Cómo imprimir una hoja de Excel en una sola página: 7 formas efectivas
Tabla de Contenidos
- Por qué las hojas de Excel no caben en una página
- Método 1: Usar la opción "Ajustar hoja en una página"
- Método 2: Ajustar el escalado de página manualmente
- Método 3: Cambiar la orientación de la página
- Método 4: Reducir márgenes y eliminar columnas adicionales
- Método 5: Establecer un área de impresión personalizada
- Método 6: Cambiar el tamaño del papel
- Método 7: Imprimir hoja de Excel en una página usando C#
- Tabla de comparación rápida
- Preguntas frecuentes
- Conclusión

Las hojas de cálculo de Excel a menudo se ven perfectas en pantalla, pero resultan difíciles de imprimir correctamente. Las tablas grandes pueden extenderse por varias páginas, las columnas se cortan o el resultado impreso se vuelve desordenado y difícil de leer.
Afortunadamente, Excel proporciona varias herramientas integradas para ayudar a ajustar las hojas de cálculo a una sola página al imprimir. Ya sea que esté imprimiendo facturas, informes, horarios, paneles o estados financieros, estos métodos pueden ayudar a crear impresiones más limpias y profesionales.
En esta guía, aprenderá 7 formas efectivas de imprimir una hoja de Excel en una página, desde configuraciones de Excel fáciles de usar hasta automatización avanzada con C# usando Spire.XLS.
Navegación rápida:
- Método 1: Usar la opción "Ajustar hoja en una página"
- Método 2: Ajustar el escalado de página manualmente
- Método 3: Cambiar la orientación de la página
- Método 4: Reducir márgenes y eliminar columnas adicionales
- Método 5: Establecer un área de impresión personalizada
- Método 6: Cambiar el tamaño del papel
- Método 7: Imprimir hoja de Excel en una página usando C#
Por qué las hojas de Excel no caben en una página
Excel separa automáticamente las hojas de cálculo en varias páginas impresas según el tamaño de página, los márgenes, el escalado y las dimensiones del contenido. Si una hoja de cálculo contiene demasiadas columnas o filas, Excel puede dividir el contenido en varias páginas durante la impresión.
Las razones comunes incluyen:
- Tablas anchas con muchas columnas
- Tamaños de fuente grandes
- Espacios en blanco excesivos
- Márgenes de página anchos
- Orientación de página incorrecta
- Celdas no utilizadas que extienden el rango de impresión
Como resultado, los informes pueden volverse difíciles de leer y desperdiciar papel innecesariamente. Los siguientes métodos le ayudarán a optimizar el diseño de su hoja de cálculo y a ajustar el contenido a una sola página impresa.
Método 1: Usar la opción "Ajustar hoja en una página"
Este es el método más fácil y utilizado. Excel incluye una función de escalado integrada que reduce automáticamente el contenido de la hoja de cálculo para que quepa en una página impresa.
Funciona especialmente bien para facturas, horarios, informes y tablas de tamaño mediano.
Pasos
- Abra su hoja de cálculo de Excel.
- Haga clic en Archivo > Imprimir.
- En Configuración, haga clic en Sin escalado.
- Seleccione Ajustar hoja en una página.
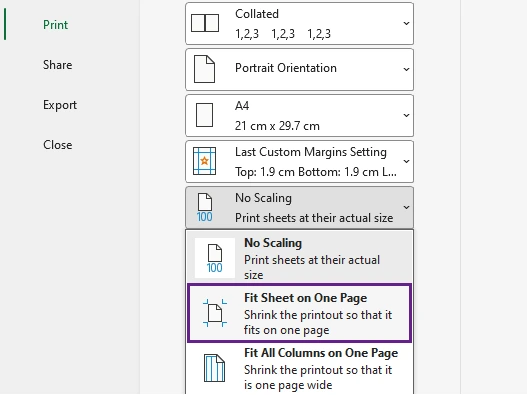
- Previsualice el resultado en el panel Vista previa de impresión.
- Haga clic en Imprimir para imprimir la hoja de cálculo.
Qué sucede
Excel escala automáticamente la hoja de cálculo para que todas las filas y columnas quepan en una sola página durante la impresión.
Ventajas
- Extremadamente fácil de usar
- No se requiere redimensionamiento manual
- Integrado directamente en Excel
Desventajas
- El texto puede volverse demasiado pequeño para hojas de cálculo muy grandes
Método 2: Ajustar el escalado de página manualmente
En lugar de forzar todo a una sola página automáticamente, puede reducir manualmente el porcentaje de escalado. Esto proporciona más control sobre la legibilidad y la apariencia de la impresión.
Por ejemplo, reducir el escalado al 85% o 90% puede ajustar el contenido de forma agradable manteniendo el texto legible.
Pasos
- Abra su hoja de cálculo de Excel y haga clic en Archivo > Imprimir.
- En Configuración, haga clic en Sin escalado.
- Seleccione Opciones de escalado personalizadas.
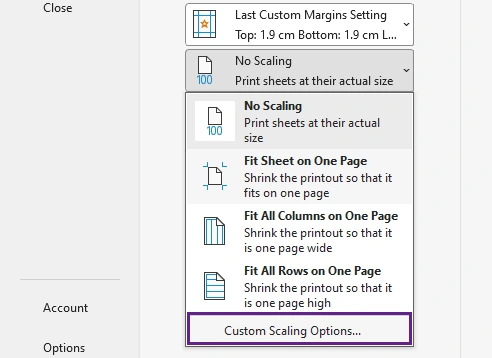
- En la configuración de escalado, reduzca el porcentaje de escalado hasta que la hoja de cálculo se ajuste mejor a la página.
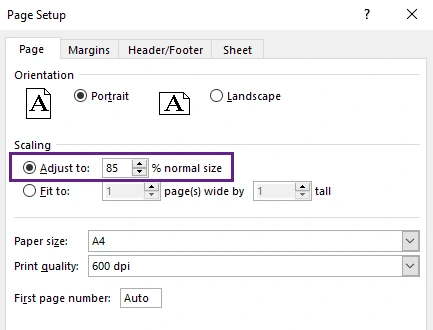
- Verifique el diseño en el panel Vista previa de impresión y continúe ajustando si es necesario.
- Una vez que la hoja de cálculo se ajuste correctamente en una página, haga clic en Imprimir.
Mejor para
- Informes financieros
- Tablas con columnas ligeramente sobredimensionadas
- Hojas de cálculo donde la legibilidad importa
Consejo: Evite reducir el escalado de forma demasiado agresiva. El texto diminuto puede hacer que los documentos impresos sean difíciles de leer.
Método 3: Cambiar la orientación de la página
Muchas hojas de cálculo de Excel son más anchas que altas. Cambiar de la orientación Vertical a Horizontal proporciona más espacio horizontal y puede reducir instantáneamente los saltos de página.
Este simple ajuste es especialmente efectivo para hojas de cálculo con muchas columnas.
Pasos
- Abra su hoja de cálculo de Excel y haga clic en Archivo > Imprimir.
- En la ventana de configuración de impresión, haga clic en Configurar página.
- En la pestaña Página, seleccione la orientación Horizontal.

- Haga clic en Aceptar para aplicar la configuración.
- Revise el diseño en el panel Vista previa de impresión.
- Si la hoja de cálculo se ajusta correctamente en una página, haga clic en Imprimir.
Por qué ayuda
El modo horizontal aumenta el ancho imprimible, permitiendo que más columnas quepan en una sola página.
Mejor para
- Tablas de datos anchas
- Paneles
- Informes con muchas columnas
Método 4: Reducir márgenes y eliminar columnas adicionales
Los márgenes de página grandes y las áreas de hoja de cálculo no utilizadas consumen valioso espacio de impresión. Reducir los márgenes y eliminar el contenido innecesario puede mejorar significativamente el ajuste de página.
Este método a menudo se combina con el escalado para obtener mejores resultados.
Pasos
- Abra su hoja de cálculo de Excel y elimine el contenido innecesario, como filas en blanco, columnas vacías, fuentes de gran tamaño, espaciado excesivo o datos que no necesitan imprimirse.
- Haga clic en Archivo > Imprimir.
- En Configuración, haga clic en Márgenes normales.
- Seleccione Estrecho para reducir los márgenes de página y crear más espacio imprimible.
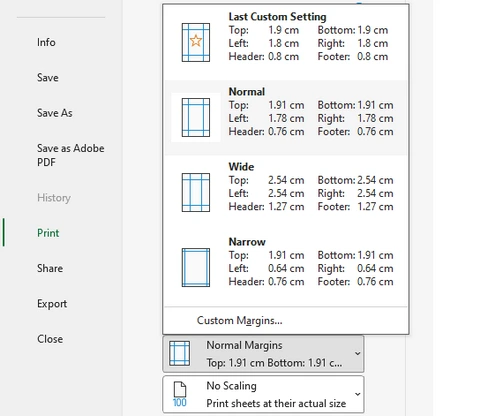
- Si necesita espacio adicional, seleccione Márgenes personalizados y reduzca manualmente los márgenes superior, inferior, izquierdo y derecho aún más.
- Revise el resultado en el panel Vista previa de impresión.
- Una vez que la hoja de cálculo se ajuste correctamente en una página, haga clic en Imprimir.
Por qué funciona
Los márgenes más pequeños proporcionan un área imprimible mayor, mientras que la limpieza del contenido no utilizado evita que Excel imprima páginas innecesarias.
Consejo: Presione Ctrl + Fin para ver la última celda utilizada por Excel. A veces, el formato oculto se extiende mucho más allá de sus datos reales.
Método 5: Establecer un área de impresión personalizada
A veces, solo se necesita imprimir una parte de la hoja de cálculo. Al definir un área de impresión personalizada, Excel ignora las celdas innecesarias y se enfoca solo en el contenido seleccionado.
Esta es una de las formas más efectivas de evitar páginas en blanco y rangos de impresión sobredimensionados.
Pasos
- Seleccione las celdas o el rango que desea imprimir.
- Vaya a la pestaña Diseño de página.
- Haga clic en Área de impresión en el grupo Configurar página.
- Seleccione Establecer área de impresión.
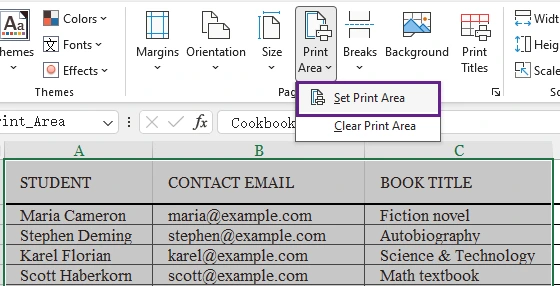
- Haga clic en Archivo > Imprimir para abrir la configuración de impresión.
- Revise el contenido seleccionado en el panel Vista previa de impresión.
- Si el diseño se ve correcto, haga clic en Imprimir.
Mejor para
- Informes
- Paneles
- Resúmenes
- Secciones de facturas
Ventajas
- Evita páginas en blanco adicionales
- Impresión más rápida
- Salida más limpia
Método 6: Cambiar el tamaño del papel
Usar un tamaño de papel más grande proporciona espacio de impresión adicional y reduce la necesidad de un escalado excesivo. Este método se usa comúnmente en oficinas para hojas de cálculo grandes e informes detallados.
Por ejemplo, cambiar de papel Carta a Legal puede mejorar drásticamente el diseño de impresión.
Pasos
- Abra su hoja de cálculo de Excel y haga clic en Archivo > Imprimir.
- En Configuración, haga clic en el tamaño de papel actual (como A4).
- Seleccione un tamaño de papel más grande, como Legal, A3 o Tabloide.
