Ordenar datos en Excel: explicación de 5 métodos sencillos y avanzados
Tabla de contenidos
- Antes de empezar
- Método 1: Ordenar datos por una sola columna en Excel (Rápido y esencial)
- Método 2: Ordenar datos por varias columnas en Excel (Orden personalizado)
- Método 3: Ordenar datos en Excel usando fórmulas (SORT y SORTBY)
- Método 4: Ordenar datos filtrados en Excel (Exploración flexible)
- Método 5: Ordenar datos de Excel usando Python (Automatización y escalabilidad)
- Tabla comparativa: ¿Qué método debería elegir?
- Reflexiones finales
- Preguntas frecuentes

Ordenar datos en Excel es una habilidad esencial para organizar, analizar y dar sentido a la información. Ya sea que trabaje con listas de clientes, informes financieros o grandes conjuntos de datos, ordenar le ayuda a identificar rápidamente patrones, tendencias y valores atípicos.
En esta guía, aprenderá 5 formas prácticas de ordenar datos en Excel, incluyendo el orden por una sola columna, el orden por varias columnas, el orden dinámico basado en fórmulas y la automatización mediante Python.
Navegación rápida
- Método 1: Ordenar datos por una sola columna en Excel (Rápido y esencial)
- Método 2: Ordenar datos por varias columnas en Excel (Orden personalizado)
- Método 3: Ordenar datos en Excel usando fórmulas (SORT y SORTBY)
- Método 4: Ordenar datos filtrados en Excel (Exploración flexible)
- Método 5: Ordenar datos de Excel usando Python (Automatización y escalabilidad)
Antes de empezar
Antes de ordenar datos en Excel, asegúrese de que:
- Su conjunto de datos incluya una fila de encabezado.
- No haya filas o columnas completamente vacías en el medio.
- Cada columna contenga tipos de datos consistentes (por ejemplo, números, fechas, texto).
Estas comprobaciones ayudan a prevenir errores de ordenación y desalineación de datos.
Método 1: Ordenar datos por una sola columna en Excel (Rápido y esencial)
La herramienta de ordenación integrada es la forma más rápida de ordenar datos por una sola columna. Es ideal para tareas sencillas como ordenar nombres alfabéticamente o números de menor a mayor.
Instrucciones paso a paso:
- Seleccione la columna única que desea ordenar.
- Vaya a la pestaña Datos en la cinta de opciones de Excel.
- Haga clic en Ordenar de A a Z (orden ascendente: A→Z, 1→100) o Ordenar de Z a A (orden descendente: Z→A, 100→1).
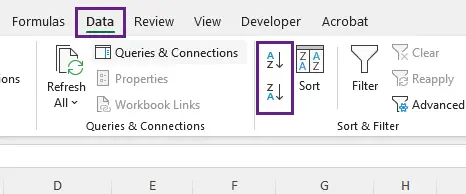
- Aparecerá una ventana emergente: Ampliar la selección. Mantenga esta opción marcada.
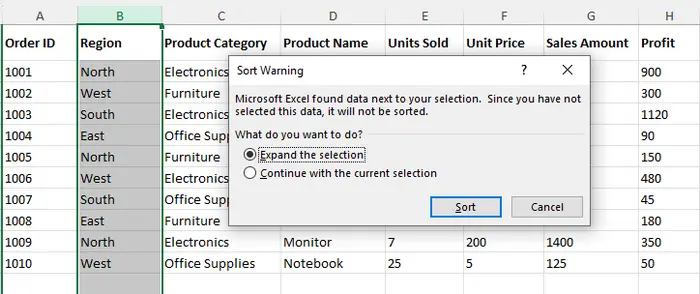
- Haga clic en Ordenar para completar el proceso.
Consejo profesional:
- La opción Ampliar la selección garantiza que todos los datos relacionados en las columnas adyacentes se ordenen junto con la columna seleccionada. En la mayoría de los casos, debe mantener esta opción marcada para evitar romper las relaciones de los datos.
- Si sus datos tienen una fila de encabezado (por ejemplo, "Nombre", "Correo electrónico"), marque la casilla Mis datos tienen encabezados en la ventana emergente. Esto evita que Excel ordene el encabezado mismo (por ejemplo, "Nombre" no terminará al final de la columna).
Método 2: Ordenar datos por varias columnas en Excel (Orden personalizado)
Para conjuntos de datos más complejos, ordenar por una sola columna no es suficiente. Por ejemplo, es posible que desee ordenar los datos de ventas primero por "Región" (ascendente) y luego por "Monto de ventas" (descendente) para ver los mejores resultados en cada región. Aquí es donde entra en juego el Orden personalizado.
Instrucciones paso a paso:
- Seleccione cualquier celda dentro de su conjunto de datos (esto asegura que Excel reconozca toda la tabla).
- Vaya a la pestaña Datos y haga clic en Ordenar (no en los botones A→Z/Z→A).
- En la ventana de Orden personalizado:
- Elija la primera columna (por ejemplo, "Región") y establezca el orden en De A a Z.
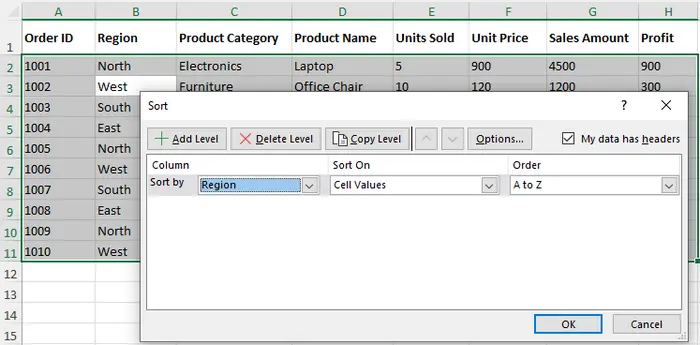
- Haga clic en Agregar nivel para añadir otra columna (por ejemplo, "Monto de ventas") y establezca el orden en De mayor a menor.
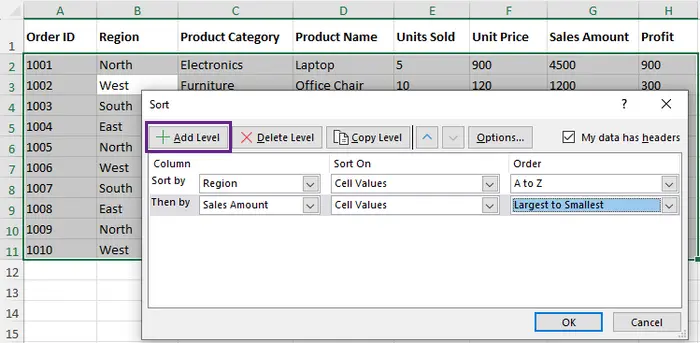
- Elija la primera columna (por ejemplo, "Región") y establezca el orden en De A a Z.
- Haga clic en Aceptar para aplicar el orden. Sus datos ahora estarán organizados por la columna "Región", con los empates resueltos por la columna "Monto de ventas".
Información clave:
Excel aplica el orden de forma jerárquica: ordena por la primera columna y luego resuelve los empates usando la siguiente columna.
Casos de uso:
- Informes de ventas (Región → Ingresos)
- Listas de empleados (Departamento → Puesto)
- Inventario (Categoría → Nivel de existencias)
Método 3: Ordenar datos en Excel usando fórmulas (SORT y SORTBY)
Si sus datos se actualizan con frecuencia, la ordenación manual se vuelve ineficiente. Las fórmulas de Excel como SORT y SORTBY le permiten crear listas ordenadas dinámicas que se actualizan automáticamente.
A diferencia de la ordenación tradicional, estas funciones no modifican los datos originales. En su lugar, generan una copia ordenada dinámicamente que se actualiza automáticamente.
Uso de la función SORT (La más sencilla para Excel moderno)
La función SORT ordena un rango de datos y devuelve una nueva matriz ordenada. Sintaxis: =SORT(rango, [índice_ordenación], [orden], [por_columna])
- En una celda vacía (por ejemplo, J1), introduzca la fórmula: =SORT(A1:H11, 1, -1, FALSE)
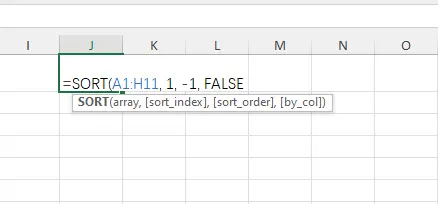
- A1:H11: Todo el conjunto de datos que desea ordenar.
- 1: La columna por la cual ordenar.
- -1: Orden de clasificación (1 = ascendente, -1 = descendente).
- FALSE: Ordenar por filas (predeterminado; use TRUE para ordenar por columnas).
- Presione Entrar. Excel generará una lista ordenada dinámica en el rango que comienza en J1. Si actualiza los datos originales (por ejemplo, cambia un monto de ventas), la lista ordenada se actualizará automáticamente.
Uso de la función SORTBY (Más flexible)
=SORTBY(A1:H11, G1:G11, -1)
La función SORTBY ordena un conjunto de datos basado en los valores de uno o más rangos separados. A diferencia de la función SORT, que depende de las posiciones de las columnas, SORTBY le permite definir exactamente qué rango controla el orden de clasificación.
Cómo funciona:
- A1:H11 → El conjunto de datos a devolver (la tabla completa)
- G1:G11 → El rango utilizado como clave de ordenación (por ejemplo, "Monto de ventas")
- -1 → Orden de clasificación (1 = ascendente, -1 = descendente)
Ejemplo de caso de uso:
Ordenar una tabla de ventas por ingresos sin cambiar el conjunto de datos original.
Método 4: Ordenar datos filtrados en Excel (Exploración flexible)
Los filtros le permiten explorar y ordenar rápidamente subconjuntos específicos de sus datos sin cambiar permanentemente el conjunto de datos original. Esto es especialmente útil cuando se trabaja con grandes conjuntos de datos, como al analizar ventas de una región o período de tiempo específico.
Instrucciones paso a paso:
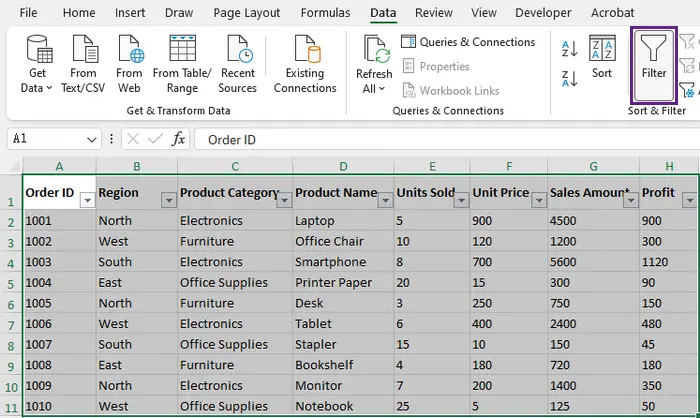
- Seleccione su conjunto de datos, incluyendo la fila de encabezado.
- Vaya a la pestaña Datos y haga clic en Filtro (o use el atajo: Ctrl+Shift+L). Aparecerán pequeñas flechas desplegables en cada celda de encabezado.
- Haga clic en la flecha desplegable en la columna que desea ordenar (por ejemplo, "Región"), desmarque las regiones que no necesita (por ejemplo, "Este", "Norte", "Sur") y luego haga clic en Aceptar.
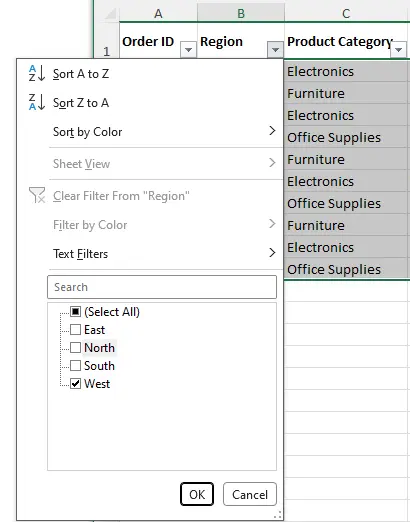
- Haga clic en la flecha desplegable en la columna Monto de ventas y elija Ordenar de menor a mayor (ascendente) o Ordenar de mayor a menor (descendente). Esto ordenará solo las filas filtradas (visibles).
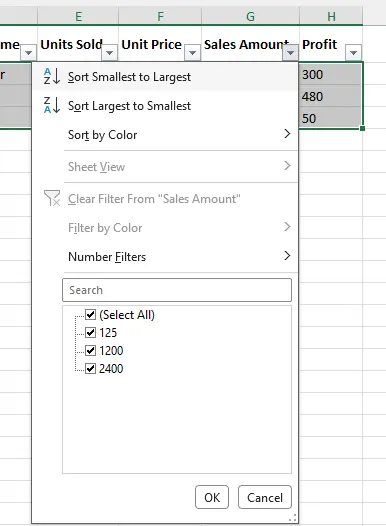
- Para eliminar el filtro y volver al conjunto de datos original, haga clic en Filtro nuevamente (o Ctrl+Shift+L).
Ventaja clave:
Los filtros le permiten combinar la ordenación con el filtrado de datos, lo que facilita la exploración de subconjuntos específicos (por ejemplo, ordenar solo las ventas de alto valor en una región específica) sin alterar la estructura original de los datos.
Método 5: Ordenar datos de Excel usando Python (Automatización y escalabilidad)
Para grandes conjuntos de datos (más de 10,000 filas) o tareas de ordenación repetitivas (por ejemplo, ordenar informes diarios de Excel), la automatización con Python cambia las reglas del juego. Usaremos Spire.XLS for Python, una potente biblioteca que simplifica la manipulación de archivos de Excel, incluida la ordenación, sin necesidad de tener Excel instalado en su máquina.
