
Knowledgebase (2344)
Children categories
In PowerPoint, properly sized slides help make the document look professional. When giving presentations in different scenarios, adjusting slide sizes to match the aspect ratio of the projector or screen ensures an optimal viewing experience for all audience members, thus increasing engagement. In this article, you will learn how to change the slide size of a PowerPoint presentation in Python using Spire.Presentation for Python.
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
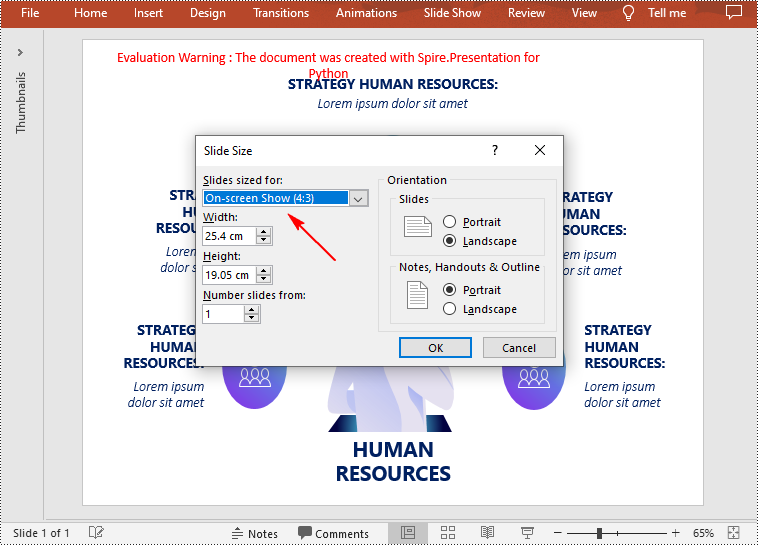
Change the Slide Size to a Preset Size in Python
Spire.Presentation for Python provides the Presentation.SlideSize.Type property to set or change the slide size to a preset size. The following are the detailed steps.
- Create a Presentation instance.
- Load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Change the slide size of the presentation using Presentation.SlideSize.Type property.
- Save the result document using Presentation.SaveToFile() method.
- Python
from spire.presentation import *
# Create a Presentation instance
presentation = Presentation()
# Load a PowerPoint document
presentation.LoadFromFile("sample.pptx")
# Set or change the slide size
presentation.SlideSize.Type = SlideSizeType.Screen4x3
# Save the result document
presentation.SaveToFile("ChangeSlideSize.pptx", FileFormat.Pptx2016)
presentation.Dispose()
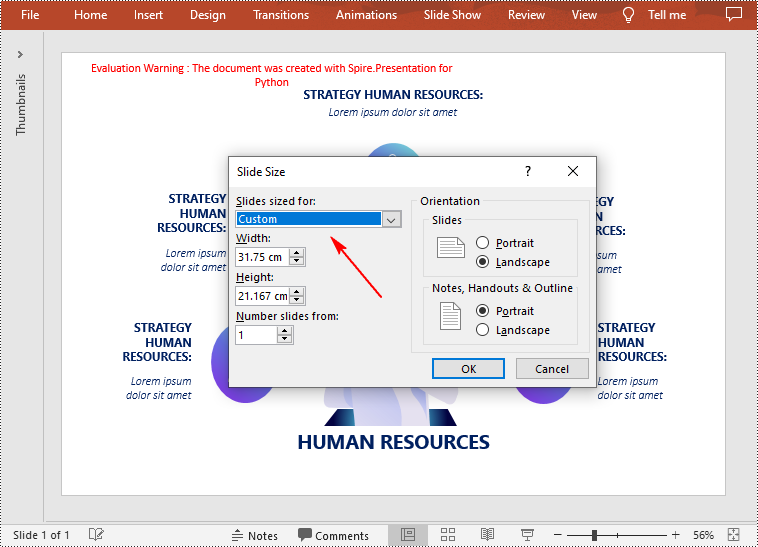
Change the Slide Size to a Custom Size in Python
Customizing the size of slides requires changing the slide size type to Custom first, and then you can set a desired size through the Presentation.SlideSize.Size property. The following are the detailed steps.
- Create a Presentation instance.
- Load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Change the slide size type to custom using Presentation.SlideSize.Type property.
- Customize the slide size using Presentation.SlideSize.Size property.
- Save the result document using Presentation.SaveToFile() method.