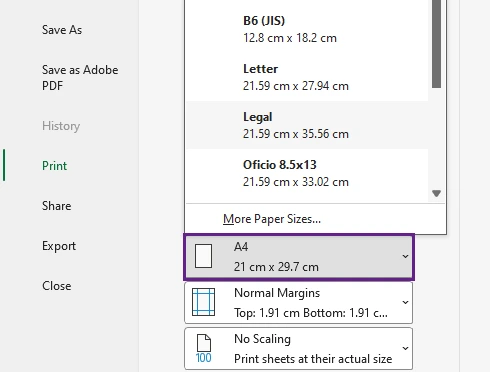
- Revise el diseño en el panel Vista previa de impresión.
- Si la hoja de cálculo se ajusta correctamente a la página, haga clic en Imprimir.
Mejor para
- Informes grandes
- Hojas de cálculo financieras
- Tablas anchas
Nota importante
Asegúrese de que su impresora admita el tamaño de papel seleccionado.
Método 7: Imprimir hoja de Excel en una página usando C#
Si necesita imprimir hojas de cálculo de Excel mediante programación, la automatización con C# proporciona una solución mucho más eficiente que la impresión manual. Este enfoque es ideal para sistemas empresariales, plataformas de informes, tareas programadas y procesamiento de documentos por lotes.
Usando Spire.XLS para .NET, puede configurar automáticamente los ajustes de página y ajustar las hojas de cálculo a una sola página impresa.
La configuración clave es:
pageSetup.IsFitToPage = true;
Esta propiedad escala automáticamente el contenido de la hoja de cálculo para que quepa en una página durante la impresión.
Instalar Spire.XLS
Puede instalar Spire.XLS a través de NuGet:
Install-Package Spire.XLS
Ejemplo de C#: Imprimir hoja de Excel en una página
using Spire.Xls;
using System.Drawing.Printing;
namespace PrintExcel
{
class Program
{
static void Main(string[] args)
{
// Cargar un documento de Excel
Workbook workbook = new Workbook();
workbook.LoadFromFile("Sample.xlsx");
// Recorrer las hojas de cálculo
for (int i = 0; i < workbook.Worksheets.Count; i++)
{
// Obtener una hoja de cálculo específica
Worksheet worksheet = workbook.Worksheets[i];
// Obtener el objeto PageSetup
PageSetup pageSetup = worksheet.PageSetup;
// Establecer márgenes de página
pageSetup.TopMargin = 0.3;
pageSetup.BottomMargin = 0.3;
pageSetup.LeftMargin = 0.3;
pageSetup.RightMargin = 0.3;
// Permitir imprimir con líneas de cuadrícula
pageSetup.IsPrintGridlines = true;
// Ajustar la hoja de cálculo a una página
pageSetup.IsFitToPage = true;
}
// Obtener PrinterSettings
PrinterSettings settings = workbook.PrintDocument.PrinterSettings;
// Especificar el nombre de la impresora
settings.PrinterName = "Your Printer Name";
// Especificar el rango de páginas a imprimir
settings.FromPage = 1;
settings.ToPage = 3;
// Ejecutar la impresión
workbook.PrintDocument.Print();
}
}
}
Ventajas de este método
- Impresión de Excel totalmente automatizada
- Soporta procesamiento por lotes
- Adecuado para aplicaciones empresariales
- Elimina las operaciones manuales de Excel
- Fácil de integrar en sistemas de informes
Como una API integral de Excel para .NET, Spire.XLS para .NET permite a los desarrolladores controlar la impresión de hojas de cálculo completamente a través de código, incluyendo escalado, áreas de impresión, márgenes, orientación, encabezados, pies de página y saltos de página.
Más allá de la impresión, también admite la creación de Excel, edición, importación/exportación de datos, cálculo de fórmulas, procesamiento de gráficos y conversión entre formatos de Excel, PDF, CSV, HTML e imagen. Se utiliza ampliamente para la generación de informes, la automatización empresarial, los sistemas financieros y las aplicaciones de procesamiento de hojas de cálculo a gran escala.
Tabla de comparación rápida
| Método | Dificultad | Mejor para | Automatización |
|---|---|---|---|
| Ajustar hoja en una página | Fácil | Impresión rápida | No |
| Escalado manual | Fácil | Mejor legibilidad | No |
| Orientación horizontal | Fácil | Hojas de cálculo anchas | No |
| Reducir márgenes | Fácil | Ajustes menores de diseño | No |
| Establecer área de impresión | Fácil | Impresión de hoja de cálculo parcial | No |
| Cambiar tamaño de papel | Fácil | Informes grandes | No |
| C# con Spire.XLS | Avanzado | Impresión por lotes/automática | Sí |
Conclusión
Imprimir hojas de cálculo de Excel en una sola página puede mejorar significativamente la legibilidad y la calidad de presentación de los documentos. Excel ofrece varias funciones integradas, como escalado, orientación horizontal, configuración del área de impresión y ajuste de márgenes, para ayudar a optimizar los diseños de impresión rápidamente.
Para desarrolladores y usuarios empresariales, la impresión programática con Spire.XLS proporciona una potente solución de automatización. Al habilitar la propiedad IsFitToPage, las hojas de cálculo de Excel pueden ajustarse automáticamente a una página impresa, lo que hace que la impresión por lotes y la generación de informes sean mucho más eficientes.
Preguntas frecuentes
P1. ¿Por qué mi hoja de Excel sigue imprimiéndose en varias páginas?
Su hoja de cálculo puede contener datos ocultos, celdas con formato no utilizado, márgenes grandes o demasiadas columnas. Verifique el área de impresión y la configuración de escalado.
P2. ¿Ajustar una hoja a una página reduce la calidad de impresión?
No. Excel solo escala el tamaño del contenido. Sin embargo, un encogimiento excesivo puede hacer que el texto sea difícil de leer.
P3. ¿Puedo ajustar solo las columnas en una página?
Sí. En Configuración, haga clic en Sin escalado y elija Ajustar todas las columnas en una página. Esto mantiene las filas fluyendo naturalmente mientras ajusta todas las columnas en una página.
P4. ¿Es el modo horizontal mejor para imprimir hojas de Excel?
Para hojas de cálculo anchas, sí. La orientación horizontal proporciona más espacio de impresión horizontal.
P5. ¿Puedo automatizar la impresión de Excel en aplicaciones de backend?
Sí. Bibliotecas como Spire.XLS permiten a los desarrolladores imprimir archivos de Excel mediante programación usando C# sin abrir Excel manualmente.
Ver también
So drucken Sie ein Excel-Arbeitsblatt auf einer Seite: 7 effektive Methoden
Inhaltsverzeichnis
- Warum Excel-Tabellen nicht auf eine Seite passen
- Methode 1: Option „Blatt auf einer Seite ausgeben“ verwenden
- Methode 2: Seiten-Skalierung manuell anpassen
- Methode 3: Seitenorientierung ändern
- Methode 4: Seitenränder reduzieren und zusätzliche Spalten entfernen
- Methode 5: Benutzerdefinierten Druckbereich festlegen
- Methode 6: Papierformat ändern
- Methode 7: Excel-Blatt mit C# auf einer Seite drucken
- Schnelle Vergleichstabelle
- FAQs
- Fazit
Excel-Tabellen sehen auf dem Bildschirm oft perfekt aus, lassen sich aber beim Drucken nur schwer richtig darstellen. Große Tabellen können über mehrere Seiten gehen, Spalten werden abgeschnitten oder das Druckergebnis wird unordentlich und schwer lesbar.
Glücklicherweise bietet Excel mehrere integrierte Werkzeuge, um Arbeitsblätter beim Drucken auf eine einzige Seite zu bringen. Egal, ob Sie Rechnungen, Berichte, Zeitpläne, Dashboards oder Finanzberichte drucken, diese Methoden können zu saubereren und professionelleren Ausdrucken führen.
In diesem Leitfaden lernen Sie 7 effektive Möglichkeiten, ein Excel-Blatt auf einer Seite zu drucken, von anfängerfreundlichen Excel-Einstellungen bis hin zur fortgeschrittenen C#-Automatisierung mit Spire.XLS.
Schnellnavigation:
- Methode 1: Option „Blatt auf einer Seite ausgeben“ verwenden
- Methode 2: Seiten-Skalierung manuell anpassen
- Methode 3: Seitenorientierung ändern
- Methode 4: Seitenränder reduzieren und zusätzliche Spalten entfernen
- Methode 5: Benutzerdefinierten Druckbereich festlegen
- Methode 6: Papierformat ändern
- Methode 7: Excel-Blatt mit C# auf einer Seite drucken
Warum Excel-Tabellen nicht auf eine Seite passen
Excel teilt Arbeitsblätter automatisch in mehrere Druckseiten auf, basierend auf Seitengröße, Rändern, Skalierung und Inhaltsabmessungen. Wenn ein Arbeitsblatt zu viele Spalten oder Zeilen enthält, kann Excel den Inhalt beim Drucken auf mehrere Seiten aufteilen.
Häufige Gründe sind:
- Breite Tabellen mit vielen Spalten
- Große Schriftgrößen
- Übermäßige Leerzeichen
- Breite Seitenränder
- Falsche Seitenorientierung
- Unbenutzte Zellen, die den Druckbereich erweitern
Dadurch können Berichte schwer lesbar werden und unnötigerweise Papier verschwendet werden. Die folgenden Methoden helfen Ihnen, das Layout Ihres Arbeitsblatts zu optimieren und den Inhalt auf eine einzige Druckseite zu bringen.
Methode 1: Option „Blatt auf einer Seite ausgeben“ verwenden
Dies ist die einfachste und am häufigsten verwendete Methode. Excel verfügt über eine integrierte Skalierungsfunktion, die den Inhalt des Arbeitsblatts automatisch verkleinert, um ihn auf eine Druckseite zu passen.
Dies funktioniert besonders gut für Rechnungen, Zeitpläne, Berichte und mittelgroße Tabellen.
Schritte
- Öffnen Sie Ihr Excel-Arbeitsblatt.
- Klicken Sie auf Datei > Drucken.
- Klicken Sie unter Einstellungen auf Keine Skalierung.
- Wählen Sie Blatt auf einer Seite ausgeben.
- Sehen Sie sich das Ergebnis in der Druckvorschau an.
- Klicken Sie auf Drucken, um das Arbeitsblatt zu drucken.
Was passiert
Excel skaliert das Arbeitsblatt automatisch, sodass alle Zeilen und Spalten beim Drucken auf eine einzige Seite passen.
Vorteile
- Extrem einfach zu bedienen
- Keine manuelle Größenänderung erforderlich
- Direkt in Excel integriert
Nachteile
- Der Text kann bei sehr großen Arbeitsblättern zu klein werden
Methode 2: Seiten-Skalierung manuell anpassen
Anstatt alles automatisch auf eine Seite zu zwingen, können Sie den Skalierungsprozentsatz manuell reduzieren. Dies bietet mehr Kontrolle über Lesbarkeit und Druckaussehen.
Zum Beispiel kann eine Reduzierung der Skalierung auf 85 % oder 90 % den Inhalt gut passen lassen und den Text lesbar halten.
Schritte
- Öffnen Sie Ihr Excel-Arbeitsblatt und klicken Sie auf Datei > Drucken.
- Klicken Sie unter Einstellungen auf Keine Skalierung.
- Wählen Sie Benutzerdefinierte Skalierungsoptionen.
- Reduzieren Sie in den Skalierungseinstellungen den Skalierungsprozentsatz, bis das Arbeitsblatt besser auf die Seite passt.
- Überprüfen Sie das Layout in der Druckvorschau und passen Sie es bei Bedarf weiter an.
- Sobald das Arbeitsblatt richtig auf eine Seite passt, klicken Sie auf Drucken.
