicher, dass Sie jedes Layout im Folienmaster aktualisieren.
Wann verwenden: Verwenden Sie es, um eine konsistente Hintergrundentfernung über eine gesamte Präsentation anzuwenden.
Fehlerbehebung bei hartnäckigen Hintergründen
Wenn Hintergrundelemente nach der Entfernung immer noch angezeigt werden, sind sie normalerweise Teil des Folienmotivs oder im Folienmaster gespeichert. Verwenden Sie die folgenden Methoden, um sie auszublenden oder zu entfernen.
1. Grafikgrafiken des Motivs ausblenden
-
Öffnen Sie den Bereich Hintergrund formatieren.
-
Aktivieren Sie das Kontrollkästchen Grafiken des Motivs ausblenden, um motivbasierte Elemente wie dekorative Linien, Formen oder Logos auszublenden.
Hinweis: Dies blendet nur Elemente aus, die vom Folienmaster übernommen wurden. Es entfernt keine Bilder oder Objekte, die manuell zur Folie hinzugefügt wurden.
2. Hintergrundelemente über den Folienmaster entfernen
- Gehen Sie zur Registerkarte Ansicht und wählen Sie Folienmaster.
- Wählen Sie im linken Bereich die oberste (übergeordnete) Masterfolie oder das spezifische Layout aus.
- Klicken Sie auf die Hintergrundgrafik oder das Logo, das Sie entfernen möchten, und drücken Sie Entf.
- Klicken Sie auf Masteransicht schließen, um die Änderungen anzuwenden.
Methode 3. Bildhintergrund in PowerPoint entfernen (Werkzeug Hintergrund entfernen)
Wenn Sie den Hintergrund eines Bildes in PowerPoint entfernen müssen, bietet das integrierte Werkzeug Hintergrund entfernen eine schnelle und effektive Lösung. Es erkennt automatisch das Hauptmotiv und entfernt unerwünschte Bereiche mit minimaler manueller Anpassung. Diese Methode ist ideal, um Bilder direkt in Ihren Folien zu bereinigen, ohne externe Tools zu verwenden.
Schritte:
-
Wählen Sie das Bild aus, von dem Sie den Hintergrund entfernen möchten.
-
Gehen Sie zur Registerkarte Bildformat.
-
Wählen Sie Hintergrund entfernen. PowerPoint hebt den Hintergrund lila hervor.
-
Passen Sie die Auswahl bei Bedarf mit Bereiche zum Beibehalten markieren oder Bereiche zum Entfernen markieren an.
-
Klicken Sie auf Änderungen beibehalten, um die Hintergrundentfernung anzuwenden.
Tipps und Hinweise:
- Diese Methode funktioniert am besten, wenn ein klarer Kontrast zwischen dem Motiv und dem Hintergrund besteht.
- Die Funktion Hintergrund entfernen ist in neueren Desktop-Versionen wie PowerPoint für Microsoft 365, 2024 und 2021 verfügbar, wird aber in einigen Webversionen möglicherweise nicht unterstützt.
- Für Bilder mit einem einfarbigen Hintergrund gehen Sie zu Bildformat > Farbe > Transparente Farbe festlegen und klicken Sie dann auf den Hintergrund, um ihn schnell transparent zu machen.
Wann verwenden: Verwenden Sie es, um Hintergründe von Bildern zu entfernen und gleichzeitig das Hauptmotiv beizubehalten.
Methode 4. Hintergrund in PowerPoint automatisch mit VBA löschen
Wenn Sie wiederkehrende Aufgaben zur Hintergrundentfernung durchführen müssen, bietet VBA eine Möglichkeit, den Prozess innerhalb von PowerPoint zu automatisieren. Durch Ausführen eines einfachen Makros können Sie mehrere Folien ohne manuelle Arbeit aktualisieren. Diese Methode ist nützlich für Benutzer, die mit grundlegenden Skripten vertraut sind.
VBA-Makro zum Entfernen von Hintergründen von allen Folien
Dieses Skript durchläuft jede Folie in der aktiven Präsentation, deaktiviert den Masterhintergrund und löscht automatisch Hintergrundelemente.
