Aggiungere bordi pagina in Word (qualsiasi pagina): 4 semplici modi
Indice

Aggiungere bordi di pagina in Microsoft Word è un modo semplice per migliorare l'aspetto del documento, sia che tu stia creando report, certificati o documenti stilizzati. Tuttavia, le opzioni di bordo integrate di Word sono principalmente progettate per documenti o sezioni intere, il che può limitare la flessibilità in alcuni scenari di layout.
In questa guida, imparerai 4 metodi semplici e pratici per aggiungere bordi di pagina in Word—coprendo l'intero documento, sezioni specifiche e persino una singola pagina utilizzando soluzioni affidabili.
Navigazione rapida:
- Metodo 1: Utilizzare la funzione Bordo Pagina in Word
- Metodo 2: Utilizzare una forma come bordo
- Metodo 3: Utilizzare una casella di testo come bordo
- Metodo 4: Utilizzare Python per aggiungere bordi automaticamente
Metodo 1: Utilizzare la funzione Bordo Pagina in Word
La funzione Bordo Pagina integrata è il modo più semplice per aggiungere bordi in Word. Funziona meglio quando vuoi applicare bordi all'intero documento o a una sezione. Tuttavia, presenta limitazioni quando si tratta di una pagina specifica.
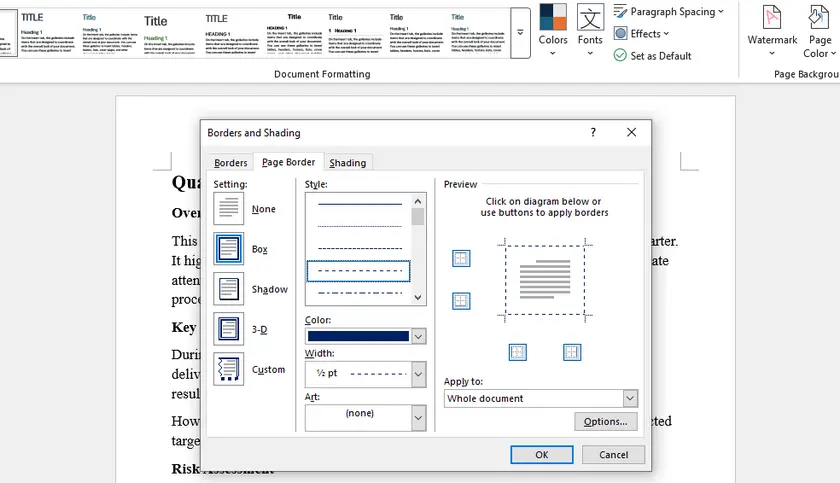
Come aggiungere bordi all'intero documento o a una sezione
- Apri il tuo documento Word.
- Vai a Design → Bordi di pagina .
- Nel dialogo Bordi e ombreggiature:
- Scegli uno stile di bordo (Rettangolo, Ombra, 3-D, Personalizzato).
- Imposta colore e larghezza.
- Sotto Applica a, seleziona:
- Intero documento, oppure
- Questa sezione
- Clicca OK.
Comprendere la limitazione
La funzione Bordo Pagina di Word offre solo queste opzioni:
- Intero documento
- Questa sezione
- Questa sezione – Solo prima pagina
- Questa sezione – Tutte tranne la prima pagina
Non c'è nessuna opzione diretta "Solo questa pagina".
Soluzione alternativa: applicare un bordo a una pagina specifica
Per aggiungere un bordo a una singola pagina utilizzando questo metodo:
- Posiziona il cursore all'inizio della pagina target.
- Vai a Layout → Interruzioni → Pagina successiva (inserisci un'interruzione di sezione).
- Posiziona il cursore alla fine di quella pagina e inserisci un'altra interruzione di sezione Pagina successiva.
- Ora vai a Design → Bordi di pagina .
- Seleziona Applica a: Questa sezione – Solo prima pagina.
- Clicca OK.
Questo funziona perché la pagina diventa la prima pagina di una nuova sezione.
Metodo 2: Utilizzare una forma come bordo
Se hai bisogno di aggiungere un bordo a una pagina specifica senza dover gestire sezioni, utilizzare una forma è uno dei metodi più semplici e flessibili. Ti consente di avere il pieno controllo sull'aspetto e funziona indipendentemente dalle limitazioni dei bordi di Word.
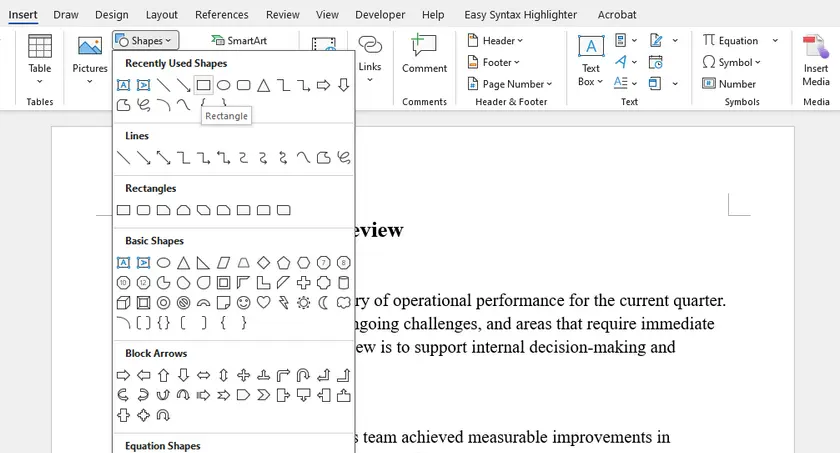
Passaggi
- Vai a Inserisci → Forme → Rettangolo .
- Disegna il rettangolo per adattarlo all'interno dei margini della pagina.
- Fai clic destro sulla forma → Formato forma :
- Imposta Riempimento → Nessun riempimento
- Personalizza Linea (colore, larghezza, stile)
- Imposta il layout della forma su Dietro al testo .
Perché utilizzare questo metodo?
- Funziona su qualsiasi pagina
- Nessuna necessità di interruzioni di sezione
- Altamente personalizzabile
Metodo 3: Utilizzare una casella di testo come bordo
Se desideri aggiungere un bordo a una pagina specifica con maggiore flessibilità—come includere testo decorativo o design—una Casella di testo è una scelta eccellente. Funziona indipendentemente dalle limitazioni dei bordi di Word e non richiede la creazione di sezioni.

Passaggi
- Vai a Inserisci → Casella di testo → Disegna casella di testo .
- Imposta il layout della casella di testo su Dietro al testo per evitare di spostare il contenuto esistente.
- Elimina il testo segnaposto all'interno della casella di testo.
- Regola la posizione e le dimensioni della casella di testo in modo che copra i bordi della pagina come desiderato.
- Fai clic destro → Formato forma :
- Imposta Riempimento su Nessun riempimento
- Personalizza Linea (colore, larghezza, stile)
Perché utilizzare questo metodo?
- Funziona su qualsiasi pagina, senza necessità di interruzioni di sezione
- Non disturba il contenuto esistente quando il layout è impostato per primo
- Può includere testo decorativo o design all'interno del bordo
- Stabile e flessibile per bordi di singole pagine
Consiglio: Se hai bisogno solo di un bordo semplice senza testo, una Forma funziona altrettanto bene ed è leggermente più leggera.
Metodo 4: Utilizzare Python per aggiungere bordi automaticamente
Se hai bisogno di applicare bordi di pagina a più documenti Word o automatizzare il processo, utilizzare Python è la soluzione più efficiente. Librerie come Spire.Doc per Python ti consentono di aggiungere e personalizzare programmaticamente i bordi di pagina con precisione.
Installa la libreria richiesta
pip install spire.doc
Esempio di codice: Aggiungi bordi a Word in Python
from spire.doc import *
from spire.doc.common import *
# Carica documento
doc = Document()
doc.LoadFromFile(r"C:\Users\Administrator\Desktop\Input-en.docx")
# Applica bordi a tutte le sezioni
for i in range(len(doc.Sections)):
section = doc.Sections[i]
setup = section.PageSetup
borders = setup.Borders
setup.PageBordersApplyType = PageBordersApplyType.AllPages
borders.BorderType(BorderStyle.DotDotDash)
borders.LineWidth(1)
borders.Color(Color.get_Blue())
# Imposta spaziatura per tutti i lati
for side in [borders.Top, borders.Bottom, borders.Left, borders.Right]:
side.Space = 20.0
# Salva risultato
doc.SaveToFile("AddWordPageBorders.docx", FileFormat.Docx)
doc.Dispose()
Output:
Perché utilizzare questo metodo?
- Ideale per l'elaborazione in batch
- Garantisce formattazione coerente
- Perfetto per flussi di lavoro di automazione
Questo approccio è particolarmente utile per generare documenti come report, fatture o certificati su larga scala.
Oltre ad aggiungere bordi, puoi anche utilizzare Spire.Doc per regolare i margini di pagina per un controllo preciso del layout; puoi applicare colori di sfondo o filigrane alle pagine di Word, migliorando il design visivo dei tuoi documenti.
Tabella di confronto rapida
| Metodo | Ideale per | Può mirare a qualsiasi pagina | Difficoltà |
|---|---|---|---|
| Bordi di pagina | Intero documento / sezioni | ✗ (richiede soluzione alternativa) | Facile |
| Interruzione di sezione + Bordi di pagina | Pagina specifica | √ | Media |
| Forma | Pagina singola o più pagine | √ | Facile |
| Casella di testo | Pagina singola con testo/decorazione opzionale | √ | Facile |
| Python (Spire.Doc) | Automazione / elaborazione in batch | √ | Avanzato |
Conclusione
Aggiungere bordi di pagina in Word dipende dalle tue esigenze specifiche e dal livello di controllo che desideri avere sul tuo documento:
- Bordi di pagina sono ideali per aggiungere bordi all'intero documento o a sezioni specifiche in modo rapido e coerente.
- Interruzioni di sezione sono utili se desideri sfruttare la funzione di bordo integrata di Word per una singola pagina mantenendo un layout corretto.
- Forme o Caselle di testo offrono un modo veloce e flessibile per aggiungere bordi su qualsiasi pagina senza influenzare il contenuto esistente; le Caselle di testo sono particolarmente utili se desideri includere testo decorativo o design.
- Automazione Python è perfetta per l'elaborazione in batch di più documenti, garantendo bordi coerenti in tutti i file.
Scegliendo il metodo giusto, puoi superare le limitazioni di Word, risparmiare tempo e creare documenti dall'aspetto professionale che corrispondono alla tua visione di design.
Domande frequenti
Perché non posso aggiungere un bordo a una sola pagina in Word?
Perché la funzione bordo di Word è basata su sezioni, non su pagine. Non c'è un'opzione integrata "solo questa pagina".
Qual è il modo più semplice per aggiungere un bordo a una singola pagina?
Utilizzare una forma (rettangolo) è il metodo più veloce e semplice.
Quale metodo è migliore per documenti professionali?
Per coerenza, utilizza Bordi di pagina con sezioni o automazione Python.
Le caselle di testo influenzano il layout del documento?
La Casella di testo non disturberà il contenuto esistente se il suo layout è impostato su Dietro al testo.
Vedi anche
Ajouter des bordures de page dans Word (n'importe quelle page) : 4 méthodes simples
Table des matières
Ajouter des bordures de page dans Microsoft Word est un moyen simple d'améliorer l'apparence d'un document, que vous créiez des rapports, des certificats ou des documents stylisés. Cependant, les options de bordure intégrées de Word sont principalement conçues pour des documents entiers ou des sections, ce qui peut limiter la flexibilité dans certains scénarios de mise en page.
Dans ce guide, vous apprendrez 4 méthodes simples et pratiques pour ajouter des bordures de page dans Word—couvrant l'ensemble du document, des sections spécifiques, et même n'importe quelle page unique en utilisant des solutions de contournement fiables.
Navigation rapide :
- Méthode 1 : Utiliser la fonction de bordures de page dans Word
- Méthode 2 : Utiliser une forme comme bordure
- Méthode 3 : Utiliser une zone de texte comme bordure
- Méthode 4 : Utiliser Python pour ajouter des bordures automatiquement
Méthode 1 : Utiliser la fonction de bordures de page dans Word
La fonction de bordures de page intégrée est le moyen le plus simple d'ajouter des bordures dans Word. Elle fonctionne mieux lorsque vous souhaitez appliquer des bordures à l'ensemble du document ou à une section. Cependant, elle présente des limitations lorsqu'il s'agit de cibler une page spécifique.
Comment ajouter des bordures à l'ensemble du document ou à une section
- Ouvrez votre document Word.
- Allez dans Conception → Bordures de page .
- Dans la boîte de dialogue Bordures et trames :
- Choisissez un style de bordure (Boîte, Ombre, 3-D, Personnalisé).
- Définissez la couleur et la largeur.
- Sous Appliquer à, sélectionnez :
- Document entier, ou
- Cette section
- Cliquez sur OK .
Comprendre la limitation
La fonction de bordures de page de Word ne fournit que ces options :
- Document entier
- Cette section
- Cette section – Première page uniquement
- Cette section – Toutes sauf la première page
Il n'y a pas d'option directe "Cette page uniquement".
Solution de contournement : Appliquer une bordure à une page spécifique
Pour ajouter une bordure à une seule page en utilisant cette méthode :
- Placez votre curseur au début de la page cible.
- Allez dans Mise en page → Sautez → Page suivante (insérez un saut de section).
- Placez le curseur à la fin de cette page et insérez un autre saut de section Page suivante.
- Maintenant, allez dans Conception → Bordures de page .
- Sélectionnez Appliquer à : Cette section – Première page uniquement .
- Cliquez sur OK .
Cela fonctionne parce que la page devient la première page d'une nouvelle section.
Méthode 2 : Utiliser une forme comme bordure
Si vous devez ajouter une bordure à une page spécifique sans gérer les sections, utiliser une forme est l'une des méthodes les plus simples et les plus flexibles. Cela permet un contrôle total sur l'apparence et fonctionne indépendamment des limitations de bordure de Word.
Étapes
- Allez dans Insérer → Formes → Rectangle .
- Dessinez le rectangle pour qu'il s'adapte aux marges de la page.
- Cliquez avec le bouton droit sur la forme → Format de la forme :
- Définir Remplissage → Pas de remplissage
- Personnaliser Ligne (couleur, largeur, style)
- Définissez la disposition de la forme sur Derrière le texte .
Pourquoi utiliser cette méthode ?
- Fonctionne sur n'importe quelle page
- Aucun besoin de sauts de section
- Très personnalisable
Méthode 3 : Utiliser une zone de texte comme bordure
Si vous souhaitez ajouter une bordure à une page spécifique avec plus de flexibilité—comme inclure du texte décoratif ou des designs—une zone de texte est un excellent choix. Elle fonctionne indépendamment des limitations de bordure de Word et ne nécessite pas de créer des sections.
Étapes
- Allez dans Insérer → Zone de texte → Dessiner une zone de texte .
- Définissez la disposition de la zone de texte sur Derrière le texte pour éviter de déplacer le contenu existant.