Am besten geeignet für
- Finanzberichte
- Tabellen mit leicht überdimensionierten Spalten
- Arbeitsblätter, bei denen die Lesbarkeit wichtig ist
Tipp: Vermeiden Sie eine zu aggressive Skalierungsreduzierung. Winziger Text kann gedruckte Dokumente schwer lesbar machen.
Methode 3: Seitenorientierung ändern
Viele Excel-Arbeitsblätter sind breiter als hoch. Der Wechsel von der Hochformat- zur Querformat-Ausrichtung bietet mehr horizontalen Platz und kann Seitenumbrüche sofort reduzieren.
Diese einfache Anpassung ist besonders effektiv für Tabellenkalkulationen mit vielen Spalten.
Schritte
- Öffnen Sie Ihr Excel-Arbeitsblatt und klicken Sie auf Datei > Drucken.
- Klicken Sie im Fenster mit den Druckeinstellungen auf Seitenlayout.
- Wählen Sie auf der Registerkarte Seite die Ausrichtung Querformat.
- Klicken Sie auf OK, um die Einstellung anzuwenden.
- Überprüfen Sie das Layout in der Druckvorschau.
- Wenn das Arbeitsblatt richtig auf eine Seite passt, klicken Sie auf Drucken.
Warum es hilft
Der Querformatmodus erhöht die Druckbreite, sodass mehr Spalten auf eine einzige Seite passen.
Am besten geeignet für
- Breite Datentabellen
- Dashboards
- Berichte mit vielen Spalten
Methode 4: Seitenränder reduzieren und zusätzliche Spalten entfernen
Große Seitenränder und ungenutzte Bereiche des Arbeitsblatts verbrauchen wertvollen Druckplatz. Das Reduzieren von Rändern und das Entfernen unnötiger Inhalte können die Seitenanpassung erheblich verbessern.
Diese Methode wird oft mit der Skalierung kombiniert, um bessere Ergebnisse zu erzielen.
Schritte
- Öffnen Sie Ihr Excel-Arbeitsblatt und entfernen Sie unnötige Inhalte wie leere Zeilen, leere Spalten, überdimensionierte Schriftarten, übermäßigen Abstand oder Daten, die nicht gedruckt werden müssen.
- Klicken Sie auf Datei > Drucken.
- Klicken Sie unter Einstellungen auf Normale Ränder.
- Wählen Sie Schmal, um die Seitenränder zu reduzieren und mehr Druckplatz zu schaffen.
- Wenn Sie zusätzlichen Platz benötigen, wählen Sie Benutzerdefinierte Ränder und reduzieren Sie die oberen, unteren, linken und rechten Ränder manuell weiter.
- Überprüfen Sie das Ergebnis in der Druckvorschau.
- Sobald das Arbeitsblatt richtig auf eine Seite passt, klicken Sie auf Drucken.
Warum es funktioniert
Kleinere Ränder bieten mehr Druckfläche, während die Bereinigung ungenutzter Inhalte verhindert, dass Excel unnötige Seiten druckt.
Tipp: Drücken Sie Strg + Ende, um die letzte verwendete Zelle von Excel anzuzeigen. Manchmal erstreckt sich die Formatierung weit über Ihre tatsächlichen Daten hinaus.
Methode 5: Benutzerdefinierten Druckbereich festlegen
Manchmal muss nur ein Teil des Arbeitsblatts gedruckt werden. Durch die Definition eines benutzerdefinierten Druckbereichs ignoriert Excel unnötige Zellen und konzentriert sich nur auf den ausgewählten Inhalt.
Dies ist eine der effektivsten Möglichkeiten, leere Seiten und überdimensionierte Druckbereiche zu vermeiden.
Schritte
- Wählen Sie die Zellen oder den Bereich aus, den Sie drucken möchten.
- Gehen Sie zur Registerkarte Seitenlayout.
- Klicken Sie im Gruppenfeld Seite einrichten auf Druckbereich.
- Wählen Sie Druckbereich festlegen.
- Klicken Sie auf Datei > Drucken, um die Druckeinstellungen zu öffnen.
- Überprüfen Sie den ausgewählten Inhalt in der Druckvorschau.
- Wenn das Layout korrekt aussieht, klicken Sie auf Drucken.
Am besten geeignet für
- Berichte
- Dashboards
- Zusammenfassungen
- Rechnungsabschnitte
Vorteile
- Verhindert zusätzliche leere Seiten
- Schnelleres Drucken
- Sauberere Ausgabe
Methode 6: Papierformat ändern
Die Verwendung eines größeren Papierformats bietet zusätzlichen Druckplatz und reduziert die Notwendigkeit einer übermäßigen Skalierung. Diese Methode wird in Büros häufig für große Tabellenkalkulationen und detaillierte Berichte verwendet.
Zum Beispiel kann der Wechsel von Letter auf Legal-Papier das Drucklayout dramatisch verbessern.
Schritte
- Öffnen Sie Ihr Excel-Arbeitsblatt und klicken Sie auf Datei > Drucken.
- Klicken Sie unter Einstellungen auf die aktuelle Papiergröße (z. B. A4).
- Wählen Sie ein größeres Papierformat, z. B. Legal, A3 oder Tabloid.
- Überprüfen Sie das Layout in der Druckvorschau.
- Wenn das Arbeitsblatt richtig auf die Seite passt, klicken Sie auf Drucken.
Am besten geeignet für
- Große Berichte
- Finanztabellenkalkulationen
- Breite Tabellen
Wichtiger Hinweis
Stellen Sie sicher, dass Ihr Drucker das gewählte Papierformat unterstützt.
Methode 7: Excel-Blatt mit C# auf einer Seite drucken
Wenn Sie Excel-Arbeitsblätter programmgesteuert drucken müssen, bietet die C#-Automatisierung eine wesentlich effizientere Lösung als das manuelle Drucken. Dieser Ansatz ist ideal für Unternehmenssysteme, Berichtsplattformen, geplante Aufgaben und die Stapelverarbeitung von Dokumenten.
Mit Spire.XLS for .NET können Sie Seiteneinstellungen automatisch konfigurieren und Arbeitsblätter auf eine einzige Druckseite anpassen.
Die wichtigste Einstellung ist:
pageSetup.IsFitToPage = true;
Diese Eigenschaft skaliert den Inhalt des Arbeitsblatts automatisch, sodass er beim Drucken auf eine Seite passt.
Spire.XLS installieren
Sie können Spire.XLS über NuGet installieren:
Install-Package Spire.XLS
C#-Beispiel: Excel-Blatt auf einer Seite drucken
using Spire.Xls;
using System.Drawing.Printing;
namespace PrintExcel
{
class Program
{
static void Main(string[] args)
{
// Ein Excel-Dokument laden
Workbook workbook = new Workbook();
workbook.LoadFromFile("Sample.xlsx");
// Durch die Arbeitsblätter schleifen
for (int i = 0; i < workbook.Worksheets.Count; i++)
{
// Ein bestimmtes Arbeitsblatt abrufen
Worksheet worksheet = workbook.Worksheets[i];
// Das PageSetup-Objekt abrufen
PageSetup pageSetup = worksheet.PageSetup;
// Seitenränder festlegen
pageSetup.TopMargin = 0.3;
pageSetup.BottomMargin = 0.3;
pageSetup.LeftMargin = 0.3;
pageSetup.RightMargin = 0.3;
// Drucken mit Gitternetzlinien zulassen
pageSetup.IsPrintGridlines = true;
// Arbeitsblatt auf eine Seite passen
pageSetup.IsFitToPage = true;
}
// PrinterSettings abrufen
PrinterSettings settings = workbook.PrintDocument.PrinterSettings;
// Druckernamen angeben
settings.PrinterName = "Ihr Druckername";
// Seitenbereich zum Drucken angeben
settings.FromPage = 1;
settings.ToPage = 3;
// Drucken ausführen
workbook.PrintDocument.Print();
}
}
}
Vorteile dieser Methode
- Vollständig automatisierter Excel-Druck
- Unterstützt Stapelverarbeitung
- Geeignet für Unternehmensanwendungen
- Eliminiert manuelle Excel-Vorgänge
- Einfach in Berichtssysteme zu integrieren
Als umfassende Excel-API für .NET ermöglicht Spire.XLS für .NET Entwicklern, den Druck von Arbeitsblättern vollständig per Code zu steuern, einschließlich Skalierung, Druckbereichen, Rändern, Ausrichtung, Kopf- und Fußzeilen sowie Seitenumbrüchen.
Über den Druck hinaus unterstützt es auch die Erstellung von Excel-Dateien, die Bearbeitung, den Datenimport/-export, die Formelberechnung, die Diagrammverarbeitung und die Konvertierung zwischen Excel-, PDF-, CSV-, HTML- und Bildformaten. Es wird häufig für die Berichterstellung, die Geschäftsautomatisierung, Finanzsysteme und Anwendungen zur Verarbeitung großer Tabellenkalkulationen verwendet.
Schnelle Vergleichstabelle
| Methode | Schwierigkeit | Am besten geeignet für | Automatisierung |
|---|---|---|---|
| Blatt auf einer Seite ausgeben | Einfach | Schnelles Drucken | Nein |
| Manuelle Skalierung | Einfach | Bessere Lesbarkeit | Nein |
| Querformat | Einfach | Breite Arbeitsblätter | Nein |
| Ränder reduzieren | Einfach | Kleine Layout-Korrekturen | Nein |
| Druckbereich festlegen | Einfach | Drucken von Teilen des Arbeitsblatts | Nein |
| Papierformat ändern | Einfach | Große Berichte | Nein |
| C# mit Spire.XLS | Fortgeschritten | Stapel-/automatischer Druck | Ja |
Fazit
Das Drucken von Excel-Arbeitsblättern auf einer einzigen Seite kann die Lesbarkeit und Präsentationsqualität von Dokumenten erheblich verbessern. Excel bietet mehrere integrierte Funktionen – einschließlich Skalierung, Querformat, Druckbereichskonfiguration und Randanpassung –, um Drucklayouts schnell zu optimieren.
Für Entwickler und Unternehmenskunden bietet der programmgesteuerte Druck mit Spire.XLS eine leistungsstarke Automatisierungslösung. Durch die Aktivierung der Eigenschaft IsFitToPage können Excel-Arbeitsblätter automatisch auf eine Druckseite passen, was den Stapeldruck und die Berichterstellung erheblich effizienter macht.
FAQs
F1. Warum wird mein Excel-Blatt immer noch auf mehreren Seiten gedruckt?
Ihr Arbeitsblatt enthält möglicherweise versteckte Daten, ungenutzte formatierte Zellen, große Ränder oder zu viele Spalten. Überprüfen Sie den Druckbereich und die Skalierungseinstellungen.
F2. Reduziert das Anpassen eines Blatts auf einer Seite die Druckqualität?
Nein. Excel skaliert nur die Inhaltsgröße. Übermäßiges Schrumpfen kann den Text jedoch schwer lesbar machen.
F3. Kann ich nur Spalten auf einer Seite unterbringen?
Ja. Klicken Sie unter Einstellungen auf Keine Skalierung und wählen Sie Alle Spalten auf einer Seite ausgeben. Dadurch werden die Zeilen natürlich fortgesetzt, während alle Spalten auf einer Seite untergebracht werden.
F4. Ist der Querformatmodus besser für den Druck von Excel-Blättern?
Für breite Tabellenkalkulationen ja. Die Querformat-Ausrichtung bietet mehr horizontalen Druckplatz.
F5. Kann ich den Excel-Druck in Backend-Anwendungen automatisieren?
Ja. Bibliotheken wie Spire.XLS ermöglichen es Entwicklern, Excel-Dateien programmgesteuert mit C# zu drucken, ohne Excel manuell öffnen zu müssen.
