
Knowledgebase (2344)
Children categories

Converting Word documents (DOCX or DOC) to HTML format is essential when you want to display formatted content on web pages, import legacy documents into content management systems, or generate web previews for DOCX files. HTML’s universal browser compatibility makes it an ideal format for sharing content online.
This guide shows how to convert Word to HTML in Python using Spire.Doc for Python. It covers both basic and advanced conversion techniques with practical examples, helping you handle diverse conversion needs.
Table of Contents
- Why Convert Word to HTML
- Install Word to HTML Converter in Python
- How to Convert Word to HTML Using Python
- Conclusion
- FAQs
Why Convert Word to HTML?
Here are some typical scenarios where converting Word to HTML is beneficial:
- Web publishing: Display Word content in a browser without requiring users to download the document.
- CMS integration: Import Word-based articles into a web-based content system.
- Content preview: Generate HTML previews for Word attachments or document archives.
- Email rendering: Convert DOCX content into HTML-friendly formats for email templates.
Install Word to HTML Converter in Python
Spire.Doc for Python is a professional library designed for Word document processing and conversion. It provides a reliable way to export Word documents to HTML while preserving accurate formatting and layout. 
Benefits of Using Spire.Doc for Word-to-HTML Conversion
- Accurate formatting: Preserves fonts, colors, styles, tables, and images.
- No Office dependency: Does not require Microsoft Word or Office Interop.
- Supports DOCX and DOC: Compatible with both modern and legacy Word formats.
- Customizable output: Fine-tune HTML export settings, including image embedding and CSS styling.
Installation
Install the library from PyPI using the following command:
pip install spire.doc
Need help with the installation? Check this step-by-step guide: How to Install Spire.Doc for Python on Windows.
How to Convert Word to HTML Using Python
This section demonstrates how to convert Word documents to HTML using Spire.Doc for Python. First, you'll see a quick example using default settings for fast export. Then, you'll learn how to customize the HTML output with advanced options.
Quick Conversion with Default Settings
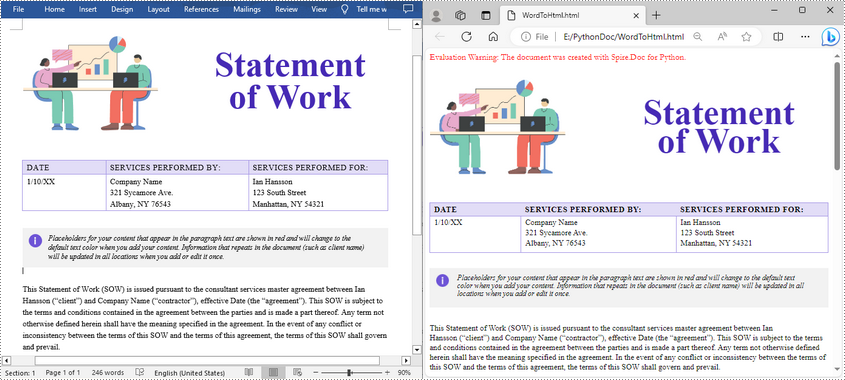
The following code snippet shows how to save a Word document to HTML format using the default export settings. It’s suitable for simple use cases where no customization is needed.
from spire.doc import *
from spire.doc.common import *
# Create a Document instance
document = Document()
# Load a doc or docx document
document.LoadFromFile("Statement.docx")
# Save the document to HTML format
document.SaveToFile("WordToHtml.html", FileFormat.Html)
document.Close()
Advanced Conversion Options
You can customize the HTML export to suit your needs by configuring options such as including headers and footers, linking to an external CSS stylesheet, choosing whether to embed images or save them separately, and exporting form fields as plain text. The example below shows how to set these options.
from spire.doc import *
from spire.doc.common import *
# Create a Document instance
document = Document()
# Load a .docx or .doc document
document.LoadFromFile("Statement.docx")
# Control whether to include headers and footers in the exported HTML
document.HtmlExportOptions.HasHeadersFooters = False
# Specify the name of the CSS file to use for styling the exported HTML
document.HtmlExportOptions.CssStyleSheetFileName = "sample.css"
# Set the CSS stylesheet type to external, so the HTML file links to the specified CSS file instead of embedding styles inline
document.HtmlExportOptions.CssStyleSheetType = CssStyleSheetType.External
# Configure image export: do not embed images inside HTML, save them to a separate folder
document.HtmlExportOptions.ImageEmbedded = False
document.HtmlExportOptions.ImagesPath = "Images/"
# Export form fields as plain text instead of interactive form elements
document.HtmlExportOptions.IsTextInputFormFieldAsText = True
# Save the document as an HTML file
document.SaveToFile("ToHtmlExportOption.html", FileFormat.Html)
document.Close()
Conclusion
Spire.Doc for Python delivers high-fidelity Word-to-HTML conversions without requiring Microsoft Word. Whether for quick exports or customized HTML output, it provides a versatile, dependable solution.