Requisitos previos:
- Instalar Spire.XLS for Python: Ejecute pip install Spire.XLS en su terminal o símbolo del sistema.
- Prepare su archivo de Excel de entrada (por ejemplo, "Input.xlsx") con los datos que desea ordenar.
Código de Python paso a paso (con explicaciones):
from spire.xls.common import *
from spire.xls import *
# Crear una instancia de libro de trabajo
workbook = Workbook()
# Cargar el archivo de Excel de entrada
workbook.LoadFromFile("Input.xlsx")
# Obtener la primera hoja de cálculo
worksheet = workbook.Worksheets[0]
# Definir la regla de ordenación: Ordenar la columna B (índice 1) por valores en orden ascendente
workbook.DataSorter.SortColumns.Add(1, SortComparsionType.Values, OrderBy.Ascending)
# Especificar el rango de celdas a ordenar
workbook.DataSorter.Sort(worksheet["A1:H11"])
# Guardar los datos ordenados en un nuevo archivo de Excel
workbook.SaveToFile("SortByColumns.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Cómo personalizar el código:
- Ordenar una columna diferente: Cambie el primer parámetro en Add() (por ejemplo, 0 para la columna A, 1 para la columna B).
- Orden descendente: Reemplace OrderBy.Ascending con OrderBy.Descending.
- Ordenar un rango más grande: Modifique worksheet["A1:H11"] (por ejemplo, worksheet["A1:G1000"] para 1000 filas y 7 columnas).
- Varias columnas: Agregue una segunda regla de ordenación con workbook.DataSorter.SortColumns.Add() (por ejemplo, ordenar la columna A de forma ascendente y luego la columna B de forma descendente).
Caso de uso:
Este método es perfecto para automatizar tareas repetitivas, por ejemplo, ordenar más de 50 archivos de Excel diariamente o procesar conjuntos de datos demasiado grandes para que Excel los maneje sin problemas.
Además de ordenar datos, también puede usar Python para automatizar otras tareas de Excel, como dar formato a hojas de cálculo, aplicar estilos y exportar archivos de Excel a PDF. Estas capacidades facilitan la creación de flujos de trabajo completos de procesamiento de documentos.
Tabla comparativa: ¿Qué método debería elegir?
| Método | Mejor para | Pros | Contras |
|---|---|---|---|
| Ordenación integrada | Ordenación rápida de una sola columna | Fácil de usar, sin configuración | Limitado a ordenación básica; manual |
| Orden personalizado | Ordenación jerárquica de varias columnas | Flexible, maneja conjuntos de datos complejos | Requiere algunos pasos adicionales |
| Fórmulas de Excel | Listas ordenadas dinámicas y autoactualizables | Sin reordenación manual; se actualiza con los datos | La función SORT solo está disponible en Excel moderno |
| Filtros | Ordenación temporal/exploración de subconjuntos | No destructivo; se combina con el filtrado | No es ideal para ordenación permanente |
| Python (Spire.XLS) | Grandes conjuntos de datos, automatización | Escalable, tareas repetitivas, no requiere Excel | Requiere conocimientos básicos de Python |
Reflexiones finales
Ordenar en Excel es más que simplemente organizar datos: se trata de hacer que la información sea utilizable y significativa.
- Use la ordenación integrada para tareas rápidas.
- Use el orden personalizado para análisis estructurados.
- Use fórmulas para resultados dinámicos.
- Use filtros para una exploración flexible.
- Use Python para la automatización a escala.
Dominar estos métodos le permitirá manejar todo, desde hojas de cálculo simples hasta flujos de trabajo de datos complejos con facilidad.
Preguntas frecuentes
P1: ¿Por qué mis datos de Excel están desalineados después de ordenarlos?
Esto suele ocurrir cuando no se selecciona Ampliar la selección. Asegúrese siempre de incluir las columnas relacionadas al ordenar.
P2: ¿Puedo ordenar por color de celda o color de fuente?
Sí. En el cuadro de diálogo Ordenar, elija Color de celda o Color de fuente en "Ordenar según".
P3: ¿Puedo ordenar datos con celdas en blanco?
Sí. Excel coloca los espacios en blanco al final (ascendente) o al principio (descendente). Puede filtrarlos si es necesario.
P4: ¿Cómo deshago una ordenación?
Presione Ctrl + Z inmediatamente después de ordenar. Si ha realizado otros cambios, es posible que la opción de deshacer no esté disponible.
P5: ¿Por qué no funciona la ordenación de Excel?
Las causas comunes incluyen:
- Tipos de datos mixtos.
- Filas o columnas ocultas.
- Rango de selección incorrecto.
Ver también
Daten in Excel sortieren: 5 einfache und fortgeschrittene Methoden erklärt
Inhaltsverzeichnis
- Bevor Sie beginnen
- Methode 1: Daten in Excel nach einer einzelnen Spalte sortieren (Schnell & Grundlegend)
- Methode 2: Daten in Excel nach mehreren Spalten sortieren (Benutzerdefiniertes Sortieren)
- Methode 3: Daten in Excel mit Formeln sortieren (SORT & SORTBY)
- Methode 4: Gefilterte Daten in Excel sortieren (Flexible Analyse)
- Methode 5: Excel-Daten mit Python sortieren (Automatisierung & Skalierbarkeit)
- Vergleichstabelle: Welche Methode sollten Sie wählen?
- Fazit
- FAQs
Das Sortieren von Daten in Excel ist eine grundlegende Fähigkeit, um Informationen zu organisieren, zu analysieren und verständlich zu machen. Egal, ob Sie mit Kundenlisten, Finanzberichten oder großen Datensätzen arbeiten – durch Sortieren können Sie Muster, Trends und Ausreißer schnell erkennen.
In diesem Leitfaden lernen Sie 5 praktische Möglichkeiten zum Sortieren von Daten in Excel kennen, einschließlich der Sortierung nach einer Spalte, der Sortierung nach mehreren Spalten, der dynamischen Sortierung mittels Formeln sowie der Automatisierung mit Python.
Schnellnavigation
- Methode 1: Daten in Excel nach einer einzelnen Spalte sortieren (Schnell & Grundlegend)
- Methode 2: Daten in Excel nach mehreren Spalten sortieren (Benutzerdefiniertes Sortieren)
- Methode 3: Daten in Excel mit Formeln sortieren (SORT & SORTBY)
- Methode 4: Gefilterte Daten in Excel sortieren (Flexible Analyse)
- Methode 5: Excel-Daten mit Python sortieren (Automatisierung & Skalierbarkeit)
Bevor Sie beginnen
Bevor Sie Daten in Excel sortieren, stellen Sie sicher, dass:
- Ihr Datensatz eine Kopfzeile enthält.
- Sich keine komplett leeren Zeilen oder Spalten innerhalb des Bereichs befinden.
- Jede Spalte einheitliche Datentypen enthält (z. B. Zahlen, Datumsangaben, Text).
Diese Überprüfungen helfen, Sortierfehler und Datenverschiebungen zu vermeiden.
Methode 1: Daten in Excel nach einer einzelnen Spalte sortieren (Schnell & Grundlegend)
Das integrierte Sortierwerkzeug ist der schnellste Weg, um Daten nach einer einzelnen Spalte zu sortieren. Es ist ideal für einfache Aufgaben, wie das alphabetische Sortieren von Namen oder das Sortieren von Zahlen von klein nach groß.
Schritt-für-Schritt-Anleitung:
- Markieren Sie die einzelne Spalte, die Sie sortieren möchten.
- Gehen Sie im Excel-Menüband auf die Registerkarte Daten.
- Klicken Sie entweder auf Von A bis Z sortieren (aufsteigende Reihenfolge: A→Z, 1→100) oder Von Z bis A sortieren (absteigende Reihenfolge: Z→A, 100→1).
- Ein Popup-Fenster erscheint: Auswahl erweitern. Lassen Sie diese Option aktiviert.
- Klicken Sie auf Sortieren, um den Vorgang abzuschließen.
Profi-Tipp:
- Die Option Auswahl erweitern stellt sicher, dass alle zugehörigen Daten in benachbarten Spalten zusammen mit der ausgewählten Spalte sortiert werden. In den meisten Fällen sollten Sie diese Option aktiviert lassen, um Datenbeziehungen nicht zu zerstören.
- Wenn Ihre Daten eine Kopfzeile haben (z. B. „Name“, „E-Mail“), aktivieren Sie das Kontrollkästchen Daten haben Überschriften im Popup-Fenster. Dies verhindert, dass Excel die Kopfzeile selbst mit sortiert (z. B. landet „Name“ dann nicht am Ende der Spalte).
Methode 2: Daten in Excel nach mehreren Spalten sortieren (Benutzerdefiniertes Sortieren)
Bei komplexeren Datensätzen reicht das Sortieren nach einer Spalte oft nicht aus. Sie möchten beispielsweise Verkaufsdaten zuerst nach „Region“ (aufsteigend) und dann nach „Verkaufsbetrag“ (absteigend) sortieren, um die leistungsstärksten Einträge in jeder Region zu sehen. Hier kommt das benutzerdefinierte Sortieren ins Spiel.
Schritt-für-Schritt-Anleitung:
- Wählen Sie eine beliebige Zelle innerhalb Ihres Datensatzes aus (damit erkennt Excel die gesamte Tabelle).
- Gehen Sie auf die Registerkarte Daten und klicken Sie auf Sortieren (nicht auf die A→Z/Z→A-Schaltflächen).
- Im Fenster „Sortieren“:
- Wählen Sie die erste Spalte (z. B. „Region“) und setzen Sie die Reihenfolge auf A bis Z.
- Klicken Sie auf Ebene hinzufügen, um eine weitere Spalte (z. B. „Verkaufsbetrag“) auszuwählen, und setzen Sie die Reihenfolge auf Größte nach Kleinste.
- Wählen Sie die erste Spalte (z. B. „Region“) und setzen Sie die Reihenfolge auf A bis Z.
- Klicken Sie auf OK, um die Sortierung anzuwenden. Ihre Daten werden nun nach der Spalte „Region“ organisiert, wobei Gleichstände durch die Spalte „Verkaufsbetrag“ aufgelöst werden.
Wichtige Erkenntnis:
Excel sortiert hierarchisch – es sortiert zuerst nach der ersten Spalte und löst dann Gleichstände anhand der nächsten Spalte auf.
Anwendungsbeispiele:
- Verkaufsberichte (Region → Umsatz)
- Mitarbeiterlisten (Abteilung → Rolle)
- Inventar (Kategorie → Lagerbestand)
Methode 3: Daten in Excel mit Formeln sortieren (SORT & SORTBY)
Wenn Ihre Daten häufig aktualisiert werden, ist manuelles Sortieren ineffizient. Excel-Formeln wie SORT und SORTBY ermöglichen es Ihnen, dynamische, automatisch aktualisierende sortierte Listen zu erstellen.
Im Gegensatz zur herkömmlichen Sortierung verändern diese Funktionen die Originaldaten nicht. Stattdessen generieren sie eine dynamisch sortierte Kopie, die sich automatisch aktualisiert.
Die SORT-Funktion verwenden (Am einfachsten für modernes Excel)
Die SORT-Funktion sortiert einen Datenbereich und gibt ein neues sortiertes Array zurück. Syntax: =SORT(Bereich; [Sortierindex]; [Sortierreihenfolge]; [Nach_Spalte])
- Geben Sie in eine leere Zelle (z. B. J1) die Formel ein: =SORT(A1:H11; 1; -1; FALSCH)
- A1:H11: Der gesamte Datensatz, den Sie sortieren möchten.
- 1: Die Spalte, nach der sortiert werden soll.
- -1: Sortierreihenfolge (1 = aufsteigend, -1 = absteigend).
- FALSCH: Sortierung nach Zeilen (Standard; verwenden Sie WAHR, um nach Spalten zu sortieren).
- Drücken Sie die Eingabetaste. Excel generiert eine dynamische sortierte Liste im Bereich ab J1. Wenn Sie die Originaldaten ändern (z. B. einen Verkaufsbetrag anpassen), aktualisiert sich die sortierte Liste automatisch.
Die SORTBY-Funktion verwenden (Flexibler)
=SORTBY(A1:H11; G1:G11; -1)
Die SORTBY-Funktion sortiert einen Datensatz basierend auf Werten in einem oder mehreren separaten Bereichen. Im Gegensatz zur SORT-Funktion, die auf Spaltenpositionen basiert, können Sie mit SORTBY genau definieren, welcher Bereich die Sortierreihenfolge bestimmt.
Funktionsweise:
- A1:H11 → Der zurückzugebende Datensatz (die vollständige Tabelle)
- G1:G11 → Der Bereich, der als Sortierschlüssel dient (z. B. „Verkaufsbetrag“)
- -1 → Sortierreihenfolge (1 = aufsteigend, -1 = absteigend)
Beispielanwendung:
Sortieren einer Verkaufstabelle nach Umsatz, ohne den ursprünglichen Datensatz zu verändern.
Methode 4: Gefilterte Daten in Excel sortieren (Flexible Analyse)
Filter ermöglichen es Ihnen, bestimmte Teilmengen Ihrer Daten schnell zu untersuchen und zu sortieren, ohne den ursprünglichen Datensatz dauerhaft zu verändern. Dies ist besonders nützlich bei großen Datensätzen, etwa bei der Analyse von Verkäufen aus einer bestimmten Region oder einem bestimmten Zeitraum.
Schritt-für-Schritt-Anleitung:
- Wählen Sie Ihren Datensatz inklusive Kopfzeile aus.
- Gehen Sie auf die Registerkarte Daten und klicken Sie auf Filtern (oder verwenden Sie das Tastenkürzel: Strg+Umschalt+L). In jeder Kopfzeilenzelle erscheinen kleine Dropdown-Pfeile.
