
Knowledgebase (2344)
Children categories
Splitting a PowerPoint presentation into smaller files or individual sections can be useful in various situations. For instance, when collaborating with a team, each member may only need a specific section of the presentation to work on. Additionally, breaking a large presentation into smaller parts can simplify sharing over email or uploading to platforms with file size restrictions. In this article, we'll show you how to split PowerPoint presentations by slides, slide ranges, and sections in Python using Spire.Presentation for Python.
- Split PowerPoint Presentations by Slides in Python
- Split PowerPoint Presentations by Slide Ranges in Python
- Split PowerPoint Presentations by Sections in Python
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Split PowerPoint Presentations by Slides in Python
Developers can use Spire.Presentation for Python to split a PowerPoint presentation into individual slides by iterating through the slides in the presentation and adding each slide to a new presentation. The detailed steps are as follows.
- Create an instance of the Presentation class.
- Load a PowerPoint presentation using the Presentation.LoadFromFile() method.
- Iterate through all slides in the presentation:
- Access the current slide through the Presentation.Slides[index] property.
- Create a new PowerPoint presentation using the Presentation class and remove its default slide using the Presentation.Slides.RemoveAt(0) method.
- Append the current slide to the new presentation using the Presentation.Slides.AppendBySlide() method.
- Save the new presentation as a file using the ISlide.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an instance of the Presentation class
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Sample.pptx")
# Iterate through all slides in the presentation
for i in range(presentation.Slides.Count):
# Get the current slide
slide = presentation.Slides[i]
# Create a new PowerPoint presentation and remove its default slide
newPresentation = Presentation()
newPresentation.Slides.RemoveAt(0)
# Append the current slide to the new presentation
newPresentation.Slides.AppendBySlide(slide)
# Save the new presentation as a file
newPresentation.SaveToFile(f"output/Presentations/Slide-{i + 1}.pptx", FileFormat.Pptx2013)
newPresentation.Dispose()
presentation.Dispose()
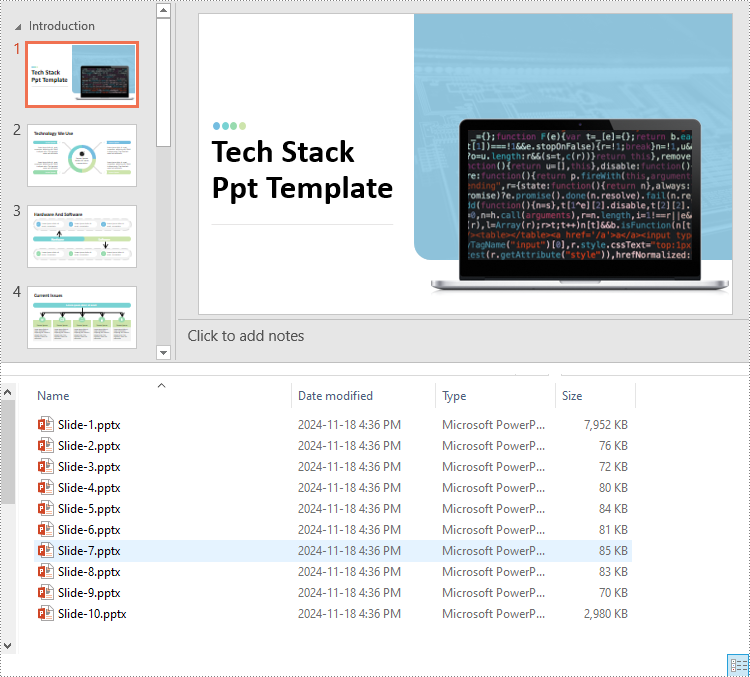
Split PowerPoint Presentations by Slide Ranges in Python
Apart from splitting a PowerPoint presentation into individual slides, developers can also divide it into specific ranges of slides by adding the desired slides to new presentations. The detailed steps are as follows.
- Create an instance of the Presentation class.
- Load a PowerPoint presentation using the Presentation.LoadFromFile() method.
