
Knowledgebase (2344)
Children categories

Watermarking is a critical technique for securing documents, indicating ownership, and preventing unauthorized copying. Whether you're distributing drafts or branding final deliverables, applying watermarks helps protect your content effectively. In this tutorial, you’ll learn how to add watermarks to a PDF in Python using the powerful and easy-to-use Spire.PDF for Python library.
We'll walk through how to insert both text and image watermarks , handle transparency and positioning, and resolve common issues — all with clean, well-documented code examples.
Table of Contents:
- Python Library for Watermarking PDFs
- Adding a Text Watermark to a PDF
- Adding an Image Watermark to a PDF
- Troubleshooting Common Issues
- Wrapping Up
- FAQs
Python Library for Watermarking PDFs
Spire.PDF for Python is a robust library that provides comprehensive PDF manipulation capabilities. For watermarking specifically, it offers:
- High precision in watermark placement and rotation.
- Flexible transparency controls.
- Support for both text and image watermarks.
- Ability to apply watermarks to specific pages or entire documents.
- Preservation of original PDF quality.
Before proceeding, ensure you have Spire.PDF installed in your Python environment:
pip install spire.pdf
Adding a Text Watermark to a PDF
This code snippet demonstrates how to add a diagonal "DO NOT COPY" watermark to each page of a PDF file. It manages the size, color, positioning, rotation, and transparency of the watermark for a professional result.
from spire.pdf import *
from spire.pdf.common import *
import math
# Create an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document from the specified path
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Create an object of PdfTrueTypeFont class for the watermark font
font = PdfTrueTypeFont("Times New Roman", 48.0, 0, True)
# Specify the watermark text
text = "DO NOT COPY"
# Measure the dimensions of the text to ensure proper positioning
text_width = font.MeasureString(text).Width
text_height = font.MeasureString(text).Height
# Loop through each page in the document
for i in range(doc.Pages.Count):
# Get the current page
page = doc.Pages.get_Item(i)
# Save the current canvas state
state = page.Canvas.Save()
# Calculate the center coordinates of the page
x = page.Canvas.Size.Width / 2
y = page.Canvas.Size.Height / 2
# Translate the coodinate system to the center so that the center of the page becomes the origin (0, 0)
page.Canvas.TranslateTransform(x, y)
# Rotate the canvas 45 degrees counterclockwise for the watermark
page.Canvas.RotateTransform(-45.0)
# Set the transparency of the watermark
page.Canvas.SetTransparency(0.7)
# Draw the watermark text at the centered position using negative offsets
page.Canvas.DrawString(text, font, PdfBrushes.get_Blue(), PointF(-text_width / 2, -text_height / 2))
# Restore the canvas state to prevent transformations from affecting subsequent drawings
page.Canvas.Restore(state)
# Save the modified document to a new PDF file
doc.SaveToFile("output/TextWatermark.pdf")
# Dispose resources
doc.Dispose()
Breakdown of the Code :
- Load the PDF Document : The script loads an input PDF file from a specified path using the PdfDocument class.
- Configure Watermark Text : A watermark text ("DO NOT COPY") is set with a specific font (Times New Roman, 48pt) and measured for accurate positioning.
- Apply Transformations : For each page, the script:
- Centers the coordinate system.
- Rotates the canvas by 45 degrees counterclockwise.
- Sets transparency (70%) for the watermark.
- Draw the Watermark : The text is drawn at (-text_width / 2, -text_height / 2), which aligns the text perfectly around the center point of the page, regardless of the rotation applied.
- Save the Document : The modified document is saved to a new PDF file.
Output:
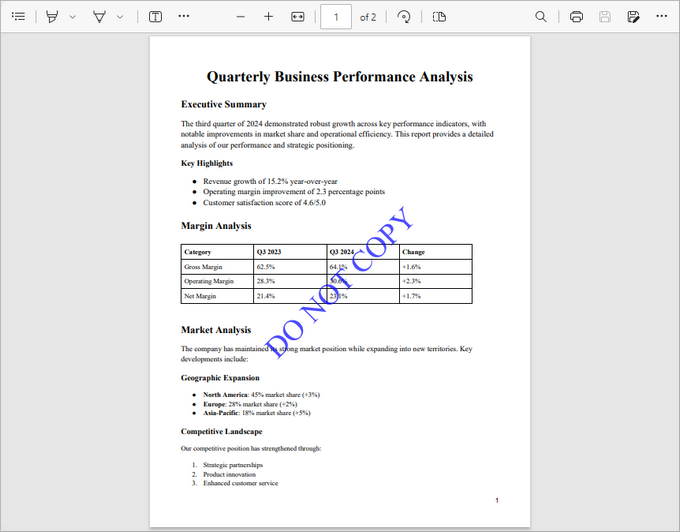
Adding an Image Watermark to a PDF
This code snippet adds a semi-transparent image watermark to each page of a PDF, ensuring proper positioning and a professional appearance.