- Klicken Sie auf den Dropdown-Pfeil in der Spalte, die Sie sortieren möchten (z. B. „Region“), deaktivieren Sie die Regionen, die Sie nicht benötigen (z. B. „Ost“, „Nord“, „Süd“), und klicken Sie auf OK.
- Klicken Sie auf den Dropdown-Pfeil in der Spalte „Verkaufsbetrag“ und wählen Sie Von Klein nach Groß sortieren (aufsteigend) oder Von Groß nach Klein sortieren (absteigend). Dies sortiert nur die gefilterten (sichtbaren) Zeilen.
- Um den Filter zu entfernen und zum ursprünglichen Datensatz zurückzukehren, klicken Sie erneut auf Filtern (oder Strg+Umschalt+L).
Hauptvorteil:
Filter erlauben es Ihnen, Sortierung mit Datenfilterung zu kombinieren, was die Untersuchung spezifischer Teilmengen erleichtert (z. B. Sortieren von hochwertigen Verkäufen nur in einer bestimmten Region), ohne die ursprüngliche Datenstruktur zu verändern.
Methode 5: Excel-Daten mit Python sortieren (Automatisierung & Skalierbarkeit)
Für große Datensätze (10.000+ Zeilen) oder wiederkehrende Sortieraufgaben (z. B. Sortieren täglicher Excel-Berichte) ist Python-Automatisierung ein echter Game-Changer. Wir verwenden Spire.XLS for Python – eine leistungsstarke Bibliothek, die die Bearbeitung von Excel-Dateien, einschließlich Sortieren, vereinfacht, ohne dass Excel auf Ihrem Computer installiert sein muss.
Voraussetzungen:
- Installieren Sie Spire.XLS for Python: Führen Sie pip install Spire.XLS in Ihrem Terminal/Eingabeaufforderung aus.
- Bereiten Sie Ihre Excel-Eingabedatei (z. B. „Input.xlsx“) mit den Daten vor, die Sie sortieren möchten.
Python-Code (Schritt für Schritt):
from spire.xls.common import *
from spire.xls import *
# Erstellen einer Workbook-Instanz
workbook = Workbook()
# Laden der Excel-Eingabedatei
workbook.LoadFromFile("Input.xlsx")
# Abrufen des ersten Arbeitsblatts
worksheet = workbook.Worksheets[0]
# Definieren der Sortierregel: Sortiere Spalte B (Index 1) nach Werten in aufsteigender Reihenfolge
workbook.DataSorter.SortColumns.Add(1, SortComparsionType.Values, OrderBy.Ascending)
# Festlegen des zu sortierenden Zellbereichs
workbook.DataSorter.Sort(worksheet["A1:H11"])
# Speichern der sortierten Daten in einer neuen Excel-Datei
workbook.SaveToFile("SortByColumns.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Anpassen des Codes:
- Andere Spalte sortieren: Ändern Sie den ersten Parameter in Add() (z. B. 0 für Spalte A, 1 für Spalte B).
- Absteigende Sortierung: Ersetzen Sie OrderBy.Ascending durch OrderBy.Descending.
- Größeren Bereich sortieren: Ändern Sie worksheet["A1:H11"] (z. B. worksheet["A1:G1000"] für 1000 Zeilen, 7 Spalten).
- Mehrere Spalten: Fügen Sie eine zweite Sortierregel mit workbook.DataSorter.SortColumns.Add() hinzu (z. B. Spalte A aufsteigend, dann Spalte B absteigend).
Anwendungsfall:
Diese Methode ist perfekt für die Automatisierung wiederkehrender Aufgaben – z. B. das tägliche Sortieren von 50+ Excel-Dateien oder das Sortieren von Datensätzen, die für Excel zu groß sind.
Neben dem Sortieren von Daten können Sie Python auch zur Automatisierung anderer Excel-Aufgaben verwenden, wie z. B. Formatierung von Arbeitsblättern, Anwenden von Stilen und Exportieren von Excel-Dateien in PDF. Diese Funktionen erleichtern den Aufbau vollständiger Dokumentenverarbeitungs-Workflows.
Vergleichstabelle: Welche Methode sollten Sie wählen?
| Methode | Am besten geeignet für | Vorteile | Nachteile |
|---|---|---|---|
| Integrierte Sortierung | Schnelle Sortierung nach einer Spalte | Einfach, keine Einrichtung erforderlich | Begrenzt auf einfache Sortierung; manuell |
| Benutzerdefinierte Sortierung | Mehrspaltige, hierarchische Sortierung | Flexibel, bewältigt komplexe Datensätze | Erfordert einige zusätzliche Schritte |
| Excel-Formeln | Dynamische, automatisch aktualisierende Listen | Kein manuelles Neusortieren; aktualisiert sich mit Daten | SORT-Funktion nur in modernem Excel verfügbar |
| Filter | Temporäres Sortieren/Untersuchen von Teilmengen | Nicht destruktiv; kombinierbar mit Filtern | Nicht ideal für dauerhafte Sortierung |
| Python (Spire.XLS) | Große Datensätze, Automatisierung | Skalierbar, wiederkehrende Aufgaben, kein Excel nötig | Erfordert grundlegende Python-Kenntnisse |
Fazit
Sortieren in Excel ist mehr als nur das Anordnen von Daten – es geht darum, Informationen nutzbar und aussagekräftig zu machen.
- Verwenden Sie die integrierte Sortierung für schnelle Aufgaben.
- Verwenden Sie die benutzerdefinierte Sortierung für strukturierte Analysen.
- Verwenden Sie Formeln für dynamische Ergebnisse.
- Verwenden Sie Filter für flexible Analysen.
- Verwenden Sie Python für die Automatisierung in großem Maßstab.
Die Beherrschung dieser Methoden ermöglicht es Ihnen, alles von einfachen Tabellen bis hin zu komplexen Daten-Workflows mühelos zu bewältigen.
FAQs
F1: Warum sind meine Excel-Daten nach dem Sortieren falsch ausgerichtet?
Dies passiert normalerweise, wenn Auswahl erweitern nicht ausgewählt wurde. Stellen Sie immer sicher, dass zugehörige Spalten beim Sortieren einbezogen werden.
F2: Kann ich nach Zellfarbe oder Schriftfarbe sortieren?
Ja. Wählen Sie im Dialogfeld „Sortieren“ unter „Sortieren nach“ die Option Zellfarbe oder Schriftfarbe.
F3: Kann ich Daten mit leeren Zellen sortieren?
Ja. Excel platziert leere Zellen am Ende (aufsteigend) oder am Anfang (absteigend). Sie können sie bei Bedarf herausfiltern.
F4: Wie mache ich eine Sortierung rückgängig?
Drücken Sie sofort nach dem Sortieren Strg + Z. Wenn Sie bereits andere Änderungen vorgenommen haben, ist das Rückgängigmachen möglicherweise nicht mehr verfügbar.
F5: Warum funktioniert die Excel-Sortierung nicht?
Häufige Ursachen sind:
- Gemischte Datentypen
- Ausgeblendete Zeilen oder Spalten
- Falscher Auswahlbereich
Siehe auch
Сортировка данных в Excel: объяснение 5 простых и продвинутых методов
Оглавление
- Перед началом работы
- Способ 1: Сортировка данных по одному столбцу в Excel (быстро и просто)
- Способ 2: Сортировка данных по нескольким столбцам в Excel (настраиваемая сортировка)
- Способ 3: Сортировка данных в Excel с помощью формул (SORT и SORTBY)
- Способ 4: Сортировка отфильтрованных данных в Excel (гибкий анализ)
- Способ 5: Сортировка данных Excel с помощью Python (автоматизация и масштабируемость)
- Сравнительная таблица: какой метод выбрать
- Заключение
- Часто задаваемые вопросы
Сортировка данных в Excel — это базовый навык, необходимый для организации, анализа и понимания информации. Работаете ли вы со списками клиентов, финансовыми отчетами или большими массивами данных, сортировка поможет вам быстро выявить закономерности, тренды и аномалии.
В этом руководстве вы узнаете 5 практических способов сортировки данных в Excel, включая сортировку по одному и нескольким столбцам, динамическую сортировку с помощью формул и автоматизацию на языке Python.
Быстрая навигация
- Способ 1: Сортировка данных по одному столбцу в Excel (быстро и просто)
- Способ 2: Сортировка данных по нескольким столбцам в Excel (настраиваемая сортировка)
- Способ 3: Сортировка данных в Excel с помощью формул (SORT и SORTBY)
- Способ 4: Сортировка отфильтрованных данных в Excel (гибкий анализ)
- Способ 5: Сортировка данных Excel с помощью Python (автоматизация и масштабируемость)
Перед началом работы
Прежде чем приступать к сортировке данных в Excel, убедитесь, что:
- Ваш набор данных содержит строку заголовков.
- Внутри таблицы нет полностью пустых строк или столбцов.
- Каждый столбец содержит однотипные данные (например, только числа, даты или текст).
Эти проверки помогут избежать ошибок при сортировке и нарушения целостности данных.
Способ 1: Сортировка данных по одному столбцу в Excel (быстро и просто)
Встроенный инструмент сортировки — самый быстрый способ упорядочить данные по одному столбцу. Он идеально подходит для простых задач, таких как сортировка имен в алфавитном порядке или чисел от меньшего к большему.
Пошаговая инструкция:
- Выберите один столбец, по которому хотите выполнить сортировку.
- Перейдите на вкладку Данные на ленте Excel.
- Нажмите Сортировка от А до Я (по возрастанию: А→Я, 1→100) или Сортировка от Я до А (по убыванию: Я→А, 100→1).
- Появится всплывающее окно: Расширить выделенный диапазон. Оставьте этот вариант выбранным.
- Нажмите Сортировка, чтобы завершить процесс.
Совет:
- Опция Расширить выделенный диапазон гарантирует, что все связанные данные в соседних столбцах будут перемещены вместе с выбранным столбцом. В большинстве случаев эту опцию следует оставлять включенной, чтобы не нарушить связи в данных.
- Если в ваших данных есть строка заголовков (например, «Имя», «Email»), установите флажок Мои данные содержат заголовки во всплывающем окне. Это предотвратит сортировку самого заголовка (например, слово «Имя» не окажется в конце списка).
Способ 2: Сортировка данных по нескольким столбцам в Excel (настраиваемая сортировка)
Для сложных наборов данных сортировки по одному столбцу недостаточно. Например, вы можете захотеть отсортировать данные о продажах сначала по «Региону» (по возрастанию), а затем по «Сумме продаж» (по убыванию), чтобы увидеть лучшие показатели в каждом регионе. Здесь на помощь приходит «Настраиваемая сортировка».
Пошаговая инструкция:
- Выберите любую ячейку внутри вашего набора данных (это позволит Excel распознать всю таблицу целиком).
- Перейдите на вкладку Данные и нажмите Сортировка (не кнопки А→Я/Я→А).
- В окне «Сортировка»:
- Выберите первый столбец (например, «Регион») и установите порядок От А до Я.
- Нажмите Добавить уровень, чтобы выбрать следующий столбец (например, «Сумма продаж»), и установите порядок По убыванию.
- Выберите первый столбец (например, «Регион») и установите порядок От А до Я.
- Нажмите ОК, чтобы применить сортировку. Теперь данные будут организованы по столбцу «Регион», а при совпадении регионов — по «Сумме продаж».
Важное замечание:
Excel применяет сортировку иерархически — сначала сортирует по первому столбцу, а затем разрешает совпадения с помощью следующего.
Примеры использования:
- Отчеты о продажах (Регион → Выручка)
- Списки сотрудников (Отдел → Должность)
- Инвентаризация (Категория → Уровень запасов)
Способ 3: Сортировка данных в Excel с помощью формул (SORT и SORTBY)
Если данные часто обновляются, ручная сортировка становится неэффективной. Формулы Excel, такие как SORT и SORTBY, позволяют создавать динамические, автоматически обновляемые списки.
В отличие от традиционной сортировки, эти функции не изменяют исходные данные. Вместо этого они создают динамически отсортированную копию, которая обновляется автоматически.
Использование функции SORT (простой вариант для современного Excel)
Функция SORT сортирует диапазон данных и возвращает новый отсортированный массив. Синтаксис: =SORT(массив; [индекс_сортировки]; [порядок_сортировки]; [по_столбцу])
- В пустой ячейке (например, J1) введите формулу: =SORT(A1:H11; 1; -1; FALSE)
- A1:H11: Весь набор данных, который нужно отсортировать.
- 1: Индекс столбца для сортировки.
- -1: Порядок сортировки (1 = по возрастанию, -1 = по убыванию).
- FALSE: Сортировка по строкам (по умолчанию; используйте TRUE для сортировки по столбцам).
- Нажмите Enter. Excel создаст динамический отсортированный список, начиная с ячейки J1. Если вы измените исходные данные (например, сумму продаж), список обновится автоматически.
Использование функции SORTBY (более гибкий вариант)
=SORTBY(A1:H11; G1:G11; -1)
Функция SORTBY сортирует набор данных на основе значений в одном или нескольких отдельных диапазонах. В отличие от функции SORT, которая опирается на номера столбцов, SORTBY позволяет точно указать диапазон, определяющий порядок сортировки.
Как это работает:
- A1:H11 → Набор данных для вывода (вся таблица).
- G1:G11 → Диапазон, используемый как ключ сортировки (например, «Сумма продаж»).
- -1 → Порядок сортировки (1 = по возрастанию, -1 = по убыванию).
Пример использования:
Отсортировать таблицу продаж по выручке, не меняя исходный набор данных.
Способ 4: Сортировка отфильтрованных данных в Excel (гибкий анализ)
Фильтры позволяют быстро просматривать и сортировать определенные подмножества данных, не меняя исходную таблицу навсегда. Это особенно полезно при работе с большими объемами данных, например, при анализе продаж в конкретном регионе или за определенный период.
