Преобразуйте DBF в отчеты Excel легко с помощью команд Python
Содержание
- Зачем конвертировать DBF в Excel
- Базовое преобразование DBF в Excel с помощью Python
- Создание отформатированных файлов Excel из файлов DBF
- Пакетное преобразование и автоматическое форматирование
- Инструмент командной строки для преобразования DBF в Excel
- Сравнение методов
- Лучшие практики и советы
- Часто задаваемые вопросы

Работа с устаревшими форматами баз данных, такими как DBF, все еще распространена, но эти файлы плохо подходят для современных рабочих процессов, таких как анализ данных, отчетность или системная интеграция. Во многих случаях вам может потребоваться преобразовать файлы DBF в файлы Excel, чтобы упростить использование, совместное использование или обработку данных. Хотя инструменты, такие как Excel или онлайн-конвертеры, могут открывать файлы DBF, им не хватает автоматизации, гибкости и надежности, особенно при работе с большими наборами данных или повторяющимися задачами.
Python предоставляет более масштабируемое решение. Он позволяет не только конвертировать файлы DBF в Excel, но и очищать данные, стандартизировать структуры и интегрировать процесс в автоматизированные рабочие процессы.
Это руководство охватывает практический подход к преобразованию DBF в Excel, включая создание повторно используемой команды и генерацию структурированных выходных данных Excel для реального использования.
Быстрая навигация
- Зачем конвертировать DBF в Excel
- Базовое преобразование DBF в Excel с помощью Python
- Создание отформатированных файлов Excel из файлов DBF
- Пакетное преобразование и автоматическое форматирование
- Инструмент командной строки для преобразования DBF в Excel
- Сравнение методов
- Лучшие практики и советы
- Часто задаваемые вопросы
Зачем конвертировать DBF в Excel и распространенные методы преобразования
Файлы DBF хранят структурированные данные, но у них есть несколько ограничений:
- Устаревшие форматы кодировки (часто вызывающие проблемы с символами)
- Ограниченная совместимость с современными инструментами
- Отсутствие поддержки форматирования или отчетности
Преобразование DBF в Excel (XLS/XLSX) позволяет вам:
- Интегрироваться с современными конвейерами данных
- Улучшить читаемость и удобство использования
- Обеспечить структурированную отчетность и анализ
Распространенные методы преобразования DBF в Excel
Существует несколько способов обработки преобразования файла DBF в файл Excel:
- Открытие DBF непосредственно в Excel
- Использование онлайн-конвертеров
- Экспорт через устаревшие инструменты баз данных
Однако у этих методов есть явные ограничения:
- ❌ Нет автоматизации
- ❌ Плохая масштабируемость
- ❌ Ограниченный контроль над выводом
- ❌ Нет поддержки структурированной отчетности
Для разработчиков и производственных рабочих процессов этих подходов недостаточно.
Python обеспечивает полный контроль, автоматизацию и расширяемость, что делает его более практичным решением.
Преобразование DBF в Excel на Python (базовое преобразование)
Чтобы выполнить базовое преобразование DBF в Excel на Python, процесс прост: прочитать файл DBF в структурированный формат, а затем экспортировать его как файл Excel (XLSX).
В этом рабочем процессе:
- Библиотека dbf используется для чтения и анализа файлов DBF, включая устаревшие форматы
- Данные организуются и экспортируются с использованием библиотек, таких как pandas (с openpyxl в качестве механизма записи Excel)
Этот подход обеспечивает простой и практичный способ преобразования файлов DBF в Excel с минимальной настройкой.
Шаг 1: Установите зависимости
Вы можете установить необходимые библиотеки с помощью pip:
pip install dbf pandas openpyxl
Шаг 2: Прочтите файл DBF
import dbf
import pandas as pd
table = dbf.Table("business_demo.dbf")
table.open()
data = [{field: record[field] for field in dbf.field_names(table)} for record in table]
df = pd.DataFrame(data)
Этот шаг преобразует записи DBF в структурированный, совместимый с Excel формат.
Шаг 3: Экспорт DBF в Excel
df.to_excel("output.xlsx", index=False)
На этом этапе данные DBF записываются в стандартный файл Excel (формат XLSX), завершая базовое преобразование DBF в XLSX.
Ниже приведено изображение сгенерированного файла Excel:
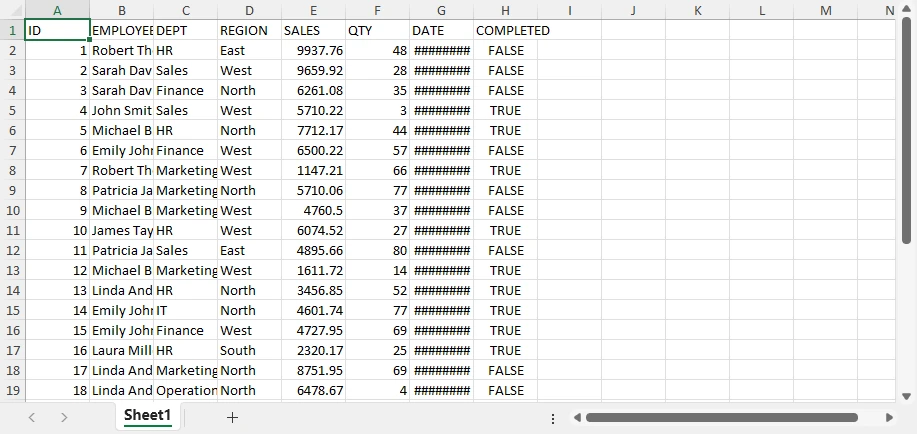
Это создает чистый, структурированный набор данных, который можно использовать напрямую или при необходимости обрабатывать дальше.
Почему этот метод работает
Этот метод широко используется, потому что он делает процесс преобразования простым и надежным:
- Преобразует записи DBF в структурированный табличный формат
- Сохраняет имена полей и организацию данных
- Работает с различными вариантами DBF (dBase, FoxPro и т. д.)
- Требует минимального кода для завершения преобразования
В результате он подходит для быстрых задач преобразования файлов .dbf в .xlsx и автоматизированных рабочих процессов.
Хотя этот подход хорошо работает для базового преобразования, он генерирует только необработанные данные Excel и не обеспечивает контроля над форматированием, макетом или структурой отчета.
Если вы также работаете с созданием файлов Excel из других источников данных, таких как CSV, JSON и XML, вы можете обратиться к Как импортировать данные в файлы Excel с помощью Python для получения подробных инструкций.
Ограничения базового преобразования
Хотя этот базовый подход к преобразованию эффективен для быстрых и простых преобразований, у него есть ограничения при экспорте файлов Excel:
- Нет стилизации или форматирования
- Нет контроля над макетом
- Нет структуры отчета
- Ограниченная применимость для готовых к использованию в бизнесе результатов
Результатом является необработанный набор данных, а не отполированный отчет.
Создание профессиональных отчетов Excel из данных DBF
Базовое преобразование DBF в Excel создает только необработанные наборы данных. Однако в реальных сценариях файлы Excel часто используются для отчетности, презентаций и принятия решений. Чтобы выйти за рамки простого экспорта данных и создавать структурированные, готовые к использованию в бизнесе результаты, вы можете использовать Spire.XLS for Python.
Типичный производственный рабочий процесс выглядит так:
- Чтение данных DBF с помощью dbf
- Запись структурированных данных Excel с помощью Spire.XLS
- Применение форматирования и макета
- Добавление диаграмм и других элементов отчета по мере необходимости
С помощью этого подхода вы можете постепенно улучшать свой файл Excel — от базовой таблицы до полностью отформатированного отчета с визуальными элементами.
Шаг 1: Установите библиотеки
Вы можете установить библиотеки с помощью pip:
pip install spire.xls dbf
Шаг 2: Прочтите данные DBF и запишите их в Excel
from spire.xls import *
import dbf
table = dbf.Table("business_demo.dbf")
table.open()
data = [{field: record[field] for field in dbf.field_names(table)} for record in table]
field_names = list(dbf.field_names(table))
workbook = Workbook()
workbook.Worksheets.Clear()
sheet = workbook.Worksheets.Add("Data")
# Записать заголовок
for j, col in enumerate(field_names):
sheet.Range[1, j+1].Value = col
# Записать данные
for i, record in enumerate(data, start=2):
for j, col in enumerate(field_names):
sheet.Range[i, j+1].Value = str(record[col])
На этом этапе файл DBF был преобразован в структурированный набор данных Excel.
Шаг 3: Примените стили и сохраните как файл Excel
После записи данных вы можете улучшить читаемость, применив стили и настройки макета.
# Стилизация заголовка
header = sheet.Range[1, 1, 1, sheet.LastColumn]
header.Style.Font.Bold = True
header.Style.Font.Size = 12
header.Style.Color = Color.get_LightGray()
# Границы данных
data_range = sheet.Range[1, 1, sheet.LastRow, sheet.LastColumn]
data_range.BorderAround(LineStyleType.Thin, ExcelColors.Black)
data_range.BorderInside(LineStyleType.Thin, ExcelColors.Black)
# Глобальный шрифт
sheet.AllocatedRange.Style.Font.Name = "Arial"
# Автоподбор ширины столбцов
sheet.AllocatedRange.AutoFitColumns()
# Сохранить рабочую книгу в файл
workbook.SaveToFile("output.xlsx", ExcelVersion.Version2016)
Сгенерированный файл Excel выглядит так:
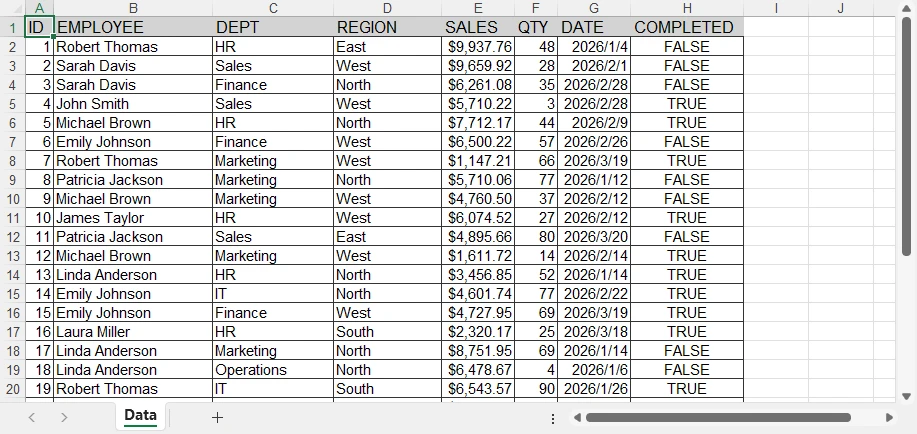
Примечания к API
Spire.XLS предоставляет модель стилизации на основе диапазонов, которая позволяет применять форматирование ко всем регионам, а не к отдельным ячейкам.
- Range[row, col] → доступ к определенной ячейке или региону
- Style.Font → управление свойствами шрифта, такими как размер, жирность и семейство
- BorderAround / BorderInside → добавить внутренние и внешние границы
- AllocatedRange → относится к используемому диапазону на листе, который включает все ячейки с данными
- AutoFitColumns / AutoFitRows → автоматически настраивать ширину столбцов и строк в диапазоне
- SaveToFile → сохранить рабочую книгу в файл в указанном формате
Примечание: для метода SaveToFile второй аргумент указывает формат файла. FileFormat.Version97to2003 представляет формат .xls, а FileFormat.Version2007 и выше представляют формат .xlsx.
Этот подход делает форматирование больших наборов данных эффективным с минимальным кодом.
На данный момент файл Excel больше не является необработанными данными — он был преобразован в чистую, читаемую таблицу. Однако это все еще отформатированный набор данных, а не полный отчет.
Добавить элементы отчета (постепенные улучшения)
Чтобы еще больше улучшить вывод, вы можете добавить аналитические и визуальные элементы.
Пример 1: Добавить диаграмму
# Агрегировать данные по РЕГИОНУ (для построения диаграмм)
region_sales = defaultdict(float)
for record in data:
region = record["REGION"]
sales = float(record["SALES"])
region_sales[region] += sales
# Создать сводный лист для агрегированных данных
summary_sheet = workbook.Worksheets.Add("Summary")
# Записать сводный заголовок
summary_sheet.Range[1, 1].Value = "Region"
summary_sheet.Range[1, 2].Value = "Total Sales"
# Записать агрегированные результаты
for i, (region, total) in enumerate(region_sales.items(), start=2):
summary_sheet.Range[i, 1].Value = region
summary_sheet.Range[i, 2].Value = total
summary_sheet.Range[2, 2, summary_sheet.LastRow, 2].NumberFormat = "$#,##0.00"
# Создать диаграмму на основе агрегированных данных
chart = summary_sheet.Charts.Add()
chart.ChartType = ExcelChartType.ColumnClustered
# Установить диапазон данных (Регион + Общие продажи)
chart.DataRange = summary_sheet.Range[
"A1:B{}".format(len(region_sales) + 1)
]
# Разместить диаграмму на листе
chart.LeftColumn = 4
chart.TopRow = 2
chart.RightColumn = 10
chart.BottomRow = 20
# Установить заголовок диаграммы
chart.ChartTitle = "Продажи по регионам"
Ниже представлен предварительный просмотр диаграммы, добавленной на лист Excel:
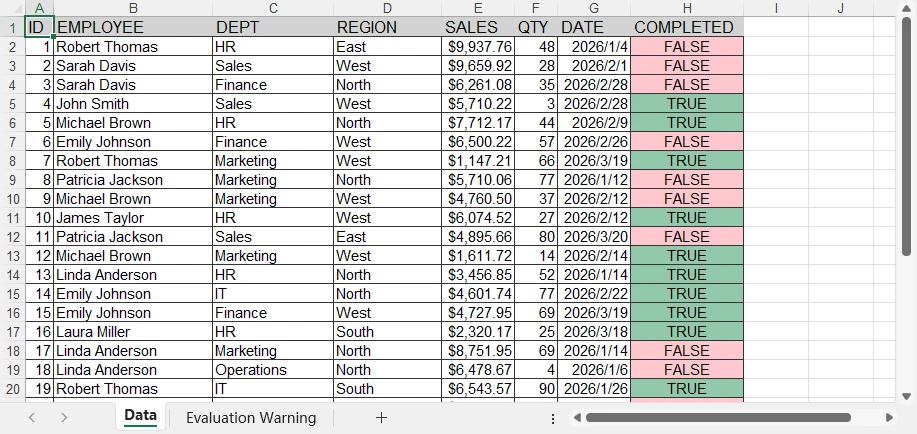
Вы можете создавать много других типов диаграмм на листах Excel с помощью Spire.XLS, таких как круговые диаграммы и столбчатые диаграммы. Выберите подходящий тип диаграммы в зависимости от ваших данных и требований.
