Textdatei in XML konvertieren: Online-Tools, Word- und Python-Methoden
Inhaltsverzeichnis

Reine Textdateien (.txt) werden aufgrund ihrer Einfachheit in professionellen Umgebungen häufig verwendet. Ihr Mangel an Formatierung macht sie leichtgewichtig und universell kompatibel. Diese Einfachheit wird jedoch zu einer Schwäche, wenn Datenintegration erforderlich ist. Wenn beispielsweise eine Mitarbeiterliste in ein ERP-System importiert oder technische Dokumente mit einer Suchmaschine synchronisiert werden, reichen reine Texte schnell nicht mehr aus. Es fehlt die Struktur, die moderne Systeme benötigen.
Im Gegensatz dazu bietet XML ein strukturiertes, maschinenlesbares Format. Dies macht die Suche nach einer zuverlässigen Methode zur Konvertierung von Textdateien in XML unerlässlich. Ob für eine schnelle Aufgabe oder für eine massive Datenbank, dieser Leitfaden bietet drei effiziente Lösungen.
- Verwendung eines Online-Text-zu-XML-Konverters
- Speichern einer Textdatei als XML mit Microsoft Word
- Konvertieren von TXT-Dateien in XML mit der kostenlosen Spire-Serie
- Auswahl der besten Methode zur Konvertierung von Textdateien in XML
- FAQs
Option 1: Verwendung eines Online-Text-zu-XML-Konverters
Wenn Sie eine einzelne, kleine Datei haben und es eilig haben, ist ein Online-Text-zu-XML-Konverter wie FreeFileConvert oft die erste Wahl, die einem in den Sinn kommt. Mit diesen webbasierten Tools können Sie eine Datei hochladen und das Ergebnis in Sekundenschnelle herunterladen.
Schritte zur Online-Konvertierung von Text in XML:
- Schritt 1. Gehen Sie zur TXT zu XML-Seite von FreeFileConvert.
- Schritt 2. Wählen Sie ein
.txt-Dokument von Ihrem lokalen Laufwerk aus und laden Sie es hoch. - Schritt 3. Klicken Sie auf die Schaltfläche Dateien konvertieren, um die Text-zu-XML-Konvertierung zu starten.
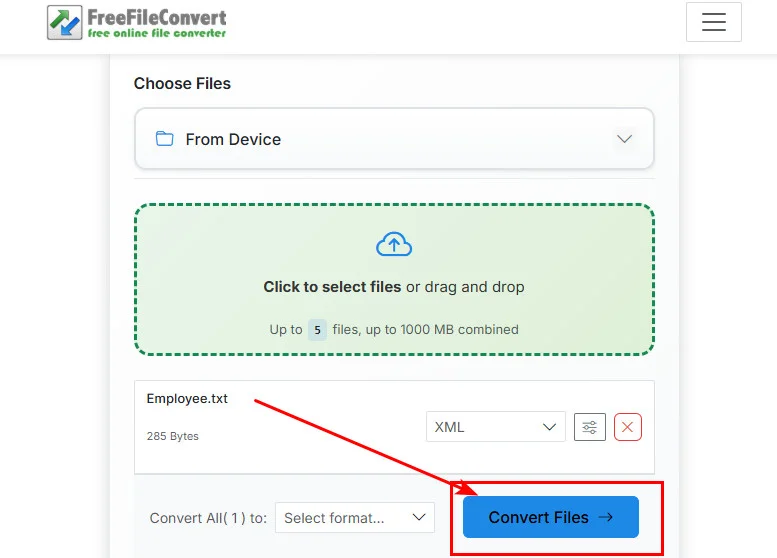
- Schritt 4. Warten Sie, bis die Verarbeitung abgeschlossen ist, und klicken Sie dann auf die Download-Schaltfläche, um Ihre neue XML-Datei zu speichern.
Vorteile:
- Keine Installation erforderlich.
- Funktioniert direkt in Ihrem Browser.
Nachteile:
- Das Hochladen sensibler Dateien auf einen Drittanbieter-Server kann gefährlich sein.
- Diese Tools haben oft Schwierigkeiten, Textdokumente in XML zu konvertieren, wenn die Daten komplexe Hierarchien aufweisen.
- Begrenzte Anzahl und Größe von Textdateien.
Am besten geeignet für: Nicht sensible, kleine persönliche Dateien, die keine spezifische Formatierung erfordern.
Option 2: Speichern einer Textdatei als XML mit Microsoft Word
Wenn Sie eine schnelle, Offline-Methode zum Speichern einer Textdatei als XML suchen, ohne zusätzliche Tools installieren zu müssen, bietet Microsoft Word eine einfache integrierte Option. Diese Methode ist besonders nützlich für die grundlegende Dokumentkonvertierung, wenn keine strenge XML-Struktur erforderlich ist.
Schritte zum Speichern einer Textdatei als XML in Word:
- Schritt 1. Öffnen Sie Microsoft Word und laden Sie Ihre
.txt-Datei. - Schritt 2. Klicken Sie auf Datei > Speichern unter.
- Schritt 3. Wählen Sie einen Speicherort und wählen Sie dann XML-Dokument (*.xml) aus der Dropdown-Liste für das Dateiformat.
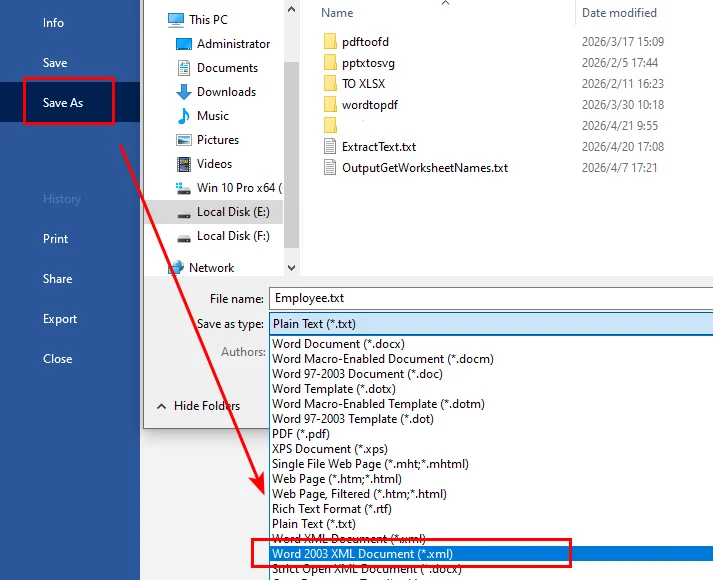
- Schritt 4. Klicken Sie auf Speichern, um die Datei zu exportieren.
Vorteile:
- Keine zusätzlichen Tools erforderlich, wenn Word bereits installiert ist.
- Vollständig offline und sicher.
- Sehr einfach für Anfänger zu bedienen.
Nachteile:
- Erzeugt Word-spezifisches XML (WordML) mit zusätzlichen Tags und Metadaten.
- Nicht geeignet für die Verarbeitung strukturierter Daten oder die Systemintegration.
- Begrenzte Kontrolle über die XML-Struktur.
Am besten geeignet für: Schnelle, einmalige Konvertierungen, bei denen Struktur und Datenreinheit nicht kritisch sind.
Option 3: Konvertieren von TXT-Dateien in XML mit der kostenlosen Spire-Serie
Während die vorherigen Methoden für kleine Aufgaben gut funktionieren, werden sie für die Konvertierung in großem Maßstab ineffizient. In solchen Fällen ist Automatisierung die bessere Wahl.
Durch die Verwendung einer dedizierten Python-Bibliothek wie Free Spire.XLS können Sie einen unordentlichen Stapel von TXT-Dateien problemlos in strukturierte XML-Daten umwandeln. Die gleiche Logik ermöglicht es Ihnen, TXT in Excel in Python zu konvertieren, wenn Ihr Projekt eine Tabellenkalkulation anstelle einer Auszeichnungssprache erfordert.
Szenario A: Konvertierung strukturierter Daten (tabellenähnliche TXT)
Diese Methode ist der beste Weg, um TXT in XML für strukturierte Datensätze wie Verkaufsberichte oder Mitarbeiterlisten zu konvertieren. Sie behandelt jede Zeile Ihrer Textdatei als strukturierten Datensatz.
from spire.xls import *
from spire.xls.common import *
# Erstellen einer Workbook-Instanz
workbook = Workbook()
# Laden einer Textdatei
workbook.LoadFromFile("/input/Employee.txt", ",", 1, 1)
# Speichern des Dokuments als XML-Dokument
workbook.SaveAsXml("/output/data_style.xml")
workbook.Dispose()
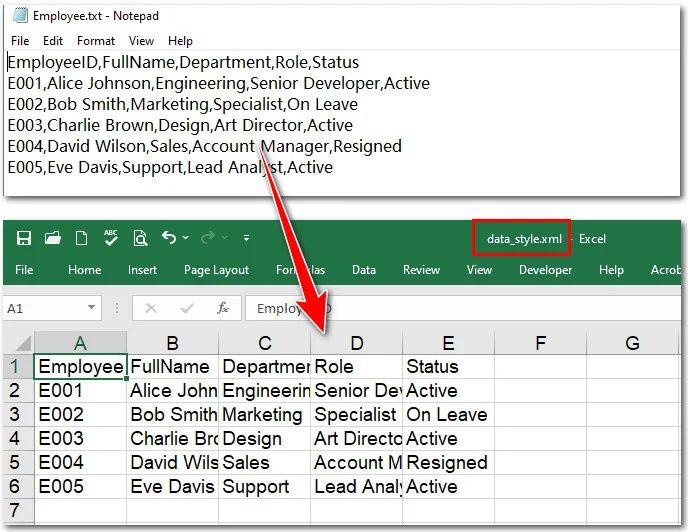
Hier ist die Vorschau der ursprünglichen Textdatei und des ausgegebenen XML-Dokuments:
Verständnis der Parameter von LoadFromFile:
Um Rohtextdaten korrekt in ein strukturiertes XML-Format zu übertragen, ist es wichtig zu verstehen, wie jeder Parameter funktioniert:
workbook.LoadFromFile("E:/Input/Employee.txt", ",", 1, 1)
- Dateipfad (
"E:/.../Employee.txt"): Gibt den Speicherort Ihrer Quelltextdatei an. - Trennzeichen (
","): Definiert, wie der Textinhalt in Spalten aufgeteilt wird. Gängige Optionen sind:","für CSV-ähnliche Daten"\t"für tabulatorgetrennte Werte" "(Leerzeichen) oder";"je nach Ihrem Datenformat
- Startzeile (
1): Gibt die Zeilennummer an, ab der der Datenimport beginnt. Verwenden Sie1, wenn Sie Kopfzeilen einschließen möchten. - Startspalte (
1): Legt die Startspaltenposition im Arbeitsblatt fest (z. B.1= Spalte A).
Diese Parameter geben Ihnen präzise Kontrolle darüber, wie Rohtext während des Konvertierungsprozesses analysiert und strukturiert wird.
Hinweis: Das Trennzeichen bestimmt, wie Spalten getrennt werden. Diese Flexibilität erleichtert auch die Konvertierung von TXT in CSV in Python bei der Arbeit mit gängigen Datenaustauschformaten.
Szenario B: Konvertierung von Textinhalten (Absatzbasierte TXT)
Wenn Ihre Textdatei Absätze, Überschriften und Listen anstelle von Rohdaten-Spalten enthält, ist Free Spire.Doc das bessere Werkzeug. Es ermöglicht Ihnen, ein Textdokument in XML zu konvertieren und dabei den logischen Fluss und die Absatzstruktur des ursprünglichen Inhalts beizubehalten.
from spire.doc import *
from spire.doc.common import *
# Erstellen einer Document-Instanz
doc = Document()
# Laden einer Textdatei
doc.LoadFromFile("/input/Technical Specification AI Integration Module.txt")
# Speichern der Textdatei als neues XML-Dokument
doc.SaveToFile("/output/texttoxml.xml", FileFormat.Xml)
doc.Close()
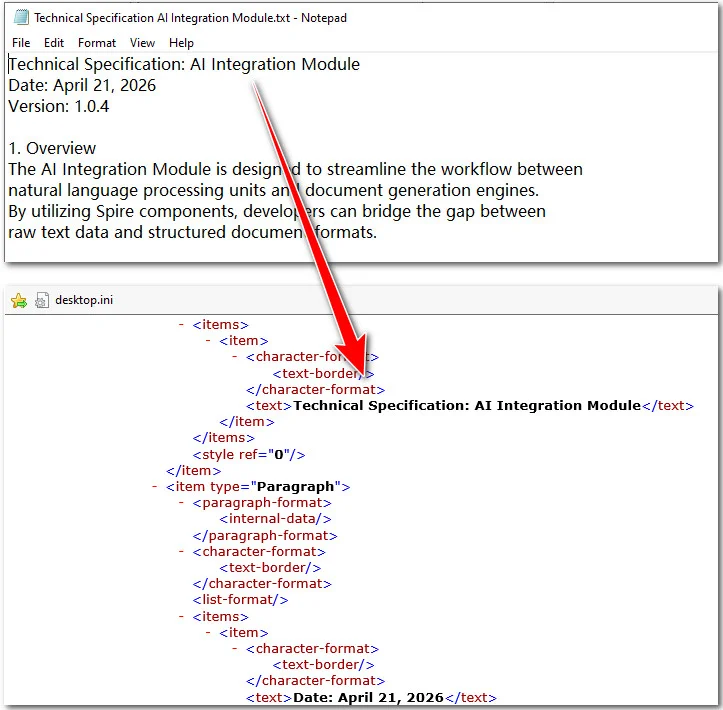
Hier ist die Vorschau der ursprünglichen Textdatei und des konvertierten XML-Dokuments:
Vorteile:
- Kein Microsoft Office erforderlich.
- Datensicherheit.
- Hohe Effizienz.
- Saubere Datenausgabe.
Nachteile:
- Lernkurve.
- Umgebungsaufbau.
Am besten geeignet für: Entwickler, Projekte auf Unternehmensebene und alle, die TXT in XML für große, sensible Datensätze konvertieren müssen.
Auswahl der besten Methode zur Konvertierung von Textdateien in XML
| Methode | Am besten geeignet für | Sicherheit | Stapelverarbeitung |
|---|---|---|---|
| Online-Konverter | Einmalige Benutzer | Gering | Schlecht |
| Microsoft Word | Grundlegender Export | Hoch | Keine |
| Kostenlose Spire-Komponenten | Entwickler & SEOs | Maximal | Ausgezeichnet |
FAQs
F1: Kann ich Microsoft Word verwenden, um eine Textdatei als XML zu speichern?
Ja, Sie können eine .txt-Datei in Word öffnen und Speichern unter > XML-Dokument auswählen. Dies erstellt jedoch eine WordML-Datei, die mit komplexem Styling-Code gefüllt ist. Für saubere, datenbereite Knoten ist die Verwendung eines Tools wie Free Spire.XLS viel effektiver.
F2: Ist es sicher, kostenlose Online-Konverter für sensible Unternehmensdaten zu verwenden?
Im Allgemeinen nein. Die meisten Online-Tools laden Ihre Daten auf einen Drittanbieter-Server hoch. Für sensible Informationen ist es sicherer, eine Textdatei lokal als XML zu speichern, indem Sie einen Offline-Editor oder Python-Code verwenden, um die Privatsphäre zu gewährleisten.
F3: Wie kann ich TXT für über 1000 Dateien in XML konvertieren?
Sie können eine Python-Schleife mit der kostenlosen Spire-Bibliothek verwenden, um ganze Ordner in Sekundenschnelle stapelweise zu verarbeiten. Wenn Sie diese strukturierten Daten später in einer Tabellenkalkulation anzeigen oder prüfen müssen, können Sie mit derselben professionellen Suite auch XML-Daten in Excel konvertieren.
Fazit
Dieser Leitfaden erklärt drei Möglichkeiten, Textdateien in XML zu konvertieren. Online-Tools sind ideal für schnelle, nicht sensible Aufgaben, während Microsoft Word eine einfache Offline-Option für den grundlegenden Dokumentexport bietet. Für professionelle Umgebungen glänzt die kostenlose Spire-Serie durch die Automatisierung von Stapelkonvertierungen zur Zeitersparnis. Letztendlich gibt es keine beste Methode; die richtige Wahl ist einfach diejenige, die am effizientesten zu Ihrem aktuellen Workflow passt.
Lesen Sie auch:
Преобразовать текстовый файл в XML: онлайн-инструменты, методы Word и Python
Оглавление
Простые текстовые файлы (.txt) широко используются в профессиональной среде благодаря своей простоте. Отсутствие форматирования делает их легкими и универсально совместимыми. Однако эта простота становится недостатком, когда требуется интеграция данных. Например, при импорте списка сотрудников в ERP-систему или синхронизации технических документов с поисковой системой, необработанный текст быстро становится недостаточным. Ему не хватает структуры, требуемой современными системами.
В отличие от этого, XML предоставляет структурированный машиночитаемый формат. Это делает поиск надежного способа конвертации текстовых файлов в XML крайне важным. Будь то для быстрой задачи или для огромной базы данных, это руководство предлагает три эффективных решения.
- Использование онлайн-конвертера текста в XML
- Сохранение текстового файла в формате XML с помощью Microsoft Word
- Конвертирование файлов TXT в XML с помощью бесплатной серии Spire
- Выбор лучшего способа конвертации текстовых файлов в XML
- Часто задаваемые вопросы
Вариант 1: Использование онлайн-конвертера текста в XML
Если у вас есть один небольшой файл, и вы торопитесь, онлайн-конвертер текста в XML, такой как FreeFileConvert, часто первым приходит на ум. Эти веб-инструменты позволяют загрузить файл и получить результат за считанные секунды.
Шаги по конвертации текста в XML онлайн:
- Шаг 1. Перейдите на страницу TXT в XML FreeFileConvert.
- Шаг 2. Выберите и загрузите документ
.txtс вашего локального диска. - Шаг 3. Нажмите кнопку Convert Files, чтобы начать конвертацию текста в XML.
- Шаг 4. Дождитесь завершения обработки, затем нажмите кнопку загрузки, чтобы сохранить ваш новый XML-файл.
Преимущества:
- Установка не требуется.
- Работает прямо в вашем браузере.
Недостатки:
- Загрузка конфиденциальных файлов на сторонний сервер может быть опасной.
- Эти инструменты часто испытывают трудности с конвертацией текстовых документов в XML, если данные имеют сложную иерархию.
- Ограниченное количество и размер текстовых файлов.