Пошаговая инструкция:
- Выберите ваш набор данных, включая строку заголовков.
- Перейдите на вкладку Данные и нажмите Фильтр (или используйте сочетание клавиш: Ctrl+Shift+L). В каждой ячейке заголовка появятся маленькие стрелки раскрывающегося списка.
- Нажмите на стрелку в столбце, который хотите отсортировать (например, «Регион»), снимите флажки с ненужных регионов (например, «Восток», «Север», «Юг») и нажмите ОК.
- Нажмите на стрелку в столбце «Сумма продаж» и выберите Сортировка от минимального к максимальному (по возрастанию) или Сортировка от максимального к минимальному (по убыванию). Это отсортирует только отфильтрованные (видимые) строки.
- Чтобы убрать фильтр и вернуться к исходным данным, снова нажмите Фильтр (или Ctrl+Shift+L).
Ключевое преимущество:
Фильтры позволяют комбинировать сортировку с фильтрацией данных, что упрощает анализ конкретных подмножеств (например, сортировка только крупных сделок в конкретном регионе) без изменения структуры исходных данных.
Способ 5: Сортировка данных Excel с помощью Python (автоматизация и масштабируемость)
Для больших наборов данных (более 10 000 строк) или повторяющихся задач (например, ежедневная сортировка отчетов) автоматизация на Python — это прорыв. Мы будем использовать Spire.XLS for Python — мощную библиотеку, которая упрощает работу с файлами Excel, включая сортировку, без необходимости установки самого Excel на вашем компьютере.
Предварительные требования:
- Установите Spire.XLS for Python: выполните команду pip install Spire.XLS в терминале или командной строке.
- Подготовьте входной файл Excel (например, «Input.xlsx») с данными, которые нужно отсортировать.
Пошаговый код Python (с пояснениями):
from spire.xls.common import *
from spire.xls import *
# Создаем экземпляр рабочей книги
workbook = Workbook()
# Загружаем входной файл Excel
workbook.LoadFromFile("Input.xlsx")
# Получаем первый рабочий лист
worksheet = workbook.Worksheets[0]
# Определяем правило сортировки: сортировать столбец B (индекс 1) по значениям по возрастанию
workbook.DataSorter.SortColumns.Add(1, SortComparsionType.Values, OrderBy.Ascending)
# Указываем диапазон ячеек для сортировки
workbook.DataSorter.Sort(worksheet["A1:H11"])
# Сохраняем отсортированные данные в новый файл Excel
workbook.SaveToFile("SortByColumns.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Как настроить код:
- Сортировка другого столбца: измените первый параметр в Add() (например, 0 для столбца A, 1 для столбца B).
- Сортировка по убыванию: замените OrderBy.Ascending на OrderBy.Descending.
- Сортировка большего диапазона: измените worksheet["A1:H11"] (например, worksheet["A1:G1000"] для 1000 строк и 7 столбцов).
- Несколько столбцов: добавьте второе правило сортировки с помощью workbook.DataSorter.SortColumns.Add() (например, сначала сортировка столбца A по возрастанию, затем столбца B по убыванию).
Пример использования:
Этот метод идеально подходит для автоматизации рутинных задач — например, ежедневной сортировки 50+ файлов Excel или обработки наборов данных, которые слишком велики для плавной работы в самом Excel.
Помимо сортировки, вы можете использовать Python для автоматизации других задач, таких как форматирование листов, применение стилей и экспорт файлов Excel в PDF. Эти возможности позволяют легко создавать полноценные рабочие процессы обработки документов.
Сравнительная таблица: какой метод выбрать
| Метод | Лучше всего подходит для | Плюсы | Минусы |
|---|---|---|---|
| Встроенная сортировка | Быстрой сортировки по одному столбцу | Простота, не требует настройки | Ограничен базовыми задачами; ручной процесс |
| Настраиваемая сортировка | Многоуровневой сортировки по нескольким столбцам | Гибкость, работа со сложными данными | Требует нескольких дополнительных шагов |
| Формулы Excel | Динамических, автоматически обновляемых списков | Нет необходимости в повторной сортировке | Функция SORT доступна только в современном Excel |
| Фильтры | Временной сортировки/анализа подмножеств | Неразрушающий метод; сочетается с фильтрацией | Не подходит для постоянной сортировки |
| Python (Spire.XLS) | Больших наборов данных, автоматизации | Масштабируемость, повторяющиеся задачи, не нужен Excel | Требуются базовые знания Python |
Заключение
Сортировка в Excel — это больше, чем просто упорядочивание данных; это способ сделать информацию полезной и понятной.
- Используйте встроенную сортировку для быстрых задач.
- Используйте настраиваемую сортировку для структурированного анализа.
- Используйте формулы для динамических результатов.
- Используйте фильтры для гибкого исследования данных.
- Используйте Python для автоматизации в больших масштабах.
Освоение этих методов позволит вам с легкостью справляться с любыми задачами: от простых таблиц до сложных рабочих процессов с данными.
Часто задаваемые вопросы
В1: Почему мои данные в Excel смещаются после сортировки?
Обычно это происходит, если не выбрана опция Расширить выделенный диапазон. Всегда следите за тем, чтобы связанные столбцы были включены в сортировку.
В2: Можно ли сортировать по цвету ячейки или шрифта?
Да. В диалоговом окне «Сортировка» выберите Цвет ячейки или Цвет шрифта в поле «Сортировка по».
В3: Можно ли сортировать данные с пустыми ячейками?
Да. Excel помещает пустые ячейки в конец (при сортировке по возрастанию) или в начало (по убыванию). При необходимости их можно отфильтровать.
В4: Как отменить сортировку?
Нажмите Ctrl + Z сразу после сортировки. Если вы уже внесли другие изменения, отмена может быть недоступна.
В5: Почему сортировка в Excel не работает?
Распространенные причины:
- Смешанные типы данных.
- Скрытые строки или столбцы.
- Неверно выбранный диапазон.
Смотрите также
Como remover quebras de página no Word (4 métodos fáceis)
Índice

Você já abriu um documento do Word e encontrou páginas em branco inesperadas ou espaços estranhos? Esses problemas geralmente são causados por quebras de página ocultas ou mal posicionadas. Quer tenham sido adicionadas manualmente ou acionadas por configurações específicas de parágrafo, saber como remover quebras de página no Word é uma habilidade essencial para manter sua formatação limpa e profissional.
Este guia aborda quatro maneiras práticas de remover quebras de página no Word, desde cliques manuais simples até soluções automatizadas.
- Remover quebras de página usando o recurso Mostrar/Ocultar
- Remover quebras de página com Localizar e Substituir
- Remover quebras de página ajustando quebras automáticas
- Remover quebras de página usando código (Free Spire.Doc)
- Perguntas frequentes
Remover uma quebra de página no Microsoft Word com o recurso Mostrar/Ocultar
Se você tem apenas uma ou duas quebras para corrigir, a maneira mais direta de remover uma quebra de página em documentos do Word é encontrar o marcador oculto e excluí-lo. O Word mantém esses marcadores invisíveis por padrão para manter a interface limpa, então você precisa primeiro torná-los visíveis. Aqui estão os passos que você pode seguir:
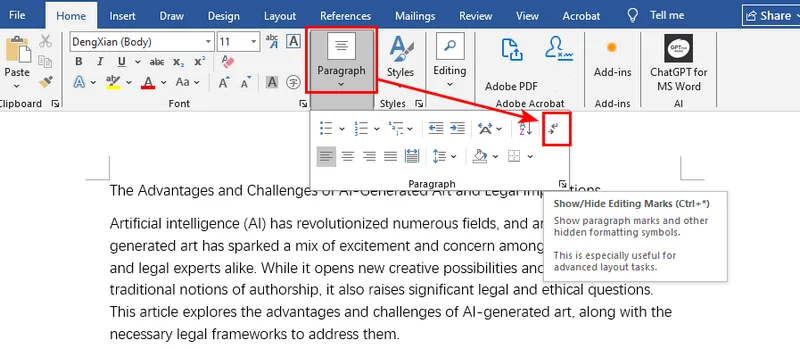
- Passo 1: Vá para a guia Página Inicial e clique no ícone Mostrar/Ocultar ¶ (ou pressione Ctrl + Shift + 8). Isso revelará todas as marcas de formatação ocultas.
- Passo 2: Encontre as quebras de página no documento. Elas aparecem como uma linha pontilhada com o rótulo "Quebra de Página".
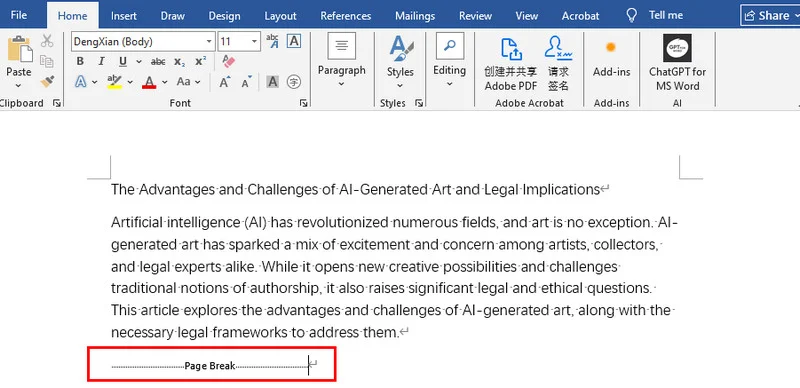
- Passo 3: Clique nessa linha e pressione a tecla Delete ou Backspace no seu teclado.
Dica profissional: Às vezes, espaços indesejados são causados por uma série de parágrafos vazios em vez de uma quebra de página. Se você vir vários símbolos ¶ sem texto, talvez também precise remover linhas em branco para organizar completamente o layout do seu documento.
Remover uma quebra de página no Microsoft Word com Localizar e Substituir
Ao trabalhar com documentos longos ou desorganizados, pode ser necessário remover todas as quebras de página de uma vez. Removê-las uma por uma pode ser demorado. Em vez disso, você pode usar a ferramenta Localizar e Substituir para limpar o documento inteiro em segundos. Além de apenas localizar e substituir texto normal, esse recurso permite que você direcione caracteres especiais e marcadores de formatação, proporcionando um nível profissional de controle sobre o layout.
- Passo 1: Pressione Ctrl + H para abrir a caixa de diálogo Localizar e Substituir.
- Passo 2: Na caixa Localizar, digite
^m(o código especial para uma quebra de página manual).
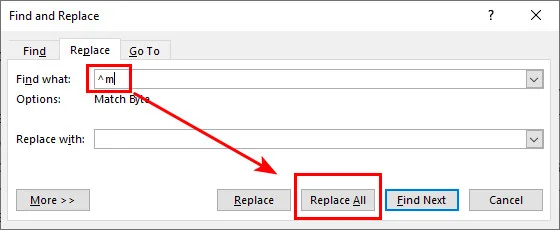
- Passo 3: Deixe a caixa Substituir por vazia e clique em Substituir Tudo.
Esta é a maneira mais rápida de remover todas as quebras de página em arquivos do Word quando você deseja redefinir completamente o fluxo do seu texto.
Remover uma quebra de página em documentos do Word ajustando quebras automáticas
Às vezes, você pode tentar remover uma quebra de página no Microsoft Word e descobrir que não há marcador para excluir. Essas quebras não aparecerão como uma linha visível de Quebra de Página, mesmo quando as marcas de formatação estiverem ativadas. Isso acontece porque a quebra é uma regra de parágrafo em vez de um caractere. Mesmo assim, ainda existem maneiras eficazes de encontrá-las e removê-las ajustando a formatação do parágrafo.
- Passo 1: Selecione o parágrafo que está pulando para uma nova página inesperadamente.
- Passo 2: Clique com o botão direito no texto e escolha Parágrafo, depois navegue até a guia Quebras de Linha e de Página.
- Passo 3: Desmarque a caixa Quebra de página antes.
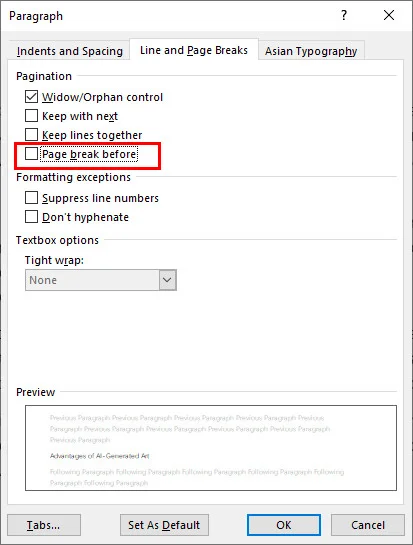
Usar este método é a maneira mais eficaz de remover quebras de página no Word que parecem presas ou inamovíveis. Ele aborda a lógica de formatação subjacente do documento em vez de procurar um caractere para excluir, garantindo que seu texto flua naturalmente sem interrupções forçadas.
Remover quebras de página em um documento do Word usando código (Free Spire.Doc)
Para aqueles que gerenciam grandes volumes de documentos, remover manualmente as quebras de página no Word não é prático. Desenvolvedores frequentemente usam bibliotecas como o Free Spire.Doc for Python para automatizar o processo.
O script irá escanear cada seção e parágrafo de um documento para identificar objetos de Quebra (Break) específicos. Uma vez que uma quebra de página é detectada dentro da estrutura do documento, o Free Spire.Doc a removerá diretamente da coleção de objetos.