Пример 2: Добавить условное форматирование
# Создать условный формат в указанном диапазоне
conditions = sheet.ConditionalFormats.Add()
conditions.AddRange(sheet.Range[2, 8, sheet.LastRow, 8])
# Добавить правило к условному формату
condition1 = conditions.AddCondition()
condition1.FormatType = ConditionalFormatType.ContainsText;
condition1.FirstFormula = "TRUE"
condition1.BackColor = Color.FromRgb(144, 200, 172)
# Добавить еще одно правило к условному формату
condition2 = conditions.AddCondition()
condition2.FormatType = ConditionalFormatType.ContainsText
condition2.FirstFormula = "FALSE"
condition2.BackColor = Color.FromRgb(255, 199, 206)
Ниже представлен предварительный просмотр сгенерированного файла Excel с примененным условным форматированием:
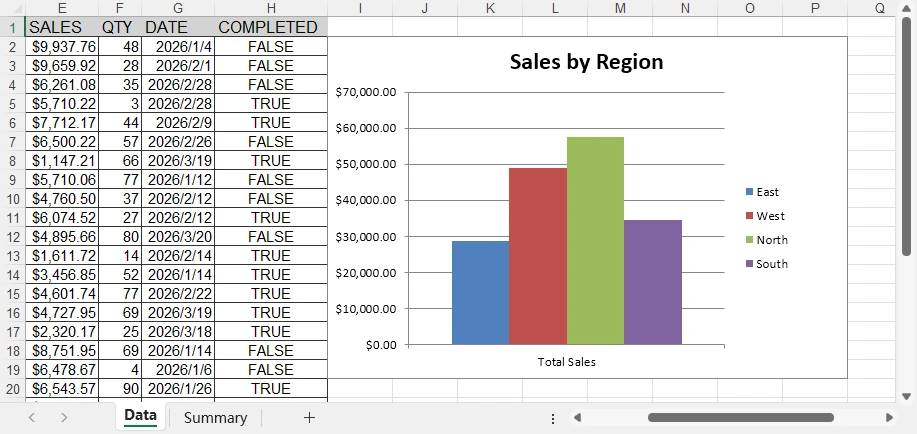
Условное форматирование позволяет достичь многих специальных эффектов на листах Excel. Вы можете обратиться к Как применить условное форматирование к листам Excel с помощью Python для получения более подробной информации.
Почему это важно
Эти улучшения превращают файл Excel из простого экспорта в инструмент отчетности.
Теперь вы можете:
- Четко представлять структурированные данные
- Выделять ключевую информацию
- Визуализировать тенденции с помощью диаграмм
Сочетая обработку структурированных данных с расширенными функциями Excel, вы можете превратить устаревшие файлы DBF в современные, удобные для использования отчеты. Этот уровень функциональности необходим для бизнес-процессов, информационных панелей и автоматизированных систем отчетности.
Расширенное преобразование: пакетная обработка и автоматическое форматирование
Для реальных рабочих процессов преобразование DBF в Excel часто не является одноразовой задачей. Вместо этого вам может потребоваться обрабатывать несколько файлов автоматически, особенно в таких сценариях, как миграция данных или запланированные задания.
Python позволяет легко масштабировать преобразование DBF в Excel с одного файла до пакетной обработки.
Пакетное преобразование файлов DBF в Excel
Если вам нужно только создавать базовые файлы Excel, вы можете объединить логику преобразования с модулем os для обработки всех файлов DBF в каталоге.
import os
import dbf
import pandas as pd
input_folder = "dbf_files"
output_folder = "excel_files"
for file in os.listdir(input_folder):
if file.endswith(".dbf"):
table = dbf.Table(os.path.join(input_folder, file))
table.open()
df = pd.DataFrame([dict(record) for record in table])
output_file = file.replace(".dbf", ".xlsx")
df.to_excel(os.path.join(output_folder, output_file), index=False)
Этот подход обеспечивает автоматический экспорт DBF в Excel для нескольких файлов и подходит для:
- Миграция устаревших систем
- Синхронизация данных
- Запланированные рабочие процессы ETL
Пакетное преобразование с автоматическим форматированием
При работе с бизнес-данными простого экспорта необработанных файлов Excel часто бывает недостаточно. Вам также может потребоваться единообразное форматирование и структурированный вывод для всех сгенерированных файлов.
Используя Spire.XLS for Python, вы можете автоматически применять форматирование во время пакетного преобразования.
import os
import dbf
from spire.xls import *
input_folder = "dbf_files"
output_folder = "formatted_reports"
for file in os.listdir(input_folder):
if file.endswith(".dbf"):
table = dbf.Table(os.path.join(input_folder, file))
table.open()
data = [{field: record[field] for field in dbf.field_names(table)} for record in table]
field_names = list(dbf.field_names(table))
workbook = Workbook()
workbook.Worksheets.Clear()
sheet = workbook.Worksheets.Add("Data")
# Записать заголовок
for j, col in enumerate(field_names):
sheet.Range[1, j+1].Value = col
# Записать данные
for i, record in enumerate(data, start=2):
for j, col in enumerate(field_names):
sheet.Range[i, j+1].Value = str(record[col])
# Создать таблицу со встроенным стилем
table_range = sheet.AllocatedRange
table_obj = sheet.ListObjects.Create("Data", table_range)
table_obj.BuiltInTableStyle = TableBuiltInStyles.TableStyleMedium13
# Автоподбор макета
sheet.AllocatedRange.AutoFitColumns()
# Сохранить файл
output_file = file.replace(".dbf", ".xlsx")
workbook.SaveToFile(os.path.join(output_folder, output_file), FileFormat.Version2016)
workbook.Dispose()
Ниже представлен предварительный просмотр встроенного стиля таблицы, примененного к данным:
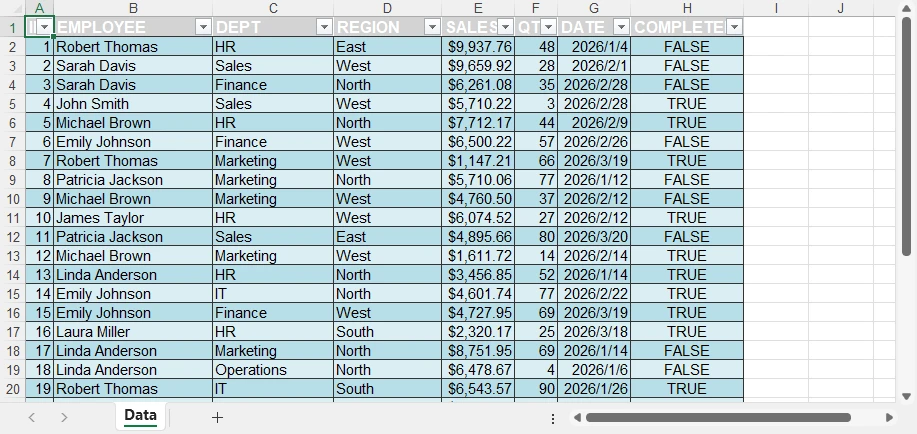
Почему этот подход важен
Сочетая пакетную обработку с автоматическим форматированием, вы можете:
- Преобразовывать несколько файлов DBF в Excel в одном рабочем процессе
- Обеспечить согласованную структуру и стилизацию для всех выходных данных
- Сократить ручную работу при создании отчетов
- Интегрировать преобразование в автоматизированные конвейеры
Это превращает простую задачу преобразования файла DBF в Excel в масштабируемое и готовое к производству решение.
С помощью Spire.XLS вы можете легко передавать данные между файлами Excel и базами данных. См. Передача данных между Excel и базой данных на Python для получения более подробной информации.
Инструмент командной строки для преобразования DBF в Excel
В дополнение к пакетной обработке вы можете еще больше улучшить автоматизацию, превратив логику преобразования в повторно используемый инструмент командной строки.
Это позволяет запускать преобразование DBF в Excel непосредственно из терминала, что делает его подходящим для сценариев, запланированных задач и серверных рабочих процессов.
Создать интерфейс командной строки
Вы можете обернуть логику преобразования в сценарий Python, который принимает пути ввода и вывода в качестве аргументов.
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
Использовать команду
Как только ваш сценарий будет готов, вы можете запустить его из командной строки:
python convert.py data.dbf output.xlsx
Этот подход позволяет повторно использовать одну и ту же логику преобразования в разных средах и интегрировать преобразование в автоматизированные рабочие процессы с минимальными усилиями.
Базовое преобразование в сравнении со Spire.XLS for Python
При преобразовании файлов DBF в Excel выбор подхода зависит от ваших целей.
| Возможность | Базовое преобразование (например, pandas и dbf) | Spire.XLS for Python и dbf |
|---|---|---|
| Экспорт из DBF в Excel | ✅ | ✅ |
| Пакетная обработка | ✅ | ✅ |
| Форматирование и стилизация | ❌ | ✅ |
| Структура отчета | ❌ | ✅ |
| Диаграммы и визуализация | ❌ | ✅ |
Когда использовать каждый подход
Используйте базовое преобразование, когда:
- Вам нужно только преобразовать DBF в Excel
- Вывод используется для хранения или дальнейшей обработки
- Форматирование или отчетность не требуются
Используйте Spire.XLS for Python и dbf, когда:
- Вам нужны структурированные отчеты Excel
- Форматирование и макет важны
- Вы хотите включить диаграммы или визуальные элементы
Выбор правильного подхода может значительно повысить как эффективность, так и качество вывода, особенно при переходе от простого преобразования файлов .dbf в .xlsx к автоматизированным рабочим процессам отчетности.
Лучшие практики для преобразования DBF в Excel
Осторожно обращайтесь с кодировкой
table = dbf.Table("file.dbf", codepage="cp1252")
Файлы DBF могут использовать разные кодировки в зависимости от их источника. Всегда проверяйте правильную кодовую страницу, чтобы предотвратить повреждение символов.
Проверка типов данных
Поля DBF не всегда чисто сопоставляются с форматами Excel. Проверяйте числовые, датные и логические значения перед экспортом, чтобы обеспечить точность.
Оптимизация для больших файлов
При работе с большими наборами данных:
- Обрабатывайте данные по частям
- Избегайте загрузки всех записей в память одновременно
Разделение преобразования и отчетности
Для большей гибкости и удобства обслуживания:
- Используйте простой подход для преобразования DBF в Excel
- Применяйте форматирование и элементы отчета только при необходимости
Заключение
Преобразование файлов DBF в Excel — это часто больше, чем просто смена формата, это о том, чтобы сделать устаревшие данные проще в использовании, совместном использовании и анализе.
С помощью Python вы можете начать с простого преобразования DBF в Excel и масштабировать до пакетной обработки и автоматизированных рабочих процессов. Для базовых нужд хорошо подходит легковесный подход. Но когда вам нужны структурированные макеты, согласованное форматирование или визуальные элементы, более продвинутые возможности Excel становятся важными.
Если вы хотите создавать профессиональные, готовые к отчетности файлы Excel, вы можете попробовать Spire.XLS for Python. Бесплатная 30-дневная лицензия доступна для изучения всех ее функций в реальных сценариях.
Часто задаваемые вопросы
Как мне преобразовать файл DBF в Excel на Python?
Используйте подход на основе Python для чтения данных DBF и их экспорта в Excel. Например, вы можете объединить dbf с такими инструментами, как pandas, для быстрого преобразования файла DBF в файл Excel.
Какой лучший способ преобразовать DBF в XLSX?
Это зависит от ваших потребностей:
- Для простого преобразования → используйте базовый подход на Python
- Для отформатированных отчетов → используйте Spire.XLS for Python
Могу ли я импортировать файл DBF напрямую в Excel?
Да, но это не подходит для автоматизации или больших наборов данных. Python предоставляет более надежное и масштабируемое решение.
Почему мой файл Excel не отформатирован?
Базовые методы преобразования экспортируют только необработанные данные без стилизации. Чтобы создавать отформатированные отчеты Excel, вам нужен инструмент, поддерживающий макет и стилизацию, такой как Spire.XLS for Python.
Как мне создать команду для преобразования DBF в Excel?
Оберните логику преобразования в сценарий и передайте пути ввода/вывода в качестве аргументов. Это позволяет запускать преобразование DBF в Excel непосредственно из командной строки.
Converter XPS para PDF: métodos integrados, online e por script
Índice
- XPS vs PDF: Qual é a diferença?
- Método 1 - Usando o Visualizador XPS + Microsoft Print to PDF
- Método 2 - Usando conversores online
- Método 3 - Usando ferramentas de linha de comando
- Método 4 - Usando bibliotecas Python (processamento em lote)
- Comparação - Qual método você deve escolher
- Conclusão
- Perguntas frequentes

Precisa converter um arquivo XPS para PDF? Você não está sozinho. Desde empresas que arquivam documentos até indivíduos que compartilham relatórios, a conversão de XPS para PDF garante que seus arquivos sejam acessíveis, compatíveis e com aparência profissional.
Neste artigo, mostraremos quatro maneiras confiáveis de converter XPS para PDF, incluindo ferramentas integradas, conversores online, opções de linha de comando e processamento em lote baseado em Python, para que você possa escolher o método que melhor se adapta às suas necessidades.
Navegação Rápida:
- Método 1 - Usando o Visualizador XPS + Microsoft Print to PDF
- Método 2 - Usando conversores online
- Método 3 - Usando ferramentas de linha de comando
- Método 4 - Usando bibliotecas Python (processamento em lote)
XPS vs PDF: Qual é a diferença?
O PDF é o padrão multiplataforma de longa data da Adobe. É rico em recursos — suportando formulários, anotações, criptografia, assinaturas digitais e perfis avançados de impressão e arquivamento — e é apoiado por um vasto ecossistema de visualizadores, editores e ferramentas profissionais. O PDF garante renderização confiável, acessibilidade e segurança robusta em todos os dispositivos e setores.
O XPS é o formato de layout fixo da Microsoft, baseado em XML e empacotado em ZIP, usado principalmente em determinados fluxos de trabalho de impressão do Windows. Seu conjunto de recursos e suporte de terceiros são limitados em comparação com o PDF, resultando em interoperabilidade mais fraca e menos ferramentas. Como o PDF oferece compatibilidade, recursos e adoção da indústria superiores, a conversão de XPS para PDF é frequentemente necessária.
Método 1 - Usando o Visualizador XPS + Microsoft Print to PDF
Para usuários do Windows, a maneira mais simples de converter um arquivo XPS é através do Visualizador XPS integrado e do Microsoft Print to PDF. Este método não requer software extra e é ideal para conversões únicas ou uso ocasional. Ao aproveitar a funcionalidade de impressão para PDF do sistema, você pode gerar rapidamente um PDF sem comprometer o layout básico.
Passos:
- Abra seu arquivo XPS usando o Visualizador XPS.
- Clique em Imprimir na barra de ferramentas.
- Selecione Microsoft Print to PDF como a impressora.
- Escolha o local de saída e salve seu PDF.
Prós:
- Gratuito e não requer instalação.
- Interface simples para usuários casuais.
Contras:
- Não é possível processar vários arquivos de uma vez.
- A formatação complexa pode mudar ligeiramente.
Método 2 - Usando conversores online
Conversores online oferecem uma maneira conveniente de converter XPS para PDF sem instalar software. Eles são particularmente úteis se você precisar de uma conversão rápida ou estiver usando uma plataforma que não seja o Windows. A maioria das ferramentas online é tão simples quanto carregar seu arquivo, selecionar PDF como formato de saída e baixar o resultado.
Passos:
- Visite um conversor online confiável, como o CloudConvert.
- Carregue seu arquivo XPS.
- Escolha PDF como o formato de destino.
- Clique em Converter e baixe o PDF resultante.
Prós:
- Funciona em qualquer plataforma (Windows, Mac, celular).
