Como substituir texto no Excel: 5 maneiras rápidas (do manual ao automatizado)
Índice
- Método 1 - Substituir Texto Manualmente com Localizar e Substituir do Excel
- Método 2 - Substituir Texto por Posição Usando a Função REPLACE do Excel
- Método 3 - Substituir Texto por Conteúdo Usando a Função SUBSTITUTE do Excel
- Método 4 - Automatizar Substituições de Texto no Excel com VBA
- Método 5 - Substituir Texto em Lote em Vários Arquivos do Excel com Python

Ao trabalhar com grandes pastas de trabalho do Excel, dados inconsistentes ou desatualizados podem rapidamente prejudicar seus relatórios e tomada de decisões. Digitalizar manualmente milhares de células para corrigir erros de digitação não é apenas demorado, mas também propenso a erros humanos custosos. Dominar como substituir texto no Excel de forma eficiente é uma habilidade crítica para qualquer profissional de dados.
Neste guia abrangente, exploramos 5 métodos práticos para substituir texto no Excel - desde a ferramenta integrada Localizar e Substituir e fórmulas de planilha até automação avançada com VBA e Python. Se você precisa atualizar uma única célula ou processar em lote centenas de pastas de trabalho, nossas instruções passo a passo o ajudarão a otimizar seu fluxo de trabalho e garantir a integridade dos dados.
Visão Geral dos Métodos
- Método 1 - Substituir Texto Manualmente com Localizar e Substituir do Excel
- Método 2 - Substituir Texto por Posição Usando a Função REPLACE do Excel
- Método 3 - Substituir Texto por Conteúdo Usando a Função SUBSTITUTE do Excel
- Método 4 - Automatizar Substituições de Texto no Excel com VBA
- Método 5 - Substituir Texto em Lote em Vários Arquivos do Excel com Python
Entendendo a Substituição de Texto no Excel
A substituição de texto no Excel não é apenas uma mudança cosmética - ela pode:
- Corrigir erros - corrigir erros de digitação ou códigos desatualizados.
- Padronizar formatos - unificar códigos de produtos, e-mails ou datas.
- Melhorar a análise de dados - garantir a consistência antes de cálculos, filtros ou tabelas dinâmicas.
- Economizar tempo em tarefas repetitivas - especialmente ao trabalhar com grandes conjuntos de dados ou vários arquivos.
Abaixo, exploraremos 5 maneiras práticas de substituir dados no Excel.
Método 1 - Substituir Texto Manualmente com Localizar e Substituir do Excel
A ferramenta integrada Localizar e Substituir do Excel é o método manual mais eficiente para substituir texto no Excel dentro de uma única planilha ou de uma pasta de trabalho inteira. É perfeito para atualizações rápidas e pontuais onde fórmulas ou automação não são necessárias.
Como Acessar a Ferramenta Localizar e Substituir:
- Atalho: Pressione Ctrl + H (Windows) ou Command + Shift + H (Mac).
- Caminho do Menu: Vá para a guia Página Inicial > grupo Edição > Localizar e Selecionar > Substituir.
Instruções Passo a Passo:
-
Abra a Pasta de Trabalho: Selecione a planilha onde você precisa realizar a substituição de texto.
-
Acesse a Ferramenta: Use o atalho ou o caminho do menu para acionar a janela Localizar e Substituir.
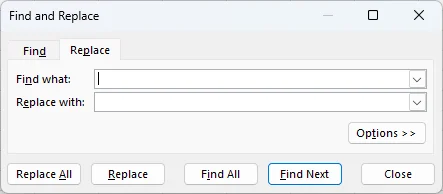
-
Insira os Dados: Na caixa Localizar, digite o texto ou os números específicos que você deseja alterar. Na caixa Substituir por, digite seu novo conteúdo.
-
Execute a Substituição: Clique em Substituir para atualizar a seleção atual e mover para a próxima ocorrência, ou Substituir Tudo para atualizar todas as ocorrências na planilha instantaneamente.
Dicas Profissionais:
Clique no botão Opções >> para desbloquear controles avançados:
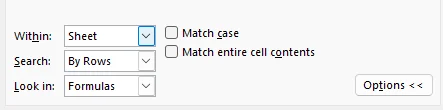
- Escopo da Pesquisa: Altere a configuração Pesquisar em de Planilha para Pasta de Trabalho para substituir texto em todas as abas de uma vez.
- Correspondência de Padrões: Use Curingas como * (múltiplos caracteres) ou ? (um único caractere) para pesquisas flexíveis (por exemplo, P*a corresponde a "Pato" e "Panda").
- Controle de Precisão: Ative Corresponder maiúsculas/minúsculas para substituir apenas correspondências exatas ou Corresponder o conteúdo da célula inteira para evitar substituir partes de palavras acidentalmente.
✅ Prós: Rápido, intuitivo e lida com alterações de formatação também.
⚠️ Limitações: Manual e repetitivo; não é adequado para processamento em lote de centenas de arquivos separados.
Você também pode se interessar por: 5 Maneiras de Quebrar Texto no Excel.
Método 2 - Substituir Texto por Posição Usando a Função REPLACE do Excel
Quando você precisa substituir texto no Excel com base em sua posição de caractere, em vez do conteúdo em si, a função REPLACE é a melhor ferramenta. Esta fórmula é ideal para limpar dados estruturados como números de telefone, códigos de série ou IDs de produtos padronizados.

Sintaxe da Função REPLACE
=REPLACE(texto_antigo, num_inicial, num_caracteres, novo_texto)
- texto_antigo: O texto original (ou a referência da célula que contém o texto).
- num_inicial: A posição (índice) do primeiro caractere que você deseja substituir.
- num_caracteres: O número total de caracteres a serem removidos.
- novo_texto: O novo texto que você deseja inserir.
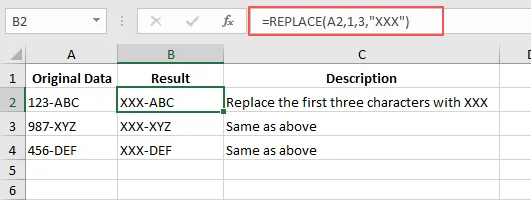
Exemplo Prático: Mascarando Dados Sensíveis
Se você tem um código de série "123-ABC" na célula A1 e deseja alterar os três primeiros números para "XXX":
- Fórmula:
=REPLACE(A1, 1, 3, "XXX") - Resultado: "XXX-ABC"
Implementação Passo a Passo:
-
Selecione uma Célula: Clique na célula onde você deseja que o texto atualizado apareça (por exemplo, B2).
-
Insira a Fórmula: Digite =REPLACE( e selecione a célula de origem (por exemplo, A2).
-
Defina o Intervalo: Insira o num_inicial (onde a substituição começa) e o num_caracteres (quantos caracteres trocar).
-
Adicione Novo Texto: Digite seu texto de substituição entre aspas (por exemplo, "XXX").
-
Aplique à Lista: Pressione Enter e use a alça de preenchimento automático (o pequeno quadrado verde) para arrastar a fórmula para as outras linhas.
Dicas Profissionais:
- Combine com Outras Funções: Use LEN() ou FIND() como num_inicial para lidar dinamicamente com strings de comprimentos variados.
- Manipule Resultados Numéricos: A função REPLACE sempre retorna texto. Para convertê-lo de volta em um número para cálculos, adicione *1 ao final de sua fórmula (por exemplo,
=REPLACE(...) * 1). - Aninhamento: Você pode aninhar várias funções REPLACE em uma única fórmula se precisar atualizar duas ou mais posições diferentes de uma vez.
✅ Prós: Perfeito para dados estruturados; garante controle preciso sobre a substituição de caracteres.
⚠️ Limitações: Menos eficaz para dados onde o texto alvo aparece em posições diferentes em cada célula.
Método 3 - Substituir Texto por Conteúdo Usando a Função SUBSTITUTE do Excel
A função SUBSTITUTE é a ferramenta ideal quando você precisa substituir texto no Excel com base em conteúdo específico, em vez de sua posição. Isso é ideal para corrigir erros de digitação repetidos, atualizar referências de ano ou expandir abreviações em um grande conjunto de dados.
Sintaxe da Função SUBSTITUTE
=SUBSTITUTE(texto, texto_antigo, novo_texto, [num_instancia])
- texto: O texto original (ou a referência da célula que contém o texto).
- texto_antigo: O caractere ou palavra específica que você deseja alterar.
- novo_texto: O texto que você deseja inserir em vez disso.
- [num_instancia]: (Opcional) Especifica qual ocorrência substituir. Se omitido, todas as ocorrências são atualizadas.
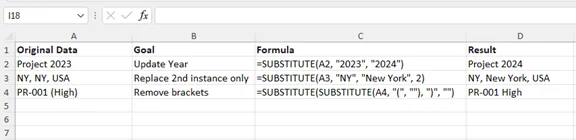
Exemplo Prático: Atualização em Massa de Anos
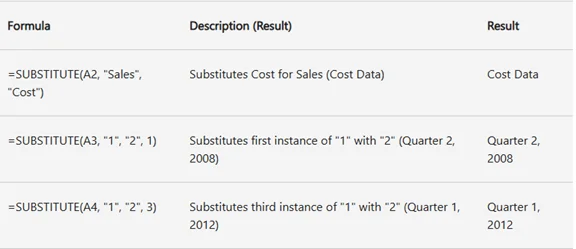
Se você precisar atualizar "Relatório 2023" para "Relatório 2024" na célula A1:
- Fórmula:
=SUBSTITUTE(A1, "2023", "2024") - Resultado: "Relatório 2024"
Avançado: SUBSTITUTE Aninhado para Múltiplas Atualizações
Você pode aninhamento várias funções SUBSTITUTE para substituir vários termos diferentes em uma única célula simultaneamente. Isso é perfeito para converter códigos abreviados em descrições completas:
- Fórmula:
=SUBSTITUTE(SUBSTITUTE(A2, "PR", "Projeto"), "ML", "Marco") - Resultado: Converte "PR-01, ML-05" em "Projeto-01, Marco-05".
Implementação Passo a Passo:
-
Identifique o Alvo: Clique na célula onde você deseja que os dados limpos apareçam.
-
Aplique a Fórmula: Digite =SUBSTITUTE( e selecione a célula de origem.
-
Defina Strings de Texto: Insira o texto_antigo e o novo_texto entre aspas duplas (por exemplo, "antigo", "novo").
-
Instância Opcional: Se você quiser substituir apenas a segunda ocorrência de uma palavra, adicione , 2 no final antes de fechar os parênteses.
-
Arraste para Aplicar: Pressione Enter e use a alça de preenchimento automático para aplicar a fórmula ao restante da sua coluna.
Dicas Profissionais:
- Sensibilidade a Maiúsculas/Minúsculas: SUBSTITUTE diferencia maiúsculas de minúsculas. Para realizar uma pesquisa que não diferencie maiúsculas de minúsculas, envolva a referência da sua célula na função UPPER ou LOWER.
- Removendo Texto: Para excluir uma palavra específica inteiramente, use uma string vazia "" como seu novo_texto.
- Não Destrutivo: Ao contrário de Localizar e Substituir, o uso de fórmulas mantém seus dados originais intactos na coluna de origem, fornecendo um melhor registro de auditoria.
✅ Prós: Excelente para substituição baseada em conteúdo; altamente flexível com aninhamento.
⚠️ Limitações: Não lida com alterações baseadas em posição; requer uma coluna auxiliar para armazenar resultados.
Método 4 - Automatizar Substituições de Texto no Excel com VBA
Quando você precisa substituir texto no Excel em várias planilhas ou lidar com tarefas de limpeza repetitivas e em larga escala, uma macro VBA é a solução mais poderosa. Este método permite automatizar o processo com um único clique, poupando você de erros manuais.
Por que Usar VBA para Substituição?
- Eficiência: Atualize centenas de células instantaneamente.
- Consistência: Garanta que a mesma lógica de substituição seja aplicada todas as vezes.
- Suporte Multi-Planilha: Ao contrário das fórmulas, o VBA pode digitalizar todas as abas do seu arquivo.
Exemplo de Macro VBA para Substituir dados na Planilha Ativa do Excel
Copie e cole o código a seguir no seu editor VBA para substituir termos específicos em sua planilha atual:
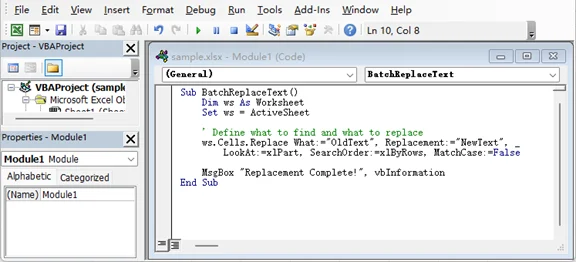
Sub BatchReplaceText()
Dim ws As Worksheet
Set ws = ActiveSheet
' Define o que encontrar e o que substituir
ws.Cells.Replace What:="TextoAntigo", Replacement:="NovoTexto", _
LookAt:=xlPart, SearchOrder:=xlByRows, MatchCase:=False
MsgBox "Substituição Concluída!", vbInformation
End Sub
Como Executar Esta Macro (Passo a Passo):
-
Abra o Editor: Pressione Alt + F11 para abrir a janela do Visual Basic for Applications.
-
Insira um Módulo: Vá em Inserir > Módulo para criar um espaço de trabalho em branco.
-
Cole o Código: Copie o script acima e cole-o no módulo. Substitua "TextoAntigo" e "NovoTexto" pelos seus dados reais.
-
Execute a Macro: Pressione F5 ou volte para o Excel e pressione Alt + F8, selecione BatchReplaceText e clique em Executar.
Dicas Profissionais:
- Controle de Precisão: No código acima, LookAt:=xlPart permite que a macro substitua texto mesmo que seja apenas parte do conteúdo de uma célula (por exemplo, mudar "App" para "Aplicativo" dentro de "App Store"). Se você precisar substituir apenas células que correspondam exatamente ao seu texto, mude este parâmetro para LookAt:=xlWhole.
- Backup Primeiro: Ao contrário das fórmulas, as ações do VBA não podem ser desfeitas (Ctrl+Z). Sempre salve uma cópia de backup do seu arquivo antes de executar uma macro.
- Loop em Todas as Planilhas: Você pode modificar o código para percorrer Cada ws Em ThisWorkbook.Worksheets para realizar uma substituição global.
- Variáveis de Palavras-chave: Para mais flexibilidade, use InputBox para permitir que os usuários digitem o texto que desejam substituir sempre que a macro for executada.
✅ Prós: Altamente eficiente para grandes conjuntos de dados; automatiza tarefas repetitivas.
⚠️ Limitações: Requer que a pasta de trabalho seja salva como uma Pasta de Trabalho Habilitada para Macro do Excel (.xlsm); não pode ser desfeita.
Método 5 - Substituir Texto em Lote em Vários Arquivos do Excel com Python
Para o nível máximo de automação, usar Python com a biblioteca Spire.XLS é a melhor maneira de substituir texto em lote em vários arquivos do Excel sem sequer abri-los. Isso é um divisor de águas para profissionais que gerenciam centenas de relatórios e precisam manter a formatação e a estrutura do documento.
Por que Usar Spire.XLS para Python?
- Preservação de Formato: Ao contrário de outras bibliotecas, Spire.XLS mantém suas fontes, cores e layouts intactos enquanto substitui o texto.
- Escalabilidade: Processe milhares de pastas de trabalho em segundos - ideal para rebranding em toda a empresa ou atualizações de dados.
- Suporte a Fórmulas: Permite inserir várias fórmulas do Excel, tornando fácil realizar cálculos complexos, mesmo sem abrir o Excel.
- Não Requer Excel: Opera independentemente do Microsoft Office, tornando-o perfeito para ambientes de servidor automatizados.
Código Python: Substituição em Lote Usando Spire.XLS
Este script itera por uma pasta inteira, pesquisa cada planilha e substitui termos específicos:
from spire.xls import *
import glob
# Caminho para sua pasta contendo arquivos Excel
files = glob.glob("C:/sua_pasta/*.xlsx")
for file in files:
# Carrega a pasta de trabalho
workbook = Workbook()
workbook.LoadFromFile(file)
# Itera por todas as planilhas para substituir texto
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Encontra todas as ocorrências do texto antigo
found_ranges = sheet.FindAll("TextoAntigo", FindType.Text, ExcelFindOptions.MatchEntireCellContent)
if found_ranges:
for cell_range in found_ranges:
# Aplica o texto de substituição
cell_range.Text = "NovoTexto"
# Salva a pasta de trabalho atualizada
workbook.SaveToFile(file, ExcelVersion.Version2016)
workbook.Dispose()
print("Substituição de texto em lote concluída com sucesso!")
Implementação Passo a Passo:
- Configure o Ambiente: Instale a biblioteca via terminal:
pip install Spire.Xls - Prepare seu Script: Cole o código em um editor como VS Code ou PyCharm.
- Configure os Parâmetros: Atualize o caminho da pasta e substitua "TextoAntigo" e "NovoTexto" pelos seus dados reais.
- Execute e Verifique: Pressione F5 para executar o script. Verifique os arquivos de saída para confirmar se os resultados da substituição estão corretos.
Dicas Profissionais:
- Substituição de Texto Parcial: Se uma célula contém uma string longa (por exemplo, "Pedido: 1001") e você deseja alterar apenas o número, use
cell_range.TextPartReplace("1001", "2002"). Isso mantém o texto circundante intacto. - Sensibilidade a Maiúsculas/Minúsculas: O parâmetro ExcelFindOptions no método FindAll permite alternar a correspondência sensível a maiúsculas/minúsculas ou de palavra inteira para maior precisão.
- Pesquisa Específica de Intervalo: Se você sabe que os dados alvo estão apenas em uma área específica, chame FindAll em um XlsRange em vez da planilha inteira:
sheet.Range["A1:C10"].FindAll(). - Regex e Padrões: Você pode combinar isso com o módulo re do Python para correspondência de padrões complexos antes de passar a string para o loop de substituição.
✅ Prós: Velocidade inigualável para tarefas de alto volume; lida com vários arquivos; preserva toda a formatação original do Excel.
⚠️ Limitações: Requer configuração de ambiente Python e conhecimento básico de programação.
Conclusão: Qual Método Escolher?
Escolher a melhor maneira de substituir texto no Excel depende da escala dos seus dados e do seu nível de conforto com automação:
- Edições Rápidas e Simples: Use a ferramenta integrada Localizar e Substituir.
- Precisão Baseada em Posição: Use a função REPLACE para dados estruturados (por exemplo, códigos de ID).
- Lógica Baseada em Conteúdo: Use a função SUBSTITUTE para corrigir termos específicos.
- Automação de Pasta de Trabalho: Use macros VBA para lidar com tarefas repetitivas em várias planilhas.
- Processamento em Lote Profissional: Use Python para gerenciar centenas de arquivos com formatação preservada.
Ao selecionar o fluxo de trabalho correto, você pode garantir a consistência dos dados, economizar horas de trabalho manual e eliminar erros humanos.
Solução de Problemas de Problemas Comuns de Substituição de Texto
Mesmo com as ferramentas certas, você pode encontrar obstáculos. Aqui estão os problemas mais comuns e como resolvê-los:
| Problema | Causa Provável | Solução |
|---|---|---|
| A substituição não ocorreu | O texto não corresponde exatamente à string Localizar ou texto_antigo. | Verifique se há espaços extras ou caracteres ocultos. Use as funções TRIM() ou CLEAN() para higienizar os dados primeiro. |
| Apenas parte do texto foi substituída | As configurações de Localizar e Substituir são muito restritivas. | No menu Opções, certifique-se de que Corresponder maiúsculas/minúsculas e Corresponder o conteúdo da célula inteira estejam desmarcados para substituições parciais. |
| Erro #VALOR! (REPLACE) | Posição inicial ou contagem de caracteres inválida. | Certifique-se de que num_inicial e num_caracteres sejam inteiros positivos e dentro do comprimento da string. |
| Resultados de fórmula são apenas texto | REPLACE e SUBSTITUTE sempre retornam texto. | Se você precisar de um número, multiplique o resultado por 1 (por exemplo, =SUBSTITUTE(...)*1) ou envolva-o em VALUE(). |
| Macro VBA não executa | Configurações de segurança de macro ou planilhas protegidas. | Habilite macros no Centro de Confiança e certifique-se de que a planilha esteja desprotegida antes da execução. |
| Erros no script Python | Caminhos de arquivo incorretos ou dependências ausentes. | Certifique-se de que Spire.Xls esteja instalado. Verifique a sintaxe do caminho da sua pasta (use / ou \\ no Windows). |
Perguntas Frequentes: Substituir Dados no Excel
P1: Posso substituir texto em várias planilhas sem VBA ou Python?
Sim. Na caixa de diálogo Localizar e Substituir, clique em Opções e altere o menu suspenso Pesquisar em de "Planilha" para "Pasta de Trabalho". Isso permite que você atualize o arquivo inteiro de uma vez.
P2: Como substituo texto preservando a formatação da célula?
Fórmulas padrão (SUBSTITUTE) criam novo texto em uma nova célula. Para manter a formatação na célula original, use a ferramenta manual Localizar e Substituir ou uma biblioteca profissional como Spire.XLS para Python, que é projetada para modificar o conteúdo sem remover estilos.
P3: Posso substituir texto com base em um padrão específico (por exemplo, quaisquer 3 dígitos)?
Sim, mas você precisará de Curingas (* ou ?) na ferramenta Localizar e Substituir, ou Expressões Regulares (Regex) em um script Python para padrões mais complexos.
P4: E se o texto alvo estiver em uma posição diferente em cada célula?
Use uma fórmula dinâmica combinando REPLACE com FIND:
=SEERRO(REPLACE(A2, ENCONTRAR("antigo", A2), NÚM.CARACT("antigo"), "novo"), A2)
Isso localiza o texto "antigo" independentemente de onde ele começa e o substitui por "novo".
P5: Como posso automatizar substituições para centenas de arquivos separados?
O método mais eficiente é usar Python. Ao alavancar glob para encontrar arquivos e Spire.XLS para processá-los, você pode atualizar milhares de pastas de trabalho em segundos sem sequer abrir o Excel.
Veja Também
Excel에서 텍스트를 바꾸는 방법: 5가지 빠른 방법 (수동에서 자동화까지)
대규모 Excel 통합 문서 작업을 할 때 일관성이 없거나 오래된 데이터는 보고 및 의사 결정에 빠르게 차질을 빚을 수 있습니다. 수천 개의 셀을 수동으로 스캔하여 오타를 수정하는 것은 시간이 많이 소요될 뿐만 아니라 비용이 많이 드는 인적 오류가 발생하기 쉽습니다. Excel에서 텍스트를 효율적으로 바꾸는 방법을 마스터하는 것은 모든 데이터 전문가에게 중요한 기술입니다.
이 포괄적인 가이드에서는 Excel에서 텍스트를 바꾸는 5가지 실용적인 방법을 살펴봅니다. 내장된 찾기 및 바꾸기 도구와 워크시트 수식부터 고급 VBA 및 Python 자동화까지 다양합니다. 단일 셀을 업데이트해야 하거나 수백 개의 통합 문서를 일괄 처리해야 하는 경우 단계별 지침을 통해 워크플로를 간소화하고 데이터 무결성을 보장할 수 있습니다.
방법 개요
- 방법 1 - Excel의 찾기 및 바꾸기를 사용하여 수동으로 텍스트 바꾸기
- 방법 2 - Excel의 REPLACE 함수를 사용하여 위치별로 텍스트 바꾸기
- 방법 3 - Excel의 SUBSTITUTE 함수를 사용하여 내용별로 텍스트 바꾸기
- 방법 4 - VBA를 사용하여 Excel에서 텍스트 바꾸기 자동화
- 방법 5 - Python을 사용하여 여러 Excel 파일에서 텍스트 일괄 바꾸기
Excel에서 텍스트 바꾸기 이해
Excel에서 텍스트를 바꾸는 것은 단순한 미용 변경이 아닙니다. 다음을 수행할 수 있습니다.
- 오류 수정 - 오타 또는 오래된 코드를 수정합니다.
- 형식 표준화 - 제품 코드, 이메일 또는 날짜를 통합합니다.
- 데이터 분석 개선 - 계산, 필터링 또는 피벗 테이블 전에 일관성을 보장합니다.
- 반복 작업 시간 절약 - 특히 대규모 데이터 세트 또는 여러 파일을 다룰 때 유용합니다.
아래에서 Excel에서 데이터를 바꾸는 5가지 실용적인 방법을 살펴보겠습니다.