Лучше всего подходит для: Неконфиденциальных, небольших личных файлов, не требующих специфического форматирования.
Вариант 2: Сохранение текстового файла в формате XML с помощью Microsoft Word
Если вы ищете быстрый автономный способ сохранить текстовый файл в формате XML без установки дополнительных инструментов, Microsoft Word предоставляет простую встроенную опцию. Этот метод особенно полезен для базовой конвертации документов, когда строгая XML-структура не требуется.
Шаги по сохранению текстового файла в формате XML в Word:
- Шаг 1. Откройте Microsoft Word и загрузите ваш файл
.txt. - Шаг 2. Нажмите Файл > Сохранить как.
- Шаг 3. Выберите местоположение, затем выберите XML-документ (*.xml) из выпадающего списка форматов файлов.
- Шаг 4. Нажмите Сохранить, чтобы экспортировать файл.
Преимущества:
- Дополнительные инструменты не требуются, если Word уже установлен.
- Полностью автономный и безопасный.
- Очень прост в использовании для новичков.
Недостатки:
- Создает XML, специфичный для Word (WordML), с дополнительными тегами и метаданными.
- Не подходит для обработки структурированных данных или системной интеграции.
- Ограниченный контроль над XML-структурой.
Лучше всего подходит для: Быстрых, одноразовых конвертаций, где структура и чистота данных не критичны.
Вариант 3: Конвертирование файлов TXT в XML с помощью бесплатной серии Spire
Хотя предыдущие методы хорошо работают для небольших задач, они становятся неэффективными для крупномасштабных конвертаций. В таких случаях автоматизация является лучшим выбором.
Используя специализированную библиотеку Python, такую как Free Spire.XLS, вы можете легко превратить беспорядочную кучу TXT-файлов в структурированные XML-данные. Эта же логика позволяет вам конвертировать TXT в Excel на Python, если ваш проект требует электронную таблицу вместо языка разметки.
Сценарий A: Конвертация структурированных данных (табличный TXT)
Этот метод является лучшим способом конвертации TXT в XML для структурированных наборов данных, таких как отчеты о продажах или списки сотрудников. Он рассматривает каждую строку вашего текстового файла как запись структурированных данных.
from spire.xls import *
from spire.xls.common import *
# Создание экземпляра Workbook
workbook = Workbook()
# Загрузка текстового файла
workbook.LoadFromFile("/input/Employee.txt", ",", 1, 1)
# Сохранение документа в формате XML
workbook.SaveAsXml("/output/data_style.xml")
workbook.Dispose()
Вот предварительный просмотр исходного текстового файла и выходного XML-документа:
Понимание параметров LoadFromFile:
Чтобы правильно сопоставить необработанные текстовые данные со структурированным XML-форматом, важно понимать, как работает каждый параметр:
workbook.LoadFromFile("E:/Input/Employee.txt", ",", 1, 1)
- Путь к файлу (
"E:/.../Employee.txt"): Указывает расположение вашего исходного текстового файла. - Разделитель (
","): Определяет, как текстовое содержимое разбивается на столбцы. Распространенные варианты включают:","для данных в стиле CSV"\t"для значений, разделенных табуляцией" "(пробел) или";"в зависимости от формата ваших данных
- Начальная строка (
1): Указывает номер строки, с которой начинается импорт данных. Используйте1, если вы хотите включить заголовки. - Начальный столбец (
1): Устанавливает начальную позицию столбца на рабочем листе (например,1= Столбец A).
Эти параметры дают вам точный контроль над тем, как необработанный текст анализируется и структурируется в процессе конвертации.
Примечание: Разделитель определяет, как разделяются столбцы. Эта гибкость также позволяет легко конвертировать TXT в CSV на Python при работе с распространенными форматами обмена данными.
Сценарий B: Конвертация текстового содержимого (параграфный TXT)
Если ваш текстовый файл состоит из параграфов, заголовков и списков, а не из необработанных столбцов данных, Free Spire.Doc является лучшим инструментом. Он позволяет конвертировать текстовый документ в XML, сохраняя логическую последовательность и структуру параграфов исходного содержимого.
from spire.doc import *
from spire.doc.common import *
# Создание экземпляра Document
doc = Document()
# Загрузка текстового файла
doc.LoadFromFile("/input/Technical Specification AI Integration Module.txt")
# Сохранение текстового файла в новый XML-документ
doc.SaveToFile("/output/texttoxml.xml", FileFormat.Xml)
doc.Close()
Вот предварительный просмотр исходного текстового файла и конвертированного XML-документа:
Преимущества:
- Microsoft Office не требуется.
- Безопасность документов.
- Высокая эффективность.
- Чистый вывод данных.
Недостатки:
- Кривая обучения.
- Настройка среды.
Лучше всего подходит для: Разработчиков, корпоративных проектов и всех, кому требуется конвертировать TXT в XML для больших, конфиденциальных наборов данных.
Выбор лучшего способа конвертации текстовых файлов в XML
| Метод | Лучше всего подходит для | Безопасность | Пакетная обработка |
|---|---|---|---|
| Онлайн-конвертер | Одноразовые пользователи | Низкая | Плохая |
| Microsoft Word | Базовый экспорт | Высокая | Нет |
| Компоненты Free Spire | Разработчики и SEO-специалисты | Максимальная | Отличная |
Часто задаваемые вопросы
В1: Могу ли я использовать Microsoft Word для сохранения текстового файла в формате XML?
Да, вы можете открыть файл .txt в Word и выбрать Сохранить как > XML-документ. Однако это создает файл WordML, заполненный сложным кодом стилей. Для чистых, готовых к обработке узлов использование такого инструмента, как Free Spire.XLS, гораздо более эффективно.
В2: Безопасно ли использовать бесплатные онлайн-конвертеры для конфиденциальных данных компании?
Как правило, нет. Большинство онлайн-инструментов загружают ваши данные на сторонний сервер. Для конфиденциальной информации безопаснее сохранять текстовый файл в формате XML локально, используя автономный редактор или код Python, чтобы обеспечить конфиденциальность.
В3: Как конвертировать TXT в XML для более чем 1000 файлов?
Вы можете использовать цикл Python с библиотекой Free Spire для пакетной обработки целых папок за секунды. Если позже вам потребуется просмотреть или проверить эти структурированные данные в электронной таблице, вы также можете конвертировать XML-данные в Excel с помощью того же профессионального набора.
Заключение
В этом руководстве описаны три способа конвертации текстовых файлов в XML. Онлайн-инструменты идеально подходят для быстрых, неконфиденциальных задач, в то время как Microsoft Word предлагает простой автономный вариант для базового экспорта документов. Для профессиональной среды серия Free Spire превосходно автоматизирует пакетные конвертации для экономии времени. В конечном итоге, не существует лучшего метода; правильный выбор — это просто тот, который наиболее эффективно соответствует вашему текущему рабочему процессу.
Также читайте:
Converter Excel em PNG: 4 métodos fáceis (soluções gratuitas e em lote)
Índice

Arquivos Excel (.xlsx ou .xls) são amplamente utilizados para organizar e analisar dados estruturados, mas nem sempre são o melhor formato para compartilhamento. A formatação pode mudar entre dispositivos e a pasta de trabalho original pode ser facilmente modificada por outros. Converter Excel para PNG transforma sua planilha em uma imagem estática, facilitando o compartilhamento, publicação ou incorporação em diferentes plataformas sem se preocupar com alterações de layout.
Neste guia, apresentaremos 4 métodos práticos para converter Excel para PNG sem perder qualidade - desde opções manuais rápidas até a conversão em lote automatizada usando Python - para que você possa escolher a abordagem que melhor se adapta às suas necessidades.
Visão Geral dos Métodos de Conversão de Excel para PNG
- Método 1 - Copiar Excel como Imagem (Forma Integrada)
- Método 2 - Captura de Tela do Excel para PNG (Usando a Ferramenta de Captura)
- Método 3 - Converter Excel para PNG Online (Sem Instalação)
- Método 4 - Converter Excel para PNG em Lote via Python (Automação)
Por Que Converter Excel para PNG?
Embora os PDFs sejam comuns, as imagens PNG oferecem vantagens únicas para conteúdo digital e relatórios:
- Consistência Pixel a Pixel: Preserva layouts, formatação de células e fontes exatamente como aparecem no Excel - sem fórmulas quebradas ou colunas desalinhadas.
- Acessibilidade Universal: PNGs podem ser visualizados em qualquer smartphone, tablet ou sistema operacional sem a necessidade do Microsoft Excel ou de um visualizador especializado.
- Integração Perfeita: Ideal para incorporar dashboards e gráficos diretamente em sites, documentação ou apresentações do PowerPoint.
- Segurança Aprimorada (Somente Leitura): "Bloqueia" efetivamente seus dados, impedindo que os destinatários alterem números brutos ou visualizem fórmulas ocultas confidenciais.
- Transparência de Alta Qualidade: Ao contrário dos JPEGs, os PNGs suportam transparência e oferecem melhor clareza para elementos de UI e visualizações de dados.
Método 1 - Copiar Excel como Imagem (Forma Integrada)
Se você deseja uma conversão rápida de Excel para PNG sem instalar software de terceiros, o recurso integrado Copiar como Imagem do Excel é uma excelente opção. Ele preserva a formatação exata das células e o layout da tabela, tornando-o ideal para exportar um intervalo selecionado para relatórios e apresentações.
Guia Passo a Passo:
-
Selecione os dados do Excel
Abra sua pasta de trabalho do Excel e destaque as células que deseja converter. -
Copiar como Imagem
Na guia Página Inicial, clique na seta ao lado de Copiar e escolha Copiar como Imagem.
-
Escolha a qualidade da imagem
Selecione Conforme exibido na tela e Imagem para obter a melhor qualidade visual, em seguida, clique em OK.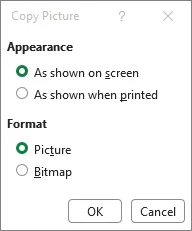
-
Cole a imagem
Selecione uma célula em branco e pressione Ctrl+V (Windows) ou Cmd+V (Mac). -
Salvar como PNG
Clique com o botão direito na imagem colada → selecione Salvar como Imagem → escolha Gráfico de Rede Portátil (*.png) → selecione uma pasta → clique em Salvar.
Dicas Profissionais:
- Este método exporta apenas as células destacadas, não a planilha inteira.
- A imagem exportada geralmente tem um fundo branco.
- Para editar ainda mais a imagem, cole-a em um editor de imagens como o Microsoft Paint (Windows) ou o Preview (Mac) em vez disso.
Quando Usar Este Método:
Melhor para conjuntos de dados pequenos e conversões únicas onde a fidelidade do layout é importante.
Se você precisar salvar um gráfico especificamente, consulte nosso guia sobre converter gráficos do Excel em imagens.
Método 2 - Captura de Tela do Excel para PNG (Usando a Ferramenta de Captura)
Usar uma ferramenta de captura de tela (como a Ferramenta de Captura do Windows ou Captura de Tela do macOS) é a maneira mais flexível de converter dados do Excel em um PNG. Ao contrário do Copiar como Imagem, essas ferramentas capturam exatamente o que você vê na tela - incluindo menus suspensos, comentários ou até mesmo várias janelas sobrepostas - tornando-a a melhor escolha para criar tutoriais de software.
Passos:
-
Prepare a Visualização
Ajuste o nível de zoom do seu Excel (por exemplo, para 150% ou superior) para obter clareza máxima e oculte quaisquer elementos indesejados (como a Faixa de Opções ou a barra de fórmulas). -
Abra a Ferramenta de Captura
Pressione Windows + Shift + S (Windows) ou Cmd + Shift + 4 (Mac). -
Selecione a Área do Excel
Clique e arraste o cursor para desenhar uma caixa ao redor do intervalo de células específico. -
Anotar (Opcional)
Clique na janela de visualização que aparece para destacar dados importantes ou desenhar setas na imagem. -
Salvar como PNG
Clique no ícone Salvar para salvar a captura diretamente como um arquivo PNG.
Dicas Profissionais:
- O atalho Windows + Shift + S funciona no Windows 10 e 11. Para versões mais antigas do Windows, pesquise por Ferramenta de Captura no menu Iniciar manualmente.
- A maioria das ferramentas oferece um modo de Captura de Forma Livre, permitindo capturar áreas não retangulares de sua planilha, se necessário.
Quando Usar Este Método:
Melhor para documentação, guias passo a passo ou quando você precisa anotar rapidamente dados antes de compartilhar.
Método 3 - Converter Excel para PNG Online (Sem Instalação)
Para usuários sem Microsoft Excel ou aqueles que trabalham em dispositivos móveis, um conversor online de Excel para PNG oferece uma maneira conveniente de transformar planilhas em imagens de alta qualidade. Essas ferramentas rodam inteiramente no navegador e geralmente suportam fundos transparentes, o que é ideal para design web ou marca d'água.
Conversores Online Mais Bem Avaliados:
- CloudConvert: Melhor para Alta Resolução. Fornece controle granular sobre a densidade de pixels (DPI) e canais alfa (fundo transparente) para garantir uma saída PNG nítida e profissional.
- Zamzar: Melhor para Simplicidade. Um veterano confiável da indústria desde 2006, oferecendo um processo de conversão limpo de três etapas de XLS ou XLSX para PNG.
- Cloudxdocs: Melhor para Layouts Complexos. Construído sobre APIs de nível profissional, ele se destaca na preservação de células mescladas e formatação original.
Como Converter Excel para PNG Online:
-
Selecione uma Ferramenta Confiável
Navegue até um site respeitável como o CloudConvert.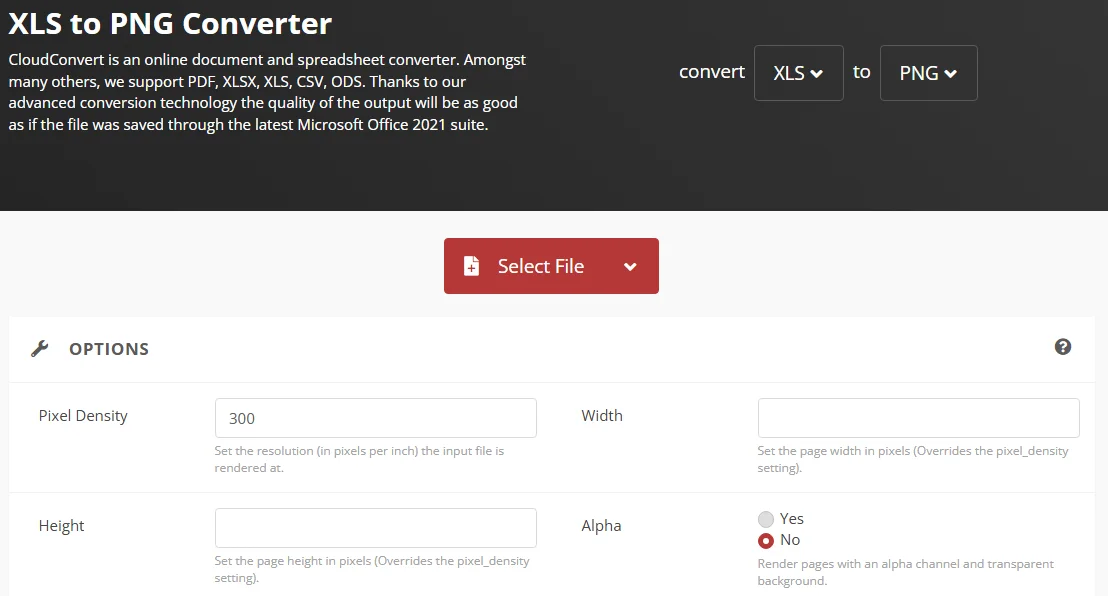
-
Faça Upload do Seu Documento
Clique em Selecionar Arquivo para procurar em seu computador ou arraste e solte sua pasta de trabalho diretamente no navegador. -
Configure as Configurações da Imagem
Escolha PNG como saída. Se disponível, defina a resolução para 300 DPI para impressão profissional ou telas de alta definição. -
Converta e Baixe
Clique em Converter. Após a conclusão, baixe suas imagens (geralmente fornecidas como um arquivo ZIP se seu Excel tiver várias planilhas).
Nota sobre Segurança e Privacidade de Dados:
Para proteger sua privacidade, faça upload apenas de informações não confidenciais para conversores públicos. Priorize sempre ferramentas que usem criptografia SSL e ofereçam exclusão automática de arquivos em até 24 horas. Para dados financeiros confidenciais, recomendamos usar o recurso Copiar como Imagem do Excel ou uma ferramenta de captura de tela local em vez disso.
Quando Usar Este Método:
- Você precisa converter Excel para PNG no celular.
- Você deseja saída PNG transparente.
- Você está convertendo planilhas inteiras ou várias planilhas em imagens de uma vez.
Método 4 - Converter Excel para PNG em Lote via Python (Automação)
Para desenvolvedores, analistas de dados e equipes que gerenciam um grande volume de arquivos Excel, automatizar a conversão de Excel para PNG com Python é a solução mais escalável. Essa abordagem permite processar em lote centenas de planilhas ou pastas de trabalho e integrar exportações de imagem em pipelines de relatórios - sem a necessidade de instalar o Microsoft Excel.
Principais Benefícios:
- Sem Dependência do Office: Funciona em servidores e Linux.
- Escala Massiva: Converta mais de 100 arquivos em segundos.
- Alta Fidelidade: Preserva a formatação original das células, fontes e cores.
Pré-requisitos
Antes de começar, certifique-se de ter:
- Python 3.7+
- Spire.XLS para Python - uma biblioteca independente que cria, edita e converte arquivos Excel sem a necessidade do Microsoft Office.
