
Knowledgebase (2344)
Children categories
How to Integrate Spire.PDF for JavaScript in a React Project
2025-02-11 07:14:00 Written by AdministratorIn the modern web development landscape, React has become the go-to framework for building dynamic and interactive user interfaces. When it comes to handling PDF documents within a React application, Spire.PDF for JavaScript stands out as a powerful tool.
This guide will walk you through how to integrate Spire.PDF for JavaScript into your React project, explore its benefits, and provide actionable insights to optimize your implementation.
- Benefits of Using Spire.PDF for JavaScript in React
- Set Up Your Environment
- Integrate Spire.PDF for JavaScript in Your Project
- Create and Save PDF Files Using JavaScript
Benefits of Using Spire.PDF for JavaScript in React
React, a widely used JavaScript library for crafting dynamic user interfaces, has become essential in modern web development. In tandem, Spire.PDF for JavaScript is a robust library tailored to enhance PDF document processing in web applications.
By incorporating Spire.PDF for JavaScript into your React project, you can introduce advanced PDF manipulation capabilities to your application. Here are some of the key advantages:
- Effortless PDF Generation: Spire.PDF for JavaScript facilitates the creation and editing of PDF documents directly within React, allowing for efficient management without the need for external applications.
- Cross-Platform Functionality: With Spire.PDF for JavaScript, you can generate PDFs that are accessible across various platforms, enabling users to view and edit documents from any location.
- Comprehensive Features: Spire.PDF for JavaScript provides a wide array of features, including text formatting, image embedding, and annotation capabilities, making it perfect for applications that require detailed PDF manipulation.
- Smooth Integration: Designed to work seamlessly with various JavaScript frameworks, including React, Spire.PDF for JavaScript integrates effortlessly into existing projects, ensuring a smooth development process.
Set Up Your Environment
Step 1. Install React and npm
Download and install Node.js from the official website. Make sure to choose the version that matches your operating system.
After the installation is complete, you can verify that Node.js and npm are working correctly by running the following commands in your terminal:
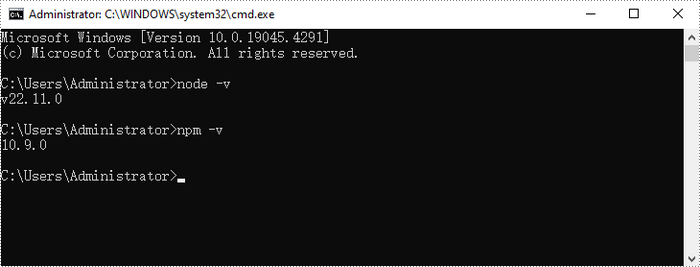
Step 2. Create a New React Project
Create a new React project named my-app using Create React App from terminal:
npx create-react-app my-app

If your React project is compiled successfully, the app will be served at http://localhost:3000, allowing you to view and test your application in a browser.
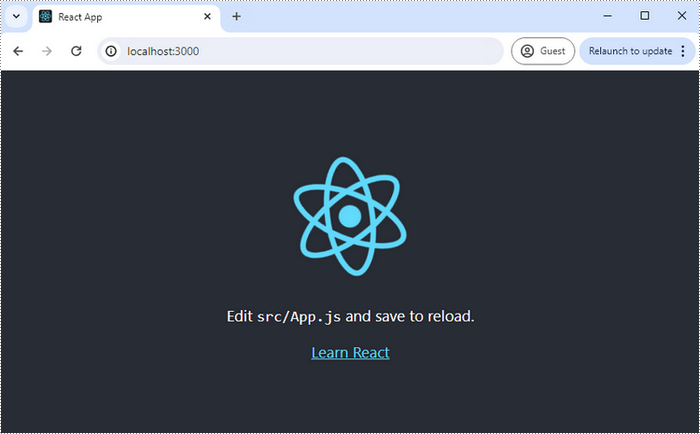
To visually browse and manage the files in your project, you can open the project using VS Code.