방법 1 - Excel의 찾기 및 바꾸기를 사용하여 수동으로 텍스트 바꾸기
Excel의 내장 찾기 및 바꾸기 도구는 단일 워크시트 또는 전체 통합 문서 내에서 Excel의 텍스트를 바꾸는 가장 효율적인 수동 방법입니다. 수식이나 자동화가 필요하지 않은 빠르고 일회성 업데이트에 적합합니다.
찾기 및 바꾸기 도구 액세스 방법:
- 바로 가기: Ctrl + H (Windows) 또는 Command + Shift + H (Mac)를 누릅니다.
- 메뉴 경로: 홈 탭 > 편집 그룹 > 찾기 및 선택 > 바꾸기로 이동합니다.
단계별 지침:
-
통합 문서 열기: 텍스트 바꾸기를 수행해야 하는 워크시트를 선택합니다.
-
도구 액세스: 바로 가기 또는 메뉴 경로를 사용하여 찾기 및 바꾸기 창을 트리거합니다.
-
데이터 입력: 찾을 내용 상자에 변경하려는 특정 텍스트 또는 숫자를 입력합니다. 바꿀 내용 상자에 새 콘텐츠를 입력합니다.
-
바꾸기 실행: 바꾸기를 클릭하여 현재 선택 항목을 업데이트하고 다음 항목으로 이동하거나 모두 바꾸기를 클릭하여 시트의 모든 항목을 즉시 업데이트합니다.
전문가 팁:
옵션 >> 버튼을 클릭하여 고급 컨트롤을 잠금 해제합니다.
- 검색 범위: 범위 설정을 시트에서 통합 문서로 변경하여 모든 탭에서 텍스트를 한 번에 바꿉니다.
- 패턴 일치: * (여러 문자) 또는 ? (단일 문자)와 같은 와일드카드를 사용하여 유연하게 검색합니다(예: S*t는 "Smart" 및 "Street"와 모두 일치).
- 정밀도 제어: 대/소문자 구분을 활성화하여 정확히 일치하는 항목만 바꾸거나 전체 셀 내용 일치를 선택하여 실수로 단어의 일부를 바꾸는 것을 방지합니다.
✅ 장점: 빠르고 직관적이며 서식 변경도 처리합니다.
⚠️ 제한 사항: 수동이고 반복적입니다. 수백 개의 별도 파일을 일괄 처리하는 데 적합하지 않습니다.
다음도 관심이 있을 수 있습니다: Excel에서 텍스트 줄 바꿈하는 5가지 방법.
방법 2 - Excel의 REPLACE 함수를 사용하여 위치별로 텍스트 바꾸기
내용이 아닌 문자 위치를 기준으로 Excel에서 텍스트를 바꿔야 할 때 REPLACE 함수가 가장 좋은 도구입니다. 이 수식은 전화번호, 일련 번호 또는 표준화된 제품 ID와 같은 구조화된 데이터를 정리하는 데 이상적입니다.
REPLACE 함수 구문
=REPLACE(old_text, start_num, num_chars, new_text)
- old_text: 원본 텍스트(또는 텍스트가 포함된 셀 참조).
- start_num: 바꾸려는 첫 번째 문자의 위치(인덱스).
- num_chars: 제거할 총 문자 수.
- new_text: 삽입하려는 새 텍스트.
실용적인 예: 민감한 데이터 마스킹
셀 A1에 "123-ABC"라는 일련 번호가 있고 처음 세 숫자를 "XXX"로 변경하려는 경우:
- 수식:
=REPLACE(A1, 1, 3, "XXX") - 결과: "XXX-ABC"
단계별 구현:
-
셀 선택: 업데이트된 텍스트가 표시될 셀을 클릭합니다(예: B2).
-
수식 입력: =REPLACE(를 입력하고 원본 셀(예: A2)을 선택합니다.
-
범위 정의: start_num(바꾸기가 시작되는 위치)과 num_chars(바꿀 문자 수)를 입력합니다.
-
새 텍스트 추가: 따옴표 안에 바꾸려는 텍스트를 입력합니다(예: "XXX").
-
목록에 적용: Enter를 누르고 자동 채우기 핸들(작은 녹색 사각형)을 사용하여 수식을 다른 행으로 끌어옵니다.
전문가 팁:
- 다른 함수와 결합: LEN() 또는 FIND()를 start_num으로 사용하여 길이가 다른 문자열을 동적으로 처리합니다.
- 숫자 결과 처리: REPLACE 함수는 항상 텍스트를 반환합니다. 계산을 위해 숫자로 다시 변환하려면 수식 끝에 *1을 추가합니다(예:
=REPLACE(...) * 1). - 중첩: 두 개 이상의 다른 위치를 한 번에 업데이트해야 하는 경우 단일 수식에 여러 REPLACE 함수를 중첩할 수 있습니다.
✅ 장점: 구조화된 데이터에 완벽하며 문자 바꾸기에 대한 정확한 제어를 보장합니다.
⚠️ 제한 사항: 대상 텍스트가 각 셀의 다른 위치에 나타나는 데이터에는 덜 효과적입니다.
방법 3 - Excel의 SUBSTITUTE 함수를 사용하여 내용별로 텍스트 바꾸기
SUBSTITUTE 함수는 위치가 아닌 특정 내용을 기준으로 Excel에서 텍스트를 바꿔야 할 때 사용되는 도구입니다. 이는 반복되는 오타 수정, 연도 참조 업데이트 또는 대규모 데이터 세트에서 약어 확장하는 데 이상적입니다.
SUBSTITUTE 함수 구문
=SUBSTITUTE(text, old_text, new_text, [instance_num])
- text: 원본 텍스트(또는 텍스트가 포함된 셀 참조).
- old_text: 변경하려는 특정 문자 또는 단어.
- new_text: 대신 삽입하려는 텍스트.
- [instance_num]: (선택 사항) 바꿀 발생 횟수를 지정합니다. 생략하면 모든 발생이 업데이트됩니다.
실용적인 예: 연도 일괄 업데이트
셀 A1에서 "Report 2023"을 "Report 2024"로 업데이트해야 하는 경우:
- 수식:
=SUBSTITUTE(A1, "2023", "2024") - 결과: "Report 2024"
여러 업데이트를 위한 중첩 SUBSTITUTE
여러 SUBSTITUTE 함수를 중첩하여 단일 셀에서 여러 다른 용어를 동시에 바꿀 수 있습니다. 이는 약어 코드를 전체 설명으로 변환하는 데 완벽합니다.
- 수식:
=SUBSTITUTE(SUBSTITUTE(A2, "PR", "Project"), "ML", "Milestone") - 결과: "PR-01, ML-05"를 "Project-01, Milestone-05"로 변환합니다.
단계별 구현:
-
대상 식별: 정리된 데이터가 표시될 셀을 클릭합니다.
-
수식 적용: =SUBSTITUTE(를 입력하고 원본 셀을 선택합니다.
-
텍스트 문자열 정의: old_text와 new_text를 큰따옴표 안에 입력합니다(예: "old", "new").
-
선택적 발생: 단어의 두 번째 발생만 바꾸려면 닫는 괄호 앞에 , 2를 추가합니다.
-
끌어서 적용: Enter를 누르고 자동 채우기 핸들을 사용하여 수식을 열의 나머지 부분에 적용합니다.
전문가 팁:
- 대/소문자 구분: SUBSTITUTE는 대/소문자를 구분합니다. 대/소문자를 구분하지 않는 검색을 수행하려면 셀 참조를 UPPER 또는 LOWER 함수로 묶습니다.
- 텍스트 제거: 특정 단어를 완전히 삭제하려면 new_text로 빈 문자열 ""을 사용합니다.
- 비파괴적: 찾기 및 바꾸기와 달리 수식을 사용하면 원본 데이터가 원본 열에 그대로 유지되어 더 나은 감사 추적을 제공합니다.
✅ 장점: 내용 기반 바꾸기에 탁월하며 중첩을 통해 매우 유연합니다.
⚠️ 제한 사항: 위치 기반 변경을 처리하지 않으며 결과를 저장하기 위해 도우미 열이 필요합니다.
방법 4 - VBA를 사용하여 Excel에서 텍스트 바꾸기 자동화
여러 시트에서 Excel의 텍스트를 바꾸거나 반복적이고 대규모 정리 작업을 처리해야 할 때 VBA 매크로가 가장 강력한 솔루션입니다. 이 방법을 사용하면 단 한 번의 클릭으로 프로세스를 자동화하여 수동 오류를 방지할 수 있습니다.
바꾸기에 VBA를 사용하는 이유
- 효율성: 수백 개의 셀을 즉시 업데이트합니다.
- 일관성: 항상 동일한 바꾸기 논리가 적용되도록 합니다.
- 다중 시트 지원: 수식과 달리 VBA는 통합 문서의 모든 탭을 검색할 수 있습니다.
활성 Excel 시트에서 데이터를 바꾸는 예제 VBA 매크로
다음 코드를 VBA 편집기에 복사하여 붙여넣어 현재 워크시트에서 특정 용어를 바꿉니다.
Sub BatchReplaceText()
Dim ws As Worksheet
Set ws = ActiveSheet
' 찾을 내용과 바꿀 내용 정의
ws.Cells.Replace What:="OldText", Replacement:="NewText", _
LookAt:=xlPart, SearchOrder:=xlByRows, MatchCase:=False
MsgBox "Replacement Complete!", vbInformation
End Sub
이 매크로 실행 방법 (단계별):
-
편집기 열기: Alt + F11을 눌러 Visual Basic for Applications 창을 엽니다.
-
모듈 삽입: 삽입 > 모듈으로 이동하여 빈 작업 공간을 만듭니다.
-
코드 붙여넣기: 위의 스크립트를 복사하여 모듈에 붙여넣습니다. "OldText" 및 "NewText"를 실제 데이터로 바꿉니다.
-
매크로 실행: F5를 누르거나 Excel로 돌아가서 Alt + F8을 누르고 BatchReplaceText를 선택한 다음 실행을 클릭합니다.
전문가 팁:
- 정밀도 제어: 위의 코드에서 LookAt:=xlPart는 매크로가 셀 내용의 일부일 뿐인 텍스트도 바꿀 수 있도록 합니다(예: "App Store" 내의 "App"을 "Application"으로 변경). 셀 내용과 정확히 일치하는 항목만 바꾸려면 이 매개변수를 LookAt:=xlWhole로 변경합니다.
- 먼저 백업: 수식과 달리 VBA 작업은 실행 취소할 수 없습니다(Ctrl+Z). 매크로를 실행하기 전에 항상 파일의 백업 복사본을 저장하십시오.
- 모든 시트 반복: 코드를 수정하여 Each ws In ThisWorkbook.Worksheets를 반복하여 전역 바꾸기를 수행할 수 있습니다.
- 키워드 변수: 더 많은 유연성을 위해 InputBox를 사용하여 매크로가 실행될 때마다 사용자가 바꾸려는 텍스트를 입력하도록 할 수 있습니다.
✅ 장점: 대규모 데이터 세트에 매우 효율적이며 반복적인 작업을 자동화합니다.
⚠️ 제한 사항: Excel 매크로 사용 통합 문서(.xlsm)로 저장해야 하며 실행 취소할 수 없습니다.
방법 5 - Python을 사용하여 여러 Excel 파일에서 텍스트 일괄 바꾸기
궁극적인 수준의 자동화를 위해 Spire.XLS 라이브러리를 사용하는 Python을 사용하면 Excel을 열지 않고도 여러 Excel 파일에서 텍스트를 일괄 바꾸는 가장 좋은 방법입니다. 이는 문서 서식 및 구조를 유지해야 하는 수백 개의 보고서를 관리하는 전문가에게 게임 체인저입니다.
Python용 Spire.XLS를 사용하는 이유
- 서식 보존: 다른 라이브러리와 달리 Spire.XLS는 텍스트를 바꾸는 동안 글꼴, 색상 및 레이아웃을 그대로 유지합니다.
- 확장성: 수천 개의 통합 문서를 몇 초 안에 처리합니다. 회사 전체의 리브랜딩 또는 데이터 업데이트에 이상적입니다.
- 수식 지원: 다양한 Excel 수식을 삽입할 수 있어 Excel을 열지 않고도 복잡한 계산을 쉽게 수행할 수 있습니다.
- Excel 불필요: Microsoft Office와 독립적으로 작동하므로 자동화된 서버 환경에 적합합니다.
Python 코드: Spire.XLS를 사용한 일괄 바꾸기
이 스크립트는 전체 폴더를 반복하고, 모든 워크시트를 검색하고, 특정 용어를 바꿉니다.
from spire.xls import *
import glob
# Excel 파일이 포함된 폴더 경로
files = glob.glob("C:/your_folder/*.xlsx")
for file in files:
# 통합 문서 로드
workbook = Workbook()
workbook.LoadFromFile(file)
# 텍스트를 바꾸기 위해 모든 워크시트 반복
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# 오래된 텍스트의 모든 발생 찾기
found_ranges = sheet.FindAll("OldText", FindType.Text, ExcelFindOptions.MatchEntireCellContent)
if found_ranges:
for cell_range in found_ranges:
# 바꾸기 텍스트 적용
cell_range.Text = "NewText"
# 업데이트된 통합 문서 저장
workbook.SaveToFile(file, ExcelVersion.Version2016)
workbook.Dispose()
print("Batch text replacement completed successfully!")
단계별 구현:
- 환경 설정: 터미널을 통해 라이브러리 설치:
pip install Spire.Xls - 스크립트 준비: 코드를 VS Code 또는 PyCharm과 같은 편집기에 붙여넣습니다.
- 매개변수 구성: 폴더 경로를 업데이트하고 "OldText" 및 "NewText"를 실제 데이터로 바꿉니다.
- 실행 및 확인: F5를 눌러 스크립트를 실행합니다. 출력 파일을 확인하여 바꾸기 결과가 올바른지 확인합니다.
전문가 팁:
- 부분 텍스트 바꾸기: 셀에 긴 문자열(예: "Order: 1001")이 포함되어 있고 숫자만 변경하려는 경우
cell_range.TextPartReplace("1001", "2002")를 사용합니다. 이렇게 하면 주변 텍스트가 그대로 유지됩니다. - 대/소문자 구분: FindAll 메서드의 ExcelFindOptions 매개변수를 사용하면 더 정확한 검색을 위해 대/소문자를 구분하거나 전체 단어 일치를 전환할 수 있습니다.
- 범위별 찾기: 대상 데이터가 특정 영역에만 있다는 것을 알고 있다면 전체 시트 대신 XlsRange에서 FindAll을 호출합니다:
sheet.Range["A1:C10"].FindAll(). - 정규식 및 패턴: Python의 re 모듈과 결합하여 바꾸기 루프에 전달하기 전에 복잡한 패턴 일치를 수행할 수 있습니다.
✅ 장점: 대량 작업에 대한 비교할 수 없는 속도. 여러 파일을 처리하고 모든 원본 Excel 서식을 보존합니다.
⚠️ 제한 사항: Python 환경 설정 및 기본적인 프로그래밍 지식이 필요합니다.
결론: 어떤 방법을 선택해야 할까요?
Excel에서 텍스트를 바꾸는 가장 좋은 방법을 선택하는 것은 데이터 규모와 자동화에 대한 편안함 수준에 따라 달라집니다.
- 빠르고 간단한 편집: 내장된 찾기 및 바꾸기 도구를 사용합니다.
- 위치 기반 정밀도: 구조화된 데이터(예: ID 코드)의 경우 REPLACE 함수를 사용합니다.
- 내용 기반 논리: 특정 용어를 수정하려면 SUBSTITUTE 함수를 사용합니다.
- 통합 문서 자동화: VBA 매크로를 사용하여 여러 시트에서 반복적인 작업을 처리합니다.
- 전문적인 일괄 처리: Python을 사용하여 서식을 유지하면서 수백 개의 파일을 관리합니다.
올바른 워크플로를 선택하면 데이터 일관성을 보장하고 수동 작업 시간을 절약하며 인적 오류를 제거할 수 있습니다.
일반적인 텍스트 바꾸기 문제 해결
올바른 도구를 사용하더라도 장애물에 부딪힐 수 있습니다. 다음은 가장 일반적인 문제와 해결 방법입니다.
| 문제 | 가능한 원인 | 해결책 |
|---|---|---|
| 바꾸기가 수행되지 않았습니다 | 텍스트가 찾기 또는 old_text 문자열과 정확히 일치하지 않습니다. | 추가 공백이나 숨겨진 문자가 있는지 확인합니다. 데이터를 먼저 정리하려면 TRIM() 또는 CLEAN() 함수를 사용합니다. |
| 텍스트의 일부만 바뀌었습니다 | 찾기 및 바꾸기 설정이 너무 제한적입니다. | 옵션 메뉴에서 부분 바꾸기의 경우 대/소문자 구분 및 전체 셀 내용 일치가 선택 취소되었는지 확인합니다. |
| #VALUE! 오류 (REPLACE) | 잘못된 시작 위치 또는 문자 수입니다. | start_num과 num_chars가 양의 정수이고 문자열 길이에 포함되는지 확인합니다. |
| 수식 결과가 텍스트만 있습니다 | REPLACE 및 SUBSTITUTE는 항상 텍스트를 반환합니다. | 숫자가 필요한 경우 결과에 1을 곱합니다(예: =SUBSTITUTE(...)*1) 또는 VALUE()로 묶습니다. |
| VBA 매크로가 실행되지 않습니다 | 매크로 보안 설정 또는 보호된 시트입니다. | 보안 센터에서 매크로를 활성화하고 실행 전에 워크시트가 보호되지 않았는지 확인합니다. |
| Python 스크립트 오류 | 잘못된 파일 경로 또는 누락된 종속성입니다. | Spire.Xls가 설치되었는지 확인합니다. 폴더 경로 구문을 다시 확인합니다(Windows에서는 / 또는 \\ 사용). |
자주 묻는 질문: Excel에서 데이터 바꾸기
Q1: VBA 또는 Python 없이 여러 시트에서 텍스트를 바꿀 수 있습니까?
예. 찾기 및 바꾸기 대화 상자에서 옵션을 클릭하고 범위 드롭다운을 "시트"에서 "통합 문서"로 변경합니다. 이렇게 하면 전체 파일을 한 번에 업데이트할 수 있습니다.
Q2: 셀 서식을 유지하면서 텍스트를 바꾸려면 어떻게 해야 합니까?
표준 수식(SUBSTITUTE)은 새 셀에 새 텍스트를 만듭니다. 원본 셀의 서식을 유지하려면 수동 찾기 및 바꾸기 도구를 사용하거나 Spire.XLS for Python과 같은 전문 라이브러리를 사용합니다. 이 라이브러리는 스타일을 제거하지 않고 콘텐츠를 수정하도록 설계되었습니다.
Q3: 특정 패턴(예: 3자리 숫자)을 기반으로 텍스트를 바꿀 수 있습니까?
예. 그러나 찾기 및 바꾸기 도구의 와일드카드(* 또는 ?) 또는 더 복잡한 패턴의 경우 Python 스크립트의 정규식(Regex)이 필요합니다.
Q4: 대상 텍스트가 각 셀의 다른 위치에 있는 경우 어떻게 해야 합니까?
REPLACE와 FIND를 결합한 동적 수식을 사용합니다.
=IFERROR(REPLACE(A2, FIND("old", A2), LEN("old"), "new"), A2)
이것은 "old" 텍스트가 시작되는 위치에 관계없이 찾아서 "new"로 바꿉니다.
Q5: 수백 개의 별도 파일에 대한 바꾸기를 자동화하려면 어떻게 해야 합니까?
가장 효율적인 방법은 Python을 사용하는 것입니다. glob를 사용하여 파일을 찾고 Spire.XLS를 사용하여 처리하면 Excel을 열지 않고도 수천 개의 통합 문서를 몇 초 안에 업데이트할 수 있습니다.
참고 자료
Come sostituire il testo in Excel: 5 modi rapidi (da manuali ad automatizzati)
Indice
- Metodo 1 - Sostituisci testo manualmente con Trova e Sostituisci di Excel
- Metodo 2 - Sostituisci testo per posizione utilizzando la funzione REPLACE di Excel
- Metodo 3 - Sostituisci testo per contenuto utilizzando la funzione SUBSTITUTE di Excel
- Metodo 4 - Automatizza le sostituzioni di testo in Excel con VBA
- Metodo 5 - Sostituisci testo in batch su più file Excel con Python
Quando si lavora con grandi cartelle di lavoro Excel, dati incoerenti o obsoleti possono rapidamente ostacolare la reportistica e il processo decisionale. Scansionare manualmente migliaia di celle per correggere errori di battitura non è solo dispendioso in termini di tempo, ma anche soggetto a costosi errori umani. Padroneggiare come sostituire il testo in Excel in modo efficiente è un'abilità fondamentale per ogni professionista dei dati.
In questa guida completa, esploriamo 5 metodi pratici per sostituire il testo in Excel, dallo strumento integrato Trova e Sostituisci e dalle formule del foglio di lavoro all'automazione avanzata con VBA e Python. Sia che tu debba aggiornare una singola cella o elaborare in batch centinaia di cartelle di lavoro, le nostre istruzioni passo passo ti aiuteranno a ottimizzare il tuo flusso di lavoro e a garantire l'integrità dei dati.
Panoramica dei metodi
- Metodo 1 - Sostituisci testo manualmente con Trova e Sostituisci di Excel
- Metodo 2 - Sostituisci testo per posizione utilizzando la funzione REPLACE di Excel
- Metodo 3 - Sostituisci testo per contenuto utilizzando la funzione SUBSTITUTE di Excel
- Metodo 4 - Automatizza le sostituzioni di testo in Excel con VBA
- Metodo 5 - Sostituisci testo in batch su più file Excel con Python
Comprendere la sostituzione del testo in Excel
La sostituzione del testo in Excel non è solo un cambiamento estetico, può:
- Correggere errori - correggere errori di battitura o codici obsoleti.
- Standardizzare i formati - unificare codici prodotto, e-mail o date.
- Migliorare l'analisi dei dati - garantire la coerenza prima di calcoli, filtri o tabelle pivot.
- Risparmiare tempo nelle attività ripetitive - specialmente quando si lavora con grandi set di dati o più file.
Di seguito, esploreremo 5 modi pratici per sostituire i dati in Excel.
Metodo 1 - Sostituisci testo manualmente con Trova e Sostituisci di Excel
Lo strumento integrato di Excel Trova e Sostituisci è il metodo manuale più efficiente per sostituire il testo in Excel all'interno di un singolo foglio di lavoro o di un'intera cartella di lavoro. È perfetto per aggiornamenti rapidi e occasionali dove formule o automazione non sono necessarie.
Come accedere allo strumento Trova e Sostituisci:
- Scorciatoia: Premi Ctrl + H (Windows) o Comando + Maiusc + H (Mac).
- Percorso del menu: Vai alla scheda Home > gruppo Modifica > Trova e seleziona > Sostituisci.
Istruzioni passo passo:
-
Apri la cartella di lavoro: Seleziona il foglio di lavoro in cui devi eseguire la sostituzione del testo.
-
Accedi allo strumento: Utilizza la scorciatoia o il percorso del menu per attivare la finestra Trova e Sostituisci.
-
Inserisci i dati: Nella casella Trova, digita il testo o i numeri specifici che desideri modificare. Nella casella Sostituisci con, digita il tuo nuovo contenuto.
-
Esegui la sostituzione: Fai clic su Sostituisci per aggiornare la selezione corrente e passare all'istanza successiva, oppure su Sostituisci tutto per aggiornare istantaneamente ogni istanza nel foglio.
Suggerimenti professionali:
Fai clic sul pulsante Opzioni >> per sbloccare i controlli avanzati:
- Ambito di ricerca: Cambia l'impostazione All'interno da Foglio a Cartella di lavoro per sostituire il testo in tutte le schede contemporaneamente.
- Corrispondenza di modelli: Utilizza caratteri jolly come * (caratteri multipli) o ? (singolo carattere) per una ricerca flessibile (ad esempio, S*t corrisponde sia a "Smart" che a "Street").
- Controllo di precisione: Abilita Maiuscole/minuscole per sostituire solo le corrispondenze esatte o Contenuto cella intero per evitare di sostituire parti di parole accidentalmente.
✅ Pro: Veloce, intuitivo e gestisce anche le modifiche di formattazione.
⚠️ Limitazioni: Manuale e ripetitivo; non adatto all'elaborazione in batch di centinaia di file separati.
Potrebbe interessarti anche: 5 modi per mandare a capo il testo in Excel.