- Supprimez le texte de remplacement à l'intérieur de la zone de texte.
- Ajustez la position et la taille de la zone de texte pour qu'elle couvre les bords de la page comme souhaité.
- Cliquez avec le bouton droit → Format de la forme :
- Définir Remplissage sur Pas de remplissage
- Personnaliser Ligne (couleur, largeur, style)
Pourquoi utiliser cette méthode ?
- Fonctionne sur n'importe quelle page, aucun saut de section nécessaire
- Ne perturbe pas le contenu existant lorsque la mise en page est définie en premier
- Peut inclure du texte décoratif ou des designs à l'intérieur de la bordure
- Stable et flexible pour les bordures de page unique
Conseil : Si vous n'avez besoin que d'une bordure simple sans texte, une forme fonctionne tout aussi bien et est légèrement plus légère.
Méthode 4 : Utiliser Python pour ajouter des bordures automatiquement
Si vous devez appliquer des bordures de page à plusieurs documents Word ou automatiser le processus, utiliser Python est la solution la plus efficace. Des bibliothèques comme Spire.Doc pour Python vous permettent d'ajouter et de personnaliser des bordures de page de manière programmatique avec précision.
Installer la bibliothèque requise
pip install spire.doc
Exemple de code : Ajouter des bordures à Word en Python
from spire.doc import *
from spire.doc.common import *
# Charger le document
doc = Document()
doc.LoadFromFile(r"C:\Users\Administrator\Desktop\Input-en.docx")
# Appliquer des bordures à toutes les sections
for i in range(len(doc.Sections)):
section = doc.Sections[i]
setup = section.PageSetup
borders = setup.Borders
setup.PageBordersApplyType = PageBordersApplyType.AllPages
borders.BorderType(BorderStyle.DotDotDash)
borders.LineWidth(1)
borders.Color(Color.get_Blue())
# Définir l'espacement pour tous les côtés
for side in [borders.Top, borders.Bottom, borders.Left, borders.Right]:
side.Space = 20.0
# Sauvegarder le résultat
doc.SaveToFile("AddWordPageBorders.docx", FileFormat.Docx)
doc.Dispose()
Sortie :
Pourquoi utiliser cette méthode ?
- Idéal pour le traitement par lots
- Assure un formatage cohérent
- Parfait pour les flux de travail d'automatisation
Cette approche est particulièrement utile pour générer des documents comme des rapports, des factures ou des certificats à grande échelle.
En plus d'ajouter des bordures, vous pouvez également utiliser Spire.Doc pour ajuster les marges de page pour un contrôle de mise en page précis ; vous pouvez appliquer des couleurs de fond ou des filigranes aux pages Word, améliorant ainsi le design visuel de vos documents.
Tableau de comparaison rapide
| Méthode | Idéal pour | Peut cibler n'importe quelle page | Difficulté |
|---|---|---|---|
| Bordures de page | Document entier / sections | ✗ (nécessite une solution de contournement) | Facile |
| Saut de section + Bordures de page | Page spécifique | √ | Moyen |
| Forme | Page unique ou plusieurs pages | √ | Facile |
| Zone de texte | Page unique avec texte/décor optionnel | √ | Facile |
| Python (Spire.Doc) | Automatisation / traitement par lots | √ | Avancé |
Conclusion
Ajouter des bordures de page dans Word dépend de vos besoins spécifiques et du niveau de contrôle que vous souhaitez sur votre document :
- Bordures de page sont idéales pour ajouter des bordures à l'ensemble du document ou à des sections spécifiques rapidement et de manière cohérente.
- Les sauts de section sont utiles si vous souhaitez tirer parti de la fonction de bordure intégrée de Word pour une seule page tout en maintenant une mise en page correcte.
- Les formes ou les zones de texte offrent un moyen rapide et flexible d'ajouter des bordures sur n'importe quelle page sans affecter le contenu existant ; les zones de texte sont particulièrement pratiques si vous souhaitez inclure du texte décoratif ou des designs.
- L'automatisation Python est parfaite pour le traitement par lots de plusieurs documents, garantissant des bordures cohérentes sur tous les fichiers.
En choisissant la bonne méthode, vous pouvez surmonter les limitations de Word, gagner du temps et créer des documents au look professionnel qui correspondent à votre vision de design.
FAQs
Pourquoi ne puis-je pas ajouter une bordure à une seule page dans Word ?
Parce que la fonction de bordure de Word est basée sur les sections, pas sur les pages. Il n'y a pas d'option intégrée "cette page uniquement".
Quelle est la façon la plus simple d'ajouter une bordure à une seule page ?
Utiliser une forme (rectangle) est la méthode la plus rapide et la plus simple.
Quelle méthode est la meilleure pour les documents professionnels ?
Pour la cohérence, utilisez les bordures de page avec des sections ou l'automatisation Python.
Les zones de texte affectent-elles la mise en page du document ?
La zone de texte ne perturbera pas le contenu existant si sa mise en page est définie sur Derrière le texte.
Voir aussi
Cómo agregar bordes de página en Word (en cualquier página): 4 formas sencillas
Tabla de Contenidos
Agregar bordes de página en Microsoft Word es una forma sencilla de mejorar la apariencia del documento, ya sea que estés creando informes, certificados o documentos estilizados. Sin embargo, las opciones de borde integradas de Word están principalmente diseñadas para documentos completos o secciones, lo que puede limitar la flexibilidad en ciertos escenarios de diseño.
En esta guía, aprenderás 4 métodos simples y prácticos para agregar bordes de página en Word, cubriendo todo el documento, secciones específicas e incluso cualquier página única utilizando soluciones confiables.
Navegación Rápida:
- Método 1: Usando la función de bordes de página en Word
- Método 2: Usando una forma como borde
- Método 3: Usando un cuadro de texto como borde
- Método 4: Usando Python para agregar bordes automáticamente
Método 1: Usando la función de bordes de página en Word
La función de Bordes de Página integrada es la forma más sencilla de agregar bordes en Word. Funciona mejor cuando deseas aplicar bordes a todo el documento o a una sección. Sin embargo, tiene limitaciones al dirigirse a una página específica.
Cómo Agregar Bordes al Documento Completo o a una Sección
- Abre tu documento de Word.
- Ve a Diseño → Bordes de Página.
- En el diálogo de Bordes y Sombreado:
- Elige un estilo de borde (Cuadro, Sombra, 3-D, Personalizado).
- Establece el color y el ancho.
- En Aplicar a, selecciona:
- Todo el documento, o
- Esta sección
- Haz clic en OK.
Entendiendo la Limitación
La función de Bordes de Página de Word solo proporciona estas opciones:
- Todo el documento
- Esta sección
- Esta sección – Solo primera página
- Esta sección – Todas excepto la primera página
No hay opción directa de “Esta página solamente”.
Solución Alternativa: Aplicar Borde a una Página Específica
Para agregar un borde a una sola página usando este método:
- Coloca el cursor al inicio de la página objetivo.
- Ve a Diseño → Saltos → Siguiente Página (inserta un salto de sección).
- Coloca el cursor al final de esa página e inserta otro salto de sección de Siguiente Página.
- Ahora ve a Diseño → Bordes de Página.
- Selecciona Aplicar a: Esta sección – Solo primera página.
- Haz clic en OK.
Esto funciona porque la página se convierte en la primera página de una nueva sección.
Método 2: Usando una Forma como Borde
Si necesitas agregar un borde a cualquier página específica sin lidiar con secciones, usar una forma es uno de los métodos más fáciles y flexibles. Permite un control total sobre la apariencia y funciona independientemente de las limitaciones de bordes de Word.
Pasos
- Ve a Insertar → Formas → Rectángulo.
- Dibuja el rectángulo para que se ajuste dentro de los márgenes de la página.
- Haz clic derecho en la forma → Formato de Forma:
- Establece Relleno → Sin Relleno
- Personaliza Línea (color, ancho, estilo)
- Establece la disposición de la forma a Detrás del Texto.
¿Por Qué Usar Este Método?
- Funciona en cualquier página
- No necesita saltos de sección
- Altamente personalizable
Método 3: Usando un Cuadro de Texto como Borde
Si deseas agregar un borde a cualquier página específica con mayor flexibilidad, como incluir texto decorativo o diseños, un Cuadro de Texto es una excelente opción. Funciona independientemente de las limitaciones de bordes de Word y no requiere crear secciones.
Pasos
- Ve a Insertar → Cuadro de Texto → Dibujar Cuadro de Texto.
- Establece la disposición del Cuadro de Texto a Detrás del Texto para evitar mover el contenido existente.
- Elimina el texto de marcador de posición dentro del Cuadro de Texto.
- Ajusta la posición y el tamaño del Cuadro de Texto para que cubra los bordes de la página como desees.
- Haz clic derecho → Formato de Forma:
- Establece Relleno a Sin Relleno
- Personaliza Línea (color, ancho, estilo)
¿Por Qué Usar Este Método?
- Funciona en cualquier página, no se necesitan saltos de sección
- No interfiere con el contenido existente cuando la disposición se establece primero
- Puede incluir texto decorativo o diseños dentro del borde
- Estable y flexible para bordes de una sola página
Consejo: Si solo necesitas un borde simple sin texto, una Forma funciona igual de bien y es ligeramente más ligera.
Método 4: Usando Python para Agregar Bordes Automáticamente
Si necesitas aplicar bordes de página a múltiples documentos de Word o automatizar el proceso, usar Python es la solución más eficiente. Bibliotecas como Spire.Doc para Python te permiten agregar y personalizar bordes de página programáticamente con precisión.
Instalar la Biblioteca Requerida
pip install spire.doc
Ejemplo de Código: Agregar Bordes a Word en Python
from spire.doc import *
from spire.doc.common import *
# Cargar documento
doc = Document()
doc.LoadFromFile(r"C:\Users\Administrator\Desktop\Input-en.docx")
# Aplicar bordes a todas las secciones
for i in range(len(doc.Sections)):
section = doc.Sections[i]
setup = section.PageSetup
borders = setup.Borders
setup.PageBordersApplyType = PageBordersApplyType.AllPages
borders.BorderType(BorderStyle.DotDotDash)
borders.LineWidth(1)
borders.Color(Color.get_Blue())
# Establecer espaciado para todos los lados
for side in [borders.Top, borders.Bottom, borders.Left, borders.Right]:
side.Space = 20.0
# Guardar resultado
doc.SaveToFile("AddWordPageBorders.docx", FileFormat.Docx)
doc.Dispose()
Salida:
¿Por Qué Usar Este Método?
- Ideal para procesamiento por lotes
- Asegura un formato consistente
- Perfecto para flujos de trabajo de automatización
Este enfoque es especialmente útil para generar documentos como informes, facturas o certificados a gran escala.
Además de agregar bordes, también puedes usar Spire.Doc para ajustar los márgenes de página para un control de diseño preciso; puedes aplicar colores de fondo o marcas de agua a las páginas de Word, mejorando el diseño visual de tus documentos.
Tabla de Comparación Rápida
| Método | Mejor Para | Puede Dirigirse a Cualquier Página | Dificultad |
|---|---|---|---|
| Bordes de Página | Todo el documento / secciones | ✗ (necesita solución alternativa) | Fácil |
| Salto de Sección + Bordes de Página | Página específica | √ | Medio |
| Forma | Página única o múltiples páginas | √ | Fácil |
| Cuadro de Texto | Página única con texto/decoración opcional | √ | Fácil |
| Python (Spire.Doc) | Automatización / procesamiento por lotes | √ | Avanzado |
Conclusión
Agregar bordes de página en Word depende de tus necesidades específicas y del nivel de control que desees sobre tu documento:
- Bordes de Página son ideales para agregar bordes a todo el documento o secciones específicas de manera rápida y consistente.
- Saltos de sección son útiles si deseas aprovechar la función de borde integrada de Word para una sola página mientras mantienes un diseño adecuado.
- Formas o Cuadros de Texto proporcionan una forma rápida y flexible de agregar bordes en cualquier página sin afectar el contenido existente; los Cuadros de Texto son especialmente útiles si deseas incluir texto decorativo o diseños.
- Automatización con Python es perfecta para el procesamiento por lotes de múltiples documentos, asegurando bordes consistentes en todos los archivos.
Al elegir el método correcto, puedes superar las limitaciones de Word, ahorrar tiempo y crear documentos de aspecto profesional que coincidan con tu visión de diseño.
Preguntas Frecuentes
¿Por qué no puedo agregar un borde solo a una página en Word?
Porque la función de borde de Word se basa en secciones, no en páginas. No hay una opción integrada de “solo esta página”.
¿Cuál es la forma más fácil de agregar un borde a una sola página?
Usar una forma (rectángulo) es el método más rápido y sencillo.
¿Qué método es mejor para documentos profesionales?
Para consistencia, usa Bordes de Página con secciones o automatización con Python.
¿Los cuadros de texto afectan el diseño del documento?
El Cuadro de Texto no interrumpirá el contenido existente si su disposición se establece en Detrás del Texto.
Ver También
Seitenränder in Word hinzufügen (beliebige Seite): 4 einfache Möglichkeiten
Inhaltsverzeichnis
Seitenränder in Microsoft Word hinzuzufügen, ist eine einfache Möglichkeit, das Erscheinungsbild von Dokumenten zu verbessern, egal ob Sie Berichte, Zertifikate oder stilisierte Dokumente erstellen. Die integrierten Randoptionen von Word sind jedoch hauptsächlich für gesamte Dokumente oder Abschnitte konzipiert, was die Flexibilität in bestimmten Layout-Szenarien einschränken kann.
In diesem Leitfaden lernen Sie 4 einfache und praktische Methoden kennen, um Seitenränder in Word hinzuzufügen – für das gesamte Dokument, bestimmte Abschnitte und sogar für eine einzelne Seite mithilfe zuverlässiger Umgehungen.
Schnelle Navigation:
- Methode 1: Verwendung der Seitenrandfunktion in Word
- Methode 2: Verwendung einer Form als Rand
- Methode 3: Verwendung eines Textfelds als Rand
- Methode 4: Verwendung von Python, um Ränder automatisch hinzuzufügen
Methode 1: Verwendung der Seitenrandfunktion in Word
Die integrierte Seitenrandfunktion ist der einfachste Weg, um Ränder in Word hinzuzufügen. Sie funktioniert am besten, wenn Sie Ränder auf das gesamte Dokument oder einen Abschnitt anwenden möchten. Sie hat jedoch Einschränkungen, wenn es darum geht, eine bestimmte Seite anzusprechen.
So fügen Sie Ränder zum gesamten Dokument oder einem Abschnitt hinzu
- Öffnen Sie Ihr Word-Dokument.
- Gehen Sie zu Design → Seitenränder .
- Im Dialogfeld Ränder und Schattierungen:
- Wählen Sie einen Randstil (Box, Schatten, 3-D, Benutzerdefiniert).
- Stellen Sie Farbe und Breite ein.
- Unter Anwenden auf wählen Sie:
- Gesamtes Dokument oder
- Diesen Abschnitt
- Klicken Sie auf OK .