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document from the specified path
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Load the watermark image from the specified path
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\logo.png")
# Get the width and height of the loaded image for positioning
imageWidth = float(image.Width)
imageHeight = float(image.Height)
# Loop through each page in the document to apply the watermark
for i in range(doc.Pages.Count):
# Get the current page
page = doc.Pages.get_Item(i)
# Set the transparency of the watermark to 50%
page.Canvas.SetTransparency(0.5)
# Get the dimensions of the current page
pageWidth = page.ActualSize.Width
pageHeight = page.ActualSize.Height
# Calculate the x and y coordinates to center the image on the page
x = (pageWidth - imageWidth) / 2
y = (pageHeight - imageHeight) / 2
# Draw the image at the calculated center position on the page
page.Canvas.DrawImage(image, x, y, imageWidth, imageHeight)
# Save the modified document to a new PDF file
doc.SaveToFile("output/ImageWatermark.pdf")
# Dispose resources
doc.Dispose()
Breakdown of the Code :
- Load the PDF Document : The script loads an input PDFfile from a specified path using the PdfDocument class.
- Configure Watermark Image : The watermark image is loaded from a specified path, and its dimensions are retrieved for accurate positioning.
- Apply Transformations : For each page, the script:
- Sets the watermark transparency (50%).
- Calculates the center position of the page for the watermark.
- Draw the Watermark : The image is drawn at the calculated center coordinates, ensuring it is centered on each page.
- Save the Document : The modified document is saved to a new PDF file.
Output:
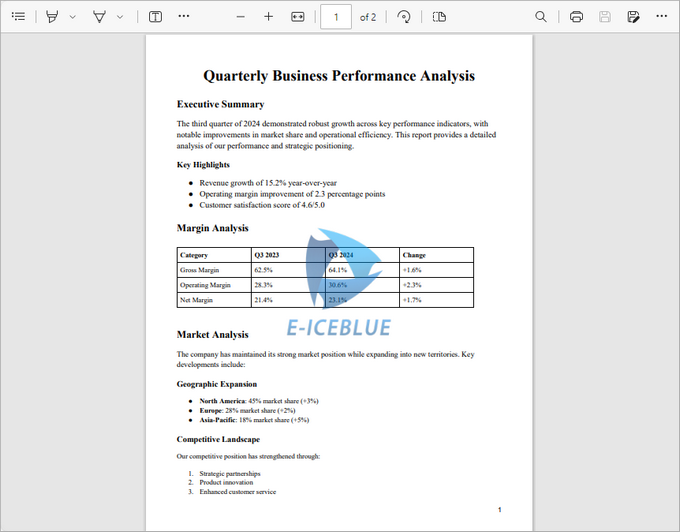
Apart from watermarks, you can also add stamps to PDFs. Unlike watermarks, which are fixed in place, stamps can be freely moved or deleted, offering greater flexibility in document annotation.
Troubleshooting Common Issues
- Watermark Not Appearing :
- Verify file paths are correct.
- Check transparency isn't set to 0 (fully transparent).
- Ensure coordinates place the watermark within page bounds.
- Quality Issues :
- For text, use higher-quality fonts.
- For images, ensure adequate resolution.
- Rotation Problems :
- Remember that rotation occurs around the current origin point.
- The order of transformations matters (translate then rotate).
Wrapping Up
With Spire.PDF for Python, adding watermarks to PDF documents becomes a simple and powerful process. Whether you need bold "Confidential" text across every page or subtle branding with logos, the library handles it all efficiently. By combining coordinate transformations, transparency settings, and drawing commands, you can create highly customized watermarking workflows tailored to your document's purpose.
FAQs
Q1. Can I add both text and image watermarks to the same PDF?
Yes, you can combine both approaches in a single loop over the PDF pages.
Q2. How can I rotate image watermarks?
Use Canvas.RotateTransform(angle) before drawing the image, similar to the text watermark example.
Q3. Does Spire.PDF support transparent PNGs for watermarks?
Yes, Spire.PDF preserves the transparency of PNG images when used as watermarks.
Q4. Can I apply different watermarks to different pages?
Absolutely. You can implement conditional logic within your page loop to apply different watermarks based on page number or other criteria.
Get a Free License
To fully experience the capabilities of Spire.PDF for Python without any evaluation limitations, you can request a free 30-day trial license.
SVG (Scalable Vector Graphics) is an XML-based vector image format that describes two-dimensional graphics using geometric shapes, text, and other graphical elements. SVG files can be easily scaled without losing image quality, which makes them ideal for various purposes such as web design, illustrations, and animations. In certain situations, you may encounter the need to convert PDF files to SVG format. In this article, we will explain how to convert PDF to SVG in Python using Spire.PDF for Python.
- Convert a PDF File to SVG in Python
- Convert a PDF File to SVG with Custom Width and Height in Python
- Convert Specific Pages of a PDF File to SVG in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert a PDF File to SVG in Python
Spire.PDF for Python provides the PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method to convert each page of a PDF file to a separate SVG file. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a sample PDF file using PdfDocument.LoadFromFile() method.