Instalação:
pip install spire.xls
Exemplo de Python - Converter Excel para Imagens PNG em Lote
Este script salva automaticamente todas as planilhas de uma pasta de trabalho como imagens PNG de alta resolução:
from spire.xls import *
# Carregar o arquivo Excel
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
# Iterar por todas as planilhas
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Salvar cada planilha como uma imagem
image = sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn)
image.Save(f"sheet_{i+1}.png")
# Liberar a pasta de trabalho
workbook.Dispose()
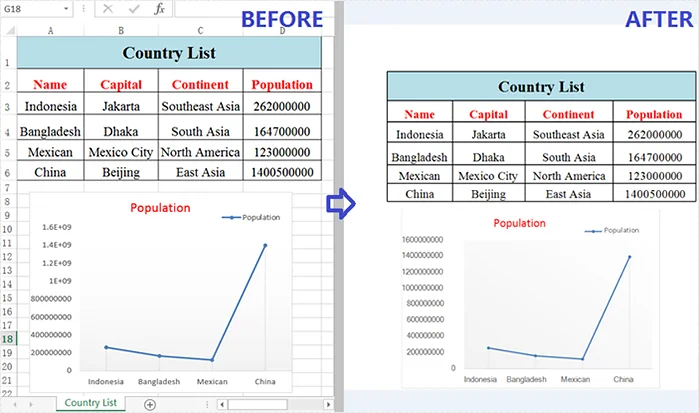
Aqui está uma prévia de um dos arquivos PNG exportados:
Opções Avançadas de Personalização
-
Exportar um intervalo específico
Em vez da planilha inteira, você pode especificar exatamente quais linhas e colunas capturar:sheet.ToImage(5, 1, 10, 4) # Parâmetros: LinhaInicial, ColunaInicial, LinhaFinal, ColunaFinal -
Converter Múltiplos Arquivos em Lote
Use a biblioteca os para iterar por uma pasta inteira e salvar automaticamente cada pasta de trabalho do Excel como um PNG:import os # Definir o caminho da pasta folder_path = r"C:\Files" files = [f for f in os.listdir(folder_path) if f.endswith(".xlsx")] for file in files: wb = Workbook() wb.LoadFromFile(os.path.join(folder_path, file)) # Converte a primeira planilha de cada arquivo para PNG sheet = wb.Worksheets[0] output_path = os.path.join(folder_path, file.replace(".xlsx", ".png")) sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn).Save(output_path) wb.Dispose()
Quando Usar Este Método:
- Você é um desenvolvedor criando um fluxo de trabalho automatizado.
- Você precisa converter muitos arquivos Excel ou pastas de trabalho inteiras.
- A conversão manual não é prática (por exemplo, relatórios agendados, pipelines, ferramentas internas).
Comparação Rápida: Qual Método de Conversão de Excel para PNG Você Deve Escolher
Para ajudá-lo a decidir, aqui está uma comparação rápida de todos os métodos de conversão de Excel para PNG discutidos acima:
| Método | Melhor Para | Facilidade de Uso | Qualidade da Saída | Software Necessário |
|---|---|---|---|---|
| Copiar como Imagem | Tabelas únicas / Pequenos intervalos | Muito Fácil | Alta | Microsoft Excel |
| Ferramentas de Captura de Tela | Tutoriais / Anotações rápidas | Mais Rápido | Média | Nenhum (Integrado) |
| Ferramentas Online | Arquivos inteiros / Usuários de celular | Fácil | Alta | Navegador Web |
| Script Python | Processamento em lote / Automação | Avançado | Profissional | Ambiente Python |
Veredito Final:
- Para um relatório único: Use Copiar como Imagem para o visual mais limpo e nativo.
- Para compartilhar um guia rápido: Use uma Ferramenta de Captura de Tela para adicionar facilmente setas e notas visuais.
- Para usuários em movimento: Conversores Online são a escolha mais conveniente e amigável para celular.
- Para automação em nível empresarial: Python é a solução mais escalável para processar um grande volume de arquivos.
Dicas Profissionais para Melhor Saída PNG
- Maximize a Clareza: Aumente o zoom do seu Excel para 150%-200% antes de capturar ou converter. Isso evita texto borrado no PNG final.
- Otimize os Visuais: Oculte as linhas de grade (Exibir > Desmarcar Linhas de Grade) e remova linhas ou colunas vazias. Uma planilha organizada garante um visual profissional e polido.
- Verifique a Compatibilidade de Fontes: Ao usar Python ou conversores online, use fontes padrão como Arial ou Calibri para garantir que a imagem exportada corresponda ao que você vê na tela.
- Validação em Lote (Usuários de Python): Teste seu script com um único arquivo primeiro para verificar se a formatação, as fontes e o layout são exportados corretamente antes de executar um grande lote.
Solução de Problemas Comuns de Conversão de Excel para PNG
- Imagem cortada: Verifique as configurações da Área de Impressão. Se uma área de impressão estiver definida, alguns conversores podem capturar apenas esse intervalo, ignorando o restante da planilha.
- Função Copiar está esmaecida: Certifique-se de não estar no Modo de Edição de Célula (cursor piscando dentro de uma célula). Pressione Esc para sair da edição antes de copiar ou exportar.
- Imagens borradas ou pixeladas: Evite esticar ou redimensionar o PNG após salvar. Para imagens maiores, reexporte com um nível de zoom mais alto em vez de dimensionar.
- Planilha muito grande para um único PNG: Planilhas muito grandes podem se tornar ilegíveis. Divida os conjuntos de dados em seções lógicas ou considere um fluxo de trabalho Excel-para-PDF-para-PNG para planilhas ultra-largas.
Perguntas Frequentes
P1: Converter Excel para PNG afeta a qualidade dos dados?
R1: Os dados em si não são alterados, mas se tornam uma imagem estática, o que significa que não podem ser editados ou recalculados.
P2: Posso converter várias planilhas do Excel para PNG em lote?
R2: Sim, você pode usar Python ou um conversor online profissional para processar arquivos ou planilhas do Excel em lote de forma eficiente.
P3: Como obtenho um PNG com fundo transparente do Excel?
R3: O Excel geralmente produz uma imagem com fundo branco. Para criar um PNG transparente, você pode:
- Usar um conversor online que suporte canais alfa.
- Colar o resultado do Copiar como Imagem em ferramentas como remove.bg, e depois salvar como PNG com transparência.
P4: Devo exportar Excel como PNG ou PDF?
R4: Depende de suas necessidades:
- PNG é perfeito para incorporar em slides, e-mails, sites ou relatórios como um visual.
- PDF é melhor para documentos de várias páginas, arquivamento oficial ou impressão de alta qualidade, especialmente quando o texto precisa permanecer pesquisável.
Veja Também
Excel을 PNG로 변환: 4가지 간편한 방법 (무료 및 일괄 처리 솔루션)
Excel 파일(.xlsx 또는 .xls)은 구조화된 데이터를 정리하고 분석하는 데 널리 사용되지만, 공유하기에 항상 최적의 형식은 아닙니다. 장치 간에 서식이 변경될 수 있으며 원본 통합 문서는 다른 사람이 쉽게 수정할 수 있습니다. Excel을 PNG로 변환하면 스프레드시트가 정적 이미지로 바뀌어 레이아웃 변경에 대한 걱정 없이 다른 플랫폼에서 더 쉽게 공유, 게시 또는 포함할 수 있습니다.
이 가이드에서는 품질 손실 없이 Excel을 PNG로 변환하는 4가지 실용적인 방법을 안내합니다. 빠른 수동 옵션부터 Python을 사용한 자동화된 일괄 변환까지, 필요에 맞는 접근 방식을 선택할 수 있습니다.
Excel을 PNG로 변환하는 방법 개요
- 방법 1 - Excel을 그림으로 복사 (내장 기능)
- 방법 2 - Excel을 PNG로 스크린샷 (캡처 도구 사용)
- 방법 3 - Excel을 온라인으로 PNG로 변환 (설치 불필요)
- 방법 4 - Python으로 Excel을 PNG로 일괄 변환 (자동화)
Excel을 PNG로 변환해야 하는 이유
PDF가 일반적이지만, PNG 이미지는 디지털 콘텐츠 및 보고에 고유한 이점을 제공합니다:
- 픽셀 단위의 일관성: Excel에서 보이는 그대로 레이아웃, 셀 스타일 및 글꼴을 정확하게 보존합니다. 깨진 수식이나 이동된 열이 없습니다.
- 보편적인 접근성: PNG는 Microsoft Excel이나 전문 뷰어 없이도 모든 스마트폰, 태블릿 또는 OS에서 볼 수 있습니다.
- 원활한 통합: 대시보드와 차트를 웹사이트, 문서 또는 PowerPoint 프레젠테이션에 직접 포함하는 데 이상적입니다.
- 향상된 보안 (읽기 전용): 데이터를 효과적으로 "잠가" 수신자가 원시 숫자를 변경하거나 민감한 숨겨진 수식을 보는 것을 방지합니다.
- 고품질 투명도: JPEG와 달리 PNG는 투명도를 지원하며 UI 요소 및 데이터 시각화에 더 나은 선명도를 제공합니다.
방법 1 - Excel을 그림으로 복사 (내장 기능)
타사 소프트웨어를 설치하지 않고 빠른 Excel을 PNG로 변환하려면 Excel의 내장 그림으로 복사 기능이 훌륭한 옵션입니다. 정확한 셀 서식과 테이블 레이아웃을 보존하여 보고서 및 프레젠테이션을 위해 선택한 범위를 내보내는 데 이상적입니다.
단계별 가이드:
-
Excel 데이터 선택
Excel 통합 문서를 열고 변환하려는 셀을 강조 표시합니다. -
그림으로 복사
홈 탭에서 복사 옆의 화살표를 클릭하고 그림으로 복사를 선택합니다. -
이미지 품질 선택
최상의 시각적 품질을 위해 화면에 표시된 대로 및 그림을 선택한 다음 확인을 클릭합니다. -
이미지 붙여넣기
빈 셀을 선택하고 Ctrl+V (Windows) 또는 Cmd+V (Mac)를 누릅니다. -
PNG로 저장
붙여넣은 이미지를 마우스 오른쪽 버튼으로 클릭 → 그림으로 저장 선택 → 휴대용 네트워크 그래픽 (*.png) 선택 → 폴더 선택 → 저장을 누릅니다.
전문가 팁:
- 이 방법은 전체 워크시트가 아닌 강조 표시된 셀만 내보냅니다.
- 내보낸 이미지는 일반적으로 흰색 배경을 가집니다.
- 이미지를 더 편집하려면 대신 Microsoft Paint (Windows) 또는 Preview (Mac)와 같은 이미지 편집기에 붙여넣으십시오.
이 방법을 사용할 때:
작은 데이터 세트와 레이아웃 충실도가 중요한 일회성 변환에 가장 적합합니다.
특히 차트를 저장해야 하는 경우, Excel 차트를 이미지로 변환하는 가이드를 참조하십시오.
방법 2 - Excel을 PNG로 스크린샷 (캡처 도구 사용)
스크린샷 도구(Windows 캡처 도구 또는 macOS 스크린샷 등)를 사용하는 것은 Excel 데이터를 PNG로 변환하는 가장 유연한 방법입니다. 그림으로 복사와 달리 이러한 도구는 화면에 보이는 것을 정확하게 캡처합니다. 드롭다운 메뉴, 주석 또는 여러 겹쳐진 창까지도 포함하므로 소프트웨어 튜토리얼을 만드는 데 가장 적합합니다.
단계:
-
보기 준비
최대한의 선명도를 위해 Excel 확대/축소 수준(예: 150% 이상)을 조정하고 원치 않는 요소(리본 또는 수식 표시줄 등)를 숨깁니다. -
캡처 도구 열기
Windows + Shift + S (Windows) 또는 Cmd + Shift + 4 (Mac)를 누릅니다. -
Excel 영역 선택
커서를 클릭하고 드래그하여 특정 셀 범위를 둘러싸는 상자를 그립니다. -
주석 달기 (선택 사항)
나타나는 미리보기 창을 클릭하여 주요 데이터를 강조 표시하거나 이미지에 화살표를 그립니다. -
PNG로 저장
저장 아이콘을 클릭하여 캡처를 PNG 파일로 직접 저장합니다.
전문가 팁:
- Windows + Shift + S 바로가기는 Windows 10 및 11에서 작동합니다. 이전 Windows 버전의 경우 시작 메뉴에서 수동으로 캡처 도구를 검색하십시오.
- 대부분의 도구는 자유 형식 캡처 모드를 제공하여 필요한 경우 스프레드시트의 비사각형 영역을 캡처할 수 있습니다.
이 방법을 사용할 때:
문서, 단계별 가이드 또는 공유 전에 데이터를 빠르게 주석 처리해야 할 때 가장 적합합니다.
방법 3 - Excel을 온라인으로 PNG로 변환 (설치 불필요)
Microsoft Excel이 없거나 모바일 장치에서 작업하는 사용자의 경우 웹 기반 Excel-PNG 변환기는 스프레드시트를 고품질 이미지로 변환하는 편리한 방법을 제공합니다. 이러한 도구는 브라우저에서 완전히 실행되며 종종 투명한 배경을 지원하므로 웹 디자인 또는 워터마킹에 이상적입니다.
최고 평점 온라인 변환기:
- CloudConvert: 고해상도에 가장 적합합니다. 픽셀 밀도(DPI) 및 알파 채널(투명 배경)에 대한 세부적인 제어를 제공하여 선명하고 전문적인 PNG 출력을 보장합니다.
- Zamzar: 단순성에 가장 적합합니다. 2006년부터 신뢰할 수 있는 업계 베테랑으로, XLS 또는 XLSX를 PNG로 변환하는 깔끔한 3단계 프로세스를 제공합니다.
- Cloudxdocs: 복잡한 레이아웃에 가장 적합합니다. 전문 등급 API를 기반으로 구축되어 병합된 셀과 원본 스타일을 보존하는 데 탁월합니다.
Excel을 PNG로 온라인 변환하는 방법:
-
신뢰할 수 있는 도구 선택
CloudConvert와 같은 평판 좋은 사이트로 이동합니다. -
문서 업로드
파일 선택을 클릭하여 컴퓨터를 검색하거나 통합 문서를 브라우저로 직접 드래그 앤 드롭합니다. -
이미지 설정 구성
출력으로 PNG를 선택합니다. 가능한 경우 전문 인쇄 또는 고화질 화면을 위해 해상도를 300 DPI로 설정합니다. -
변환 및 다운로드
변환을 클릭합니다. 완료되면 이미지를 다운로드합니다(Excel에 여러 시트가 있는 경우 종종 ZIP 파일로 제공됨).
데이터 보안 및 개인 정보 보호 참고 사항:
개인 정보를 보호하려면 공개 변환기에 민감하지 않은 정보만 업로드하십시오. 항상 SSL 암호화를 사용하고 24시간 이내에 자동 파일 삭제를 제공하는 도구를 우선적으로 사용하십시오. 기밀 재무 데이터의 경우 Excel 그림으로 복사 기능이나 로컬 캡처 도구를 사용하는 것이 좋습니다.
이 방법을 사용할 때:
- 모바일에서 Excel을 PNG로 변환해야 할 때.
- 투명한 PNG 출력을 원할 때.
- 전체 워크시트 또는 여러 시트를 한 번에 이미지로 변환할 때.
방법 4 - Python으로 Excel을 PNG로 일괄 변환 (자동화)
개발자, 데이터 분석가 및 대량 Excel 파일을 관리하는 팀의 경우 Python으로 Excel을 PNG로 변환하는 것을 자동화하는 것이 가장 확장 가능한 솔루션입니다. 이 접근 방식을 사용하면 수백 개의 워크시트 또는 통합 문서를 일괄 처리하고 Microsoft Excel을 설치할 필요 없이 이미지 내보내기를 보고 파이프라인에 통합할 수 있습니다.
주요 이점:
- Office 종속성 없음: 서버 및 Linux에서 작동합니다.
- 대규모 확장성: 100개 이상의 파일을 몇 초 안에 변환합니다.
- 높은 충실도: 원본 셀 서식, 글꼴 및 색상을 보존합니다.
전제 조건
시작하기 전에 다음이 있는지 확인하십시오.
- Python 3.7+
- Spire.XLS for Python - Microsoft Office를 설치할 필요 없이 Excel 파일을 생성, 편집 및 변환하는 독립 라이브러리입니다.
설치:
pip install spire.xls
Python 예제 - Excel을 PNG 이미지로 일괄 변환
이 스크립트는 통합 문서의 모든 워크시트를 고해상도 PNG 이미지로 자동 저장합니다.
from spire.xls import *
# Excel 파일 로드
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
# 모든 워크시트 반복
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# 각 시트를 이미지로 저장
image = sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn)
image.Save(f"sheet_{i+1}.png")
# 통합 문서 폐기
workbook.Dispose()
내보낸 PNG 파일 중 하나의 미리보기입니다.
고급 사용자 정의 옵션
-
특정 범위 내보내기
전체 시트 대신 캡처할 행과 열을 정확하게 지정할 수 있습니다.sheet.ToImage(5, 1, 10, 4) # 매개변수: 시작 행, 시작 열, 끝 행, 끝 열 -
여러 파일 일괄 변환
os 라이브러리를 사용하여 전체 폴더를 반복하고 모든 Excel 통합 문서를 PNG로 자동 저장합니다.import os # 폴더 경로 정의 folder_path = r"C:\Files" files = [f for f in os.listdir(folder_path) if f.endswith(".xlsx")] for file in files: wb = Workbook() wb.LoadFromFile(os.path.join(folder_path, file)) # 각 파일의 첫 번째 워크시트를 PNG로 변환 sheet = wb.Worksheets[0] output_path = os.path.join(folder_path, file.replace(".xlsx", ".png")) sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn).Save(output_path) wb.Dispose()
이 방법을 사용할 때:
- 자동화된 워크플로우를 구축하는 개발자일 때.
- 많은 Excel 파일 또는 전체 통합 문서를 변환해야 할 때.
- 수동 변환이 실용적이지 않을 때 (예: 예약된 보고, 파이프라인, 내부 도구).
빠른 비교: 어떤 Excel을 PNG로 변환하는 방법을 선택해야 할까요?
결정을 돕기 위해 위에서 논의된 모든 Excel을 PNG로 변환하는 방법에 대한 빠른 비교입니다.
| 방법 | 가장 적합한 대상 | 사용 편의성 | 출력 품질 | 필요한 소프트웨어 |
|---|---|---|---|---|
| 그림으로 복사 | 단일 테이블 / 작은 범위 | 매우 쉬움 | 높음 | Microsoft Excel |
| 캡처 도구 | 튜토리얼 / 빠른 주석 | 가장 빠름 | 중간 | 없음 (내장) |
| 온라인 도구 | 전체 파일 / 모바일 사용자 | 쉬움 | 높음 | 웹 브라우저 |
| Python 스크립트 | 일괄 처리 / 자동화 | 고급 | 전문적 | Python 환경 |
최종 결정:
- 일회성 보고서의 경우: 가장 깔끔하고 네이티브한 모양을 위해 그림으로 복사를 사용하십시오.
- 빠른 가이드를 공유하려면: 캡처 도구를 사용하여 시각적 화살표와 메모를 쉽게 추가하십시오.