Verständnis der Einschränkung
Die Seitenrandfunktion von Word bietet nur diese Optionen:
- Gesamtes Dokument
- Diesen Abschnitt
- Diesen Abschnitt – Nur erste Seite
- Diesen Abschnitt – Alle außer der ersten Seite
Es gibt keine direkte Option „Nur diese Seite“.
Umgehung: Rand auf einer bestimmten Seite anwenden
Um mit dieser Methode einen Rand zu einer einzelnen Seite hinzuzufügen:
- Setzen Sie den Cursor am Anfang der Zielseite.
- Gehen Sie zu Layout → Umbrüche → Nächste Seite (fügen Sie einen Abschnittswechsel ein).
- Setzen Sie den Cursor am Ende dieser Seite und fügen Sie einen weiteren Nächste Seite Abschnittswechsel ein.
- Gehen Sie nun zu Design → Seitenränder .
- Wählen Sie Anwenden auf: Dieser Abschnitt – Nur erste Seite .
- Klicken Sie auf OK .
Das funktioniert, weil die Seite die erste Seite eines neuen Abschnitts wird.
Methode 2: Verwendung einer Form als Rand
Wenn Sie einen Rand zu einer bestimmten Seite hinzufügen müssen, ohne mit Abschnitten umzugehen, ist die Verwendung einer Form eine der einfachsten und flexibelsten Methoden. Sie ermöglicht volle Kontrolle über das Erscheinungsbild und funktioniert unabhängig von den Randbeschränkungen von Word.
Schritte
- Gehen Sie zu Einfügen → Formen → Rechteck .
- Zeichnen Sie das Rechteck so, dass es innerhalb der Seitenränder passt.
- Klicken Sie mit der rechten Maustaste auf die Form → Form formatieren :
- Setzen Sie Füllung → Keine Füllung
- Gestalten Sie Linie (Farbe, Breite, Stil)
- Setzen Sie das Layout der Form auf Hinter Text .
Warum diese Methode verwenden?
- Funktioniert auf jeder Seite
- Keine Abschnittswechsel erforderlich
- Sehr anpassbar
Methode 3: Verwendung eines Textfelds als Rand
Wenn Sie einen Rand zu einer bestimmten Seite mit zusätzlicher Flexibilität hinzufügen möchten – z. B. dekorativen Text oder Designs – ist ein Textfeld eine großartige Wahl. Es funktioniert unabhängig von den Randbeschränkungen von Word und erfordert keine Erstellung von Abschnitten.
Schritte
- Gehen Sie zu Einfügen → Textfeld → Textfeld zeichnen .
- Setzen Sie das Layout des Textfelds auf Hinter Text, um zu verhindern, dass vorhandene Inhalte verschoben werden.
- Löschen Sie den Platzhaltertext im Textfeld.
- Passen Sie die Position und Größe des Textfelds an, damit es die Seitenränder nach Wunsch abdeckt.
- Klicken Sie mit der rechten Maustaste → Form formatieren :
- Setzen Sie Füllung auf Keine Füllung
- Gestalten Sie Linie (Farbe, Breite, Stil)
Warum diese Methode verwenden?
- Funktioniert auf jeder Seite, keine Abschnittswechsel erforderlich
- Stört vorhandene Inhalte nicht, wenn das Layout zuerst festgelegt wird
- Kann dekorativen Text oder Designs innerhalb des Randes enthalten
- Stabil und flexibel für einseitige Ränder
Tip: Wenn Sie nur einen einfachen Rand ohne Text benötigen, funktioniert eine Form ebenso gut und ist etwas leichter.
Methode 4: Verwendung von Python, um Ränder automatisch hinzuzufügen
Wenn Sie Seitenränder auf mehrere Word-Dokumente anwenden oder den Prozess automatisieren müssen, ist die Verwendung von Python die effizienteste Lösung. Bibliotheken wie Spire.Doc für Python ermöglichen es Ihnen, programmatisch Seitenränder mit Präzision hinzuzufügen und anzupassen.
Erforderliche Bibliothek installieren
pip install spire.doc
Codebeispiel: Ränder in Word mit Python hinzufügen
from spire.doc import *
from spire.doc.common import *
# Dokument laden
doc = Document()
doc.LoadFromFile(r"C:\Users\Administrator\Desktop\Input-en.docx")
# Ränder auf alle Abschnitte anwenden
for i in range(len(doc.Sections)):
section = doc.Sections[i]
setup = section.PageSetup
borders = setup.Borders
setup.PageBordersApplyType = PageBordersApplyType.AllPages
borders.BorderType(BorderStyle.DotDotDash)
borders.LineWidth(1)
borders.Color(Color.get_Blue())
# Abstände für alle Seiten festlegen
for side in [borders.Top, borders.Bottom, borders.Left, borders.Right]:
side.Space = 20.0
# Ergebnis speichern
doc.SaveToFile("AddWordPageBorders.docx", FileFormat.Docx)
doc.Dispose()
Ausgabe:
Warum diese Methode verwenden?
- Ideal für die Batchverarbeitung
- Stellt konsistente Formatierung sicher
- Perfekt für Automatisierungs-Workflows
Dieser Ansatz ist besonders nützlich für die Erstellung von Dokumenten wie Berichten, Rechnungen oder Zertifikaten in großem Maßstab.
Zusätzlich zum Hinzufügen von Rändern können Sie Spire.Doc auch verwenden, um Seitenränder anzupassen für präzise Layoutkontrolle; Sie können Hintergrundfarben oder Wasserzeichen auf Word-Seiten anwenden, um das visuelle Design Ihrer Dokumente zu verbessern.
Schnellvergleichstabelle
| Methode | Am besten geeignet für | Kann jede Seite ansprechen | Schwierigkeit |
|---|---|---|---|
| Seitenränder | Gesamtes Dokument / Abschnitte | ✗ (benötigt Umgehung) | Einfach |
| Abschnittswechsel + Seitenränder | Bestimmte Seite | √ | Mittel |
| Form | Einzelne Seite oder mehrere Seiten | √ | Einfach |
| Textfeld | Einzelne Seite mit optionalem Text/Dekor | √ | Einfach |
| Python (Spire.Doc) | Automatisierung / Batchverarbeitung | √ | Fortgeschritten |
Fazit
Das Hinzufügen von Seitenrändern in Word hängt von Ihren spezifischen Bedürfnissen und dem Grad der Kontrolle ab, den Sie über Ihr Dokument wünschen:
- Seitenränder sind ideal, um schnell und konsistent Ränder zum gesamten Dokument oder bestimmten Abschnitten hinzuzufügen.
- Abschnittswechsel sind nützlich, wenn Sie die integrierte Randfunktion von Word für eine einzelne Seite nutzen möchten, während Sie das richtige Layout beibehalten.
- Formen oder Textfelder bieten eine schnelle, flexible Möglichkeit, Ränder auf jeder Seite hinzuzufügen, ohne vorhandene Inhalte zu beeinträchtigen; Textfelder sind besonders praktisch, wenn Sie dekorativen Text oder Designs einfügen möchten.
- Python-Automatisierung ist perfekt für die Batchverarbeitung mehrerer Dokumente und sorgt für konsistente Ränder in allen Dateien.
Durch die Wahl der richtigen Methode können Sie die Einschränkungen von Word überwinden, Zeit sparen und professionell aussehende Dokumente erstellen, die Ihrer Designvision entsprechen.
Häufig gestellte Fragen
Warum kann ich in Word keinen Rand nur für eine Seite hinzufügen?
Weil die Randfunktion von Word abschnittsbasiert und nicht seitenbasiert ist. Es gibt keine integrierte Option „nur diese Seite“.
Was ist der einfachste Weg, um einen Rand zu einer einzelnen Seite hinzuzufügen?
Die Verwendung einer Form (Rechteck) ist die schnellste und einfachste Methode.
Welche Methode ist am besten für professionelle Dokumente?
Für Konsistenz verwenden Sie Seitenränder mit Abschnitten oder Python-Automatisierung.
Beeinflussen Textfelder das Layout des Dokuments?
Textfelder stören vorhandene Inhalte nicht, wenn ihr Layout auf Hinter Text gesetzt ist.
Siehe auch
Добавление границ страницы в Word (на любую страницу): 4 простых способа
Содержание
Добавление границ страниц в Microsoft Word — это простой способ улучшить внешний вид документа, будь то отчеты, сертификаты или стилизованные документы. Однако встроенные параметры границ Word в основном предназначены для целых документов или разделов, что может ограничивать гибкость в определенных сценариях макета.
В этом руководстве вы узнаете 4 простых и практических метода добавления границ страниц в Word — охватывающих весь документ, конкретные разделы и даже любую отдельную страницу с помощью надежных обходных путей.
Быстрая навигация:
- Метод 1: Использование функции границ страницы в Word
- Метод 2: Использование фигуры в качестве границы
- Метод 3: Использование текстового поля в качестве границы
- Метод 4: Использование Python для автоматического добавления границ
Метод 1: Использование функции границ страницы в Word
Встроенная функция границ страницы — это самый простой способ добавить границы в Word. Она лучше всего работает, когда вы хотите применить границы ко всему документу или разделу. Однако она имеет ограничения при нацеливании на конкретную страницу.
Как добавить границы ко всему документу или разделу
- Откройте ваш документ Word.
- Перейдите в Дизайн → Границы страницы .
- В диалоговом окне Границы и заливка:
- Выберите стиль границы (Коробка, Тень, 3-D, Пользовательский).
- Установите цвет и ширину.
- В разделе Применить к выберите:
- Весь документ, или
- Этот раздел
- Нажмите ОК .
Понимание ограничения
Функция границ страницы Word предоставляет только эти варианты:
- Весь документ
- Этот раздел
- Этот раздел – только первая страница
- Этот раздел – все, кроме первой страницы
Существует нет прямого варианта «Только эта страница».
Обходной путь: Применить границу к конкретной странице
Чтобы добавить границу на одну страницу с помощью этого метода:
- Поместите курсор в начале целевой страницы.
- Перейдите в Макет → Разрывы → Следующая страница (вставьте разрыв раздела).
- Поместите курсор в конце этой страницы и вставьте еще один Следующая страница разрыв раздела.
- Теперь перейдите в Дизайн → Границы страницы .
- Выберите Применить к: Этот раздел – только первая страница .
- Нажмите ОК .
Это работает, потому что страница становится первой страницей нового раздела.
Метод 2: Использование фигуры в качестве границы
Если вам нужно добавить границу к конкретной странице, не имея дело с разделами, использование фигуры — один из самых простых и гибких методов. Это позволяет полностью контролировать внешний вид и работает независимо от ограничений границ Word.
Шаги
- Перейдите в Вставка → Фигуры → Прямоугольник .
- Нарисуйте прямоугольник, чтобы он вписывался в поля страницы.
- Щелкните правой кнопкой мыши на фигуре → Формат фигуры :
- Установите Заливка → Нет заливки
- Настройте Линию (цвет, ширина, стиль)
- Установите макет фигуры на Позади текста .
Почему стоит использовать этот метод?
- Работает на любой странице
- Нет необходимости в разрывах разделов
- Высокая настраиваемость
Метод 3: Использование текстового поля в качестве границы
Если вы хотите добавить границу к конкретной странице с дополнительной гибкостью — например, включая декоративный текст или дизайны — Текстовое поле — отличный выбор. Оно работает независимо от ограничений границ Word и не требует создания разделов.
Шаги
- Перейдите в Вставка → Текстовое поле → Нарисовать текстовое поле .
- Установите макет текстового поля на Позади текста, чтобы предотвратить перемещение существующего содержимого.
- Удалите текст-заполнитель внутри текстового поля.
- Отрегулируйте положение и размер текстового поля, чтобы оно покрывало края страницы по желанию.
- Щелкните правой кнопкой мыши → Формат фигуры :
- Установите Заливка на Нет заливки
- Настройте Линию (цвет, ширина, стиль)
Почему стоит использовать этот метод?
- Работает на любой странице, не нужны разрывы разделов
- Не нарушает существующее содержимое, если макет установлен первым
- Можно включать декоративный текст или дизайны внутри границы
- Стабильный и гибкий для границ на одной странице
Совет: Если вам нужна только простая граница без текста, Фигура также подойдет и немного легче.
Метод 4: Использование Python для автоматического добавления границ
Если вам нужно применить границы страниц к нескольким документам Word или автоматизировать процесс, использование Python — наиболее эффективное решение. Библиотеки, такие как Spire.Doc для Python, позволяют программно добавлять и настраивать границы страниц с точностью.
Установите необходимую библиотеку
pip install spire.doc
Пример кода: Добавление границ в Word на Python
from spire.doc import *
from spire.doc.common import *
# Загрузить документ
doc = Document()
doc.LoadFromFile(r"C:\Users\Administrator\Desktop\Input-en.docx")
# Применить границы ко всем разделам
for i in range(len(doc.Sections)):
section = doc.Sections[i]
setup = section.PageSetup
borders = setup.Borders
setup.PageBordersApplyType = PageBordersApplyType.AllPages
borders.BorderType(BorderStyle.DotDotDash)
borders.LineWidth(1)
borders.Color(Color.get_Blue())
# Установить отступ для всех сторон
for side in [borders.Top, borders.Bottom, borders.Left, borders.Right]:
side.Space = 20.0
# Сохранить результат
doc.SaveToFile("AddWordPageBorders.docx", FileFormat.Docx)
doc.Dispose()
Результат:
Почему стоит использовать этот метод?
- Идеально для пакетной обработки
- Обеспечивает согласованное форматирование
- Отлично подходит для автоматизации рабочих процессов
Этот подход особенно полезен для генерации документов, таких как отчеты, счета или сертификаты в большом количестве.
В дополнение к добавлению границ, вы также можете использовать Spire.Doc для регулировки полей страницы для точного контроля макета; вы можете применять фоновый цвет или водяные знаки к страницам Word, улучшая визуальный дизайн ваших документов.
Быстрая сравнительная таблица
| Метод | Лучше всего для | Можно нацелиться на любую страницу | Сложность |
|---|---|---|---|
| Границы страницы | Весь документ / разделы | ✗ (нужен обходной путь) | Простой |
| Разрыв раздела + Границы страницы | Конкретная страница | √ | Средний |
| Фигура | Одна страница или несколько страниц | √ | Простой |
| Текстовое поле | Одна страница с необязательным текстом/декором | √ | Простой |
| Python (Spire.Doc) | Автоматизация / пакетная обработка | √ | Продвинутый |
Заключение
Добавление границ страниц в Word зависит от ваших конкретных потребностей и уровня контроля, который вы хотите иметь над вашим документом:
- Границы страниц идеально подходят для быстрого и последовательного добавления границ ко всему документу или конкретным разделам.
- Разрывы разделов полезны, если вы хотите использовать встроенную функцию границ Word для одной страницы, сохраняя правильный макет.
- Фигуры или текстовые поля предоставляют быстрый, гибкий способ добавления границ на любой странице, не влияя на существующее содержимое; текстовые поля особенно удобны, если вы хотите включить декоративный текст или дизайны.
- Автоматизация на Python идеально подходит для пакетной обработки нескольких документов, обеспечивая согласованные границы во всех файлах.
