
Knowledgebase (2344)
Children categories
Drop-down lists in Excel worksheets are an indispensable tool for enhancing data accuracy, efficiency, and usability in spreadsheet management. By offering pre-defined options within a cell, they not only streamline data entry processes but also enforce consistency, reducing the likelihood of input errors. This feature is particularly valuable when working with large datasets or collaborative projects where maintaining uniformity across multiple entries is crucial. This article demonstrates how to create customized drop-down lists within Excel worksheets using Spire.XLS for Python, empowering users to create organized and user-friendly worksheets.
- Create Drop-Down Lists Based on Cell Values Using Python
- Create Drop-Down Lists Based on Strings Using Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to: How to Install Spire.XLS for Python on Windows
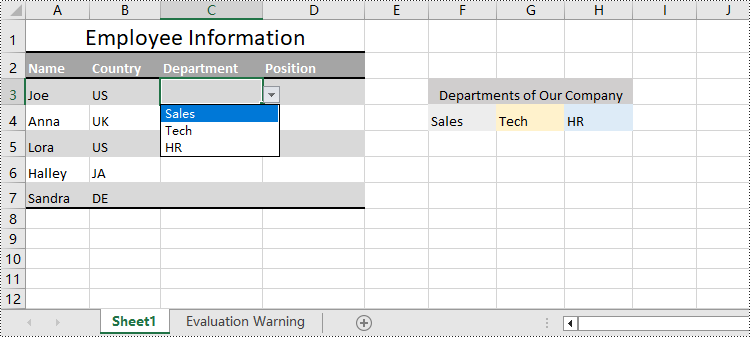
Create Drop-Down Lists Based on Cell Values Using Python
In Excel worksheets, creating drop-down lists is accomplished through the data validation feature. With Spire.XLS for Python, developers can use the CellRange.DataValidation.DataRange property to create drop-down lists within cells and use the data from the specified cell range as list options.
The detailed steps for creating a drop-down list based on cell values are as follows:
- Create an instance of Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a worksheet using Workbook.Worksheets.get_Item() method.
- Get a specific cell range through Worksheet.Range[] property.
- Set the data range for data validation of the cell range through CellRange.DataValidation.DataRange property to create drop-down lists with cell values.
- Save the workbook using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create an instance of Workbook
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets.get_Item(0)
# Get a specific cell range
cellRange = sheet.Range["C3:C7"]
# Set the data range for data validation to create drop-down lists in the cell range
cellRange.DataValidation.DataRange = sheet.Range["F4:H4"]
# Save the workbook
workbook.SaveToFile("output/DropDownListExcel.xlsx", FileFormat.Version2016)
workbook.Dispose()
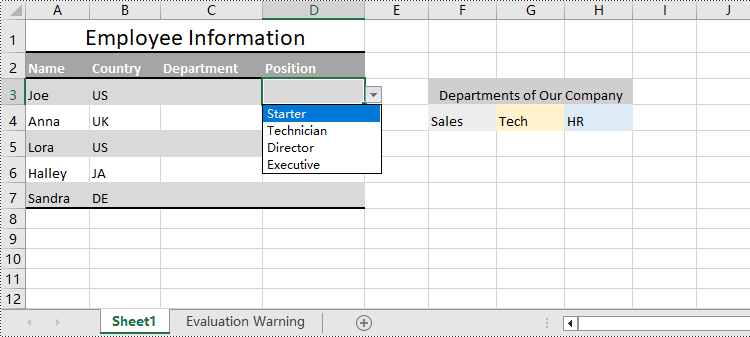
Create Drop-Down Lists Based on String Using Python
Spire.XLS for Python also provides the CellRange.DataValidation.Values property to create drop-down lists in cells directly using string lists.
The detailed steps for creating drop-down lists based on values are as follows:
- Create an instance of Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a worksheet using Workbook.Worksheets.get_Item() method.
- Get a specific cell range through Worksheet.Range[] property.
- Set a string list as the values of data validation in the cell range through CellRange.DataValidation.Values property to create drop-down lists based on strings.