- 이동 중인 사용자의 경우: 온라인 변환기가 가장 편리하고 모바일 친화적인 선택입니다.
- 엔터프라이즈급 자동화의 경우: Python은 대량 파일을 처리하는 데 가장 확장 가능한 솔루션입니다.
더 나은 PNG 출력을 위한 전문가 팁
- 선명도 극대화: 캡처 또는 변환 전에 Excel 확대/축소 수준을 150%-200%로 높입니다. 이렇게 하면 최종 PNG에서 텍스트가 흐릿해지는 것을 방지할 수 있습니다.
- 시각 자료 최적화: 눈금선(보기 > 눈금선 선택 취소)을 숨기고 빈 행 또는 열을 제거합니다. 깔끔한 스프레드시트는 전문적이고 세련된 모양을 보장합니다.
- 글꼴 호환성 확인: Python 또는 온라인 변환기를 사용할 때 Arial 또는 Calibri와 같은 표준 글꼴을 사용하여 내보낸 이미지가 화면에서 보는 것과 일치하는지 확인하십시오.
- 일괄 유효성 검사 (Python 사용자): 대량 실행 전에 단일 파일로 스크립트를 테스트하여 서식, 글꼴 및 레이아웃이 올바르게 내보내지는지 확인하십시오.
일반적인 Excel을 PNG로 변환 문제 해결
- 이미지가 잘림: 인쇄 영역 설정을 확인하십시오. 인쇄 영역이 정의된 경우 일부 변환기는 해당 범위만 캡처하고 나머지 시트는 무시할 수 있습니다.
- 복사 기능이 회색으로 표시됨: 셀 편집 모드(셀 안의 깜박이는 커서)가 아닌지 확인하십시오. 복사 또는 내보내기 전에 편집을 종료하려면 Esc를 누릅니다.
- 흐릿하거나 픽셀화된 이미지: 저장 후 PNG를 늘리거나 크기를 조정하지 마십시오. 더 큰 이미지의 경우 크기 조정 대신 더 높은 확대/축소 수준에서 다시 내보냅니다.
- 시트가 하나의 PNG에 비해 너무 큼: 매우 큰 시트는 읽을 수 없게 될 수 있습니다. 데이터 세트를 논리적 섹션으로 분할하거나 매우 넓은 스프레드시트의 경우 Excel-PDF-PNG 워크플로를 고려하십시오.
자주 묻는 질문
Q1: Excel을 PNG로 변환하면 데이터 품질에 영향을 미칩니까?
A1: 데이터 자체는 변경되지 않지만 정적 이미지가 되므로 편집하거나 다시 계산할 수 없습니다.
Q2: 여러 Excel 시트를 일괄적으로 PNG로 변환할 수 있습니까?
A2: 예, Python 또는 전문 온라인 변환기를 사용하여 Excel 파일 또는 시트를 효율적으로 일괄 처리할 수 있습니다.
Q3: Excel에서 투명한 배경 PNG를 얻으려면 어떻게 해야 합니까?
A3: Excel은 일반적으로 흰색 배경 이미지를 출력합니다. 투명한 PNG를 만들려면 다음을 수행할 수 있습니다.
- 알파 채널을 지원하는 온라인 변환기를 사용합니다.
- 그림으로 복사 결과를 remove.bg와 같은 도구에 붙여넣은 다음 투명도로 PNG로 저장합니다.
Q4: Excel을 PNG 또는 PDF로 내보내야 합니까?
A4: 필요에 따라 다릅니다.
- PNG는 슬라이드, 이메일, 웹사이트 또는 보고서에 시각 자료로 포함하는 데 적합합니다.
- PDF는 여러 페이지 문서, 공식 보관 또는 고품질 인쇄에 더 적합하며, 특히 텍스트를 검색 가능하게 유지해야 할 때 그렇습니다.
참고 자료
Convertire Excel in PNG: 4 metodi semplici (soluzioni gratuite e batch)
Indice
I file Excel (.xlsx o .xls) sono ampiamente utilizzati per organizzare e analizzare dati strutturati, ma non sono sempre il formato migliore per la condivisione. La formattazione può cambiare tra dispositivi e il file originale può essere facilmente modificato da altri. La conversione di Excel in PNG trasforma il tuo foglio di calcolo in un'immagine statica, rendendolo più facile da condividere, pubblicare o incorporare su diverse piattaforme senza preoccuparsi di modifiche al layout.
In questa guida, ti illustreremo 4 metodi pratici per convertire Excel in PNG senza perdere qualità: da opzioni manuali rapide alla conversione batch automatizzata tramite Python, in modo che tu possa scegliere l'approccio più adatto alle tue esigenze.
Panoramica dei metodi da Excel a PNG
- Metodo 1 - Copia Excel come immagine (integrato)
- Metodo 2 - Screenshot di Excel in PNG (con Strumento di cattura)
- Metodo 3 - Converti Excel in PNG online (senza installazione)
- Metodo 4 - Conversione batch di Excel in PNG tramite Python (automazione)
Perché convertire Excel in PNG?
Sebbene i PDF siano comuni, le immagini PNG offrono vantaggi unici per contenuti digitali e reportistica:
- Coerenza pixel per pixel: Preserva layout, stile delle celle e font esattamente come appaiono in Excel, senza formule interrotte o colonne spostate.
- Accessibilità universale: I PNG possono essere visualizzati su qualsiasi smartphone, tablet o sistema operativo senza richiedere Microsoft Excel o un visualizzatore specializzato.
- Integrazione senza interruzioni: Ideale per incorporare dashboard e grafici direttamente in siti web, documentazione o presentazioni PowerPoint.
- Sicurezza migliorata (sola lettura): "Blocca" efficacemente i tuoi dati, impedendo ai destinatari di modificare numeri grezzi o visualizzare formule nascoste sensibili.
- Trasparenza di alta qualità: A differenza dei JPEG, i PNG supportano la trasparenza e offrono una migliore chiarezza per elementi UI e visualizzazioni di dati.
Metodo 1 - Copia Excel come immagine (integrato)
Se desideri una conversione rapida da Excel a PNG senza installare software di terze parti, la funzione integrata di Excel Copia come immagine è un'ottima opzione. Preserva la formattazione esatta delle celle e il layout della tabella, rendendola ideale per esportare un intervallo selezionato per report e presentazioni.
Guida passo passo:
-
Seleziona i dati di Excel
Apri la tua cartella di lavoro Excel ed evidenzia le celle che desideri convertire. -
Copia come immagine
Nella scheda Home, fai clic sulla freccia accanto a Copia e scegli Copia come immagine. -
Scegli la qualità dell'immagine
Seleziona Come visualizzato sullo schermo e Immagine per la migliore qualità visiva, quindi fai clic su OK. -
Incolla l'immagine
Seleziona una cella vuota e premi Ctrl+V (Windows) o Cmd+V (Mac). -
Salva come PNG
Fai clic con il pulsante destro del mouse sull'immagine incollata → seleziona Salva immagine con nome → scegli Grafica di rete portatile (*.png) → scegli una cartella → fai clic su Salva.
Suggerimenti professionali:
- Questo metodo esporta solo le celle evidenziate, non l'intero foglio di lavoro.
- L'immagine esportata ha tipicamente uno sfondo bianco.
- Per modificare ulteriormente l'immagine, incollala invece in un editor di immagini come Microsoft Paint (Windows) o Anteprima (Mac).
Quando usare questo metodo:
Ideale per piccoli set di dati e conversioni una tantum in cui la fedeltà del layout è importante.
Se hai bisogno di salvare specificamente un grafico, consulta la nostra guida su come convertire grafici Excel in immagini.
Metodo 2 - Screenshot di Excel in PNG (con Strumento di cattura)
Utilizzare uno strumento di cattura (come lo Strumento di cattura di Windows o lo Screenshot di macOS) è il modo più flessibile per convertire dati Excel in un PNG. A differenza di Copia come immagine, questi strumenti catturano esattamente ciò che vedi sullo schermo, inclusi menu a discesa, commenti o persino più finestre sovrapposte, rendendolo la scelta migliore per creare tutorial software.
Passaggi:
-
Prepara la visualizzazione
Regola il livello di zoom di Excel (ad esempio, al 150% o superiore) per la massima chiarezza e nascondi eventuali elementi indesiderati (come la barra multifunzione o la barra della formula). -
Apri lo Strumento di cattura
Premi Windows + Maiusc + S (Windows) o Cmd + Maiusc + 4 (Mac). -
Seleziona l'area di Excel
Fai clic e trascina il cursore per disegnare un riquadro attorno all'intervallo di celle specifico. -
Annota (facoltativo)
Fai clic sulla finestra di anteprima che appare per evidenziare i dati chiave o disegnare frecce sull'immagine. -
Salva come PNG
Fai clic sull'icona Salva per salvare la cattura direttamente come file PNG.
Suggerimenti professionali:
- La scorciatoia Windows + Maiusc + S funziona su Windows 10 e 11. Per versioni precedenti di Windows, cerca manualmente lo Strumento di cattura nel menu Start.
- La maggior parte degli strumenti offre una modalità di cattura a mano libera, che consente di catturare aree non rettangolari del foglio di calcolo, se necessario.
Quando usare questo metodo:
Ideale per documentazione, guide passo passo o quando è necessario annotare rapidamente i dati prima della condivisione.
Metodo 3 - Converti Excel in PNG online (senza installazione)
Per gli utenti senza Microsoft Excel o per coloro che lavorano su dispositivi mobili, un convertitore online da Excel a PNG offre un modo conveniente per trasformare i fogli di calcolo in immagini di alta qualità. Questi strumenti funzionano interamente nel browser e spesso supportano sfondi trasparenti, ideali per il web design o il watermarking.
Convertitori online più votati:
- CloudConvert: Il migliore per l'alta risoluzione. Offre un controllo granulare sulla densità dei pixel (DPI) e sui canali alfa (sfondo trasparente) per garantire un output PNG nitido e professionale.
- Zamzar: Il migliore per la semplicità. Un veterano fidato del settore dal 2006, offre un processo di conversione pulito in tre passaggi da XLS o XLSX a PNG.
- Cloudxdocs: Il migliore per layout complessi. Costruito su API di livello professionale, eccelle nel preservare celle unite e stile originale.
Come convertire Excel in PNG online:
-
Seleziona uno strumento affidabile
Naviga su un sito affidabile come CloudConvert. -
Carica il tuo documento
Fai clic su Seleziona file per sfogliare il tuo computer o trascina e rilascia la tua cartella di lavoro direttamente nel browser. -
Configura le impostazioni dell'immagine
Scegli PNG come output. Se disponibile, imposta la risoluzione su 300 DPI per la stampa professionale o per schermi ad alta definizione. -
Converti e scarica
Fai clic su Converti. Una volta completato, scarica le tue immagini (spesso fornite come file ZIP se il tuo Excel contiene più fogli).
Nota sulla sicurezza e privacy dei dati:
Per proteggere la tua privacy, carica solo informazioni non sensibili sui convertitori pubblici. Dai sempre la priorità agli strumenti che utilizzano la crittografia SSL e offrono l'eliminazione automatica dei file entro 24 ore. Per dati finanziari riservati, consigliamo invece di utilizzare la funzionalità Copia come immagine di Excel o uno strumento di cattura locale.
Quando usare questo metodo:
- È necessaria la conversione da Excel a PNG su dispositivi mobili.
- Si desidera un output PNG trasparente.
- Si stanno convertendo fogli di lavoro interi o più fogli in immagini contemporaneamente.
Metodo 4 - Conversione batch di Excel in PNG tramite Python (automazione)
Per sviluppatori, analisti di dati e team che gestiscono un elevato volume di file Excel, automatizzare la conversione da Excel a PNG con Python è la soluzione più scalabile. Questo approccio consente di elaborare in batch centinaia di fogli di lavoro o cartelle di lavoro e integrare esportazioni di immagini nelle pipeline di reportistica, senza la necessità di installare Microsoft Excel.
Vantaggi chiave:
- Nessuna dipendenza da Office: Funziona su server e Linux.
- Scala massiccia: Converti oltre 100 file in pochi secondi.
- Alta fedeltà: Preserva la formattazione originale delle celle, i font e i colori.
Prerequisiti
Prima di iniziare, assicurati di avere:
- Python 3.7+
- Spire.XLS per Python: una libreria indipendente che crea, modifica e converte file Excel senza richiedere Microsoft Office.
Installazione:
pip install spire.xls
Esempio Python - Conversione batch di Excel in immagini PNG
Questo script salva automaticamente tutti i fogli di lavoro di una cartella di lavoro come immagini PNG ad alta risoluzione:
from spire.xls import *
# Carica il file Excel
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
# Cicla attraverso tutti i fogli di lavoro
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Salva ogni foglio come immagine
image = sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn)
image.Save(f"sheet_{i+1}.png")
# Elimina la cartella di lavoro
workbook.Dispose()
Ecco un'anteprima di uno dei file PNG esportati:
Opzioni di personalizzazione avanzate
-
Esporta un intervallo specifico
Invece dell'intero foglio, puoi specificare esattamente quali righe e colonne catturare:sheet.ToImage(5, 1, 10, 4) # Parametri: RigaInizio, ColonnaInizio, RigaFine, ColonnaFine -
Conversione batch di più file
Utilizza la libreria os per scorrere un'intera cartella e salvare automaticamente ogni cartella di lavoro Excel come PNG:import os # Definisci il percorso della cartella folder_path = r"C:\Files" files = [f for f in os.listdir(folder_path) if f.endswith(".xlsx")] for file in files: wb = Workbook() wb.LoadFromFile(os.path.join(folder_path, file)) # Converte il primo foglio di lavoro di ogni file in PNG sheet = wb.Worksheets[0] output_path = os.path.join(folder_path, file.replace(".xlsx", ".png")) sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn).Save(output_path) wb.Dispose()
Quando usare questo metodo:
- Sei uno sviluppatore che crea un flusso di lavoro automatizzato.
- È necessario convertire molti file Excel o intere cartelle di lavoro.
- La conversione manuale non è pratica (ad esempio, reportistica pianificata, pipeline, strumenti interni).
Confronto rapido: quale metodo da Excel a PNG scegliere
Per aiutarti a decidere, ecco un confronto rapido di tutti i metodi da Excel a PNG discussi sopra:
| Metodo | Ideale per | Facilità d'uso | Qualità dell'output | Software necessario |
|---|---|---|---|---|
| Copia come immagine | Tabelle singole / Intervalli piccoli | Molto facile | Alto | Microsoft Excel |
| Strumenti di cattura | Tutorial / Annotazioni rapide | Più veloce | Medio | Nessuno (integrato) |
| Strumenti online | File interi / Utenti mobili | Facile | Alto | Browser Web |
| Script Python | Elaborazione batch / Automazione | Avanzato | Professionale | Ambiente Python |
Verdetto finale:
- Per un report una tantum: Usa Copia come immagine per l'aspetto più pulito e nativo.
- Per condividere una guida rapida: Usa uno Strumento di cattura per aggiungere facilmente frecce e note visive.
- Per gli utenti in movimento: I Convertitori online sono la scelta più conveniente e adatta ai dispositivi mobili.
- Per l'automazione a livello aziendale: Python è la soluzione più scalabile per l'elaborazione di file ad alto volume.
Suggerimenti professionali per un migliore output PNG
- Massimizza la chiarezza: Aumenta lo zoom di Excel al 150%-200% prima di catturare o convertire. Questo evita testo sfocato nel PNG finale.
- Ottimizza le immagini: Nascondi le linee della griglia (Visualizza > Deseleziona Linee griglia) e rimuovi righe o colonne vuote. Un foglio di calcolo ordinato garantisce un aspetto professionale e rifinito.
- Verifica compatibilità font: Quando usi Python o convertitori online, attieniti a font standard come Arial o Calibri per garantire che l'immagine esportata corrisponda a ciò che vedi sullo schermo.
- Validazione batch (utenti Python): Testa il tuo script con un singolo file prima per verificare che la formattazione, i font e il layout vengano esportati correttamente prima di eseguire un batch di grandi dimensioni.
Risoluzione dei problemi comuni di Excel in PNG
- Immagine tagliata: Controlla le impostazioni dell'Area di stampa. Se è definita un'area di stampa, alcuni convertitori potrebbero catturare solo quell'intervallo, ignorando il resto del foglio.
- Funzione Copia disattivata: Assicurati di non essere in modalità Modifica cella (cursore lampeggiante all'interno di una cella). Premi Esc per uscire dalla modifica prima di copiare o esportare.
- Immagini sfocate o pixelate: Evita di allungare o ridimensionare il PNG dopo il salvataggio. Per immagini più grandi, esporta nuovamente con uno zoom maggiore invece di ridimensionare.
- Foglio troppo grande per un singolo PNG: Fogli molto grandi possono diventare illeggibili. Dividi i set di dati in sezioni logiche o considera un flusso di lavoro da Excel a PDF a PNG per fogli di calcolo ultra-larghi.
Domande frequenti
D1: La conversione di Excel in PNG influisce sulla qualità dei dati?
R1: I dati in sé non vengono modificati, ma diventano un'immagine statica, il che significa che non possono essere modificati o ricalcolati.
D2: Posso convertire più fogli Excel in PNG in batch?
R2: Sì, puoi usare Python o un convertitore online professionale per elaborare in batch file o fogli Excel in modo efficiente.
D3: Come ottengo un PNG con sfondo trasparente da Excel?
R3: Excel di solito produce un'immagine con sfondo bianco. Per creare un PNG trasparente, puoi:
- Utilizzare un convertitore online che supporti i canali alfa.
- Incollare il risultato di Copia come immagine in strumenti come remove.bg, quindi salvare come PNG con trasparenza.
D4: Dovrei esportare Excel come PNG o PDF?
R4: Dipende dalle tue esigenze:
- PNG è perfetto per l'incorporamento in diapositive, e-mail, siti web o report come elemento visivo.
- PDF è migliore per documenti multipagina, archiviazione ufficiale o stampa di alta qualità, specialmente quando il testo deve rimanere ricercabile.
Vedi anche
Convertir Excel en PNG : 4 méthodes simples (solutions gratuites et par lots)
Table des matières
Les fichiers Excel (.xlsx ou .xls) sont largement utilisés pour organiser et analyser des données structurées, mais ils ne sont pas toujours le meilleur format pour le partage. La mise en forme peut changer d'un appareil à l'autre et le classeur d'origine peut être facilement modifié par d'autres. La conversion d'Excel en PNG transforme votre feuille de calcul en une image statique, ce qui facilite le partage, la publication ou l'intégration sur différentes plateformes sans se soucier des changements de mise en page.