Выбирая правильный метод, вы можете преодолеть ограничения Word, сэкономить время и создать профессионально выглядящие документы, которые соответствуют вашему дизайнерскому видению.
Часто задаваемые вопросы
Почему я не могу добавить границу только на одну страницу в Word?
Потому что функция границ Word основана на разделах, а не на страницах. Нет встроенного варианта «только эта страница».
Какой самый простой способ добавить границу к одной странице?
Использование фигуры (прямоугольника) — самый быстрый и простой метод.
Какой метод лучше всего подходит для профессиональных документов?
Для согласованности используйте границы страниц с разделами или автоматизацию на Python.
Влияют ли текстовые поля на макет документа?
Текстовое поле не нарушит существующее содержимое, если его макет установлен на «Позади текста».
Смотрите также
Como adicionar assinatura digital no Excel (visível e invisível)
Índice
- O que é uma assinatura digital no Excel?
- Pré-requisito: Obtenha um Certificado Digital
- Exemplo 1: Adicionar uma Assinatura Digital Invisível no Excel
- Exemplo 2: Inserir uma Linha de Assinatura Visível no Excel
- Bônus: Adicionar Programaticamente uma Assinatura Digital Usando C#
- Perguntas Frequentes Sobre a Adição de Assinaturas Digitais no Excel

Garantir a autenticidade e a integridade das pastas de trabalho do Excel é essencial nas operações comerciais modernas. Quer o documento seja uma fatura, um relatório financeiro ou um contrato, inserir uma assinatura digital no Excel confirma que o arquivo é genuíno, não foi alterado e provém de uma fonte confiável.
Este artigo irá guiá-lo sobre como adicionar uma assinatura digital no Excel, incluindo os pré-requisitos para obter um certificado digital, adicionar assinaturas visíveis ou invisíveis e uma abordagem programática em C# para desenvolvedores automatizarem a assinatura em lote. Ao final, você será capaz de assinar digitalmente pastas de trabalho do Excel com confiança para uso legal, financeiro ou interno.
- O que é uma assinatura digital no Excel?
- Pré-requisito: Obtenha um Certificado Digital
- Exemplo 1: Adicionar uma Assinatura Digital Invisível no Excel
- Exemplo 2: Inserir uma Linha de Assinatura Visível no Excel
- Bônus: Adicionar Programaticamente uma Assinatura Digital Usando C#
- Perguntas Frequentes Sobre a Adição de Assinaturas Digitais no Excel
O que é uma Assinatura Digital no Excel? (Visível vs. Invisível)
No Microsoft Excel, existem dois tipos principais de assinaturas disponíveis:
1. Linha de Assinatura (Assinatura Visível)
Isso cria uma linha visível onde um signatário pode digitar seu nome, desenhar uma assinatura usando uma caneta ou mouse, ou carregar uma imagem de sua assinatura física. É frequentemente usado para contratos, formulários de aprovação e acordos legalmente vinculativos onde uma assinatura visível é necessária.
2. Assinatura Digital (Invisível/Backend)
Isso adiciona um "selo" criptográfico ao arquivo. A assinatura não aparece dentro das células, mas é exibida na barra de assinatura. Ela certifica a integridade de toda a pasta de trabalho e impede edições não autorizadas.
⚠️ Esclarecimento Importante: Digitar um nome em uma célula ou colar uma imagem não constitui uma assinatura digital. Uma verdadeira assinatura digital requer um certificado digital emitido por uma Autoridade de Certificação (AC) ou um certificado autoassinado para fins de teste.
Pré-requisito: Obtenha um Certificado Digital
Antes de adicionar uma assinatura digital ao Excel, você primeiro precisa de um certificado digital—uma identidade eletrônica que verifica sua identidade. Pense nele como um “passaporte digital” para sua assinatura. Abaixo estão as três maneiras de obter um,
1. Certificado Autoassinado Gratuito (Para Uso Pessoal/Teste)
O Microsoft Office inclui uma ferramenta chamada SelfCert.exe que permite criar um certificado autoassinado gratuito. Isso é ótimo para uso pessoal, testes ou documentos internos da equipe, mas não será confiável por terceiros, pois não é verificado por uma AC de terceiros.
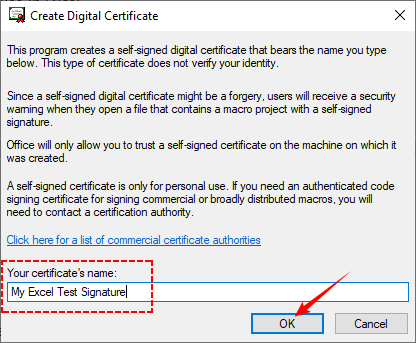
Como criar seu próprio certificado digital:
- Abra o Explorador de Arquivos e navegue para: “C:\Program Files (x86)\Microsoft Office\root\Office16\” (ou "C:\Program Files\Microsoft Office\root\Office16")
- Dê um duplo clique em SELF CERT.EXE, e uma janela “Criar Certificado Digital” aparecerá.
- Nomeie seu certificado (por exemplo, “Minha Assinatura de Teste do Excel”) e clique em "OK".
- Você verá uma mensagem de sucesso indicando que o certificado está agora instalado e pronto para uso no Excel.
2. Certificado de Terceiros (Para Uso Comercial/Externo)
Para documentos compartilhados com clientes, parceiros ou reguladores, use um certificado de uma Autoridade de Certificação (AC) confiável (por exemplo, DigiCert, GlobalSign). Esses certificados são verificados por terceiros, portanto, são universalmente confiáveis. A maioria das ACs cobra uma taxa (anual ou única), mas algumas oferecem opções gratuitas para uso pessoal.
3. Certificado Organizacional (Para Usuários Corporativos)
Se você trabalha para uma grande empresa, seu departamento de TI pode emitir um certificado digital como parte dos protocolos de segurança de sua organização. Isso é ideal para documentos internos e conformidade com as políticas da empresa.
Onde obter? Entre em contato com o suporte de TI—eles fornecerão um arquivo .pfx ou instalarão o certificado diretamente no seu repositório de certificados do Windows.
Exemplo 1: Adicionar uma Assinatura Digital Invisível no Excel
Se você está enviando um arquivo que contém macros, fórmulas ou dados sensíveis que você não quer que sejam alterados após o envio, você deve usar uma assinatura digital invisível.
Passo 1: Abra sua Pasta de Trabalho e Acesse o Painel de Informações
Inicie o Microsoft Excel e abra a pasta de trabalho que você deseja assinar.
Passo 2: Localize a Opção “Adicionar uma Assinatura Digital”
- Clique em “Arquivo” no canto superior esquerdo e selecione “Informações”.
- No painel “Informações”, clique na seta suspensa “Proteger Pasta de Trabalho”.
- No menu suspenso, selecione “Adicionar uma Assinatura Digital”.
- Leia o aviso pop-up e clique em “OK”.
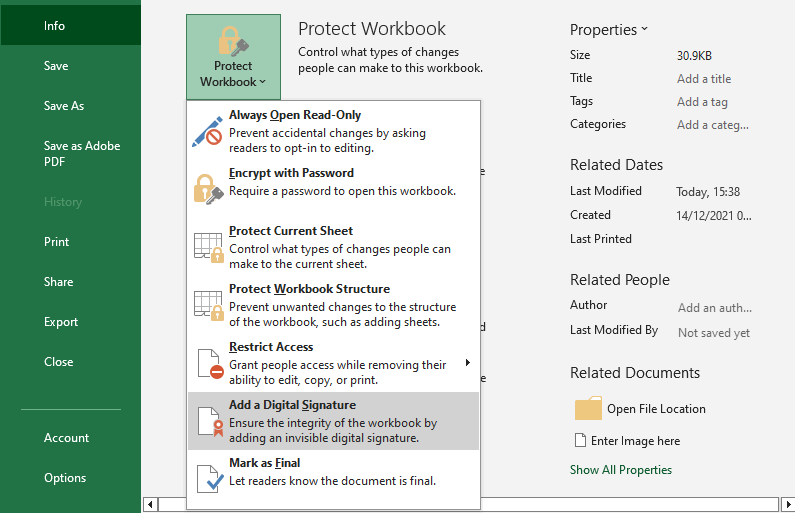
Passo 3: Escolha seu Certificado Digital e Assine
A “Assinar” janela será aberta. Aqui você configura os detalhes da assinatura.
- Selecione um “Tipo de Compromisso”.
- Digite um propósito para a assinatura (por exemplo, “Aprovando Relatório Financeiro do 3º Trimestre”).
- Clique em “Alterar” se desejar selecionar outro certificado.
- Clique no “Assinar” botão. O Excel salvará a pasta de trabalho e aplicará a assinatura digital.
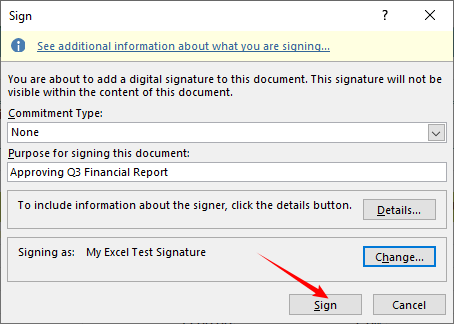
Passo 4: Confirme e Verifique a Assinatura
- Uma mensagem de confirmação aparecerá. Clique em “OK”.
- Para verificar, clique no botão “Assinatura” na parte inferior da janela do Excel, e uma barra lateral será aberta à direita, exibindo a assinatura aplicada.
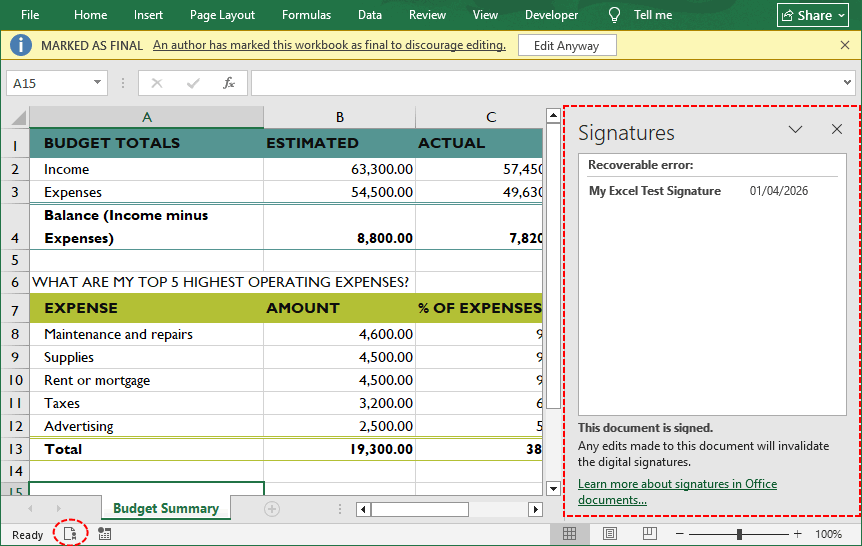
Dica Profissional: Antes de aplicar uma assinatura digital, você pode bloquear certas células do Excel (por exemplo, fórmulas ou totais) para que os signatários não possam editá-las. Isso garante tanto a integridade quanto o controle de edição granular.
Exemplo 2: Inserir uma Linha de Assinatura Visível no Excel
Esta é a maneira mais comum de criar um campo de assinatura dedicado onde um usuário pode assinar formalmente o documento, semelhante a um contrato em papel.
Passo 1: Abra sua Pasta de Trabalho
Abra o arquivo Excel onde você precisa da assinatura.
Passo 2: Inserir a Linha de Assinatura
- Selecione uma célula onde você deseja que a assinatura apareça.
- Navegue até a “Inserir” guia na faixa de opções.
- No “Texto” grupo, clique na “Linha de Assinatura” seta suspensa (parece um documento com um lápis).
- Selecione “Linha de Assinatura do Microsoft Office”.
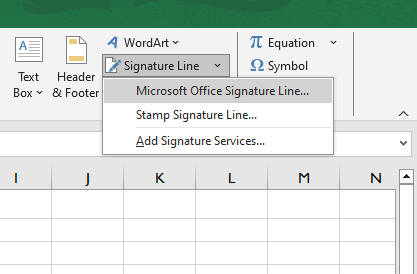
Passo 3: Configurar a Configuração da Assinatura
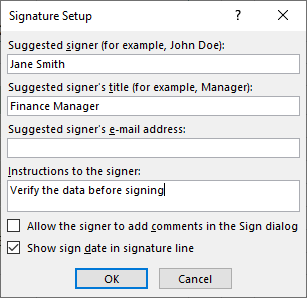
Uma caixa de diálogo intitulada "Configuração da Assinatura" aparecerá. Aqui, você pode preencher:
- Signatário sugerido: Nome completo da pessoa que assina (por exemplo, “Jane Smith”).
- Cargo do signatário sugerido: Cargo (por exemplo, “Gerente Financeiro”).
- E-mail do signatário sugerido: Endereço de e-mail de contato (opcional).
- Instruções para o signatário: Adicione quaisquer notas especiais (por exemplo, “Verifique os dados antes de assinar”).
Você também pode marcar as caixas para permitir que o signatário adicione comentários ou para mostrar a data da assinatura. Clique em “OK”.
Passo 4: Assine o Documento
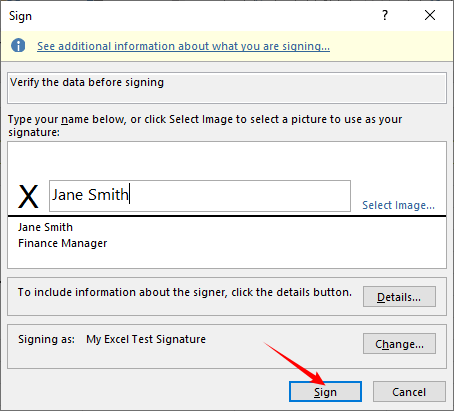
Uma vez que a linha é inserida, clique duas vezes na linha de assinatura.
- Para assinar: Digite seu nome, clique em "Selecionar Imagem" para carregar uma assinatura digitalizada, ou escreva-a usando uma tela de toque.
- Para finalizar: Clique em “Assinar” para aplicar a assinatura digital.
A linha de assinatura (parece uma linha horizontal com um “X”) agora mostrará sua assinatura, e a pasta de trabalho será bloqueada para edições. Uma faixa amarela pode aparecer indicando que o documento foi marcado como final.