Este método garante consistência em centenas de arquivos sem abri-los um por um. Abaixo está um exemplo em Python de como remover todas as quebras de página em um arquivo Word usando a biblioteca Free Spire.Doc:
from spire.doc import *
from spire.doc.common import *
inputFile = "/input/sample.docx"
outputFile = "/output/RemovePageBreaks.docx"
# Criar um objeto Document
document = Document()
# Carregar um documento Word
document.LoadFromFile(inputFile)
# Iterar por todas as seções no documento
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
# Iterar por todos os parágrafos em cada seção
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
# Iterar pelos objetos filhos de trás para frente para evitar erros de índice durante a remoção
for k in range(paragraph.ChildObjects.Count - 1, -1, -1):
child = paragraph.ChildObjects.get_Item(k)
# Verificar se o objeto é uma quebra
if isinstance(child, Break):
break_obj = child
# Remover o objeto se for uma quebra de página
if break_obj.BreakType == BreakType.PageBreak:
paragraph.ChildObjects.Remove(break_obj)
# Salvar o arquivo resultante
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
Aqui está a prévia do documento Word original e do arquivo de saída:

Conclusão
Gerenciar o fluxo do documento torna-se muito mais fácil quando você entende como as quebras de página funcionam. Se você prefere o botão Mostrar/Ocultar, o método Localizar e Substituir ou ajustar as configurações de parágrafo, agora você tem as ferramentas para remover quebras de página em documentos do Word de forma eficaz. Para ainda mais eficiência, usar código com o Free Spire.Doc permite que você lide com tarefas complexas em vários arquivos. Ao dominar essas quatro técnicas, você pode garantir que seus documentos sempre tenham a aparência pretendida, sem interrupções inesperadas.
Perguntas frequentes sobre como remover quebras de página
P1: Como removo todas as quebras de página no Word de uma só vez?
R: A maneira mais rápida é usar a ferramenta Localizar e Substituir. Pressione Ctrl + H, digite ^m na caixa Localizar e clique em Substituir Tudo. Isso limpará instantaneamente todas as quebras de página manuais no seu documento.
P2: Por que não consigo excluir certas quebras de página no meu documento?
R: Se uma quebra não se move, geralmente é devido a uma de duas coisas: ou o Controle de Alterações está ativado ou você está lidando com uma configuração de parágrafo de Quebra de página antes. Além disso, certifique-se de não confundir uma quebra de página com uma quebra de seção; para remover uma quebra de seção, você precisaria pesquisar por ^b em vez disso.
P3: Como remover quebras de página no Word sem excluir texto?
R: Remover uma quebra de página não exclui suas palavras. Basta ativar as marcas de formatação (¶), colocar o cursor diretamente na linha pontilhada da Quebra de Página e pressionar Delete. Seu texto permanecerá intacto, mas simplesmente subirá para preencher a página anterior.
P4: Existe diferença ao remover quebras de página no Word no Mac?
R: A lógica permanece a mesma. Você pode usar Cmd + 8 para alternar as marcas de formatação ou navegar para Editar > Localizar > Localizar e Substituir Avançado para realizar remoções em lote. A principal diferença é simplesmente usar a tecla Command (⌘) em vez de Control (Ctrl) para seus atalhos.
Leia também:
Word에서 페이지 나누기를 제거하는 방법 (4가지 쉬운 방법)
Word 문서를 열었을 때 예상치 못한 빈 페이지나 어색한 간격을 발견한 적이 있으신가요? 이러한 문제는 대개 숨겨져 있거나 잘못 배치된 페이지 나누기로 인해 발생합니다. 수동으로 추가되었든 특정 단락 설정에 의해 트리거되었든, Word에서 페이지 나누기를 제거하는 방법을 아는 것은 문서 서식을 깔끔하고 전문적으로 유지하는 데 필수적인 기술입니다.
이 가이드에서는 간단한 수동 클릭부터 자동화된 솔루션까지, Word에서 페이지 나누기를 제거하는 네 가지 실용적인 방법을 다룹니다.
- 표시/숨기기 기능을 사용하여 페이지 나누기 제거
- 찾기 및 바꾸기로 페이지 나누기 제거
- 자동 페이지 나누기 조정을 통해 페이지 나누기 제거
- 코드를 사용하여 페이지 나누기 제거 (Free Spire.Doc)
- 자주 묻는 질문(FAQs)
표시/숨기기 기능을 사용하여 Microsoft Word에서 페이지 나누기 제거
수정해야 할 나누기가 한두 개뿐이라면, Word 문서에서 페이지 나누기를 제거하는 가장 직접적인 방법은 숨겨진 표시를 찾아 삭제하는 것입니다. Word는 인터페이스를 깔끔하게 유지하기 위해 기본적으로 이러한 표시를 숨기므로, 먼저 이를 보이게 설정해야 합니다. 다음 단계를 따르세요:
- 1단계: 홈 탭으로 이동하여 표시/숨기기 ¶ 아이콘을 클릭합니다(또는 Ctrl + Shift + 8을 누릅니다). 모든 숨겨진 서식 기호가 나타납니다.
- 2단계: 문서에서 페이지 나누기를 찾습니다. "페이지 나누기"라고 표시된 점선으로 나타납니다.
- 3단계: 해당 선을 클릭하고 키보드의 Delete 또는 Backspace 키를 누릅니다.
전문가 팁: 때때로 원치 않는 간격은 페이지 나누기가 아니라 일련의 빈 단락 때문에 발생합니다. 텍스트가 없는 ¶ 기호가 여러 개 보인다면, 문서 레이아웃을 완전히 정리하기 위해 빈 줄 제거가 필요할 수도 있습니다.
찾기 및 바꾸기를 사용하여 Microsoft Word에서 페이지 나누기 제거
길거나 복잡한 문서를 작업할 때는 모든 페이지 나누기를 한 번에 제거해야 할 수도 있습니다. 하나씩 제거하는 것은 시간이 많이 걸릴 수 있습니다. 대신 찾기 및 바꾸기 도구를 사용하여 몇 초 만에 문서 전체를 정리할 수 있습니다. 단순히 일반 텍스트를 찾고 바꾸는 것을 넘어, 이 기능을 사용하면 특수 문자 및 서식 표시를 대상으로 지정하여 레이아웃을 전문적으로 제어할 수 있습니다.
- 1단계: Ctrl + H를 눌러 찾기 및 바꾸기 대화 상자를 엽니다.
- 2단계: 찾을 내용 상자에
^m(수동 페이지 나누기에 대한 특수 코드)을 입력합니다.
- 3단계: 바꿀 내용 상자는 비워두고 모두 바꾸기를 클릭합니다.
이는 텍스트 흐름을 완전히 재설정하고 싶을 때 Word 파일에서 모든 페이지 나누기를 제거하는 가장 빠른 방법입니다.
자동 페이지 나누기 조정을 통해 Word 문서에서 페이지 나누기 제거
때때로 Microsoft Word에서 페이지 나누기를 제거하려고 해도 삭제할 표시가 없는 경우가 있습니다. 이러한 나누기는 서식 기호를 활성화해도 눈에 보이는 '페이지 나누기' 선으로 나타나지 않습니다. 이는 해당 나누기가 문자가 아닌 단락 규칙이기 때문입니다. 그럼에도 불구하고 단락 서식을 조정하여 이를 찾고 제거하는 효과적인 방법이 있습니다.
- 1단계: 예기치 않게 새 페이지로 넘어가는 단락을 선택합니다.
- 2단계: 텍스트를 마우스 오른쪽 버튼으로 클릭하고 단락을 선택한 다음, 줄 및 페이지 나누기 탭으로 이동합니다.
- 3단계: 페이지 나누기 전 확인란의 선택을 취소합니다.
이 방법을 사용하는 것은 고정되어 있거나 삭제할 수 없는 것처럼 느껴지는 Word의 페이지 나누기를 제거하는 가장 효과적인 방법입니다. 삭제할 문자를 찾는 대신 문서의 기본 서식 논리를 해결하므로, 강제적인 중단 없이 텍스트가 자연스럽게 흐르도록 보장합니다.
코드를 사용하여 Word 문서에서 페이지 나누기 제거 (Free Spire.Doc)
대량의 문서를 관리하는 경우 수동으로 Word의 페이지 나누기를 제거하는 것은 실용적이지 않습니다. 개발자들은 종종 Free Spire.Doc for Python과 같은 라이브러리를 사용하여 이 과정을 자동화합니다.
이 스크립트는 문서의 모든 섹션과 단락을 스캔하여 특정 Break 객체를 식별합니다. 문서 구조 내에서 페이지 나누기가 감지되면 Free Spire.Doc이 객체 컬렉션에서 직접 이를 제거합니다.
이 방법을 사용하면 수백 개의 파일을 하나씩 열지 않고도 일관성을 유지할 수 있습니다. 다음은 Free Spire.Doc 라이브러리를 사용하여 Word 파일에서 모든 페이지 나누기를 제거하는 Python 예제입니다:
from spire.doc import *
from spire.doc.common import *
inputFile = "/input/sample.docx"
outputFile = "/output/RemovePageBreaks.docx"
# Document 객체 생성
document = Document()
# Word 문서 로드
document.LoadFromFile(inputFile)
# 문서의 모든 섹션을 반복
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
# 각 섹션의 모든 단락을 반복
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
# 제거 중 인덱스 오류를 방지하기 위해 자식 객체를 역순으로 반복
for k in range(paragraph.ChildObjects.Count - 1, -1, -1):
child = paragraph.ChildObjects.get_Item(k)
# 객체가 Break인지 확인
if isinstance(child, Break):
break_obj = child
# 페이지 나누기인 경우 객체 제거
if break_obj.BreakType == BreakType.PageBreak:
paragraph.ChildObjects.Remove(break_obj)
# 결과 파일 저장
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
다음은 원본 Word 문서와 결과 파일의 미리보기입니다:
결론
페이지 나누기가 어떻게 작동하는지 이해하면 문서 흐름을 관리하기가 훨씬 쉬워집니다. 표시/숨기기 버튼, 찾기 및 바꾸기 방법, 또는 단락 설정 조정 중 무엇을 선호하든, 이제 Word 문서에서 페이지 나누기를 효과적으로 제거할 수 있는 도구를 갖추게 되었습니다. 더 높은 효율성을 위해 Free Spire.Doc을 사용한 코딩은 여러 파일에 걸친 복잡한 작업을 처리할 수 있게 해줍니다. 이 네 가지 기술을 마스터하면 예기치 않은 중단 없이 문서가 항상 의도한 대로 보이도록 할 수 있습니다.
페이지 나누기 제거에 관한 자주 묻는 질문(FAQs)
Q1: Word에서 모든 페이지 나누기를 한 번에 제거하려면 어떻게 하나요?
A: 가장 빠른 방법은 찾기 및 바꾸기 도구를 사용하는 것입니다. Ctrl + H를 누르고 찾을 내용 상자에 ^m을 입력한 다음 모두 바꾸기를 클릭하세요. 이렇게 하면 문서의 모든 수동 페이지 나누기가 즉시 제거됩니다.
Q2: 문서의 특정 페이지 나누기를 삭제할 수 없는 이유는 무엇인가요?
A: 나누기가 제거되지 않는다면 대개 두 가지 이유 중 하나입니다. 변경 내용 추적이 활성화되어 있거나 페이지 나누기 전 단락 설정과 관련된 경우입니다. 또한, 페이지 나누기를 구역 나누기와 혼동하지 않도록 주의하세요. 구역 나누기를 제거하려면 대신 ^b를 검색해야 합니다.
Q3: 텍스트를 삭제하지 않고 Word에서 페이지 나누기를 제거하려면 어떻게 하나요?
A: 페이지 나누기를 제거해도 텍스트는 삭제되지 않습니다. 단순히 서식 기호(¶)를 켜고, 커서를 페이지 나누기 점선 바로 위에 놓은 다음 Delete를 누르세요. 텍스트는 그대로 유지되면서 이전 페이지를 채우기 위해 위로 이동합니다.
Q4: Mac의 Word에서 페이지 나누기를 제거할 때 차이점이 있나요?
A: 논리는 동일합니다. Cmd + 8을 사용하여 서식 기호를 전환하거나 편집 > 찾기 > 고급 찾기 및 바꾸기로 이동하여 일괄 제거를 수행할 수 있습니다. 주요 차이점은 단축키 사용 시 Control (Ctrl) 대신 Command (⌘) 키를 사용하는 것뿐입니다.
더 읽어보기:
Come rimuovere le interruzioni di pagina in Word (4 metodi semplici)
Indice
Ti è mai capitato di aprire un documento Word e trovare pagine vuote inaspettate o spazi vuoti fastidiosi? Questi problemi sono solitamente causati da interruzioni di pagina nascoste o fuori posto. Che siano state aggiunte manualmente o attivate da specifiche impostazioni di paragrafo, sapere come rimuovere le interruzioni di pagina in Word è una competenza essenziale per mantenere la formattazione pulita e professionale.
Questa guida illustra quattro modi pratici per rimuovere le interruzioni di pagina in Word, che spaziano da semplici clic manuali a soluzioni automatizzate.
- Rimuovere le interruzioni di pagina usando la funzione Mostra/Nascondi
- Rimuovere le interruzioni di pagina con Trova e Sostituisci
- Rimuovere le interruzioni di pagina regolando le interruzioni automatiche
- Rimuovere le interruzioni di pagina tramite codice (Free Spire.Doc)
- Domande frequenti (FAQ)
Rimuovere un'interruzione di pagina in Microsoft Word con la funzione Mostra/Nascondi
Se devi correggere solo una o due interruzioni, il modo più diretto per rimuovere un'interruzione di pagina nei documenti Word è trovare il marcatore nascosto ed eliminarlo. Word mantiene questi marcatori invisibili per impostazione predefinita per mantenere l'interfaccia pulita, quindi per prima cosa devi renderli visibili. Ecco i passaggi da seguire:
- Passaggio 1: Vai nella scheda Home e fai clic sull'icona Mostra/Nascondi ¶ (o premi Ctrl + Shift + 8). Verranno rivelati tutti i segni di formattazione nascosti.