Siehe auch
Как распечатать лист Excel на одной странице: 7 эффективных способов
Содержание
- Почему листы Excel не помещаются на одной странице
- Способ 1: Использовать опцию «Разместить лист на одной странице»
- Способ 2: Настроить масштабирование страницы вручную
- Способ 3: Изменить ориентацию страницы
- Способ 4: Уменьшить поля и удалить лишние столбцы
- Способ 5: Установить пользовательскую область печати
- Способ 6: Изменить размер бумаги
- Способ 7: Печать листа Excel на одной странице с помощью C#
- Сводная таблица сравнения
- Часто задаваемые вопросы
- Заключение
Таблицы Excel часто выглядят идеально на экране, но их сложно правильно распечатать. Большие таблицы могут выходить за пределы нескольких страниц, столбцы обрезаются, или результат печати становится неряшливым и трудночитаемым.
К счастью, Excel предоставляет несколько встроенных инструментов, которые помогут разместить рабочие листы на одной странице при печати. Независимо от того, печатаете ли вы счета-фактуры, отчеты, расписания, панели мониторинга или финансовые отчеты, эти методы помогут создать более четкие и профессиональные распечатки.
В этом руководстве вы узнаете о 7 эффективных способах печати листа Excel на одной странице, от настроек Excel для начинающих до продвинутой автоматизации с помощью C# и Spire.XLS.
Быстрая навигация:
- Способ 1: Использовать опцию «Разместить лист на одной странице»
- Способ 2: Настроить масштабирование страницы вручную
- Способ 3: Изменить ориентацию страницы
- Способ 4: Уменьшить поля и удалить лишние столбцы
- Способ 5: Установить пользовательскую область печати
- Способ 6: Изменить размер бумаги
- Способ 7: Печать листа Excel на одной странице с помощью C#
Почему листы Excel не помещаются на одной странице
Excel автоматически разделяет рабочие листы на несколько печатных страниц в зависимости от размера страницы, полей, масштабирования и размеров содержимого. Если рабочий лист содержит слишком много столбцов или строк, Excel может разделить содержимое на несколько страниц при печати.
Распространенные причины включают:
- Широкие таблицы с большим количеством столбцов
- Крупные размеры шрифтов
- Избыточные пустые пространства
- Широкие поля страницы
- Неправильная ориентация страницы
- Неиспользуемые ячейки, выходящие за пределы диапазона печати
В результате отчеты могут стать трудночитаемыми и привести к ненужной трате бумаги. Следующие методы помогут вам оптимизировать макет рабочего листа и разместить содержимое на одной печатной странице.
Способ 1: Использовать опцию «Разместить лист на одной странице»
Это самый простой и часто используемый метод. Excel включает встроенную функцию масштабирования, которая автоматически сжимает содержимое рабочего листа, чтобы оно поместилось на одной печатной странице.
Он особенно хорошо работает для счетов-фактур, расписаний, отчетов и таблиц среднего размера.
Шаги
- Откройте рабочий лист Excel.
- Нажмите Файл > Печать.
- В разделе Параметры нажмите Без масштабирования.
- Выберите Разместить лист на одной странице.
- Предварительно просмотрите результат в области Предварительный просмотр.
- Нажмите Печать, чтобы распечатать рабочий лист.
Что происходит
Excel автоматически масштабирует рабочий лист так, чтобы все строки и столбцы поместились на одной странице при печати.
Плюсы
- Чрезвычайно прост в использовании
- Ручное изменение размера не требуется
- Встроен непосредственно в Excel
Минусы
- Текст может стать слишком мелким для очень больших рабочих листов
Способ 2: Настроить масштабирование страницы вручную
Вместо того чтобы автоматически принудительно размещать все на одной странице, вы можете вручную уменьшить процент масштабирования. Это дает больше контроля над читаемостью и внешним видом печати.
Например, уменьшение масштабирования до 85% или 90% может хорошо подогнать содержимое, сохраняя при этом читаемость текста.
Шаги
- Откройте рабочий лист Excel и нажмите Файл > Печать.
- В разделе Параметры нажмите Без масштабирования.
- Выберите Параметры пользовательского масштабирования.
- В настройках масштабирования уменьшите процент масштабирования до тех пор, пока рабочий лист не будет лучше помещаться на странице.
- Проверьте макет в области Предварительный просмотр и продолжайте настройку при необходимости.
- Как только рабочий лист будет правильно помещаться на одной странице, нажмите Печать.
Лучше всего подходит для
- Финансовые отчеты
- Таблицы с немного увеличенными столбцами
- Рабочие листы, где важна читаемость
Совет: Избегайте слишком агрессивного уменьшения масштабирования. Мелкий текст может затруднить чтение печатных документов.
Способ 3: Изменить ориентацию страницы
Многие листы Excel шире, чем выше. Переключение с книжной ориентации на альбомную обеспечивает больше горизонтального пространства и может мгновенно уменьшить разрывы страниц.
Эта простая настройка особенно эффективна для электронных таблиц с большим количеством столбцов.
Шаги
- Откройте рабочий лист Excel и нажмите Файл > Печать.
- В окне настроек печати нажмите Параметры страницы.
- На вкладке Страница выберите альбомную ориентацию Альбомная.
- Нажмите ОК, чтобы применить настройку.
- Просмотрите макет в области Предварительный просмотр.
- Если рабочий лист правильно помещается на одной странице, нажмите Печать.
Почему это помогает
Альбомный режим увеличивает ширину печати, позволяя большему количеству столбцов поместиться на одной странице.
Лучше всего подходит для
- Широкие таблицы данных
- Панели мониторинга
- Отчеты с большим количеством столбцов
Способ 4: Уменьшить поля и удалить лишние столбцы
Большие поля страницы и неиспользуемые области рабочего листа занимают ценное пространство для печати. Уменьшение полей и удаление ненужного содержимого может значительно улучшить размещение на странице.
Этот метод часто комбинируется с масштабированием для лучших результатов.
Шаги
- Откройте рабочий лист Excel и удалите ненужное содержимое, такое как пустые строки, пустые столбцы, слишком крупные шрифты, избыточные пробелы или данные, которые не нужно печатать.
- Нажмите Файл > Печать.
- В разделе Параметры нажмите Обычные поля.
- Выберите Узкие, чтобы уменьшить поля страницы и создать больше пространства для печати.
- Если вам нужно дополнительное пространство, выберите Настраиваемые поля и вручную уменьшите верхние, нижние, левые и правые поля еще больше.
- Просмотрите результат в области Предварительный просмотр.
- Как только рабочий лист будет правильно помещаться на одной странице, нажмите Печать.
Почему это работает
Меньшие поля обеспечивают большую область печати, а очистка неиспользуемого содержимого предотвращает печать Excel ненужных страниц.
Совет: Нажмите Ctrl + End, чтобы увидеть последнюю использованную ячейку Excel. Иногда скрытое форматирование выходит далеко за пределы ваших фактических данных.
Способ 5: Установить пользовательскую область печати
Иногда нужно напечатать только часть рабочего листа. Определив пользовательскую область печати, Excel игнорирует ненужные ячейки и фокусируется только на выбранном содержимом.
Это один из самых эффективных способов предотвратить появление пустых страниц и слишком больших диапазонов печати.
Шаги
- Выберите ячейки или диапазон, которые вы хотите напечатать.
- Перейдите на вкладку Макет страницы.
- Нажмите Область печати в группе Параметры страницы.
- Выберите Задать область печати.
- Нажмите Файл > Печать, чтобы открыть настройки печати.
- Просмотрите выбранное содержимое в области Предварительный просмотр.
- Если макет выглядит правильно, нажмите Печать.
Лучше всего подходит для
- Отчеты
- Панели мониторинга
- Сводки
- Разделы счетов-фактур
Плюсы
- Предотвращает появление дополнительных пустых страниц
- Более быстрая печать
- Более чистый вывод
Способ 6: Изменить размер бумаги
Использование большего размера бумаги обеспечивает дополнительное пространство для печати и снижает необходимость чрезмерного масштабирования. Этот метод обычно используется в офисах для больших электронных таблиц и подробных отчетов.
Например, переход с бумаги формата Letter на Legal может значительно улучшить макет печати.
Шаги
- Откройте рабочий лист Excel и нажмите Файл > Печать.
- В разделе Параметры нажмите на текущий размер бумаги (например, A4).
- Выберите больший размер бумаги, например Legal, A3 или Tabloid.
- Просмотрите макет в области Предварительный просмотр.
- Если рабочий лист правильно помещается на странице, нажмите Печать.
Лучше всего подходит для
- Большие отчеты
- Финансовые электронные таблицы
- Широкие таблицы
Важное примечание
Убедитесь, что ваш принтер поддерживает выбранный размер бумаги.
Способ 7: Печать листа Excel на одной странице с помощью C#
Если вам нужно печатать рабочие листы Excel программно, автоматизация с помощью C# предоставляет гораздо более эффективное решение, чем ручная печать. Этот подход идеально подходит для корпоративных систем, платформ отчетности, запланированных задач и пакетной обработки документов.
Используя Spire.XLS для .NET, вы можете автоматически настраивать параметры страницы и размещать рабочие листы на одной печатной странице.
Ключевая настройка:
pageSetup.IsFitToPage = true;
Это свойство автоматически масштабирует содержимое рабочего листа, чтобы оно поместилось на одной странице при печати.
Установка Spire.XLS
Вы можете установить Spire.XLS через NuGet:
Install-Package Spire.XLS
Пример C#: Печать листа Excel на одной странице
using Spire.Xls;
using System.Drawing.Printing;
namespace PrintExcel
{
class Program
{
static void Main(string[] args)
{
// Загрузка документа Excel
Workbook workbook = new Workbook();
workbook.LoadFromFile("Sample.xlsx");
// Цикл по рабочим листам
for (int i = 0; i < workbook.Worksheets.Count; i++)
{
// Получение конкретного рабочего листа
Worksheet worksheet = workbook.Worksheets[i];
// Получение объекта PageSetup
PageSetup pageSetup = worksheet.PageSetup;
// Установка полей страницы
pageSetup.TopMargin = 0.3;
pageSetup.BottomMargin = 0.3;
pageSetup.LeftMargin = 0.3;
pageSetup.RightMargin = 0.3;
// Разрешить печать с сеткой
pageSetup.IsPrintGridlines = true;
// Разместить рабочий лист на одной странице
pageSetup.IsFitToPage = true;
}
// Получение PrinterSettings
PrinterSettings settings = workbook.PrintDocument.PrinterSettings;
// Указание имени принтера
settings.PrinterName = "Имя вашего принтера";
// Указание диапазона страниц для печати
settings.FromPage = 1;
settings.ToPage = 3;
// Выполнение печати
workbook.PrintDocument.Print();
}
}
}
Преимущества этого метода
- Полностью автоматизированная печать Excel
- Поддержка пакетной обработки
- Подходит для корпоративных приложений
- Исключает ручные операции в Excel
- Легко интегрируется в системы отчетности
Являясь комплексным API для работы с Excel в .NET, Spire.XLS для .NET позволяет разработчикам полностью управлять печатью рабочих листов с помощью кода, включая масштабирование, области печати, поля, ориентацию, колонтитулы и разрывы страниц.
Помимо печати, он также поддерживает создание Excel, редактирование, импорт/экспорт данных, вычисление формул, обработку диаграмм и преобразование между форматами Excel, PDF, CSV, HTML и изображений. Он широко используется для генерации отчетов, автоматизации бизнеса, финансовых систем и крупномасштабных приложений для обработки электронных таблиц.