Dans ce guide, nous allons vous présenter 4 méthodes pratiques pour convertir Excel en PNG sans perte de qualité - des options manuelles rapides à la conversion par lots automatisée à l'aide de Python - afin que vous puissiez choisir l'approche qui convient à vos besoins.
Aperçu des méthodes de conversion d'Excel en PNG
- Méthode 1 - Copier Excel en image (méthode intégrée)
- Méthode 2 - Capturer un écran Excel en PNG (avec l'outil Capture d'écran)
- Méthode 3 - Convertir Excel en PNG en ligne (sans installation)
- Méthode 4 - Conversion par lots d'Excel en PNG via Python (automatisation)
Pourquoi convertir Excel en PNG ?
Bien que les PDF soient courants, les images PNG offrent des avantages uniques pour le contenu numérique et les rapports :
- Cohérence parfaite des pixels : Préserve les mises en page, le style des cellules et les polices exactement comme ils apparaissent dans Excel - pas de formules cassées ou de colonnes décalées.
- Accessibilité universelle : Les PNG peuvent être visualisés sur n'importe quel smartphone, tablette ou système d'exploitation sans nécessiter Microsoft Excel ou un visualiseur spécialisé.
- Intégration transparente : Idéal pour intégrer des tableaux de bord et des graphiques directement dans des sites Web, de la documentation ou des présentations PowerPoint.
- Sécurité renforcée (lecture seule) : "Verrouille" efficacement vos données, empêchant les destinataires de modifier les chiffres bruts ou de visualiser des formules cachées sensibles.
- Transparence de haute qualité : Contrairement aux JPEG, les PNG prennent en charge la transparence et offrent une meilleure clarté pour les éléments d'interface utilisateur et les visualisations de données.
Méthode 1 - Copier Excel en image (méthode intégrée)
Si vous souhaitez une conversion rapide d'Excel en PNG sans installer de logiciel tiers, la fonction intégrée Copier en tant qu'image d'Excel est une excellente option. Elle préserve la mise en forme exacte de vos cellules et la disposition de votre tableau, ce qui la rend idéale pour exporter une plage sélectionnée pour des rapports et des présentations.
Guide étape par étape :
-
Sélectionner les données Excel
Ouvrez votre classeur Excel et mettez en surbrillance les cellules que vous souhaitez convertir. -
Copier en tant qu'image
Dans l'onglet Accueil, cliquez sur la flèche à côté de Copier et choisissez Copier en tant qu'image. -
Choisir la qualité de l'image
Sélectionnez Tel qu'affiché à l'écran et Image pour la meilleure qualité visuelle, puis cliquez sur OK. -
Coller l'image
Sélectionnez une cellule vide et appuyez sur Ctrl+V (Windows) ou Cmd+V (Mac). -
Enregistrer en PNG
Cliquez avec le bouton droit sur l'image collée → sélectionnez Enregistrer sous forme d'image → choisissez Portable Network Graphics (*.png) → sélectionnez un dossier → cliquez sur Enregistrer.
Conseils de pro :
- Cette méthode exporte uniquement les cellules mises en surbrillance, pas la feuille de calcul entière.
- L'image exportée a généralement un fond blanc.
- Pour modifier davantage l'image, collez-la dans un éditeur d'images tel que Paint (Windows) ou Aperçu (Mac) à la place.
Quand utiliser cette méthode :
Idéal pour les petits ensembles de données et les conversions ponctuelles où la fidélité de la mise en page est importante.
Si vous avez besoin d'enregistrer un graphique spécifiquement, consultez notre guide sur la conversion de graphiques Excel en images.
Méthode 2 - Capturer un écran Excel en PNG (avec l'outil Capture d'écran)
L'utilisation d'un outil de capture d'écran (comme l'outil Capture d'écran de Windows ou la capture d'écran de macOS) est le moyen le plus flexible de convertir des données Excel en PNG. Contrairement à Copier en tant qu'image, ces outils capturent exactement ce que vous voyez à l'écran - y compris les menus déroulants, les commentaires ou même plusieurs fenêtres qui se chevauchent - ce qui en fait le meilleur choix pour créer des tutoriels logiciels.
Étapes :
-
Préparer la vue
Ajustez le niveau de zoom de votre Excel (par exemple, à 150 % ou plus) pour une clarté maximale et masquez les éléments indésirables (comme le ruban ou la barre de formule). -
Ouvrir l'outil Capture d'écran
Appuyez sur Windows + Maj + S (Windows) ou Cmd + Maj + 4 (Mac). -
Sélectionner la zone Excel
Cliquez et faites glisser votre curseur pour dessiner un rectangle autour de la plage de cellules spécifique. -
Annoter (facultatif)
Cliquez sur la fenêtre d'aperçu qui apparaît pour mettre en surbrillance les données clés ou dessiner des flèches sur l'image. -
Enregistrer en PNG
Cliquez sur l'icône Enregistrer pour enregistrer la capture directement sous forme de fichier PNG.
Conseils de pro :
- Le raccourci Windows + Maj + S fonctionne sur Windows 10 et 11. Pour les versions antérieures de Windows, recherchez manuellement l'outil Capture d'écran dans le menu Démarrer.
- La plupart des outils proposent un mode de capture à main levée, vous permettant de capturer des zones non rectangulaires de votre feuille de calcul si nécessaire.
Quand utiliser cette méthode :
Idéal pour la documentation, les guides étape par étape ou lorsque vous devez annoter rapidement des données avant de les partager.
Méthode 3 - Convertir Excel en PNG en ligne (sans installation)
Pour les utilisateurs sans Microsoft Excel ou ceux qui travaillent sur des appareils mobiles, un convertisseur Excel en PNG basé sur le Web offre un moyen pratique de transformer des feuilles de calcul en images de haute qualité. Ces outils s'exécutent entièrement dans le navigateur et prennent souvent en charge les arrière-plans transparents, ce qui est idéal pour la conception Web ou le filigrane.
Convertisseurs en ligne les mieux notés :
- CloudConvert : Idéal pour la haute résolution. Offre un contrôle granulaire sur la densité des pixels (DPI) et les canaux alpha (arrière-plan transparent) pour garantir une sortie PNG nette et professionnelle.
- Zamzar : Idéal pour la simplicité. Un vétéran de confiance de l'industrie depuis 2006, offrant un processus de conversion propre en trois étapes pour XLS ou XLSX en PNG.
- Cloudxdocs : Idéal pour les mises en page complexes. Construit sur des API de qualité professionnelle, il excelle à préserver les cellules fusionnées et le style d'origine.
Comment convertir Excel en PNG en ligne :
-
Sélectionner un outil de confiance
Accédez à un site réputé comme CloudConvert. -
Télécharger votre document
Cliquez sur Sélectionner un fichier pour parcourir votre ordinateur ou faites glisser et déposez votre classeur directement dans le navigateur. -
Configurer les paramètres de l'image
Choisissez PNG comme sortie. Si disponible, définissez la résolution sur 300 DPI pour une impression professionnelle ou des écrans haute définition. -
Convertir et télécharger
Cliquez sur Convertir. Une fois terminé, téléchargez vos images (souvent fournies sous forme de fichier ZIP si votre Excel contient plusieurs feuilles).
Note sur la sécurité et la confidentialité des données :
Pour protéger votre vie privée, ne téléchargez que des informations non sensibles sur des convertisseurs publics. Privilégiez toujours les outils qui utilisent le cryptage SSL et offrent la suppression automatique des fichiers dans les 24 heures. Pour les données financières confidentielles, nous vous recommandons plutôt d'utiliser la fonction Copier en tant qu'image d'Excel ou un outil de capture d'écran local.
Quand utiliser cette méthode :
- Vous avez besoin de convertir Excel en PNG sur mobile.
- Vous souhaitez une sortie PNG transparente.
- Vous convertissez des feuilles de calcul entières ou plusieurs feuilles en images à la fois.
Méthode 4 - Conversion par lots d'Excel en PNG via Python (automatisation)
Pour les développeurs, les analystes de données et les équipes gérant un grand volume de fichiers Excel, l'automatisation de la conversion d'Excel en PNG avec Python est la solution la plus évolutive. Cette approche vous permet de traiter par lots des centaines de feuilles de calcul ou de classeurs et d'intégrer des exportations d'images dans des pipelines de reporting - sans avoir besoin d'installer Microsoft Excel.
Avantages clés :
- Aucune dépendance Office : Fonctionne sur les serveurs et sous Linux.
- Échelle massive : Convertissez plus de 100 fichiers en quelques secondes.
- Haute fidélité : Préserve la mise en forme des cellules, les polices et les couleurs d'origine.
Prérequis
Avant de commencer, assurez-vous d'avoir :
- Python 3.7+
- Spire.XLS pour Python - une bibliothèque indépendante qui crée, modifie et convertit des fichiers Excel sans nécessiter Microsoft Office.
Installation :
pip install spire.xls
Exemple Python - Conversion par lots d'Excel en images PNG
Ce script enregistre automatiquement toutes les feuilles de calcul d'un classeur sous forme d'images PNG haute résolution :
from spire.xls import *
# Charger le fichier Excel
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
# Parcourir toutes les feuilles de calcul
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Enregistrer chaque feuille sous forme d'image
image = sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn)
image.Save(f"sheet_{i+1}.png")
# Libérer le classeur
workbook.Dispose()
Voici un aperçu de l'un des fichiers PNG exportés :
Options de personnalisation avancées
-
Exporter une plage spécifique
Au lieu de la feuille entière, vous pouvez spécifier exactement quelles lignes et colonnes capturer :sheet.ToImage(5, 1, 10, 4) # Paramètres : Ligne de début, Colonne de début, Ligne de fin, Colonne de fin -
Conversion par lots de plusieurs fichiers
Utilisez la bibliothèque os pour parcourir un dossier entier et enregistrer automatiquement chaque classeur Excel en tant que PNG :import os # Définir le chemin du dossier folder_path = r"C:\Files" files = [f for f in os.listdir(folder_path) if f.endswith(".xlsx")] for file in files: wb = Workbook() wb.LoadFromFile(os.path.join(folder_path, file)) # Convertit la première feuille de calcul de chaque fichier en PNG sheet = wb.Worksheets[0] output_path = os.path.join(folder_path, file.replace(".xlsx", ".png")) sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn).Save(output_path) wb.Dispose()
Quand utiliser cette méthode :
- Vous êtes un développeur qui crée un flux de travail automatisé.
- Vous devez convertir de nombreux fichiers Excel ou des classeurs entiers.
- La conversion manuelle n'est pas pratique (par exemple, rapports planifiés, pipelines, outils internes).
Comparaison rapide : Quelle méthode de conversion d'Excel en PNG devriez-vous choisir
Pour vous aider à décider, voici une comparaison rapide de toutes les méthodes de conversion d'Excel en PNG discutées ci-dessus :
| Méthode | Idéal pour | Facilité d'utilisation | Qualité de sortie | Logiciel nécessaire |
|---|---|---|---|---|
| Copier en tant qu'image | Tables uniques / Petites plages | Très facile | Élevée | Microsoft Excel |
| Outils de capture d'écran | Tutoriels / Annotations rapides | Le plus rapide | Moyenne | Aucun (intégré) |
| Outils en ligne | Fichiers entiers / Utilisateurs mobiles | Facile | Élevée | Navigateur Web |
| Script Python | Traitement par lots / Automatisation | Avancé | Professionnel | Environnement Python |
Verdict final :
- Pour un rapport unique : Utilisez Copier en tant qu'image pour un aspect natif plus propre.
- Pour partager un guide rapide : Utilisez un outil de capture d'écran pour ajouter facilement des flèches et des notes visuelles.
- Pour les utilisateurs en déplacement : Les convertisseurs en ligne sont le choix le plus pratique et le plus adapté aux mobiles.
- Pour l'automatisation au niveau de l'entreprise : Python est la solution la plus évolutive pour le traitement d'un grand volume de fichiers.
Conseils de pro pour une meilleure sortie PNG
- Maximiser la clarté : Augmentez le zoom de votre Excel à 150 % - 200 % avant de capturer ou de convertir. Cela évite le texte flou dans le PNG final.
- Optimiser les visuels : Masquez les lignes de grille (Affichage > Désélectionner Lignes de grille) et supprimez les lignes ou colonnes vides. Une feuille de calcul bien rangée garantit un aspect professionnel et soigné.
- Vérifier la compatibilité des polices : Lors de l'utilisation de Python ou de convertisseurs en ligne, utilisez des polices standard comme Arial ou Calibri pour vous assurer que l'image exportée correspond à ce que vous voyez à l'écran.
- Validation par lots (utilisateurs Python) : Testez votre script avec un seul fichier d'abord pour vérifier que la mise en forme, les polices et la disposition sont correctement exportées avant d'exécuter un lot important.
Dépannage des problèmes courants de conversion d'Excel en PNG
- L'image est coupée : Vérifiez les paramètres de votre zone d'impression. Si une zone d'impression est définie, certains convertisseurs peuvent ne capturer que cette plage, ignorant le reste de la feuille.
- La fonction Copier est grisée : Assurez-vous de ne pas être en mode Édition de cellule (curseur clignotant à l'intérieur d'une cellule). Appuyez sur Échap pour quitter l'édition avant de copier ou d'exporter.
- Images floues ou pixellisées : Évitez d'étirer ou de redimensionner le PNG après l'enregistrement. Pour les images plus grandes, réexportez avec un niveau de zoom plus élevé au lieu de redimensionner.
- La feuille est trop grande pour un seul PNG : Les feuilles très grandes peuvent devenir illisibles. Divisez les ensembles de données en sections logiques ou envisagez un flux de travail Excel-vers-PDF-vers-PNG pour les feuilles de calcul ultra-larges.
Questions fréquemment posées
Q1 : La conversion d'Excel en PNG affecte-t-elle la qualité des données ?
R1 : Les données elles-mêmes ne sont pas modifiées, mais elles deviennent une image statique, ce qui signifie qu'elles ne peuvent pas être modifiées ou recalculées.
Q2 : Puis-je convertir plusieurs feuilles Excel en PNG par lots ?
R2 : Oui, vous pouvez utiliser Python ou un convertisseur en ligne professionnel pour traiter efficacement des fichiers ou des feuilles Excel par lots.
Q3 : Comment obtenir un PNG avec un arrière-plan transparent à partir d'Excel ?
R3 : Excel produit généralement une image avec un arrière-plan blanc. Pour créer un PNG transparent, vous pouvez :
- Utiliser un convertisseur en ligne qui prend en charge les canaux alpha.
- Collez le résultat de Copier en tant qu'image dans des outils comme remove.bg, puis enregistrez en tant que PNG avec transparence.
Q4 : Dois-je exporter Excel en PNG ou en PDF ?
R4 : Cela dépend de vos besoins :
- PNG est parfait pour l'intégration dans des diapositives, des e-mails, des sites Web ou des rapports en tant que visuel.
- PDF est préférable pour les documents multipages, l'archivage officiel ou l'impression de haute qualité, en particulier lorsque le texte doit rester consultable.
Voir aussi
Convertir Excel a PNG: 4 métodos sencillos (soluciones gratuitas y por lotes)
Tabla de Contenidos
Los archivos de Excel (.xlsx o .xls) se utilizan ampliamente para organizar y analizar datos estructurados, pero no siempre son el mejor formato para compartir. El formato puede cambiar entre dispositivos y el libro de trabajo original puede ser modificado fácilmente por otros. Convertir Excel a PNG transforma tu hoja de cálculo en una imagen estática, lo que facilita compartirla, publicarla o incrustarla en diferentes plataformas sin preocuparse por cambios en el diseño.
En esta guía, te mostraremos 4 métodos prácticos para convertir Excel a PNG sin perder calidad, desde opciones manuales rápidas hasta la conversión por lotes automatizada usando Python, para que puedas elegir el enfoque que mejor se adapte a tus necesidades.
Resumen de Métodos de Excel a PNG
- Método 1 - Copiar Excel como Imagen (Forma Integrada)
- Método 2 - Capturar Pantalla de Excel a PNG (Usando la Herramienta Recortes)
- Método 3 - Convertir Excel a PNG en Línea (Sin Instalación)
- Método 4 - Convertir Excel a PNG por Lotes mediante Python (Automatización)
¿Por qué Convertir Excel a PNG?
Si bien los PDF son comunes, las imágenes PNG ofrecen ventajas únicas para el contenido digital y la presentación de informes:
- Consistencia Píxel a Píxel: Conserva diseños, estilos de celda y fuentes exactamente como aparecen en Excel, sin fórmulas rotas ni columnas desplazadas.
- Accesibilidad Universal: Los PNG se pueden ver en cualquier smartphone, tablet o sistema operativo sin necesidad de Microsoft Excel o un visor especializado.
- Integración sin Problemas: Ideal para incrustar paneles y gráficos directamente en sitios web, documentación o presentaciones de PowerPoint.
- Seguridad Mejorada (Solo Lectura): "Bloquea" efectivamente tus datos, impidiendo que los destinatarios alteren números brutos o vean fórmulas ocultas confidenciales.
- Transparencia de Alta Calidad: A diferencia de los JPEG, los PNG admiten transparencia y ofrecen una mejor claridad para elementos de interfaz de usuario y visualizaciones de datos.
Método 1 - Copiar Excel como Imagen (Forma Integrada)
Si deseas una conversión rápida de Excel a PNG sin instalar software de terceros, la función integrada Copiar como Imagen de Excel es una excelente opción. Conserva el formato exacto de las celdas y el diseño de la tabla, lo que la hace ideal para exportar un rango seleccionado para informes y presentaciones.
Guía Paso a Paso:
-
Seleccionar los datos de Excel
Abre tu libro de Excel y resalta las celdas que deseas convertir. -
Copiar como Imagen
En la pestaña Inicio, haz clic en la flecha junto a Copiar y elige Copiar como Imagen. -
Elegir la calidad de la imagen
Selecciona Como se muestra en pantalla y Imagen para obtener la mejor calidad visual, luego haz clic en Aceptar. -
Pegar la imagen
Selecciona una celda en blanco y presiona Ctrl+V (Windows) o Cmd+V (Mac). -
Guardar como PNG
Haz clic derecho en la imagen pegada → selecciona Guardar como imagen → elige Gráfico de red portátil (*.png) → selecciona una carpeta → haz clic en Guardar.
Consejos Profesionales:
- Este método exporta solo las celdas resaltadas, no toda la hoja de cálculo.
- La imagen exportada generalmente tiene un fondo blanco.