Metodo 2 - Sostituisci testo per posizione utilizzando la funzione REPLACE di Excel
Quando è necessario sostituire il testo in Excel in base alla sua posizione del carattere anziché al contenuto stesso, la funzione REPLACE è lo strumento migliore. Questa formula è ideale per pulire dati strutturati come numeri di telefono, codici seriali o ID prodotto standardizzati.
Sintassi della funzione Replace
=REPLACE(vecchio_testo, num_inizio, num_caratteri, nuovo_testo)
- vecchio_testo: Il testo originale (o il riferimento alla cella contenente il testo).
- num_inizio: La posizione (indice) del primo carattere che si desidera sostituire.
- num_caratteri: Il numero totale di caratteri da rimuovere.
- nuovo_testo: Il nuovo testo che si desidera inserire.
Esempio pratico: Mascheramento di dati sensibili
Se hai un codice seriale "123-ABC" nella cella A1 e vuoi cambiare i primi tre numeri in "XXX":
- Formula:
=REPLACE(A1, 1, 3, "XXX") - Risultato: "XXX-ABC"
Implementazione passo passo:
-
Seleziona una cella: Fai clic sulla cella in cui desideri che appaia il testo aggiornato (ad esempio, B2).
-
Inserisci la formula: Digita =REPLACE( e seleziona la cella di origine (ad esempio, A2).
-
Definisci l'intervallo: Inserisci num_inizio (dove inizia la sostituzione) e num_caratteri (quanti caratteri scambiare).
-
Aggiungi nuovo testo: Digita il testo di sostituzione tra virgolette (ad esempio, "XXX").
-
Applica all'elenco: Premi Invio e utilizza il quadrato di riempimento automatico (il piccolo quadrato verde) per trascinare la formula verso il basso nelle altre righe.
Suggerimenti professionali:
- Combina con altre funzioni: Utilizza LEN() o FIND() come num_inizio per gestire dinamicamente stringhe di lunghezze variabili.
- Gestisci risultati numerici: La funzione REPLACE restituisce sempre testo. Per riconvertirlo in un numero per i calcoli, aggiungi *1 alla fine della formula (ad esempio,
=REPLACE(...) * 1). - Annidamento: Puoi annidare più funzioni REPLACE in un'unica formula se devi aggiornare due o più posizioni diverse contemporaneamente.
✅ Pro: Perfetto per dati strutturati; garantisce un controllo preciso sulla sostituzione dei caratteri.
⚠️ Limitazioni: Meno efficace per dati in cui il testo di destinazione appare in posizioni diverse in ogni cella.
Metodo 3 - Sostituisci testo per contenuto utilizzando la funzione SUBSTITUTE di Excel
La funzione SUBSTITUTE è lo strumento di riferimento quando è necessario sostituire il testo in Excel in base a un contenuto specifico anziché alla sua posizione. Questo è ideale per correggere errori di battitura ripetuti, aggiornare riferimenti annuali o espandere abbreviazioni in un ampio set di dati.
Sintassi della funzione SUBSTITUTE
=SOSTITUISCI(testo, vecchio_testo, nuovo_testo, [num_istanza])
- testo: Il testo originale (o il riferimento alla cella contenente il testo).
- vecchio_testo: Il carattere o la parola specifica che si desidera modificare.
- nuovo_testo: Il testo che si desidera inserire al posto.
- [num_istanza]: (Opzionale) Specifica quale occorrenza sostituire. Se omesso, tutte le occorrenze vengono aggiornate.
Esempio pratico: Aggiornamento in blocco degli anni
Se devi aggiornare "Report 2023" in "Report 2024" nella cella A1:
- Formula:
=SOSTITUISCI(A1, "2023", "2024") - Risultato: "Report 2024"
Avanzato: SUBSTITUTE annidato per aggiornamenti multipli
Puoi annidare più funzioni SUBSTITUTE per sostituire più termini diversi in una singola cella contemporaneamente. Questo è perfetto per convertire codici abbreviati in descrizioni complete:
- Formula:
=SOSTITUISCI(SOSTITUISCI(A2, "PR", "Progetto"), "ML", "Milestone") - Risultato: Converte "PR-01, ML-05" in "Progetto-01, Milestone-05".
Implementazione passo passo:
-
Identifica il target: Fai clic sulla cella in cui desideri che appaiano i dati puliti.
-
Applica la formula: Digita =SOSTITUISCI( e seleziona la cella di origine.
-
Definisci le stringhe di testo: Inserisci vecchio_testo e nuovo_testo tra virgolette doppie (ad esempio, "vecchio", "nuovo").
-
Istanza opzionale: Se desideri sostituire solo la seconda occorrenza di una parola, aggiungi , 2 alla fine prima di chiudere la parentesi.
-
Trascina per applicare: Premi Invio e utilizza il quadrato di riempimento automatico per applicare la formula al resto della tua colonna.
Suggerimenti professionali:
- Sensibilità alle maiuscole/minuscole: SUBSTITUTE è sensibile alle maiuscole/minuscole. Per eseguire una ricerca non sensibile alle maiuscole/minuscole, racchiudi il riferimento alla cella nella funzione UPPER o LOWER.
- Rimozione del testo: Per eliminare completamente una parola specifica, usa una stringa vuota "" come nuovo_testo.
- Non distruttivo: A differenza di Trova e Sostituisci, l'uso delle formule mantiene intatti i dati originali nella colonna di origine, fornendo una migliore traccia di controllo.
✅ Pro: Eccellente per la sostituzione basata sul contenuto; altamente flessibile con l'annidamento.
⚠️ Limitazioni: Non gestisce modifiche basate sulla posizione; richiede una colonna di supporto per memorizzare i risultati.
Metodo 4 - Automatizza le sostituzioni di testo in Excel con VBA
Quando è necessario sostituire il testo in Excel in più fogli o gestire attività di pulizia ripetitive e su larga scala, una macro VBA è la soluzione più potente. Questo metodo consente di automatizzare il processo con un singolo clic, risparmiandoti errori manuali.
Perché usare VBA per la sostituzione?
- Efficienza: Aggiorna centinaia di celle istantaneamente.
- Coerenza: Assicura che la stessa logica di sostituzione venga applicata ogni volta.
- Supporto multi-foglio: A differenza delle formule, VBA può scansionare ogni scheda della tua cartella di lavoro.
Esempio di macro VBA per sostituire dati nel foglio Excel attivo
Copia e incolla il seguente codice nell'editor VBA per sostituire termini specifici nel tuo foglio di lavoro corrente:
Sub BatchReplaceText()
Dim ws As Worksheet
Set ws = ActiveSheet
' Definisci cosa trovare e cosa sostituire
ws.Cells.Replace What:="VecchioTesto", Replacement:="NuovoTesto", _
LookAt:=xlPart, SearchOrder:=xlByRows, MatchCase:=False
MsgBox "Sostituzione completata!", vbInformation
End Sub
Come eseguire questa macro (passo passo):
-
Apri l'editor: Premi Alt + F11 per aprire la finestra Visual Basic for Applications.
-
Inserisci un modulo: Vai su Inserisci > Modulo per creare uno spazio di lavoro vuoto.
-
Incolla il codice: Copia lo script sopra e incollalo nel modulo. Sostituisci "VecchioTesto" e "NuovoTesto" con i tuoi dati effettivi.
-
Esegui la macro: Premi F5 o torna in Excel e premi Alt + F8, seleziona BatchReplaceText e fai clic su Esegui.
Suggerimenti professionali:
- Controllo di precisione: Nel codice sopra, LookAt:=xlPart consente alla macro di sostituire il testo anche se è solo una parte del contenuto di una cella (ad esempio, cambiare "App" in "Applicazione" all'interno di "App Store"). Se devi sostituire solo le celle che corrispondono esattamente al tuo testo, cambia questo parametro in LookAt:=xlWhole.
- Backup prima: A differenza delle formule, le azioni VBA non possono essere annullate (Ctrl+Z). Salva sempre una copia di backup del tuo file prima di eseguire una macro.
- Ciclo su tutti i fogli: Puoi modificare il codice per ciclare su Each ws In ThisWorkbook.Worksheets per eseguire una sostituzione globale.
- Variabili per parole chiave: Per maggiore flessibilità, usa InputBox per consentire agli utenti di digitare il testo che desiderano sostituire ogni volta che la macro viene eseguita.
✅ Pro: Altamente efficiente per grandi set di dati; automatizza attività ripetitive.
⚠️ Limitazioni: Richiede che la cartella di lavoro venga salvata come Cartella di lavoro con attivazione macro di Excel (.xlsm); non può essere annullata.
Metodo 5 - Sostituisci testo in batch su più file Excel con Python
Per il massimo livello di automazione, l'utilizzo di Python con la libreria Spire.XLS è il modo migliore per sostituire testo in batch su più file Excel senza nemmeno aprirli. Questo cambia le regole del gioco per i professionisti che gestiscono centinaia di report e necessitano di mantenere la formattazione e la struttura dei documenti.
Perché usare Spire.XLS per Python?
- Preservazione della formattazione: A differenza di altre librerie, Spire.XLS mantiene intatti font, colori e layout durante la sostituzione del testo.
- Scalabilità: Elabora migliaia di cartelle di lavoro in pochi secondi, ideale per rebranding o aggiornamenti di dati a livello aziendale.
- Supporto formule: Consente di inserire varie formule Excel, rendendo facile eseguire calcoli complessi, anche senza aprire Excel.
- Non è necessario Excel: Opera indipendentemente da Microsoft Office, rendendolo perfetto per ambienti server automatizzati.
Codice Python: Sostituzione in batch utilizzando Spire.XLS
Questo script itera su un'intera cartella, cerca ogni foglio di lavoro e sostituisce termini specifici:
from spire.xls import *
import glob
# Percorso della tua cartella contenente i file Excel
files = glob.glob("C:/tua_cartella/*.xlsx")
for file in files:
# Carica la cartella di lavoro
workbook = Workbook()
workbook.LoadFromFile(file)
# Itera su tutti i fogli di lavoro per sostituire il testo
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Trova tutte le istanze del vecchio testo
found_ranges = sheet.FindAll("VecchioTesto", FindType.Text, ExcelFindOptions.MatchEntireCellContent)
if found_ranges:
for cell_range in found_ranges:
# Applica il testo di sostituzione
cell_range.Text = "NuovoTesto"
# Salva la cartella di lavoro aggiornata
workbook.SaveToFile(file, ExcelVersion.Version2016)
workbook.Dispose()
print("Sostituzione del testo in batch completata con successo!")
Implementazione passo passo:
- Prepara l'ambiente: Installa la libreria tramite terminale:
pip install Spire.Xls - Prepara il tuo script: Incolla il codice in un editor come VS Code o PyCharm.
- Configura i parametri: Aggiorna il percorso della cartella e sostituisci "VecchioTesto" e "NuovoTesto" con i tuoi dati effettivi.
- Esegui e verifica: Premi F5 per eseguire lo script. Verifica i file di output per confermare che i risultati della sostituzione siano corretti.
Suggerimenti professionali:
- Sostituzione di testo parziale: Se una cella contiene una stringa lunga (ad esempio, "Ordine: 1001") e vuoi cambiare solo il numero, usa
cell_range.TextPartReplace("1001", "2002"). Questo mantiene intatto il testo circostante. - Sensibilità alle maiuscole/minuscole: Il parametro ExcelFindOptions nel metodo FindAll consente di attivare la corrispondenza sensibile alle maiuscole/minuscole o la corrispondenza di parole intere per una maggiore precisione.
- Ricerca specifica per intervallo: Se sai che i dati di destinazione si trovano solo in un'area specifica, chiama FindAll su un XlsRange anziché sull'intero foglio:
sheet.Range["A1:C10"].FindAll(). - Regex e modelli: Puoi combinarlo con il modulo re di Python per la corrispondenza di modelli complessi prima di passare la stringa al ciclo di sostituzione.
✅ Pro: Velocità impareggiabile per attività ad alto volume; gestisce più file; preserva tutta la formattazione Excel originale.
⚠️ Limitazioni: Richiede la configurazione di un ambiente Python e conoscenze di programmazione di base.
Conclusione: Quale metodo scegliere?
La scelta del modo migliore per sostituire il testo in Excel dipende dalla scala dei tuoi dati e dal tuo livello di comfort con l'automazione:
- Modifiche rapide e semplici: Utilizza lo strumento integrato Trova e Sostituisci.
- Precisione basata sulla posizione: Utilizza la funzione REPLACE per dati strutturati (ad esempio, codici ID).
- Logica basata sul contenuto: Utilizza la funzione SUBSTITUTE per correggere termini specifici.
- Automazione della cartella di lavoro: Utilizza le macro VBA per gestire attività ripetitive su più fogli.
- Elaborazione batch professionale: Utilizza Python per gestire centinaia di file con formattazione preservata.
Selezionando il giusto flusso di lavoro, puoi garantire la coerenza dei dati, risparmiare ore di lavoro manuale ed eliminare gli errori umani.
Risoluzione dei problemi comuni di sostituzione del testo
Anche con gli strumenti giusti, potresti incontrare ostacoli. Ecco i problemi più comuni e come risolverli:
| Problema | Causa probabile | Soluzione |
|---|---|---|
| La sostituzione non è avvenuta | Il testo non corrisponde esattamente alla stringa Trova o vecchio_testo. | Verifica la presenza di spazi aggiuntivi o caratteri nascosti. Utilizza le funzioni TRIM() o CLEAN() per sanificare i dati prima. |
| Solo una parte del testo è stata sostituita | Le impostazioni di Trova e Sostituisci sono troppo restrittive. | Nel menu Opzioni, assicurati che Maiuscole/minuscole e Contenuto cella intero siano deselezionati per le sostituzioni parziali. |
| Errore #VALORE! (REPLACE) | Posizione di inizio o numero di caratteri non validi. | Assicurati che num_inizio e num_caratteri siano numeri interi positivi e rientrino nella lunghezza della stringa. |
| I risultati delle formule sono solo testo | REPLACE e SUBSTITUTE restituiscono sempre testo. | Se hai bisogno di un numero, moltiplica il risultato per 1 (ad esempio, =SOSTITUISCI(...)*1) o racchiudilo in VALUE(). |
| La macro VBA non viene eseguita | Impostazioni di sicurezza macro o fogli protetti. | Abilita le macro nel Centro Protezione e assicurati che il foglio di lavoro sia non protetto prima dell'esecuzione. |
| Errori nello script Python | Percorsi file errati o dipendenze mancanti. | Assicurati che Spire.Xls sia installato. Ricontrolla la sintassi del percorso della tua cartella (usa / o \\ in Windows). |
Domande frequenti: Sostituisci dati in Excel
D1: Posso sostituire testo in più fogli senza VBA o Python?
Sì. Nella finestra di dialogo Trova e Sostituisci, fai clic su Opzioni e cambia il menu a discesa All'interno da "Foglio" a "Cartella di lavoro". Questo ti consente di aggiornare l'intero file contemporaneamente.
D2: Come sostituisco il testo preservando la formattazione della cella?
Le formule standard (SUBSTITUTE) creano nuovo testo in una nuova cella. Per mantenere la formattazione nella cella originale, usa lo strumento manuale Trova e Sostituisci o una libreria professionale come Spire.XLS per Python, progettata per modificare il contenuto senza rimuovere gli stili.
D3: Posso sostituire testo in base a uno schema specifico (ad esempio, qualsiasi cifra a 3 cifre)?
Sì, ma avrai bisogno di caratteri jolly (* o ?) nello strumento Trova e Sostituisci, o di espressioni regolari (Regex) in uno script Python per modelli più complessi.
D4: Cosa succede se il testo di destinazione si trova in una posizione diversa in ogni cella?
Utilizza una formula dinamica che combina REPLACE con FIND:
=SE.ERRORE(REPLACE(A2, TROVA("vecchio", A2), LUNGHEZZA("vecchio"), "nuovo"), A2)
Questo individua il testo "vecchio" indipendentemente da dove inizia e lo sostituisce con "nuovo".
D5: Come posso automatizzare le sostituzioni per centinaia di file separati?
Il metodo più efficiente è utilizzare Python. Sfruttando glob per trovare i file e Spire.XLS per elaborarli, puoi aggiornare migliaia di cartelle di lavoro in pochi secondi senza nemmeno aprire Excel.
Vedi anche
Comment remplacer du texte dans Excel : 5 méthodes rapides (de manuelles à automatisées)
Table des matières
- Méthode 1 - Remplacer le texte manuellement avec Rechercher & Remplacer d'Excel
- Méthode 2 - Remplacer le texte par position à l'aide de la fonction REPLACE d'Excel
- Méthode 3 - Remplacer le texte par contenu à l'aide de la fonction SUBSTITUTE d'Excel
- Méthode 4 - Automatiser les remplacements de texte dans Excel avec VBA
- Méthode 5 - Remplacer le texte par lots dans plusieurs fichiers Excel avec Python
Lorsque vous travaillez avec de grands classeurs Excel, des données incohérentes ou obsolètes peuvent rapidement faire dérailler vos rapports et votre prise de décision. Scanner manuellement des milliers de cellules pour corriger des fautes de frappe est non seulement chronophage, mais aussi sujet à des erreurs humaines coûteuses. Maîtriser comment remplacer du texte dans Excel efficacement est une compétence essentielle pour tout professionnel des données.
Dans ce guide complet, nous explorons 5 méthodes pratiques pour remplacer du texte dans Excel - allant de l'outil intégré Rechercher & Remplacer et des formules de feuille de calcul à l'automatisation avancée VBA et Python. Que vous ayez besoin de mettre à jour une seule cellule ou de traiter par lots des centaines de classeurs, nos instructions étape par étape vous aideront à rationaliser votre flux de travail et à garantir l'intégrité des données.
Aperçu des méthodes
- Méthode 1 - Remplacer le texte manuellement avec Rechercher & Remplacer d'Excel
- Méthode 2 - Remplacer le texte par position à l'aide de la fonction REPLACE d'Excel
- Méthode 3 - Remplacer le texte par contenu à l'aide de la fonction SUBSTITUTE d'Excel
- Méthode 4 - Automatiser les remplacements de texte dans Excel avec VBA
- Méthode 5 - Remplacer le texte par lots dans plusieurs fichiers Excel avec Python
Comprendre le remplacement de texte dans Excel
Le remplacement de texte dans Excel n'est pas seulement un changement cosmétique - il peut :
- Corriger des erreurs - corriger des fautes de frappe ou des codes obsolètes.
- Standardiser les formats - unifier les codes produit, les e-mails ou les dates.
- Améliorer l'analyse des données - assurer la cohérence avant les calculs, le filtrage ou les tableaux croisés dynamiques.
- Gagner du temps dans les tâches répétitives - en particulier lors du travail avec de grands ensembles de données ou plusieurs fichiers.
Ci-dessous, nous explorerons 5 façons pratiques de remplacer des données dans Excel.
Méthode 1 - Remplacer le texte manuellement avec Rechercher & Remplacer d'Excel
L'outil intégré Rechercher et remplacer d'Excel est la méthode manuelle la plus efficace pour remplacer du texte dans Excel au sein d'une seule feuille de calcul ou d'un classeur entier. Il est parfait pour les mises à jour rapides et ponctuelles où les formules ou l'automatisation ne sont pas nécessaires.
Comment accéder à l'outil Rechercher et remplacer :
- Raccourci : Appuyez sur Ctrl + H (Windows) ou Commande + Maj + H (Mac).
- Chemin du menu : Allez dans l'onglet Accueil > groupe Édition > Rechercher et sélectionner > Remplacer.
Instructions étape par étape :
-
Ouvrir le classeur : Sélectionnez la feuille de calcul où vous devez effectuer le remplacement de texte.
-
Accéder à l'outil : Utilisez le raccourci ou le chemin du menu pour déclencher la fenêtre Rechercher et remplacer.
-
Saisir les données : Dans la zone Rechercher, tapez le texte ou les nombres spécifiques que vous souhaitez modifier. Dans la zone Remplacer par, tapez votre nouveau contenu.
-
Exécuter le remplacement : Cliquez sur Remplacer pour mettre à jour la sélection actuelle et passer à l'instance suivante, ou sur Remplacer tout pour mettre à jour toutes les instances de la feuille instantanément.
Conseils Pro :
Cliquez sur le bouton Options >> pour débloquer les contrôles avancés :
- Portée de la recherche : Changez le paramètre Dans de Feuille à Classeur pour remplacer le texte dans tous les onglets à la fois.
- Correspondance de modèle : Utilisez des caractères génériques comme * (caractères multiples) ou ? (caractère unique) pour une recherche flexible (par exemple, S*t correspond à la fois à "Smart" et à "Street").
- Contrôle de précision : Activez Respecter la casse pour remplacer uniquement les correspondances exactes ou Cellule entière pour éviter de remplacer accidentellement des parties de mots.
✅ Avantages : Rapide, intuitif et gère également les changements de formatage.
⚠️ Limites : Manuel et répétitif ; ne convient pas au traitement par lots de centaines de fichiers distincts.
Vous pourriez également être intéressé par : 5 façons de renvoyer le texte à la ligne dans Excel.
Méthode 2 - Remplacer le texte par position à l'aide de la fonction REPLACE d'Excel
Lorsque vous avez besoin de remplacer du texte dans Excel en fonction de sa position de caractère plutôt que de son contenu, la fonction REPLACE est le meilleur outil. Cette formule est idéale pour nettoyer des données structurées comme des numéros de téléphone, des codes de série ou des identifiants de produit standardisés.
Syntaxe de la fonction Replace
=REPLACE(ancien_texte, no_début, no_caractères, nouveau_texte)
- ancien_texte : Le texte d'origine (ou la référence de cellule contenant le texte).
- no_début : La position (index) du premier caractère que vous souhaitez remplacer.
- no_caractères : Le nombre total de caractères à supprimer.
- nouveau_texte : Le nouveau texte que vous souhaitez insérer.
Exemple pratique : Masquer des données sensibles
Si vous avez un code de série "123-ABC" dans la cellule A1 et que vous souhaitez changer les trois premiers chiffres en "XXX" :
- Formule :
=REPLACE(A1, 1, 3, "XXX") - Résultat : "XXX-ABC"
Mise en œuvre étape par étape :
-
Sélectionner une cellule : Cliquez sur la cellule où vous souhaitez que le texte mis à jour apparaisse (par exemple, B2).
-
Entrer la formule : Tapez =REPLACE( et sélectionnez la cellule source (par exemple, A2).
-
Définir la plage : Entrez le no_début (où commence le remplacement) et le no_caractères (combien de caractères échanger).
-
Ajouter le nouveau texte : Tapez votre texte de remplacement entre guillemets (par exemple, "XXX").
-
Appliquer à la liste : Appuyez sur Entrée et utilisez la poignée de recopie automatique (le petit carré vert) pour faire glisser la formule vers les autres lignes.
Conseils Pro :
- Combiner avec d'autres fonctions : Utilisez NBCAR() ou CHERCHE() comme no_début pour gérer dynamiquement des chaînes de longueurs variables.
- Gérer les résultats numériques : La fonction REPLACE renvoie toujours du texte. Pour le reconvertir en nombre pour les calculs, ajoutez *1 à la fin de votre formule (par exemple,
=REPLACE(...) * 1). - Imbrication : Vous pouvez imbriquer plusieurs fonctions REPLACE dans une seule formule si vous devez mettre à jour deux positions ou plus différentes à la fois.
✅ Avantages : Parfait pour les données structurées ; assure un contrôle précis sur le remplacement de caractères.
⚠️ Limites : Moins efficace pour les données où le texte cible apparaît à différentes positions dans chaque cellule.
Méthode 3 - Remplacer le texte par contenu à l'aide de la fonction SUBSTITUTE d'Excel
La fonction SUBSTITUTE est l'outil de prédilection lorsque vous devez remplacer du texte dans Excel en fonction d'un contenu spécifique plutôt que de sa position. Ceci est idéal pour corriger des fautes de frappe répétées, mettre à jour des références d'année ou développer des abréviations dans un grand ensemble de données.
Syntaxe de la fonction SUBSTITUTE
=SUBSTITUTE(texte, ancien_texte, nouveau_texte, [no_instance])
- texte : Le texte d'origine (ou la référence de cellule contenant le texte).
- ancien_texte : Le caractère ou le mot spécifique que vous souhaitez modifier.
- nouveau_texte : Le texte que vous souhaitez insérer à la place.
- [no_instance] : (Facultatif) Spécifie quelle occurrence remplacer. S'il est omis, toutes les occurrences sont mises à jour.