- Passaggio 2: Trova le interruzioni di pagina nel documento. Appaiono come una linea tratteggiata con l'etichetta "Interruzione di pagina".
- Passaggio 3: Fai clic su quella linea e premi il tasto Canc o Backspace sulla tastiera.
Suggerimento: A volte, gli spazi indesiderati sono causati da una serie di paragrafi vuoti piuttosto che da un'interruzione di pagina. Se vedi più simboli ¶ senza testo, potresti dover anche rimuovere le righe vuote per sistemare completamente il layout del documento.
Rimuovere un'interruzione di pagina in Microsoft Word con Trova e Sostituisci
Quando lavori con documenti lunghi o disordinati, potresti aver bisogno di rimuovere tutte le interruzioni di pagina in una volta sola. Rimuoverle una per una può richiedere molto tempo. Invece, puoi utilizzare lo strumento Trova e Sostituisci per pulire l'intero documento in pochi secondi. Oltre a trovare e sostituire il testo normale, questa funzione ti consente di puntare a caratteri speciali e marcatori di formattazione, offrendo un controllo di livello professionale sul layout.
- Passaggio 1: Premi Ctrl + H per aprire la finestra di dialogo Trova e Sostituisci.
- Passaggio 2: Nella casella Trova, digita
^m(il codice speciale per un'interruzione di pagina manuale).
- Passaggio 3: Lascia vuota la casella Sostituisci con e fai clic su Sostituisci tutto.
Questo è il modo più veloce per rimuovere tutte le interruzioni di pagina nei file Word quando vuoi ripristinare completamente il flusso del testo.
Rimuovere un'interruzione di pagina nei documenti Word regolando le interruzioni automatiche
A volte, potresti provare a rimuovere un'interruzione di pagina in Microsoft Word solo per scoprire che non c'è alcun marcatore da eliminare. Queste interruzioni non appariranno come una linea di interruzione di pagina visibile, nemmeno quando i segni di formattazione sono abilitati. Ciò accade perché l'interruzione è una regola di paragrafo piuttosto che un carattere. Anche così, ci sono modi efficaci per trovarle e rimuoverle regolando la formattazione del paragrafo.
- Passaggio 1: Seleziona il paragrafo che salta inaspettatamente a una nuova pagina.
- Passaggio 2: Fai clic con il tasto destro sul testo e scegli Paragrafo, quindi vai alla scheda Distribuzione testo.
- Passaggio 3: Deseleziona la casella Interruzione pagina prima.
L'utilizzo di questo metodo è il modo più efficace per rimuovere le interruzioni di pagina in Word che sembrano bloccate o impossibili da spostare. Risolve la logica di formattazione sottostante del documento invece di cercare un carattere da eliminare, assicurando che il testo scorra naturalmente senza interruzioni forzate.
Rimuovere le interruzioni di pagina in un documento Word tramite codice (Free Spire.Doc)
Per chi gestisce grandi volumi di documenti, rimuovere manualmente le interruzioni di pagina in Word non è pratico. Gli sviluppatori utilizzano spesso librerie come Free Spire.Doc for Python per automatizzare il processo.
Lo script scansionerà ogni sezione e paragrafo di un documento per identificare oggetti di tipo Interruzione (Break) specifici. Una volta rilevata un'interruzione di pagina all'interno della struttura del documento, Free Spire.Doc la rimuoverà direttamente dalla raccolta di oggetti.
Questo metodo garantisce coerenza su centinaia di file senza doverli aprire uno per uno. Di seguito è riportato un esempio in Python su come rimuovere tutte le interruzioni di pagina in un file Word utilizzando la libreria Free Spire.Doc:
from spire.doc import *
from spire.doc.common import *
inputFile = "/input/sample.docx"
outputFile = "/output/RemovePageBreaks.docx"
# Crea un oggetto Document
document = Document()
# Carica un documento Word
document.LoadFromFile(inputFile)
# Itera attraverso tutte le sezioni nel documento
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
# Itera attraverso tutti i paragrafi in ogni sezione
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
# Itera attraverso gli oggetti figlio al contrario per evitare errori di indice durante la rimozione
for k in range(paragraph.ChildObjects.Count - 1, -1, -1):
child = paragraph.ChildObjects.get_Item(k)
# Controlla se l'oggetto è un'interruzione
if isinstance(child, Break):
break_obj = child
# Rimuovi l'oggetto se è un'interruzione di pagina
if break_obj.BreakType == BreakType.PageBreak:
paragraph.ChildObjects.Remove(break_obj)
# Salva il file risultante
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
Ecco un'anteprima del documento Word originale e del file di output:
Conclusione
Gestire il flusso del documento diventa molto più semplice una volta capito come funzionano le interruzioni di pagina. Che tu preferisca il pulsante Mostra/Nascondi, il metodo Trova e Sostituisci o la regolazione delle impostazioni di paragrafo, ora hai gli strumenti per rimuovere le interruzioni di pagina nei documenti Word in modo efficace. Per una maggiore efficienza, l'uso del codice con Free Spire.Doc ti consente di gestire attività complesse su più file. Padroneggiando queste quattro tecniche, puoi assicurarti che i tuoi documenti appaiano sempre esattamente come desideravi, senza interruzioni impreviste.
Domande frequenti (FAQ) sulla rimozione delle interruzioni di pagina
Q1: Come posso rimuovere tutte le interruzioni di pagina in Word in una volta sola?
A: Il modo più veloce è utilizzare lo strumento Trova e Sostituisci. Premi Ctrl + H, inserisci ^m nella casella Trova e fai clic su Sostituisci tutto. Questo eliminerà istantaneamente ogni interruzione di pagina manuale nel tuo documento.
Q2: Perché non riesco a eliminare alcune interruzioni di pagina nel mio documento?
A: Se un'interruzione non si sposta, solitamente è dovuto a una di queste due cose: o è attiva la funzione Revisioni o hai a che fare con un'impostazione di paragrafo Interruzione pagina prima. Inoltre, assicurati di non confondere un'interruzione di pagina con un'interruzione di sezione; per rimuovere un'interruzione di sezione, dovresti cercare ^b.
Q3: Come rimuovere le interruzioni di pagina in Word senza eliminare il testo?
A: Rimuovere un'interruzione di pagina non elimina le tue parole. Attiva semplicemente i segni di formattazione (¶), posiziona il cursore direttamente sulla linea tratteggiata Interruzione di pagina e premi Canc. Il tuo testo rimarrà intatto ma si sposterà semplicemente verso l'alto per riempire la pagina precedente.
Q4: C'è differenza nel rimuovere le interruzioni di pagina in Word su Mac?
A: La logica rimane la stessa. Puoi usare Cmd + 8 per attivare/disattivare i segni di formattazione o andare su Modifica > Trova > Trova e sostituisci avanzato per eseguire rimozioni in blocco. La differenza principale è semplicemente l'uso del tasto Command (⌘) invece di Control (Ctrl) per le tue scorciatoie.
Leggi anche:
Comment supprimer les sauts de page dans Word (4 méthodes simples)
Table des matières
Vous est-il déjà arrivé d'ouvrir un document Word et de trouver des pages blanches inattendues ou des espaces gênants ? Ces problèmes sont généralement causés par des sauts de page cachés ou mal placés. Qu'ils aient été ajoutés manuellement ou déclenchés par des paramètres de paragraphe spécifiques, savoir comment supprimer les sauts de page dans Word est une compétence essentielle pour maintenir une mise en forme propre et professionnelle.
Ce guide couvre quatre méthodes pratiques pour supprimer les sauts de page dans Word, allant de simples clics manuels à des solutions automatisées.
- Supprimer les sauts de page à l'aide de la fonction Afficher/Masquer
- Supprimer les sauts de page avec Rechercher et remplacer
- Supprimer les sauts de page en ajustant les sauts automatiques
- Supprimer les sauts de page à l'aide de code (Free Spire.Doc)
- FAQ
Supprimer un saut de page dans Microsoft Word avec la fonction Afficher/Masquer
Si vous n'avez qu'un ou deux sauts à corriger, le moyen le plus direct de supprimer un saut de page dans les documents Word est de trouver le marqueur caché et de le supprimer. Word garde ces marqueurs invisibles par défaut pour garder l'interface propre, vous devez donc d'abord les rendre visibles. Voici les étapes à suivre :
- Étape 1 : Allez dans l'onglet Accueil et cliquez sur l'icône Afficher/Masquer ¶ (ou appuyez sur Ctrl + Maj + 8). Cela révélera toutes les marques de mise en forme masquées.
- Étape 2 : Trouvez les sauts de page dans le document. Ils ressemblent à une ligne pointillée étiquetée "Saut de page".
- Étape 3 : Cliquez sur cette ligne et appuyez sur la touche Suppr ou Retour arrière de votre clavier.
Conseil de pro : Parfois, les espaces indésirables sont causés par une série de paragraphes vides plutôt que par un saut de page. Si vous voyez plusieurs symboles ¶ sans texte, vous devrez peut-être aussi supprimer les lignes vides pour nettoyer complètement la mise en page de votre document.
Supprimer un saut de page dans Microsoft Word avec Rechercher et remplacer
Lorsque vous travaillez sur des documents longs ou désordonnés, vous devrez peut-être supprimer tous les sauts de page en une seule fois. Les supprimer un par un peut prendre du temps. Au lieu de cela, vous pouvez utiliser l'outil Rechercher et remplacer pour nettoyer tout le document en quelques secondes. Au-delà de la simple recherche et remplacement de texte normal, cette fonctionnalité vous permet de cibler des caractères spéciaux et des marqueurs de mise en forme, offrant un niveau de contrôle professionnel sur la mise en page.
- Étape 1 : Appuyez sur Ctrl + H pour ouvrir la boîte de dialogue Rechercher et remplacer.
- Étape 2 : Dans la zone Rechercher, tapez
^m(le code spécial pour un saut de page manuel).
- Étape 3 : Laissez la zone Remplacer par vide et cliquez sur Remplacer tout.
C'est le moyen le plus rapide de supprimer tous les sauts de page dans les fichiers Word lorsque vous souhaitez réinitialiser complètement le flux de votre texte.
Supprimer un saut de page dans les documents Word en ajustant les sauts automatiques
Parfois, vous pouvez essayer de supprimer un saut de page dans Microsoft Word pour découvrir qu'il n'y a aucun marqueur à supprimer. Ces sauts n'apparaîtront pas comme une ligne de saut de page visible, même lorsque les marques de mise en forme sont activées. Cela se produit parce que le saut est une règle de paragraphe plutôt qu'un caractère. Même ainsi, il existe toujours des moyens efficaces de les trouver et de les supprimer en ajustant la mise en forme de vos paragraphes.
- Étape 1 : Sélectionnez le paragraphe qui saute de manière inattendue sur une nouvelle page.
- Étape 2 : Faites un clic droit sur le texte et choisissez Paragraphe, puis accédez à l'onglet Enchaînements.
- Étape 3 : Décochez la case Saut de page avant.
L'utilisation de cette méthode est le moyen le plus efficace de supprimer les sauts de page dans Word qui semblent bloqués ou impossibles à déplacer. Elle traite la logique de mise en forme sous-jacente du document plutôt que de chercher un caractère à supprimer, garantissant que votre texte s'écoule naturellement sans interruptions forcées.
Supprimer les sauts de page dans un document Word à l'aide de code (Free Spire.Doc)
Pour ceux qui gèrent de gros volumes de documents, supprimer manuellement les sauts de page dans Word n'est pas pratique. Les développeurs utilisent souvent des bibliothèques comme Free Spire.Doc for Python pour automatiser le processus.
Le script analysera chaque section et paragraphe d'un document pour identifier des objets Saut spécifiques. Une fois qu'un saut de page est détecté dans la structure du document, Free Spire.Doc le supprimera directement de la collection d'objets.
Cette méthode garantit la cohérence sur des centaines de fichiers sans avoir à les ouvrir un par un. Voici un exemple Python montrant comment supprimer tous les sauts de page dans un fichier Word à l'aide de la bibliothèque Free Spire.Doc :
from spire.doc import *
from spire.doc.common import *
inputFile = "/input/sample.docx"
outputFile = "/output/RemovePageBreaks.docx"
# Créer un objet Document
document = Document()
# Charger un document Word
document.LoadFromFile(inputFile)
# Parcourir toutes les sections du document
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
# Parcourir tous les paragraphes de chaque section
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
# Parcourir les objets enfants à l'envers pour éviter les erreurs d'index lors de la suppression
for k in range(paragraph.ChildObjects.Count - 1, -1, -1):
child = paragraph.ChildObjects.get_Item(k)
# Vérifier si l'objet est un saut
if isinstance(child, Break):
break_obj = child
# Supprimer l'objet s'il s'agit d'un saut de page
if break_obj.BreakType == BreakType.PageBreak:
paragraph.ChildObjects.Remove(break_obj)
# Enregistrer le fichier résultat
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
Voici un aperçu du document Word original et du fichier de sortie :
Conclusion
La gestion du flux de documents devient beaucoup plus facile une fois que vous comprenez comment fonctionnent les sauts de page. Que vous préfériez le bouton Afficher/Masquer, la méthode Rechercher et remplacer ou l'ajustement des paramètres de paragraphe, vous disposez désormais des outils nécessaires pour supprimer efficacement les sauts de page dans les documents Word. Pour encore plus d'efficacité, l'utilisation de code avec Free Spire.Doc vous permet de gérer des tâches complexes sur plusieurs fichiers. En maîtrisant ces quatre techniques, vous pouvez vous assurer que vos documents ressemblent toujours exactement à ce que vous aviez prévu, sans interruptions inattendues.
FAQ sur la suppression des sauts de page
Q1 : Comment supprimer tous les sauts de page dans Word en une seule fois ?