Сводная таблица сравнения
| Метод | Сложность | Лучше всего подходит для | Автоматизация |
|---|---|---|---|
| Разместить лист на одной странице | Легко | Быстрая печать | Нет |
| Ручное масштабирование | Легко | Лучшая читаемость | Нет |
| Альбомная ориентация | Легко | Широкие рабочие листы | Нет |
| Уменьшить поля | Легко | Незначительные исправления макета | Нет |
| Задать область печати | Легко | Печать части рабочего листа | Нет |
| Изменить размер бумаги | Легко | Большие отчеты | Нет |
| C# с Spire.XLS | Продвинутый | Пакетная/автоматическая печать | Да |
Заключение
Печать рабочих листов Excel на одной странице может значительно улучшить читаемость и качество представления документов. Excel предлагает несколько встроенных функций, включая масштабирование, альбомную ориентацию, настройку области печати и регулировку полей, чтобы быстро оптимизировать макет печати.
Для разработчиков и корпоративных пользователей программная печать с помощью Spire.XLS предоставляет мощное решение для автоматизации. Включив свойство IsFitToPage, рабочие листы Excel могут автоматически помещаться на одной печатной странице, что делает пакетную печать и генерацию отчетов гораздо более эффективными.
Часто задаваемые вопросы
В1. Почему мой лист Excel по-прежнему печатается на нескольких страницах?
Ваш рабочий лист может содержать скрытые данные, неиспользуемые отформатированные ячейки, большие поля или слишком много столбцов. Проверьте область печати и настройки масштабирования.
В2. Уменьшает ли размещение листа на одной странице качество печати?
Нет. Excel только масштабирует размер содержимого. Однако чрезмерное сжатие может сделать текст трудночитаемым.
В3. Могу ли я разместить только столбцы на одной странице?
Да. В разделе Параметры нажмите Без масштабирования и выберите Разместить все столбцы на одной странице. Это сохранит естественное течение строк, при этом все столбцы будут помещаться на одной странице.
В4. Лучше ли альбомный режим для печати листов Excel?
Для широких электронных таблиц — да. Альбомная ориентация обеспечивает больше пространства для горизонтальной печати.
В5. Могу ли я автоматизировать печать Excel в серверных приложениях?
Да. Библиотеки, такие как Spire.XLS, позволяют разработчикам печатать файлы Excel программно с помощью C# без ручного открытия Excel.
См. также
Como imprimir PDFs no Windows: 5 maneiras fáceis e eficazes
Sumário
- Método 1: Imprimir PDFs usando o Microsoft Edge
- Método 2: Imprimir PDFs com o Adobe Acrobat Reader
- Método 3: Imprimir PDFs usando o Google Chrome
- Método 4: Imprimir PDFs do Explorador de Arquivos (Impressão Rápida)
- Método 5: Imprimir PDFs Programaticamente em C#
- Tabela de Comparação Rápida
- Perguntas Frequentes
- Conclusão

Imprimir arquivos PDF no Windows é simples quando você conhece as ferramentas certas. Quer você queira uma maneira rápida de imprimir um único PDF, precise de configurações de impressão mais avançadas ou queira automatizar a impressão em seu próprio aplicativo, o Windows oferece várias opções práticas.
Neste guia, você aprenderá 5 maneiras eficazes de imprimir PDFs no Windows, incluindo soluções integradas, métodos baseados em navegador e uma abordagem de programação C# para desenvolvedores.
Visão geral dos métodos abordados:
- Método 1: Imprimir PDFs usando o Microsoft Edge
- Método 2: Imprimir PDFs com o Adobe Acrobat Reader
- Método 3: Imprimir PDFs usando o Google Chrome
- Método 4: Imprimir PDFs do Explorador de Arquivos (Impressão Rápida)
- Método 5: Imprimir PDFs Programaticamente em C#
Método 1: Imprimir PDFs usando o Microsoft Edge
Ideal para: Usuários comuns que desejam uma solução de impressão rápida e simples
O Microsoft Edge vem pré-instalado no Windows 10 e Windows 11, tornando-o uma das maneiras mais acessíveis de imprimir arquivos PDF. O navegador inclui um visualizador de PDF integrado que suporta recursos de impressão comuns sem a necessidade de software de terceiros. Para usuários que precisam apenas de impressão ocasional de PDF, o Edge oferece uma solução leve e conveniente.
Passos
- Clique com o botão direito no seu arquivo PDF.
- Escolha Abrir com > Microsoft Edge .
- Pressione Ctrl + P ou clique no ícone Imprimir na barra de ferramentas.
- Configure as configurações de impressão:
- Impressora
- Cópias
- Intervalo de páginas
- Orientação
- Modo de cor
- Escala
- Clique em Imprimir .
Vantagens
- Nenhuma instalação adicional necessária
- Rápido e leve
- Fácil para iniciantes
Limitações
- Recursos de impressão avançados limitados
- Não ideal para layouts de impressão profissionais
Método 2: Imprimir PDFs com o Adobe Acrobat Reader
Ideal para: Impressão precisa e configurações de impressão avançadas
O Adobe Acrobat Reader é um dos aplicativos de PDF mais usados e é conhecido por seu mecanismo de renderização de PDF confiável. Ele oferece recursos de impressão mais avançados do que a maioria dos visualizadores integrados, tornando-o adequado para documentos comerciais, formulários, apresentações e arquivos prontos para impressão. Se você trabalha frequentemente com PDFs complexos, o Acrobat Reader geralmente oferece os resultados mais consistentes.
Passos
- Abra o arquivo PDF no Adobe Acrobat Reader.
- Pressione Ctrl + P .
- Ajuste as configurações de impressão, como:
- Impressão duplex
- Impressão em tons de cinza
- Impressão de pôster
- Várias páginas por folha
- Impressão de livreto
- Clique em Imprimir .
Vantagens
- Excelente compatibilidade com PDFs complexos
- Personalização avançada de impressão
- Renderização precisa de PDF
Limitações
- Tamanho de instalação maior
- Pode consumir mais recursos do sistema
Método 3: Imprimir PDFs usando o Google Chrome
Ideal para: Usuários que trabalham frequentemente dentro de um navegador da web
O Google Chrome inclui um visualizador de PDF integrado que permite aos usuários abrir e imprimir arquivos PDF diretamente da janela do navegador. Como muitas pessoas já usam o Chrome diariamente, este método é conveniente e requer quase nenhuma curva de aprendizado. É especialmente útil ao baixar PDFs de sites ou anexos de e-mail e imprimi-los imediatamente.
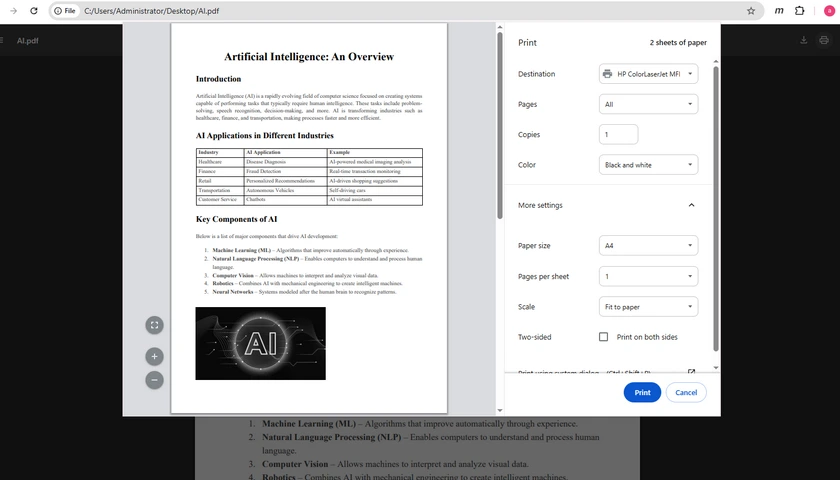
Passos
- Arraste e solte o PDF no Chrome.
- Pressione Ctrl + P .
- Configure as configurações de impressão.
- Clique em Imprimir .
Vantagens
- Conveniente e fácil de usar
- Inicialização rápida
- Nenhum software de PDF dedicado necessário
Limitações
- Menos opções de impressão profissional
- Menos adequado para PDFs muito grandes
Método 4: Imprimir PDFs do Explorador de Arquivos (Impressão Rápida)
Ideal para: Impressão de PDF com um clique
O Explorador de Arquivos do Windows inclui um atalho "Imprimir" integrado que permite aos usuários imprimir arquivos PDF diretamente do menu de contexto do botão direito. Este método é extremamente rápido porque você não precisa abrir o documento manualmente primeiro. Funciona bem para tarefas de impressão rápidas, especialmente ao lidar com documentos simples ou fluxos de trabalho de escritório rotineiros.
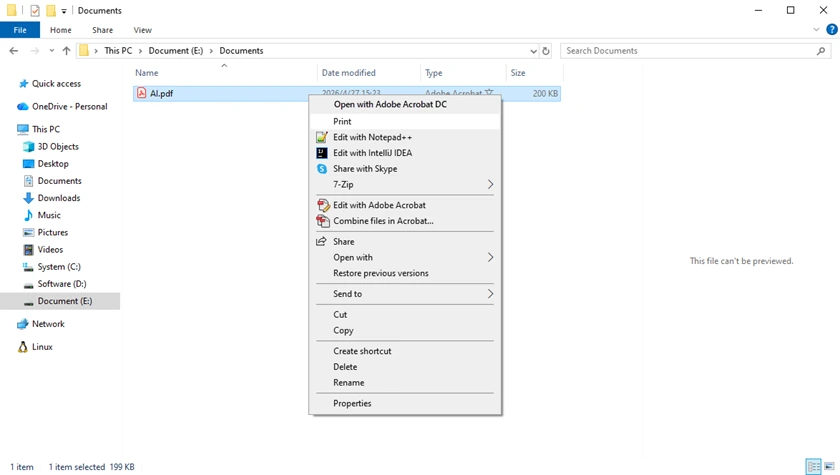
Passos
- Localize o arquivo PDF em seu computador.
- Clique com o botão direito no arquivo.
- Selecione Imprimir .
O Windows enviará automaticamente o PDF para sua impressora padrão usando o aplicativo PDF padrão.
Vantagens
- Extremamente rápido
- Fluxo de trabalho simples de um clique
- Útil para tarefas de impressão rápidas
Limitações
- Controle mínimo sobre as configurações de impressão
- Depende do visualizador de PDF padrão
Método 5: Imprimir PDFs Programaticamente em C#
Ideal para: Desenvolvedores que criam fluxos de trabalho automatizados de PDF
Se você precisar imprimir PDFs automaticamente em aplicativos desktop, sistemas corporativos ou serviços de backend, usar C# é uma solução muito mais flexível.
Com o Spire.PDF for .NET, os desenvolvedores podem imprimir arquivos PDF com configurações avançadas, como intervalos de páginas, impressão duplex, impressão em tons de cinza, seleção de impressora e processamento em lote.