Exemple pratique : Mise à jour en masse des années
Si vous devez mettre à jour "Rapport 2023" en "Rapport 2024" dans la cellule A1 :
- Formule :
=SUBSTITUTE(A1, "2023", "2024") - Résultat : "Rapport 2024"
Avancé : SUBSTITUTE imbriqué pour plusieurs mises à jour
Vous pouvez imbriquer plusieurs fonctions SUBSTITUTE pour remplacer plusieurs termes différents dans une seule cellule simultanément. C'est parfait pour convertir des codes abrégés en descriptions complètes :
- Formule :
=SUBSTITUTE(SUBSTITUTE(A2, "PR", "Projet"), "ML", "Jalon") - Résultat : Convertit "PR-01, ML-05" en "Projet-01, Jalon-05".
Mise en œuvre étape par étape :
-
Identifier la cible : Cliquez sur la cellule où vous souhaitez que les données nettoyées apparaissent.
-
Appliquer la formule : Tapez =SUBSTITUTE( et sélectionnez la cellule source.
-
Définir les chaînes de texte : Entrez l'ancien_texte et le nouveau_texte entre guillemets doubles (par exemple, "ancien", "nouveau").
-
Instance facultative : Si vous ne souhaitez remplacer que la deuxième occurrence d'un mot, ajoutez , 2 à la fin avant de fermer la parenthèse.
-
Faire glisser pour appliquer : Appuyez sur Entrée et utilisez la poignée de recopie automatique pour appliquer la formule au reste de votre colonne.
Conseils Pro :
- Sensibilité à la casse : SUBSTITUTE est sensible à la casse. Pour effectuer une recherche insensible à la casse, encapsulez votre référence de cellule dans la fonction MAJUSCULE ou MINUSCULE.
- Supprimer du texte : Pour supprimer complètement un mot spécifique, utilisez une chaîne vide "" comme nouveau_texte.
- Non destructif : Contrairement à Rechercher et remplacer, l'utilisation de formules conserve vos données d'origine intactes dans la colonne source, offrant une meilleure piste d'audit.
✅ Avantages : Excellent pour le remplacement basé sur le contenu ; très flexible avec l'imbrication.
⚠️ Limites : Ne gère pas les changements basés sur la position ; nécessite une colonne d'aide pour stocker les résultats.
Méthode 4 - Automatiser les remplacements de texte dans Excel avec VBA
Lorsque vous devez remplacer du texte dans Excel sur plusieurs feuilles ou gérer des tâches de nettoyage répétitives et à grande échelle, une macro VBA est la solution la plus puissante. Cette méthode vous permet d'automatiser le processus en un seul clic, vous évitant ainsi les erreurs manuelles.
Pourquoi utiliser VBA pour le remplacement ?
- Efficacité : Mettez à jour des centaines de cellules instantanément.
- Cohérence : Assurez-vous que la même logique de remplacement est appliquée à chaque fois.
- Support multi-feuilles : Contrairement aux formules, VBA peut scanner tous les onglets de votre classeur.
Exemple de macro VBA pour remplacer des données dans la feuille Excel active
Copiez et collez le code suivant dans votre éditeur VBA pour remplacer des termes spécifiques dans votre feuille de calcul actuelle :
Sub BatchReplaceText()
Dim ws As Worksheet
Set ws = ActiveSheet
' Définir ce qu'il faut trouver et par quoi remplacer
ws.Cells.Replace What:="AncienTexte", Replacement:="NouveauTexte", _
LookAt:=xlPart, SearchOrder:=xlByRows, MatchCase:=False
MsgBox "Remplacement terminé !", vbInformation
End Sub
Comment exécuter cette macro (étape par étape) :
-
Ouvrir l'éditeur : Appuyez sur Alt + F11 pour ouvrir la fenêtre Visual Basic for Applications.
-
Insérer un module : Allez dans Insertion > Module pour créer un espace de travail vide.
-
Coller le code : Copiez le script ci-dessus et collez-le dans le module. Remplacez "AncienTexte" et "NouveauTexte" par vos données réelles.
-
Exécuter la macro : Appuyez sur F5 ou retournez dans Excel et appuyez sur Alt + F8, sélectionnez BatchReplaceText, puis cliquez sur Exécuter.
Conseils Pro :
- Contrôle de précision : Dans le code ci-dessus, LookAt:=xlPart permet à la macro de remplacer du texte même s'il ne fait partie du contenu d'une cellule (par exemple, changer "App" en "Application" dans "App Store"). Si vous devez remplacer uniquement les cellules qui correspondent exactement à votre texte, changez ce paramètre en LookAt:=xlWhole.
- Sauvegarder d'abord : Contrairement aux formules, les actions VBA ne peuvent pas être annulées (Ctrl+Z). Sauvegardez toujours une copie de sauvegarde de votre fichier avant d'exécuter une macro.
- Parcourir toutes les feuilles : Vous pouvez modifier le code pour parcourir Chaque ws Dans ThisWorkbook.Worksheets pour effectuer un remplacement global.
- Variables de mots-clés : Pour plus de flexibilité, utilisez InputBox pour permettre aux utilisateurs de taper le texte qu'ils souhaitent remplacer chaque fois que la macro s'exécute.
✅ Avantages : Très efficace pour les grands ensembles de données ; automatise les tâches répétitives.
⚠️ Limites : Nécessite que le classeur soit enregistré en tant que classeur Excel prenant en charge les macros (.xlsm) ; ne peut pas être annulé.
Méthode 5 - Remplacer le texte par lots dans plusieurs fichiers Excel avec Python
Pour le plus haut niveau d'automatisation, l'utilisation de Python avec la bibliothèque Spire.XLS est le meilleur moyen de remplacer par lots du texte dans plusieurs fichiers Excel sans même les ouvrir. C'est un game-changer pour les professionnels gérant des centaines de rapports qui ont besoin de maintenir le formatage et la structure des documents.
Pourquoi utiliser Spire.XLS pour Python ?
- Préservation du formatage : Contrairement à d'autres bibliothèques, Spire.XLS conserve vos polices, couleurs et mises en page intactes tout en remplaçant le texte.
- Scalabilité : Traitez des milliers de classeurs en quelques secondes - idéal pour le rebrading à l'échelle de l'entreprise ou les mises à jour de données.
- Support des formules : Permet d'insérer diverses formules Excel, ce qui facilite la réalisation de calculs complexes, même sans ouvrir Excel.
- Aucun Excel requis : Fonctionne indépendamment de Microsoft Office, ce qui le rend parfait pour les environnements de serveur automatisés.
Code Python : Remplacement par lots à l'aide de Spire.XLS
Ce script parcourt un dossier entier, recherche dans chaque feuille de calcul et remplace des termes spécifiques :
from spire.xls import *
import glob
# Chemin de votre dossier contenant les fichiers Excel
files = glob.glob("C:/votre_dossier/*.xlsx")
for file in files:
# Charger le classeur
workbook = Workbook()
workbook.LoadFromFile(file)
# Parcourir toutes les feuilles de calcul pour remplacer le texte
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Trouver toutes les occurrences de l'ancien texte
found_ranges = sheet.FindAll("AncienTexte", FindType.Text, ExcelFindOptions.MatchEntireCellContent)
if found_ranges:
for cell_range in found_ranges:
# Appliquer le texte de remplacement
cell_range.Text = "NouveauTexte"
# Enregistrer le classeur mis à jour
workbook.SaveToFile(file, ExcelVersion.Version2016)
workbook.Dispose()
print("Remplacement de texte par lots terminé avec succès !")
Mise en œuvre étape par étape :
- Configurer l'environnement : Installez la bibliothèque via le terminal :
pip install Spire.Xls - Préparer votre script : Collez le code dans un éditeur comme VS Code ou PyCharm.
- Configurer les paramètres : Mettez à jour le chemin du dossier et remplacez "AncienTexte" et "NouveauTexte" par vos données réelles.
- Exécuter et vérifier : Appuyez sur F5 pour exécuter le script. Vérifiez les fichiers de sortie pour confirmer que les résultats du remplacement sont corrects.
Conseils Pro :
- Remplacement de texte partiel : Si une cellule contient une longue chaîne (par exemple, "Commande : 1001") et que vous ne souhaitez changer que le nombre, utilisez
cell_range.TextPartReplace("1001", "2002"). Cela conserve le texte environnant intact. - Sensibilité à la casse : Le paramètre ExcelFindOptions dans la méthode FindAll vous permet d'activer la correspondance sensible à la casse ou la correspondance de mot entier pour une plus grande précision.
- Recherche spécifique à une plage : Si vous savez que les données cibles se trouvent uniquement dans une zone spécifique, appelez FindAll sur une XlsRange au lieu de toute la feuille :
sheet.Range["A1:C10"].FindAll(). - Regex et modèles : Vous pouvez combiner cela avec le module re de Python pour une correspondance de modèle complexe avant de passer la chaîne à la boucle de remplacement.
✅ Avantages : Vitesse inégalée pour les tâches à haut volume ; gère plusieurs fichiers ; conserve tout le formatage Excel d'origine.
⚠️ Limites : Nécessite une configuration d'environnement Python et des connaissances de base en programmation.
Conclusion : Quelle méthode choisir ?
Choisir la meilleure façon de remplacer du texte dans Excel dépend de l'échelle de vos données et de votre niveau de confort avec l'automatisation :
- Modifications rapides et simples : Utilisez l'outil intégré Rechercher & Remplacer.
- Précision basée sur la position : Utilisez la fonction REPLACE pour les données structurées (par exemple, codes d'identification).
- Logique basée sur le contenu : Utilisez la fonction SUBSTITUTE pour corriger des termes spécifiques.
- Automatisation du classeur : Utilisez les macros VBA pour gérer les tâches répétitives sur plusieurs feuilles.
- Traitement par lots professionnel : Utilisez Python pour gérer des centaines de fichiers avec le formatage conservé.
En choisissant le bon flux de travail, vous pouvez assurer la cohérence des données, gagner des heures de travail manuel et éliminer les erreurs humaines.
Dépannage des problèmes courants de remplacement de texte
Même avec les bons outils, vous pourriez rencontrer des obstacles. Voici les problèmes les plus courants et comment les résoudre :
| Problème | Cause probable | Solution |
|---|---|---|
| Le remplacement n'a pas eu lieu | Le texte ne correspond pas exactement à la chaîne Rechercher ou ancien_texte. | Vérifiez les espaces supplémentaires ou les caractères cachés. Utilisez les fonctions SUPPRESPACE() ou NETTOYER() pour assainir les données au préalable. |
| Seule une partie du texte a été remplacée | Les paramètres Rechercher & Remplacer sont trop restrictifs. | Dans le menu Options, assurez-vous que Respecter la casse et Cellule entière ne sont pas cochés pour les remplacements partiels. |
| Erreur #VALEUR ! (REPLACE) | Position de départ ou nombre de caractères invalide. | Assurez-vous que no_début et no_caractères sont des entiers positifs et dans la longueur de la chaîne. |
| Les résultats des formules sont uniquement du texte | REPLACE et SUBSTITUTE renvoient toujours du texte. | Si vous avez besoin d'un nombre, multipliez le résultat par 1 (par exemple, =SUBSTITUTE(...)*1) ou encapsulez-le dans VALEUR(). |
| La macro VBA ne s'exécute pas | Paramètres de sécurité des macros ou feuilles protégées. | Activez les macros dans le Centre de gestion de la confidentialité et assurez-vous que la feuille de calcul est déprotégée avant l'exécution. |
| Erreurs de script Python | Chemins de fichiers incorrects ou dépendances manquantes. | Assurez-vous que Spire.Xls est installé. Vérifiez la syntaxe de votre chemin de dossier (utilisez / ou \\ sous Windows). |
FAQ : Remplacer des données dans Excel
Q1 : Puis-je remplacer du texte dans plusieurs feuilles sans VBA ou Python ?
Oui. Dans la boîte de dialogue Rechercher & Remplacer, cliquez sur Options et changez la liste déroulante Dans de "Feuille" à "Classeur". Cela vous permet de mettre à jour l'ensemble du fichier en une seule fois.
Q2 : Comment remplacer du texte tout en préservant le formatage des cellules ?
Les formules standard (SUBSTITUTE) créent du nouveau texte dans une nouvelle cellule. Pour conserver le formatage dans la cellule d'origine, utilisez l'outil manuel Rechercher & Remplacer ou une bibliothèque professionnelle comme Spire.XLS pour Python, qui est conçue pour modifier le contenu sans supprimer les styles.
Q3 : Puis-je remplacer du texte basé sur un modèle spécifique (par exemple, n'importe quels 3 chiffres) ?
Oui, mais vous aurez besoin de caractères génériques (* ou ?) dans l'outil Rechercher et remplacer, ou d'expressions régulières (Regex) dans un script Python pour des modèles plus complexes.
Q4 : Que faire si le texte cible se trouve à une position différente dans chaque cellule ?
Utilisez une formule dynamique combinant REPLACE avec FIND :
=SIERREUR(REPLACE(A2, TROUVE("ancien", A2), NBCAR("ancien"), "nouveau"), A2)
Cela localise le texte "ancien" quelle que soit sa position de départ et le remplace par "nouveau".
Q5 : Comment puis-je automatiser les remplacements pour des centaines de fichiers distincts ?
La méthode la plus efficace est d'utiliser Python. En utilisant glob pour trouver les fichiers et Spire.XLS pour les traiter, vous pouvez mettre à jour des milliers de classeurs en quelques secondes sans même ouvrir Excel.
Voir aussi
Cómo reemplazar texto en Excel: 5 formas rápidas (de manuales a automatizadas)
Tabla de Contenidos
- Método 1 - Reemplazar Texto Manualmente con Buscar y Reemplazar de Excel
- Método 2 - Reemplazar Texto por Posición Usando la Función REPLACE de Excel
- Método 3 - Reemplazar Texto por Contenido Usando la Función SUBSTITUTE de Excel
- Método 4 - Automatizar Reemplazos de Texto en Excel con VBA
- Método 5 - Reemplazar Texto en Lote en Múltiples Archivos de Excel con Python
Al trabajar con grandes libros de Excel, los datos inconsistentes u obsoletos pueden descarrilar rápidamente sus informes y toma de decisiones. Escanear manualmente miles de celdas para corregir errores tipográficos no solo consume tiempo, sino que también es propenso a errores humanos costosos. Dominar cómo reemplazar texto en Excel de manera eficiente es una habilidad crítica para cualquier profesional de datos.
En esta guía completa, exploramos 5 métodos prácticos para reemplazar texto en Excel, desde la herramienta integrada Buscar y Reemplazar y las fórmulas de hoja de cálculo hasta la automatización avanzada con VBA y Python. Ya sea que necesite actualizar una sola celda o procesar cientos de libros de trabajo en lote, nuestras instrucciones paso a paso lo ayudarán a optimizar su flujo de trabajo y garantizar la integridad de los datos.
Resumen de Métodos
- Método 1 - Reemplazar Texto Manualmente con Buscar y Reemplazar de Excel
- Método 2 - Reemplazar Texto por Posición Usando la Función REPLACE de Excel
- Método 3 - Reemplazar Texto por Contenido Usando la Función SUBSTITUTE de Excel
- Método 4 - Automatizar Reemplazos de Texto en Excel con VBA
- Método 5 - Reemplazar Texto en Lote en Múltiples Archivos de Excel con Python
Comprendiendo el Reemplazo de Texto en Excel
El reemplazo de texto en Excel no es solo un cambio cosmético, puede:
- Corregir errores: corregir errores tipográficos o códigos obsoletos.
- Estandarizar formatos: unificar códigos de producto, correos electrónicos o fechas.
- Mejorar el análisis de datos: garantizar la coherencia antes de realizar cálculos, filtros o tablas dinámicas.
- Ahorrar tiempo en tareas repetitivas: especialmente al trabajar con grandes conjuntos de datos o múltiples archivos.
A continuación, exploraremos 5 formas prácticas de reemplazar datos en Excel.
Método 1 - Reemplazar Texto Manualmente con Buscar y Reemplazar de Excel
La herramienta integrada Buscar y Reemplazar de Excel es el método manual más eficiente para reemplazar texto en Excel dentro de una sola hoja de cálculo o un libro de trabajo completo. Es perfecto para actualizaciones rápidas y puntuales donde no se requieren fórmulas o automatización.
Cómo Acceder a la Herramienta Buscar y Reemplazar:
- Atajo: Presione Ctrl + H (Windows) o Comando + Shift + H (Mac).
- Ruta del Menú: Vaya a la pestaña Inicio > grupo Edición > Buscar y Seleccionar > Reemplazar.
Instrucciones Paso a Paso:
-
Abrir el Libro de Trabajo: Seleccione la hoja de cálculo donde necesita realizar el reemplazo de texto.
-
Acceder a la Herramienta: Use el atajo o la ruta del menú para activar la ventana Buscar y Reemplazar.
-
Ingresar Datos: En el cuadro Buscar, escriba el texto o los números específicos que desea cambiar. En el cuadro Reemplazar con, escriba su nuevo contenido.
-
Ejecutar Reemplazo: Haga clic en Reemplazar para actualizar la selección actual y pasar a la siguiente instancia, o en Reemplazar todos para actualizar todas las instancias en la hoja al instante.
Consejos Profesionales:
Haga clic en el botón Opciones >> para desbloquear controles avanzados:
- Ámbito de Búsqueda: Cambie la configuración Dentro de Hoja a Libro de trabajo para reemplazar texto en todas las pestañas a la vez.
- Coincidencia de Patrones: Use Comodines como * (múltiples caracteres) o ? (un solo carácter) para búsquedas flexibles (por ejemplo, S*t coincide con "Smart" y "Street").
- Control de Precisión: Habilite Coincidir mayúsculas y minúsculas para reemplazar solo coincidencias exactas o Coincidir con el contenido de toda la celda para evitar reemplazar partes de palabras accidentalmente.
✅ Pros: Rápido, intuitivo y también maneja cambios de formato.
⚠️ Limitaciones: Manual y repetitivo; no apto para procesar cientos de archivos separados en lote.
También te puede interesar: 5 Formas de Ajustar Texto en Excel.
Método 2 - Reemplazar Texto por Posición Usando la Función REPLACE de Excel
Cuando necesite reemplazar texto en Excel basándose en su posición de carácter en lugar de su contenido, la función REPLACE es la mejor herramienta. Esta fórmula es ideal para limpiar datos estructurados como números de teléfono, códigos de serie o identificadores de productos estandarizados.
Sintaxis de la Función Replace
=REEMPLAZAR(texto_original, num_inicio, num_caracteres, texto_nuevo)
- texto_original: El texto original (o la referencia de celda que contiene el texto).
- num_inicio: La posición (índice) del primer carácter que desea reemplazar.
- num_caracteres: El número total de caracteres a eliminar.
- texto_nuevo: El nuevo texto que desea insertar.
Ejemplo Práctico: Enmascarar Datos Sensibles
Si tiene un código de serie "123-ABC" en la celda A1 y desea cambiar los primeros tres números a "XXX":
- Fórmula:
=REEMPLAZAR(A1, 1, 3, "XXX") - Resultado: "XXX-ABC"
Implementación Paso a Paso:
-
Seleccionar una Celda: Haga clic en la celda donde desea que aparezca el texto actualizado (por ejemplo, B2).
-
Ingresar la Fórmula: Escriba =REEMPLAZAR( y seleccione la celda de origen (por ejemplo, A2).
-
Definir el Rango: Ingrese el num_inicio (donde comienza el reemplazo) y el num_caracteres (cuántos caracteres intercambiar).
-
Agregar Texto Nuevo: Escriba su texto de reemplazo entre comillas (por ejemplo, "XXX").
-
Aplicar a la Lista: Presione Enter y use el controlador de Relleno automático (el pequeño cuadrado verde) para arrastrar la fórmula hacia abajo a otras filas.
Consejos Profesionales:
- Combinar con Otras Funciones: Use LARGO() o HALLAR() como num_inicio para manejar cadenas de diferentes longitudes dinámicamente.
- Manejar Resultados Numéricos: La función REPLACE siempre devuelve texto. Para convertirlo de nuevo a un número para cálculos, agregue *1 al final de su fórmula (por ejemplo,
=REEMPLAZAR(...) * 1). - Anidamiento: Puede anidar múltiples funciones REPLACE en una sola fórmula si necesita actualizar dos o más posiciones diferentes a la vez.
✅ Pros: Perfecto para datos estructurados; garantiza un control preciso sobre el reemplazo de caracteres.
⚠️ Limitaciones: Menos efectivo para datos donde el texto objetivo aparece en diferentes posiciones en cada celda.
Método 3 - Reemplazar Texto por Contenido Usando la Función SUBSTITUTE de Excel
La función SUBSTITUTE es la herramienta ideal cuando necesita reemplazar texto en Excel basándose en contenido específico en lugar de su posición. Esto es ideal para corregir errores tipográficos repetidos, actualizar referencias de año o expandir abreviaturas en un gran conjunto de datos.
Sintaxis de la Función SUBSTITUTE
=SUSTITUIR(texto, texto_antiguo, texto_nuevo, [num_instancia])
- texto: El texto original (o la referencia de celda que contiene el texto).
- texto_antiguo: El carácter o palabra específica que desea cambiar.
- texto_nuevo: El texto que desea insertar en su lugar.
- [num_instancia]: (Opcional) Especifica qué ocurrencia reemplazar. Si se omite, se actualizan todas las instancias.
Ejemplo Práctico: Actualización en Lote de Años
Si necesita actualizar "Informe 2023" a "Informe 2024" en la celda A1:
- Fórmula:
=SUSTITUIR(A1, "2023", "2024") - Resultado: "Informe 2024"
Avanzado: SUBSTITUTE Anidado para Múltiples Actualizaciones
Puede anidar múltiples funciones SUBSTITUTE para reemplazar varios términos diferentes en una sola celda simultáneamente. Esto es perfecto para convertir códigos abreviados en descripciones completas:
- Fórmula:
=SUSTITUIR(SUSTITUIR(A2, "PR", "Proyecto"), "ML", "Hito") - Resultado: Convierte "PR-01, ML-05" en "Proyecto-01, Hito-05".
Implementación Paso a Paso:
-
Identificar el Objetivo: Haga clic en la celda donde desea que aparezcan los datos limpios.
-
Aplicar la Fórmula: Escriba =SUSTITUIR( y seleccione la celda de origen.
-
Definir Cadenas de Texto: Ingrese el texto_antiguo y el texto_nuevo entre comillas dobles (por ejemplo, "antiguo", "nuevo").
-
Instancia Opcional: Si solo desea reemplazar la segunda ocurrencia de una palabra, agregue , 2 al final antes de cerrar el paréntesis.
-
Arrastrar para Aplicar: Presione Enter y use el controlador de Relleno automático para aplicar la fórmula al resto de su columna.
Consejos Profesionales:
- Sensibilidad a Mayúsculas y Minúsculas: SUBSTITUTE es sensible a mayúsculas y minúsculas. Para realizar una búsqueda insensible a mayúsculas y minúsculas, envuelva la referencia de su celda en la función MAYUSC o MINUSC.
- Eliminar Texto: Para eliminar una palabra específica por completo, use una cadena vacía "" como su texto_nuevo.
- No Destructivo: A diferencia de Buscar y Reemplazar, el uso de fórmulas mantiene intactos sus datos originales en la columna de origen, proporcionando un mejor rastro de auditoría.
✅ Pros: Excelente para reemplazo basado en contenido; muy flexible con anidamiento.
⚠️ Limitaciones: No maneja cambios basados en posición; requiere una columna auxiliar para almacenar resultados.
Método 4 - Automatizar Reemplazos de Texto en Excel con VBA
Cuando necesite reemplazar texto en Excel en varias hojas o manejar tareas de limpieza repetitivas y a gran escala, una macro VBA es la solución más potente. Este método le permite automatizar el proceso con un solo clic, ahorrándole errores manuales.
¿Por Qué Usar VBA para Reemplazar?
- Eficiencia: Actualice cientos de celdas al instante.
- Consistencia: Asegure que la misma lógica de reemplazo se aplique cada vez.
- Soporte Multi-Hoja: A diferencia de las fórmulas, VBA puede escanear cada pestaña de su libro de trabajo.
Macro VBA de Ejemplo para Reemplazar datos en la Hoja de Excel Activa
Copie y pegue el siguiente código en su editor de VBA para reemplazar términos específicos en su hoja de cálculo actual:
Sub BatchReplaceText()
Dim ws As Worksheet
Set ws = ActiveSheet
' Definir qué buscar y qué reemplazar
ws.Cells.Replace What:="TextoAntiguo", Replacement:="TextoNuevo", _
LookAt:=xlPart, SearchOrder:=xlByRows, MatchCase:=False
MsgBox "¡Reemplazo Completado!", vbInformation
End Sub
Cómo Ejecutar Esta Macro (Paso a Paso):
-
Abrir el Editor: Presione Alt + F11 para abrir la ventana de Visual Basic para Aplicaciones.