R : Le moyen le plus rapide est d'utiliser l'outil Rechercher et remplacer. Appuyez sur Ctrl + H, entrez ^m dans la zone Rechercher, et cliquez sur Remplacer tout. Cela supprimera instantanément tous les sauts de page manuels de votre document.
Q2 : Pourquoi ne puis-je pas supprimer certains sauts de page dans mon document ?
R : Si un saut ne bouge pas, c'est généralement dû à l'une de ces deux choses : soit le Suivi des modifications est activé, soit vous avez affaire à un paramètre de paragraphe Saut de page avant. De plus, assurez-vous de ne pas confondre un saut de page avec un saut de section ; pour supprimer un saut de section, vous devrez rechercher ^b à la place.
Q3 : Comment supprimer les sauts de page dans Word sans supprimer le texte ?
R : La suppression d'un saut de page ne supprime pas vos mots. Activez simplement les marques de mise en forme (¶), placez votre curseur directement sur la ligne pointillée Saut de page, et appuyez sur Suppr. Votre texte restera intact mais remontera simplement pour remplir la page précédente.
Q4 : Y a-t-il une différence lors de la suppression des sauts de page dans Word sur Mac ?
R : La logique reste la même. Vous pouvez utiliser Cmd + 8 pour basculer les marques de mise en forme ou accéder à Édition > Rechercher > Recherche avancée et remplacer pour effectuer des suppressions par lots. La principale différence est simplement d'utiliser la touche Commande (⌘) au lieu de Contrôle (Ctrl) pour vos raccourcis.
À lire aussi :
- Ajouter des bordures de page dans Word (n'importe quelle page) : 4 méthodes simples
- Méthodes simples pour éliminer l'en-tête dans les documents Word
- Supprimer une zone de texte dans Word — Étapes manuelles et automatisation C#
- Python : Ajouter ou supprimer des numéros de ligne dans les documents Word
Cómo eliminar saltos de página en Word (4 métodos sencillos)
Tabla de contenidos
¿Alguna vez ha abierto un documento de Word y se ha encontrado con páginas en blanco inesperadas o espacios extraños? Estos problemas suelen ser causados por saltos de página ocultos o mal colocados. Ya sea que se hayan añadido manualmente o activado por configuraciones de párrafo específicas, saber cómo eliminar saltos de página en Word es una habilidad esencial para mantener su formato limpio y profesional.
Esta guía cubre cuatro formas prácticas de eliminar saltos de página en Word, desde simples clics manuales hasta soluciones automatizadas.
- Eliminar saltos de página usando la función Mostrar/Ocultar
- Eliminar saltos de página con Buscar y reemplazar
- Eliminar saltos de página ajustando los saltos automáticos
- Eliminar saltos de página mediante código (Free Spire.Doc)
- Preguntas frecuentes
Eliminar un salto de página en Microsoft Word con la función Mostrar/Ocultar
Si solo tiene uno o dos saltos que corregir, la forma más directa de eliminar un salto de página en documentos de Word es encontrar el marcador oculto y eliminarlo. Word mantiene estos marcadores invisibles de forma predeterminada para mantener la interfaz limpia, por lo que primero debe hacerlos visibles. Estos son los pasos que puede seguir:
- Paso 1: Vaya a la pestaña Inicio y haga clic en el icono Mostrar/Ocultar ¶ (o presione Ctrl + Shift + 8). Esto revelará todas las marcas de formato ocultas.
- Paso 2: Busque los saltos de página en el documento. Aparecen como una línea punteada con la etiqueta "Salto de página".
- Paso 3: Haga clic en esa línea y presione la tecla Suprimir o Retroceso en su teclado.
Consejo profesional: A veces, los espacios no deseados son causados por una serie de párrafos vacíos en lugar de un salto de página. Si ve múltiples símbolos ¶ sin texto, es posible que también necesite eliminar líneas en blanco para ordenar completamente el diseño de su documento.
Eliminar un salto de página en Microsoft Word con Buscar y reemplazar
Al trabajar con documentos largos o desordenados, es posible que necesite eliminar todos los saltos de página a la vez. Eliminarlos uno por uno puede llevar mucho tiempo. En su lugar, puede usar la herramienta Buscar y reemplazar para limpiar todo el documento en segundos. Más allá de simplemente buscar y reemplazar texto normal, esta función le permite apuntar a caracteres especiales y marcadores de formato, proporcionando un nivel profesional de control sobre el diseño.
- Paso 1: Presione Ctrl + H para abrir el cuadro de diálogo Buscar y reemplazar.
- Paso 2: En el cuadro Buscar, escriba
^m(el código especial para un salto de página manual).
- Paso 3: Deje el cuadro Reemplazar con vacío y haga clic en Reemplazar todos.
Esta es la forma más rápida de eliminar todos los saltos de página en archivos de Word cuando desea restablecer el flujo de su texto por completo.
Eliminar un salto de página en documentos de Word ajustando los saltos automáticos
A veces, puede intentar eliminar un salto de página en Microsoft Word y descubrir que no hay ningún marcador para eliminar. Estos saltos no aparecerán como una línea de salto de página visible, incluso cuando las marcas de formato estén habilitadas. Esto sucede porque el salto es una regla de párrafo en lugar de un carácter. Aun así, existen formas efectivas de encontrarlos y eliminarlos ajustando el formato de párrafo.
- Paso 1: Seleccione el párrafo que salta a una nueva página inesperadamente.
- Paso 2: Haga clic derecho en el texto y elija Párrafo, luego navegue a la pestaña Líneas y saltos de página.
- Paso 3: Desmarque la casilla Salto de página anterior.
Usar este método es la forma más efectiva de eliminar saltos de página en Word que parecen bloqueados o inamovibles. Aborda la lógica de formato subyacente del documento en lugar de buscar un carácter para eliminar, asegurando que su texto fluya naturalmente sin interrupciones forzadas.
Eliminar saltos de página en un documento de Word mediante código (Free Spire.Doc)
Para aquellos que gestionan grandes volúmenes de documentos, eliminar manualmente los saltos de página en Word no es práctico. Los desarrolladores suelen utilizar bibliotecas como Free Spire.Doc for Python para automatizar el proceso.
El script escaneará cada sección y párrafo de un documento para identificar objetos de Salto específicos. Una vez que se detecta un salto de página dentro de la estructura del documento, Free Spire.Doc lo eliminará directamente de la colección de objetos.
Este método garantiza la coherencia en cientos de archivos sin tener que abrirlos uno por uno. A continuación, se muestra un ejemplo en Python de cómo eliminar todos los saltos de página en un archivo de Word utilizando la biblioteca Free Spire.Doc:
from spire.doc import *
from spire.doc.common import *
inputFile = "/input/sample.docx"
outputFile = "/output/RemovePageBreaks.docx"
# Crear un objeto Document
document = Document()
# Cargar un documento de Word
document.LoadFromFile(inputFile)
# Iterar a través de todas las secciones del documento
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
# Iterar a través de todos los párrafos en cada sección
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
# Iterar a través de los objetos secundarios en orden inverso para evitar errores de índice durante la eliminación
for k in range(paragraph.ChildObjects.Count - 1, -1, -1):
child = paragraph.ChildObjects.get_Item(k)
# Comprobar si el objeto es un salto
if isinstance(child, Break):
break_obj = child
# Eliminar el objeto si es un salto de página
if break_obj.BreakType == BreakType.PageBreak:
paragraph.ChildObjects.Remove(break_obj)
# Guardar el archivo resultante
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
Aquí tiene la vista previa del documento de Word original y el archivo de salida:
Conclusión
Gestionar el flujo de documentos se vuelve mucho más fácil una vez que comprende cómo funcionan los saltos de página. Ya sea que prefiera el botón Mostrar/Ocultar, el método de Buscar y reemplazar o ajustar la configuración de párrafo, ahora tiene las herramientas para eliminar saltos de página en documentos de Word de manera efectiva. Para una mayor eficiencia, el uso de código con Free Spire.Doc le permite manejar tareas complejas en múltiples archivos. Al dominar estas cuatro técnicas, puede asegurarse de que sus documentos siempre se vean exactamente como usted pretendía, sin interrupciones inesperadas.
Preguntas frecuentes sobre la eliminación de saltos de página
P1: ¿Cómo elimino todos los saltos de página en Word a la vez?
R: La forma más rápida es usar la herramienta Buscar y reemplazar. Presione Ctrl + H, ingrese ^m en el cuadro Buscar y haga clic en Reemplazar todos. Esto borrará instantáneamente cada salto de página manual en su documento.
P2: ¿Por qué no puedo eliminar ciertos saltos de página en mi documento?
R: Si un salto no se mueve, generalmente se debe a una de estas dos cosas: o el Control de cambios está habilitado o está tratando con una configuración de párrafo de Salto de página anterior. Además, asegúrese de no confundir un salto de página con un salto de sección; para eliminar un salto de sección, deberá buscar ^b en su lugar.
P3: ¿Cómo eliminar saltos de página en Word sin borrar texto?
R: Eliminar un salto de página no borra sus palabras. Simplemente active las marcas de formato (¶), coloque el cursor directamente sobre la línea punteada de Salto de página y presione Suprimir. Su texto permanecerá intacto, pero simplemente se moverá hacia arriba para llenar la página anterior.
P4: ¿Hay alguna diferencia al eliminar saltos de página en Word en Mac?
R: La lógica sigue siendo la misma. Puede usar Cmd + 8 para activar/desactivar las marcas de formato o navegar a Edición > Buscar > Búsqueda avanzada y reemplazar para realizar eliminaciones por lotes. La principal diferencia es simplemente usar la tecla Command (⌘) en lugar de Control (Ctrl) para sus atajos.
Lea también:
Seitenumbrüche in Word entfernen (4 einfache Methoden)
Inhaltsverzeichnis
Haben Sie schon einmal ein Word-Dokument geöffnet und unerwartete leere Seiten oder seltsame Lücken gefunden? Diese Probleme werden meist durch versteckte oder falsch platzierte Seitenumbrüche verursacht. Egal, ob sie manuell eingefügt oder durch bestimmte Absatzformatierungen ausgelöst wurden: Zu wissen, wie man Seitenumbrüche in Word entfernt, ist eine grundlegende Fähigkeit, um Ihre Dokumente sauber und professionell zu halten.
Dieser Leitfaden behandelt vier praktische Methoden zum Entfernen von Seitenumbrüchen in Word, von einfachen manuellen Klicks bis hin zu automatisierten Lösungen.
- Seitenumbrüche mit der Funktion „Anzeigen/Ausblenden“ entfernen
- Seitenumbrüche mit „Suchen und Ersetzen“ entfernen
- Seitenumbrüche durch Anpassen automatischer Umbrüche entfernen
- Seitenumbrüche per Code entfernen (Free Spire.Doc)
- Häufig gestellte Fragen (FAQs)
Seitenumbruch in Microsoft Word mit der Funktion „Anzeigen/Ausblenden“ entfernen
Wenn Sie nur ein oder zwei Umbrüche korrigieren müssen, ist der direkteste Weg, einen Seitenumbruch in Word-Dokumenten zu entfernen, das Auffinden und Löschen der versteckten Markierung. Word hält diese Markierungen standardmäßig unsichtbar, um die Benutzeroberfläche sauber zu halten. Sie müssen sie also zuerst sichtbar machen. Hier sind die Schritte, die Sie befolgen können:
- Schritt 1: Gehen Sie auf die Registerkarte Start und klicken Sie auf das Symbol Anzeigen/Ausblenden ¶ (oder drücken Sie Strg + Umschalt + 8). Dadurch werden alle versteckten Formatierungszeichen sichtbar.
- Schritt 2: Suchen Sie die Seitenumbrüche im Dokument. Sie sehen aus wie eine gepunktete Linie mit der Beschriftung „Seitenumbruch“.
- Schritt 3: Klicken Sie auf diese Linie und drücken Sie die Entf- oder Rücktaste auf Ihrer Tastatur.
Profi-Tipp: Manchmal werden unerwünschte Lücken durch eine Reihe leerer Absätze statt durch einen Seitenumbruch verursacht. Wenn Sie mehrere ¶-Symbole ohne Text sehen, müssen Sie möglicherweise auch leere Zeilen entfernen, um Ihr Dokumentlayout vollständig zu bereinigen.
Seitenumbruch in Microsoft Word mit „Suchen und Ersetzen“ entfernen
Bei der Arbeit mit langen oder unübersichtlichen Dokumenten müssen Sie möglicherweise alle Seitenumbrüche auf einmal entfernen. Diese einzeln zu löschen, kann zeitaufwendig sein. Stattdessen können Sie das Tool Suchen und Ersetzen verwenden, um das gesamte Dokument in Sekunden zu bereinigen. Über das bloße Suchen und Ersetzen von normalem Text hinaus ermöglicht Ihnen diese Funktion, gezielt nach Sonderzeichen und Formatierungsmarkierungen zu suchen, was Ihnen eine professionelle Kontrolle über das Layout bietet.
- Schritt 1: Drücken Sie Strg + H, um das Dialogfeld Suchen und Ersetzen zu öffnen.
- Schritt 2: Geben Sie im Feld Suchen nach den Code
^mein (der spezielle Code für einen manuellen Seitenumbruch).
- Schritt 3: Lassen Sie das Feld Ersetzen durch leer und klicken Sie auf Alle ersetzen.
Dies ist der schnellste Weg, um alle Seitenumbrüche in Word-Dateien zu entfernen, wenn Sie den Textfluss vollständig zurücksetzen möchten.