- Python
from spire.presentation import *
# Create a Presentation instance
presentation = Presentation()
# Load a PowerPoint document
presentation.LoadFromFile("sample.pptx")
# Change the slide size type to custom
presentation.SlideSize.Type = SlideSizeType.Custom
# Set the slide size
presentation.SlideSize.Size = SizeF(900.0,600.0)
# Save the result document
presentation.SaveToFile("CustomSlideSize.pptx", FileFormat.Pptx2016)
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Text files have a distinct advantage over Excel spreadsheets in terms of simplicity as they don't contain complex formatting, macros or formulas. This streamlined nature not only enhances portability, but also reduces the possibility of file corruption. Consequently, converting Excel files to text files can greatly facilitates data parsing and ensures compatibility with various applications. In this article, you will learn how to convert Excel to TXT text file in Python using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
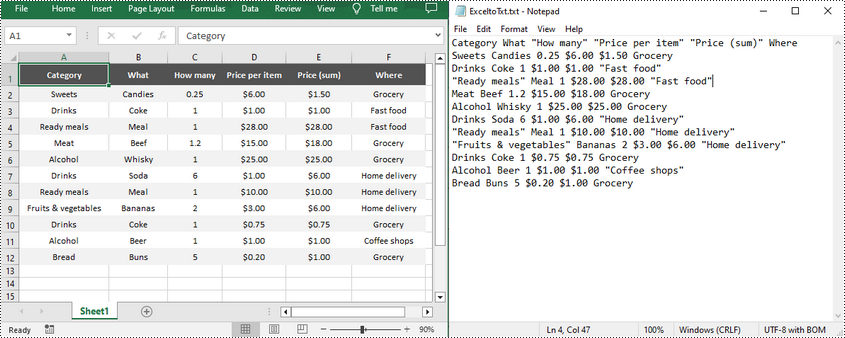
Convert Excel to TXT in Python
Spire.XLS for Python offers the Worksheet.SaveToFile(fileName: str, separator: str, encoding: Encoding) method to convert a specified worksheet to a TXT text file. The three parameters represent:
- fileName: Specifies the path and the name of the output text file.
- separator: Specifies the separator for the output text file. Common separators include commas (,), tabs, semicolons (;), etc.
- encoding: Specifies the encoding format of the file, e.g. UTF-8, Unicode, ASCII, etc. You need to use the correct encoding format to ensure that the text is represented and interpreted correctly.
The following are the detailed steps to convert Excel to text files in Python.
- Create a Workbook instance.
- Load a sample Excel file using Workbook.LoadFromFile() method.
- Get a specified worksheet by its index using Workbook.Worksheets[sheetIndex] property.
- Convert the Excel worksheet to a TXT file using Worksheet.SaveToFile() method.
- Python
import os import sys curPath = os.path.abspath(os.path.dirname(__file__)) rootPath = os.path.split(curPath)[0] sys.path.append(rootPath) from spire.xls import * from spire.xls.common import * inputFile = "Inventories.xlsx" outputFile = "ExceltoTxt.txt" # Create a Workbook instance workbook = Workbook() # Load an Excel document from disk workbook.LoadFromFile(inputFile) # Get the first worksheet sheet = workbook.Worksheets[0] # Save the worksheet as a txt file sheet.SaveToFile(outputFile, " ", Encoding.get_UTF8()) workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
In the realm of document management, the ability to add headers and footers to PDFs has become an essential feature. This functionality allows individuals and businesses to enhance the visual appeal, branding, and organization of their PDF documents.
By incorporating headers and footers, users can customize their PDFs with important contextual information, such as document titles, page numbers, logos, dates, copyright notices, or confidentiality disclaimers. This not only helps establish a professional look but also improves document navigation and ensures compliance with legal requirements.
In this article, we will delve into the process of seamlessly integrating headers and footers into existing PDF files by using the Spire.PDF for Python library.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
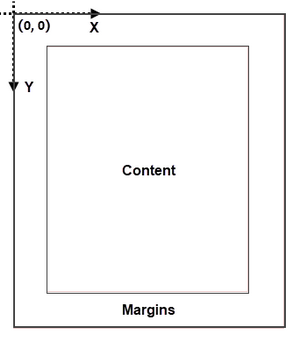
Coordinate System in an Existing PDF
When using Spire.PDF for Python to manipulate an existing PDF document, the coordinate system's origin is positioned at the top left corner of the page. The x-axis extends to the right, while the y-axis extends downward.
Understanding coordinate system is crucial for us, as nearly all newly added elements on a PDF page need to be positioned using specified coordinates. The process of creating headers and footers on PDF pages involves adding text, images, shapes, automatic fields, or other elements to the upper or lower margins of the page at designated coordinates.
Classes and Methods for Creating Header and Footer
In Spire.PDF for Python, there are several methods available for drawing elements on a PDF page. The PdfCanvas class provides the methods DrawString(), DrawImage(), and DrawLine(), which allow users to draw strings, images, and lines respectively, at specific coordinates on the page.
Additionally, Spire.PDF for Python offers specialized classes such as PdfPageNumberField, PdfPageCountField, and PdfSectionNumberField. These classes enable automatic access to the current page number, page count, and section number. Moreover, these classes include the Draw() method, which facilitates the easy addition of dynamic information to the header or footer section of the PDF document.