-
Insertar un Módulo: Vaya a Insertar > Módulo para crear un espacio de trabajo en blanco.
-
Pegar el Código: Copie el script anterior y péguelo en el módulo. Reemplace "TextoAntiguo" y "TextoNuevo" con sus datos reales.
-
Ejecutar la Macro: Presione F5 o regrese a Excel y presione Alt + F8, seleccione BatchReplaceText y haga clic en Ejecutar.
Consejos Profesionales:
- Control de Precisión: En el código anterior, LookAt:=xlPart permite que la macro reemplace texto incluso si es solo parte del contenido de una celda (por ejemplo, cambiar "App" por "Aplicación" dentro de "App Store"). Si necesita reemplazar solo celdas que coincidan exactamente con su texto, cambie este parámetro a LookAt:=xlWhole.
- Copia de Seguridad Primero: A diferencia de las fórmulas, las acciones de VBA no se pueden deshacer (Ctrl+Z). Siempre guarde una copia de seguridad de su archivo antes de ejecutar una macro.
- Recorrer Todas las Hojas: Puede modificar el código para recorrer Cada ws En ThisWorkbook.Worksheets para realizar un reemplazo global.
- Variables de Palabra Clave: Para mayor flexibilidad, use InputBox para permitir a los usuarios escribir el texto que desean reemplazar cada vez que se ejecuta la macro.
✅ Pros: Altamente eficiente para grandes conjuntos de datos; automatiza tareas repetitivas.
⚠️ Limitaciones: Requiere que el libro de trabajo se guarde como un Libro de Excel habilitado para macros (.xlsm); no se puede deshacer.
Método 5 - Reemplazar Texto en Lote en Múltiples Archivos de Excel con Python
Para el máximo nivel de automatización, usar Python con la biblioteca Spire.XLS es la mejor manera de reemplazar texto en lote en múltiples archivos de Excel sin siquiera abrirlos. Esto cambia las reglas del juego para los profesionales que administran cientos de informes y necesitan mantener el formato y la estructura del documento.
¿Por Qué Usar Spire.XLS para Python?
- Preservación del Formato: A diferencia de otras bibliotecas, Spire.XLS mantiene sus fuentes, colores y diseños intactos mientras reemplaza el texto.
- Escalabilidad: Procese miles de libros de trabajo en segundos, ideal para el cambio de marca o actualizaciones de datos a nivel de empresa.
- Soporte de Fórmulas: Permite insertar varias fórmulas de Excel, lo que facilita la realización de cálculos complejos, incluso sin abrir Excel.
- No Requiere Excel: Opera independientemente de Microsoft Office, lo que lo hace perfecto para entornos de servidor automatizados.
Código Python: Reemplazo en Lote Usando Spire.XLS
Este script itera a través de una carpeta completa, busca en cada hoja de cálculo y reemplaza términos específicos:
from spire.xls import *
import glob
# Ruta a su carpeta que contiene archivos de Excel
files = glob.glob("C:/su_carpeta/*.xlsx")
for file in files:
# Cargar el libro de trabajo
workbook = Workbook()
workbook.LoadFromFile(file)
# Iterar a través de todas las hojas de cálculo para reemplazar texto
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Encontrar todas las instancias del texto antiguo
found_ranges = sheet.FindAll("TextoAntiguo", FindType.Text, ExcelFindOptions.MatchEntireCellContent)
if found_ranges:
for cell_range in found_ranges:
# Aplicar el texto de reemplazo
cell_range.Text = "TextoNuevo"
# Guardar el libro de trabajo actualizado
workbook.SaveToFile(file, ExcelVersion.Version2016)
workbook.Dispose()
print("¡Reemplazo de texto en lote completado con éxito!")
Implementación Paso a Paso:
- Configurar Entorno: Instale la biblioteca a través de la terminal:
pip install Spire.Xls - Preparar su Script: Pegue el código en un editor como VS Code o PyCharm.
- Configurar Parámetros: Actualice la ruta de la carpeta y reemplace "TextoAntiguo" y "TextoNuevo" con sus datos reales.
- Ejecutar y Verificar: Presione F5 para ejecutar el script. Verifique los archivos de salida para confirmar que los resultados del reemplazo son correctos.
Consejos Profesionales:
- Reemplazo de Texto Parcial: Si una celda contiene una cadena larga (por ejemplo, "Pedido: 1001") y solo desea cambiar el número, use
cell_range.TextPartReplace("1001", "2002"). Esto mantiene intacto el texto circundante. - Sensibilidad a Mayúsculas y Minúsculas: El parámetro ExcelFindOptions en el método FindAll le permite alternar la coincidencia sensible a mayúsculas y minúsculas o de palabra completa para mayor precisión.
- Búsqueda Específica de Rango: Si sabe que los datos objetivo solo están en un área específica, llame a FindAll en un XlsRange en lugar de la Hoja completa:
sheet.Range["A1:C10"].FindAll(). - Regex y Patrones: Puede combinar esto con el módulo re de Python para coincidencias de patrones complejas antes de pasar la cadena al bucle de reemplazo.
✅ Pros: Velocidad inigualable para tareas de alto volumen; maneja múltiples archivos; preserva todo el formato original de Excel.
⚠️ Limitaciones: Requiere una configuración del entorno Python y conocimientos básicos de programación.
Conclusión: ¿Qué Método Debería Elegir?
Elegir la mejor manera de reemplazar texto en Excel depende de la escala de sus datos y su nivel de comodidad con la automatización:
- Ediciones Rápidas y Sencillas: Use la herramienta integrada Buscar y Reemplazar.
- Precisión Basada en Posición: Use la función REPLACE para datos estructurados (por ejemplo, códigos de identificación).
- Lógica Basada en Contenido: Use la función SUBSTITUTE para corregir términos específicos.
- Automatización de Libros de Trabajo: Use macros VBA para manejar tareas repetitivas en varias hojas.
- Procesamiento en Lote Profesional: Use Python para administrar cientos de archivos con formato preservado.
Al seleccionar el flujo de trabajo correcto, puede garantizar la coherencia de los datos, ahorrar horas de trabajo manual y eliminar errores humanos.
Solución de Problemas Comunes de Reemplazo de Texto
Incluso con las herramientas adecuadas, puede encontrar obstáculos. Aquí están los problemas más comunes y cómo solucionarlos:
| Problema | Causa Probable | Solución |
|---|---|---|
| El reemplazo no se realizó | El texto no coincide exactamente con la cadena Buscar o texto_antiguo. | Verifique si hay espacios adicionales o caracteres ocultos. Use las funciones ESPACIOS() o LIMPIAR() para sanear los datos primero. |
| Solo se reemplazó parte del texto | La configuración de Buscar y Reemplazar es demasiado restrictiva. | En el menú Opciones, asegúrese de que Coincidir mayúsculas y minúsculas y Coincidir con el contenido de toda la celda no estén marcados para reemplazos parciales. |
| Error #¡VALOR! (REPLACE) | Posición de inicio o recuento de caracteres no válidos. | Asegúrese de que num_inicio y num_caracteres sean enteros positivos y estén dentro de la longitud de la cadena. |
| Los resultados de la fórmula son solo texto | REPLACE y SUBSTITUTE siempre devuelven texto. | Si necesita un número, multiplique el resultado por 1 (por ejemplo, =SUSTITUIR(...)*1) o envuélvalo en VALOR(). |
| La macro VBA no se ejecuta | Configuración de seguridad de macros o hojas protegidas. | Habilite las macros en el Centro de confianza y asegúrese de que la hoja de cálculo esté sin protección antes de la ejecución. |
| Errores en el script de Python | Rutas de archivo incorrectas o dependencias faltantes. | Asegúrese de que Spire.Xls esté instalado. Verifique la sintaxis de la ruta de su carpeta (use / o \\ en Windows). |
Preguntas Frecuentes: Reemplazar Datos en Excel
P1: ¿Puedo reemplazar texto en varias hojas sin VBA o Python?
Sí. En el cuadro de diálogo Buscar y Reemplazar, haga clic en Opciones y cambie el menú desplegable Dentro de "Hoja" a "Libro de trabajo". Esto le permite actualizar todo el archivo a la vez.
P2: ¿Cómo reemplazo texto conservando el formato de la celda?
Las fórmulas estándar (SUBSTITUTE) crean texto nuevo en una nueva celda. Para mantener el formato en la celda original, use la herramienta manual Buscar y Reemplazar o una biblioteca profesional como Spire.XLS para Python, que está diseñada para modificar el contenido sin eliminar estilos.
P3: ¿Puedo reemplazar texto según un patrón específico (por ejemplo, cualquier dígito de 3)?
Sí, pero necesitará Comodines (* o ?) en la herramienta Buscar y Reemplazar, o Expresiones Regulares (Regex) en un script de Python para patrones más complejos.
P4: ¿Qué pasa si el texto objetivo está en una posición diferente en cada celda?
Use una fórmula dinámica que combine REPLACE con FIND:
=SI.ERROR(REEMPLAZAR(A2, HALLAR("antiguo", A2), LARGO("antiguo"), "nuevo"), A2)
Esto localiza el texto "antiguo" independientemente de dónde comience y lo reemplaza con "nuevo".
P5: ¿Cómo puedo automatizar reemplazos para cientos de archivos separados?
El método más eficiente es usar Python. Al aprovechar glob para encontrar archivos y Spire.XLS para procesarlos, puede actualizar miles de libros de trabajo en segundos sin siquiera abrir Excel.
Ver También
Text in Excel ersetzen: 5 schnelle Methoden (von manuell bis automatisiert)
Inhaltsverzeichnis
- Methode 1 – Text manuell mit Suchen & Ersetzen in Excel ersetzen
- Methode 2 – Text nach Position mit der REPLACE-Funktion in Excel ersetzen
- Methode 3 – Text nach Inhalt mit der SUBSTITUTE-Funktion in Excel ersetzen
- Methode 4 – Textersetzungen in Excel mit VBA automatisieren
- Methode 5 – Text stapelweise über mehrere Excel-Dateien mit Python ersetzen
Wenn Sie mit großen Excel-Arbeitsmappen arbeiten, können inkonsistente oder veraltete Daten Ihre Berichterstattung und Entscheidungsfindung schnell beeinträchtigen. Das manuelle Durchsuchen Tausender von Zellen zur Korrektur von Tippfehlern ist nicht nur zeitaufwendig, sondern auch fehleranfällig. Die Beherrschung von effizienten Methoden zum Ersetzen von Text in Excel ist eine entscheidende Fähigkeit für jeden Datenprofi.
In dieser umfassenden Anleitung untersuchen wir 5 praktische Methoden zum Ersetzen von Text in Excel – von dem integrierten Werkzeug Suchen & Ersetzen und Arbeitsblattformeln bis hin zu fortgeschrittener VBA- und Python-Automatisierung. Egal, ob Sie eine einzelne Zelle aktualisieren oder Hunderte von Arbeitsmappen stapelweise verarbeiten müssen, unsere Schritt-für-Schritt-Anleitungen helfen Ihnen, Ihren Arbeitsablauf zu optimieren und die Datenintegrität sicherzustellen.
Übersicht der Methoden
- Methode 1 – Text manuell mit Suchen & Ersetzen in Excel ersetzen
- Methode 2 – Text nach Position mit der REPLACE-Funktion in Excel ersetzen
- Methode 3 – Text nach Inhalt mit der SUBSTITUTE-Funktion in Excel ersetzen
- Methode 4 – Textersetzungen in Excel mit VBA automatisieren
- Methode 5 – Text stapelweise über mehrere Excel-Dateien mit Python ersetzen
Textersetzung in Excel verstehen
Textersetzung in Excel ist nicht nur eine kosmetische Änderung – sie kann:
- Fehler korrigieren – Tippfehler oder veraltete Codes beheben.
- Formate standardisieren – Produktcodes, E-Mails oder Daten vereinheitlichen.
- Datenanalyse verbessern – Konsistenz vor Berechnungen, Filterungen oder Pivot-Tabellen sicherstellen.
- Zeit bei repetitiven Aufgaben sparen – insbesondere bei großen Datensätzen oder mehreren Dateien.
Nachfolgend untersuchen wir 5 praktische Möglichkeiten, Daten in Excel zu ersetzen.
Methode 1 – Text manuell mit Suchen & Ersetzen in Excel ersetzen
Das integrierte Werkzeug Suchen und Ersetzen von Excel ist die effizienteste manuelle Methode, um Text in Excel innerhalb eines einzelnen Arbeitsblatts oder einer gesamten Arbeitsmappe zu ersetzen. Es ist perfekt für schnelle, einmalige Aktualisierungen, bei denen Formeln oder Automatisierung nicht erforderlich sind.
Zugriff auf das Werkzeug Suchen & Ersetzen:
- Tastenkombination: Drücken Sie Strg + H (Windows) oder Cmd + Umschalt + H (Mac).
- Menüpfad: Gehen Sie zur Registerkarte Start > Gruppe Bearbeiten > Suchen und Auswählen > Ersetzen.
Schritt-für-Schritt-Anleitung:
-
Arbeitsmappe öffnen: Wählen Sie das Arbeitsblatt aus, auf dem Sie Text ersetzen müssen.
-
Werkzeug aufrufen: Verwenden Sie die Tastenkombination oder den Menüpfad, um das Fenster Suchen und Ersetzen zu öffnen.
-
Daten eingeben: Geben Sie im Feld Suchen nach den spezifischen Text oder die Zahlen ein, die Sie ändern möchten. Geben Sie im Feld Ersetzen durch Ihren neuen Inhalt ein.
-
Ersetzung ausführen: Klicken Sie auf Ersetzen, um die aktuelle Auswahl zu aktualisieren und zur nächsten Instanz zu wechseln, oder auf Alle ersetzen, um sofort jede Instanz im Blatt zu aktualisieren.
Profi-Tipps:
Klicken Sie auf die Schaltfläche Optionen >>, um erweiterte Steuerelemente zu aktivieren:
- Suchbereich: Ändern Sie die Einstellung Innerhalb von Blatt auf Arbeitsmappe, um Text auf allen Registerkarten gleichzeitig zu ersetzen.
- Mustererkennung: Verwenden Sie Platzhalter wie * (mehrere Zeichen) oder ? (ein einzelnes Zeichen) für flexible Suchen (z. B. S*t passt sowohl auf "Smart" als auch auf "Street").
- Präzisionskontrolle: Aktivieren Sie Groß-/Kleinschreibung beachten, um nur exakte Übereinstimmungen zu ersetzen, oder Gesamten Zellinhalt vergleichen, um versehentliches Ersetzen von Wortteilen zu vermeiden.
✅ Vorteile: Schnell, intuitiv und behandelt auch Formatierungsänderungen.
⚠️ Einschränkungen: Manuell und repetitiv; nicht für die Stapelverarbeitung von Hunderten separater Dateien geeignet.
Das könnte Sie auch interessieren: 7 Wege, Text in Excel umzubrechen.
Methode 2 – Text nach Position mit der REPLACE-Funktion in Excel ersetzen
Wenn Sie Text in Excel basierend auf seiner Zeichenposition und nicht auf dem Inhalt selbst ersetzen müssen, ist die REPLACE-Funktion das beste Werkzeug. Diese Formel ist ideal für die Bereinigung strukturierter Daten wie Telefonnummern, Seriennummern oder standardisierter Produkt-IDs.
Syntax der REPLACE-Funktion
=ERSETZEN(alter_text; start_num; num_chars; neuer_text)
- alter_text: Der ursprüngliche Text (oder der Zellbezug, der den Text enthält).
- start_num: Die Position (Index) des ersten Zeichens, das Sie ersetzen möchten.
- num_chars: Die Gesamtzahl der zu entfernenden Zeichen.
- neuer_text: Der neue Text, den Sie einfügen möchten.
Praktisches Beispiel: Sensible Daten maskieren
Wenn Sie in Zelle A1 den Seriencode "123-ABC" haben und die ersten drei Zahlen in "XXX" ändern möchten:
- Formel:
=ERSETZEN(A1; 1; 3; "XXX") - Ergebnis: "XXX-ABC"
Schritt-für-Schritt-Implementierung:
-
Zelle auswählen: Klicken Sie auf die Zelle, in der der aktualisierte Text erscheinen soll (z. B. B2).
-
Formel eingeben: Geben Sie =ERSETZEN( ein und wählen Sie die Quellzelle aus (z. B. A2).
-
Bereich definieren: Geben Sie die start_num (wo die Ersetzung beginnt) und die num_chars (wie viele Zeichen ersetzt werden sollen) ein.
-
Neuen Text hinzufügen: Geben Sie Ihren Ersetzungstext in Anführungszeichen ein (z. B. "XXX").
-
Auf Liste anwenden: Drücken Sie Enter und verwenden Sie den Ausfüllkästchen (das kleine grüne Quadrat), um die Formel auf andere Zeilen zu ziehen.
Profi-Tipps:
- Kombinieren mit anderen Funktionen: Verwenden Sie LÄNGE() oder FINDEN() als start_num, um Zeichenfolgen unterschiedlicher Länge dynamisch zu verarbeiten.
- Numerische Ergebnisse behandeln: Die REPLACE-Funktion gibt immer Text zurück. Um ihn für Berechnungen wieder in eine Zahl umzuwandeln, fügen Sie *1 am Ende Ihrer Formel hinzu (z. B.
=ERSETZEN(...) * 1). - Verschachtelung: Sie können mehrere ERSETZEN-Funktionen in einer einzigen Formel verschachteln, wenn Sie zwei oder mehr verschiedene Positionen gleichzeitig aktualisieren müssen.
✅ Vorteile: Perfekt für strukturierte Daten; gewährleistet präzise Kontrolle über die Zeichenersetzung.
⚠️ Einschränkungen: Weniger effektiv für Daten, bei denen der Zieltext in jeder Zelle an unterschiedlichen Positionen vorkommt.
Methode 3 – Text nach Inhalt mit der SUBSTITUTE-Funktion in Excel ersetzen
Die SUBSTITUTE-Funktion ist das Werkzeug der Wahl, wenn Sie Text in Excel basierend auf spezifischem Inhalt anstelle seiner Position ersetzen müssen. Dies ist ideal für die Korrektur wiederholter Tippfehler, die Aktualisierung von Jahreszahlen oder die Erweiterung von Abkürzungen in einem großen Datensatz.
Syntax der SUBSTITUTE-Funktion
=WECHSELN(text; alter_text; neuer_text; [instanz_num])
- text: Der ursprüngliche Text (oder der Zellbezug, der den Text enthält).
- alter_text: Das spezifische Zeichen oder Wort, das Sie ändern möchten.
- neuer_text: Der Text, den Sie stattdessen einfügen möchten.
- [instanz_num]: (Optional) Gibt an, welche Instanz ersetzt werden soll. Wenn weggelassen, werden alle Instanzen aktualisiert.
Praktisches Beispiel: Jahreszahlen massenhaft aktualisieren
Wenn Sie "Bericht 2023" in Zelle A1 in "Bericht 2024" ändern müssen:
- Formel:
=WECHSELN(A1; "2023"; "2024") - Ergebnis: "Bericht 2024"
Erweitert: Verschachtelte SUBSTITUTE für mehrere Aktualisierungen
Sie können mehrere SUBSTITUTE-Funktionen verschachteln, um mehrere verschiedene Begriffe gleichzeitig in einer einzigen Zelle zu ersetzen. Dies ist perfekt für die Umwandlung von Kurzschreibweisen in vollständige Beschreibungen:
- Formel:
=WECHSELN(WECHSELN(A2; "PR"; "Projekt"); "ML"; "Meilenstein") - Ergebnis: Wandelt "PR-01, ML-05" in "Projekt-01, Meilenstein-05" um.
Schritt-für-Schritt-Implementierung:
-
Ziel identifizieren: Klicken Sie auf die Zelle, in der die bereinigten Daten erscheinen sollen.
-
Formel anwenden: Geben Sie =WECHSELN( ein und wählen Sie die Quellzelle aus.
-
Textzeichenfolgen definieren: Geben Sie den alter_text und den neuer_text in doppelte Anführungszeichen ein (z. B. "alt", "neu").
-
Optionale Instanz: Wenn Sie nur die zweite Instanz eines Wortes ersetzen möchten, fügen Sie , 2 am Ende hinzu, bevor Sie die Klammer schließen.
-
Ziehen zum Anwenden: Drücken Sie Enter und verwenden Sie das Ausfüllkästchen, um die Formel auf den Rest Ihrer Spalte anzuwenden.
Profi-Tipps:
- Groß-/Kleinschreibung: SUBSTITUTE beachtet die Groß- und Kleinschreibung. Um eine Suche ohne Berücksichtigung der Groß- und Kleinschreibung durchzuführen, umschließen Sie Ihren Zellbezug mit der Funktion GROSS oder KLEIN.
- Text löschen: Um ein bestimmtes Wort vollständig zu löschen, verwenden Sie eine leere Zeichenfolge "" als neuer_text.
- Nicht-destruktiv: Im Gegensatz zu Suchen & Ersetzen behalten Formeln Ihre Originaldaten in der Quellspalte intakt, was eine bessere Nachverfolgung ermöglicht.
✅ Vorteile: Hervorragend für inhaltsbasierte Ersetzungen; sehr flexibel durch Verschachtelung.
⚠️ Einschränkungen: Behandelt keine positionsbasierten Änderungen; erfordert eine Hilfsspalte zur Speicherung der Ergebnisse.
Methode 4 – Textersetzungen in Excel mit VBA automatisieren
Wenn Sie Text in Excel über mehrere Blätter hinweg ersetzen oder repetitive, groß angelegte Bereinigungsaufgaben durchführen müssen, ist ein VBA-Makro die leistungsstärkste Lösung. Diese Methode ermöglicht es Ihnen, den Prozess mit einem einzigen Klick zu automatisieren und manuelle Fehler zu vermeiden.
Warum VBA für Ersetzungen verwenden?
- Effizienz: Hunderte von Zellen sofort aktualisieren.
- Konsistenz: Sicherstellen, dass jedes Mal dieselbe Ersetzungslogik angewendet wird.
- Unterstützung mehrerer Blätter: Im Gegensatz zu Formeln kann VBA jedes Tab in Ihrer Arbeitsmappe durchsuchen.
Beispiel-VBA-Makro zum Ersetzen von Daten im aktiven Excel-Blatt
Kopieren Sie den folgenden Code und fügen Sie ihn in Ihren VBA-Editor ein, um bestimmte Begriffe auf Ihrem aktuellen Arbeitsblatt zu ersetzen:
Sub BatchReplaceText()
Dim ws As Worksheet
Set ws = ActiveSheet
' Definieren, was gesucht und was ersetzt werden soll
ws.Cells.Replace What:="AlterText", Replacement:="NeuerText", _
LookAt:=xlPart, SearchOrder:=xlByRows, MatchCase:=False
MsgBox "Ersetzung abgeschlossen!", vbInformation
End Sub
So führen Sie dieses Makro aus (Schritt für Schritt):
-
Editor öffnen: Drücken Sie Alt + F11, um das Fenster Visual Basic for Applications zu öffnen.
-
Modul einfügen: Gehen Sie zu Einfügen > Modul, um einen leeren Arbeitsbereich zu erstellen.
-
Code einfügen: Kopieren Sie das obige Skript und fügen Sie es in das Modul ein. Ersetzen Sie "AlterText" und "NeuerText" durch Ihre tatsächlichen Daten.
-
Makro ausführen: Drücken Sie F5 oder kehren Sie zu Excel zurück und drücken Sie Alt + F8, wählen Sie BatchReplaceText und klicken Sie auf Ausführen.
Profi-Tipps:
- Präzisionskontrolle: Im obigen Code ermöglicht LookAt:=xlPart dem Makro, Text zu ersetzen, auch wenn er nur ein Teil des Zellinhalts ist (z. B. Ändern von "App" in "Application" innerhalb von "App Store"). Wenn Sie nur Zellen ersetzen müssen, die exakt mit Ihrem Text übereinstimmen, ändern Sie diesen Parameter auf LookAt:=xlWhole.
- Zuerst sichern: Im Gegensatz zu Formeln können VBA-Aktionen nicht rückgängig gemacht werden (Strg + Z). Speichern Sie immer eine Sicherungskopie Ihrer Datei, bevor Sie ein Makro ausführen.