- Nenhuma instalação de software necessária.
- Interface rápida de arrastar e soltar.
Contras:
- Limites de tamanho de arquivo podem ser aplicados.
- Conexão com a Internet necessária.
- Potenciais preocupações com a privacidade de arquivos confidenciais.
Método 3 - Usando ferramentas de linha de comando (MuPDF)
Para usuários avançados ou fluxos de trabalho de automação, as ferramentas de linha de comando oferecem opções de conversão flexíveis. O MuPDF fornece um utilitário de linha de comando leve (mutool) que pode converter arquivos XPS para PDF, individualmente ou em scripts em lote. Este método é ideal para desenvolvedores ou administradores de TI que precisam de resultados consistentes em vários arquivos.
Passos:
-
Baixe o MuPDF.
- Acesse o site oficial do MuPDF: https://mupdf.com/downloads/
- Baixe o pacote de ferramentas MuPDF para o seu sistema operacional (Windows, macOS ou Linux)
- Extraia o pacote para uma pasta, por exemplo, C:\MuPDF
-
Abra um Prompt de Comando / Terminal.
- Windows: Pressione Win + R, digite cmd, pressione Enter
- macOS/Linux: Abra o Terminal
-
Navegue até a pasta do seu arquivo XPS.
Use o comando cd para alterar o diretório para onde seu arquivo XPS está localizado. Exemplo:
cd C:\Users\Administrator\Desktop\XPSFiles -
Execute o comando de conversão.
Use mutool convert com a opção -o para especificar o PDF de saída:
C:\MuPDF\mutool.exe convert -o output.pdf input.xpsExplicação:
- convert → diz ao MuPDF para converter formatos de arquivo
- -o output.pdf → especifica o nome do arquivo PDF de saída
- input.xps → seu arquivo XPS
No Linux/macOS, pode parecer com:
./mutool convert -o output.pdf input.xps -
Verifique o PDF de saída na sua pasta de destino.
Prós:
- Automatizável e programável para processamento em massa.
- Multiplataforma (Windows, Mac, Linux).
Contras:
- Requer conhecimento técnico.
- A configuração e a sintaxe podem ser complexas para iniciantes.
Método 4 - Usando bibliotecas Python (processamento em lote com Spire.PDF)
Para desenvolvedores ou empresas que precisam de processamento em lote, as bibliotecas Python fornecem uma solução eficiente. Usando o Spire.PDF para Python, você pode converter vários arquivos XPS em PDFs programaticamente, preservando imagens de alta qualidade e a integridade do layout. Essa abordagem é ideal para automatizar grandes fluxos de trabalho ou integrar em sistemas de backend.
Passos:
- Instale a biblioteca necessária.
- Use o script a seguir para converter um único arquivo XPS em um arquivo PDF.
pip install spire.pdffrom spire.pdf.common import *
from spire.pdf import *
# Load an XPS file
doc = PdfDocument()
doc.LoadFromFile("Input.xps", FileFormat.XPS)
# Preserve images' quality
doc.ConvertOptions.SetXpsToPdfOptions(True)
# Save to PDF
doc.SaveToFile("XpsToPdf.pdf", FileFormat.PDF)
doc.Dispose()
Saída:
Exemplo de processamento em lote:
import os
from spire.pdf.common import *
from spire.pdf import *
folder = r"C:\path\to\your\folder"
for name in os.listdir(folder):
if not name.lower().endswith(".xps"):
continue
in_path = os.path.join(folder, name)
out_path = os.path.join(folder, os.path.splitext(name)[0] + ".pdf")
doc = PdfDocument()
doc.LoadFromFile(in_path, FileFormat.XPS)
doc.ConvertOptions.SetXpsToPdfOptions(True)
doc.SaveToFile(out_path, FileFormat.PDF)
doc.Dispose()
Prós:
- Controle total sobre a conversão em lote.
- Preservação de alta fidelidade do layout e das imagens.
- Integra-se facilmente em fluxos de trabalho automatizados.
Contras:
- Requer conhecimento de codificação.
- Instalação de biblioteca necessária.
Além de converter XPS para PDF, o Spire.PDF para Python também permite que você aplique marcas d'água, adicione anotações e criptografe documentos PDF programaticamente. Você pode explorar esses recursos para aprimorar ou proteger seus arquivos PDF diretamente do seu código, tornando-o uma solução versátil para muitas tarefas de automação de PDF.
Comparação – Qual método você deve escolher?
| Método | Facilidade de uso | Suporte a Lote | Plataforma | Prós | Contras |
|---|---|---|---|---|---|
| Visualizador XPS | ★★★★ | ✗ | Windows | Gratuito, simples | Arquivo único, problemas de formatação |
| Conversores Online | ★★★★ | ✗ | Qualquer | Sem instalação, rápido | Privacidade, limites de tamanho de arquivo |
| MuPDF | ★★ | ✓ | Windows / Mac / Linux | Automatizável | Configuração técnica necessária |
| Python / Spire.PDF | ★★ | ✓ | Multiplataforma | Processamento em lote, alta fidelidade | Requer conhecimento de codificação |
Conclusão
A escolha do método certo depende de suas necessidades: usuários casuais podem preferir o Visualizador XPS ou conversores online, enquanto desenvolvedores e empresas que lidam com vários arquivos se beneficiarão do MuPDF ou Python/Spire.PDF para processamento em lote. Para conversão de alta qualidade, automatizada e escalável, o Spire.PDF é uma solução robusta que garante que sua saída em PDF mantenha a integridade dos arquivos XPS originais.
Perguntas frequentes
P1: Posso converter vários arquivos XPS de uma vez?
Sim, a conversão em lote é possível usando ferramentas de linha de comando como o MuPDF ou bibliotecas Python como o Spire.PDF.
P2: Os conversores online são seguros para documentos confidenciais?
Depende da plataforma. Para arquivos confidenciais, é recomendável usar ferramentas offline como o Visualizador XPS ou o Spire.PDF.
P3: O Python pode converter XPS para PDF no Mac/Linux?
Sim, o Spire.PDF para Python suporta conversão multiplataforma, e a ferramenta de linha de comando fornecida pelo MuPDF também é compatível com Mac e Linux.
P4: O PDF manterá o layout e as imagens originais?
A maioria dos métodos preserva o layout, mas soluções em lote e programáticas como o Spire.PDF fornecem a mais alta fidelidade, especialmente para arquivos XPS complexos.
Veja também
XPS를 PDF로 변환: 내장형, 온라인 및 스크립트 방식
XPS 파일을 PDF로 변환해야 하나요? 당신만 그런 것이 아닙니다. 문서를 보관하는 기업부터 보고서를 공유하는 개인에 이르기까지, XPS를 PDF로 변환하면 파일에 쉽게 접근하고, 호환성을 확보하며, 전문적인 외관을 유지할 수 있습니다.
이 기사에서는 내장 도구, 온라인 변환기, 명령줄 옵션, Python 기반 일괄 처리를 포함하여 XPS를 PDF로 변환하는 네 가지 신뢰할 수 있는 방법을 안내하여 귀하의 필요에 가장 적합한 방법을 선택할 수 있도록 도와드립니다.
빠른 탐색:
- 방법 1 - XPS 뷰어 + Microsoft Print to PDF 사용
- 방법 2 - 온라인 변환기 사용
- 방법 3 - 명령줄 도구 사용
- 방법 4 - Python 라이브러리 사용 (일괄 처리)
XPS와 PDF: 차이점은 무엇인가요?
PDF는 Adobe의 오랜 크로스 플랫폼 표준입니다. 양식, 주석, 암호화, 디지털 서명, 고급 인쇄 및 보관 프로필을 지원하는 등 기능이 풍부하며, 방대한 뷰어, 편집기 및 전문 도구 생태계의 지원을 받습니다. PDF는 장치와 산업 전반에 걸쳐 신뢰할 수 있는 렌더링, 접근성 및 강력한 보안을 보장합니다.
XPS는 Microsoft의 XML 기반, ZIP 패키지 고정 레이아웃 형식으로, 주로 특정 Windows 인쇄 워크플로에서 사용됩니다. 기능 세트와 타사 지원이 PDF에 비해 제한적이어서 상호 운용성이 약하고 도구가 적습니다. PDF가 우수한 호환성, 기능 및 산업 채택률을 제공하기 때문에 XPS를 PDF로 변환하는 것이 종종 필요합니다.
방법 1 - XPS 뷰어 + Microsoft Print to PDF 사용
Windows 사용자의 경우 XPS 파일을 변환하는 가장 간단한 방법은 내장된 XPS 뷰어와 Microsoft Print to PDF를 사용하는 것입니다. 이 방법은 추가 소프트웨어가 필요 없으며 일회성 변환이나 가끔 사용하는 데 이상적입니다. 시스템의 PDF로 인쇄 기능을 활용하여 기본 레이아웃을 손상시키지 않고 신속하게 PDF를 생성할 수 있습니다.
단계:
- XPS 뷰어를 사용하여 XPS 파일을 엽니다.
- 도구 모음에서 인쇄를 클릭합니다.
- 프린터로 Microsoft Print to PDF를 선택합니다.
- 출력 위치를 선택하고 PDF를 저장합니다.
장점:
- 무료이며 설치가 필요 없습니다.
- 일반 사용자를 위한 간단한 인터페이스.
단점:
- 한 번에 여러 파일을 처리할 수 없습니다.
- 복잡한 서식이 약간 변경될 수 있습니다.
방법 2 - 온라인 변환기 사용
온라인 변환기는 소프트웨어를 설치하지 않고도 XPS를 PDF로 변환하는 편리한 방법을 제공합니다. 빠른 변환이 필요하거나 Windows가 아닌 플랫폼을 사용하는 경우 특히 유용합니다. 대부분의 온라인 도구는 파일을 업로드하고 출력 형식으로 PDF를 선택한 다음 결과를 다운로드하는 것만큼 간단합니다.
단계:
- CloudConvert와 같은 신뢰할 수 있는 온라인 변환기를 방문합니다.
- XPS 파일을 업로드합니다.
- 대상 형식으로 PDF를 선택합니다.
- 변환을 클릭하고 결과 PDF를 다운로드합니다.
장점:
- 모든 플랫폼(Windows, Mac, 모바일)에서 작동합니다.
- 소프트웨어 설치가 필요 없습니다.
- 빠른 드래그 앤 드롭 인터페이스.
단점:
- 파일 크기 제한이 적용될 수 있습니다.
- 인터넷 연결이 필요합니다.
- 민감한 파일에 대한 잠재적인 개인 정보 보호 문제.
방법 3 - 명령줄 도구 사용 (MuPDF)
고급 사용자나 자동화 워크플로를 위해 명령줄 도구는 유연한 변환 옵션을 제공합니다. MuPDF는 개별적으로 또는 배치 스크립트에서 XPS 파일을 PDF로 변환할 수 있는 경량 명령줄 유틸리티( mutool )를 제공합니다. 이 방법은 여러 파일에 걸쳐 일관된 결과가 필요한 개발자나 IT 관리자에게 이상적입니다.
단계:
-
MuPDF를 다운로드합니다.
- 공식 MuPDF 웹사이트로 이동합니다: https://mupdf.com/downloads/
- 운영 체제(Windows, macOS 또는 Linux)용 MuPDF 도구 패키지를 다운로드합니다.
- 패키지를 폴더(예: C:\MuPDF)에 압축 해제합니다.
-
명령 프롬프트 / 터미널을 엽니다.
- Windows: Win + R을 누르고 cmd를 입력한 다음 Enter를 누릅니다.
- macOS/Linux: 터미널을 엽니다.
-
XPS 파일 폴더로 이동합니다.
cd 명령을 사용하여 XPS 파일이 있는 디렉터리로 변경합니다. 예:
cd C:\Users\Administrator\Desktop\XPSFiles -
변환 명령을 실행합니다.
mutool convert를 -o 옵션과 함께 사용하여 출력 PDF를 지정합니다:
C:\MuPDF\mutool.exe convert -o output.pdf input.xps설명:
- convert → MuPDF에 파일 형식 변환을 지시합니다.
- -o output.pdf → PDF 출력 파일 이름을 지정합니다.
- input.xps → 당신의 XPS 파일
Linux/macOS에서는 다음과 같이 보일 수 있습니다:
./mutool convert -o output.pdf input.xps -
대상 폴더에서 출력 PDF를 확인합니다.
장점:
- 대량 처리를 위해 자동화 및 스크립트 작성이 가능합니다.
- 크로스 플랫폼(Windows, Mac, Linux).
단점:
- 기술적 지식이 필요합니다.
- 초보자에게는 설정 및 구문이 복잡할 수 있습니다.
방법 4 - Python 라이브러리 사용 (Spire.PDF로 일괄 처리)
일괄 처리가 필요한 개발자나 기업을 위해 Python 라이브러리는 효율적인 솔루션을 제공합니다. Spire.PDF for Python을 사용하면 고품질 이미지와 레이아웃 무결성을 유지하면서 여러 XPS 파일을 프로그래밍 방식으로 PDF로 변환할 수 있습니다. 이 접근 방식은 대규모 워크플로를 자동화하거나 백엔드 시스템에 통합하는 데 이상적입니다.
단계:
- 필요한 라이브러리를 설치합니다.
- 다음 스크립트를 사용하여 단일 XPS를 PDF 파일로 변환합니다.
pip install spire.pdffrom spire.pdf.common import *
from spire.pdf import *
# XPS 파일 로드
doc = PdfDocument()
doc.LoadFromFile("Input.xps", FileFormat.XPS)
# 이미지 품질 보존
doc.ConvertOptions.SetXpsToPdfOptions(True)
# PDF로 저장
doc.SaveToFile("XpsToPdf.pdf", FileFormat.PDF)
doc.Dispose()
출력:
일괄 처리 예제:
import os
from spire.pdf.common import *
from spire.pdf import *
folder = r"C:\path\to\your\folder"
for name in os.listdir(folder):
if not name.lower().endswith(".xps"):
continue
in_path = os.path.join(folder, name)
out_path = os.path.join(folder, os.path.splitext(name)[0] + ".pdf")
doc = PdfDocument()
doc.LoadFromFile(in_path, FileFormat.XPS)
doc.ConvertOptions.SetXpsToPdfOptions(True)
doc.SaveToFile(out_path, FileFormat.PDF)
doc.Dispose()
장점:
- 일괄 변환에 대한 완전한 제어.
- 레이아웃 및 이미지의 높은 충실도 보존.
- 자동화된 워크플로에 쉽게 통합됩니다.
단점:
- 코딩 지식이 필요합니다.
- 라이브러리 설치가 필요합니다.
XPS를 PDF로 변환하는 것 외에도 Spire.PDF for Python을 사용하면 프로그래밍 방식으로 워터마크를 적용하고, 주석을 추가하고, PDF 문서를 암호화할 수 있습니다. 이러한 기능을 탐색하여 코드에서 직접 PDF 파일을 향상시키거나 보호할 수 있으므로 많은 PDF 자동화 작업에 다용도 솔루션이 됩니다.