Sub RemoveAllBackgrounds()
Dim sld As Slide
' Schleife durch jede Folie in der Präsentation
For Each sld In ActivePresentation.Slides
' Master-Hintergrund folgen: Auf False setzen, um anzupassen
sld.FollowMasterBackground = msoFalse
' Hintergrundfüllung auf sichtbar = false setzen (Transparent/Keine Füllung)
sld.Background.Fill.Visible = msoFalse
' Alternativ Hintergrundgrafiken ausblenden (wie Logos/Motive)
sld.DisplayMasterShapes = msoFalse
Next sld
MsgBox "Alle Folienhintergründe wurden entfernt!", vbInformation
End Sub
Erklärte Schlüsseleigenschaften:
- FollowMasterBackground: Auf msoFalse setzen, um den Hintergrund des Folienmasters zu überschreiben.
- DisplayMasterShapes: Blendt Hintergrundelemente wie Logos oder Designformen vom Folienmaster aus.
- Background.Fill.Visible: Steuert, ob die Hintergrundfüllung sichtbar ist.
So verwenden Sie das Skript:
- Drücken Sie Alt + F11, um den VBA-Editor zu öffnen.
- Gehen Sie zu Einfügen > Modul.
- Fügen Sie den Code in das Modulfenster ein.
- Drücken Sie F5 oder klicken Sie auf die Schaltfläche Ausführen, um das Makro auszuführen.
Hinweise:
- Diese Methode entfernt keine als Formen eingefügten Bilder. Wenn Ihr Hintergrund ein Bildobjekt ist, benötigen Sie ein separates Skript, um diese Formen zu löschen.
- Speichern Sie immer eine Kopie Ihrer Präsentation, bevor Sie Makros ausführen, da VBA-Aktionen nicht rückgängig gemacht werden können.
- Wenn Makros deaktiviert sind, gehen Sie zu Datei > Optionen > Vertrauenscenter > Einstellungen für das Vertrauenscenter > Makroeinstellungen, um sie zu aktivieren.
Wann verwenden: Ideal für die Automatisierung wiederkehrender Aufgaben zur Hintergrundentfernung innerhalb von PowerPoint.
Methode 5. Hintergrundstapelverarbeitung in PowerPoint mit Python
Für groß angelegte Aufgaben, die mehrere PowerPoint-Dateien umfassen, kann die Verwendung von Python die Effizienz erheblich steigern. Mit der richtigen Bibliothek wie Spire.Presentation für Python können Sie die Hintergrundentfernung über Präsentationen hinweg automatisieren, ohne PowerPoint manuell öffnen zu müssen. Diese Methode ist ideal für die Stapelverarbeitung und Backend-Workflows.
Schritt-für-Schritt-Anleitung:
-
Installieren Sie die Bibliothek über pip:
pip install spire.presentation -
Schreiben Sie ein Python-Skript:
Das folgende Beispiel zeigt, wie Sie den Folienhintergrund von mehreren PowerPoint .pptx-Dateien stapelweise entfernen:
from spire.presentation import * import os # Ordner mit den zu verarbeitenden PPTX-Dateien input_folder = "presentations" # Ordner mit allen PPTX-Dateien output_folder = "processed" # Ordner zum Speichern verarbeiteter Dateien # Erstellen Sie den Ausgabeordner, falls er nicht existiert if not os.path.exists(output_folder): os.makedirs(output_folder) # Schleife durch alle PPTX-Dateien im Eingabeordner for filename in os.listdir(input_folder): if filename.lower().endswith(".pptx"): input_path = os.path.join(input_folder, filename) output_path = os.path.join(output_folder, f"RemoveBackground_{filename}") # Präsentation laden presentation = Presentation() presentation.LoadFromFile(input_path) # Jede Folie durchlaufen und Hintergrund entfernen for slide in presentation.Slides: slide.SlideBackground.Type = BackgroundType.none # Modifizierte Präsentation speichern presentation.SaveToFile(output_path, FileFormat.Pptx2010) presentation.Dispose() print(f"Verarbeitet: {filename} → {output_path}") print("Alle Präsentationen wurden erfolgreich verarbeitet.")
Tipp: Zusätzlich zum Entfernen des Hintergrunds von Folien können Sie auch den Hintergrund von Folienmastern entfernen.
Wann verwenden: Ideal für die effiziente Stapelverarbeitung mehrerer PowerPoint-Dateien.
Vergleich: Welche Methode sollten Sie wählen?
Die Wahl der richtigen Methode zum Entfernen des Hintergrunds in PowerPoint hängt davon ab, wie viele Folien Sie bearbeiten und ob Sie Automatisierung benötigen.