- Alle Blätter durchlaufen: Sie können den Code ändern, um Each ws In ThisWorkbook.Worksheets zu durchlaufen, um eine globale Ersetzung durchzuführen.
- Schlüsselwortvariablen: Für mehr Flexibilität können Sie InputBox verwenden, damit Benutzer den zu ersetzenden Text eingeben können, wenn das Makro ausgeführt wird.
✅ Vorteile: Hochgradig effizient für große Datensätze; automatisiert repetitive Aufgaben.
⚠️ Einschränkungen: Erfordert, dass die Arbeitsmappe als Excel-Arbeitsmappe mit Makros (.xlsm) gespeichert wird; kann nicht rückgängig gemacht werden.
Methode 5 – Text stapelweise über mehrere Excel-Dateien mit Python ersetzen
Für das ultimative Automatisierungsniveau ist die Verwendung von Python mit der Spire.XLS-Bibliothek der beste Weg, um Text stapelweise über mehrere Excel-Dateien zu ersetzen, ohne sie überhaupt öffnen zu müssen. Dies ist ein Game-Changer für Fachleute, die Hunderte von Berichten verwalten und die Dokumentenformatierung und -struktur beibehalten müssen.
Warum Spire.XLS für Python verwenden?
- Formatbeibehaltung: Im Gegensatz zu anderen Bibliotheken behält Spire.XLS Ihre Schriftarten, Farben und Layouts bei, während Text ersetzt wird.
- Skalierbarkeit: Verarbeiten Sie Tausende von Arbeitsmappen in Sekunden – ideal für unternehmensweite Rebranding- oder Datenaktualisierungen.
- Formelunterstützung: Ermöglicht das Einfügen verschiedener Excel-Formeln, wodurch es einfach ist, komplexe Berechnungen durchzuführen, auch ohne Excel zu öffnen.
- Kein Excel erforderlich: Funktioniert unabhängig von Microsoft Office, was es perfekt für automatisierte Serverumgebungen macht.
Python-Code: Stapelweise Ersetzung mit Spire.XLS
Dieses Skript durchläuft einen gesamten Ordner, durchsucht jedes Arbeitsblatt und ersetzt bestimmte Begriffe:
from spire.xls import *
import glob
# Pfad zu Ihrem Ordner mit Excel-Dateien
files = glob.glob("C:/Ihr_Ordner/*.xlsx")
for file in files:
# Arbeitsmappe laden
workbook = Workbook()
workbook.LoadFromFile(file)
# Alle Arbeitsblätter durchlaufen, um Text zu ersetzen
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Alle Instanzen des alten Textes finden
found_ranges = sheet.FindAll("AlterText", FindType.Text, ExcelFindOptions.MatchEntireCellContent)
if found_ranges:
for cell_range in found_ranges:
# Ersetzungstext anwenden
cell_range.Text = "NeuerText"
# Aktualisierte Arbeitsmappe speichern
workbook.SaveToFile(file, ExcelVersion.Version2016)
workbook.Dispose()
print("Stapelweise Textersetzung erfolgreich abgeschlossen!")
Schritt-für-Schritt-Implementierung:
- Umgebung einrichten: Installieren Sie die Bibliothek über das Terminal:
pip install Spire.Xls - Skript vorbereiten: Fügen Sie den Code in einen Editor wie VS Code oder PyCharm ein.
- Parameter konfigurieren: Aktualisieren Sie den Ordnerpfad und ersetzen Sie "AlterText" und "NeuerText" durch Ihre tatsächlichen Daten.
- Ausführen & Überprüfen: Drücken Sie F5, um das Skript auszuführen. Überprüfen Sie die Ausgabedateien, um sicherzustellen, dass die Ersetzungsergebnisse korrekt sind.
Profi-Tipps:
- Teilweiser Textersetzung: Wenn eine Zelle eine lange Zeichenfolge enthält (z. B. "Bestellung: 1001") und Sie nur die Zahl ändern möchten, verwenden Sie
cell_range.TextPartReplace("1001", "2002"). Dies behält den umgebenden Text intakt. - Groß-/Kleinschreibung: Der Parameter ExcelFindOptions in der Methode FindAll ermöglicht es Ihnen, die Groß-/Kleinschreibung oder die genaue Wortübereinstimmung für höhere Präzision zu aktivieren.
- Bereichsspezifische Suche: Wenn Sie wissen, dass die Zieldaten nur in einem bestimmten Bereich liegen, rufen Sie FindAll für einen XlsRange anstelle des gesamten Blatts auf:
sheet.Range["A1:C10"].FindAll(). - Regex & Muster: Sie können dies mit dem Python re-Modul für komplexe Mustererkennung kombinieren, bevor Sie die Zeichenfolge an die Ersetzungsschleife übergeben.
✅ Vorteile: Unübertroffene Geschwindigkeit für Aufgaben mit hohem Volumen; verarbeitet mehrere Dateien; behält alle ursprünglichen Excel-Formatierungen bei.
⚠️ Einschränkungen: Erfordert eine Python-Umgebungseinrichtung und grundlegende Programmierkenntnisse.
Fazit: Welche Methode sollten Sie wählen?
Die Wahl der besten Methode zum Ersetzen von Text in Excel hängt vom Umfang Ihrer Daten und Ihrem Komfort mit Automatisierung ab:
- Schnelle & einfache Bearbeitungen: Verwenden Sie das integrierte Werkzeug Suchen & Ersetzen.
- Positionsbasierte Präzision: Verwenden Sie die REPLACE-Funktion für strukturierte Daten (z. B. ID-Codes).
- Inhaltsbasierte Logik: Verwenden Sie die SUBSTITUTE-Funktion zur Korrektur spezifischer Begriffe.
- Automatisierung der Arbeitsmappe: Verwenden Sie VBA-Makros, um repetitive Aufgaben über mehrere Blätter hinweg zu bewältigen.
- Professionelle Stapelverarbeitung: Verwenden Sie Python, um Hunderte von Dateien mit beibehaltener Formatierung zu verwalten.
Durch die Auswahl des richtigen Workflows können Sie Datenkonsistenz sicherstellen, Stunden manueller Arbeit sparen und menschliche Fehler eliminieren.
Häufige Probleme bei der Textersetzung beheben
Auch mit den richtigen Werkzeugen können Sie auf Hindernisse stoßen. Hier sind die häufigsten Probleme und wie Sie sie beheben können:
| Problem | Wahrscheinliche Ursache | Lösung |
|---|---|---|
| Ersetzung fand nicht statt | Der Text stimmt nicht exakt mit der Such- oder alten Textzeichenfolge überein. | Prüfen Sie auf zusätzliche Leerzeichen oder versteckte Zeichen. Verwenden Sie zuerst die Funktionen GLÄTTEN() oder BEREINIGEN(), um Daten zu bereinigen. |
| Nur ein Teil des Textes wurde ersetzt | Die Einstellungen für Suchen & Ersetzen sind zu restriktiv. | Stellen Sie im Menü Optionen sicher, dass Groß-/Kleinschreibung beachten und Gesamten Zellinhalt vergleichen für Teilersetzungen deaktiviert sind. |
| #WERT!-Fehler (ERSETZEN) | Ungültige Startposition oder Zeichenanzahl. | Stellen Sie sicher, dass start_num und num_chars positive ganze Zahlen sind und innerhalb der Länge der Zeichenfolge liegen. |
| Formelergebnisse sind nur Text | REPLACE und SUBSTITUTE geben immer Text zurück. | Wenn Sie eine Zahl benötigen, multiplizieren Sie das Ergebnis mit 1 (z. B. =WECHSELN(...)*1) oder umschließen Sie es mit WERT(). |
| VBA-Makro lässt sich nicht ausführen | Makrosicherheitseinstellungen oder geschützte Blätter. | Aktivieren Sie Makros im Trust Center und stellen Sie sicher, dass das Arbeitsblatt vor der Ausführung entschlüsselt ist. |
| Python-Skriptfehler | Falsche Dateipfade oder fehlende Abhängigkeiten. | Stellen Sie sicher, dass Spire.Xls installiert ist. Überprüfen Sie die Syntax Ihres Ordnerpfads (verwenden Sie / oder \\ unter Windows). |
FAQs: Daten in Excel ersetzen
F1: Kann ich Text über mehrere Blätter hinweg ersetzen, ohne VBA oder Python zu verwenden?
Ja. Klicken Sie im Dialogfeld Suchen & Ersetzen auf Optionen und ändern Sie das Dropdown-Menü Innerhalb von "Blatt" in "Arbeitsmappe". Dadurch können Sie die gesamte Datei auf einmal aktualisieren.
F2: Wie ersetze ich Text unter Beibehaltung der Zellformatierung?
Standardformeln (SUBSTITUTE) erstellen neuen Text in einer neuen Zelle. Um die Formatierung in der ursprünglichen Zelle beizubehalten, verwenden Sie das manuelle Werkzeug Suchen & Ersetzen oder eine professionelle Bibliothek wie Spire.XLS für Python, die darauf ausgelegt ist, Inhalte zu ändern, ohne Stile zu entfernen.
F3: Kann ich Text basierend auf einem bestimmten Muster ersetzen (z. B. beliebige 3 Ziffern)?
Ja, aber Sie benötigen Platzhalter (* oder ?) im Werkzeug Suchen & Ersetzen oder Reguläre Ausdrücke (Regex) in einem Python-Skript für komplexere Muster.
F4: Was ist, wenn sich der Zieltext in jeder Zelle an einer anderen Position befindet?
Verwenden Sie eine dynamische Formel, die REPLACE mit FIND kombiniert:
=WENNFEHLER(ERSETZEN(A2; FINDEN("alt"; A2); LÄNGE("alt"); "neu"); A2)
Dies findet den "alten" Text, unabhängig davon, wo er beginnt, und ersetzt ihn durch "neu".
F5: Wie kann ich Ersetzungen für Hunderte von separaten Dateien automatisieren?
Die effizienteste Methode ist die Verwendung von Python. Durch die Nutzung von glob zum Auffinden von Dateien und Spire.XLS zur Verarbeitung können Sie Tausende von Arbeitsmappen in Sekunden aktualisieren, ohne Excel öffnen zu müssen.
Siehe auch
Как заменить текст в Excel: 5 быстрых способов (от ручных до автоматизированных)
Содержание
- Метод 1 - Ручная замена текста с помощью функции "Найти и заменить" в Excel
- Метод 2 - Замена текста по позиции с помощью функции REPLACE в Excel
- Метод 3 - Замена текста по содержимому с помощью функции SUBSTITUTE в Excel
- Метод 4 - Автоматизация замены текста в Excel с помощью VBA
- Метод 5 - Пакетная замена текста в нескольких файлах Excel с помощью Python
При работе с большими рабочими книгами Excel несогласованные или устаревшие данные могут быстро помешать вашей отчетности и принятию решений. Ручное сканирование тысяч ячеек для исправления опечаток не только отнимает много времени, но и подвержено дорогостоящим человеческим ошибкам. Освоение способов замены текста в Excel является критически важным навыком для любого специалиста по данным.
В этом подробном руководстве мы рассмотрим 5 практических методов замены текста в Excel - от встроенного инструмента "Найти и заменить" и формул рабочего листа до продвинутой автоматизации VBA и Python. Независимо от того, нужно ли вам обновить одну ячейку или пакетно обработать сотни рабочих книг, наши пошаговые инструкции помогут вам оптимизировать рабочий процесс и обеспечить целостность данных.
Обзор методов
- Метод 1 - Ручная замена текста с помощью функции "Найти и заменить" в Excel
- Метод 2 - Замена текста по позиции с помощью функции REPLACE в Excel
- Метод 3 - Замена текста по содержимому с помощью функции SUBSTITUTE в Excel
- Метод 4 - Автоматизация замены текста в Excel с помощью VBA
- Метод 5 - Пакетная замена текста в нескольких файлах Excel с помощью Python
Понимание замены текста в Excel
Замена текста в Excel - это не просто косметическое изменение, она может:
- Исправлять ошибки - исправлять опечатки или устаревшие коды.
- Стандартизировать форматы - унифицировать коды продуктов, адреса электронной почты или даты.
- Улучшать анализ данных - обеспечивать согласованность перед выполнением расчетов, фильтрацией или сводными таблицами.
- Экономить время при выполнении повторяющихся задач - особенно при работе с большими наборами данных или несколькими файлами.
Ниже мы рассмотрим 5 практических способов замены данных в Excel.
Метод 1 - Ручная замена текста с помощью функции "Найти и заменить" в Excel
Встроенный инструмент Excel "Найти и заменить" является наиболее эффективным ручным методом для замены текста в Excel в пределах одного листа или всей рабочей книги. Он идеально подходит для быстрых, разовых обновлений, когда формулы или автоматизация не требуются.
Как получить доступ к инструменту "Найти и заменить":
- Сочетание клавиш: Нажмите Ctrl + H (Windows) или Command + Shift + H (Mac).
- Путь в меню: Перейдите на вкладку Главная > группа Редактирование > Найти и выделить > Заменить.
Пошаговые инструкции:
-
Откройте рабочую книгу: Выберите лист, на котором вам нужно выполнить замену текста.
-
Получите доступ к инструменту: Используйте сочетание клавиш или путь в меню, чтобы вызвать окно "Найти и заменить".
-
Введите данные: В поле Найти введите конкретный текст или числа, которые вы хотите изменить. В поле Заменить на введите новое содержимое.
-
Выполните замену: Нажмите Заменить, чтобы обновить текущее выделение и перейти к следующему экземпляру, или Заменить все, чтобы мгновенно обновить все экземпляры на листе.
Советы:
Нажмите кнопку Параметры >>, чтобы разблокировать расширенные элементы управления:
- Область поиска: Измените настройку В пределах с Лист на Рабочая книга, чтобы заменить текст во всех вкладках одновременно.
- Сопоставление с шаблоном: Используйте подстановочные знаки, такие как * (несколько символов) или ? (один символ), для гибкого поиска (например, S*t соответствует как "Smart", так и "Street").
- Контроль точности: Включите Учитывать регистр, чтобы заменять только точные совпадения, или Ячейка целиком, чтобы случайно не заменять части слов.
✅ Плюсы: Быстро, интуитивно понятно и обрабатывает изменения форматирования.
⚠️ Ограничения: Ручной и повторяющийся; не подходит для пакетной обработки сотен отдельных файлов.
Вам также может быть интересно: 5 способов переноса текста в Excel.
Метод 2 - Замена текста по позиции с помощью функции REPLACE в Excel
Когда вам нужно заменить текст в Excel на основе позиции символа, а не самого содержимого, функция REPLACE является лучшим инструментом. Эта формула идеально подходит для очистки структурированных данных, таких как номера телефонов, серийные коды или стандартизированные идентификаторы продуктов.
Синтаксис функции REPLACE
=REPLACE(old_text, start_num, num_chars, new_text)
- old_text: Исходный текст (или ссылка на ячейку, содержащую текст).
- start_num: Позиция (индекс) первого символа, который вы хотите заменить.
- num_chars: Общее количество символов для удаления.
- new_text: Новый текст, который вы хотите вставить.
Практический пример: Маскирование конфиденциальных данных
Если у вас есть серийный код "123-ABC" в ячейке A1, и вы хотите заменить первые три цифры на "XXX":
- Формула:
=REPLACE(A1, 1, 3, "XXX") - Результат: "XXX-ABC"
Пошаговая реализация:
-
Выберите ячейку: Щелкните ячейку, где вы хотите видеть обновленный текст (например, B2).
-
Введите формулу: Введите =REPLACE( и выберите исходную ячейку (например, A2).
-
Определите диапазон: Введите start_num (где начинается замена) и num_chars (сколько символов заменить).
-
Добавьте новый текст: Введите текст замены в кавычках (например, "XXX").
-
Примените к списку: Нажмите Enter и используйте маркер автозаполнения (маленький зеленый квадрат), чтобы перетащить формулу вниз к другим строкам.
Советы:
- Комбинирование с другими функциями: Используйте LEN() или FIND() в качестве start_num для динамической обработки строк разной длины.
- Обработка числовых результатов: Функция REPLACE всегда возвращает текст. Чтобы преобразовать его обратно в число для расчетов, добавьте *1 в конец формулы (например,
=REPLACE(...) * 1). - Вложенность: Вы можете вложить несколько функций REPLACE в одну формулу, если вам нужно обновить две или более разные позиции одновременно.
✅ Плюсы: Идеально подходит для структурированных данных; обеспечивает точный контроль над заменой символов.
⚠️ Ограничения: Менее эффективен для данных, где целевой текст появляется в разных позициях в каждой ячейке.
Метод 3 - Замена текста по содержимому с помощью функции SUBSTITUTE в Excel
Функция SUBSTITUTE является основным инструментом, когда вам нужно заменить текст в Excel на основе конкретного содержимого, а не его позиции. Это идеально подходит для исправления повторяющихся опечаток, обновления ссылок на годы или расшифровки аббревиатур в большом наборе данных.
Синтаксис функции SUBSTITUTE
=SUBSTITUTE(text, old_text, new_text, [instance_num])
- text: Исходный текст (или ссылка на ячейку, содержащую текст).
- old_text: Конкретный символ или слово, которое вы хотите изменить.
- new_text: Текст, который вы хотите вставить вместо него.
- [instance_num]: (Необязательно) Указывает, какое вхождение заменить. Если опущено, обновляются все вхождения.
Практический пример: Пакетное обновление годов
Если вам нужно обновить "Отчет 2023" на "Отчет 2024" в ячейке A1:
- Формула:
=SUBSTITUTE(A1, "2023", "2024") - Результат: "Отчет 2024"
Расширенный вариант: Вложенный SUBSTITUTE для нескольких обновлений
Вы можете вложить несколько функций SUBSTITUTE для одновременной замены нескольких разных терминов в одной ячейке. Это идеально подходит для преобразования сокращенных кодов в полные описания:
- Формула:
=SUBSTITUTE(SUBSTITUTE(A2, "PR", "Project"), "ML", "Milestone") - Результат: Преобразует "PR-01, ML-05" в "Project-01, Milestone-05".
Пошаговая реализация:
-
Определите цель: Щелкните ячейку, где вы хотите видеть очищенные данные.
-
Примените формулу: Введите =SUBSTITUTE( и выберите исходную ячейку.
-
Определите текстовые строки: Введите old_text и new_text в двойных кавычках (например, "старый", "новый").
-
Необязательное вхождение: Если вы хотите заменить только *второе* вхождение слова, добавьте , 2 в конце перед закрытием скобок.
-
Перетащите для применения: Нажмите Enter и используйте маркер автозаполнения, чтобы применить формулу к остальной части столбца.
Советы:
- Учет регистра: SUBSTITUTE чувствителен к регистру. Чтобы выполнить поиск без учета регистра, заключите ссылку на ячейку в функцию UPPER или LOWER.
- Удаление текста: Чтобы полностью удалить определенное слово, используйте пустую строку "" в качестве new_text.
- Неразрушающий: В отличие от "Найти и заменить", использование формул сохраняет исходные данные в исходном столбце, обеспечивая лучший аудит.
✅ Плюсы: Отлично подходит для замены на основе содержимого; очень гибкий благодаря вложенности.
⚠️ Ограничения: Не обрабатывает изменения на основе позиции; требует вспомогательного столбца для хранения результатов.
Метод 4 - Автоматизация замены текста в Excel с помощью VBA
Когда вам нужно заменить текст в Excel на нескольких листах или выполнять повторяющиеся, крупномасштабные задачи очистки, макрос VBA является наиболее мощным решением. Этот метод позволяет автоматизировать процесс одним щелчком мыши, избавляя вас от ручных ошибок.
Зачем использовать VBA для замены?
- Эффективность: Мгновенно обновляйте сотни ячеек.
- Согласованность: Обеспечьте применение одной и той же логики замены каждый раз.
- Поддержка нескольких листов: В отличие от формул, VBA может сканировать каждую вкладку в вашей рабочей книге.
Пример макроса VBA для замены данных на активном листе Excel
Скопируйте и вставьте следующий код в редактор VBA, чтобы заменить определенные термины на текущем листе:
Sub BatchReplaceText()
Dim ws As Worksheet
Set ws = ActiveSheet
' Определите, что искать и чем заменять
ws.Cells.Replace What:="OldText", Replacement:="NewText", _
LookAt:=xlPart, SearchOrder:=xlByRows, MatchCase:=False
MsgBox "Замена завершена!", vbInformation
End Sub
Как запустить этот макрос (пошагово):
-
Откройте редактор: Нажмите Alt + F11, чтобы открыть окно Visual Basic for Applications.
-
Вставьте модуль: Перейдите в Insert > Module, чтобы создать пустое рабочее пространство.
-
Вставьте код: Скопируйте приведенный выше скрипт и вставьте его в модуль. Замените "OldText" и "NewText" на ваши фактические данные.
-
Выполните макрос: Нажмите F5 или вернитесь в Excel и нажмите Alt + F8, выберите BatchReplaceText и нажмите Выполнить.
Советы:
- Контроль точности: В приведенном выше коде LookAt:=xlPart позволяет макросу заменять текст, даже если он является лишь частью содержимого ячейки (например, изменение "App" на "Application" в "App Store"). Если вам нужно заменить только ячейки, точно соответствующие вашему тексту, измените этот параметр на LookAt:=xlWhole.
- Сначала резервное копирование: В отличие от формул, действия VBA нельзя отменить (Ctrl+Z). Всегда сохраняйте резервную копию файла перед запуском макроса.
- Цикл по всем листам: Вы можете изменить код, чтобы он проходил по каждому ws в ThisWorkbook.Worksheets, чтобы выполнить глобальную замену.
- Переменные ключевых слов: Для большей гибкости используйте InputBox, чтобы позволить пользователям вводить текст, который они хотят заменить, каждый раз, когда макрос запускается.
✅ Плюсы: Высокая эффективность для больших наборов данных; автоматизирует повторяющиеся задачи.
⚠️ Ограничения: Требует сохранения рабочей книги как "Книга Excel с поддержкой макросов" (.xlsm); не может быть отменено.
Метод 5 - Пакетная замена текста в нескольких файлах Excel с помощью Python
Для максимального уровня автоматизации использование Python с библиотекой Spire.XLS является лучшим способом пакетной замены текста в нескольких файлах Excel, даже не открывая их. Это меняет правила игры для профессионалов, управляющих сотнями отчетов, которым необходимо сохранять форматирование и структуру документов.
Зачем использовать Spire.XLS для Python?
- Сохранение форматирования: В отличие от других библиотек, Spire.XLS сохраняет шрифты, цвета и макеты при замене текста.
- Масштабируемость: Обрабатывайте тысячи рабочих книг за секунды - идеально подходит для ребрендинга всей компании или обновления данных.
- Поддержка формул: Позволяет вставлять различные формулы Excel, что упрощает выполнение сложных расчетов, даже без открытия Excel.
- Excel не требуется: Работает независимо от Microsoft Office, что делает его идеальным для автоматизированных серверных сред.
Код Python: Пакетная замена с использованием Spire.XLS
Этот скрипт проходит по всей папке, ищет на каждом листе и заменяет определенные термины:
from spire.xls import *
import glob
# Путь к вашей папке с файлами Excel
files = glob.glob("C:/your_folder/*.xlsx")
for file in files:
# Загрузка рабочей книги
workbook = Workbook()
workbook.LoadFromFile(file)
# Итерация по всем листам для замены текста
for i in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[i]
# Поиск всех вхождений старого текста
found_ranges = sheet.FindAll("OldText", FindType.Text, ExcelFindOptions.MatchEntireCellContent)
if found_ranges:
for cell_range in found_ranges:
# Применение текста замены
cell_range.Text = "NewText"
# Сохранение обновленной рабочей книги
workbook.SaveToFile(file, ExcelVersion.Version2016)
workbook.Dispose()
print("Пакетная замена текста успешно завершена!")
Пошаговая реализация:
- Настройте среду: Установите библиотеку через терминал:
pip install Spire.Xls - Подготовьте скрипт: Вставьте код в редактор, такой как VS Code или PyCharm.
- Настройте параметры: Обновите путь к папке и замените "OldText" и "NewText" на ваши фактические данные.
- Запустите и проверьте: Нажмите F5, чтобы выполнить скрипт. Проверьте выходные файлы, чтобы убедиться в правильности результатов замены.
Советы:
- Частичная замена текста: Если ячейка содержит длинную строку (например, "Заказ: 1001") и вы хотите изменить только число, используйте
cell_range.TextPartReplace("1001", "2002"). Это сохранит окружающий текст без изменений. - Учет регистра: Параметр ExcelFindOptions в методе FindAll позволяет переключать чувствительность к регистру или поиск по целым словам для большей точности.