Seitenumbruch in Word-Dokumenten durch Anpassen automatischer Umbrüche entfernen
Manchmal versuchen Sie, einen Seitenumbruch in Microsoft Word zu entfernen, stellen aber fest, dass keine Markierung zum Löschen vorhanden ist. Diese Umbrüche erscheinen nicht als sichtbare Seitenumbruch-Linie, selbst wenn Formatierungszeichen aktiviert sind. Dies geschieht, weil der Umbruch eine Absatzregel und kein Zeichen ist. Dennoch gibt es effektive Möglichkeiten, sie durch Anpassen Ihrer Absatzformatierung zu finden und zu entfernen.
- Schritt 1: Markieren Sie den Absatz, der unerwartet auf eine neue Seite springt.
- Schritt 2: Klicken Sie mit der rechten Maustaste auf den Text, wählen Sie Absatz und navigieren Sie zur Registerkarte Zeilen- und Seitenumbruch.
- Schritt 3: Deaktivieren Sie das Kontrollkästchen Seitenumbruch vor dem Absatz.
Diese Methode ist am effektivsten, um Seitenumbrüche in Word zu entfernen, die „festzustecken“ scheinen. Sie adressiert die zugrunde liegende Formatierungslogik des Dokuments, anstatt nach einem zu löschenden Zeichen zu suchen, und stellt sicher, dass Ihr Text natürlich ohne erzwungene Unterbrechungen fließt.
Seitenumbrüche in einem Word-Dokument per Code entfernen (Free Spire.Doc)
Für diejenigen, die große Mengen an Dokumenten verwalten, ist das manuelle Entfernen von Seitenumbrüchen in Word nicht praktikabel. Entwickler verwenden häufig Bibliotheken wie Free Spire.Doc for Python, um den Prozess zu automatisieren.
Das Skript scannt jeden Abschnitt und jeden Absatz eines Dokuments, um spezifische Break-Objekte zu identifizieren. Sobald ein Seitenumbruch innerhalb der Dokumentstruktur erkannt wird, entfernt Free Spire.Doc ihn direkt aus der Objektsammlung.
Diese Methode gewährleistet Konsistenz über Hunderte von Dateien hinweg, ohne diese einzeln öffnen zu müssen. Unten finden Sie ein Python-Beispiel, wie Sie alle Seitenumbrüche in einer Word-Datei mit der Free Spire.Doc-Bibliothek entfernen:
from spire.doc import *
from spire.doc.common import *
inputFile = "/input/sample.docx"
outputFile = "/output/RemovePageBreaks.docx"
# Erstellen eines Document-Objekts
document = Document()
# Laden eines Word-Dokuments
document.LoadFromFile(inputFile)
# Durchlaufen aller Abschnitte im Dokument
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
# Durchlaufen aller Absätze in jedem Abschnitt
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
# Durchlaufen der untergeordneten Objekte in umgekehrter Reihenfolge, um Indexfehler beim Entfernen zu vermeiden
for k in range(paragraph.ChildObjects.Count - 1, -1, -1):
child = paragraph.ChildObjects.get_Item(k)
# Prüfen, ob das Objekt ein Umbruch ist
if isinstance(child, Break):
break_obj = child
# Entfernen des Objekts, wenn es ein Seitenumbruch ist
if break_obj.BreakType == BreakType.PageBreak:
paragraph.ChildObjects.Remove(break_obj)
# Speichern der Ergebnisdatei
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
Hier ist eine Vorschau des ursprünglichen Word-Dokuments und der Ausgabedatei:
Fazit
Die Verwaltung des Dokumentenflusses wird viel einfacher, sobald Sie verstehen, wie Seitenumbrüche funktionieren. Egal, ob Sie die „Anzeigen/Ausblenden“-Schaltfläche, die „Suchen und Ersetzen“-Methode oder die Anpassung der Absatz-Einstellungen bevorzugen – Sie haben nun die Werkzeuge, um Seitenumbrüche in Word-Dokumenten effektiv zu entfernen. Für noch mehr Effizienz ermöglicht Ihnen die Verwendung von Code mit Free Spire.Doc die Bewältigung komplexer Aufgaben über mehrere Dateien hinweg. Durch die Beherrschung dieser vier Techniken stellen Sie sicher, dass Ihre Dokumente immer genau so aussehen, wie Sie es beabsichtigt haben, ohne unerwartete Unterbrechungen.
FAQs zum Entfernen von Seitenumbrüchen
F1: Wie entferne ich alle Seitenumbrüche in Word auf einmal?
A: Der schnellste Weg ist das Tool Suchen und Ersetzen. Drücken Sie Strg + H, geben Sie ^m in das Feld Suchen nach ein und klicken Sie auf Alle ersetzen. Dies entfernt sofort jeden manuellen Seitenumbruch in Ihrem Dokument.
F2: Warum kann ich bestimmte Seitenumbrüche in meinem Dokument nicht löschen?
A: Wenn sich ein Umbruch nicht entfernen lässt, liegt das meist an einem von zwei Dingen: Entweder ist die Funktion Änderungen nachverfolgen aktiviert, oder Sie haben es mit einer Absatz-Einstellung für einen Seitenumbruch davor zu tun. Stellen Sie außerdem sicher, dass Sie einen Seitenumbruch nicht mit einem Abschnittsumbruch verwechseln; um einen Abschnittsumbruch zu entfernen, müssten Sie stattdessen nach ^b suchen.
F3: Wie entferne ich Seitenumbrüche in Word, ohne Text zu löschen?
A: Das Entfernen eines Seitenumbruchs löscht nicht Ihren Text. Aktivieren Sie einfach die Formatierungszeichen (¶), platzieren Sie Ihren Cursor direkt auf die gepunktete Linie des Seitenumbruchs und drücken Sie Entf. Ihr Text bleibt intakt, rückt aber einfach nach oben, um die vorherige Seite zu füllen.
F4: Gibt es einen Unterschied beim Entfernen von Seitenumbrüchen in Word auf dem Mac?
A: Die Logik bleibt dieselbe. Sie können Cmd + 8 verwenden, um Formatierungszeichen ein- oder auszuschalten, oder zu Bearbeiten > Suchen > Erweiterte Suche & Ersetzen navigieren, um Stapelentfernungen durchzuführen. Der Hauptunterschied besteht lediglich darin, die Command (⌘)-Taste anstelle der Control (Ctrl)-Taste für Ihre Tastenkombinationen zu verwenden.
Ebenfalls lesen:
Как убрать разрывы страниц в Word (4 простых способа)
Содержание
Вы когда-нибудь открывали документ Word и обнаруживали неожиданные пустые страницы или странные пробелы? Эти проблемы обычно вызваны скрытыми или неправильно расставленными разрывами страниц. Независимо от того, были ли они добавлены вручную или вызваны определенными настройками абзацев, знание того, как удалить разрывы страниц в Word, является важным навыком для поддержания чистого и профессионального форматирования.
В этом руководстве рассматриваются четыре практических способа удаления разрывов страниц в Word, от простых кликов вручную до автоматизированных решений.
- Удаление разрывов страниц с помощью функции «Отобразить/скрыть»
- Удаление разрывов страниц с помощью функции «Найти и заменить»
- Удаление разрывов страниц путем настройки автоматических разрывов
- Удаление разрывов страниц с помощью кода (Free Spire.Doc)
- Часто задаваемые вопросы
Удаление разрыва страницы в Microsoft Word с помощью функции «Отобразить/скрыть»
Если вам нужно исправить всего один или два разрыва, самый прямой способ удалить разрыв страницы в документах Word — найти скрытый маркер и удалить его. По умолчанию Word скрывает эти маркеры, чтобы интерфейс выглядел чище, поэтому сначала нужно сделать их видимыми. Вот шаги, которые вы можете выполнить:
- Шаг 1: Перейдите на вкладку Главная и нажмите значок Отобразить все знаки ¶ (или нажмите Ctrl + Shift + 8). Это откроет все скрытые знаки форматирования.
- Шаг 2: Найдите разрывы страниц в документе. Они выглядят как пунктирная линия с надписью «Разрыв страницы» (Page Break).
- Шаг 3: Нажмите на эту линию и нажмите клавишу Delete или Backspace на клавиатуре.
Совет: Иногда нежелательные пробелы возникают из-за серии пустых абзацев, а не из-за разрыва страницы. Если вы видите несколько символов ¶ без текста, вам также может потребоваться удалить пустые строки, чтобы полностью привести в порядок макет документа.
Удаление разрыва страницы в Microsoft Word с помощью функции «Найти и заменить»
При работе с длинными или сложными документами может потребоваться удалить все разрывы страниц сразу. Удаление их по одному может занять много времени. Вместо этого вы можете использовать инструмент Найти и заменить, чтобы очистить весь документ за секунды. Помимо простого поиска и замены обычного текста, эта функция позволяет находить специальные символы и маркеры форматирования, обеспечивая профессиональный уровень контроля над макетом.
- Шаг 1: Нажмите Ctrl + H, чтобы открыть диалоговое окно Найти и заменить.
- Шаг 2: В поле Найти введите
^m(специальный код для ручного разрыва страницы).
- Шаг 3: Оставьте поле Заменить на пустым и нажмите Заменить все.
Это самый быстрый способ удалить все разрывы страниц в файлах Word, когда вы хотите полностью сбросить поток текста.
Удаление разрыва страницы в документах Word путем настройки автоматических разрывов
Иногда вы можете попытаться удалить разрыв страницы в Microsoft Word и обнаружить, что нет маркера для удаления. Эти разрывы не отображаются как видимая линия «Разрыв страницы», даже если включены знаки форматирования. Это происходит потому, что разрыв является правилом абзаца, а не символом. Тем не менее, существуют эффективные способы найти и удалить их, настроив форматирование абзаца.
- Шаг 1: Выделите абзац, который неожиданно перескакивает на новую страницу.
- Шаг 2: Щелкните правой кнопкой мыши по тексту и выберите Абзац, затем перейдите на вкладку Положение на странице.
- Шаг 3: Снимите флажок С новой страницы.
Использование этого метода — самый эффективный способ удаления разрывов страниц в Word, которые кажутся «застрявшими» или не поддающимися удалению. Он устраняет базовую логику форматирования документа, а не ищет символ для удаления, гарантируя, что ваш текст будет течь естественно без принудительных прерываний.
Удаление разрывов страниц в документе Word с помощью кода (Free Spire.Doc)
Для тех, кто работает с большими объемами документов, ручное удаление разрывов страниц в Word непрактично. Разработчики часто используют библиотеки, такие как Free Spire.Doc for Python, для автоматизации этого процесса.
Скрипт будет сканировать каждый раздел и абзац документа, чтобы идентифицировать конкретные объекты Break (разрыва). Как только разрыв страницы будет обнаружен в структуре документа, Free Spire.Doc удалит его непосредственно из коллекции объектов.
Этот метод обеспечивает единообразие в сотнях файлов без необходимости открывать их по одному. Ниже приведен пример на Python, показывающий, как удалить все разрывы страниц в файле Word с помощью библиотеки Free Spire.Doc:
from spire.doc import *
from spire.doc.common import *
inputFile = "/input/sample.docx"
outputFile = "/output/RemovePageBreaks.docx"
# Создать объект документа
document = Document()
# Загрузить документ Word
document.LoadFromFile(inputFile)
# Перебрать все разделы в документе
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
# Перебрать все абзацы в каждом разделе
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
# Перебрать дочерние объекты в обратном порядке, чтобы избежать ошибок индекса при удалении
for k in range(paragraph.ChildObjects.Count - 1, -1, -1):
child = paragraph.ChildObjects.get_Item(k)
# Проверить, является ли объект разрывом
if isinstance(child, Break):
break_obj = child
# Удалить объект, если это разрыв страницы
if break_obj.BreakType == BreakType.PageBreak:
paragraph.ChildObjects.Remove(break_obj)
# Сохранить результирующий файл
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
Вот предварительный просмотр исходного документа Word и выходного файла:
Заключение
Управлять потоком документа становится намного проще, когда вы понимаете, как работают разрывы страниц. Независимо от того, предпочитаете ли вы кнопку «Отобразить/скрыть», способ «Найти и заменить» или настройку параметров абзаца, теперь у вас есть инструменты для эффективного удаления разрывов страниц в документах Word. Для еще большей эффективности использование кода с Free Spire.Doc позволяет выполнять сложные задачи с несколькими файлами. Освоив эти четыре метода, вы сможете гарантировать, что ваши документы всегда выглядят именно так, как вы задумали, без каких-либо неожиданных прерываний.
Часто задаваемые вопросы об удалении разрывов страниц
В1: Как удалить все разрывы страниц в Word сразу?
О: Самый быстрый способ — использовать инструмент Найти и заменить. Нажмите Ctrl + H, введите ^m в поле Найти и нажмите Заменить все. Это мгновенно очистит каждый ручной разрыв страницы в вашем документе.
В2: Почему я не могу удалить некоторые разрывы страниц в своем документе?
О: Если разрыв не удаляется, это обычно связано с одной из двух причин: либо включен режим Исправления (Track Changes), либо вы имеете дело с настройкой абзаца С новой страницы. Кроме того, убедитесь, что вы не путаете разрыв страницы с разрывом раздела; чтобы удалить разрыв раздела, вам нужно искать ^b.
В3: Как удалить разрывы страниц в Word, не удаляя текст?
О: Удаление разрыва страницы не удаляет ваши слова. Просто включите знаки форматирования (¶), поместите курсор прямо на пунктирную линию Разрыв страницы и нажмите Delete. Ваш текст останется нетронутым, но просто переместится вверх, чтобы заполнить предыдущую страницу.
В4: Есть ли разница при удалении разрывов страниц в Word на Mac?
О: Логика остается прежней. Вы можете использовать Cmd + 8 для переключения знаков форматирования или перейти в Правка > Найти > Расширенный поиск и замена для пакетного удаления. Основное отличие заключается лишь в использовании клавиши Command (⌘) вместо Control (Ctrl) для ваших сочетаний клавиш.