- Convert each page of the PDF file to SVG using PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Sample.pdf")
# Save each page of the file to a separate SVG file
doc.SaveToFile("PdfToSVG/ToSVG.svg", FileFormat.SVG)
# Close the PdfDocument object
doc.Close()
Convert a PDF File to SVG with Custom Width and Height in Python
The PdfDocument.PdfConvertOptions.SetPdfToSvgOptions(wPixel:float, hPixel:float) method provided by Spire.PDF for Python allows you to specify the width and height of the SVG files converted from PDF. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a sample PDF file using PdfDocument.LoadFromFile() method.
- Specify the width and height of the output SVG files using PdfDocument.PdfConvertOptions.SetPdfToSvgOptions(wPixel:float, hPixel:float) method.
- Convert each page of the PDF file to SVG using PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Sample.pdf")
# Specify the width and height of output SVG files
doc.ConvertOptions.SetPdfToSvgOptions(800.0, 1200.0)
# Save each page of the file to a separate SVG file
doc.SaveToFile("PdfToSVGWithCustomWidthAndHeight/ToSVG.svg", FileFormat.SVG)
# Close the PdfDocument object
doc.Close()
Convert Specific Pages of a PDF File to SVG in Python
The PdfDocument.SaveToFile(filename:str, startIndex:int, endIndex:int, fileFormat:FileFormat) method provided by Spire.PDF for Python allows you to convert specific pages of a PDF file to SVG files. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a sample PDF file using PdfDocument.LoadFromFile() method.
- Convert specific pages of the PDF file to SVG using PdfDocument.SaveToFile(filename:str, startIndex:int, endIndex:int, fileFormat:FileFormat) method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Sample.pdf")
# Save specific pages of the file to SVG files
doc.SaveToFile("PdfPagesToSVG/ToSVG.svg", 1, 2, FileFormat.SVG)
# Close the PdfDocument object
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Add, Replace, or Remove Images in a PDF Document
2023-10-17 00:46:55 Written by AdministratorAlongside textual content, images in a PDF play a crucial role in conveying messages effectively. Being able to manipulate images within a PDF document, such as adding, replacing, or removing them, can be incredibly useful for enhancing the visual appeal, updating outdated graphics, or modifying the document's content. In this article, you will learn how to add, replace, or delete images in a PDF document in Python using Spire.PDF for Python.
- Add an Image to a PDF Document in Python
- Replace an Image in a PDF Document in Python
- Remove an Image from a PDF Document in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Add an Image to a PDF Document in Python
To add an image to a PDF page, you can use the PdfPage.Canvas.DrawImage() method. The following are the detailed steps.
- Create a PdfDocument object.
- Add a page to the document using PdfDocument.Pages.Add() method.
- Load an image using PdfImage.FromFile() method.
- Draw the image on the page using PdfPageBase.Canvas.DrawImage() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Set the page margins
doc.PageSettings.SetMargins(30.0, 30.0, 30.0, 30.0)
# Add a page
page = doc.Pages.Add()
# Load an image
image = PdfImage.FromFile('C:/Users/Administrator/Desktop/logo.png')
# Specify the size of the image in the document
width = image.Width * 0.70
height = image.Height * 0.70
# Specify the X and Y coordinates where the image will be drawn
x = 10.0
y = 30.0
# Draw the image at a specified location on the page
page.Canvas.DrawImage(image, x, y, width, height)
# Save the result document
doc.SaveToFile("output/AddImage.pdf", FileFormat.PDF)
Replace an Image in a PDF Document in Python
Spire.PDF for Python offers the PdfImageHelper class to help us get and deal with the images in a certain page. To replace an image with a new one, you can use the PdfImageHelper.ReplaceImage() method. The following are the steps.
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get a specific page through PdfDocument.Pages[index] property.
- Load an image using PdfImage.FromFile() method.
- Create a PdfImageHelper object, and get the image information from the specified page using PdfImageHelper.GetImagesInfo() method.
- Replace an existing image in the page with the new image using PdfImageHelper.ReplaceImage() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile('C:/Users/Administrator/Desktop/input.pdf')
# Get the first page
page = doc.Pages.get_Item(0)
# Load an image
image = PdfImage.FromFile('C:/Users/Administrator/Desktop/newImage.png')
# Create a PdfImageHelper instance
imageHelper = PdfImageHelper()
# Get the image information from the page
imageInfo = imageHelper.GetImagesInfo(page)
# Replace the first image on the page with the loaded image
imageHelper.ReplaceImage(imageInfo[0], image)
# Save the result document
doc.SaveToFile("output/ReplaceImage.pdf", FileFormat.PDF)
Remove an Image from a PDF Document in Python
To remove a specific image from a page, use the PdfPageBase.DeleteImage(index) method. The following are the steps.
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get a specific page through PdfDocument.Pages[index] property.
- Delete a certain image in the page by its index using PdfPageBase.DeleteImage() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile('C:/Users/Administrator/Desktop/input.pdf')
# Get the first page
page = doc.Pages.get_Item(0)
# Delete the first image on the page
page.DeleteImage(0)
# Save the result document
doc.SaveToFile('output/DeleteImage.pdf', FileFormat.PDF)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