비교 – 어떤 방법을 선택해야 할까요?
| 방법 | 사용 편의성 | 일괄 지원 | 플랫폼 | 장점 | 단점 |
|---|---|---|---|---|---|
| XPS 뷰어 | ★★★★ | ✗ | Windows | 무료, 간단함 | 단일 파일, 서식 문제 |
| 온라인 변환기 | ★★★★ | ✗ | 모두 | 설치 불필요, 빠름 | 개인 정보 보호, 파일 크기 제한 |
| MuPDF | ★★ | ✓ | Windows / Mac / Linux | 자동화 가능 | 기술적 설정 필요 |
| Python / Spire.PDF | ★★ | ✓ | 크로스 플랫폼 | 일괄 처리, 높은 충실도 | 코딩 지식 필요 |
결론
올바른 방법을 선택하는 것은 필요에 따라 다릅니다. 일반 사용자는 XPS 뷰어나 온라인 변환기를 선호할 수 있으며, 여러 파일을 처리하는 개발자 및 기업은 일괄 처리를 위해 MuPDF 또는 Python/Spire.PDF를 사용하는 것이 좋습니다. 고품질의 자동화되고 확장 가능한 변환을 위해 Spire.PDF는 PDF 출력이 원본 XPS 파일의 무결성을 유지하도록 보장하는 강력한 솔루션입니다.
자주 묻는 질문
Q1: 한 번에 여러 XPS 파일을 변환할 수 있나요?
예, MuPDF와 같은 명령줄 도구나 Spire.PDF와 같은 Python 라이브러리를 사용하여 일괄 변환이 가능합니다.
Q2: 온라인 변환기는 기밀 문서에 안전한가요?
플랫폼에 따라 다릅니다. 민감한 파일의 경우 XPS 뷰어나 Spire.PDF와 같은 오프라인 도구를 사용하는 것이 좋습니다.
Q3: Python으로 Mac/Linux에서 XPS를 PDF로 변환할 수 있나요?
예, Spire.PDF for Python은 크로스 플랫폼 변환을 지원하며, MuPDF에서 제공하는 명령줄 도구도 Mac 및 Linux와 호환됩니다.
Q4: PDF가 원본 레이아웃과 이미지를 유지하나요?
대부분의 방법은 레이아웃을 보존하지만, Spire.PDF와 같은 일괄 및 프로그래밍 방식 솔루션은 특히 복잡한 XPS 파일에 대해 최고의 충실도를 제공합니다.
관련 항목
Convertire XPS in PDF: metodi integrati, online e tramite script
Indice
- XPS vs PDF: Qual è la differenza?
- Metodo 1 - Utilizzo di XPS Viewer + Microsoft Print to PDF
- Metodo 2 - Utilizzo di convertitori online
- Metodo 3 - Utilizzo di strumenti da riga di comando
- Metodo 4 - Utilizzo di librerie Python (elaborazione batch)
- Confronto - Quale metodo scegliere
- Conclusione
- Domande frequenti
Devi convertire un file XPS in PDF? Non sei solo. Dalle aziende che archiviano documenti ai privati che condividono report, la conversione da XPS a PDF garantisce che i tuoi file siano accessibili, compatibili e dall'aspetto professionale.
In questo articolo, ti guideremo attraverso quattro modi affidabili per convertire XPS in PDF, inclusi strumenti integrati, convertitori online, opzioni da riga di comando ed elaborazione batch basata su Python, in modo che tu possa scegliere il metodo che meglio si adatta alle tue esigenze.
Navigazione rapida:
- Metodo 1 - Utilizzo di XPS Viewer + Microsoft Print to PDF
- Metodo 2 - Utilizzo di convertitori online
- Metodo 3 - Utilizzo di strumenti da riga di comando
- Metodo 4 - Utilizzo di librerie Python (elaborazione batch)
XPS vs PDF: Qual è la differenza?
PDF è lo standard multipiattaforma di lunga data di Adobe. È ricco di funzionalità, supportando moduli, annotazioni, crittografia, firme digitali e profili di stampa e archiviazione avanzati, ed è supportato da un vasto ecosistema di visualizzatori, editor e strumenti professionali. Il PDF garantisce un rendering affidabile, accessibilità e una solida sicurezza su tutti i dispositivi e settori.
XPS è il formato a layout fisso basato su XML e compresso in ZIP di Microsoft, utilizzato principalmente in determinati flussi di lavoro di stampa di Windows. Il suo set di funzionalità e il supporto di terze parti sono limitati rispetto al PDF, con conseguente minore interoperabilità e meno strumenti. Poiché il PDF offre compatibilità, funzionalità e adozione nel settore superiori, la conversione da XPS a PDF è spesso necessaria.
Metodo 1 - Utilizzo di XPS Viewer + Microsoft Print to PDF
Per gli utenti Windows, il modo più semplice per convertire un file XPS è tramite il visualizzatore XPS integrato e Microsoft Print to PDF. Questo metodo non richiede software aggiuntivo ed è ideale per conversioni una tantum o per un uso occasionale. Sfruttando la funzionalità di stampa in PDF del sistema, è possibile generare rapidamente un PDF senza compromettere il layout di base.
Passaggi:
- Apri il tuo file XPS utilizzando XPS Viewer.
- Fai clic su Stampa nella barra degli strumenti.
- Seleziona Microsoft Print to PDF come stampante.
- Scegli la posizione di output e salva il tuo PDF.
Vantaggi:
- Gratuito e non richiede installazione.
- Interfaccia semplice per utenti occasionali.
Svantaggi:
- Non è possibile elaborare più file contemporaneamente.
- La formattazione complessa potrebbe subire lievi variazioni.
Metodo 2 - Utilizzo di convertitori online
I convertitori online offrono un modo comodo per convertire XPS in PDF senza installare software. Sono particolarmente utili se hai bisogno di una conversione rapida o se utilizzi una piattaforma non Windows. La maggior parte degli strumenti online è semplice: basta caricare il file, selezionare PDF come formato di output e scaricare il risultato.
Passaggi:
- Visita un convertitore online affidabile, come CloudConvert.
- Carica il tuo file XPS.
- Scegli PDF come formato di destinazione.
- Fai clic su Converti e scarica il PDF risultante.
Vantaggi:
- Funziona su qualsiasi piattaforma (Windows, Mac, mobile).
- Nessuna installazione di software richiesta.
- Interfaccia rapida con trascinamento della selezione.
Svantaggi:
- Potrebbero essere applicati limiti sulla dimensione del file.
- Connessione Internet richiesta.
- Potenziali problemi di privacy per i file sensibili.
Metodo 3 - Utilizzo di strumenti da riga di comando (MuPDF)
Per utenti avanzati o flussi di lavoro di automazione, gli strumenti da riga di comando offrono opzioni di conversione flessibili. MuPDF fornisce un'utilità da riga di comando leggera ( mutool ) in grado di convertire file XPS in PDF, singolarmente o in script batch. Questo metodo è ideale per sviluppatori o amministratori IT che necessitano di risultati coerenti su più file.
Passaggi:
-
Scarica MuPDF.
- Vai al sito Web ufficiale di MuPDF: https://mupdf.com/downloads/
- Scarica il pacchetto di strumenti MuPDF per il tuo sistema operativo (Windows, macOS o Linux)
- Estrai il pacchetto in una cartella, ad es. C:\MuPDF
-
Apri un prompt dei comandi/terminale.
- Windows: premi Win + R, digita cmd, premi Invio
- macOS/Linux: apri il terminale
-
Vai alla cartella del tuo file XPS.
Usa il comando cd per cambiare la directory in quella in cui si trova il tuo file XPS. Esempio:
cd C:\Users\Administrator\Desktop\XPSFiles -
Esegui il comando di conversione.
Usa mutool convert con l'opzione -o per specificare il PDF di output:
C:\MuPDF\mutool.exe convert -o output.pdf input.xpsSpiegazione:
- convert → dice a MuPDF di convertire i formati di file
- -o output.pdf → specifica il nome del file PDF di output
- input.xps → il tuo file XPS
Su Linux/macOS, potrebbe assomigliare a:
./mutool convert -o output.pdf input.xps -
Controlla il PDF di output nella cartella di destinazione.
Vantaggi:
- Automatizzabile e scriptabile per l'elaborazione di massa.
- Multipiattaforma (Windows, Mac, Linux).
Svantaggi:
- Richiede conoscenze tecniche.
- L'installazione e la sintassi possono essere complesse per i principianti.
Metodo 4 - Utilizzo di librerie Python (elaborazione batch con Spire.PDF)
Per sviluppatori o aziende che necessitano di elaborazione batch, le librerie Python forniscono una soluzione efficiente. Utilizzando Spire.PDF per Python , è possibile convertire più file XPS in PDF in modo programmatico preservando l'integrità delle immagini e del layout di alta qualità. Questo approccio è ideale per automatizzare grandi flussi di lavoro o per l'integrazione in sistemi backend.
Passaggi:
- Installa la libreria richiesta.
- Utilizza lo script seguente per convertire un singolo file XPS in un file PDF.
pip install spire.pdffrom spire.pdf.common import *
from spire.pdf import *
# Carica un file XPS
doc = PdfDocument()
doc.LoadFromFile("Input.xps", FileFormat.XPS)
# Preserva la qualità delle immagini
doc.ConvertOptions.SetXpsToPdfOptions(True)
# Salva in PDF
doc.SaveToFile("XpsToPdf.pdf", FileFormat.PDF)
doc.Dispose()
Output:
Esempio di elaborazione batch:
import os
from spire.pdf.common import *
from spire.pdf import *
folder = r"C:\path\to\your\folder"
for name in os.listdir(folder):
if not name.lower().endswith(".xps"):
continue
in_path = os.path.join(folder, name)
out_path = os.path.join(folder, os.path.splitext(name)[0] + ".pdf")
doc = PdfDocument()
doc.LoadFromFile(in_path, FileFormat.XPS)
doc.ConvertOptions.SetXpsToPdfOptions(True)
doc.SaveToFile(out_path, FileFormat.PDF)
doc.Dispose()
Vantaggi:
- Pieno controllo sulla conversione batch.
- Conservazione ad alta fedeltà di layout e immagini.
- Si integra facilmente nei flussi di lavoro automatizzati.
Svantaggi:
- Richiede conoscenze di programmazione.
- È necessaria l'installazione della libreria.
Oltre a convertire XPS in PDF, Spire.PDF per Python consente anche di applicare filigrane, aggiungere annotazioni e crittografare documenti PDF in modo programmatico. È possibile esplorare queste funzionalità per migliorare o proteggere i file PDF direttamente dal codice, rendendola una soluzione versatile per molte attività di automazione PDF.
Confronto – Quale metodo scegliere?
| Metodo | Facilità d'uso | Supporto batch | Piattaforma | Vantaggi | Svantaggi |
|---|---|---|---|---|---|
| Visualizzatore XPS | ★★★★ | ✗ | Windows | Gratuito, semplice | File singolo, problemi di formattazione |
| Convertitori online | ★★★★ | ✗ | Qualsiasi | Nessuna installazione, veloce | Privacy, limiti di dimensione del file |
| MuPDF | ★★ | ✓ | Windows / Mac / Linux | Automatizzabile | Richiesta configurazione tecnica |
| Python / Spire.PDF | ★★ | ✓ | Multipiattaforma | Elaborazione batch, alta fedeltà | Richiede conoscenze di programmazione |
Conclusione
La scelta del metodo giusto dipende dalle tue esigenze: gli utenti occasionali potrebbero preferire il Visualizzatore XPS o i convertitori online, while developers and businesses handling multiple files will benefit from MuPDF or Python/Spire.PDF per l'elaborazione batch. Per una conversione di alta qualità, automatizzata e scalabile, Spire.PDF è una soluzione solida che garantisce che l'output PDF mantenga l'integrità dei file XPS originali.
Domande frequenti
D1: Posso convertire più file XPS contemporaneamente?
Sì, la conversione batch è possibile utilizzando strumenti da riga di comando come MuPDF o librerie Python come Spire.PDF.
D2: I convertitori online sono sicuri per i documenti riservati?
Dipende dalla piattaforma. Per i file sensibili, si consiglia di utilizzare strumenti offline come XPS Viewer o Spire.PDF.
D3: Python può convertire XPS in PDF su Mac/Linux?
Sì, Spire.PDF per Python supporta la conversione multipiattaforma e anche lo strumento da riga di comando fornito da MuPDF è compatibile con Mac e Linux.
D4: Il PDF manterrà il layout e le immagini originali?
La maggior parte dei metodi preserva il layout, ma le soluzioni batch e programmatiche come Spire.PDF forniscono la massima fedeltà, specialmente per i file XPS complessi.
Vedi anche
Convertir XPS en PDF : méthodes intégrées, en ligne et par script
Table des matières
- XPS vs PDF : Quelle est la différence ?
- Méthode 1 - Utilisation de la visionneuse XPS + Microsoft Print to PDF
- Méthode 2 - Utilisation de convertisseurs en ligne
- Méthode 3 - Utilisation d'outils en ligne de commande
- Méthode 4 - Utilisation de bibliothèques Python (traitement par lots)
- Comparaison - Quelle méthode choisir
- Conclusion
- FAQ
Besoin de convertir un fichier XPS en PDF ? Vous n'êtes pas seul. Des entreprises archivant des documents aux particuliers partageant des rapports, la conversion de XPS en PDF garantit que vos fichiers sont accessibles, compatibles et d'aspect professionnel.
Dans cet article, nous vous présenterons quatre méthodes fiables pour convertir XPS en PDF, y compris des outils intégrés, des convertisseurs en ligne, des options de ligne de commande et un traitement par lots basé sur Python, afin que vous puissiez choisir la méthode qui correspond le mieux à vos besoins.
Navigation rapide:
- Méthode 1 - Utilisation de la visionneuse XPS + Microsoft Print to PDF
- Méthode 2 - Utilisation de convertisseurs en ligne
- Méthode 3 - Utilisation d'outils en ligne de commande
- Méthode 4 - Utilisation de bibliothèques Python (traitement par lots)
XPS vs PDF : Quelle est la différence ?
PDF est la norme multiplateforme de longue date d'Adobe. Il est riche en fonctionnalités — prenant en charge les formulaires, les annotations, le cryptage, les signatures numériques et les profils d'impression et d'archivage avancés — et est soutenu par un vaste écosystème de visionneuses, d'éditeurs et d'outils professionnels. Le PDF garantit un rendu fiable, une accessibilité et une sécurité robuste sur tous les appareils et dans tous les secteurs.
XPS est le format à mise en page fixe de Microsoft, basé sur XML et compressé en ZIP, principalement utilisé dans certains flux de travail d'impression Windows. Son ensemble de fonctionnalités et son support tiers sont limités par rapport au PDF, ce qui se traduit par une interopérabilité plus faible et moins d'outils. Étant donné que le PDF offre une compatibilité, des fonctionnalités et une adoption par l'industrie supérieures, la conversion de XPS en PDF est souvent nécessaire.
Méthode 1 - Utilisation de la visionneuse XPS + Microsoft Print to PDF
Pour les utilisateurs de Windows, le moyen le plus simple de convertir un fichier XPS consiste à utiliser la visionneuse XPS intégrée et Microsoft Print to PDF. Cette méthode ne nécessite aucun logiciel supplémentaire et est idéale pour les conversions ponctuelles ou une utilisation occasionnelle. En tirant parti de la fonctionnalité d'impression au format PDF du système, vous pouvez rapidement générer un PDF sans compromettre la mise en page de base.