Add Header to an Existing PDF Document in Python
A header refers to a section that appears at the top of each page. The header typically contains information such as a logo, document title, date, or any other relevant details that provide context or branding to the document.
To add a header consisting of text, an image, a line and a section number to a PDF document, you can follow these steps:
- Create a PdfDocuemnt object.
- Load an existing PDF document from the specified path.
- Define the header content:
- Specify the text to be added to the header.
- Load an image for the header.
- Create a PdfSectionNumberField object to get the current section number, and create a PdfCompositeField object to combine text and the section number in a single field.
- Add the header to each page: Iterate through each page of the PDF document and add the header content at the designated position by using the Canvas.DrawString(), Canvas.DrawImage(), Canvas.DrawLine(), and PdfCompositeField.Draw() methods. When calling these methods, you need to consider the page size and margins when determining the position.
- Save the modified PDF to a new file or overwrite the existing file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Terms of service.pdf")
# Load an image
headerImage = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\Logo-Small.png")
# Get the image width in pixel
width = headerImage.Width
# Get the image width in point
unitCvtr = PdfUnitConvertor()
pointWidth = unitCvtr.ConvertUnits(width, PdfGraphicsUnit.Pixel, PdfGraphicsUnit.Point)
# Create font, brush and pen
firstFont = PdfTrueTypeFont("Times New Roman", 18.0, PdfFontStyle.Bold, True)
secondFont = PdfTrueTypeFont("Times New Roman", 12.0, PdfFontStyle.Regular, True)
brush = PdfBrushes.get_DarkBlue()
pen = PdfPen(PdfBrushes.get_Black(), 1.5)
# Specify text to add to header
headerText = "TERMS OF SERVICE"
# Create a PdfSectionNumberField object
sectionField = PdfSectionNumberField(firstFont, brush)
# Create a PdfCompositeField object
compositeField = PdfCompositeField(secondFont, brush, "Section: [{0}]", [sectionField])
# Set the location of the composite field
compositeField.Location = PointF(72.0, 45.0)
# Iterate throuh the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Draw an image at the specified position
page.Canvas.DrawImage(headerImage, page.ActualSize.Width - pointWidth - 72.0, 20.0)
# Draw a string at the specified position
page.Canvas.DrawString(headerText, firstFont, brush, 72.0, 25.0)
# Draw a line at the specified position
page.Canvas.DrawLine(pen, 72.0, 65.0, page.ActualSize.Width - 72.0, 65.0)
# Draw composite on the page
compositeField.Draw(page.Canvas, 0.0, 0.0)
# Save the changes to a different PDF file
doc.SaveToFile("Output/AddHeader.pdf")
# Dispose resources
doc.Dispose()

Add Footer to an Existing PDF Document in Python
A footer refers to a section that appears at the bottom of each page. The footer may contain information such as page numbers, copyright information, author name, date, or any other relevant details that provide additional context or navigation aids to the reader.
To add a footer which includes a line and "Page X of Y" to a PDF document, follow the steps below.
- Create a PdfDocuemnt object.
- Load an existing PDF document from the specified path.
- Define the footer content: Create a PdfPageNumberField object to get the current page number, and a PdfPageCountField object to get the total page count. In order to create a "Page X of Y" format, you can utilize a PdfCompositeField object to combine text and these two automatic fields in a single field.
- Add the footer to each page: Iterate through each page of the PDF document and add a line using the Canvas.DrawLine() method. Add the page number and page count to the footer space using the PdfCompositeField.Draw() method. When calling these methods, you need to consider the page size and margins when determining the position.
- Save the modified PDF to a new file or overwrite the existing file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Terms of service.pdf")
# Create font, brush and pen
font = PdfTrueTypeFont("Times New Roman", 12.0, PdfFontStyle.Bold, True)
brush = PdfBrushes.get_Black()
pen = PdfPen(brush, 1.5)
# Create a PdfPageNumberField object and a PdfPageCountField object
pageNumberField = PdfPageNumberField()
pageCountField = PdfPageCountField()
# Create a PdfCompositeField object to combine page count field and page number field in a single string
compositeField = PdfCompositeField(font, brush, "Page {0} of {1}", [pageNumberField, pageCountField])
# Get the page size
pageSize = doc.Pages[0].Size
# Set the location of the composite field
compositeField.Location = PointF(72.0, pageSize.Height - 45.0)
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Draw a line at the specified position
page.Canvas.DrawLine(pen, 72.0, pageSize.Height - 50.0, pageSize.Width - 72.0, pageSize.Height - 50.0)
# Draw the composite field on the page
compositeField.Draw(page.Canvas, 0.0, 0.0)
# Save to a different PDF file
doc.SaveToFile("Output/AddFooter.pdf")
# Dispose resources
doc.Dispose()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