- Para editar aún más la imagen, pégala en un editor de imágenes como Microsoft Paint (Windows) o Vista Previa (Mac) en su lugar.
Cuándo Usar Este Método:
Ideal para conjuntos de datos pequeños y conversiones únicas donde la fidelidad del diseño es importante.
Si necesitas guardar un gráfico específicamente, consulta nuestra guía sobre cómo convertir gráficos de Excel a imágenes.
Método 2 - Capturar Pantalla de Excel a PNG (Usando la Herramienta Recortes)
Usar una herramienta de recorte (como la Herramienta Recortes de Windows o Captura de Pantalla de macOS) es la forma más flexible de convertir datos de Excel a PNG. A diferencia de Copiar como Imagen, estas herramientas capturan exactamente lo que ves en tu pantalla, incluyendo menús desplegables, comentarios o incluso múltiples ventanas superpuestas, lo que la convierte en la mejor opción para crear tutoriales de software.
Pasos:
-
Preparar la Vista
Ajusta el nivel de zoom de tu Excel (por ejemplo, al 150% o superior) para obtener la máxima claridad y oculta cualquier elemento no deseado (como la Cinta de opciones o la barra de fórmulas). -
Abrir la Herramienta Recortes
Presiona Windows + Shift + S (Windows) o Cmd + Shift + 4 (Mac). -
Seleccionar el Área de Excel
Haz clic y arrastra el cursor para dibujar un cuadro alrededor del rango de celdas específico. -
Anotar (Opcional)
Haz clic en la ventana de vista previa que aparece para resaltar datos clave o dibujar flechas en la imagen. -
Guardar como PNG
Haz clic en el icono de Guardar para guardar la captura directamente como un archivo PNG.
Consejos Profesionales:
- El atajo Windows + Shift + S funciona en Windows 10 y 11. Para versiones anteriores de Windows, busca la Herramienta Recortes en el menú Inicio manualmente.
- La mayoría de las herramientas ofrecen un modo de Recorte de Forma Libre, que te permite capturar áreas no rectangulares de tu hoja de cálculo si es necesario.
Cuándo Usar Este Método:
Ideal para documentación, guías paso a paso o cuando necesitas anotar datos rápidamente antes de compartir.
Método 3 - Convertir Excel a PNG en Línea (Sin Instalación)
Para usuarios sin Microsoft Excel o aquellos que trabajan en dispositivos móviles, un convertidor de Excel a PNG basado en web proporciona una forma conveniente de transformar hojas de cálculo en imágenes de alta calidad. Estas herramientas se ejecutan completamente en el navegador y a menudo admiten fondos transparentes, lo que es ideal para diseño web o marcas de agua.
Conversores en Línea Mejor Calificados:
- CloudConvert: El mejor para Alta Resolución. Proporciona control granular sobre la densidad de píxeles (DPI) y los canales alfa (fondo transparente) para garantizar una salida PNG nítida y profesional.
- Zamzar: El mejor para Simplicidad. Un veterano de confianza en la industria desde 2006, que ofrece un proceso de conversión limpio de tres pasos para XLS o XLSX a PNG.
- Cloudxdocs: El mejor para Diseños Complejos. Construido sobre APIs de nivel profesional, se destaca en la conservación de celdas combinadas y el estilo original.
Cómo Convertir Excel a PNG en Línea:
-
Seleccionar una Herramienta de Confianza
Navega a un sitio de buena reputación como CloudConvert. -
Subir tu Documento
Haz clic en Seleccionar Archivo para buscar en tu computadora o arrastra y suelta tu libro de trabajo directamente en el navegador. -
Configurar los Ajustes de Imagen
Elige PNG como salida. Si está disponible, establece la resolución a 300 DPI para impresión profesional o pantallas de alta definición. -
Convertir y Descargar
Haz clic en Convertir. Una vez completado, descarga tus imágenes (a menudo se proporcionan como un archivo ZIP si tu Excel tiene varias hojas).
Nota sobre Seguridad y Privacidad de Datos:
Para proteger tu privacidad, solo sube información no sensible a conversores públicos. Siempre prioriza las herramientas que utilizan cifrado SSL y ofrecen eliminación automática de archivos en 24 horas. Para datos financieros confidenciales, recomendamos usar la función Copiar como Imagen de Excel o una herramienta de recorte local en su lugar.
Cuándo Usar Este Método:
- Necesitas convertir Excel a PNG en dispositivos móviles.
- Quieres una salida PNG transparente.
- Estás convirtiendo hojas de cálculo completas o varias hojas a imágenes a la vez.
Método 4 - Convertir Excel a PNG por Lotes mediante Python (Automatización)
Para desarrolladores, analistas de datos y equipos que gestionan un gran volumen de archivos de Excel, automatizar la conversión de Excel a PNG con Python es la solución más escalable. Este enfoque te permite procesar por lotes cientos de hojas de cálculo o libros de trabajo e integrar exportaciones de imágenes en flujos de informes, ¡sin necesidad de tener Microsoft Excel instalado!
Beneficios Clave:
- Sin Dependencia de Office: Funciona en servidores y Linux.
- Escala Masiva: Convierte más de 100 archivos en segundos.
- Alta Fidelidad: Conserva el formato de celda, fuentes y colores originales.
Prerrequisitos
Antes de empezar, asegúrate de tener:
- Python 3.7+
- Spire.XLS para Python: una biblioteca independiente que crea, edita y convierte archivos de Excel sin necesidad de Microsoft Office.
Instalación:
pip install spire.xls
Ejemplo de Python - Convertir Excel a Imágenes PNG por Lotes
Este script guarda automáticamente todas las hojas de cálculo de un libro como imágenes PNG de alta resolución:
from spire.xls import *
# Cargar el archivo de Excel
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
# Recorrer todas las hojas de cálculo
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Guardar cada hoja como una imagen
image = sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn)
image.Save(f"sheet_{i+1}.png")
# Liberar el libro de trabajo
workbook.Dispose()
Aquí tienes una vista previa de uno de los archivos PNG exportados:
Opciones Avanzadas de Personalización
-
Exportar un rango específico
En lugar de toda la hoja, puedes especificar exactamente qué filas y columnas capturar:sheet.ToImage(5, 1, 10, 4) # Parámetros: FilaInicio, ColumnaInicio, FilaFin, ColumnaFin -
Convertir Múltiples Archivos por Lotes
Usa la biblioteca os para recorrer una carpeta completa y guardar automáticamente cada libro de Excel como PNG:import os # Definir la ruta de la carpeta folder_path = r"C:\Files" files = [f for f in os.listdir(folder_path) if f.endswith(".xlsx")] for file in files: wb = Workbook() wb.LoadFromFile(os.path.join(folder_path, file)) # Convierte la primera hoja de cálculo de cada archivo a PNG sheet = wb.Worksheets[0] output_path = os.path.join(folder_path, file.replace(".xlsx", ".png")) sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn).Save(output_path) wb.Dispose()
Cuándo Usar Este Método:
- Eres un desarrollador que crea un flujo de trabajo automatizado.
- Necesitas convertir muchos archivos de Excel o libros de trabajo completos.
- La conversión manual no es práctica (por ejemplo, informes programados, pipelines, herramientas internas).
Comparación Rápida: ¿Qué Método de Excel a PNG Deberías Elegir?
Para ayudarte a decidir, aquí tienes una comparación rápida de todos los métodos de Excel a PNG discutidos anteriormente:
| Método | Ideal Para | Facilidad de Uso | Calidad de Salida | Software Necesario |
|---|---|---|---|---|
| Copiar como Imagen | Tablas individuales / Rangos pequeños | Muy Fácil | Alta | Microsoft Excel |
| Herramientas de Recorte | Tutoriales / Anotaciones rápidas | El más rápido | Media | Ninguno (Integrado) |
| Herramientas en Línea | Archivos completos / Usuarios móviles | Fácil | Alta | Navegador Web |
| Script de Python | Procesamiento por lotes / Automatización | Avanzado | Profesional | Entorno Python |
Veredicto Final:
- Para un informe único: Usa Copiar como Imagen para obtener el aspecto nativo más limpio.
- Para compartir una guía rápida: Usa una Herramienta de Recorte para agregar fácilmente flechas y notas visuales.
- Para usuarios en movimiento: Los Conversores en Línea son la opción más conveniente y amigable para dispositivos móviles.
- Para automatización a nivel empresarial: Python es la solución más escalable para procesar archivos de alto volumen.
Consejos Profesionales para una Mejor Salida PNG
- Maximizar la Claridad: Aumenta el zoom de tu Excel a 150%-200% antes de capturar o convertir. Esto evita texto borroso en el PNG final.
- Optimizar Visuales: Oculta las líneas de cuadrícula (Ver > Desmarcar Líneas de Cuadrícula) y elimina filas o columnas vacías. Una hoja de cálculo ordenada garantiza un aspecto profesional y pulido.
- Verificar Compatibilidad de Fuentes: Al usar Python o conversores en línea, utiliza fuentes estándar como Arial o Calibri para asegurar que la imagen exportada coincida con lo que ves en pantalla.
- Validación por Lotes (Usuarios de Python): Prueba tu script con un solo archivo primero para verificar que el formato, las fuentes y el diseño se exporten correctamente antes de ejecutar un lote grande.
Solución de Problemas Comunes de Excel a PNG
- La imagen está cortada: Verifica la configuración del Área de Impresión. Si se define un área de impresión, algunos conversores solo capturarán ese rango, ignorando el resto de la hoja.
- La función Copiar está atenuada: Asegúrate de no estar en Modo de Edición de Celda (cursor parpadeante dentro de una celda). Presiona Esc para salir de la edición antes de copiar o exportar.
- Imágenes borrosas o pixeladas: Evita estirar o redimensionar el PNG después de guardarlo. Para imágenes más grandes, reexporta con un nivel de zoom más alto en lugar de escalar.
- La hoja es demasiado grande para un solo PNG: Las hojas muy grandes pueden volverse ilegibles. Divide los conjuntos de datos en secciones lógicas o considera un flujo de trabajo de Excel a PDF a PNG para hojas de cálculo ultra anchas.
Preguntas Frecuentes
P1: ¿Convertir Excel a PNG afecta la calidad de los datos?
R1: Los datos en sí no se modifican, pero se convierten en una imagen estática, lo que significa que no se pueden editar ni recalcular.
P2: ¿Puedo convertir varias hojas de Excel a PNG por lotes?
R2: Sí, puedes usar Python o un conversor profesional en línea para procesar archivos u hojas de Excel por lotes de manera eficiente.
P3: ¿Cómo obtengo un PNG con fondo transparente de Excel?
R3: Excel generalmente produce una imagen con fondo blanco. Para crear un PNG transparente, puedes:
- Usar un conversor en línea que admita canales alfa.
- Pega el resultado de Copiar como Imagen en herramientas como remove.bg, y luego guarda como PNG con transparencia.
P4: ¿Debería exportar Excel como PNG o PDF?
R4: Depende de tus necesidades:
- PNG es perfecto para incrustar en diapositivas, correos electrónicos, sitios web o informes como una imagen visual.
- PDF es mejor para documentos de varias páginas, archivo oficial o impresión de alta calidad, especialmente cuando el texto necesita seguir siendo buscable.
Ver También
Excel in PNG umwandeln: 4 einfache Methoden (kostenlose Lösungen & Stapelverarbeitung)
Inhaltsverzeichnis
Excel-Dateien (.xlsx oder .xls) werden häufig zur Organisation und Analyse strukturierter Daten verwendet, sind aber nicht immer das beste Format für die Weitergabe. Die Formatierung kann sich auf verschiedenen Geräten verschieben und die ursprüngliche Arbeitsmappe kann leicht von anderen geändert werden. Die Konvertierung von Excel in PNG verwandelt Ihre Tabelle in ein statisches Bild, das sich leichter weitergeben, veröffentlichen oder auf verschiedenen Plattformen einbetten lässt, ohne sich Gedanken über Layoutänderungen machen zu müssen.
In dieser Anleitung führen wir Sie durch 4 praktische Methoden, um Excel in PNG zu konvertieren, ohne Qualitätsverluste – von schnellen manuellen Optionen bis hin zur automatisierten Stapelkonvertierung mit Python – damit Sie den Ansatz wählen können, der Ihren Bedürfnissen entspricht.
Übersicht der Methoden zur Konvertierung von Excel in PNG
- Methode 1 - Excel als Bild kopieren (integrierte Funktion)
- Methode 2 - Excel als PNG screenshotten (mit Snipping Tool)
- Methode 3 - Excel online in PNG konvertieren (keine Installation)
- Methode 4 - Excel per Python in Stapelverarbeitung in PNG konvertieren (Automatisierung)
Warum Excel in PNG konvertieren?
Während PDFs üblich sind, bieten PNG-Bilder einzigartige Vorteile für digitale Inhalte und Berichte:
- Pixelgenaue Konsistenz: Behält Layouts, Zellformatierungen und Schriftarten genau so bei, wie sie in Excel erscheinen – keine kaputten Formeln oder verschobenen Spalten.
- Universelle Zugänglichkeit: PNGs können auf jedem Smartphone, Tablet oder Betriebssystem angezeigt werden, ohne Microsoft Excel oder einen speziellen Betrachter zu benötigen.
- Nahtlose Integration: Ideal zum Einbetten von Dashboards und Diagrammen direkt in Websites, Dokumentationen oder PowerPoint-Präsentationen.
- Verbesserte Sicherheit (Nur-Lese): Sperrt Ihre Daten effektiv und verhindert, dass Empfänger Rohdaten ändern oder sensible versteckte Formeln einsehen können.
- Hochwertige Transparenz: Im Gegensatz zu JPEGs unterstützen PNGs Transparenz und bieten eine bessere Klarheit für UI-Elemente und Datenvisualisierungen.
Methode 1 - Excel als Bild kopieren (integrierte Funktion)
Wenn Sie eine schnelle Excel-zu-PNG-Konvertierung ohne Installation von Drittanbietersoftware wünschen, ist die integrierte Funktion Als Bild kopieren von Excel eine ausgezeichnete Option. Sie bewahrt Ihre exakte Zellformatierung und Ihr Tabellenlayout und eignet sich daher ideal zum Exportieren eines ausgewählten Bereichs für Berichte und Präsentationen.
Schritt-für-Schritt-Anleitung:
-
Excel-Daten auswählen
Öffnen Sie Ihre Excel-Arbeitsmappe und markieren Sie die Zellen, die Sie konvertieren möchten. -
Als Bild kopieren
Klicken Sie auf der Registerkarte Start auf den Pfeil neben Kopieren und wählen Sie Als Bild kopieren. -
Bildqualität wählen
Wählen Sie Wie auf dem Bildschirm angezeigt und Bild für die beste visuelle Qualität und klicken Sie dann auf OK. -
Bild einfügen
Wählen Sie eine leere Zelle und drücken Sie Strg+V (Windows) oder Cmd+V (Mac). -
Als PNG speichern
Klicken Sie mit der rechten Maustaste auf das eingefügte Bild → wählen Sie Als Bild speichern → wählen Sie Portable Network Graphics (*.png) → wählen Sie einen Ordner → klicken Sie auf Speichern.
Profi-Tipps:
- Diese Methode exportiert nur die markierten Zellen, nicht das gesamte Arbeitsblatt.
- Das exportierte Bild hat normalerweise einen weißen Hintergrund.
- Um das Bild weiter zu bearbeiten, fügen Sie es stattdessen in einen Bildeditor wie Microsoft Paint (Windows) oder Vorschau (Mac) ein.
Wann diese Methode verwenden:
Am besten für kleine Datensätze und einmalige Konvertierungen, bei denen die Layouttreue wichtig ist.
Wenn Sie speziell ein Diagramm speichern müssen, lesen Sie unsere Anleitung zum Konvertieren von Excel-Diagrammen in Bilder.
Methode 2 - Excel als PNG screenshotten (mit Snipping Tool)
Die Verwendung eines Snipping-Tools (wie dem Windows Snipping Tool oder macOS Screenshot) ist die flexibelste Methode, um Excel-Daten in ein PNG zu konvertieren. Im Gegensatz zu "Als Bild kopieren" erfassen diese Tools genau das, was Sie auf Ihrem Bildschirm sehen – einschließlich Dropdown-Menüs, Kommentaren oder sogar mehreren überlappenden Fenstern – was sie zur besten Wahl für die Erstellung von Software-Tutorials macht.
Schritte:
-
Ansicht vorbereiten
Passen Sie die Zoomstufe Ihres Excel (z. B. auf 150 % oder höher) für maximale Klarheit an und blenden Sie unerwünschte Elemente aus (wie das Menüband oder die Bearbeitungsleiste). -
Snipping Tool öffnen
Drücken Sie Windows + Umschalt + S (Windows) oder Cmd + Umschalt + 4 (Mac). -
Excel-Bereich auswählen
Klicken und ziehen Sie Ihren Cursor, um einen Rahmen um den spezifischen Zellbereich zu ziehen. -
Annotieren (Optional)
Klicken Sie auf das Vorschaufenster, das erscheint, um wichtige Daten hervorzuheben oder Pfeile auf das Bild zu zeichnen. -
Als PNG speichern
Klicken Sie auf das Speichern-Symbol, um die Aufnahme direkt als PNG-Datei zu speichern.
Profi-Tipps:
- Die Tastenkombination Windows + Umschalt + S funktioniert unter Windows 10 und 11. Für ältere Windows-Versionen suchen Sie das Snipping Tool manuell im Startmenü.
- Die meisten Tools bieten einen Freiform-Schnip-Modus, mit dem Sie bei Bedarf nicht-rechteckige Bereiche Ihrer Tabelle erfassen können.
Wann diese Methode verwenden:
Am besten für Dokumentationen, Schritt-für-Schritt-Anleitungen oder wenn Sie Daten vor der Weitergabe schnell annotieren müssen.
Methode 3 - Excel online in PNG konvertieren (keine Installation)
Für Benutzer ohne Microsoft Excel oder für diejenigen, die auf mobilen Geräten arbeiten, bietet ein webbasierter Excel-zu-PNG-Konverter eine bequeme Möglichkeit, Tabellen in hochwertige Bilder umzuwandeln. Diese Tools laufen vollständig im Browser und unterstützen oft transparente Hintergründe, was ideal für Webdesign oder Wasserzeichen ist.
Top-bewertete Online-Konverter:
- CloudConvert: Am besten für hohe Auflösung. Bietet detaillierte Kontrolle über Pixeldichte (DPI) und Alphakanäle (transparenter Hintergrund), um eine scharfe, professionelle PNG-Ausgabe zu gewährleisten.