- Create new PowerPoint presentations using the Presentation class and remove the default slides within them using the Presentation.Slides.RemoveAt(0) method.
- Append specified ranges of slides to the new presentations using the Presentation.Slides.AppendBySlide() method.
- Save the new presentations as files using the Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an instance of the Presentation class
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Sample.pptx")
# Create two new PowerPoint presentations and remove their default slides
presentation1 = Presentation()
presentation2 = Presentation()
presentation1.Slides.RemoveAt(0)
presentation2.Slides.RemoveAt(0)
# Append slides 1-3 to the first new presentation
for i in range(3):
presentation1.Slides.AppendBySlide(presentation.Slides[i])
# Append the remaining slides to the second new presentation
for i in range(3, presentation.Slides.Count):
presentation2.Slides.AppendBySlide(presentation.Slides[i])
# Save the new presentations as files
presentation1.SaveToFile("output/Presentations/SlideRange1.pptx", FileFormat.Pptx2013)
presentation2.SaveToFile("output/Presentations/SlideRange2.pptx", FileFormat.Pptx2013)
presentation1.Dispose()
presentation2.Dispose()
presentation.Dispose()
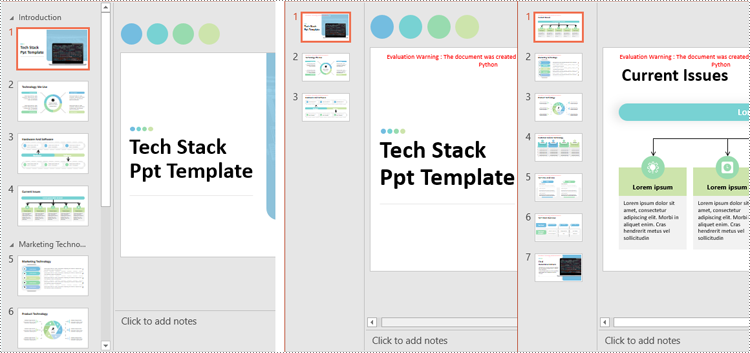
Split PowerPoint Presentations by Sections in Python
Sections in PowerPoint are often used to organize slides into manageable groups. With Spire.Presentation for Python, developers can split a PowerPoint presentation into sections by iterating through the sections in the presentation and adding the slides within each section to a new presentation. The detailed steps are as follows.
- Create an instance of the Presentation class.
- Load a PowerPoint presentation using the Presentation.LoadFromFile() method.
- Iterate through all sections in the presentation:
- Access the current section through the Presentation.SectionList[] property.
- Create a new PowerPoint presentation using the Presentation class and remove its default slide using the Presentation.Slides.RemoveAt(0) method.
- Add a section to the new presentation with the same name using the Presentation.SectionList.Append() method.
- Retrieve the slides of the current section using the Section.GetSlides() method.
- Iterate through the retrieved slides and add them to the section of the new presentation using the Section.Insert() method.
- Save the new presentation as a file using the Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an instance of the Presentation class
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Sample.pptx")
# Iterate through all sections
for i in range(presentation.SectionList.Count):
# Get the current section
section = presentation.SectionList.get_Item(0)
# Create a new PowerPoint presentation and remove its default slide
newPresentation = Presentation()
newPresentation.Slides.RemoveAt(0)
# Add a section to the new presentation
newSection = newPresentation.SectionList.Append(section.Name)
# Retrieve the slides of the current section
slides = section.GetSlides()
# Insert each retrieved slide into the section of the new presentation
for slide_index, slide in enumerate(slides):
newSection.Insert(slide_index, slide)
# Save the new presentation as a file
newPresentation.SaveToFile(f"output/Presentations/Section-{i + 1}.pptx", FileFormat.Pptx2019)
newPresentation.Dispose()
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
In PowerPoint, comments are a very useful feature that can help you add notes or feedback to your slides. In addition to adding or removing comments, sometimes you may need to modify existing comments to correct errors or outdated information. Or in a collaborative editing scenario, you may need to extract comments to collect suggestions of all members. This article will demonstrate how to modify or extract comments in PowerPoint in C# using Spire.Presentation for .NET.