Beyond HTML conversion, Spire.Doc supports a wide range of Word automation tasks such as document merging, text replacement, and PDF conversion, empowering developers to build robust document processing pipelines. To explore these capabilities further, check out the full Python Word programming guide and start enhancing your document workflows today.
FAQs
Q1: Can Spire.Doc convert both DOC and DOCX files to HTML?
A1: Yes, it supports exporting both legacy DOC and modern DOCX formats.
Q2: Is Microsoft Word required for conversion?
A2: No, Spire.Doc works independently without needing Microsoft Word or Office Interop.
Q3: Can images be embedded directly in the HTML instead of saved separately?
A3: Yes, you can embed images directly into the HTML output by setting ImageEmbedded to True. This ensures that all images are included within the HTML file itself, without creating separate image files or folders.
Get a Free License
To fully experience the capabilities of Spire.Doc for Python without any evaluation limitations, you can request a free 30-day trial license.
Page margins are the blank spaces at the top, bottom, left, and right edges of a document page. In Word, it may sometimes be quite necessary to adjust the margins to meet the layout requirements of specific documents, such as academic papers, business reports, or creative projects. This article will demonstrate how to programmatically change the page margins of an existing Word document using Spire.Doc for C++.
Install Spire.Doc for C++
There are two ways to integrate Spire.Doc for C++ into your application. One way is to install it through NuGet, and the other way is to download the package from our website and copy the libraries into your program. Installation via NuGet is simpler and more recommended. You can find more details by visiting the following link.
Integrate Spire.Doc for C++ in a C++ Application
Set Page Margins in Word in C++
The MarginsF class provided by Spire.Doc for C++ represents the page margins in Word. To set or change the margins of a Word document, you can use the methods of MarginsF class. The following are the detailed steps.
- Create a Document object.
- Load a Word document using Document->LoadFromFile() method.
- Get a specified section using Document->GetSections()->GetItemInSectionCollection() method.
- Get the page margins of the section using Section->GetPageSetup()->GetMargins() method.
- Set the top, bottom, left and right margins for the pages in the section using MarginsF->SetTop(), MarginsF->SetBottom(), MarginsF->SetLeft(), MarginsF->SetRight() methods.
- Save the result document using Document.SaveToFile() method.
- C++
#include "Spire.Doc.o.h"
using namespace std;
using namespace Spire::Doc;
int main() {
//Specify the input and output file paths
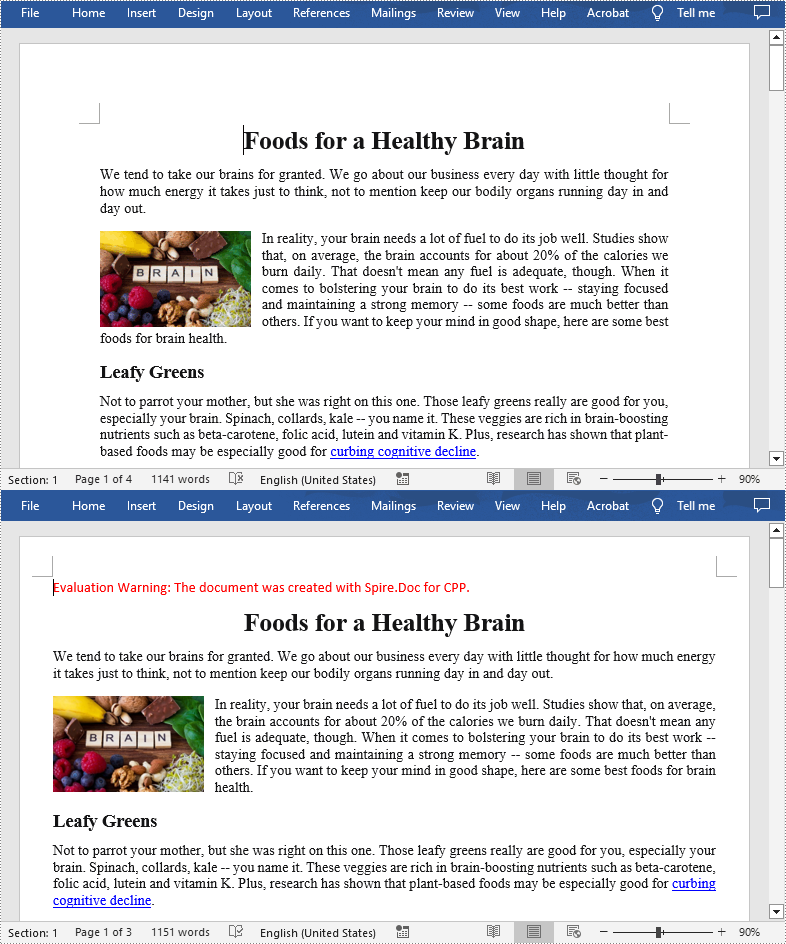
wstring inputFile = L"Data\\Foods.docx";
wstring outputFile = L"SetMargins.docx";
//Create a Document instance
intrusive_ptr<Document> document = new Document();
//Load a Word document
document->LoadFromFile(inputFile.c_str());
//Get the first section
intrusive_ptr<Section> section = document->GetSections()->GetItemInSectionCollection(0);
//Set top, bottom, left and right page margins for the section
section->GetPageSetup()->GetMargins()->SetTop(38.0f);
section->GetPageSetup()->GetMargins()->SetBottom(38.0f);