- Zamzar: Am besten für Einfachheit. Ein etablierter Branchenveteran seit 2006, der einen sauberen Drei-Schritte-Konvertierungsprozess für XLS oder XLSX in PNG bietet.
- Cloudxdocs: Am besten für komplexe Layouts. Basiert auf professionellen APIs und zeichnet sich durch die Beibehaltung von zusammengeführten Zellen und ursprünglichen Formatierungen aus.
So konvertieren Sie Excel online in PNG:
-
Vertrauenswürdiges Tool auswählen
Navigieren Sie zu einer seriösen Website wie CloudConvert. -
Dokument hochladen
Klicken Sie auf Datei auswählen, um Ihren Computer zu durchsuchen, oder ziehen Sie Ihre Arbeitsmappe direkt in den Browser. -
Bildeinstellungen konfigurieren
Wählen Sie PNG als Ausgabeformat. Wenn verfügbar, stellen Sie die Auflösung auf 300 DPI für professionellen Druck oder hochauflösende Bildschirme ein. -
Konvertieren & Herunterladen
Klicken Sie auf Konvertieren. Sobald abgeschlossen, laden Sie Ihre Bilder herunter (oft als ZIP-Datei bereitgestellt, wenn Ihr Excel mehrere Blätter enthält).
Hinweis zu Datensicherheit & Datenschutz:
Um Ihre Privatsphäre zu schützen, laden Sie nur nicht-sensible Informationen auf öffentliche Konverter hoch. Bevorzugen Sie immer Tools, die SSL-Verschlüsselung verwenden und eine automatische Dateilöschung innerhalb von 24 Stunden anbieten. Für vertrauliche Finanzdaten empfehlen wir die Verwendung der Funktion "Als Bild kopieren" in Excel oder eines lokalen Snipping-Tools.
Wann diese Methode verwenden:
- Sie benötigen die Konvertierung von Excel in PNG auf dem Mobilgerät.
- Sie möchten eine PNG-Ausgabe mit transparentem Hintergrund.
- Sie konvertieren ganze Arbeitsblätter oder mehrere Blätter auf einmal in Bilder.
Methode 4 - Excel per Python in Stapelverarbeitung in PNG konvertieren (Automatisierung)
Für Entwickler, Datenanalysten und Teams, die mit einer großen Anzahl von Excel-Dateien arbeiten, ist die Automatisierung der Excel-zu-PNG-Konvertierung mit Python die skalierbarste Lösung. Dieser Ansatz ermöglicht es Ihnen, Hunderte von Arbeitsblättern oder Arbeitsmappen in Stapel zu verarbeiten und Bildexporte in Reporting-Pipelines zu integrieren – ohne Microsoft Excel installieren zu müssen.
Wichtige Vorteile:
- Keine Office-Abhängigkeit: Funktioniert auf Servern und unter Linux.
- Massive Skalierbarkeit: Konvertiert über 100 Dateien in Sekunden.
- Hohe Wiedergabetreue: Behält die ursprüngliche Zellformatierung, Schriftarten und Farben bei.
Voraussetzungen
Stellen Sie vor dem Start sicher, dass Sie Folgendes haben:
- Python 3.7+
- Spire.XLS für Python – eine unabhängige Bibliothek, die Excel-Dateien erstellt, bearbeitet und konvertiert, ohne Microsoft Office zu benötigen.
Installation:
pip install spire.xls
Python-Beispiel – Stapelverarbeitung von Excel in PNG-Bilder
Dieses Skript speichert automatisch alle Arbeitsblätter einer Arbeitsmappe als hochauflösende PNG-Bilder:
from spire.xls import *
# Excel-Datei laden
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
# Alle Arbeitsblätter durchlaufen
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Jedes Blatt als Bild speichern
image = sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn)
image.Save(f"sheet_{i+1}.png")
# Arbeitsmappe freigeben
workbook.Dispose()
Hier ist eine Vorschau eines der exportierten PNG-Dateien:
Erweiterte Anpassungsoptionen
-
Einen bestimmten Bereich exportieren
Anstatt des gesamten Blatts können Sie genau angeben, welche Zeilen und Spalten erfasst werden sollen:sheet.ToImage(5, 1, 10, 4) # Parameter: StartRow, StartColumn, EndRow, EndColumn -
Mehrere Dateien in Stapelverarbeitung konvertieren
Verwenden Sie die os-Bibliothek, um einen ganzen Ordner zu durchlaufen und jede Excel-Arbeitsmappe automatisch als PNG zu speichern:import os # Ordnerpfad definieren folder_path = r"C:\Files" files = [f for f in os.listdir(folder_path) if f.endswith(".xlsx")] for file in files: wb = Workbook() wb.LoadFromFile(os.path.join(folder_path, file)) # Konvertiert das erste Arbeitsblatt jeder Datei in PNG sheet = wb.Worksheets[0] output_path = os.path.join(folder_path, file.replace(".xlsx", ".png")) sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn).Save(output_path) wb.Dispose()
Wann diese Methode verwenden:
- Sie sind Entwickler und erstellen einen automatisierten Workflow.
- Sie müssen viele Excel-Dateien oder ganze Arbeitsmappen konvertieren.
- Manuelle Konvertierung ist nicht praktikabel (z. B. geplante Berichterstattung, Pipelines, interne Tools).
Schneller Vergleich: Welche Methode zur Konvertierung von Excel in PNG sollten Sie wählen
Um Ihnen bei der Entscheidung zu helfen, hier ein schneller Vergleich aller oben genannten Methoden zur Konvertierung von Excel in PNG:
| Methode | Am besten geeignet für | Benutzerfreundlichkeit | Ausgabequalität | Benötigte Software |
|---|---|---|---|---|
| Als Bild kopieren | Einzelne Tabellen / Kleine Bereiche | Sehr einfach | Hoch | Microsoft Excel |
| Snipping Tools | Tutorials / Schnelle Anmerkungen | Am schnellsten | Mittel | Keine (integriert) |
| Online-Tools | Ganze Dateien / Mobile Benutzer | Einfach | Hoch | Webbrowser |
| Python-Skript | Stapelverarbeitung / Automatisierung | Fortgeschritten | Professionell | Python-Umgebung |
Endgültiges Urteil:
- Für einen einmaligen Bericht: Verwenden Sie "Als Bild kopieren" für den saubersten, nativen Look.
- Zum Teilen einer schnellen Anleitung: Verwenden Sie ein Snipping Tool, um einfach visuelle Pfeile und Notizen hinzuzufügen.
- Für Benutzer unterwegs: Online-Konverter sind die bequemste, mobilfreundliche Wahl.
- Für Enterprise-Automatisierung: Python ist die skalierbarste Lösung für die Verarbeitung großer Datenmengen.
Profi-Tipps für bessere PNG-Ausgabe
- Maximale Klarheit: Erhöhen Sie die Excel-Zoomstufe auf 150 % - 200 %, bevor Sie aufnehmen oder konvertieren. Dies verhindert unscharfen Text in der endgültigen PNG-Datei.
- Visuelle Elemente optimieren: Blenden Sie Gitternetzlinien aus (Ansicht > Gitternetzlinien deaktivieren) und entfernen Sie leere Zeilen oder Spalten. Eine aufgeräumte Tabelle sorgt für ein professionelles, poliertes Aussehen.
- Schriftartkompatibilität prüfen: Verwenden Sie bei der Verwendung von Python oder Online-Konvertern Standard-Schriftarten wie Arial oder Calibri, um sicherzustellen, dass das exportierte Bild mit dem auf dem Bildschirm übereinstimmt.
- Stapelvalidierung (Python-Benutzer): Testen Sie Ihr Skript zuerst mit einer einzelnen Datei, um zu überprüfen, ob Formatierung, Schriftarten und Layout korrekt exportiert werden, bevor Sie einen großen Stapel ausführen.
Häufige Probleme bei der Konvertierung von Excel in PNG beheben
- Bild ist abgeschnitten: Überprüfen Sie Ihre Einstellungen für den Druckbereich. Wenn ein Druckbereich definiert ist, erfassen einige Konverter möglicherweise nur diesen Bereich und ignorieren den Rest des Blatts.
- Kopierfunktion ist ausgegraut: Stellen Sie sicher, dass Sie sich nicht im Zellbearbeitungsmodus befinden (blinkender Cursor in einer Zelle). Drücken Sie Esc, um die Bearbeitung zu beenden, bevor Sie kopieren oder exportieren.
- Unscharfe oder verpixelte Bilder: Vermeiden Sie es, die PNG nach dem Speichern zu strecken oder zu vergrößern. Für größere Bilder exportieren Sie stattdessen mit einer höheren Zoomstufe, anstatt zu skalieren.
- Blatt zu groß für ein PNG: Sehr große Blätter können unleserlich werden. Teilen Sie Datensätze in logische Abschnitte oder erwägen Sie einen Workflow von Excel zu PDF zu PNG für extrem breite Tabellen.
Häufig gestellte Fragen
F1: Beeinträchtigt die Konvertierung von Excel in PNG die Datenqualität?
A1: Die Daten selbst werden nicht geändert, aber sie werden zu einem statischen Bild, was bedeutet, dass sie nicht bearbeitet oder neu berechnet werden können.
F2: Kann ich mehrere Excel-Blätter in Stapelverarbeitung in PNG konvertieren?
A2: Ja, Sie können Python oder einen professionellen Online-Konverter verwenden, um Excel-Dateien oder Blätter effizient in Stapel zu verarbeiten.
F3: Wie erhalte ich ein PNG mit transparentem Hintergrund aus Excel?
A3: Excel gibt normalerweise ein Bild mit weißem Hintergrund aus. Um ein transparentes PNG zu erstellen, können Sie:
- Einen Online-Konverter verwenden, der Alphakanäle unterstützt.
- Ihr Ergebnis von "Als Bild kopieren" in Tools wie remove.bg einfügen und dann als PNG mit Transparenz speichern.
F4: Sollte ich Excel als PNG oder PDF exportieren?
A4: Das hängt von Ihren Bedürfnissen ab:
- PNG ist perfekt zum Einbetten in Folien, E-Mails, Websites oder Berichte als visuelles Element.
- PDF ist besser für mehrseitige Dokumente, offizielle Archivierung oder hochwertigen Druck, insbesondere wenn Text durchsuchbar bleiben soll.
Siehe auch
Преобразовать Excel в PNG: 4 простых метода (бесплатные и пакетные решения)
Оглавление
Файлы Excel (.xlsx или .xls) широко используются для организации и анализа структурированных данных, но они не всегда являются лучшим форматом для обмена. Форматирование может смещаться на разных устройствах, а исходную книгу легко изменить. Преобразование Excel в PNG превращает вашу электронную таблицу в статичное изображение, что упрощает обмен, публикацию или встраивание на различных платформах без беспокойства об изменении макета.
В этом руководстве мы рассмотрим 4 практических способа преобразования Excel в PNG без потери качества - от быстрых ручных вариантов до автоматизированного пакетного преобразования с помощью Python, чтобы вы могли выбрать подходящий вам подход.
Обзор способов преобразования Excel в PNG
- Способ 1 - Копировать Excel как изображение (встроенный способ)
- Способ 2 - Скриншот Excel в PNG (с помощью инструмента "Ножницы")
- Способ 3 - Конвертировать Excel в PNG онлайн (без установки)
- Способ 4 - Пакетное преобразование Excel в PNG с помощью Python (автоматизация)
Зачем конвертировать Excel в PNG?
Хотя PDF-файлы распространены, PNG-изображения предлагают уникальные преимущества для цифрового контента и отчетности:
- Точная согласованность пикселей: Сохраняет макеты, стили ячеек и шрифты точно так, как они отображаются в Excel - без сломанных формул или смещенных столбцов.
- Универсальная доступность: PNG-файлы можно просматривать на любом смартфоне, планшете или операционной системе без необходимости установки Microsoft Excel или специализированного просмотрщика.
- Бесшовная интеграция: Идеально подходит для встраивания панелей мониторинга и диаграмм непосредственно на веб-сайты, в документацию или презентации PowerPoint.
- Улучшенная безопасность (только для чтения): Эффективно "блокирует" ваши данные, предотвращая изменение исходных чисел или просмотр конфиденциальных скрытых формул получателями.
- Высококачественная прозрачность: В отличие от JPEG, PNG поддерживает прозрачность и обеспечивает лучшую четкость для элементов пользовательского интерфейса и визуализации данных.
Способ 1 - Копировать Excel как изображение (встроенный способ)
Если вам нужно быстрое преобразование Excel в PNG без установки стороннего программного обеспечения, встроенная функция Excel "Копировать как изображение" является отличным вариантом. Она сохраняет точное форматирование ячеек и макет таблицы, что делает ее идеальной для экспорта выбранного диапазона для отчетов и презентаций.
Пошаговое руководство:
-
Выделите данные Excel
Откройте книгу Excel и выделите ячейки, которые вы хотите преобразовать. -
Копировать как изображение
На вкладке Главная нажмите стрелку рядом с кнопкой Копировать и выберите Копировать как изображение. -
Выберите качество изображения
Выберите Как показано на экране и Изображение для наилучшего визуального качества, затем нажмите ОК. -
Вставьте изображение
Выберите пустую ячейку и нажмите Ctrl+V (Windows) или Cmd+V (Mac). -
Сохранить как PNG
Щелкните правой кнопкой мыши по вставленному изображению → выберите Сохранить как изображение → выберите Portable Network Graphics (*.png) → выберите папку → нажмите Сохранить.
Советы:
- Этот метод экспортирует только выделенные ячейки, а не весь лист.
- Экспортированное изображение обычно имеет белый фон.
- Для дальнейшего редактирования изображения вставьте его в графический редактор, такой как Microsoft Paint (Windows) или Preview (Mac).
Когда использовать этот метод:
Лучше всего подходит для небольших наборов данных и разовых преобразований, когда важна точность макета.
Если вам нужно сохранить конкретную диаграмму, см. наше руководство по преобразованию диаграмм Excel в изображения.
Способ 2 - Скриншот Excel в PNG (с помощью инструмента "Ножницы")
Использование инструмента для создания снимков экрана (например, "Ножницы" в Windows или Screenshot в macOS) — это самый гибкий способ преобразования данных Excel в PNG. В отличие от "Копировать как изображение", эти инструменты захватывают именно то, что вы видите на экране, включая выпадающие меню, комментарии или даже несколько перекрывающихся окон, что делает их лучшим выбором для создания учебных пособий по программному обеспечению.
Шаги:
-
Подготовьте вид
Отрегулируйте уровень масштабирования Excel (например, до 150% или выше) для максимальной четкости и скройте любые нежелательные элементы (например, ленту или строку формул). -
Откройте инструмент для создания снимков экрана
Нажмите Windows + Shift + S (Windows) или Cmd + Shift + 4 (Mac). -
Выберите область Excel
Нажмите и перетащите курсор, чтобы нарисовать рамку вокруг нужного диапазона ячеек. -
Аннотируйте (необязательно)
Нажмите на появившееся окно предварительного просмотра, чтобы выделить ключевые данные или нарисовать стрелки на изображении. -
Сохранить как PNG
Нажмите значок сохранения, чтобы сохранить снимок непосредственно как PNG-файл.
Советы:
- Сочетание клавиш Windows + Shift + S работает в Windows 10 и 11. Для более старых версий Windows найдите "Ножницы" в меню "Пуск" вручную.
- Большинство инструментов предлагают режим "Произвольный фрагмент", позволяющий захватывать непрямоугольные области электронной таблицы при необходимости.
Когда использовать этот метод:
Лучше всего подходит для документации, пошаговых руководств или когда вам нужно быстро аннотировать данные перед обменом.
Способ 3 - Конвертировать Excel в PNG онлайн (без установки)
Для пользователей, у которых нет Microsoft Excel, или для тех, кто работает на мобильных устройствах, онлайн-конвертер Excel в PNG предоставляет удобный способ преобразования электронных таблиц в высококачественные изображения. Эти инструменты работают полностью в браузере и часто поддерживают прозрачный фон, что идеально подходит для веб-дизайна или добавления водяных знаков.
Лучшие онлайн-конвертеры:
- CloudConvert: Лучший для высокого разрешения. Предоставляет детальный контроль над плотностью пикселей (DPI) и альфа-каналами (прозрачный фон) для обеспечения четкого, профессионального вывода PNG.
- Zamzar: Лучший за простоту. Надежный ветеран отрасли с 2006 года, предлагающий чистый трехэтапный процесс преобразования XLS или XLSX в PNG.
- Cloudxdocs: Лучший для сложных макетов. Основан на профессиональных API, отлично сохраняет объединенные ячейки и исходное форматирование.
Как конвертировать Excel в PNG онлайн:
-
Выберите надежный инструмент
Перейдите на авторитетный сайт, например CloudConvert. -
Загрузите свой документ
Нажмите Выбрать файл, чтобы найти файл на компьютере, или перетащите свою книгу непосредственно в браузер. -
Настройте параметры изображения
Выберите PNG в качестве выходного формата. Если доступно, установите разрешение 300 DPI для профессиональной печати или экранов высокой четкости. -
Конвертировать и скачать
Нажмите Конвертировать. После завершения скачайте свои изображения (часто предоставляются в виде ZIP-архива, если в вашем Excel несколько листов).
Примечание о безопасности и конфиденциальности данных:
Для защиты вашей конфиденциальности загружайте только неконфиденциальную информацию в общедоступные конвертеры. Всегда отдавайте предпочтение инструментам, использующим SSL-шифрование и предлагающим автоматическое удаление файлов в течение 24 часов. Для конфиденциальных финансовых данных мы рекомендуем использовать функцию "Копировать как изображение" в Excel или локальный инструмент для создания снимков экрана.
Когда использовать этот метод:
- Вам нужно преобразовать Excel в PNG на мобильном устройстве.
- Вы хотите получить PNG с прозрачным фоном.
- Вы конвертируете целые листы или несколько листов в изображения одновременно.
Способ 4 - Пакетное преобразование Excel в PNG с помощью Python (автоматизация)
Для разработчиков, аналитиков данных и команд, работающих с большим объемом файлов Excel, автоматизация преобразования Excel в PNG с помощью Python является наиболее масштабируемым решением. Этот подход позволяет пакетно обрабатывать сотни листов или книг и интегрировать экспорт изображений в конвейеры отчетности — без необходимости установки Microsoft Excel.
Ключевые преимущества:
- Независимость от Office: Работает на серверах и Linux.