- Поиск в диапазоне: Если вы знаете, что целевые данные находятся только в определенной области, вызовите FindAll для XlsRange вместо всего листа:
sheet.Range["A1:C10"].FindAll(). - Регулярные выражения и шаблоны: Вы можете комбинировать это с модулем re Python для сложного сопоставления с шаблоном перед передачей строки в цикл замены.
✅ Плюсы: Непревзойденная скорость для задач с большим объемом; обрабатывает несколько файлов; сохраняет все исходное форматирование Excel.
⚠️ Ограничения: Требует настройки среды Python и базовых знаний программирования.
Заключение: Какой метод выбрать?
Выбор лучшего способа замены текста в Excel зависит от масштаба ваших данных и вашего уровня комфорта с автоматизацией:
- Быстрые и простые правки: Используйте встроенный инструмент "Найти и заменить".
- Точность на основе позиции: Используйте функцию REPLACE для структурированных данных (например, идентификационных кодов).
- Логика на основе содержимого: Используйте функцию SUBSTITUTE для исправления конкретных терминов.
- Автоматизация рабочей книги: Используйте макросы VBA для выполнения повторяющихся задач на нескольких листах.
- Профессиональная пакетная обработка: Используйте Python для управления сотнями файлов с сохранением форматирования.
Выбрав правильный рабочий процесс, вы можете обеспечить согласованность данных, сэкономить часы ручного труда и исключить человеческие ошибки.
Устранение распространенных проблем с заменой текста
Даже с правильными инструментами вы можете столкнуться с трудностями. Вот наиболее распространенные проблемы и способы их решения:
| Проблема | Вероятная причина | Решение |
|---|---|---|
| Замена не произошла | Текст не точно соответствует строке поиска или old_text. | Проверьте наличие лишних пробелов или скрытых символов. Используйте функции TRIM() или CLEAN() для предварительной очистки данных. |
| Заменена только часть текста | Настройки "Найти и заменить" слишком строгие. | В меню "Параметры" убедитесь, что Учитывать регистр и Ячейка целиком сняты для частичных замен. |
| Ошибка #ЗНАЧ! (REPLACE) | Недопустимая начальная позиция или количество символов. | Убедитесь, что start_num и num_chars являются положительными целыми числами и находятся в пределах длины строки. |
| Результаты формул только в текстовом формате | REPLACE и SUBSTITUTE всегда возвращают текст. | Если вам нужно число, умножьте результат на 1 (например, =SUBSTITUTE(...)*1) или заключите его в VALUE(). |
| Макрос VBA не запускается | Настройки безопасности макросов или защищенные листы. | Включите макросы в Центре безопасности и убедитесь, что лист снят с защиты перед выполнением. |
| Ошибки в скрипте Python | Неправильные пути к файлам или отсутствующие зависимости. | Убедитесь, что Spire.Xls установлен. Дважды проверьте синтаксис пути к папке (используйте / или \\ в Windows). |
Часто задаваемые вопросы: Замена данных в Excel
В1: Могу ли я заменить текст в нескольких листах без VBA или Python?
Да. В диалоговом окне "Найти и заменить" нажмите "Параметры" и измените раскрывающийся список "В пределах" с "Лист" на "Рабочая книга". Это позволит вам обновить весь файл одновременно.
В2: Как заменить текст, сохраняя форматирование ячеек?
Стандартные формулы (SUBSTITUTE) создают новый текст в новой ячейке. Чтобы сохранить форматирование в исходной ячейке, используйте ручной инструмент "Найти и заменить" или профессиональную библиотеку, такую как Spire.XLS для Python, которая разработана для изменения содержимого без удаления стилей.
В3: Могу ли я заменить текст на основе определенного шаблона (например, любых 3 цифр)?
Да, но вам понадобятся подстановочные знаки (* или ?) в инструменте "Найти и заменить" или регулярные выражения (Regex) в скрипте Python для более сложных шаблонов.
В4: Что делать, если целевой текст находится в разных позициях в каждой ячейке?
Используйте динамическую формулу, комбинирующую REPLACE с FIND:
=IFERROR(REPLACE(A2, FIND("old", A2), LEN("old"), "new"), A2)
Это найдет текст "old" независимо от того, где он начинается, и заменит его на "new".
В5: Как автоматизировать замены для сотен отдельных файлов?
Наиболее эффективным методом является использование Python. Используя glob для поиска файлов и Spire.XLS для их обработки, вы можете обновить тысячи рабочих книг за секунды, даже не открывая Excel.
См. также
Remover a proteção de arquivos do Word: 5 maneiras fáceis
Sumário
- Por que remover a proteção de um arquivo Word?
- Antes de começar: Tipos de proteção do Word
- Método 1: Remover proteção usando o Microsoft Word
- Método 2: Remover restrições básicas de edição no Word
- Método 3: Remover proteção usando o Google Docs
- Método 4: Remover proteção usando macros VBA
- Método 5: Automatizar a remoção usando Python (Spire.Doc)
- Qual método escolher?
- Conclusão
- Perguntas frequentes

Documentos Word protegidos por senha são úteis para manter informações confidenciais seguras – mas também podem se tornar um incômodo quando você precisa editar, compartilhar ou automatizar documentos. Isso é especialmente comum ao trabalhar com arquivos recebidos de outras pessoas ou documentos mais antigos com configurações esquecidas.
Seja você conhecendo a senha ou lidando com restrições de edição, este guia abrange 5 maneiras eficazes de remover a proteção de arquivos Word, incluindo ferramentas gratuitas, recursos integrados e um método de automação Python usando Spire.Doc.
Visão geral dos métodos abordados:
- Método 1: Remover proteção usando o Microsoft Word
- Método 2: Remover restrições básicas de edição no Word
- Método 3: Remover proteção usando o Google Docs
- Método 4: Remover proteção usando macros VBA
- Método 5: Automatizar a remoção usando Python (Spire.Doc)
Por que remover a proteção de um arquivo Word?
Aqui estão algumas razões comuns pelas quais os usuários desejam remover a proteção:
- Você já conhece a senha e deseja acesso mais rápido.
- Você precisa editar um documento restrito.
- Você deseja remover limitações desnecessárias antes de compartilhar.
- Você precisa processar arquivos em lote (automação).
O método correto depende do tipo de proteção aplicado ao documento.
Antes de começar: Tipos de proteção do Word
Entender essas diferenças é crucial, pois nem todos os métodos funcionam para todos os casos.
1. Senha de Abertura (Criptografia)
Criptografia forte necessária para abrir o arquivo; não pode ser contornada sem a senha correta.
2. Restrições de Edição (Sem Senha)
Os arquivos abrem normalmente com acesso de edição limitado; nenhuma senha de proteção é necessária para desbloquear.
3. Restrições de Edição com Senha de Proteção
Os arquivos abrem livremente, mas a edição é bloqueada. Uma senha de proteção é necessária para remoção oficial, e essa proteção fraca pode ser contornada pela maioria das ferramentas.
Observação: Este tipo de proteção é mais fraco que a criptografia e pode ser removido por algumas ferramentas sem a necessidade da senha de proteção.
Método 1: Remover proteção usando o Microsoft Word
Escopo Aplicável: Documentos com senhas de abertura conhecidas ou senhas de proteção conhecidas; todas as versões mainstream do Word (2016/2019/2021/365)
Melhor Para: Iniciantes, cenários de escritório formais, arquivos que exigem 100% de integridade de formato e conteúdo
Esta é a solução oficial mais segura fornecida pela Microsoft. Ela modifica a criptografia do documento e as configurações de restrição nativamente, com risco zero de corrupção de arquivo, perda de formatação ou distorção de conteúdo. Ela suporta o cancelamento tanto da criptografia de abertura quanto das restrições de edição, mas você deve inserir a senha correspondente correta para concluir a operação.
Instruções Passo a Passo
- Clique duas vezes para abrir o arquivo Word protegido e insira a senha de abertura necessária, se solicitado.
- Navegue até Arquivo > Informações > Proteger Documento.
- Selecione Criptografar com Senha.
- Exclua todos os caracteres na caixa de entrada de senha e deixe-a em branco.
- Clique em OK e pressione Ctrl+S para salvar as alterações permanentemente.
- Para restrições de edição: Vá para Revisão > Restringir Edição, insira a senha de proteção e pare a proteção.
Método 2: Remover restrições básicas de edição no Word
Escopo Aplicável: Documentos com limites de edição, mas sem senha de proteção definida; sem criptografia de abertura completa
Melhor Para: Documentos diários levemente restritos, desbloqueio rápido com um clique
Esta solução nativa do Word visa travas de edição de baixo nível sem senha de proteção. Você pode desativar todas as restrições em segundos sem ferramentas externas ou operações técnicas. Ela funciona apenas para limites de permissão simples e falhará se uma senha de proteção for configurada.
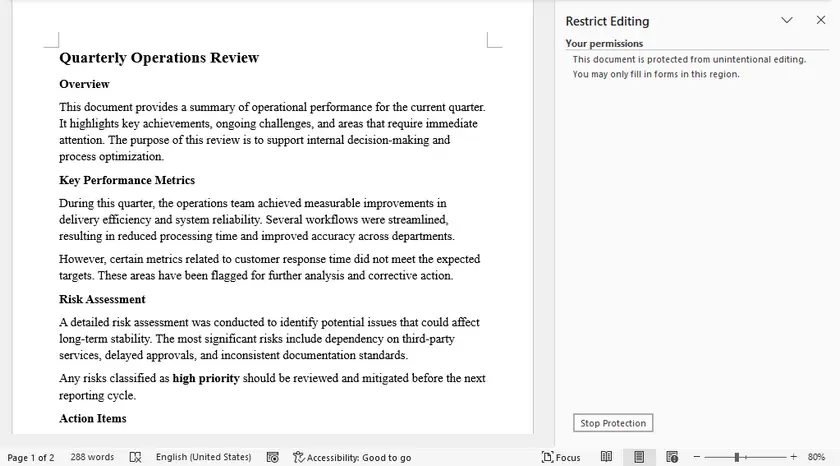
Instruções Passo a Passo
- Abra o documento Word restrito normalmente.
- Mude para a guia Revisão na faixa de opções superior.
- Clique em Restringir Edição na barra lateral direita.
- Clique diretamente em Parar Proteção; nenhuma entrada de senha é necessária.
- Salve o arquivo para manter o acesso de edição irrestrito.
Método 3: Remover proteção usando o Google Docs
Escopo Aplicável: Arquivos Word não criptografados ou arquivos com senha de abertura conhecida; documentos bloqueados por senha de proteção
Melhor Para: Usuários sem direitos de administrador local do Word, desbloqueio gratuito entre dispositivos, cenários de senha de proteção desconhecida
O Google Docs remove automaticamente as regras de restrição de edição personalizadas do Word durante a conversão de formato. É o truque gratuito mais popular para contornar senhas de proteção desconhecidas. Desde que você consiga abrir o arquivo (com uma senha de abertura, se necessário), todos os bloqueios de edição serão removidos após o re-download.
Instruções Passo a Passo
- Faça login no Google Drive e carregue seu arquivo Word protegido (.docx/.doc).
- Clique com o botão direito no arquivo carregado e selecione Abrir com > Google Docs.
- Insira a senha de abertura se o documento estiver criptografado.
- Assim que carregado, todas as restrições de edição e limites de senha de proteção são automaticamente removidos.
- Navegue até Arquivo > Fazer download > Microsoft Word (.docx).
- O novo arquivo baixado está totalmente desbloqueado e editável.
Método 4: Remover proteção usando macros VBA
Escopo Aplicável: Automação do Microsoft Word apenas para Windows, requer senhas corretas (não contorna a proteção)
Melhor Para: Usuários intermediários, ambientes de escritório offline, demandas frequentes de desbloqueio
Macros VBA são executadas localmente no Microsoft Word e podem ser usadas para remover programaticamente a proteção de documentos. Ao contrário de algumas ferramentas online, este método não contorna senhas — você deve fornecer a senha de abertura correta para acessar o documento e a senha de edição (permissão) correta para remover as restrições. Uma vez que o documento esteja acessível, a macro pode automatizar o processo de desativar a proteção e salvar uma cópia desprotegida. Isso o torna uma solução offline útil para processamento em lote ou tarefas repetitivas, mas não pode quebrar ou contornar qualquer criptografia protegida por senha.
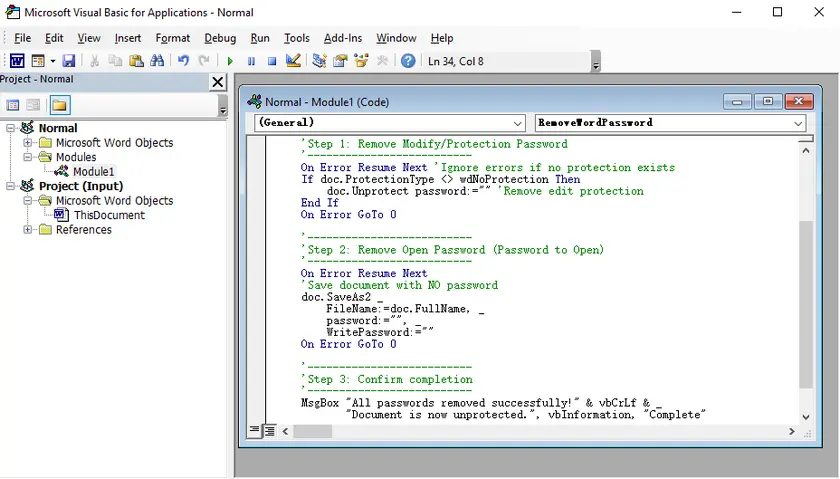
Instruções Passo a Passo (Processamento em Lote)
- Prepare uma pasta contendo todos os documentos Word que você deseja desbloquear. Certifique-se de conhecer a senha de abertura (se houver) e a senha de restrição de edição usadas nesses arquivos.
- Abra o Microsoft Word (não é necessário abrir um documento específico).
- Pressione Alt + F11 para iniciar o Editor VBA.
- No menu superior, clique em Inserir > Módulo para criar um novo módulo.
- Cole o código VBA em lote na janela do módulo.
- Atualize as seguintes variáveis no código:
- folderPath → o caminho para sua pasta de destino
- openPwd → a senha de abertura do documento (deixe em branco se não houver)
- editPwd → a senha de restrição de edição
- Pressione F5 (ou clique em Executar) para executar a macro.
- A macro processará todos os arquivos .docx na pasta e salvará cópias desbloqueadas (por exemplo, unlocked_filename.docx) no mesmo diretório.
Código VBA:
Sub BatchRemoveProtection()
Dim folderPath As String
Dim fileName As String
Dim doc As Document
'==========================
' Entradas do Usuário
'==========================
folderPath = "C:\Docs\" ' <-- atualizar caminho da pasta
Dim openPwd As String
openPwd = "" ' <-- definir se os arquivos têm senha de abertura
Dim editPwd As String
editPwd = "sua_senha_de_edicao" ' <-- definir senha de restrição de edição
'==========================
' Loop através de todos os arquivos DOCX
'==========================
fileName = Dir(folderPath & "*.docx")
While fileName <> ""
' Abrir documento (com senha de abertura opcional)
Set doc = Documents.Open( _
FileName:=folderPath & fileName, _
PasswordDocument:=openPwd, _
ReadOnly:=False)
' Remover restrições de edição
If doc.ProtectionType <> wdNoProtection Then
doc.Unprotect Password:=editPwd
End If
' Remover recomendação de somente leitura
doc.ReadOnlyRecommended = False
' Salvar como novo arquivo
doc.SaveAs2 _
FileName:=folderPath & "unlocked_" & fileName, _
Password:="", _
WritePassword:=""
doc.Close SaveChanges:=False
fileName = Dir()
Wend
MsgBox "Processamento em lote concluído!"
End Sub
Método 5: Automatizar a remoção usando Python (Spire.Doc)
Escopo Aplicável: Processamento de documentos em massa, fluxos de trabalho de automação personalizados, integração de desenvolvedores; arquivos com senhas de abertura conhecidas
Melhor Para: Desenvolvedores, processamento em lote empresarial, integração de sistemas de backend, automação de fluxo de trabalho repetitivo
Combinar Python e a biblioteca Spire.Doc permite a descriptografia programática de documentos e a remoção de proteção. Este método é projetado para processamento de arquivos em massa e desenvolvimento secundário, com desempenho estável e retenção completa de formato para cenários de negócios formais.
Instruções Passo a Passo
1. Instale a Biblioteca Spire.Doc
pip install spire.doc
2. Remover Senha com Python
from spire.doc import *
from spire.doc.common import *
# Carregar o documento com senha
document = Document()
document.LoadFromFile("input.docx", FileFormat.Auto, "senha-abertura")
# Remover criptografia
document.RemoveEncryption()
# Remover a restrição de edição definindo o tipo de restrição como None
document.Protect(ProtectionType.NoProtection)
# Salvar o documento desbloqueado
document.SaveToFile("desbloqueado.docx", FileFormat.Docx)
document.Close()
Por que usar Python para esta tarefa?
- Processe dezenas de arquivos Word bloqueados em um único lote.
- Incorpore funções de desbloqueio em sistemas de escritório internos.
- Reduza operações manuais repetitivas e melhore a eficiência do trabalho.
Como uma biblioteca Word abrangente, o Spire.Doc não apenas permite remover senhas e restrições de edição, mas também fornece recursos poderosos de limpeza de documentos, como remover marcas d'água, excluir hiperlinks e modificar a estrutura do documento programaticamente.
Você pode estender ainda mais seu fluxo de trabalho integrando recursos como extração de conteúdo, controle de formatação e transformação de documentos em lote para cenários de automação mais avançados. Isso facilita a criação de pipelines de processamento de documentos de ponta a ponta sem depender do Microsoft Word.
Qual método escolher?
| Método | Caso de Uso Principal | Recurso Chave |
|---|---|---|
| Oficial Nativo do Word | Senha conhecida, uso seguro em escritório | Oficial, sem danos ao arquivo |
| Remoção de Restrição Básica | Travas de edição simples, sem senha | Desbloqueio rápido com um clique |
| Google Docs | Contornar senha de proteção desconhecida | Gratuito, sem software adicional |
| Script VBA | Desbloqueio local offline no Windows | Desbloqueio automatizado |
| Python + Spire.Doc | Automação personalizada e tarefas de desenvolvedor | Processamento automático baseado em código |
Conclusão
A proteção de documentos Word é projetada para segurança de dados, mas configurações de restrição irracionais muitas vezes dificultam a colaboração e a edição diárias.
Separamos 5 soluções de desbloqueio diferenciadas que cobrem escritório casual, contorno gratuito, script offline e automação empresarial. Sempre confirme o tipo de proteção do seu documento primeiro:
- Para criptografia de senha de abertura, tanto as ferramentas oficiais quanto as de terceiros com a senha correta funcionam;
- Para travas de edição com senha de proteção, o Google Docs e o Python podem remover as restrições de edição em muitos casos.
Escolha a solução correspondente com base no sistema do seu dispositivo, ambiente de rede e volume de arquivos para remover rapidamente a proteção do Word sem danificar o conteúdo e a formatação originais.
Perguntas frequentes
P1: Esses métodos podem quebrar um arquivo Word com uma senha de abertura desconhecida?
Não. A senha de abertura adota criptografia forte. Todos os métodos acima exigem a senha correta para abrir o arquivo. Apenas senhas de proteção de edição podem ser contornadas.
P2: O desbloqueio danificará a formatação, imagens ou tabelas do meu Word?
O Word oficial e o Python Spire.Doc garantem a retenção completa do formato. O Google Docs pode distorcer layouts complexos; o VBA tem quase nenhum impacto no conteúdo do arquivo.
P3: O VBA é seguro para documentos confidenciais da empresa?
Sim. O script VBA é executado localmente offline, sem risco de upload ou vazamento de dados, tornando-o adequado para arquivos internos confidenciais.
P4: Isso funciona para o formato .doc antigo e para o novo formato .docx?
Todos os métodos suportam o .docx mainstream; o Google Docs e o Spire.Doc também são compatíveis com arquivos .doc legados.
Veja também
- Adicionar Bordas de Página no Word (Qualquer Página): 4 Maneiras Simples
- Remover Linhas em Branco no Word Rapidamente: Manual & VBA/Python
- Mesclar Documentos Word: Preservar ou Unificar Formatação
- 5 Maneiras Fáceis de Tornar um Arquivo Word Somente Leitura
- Localizar e Substituir Texto em Documentos Word: 5 Métodos Fáceis
Word 파일 보호 해제: 5가지 쉬운 방법
암호로 보호된 Word 문서는 민감한 정보를 안전하게 보관하는 데 유용하지만, 문서를 편집, 공유 또는 자동화해야 할 때 번거로울 수 있습니다. 이는 특히 다른 사람으로부터 받은 파일이나 잊어버린 설정이 있는 오래된 문서를 다룰 때 흔히 발생합니다.
암호를 알고 있든 편집 제한을 다루고 있든, 이 가이드에서는 Word 파일 보호를 제거하는 5가지 효과적인 방법을 다룹니다. 여기에는 무료 도구, 내장 기능 및 Spire.Doc을 사용한 Python 자동화 방법이 포함됩니다.
다루는 방법 개요:
- 방법 1: Microsoft Word를 사용하여 보호 제거
- 방법 2: Word에서 기본 편집 제한 제거
- 방법 3: Google Docs를 사용하여 보호 제거
- 방법 4: VBA 매크로를 사용하여 보호 제거
- 방법 5: Python (Spire.Doc)을 사용하여 제거 자동화
Word 파일 보호 제거 이유
사용자가 보호를 제거하려는 몇 가지 일반적인 이유는 다음과 같습니다.
- 이미 암호를 알고 있어 더 빠른 액세스를 원합니다.
- 제한된 문서를 편집해야 합니다.
- 공유하기 전에 불필요한 제한을 제거하고 싶습니다.
- 파일을 대량으로 처리(자동화)해야 합니다.
적절한 방법은 문서에 적용된 보호 유형에 따라 다릅니다.
시작하기 전: Word 보호 유형
이러한 차이점을 이해하는 것이 중요합니다. 모든 방법이 모든 경우에 적용되는 것은 아니기 때문입니다.
1. 열기 암호 (암호화)
파일을 열려면 강력한 암호화가 필요합니다. 올바른 암호 없이는 우회할 수 없습니다.
2. 편집 제한 (암호 없음)
파일은 정상적으로 열리지만 편집 액세스가 제한됩니다. 잠금을 해제하기 위해 보호 암호가 필요하지 않습니다.
3. 편집 제한 및 보호 암호
파일은 자유롭게 열리지만 편집이 잠겨 있습니다. 공식적인 제거를 위해서는 보호 암호가 필요하며, 이 약한 보호는 대부분의 도구로 우회할 수 있습니다.
참고: 이 유형의 보호는 암호화보다 약하며 일부 도구에서는 보호 암호 없이 제거될 수 있습니다.
방법 1: Microsoft Word를 사용하여 보호 제거
적용 범위: 열기 암호 또는 보호 암호를 알고 있는 문서; 모든 주류 Word 버전 (2016/2019/2021/365)
최적: 초보자, 공식적인 사무 환경, 100% 형식 및 내용 무결성이 필요한 파일
이것은 Microsoft에서 제공하는 가장 안전하고 공식적인 솔루션입니다. 문서 암호화 및 제한 설정을 기본적으로 수정하므로 파일 손상, 서식 손실 또는 내용 왜곡의 위험이 전혀 없습니다. 열기 암호화 및 편집 제한 모두 취소가 가능하지만, 작업을 완료하려면 해당하는 올바른 암호를 입력해야 합니다.
단계별 지침
- 보호된 Word 파일을 두 번 클릭하여 열고, 요청 시 필요한 열기 암호를 입력합니다.
- 파일 > 정보 > 문서 보호로 이동합니다.
- 암호로 암호화를 선택합니다.
- 암호 입력란의 모든 문자를 삭제하고 비워 둡니다.
- 확인을 클릭한 다음 Ctrl+S를 눌러 변경 사항을 영구적으로 저장합니다.
- 편집 제한의 경우: 검토 > 편집 제한으로 이동하여 보호 암호를 입력하고 보호를 중지합니다.