Integrate Spire.PDF for JavaScript in Your Project
Download Spire.PDF for JavaScript from our website and unzip it to a location on your disk. The downloaded product package integrates Spire.Doc for JavaScript, Spire.XLS for JavaScript, Spire.PDF for JavaScript, and Spire.Presentation for JavaScript. When using the features of Spire.PDF for JavaScript, the required files are: spire.pdf.js, Spire.Pdf.Wasm.zip, spire.common.js, Spire.Common.Wasm.zip, and the _framework folder.
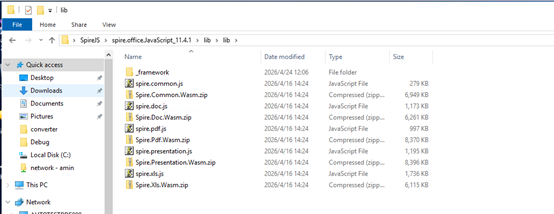
Alternatively, you can download Spire.PDF for JavaScript using npm. In the terminal within VS Code, run the following command:
npm i spire.office
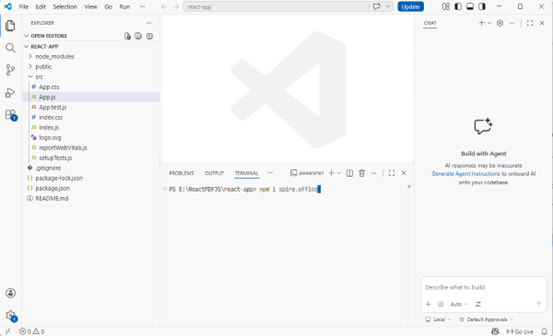
Once the installation is complete, the product packages will be saved in the node_modules/spire.office path of your project.
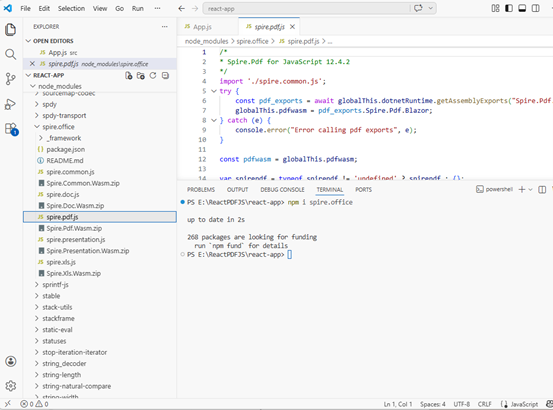
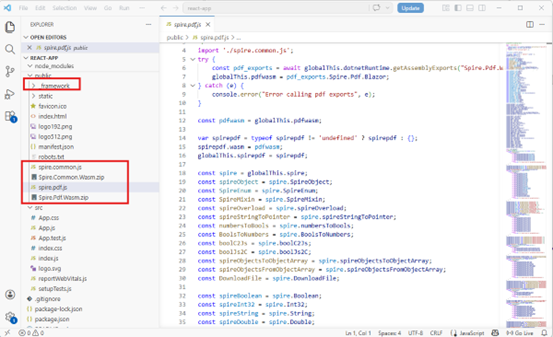
Copy the spire.pdf.js, Spire.Pdf.Wasm.zip, spire.common.js, Spire.Common.Wasm.zip, and the _framework folder five files into the "public" folder in your React project.
Add font files you plan to use to the "public/static/font" folder in your project. (Not always necessary)
Create and Save PDF Files Using JavaScript
Modify the code in the "App.js" file to generate a PDF file using the WebAssembly (WASM) module.