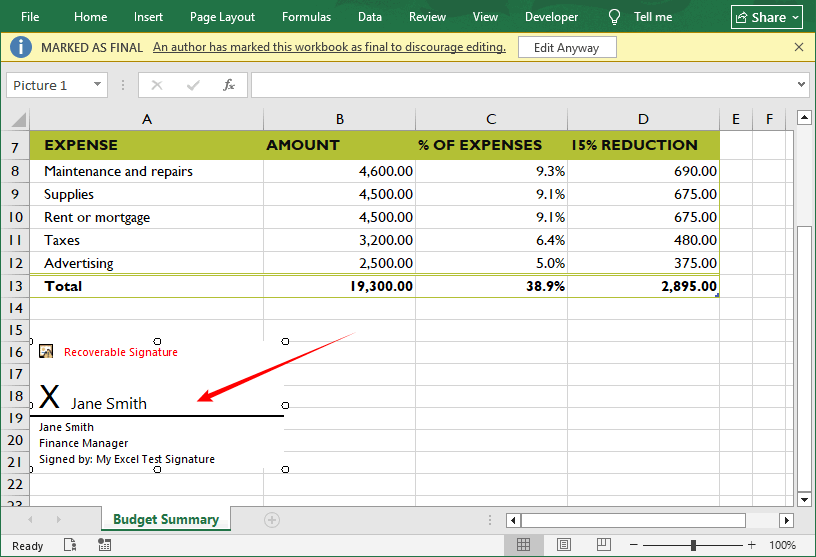
Para uma estratégia de segurança completa, a adição de uma assinatura digital deve ser combinada com outras medidas de proteção, como criptografar a pasta de trabalho com uma senha, para garantir que apenas usuários autorizados possam visualizar ou modificar os dados.
Bônus: Adicionar Programaticamente uma Assinatura Digital Usando C#
Se você é um desenvolvedor que procura automatizar o processo de assinatura, pode usar a Spire.XLS for .NET biblioteca. Esta biblioteca permite que você programaticamente adicione ou exclua assinaturas digitais do Excel em C# sem a necessidade de ter o Microsoft Office instalado no servidor.
Passo 1: Instale o Spire.XLS
Abra o Visual Studio, vá para “Ferramentas > Gerenciador de Pacotes NuGet > Console do Gerenciador de Pacotes”, e execute:
Install-Package Spire.XLS
Ou você pode procurar por "Spire.XLS" na interface do usuário do Gerenciador de Pacotes NuGet e instalar.
Passo 2: Prepare um Certificado PFX
Use um certificado PFX válido (.pfx arquivo) que contenha as chaves pública e privada. Você pode:
- Obter um de uma Autoridade de Certificação (AC).
- Exportar um certificado autoassinado para teste usando o PowerShell.
Certifique-se de que o .pfx arquivo esteja acessível a partir do sistema de arquivos da sua aplicação.
Passo 3: Código C# para Adicionar uma Assinatura Digital no Excel
Abaixo está um exemplo completo em C# que carrega um arquivo Excel existente, aplica uma assinatura digital invisível e salva a pasta de trabalho assinada.
using Spire.Xls;
using System;
namespace AddSignatureInExcel
{
class Program
{
static void Main(string[] args)
{
// Create a Workbook instance
Workbook workbook = new Workbook();
// Load an existing Excel file
workbook.LoadFromFile("Input.xlsx");
// Define the path to the certificate file and its password
string certificatePath = @"C:\Users\Administrator\Desktop\My Excel Test Signature.pfx";
string certificatePassword = "123abc";
// (Optional) Set a signing time
DateTime signingTime = new DateTime(2026, 4, 1, 7, 10, 36);
// Add a digital signature to the workbook
workbook.AddDigitalSignature(certificatePath, certificatePassword, "Test Signature", signingTime);
// Save the signed file
workbook.SaveToFile("AddDigitalSignature.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
Neste código, o AddDigitalSignature método aplica a assinatura digital usando o arquivo PFX. Os parâmetros são:
- certificatePath: Caminho para o seu .pfx arquivo.
- certificatePassword: Senha para a chave privada.
- comments: Uma string que aparece nos detalhes da assinatura (por exemplo, “Assinatura de Teste”).
- signTime: Um DateTime que representa o tempo da assinatura (este não é um carimbo de data/hora criptográfico, mas pode ser usado para fins de exibição).
A assinatura digital adicionada: 
✅ Casos de Uso: Assinatura em lote, automação do lado do servidor, integração de fluxo de trabalho empresarial.
Conclusão
Adicionar uma assinatura digital no Excel é essencial para proteger dados sensíveis—quer você use os passos manuais para arquivos únicos ou o método C# Spire.XLS para assinatura em lote automatizada. Ambas as abordagens criam assinaturas digitais seguras e legalmente vinculativas que protegem suas pastas de trabalho contra adulteração e verificam a autenticidade.
Sempre use certificados digitais confiáveis para compartilhamento externo, faça backup de suas credenciais e verifique as assinaturas antes de compartilhar ou aceitar arquivos do Excel. Seguindo os procedimentos descritos neste guia, os usuários podem proteger suas pastas de trabalho do Excel contra alterações não autorizadas e verificar a autenticidade dos signatários com confiança.
Perguntas Frequentes Sobre a Adição de Assinaturas Digitais no Excel
Q1. Como insiro uma assinatura eletrônica no Excel?
Você tem duas opções principais: (a) Linha de assinatura visível – vá para Inserir > Linha de Assinatura, ou (b) Assinatura digital invisível – vá para Arquivo > Informações > Proteger Pasta de Trabalho > Adicionar uma Assinatura Digital. Escolha com base na necessidade de uma assinatura visível ou integridade de backend.
Q2. Posso adicionar uma assinatura digital ao Excel gratuitamente?
Sim. Use a ferramenta integrada SelfCert.exe para criar um certificado autoassinado gratuito. No entanto, este certificado só é confiável no seu próprio computador. Para compartilhamento externo, você pode precisar de um certificado de AC pago.
Q3: Como removo uma assinatura digital do Excel?
Vá para “Arquivo > Informações > Exibir Assinaturas”, clique com o botão direito na assinatura e selecione “Remover Assinatura”.
Q4: Posso adicionar uma assinatura ao Excel sem um certificado?
Você pode adicionar uma assinatura de imagem visual, mas não é uma assinatura digital segura e verificável.
Veja Também
- 5 Métodos Fáceis para Congelar Linhas e Colunas no Excel
- Reduzir o Tamanho do Arquivo do Excel: 6 Maneiras Comprovadas de Diminuir Planilhas
- Como Inserir Fórmulas no Excel: Seis Métodos Fáceis
- Java: Adicionar ou Excluir Assinaturas Digitais no Excel
- Python: Detectar e Remover Assinaturas Digitais em Arquivos Excel
Excel에서 디지털 서명을 추가하는 방법 (표시 및 숨기기)
Excel 통합 문서의 신뢰성과 무결성을 보장하는 것은 현대 비즈니스 운영에서 필수적입니다. 문서가 송장, 재무 보고서 또는 계약서이든, Excel에 디지털 서명을 삽입하면 파일이 진짜이고 변경되지 않았으며 신뢰할 수 있는 출처에서 왔음을 확인합니다.
이 기사에서는 디지털 인증서 획득을 위한 전제 조건, 보이는 서명 또는 보이지 않는 서명 추가, 개발자가 일괄 서명을 자동화하기 위한 C# 프로그래밍 방식 접근법을 포함하여 Excel에 디지털 서명을 추가하는 방법을 안내합니다. 이 글을 마치면 법적, 재정적 또는 내부용으로 Excel 통합 문서에 자신 있게 디지털 서명을 할 수 있게 될 것입니다.
- Excel의 디지털 서명이란 무엇인가요?
- 전제 조건: 디지털 인증서 받기
- 예제 1: Excel에 보이지 않는 디지털 서명 추가
- 예제 2: Excel에 보이는 서명란 삽입
- 보너스: C#을 사용하여 프로그래밍 방식으로 디지털 서명 추가
- Excel에서 디지털 서명 추가에 대한 FAQ
Excel의 디지털 서명이란 무엇인가요? (보이는 서명 vs. 보이지 않는 서명)
Microsoft Excel에서는 두 가지 기본 유형의 서명을 사용할 수 있습니다.
1. 서명란 (보이는 서명)
이는 서명자가 자신의 이름을 입력하거나, 스타일러스나 마우스를 사용하여 서명을 그리거나, 실제 서명 이미지를 업로드할 수 있는 보이는 줄을 만듭니다. 계약서, 승인 양식 및 보이는 서명이 필요한 법적 구속력이 있는 계약에 자주 사용됩니다.
2. 디지털 서명 (보이지 않는/백엔드)
이는 파일에 암호화된 "봉인"을 추가합니다. 서명은 셀 내부에 나타나지 않지만 서명 표시줄에 표시됩니다. 전체 통합 문서의 무결성을 인증하고 무단 편집을 방지합니다.
⚠️ 중요 설명: 셀에 이름을 입력하거나 이미지를 붙여넣는 것은 디지털 서명에 해당하지 않습니다. 진정한 디지털 서명은 인증 기관(CA)에서 발급한 디지털 인증서 또는 테스트 목적으로 자체 서명된 인증서가 필요합니다.
전제 조건: 디지털 인증서 받기
Excel에 디지털 서명을 추가하기 전에 먼저 신원을 확인하는 전자 ID인 디지털 인증서가 필요합니다. 서명을 위한 "디지털 여권"이라고 생각하면 됩니다. 아래는 인증서를 얻는 세 가지 방법입니다.
1. 무료 자체 서명 인증서 (개인/테스트용)
Microsoft Office에는 SelfCert.exe라는 도구가 포함되어 있어 무료 자체 서명 인증서를 만들 수 있습니다. 이는 개인적인 사용, 테스트 또는 내부 팀 문서에 적합하지만, 제3자 CA에 의해 검증되지 않았기 때문에 외부에서는 신뢰받지 못합니다.
자신만의 디지털 인증서를 만드는 방법:
- 파일 탐색기를 열고 “C:\Program Files (x86)\Microsoft Office\root\Office16\” (또는 "C:\Program Files\Microsoft Office\root\Office16")으로 이동합니다.
- SELF CERT.EXE를 두 번 클릭하면 "디지털 인증서 만들기" 창이 나타납니다.
- 인증서 이름을 지정하고(예: "내 Excel 테스트 서명") "확인"을 클릭합니다.
- 인증서가 이제 설치되어 Excel에서 사용할 준비가 되었음을 나타내는 성공 메시지가 표시됩니다.
2. 제3자 인증서 (비즈니스/외부용)
고객, 파트너 또는 규제 기관과 공유하는 문서의 경우 신뢰할 수 있는 인증 기관(CA)(예: DigiCert, GlobalSign)의 인증서를 사용하십시오. 이러한 인증서는 제3자에 의해 검증되므로 보편적으로 신뢰됩니다. 대부분의 CA는 수수료(연간 또는 일회성)를 부과하지만 일부는 개인용으로 무료 옵션을 제공합니다.
3. 조직 인증서 (엔터프라이즈 사용자용)
대기업에서 근무하는 경우 IT 부서에서 조직의 보안 프로토콜의 일부로 디지털 인증서를 발급할 수 있습니다. 이는 내부 문서 및 회사 정책 준수에 이상적입니다.
어디서 받을 수 있나요? IT 헬프 데스크에 문의하십시오. 그들은 .pfx 파일을 제공하거나 Windows 인증서 저장소에 직접 인증서를 설치해 줄 것입니다.
예제 1: Excel에 보이지 않는 디지털 서명 추가
매크로, 수식 또는 전송 후 변경되기를 원하지 않는 민감한 데이터가 포함된 파일을 보내는 경우 보이지 않는 디지털 서명을 사용해야 합니다.
1단계: 통합 문서 열고 정보 패널에 액세스하기
Microsoft Excel을 실행하고 서명하려는 통합 문서를 엽니다.
2단계: "디지털 서명 추가" 옵션 찾기
- 왼쪽 상단의 "파일"을 클릭하고 "정보"를 선택합니다.
- "정보" 패널에서 "통합 문서 보호" 드롭다운 화살표를 클릭합니다.
- 드롭다운 메뉴에서 "디지털 서명 추가"를 선택합니다.
- 팝업 프롬프트를 읽고 "확인"을 클릭합니다.
3단계: 디지털 인증서 선택 및 서명
"서명" 창이 열립니다. 여기서 서명 세부 정보를 구성합니다.
- "약정 유형"을 선택합니다.
- 서명 목적을 입력합니다(예: "3분기 재무 보고서 승인").
- 다른 인증서를 선택하려면 "변경"을 클릭합니다.
- "서명" 버튼을 클릭합니다. Excel이 통합 문서를 저장하고 디지털 서명을 적용합니다.
4단계: 서명 확인 및 검증
- 확인 메시지가 나타납니다. "확인"을 클릭합니다.
- 확인하려면 Excel 창 하단의 "서명" 버튼을 클릭하면 오른쪽에 사이드바가 열리면서 적용된 서명이 표시됩니다.
프로 팁: 디지털 서명을 적용하기 전에 특정 Excel 셀을 잠글 수 있습니다(예: 수식 또는 합계). 이렇게 하면 서명자가 편집할 수 없도록 하여 무결성과 세분화된 편집 제어를 모두 보장합니다.
예제 2: Excel에 보이는 서명란 삽입
이는 사용자가 종이 계약서와 유사하게 문서에 공식적으로 서명할 수 있는 전용 서명 필드를 만드는 가장 일반적인 방법입니다.
1단계: 통합 문서 열기
서명이 필요한 Excel 파일을 엽니다.
2단계: 서명란 삽입
- 서명이 나타날 셀을 선택합니다.
- 리본의 "삽입" 탭으로 이동합니다.
- "텍스트" 그룹에서 "서명란" 드롭다운 화살표(연필이 있는 문서 모양)를 클릭합니다.
- "Microsoft Office 서명란"을 선택합니다.
3단계: 서명 설정 구성
"서명 설정"이라는 제목의 대화 상자가 나타납니다. 여기서 다음을 채울 수 있습니다.
- 제안된 서명자: 서명하는 사람의 전체 이름(예: "홍길동").
- 제안된 서명자의 직위: 직책(예: "재무 관리자").
- 제안된 서명자의 이메일: 연락처 이메일 주소(선택 사항).
- 서명자에 대한 지침: 특별한 메모 추가(예: "서명하기 전에 데이터를 확인하십시오").
서명자가 설명을 추가하거나 서명 날짜를 표시하도록 허용하는 확인란을 선택할 수도 있습니다. "확인"을 클릭합니다.
4단계: 문서 서명
줄이 삽입되면 서명란을 두 번 클릭합니다.
- 서명하려면: 이름을 입력하거나, "이미지 선택"을 클릭하여 스캔한 서명을 업로드하거나, 터치 스크린을 사용하여 작성합니다.
- 마무리하려면: "서명"을 클릭하여 디지털 서명을 적용합니다.
서명란("X"가 있는 수평선 모양)에 이제 서명이 표시되고 통합 문서는 편집이 잠깁니다. 문서가 최종본으로 표시되었음을 나타내는 노란색 리본이 나타날 수 있습니다.
완전한 보안 전략을 위해 디지털 서명 추가는 암호로 통합 문서 암호화와 같은 다른 보호 조치와 함께 사용하여 승인된 사용자만 데이터를 보거나 수정할 수 있도록 해야 합니다.
보너스: C#을 사용하여 프로그래밍 방식으로 디지털 서명 추가
서명 프로세스를 자동화하려는 개발자라면 Spire.XLS for .NET 라이브러리를 사용할 수 있습니다. 이 라이브러리를 사용하면 서버에 Microsoft Office를 설치할 필요 없이 C#에서 프로그래밍 방식으로 Excel 디지털 서명을 추가하거나 삭제할 수 있습니다.