- Save the workbook using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create an instance of Workbook
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets.get_Item(0)
# Get a cell range
cellRange = sheet.Range["D3:D7"]
# Set the value for data validation to create drop-down lists
cellRange.DataValidation.Values = ["Starter", "Technician", "Director", "Executive"]
# Save the workbook
workbook.SaveToFile("output/ValueDropDownListExcel.xlsx", FileFormat.Version2016)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Presenting information in a logical sequence is vital for an effective PowerPoint presentation. Reordering slides in a PowerPoint document gives you the flexibility to fine-tune your presentation and ensure that it delivers your message with maximum impact. By organizing your slides strategically, you can create a dynamic and engaging presentation experience.
In this article, you will learn how to reorder slides in a PowerPoint document in Java using the Spire.Presentation for Java library.
Install Spire.Presentation for Java
First of all, you're required to add the Spire.Presentation.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.presentation</artifactId>
<version>11.5.1</version>
</dependency>
</dependencies>
Reorder Slides in a PowerPoint Document in Java
To rearrange the slides in a PowerPoint presentation, you need to create two presentation objects. One object will be used to load the original document while the other will be used to create a new document. By copying the slides from the original document to the new document in the desired order, you can effectively rearrange the slides.
The following are the steps to rearrange slides in a PowerPoint document using Java.
- Create a Presentationobject.
- Load a PowerPoint document using Presentation.loadFromFile() method.
- Specify the slide order within an array.
- Create another Presentation object for creating a new presentation.
- Add the slides from the original document to the new presentation in the specified order using Presentation.getSlides().append() method.
- Save the new presentation to a PPTX file using Presentation.saveToFile() method.
- Java
import com.spire.presentation.FileFormat;
import com.spire.presentation.Presentation;
public class ReorderSlides {
public static void main(String[] args) throws Exception {
// Create a Presentation object
Presentation presentation = new Presentation();
// Load a PowerPoint file
presentation.loadFromFile("C:\\Users\\Administrator\\Desktop\\input.pptx");
// Specify the new slide order within an array
int[] newSlideOrder = new int[] { 3, 4, 1, 2 };
// Create another Presentation object
Presentation new_presentation = new Presentation();
// Remove the default slide
new_presentation.getSlides().removeAt(0);
// Iterate through the array
for (int i = 0; i < newSlideOrder.length; i++)
{
// Add the slides from the original PowerPoint file to the new PowerPoint document in the new order
new_presentation.getSlides().append(presentation.getSlides().get(newSlideOrder[i] - 1));
}
// Save the new presentation to file
new_presentation.saveToFile("output/NewOrder.pptx", FileFormat.PPTX_2019);
// Dispose resources
presentation.dispose();
new_presentation.dispose();
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
With the increasing popularity of team collaboration, the track changes function in Word documents has become the cornerstone of version control and content review. However, for developers who pursue automation and efficiency, how to flexibly extract these revision information from Word documents remains a significant challenge. This article will introduce you to how to use Spire.Doc for Python to obtain revision information in Word documents.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
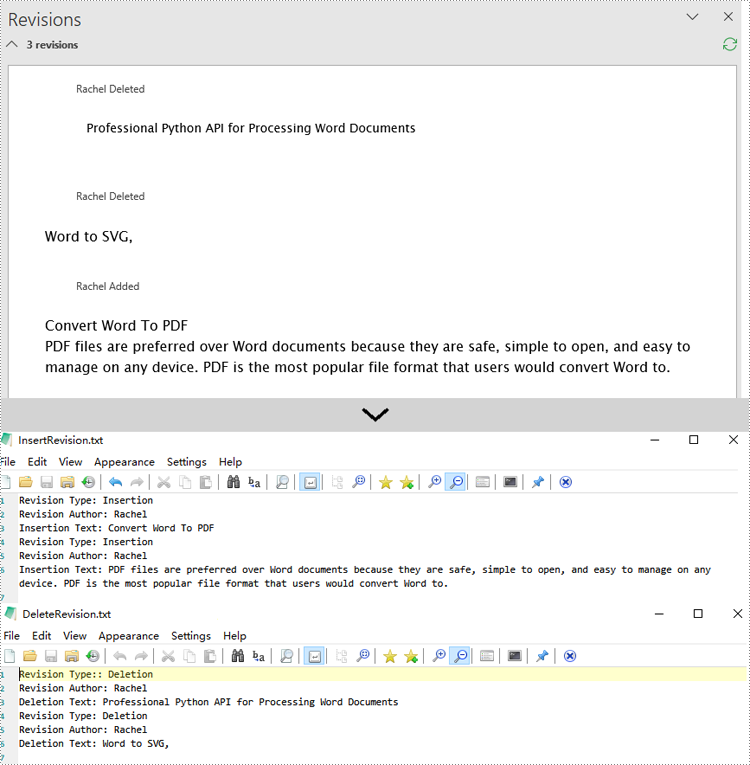
Get Revisions of Word Document in Python
Spire.Doc for Python provides the IsInsertRevision and DeleteRevision properties to support determining whether an element in a Word document is an insertion revision or a deletion revision. Here are the detailed steps:
- Create an instance of the Document class and load the Word document that contains revisions.