Étapes:
- Ouvrez votre fichier XPS à l'aide de la visionneuse XPS.
- Cliquez sur Imprimer dans la barre d'outils.
- Sélectionnez Microsoft Print to PDF comme imprimante.
- Choisissez l'emplacement de sortie et enregistrez votre PDF.
Avantages:
- Gratuit et ne nécessite aucune installation.
- Interface simple pour les utilisateurs occasionnels.
Inconvénients:
- Impossible de traiter plusieurs fichiers à la fois.
- La mise en forme complexe peut légèrement se décaler.
Méthode 2 - Utilisation de convertisseurs en ligne
Les convertisseurs en ligne offrent un moyen pratique de convertir XPS en PDF sans installer de logiciel. Ils sont particulièrement utiles si vous avez besoin d'une conversion rapide ou si vous utilisez une plate-forme non Windows. La plupart des outils en ligne sont aussi simples que de télécharger votre fichier, de sélectionner PDF comme format de sortie et de télécharger le résultat.
Étapes:
- Visitez un convertisseur en ligne réputé, tel que CloudConvert.
- Téléchargez votre fichier XPS.
- Choisissez PDF comme format cible.
- Cliquez sur Convertir et téléchargez le PDF résultant.
Avantages:
- Fonctionne sur n'importe quelle plate-forme (Windows, Mac, mobile).
- Aucune installation de logiciel n'est nécessaire.
- Interface rapide par glisser-déposer.
Inconvénients:
- Des limites de taille de fichier peuvent s'appliquer.
- Connexion Internet requise.
- Problèmes de confidentialité potentiels pour les fichiers sensibles.
Méthode 3 - Utilisation d'outils en ligne de commande (MuPDF)
Pour les utilisateurs avancés ou les flux de travail d'automatisation, les outils en ligne de commande offrent des options de conversion flexibles. MuPDF fournit un utilitaire de ligne de commande léger ( mutool ) qui peut convertir des fichiers XPS en PDF, individuellement ou dans des scripts par lots. Cette méthode est idéale pour les développeurs ou les administrateurs informatiques qui ont besoin de résultats cohérents sur plusieurs fichiers.
Étapes:
-
Téléchargez MuPDF.
- Allez sur le site officiel de MuPDF : https://mupdf.com/downloads/
- Téléchargez le package d'outils MuPDF pour votre système d'exploitation (Windows, macOS ou Linux)
- Extrayez le package dans un dossier, par exemple, C:\MuPDF
-
Ouvrez une invite de commandes / un terminal.
- Windows : Appuyez sur Win + R, tapez cmd, appuyez sur Entrée
- macOS/Linux : Ouvrez le terminal
-
Accédez au dossier de votre fichier XPS.
Utilisez la commande cd pour changer le répertoire où se trouve votre fichier XPS. Exemple :
cd C:\Users\Administrator\Desktop\XPSFiles -
Exécutez la commande de conversion.
Utilisez mutool convert avec l'option -o pour spécifier le PDF de sortie :
C:\MuPDF\mutool.exe convert -o output.pdf input.xpsExplication :
- convert → indique à MuPDF de convertir les formats de fichiers
- -o output.pdf → spécifie le nom du fichier PDF de sortie
- input.xps → votre fichier XPS
Sous Linux/macOS, cela pourrait ressembler à :
./mutool convert -o output.pdf input.xps -
Vérifiez le PDF de sortie dans votre dossier cible.
Avantages:
- Automatisable et scriptable pour le traitement en masse.
- Multiplateforme (Windows, Mac, Linux).
Inconvénients:
- Nécessite des connaissances techniques.
- La configuration et la syntaxe peuvent être complexes pour les débutants.
Méthode 4 - Utilisation de bibliothèques Python (traitement par lots avec Spire.PDF)
Pour les développeurs ou les entreprises ayant besoin d'un traitement par lots, les bibliothèques Python offrent une solution efficace. En utilisant Spire.PDF pour Python, vous pouvez convertir plusieurs fichiers XPS en PDF par programme tout en préservant des images de haute qualité et l'intégrité de la mise en page. Cette approche est idéale pour automatiser de grands flux de travail ou pour s'intégrer dans des systèmes backend.
Étapes:
- Installez la bibliothèque requise.
- Utilisez le script suivant pour convertir un seul fichier XPS en fichier PDF.
pip install spire.pdffrom spire.pdf.common import *
from spire.pdf import *
# Charger un fichier XPS
doc = PdfDocument()
doc.LoadFromFile("Input.xps", FileFormat.XPS)
# Préserver la qualité des images
doc.ConvertOptions.SetXpsToPdfOptions(True)
# Enregistrer en PDF
doc.SaveToFile("XpsToPdf.pdf", FileFormat.PDF)
doc.Dispose()
Sortie:
Exemple de traitement par lots :
import os
from spire.pdf.common import *
from spire.pdf import *
folder = r"C:\path\to\your\folder"
for name in os.listdir(folder):
if not name.lower().endswith(".xps"):
continue
in_path = os.path.join(folder, name)
out_path = os.path.join(folder, os.path.splitext(name)[0] + ".pdf")
doc = PdfDocument()
doc.LoadFromFile(in_path, FileFormat.XPS)
doc.ConvertOptions.SetXpsToPdfOptions(True)
doc.SaveToFile(out_path, FileFormat.PDF)
doc.Dispose()
Avantages:
- Contrôle total sur la conversion par lots.
- Préservation haute fidélité de la mise en page et des images.
- S'intègre facilement dans les flux de travail automatisés.
Inconvénients:
- Nécessite des connaissances en codage.
- Installation de la bibliothèque nécessaire.
En plus de la conversion de XPS en PDF, Spire.PDF pour Python vous permet également d'appliquer par programme des filigranes, d'ajouter des annotations et de crypter des documents PDF. Vous pouvez explorer ces fonctionnalités pour améliorer ou sécuriser vos fichiers PDF directement depuis votre code, ce qui en fait une solution polyvalente pour de nombreuses tâches d'automatisation PDF.
Comparaison – Quelle méthode choisir ?
| Méthode | Facilité d'utilisation | Support par lots | Plate-forme | Avantages | Inconvénients |
|---|---|---|---|---|---|
| Visionneuse XPS | ★★★★ | ✗ | Windows | Gratuit, simple | Fichier unique, problèmes de formatage |
| Convertisseurs en ligne | ★★★★ | ✗ | Toutes | Aucune installation, rapide | Confidentialité, limites de taille de fichier |
| MuPDF | ★★ | ✓ | Windows / Mac / Linux | Automatisable | Configuration technique requise |
| Python / Spire.PDF | ★★ | ✓ | Multiplateforme | Traitement par lots, haute fidélité | Nécessite des connaissances en codage |
Conclusion
Le choix de la bonne méthode dépend de vos besoins : les utilisateurs occasionnels peuvent préférer la visionneuse XPS ou les convertisseurs en ligne, tandis que les développeurs et les entreprises qui manipulent plusieurs fichiers bénéficieront de MuPDF ou de Python/Spire.PDF pour le traitement par lots. Pour une conversion de haute qualité, automatisée et évolutive, Spire.PDF est une solution robuste qui garantit que votre sortie PDF conserve l'intégrité des fichiers XPS d'origine.
FAQ
Q1 : Puis-je convertir plusieurs fichiers XPS à la fois ?
Oui, la conversion par lots est possible à l'aide d'outils en ligne de commande comme MuPDF ou de bibliothèques Python telles que Spire.PDF.
Q2 : Les convertisseurs en ligne sont-ils sûrs pour les documents confidentiels ?
Cela dépend de la plate-forme. Pour les fichiers sensibles, il est recommandé d'utiliser des outils hors ligne comme la visionneuse XPS ou Spire.PDF.
Q3 : Python peut-il convertir XPS en PDF sur Mac/Linux ?
Oui, Spire.PDF pour Python prend en charge la conversion multiplateforme, et l'outil de ligne de commande fourni par MuPDF est également compatible avec Mac et Linux.
Q4 : Le PDF conservera-t-il la mise en page et les images d'origine ?
La plupart des méthodes préservent la mise en page, mais les solutions par lots et programmatiques comme Spire.PDF offrent la plus haute fidélité, en particulier pour les fichiers XPS complexes.
Voir aussi
Convertir XPS a PDF: métodos integrados, en línea y mediante scripts
Tabla de Contenidos
- XPS vs PDF: ¿Cuál es la diferencia?
- Método 1 - Usando el Visor XPS + Microsoft Print to PDF
- Método 2 - Usando convertidores en línea
- Método 3 - Usando herramientas de línea de comandos
- Método 4 - Usando bibliotecas de Python (Procesamiento por lotes)
- Comparación - ¿Qué método debería elegir?
- Conclusión
- Preguntas frecuentes
¿Necesita convertir un archivo XPS a PDF? No está solo. Desde empresas que archivan documentos hasta particulares que comparten informes, convertir XPS a PDF garantiza que sus archivos sean accesibles, compatibles y de aspecto profesional.
En este artículo, le guiaremos a través de cuatro formas fiables de convertir XPS a PDF, incluyendo herramientas integradas, convertidores en línea, opciones de línea de comandos y procesamiento por lotes basado en Python, para que pueda elegir el método que mejor se adapte a sus necesidades.
Navegación rápida:
- Método 1 - Usando el Visor XPS + Microsoft Print to PDF
- Método 2 - Usando convertidores en línea
- Método 3 - Usando herramientas de línea de comandos
- Método 4 - Usando bibliotecas de Python (Procesamiento por lotes)
XPS vs PDF: ¿Cuál es la diferencia?
PDF es el estándar multiplataforma de larga data de Adobe. Es rico en funciones—admite formularios, anotaciones, cifrado, firmas digitales y perfiles avanzados de impresión y archivo—y está respaldado por un vasto ecosistema de visores, editores y herramientas profesionales. El PDF garantiza una representación fiable, accesibilidad y una seguridad robusta en todos los dispositivos e industrias.
XPS es el formato de diseño fijo basado en XML y empaquetado en ZIP de Microsoft, utilizado principalmente en ciertos flujos de trabajo de impresión de Windows. Su conjunto de características y el soporte de terceros son limitados en comparación con el PDF, lo que resulta en una interoperabilidad más débil y menos herramientas. Debido a que el PDF ofrece una compatibilidad, características y adopción de la industria superiores, a menudo es necesario convertir XPS a PDF.
Método 1 - Usando el Visor XPS + Microsoft Print to PDF
Para los usuarios de Windows, la forma más sencilla de convertir un archivo XPS es a través del Visor XPS integrado y Microsoft Print to PDF. Este método no requiere software adicional y es ideal para conversiones únicas o de uso ocasional. Al aprovechar la funcionalidad de imprimir a PDF del sistema, puede generar rápidamente un PDF sin comprometer el diseño básico.
Pasos:
- Abra su archivo XPS usando el Visor XPS.
- Haga clic en Imprimir en la barra de herramientas.
- Seleccione Microsoft Print to PDF como la impresora.
- Elija la ubicación de salida y guarde su PDF.
Ventajas:
- Gratis y no requiere instalación.
- Interfaz sencilla para usuarios ocasionales.
Desventajas:
- No puede procesar varios archivos a la vez.
- El formato complejo puede cambiar ligeramente.
Método 2 - Usando convertidores en línea
Los convertidores en línea ofrecen una forma conveniente de convertir XPS a PDF sin instalar software. Son particularmente útiles si necesita una conversión rápida o si está utilizando una plataforma que no es Windows. La mayoría de las herramientas en línea son tan simples como cargar su archivo, seleccionar PDF como formato de salida y descargar el resultado.
Pasos:
- Visite un convertidor en línea de buena reputación, como CloudConvert.
- Cargue su archivo XPS.
- Elija PDF como formato de destino.
- Haga clic en Convertir y descargue el PDF resultante.
Ventajas:
- Funciona en cualquier plataforma (Windows, Mac, móvil).
- No se necesita instalación de software.
- Interfaz rápida de arrastrar y soltar.
Desventajas:
- Pueden aplicarse límites de tamaño de archivo.
- Se requiere conexión a Internet.
- Posibles problemas de privacidad para archivos sensibles.
Método 3 - Usando herramientas de línea de comandos (MuPDF)
Para usuarios avanzados o flujos de trabajo de automatización, las herramientas de línea de comandos ofrecen opciones de conversión flexibles. MuPDF proporciona una utilidad de línea de comandos ligera ( mutool ) que puede convertir archivos XPS a PDF, ya sea individualmente o en scripts por lotes. Este método es ideal para desarrolladores o administradores de TI que necesitan resultados consistentes en múltiples archivos.
Pasos:
-
Descargar MuPDF.
- Vaya al sitio web oficial de MuPDF: https://mupdf.com/downloads/
- Descargue el paquete de herramientas de MuPDF para su sistema operativo (Windows, macOS o Linux)
- Extraiga el paquete a una carpeta, por ejemplo, C:\MuPDF
-
Abra un Símbolo del sistema / Terminal.
- Windows: Presione Win + R, escriba cmd, presione Enter
- macOS/Linux: Abra la Terminal
-
Navegue a la carpeta de su archivo XPS.
Use el comando cd para cambiar el directorio a donde se encuentra su archivo XPS. Ejemplo:
cd C:\Users\Administrator\Desktop\XPSFiles -
Ejecute el comando de conversión.
Use mutool convert con la opción -o para especificar el PDF de salida:
C:\MuPDF\mutool.exe convert -o output.pdf input.xpsExplicación:
- convert → le dice a MuPDF que convierta formatos de archivo
- -o output.pdf → especifica el nombre del archivo PDF de salida
- input.xps → su archivo XPS
En Linux/macOS, podría verse así:
./mutool convert -o output.pdf input.xps -
Verifique el PDF de salida en su carpeta de destino.
Ventajas:
- Automatizable y programable para procesamiento masivo.
- Multiplataforma (Windows, Mac, Linux).
Desventajas:
- Requiere conocimientos técnicos.
- La configuración y la sintaxis pueden ser complejas para los principiantes.
Método 4 - Usando bibliotecas de Python (Procesamiento por lotes con Spire.PDF)
Para desarrolladores o empresas que necesitan procesamiento por lotes, las bibliotecas de Python proporcionan una solución eficiente. Usando Spire.PDF para Python, puede convertir múltiples archivos XPS en PDF de forma programática conservando imágenes de alta calidad y la integridad del diseño. Este enfoque es ideal para automatizar grandes flujos de trabajo o para integrarse en sistemas de backend.
Pasos:
- Instale la biblioteca requerida.
- Use el siguiente script para convertir un solo archivo XPS a un archivo PDF.
pip install spire.pdffrom spire.pdf.common import *
from spire.pdf import *
# Load an XPS file
doc = PdfDocument()
doc.LoadFromFile("Input.xps", FileFormat.XPS)
# Preserve images' quality
doc.ConvertOptions.SetXpsToPdfOptions(True)
# Save to PDF
doc.SaveToFile("XpsToPdf.pdf", FileFormat.PDF)
doc.Dispose()
Salida:
Ejemplo de procesamiento por lotes:
import os
from spire.pdf.common import *
from spire.pdf import *
folder = r"C:\path\to\your\folder"
for name in os.listdir(folder):
if not name.lower().endswith(".xps"):
continue
in_path = os.path.join(folder, name)
out_path = os.path.join(folder, os.path.splitext(name)[0] + ".pdf")
doc = PdfDocument()
doc.LoadFromFile(in_path, FileFormat.XPS)
doc.ConvertOptions.SetXpsToPdfOptions(True)
doc.SaveToFile(out_path, FileFormat.PDF)
doc.Dispose()
Ventajas:
- Control total sobre la conversión por lotes.