1단계: Spire.XLS 설치
Visual Studio를 열고 "도구 > NuGet 패키지 관리자 > 패키지 관리자 콘솔"로 이동하여 다음을 실행합니다.
Install-Package Spire.XLS
또는 NuGet 패키지 관리자 UI에서 "Spire.XLS"를 검색하여 설치할 수 있습니다.
2단계: PFX 인증서 준비
공개 키와 개인 키를 모두 포함하는 유효한 PFX 인증서(.pfx 파일)를 사용합니다. 다음을 수행할 수 있습니다.
- 인증 기관(CA)에서 하나를 얻습니다.
- PowerShell을 사용하여 테스트용 자체 서명 인증서 내보내기.
애플리케이션의 파일 시스템에서 .pfx 파일에 액세스할 수 있는지 확인하십시오.
3단계: Excel에 디지털 서명을 추가하는 C# 코드
아래는 기존 Excel 파일을 로드하고, 보이지 않는 디지털 서명을 적용하고, 서명된 통합 문서를 저장하는 완전한 C# 예제입니다.
using Spire.Xls;
using System;
namespace AddSignatureInExcel
{
class Program
{
static void Main(string[] args)
{
// Workbook 인스턴스 생성
Workbook workbook = new Workbook();
// 기존 Excel 파일 로드
workbook.LoadFromFile("Input.xlsx");
// 인증서 파일 경로 및 암호 정의
string certificatePath = @"C:\Users\Administrator\Desktop\My Excel Test Signature.pfx";
string certificatePassword = "123abc";
// (선택 사항) 서명 시간 설정
DateTime signingTime = new DateTime(2026, 4, 1, 7, 10, 36);
// 통합 문서에 디지털 서명 추가
workbook.AddDigitalSignature(certificatePath, certificatePassword, "Test Signature", signingTime);
// 서명된 파일 저장
workbook.SaveToFile("AddDigitalSignature.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
이 코드에서 AddDigitalSignature 메서드는 PFX 파일을 사용하여 디지털 서명을 적용합니다. 매개변수는 다음과 같습니다.
- certificatePath: .pfx 파일 경로.
- certificatePassword: 개인 키의 암호.
- comments: 서명 세부 정보에 나타나는 문자열(예: "테스트 서명").
- signTime: 서명 시간을 나타내는 DateTime(이는 암호화 타임스탬프는 아니지만 표시 목적으로 사용할 수 있음).
추가된 디지털 서명:
✅ 사용 사례: 일괄 서명, 서버 측 자동화, 엔터프라이즈 워크플로 통합.
마무리
Excel에 디지털 서명을 추가하는 것은 민감한 데이터를 보호하는 데 필수적입니다. 일회성 파일에 대한 수동 단계를 사용하든, 자동화된 일괄 서명을 위해 C# Spire.XLS 메서드를 사용하든 상관없습니다. 두 접근 방식 모두 통합 문서를 변조로부터 보호하고 신뢰성을 확인하는 안전하고 법적 구속력이 있는 디지털 서명을 만듭니다.
외부 공유를 위해 항상 신뢰할 수 있는 디지털 인증서를 사용하고, 자격 증명을 백업하고, Excel 파일을 공유하거나 수락하기 전에 서명을 확인하십시오. 이 가이드에 설명된 절차를 따르면 사용자는 무단 변경으로부터 Excel 통합 문서를 보호하고 서명자의 신뢰성을 자신 있게 확인할 수 있습니다.
Excel에서 디지털 서명 추가에 대한 FAQ
Q1. Excel에 전자 서명을 어떻게 삽입하나요?
두 가지 주요 옵션이 있습니다: (a) 보이는 서명란 – 삽입 > 서명란으로 이동하거나, (b) 보이지 않는 디지털 서명 – 파일 > 정보 > 통합 문서 보호 > 디지털 서명 추가로 이동합니다. 보이는 서명이 필요한지 또는 백엔드 무결성이 필요한지에 따라 선택하십시오.
Q2. Excel에 무료로 디지털 서명을 추가할 수 있나요?
예. 내장된 SelfCert.exe 도구를 사용하여 무료 자체 서명 인증서를 만들 수 있습니다. 그러나 이 인증서는 자신의 컴퓨터에서만 신뢰됩니다. 외부 공유를 위해서는 유료 CA 인증서가 필요할 수 있습니다.
Q3: Excel에서 디지털 서명을 어떻게 제거하나요?
"파일 > 정보 > 서명 보기"로 이동하여 서명을 마우스 오른쪽 버튼으로 클릭하고 "서명 제거"를 선택합니다.
Q4: 인증서 없이 Excel에 서명을 추가할 수 있나요?
시각적 이미지 서명을 추가할 수는 있지만, 안전하고 검증 가능한 디지털 서명은 아닙니다.
참고 항목
Come aggiungere una firma digitale in Excel (visibile e invisibile)
Indice
- Cos'è una firma digitale in Excel?
- Prerequisito: ottenere un certificato digitale
- Esempio 1: Aggiungere una firma digitale invisibile in Excel
- Esempio 2: Inserire una riga della firma visibile in Excel
- Bonus: Aggiungere programmaticamente una firma digitale utilizzando C#
- Domande frequenti sull'aggiunta di firme digitali in Excel
Garantire l'autenticità e l'integrità delle cartelle di lavoro di Excel è essenziale nelle moderne operazioni aziendali. Che il documento sia una fattura, un report finanziario o un contratto, l'inserimento della firma digitale in Excel conferma che il file è autentico, non è stato alterato e proviene da una fonte attendibile.
Questo articolo ti guiderà attraverso come aggiungere una firma digitale in Excel, inclusi i prerequisiti per ottenere un certificato digitale, l'aggiunta di firme visibili o invisibili e un approccio programmatico in C# per gli sviluppatori per automatizzare la firma in batch. Alla fine, sarai in grado di firmare digitalmente con sicurezza le cartelle di lavoro di Excel per uso legale, finanziario o interno.
- Cos'è una firma digitale in Excel?
- Prerequisito: ottenere un certificato digitale
- Esempio 1: Aggiungere una firma digitale invisibile in Excel
- Esempio 2: Inserire una riga della firma visibile in Excel
- Bonus: Aggiungere programmaticamente una firma digitale utilizzando C#
- Domande frequenti sull'aggiunta di firme digitali in Excel
Cos'è una firma digitale in Excel? (Visibile vs. Invisibile)
In Microsoft Excel, sono disponibili due tipi principali di firme:
1. Riga della firma (firma visibile)
Questo crea una riga visibile in cui un firmatario può digitare il proprio nome, disegnare una firma utilizzando uno stilo o un mouse o caricare un'immagine della propria firma fisica. Viene spesso utilizzato per contratti, moduli di approvazione e accordi legalmente vincolanti in cui è richiesta un'approvazione visibile.
2. Firma digitale (invisibile/backend)
Questo aggiunge un "sigillo" crittografico al file. La firma non appare all'interno delle celle ma viene visualizzata nella barra della firma. Certifica l'integrità dell'intera cartella di lavoro e impedisce modifiche non autorizzate.
⚠️ Chiarimento importante: digitare un nome in una cella o incollare un'immagine non costituisce una firma digitale. Una vera firma digitale richiede un certificato digitale rilasciato da un'autorità di certificazione (CA) o un certificato autofirmato a scopo di test.
Prerequisito: ottenere un certificato digitale
Prima di aggiungere una firma digitale a Excel, è necessario innanzitutto un certificato digitale, un ID elettronico che verifica la tua identità. Pensalo come un "passaporto digitale" per la tua firma. Di seguito sono riportati i tre modi per ottenerne uno,
1. Certificato autofirmato gratuito (per uso personale/di prova)
Microsoft Office include uno strumento chiamato SelfCert.exe che ti consente di creare un certificato autofirmato gratuito. Questo è ottimo per uso personale, test o documenti interni del team, ma non sarà considerato attendibile da parti esterne poiché non è verificato da una CA di terze parti.
Come creare il proprio certificato digitale:
- Apri Esplora file e vai a: “C:\Program Files (x86)\Microsoft Office\root\Office16\” (o "C:\Program Files\Microsoft Office\root\Office16")
- Fai doppio clic su SELF CERT.EXE e apparirà una finestra “Crea certificato digitale”.
- Assegna un nome al tuo certificato (ad es. “La mia firma di prova di Excel”) e fai clic su "OK".
- Vedrai un messaggio di successo che indica che il certificato è ora installato e pronto per l'uso in Excel.
2. Certificato di terze parti (per uso aziendale/esterno)
Per i documenti condivisi con clienti, partner o autorità di regolamentazione, utilizzare un certificato di un'autorità di certificazione (CA) attendibile (ad es. DigiCert, GlobalSign). Questi certificati sono verificati da una terza parte, quindi sono universalmente attendibili. La maggior parte delle CA addebita una tariffa (annuale o una tantum), ma alcune offrono opzioni gratuite per uso personale.
3. Certificato organizzativo (per utenti aziendali)
Se lavori per una grande azienda, il tuo reparto IT potrebbe rilasciare un certificato digitale come parte dei protocolli di sicurezza della tua organizzazione. Questo è l'ideale per i documenti interni e la conformità con le politiche aziendali.
Dove ottenerlo? Contatta il tuo help desk IT: ti forniranno un file .pfx o installeranno il certificato direttamente nell'archivio certificati di Windows.
Esempio 1: Aggiungere una firma digitale invisibile in Excel
Se stai inviando un file che contiene macro, formule o dati sensibili che non vuoi che vengano alterati dopo l'invio, dovresti usare una firma digitale invisibile.
Passaggio 1: apri la cartella di lavoro e accedi al pannello Informazioni
Avvia Microsoft Excel e apri la cartella di lavoro che desideri firmare.
Passaggio 2: individuare l'opzione "Aggiungi una firma digitale"
- Fai clic su “File” nell'angolo in alto a sinistra e seleziona “Informazioni”.
- Nel pannello “Informazioni”, fai clic sulla freccia a discesa “Proteggi cartella di lavoro”.
- Dal menu a discesa, seleziona “Aggiungi una firma digitale”.
- Leggi la richiesta pop-up e fai clic su “OK”.
Passaggio 3: scegli il tuo certificato digitale e firma
Si aprirà la finestra “Firma”. Qui puoi configurare i dettagli della firma.
- Seleziona un “Tipo di impegno”.
- Digita uno scopo per la firma (ad es. “Approvazione del report finanziario del terzo trimestre”).
- Fai clic su “Cambia” se desideri selezionare un altro certificato.
- Fai clic sul pulsante “Firma”. Excel salverà la cartella di lavoro e applicherà la firma digitale.
Passaggio 4: conferma e verifica la firma
- Apparirà un messaggio di conferma. Fai clic su “OK”.
- Per verificare, fai clic sul pulsante “Firma” nella parte inferiore della finestra di Excel e si aprirà una barra laterale a destra, che mostra la firma applicata.
Suggerimento pro: Prima di applicare una firma digitale, puoi bloccare determinate celle di Excel (ad es. formule o totali) in modo che i firmatari non possano modificarle. Ciò garantisce sia l'integrità che il controllo granulare delle modifiche.
Esempio 2: Inserire una riga della firma visibile in Excel
Questo è il modo più comune per creare un campo firma dedicato in cui un utente può firmare formalmente il documento, in modo simile a un contratto cartaceo.
Passaggio 1: apri la cartella di lavoro
Apri il file Excel in cui hai bisogno della firma.
Passaggio 2: inserire la riga della firma
- Seleziona una cella in cui desideri che appaia la firma.
- Vai alla scheda “Inserisci” sulla barra multifunzione.
- Nel gruppo “Testo”, fai clic sulla freccia a discesa “Riga della firma” (sembra un documento con una matita).
- Seleziona “Riga della firma di Microsoft Office”.
Passaggio 3: configurare l'impostazione della firma
Apparirà una finestra di dialogo intitolata "Impostazione firma". Qui puoi compilare:
- Firmatario suggerito: nome completo della persona che firma (ad es. “Jane Smith”).
- Titolo del firmatario suggerito: titolo professionale (ad es. “Responsabile finanziario”).
- Email del firmatario suggerito: indirizzo email di contatto (opzionale).
- Istruzioni per il firmatario: aggiungi eventuali note speciali (ad es. “Verificare i dati prima di firmare”).
Puoi anche selezionare le caselle per consentire al firmatario di aggiungere commenti o per mostrare la data della firma. Fai clic su “OK”.
Passaggio 4: firma il documento
Una volta inserita la riga, fai doppio clic sulla riga della firma.
- Per firmare: digita il tuo nome, fai clic su "Seleziona immagine" per caricare una firma scansionata o scrivila utilizzando un touch screen.
- Per finalizzare: fai clic su “Firma” per applicare la firma digitale.
La riga della firma (sembra una linea orizzontale con una “X”) ora mostrerà la tua firma e la cartella di lavoro sarà bloccata dalle modifiche. Potrebbe apparire un nastro giallo che indica che il documento è stato contrassegnato come finale.
Per una strategia di sicurezza completa, l'aggiunta di una firma digitale dovrebbe essere abbinata ad altre misure di protezione, come la crittografia della cartella di lavoro con una password, per garantire che solo gli utenti autorizzati possano visualizzare o modificare i dati.
Bonus: Aggiungere programmaticamente una firma digitale utilizzando C#
Se sei uno sviluppatore che cerca di automatizzare il processo di firma, puoi utilizzare la libreria Spire.XLS per .NET. Questa libreria ti consente di aggiungere o eliminare programmaticamente le firme digitali di Excel in C# senza la necessità di installare Microsoft Office sul server.
Passaggio 1: installa Spire.XLS
Apri Visual Studio, vai su “Strumenti > Gestione pacchetti NuGet > Console di Gestione pacchetti”, ed esegui:
Install-Package Spire.XLS
Oppure puoi cercare "Spire.XLS" nell'interfaccia utente di Gestione pacchetti NuGet e installarlo.
Passaggio 2: prepara un certificato PFX
Utilizza un certificato PFX valido (.pfx) che contenga sia la chiave pubblica che quella privata. Puoi:
- Ottenerne uno da un'autorità di certificazione (CA).
- Esporta un certificato autofirmato per i test utilizzando PowerShell.
Assicurati che il file .pfx sia accessibile dal file system della tua applicazione.
Passaggio 3: codice C# per aggiungere una firma digitale in Excel
Di seguito è riportato un esempio C# completo che carica un file Excel esistente, applica una firma digitale invisibile e salva la cartella di lavoro firmata.
using Spire.Xls;
using System;
namespace AddSignatureInExcel
{
class Program
{
static void Main(string[] args)
{
// Create a Workbook instance
Workbook workbook = new Workbook();
// Load an existing Excel file
workbook.LoadFromFile("Input.xlsx");
// Define the path to the certificate file and its password
string certificatePath = @"C:\Users\Administrator\Desktop\My Excel Test Signature.pfx";
string certificatePassword = "123abc";
// (Optional) Set a signing time
DateTime signingTime = new DateTime(2026, 4, 1, 7, 10, 36);
// Add a digital signature to the workbook
workbook.AddDigitalSignature(certificatePath, certificatePassword, "Test Signature", signingTime);
// Save the signed file
workbook.SaveToFile("AddDigitalSignature.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
In questo codice, il metodo AddDigitalSignature applica la firma digitale utilizzando il file PFX. I parametri sono:
- certificatePath: percorso del file .pfx.