Instalar a Biblioteca
Install-Package Spire.PDF
Exemplo em C#: Imprimir um Arquivo PDF
using Spire.Pdf;
using System.Drawing.Printing;
namespace PrintPdf
{
class Program
{
static void Main(string[] args)
{
// Carregar um arquivo pdf
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("Input.pdf");
// Especificar o nome da impressora
doc.PrintSettings.PrinterName = "Seu Nome da Impressora";
// Selecionar um intervalo de páginas para imprimir
doc.PrintSettings.SelectPageRange(1, 5);
// Ou selecionar páginas descontinuadas
// doc.PrintSettings.SelectSomePages(new int[] { 1, 3, 5, 7 });
// Especificar cópias
doc.PrintSettings.Copies = 1;
// Habilitar impressão duplex
doc.PrintSettings.Duplex = Duplex.Default;
// Habilitar impressão em tons de cinza
doc.PrintSettings.Color = false;
// Executar a impressão
doc.Print();
// Liberar recursos
doc.Dispose();
}
}
}
Exemplo em C#: Imprimir PDFs em Lote
using Spire.Pdf;
using System.IO;
namespace BatchPrintPdf
{
class Program
{
static void Main(string[] args)
{
// Especificar a pasta contendo os arquivos PDF
string folderPath = @"C:\PDFs\";
// Obter todos os arquivos PDF na pasta
string[] files = Directory.GetFiles(folderPath, "*.pdf");
// Iterar por cada arquivo PDF
foreach (string file in files)
{
// Carregar o documento PDF
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(file);
// Especificar o nome da impressora
doc.PrintSettings.PrinterName = "Seu Nome da Impressora";
// Imprimir o PDF
doc.Print();
// Liberar recursos
doc.Dispose();
}
}
}
}
Leia Mais: Como Imprimir Documentos PDF em C# (Sem Adobe)
Vantagens
- Suporte total de automação
- Personalização avançada de impressão
- Adequado para fluxos de trabalho corporativos
- Suporta impressão silenciosa e em lote
Limitações
- Requer conhecimento de programação
- Precisa de configuração do ambiente de desenvolvimento
Como uma biblioteca profissional de PDF para .NET, o Spire.PDF for .NET não apenas suporta a impressão de PDF, mas também permite que os desenvolvedores criem, editem, convertam, dividam, mescle, protejam e extraiam conteúdo de documentos PDF programaticamente. É adequado para aplicativos desktop, projetos ASP.NET, serviços em nuvem e sistemas de processamento de documentos automatizados.
Tabela de Comparação Rápida
| Método | Ideal para | Dificuldade | Recursos Avançados |
|---|---|---|---|
| Microsoft Edge | Impressão básica de PDF | Fácil | Baixo |
| Adobe Acrobat Reader | Impressão profissional | Fácil | Alto |
| Google Chrome | Impressão baseada em navegador | Fácil | Médio |
| Impressão Rápida do Explorador de Arquivos | Impressão com um clique | Muito Fácil | Baixo |
| Programação em C# | Automação e fluxos de trabalho corporativos | Avançado | Muito Alto |
Conclusão
Existem várias maneiras fáceis de imprimir PDFs no Windows, dependendo de suas necessidades. Para usuários casuais, ferramentas integradas como Microsoft Edge e Google Chrome oferecem impressão rápida e conveniente. O Adobe Acrobat Reader oferece controles de impressão mais profissionais e melhor compatibilidade com arquivos PDF complexos.
Para desenvolvedores e empresas, a impressão programática em C# oferece o mais alto nível de flexibilidade e automação. Usando bibliotecas como Spire.PDF for .NET, você pode integrar a impressão de PDF diretamente em seus próprios aplicativos e fluxos de trabalho de documentos com o mínimo de código.
Perguntas Frequentes
P1. O Windows pode imprimir PDFs sem o Adobe Reader?
Sim. Os usuários do Windows podem imprimir PDFs usando ferramentas integradas como o Microsoft Edge ou navegadores da web como o Google Chrome sem instalar o Adobe Reader.
P2. Por que meu PDF não está imprimindo corretamente?
Escalonamento incorreto, fontes não suportadas, arquivos PDF corrompidos ou drivers de impressora desatualizados podem causar problemas de impressão. Tentar outro visualizador de PDF ou atualizar o driver da impressora geralmente ajuda a resolver o problema.
P3. Como imprimo apenas páginas específicas de um PDF?
A maioria dos visualizadores de PDF permite que você especifique um intervalo de páginas personalizado na caixa de diálogo de impressão. Por exemplo, você pode imprimir as páginas 1-3, 5 ou 7-10 em vez do documento inteiro.
P4. Posso imprimir PDFs em preto e branco?
Sim. A maioria das ferramentas de impressão de PDF inclui uma opção em tons de cinza ou monocromática nas configurações de impressão. Isso ajuda a reduzir o uso de tinta colorida.
P5. Como os desenvolvedores podem automatizar a impressão de PDF em C#?
Os desenvolvedores podem usar bibliotecas de PDF como o Spire.PDF for .NET para automatizar a impressão de PDF com recursos como seleção de impressora, impressão de intervalo de páginas, modo duplex e impressão silenciosa.
Windows에서 PDF 인쇄하는 방법: 5가지 쉽고 효과적인 방법
Windows에서 PDF 파일을 인쇄하는 것은 올바른 도구를 알면 간단합니다. 단일 PDF를 빠르게 인쇄하거나, 더 고급 인쇄 설정이 필요하거나, 자체 애플리케이션에서 인쇄를 자동화하려는 경우 Windows는 여러 가지 실용적인 옵션을 제공합니다.
이 가이드에서는 기본 제공 솔루션, 브라우저 기반 방법 및 개발자를 위한 C# 프로그래밍 접근 방식을 포함하여 Windows에서 PDF를 인쇄하는 5가지 효과적인 방법을 배웁니다.
다루는 방법 개요:
- 방법 1: Microsoft Edge를 사용하여 PDF 인쇄
- 방법 2: Adobe Acrobat Reader로 PDF 인쇄
- 방법 3: Google Chrome을 사용하여 PDF 인쇄
- 방법 4: 파일 탐색기에서 PDF 인쇄 (빠른 인쇄)
- 방법 5: C#에서 프로그래밍 방식으로 PDF 인쇄
방법 1: Microsoft Edge를 사용하여 PDF 인쇄
적합 대상: 빠르고 간단한 인쇄 솔루션을 원하는 일반 사용자
Microsoft Edge는 Windows 10 및 Windows 11에 사전 설치되어 있어 PDF 파일을 인쇄하는 가장 접근하기 쉬운 방법 중 하나입니다. 이 브라우저에는 타사 소프트웨어 없이 일반적인 인쇄 기능을 지원하는 내장 PDF 뷰어가 포함되어 있습니다. 가끔 PDF 인쇄만 필요한 사용자의 경우 Edge는 가볍고 편리한 솔루션을 제공합니다.
단계
- PDF 파일을 마우스 오른쪽 버튼으로 클릭합니다.
- 다른 이름으로 열기 > Microsoft Edge를 선택합니다.
- Ctrl + P를 누르거나 도구 모음의 인쇄 아이콘을 클릭합니다.
- 인쇄 설정을 구성합니다:
- 프린터
- 복사본 수
- 페이지 범위
- 방향
- 색상 모드
- 확대/축소
- 인쇄를 클릭합니다.
장점
- 추가 설치가 필요하지 않습니다.
- 빠르고 가볍습니다.
- 초보자에게 쉽습니다.
단점
- 고급 인쇄 기능이 제한적입니다.
- 전문적인 인쇄 레이아웃에는 적합하지 않습니다.
방법 2: Adobe Acrobat Reader로 PDF 인쇄
적합 대상: 정확한 인쇄 및 고급 인쇄 설정
Adobe Acrobat Reader는 가장 널리 사용되는 PDF 애플리케이션 중 하나이며 안정적인 PDF 렌더링 엔진으로 유명합니다. 대부분의 내장 뷰어보다 더 고급 인쇄 기능을 제공하므로 비즈니스 문서, 양식, 프레젠테이션 및 인쇄 준비 파일에 적합합니다. 복잡한 PDF를 자주 다루는 경우 Acrobat Reader는 일반적으로 가장 일관된 결과를 제공합니다.
단계
- Adobe Acrobat Reader에서 PDF 파일을 엽니다.
- Ctrl + P를 누릅니다.
- 다음과 같은 인쇄 설정을 조정합니다:
- 양면 인쇄
- 회색조 인쇄
- 포스터 인쇄
- 페이지당 여러 페이지
- 책자 인쇄
- 인쇄를 클릭합니다.
장점
- 복잡한 PDF와의 뛰어난 호환성
- 고급 인쇄 사용자 지정
- 정확한 PDF 렌더링
단점
- 설치 크기가 큽니다.
- 더 많은 시스템 리소스를 소비할 수 있습니다.
방법 3: Google Chrome을 사용하여 PDF 인쇄
적합 대상: 웹 브라우저 내에서 자주 작업하는 사용자
Google Chrome에는 사용자가 브라우저 창에서 직접 PDF 파일을 열고 인쇄할 수 있는 내장 PDF 뷰어가 포함되어 있습니다. 많은 사람들이 이미 매일 Chrome을 사용하고 있기 때문에 이 방법은 편리하며 거의 학습 곡선이 필요하지 않습니다. 웹사이트나 이메일 첨부 파일에서 PDF를 다운로드하고 즉시 인쇄할 때 특히 유용합니다.
단계
- PDF를 Chrome으로 드래그 앤 드롭합니다.
- Ctrl + P를 누릅니다.
- 인쇄 설정을 구성합니다.
- 인쇄를 클릭합니다.
장점
- 편리하고 사용하기 쉽습니다.
- 빠른 시작
- 전용 PDF 소프트웨어가 필요하지 않습니다.
단점
- 전문적인 인쇄 옵션이 적습니다.
- 매우 큰 PDF에는 덜 적합합니다.
방법 4: 파일 탐색기에서 PDF 인쇄 (빠른 인쇄)
적합 대상: 한 번의 클릭으로 PDF 인쇄
Windows 파일 탐색기에는 사용자가 마우스 오른쪽 버튼 클릭 컨텍스트 메뉴에서 직접 PDF 파일을 인쇄할 수 있는 내장 "인쇄" 바로가기가 포함되어 있습니다. 이 방법은 문서를 먼저 수동으로 열 필요가 없기 때문에 매우 빠릅니다. 특히 간단한 문서나 일반적인 사무 워크플로우를 처리할 때 빠른 인쇄 작업에 잘 작동합니다.
단계
- 컴퓨터에서 PDF 파일을 찾습니다.
- 파일을 마우스 오른쪽 버튼으로 클릭합니다.
- 인쇄를 선택합니다.
Windows는 기본 PDF 애플리케이션을 사용하여 PDF를 기본 프린터로 자동 전송합니다.
장점
- 매우 빠릅니다.
- 간단한 한 번의 클릭 워크플로우
- 빠른 인쇄 작업에 유용합니다.
단점
- 인쇄 설정에 대한 제어가 최소화됩니다.
- 기본 PDF 뷰어에 의존합니다.
방법 5: C#에서 프로그래밍 방식으로 PDF 인쇄
적합 대상: 자동화된 PDF 워크플로우를 구축하는 개발자
데스크톱 애플리케이션, 엔터프라이즈 시스템 또는 백엔드 서비스 내에서 PDF를 자동으로 인쇄해야 하는 경우 C#을 사용하는 것이 훨씬 더 유연한 솔루션입니다.
Spire.PDF for .NET을 사용하면 개발자는 페이지 범위, 양면 인쇄, 회색조 인쇄, 프린터 선택 및 일괄 처리와 같은 고급 설정을 사용하여 PDF 파일을 인쇄할 수 있습니다.
라이브러리 설치
Install-Package Spire.PDF
C# 예제: PDF 파일 인쇄
using Spire.Pdf;
using System.Drawing.Printing;
namespace PrintPdf
{
class Program
{
static void Main(string[] args)
{
// Load a pdf file
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("Input.pdf");
// Specify the printer name
doc.PrintSettings.PrinterName = "Your Printer Name";
// Select a page range to print
doc.PrintSettings.SelectPageRange(1, 5);
// Or select discontinuous pages
// doc.PrintSettings.SelectSomePages(new int[] { 1, 3, 5, 7 });
// Specify copies
doc.PrintSettings.Copies = 1;
// Enable duplex printing
doc.PrintSettings.Duplex = Duplex.Default;
// Enable grayscale printing
doc.PrintSettings.Color = false;
// Execute printing
doc.Print();
// Dispose resources
doc.Dispose();
}
}
}
C# 예제: PDF 파일 일괄 인쇄
using Spire.Pdf;
using System.IO;
namespace BatchPrintPdf
{
class Program
{
static void Main(string[] args)
{
// Specify the folder containing PDF files
string folderPath = @"C:\PDFs\";
// Get all PDF files in the folder
string[] files = Directory.GetFiles(folderPath, "*.pdf");
// Loop through each PDF file
foreach (string file in files)
{
// Load the PDF document
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(file);
// Specify printer name
doc.PrintSettings.PrinterName = "Your Printer Name";
// Print the PDF
doc.Print();
// Dispose resources
doc.Dispose();
}
}
}
}
더 읽어보기: C#에서 PDF 문서 인쇄 방법 (Adobe 없이)
장점
- 완전한 자동화 지원
- 고급 인쇄 사용자 지정
- 엔터프라이즈 워크플로우에 적합
- 무음 및 일괄 인쇄 지원
단점
- 프로그래밍 지식이 필요합니다.