Install Spire.Presentation for .NET
To begin with, you need to add the DLL files included in the Spire.Presentation for .NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.Presentation
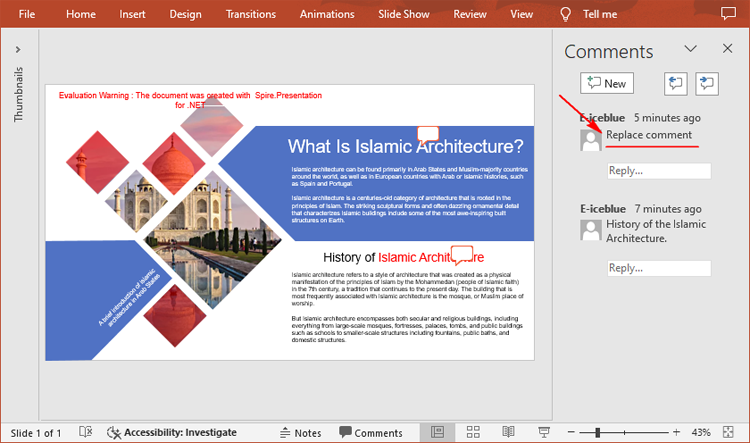
Modify Comments on a Presentation Slide in C#
The ISlide.Comments[].Text property provided by Spire.Presentation for .NET allows you to update the content of a specified comment with new text. The following are the detailed steps.
- Create a Presentation instance.
- Load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Get a specified slide through Prenstion.Slides[] property.
- Update a specified comment on the slide through ISlide.Comments[].Text property.
- Save the result file using Presentation.SaveToFile() method.
- C#
using Spire.Presentation;
namespace ModifyComment
{
class Program
{
static void Main(string[] args)
{
// Create a Presentation instance
Presentation presentation = new Presentation();
// Load a PowerPoint presentation
presentation.LoadFromFile("Comments.pptx");
// Get the first slide
ISlide slide = presentation.Slides[0];
// Update the first comment in the slide
slide.Comments[0].Text = "Replace comment";
// Save the result file
presentation.SaveToFile("ModifyComment.pptx", FileFormat.Pptx2016);
}
}
}
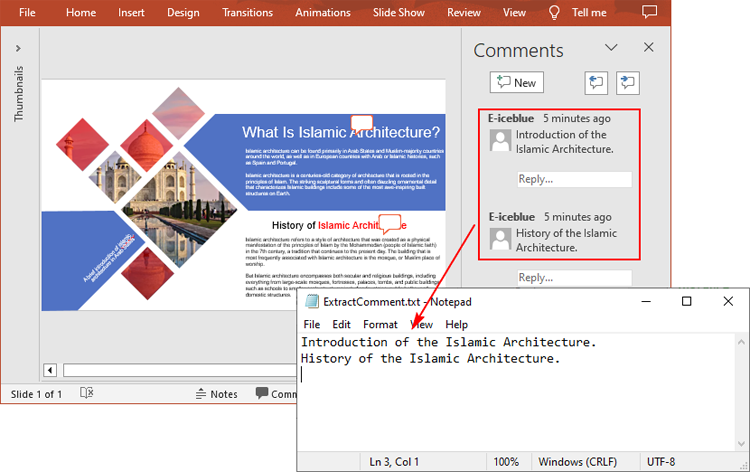
Extract Comments from a Presentation Slide in C#
To extract comments from a slide, you need to get all the comments in the slide via the ISlide.Comments property, and then iterate through each comment to get its text content via the Comment.Text property. The following are the detailed steps.
- Create a Presentation instance.
- Load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Create a StringBuilder instance.
- Get a specified slide through Prenstion.Slides[] property.
- Get all comments in the slide through ISlide.Comments property.
- Iterate over each comment to get its text content through Comment.Text property, and then append to the StringBuilder instance.