- certificatePassword: password per la chiave privata.
- comments: una stringa che appare nei dettagli della firma (ad es. “Firma di prova”).
- signTime: un DateTime che rappresenta l'ora della firma (questo non è un timestamp crittografico ma può essere utilizzato a scopo di visualizzazione).
La firma digitale aggiunta:
✅ Casi d'uso: Firma in batch, automazione lato server, integrazione del flusso di lavoro aziendale.
In conclusione
L'aggiunta di una firma digitale in Excel è essenziale per proteggere i dati sensibili, sia che si utilizzino i passaggi manuali per i file singoli sia che si utilizzi il metodo C# Spire.XLS per la firma in batch automatizzata. Entrambi gli approcci creano firme digitali sicure e legalmente vincolanti che proteggono le cartelle di lavoro da manomissioni e ne verificano l'autenticità.
Utilizzare sempre certificati digitali attendibili per la condivisione esterna, eseguire il backup delle credenziali e verificare le firme prima di condividere o accettare file di Excel. Seguendo le procedure descritte in questa guida, gli utenti possono proteggere le proprie cartelle di lavoro di Excel da modifiche non autorizzate e verificare con sicurezza l'autenticità dei firmatari.
Domande frequenti sull'aggiunta di firme digitali in Excel
Q1. Come si inserisce una firma elettronica in Excel?
Hai due opzioni principali: (a) Riga della firma visibile – vai su Inserisci > Riga della firma, oppure (b) Firma digitale invisibile – vai su File > Informazioni > Proteggi cartella di lavoro > Aggiungi una firma digitale. Scegli in base alla necessità di un'approvazione visibile o dell'integrità del backend.
Q2. Posso aggiungere una firma digitale a Excel gratuitamente?
Sì. Utilizza lo strumento SelfCert.exe integrato per creare un certificato autofirmato gratuito. Tuttavia, questo certificato è considerato attendibile solo sul tuo computer. Per la condivisione esterna, potrebbe essere necessario un certificato CA a pagamento.
Q3: Come si rimuove una firma digitale da Excel?
Vai su “File > Informazioni > Visualizza firme”, fai clic con il pulsante destro del mouse sulla firma e seleziona “Rimuovi firma”.
Q4: Posso aggiungere una firma a Excel senza un certificato?
Puoi aggiungere una firma immagine visiva, ma non è una firma digitale sicura e verificabile.
Vedi anche
- 5 semplici metodi per bloccare righe e colonne in Excel
- Riduci le dimensioni dei file di Excel: 6 modi comprovati per ridurre i fogli di calcolo
- Come inserire formule in Excel: sei semplici metodi
- Java: aggiungi o elimina firme digitali in Excel
- Python: rileva e rimuovi le firme digitali nei file di Excel
Comment ajouter une signature numérique dans Excel (visible et invisible)
Table des matières
- Qu'est-ce qu'une signature numérique dans Excel ?
- Prérequis : Obtenir un certificat numérique
- Exemple 1 : Ajouter une signature numérique invisible dans Excel
- Exemple 2 : Insérer une ligne de signature visible dans Excel
- Bonus : Ajouter une signature numérique par programmation en C#
- FAQ sur l'ajout de signatures numériques dans Excel
Garantir l'authenticité et l'intégrité des classeurs Excel est essentiel dans les opérations commerciales modernes. Que le document soit une facture, un rapport financier ou un contrat, l'insertion d'une signature numérique dans Excel confirme que le fichier est authentique, n'a pas été modifié et provient d'une source fiable.
Cet article vous expliquera comment ajouter une signature numérique dans Excel, y compris les prérequis pour obtenir un certificat numérique, l'ajout de signatures visibles ou invisibles, et une approche programmatique en C# pour les développeurs afin d'automatiser la signature par lots. À la fin, vous serez en mesure de signer numériquement en toute confiance des classeurs Excel à des fins juridiques, financières ou internes.
- Qu'est-ce qu'une signature numérique dans Excel ?
- Prérequis : Obtenir un certificat numérique
- Exemple 1 : Ajouter une signature numérique invisible dans Excel
- Exemple 2 : Insérer une ligne de signature visible dans Excel
- Bonus : Ajouter une signature numérique par programmation en C#
- FAQ sur l'ajout de signatures numériques dans Excel
Qu'est-ce qu'une signature numérique dans Excel ? (Visible ou invisible)
Dans Microsoft Excel, il existe deux principaux types de signatures disponibles :
1. Ligne de signature (Signature visible)
Cela crée une ligne visible où un signataire peut taper son nom, dessiner une signature à l'aide d'un stylet ou d'une souris, ou télécharger une image de sa signature physique. Elle est souvent utilisée pour les contrats, les formulaires d'approbation et les accords juridiquement contraignants où une signature visible est requise.
2. Signature numérique (Invisible/Backend)
Cela ajoute un « sceau » cryptographique au fichier. La signature n'apparaît pas dans les cellules mais est affichée dans la barre de signature. Elle certifie l'intégrité de l'ensemble du classeur et empêche les modifications non autorisées.
⚠️ Clarification importante : Taper un nom dans une cellule ou coller une image ne constitue pas une signature numérique. Une véritable signature numérique nécessite un certificat numérique délivré par une autorité de certification (AC) ou un certificat auto-signé à des fins de test.
Prérequis : Obtenir un certificat numérique
Avant de pouvoir ajouter une signature numérique à Excel, vous avez d'abord besoin d'un certificat numérique, une pièce d'identité électronique qui vérifie votre identité. Considérez-le comme un « passeport numérique » pour votre signature. Voici les trois façons d'en obtenir un,
1. Certificat auto-signé gratuit (pour un usage personnel/de test)
Microsoft Office inclut un outil appelé SelfCert.exe qui vous permet de créer un certificat auto-signé gratuit. C'est idéal pour un usage personnel, des tests ou des documents d'équipe internes, mais il ne sera pas approuvé par des tiers car il n'est pas vérifié par une autorité de certification tierce.
Comment créer votre propre certificat numérique :
- Ouvrez l'Explorateur de fichiers et accédez à : « C:\Program Files (x86)\Microsoft Office\root\Office16\ » (ou « C:\Program Files\Microsoft Office\root\Office16 »)
- Double-cliquez sur SELF CERT.EXE, et une fenêtre « Créer un certificat numérique » apparaîtra.
- Nommez votre certificat (par exemple, « Ma signature de test Excel ») et cliquez sur « OK ».
- Vous verrez un message de réussite indiquant que le certificat est maintenant installé et prêt à être utilisé dans Excel.
2. Certificat tiers (pour un usage professionnel/externe)
Pour les documents partagés avec des clients, des partenaires ou des régulateurs, utilisez un certificat d'une autorité de certification (AC) de confiance (par exemple, DigiCert, GlobalSign). Ces certificats sont vérifiés par un tiers, ils sont donc universellement reconnus. La plupart des AC facturent des frais (annuels ou uniques), mais certaines offrent des options gratuites pour un usage personnel.
3. Certificat d'organisation (pour les utilisateurs d'entreprise)
Si vous travaillez pour une grande entreprise, votre service informatique peut émettre un certificat numérique dans le cadre des protocoles de sécurité de votre organisation. C'est idéal pour les documents internes et la conformité avec les politiques de l'entreprise.
Où l'obtenir ? Contactez votre service d'assistance informatique — ils vous fourniront un fichier .pfx ou installeront le certificat directement dans votre magasin de certificats Windows.
Exemple 1 : Ajouter une signature numérique invisible dans Excel
Si vous envoyez un fichier contenant des macros, des formules ou des données sensibles que vous ne souhaitez pas voir modifiées après l'envoi, vous devez utiliser une signature numérique invisible.
Étape 1 : Ouvrez votre classeur et accédez au panneau d'informations
Lancez Microsoft Excel et ouvrez le classeur que vous souhaitez signer.
Étape 2 : Localisez l'option « Ajouter une signature numérique »
- Cliquez sur « Fichier » dans le coin supérieur gauche et sélectionnez « Informations ».
- Dans le panneau « Informations », cliquez sur la flèche déroulante « Protéger le classeur ».
- Dans le menu déroulant, sélectionnez « Ajouter une signature numérique ».
- Lisez l'invite contextuelle et cliquez sur « OK ».
Étape 3 : Choisissez votre certificat numérique et signez
La fenêtre « Signer » s'ouvrira. Ici, vous configurez les détails de la signature.
- Sélectionnez un « Type d'engagement ».
- Saisissez un motif pour la signature (par exemple, « Approbation du rapport financier du T3 »).
- Cliquez sur « Modifier » si vous souhaitez sélectionner un autre certificat.
- Cliquez sur le bouton « Signer ». Excel enregistrera le classeur et appliquera la signature numérique.
Étape 4 : Confirmez et vérifiez la signature
- Un message de confirmation apparaîtra. Cliquez sur « OK ».
- Pour vérifier, cliquez sur le bouton « Signature » en bas de la fenêtre Excel, et une barre latérale s'ouvrira à droite, affichant la signature appliquée.
Conseil de pro: Avant d'appliquer une signature numérique, vous pouvez verrouiller certaines cellules Excel (par exemple, les formules ou les totaux) afin que les signataires ne puissent pas les modifier. Cela garantit à la fois l'intégrité et un contrôle granulaire des modifications.
Exemple 2 : Insérer une ligne de signature visible dans Excel
C'est la manière la plus courante de créer un champ de signature dédié où un utilisateur peut signer formellement le document, à la manière d'un contrat papier.
Étape 1 : Ouvrez votre classeur
Ouvrez le fichier Excel où vous avez besoin de la signature.
Étape 2 : Insérez la ligne de signature
- Sélectionnez une cellule où vous souhaitez que la signature apparaisse.
- Accédez à l'onglet « Insertion » du ruban.
- Dans le groupe « Texte », cliquez sur la flèche déroulante « Ligne de signature » (ressemble à un document avec un crayon).
- Sélectionnez « Ligne de signature Microsoft Office ».
Étape 3 : Configurez la configuration de la signature
Une boîte de dialogue intitulée « Configuration de la signature » apparaîtra. Ici, vous pouvez remplir :
- Signataire suggéré : Nom complet de la personne qui signe (par exemple, « Jane Smith »).
- Titre du signataire suggéré : Titre du poste (par exemple, « Directeur financier »).
- E-mail du signataire suggéré : Adresse e-mail de contact (facultatif).
- Instructions au signataire : Ajoutez des notes spéciales (par exemple, « Vérifiez les données avant de signer »).
Vous pouvez également cocher les cases pour autoriser le signataire à ajouter des commentaires ou pour afficher la date de signature. Cliquez sur « OK ».
Étape 4 : Signez le document
Une fois la ligne insérée, double-cliquez sur la ligne de signature.
- Pour signer : Tapez votre nom, cliquez sur « Sélectionner une image » pour télécharger une signature numérisée, ou écrivez-la à l'aide d'un écran tactile.
- Pour finaliser : Cliquez sur « Signer » pour appliquer la signature numérique.
La ligne de signature (ressemble à une ligne horizontale avec un « X ») affichera maintenant votre signature, et le classeur sera verrouillé contre les modifications. Un ruban jaune peut apparaître indiquant que le document a été marqué comme final.
Pour une stratégie de sécurité complète, l'ajout d'une signature numérique doit être associé à d'autres mesures de protection, telles que le chiffrement du classeur avec un mot de passe, pour garantir que seuls les utilisateurs autorisés peuvent afficher ou modifier les données.
Bonus : Ajouter une signature numérique par programmation en C#
Si vous êtes un développeur cherchant à automatiser le processus de signature, vous pouvez utiliser la bibliothèque Spire.XLS for .NET. Cette bibliothèque vous permet d' ajouter ou de supprimer par programmation des signatures numériques Excel en C# sans avoir besoin que Microsoft Office soit installé sur le serveur.
Étape 1 : Installez Spire.XLS
Ouvrez Visual Studio, allez dans « Outils > Gestionnaire de packages NuGet > Console du gestionnaire de packages », et exécutez :
Install-Package Spire.XLS
Ou vous pouvez rechercher « Spire.XLS » dans l'interface utilisateur du gestionnaire de packages NuGet et l'installer.
Étape 2 : Préparez un certificat PFX
Utilisez un certificat PFX valide (.pfx file) qui contient à la fois les clés publique et privée. Vous pouvez :
- En obtenir un auprès d'une autorité de certification (AC).
- Exporter un certificat auto-signé pour les tests à l'aide de PowerShell.
Assurez-vous que le fichier .pfx est accessible depuis le système de fichiers de votre application.
Étape 3 : Code C# pour ajouter une signature numérique dans Excel
Vous trouverez ci-dessous un exemple C# complet qui charge un fichier Excel existant, applique une signature numérique invisible et enregistre le classeur signé.
using Spire.Xls;
using System;
namespace AddSignatureInExcel
{
class Program
{
static void Main(string[] args)
{
// Create a Workbook instance
Workbook workbook = new Workbook();
// Load an existing Excel file
workbook.LoadFromFile("Input.xlsx");
// Define the path to the certificate file and its password
string certificatePath = @"C:\Users\Administrator\Desktop\My Excel Test Signature.pfx";
string certificatePassword = "123abc";
// (Facultatif) Définir une heure de signature
DateTime signingTime = new DateTime(2026, 4, 1, 7, 10, 36);
// Add a digital signature to the workbook
workbook.AddDigitalSignature(certificatePath, certificatePassword, "Test Signature", signingTime);
// Save the signed file
workbook.SaveToFile("AddDigitalSignature.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
Dans ce code, la méthode AddDigitalSignature applique la signature numérique à l'aide du fichier PFX. Les paramètres sont :
- certificatePath : Chemin d'accès à votre fichier .pfx.
- certificatePassword : Mot de passe de la clé privée.
- comments : Une chaîne qui apparaît dans les détails de la signature (par exemple, « Signature de test »).
- signTime : Un DateTime représentant l'heure de la signature (ce n'est pas un horodatage cryptographique mais peut être utilisé à des fins d'affichage).
La signature numérique ajoutée :
✅ Cas d'utilisation: Signature par lots, automatisation côté serveur, intégration de flux de travail d'entreprise.
Conclusion
L'ajout d'une signature numérique dans Excel est essentiel pour sécuriser les données sensibles, que vous utilisiez les étapes manuelles pour des fichiers uniques ou la méthode C# Spire.XLS pour la signature par lots automatisée. Les deux approches créent des signatures numériques sécurisées et juridiquement contraignantes qui protègent vos classeurs contre la falsification et vérifient l'authenticité.