- 개발 환경 설정이 필요합니다.
전문 .NET PDF 라이브러리인 Spire.PDF for .NET은 PDF 인쇄를 지원할 뿐만 아니라 개발자가 PDF 문서를 프로그래밍 방식으로 생성, 편집, 변환, 분할, 병합, 보안 및 콘텐츠 추출할 수 있도록 합니다. 데스크톱 애플리케이션, ASP.NET 프로젝트, 클라우드 서비스 및 자동 문서 처리 시스템에 적합합니다.
빠른 비교표
| 방법 | 적합 대상 | 난이도 | 고급 기능 |
|---|---|---|---|
| Microsoft Edge | 기본 PDF 인쇄 | 쉬움 | 낮음 |
| Adobe Acrobat Reader | 전문 인쇄 | 쉬움 | 높음 |
| Google Chrome | 브라우저 기반 인쇄 | 쉬움 | 중간 |
| 파일 탐색기 빠른 인쇄 | 한 번의 클릭으로 인쇄 | 매우 쉬움 | 낮음 |
| C# 프로그래밍 | 자동화 및 엔터프라이즈 워크플로우 | 고급 | 매우 높음 |
결론
필요에 따라 Windows에서 PDF를 인쇄하는 몇 가지 쉬운 방법이 있습니다. 일반 사용자의 경우 Microsoft Edge 및 Google Chrome과 같은 내장 도구는 빠르고 편리한 인쇄를 제공합니다. Adobe Acrobat Reader는 더 전문적인 인쇄 제어와 복잡한 PDF 파일과의 더 나은 호환성을 제공합니다.
개발자 및 기업의 경우 C#에서 프로그래밍 방식으로 인쇄하면 가장 높은 수준의 유연성과 자동화를 제공합니다. Spire.PDF for .NET과 같은 라이브러리를 사용하면 최소한의 코드로 자체 애플리케이션 및 문서 워크플로우에 PDF 인쇄를 직접 통합할 수 있습니다.
자주 묻는 질문
Q1. Windows에서 Adobe Reader 없이 PDF를 인쇄할 수 있습니까?
예. Windows 사용자는 Adobe Reader를 설치하지 않고도 Microsoft Edge와 같은 내장 도구나 Google Chrome과 같은 웹 브라우저를 사용하여 PDF를 인쇄할 수 있습니다.
Q2. PDF가 제대로 인쇄되지 않는 이유는 무엇입니까?
잘못된 확대/축소, 지원되지 않는 글꼴, 손상된 PDF 파일 또는 오래된 프린터 드라이버가 모두 인쇄 문제를 일으킬 수 있습니다. 다른 PDF 뷰어를 사용하거나 프린터 드라이버를 업데이트하면 문제가 해결되는 경우가 많습니다.
Q3. PDF에서 특정 페이지만 인쇄하려면 어떻게 해야 합니까?
대부분의 PDF 뷰어에서는 인쇄 대화 상자에서 사용자 지정 페이지 범위를 지정할 수 있습니다. 예를 들어 전체 문서 대신 페이지 1-3, 5 또는 7-10을 인쇄할 수 있습니다.
Q4. PDF를 흑백으로 인쇄할 수 있습니까?
예. 대부분의 PDF 인쇄 도구에는 인쇄 설정에 회색조 또는 단색 옵션이 포함되어 있습니다. 이렇게 하면 컬러 잉크 사용량을 줄이는 데 도움이 됩니다.
Q5. 개발자는 C#에서 PDF 인쇄를 어떻게 자동화할 수 있습니까?
개발자는 Spire.PDF for .NET과 같은 PDF 라이브러리를 사용하여 프린터 선택, 페이지 범위 인쇄, 양면 모드 및 무음 인쇄와 같은 기능을 통해 PDF 인쇄를 자동화할 수 있습니다.
Come stampare PDF su Windows: 5 modi semplici ed efficaci
Indice
Stampare file PDF su Windows è semplice una volta che si conoscono gli strumenti giusti da utilizzare. Sia che tu voglia un modo rapido per stampare un singolo PDF, necessiti di impostazioni di stampa più avanzate o desideri automatizzare la stampa nella tua applicazione, Windows offre diverse opzioni pratiche.
In questa guida, imparerai 5 modi efficaci per stampare PDF su Windows, incluse soluzioni integrate, metodi basati su browser e un approccio di programmazione C# per sviluppatori.
Panoramica dei metodi trattati:
- Metodo 1: Stampare PDF con Microsoft Edge
- Metodo 2: Stampare PDF con Adobe Acrobat Reader
- Metodo 3: Stampare PDF con Google Chrome
- Metodo 4: Stampare PDF da Esplora file (Stampa rapida)
- Metodo 5: Stampare PDF programmaticamente in C#
Metodo 1: Stampare PDF con Microsoft Edge
Ideale per: Utenti comuni che desiderano una soluzione di stampa rapida e semplice
Microsoft Edge è preinstallato su Windows 10 e Windows 11, rendendolo uno dei modi più accessibili per stampare file PDF. Il browser include un visualizzatore PDF integrato che supporta le funzionalità di stampa comuni senza richiedere alcun software di terze parti. Per gli utenti che necessitano solo di stampare PDF occasionalmente, Edge offre una soluzione leggera e conveniente.
Passaggi
- Fare clic con il pulsante destro del mouse sul file PDF.
- Scegliere Apri con > Microsoft Edge.
- Premere Ctrl + P o fare clic sull'icona Stampa nella barra degli strumenti.
- Configurare le impostazioni di stampa:
- Stampante
- Copie
- Intervallo pagine
- Orientamento
- Modalità colore
- Scala
- Fare clic su Stampa.
Vantaggi
- Nessuna installazione aggiuntiva richiesta
- Veloce e leggero
- Facile per i principianti
Limitazioni
- Funzionalità di stampa avanzate limitate
- Non ideale per layout di stampa professionali
Metodo 2: Stampare PDF con Adobe Acrobat Reader
Ideale per: Stampa accurata e impostazioni di stampa avanzate
Adobe Acrobat Reader è una delle applicazioni PDF più utilizzate ed è noto per il suo motore di rendering PDF affidabile. Offre funzionalità di stampa più avanzate rispetto alla maggior parte dei visualizzatori integrati, rendendolo adatto per documenti aziendali, moduli, presentazioni e file pronti per la stampa. Se lavori frequentemente con PDF complessi, Acrobat Reader di solito fornisce i risultati più coerenti.
Passaggi
- Aprire il file PDF in Adobe Acrobat Reader.
- Premere Ctrl + P.
- Regolare le impostazioni di stampa come:
- Stampa fronte-retro
- Stampa in scala di grigi
- Stampa poster
- Pagine multiple per foglio
- Stampa opuscolo
- Fare clic su Stampa.
Vantaggi
- Eccellente compatibilità con PDF complessi
- Personalizzazione avanzata della stampa
- Rendering PDF accurato
Limitazioni
- Dimensioni di installazione maggiori
- Può consumare più risorse di sistema
Metodo 3: Stampare PDF con Google Chrome
Ideale per: Utenti che lavorano frequentemente all'interno di un browser web
Google Chrome include un visualizzatore PDF integrato che consente agli utenti di aprire e stampare file PDF direttamente dalla finestra del browser. Poiché molte persone usano già Chrome quotidianamente, questo metodo è conveniente e richiede quasi nessuna curva di apprendimento. È particolarmente utile quando si scaricano PDF da siti Web o allegati e-mail e li si stampa immediatamente.
Passaggi
- Trascinare e rilasciare il PDF in Chrome.
- Premere Ctrl + P.
- Configurare le impostazioni di stampa.
- Fare clic su Stampa.
Vantaggi
- Conveniente e facile da usare
- Avvio rapido
- Nessun software PDF dedicato richiesto
Limitazioni
- Meno opzioni di stampa professionali
- Meno adatto per PDF molto grandi
Metodo 4: Stampare PDF da Esplora file (Stampa rapida)
Ideale per: Stampa PDF con un clic
Esplora file di Windows include un collegamento "Stampa" integrato che consente agli utenti di stampare file PDF direttamente dal menu di scelta rapida. Questo metodo è estremamente veloce perché non è necessario aprire manualmente il documento prima. Funziona bene per attività di stampa rapide, specialmente quando si tratta di documenti semplici o flussi di lavoro d'ufficio di routine.
Passaggi
- Individuare il file PDF sul computer.
- Fare clic con il pulsante destro del mouse sul file.
- Selezionare Stampa.
Windows invierà automaticamente il PDF alla stampante predefinita utilizzando l'applicazione PDF predefinita.
Vantaggi
- Estremamente veloce
- Semplice flusso di lavoro con un clic
- Utile per attività di stampa rapide
Limitazioni
- Controllo minimo sulle impostazioni di stampa
- Dipende dal visualizzatore PDF predefinito
Metodo 5: Stampare PDF programmaticamente in C#
Ideale per: Sviluppatori che creano flussi di lavoro PDF automatizzati
Se è necessario stampare PDF automaticamente all'interno di applicazioni desktop, sistemi aziendali o servizi backend, l'utilizzo di C# è una soluzione molto più flessibile.
Con Spire.PDF for .NET, gli sviluppatori possono stampare file PDF con impostazioni avanzate come intervalli di pagine, stampa fronte-retro, stampa in scala di grigi, selezione della stampante ed elaborazione batch.
Installa la libreria
Install-Package Spire.PDF
Esempio C#: Stampa un file PDF
using Spire.Pdf;
using System.Drawing.Printing;
namespace PrintPdf
{
class Program
{
static void Main(string[] args)
{
// Carica un file pdf
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("Input.pdf");
// Specifica il nome della stampante
doc.PrintSettings.PrinterName = "Il tuo nome stampante";
// Seleziona un intervallo di pagine da stampare
doc.PrintSettings.SelectPageRange(1, 5);
// Oppure seleziona pagine discontinue
// doc.PrintSettings.SelectSomePages(new int[] { 1, 3, 5, 7 });
// Specifica le copie
doc.PrintSettings.Copies = 1;
// Abilita la stampa fronte-retro
doc.PrintSettings.Duplex = Duplex.Default;
// Abilita la stampa in scala di grigi
doc.PrintSettings.Color = false;
// Esegui la stampa
doc.Print();
// Rilascia le risorse
doc.Dispose();
}
}
}
Esempio C#: Stampa batch di file PDF
using Spire.Pdf;
using System.IO;
namespace BatchPrintPdf
{
class Program
{
static void Main(string[] args)
{
// Specifica la cartella contenente i file PDF
string folderPath = @"C:\PDFs\";
// Ottieni tutti i file PDF nella cartella
string[] files = Directory.GetFiles(folderPath, "*.pdf");
// Cicla ogni file PDF
foreach (string file in files)
{
// Carica il documento PDF
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(file);
// Specifica il nome della stampante
doc.PrintSettings.PrinterName = "Il tuo nome stampante";
// Stampa il PDF
doc.Print();
// Rilascia le risorse
doc.Dispose();
}
}
}
}
Leggi ulteriormente: Come stampare documenti PDF in C# (senza Adobe)
Vantaggi
- Supporto completo per l'automazione
- Personalizzazione avanzata della stampa
- Adatto per flussi di lavoro aziendali
- Supporta la stampa silenziosa e batch
Limitazioni
- Richiede conoscenze di programmazione
- Necessita di configurazione dell'ambiente di sviluppo
Come libreria PDF .NET professionale, Spire.PDF for .NET non solo supporta la stampa di PDF, ma consente anche agli sviluppatori di creare, modificare, convertire, dividere, unire, proteggere ed estrarre contenuti da documenti PDF programmaticamente. È adatto per applicazioni desktop, progetti ASP.NET, servizi cloud e sistemi di elaborazione documenti automatizzati.