- Write to a text file using Presentation.SaveToFile() method.
- C#
using Spire.Presentation;
using System.IO;
using System.Text;
namespace ExtractComment
{
class Program
{
static void Main(string[] args)
{
// Create a Presentation instance
Presentation presentation = new Presentation();
// Load a PowerPoint presentation
presentation.LoadFromFile("Comments.pptx");
// Create a StringBuilder instance
StringBuilder str = new StringBuilder();
// Get the first slide
ISlide slide = presentation.Slides[0];
// Get all comments in the slide
Comment[] comments = slide.Comments;
// Append the comment text to the StringBuilder instance
for (int i = 0; i < comments.Length; i++)
{
str.Append(comments[i].Text + "\r\n");
}
// Write to a text file
File.WriteAllText("ExtractComment.txt", str.ToString());
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert Excel Data to Word Table with Formatting
2024-11-18 01:07:09 Written by AdministratorExcel is ideal for data calculations, analysis, and organization, while Word shines at creating polished, well-formatted documents and reports. Transferring data from Excel to Word is often necessary for professionals preparing reports or presentations, as it allows for advanced formatting options that enhance readability and create a more professional look. In this guide, you will learn how to convert data in an Excel sheet to a Word table with formatting in Python using Spire.Office for Python.
Install Spire.Office for Python
This scenario requires Spire.Office for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Office
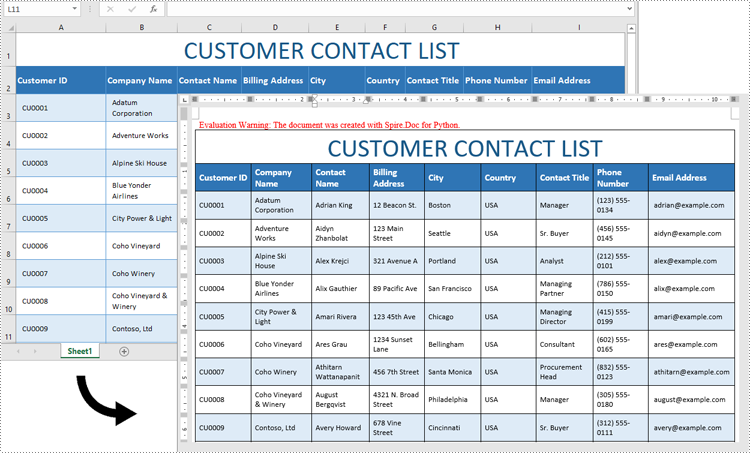
Convert Excel Data to Word Table with Formatting in Python
This process uses two libraries in the Spire.Office for Python package. They’re Spire.XLS for Python and Spire.Doc for Python. The former is used to read data and formatting from an Excel worksheet, and the latter is used to create a Word document and write data, including formatting, into a table. To make this code example easy to understand, we have defined the following two custom methods that handle specific tasks:
- MergeCells() - Merge the corresponding cells in the Word table based on the merged cells in the Excel sheet.
- CopyStyle() - Copy various cell styles from the Excel worksheet to the Word table, including font style, background color, and text alignment.
The following steps demonstrate how to convert data from an Excel sheet to a Word table with formatting using Spire.Office for Python.
- Create an object of the Workbook class and load a sample Excel file using the Workbook.LoadFromFile() method.
- Get a specific worksheet through the Workbook.Worksheets[index] property.
- Create a new Word document using the Document class, and add a section to it.
- Add a table to the Word document using the Section.AddTable() method.
- Detect the merged cells in the worksheet and merge the corresponding cells in the Word tale using the custom method MergeCells().
- Iterate through the cells in the worksheet, read the data of the cells through the CellRange.Value property and add the data to Word table cells using the TableCell.AddParagraph().AppendText() method.
- Copy the cell styles from the Excel worksheet to the Word table using the custom method CopyStyle().
- Save the Word document to a file using the Document.SaveToFile() method.