Here is the entire code:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.pdf.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.pdf.js:', error);
}
})();
}, []);
const CreatePdfDocument = async () => {
const wasmModule = window.wasmModule.spirepdf;
if (wasmModule) {
// Load the ARIALUNI.TTF font file into the virtual file system (VFS)
await window.spire.FetchFileToVFS("ARIALUNI.TTF", "/Library/Fonts/", `${import.meta.env.BASE_URL}static/font/`);
// Create a pdf instance
let doc = new wasmModule.PdfDocument();
// Create one page
let pagebase = doc.Pages.Add();
const text = "Hello World";
let pdffont = new wasmModule.PdfFont({fontFamily:wasmModule.PdfFontFamily.Helvetica, size:30.0});
let pdfBrush = new wasmModule.PdfSolidBrush({pdfRGBColor: new wasmModule.PdfRGBColor({color: wasmModule.Color.get_Black()})});
// Draw the text
pagebase.Canvas.DrawString({s: text, font: pdffont, brush: pdfBrush, x: 10, y: 10});
// Define the output file name
const outputFileName = "HelloWorld_out.pdf";
// Save the document to the specified path
doc.SaveToFile(outputFileName);
doc.Close();
// Read the saved file and convert to a Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: "application/pdf" });
// Clean up resources
doc.Dispose();
// Create a URL for the Blob
const url = URL.createObjectURL(modifiedFile);
// Create an anchor element to trigger the download
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Create a PDF Document in React</h1>
<button onClick={CreatePdfDocument} disabled={!wasmModule}>
Generate
</button>
</div>
);
}
export default App;
Save the changes by clicking "File" - "Save".
Start the development server by entering the following command in the terminal within VS
npm start
Once the React app is successfully compiled, it will open in your default web browser, typically at http://localhost:3000.

Click "Generate," and a "Save As" window will prompt you to save the output file in the designated folder.

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Convert Excel to OpenXML and OpenXML to Excel with JavaScript in React
2025-02-10 01:05:26 Written by AdministratorOpenXML is a widely used format for creating and manipulating Microsoft Office documents, including Excel files. It provides a structured, XML-based representation of spreadsheet data, making it ideal for interoperability and automation. Converting an Excel file to OpenXML allows users to extract and process data programmatically, while converting OpenXML back to Excel ensures compatibility with Microsoft Excel and other spreadsheet applications. This article will guide you through the process of converting Excel to OpenXML and OpenXML back to Excel in React using Spire.XLS for JavaScript.
Install Spire.XLS for JavaScript
To get started with converting Excel to OpenXML and OpenXML to Excel in a React application, you can either download Spire.XLS for JavaScript from the official website or install it via npm with the following command:
npm i spire.office
The downloaded product package has been integrated Spire.Doc for JavaScript,Spire.XLS for JavaScript,Spire.PDF for JavaScript,Spire.Presentation for JavaScript. To use the functionality of Spire.XLS for JavaScript, you need to copy the corresponding files (spire.xls.js, Spire.Xls.Wasm.zip, spire.common.js, Spire.Common.Wasm.zip, and _framework) to the project's "public" folder. At the same time, in order to ensure text rendering, the related font files can be added with custom paths. In the following example, the font addition path is: public\static\font.
For more details, refer to the documentation: How to Integrate Spire.XLS for JavaScript in a React Project.
Convert Excel to OpenXML with JavaScript
Converting an Excel workbook to OpenXML format can be easily achieved using the Workbook.SaveAsXml() method provided by Spire.XLS for JavaScript. Below are the key steps:
- Load the font file to ensure correct text rendering.
- Create a Workbook object using the new wasmModule.Workbook() method.
- Load the Excel file using the Workbook.LoadFromFile() method.
- Save the Excel file as an OpenXML file using the Workbook.SaveAsXml() method.