- Preservación de alta fidelidad del diseño y las imágenes.
- Se integra fácilmente en flujos de trabajo automatizados.
Desventajas:
- Requiere conocimientos de codificación.
- Se necesita instalación de la biblioteca.
Además de convertir XPS a PDF, Spire.PDF para Python también le permite aplicar marcas de agua, agregar anotaciones y cifrar documentos PDF de forma programática. Puede explorar estas características para mejorar o proteger sus archivos PDF directamente desde su código, lo que lo convierte en una solución versátil para muchas tareas de automatización de PDF.
Comparación – ¿Qué método debería elegir?
| Método | Facilidad de uso | Soporte por lotes | Plataforma | Ventajas | Desventajas |
|---|---|---|---|---|---|
| Visor XPS | ★★★★ | ✗ | Windows | Gratis, simple | Archivo único, problemas de formato |
| Convertidores en línea | ★★★★ | ✗ | Cualquiera | Sin instalación, rápido | Privacidad, límites de tamaño de archivo |
| MuPDF | ★★ | ✓ | Windows / Mac / Linux | Automatizable | Se requiere configuración técnica |
| Python / Spire.PDF | ★★ | ✓ | Multiplataforma | Procesamiento por lotes, alta fidelidad | Requiere conocimientos de codificación |
Conclusión
Elegir el método correcto depende de sus necesidades: los usuarios ocasionales pueden preferir el Visor XPS o los convertidores en línea, mientras que los desarrolladores y las empresas que manejan múltiples archivos se beneficiarán de MuPDF o Python/Spire.PDF para el procesamiento por lotes. Para una conversión de alta calidad, automatizada y escalable, Spire.PDF es una solución robusta que garantiza que su salida de PDF mantenga la integridad de los archivos XPS originales.
Preguntas frecuentes
P1: ¿Puedo convertir varios archivos XPS a la vez?
Sí, la conversión por lotes es posible utilizando herramientas de línea de comandos como MuPDF o bibliotecas de Python como Spire.PDF.
P2: ¿Son seguros los convertidores en línea para documentos confidenciales?
Depende de la plataforma. Para archivos sensibles, se recomienda utilizar herramientas sin conexión como el Visor XPS o Spire.PDF.
P3: ¿Puede Python convertir XPS a PDF en Mac/Linux?
Sí, Spire.PDF para Python admite la conversión multiplataforma, y la herramienta de línea de comandos proporcionada por MuPDF también es compatible con Mac y Linux.
P4: ¿El PDF conservará el diseño y las imágenes originales?
La mayoría de los métodos conservan el diseño, pero las soluciones por lotes y programáticas como Spire.PDF proporcionan la más alta fidelidad, especialmente para archivos XPS complejos.
Ver también
XPS in PDF konvertieren: Integrierte, Online- und Skript-Methoden
Inhaltsverzeichnis
- XPS vs PDF: Was ist der Unterschied?
- Methode 1 - Verwendung von XPS Viewer + Microsoft Print to PDF
- Methode 2 - Verwendung von Online-Konvertern
- Methode 3 - Verwendung von Kommandozeilen-Tools
- Methode 4 - Verwendung von Python-Bibliotheken (Stapelverarbeitung)
- Vergleich - Welche Methode sollten Sie wählen
- Fazit
- FAQs
Müssen Sie eine XPS-Datei in PDF konvertieren? Sie sind nicht allein. Von Unternehmen, die Dokumente archivieren, bis hin zu Privatpersonen, die Berichte teilen – die Konvertierung von XPS zu PDF stellt sicher, dass Ihre Dateien zugänglich, kompatibel und professionell aussehen.
In diesem Artikel führen wir Sie durch vier zuverlässige Methoden zur Konvertierung von XPS in PDF, darunter integrierte Tools, Online-Konverter, Kommandozeilenoptionen und Python-basierte Stapelverarbeitung, damit Sie die Methode wählen können, die am besten zu Ihren Bedürfnissen passt.
Schnelle Navigation:
- Methode 1 - Verwendung von XPS Viewer + Microsoft Print to PDF
- Methode 2 - Verwendung von Online-Konvertern
- Methode 3 - Verwendung von Kommandozeilen-Tools
- Methode 4 - Verwendung von Python-Bibliotheken (Stapelverarbeitung)
XPS vs PDF: Was ist der Unterschied?
PDF ist Adobes langjähriger, plattformübergreifender Standard. Es ist funktionsreich – unterstützt Formulare, Anmerkungen, Verschlüsselung, digitale Signaturen sowie erweiterte Druck- und Archivierungsprofile – und wird von einem umfangreichen Ökosystem aus Betrachtern, Editoren und professionellen Tools unterstützt. PDF gewährleistet zuverlässige Darstellung, Barrierefreiheit und robuste Sicherheit über Geräte und Branchen hinweg.
XPS ist Microsofts XML-basiertes, ZIP-verpacktes Fixed-Layout-Format, das hauptsächlich in bestimmten Windows-Druckabläufen verwendet wird. Sein Funktionsumfang und die Unterstützung durch Drittanbieter sind im Vergleich zu PDF begrenzt, was zu geringerer Interoperabilität und weniger Tools führt. Da PDF überlegene Kompatibilität, Funktionen und Branchenakzeptanz bietet, ist die Konvertierung von XPS zu PDF oft notwendig.
Methode 1 - Verwendung von XPS Viewer + Microsoft Print to PDF
Für Windows-Benutzer ist der einfachste Weg, eine XPS-Datei zu konvertieren, der integrierte XPS Viewer und Microsoft Print to PDF. Diese Methode erfordert keine zusätzliche Software und eignet sich ideal für Einzelkonvertierungen oder gelegentliche Nutzung. Durch die Nutzung der systemeigenen Druck-zu-PDF-Funktion können Sie schnell ein PDF erstellen, ohne das grundlegende Layout zu beeinträchtigen.
Schritte:
- Öffnen Sie Ihre XPS-Datei mit dem XPS Viewer.
- Klicken Sie in der Symbolleiste auf Drucken.
- Wählen Sie Microsoft Print to PDF als Drucker aus.
- Wählen Sie den Speicherort und speichern Sie Ihr PDF.
Vorteile:
- Kostenlos und erfordert keine Installation.
- Einfache Benutzeroberfläche für Gelegenheitsnutzer.
Nachteile:
- Kann nicht mehrere Dateien gleichzeitig verarbeiten.
- Komplexe Formatierungen können leicht verschoben werden.
Methode 2 - Verwendung von Online-Konvertern
Online-Konverter bieten eine bequeme Möglichkeit, XPS in PDF zu konvertieren, ohne Software zu installieren. Sie sind besonders nützlich, wenn Sie eine schnelle Konvertierung benötigen oder eine Nicht-Windows-Plattform verwenden. Die meisten Online-Tools sind so einfach wie das Hochladen Ihrer Datei, die Auswahl von PDF als Ausgabeformat und das Herunterladen des Ergebnisses.
Schritte:
- Besuchen Sie einen seriösen Online-Konverter wie CloudConvert.
- Laden Sie Ihre XPS-Datei hoch.
- Wählen Sie PDF als Zielformat.
- Klicken Sie auf Konvertieren und laden Sie das resultierende PDF herunter.
Vorteile:
- Funktioniert auf jeder Plattform (Windows, Mac, mobil).
- Keine Softwareinstallation erforderlich.
- Schnelle Drag-and-Drop-Oberfläche.
Nachteile:
- Dateigrößenbeschränkungen können gelten.
- Internetverbindung erforderlich.
- Mögliche Datenschutzbedenken bei sensiblen Dateien.
Methode 3 - Verwendung von Kommandozeilen-Tools (MuPDF)
Für fortgeschrittene Benutzer oder Automatisierungsabläufe bieten Kommandozeilen-Tools flexible Konvertierungsoptionen. MuPDF stellt ein leichtgewichtiges Kommandozeilen-Tool ( mutool ) bereit, mit dem XPS-Dateien einzeln oder in Stapelskripten in PDF konvertiert werden können. Diese Methode ist ideal für Entwickler oder IT-Administratoren, die konsistente Ergebnisse über mehrere Dateien benötigen.
Schritte:
-
MuPDF herunterladen.
- Besuchen Sie die offizielle MuPDF-Webseite: https://mupdf.com/downloads/
- Laden Sie das MuPDF-Tools-Paket für Ihr Betriebssystem (Windows, macOS oder Linux) herunter
- Entpacken Sie das Paket in einen Ordner, z.B. C:\MuPDF
-
Öffnen Sie die Eingabeaufforderung / das Terminal.
- Windows: Drücken Sie Win + R, geben Sie cmd ein, drücken Sie Enter
- macOS/Linux: Terminal öffnen
-
Navigieren Sie zu Ihrem XPS-Dateiordner.
Verwenden Sie den cd-Befehl, um in das Verzeichnis zu wechseln, in dem sich Ihre XPS-Datei befindet. Beispiel:
cd C:\Users\Administrator\Desktop\XPSFiles -
Führen Sie den Konvertierungsbefehl aus.
Verwenden Sie mutool convert mit der -o Option, um die Ausgabedatei anzugeben:
C:\MuPDF\mutool.exe convert -o output.pdf input.xpsErklärung:
- convert → weist MuPDF an, Dateiformate zu konvertieren
- -o output.pdf → gibt den Namen der PDF-Ausgabedatei an
- input.xps → Ihre XPS-Datei
Unter Linux/macOS könnte es so aussehen:
./mutool convert -o output.pdf input.xps -
Überprüfen Sie das Ausgabe-PDF in Ihrem Zielordner.
Vorteile:
- Automatisierbar und skriptfähig für die Stapelverarbeitung.
- Plattformübergreifend (Windows, Mac, Linux).
Nachteile:
- Erfordert technisches Wissen.
- Einrichtung und Syntax können für Anfänger komplex sein.
Methode 4 - Verwendung von Python-Bibliotheken (Stapelverarbeitung mit Spire.PDF)
Für Entwickler oder Unternehmen, die Stapelverarbeitung benötigen, bieten Python-Bibliotheken eine effiziente Lösung. Mit Spire.PDF für Python können Sie mehrere XPS-Dateien programmgesteuert in PDFs konvertieren und dabei hochwertige Bilder und Layoutintegrität bewahren. Dieser Ansatz eignet sich ideal zur Automatisierung großer Workflows oder zur Integration in Backend-Systeme.
Schritte:
- Installieren Sie die benötigte Bibliothek.
- Verwenden Sie folgendes Skript, um eine einzelne XPS-Datei in eine PDF-Datei zu konvertieren.
pip install spire.pdffrom spire.pdf.common import *
from spire.pdf import *
# Laden einer XPS-Datei
doc = PdfDocument()
doc.LoadFromFile("Input.xps", FileFormat.XPS)
# Qualität der Bilder bewahren
doc.ConvertOptions.SetXpsToPdfOptions(True)
# Als PDF speichern
doc.SaveToFile("XpsToPdf.pdf", FileFormat.PDF)
doc.Dispose()
Ausgabe:
Beispiel für Stapelverarbeitung:
import os
from spire.pdf.common import *
from spire.pdf import *
folder = r"C:\path\to\your\folder"
for name in os.listdir(folder):
if not name.lower().endswith(".xps"):
continue
in_path = os.path.join(folder, name)
out_path = os.path.join(folder, os.path.splitext(name)[0] + ".pdf")
doc = PdfDocument()
doc.LoadFromFile(in_path, FileFormat.XPS)
doc.ConvertOptions.SetXpsToPdfOptions(True)
doc.SaveToFile(out_path, FileFormat.PDF)
doc.Dispose()
Vorteile:
- Volle Kontrolle über die Stapelkonvertierung.
- Hohe Genauigkeit bei Layout und Bildern.
- Einfache Integration in automatisierte Workflows.
Nachteile:
- Erfordert Programmierkenntnisse.
- Bibliotheksinstallation erforderlich.
Neben der Konvertierung von XPS zu PDF ermöglicht Spire.PDF für Python auch das programmgesteuerte Hinzufügen von Wasserzeichen, das Einfügen von Anmerkungen und das Verschlüsseln von PDF-Dokumenten. Sie können diese Funktionen nutzen, um Ihre PDF-Dateien direkt aus dem Code heraus zu verbessern oder zu sichern, was es zu einer vielseitigen Lösung für viele PDF-Automatisierungsaufgaben macht.
Vergleich – Welche Methode sollten Sie wählen?
| Methode | Benutzerfreundlichkeit | Stapelverarbeitung | Plattform | Vorteile | Nachteile |
|---|---|---|---|---|---|
| XPS Viewer | ★★★★ | ✗ | Windows | Kostenlos, einfach | Einzeldatei, Formatierungsprobleme |
| Online-Konverter | ★★★★ | ✗ | Beliebig | Keine Installation, schnell | Datenschutz, Dateigrößenbeschränkungen |
| MuPDF | ★★ | ✓ | Windows / Mac / Linux | Automatisierbar | Technische Einrichtung erforderlich |
| Python / Spire.PDF | ★★ | ✓ | Plattformübergreifend | Stapelverarbeitung, hohe Genauigkeit | Erfordert Programmierkenntnisse |
Fazit
Die Wahl der richtigen Methode hängt von Ihren Bedürfnissen ab: Gelegenheitsnutzer bevorzugen möglicherweise XPS Viewer oder Online-Konverter, während Entwickler und Unternehmen, die mehrere Dateien verarbeiten, von MuPDF oder Python/Spire.PDF für die Stapelverarbeitung profitieren. Für hochwertige, automatisierte und skalierbare Konvertierung ist Spire.PDF eine robuste Lösung, die sicherstellt, dass Ihre PDF-Ausgabe die Integrität der ursprünglichen XPS-Dateien bewahrt.
FAQs
F1: Kann ich mehrere XPS-Dateien gleichzeitig konvertieren?
Ja, Stapelkonvertierung ist mit Kommandozeilen-Tools wie MuPDF oder Python-Bibliotheken wie Spire.PDF möglich.
F2: Sind Online-Konverter sicher für vertrauliche Dokumente?
Das hängt von der Plattform ab. Für sensible Dateien wird empfohlen, Offline-Tools wie XPS Viewer oder Spire.PDF zu verwenden.
F3: Kann Python XPS auf Mac/Linux in PDF konvertieren?
Ja, Spire.PDF für Python unterstützt plattformübergreifende Konvertierung, und das von MuPDF bereitgestellte Kommandozeilen-Tool ist ebenfalls mit Mac und Linux kompatibel.
F4: Behält das PDF das ursprüngliche Layout und die Bilder bei?
Die meisten Methoden bewahren das Layout, aber Stapel- und programmgesteuerte Lösungen wie Spire.PDF bieten die höchste Genauigkeit, insbesondere bei komplexen XPS-Dateien.
Siehe auch
Преобразование XPS в PDF: встроенные, онлайн и программные методы
Содержание
- XPS против PDF: в чем разница?