Hier ist ein schneller Vergleich der fünf Methoden:
| Methode | Am besten geeignet für | Umfang | Fähigkeitslevel |
|---|---|---|---|
| Hintergrund formatieren | Schnelle Folienbereinigung | Einzelne / wenige Folien | Anfänger |
| Folienmaster | Präsentationsweite Konsistenz | Gesamte Präsentation | Anfänger |
| Hintergrund entfernen (Bild) | Bildbearbeitung | Einzelne Bilder | Anfänger |
| VBA | Wiederkehrende Aufgaben in PowerPoint | Mehrere Folien | Fortgeschritten |
| Python | Stapelverarbeitung | Mehrere Präsentationen | Experte |
Schnelle Empfehlung:
- Für die meisten Benutzer reichen Hintergrund formatieren und Folienmaster für alltägliche Aufgaben aus.
- Verwenden Sie VBA, wenn Sie wiederholte Aktionen innerhalb von PowerPoint automatisieren müssen.
- Wählen Sie Python, wenn Sie mehrere Dateien verarbeiten oder automatisierte Workflows erstellen müssen.
Warum Hintergrund in PowerPoint entfernen
Das Entfernen von Hintergründen in PowerPoint dient nicht nur der visuellen Bereinigung – es kann das Aussehen und die Leistung Ihrer Präsentation erheblich verbessern. Hier sind die Hauptvorteile:
- Verbesserte visuelle Klarheit: Entfernen Sie ablenkende Elemente, die mit Ihren Inhalten konkurrieren.
- Markenkonsistenz: Entfernen Sie inkonsistente oder unerwünschte Hintergründe.
- Verbesserte Lesbarkeit: Klare Hintergründe helfen, Text deutlicher hervorzuheben.
- Vereinfachtes Design: Entfernen Sie unnötige visuelle Elemente und konzentrieren Sie sich auf die Kerninformationen.
- Professionelle Qualität: Erstellen Sie saubere, ablenkungsfreie Präsentationen.
Häufige Probleme bei der Hintergrundentfernung und Lösungen
- Hintergrundgrafiken oder Logos sind immer noch sichtbar – Diese Elemente sind oft Teil des Folienmasters. Um sie zu entfernen, gehen Sie zu Ansicht > Folienmaster, wählen Sie die übergeordnete Folie oder die betroffenen Layouts aus, löschen Sie die Elemente und schließen Sie dann die Masteransicht.
- Hintergrund kann nicht entfernt werden – Die Präsentation ist möglicherweise geschützt oder eingeschränkt. Überprüfen Sie die Bearbeitungsberechtigungen der Datei und aktivieren Sie die Bearbeitung, falls erforderlich, bevor Sie Änderungen vornehmen.
- Änderungen werden nicht auf alle Folien angewendet – Das Entfernen des Hintergrunds auf einer Folie wirkt sich nicht auf andere aus. Verwenden Sie Übernehmen für alle im Bereich „Hintergrund formatieren“ oder aktualisieren Sie den Folienmaster, um Änderungen auf die gesamte Präsentation anzuwenden.
FAQs: Hintergrund in PowerPoint entfernen
F1: Kann ich Hintergründe von allen Folien gleichzeitig entfernen?
A1: Ja, mit Folienmaster, VBA oder Python-Automatisierung können Sie Hintergründe in einer gesamten Präsentation oder mehreren Dateien entfernen.
F2: Kann ich Hintergründe ohne PowerPoint entfernen?
A2: Ja, Python-Bibliotheken wie Spire.Presentation ermöglichen die Entfernung von Hintergründen ohne installierte Microsoft PowerPoint.
F3: Beeinträchtigt das Entfernen des Hintergrunds Bilder oder Text auf meinen Folien?
A3: Nein, das Entfernen des Folienhintergrunds beeinträchtigt in der Regel keine anderen Folieninhalte wie Textfelder oder Bilder. Erstellen Sie jedoch immer ein Backup, bevor Sie automatisierte Tools wie VBA- oder Python-Skripte verwenden, um versehentliche Änderungen zu vermeiden.
F4: Ist VBA sicher für die Entfernung von PowerPoint-Hintergründen?
A4: Ja, solange Sie Makros nur aus vertrauenswürdigen Quellen aktivieren und vor dem Ausführen des Skripts ein Backup speichern.