Code example:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.XLS
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.xls.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.xls.js WASM module:', error);
}
})();
}, []);
// Function to convert Excel to OpenXML
const ExcelToOpenXML = async () => {
const wasmModule = window.wasmModule.spirexls;
if (wasmModule) {
// Load font into Virtual File System (VFS)
await window.spire.FetchFileToVFS('Arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Load input file into Virtual File System (VFS)
const inputFileName = 'sample.xlsx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new workbook
const workbook = new wasmModule.Workbook();
// Load an existing HTML file
workbook.LoadFromHtml({ fileName: inputFileName });
// Specify the output OpenXML file path
const outputFileName = 'ExcelXML.xml';
// Save the workbook as an OpenXML file
workbook.SaveAsXml({ fileName: outputFileName });
// Read the saved file and convert to Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/xml' });
// Create a URL for the Blob and initiate download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbook
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert an Excel File to OpenXML Using JavaScript in React</h1>
<button onClick={ExcelToOpenXML} disabled={!wasmModule}>
Convert
</button>
</div>
);
}
export default App;
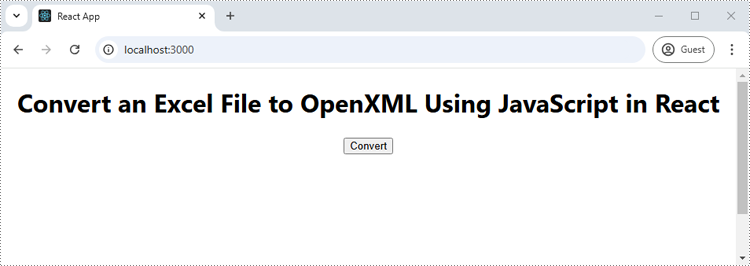
Run the code to launch the React app at localhost:3000. Once it's running, click on the "Convert" button to save the Excel file as an OpenXML file:
The below screenshot shows the input Excel file and the converted OpenXML file:
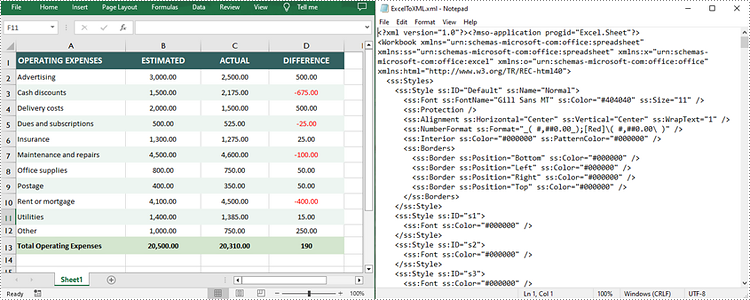
Convert OpenXML to Excel with JavaScript
To convert an OpenXML file back to Excel, you can use the Workbook.LoadFromXml() method to load the OpenXML file and the Workbook.SaveToFile() method to save it in Excel format. Below are the key steps:
- Load the font file to ensure correct text rendering.
- Create a Workbook object using the new wasmModule.Workbook() method.
- Read an OpenXML file into a stream using the wasmModule.Stream.CreateByFile() method.
- Load the OpenXML file from the stream using the Workbook.LoadFromXml() method.
- Save the OpenXML file as an Excel file using the Workbook.SaveToFile() method.
Code example:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.XLS
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.xls.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.xls.js WASM module:', error);
}
})();
}, []);
// Function to convert OpenXML to Excel
const OpenXMLToExcel = async () => {
const wasmModule = window.wasmModule.spirexls;
if (wasmModule) {
// Load font into Virtual File System (VFS)
await window.spire.FetchFileToVFS('Arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Load input file into Virtual File System (VFS)
const inputFileName = 'in.xml';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new workbook
const workbook = new wasmModule.Workbook();
// Read an OpenXML file into a stream
let fileStream = new wasmModule.Stream(inputFileName);
// Load the OpenXML file from the stream
workbook.LoadFromXml({ stream: fileStream });
// Specify the output Excel file path
const outputFileName = 'XMLToExcel.xlsx';
// Save the OpenXML file as an Excel file
workbook.SaveToFile({ fileName: outputFileName, version: wasmModule.ExcelVersion.Version2013 });
// Read the saved file and convert to Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet' });
// Create a URL for the Blob and initiate download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbook
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert an OpenXML File to Excel Using JavaScript in React</h1>
<button onClick={OpenXMLToExcel} disabled={!wasmModule}>
Convert
</button>
</div>
);
}
export default App;
Get a Free License
To fully experience the capabilities of Spire.XLS for JavaScript without any evaluation limitations, you can request a free 30-day trial license.