- Метод 1 - Использование XPS Viewer + Microsoft Print to PDF
- Метод 2 - Использование онлайн-конвертеров
- Метод 3 - Использование командной строки
- Метод 4 - Использование библиотек Python (пакетная обработка)
- Сравнение - какой метод выбрать
- Заключение
- Часто задаваемые вопросы
Нужно конвертировать файл XPS в PDF? Вы не одиноки. От компаний, архивирующих документы, до частных лиц, обменивающихся отчетами — конвертация XPS в PDF гарантирует, что ваши файлы будут доступны, совместимы и выглядеть профессионально.
В этой статье мы рассмотрим четыре надежных способа конвертации XPS в PDF, включая встроенные инструменты, онлайн-конвертеры, командную строку и пакетную обработку на Python, чтобы вы могли выбрать метод, который лучше всего подходит для ваших нужд.
Быстрая навигация:
- Метод 1 - Использование XPS Viewer + Microsoft Print to PDF
- Метод 2 - Использование онлайн-конвертеров
- Метод 3 - Использование командной строки
- Метод 4 - Использование библиотек Python (пакетная обработка)
XPS против PDF: в чем разница?
PDF — это давно устоявшийся кроссплатформенный стандарт Adobe. Он богат функциями — поддерживает формы, аннотации, шифрование, цифровые подписи, расширенные профили печати и архивирования — и поддерживается огромной экосистемой просмотрщиков, редакторов и профессиональных инструментов. PDF обеспечивает надежное отображение, доступность и высокую безопасность на разных устройствах и в разных отраслях.
XPS — это основанный на XML формат с фиксированным макетом, упакованный в ZIP, разработанный Microsoft, в основном используемый в некоторых рабочих процессах печати Windows. Его функциональность и поддержка сторонних приложений ограничены по сравнению с PDF, что приводит к худшей совместимости и меньшему количеству инструментов. Поскольку PDF предлагает лучшую совместимость, функции и широкое распространение, конвертация XPS в PDF часто необходима.
Метод 1 - Использование XPS Viewer + Microsoft Print to PDF
Для пользователей Windows самый простой способ конвертировать файл XPS — использовать встроенный XPS Viewer и Microsoft Print to PDF. Этот метод не требует дополнительного ПО и идеально подходит для разовых конвертаций или редкого использования. Используя функцию печати в PDF системы, вы быстро получите PDF без потери базового оформления.
Шаги:
- Откройте ваш файл XPS с помощью XPS Viewer.
- Нажмите Печать на панели инструментов.
- Выберите Microsoft Print to PDF в качестве принтера.
- Выберите место сохранения и сохраните PDF.
Плюсы:
- Бесплатно и не требует установки.
- Простой интерфейс для непрофессиональных пользователей.
Минусы:
- Нельзя обрабатывать несколько файлов одновременно.
- Сложное форматирование может немного сместиться.
Метод 2 - Использование онлайн-конвертеров
Онлайн-конвертеры предлагают удобный способ преобразования XPS в PDF без установки программ. Они особенно полезны, если нужна быстрая конвертация или вы используете не-Windows платформу. Большинство онлайн-инструментов просты: загрузите файл, выберите PDF как формат вывода и скачайте результат.
Шаги:
- Перейдите на надежный онлайн-конвертер, например, CloudConvert.
- Загрузите ваш файл XPS.
- Выберите PDF как целевой формат.
- Нажмите Конвертировать и скачайте полученный PDF.
Плюсы:
- Работает на любой платформе (Windows, Mac, мобильные).
- Не требует установки ПО.
- Быстрый интерфейс с перетаскиванием.
Минусы:
- Могут быть ограничения по размеру файла.
- Требуется подключение к интернету.
- Возможны проблемы с конфиденциальностью для чувствительных файлов.
Метод 3 - Использование командной строки (MuPDF)
Для продвинутых пользователей или автоматизации командная строка предлагает гибкие варианты конвертации. MuPDF предоставляет легковесную утилиту командной строки ( mutool ), которая может конвертировать XPS в PDF как по одному файлу, так и пакетно. Этот метод идеально подходит для разработчиков или IT-администраторов, которым нужны стабильные результаты для множества файлов.
Шаги:
-
Скачайте MuPDF.
- Перейдите на официальный сайт MuPDF: https://mupdf.com/downloads/
- Скачайте пакет инструментов MuPDF для вашей ОС (Windows, macOS или Linux)
- Распакуйте пакет в папку, например, C:\MuPDF
-
Откройте командную строку / терминал.
- Windows: нажмите Win + R, введите cmd, нажмите Enter
- macOS/Linux: откройте Терминал
-
Перейдите в папку с вашим файлом XPS.
Используйте команду cd, чтобы перейти в нужный каталог. Пример:
cd C:\Users\Administrator\Desktop\XPSFiles -
Запустите команду конвертации.
Используйте mutool convert с опцией -o для указания выходного PDF:
C:\MuPDF\mutool.exe convert -o output.pdf input.xpsОбъяснение:
- convert → команда для конвертации форматов
- -o output.pdf → имя выходного PDF-файла
- input.xps → ваш файл XPS
На Linux/macOS команда может выглядеть так:
./mutool convert -o output.pdf input.xps -
Проверьте выходной PDF в целевой папке.
Плюсы:
- Автоматизация и скрипты для пакетной обработки.
- Кроссплатформенность (Windows, Mac, Linux).
Минусы:
- Требуются технические знания.
- Настройка и синтаксис могут быть сложны для новичков.
Метод 4 - Использование библиотек Python (пакетная обработка с Spire.PDF)
Для разработчиков или компаний, нуждающихся в пакетной обработке, библиотеки Python предлагают эффективное решение. С помощью Spire.PDF для Python вы можете программно конвертировать несколько файлов XPS в PDF, сохраняя высокое качество изображений и целостность макета. Этот подход идеально подходит для автоматизации больших рабочих процессов или интеграции в серверные системы.
Шаги:
- Установите необходимую библиотеку.
- Используйте следующий скрипт для конвертации одного XPS в PDF.
pip install spire.pdffrom spire.pdf.common import *
from spire.pdf import *
# Загрузить файл XPS
doc = PdfDocument()
doc.LoadFromFile("Input.xps", FileFormat.XPS)
# Сохранить качество изображений
doc.ConvertOptions.SetXpsToPdfOptions(True)
# Сохранить в PDF
doc.SaveToFile("XpsToPdf.pdf", FileFormat.PDF)
doc.Dispose()
Результат:
Пример пакетной обработки:
import os
from spire.pdf.common import *
from spire.pdf import *
folder = r"C:\path\to\your\folder"
for name in os.listdir(folder):
if not name.lower().endswith(".xps"):
continue
in_path = os.path.join(folder, name)
out_path = os.path.join(folder, os.path.splitext(name)[0] + ".pdf")
doc = PdfDocument()
doc.LoadFromFile(in_path, FileFormat.XPS)
doc.ConvertOptions.SetXpsToPdfOptions(True)
doc.SaveToFile(out_path, FileFormat.PDF)
doc.Dispose()
Плюсы:
- Полный контроль над пакетной конвертацией.
- Высокое качество сохранения макета и изображений.
- Легко интегрируется в автоматизированные процессы.
Минусы:
- Требуются навыки программирования.
- Необходима установка библиотеки.
Помимо конвертации XPS в PDF, Spire.PDF для Python позволяет программно добавлять водяные знаки, создавать аннотации и шифровать PDF-документы. Вы можете использовать эти функции для улучшения или защиты ваших PDF-файлов прямо из кода, что делает этот инструмент универсальным решением для многих задач автоматизации PDF.
Сравнение – какой метод выбрать?
| Метод | Простота использования | Поддержка пакетной обработки | Платформа | Плюсы | Минусы |
|---|---|---|---|---|---|
| XPS Viewer | ★★★★ | ✗ | Windows | Бесплатно, просто | Один файл, проблемы с форматированием |
| Онлайн-конвертеры | ★★★★ | ✗ | Любая | Без установки, быстро | Конфиденциальность, ограничения размера файлов |
| MuPDF | ★★ | ✓ | Windows / Mac / Linux | Автоматизация | Требуется техническая настройка |
| Python / Spire.PDF | ★★ | ✓ | Кроссплатформенно | Пакетная обработка, высокое качество | Требуются знания программирования |
Заключение
Выбор подходящего метода зависит от ваших потребностей: обычным пользователям подойдут XPS Viewer или онлайн-конвертеры, а разработчикам и компаниям, работающим с множеством файлов, будут полезны MuPDF или Python/Spire.PDF для пакетной обработки. Для качественной, автоматизированной и масштабируемой конвертации Spire.PDF — надежное решение, которое сохраняет целостность оригинальных файлов XPS в PDF.
Часто задаваемые вопросы
В1: Можно ли конвертировать несколько файлов XPS одновременно?
Да, пакетная конвертация возможна с помощью командных утилит, таких как MuPDF, или библиотек Python, например Spire.PDF.
В2: Безопасны ли онлайн-конвертеры для конфиденциальных документов?
Это зависит от платформы. Для чувствительных файлов рекомендуется использовать офлайн-инструменты, такие как XPS Viewer или Spire.PDF.
В3: Может ли Python конвертировать XPS в PDF на Mac/Linux?
Да, Spire.PDF для Python поддерживает кроссплатформенную конвертацию, а командная утилита MuPDF также совместима с Mac и Linux.
В4: Сохраняет ли PDF исходный макет и изображения?
Большинство методов сохраняют макет, но пакетные и программные решения, такие как Spire.PDF, обеспечивают наивысшее качество, особенно для сложных файлов XPS.
Смотрите также
Converter Word para XPS: 4 métodos fáceis (gratuitos e automatizados)
Índice
- Por que Converter Word para XPS?
- Método 1 - Usando o Microsoft Word
- Método 2 - Usando a Impressão do Windows para XPS
- Método 3 - Usando Conversores Online
- Método 4 - Usando Python (Processamento em Lote)
- Tabela Comparativa – Qual Método Você Deve Escolher?
- Melhores Práticas para Saída XPS de Alta Qualidade
- Conclusão
- Perguntas Frequentes

Converter documentos Word para o formato XPS é uma forma útil de preservar o layout, garantir uma visualização consistente e preparar arquivos para compartilhamento ou impressão. Seja trabalhando com relatórios, contratos ou documentos técnicos, o XPS oferece um formato de layout fixo semelhante ao PDF, mas suportado nativamente em ambientes Windows.
Neste guia, você aprenderá quatro métodos fáceis para converter Word para XPS, incluindo abordagens manuais, ferramentas online e soluções automatizadas para processamento em lote.
Navegação Rápida:
- Método 1 - Usando o Microsoft Word
- Método 2 - Usando a Impressão do Windows para XPS
- Método 3 - Usando Conversores Online
- Método 4 - Usando Python (Processamento em Lote)
Por que Converter Word para XPS?
XPS (XML Paper Specification) foi projetado para manter a fidelidade do documento em diferentes sistemas e dispositivos. Ele fixa a formatação, fontes e layout, tornando-o ideal para versões finais de documentos que não devem ser editados.
Além disso, arquivos XPS se integram bem com sistemas Windows e podem ser visualizados sem necessidade de software de terceiros. Para desenvolvedores e empresas, o XPS também é útil em fluxos de trabalho que exigem renderização consistente de documentos.
Método 1 – Usando o Microsoft Word
O Microsoft Word inclui um recurso embutido que permite salvar documentos diretamente como arquivos XPS. Como a conversão é feita internamente pelo Word, este método oferece simplicidade e alta fidelidade.
Ideal para: Conversões rápidas e pontuais onde a precisão é importante.
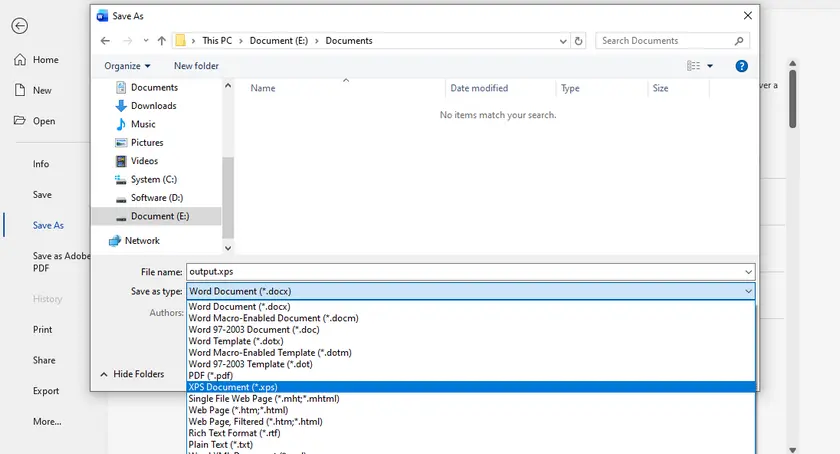
Passos para Converter Word para XPS Usando o MS Word
- Abra seu documento Word no Microsoft Word.
- Clique em Arquivo → Salvar Como.
- Escolha o local onde deseja salvar o arquivo.
- Selecione Documento XPS (*.xps) no menu suspenso de tipo de arquivo.
- Clique em Salvar.
Prós
- Saída de alta qualidade com formatação precisa.
- Simples e amigável para iniciantes.
Contras
- Requer instalação do Microsoft Word.
- Sem suporte para processamento em lote.
Método 2 – Usando a Impressão do Windows para XPS
O Windows inclui uma impressora virtual chamada Microsoft XPS Document Writer que permite converter qualquer documento imprimível para o formato XPS. Este método funciona com praticamente qualquer aplicativo que suporte impressão — não apenas o Word.
Ideal para: Quando você prefere não depender de recursos de exportação específicos de aplicativos.
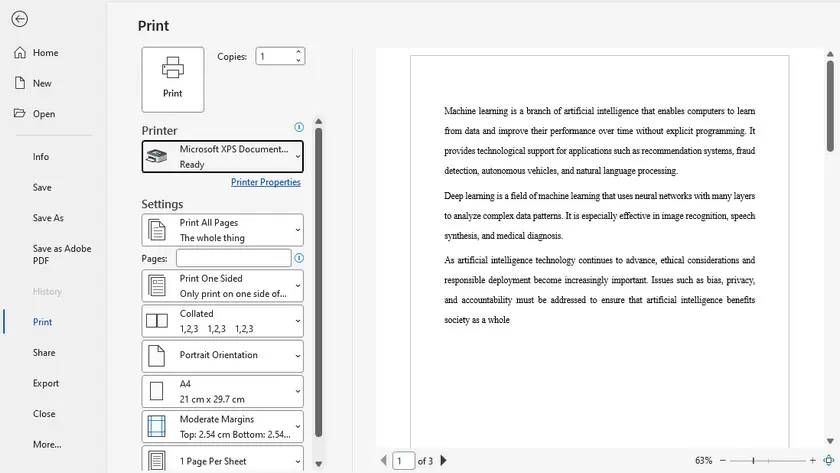
Passos para Converter Word para XPS Usando o XPS Document Writer
- Abra o documento Word.
- Vá para Arquivo → Imprimir.
- Selecione Microsoft XPS Document Writer como impressora.
- Clique em Imprimir.
- Escolha um nome de arquivo e local para salvar.