- Python
from spire.xls import *
from spire.doc import *
def MergeCells(sheet, table):
"""Merge cells in the Word table based on merged cells in the Excel sheet."""
if sheet.HasMergedCells:
ranges = sheet.MergedCells
for i in range(len(ranges)):
startRow = ranges[i].Row
startColumn = ranges[i].Column
rowCount = ranges[i].RowCount
columnCount = ranges[i].ColumnCount
if rowCount > 1 and columnCount > 1:
for j in range(startRow, startRow + rowCount):
table.ApplyHorizontalMerge(j - 1, startColumn - 1, startColumn - 1 + columnCount - 1)
table.ApplyVerticalMerge(startColumn - 1, startRow - 1, startRow - 1 + rowCount - 1)
if rowCount > 1 and columnCount == 1:
table.ApplyVerticalMerge(startColumn - 1, startRow - 1, startRow - 1 + rowCount - 1)
if columnCount > 1 and rowCount == 1:
table.ApplyHorizontalMerge(startRow - 1, startColumn - 1, startColumn - 1 + columnCount - 1)
def CopyStyle(wTextRange, xCell, wCell):
"""Copy cell styling from Excel to Word."""
# Copy font style
wTextRange.CharacterFormat.TextColor = Color.FromRgb(xCell.Style.Font.Color.R, xCell.Style.Font.Color.G, xCell.Style.Font.Color.B)
wTextRange.CharacterFormat.FontSize = float(xCell.Style.Font.Size)
wTextRange.CharacterFormat.FontName = xCell.Style.Font.FontName
wTextRange.CharacterFormat.Bold = xCell.Style.Font.IsBold
wTextRange.CharacterFormat.Italic = xCell.Style.Font.IsItalic
# Copy background color
if xCell.Style.FillPattern is not ExcelPatternType.none:
wCell.CellFormat.Shading.BackgroundPatternColor=Color.FromRgb(xCell.Style.Color.R, xCell.Style.Color.G, xCell.Style.Color.B)
# Copy horizontal alignment
if xCell.HorizontalAlignment == HorizontalAlignType.Left:
wTextRange.OwnerParagraph.Format.HorizontalAlignment = HorizontalAlignment.Left
elif xCell.HorizontalAlignment == HorizontalAlignType.Center:
wTextRange.OwnerParagraph.Format.HorizontalAlignment = HorizontalAlignment.Center
elif xCell.HorizontalAlignment == HorizontalAlignType.Right:
wTextRange.OwnerParagraph.Format.HorizontalAlignment = HorizontalAlignment.Right
# Copy vertical alignment
if xCell.VerticalAlignment == VerticalAlignType.Bottom:
wCell.CellFormat.VerticalAlignment = VerticalAlignment.Bottom
elif xCell.VerticalAlignment == VerticalAlignType.Center:
wCell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
elif xCell.VerticalAlignment == VerticalAlignType.Top:
wCell.CellFormat.VerticalAlignment = VerticalAlignment.Top
# Load an Excel file
workbook = Workbook()
workbook.LoadFromFile("Contact list.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Create a Word document
doc = Document()
section = doc.AddSection()
section.PageSetup.Orientation = PageOrientation.Landscape
# Add a table
table = section.AddTable(True)
table.ResetCells(sheet.LastRow, sheet.LastColumn)
# Merge cells
MergeCells(sheet, table)
# Export data and styles from Excel to Word table
for r in range(1, sheet.LastRow + 1):
table.Rows[r - 1].Height = float(sheet.Rows[r - 1].RowHeight)
for c in range(1, sheet.LastColumn + 1):
xCell = sheet.Range[r, c]
wCell = table.Rows[r - 1].Cells[c - 1]
# Add text from Excel to Word table cell
textRange = wCell.AddParagraph().AppendText(xCell.NumberText)
# Copy font and cell style
CopyStyle(textRange, xCell, wCell)
# Save the document to a Word file
doc.SaveToFile("ConvertExcelDataToWordTable.docx", FileFormat.Docx)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