방법 2: Word에서 기본 편집 제한 제거
적용 범위: 편집 제한이 있지만 보호 암호가 설정되지 않은 문서; 전체 열기 암호화 없음
최적: 가볍게 제한된 일상 문서, 빠른 원클릭 잠금 해제
이 Word 기본 솔루션은 보호 암호가 없는 낮은 수준의 편집 잠금을 대상으로 합니다. 외부 도구나 기술적인 작업 없이 몇 초 안에 모든 제한을 비활성화할 수 있습니다. 간단한 권한 제한에만 작동하며 보호 암호가 구성된 경우 실패합니다.
단계별 지침
- 제한된 Word 문서를 정상적으로 엽니다.
- 상단 리본 메뉴에서 검토 탭으로 전환합니다.
- 오른쪽 사이드바에서 편집 제한을 클릭합니다.
- 보호 중지를 직접 클릭합니다. 암호 입력이 필요하지 않습니다.
- 파일을 저장하여 제한 없는 편집 액세스를 유지합니다.
방법 3: Google Docs를 사용하여 보호 제거
적용 범위: 암호화되지 않은 Word 파일 또는 열기 암호를 알고 있는 파일; 보호 암호로 잠긴 문서
최적: 로컬 Word 관리자 권한이 없는 사용자, 무료 교차 장치 잠금 해제, 알 수 없는 보호 암호 시나리오
Google Docs는 형식 변환 중에 Word의 사용자 정의 편집 제한 규칙을 자동으로 제거합니다. 알 수 없는 보호 암호를 우회하는 가장 인기 있는 무료 방법입니다. 파일을 열 수 있다면(필요한 경우 열기 암호 사용), 다시 다운로드하면 모든 편집 제한이 제거됩니다.
단계별 지침
- Google Drive에 로그인하고 보호된 Word(.docx/.doc) 파일을 업로드합니다.
- 업로드된 파일을 마우스 오른쪽 버튼으로 클릭하고 다음으로 열기 > Google Docs를 선택합니다.
- 문서가 암호화된 경우 열기 암호를 입력합니다.
- 로딩되면 모든 편집 제한 및 보호 암호 제한이 자동으로 해제됩니다.
- 파일 > 다운로드 > Microsoft Word (.docx)로 이동합니다.
- 다운로드된 새 파일은 완전히 잠금 해제되어 편집 가능합니다.
방법 4: VBA 매크로를 사용하여 보호 제거
적용 범위: Windows 전용 Microsoft Word 자동화, 올바른 암호 필요 (보호 우회 불가)
최적: 중급 사용자, 오프라인 사무 환경, 빈번한 잠금 해제 요구
VBA 매크로는 Microsoft Word에서 로컬로 실행되며 프로그래밍 방식으로 문서 보호를 제거하는 데 사용할 수 있습니다. 일부 온라인 도구와 달리 이 방법은 암호를 우회하지 않습니다. 문서를 열려면 올바른 열기 암호를, 제한을 제거하려면 올바른 편집(권한) 암호를 제공해야 합니다. 문서에 액세스할 수 있게 되면 매크로는 보호를 비활성화하고 보호되지 않은 복사본을 저장하는 프로세스를 자동화할 수 있습니다. 따라서 배치 처리 또는 반복 작업에 유용한 오프라인 솔루션이지만 암호로 보호된 암호화를 깨거나 우회할 수는 없습니다.
단계별 지침 (배치 처리)
- 잠금 해제하려는 모든 Word 문서가 포함된 폴더를 준비합니다. 이러한 파일에 사용된 열기 암호(있는 경우)와 편집 제한 암호를 알고 있는지 확인하십시오.
- Microsoft Word를 엽니다 (특정 문서를 열 필요 없음).
- Alt + F11을 눌러 VBA 편집기를 실행합니다.
- 상단 메뉴에서 삽입 > 모듈을 클릭하여 새 모듈을 만듭니다.
- 배치 VBA 코드를 모듈 창에 붙여넣습니다.
- 코드에서 다음 변수를 업데이트합니다.
- folderPath → 대상 폴더 경로
- openPwd → 문서 열기 암호 (없는 경우 비워 둠)
- editPwd → 편집 제한 암호
- F5를 누르거나 실행을 클릭하여 매크로를 실행합니다.
- 매크로는 폴더의 모든 .docx 파일을 처리하고 동일한 디렉토리에 잠금 해제된 복사본(예: unlocked_filename.docx)을 저장합니다.
VBA 코드:
Sub BatchRemoveProtection()
Dim folderPath As String
Dim fileName As String
Dim doc As Document
'==========================
' 사용자 입력
'==========================
folderPath = "C:\Docs\" ' <-- 폴더 경로 업데이트
Dim openPwd As String
openPwd = "" ' <-- 파일에 열기 암호가 있는 경우 설정
Dim editPwd As String
editPwd = "your_edit_password" ' <-- 편집 제한 암호 설정
'==========================
' 모든 DOCX 파일 반복
'==========================
fileName = Dir(folderPath & "*.docx")
While fileName <> ""
' 문서 열기 (선택적 열기 암호 포함)
Set doc = Documents.Open( _
FileName:=folderPath & fileName, _
PasswordDocument:=openPwd, _
ReadOnly:=False)
' 편집 제한 제거
If doc.ProtectionType <> wdNoProtection Then
doc.Unprotect Password:=editPwd
End If
' 읽기 전용 권장 사항 제거
doc.ReadOnlyRecommended = False
' 새 파일로 저장
doc.SaveAs2 _
FileName:=folderPath & "unlocked_" & fileName, _
Password:="", _
WritePassword:=""
doc.Close SaveChanges:=False
fileName = Dir()
Wend
MsgBox "배치 처리가 완료되었습니다!"
End Sub
방법 5: Python (Spire.Doc)을 사용하여 제거 자동화
적용 범위: 대량 문서 처리, 사용자 정의 자동화 워크플로, 개발자 통합; 열기 암호를 알고 있는 파일
최적: 개발자, 기업 배치 처리, 백엔드 시스템 통합, 반복 워크플로 자동화
Python과 Spire.Doc 라이브러리를 결합하면 프로그래밍 방식으로 문서 암호 해독 및 보호 제거가 가능합니다. 이 방법은 대량 파일 처리 및 2차 개발을 위해 설계되었으며, 공식적인 비즈니스 시나리오에 대한 안정적인 성능과 완전한 형식 보존을 제공합니다.
단계별 지침
1. Spire.Doc 라이브러리 설치
pip install spire.doc
2. Python으로 암호 제거
from spire.doc import *
from spire.doc.common import *
# 암호로 문서 로드
document = Document()
document.LoadFromFile("input.docx", FileFormat.Auto, "open-pwd")
# 암호화 제거
document.RemoveEncryption()
# 제한 유형을 NoProtection으로 설정하여 편집 제한 제거
document.Protect(ProtectionType.NoProtection)
# 잠금 해제된 문서 저장
document.SaveToFile("unlocked.docx", FileFormat.Docx)
document.Close()
이 작업을 위해 Python을 사용하는 이유는 무엇인가요?
- 한 번의 배치로 수십 개의 잠긴 Word 파일을 처리합니다.
- 내부 사무 시스템에 잠금 해제 기능을 통합합니다.
- 수동 반복 작업을 줄이고 작업 효율성을 향상시킵니다.
포괄적인 Word 라이브러리인 Spire.Doc은 암호 및 편집 제한 제거뿐만 아니라 워터마크 제거, 하이퍼링크 삭제, 문서 구조 프로그래밍 방식 수정과 같은 강력한 문서 정리 기능도 제공합니다.
콘텐츠 추출, 서식 제어, 배치 문서 변환과 같은 기능을 통합하여 워크플로를 더욱 확장하여 고급 자동화 시나리오를 구현할 수 있습니다. 이를 통해 Microsoft Word에 의존하지 않고 종단 간 문서 처리 파이프라인을 쉽게 구축할 수 있습니다.
어떤 방법을 선택해야 할까요?
| 방법 | 핵심 사용 사례 | 주요 기능 |
|---|---|---|
| 기본 Word 공식 | 암호 알고 있음, 안전한 사무 사용 | 공식, 파일 손상 없음 |
| 기본 제한 제거 | 간단한 편집 잠금, 암호 없음 | 빠른 원클릭 잠금 해제 |
| Google Docs | 알 수 없는 보호 암호 우회 | 무료, 추가 소프트웨어 없음 |
| VBA 스크립트 | 오프라인 Windows 로컬 잠금 해제 | 자동 잠금 해제 |
| Python + Spire.Doc | 사용자 정의 자동화 및 개발자 작업 | 코드 기반 자동 처리 |
결론
Word 문서 보호는 데이터 보안을 위해 설계되었지만, 불합리한 제한 설정은 종종 일상적인 협업 및 편집을 방해합니다.
일반적인 사무, 무료 해결 방법, 오프라인 스크립팅 및 기업 자동화를 포괄하는 5가지 차별화된 잠금 해제 솔루션을 정리했습니다. 항상 먼저 문서의 보호 유형을 확인하십시오.
- 열기 암호 암호화의 경우, 올바른 암호를 사용하는 공식 및 타사 도구 모두 작동합니다.
- 보호 암호 편집 잠금의 경우, Google Docs 및 Python은 많은 경우 편집 제한을 제거할 수 있습니다.
장치 시스템, 네트워크 환경 및 파일 볼륨에 따라 해당 솔루션을 선택하여 원본 콘텐츠 및 서식을 손상시키지 않고 Word 보호를 신속하게 제거하십시오.
자주 묻는 질문
Q1: 이러한 방법으로 알 수 없는 열기 암호가 있는 Word 파일을 크랙할 수 있나요?
아니요. 열기 암호는 강력한 암호화를 사용합니다. 위의 모든 방법은 파일을 열기 위해 올바른 암호를 요구합니다. 편집 보호 암호만 우회할 수 있습니다.
Q2: 잠금 해제하면 Word 서식, 이미지 또는 표가 손상되나요?
공식 Word 및 Python Spire.Doc은 완전한 서식 보존을 보장합니다. Google Docs는 복잡한 레이아웃을 왜곡할 수 있습니다. VBA는 파일 내용에 거의 영향을 미치지 않습니다.
Q3: 민감한 회사 문서에 VBA가 안전한가요?
예. VBA 스크립트는 오프라인에서 로컬로 실행되며 데이터 업로드 또는 유출 위험이 없어 기밀 내부 파일에 적합합니다.
Q4: 이것이 오래된 .doc 형식과 새 .docx 형식 모두에 작동하나요?
모든 방법은 주류 .docx를 지원합니다. Google Docs 및 Spire.Doc은 레거시 .doc 파일과도 호환됩니다.
참고 자료
Rimuovere la protezione dai file Word: 5 modi semplici
Indice
- Perché rimuovere la protezione da un file Word?
- Prima di iniziare: Tipi di protezione di Word
- Metodo 1: Rimuovere la protezione utilizzando Microsoft Word
- Metodo 2: Rimuovere le restrizioni di modifica di base in Word
- Metodo 3: Rimuovere la protezione utilizzando Google Docs
- Metodo 4: Rimuovere la protezione utilizzando macro VBA
- Metodo 5: Automatizzare la rimozione utilizzando Python (Spire.Doc)
- Quale metodo scegliere?
- Conclusione
- FAQ
I documenti Word protetti da password sono utili per mantenere sicure le informazioni sensibili, ma possono anche diventare un fastidio quando è necessario modificare, condividere o automatizzare i documenti. Ciò è particolarmente comune quando si lavora con file ricevuti da altri o con documenti più vecchi con impostazioni dimenticate.
Sia che tu conosca la password o che tu abbia a che fare con restrizioni di modifica, questa guida copre 5 modi efficaci per rimuovere la protezione dai file Word, inclusi strumenti gratuiti, funzionalità integrate e un metodo di automazione Python utilizzando Spire.Doc.
Panoramica dei metodi trattati:
- Metodo 1: Rimuovere la protezione utilizzando Microsoft Word
- Metodo 2: Rimuovere le restrizioni di modifica di base in Word
- Metodo 3: Rimuovere la protezione utilizzando Google Docs
- Metodo 4: Rimuovere la protezione utilizzando macro VBA
- Metodo 5: Automatizzare la rimozione utilizzando Python (Spire.Doc)
Perché rimuovere la protezione da un file Word?
Ecco alcuni motivi comuni per cui gli utenti desiderano rimuovere la protezione:
- Conosci già la password e desideri un accesso più rapido.
- È necessario modificare un documento protetto.
- Vuoi rimuovere limitazioni non necessarie prima della condivisione.
- È necessario elaborare file in blocco (automazione).
Il metodo giusto dipende dal tipo di protezione applicata al documento.
Prima di iniziare: Tipi di protezione di Word
Comprendere queste differenze è fondamentale, poiché non tutti i metodi funzionano in ogni caso.
1. Password di apertura (Crittografia)
Crittografia forte richiesta per aprire il file; non può essere aggirata senza la password corretta.
2. Restrizioni di modifica (Nessuna password)
I file si aprono normalmente con accesso limitato alla modifica; nessuna password di protezione necessaria per sbloccare.
3. Restrizioni di modifica con password di protezione
I file si aprono liberamente, ma la modifica è bloccata. È necessaria una password di protezione per la rimozione ufficiale, e questa protezione debole può essere aggirata dalla maggior parte degli strumenti.
Nota: Questo tipo di protezione è più debole della crittografia e può essere rimosso da alcuni strumenti senza bisogno della password di protezione.
Metodo 1: Rimuovere la protezione utilizzando Microsoft Word
Ambito di applicazione: Documenti con password di apertura note o password di protezione note; tutte le versioni mainstream di Word (2016/2019/2021/365)
Ideale per: Principianti, scenari d'ufficio formali, file che richiedono un'integrità del formato e del contenuto al 100%
Questa è la soluzione ufficiale più sicura fornita da Microsoft. Modifica la crittografia del documento e le impostazioni di restrizione in modo nativo, con zero rischio di corruzione del file, perdita di formattazione o distorsione del contenuto. Supporta l'annullamento sia della crittografia di apertura che delle restrizioni di modifica, ma è necessario inserire la password corrispondente corretta per completare l'operazione.
Istruzioni passo passo
- Fare doppio clic per aprire il file Word protetto e inserire la password di apertura richiesta, se richiesto.
- Navigare su File > Info > Proteggi documento.
- Selezionare Crittografa con password.
- Eliminare tutti i caratteri nella casella di inserimento della password e lasciarla vuota.
- Fare clic su OK, quindi premere Ctrl+S per salvare le modifiche in modo permanente.
- Per le restrizioni di modifica: Andare su Revisione > Restringi modifica, inserire la password di protezione e interrompere la protezione.
Metodo 2: Rimuovere le restrizioni di modifica di base in Word
Ambito di applicazione: Documenti con limiti di modifica ma nessuna password di protezione impostata; nessuna crittografia di apertura completa
Ideale per: Documenti quotidiani leggermente limitati, sblocco rapido con un clic
Questa soluzione nativa di Word mira ai blocchi di modifica di basso livello senza password di protezione. È possibile disabilitare tutte le restrizioni in pochi secondi senza strumenti esterni o operazioni tecniche. Funziona solo per semplici limiti di autorizzazione e fallirà se è configurata una password di protezione.
Istruzioni passo passo
- Aprire normalmente il documento Word protetto.
- Passare alla scheda Revisione sulla barra multifunzione superiore.
- Fare clic su Restringi modifica nella barra laterale destra.
- Fare clic direttamente su Interrompi protezione; non è necessario inserire password.
- Salvare il file per mantenere l'accesso illimitato alla modifica.
Metodo 3: Rimuovere la protezione utilizzando Google Docs
Ambito di applicazione: File Word non crittografati o file con una password di apertura nota; documenti bloccati da password di protezione
Ideale per: Utenti senza diritti di amministratore locali di Word, sblocco gratuito multipiattaforma, scenari con password di protezione sconosciute
Google Docs rimuove automaticamente le regole di modifica personalizzate di Word durante la conversione del formato. È il trucco gratuito più popolare per aggirare password di protezione sconosciute. Finché è possibile aprire il file (con una password di apertura, se necessario), tutte le restrizioni di modifica verranno rimosse dopo il re-download.
Istruzioni passo passo
- Accedere a Google Drive e caricare il file Word protetto (.docx/.doc).
- Fare clic con il pulsante destro del mouse sul file caricato e selezionare Apri con > Google Docs.
- Inserire la password di apertura se il documento è crittografato.
- Una volta caricato, tutte le restrizioni di modifica e i limiti della password di protezione vengono automaticamente rimossi.
- Navigare su File > Scarica > Microsoft Word (.docx).
- Il nuovo file scaricato è completamente sbloccato e modificabile.
Metodo 4: Rimuovere la protezione utilizzando macro VBA
Ambito di applicazione: Automazione Microsoft Word solo per Windows, richiede password corrette (non aggira la protezione)
Ideale per: Utenti intermedi, ambienti d'ufficio offline, frequenti richieste di sblocco
Le macro VBA vengono eseguite localmente in Microsoft Word e possono essere utilizzate per rimuovere programmaticamente la protezione del documento. A differenza di alcuni strumenti online, questo metodo non aggira le password: è necessario fornire la password di apertura corretta per accedere al documento e la password di modifica (autorizzazione) corretta per rimuovere le restrizioni. Una volta che il documento è accessibile, la macro può automatizzare il processo di disabilitazione della protezione e salvataggio di una copia non protetta. Ciò lo rende una soluzione offline utile per l'elaborazione in blocco o attività ripetitive, ma non può rompere o aggirare alcuna crittografia protetta da password.
Istruzioni passo passo (Elaborazione in blocco)
- Preparare una cartella contenente tutti i documenti Word che si desidera sbloccare. Assicurarsi di conoscere la password di apertura (se presente) e la password di restrizione di modifica utilizzate in questi file.
- Aprire Microsoft Word (non è necessario aprire un documento specifico).
- Premere Alt + F11 per avviare l'Editor VBA.
- Nel menu in alto, fare clic su Inserisci > Modulo per creare un nuovo modulo.
- Incollare il codice VBA batch nella finestra del modulo.
- Aggiornare le seguenti variabili nel codice:
- folderPath → il percorso della cartella di destinazione
- openPwd → la password di apertura del documento (lasciare vuoto se non presente)
- editPwd → la password di restrizione di modifica
- Premere F5 (o fare clic su Esegui) per eseguire la macro.
- La macro elaborerà tutti i file .docx nella cartella e salverà copie sbloccate (ad esempio, unlocked_nomefile.docx) nella stessa directory.
Codice VBA:
Sub BatchRemoveProtection()
Dim folderPath As String
Dim fileName As String
Dim doc As Document
'==========================
' Input utente
'==========================
folderPath = "C:\Docs\" ' <-- aggiorna il percorso della cartella
Dim openPwd As String
openPwd = "" ' <-- imposta se i file hanno una password di apertura
Dim editPwd As String
editPwd = "tua_password_di_modifica" ' <-- imposta la password di restrizione di modifica
'==========================
' Cicla attraverso tutti i file DOCX
'==========================
fileName = Dir(folderPath & "*.docx")
While fileName <> ""
' Apri documento (con password di apertura opzionale)
Set doc = Documents.Open( _
FileName:=folderPath & fileName, _
PasswordDocument:=openPwd, _
ReadOnly:=False)
' Rimuovi restrizioni di modifica
If doc.ProtectionType <> wdNoProtection Then
doc.Unprotect Password:=editPwd
End If
' Rimuovi raccomandazione di sola lettura
doc.ReadOnlyRecommended = False
' Salva come nuovo file
doc.SaveAs2 _
FileName:=folderPath & "unlocked_" & fileName, _
Password:="", _
WritePassword:=""
doc.Close SaveChanges:=False
fileName = Dir()
Wend
MsgBox "Elaborazione batch completata!"
End Sub
Metodo 5: Automatizzare la rimozione utilizzando Python (Spire.Doc)
Ambito di applicazione: Elaborazione di documenti in blocco, flussi di lavoro di automazione personalizzati, integrazione con sviluppatori; file con password di apertura note
Ideale per: Sviluppatori, elaborazione batch aziendale, integrazione di sistemi backend, automazione di flussi di lavoro ripetitivi
Combinare Python e la libreria Spire.Doc consente la decrittazione programmabile dei documenti e la rimozione della protezione. Questo metodo è progettato per l'elaborazione di file di massa e lo sviluppo secondario, con prestazioni stabili e conservazione completa del formato per scenari aziendali formali.
Istruzioni passo passo
1. Installa la libreria Spire.Doc
pip install spire.doc
2. Rimuovere la password con Python
from spire.doc import *
from spire.doc.common import *
# Carica il documento con password
document = Document()
document.LoadFromFile("input.docx", FileFormat.Auto, "password-apertura")
# Rimuovi la crittografia
document.RemoveEncryption()
# Rimuovi la restrizione di modifica impostando il tipo di restrizione su Nessuna protezione
document.Protect(ProtectionType.NoProtection)
# Salva il documento sbloccato
document.SaveToFile("sbloccato.docx", FileFormat.Docx)
document.Close()
Perché usare Python per questo compito?
- Elabora decine di file Word bloccati in un unico batch.
- Incorpora funzioni di sblocco nei sistemi d'ufficio interni.
- Riduci le operazioni manuali ripetitive e migliora l'efficienza del lavoro.
Come libreria Word completa, Spire.Doc non solo ti consente di rimuovere password e restrizioni di modifica, ma fornisce anche potenti funzionalità di pulizia dei documenti come la rimozione di watermark, la cancellazione di collegamenti ipertestuali e la modifica programmatica della struttura del documento.
Puoi estendere ulteriormente il tuo flusso di lavoro integrando funzionalità come l'estrazione di contenuti, il controllo della formattazione e la trasformazione di documenti in blocco per scenari di automazione più avanzati. Ciò rende facile creare pipeline di elaborazione di documenti end-to-end senza fare affidamento su Microsoft Word.
Quale metodo scegliere?
| Metodo | Caso d'uso principale | Funzionalità chiave |
|---|---|---|
| Word nativo ufficiale | Password nota, uso sicuro in ufficio | Ufficiale, nessun danno al file |
| Rimozione restrizioni di base | Blocchi di modifica semplici, nessuna password | Sblocco rapido con un clic |
| Google Docs | Aggirare password di protezione sconosciute | Gratuito, nessun software aggiuntivo |
| Script VBA | Sblocco locale offline su Windows | Sblocco automatizzato |
| Python + Spire.Doc | Automazione personalizzata e attività per sviluppatori | Elaborazione automatica basata su codice |
Conclusione
La protezione dei documenti Word è progettata per la sicurezza dei dati, ma impostazioni di restrizione irragionevoli ostacolano spesso la collaborazione e la modifica quotidiana.
Abbiamo organizzato 5 soluzioni di sblocco differenziate che coprono l'uso occasionale in ufficio, le soluzioni gratuite, lo scripting offline e l'automazione aziendale. Conferma sempre prima il tipo di protezione del tuo documento:
- Per la crittografia con password di apertura, funzionano sia gli strumenti ufficiali che quelli di terze parti con la password corretta;
- Per i blocchi di modifica con password di protezione, Google Docs e Python possono rimuovere le restrizioni di modifica in molti casi.
Scegli la soluzione corrispondente in base al sistema del tuo dispositivo, all'ambiente di rete e al volume dei file per rimuovere rapidamente la protezione di Word senza danneggiare il contenuto e la formattazione originali.
FAQ
D1: Questi metodi possono decifrare un file Word con una password di apertura sconosciuta?
No. La password di apertura adotta una crittografia forte. Tutti i metodi sopra descritti richiedono la password corretta per aprire il file. Solo le password di protezione della modifica possono essere aggirate.
D2: Lo sblocco danneggerà la formattazione, le immagini o le tabelle del mio Word?
Word ufficiale e Python Spire.Doc garantiscono la completa conservazione del formato. Google Docs potrebbe distorcere layout complessi; VBA ha quasi nessun impatto sul contenuto del file.
D3: VBA è sicuro per documenti aziendali sensibili?
Sì. Lo script VBA viene eseguito localmente offline, senza rischio di caricamento o fuga di dati, rendendolo adatto a file interni riservati.
D4: Funziona per il vecchio formato .doc e il nuovo formato .docx?
Tutti i metodi supportano il .docx mainstream; Google Docs e Spire.Doc sono compatibili anche con i file .doc legacy.
Vedi anche
- Aggiungere bordi pagina in Word (qualsiasi pagina): 4 semplici modi
- Rimuovere righe vuote in Word rapidamente: Manuale e VBA/Python
- Unire documenti Word: Conservare o unificare la formattazione
- 5 semplici modi per rendere un file Word di sola lettura
- Trova e sostituisci testo nei documenti Word: 5 metodi semplici