Utilisez toujours des certificats numériques de confiance pour le partage externe, sauvegardez vos informations d'identification et vérifiez les signatures avant de partager ou d'accepter des fichiers Excel. En suivant les procédures décrites dans ce guide, les utilisateurs peuvent sécuriser leurs classeurs Excel contre les modifications non autorisées et vérifier l'authenticité des signataires en toute confiance.
FAQ sur l'ajout de signatures numériques dans Excel
Q1. Comment insérer une signature électronique dans Excel ?
Vous avez deux options principales : (a) Ligne de signature visible – allez dans Insertion > Ligne de signature, ou (b) Signature numérique invisible – allez dans Fichier > Informations > Protéger le classeur > Ajouter une signature numérique. Choisissez en fonction de si vous avez besoin d'une signature visible ou d'une intégrité backend.
Q2. Puis-je ajouter une signature numérique à Excel gratuitement ?
Oui. Utilisez l'outil intégré SelfCert.exe pour créer un certificat auto-signé gratuit. Cependant, ce certificat n'est approuvé que sur votre propre ordinateur. Pour le partage externe, vous pourriez avoir besoin d'un certificat d'AC payant.
Q3 : Comment supprimer une signature numérique d'Excel ?
Allez dans « Fichier > Informations > Afficher les signatures », faites un clic droit sur la signature et sélectionnez « Supprimer la signature ».
Q4 : Puis-je ajouter une signature à Excel sans certificat ?
Vous pouvez ajouter une signature d'image visuelle, mais ce n'est pas une signature numérique sécurisée et vérifiable.
Voir aussi
- 5 méthodes faciles pour figer les lignes et les colonnes dans Excel
- Réduire la taille des fichiers Excel : 6 façons éprouvées de réduire les feuilles de calcul
- Comment insérer des formules dans Excel : Six méthodes faciles
- Java : Ajouter ou supprimer des signatures numériques dans Excel
- Python : Détecter et supprimer les signatures numériques dans les fichiers Excel
Cómo agregar una firma digital en Excel (visible e invisible)
Tabla de Contenidos
- ¿Qué es una Firma Digital en Excel?
- Prerrequisito: Obtener un Certificado Digital
- Ejemplo 1: Añadir una Firma Digital Invisible en Excel
- Ejemplo 2: Insertar una Línea de Firma Visible en Excel
- Extra: Añadir Programáticamente una Firma Digital Usando C#
- Preguntas Frecuentes Sobre Añadir Firmas Digitales en Excel
Asegurar la autenticidad e integridad de los libros de trabajo de Excel es esencial en las operaciones comerciales modernas. Ya sea que el documento sea una factura, un informe financiero o un contrato, insertar una firma digital en Excel confirma que el archivo es genuino, no ha sido alterado y proviene de una fuente confiable.
Este artículo lo guiará a través de cómo añadir una firma digital en Excel, incluyendo los prerrequisitos para obtener un certificado digital, añadir firmas visibles o invisibles, y un enfoque programático en C# para que los desarrolladores automaticen la firma por lotes. Al final, podrá firmar digitalmente libros de trabajo de Excel con confianza para uso legal, financiero o interno.
- ¿Qué es una Firma Digital en Excel?
- Prerrequisito: Obtener un Certificado Digital
- Ejemplo 1: Añadir una Firma Digital Invisible en Excel
- Ejemplo 2: Insertar una Línea de Firma Visible en Excel
- Extra: Añadir Programáticamente una Firma Digital Usando C#
- Preguntas Frecuentes Sobre Añadir Firmas Digitales en Excel
¿Qué es una Firma Digital en Excel? (Visible vs. Invisible)
En Microsoft Excel, hay dos tipos principales de firmas disponibles:
1. Línea de Firma (Firma Visible)
Esto crea una línea visible donde un firmante puede escribir su nombre, dibujar una firma usando un lápiz óptico o un ratón, o subir una imagen de su firma física. A menudo se utiliza para contratos, formularios de aprobación y acuerdos legalmente vinculantes donde se requiere una firma visible.
2. Firma Digital (Invisible/Backend)
Esto añade un "sello" criptográfico al archivo. La firma no aparece dentro de las celdas, pero se muestra en la barra de firmas. Certifica la integridad de todo el libro de trabajo y previene ediciones no autorizadas.
⚠️ Aclaración Importante: Escribir un nombre en una celda o pegar una imagen no constituye una firma digital. Una verdadera firma digital requiere un certificado digital emitido por una Autoridad de Certificación (CA) o un certificado autofirmado para fines de prueba.
Prerrequisito: Obtener un Certificado Digital
Antes de añadir una firma digital a Excel, primero necesita un certificado digital, una identificación electrónica que verifica su identidad. Piense en ello como un “pasaporte digital” para su firma. A continuación se presentan las tres formas de obtener uno,
1. Certificado Autofirmado Gratuito (Para Uso Personal/De Prueba)
Microsoft Office incluye una herramienta llamada SelfCert.exe que le permite crear un certificado autofirmado gratuito. Esto es ideal para uso personal, pruebas o documentos internos del equipo, pero no será confiable para terceros ya que no está verificado por una CA de terceros.
Cómo crear su propio certificado digital:
- Abra el Explorador de archivos y navegue a: “C:\Program Files (x86)\Microsoft Office\root\Office16\” (o "C:\Program Files\Microsoft Office\root\Office16")
- Haga doble clic en SELF CERT.EXE y aparecerá una ventana de “Crear Certificado Digital”.
- Nombre su certificado (p. ej., “Mi Firma de Prueba de Excel”) y haga clic en "Aceptar".
- Verá un mensaje de éxito que indica que el certificado ya está instalado y listo para usar en Excel.
2. Certificado de Terceros (Para Uso Comercial/Externo)
Para documentos compartidos con clientes, socios o reguladores, utilice un certificado de una Autoridad de Certificación (CA) de confianza (p. ej., DigiCert, GlobalSign). Estos certificados son verificados por un tercero, por lo que son universalmente confiables. La mayoría de las CA cobran una tarifa (anual o única), pero algunas ofrecen opciones gratuitas para uso personal.
3. Certificado Organizacional (Para Usuarios Empresariales)
Si trabaja para una gran empresa, su departamento de TI puede emitir un certificado digital como parte de los protocolos de seguridad de su organización. Esto es ideal para documentos internos y para el cumplimiento de las políticas de la empresa.
¿Dónde obtenerlo? Póngase en contacto con su servicio de asistencia de TI: le proporcionarán un archivo .pfx o instalarán el certificado directamente en su almacén de certificados de Windows.
Ejemplo 1: Añadir una Firma Digital Invisible en Excel
Si va a enviar un archivo que contiene macros, fórmulas o datos confidenciales que no desea que se modifiquen después de enviarlo, debe utilizar una firma digital invisible.
Paso 1: Abra su Libro de Trabajo y Acceda al Panel de Información
Inicie Microsoft Excel y abra el libro de trabajo que desea firmar.
Paso 2: Localice la Opción “Añadir una Firma Digital”
- Haga clic en “Archivo” en la esquina superior izquierda y seleccione “Información”.
- En el “Info” panel, haga clic en la flecha desplegable “Proteger libro”.
- En el menú desplegable, seleccione “Añadir una Firma Digital”.
- Lea el aviso emergente y haga clic en “Aceptar”.
Paso 3: Elija su Certificado Digital y Firme
Se abrirá la ventana “Firmar”. Aquí puede configurar los detalles de la firma.
- Seleccione un “Tipo de compromiso”.
- Escriba un propósito para la firma (p. ej., “Aprobando el Informe Financiero del 3T”).
- Haga clic en “Cambiar” si desea seleccionar otro certificado.
- Haga clic en el “Firmar” botón. Excel guardará el libro de trabajo y aplicará la firma digital.
Paso 4: Confirme y Verifique la Firma
- Aparecerá un mensaje de confirmación. Haga clic en “Aceptar”.
- Para verificar, haga clic en el botón “Firma” en la parte inferior de la ventana de Excel, y se abrirá una barra lateral a la derecha, mostrando la firma aplicada.
Consejo Profesional: Antes de aplicar una firma digital, puede bloquear ciertas celdas de Excel (p. ej., fórmulas o totales) para que los firmantes no puedan editarlas. Esto garantiza tanto la integridad como un control de edición granular.
Ejemplo 2: Insertar una Línea de Firma Visible en Excel
Esta es la forma más común de crear un campo de firma dedicado donde un usuario puede firmar formalmente el documento, de manera similar a un contrato en papel.
Paso 1: Abra su Libro de Trabajo
Abra el archivo de Excel donde necesita la firma.
Paso 2: Inserte la Línea de Firma
- Seleccione una celda donde desea que aparezca la firma.
- Navegue a la “Insertar” pestaña en la cinta de opciones.
- En el “Texto” grupo, haga clic en la “Línea de firma” flecha desplegable (parece un documento con un lápiz).
- Seleccione “Línea de firma de Microsoft Office”.
Paso 3: Configure la Configuración de la Firma
Aparecerá un cuadro de diálogo titulado "Configuración de firma". Aquí, puede rellenar:
- Firmante sugerido: Nombre completo de la persona que firma (p. ej., “Jane Smith”).
- Cargo del firmante sugerido: Cargo (p. ej., “Gerente de Finanzas”).
- Correo electrónico del firmante sugerido: Dirección de correo electrónico de contacto (opcional).
- Instrucciones para el firmante: Añada cualquier nota especial (p. ej., “Verifique los datos antes de firmar”).
También puede marcar las casillas para permitir que el firmante agregue comentarios o para mostrar la fecha de la firma. Haga clic en “Aceptar”.
Paso 4: Firme el Documento
Una vez insertada la línea, haga doble clic en la línea de firma.
- Para firmar: Escriba su nombre, haga clic en "Seleccionar imagen" para cargar una firma escaneada, o escríbala usando una pantalla táctil.
- Para finalizar: Haga clic en “Firmar” para aplicar la firma digital.
La línea de firma (parece una línea horizontal con una “X”) ahora mostrará su firma, y el libro de trabajo se bloqueará para evitar ediciones. Puede aparecer una cinta amarilla que indica que el documento ha sido marcado como final.
Para una estrategia de seguridad completa, añadir una firma digital debe combinarse con otras medidas de protección, como cifrar el libro de trabajo con una contraseña, para garantizar que solo los usuarios autorizados puedan ver o modificar los datos.
Extra: Añadir Programáticamente una Firma Digital Usando C#
Si es un desarrollador que busca automatizar el proceso de firma, puede usar la biblioteca Spire.XLS for .NET. Esta biblioteca le permite añadir o eliminar firmas digitales de Excel en C# programáticamente sin necesidad de tener Microsoft Office instalado en el servidor.
Paso 1: Instalar Spire.XLS
Abra Visual Studio, vaya a “Herramientas > Administrador de paquetes NuGet > Consola del Administrador de paquetes”, y ejecute:
Install-Package Spire.XLS
O puede buscar "Spire.XLS" en la interfaz de usuario del Administrador de paquetes NuGet e instalar.
Paso 2: Preparar un Certificado PFX
Use un certificado PFX válido (.pfx file) que contenga tanto la clave pública como la privada. Puede:
- Obtener uno de una Autoridad de Certificación (CA).
- Exportar un certificado autofirmado para pruebas usando PowerShell.
Asegúrese de que el archivo .pfx sea accesible desde el sistema de archivos de su aplicación.
Paso 3: Código C# para Añadir una Firma Digital en Excel
A continuación se muestra un ejemplo completo en C# que carga un archivo de Excel existente, aplica una firma digital invisible y guarda el libro de trabajo firmado.
using Spire.Xls;
using System;
namespace AddSignatureInExcel
{
class Program
{
static void Main(string[] args)
{
// Create a Workbook instance
Workbook workbook = new Workbook();
// Load an existing Excel file
workbook.LoadFromFile("Input.xlsx");
// Define the path to the certificate file and its password
string certificatePath = @"C:\Users\Administrator\Desktop\My Excel Test Signature.pfx";
string certificatePassword = "123abc";
// (Optional) Set a signing time
DateTime signingTime = new DateTime(2026, 4, 1, 7, 10, 36);
// Add a digital signature to the workbook
workbook.AddDigitalSignature(certificatePath, certificatePassword, "Test Signature", signingTime);
// Save the signed file
workbook.SaveToFile("AddDigitalSignature.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
En este código, el método AddDigitalSignature aplica la firma digital utilizando el archivo PFX. Los parámetros son:
- certificatePath: Ruta a su archivo .pfx.
- certificatePassword: Contraseña para la clave privada.
- comments: Una cadena que aparece en los detalles de la firma (p. ej., “Firma de Prueba”).
- signTime: Un DateTime que representa la hora de la firma (esto no es una marca de tiempo criptográfica, pero se puede usar para fines de visualización).
La firma digital añadida:
✅ Casos de Uso: Firma por lotes, automatización del lado del servidor, integración de flujos de trabajo empresariales.
Conclusión
Añadir una firma digital en Excel es esencial para proteger datos confidenciales, ya sea que utilice los pasos manuales para archivos únicos o el método C# Spire.XLS para la firma por lotes automatizada. Ambos enfoques crean firmas digitales seguras y legalmente vinculantes que protegen sus libros de trabajo contra la manipulación y verifican la autenticidad.
Utilice siempre certificados digitales de confianza para el intercambio externo, haga una copia de seguridad de sus credenciales y verifique las firmas antes de compartir o aceptar archivos de Excel. Siguiendo los procedimientos descritos en esta guía, los usuarios pueden proteger sus libros de trabajo de Excel contra cambios no autorizados y verificar la autenticidad de los firmantes con confianza.
Preguntas Frecuentes Sobre Añadir Firmas Digitales en Excel
P1. ¿Cómo inserto una firma electrónica en Excel?
Tiene dos opciones principales: (a) Línea de firma visible – vaya a Insertar > Línea de firma, o (b) Firma digital invisible – vaya a Archivo > Información > Proteger libro > Añadir una Firma Digital. Elija según si necesita una firma visible o integridad de backend.
P2. ¿Puedo añadir una firma digital a Excel de forma gratuita?
Sí. Utilice la herramienta integrada SelfCert.exe para crear un certificado autofirmado gratuito. Sin embargo, este certificado solo es de confianza en su propio ordenador. Para compartirlo externamente, es posible que necesite un certificado de CA de pago.
P3: ¿Cómo elimino una firma digital de Excel?
Vaya a “Archivo > Información > Ver firmas”, haga clic con el botón derecho en la firma y seleccione “Quitar firma”.
P4: ¿Puedo añadir una firma a Excel sin un certificado?
Puede añadir una firma de imagen visual, pero no es una firma digital segura y verificable.
Ver También
- 5 Métodos Fáciles para Inmovilizar Filas y Columnas en Excel
- Reducir el Tamaño del Archivo de Excel: 6 Formas Comprobadas de Reducir Hojas de Cálculo
- Cómo Insertar Fórmulas en Excel: Seis Métodos Fáciles
- Java: Añadir o Eliminar Firmas Digitales en Excel
- Python: Detectar y Eliminar Firmas Digitales en Archivos de Excel