section->GetPageSetup()->GetMargins()->SetLeft(29.5f);
section->GetPageSetup()->GetMargins()->SetRight(29.5f);
//Save the result document
document->SaveToFile(outputFile.c_str(), FileFormat::Docx2016);
document->Close();
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Adding and deleting slides in PowerPoint are essential actions that allow presenters to control the structure and content of their presentations. Adding slides provides the opportunity to expand and enhance the presentation by introducing new topics or providing supporting information. On the other hand, deleting slides helps streamline the presentation by removing redundant, repetitive, or irrelevant content. In this article, we will demonstrate how to add or delete slides in a PowerPoint Presentation in Python using Spire.Presentation for Python.
- Add a New Slide at the End of the PowerPoint Document in Python
- Insert a New Slide Before a Specific Slide in PowerPoint in Python
- Delete a Specific Slide from a PowerPoint Document in Python
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Add a New Slide at the End of the PowerPoint Document in Python
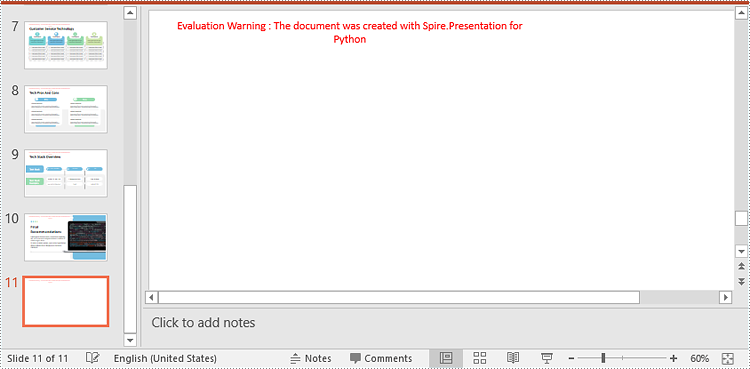
Spire.Presentation for Python provides the Presentation.Slides.Append() method to add a new slide after the last slide of a PowerPoint presentation. The detailed steps are as follows.
- Create an object of the Presentation class.
- Load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Add a new blank slide at the end of the presentation using Presentation.Slides.Append() method.
- Save the result presentation using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Sample.pptx")
# Add a new slide at the end of the presentation
presentation.Slides.Append()
# Save the result presentation to a .pptx file
presentation.SaveToFile("AddSlide.pptx", FileFormat.Pptx2013)
presentation.Dispose()
Insert a New Slide Before a Specific Slide in PowerPoint in Python
You can use the Presentation.Slides.Insert() method to insert a new slide before a specific slide of a PowerPoint presentation. The detailed steps are as follows.
- Create an object of the Presentation class.
- Load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Insert a blank slide before a specific slide using Presentation.Slides.Insert() method.
- Save the result presentation using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Sample.pptx")
# Insert a blank slide before the second slide
presentation.Slides.Insert(1)
# Save the result presentation to a .pptx file
presentation.SaveToFile("InsertSlide.pptx", FileFormat.Pptx2013)
presentation.Dispose()
Delete a Specific Slide from a PowerPoint Document in Python
To delete a specific slide from a PowerPoint presentation, you can use the Presentation.Slides.RemoveAt() method. The detailed steps are as follows.
- Create an object of the Presentation class.
- Load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Remove a specific slide from the presentation using Presentation.Slides.RemoveAt() method.
- Save the result presentation using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Sample.pptx")
# Remove the first slide
presentation.Slides.RemoveAt(0)
# Save the result presentation to a .pptx file
presentation.SaveToFile("RemoveSlide.pptx", FileFormat.Pptx2013)
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