- Initialize lists to collect insertion and deletion revision information.
- Iterate through the sections of the document and their body elements.
- Obtain the paragraphs in the body and use the IsInsertRevision property to determine if the paragraph is an insertion revision.
- Get the type, author, and associated text of the insertion revision.
- Use the IsDeleteRevision property to determine if the paragraph is a deletion revision, and obtain its revision type, author, and associated text.
- Iterate through the child elements of the paragraph, similarly checking if the TextRange is an insertion or deletion revision, and retrieve the revision type, author, and associated text.
- Define a WriteAllText function to save the insertion and deletion revision information to TXT documents.
- Python
from spire.doc import *
# Function to write text to a file
def WriteAllText(fname: str, text: str):
with open(fname, "w", encoding='utf-8') as fp:
fp.write(text)
# Input and output file names
inputFile = "sample.docx"
outputFile1 = "InsertRevision.txt"
outputFile2 = "DeleteRevision.txt"
# Create a Document object
document = Document()
# Load the Word document
document.LoadFromFile(inputFile)
# Initialize lists to store insert and delete revisions
insert_revisions = []
delete_revisions = []
# Iterate through sections in the document
for k in range(document.Sections.Count):
sec = document.Sections.get_Item(k)
# Iterate through body elements in the section
for m in range(sec.Body.ChildObjects.Count):
# Check if the item is a Paragraph
docItem = sec.Body.ChildObjects.get_Item(m)
if isinstance(docItem, Paragraph):
para = docItem
para.AppendField("",FieldType.FieldDocVariable)
# Check if the paragraph is an insertion revision
if para.IsInsertRevision:
insRevison = para.InsertRevision
insType = insRevison.Type
insAuthor = insRevison.Author
# Add insertion revision details to the list
insert_revisions.append(f"Revision Type: {insType.name}\n")
insert_revisions.append(f"Revision Author: {insAuthor}\n")
insert_revisions.append(f"Insertion Text: {para.Text}\n")
# Check if the paragraph is a deletion revision
elif para.IsDeleteRevision:
delRevison = para.DeleteRevision
delType = delRevison.Type
delAuthor = delRevison.Author
# Add deletion revision details to the list
delete_revisions.append(f"Revision Type:: {delType.name}\n")
delete_revisions.append(f"Revision Author: {delAuthor}\n")
delete_revisions.append(f"Deletion Text: {para.Text}\n")
else:
# Iterate through all child objects of Paragraph
for j in range(para.ChildObjects.Count):
obj = para.ChildObjects.get_Item(j)
# Check if the current object is an instance of TextRange
if isinstance(obj, TextRange):
textRange = obj
# Check if the textrange is an insertion revision
if textRange.IsInsertRevision:
insRevison = textRange.InsertRevision
insType = insRevison.Type
insAuthor = insRevison.Author
# Add insertion revision details to the list
insert_revisions.append(f"Revision Type: {insType.name}\n")
insert_revisions.append(f"Revision Author: {insAuthor}\n")
insert_revisions.append(f"Insertion Text: {textRange.Text}\n")
# Check if the textrange is a deletion revision
elif textRange.IsDeleteRevision:
delRevison = textRange.DeleteRevision
delType = delRevison.Type
delAuthor = delRevison.Author
# Add deletion revision details to the list
delete_revisions.append(f"Revision Type: {delType.name}\n")
delete_revisions.append(f"Revision Author: {delAuthor}\n")
delete_revisions.append(f"Deletion Text: {textRange.Text}\n")
# Write all the insertion revision details to the 'outputFile1' file
WriteAllText(outputFile1, ''.join(insert_revisions))
# Write all the deletion revision details to the 'outputFile2' file
WriteAllText(outputFile2, ''.join(delete_revisions))
# Dispose the document
document.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