In modern web development, generating PDFs directly from HTML is essential for applications requiring dynamic reports, invoices, or user-specific documents. Using JavaScript to convert HTML to PDF in React applications ensures the preservation of structure, styling, and interactivity, transforming content into a portable, print-ready format. This method eliminates the need for separate PDF templates, leverages React's component-based architecture for dynamic rendering, and reduces server-side dependencies. By embedding PDF conversion into the front end, developers can provide a consistent user experience, enable instant document downloads, and maintain full control over design and layout. This article explores how to use Spire.Doc for JavaScript to convert HTML files and strings to PDF in React applications.
Install Spire.Doc for JavaScript
To get started with converting HTML to PDF in a React application, you can either download Spire.Doc for JavaScript from our website or install it via npm with the following command:
npm i spire.officeThe downloaded product package integrates Spire.Doc for JavaScript, Spire.XLS for JavaScript, Spire.PDF for JavaScript, and Spire.Presentation for JavaScript. To use the features of Spire.Doc for JavaScript, you need to copy the corresponding files (spire.doc.js, Spire.Doc.Wasm.zip, spire.common.js, Spire.Common.Wasm.zip, and the _framework folder) to the public folder of your project. To ensure proper text rendering, you can add relevant font files with a custom path. In the following example, the font is added to the path: public\static\font.
For more details, refer to the documentation: How to Integrate Spire.Doc for JavaScript in a React Project
Convert an HTML File to PDF with JavaScript
Using the Spire.Doc WASM module, developers can load HTML files into a Document object with the Document.LoadFromFile() method and then convert them to PDF documents using the Document.SaveToFile() method. This approach provides a concise and efficient solution for HTML-to-PDF conversion in web development.
The detailed steps are as follows:
- Load the Spire.Doc.Base.js file to initialize the WebAssembly module.
- Load the HTML file and the font files used in the HTML file into the virtual file system using the window.spire.FetchFileToVFS() method.
- Create an instance of the Document class using the new wasmModule.Document() method.
- Load the HTML file into the Document instance using the Document.LoadFromFile() method.
- Convert the HTML file to PDF format and save it using the Document.SaveToFile() method.
- Read the converted file as a file array and download it.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.Doc
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.doc.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.doc.js WASM module:', error);
}
})();
}, []);
// Function to convert HTML files to PDF document
const ConvertHTMLFileToPDF = async () => {
const wasmModule = window.wasmModule.spiredoc;
if (wasmModule) {
// Load the font files into the virtual file system (VFS)
await window.spire.FetchFileToVFS('CALIBRI.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Specify the input file name and the output file name
const inputFileName = 'Sample.html';
const outputFileName = 'HTMLFileToPDF.pdf';
// Fetch the input file and add it to the VFS
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create an instance of the Document class
const doc = new wasmModule.Document();
// Load the Word document
doc.LoadFromFile({ fileName: inputFileName, fileFormat: wasmModule.FileFormat.Html, validationType: wasmModule.XHTMLValidationType.None });
// Save the document to a PDF file
doc.SaveToFile({ fileName: outputFileName, fileFormat: wasmModule.FileFormat.PDF });
// Release resources
doc.Dispose();
// Read the saved file from the VFS
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
// Generate a Blob from the file array and trigger a download
const blob = new Blob([modifiedFileArray], { type: 'application/pdf' });
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert HTML files to PDF Using JavaScript in React</h1>
<button onClick={ConvertHTMLFileToPDF} disabled={!wasmModule}>
Convert
</button>
</div>
);
}
export default App;
Convert an HTML String to PDF with JavaScript
Spire.Doc for JavaScript offers the Paragraph.AppendHTML() method, which allows developers to insert HTML-formatted content directly into a document paragraph. Once the HTML content is added, the document can be saved as a PDF, enabling a seamless conversion from an HTML string to a PDF file.