Prós
- Integrado ao Windows (não precisa instalar).
- Funciona com múltiplos aplicativos.
- Confiável para preservar o layout.
Contras
- Processo manual, não adequado para conversão em massa.
- Um pouco mais lento que a exportação direta.
Método 3 – Usando Conversores Online
Conversores online oferecem uma forma conveniente de converter arquivos Word para XPS sem instalar nenhum software. Essas ferramentas geralmente suportam upload por arrastar e soltar e downloads rápidos, tornando-as acessíveis em qualquer dispositivo.
Ideal para: Uso ocasional ou quando estiver em sistemas onde não é possível instalar software.
Passos para Converter Word para XPS Online
- Abra um site conversor online (ex.: cloudxdocs).
- Envie seu documento Word.
- A conversão começa automaticamente assim que o upload termina.
- Baixe o arquivo convertido.
Prós
- Não requer instalação.
- Acessível de qualquer dispositivo.
- Rápido e fácil para uso ocasional.
Contras
- Limites de tamanho de arquivo em planos gratuitos.
- Possíveis preocupações com privacidade/segurança.
- Requer conexão com a internet.
Método 4 – Usando Python (Processamento em Lote)
Para desenvolvedores ou usuários que lidam com múltiplos arquivos, a automação é a solução mais eficiente. Usando bibliotecas como Spire.Doc para Python, você pode converter documentos Word para XPS em lote programaticamente com esforço mínimo.
Esta abordagem é ideal para sistemas backend, fluxos de trabalho de documentos ou tarefas de processamento em larga escala onde a conversão manual seria muito demorada.
Passos para Converter Word para XPS em Lote com Python
- Crie um programa em Python.
- Instale a biblioteca Spire.Doc para Python.
- Execute o script abaixo para realizar a conversão.
import os
from spire.doc import *
from spire.doc.common import *
# Pastas de entrada e saída
input_folder = "input_docs"
output_folder = "output_xps"
# Cria a pasta de saída se não existir
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# Percorre todos os arquivos na pasta de entrada
for file_name in os.listdir(input_folder):
if file_name.endswith((".doc", ".docx")):
input_path = os.path.join(input_folder, file_name)
output_name = os.path.splitext(file_name)[0] + ".xps"
output_path = os.path.join(output_folder, output_name)
# Cria um objeto Documento
doc = Document()
# Carrega o documento Word
doc.LoadFromFile(input_path)
# Salva como XPS
doc.SaveToFile(output_path, FileFormat.XPS)
# Descarta o documento
doc.Dispose()
print(f"Convertido: {file_name} → {output_name}")
print("Conversão em lote concluída.")
Prós
- Suporta conversão em lote (alta eficiência).
- Fluxo de trabalho totalmente automatizado.
- Fácil de integrar em sistemas ou pipelines.
Contras
- Requer conhecimento de programação.
- Necessita configuração do ambiente e dependências.
- A configuração inicial leva mais tempo que métodos manuais.
Além da conversão para XPS, o Spire.Doc permite converter Word para PDF, ou exportar Word como imagens, dando controle total sobre como seus documentos são compartilhados e exibidos.
Tabela Comparativa – Qual Método Você Deve Escolher?
| Método | Ideal Para | Facilidade de Uso | Suporte a Lote | Requer Instalação | Custo |
|---|---|---|---|---|---|
| Microsoft Word | Conversão rápida e de alta qualidade | ★★★★★ | x | √ | Pago (licença Office) |
| Impressão para XPS | Flexível, funciona com qualquer app | ★★★★★ | x | x (integrado) | Grátis |
| Ferramentas Online | Conveniência, sem instalação | ★★★★★ | x | x | Grátis (limitado) / Pago |
| Python (Spire.Doc) | Automação, processamento em lote | ★★★☆☆ | √ | √ | Grátis (limitado) / Pago |
Melhores Práticas para Saída XPS de Alta Qualidade
Antes de converter, certifique-se de que seu documento Word está finalizado, incluindo fontes, imagens e layout. Como o XPS preserva a formatação exatamente, quaisquer problemas no arquivo original serão mantidos na saída.
Também é recomendável incorporar fontes e evitar elementos não suportados para garantir compatibilidade em diferentes sistemas. Para processamento em lote, teste alguns arquivos primeiro para confirmar resultados consistentes.
Conclusão
Converter Word para XPS pode ser feito usando vários métodos dependendo das suas necessidades. Para resultados rápidos e confiáveis, opções integradas como Microsoft Word ou Impressão do Windows para XPS funcionam bem. Se precisar de flexibilidade ou portabilidade, ferramentas online são uma boa escolha.
Para usuários avançados e desenvolvedores, a automação em Python com bibliotecas como Spire.Doc oferece uma forma poderosa de lidar com grandes volumes de documentos de forma eficiente.
Perguntas Frequentes
P1: O XPS é melhor que PDF?
XPS e PDF são similares no sentido de que ambos preservam o layout do documento. PDF é mais amplamente suportado, enquanto XPS é mais integrado aos sistemas Windows.
P2: Posso converter XPS de volta para Word?
Sim, mas geralmente requer ferramentas de terceiros ou conversão intermediária (ex.: XPS → PDF → Word), e a formatação pode não ser perfeitamente preservada.
P3: Converter para XPS reduz a qualidade do arquivo?
Não, o XPS mantém o layout e a qualidade originais. No entanto, configurações de compressão e recursos incorporados podem afetar o tamanho do arquivo.
P4: Qual método é melhor para conversão em massa?
O método Python usando Spire.Doc é a melhor escolha para processamento em lote e automação.
P5: Como abrir um arquivo XPS?
Você pode abrir um arquivo XPS usando o visualizador XPS embutido no Windows. Basta dar um duplo clique no arquivo, ou clicar com o botão direito e escolher Abrir com → Visualizador XPS.
Veja Também
Word를 XPS로 변환: 4가지 쉬운 방법 (무료 및 자동화)
Word 문서를 XPS 형식으로 변환하는 것은 레이아웃을 보존하고 일관된 보기 환경을 보장하며 파일 공유나 인쇄 준비에 유용한 방법입니다. 보고서, 계약서 또는 기술 문서 작업 시 XPS는 PDF와 유사한 고정 레이아웃 형식을 제공하며 Windows 환경에서 기본 지원됩니다.
이 가이드에서는 Word를 XPS로 변환하는 네 가지 쉬운 방법을 배우게 됩니다. 수동 방법, 온라인 도구, 그리고 배치 처리를 위한 자동화 솔루션을 포함합니다.
빠른 탐색:
- 방법 1 - Microsoft Word 사용하기
- 방법 2 - Windows 인쇄 기능으로 XPS 만들기
- 방법 3 - 온라인 변환기 사용하기
- 방법 4 - Python 사용하기 (배치 처리)
왜 Word를 XPS로 변환해야 하나요?
XPS (XML Paper Specification)는 다양한 시스템과 장치에서 문서의 충실도를 유지하도록 설계되었습니다. 서식, 글꼴, 레이아웃을 고정하여 편집되지 않아야 하는 문서의 최종 버전에 이상적입니다.
또한 XPS 파일은 Windows 시스템과 잘 통합되며 별도의 소프트웨어 없이도 볼 수 있습니다. 개발자와 기업에게는 일관된 문서 렌더링이 필요한 워크플로우에서 유용합니다.
방법 1 – Microsoft Word 사용하기
Microsoft Word에는 문서를 직접 XPS 파일로 저장할 수 있는 내장 기능이 있습니다. 변환이 Word 내부에서 처리되므로 이 방법은 간단하면서도 높은 충실도를 제공합니다.
추천 대상: 정확도가 중요한 빠른 단일 변환에 적합합니다.
Microsoft Word로 Word를 XPS로 변환하는 단계
- Microsoft Word에서 문서를 엽니다.
- 파일 → 다른 이름으로 저장을 클릭합니다.
- 파일을 저장할 위치를 선택합니다.
- 파일 형식 드롭다운에서 XPS 문서 (*.xps)를 선택합니다.
- 저장을 클릭합니다.
장점
- 정확한 서식으로 고품질 출력.
- 간단하고 초보자도 사용하기 쉬움.
단점
- Microsoft Word 설치 필요.
- 배치 처리 지원 안 함.
방법 2 – Windows 인쇄 기능으로 XPS 만들기
Windows에는 Microsoft XPS 문서 작성기라는 가상 프린터가 포함되어 있어 인쇄 가능한 모든 문서를 XPS 형식으로 변환할 수 있습니다. 이 방법은 Word뿐만 아니라 인쇄를 지원하는 거의 모든 응용 프로그램에서 작동합니다.
추천 대상: 응용 프로그램별 내보내기 기능에 의존하지 않으려는 경우.
XPS 문서 작성기로 Word를 XPS로 변환하는 단계
- Word 문서를 엽니다.
- 파일 → 인쇄로 이동합니다.
- 프린터로 Microsoft XPS 문서 작성기를 선택합니다.
- 인쇄를 클릭합니다.
- 파일 이름과 저장 위치를 선택합니다.
장점
- Windows에 내장되어 있어 설치 불필요.
- 여러 응용 프로그램에서 사용 가능.
- 레이아웃 보존에 신뢰할 수 있음.
단점
- 수동 프로세스이며 대량 변환에는 부적합.
- 직접 내보내기보다 약간 느림.
방법 3 – 온라인 변환기 사용하기
온라인 변환기는 소프트웨어 설치 없이 Word 파일을 XPS로 변환할 수 있는 편리한 방법을 제공합니다. 일반적으로 드래그 앤 드롭 업로드와 빠른 다운로드를 지원하여 어떤 장치에서도 접근할 수 있습니다.
추천 대상: 가끔 사용하거나 소프트웨어 설치가 불가능한 시스템에서 작업할 때.
온라인에서 Word를 XPS로 변환하는 단계
- 온라인 변환기 웹사이트(예: cloudxdocs)를 엽니다.
- Word 문서를 업로드합니다.
- 업로드가 완료되면 변환이 자동으로 시작됩니다.
- 변환된 파일을 다운로드합니다.
장점
- 설치 불필요.
- 어떤 장치에서도 접근 가능.
- 가끔 사용하기에 빠르고 쉬움.
단점
- 무료 플랜의 파일 크기 제한.
- 개인정보/보안 우려 가능성.
- 인터넷 연결 필요.
방법 4 – Python 사용하기 (배치 처리)
여러 파일을 다루는 개발자나 사용자의 경우 자동화가 가장 효율적인 솔루션입니다. Spire.Doc for Python과 같은 라이브러리를 사용하면 최소한의 노력으로 Word 문서를 일괄적으로 XPS로 변환할 수 있습니다.
이 방법은 수동 변환에 시간이 많이 걸리는 백엔드 시스템, 문서 워크플로우 또는 대규모 처리 작업에 이상적입니다.
Python에서 Word를 XPS로 일괄 변환하는 단계
- Python 프로그램을 만듭니다.
- Python용 Spire.Doc 라이브러리를 설치합니다.
- 다음 스크립트를 실행하여 변환을 수행합니다.
import os
from spire.doc import *
from spire.doc.common import *
# Input and output folders
input_folder = "input_docs"
output_folder = "output_xps"
# Create output folder if it doesn't exist
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# Loop through all files in the input folder
for file_name in os.listdir(input_folder):
if file_name.endswith((".doc", ".docx")):
input_path = os.path.join(input_folder, file_name)
output_name = os.path.splitext(file_name)[0] + ".xps"
output_path = os.path.join(output_folder, output_name)
# Create a Document object
doc = Document()
# Load the Word document
doc.LoadFromFile(input_path)
# Save as XPS
doc.SaveToFile(output_path, FileFormat.XPS)
# Dispose the document
doc.Dispose()
print(f"Converted: {file_name} → {output_name}")
print("Batch conversion completed.")
장점
- 배치 변환 지원 (높은 효율성).
- 완전 자동화된 워크플로우.
- 시스템이나 파이프라인에 쉽게 통합 가능.
단점
- 프로그래밍 지식 필요.
- 환경 설정과 의존성 필요.
- 초기 설정에 수동 방법보다 시간이 더 걸림.
XPS 변환 외에도 Spire.Doc은 Word를 PDF로 변환하거나, Word를 이미지로 내보내기를 지원하여 문서 공유 및 표시 방식을 완벽하게 제어할 수 있습니다.
비교표 – 어떤 방법을 선택해야 할까요?
| 방법 | 추천 대상 | 사용 편의성 | 배치 지원 | 설치 필요 여부 | 비용 |
|---|---|---|---|---|---|
| Microsoft Word | 빠르고 고품질 변환 | ★★★★★ | x | √ | 유료 (오피스 라이선스) |
| Print to XPS | 유연하며 모든 앱에서 사용 가능 | ★★★★★ | x | x (내장) | 무료 |
| 온라인 도구 | 편리함, 설치 불필요 | ★★★★★ | x | x | 무료 (제한 있음) / 유료 |
| Python (Spire.Doc) | 자동화, 대량 처리 | ★★★☆☆ | √ | √ | 무료 (제한 있음) / 유료 |
고품질 XPS 출력의 모범 사례
변환 전에 Word 문서가 최종본인지 확인하세요. 글꼴, 이미지, 레이아웃이 모두 포함되어야 합니다. XPS는 서식을 정확히 보존하므로 원본 파일의 문제도 그대로 반영됩니다.
호환성을 위해 글꼴을 포함하고 지원되지 않는 요소는 피하는 것이 좋습니다. 배치 처리 시에는 몇 개의 파일을 먼저 테스트하여 일관된 결과를 확인하세요.
결론
Word를 XPS로 변환하는 방법은 필요에 따라 다양합니다. 빠르고 신뢰할 수 있는 결과를 원한다면 Microsoft Word나 Windows 인쇄 기능이 적합합니다. 유연성과 휴대성을 원한다면 온라인 도구가 좋은 선택입니다.
고급 사용자와 개발자에게는 Spire.Doc과 같은 라이브러리를 활용한 Python 자동화가 대량 문서 처리에 강력한 방법입니다.
자주 묻는 질문
Q1: XPS가 PDF보다 더 좋은가요?
XPS와 PDF는 모두 문서 레이아웃을 보존한다는 점에서 유사합니다. PDF가 더 널리 지원되는 반면, XPS는 Windows 시스템과 더 긴밀하게 통합되어 있습니다.
Q2: XPS를 다시 Word로 변환할 수 있나요?
예, 가능하지만 보통 서드파티 도구나 중간 변환(XPS → PDF → Word)이 필요하며 서식이 완벽하게 보존되지 않을 수 있습니다.
Q3: XPS 변환 시 파일 품질이 떨어지나요?
아니요, XPS는 원본 레이아웃과 품질을 유지합니다. 다만 압축 설정과 포함된 리소스에 따라 파일 크기에 영향을 줄 수 있습니다.
Q4: 대량 변환에 가장 좋은 방법은 무엇인가요?
Spire.Doc을 사용하는 Python 방법이 배치 처리와 자동화에 가장 적합합니다.
Q5: XPS 파일은 어떻게 열 수 있나요?
Windows에 내장된 XPS 뷰어를 사용하여 열 수 있습니다. 파일을 더블 클릭하거나 마우스 오른쪽 버튼 클릭 후 열기 → XPS 뷰어 를 선택하세요.