- Масштабность: Конвертируйте более 100 файлов за секунды.
- Высокая точность: Сохраняет исходное форматирование ячеек, шрифты и цвета.
Предварительные требования
Перед началом убедитесь, что у вас есть:
- Python 3.7+
- Spire.XLS для Python — независимая библиотека, которая создает, редактирует и конвертирует файлы Excel без необходимости установки Microsoft Office.
Установка:
pip install spire.xls
Пример на Python - Пакетное преобразование Excel в PNG-изображения
Этот скрипт автоматически сохраняет все листы книги в виде PNG-изображений высокого разрешения:
from spire.xls import *
# Загрузка файла Excel
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
# Перебор всех листов
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Сохранение каждого листа как изображения
image = sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn)
image.Save(f"sheet_{i+1}.png")
# Освобождение ресурсов книги
workbook.Dispose()
Вот предварительный просмотр одного из экспортированных PNG-файлов:
Расширенные параметры настройки
-
Экспорт определенного диапазона
Вместо всего листа вы можете указать, какие именно строки и столбцы захватывать:sheet.ToImage(5, 1, 10, 4) # Параметры: StartRow, StartColumn, EndRow, EndColumn -
Пакетное преобразование нескольких файлов
Используйте библиотеку os для перебора всей папки и автоматического сохранения каждой книги Excel в виде PNG:import os # Определение пути к папке folder_path = r"C:\Files" files = [f for f in os.listdir(folder_path) if f.endswith(".xlsx")] for file in files: wb = Workbook() wb.LoadFromFile(os.path.join(folder_path, file)) # Конвертация первого листа каждого файла в PNG sheet = wb.Worksheets[0] output_path = os.path.join(folder_path, file.replace(".xlsx", ".png")) sheet.ToImage(sheet.FirstRow, sheet.FirstColumn, sheet.LastRow, sheet.LastColumn).Save(output_path) wb.Dispose()
Когда использовать этот метод:
- Вы разработчик, создающий автоматизированный рабочий процесс.
- Вам нужно конвертировать много файлов Excel или целые книги.
- Ручное преобразование непрактично (например, запланированное составление отчетов, конвейеры, внутренние инструменты).
Краткое сравнение: Какой метод преобразования Excel в PNG выбрать
Чтобы помочь вам принять решение, вот краткое сравнение всех рассмотренных выше методов преобразования Excel в PNG:
| Метод | Лучше всего подходит для | Простота использования | Качество вывода | Необходимое ПО |
|---|---|---|---|---|
| Копировать как изображение | Отдельные таблицы / Небольшие диапазоны | Очень просто | Высокое | Microsoft Excel |
| Инструменты для снимков экрана | Учебные пособия / Быстрые аннотации | Самый быстрый | Среднее | Нет (встроенный) |
| Онлайн-инструменты | Целые файлы / Мобильные пользователи | Просто | Высокое | Веб-браузер |
| Скрипт Python | Пакетная обработка / Автоматизация | Продвинутый | Профессиональное | Среда Python |
Окончательный вердикт:
- Для разового отчета: Используйте "Копировать как изображение" для самого чистого, естественного вида.
- Для обмена кратким руководством: Используйте инструмент для снимков экрана, чтобы легко добавлять визуальные стрелки и заметки.
- Для пользователей на ходу: Онлайн-конвертеры — самый удобный и мобильный вариант.
- Для корпоративной автоматизации: Python — самое масштабируемое решение для обработки больших объемов файлов.
Советы для лучшего вывода PNG
- Максимизируйте четкость: Увеличьте масштаб Excel до 150%-200% перед захватом или преобразованием. Это предотвратит размытие текста на конечном PNG.
- Оптимизируйте визуальные эффекты: Скройте сетку (Вид > Снять флажок "Сетка") и удалите пустые строки или столбцы. Аккуратная электронная таблица обеспечит профессиональный, отполированный вид.
- Проверьте совместимость шрифтов: При использовании Python или онлайн-конвертеров придерживайтесь стандартных шрифтов, таких как Arial или Calibri, чтобы экспортированное изображение соответствовало тому, что вы видите на экране.
- Пакетная проверка (для пользователей Python): Сначала протестируйте свой скрипт на одном файле, чтобы убедиться, что форматирование, шрифты и макет экспортируются правильно, прежде чем запускать большую пакетную обработку.
Устранение распространенных проблем с преобразованием Excel в PNG
- Изображение обрезано: Проверьте настройки области печати. Если область печати определена, некоторые конвертеры могут захватывать только этот диапазон, игнорируя остальную часть листа.
- Функция "Копировать" неактивна: Убедитесь, что вы не находитесь в режиме редактирования ячейки (мигающий курсор внутри ячейки). Нажмите Esc, чтобы выйти из режима редактирования перед копированием или экспортом.
- Размытые или пикселизированные изображения: Избегайте растягивания или изменения размера PNG после сохранения. Для более крупных изображений экспортируйте повторно с более высоким уровнем масштабирования вместо масштабирования.
- Лист слишком большой для одного PNG: Очень большие листы могут стать нечитаемыми. Разделите наборы данных на логические разделы или рассмотрите рабочий процесс Excel-to-PDF-to-PNG для сверхшироких электронных таблиц.
Часто задаваемые вопросы
В1: Влияет ли преобразование Excel в PNG на качество данных?
О1: Сами данные не изменяются, но они становятся статичным изображением, что означает, что их нельзя редактировать или пересчитывать.
В2: Могу ли я пакетно конвертировать несколько листов Excel в PNG?
О2: Да, вы можете использовать Python или профессиональный онлайн-конвертер для эффективной пакетной обработки файлов или листов Excel.
В3: Как получить PNG с прозрачным фоном из Excel?
О3: Excel обычно выводит изображение с белым фоном. Чтобы создать прозрачный PNG, вы можете:
- Использовать онлайн-конвертер, поддерживающий альфа-каналы.
- Вставить результат "Копировать как изображение" в такие инструменты, как remove.bg, а затем сохранить как PNG с прозрачностью.
В4: Следует ли экспортировать Excel как PNG или PDF?
О4: Это зависит от ваших потребностей:
- PNG идеально подходит для встраивания в слайды, электронные письма, веб-сайты или отчеты в качестве визуального элемента.
- PDF лучше подходит для многостраничных документов, официального архивирования или высококачественной печати, особенно когда текст должен оставаться доступным для поиска.
См. также
Remover hiperlinks de PDF – 4 métodos rápidos
Índice

Hiperlinks em PDFs são incrivelmente úteis para navegação digital. No entanto, existem muitas situações em que esses mesmos hiperlinks podem ser distrativos ou redundantes. Talvez você esteja preparando um documento para impressão, compartilhando um relatório estático ou simplesmente querendo manter o layout limpo. Seja qual for o seu motivo, aprender a remover hiperlinks de arquivos PDF é uma habilidade essencial.
Este guia compartilha quatro métodos confiáveis para **remover hiperlinks de PDF** — desde um recurso integrado gratuito do Windows até software profissional como o Adobe Acrobat Pro, e até mesmo uma solução automatizada em C# para desenvolvedores.
Aqui está o que você aprenderá:
- Método 1: Recurso Integrado "Imprimir em PDF"
- Método 2: Usando o Adobe Acrobat Pro
- Método 3: Removedores Gratuitos de Hiperlinks de PDF Online
- Método 4: Automação C# com Spire.PDF Gratuito
- Dicas Profissionais Após Desativar Hiperlinks em PDF
- Perguntas Frequentes Sobre a Remoção de Hiperlinks de PDF
Método 1: Recurso Integrado "Imprimir em PDF"
Se você deseja uma solução rápida sem baixar aplicativos, use o recurso integrado "Imprimir em PDF" para "achatar" o documento PDF e remover todos os hiperlinks com um único clique.
Passo a Passo:
- Abra o arquivo PDF com hiperlinks usando seu visualizador de PDF padrão (por exemplo, Microsoft Edge).
- Clique no ícone Imprimir ou use o atalho "Ctrl+P" (Windows).
- No menu suspenso "Impressora", selecione "Microsoft Print to PDF".
- Clique em Imprimir e escolha um local para salvar o novo PDF.
- Abra o arquivo salvo — todos os hiperlinks serão removidos.
Quando usar isso: Uma remoção rápida e única quando você não precisa editar o arquivo depois.
Método 2: Usando o Adobe Acrobat Pro
O Adobe Acrobat Pro é o padrão da indústria para edição de PDF. Ao contrário da solução alternativa "Imprimir em PDF", o Acrobat permite excluir hiperlinks em PDF individualmente ou em massa sem achatar o documento, preservando a editabilidade completa.
Remover Hiperlinks do Adobe Acrobat:
- Abra seu PDF no Adobe Acrobat Pro.
- Clique em Ferramentas no menu superior, depois selecione "Editar PDF".
- Para remover um único hiperlink: Clique com o botão direito no texto/imagem vinculada e selecione "Excluir Link".
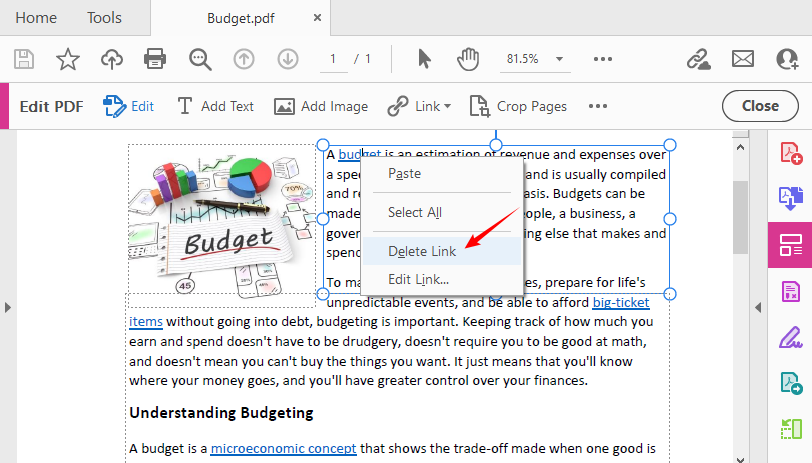
- Para remover todos os links do PDF:
- Clique em "Link > Remover Links da Web".
- Uma janela pop-up aparecerá perguntando quais páginas você deseja processar. Selecione "Todas" (ou escolha um intervalo de páginas como 1–5).
- Clique em "OK". O Acrobat irá escanear todas as páginas e excluir todas as anotações de links da web.
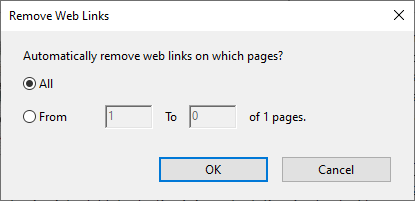
Ideal para: Profissionais, empresas e qualquer pessoa que precise de controle preciso e resultados altamente precisos.
Método 3: Removedores Gratuitos de Hiperlinks de PDF Online
Para usuários casuais sem acesso ao Adobe Acrobat, ferramentas gratuitas baseadas na web (como PDFQ, Zia Sign) oferecem uma maneira descomplicada de remover hiperlinks em PDF online gratuitamente, embora possam ter limites de tamanho de arquivo ou exigir uma conexão com a internet.
Exemplo de uso do PDFQ:
- Acesse a ferramenta de remoção de hiperlinks do PDFQ.
- Clique em "Selecionar arquivos" para carregar seu PDF.
- A ferramenta irá escanear e remover automaticamente todos os hiperlinks.
- Visualize o PDF limpo para confirmar que todos os hiperlinks foram removidos.
- Baixe o arquivo PDF sem hiperlinks.
A maioria das ferramentas removedoras de links de PDF exclui hiperlinks de todas as páginas do PDF. Se você precisar de remoção seletiva de links (por exemplo, apenas das páginas 5–10), basta dividir o PDF nos intervalos de páginas necessários antes de executar a ferramenta.
Nota de Segurança: Evite carregar PDFs confidenciais, legais ou médicos para qualquer serviço online. Para arquivos sensíveis, use métodos offline (Método 1, 2 ou 4).
Método 4: Automação C# com Spire.PDF Gratuito
Para desenvolvedores ou equipes de TI que precisam automatizar a remoção de hiperlinks em centenas de arquivos, o Free Spire.PDF para .NET é uma solução confiável baseada em código. Esta biblioteca gratuita .NET suporta uma ampla gama de recursos de processamento de PDF, incluindo adição e exclusão de hiperlinks.
Código C# para Remover Todos os Hiperlinks de um PDF
O código a seguir carrega um PDF, itera por cada página, identifica todas as anotações de links da web e as remove.
using Spire.Pdf;
using Spire.Pdf.Annotations;
using System;
namespace DeleteHyperlink
{
internal class Program
{
static void Main(string[] args)
{
// Create an object of PdfDocument
PdfDocument pdf = new PdfDocument();
// Load a PDF file
pdf.LoadFromFile("Sample.pdf");
// Remove all hyperlinks in the document
// Loop through each page
foreach (PdfPageBase page in pdf.Pages)
{
// Get the annotation collection of the page
PdfAnnotationCollection collection = page.Annotations;
// Iterate backwards to safely remove items
for (int i = collection.Count - 1; i >= 0; i--)
{
PdfAnnotation annotation = collection[i];
// Check if the annotation is a hyperlink (URI widget)
if (annotation is PdfUriAnnotationWidget)
{
PdfUriAnnotationWidget url = (PdfUriAnnotationWidget)annotation;
// Remove the hyperlink
collection.Remove(url);
}
}
}
// Save the updated document
pdf.SaveToFile("DeleteHyperlinks.pdf");
pdf.Dispose();
}
}
}
O Free Spire.PDF fornece a classe PdfUriAnnotationWidget para representar anotações de hiperlinks da web/URL clicáveis em PDFs. Se uma anotação for detectada como este tipo de link da web, chame o método Remove() para desativar os links no PDF.
Resultado: Os links clicáveis no PDF são removidos e o texto subjacente permanece inalterado (cor azul, sublinhado).
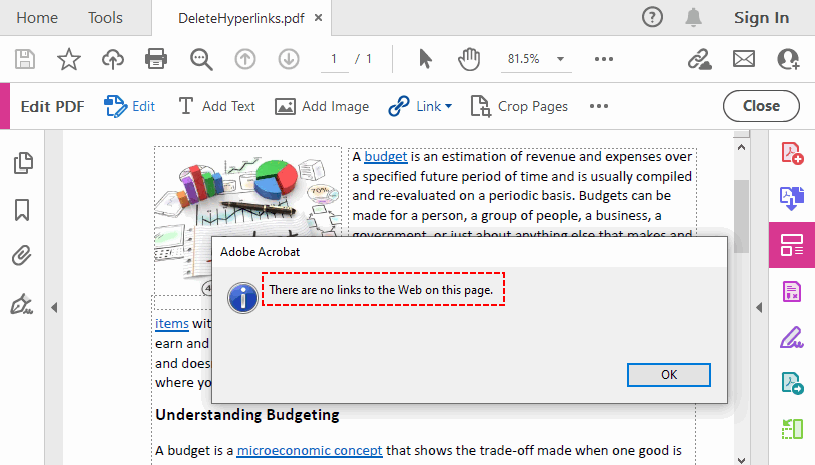
Opcional: Remover Apenas um Hiperlink Específico
Se você quiser excluir um único hiperlink designado (por exemplo, o segundo hiperlink na primeira página), substitua o loop interno por:
PdfPageBase page = pdf.Pages[0];
if (page.Annotations.Count > 1)
{
page.AnnotationsWidget.RemoveAt(1); // zero-based index
}
✔ Prós: Suporta automação em lote, gratuito para uso comercial e não comercial (limite de 10 páginas por arquivo), preserva totalmente a editabilidade e a formatação do PDF.
✘ Contras: Requer conhecimento básico de programação C#, precisa de instalação do pacote FreeSpire.PDF via NuGet.
Dicas Profissionais Após Desativar Hiperlinks em PDF
- Verifique seu documento duas vezes: Algumas ferramentas podem excluir texto se usadas incorretamente. Sempre mantenha um backup do PDF original.
- Achatar para Segurança: Se você quiser garantir que os links não possam ser reativados, imprima o PDF em um novo PDF usando "Imprimir em PDF" (Método 1).
- Reduzir o tamanho do arquivo PDF: Após a remoção de links, use um compressor online ou "Salvar como Otimizado" do Acrobat para reduzir o arquivo.
- Verifique se há links ocultos: Imagens, botões e até mesmo espaços em branco podem conter links. Use o modo "Editar" do Acrobat para ver todas as anotações.
Conclusão
Remover hiperlinks de PDFs é simples e não requer habilidades avançadas. Este guia oferece 4 métodos confiáveis para todos os cenários: O gratuito Imprimir em PDF para correções rápidas e únicas, o Adobe Acrobat Pro para precisão profissional, ferramentas online para edições baseadas em navegador sem instalação, ou um script C# (Free Spire.PDF) para processamento em lote por desenvolvedores.
Escolha o método que melhor se adapta ao seu tipo de documento, nível de habilidade e requisitos específicos para criar PDFs limpos, profissionais e sem links em minutos. Todas as abordagens preservam seu conteúdo e layout originais enquanto removem hiperlinks indesejados, resultando em documentos finais polidos.
Perguntas Frequentes Sobre a Remoção de Hiperlinks de PDF
P1: A remoção de hiperlinks exclui o texto?
Não. Remover um link apenas exclui a anotação clicável — o texto permanece inalterado. No entanto, se você usar um método destrutivo (como excluir a caixa de texto), poderá perder conteúdo.
P2: Qual é a maneira mais rápida de remover todos os hiperlinks de uma vez?
- Para PDFs pequenos: O recurso integrado Imprimir em PDF (10 segundos).
- Para PDFs grandes/editáveis: Remoção em massa de links do Adobe Acrobat Pro.
- Para processamento em lote: O método de automação C# + Free Spire.PDF.
P3: A remoção de hiperlinks quebrará a formatação do meu PDF?
Não. Ferramentas como o Adobe Acrobat e o script C# apenas excluem anotações de hiperlinks, preservando todo o layout, texto e imagens. O método Imprimir em PDF achata o PDF, mas mantém a formatação inalterada (apenas perde a editabilidade).
P4: Os removedores de links de PDF online são seguros?
Apenas para documentos não confidenciais. Evite carregar PDFs confidenciais, legais ou médicos para serviços online não confiáveis. Para tais arquivos, use métodos offline (Métodos 1, 2, 4).