The detailed steps are as follows:
- Load the Spire.Doc.Base.js file to initialize the WebAssembly module.
- Define the HTML string.
- Load the font files used in the HTML string using the window.spire.FetchFileToVFS() method.
- Create a new Document instance using the new wasmModule.Document() method.
- Add a section to the document using the Document.AddSection() method.
- Add a paragraph to the section using the Section.AddParagraph() method.
- Insert the HTML content into the paragraph using the Paragraph.AppendHTML() method.
- Save the document as a PDF file using the Document.SaveToFile() method.
- Read the converted file as a file array and download it.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.Doc
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.doc.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.doc.js WASM module:', error);
}
})();
}, []);
// Function to convert HTML string to PDF
const ConvertHTMLStringToPDF = async () => {
const wasmModule = window.wasmModule.spiredoc;
if (wasmModule) {
// Load the font files into the virtual file system (VFS)
await window.spire.FetchFileToVFS('CALIBRI.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Create an instance of the Document class
const doc = new wasmModule.Document();
// Specify the output file name
const outputFileName = 'HTMLStringToPDF.pdf';
// Define the HTML string
const htmlString = `
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sales Snippet</title>
</head>
<body style="font-family: Arial, sans-serif; margin: 20px;">
<div style="border: 1px solid #ddd; padding: 15px; max-width: 600px; margin: auto; background-color: #f9f9f9;">
<h1 style="color: #e74c3c; text-align: center;">Limited Time Offer!</h1>
<p style="font-size: 1.1em; color: #333; line-height: 1.5;">
Get ready to save big on all your favorites. This week only, enjoy 15% off site wide. From trendy clothing to home decor, find everything you love at unbeatable prices.
</p>
<div style="text-align: center;">
<button
style="background-color: #5cb85c; border: none; color: white; padding: 10px 20px; text-align: center; text-decoration: none; display: inline-block; font-size: 16px; margin: 4px 2px; cursor: pointer; border-radius: 8px;">
Shop Deals
</button>
</div>
</div>
</body>
</html>
`;
// Add a section to the document
const section = doc.AddSection();
// Add a paragraph to the section
const paragraph = section.AddParagraph();
// Insert the HTML content to the paragraph
paragraph.AppendHTML(htmlString)
// Save the document to a PDF file
doc.SaveToFile({fileName: outputFileName, fileFormat: wasmModule.FileFormat.PDF});
// Release resources
doc.Dispose();
// Read the saved file from the VFS
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
// Generate a Blob from the file array and trigger a download
const blob = new Blob([modifiedFileArray], {type: 'application/pdf'});
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert HTML Strings to PDF Using JavaScript in React</h1>
<button onClick={ConvertHTMLStringToPDF} disabled={!wasmModule}>
Convert and Download
</button>
</div>
);
}
export default App;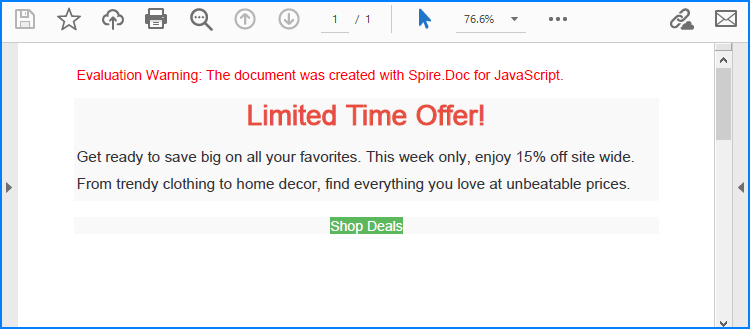
Get a Free License
To fully experience the capabilities of Spire.Doc for JavaScript without any evaluation limitations, you can request a free 30-day trial license.