Tabella di confronto rapido
| Metodo | Ideale per | Difficoltà | Funzionalità avanzate |
|---|---|---|---|
| Microsoft Edge | Stampa PDF di base | Facile | Bassa |
| Adobe Acrobat Reader | Stampa professionale | Facile | Alta |
| Google Chrome | Stampa basata su browser | Facile | Media |
| Stampa rapida da Esplora file | Stampa con un clic | Molto facile | Bassa |
| Programmazione C# | Automazione e flussi di lavoro aziendali | Avanzato | Molto alta |
Conclusione
Ci sono diversi modi semplici per stampare PDF su Windows, a seconda delle tue esigenze. Per gli utenti occasionali, gli strumenti integrati come Microsoft Edge e Google Chrome offrono una stampa rapida e conveniente. Adobe Acrobat Reader offre controlli di stampa più professionali e una migliore compatibilità con file PDF complessi.
Per sviluppatori e aziende, la stampa programmatica in C# offre il massimo livello di flessibilità e automazione. Utilizzando librerie come Spire.PDF for .NET, puoi integrare la stampa di PDF direttamente nelle tue applicazioni e nei tuoi flussi di lavoro documentali con il minimo codice.
Domande frequenti
D1. Windows può stampare PDF senza Adobe Reader?
Sì. Gli utenti Windows possono stampare PDF utilizzando strumenti integrati come Microsoft Edge o browser web come Google Chrome senza installare Adobe Reader.
D2. Perché il mio PDF non viene stampato correttamente?
Scala errata, font non supportati, file PDF corrotti o driver di stampante obsoleti possono causare problemi di stampa. Provare un altro visualizzatore PDF o aggiornare il driver della stampante spesso aiuta a risolvere il problema.
D3. Come stampo solo pagine specifiche da un PDF?
La maggior parte dei visualizzatori PDF consente di specificare un intervallo di pagine personalizzato nella finestra di dialogo di stampa. Ad esempio, puoi stampare le pagine 1-3, 5 o 7-10 invece dell'intero documento.
D4. Posso stampare PDF in bianco e nero?
Sì. La maggior parte degli strumenti di stampa PDF include un'opzione in scala di grigi o monocromatica nelle impostazioni di stampa. Questo aiuta a ridurre l'uso di inchiostro a colori.
D5. Come possono gli sviluppatori automatizzare la stampa di PDF in C#?
Gli sviluppatori possono utilizzare librerie PDF come Spire.PDF for .NET per automatizzare la stampa di PDF con funzionalità come la selezione della stampante, la stampa di intervalli di pagine, la modalità fronte-retro e la stampa silenziosa.
Comment imprimer des PDF sur Windows : 5 méthodes simples et efficaces
Table des matières
- Méthode 1 : Imprimer des PDF avec Microsoft Edge
- Méthode 2 : Imprimer des PDF avec Adobe Acrobat Reader
- Méthode 3 : Imprimer des PDF avec Google Chrome
- Méthode 4 : Imprimer des PDF depuis l'Explorateur de fichiers (Impression rapide)
- Méthode 5 : Imprimer des PDF par programmation en C#
- Tableau comparatif rapide
- FAQ
- Conclusion
L'impression de fichiers PDF sous Windows est simple une fois que vous connaissez les bons outils à utiliser. Que vous souhaitiez un moyen rapide d'imprimer un seul PDF, que vous ayez besoin de paramètres d'impression plus avancés ou que vous souhaitiez automatiser l'impression dans votre propre application, Windows offre plusieurs options pratiques.
Dans ce guide, vous découvrirez 5 méthodes efficaces pour imprimer des PDF sous Windows, y compris des solutions intégrées, des méthodes basées sur un navigateur et une approche de programmation C# pour les développeurs.
Aperçu des méthodes abordées :
- Méthode 1 : Imprimer des PDF avec Microsoft Edge
- Méthode 2 : Imprimer des PDF avec Adobe Acrobat Reader
- Méthode 3 : Imprimer des PDF avec Google Chrome
- Méthode 4 : Imprimer des PDF depuis l'Explorateur de fichiers (Impression rapide)
- Méthode 5 : Imprimer des PDF par programmation en C#
Méthode 1 : Imprimer des PDF avec Microsoft Edge
Idéal pour : Les utilisateurs quotidiens qui souhaitent une solution d'impression rapide et simple
Microsoft Edge est préinstallé sur Windows 10 et Windows 11, ce qui en fait l'un des moyens les plus accessibles d'imprimer des fichiers PDF. Le navigateur inclut un visualiseur PDF intégré qui prend en charge les fonctionnalités d'impression courantes sans nécessiter de logiciel tiers. Pour les utilisateurs qui n'ont besoin que d'imprimer des PDF occasionnellement, Edge offre une solution légère et pratique.
Étapes
- Cliquez avec le bouton droit sur votre fichier PDF.
- Choisissez Ouvrir avec > Microsoft Edge .
- Appuyez sur Ctrl + P ou cliquez sur l'icône Imprimer dans la barre d'outils.
- Configurez les paramètres d'impression :
- Imprimante
- Copies
- Plage de pages
- Orientation
- Mode couleur
- Échelle
- Cliquez sur Imprimer .
Avantages
- Aucune installation supplémentaire requise
- Rapide et léger
- Facile pour les débutants
Limites
- Fonctionnalités d'impression avancées limitées
- Pas idéal pour les mises en page d'impression professionnelles
Méthode 2 : Imprimer des PDF avec Adobe Acrobat Reader
Idéal pour : Impression précise et paramètres d'impression avancés
Adobe Acrobat Reader est l'une des applications PDF les plus utilisées et est connu pour son moteur de rendu PDF fiable. Il offre des capacités d'impression plus avancées que la plupart des visualiseurs intégrés, ce qui le rend adapté aux documents professionnels, aux formulaires, aux présentations et aux fichiers prêts à l'impression. Si vous travaillez fréquemment avec des PDF complexes, Acrobat Reader offre généralement les résultats les plus cohérents.
Étapes
- Ouvrez le fichier PDF dans Adobe Acrobat Reader.
- Appuyez sur Ctrl + P .
- Ajustez les paramètres d'impression tels que :
- Impression recto verso
- Impression en niveaux de gris
- Impression en affiche
- Plusieurs pages par feuille
- Impression de livret
- Cliquez sur Imprimer .
Avantages
- Excellente compatibilité avec les PDF complexes
- Personnalisation avancée de l'impression
- Rendu PDF précis
Limites
- Taille d'installation plus importante
- Peut consommer plus de ressources système
Méthode 3 : Imprimer des PDF avec Google Chrome
Idéal pour : Les utilisateurs qui travaillent fréquemment dans un navigateur Web
Google Chrome inclut un visualiseur PDF intégré qui permet aux utilisateurs d'ouvrir et d'imprimer des fichiers PDF directement depuis la fenêtre du navigateur. Comme beaucoup de gens utilisent déjà Chrome quotidiennement, cette méthode est pratique et ne nécessite pratiquement aucune courbe d'apprentissage. Elle est particulièrement utile lorsque vous téléchargez des PDF à partir de sites Web ou de pièces jointes d'e-mails et que vous les imprimez immédiatement.
Étapes
- Faites glisser et déposez le PDF dans Chrome.
- Appuyez sur Ctrl + P .
- Configurez les paramètres d'impression.
- Cliquez sur Imprimer .
Avantages
- Pratique et facile à utiliser
- Démarrage rapide
- Aucun logiciel PDF dédié requis
Limites
- Moins d'options d'impression professionnelles
- Moins adapté aux PDF très volumineux
Méthode 4 : Imprimer des PDF depuis l'Explorateur de fichiers (Impression rapide)
Idéal pour : Impression PDF en un clic
L'Explorateur de fichiers Windows inclut un raccourci "Imprimer" intégré qui permet aux utilisateurs d'imprimer des fichiers PDF directement depuis le menu contextuel du clic droit. Cette méthode est extrêmement rapide car vous n'avez pas besoin d'ouvrir manuellement le document au préalable. Elle fonctionne bien pour les tâches d'impression rapides, en particulier lorsque vous traitez des documents simples ou des flux de travail de bureau courants.
Étapes
- Localisez le fichier PDF sur votre ordinateur.
- Cliquez avec le bouton droit sur le fichier.
- Sélectionnez Imprimer .
Windows enverra automatiquement le PDF à votre imprimante par défaut en utilisant l'application PDF par défaut.
Avantages
- Extrêmement rapide
- Flux de travail simple en un clic
- Utile pour les tâches d'impression rapides
Limites
- Contrôle minimal sur les paramètres d'impression
- Repose sur le visualiseur PDF par défaut
Méthode 5 : Imprimer des PDF par programmation en C#
Idéal pour : Les développeurs qui créent des flux de travail PDF automatisés
Si vous devez imprimer des PDF automatiquement dans des applications de bureau, des systèmes d'entreprise ou des services backend, l'utilisation de C# est une solution beaucoup plus flexible.
Avec Spire.PDF pour .NET, les développeurs peuvent imprimer des fichiers PDF avec des paramètres avancés tels que les plages de pages, l'impression recto verso, l'impression en niveaux de gris, la sélection de l'imprimante et le traitement par lots.
Installer la bibliothèque
Install-Package Spire.PDF
Exemple C# : Imprimer un fichier PDF
using Spire.Pdf;
using System.Drawing.Printing;
namespace PrintPdf
{
class Program
{
static void Main(string[] args)
{
// Charger un fichier pdf
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("Input.pdf");
// Spécifier le nom de l'imprimante
doc.PrintSettings.PrinterName = "Votre nom d'imprimante";
// Sélectionner une plage de pages à imprimer
doc.PrintSettings.SelectPageRange(1, 5);
// Ou sélectionner des pages discontinues
// doc.PrintSettings.SelectSomePages(new int[] { 1, 3, 5, 7 });
// Spécifier les copies
doc.PrintSettings.Copies = 1;
// Activer l'impression recto verso
doc.PrintSettings.Duplex = Duplex.Default;
// Activer l'impression en niveaux de gris
doc.PrintSettings.Color = false;
// Exécuter l'impression
doc.Print();
// Libérer les ressources
doc.Dispose();
}
}
}
Exemple C# : Impression par lots de fichiers PDF
using Spire.Pdf;
using System.IO;
namespace BatchPrintPdf
{
class Program
{
static void Main(string[] args)
{
// Spécifier le dossier contenant les fichiers PDF
string folderPath = @"C:\PDFs\";
// Obtenir tous les fichiers PDF du dossier
string[] files = Directory.GetFiles(folderPath, "*.pdf");
// Parcourir chaque fichier PDF
foreach (string file in files)
{
// Charger le document PDF
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(file);
// Spécifier le nom de l'imprimante
doc.PrintSettings.PrinterName = "Votre nom d'imprimante";
// Imprimer le PDF
doc.Print();
// Libérer les ressources
doc.Dispose();
}
}
}
}
Lire la suite : Comment imprimer des documents PDF en C# (sans Adobe)
Avantages
- Prise en charge complète de l'automatisation
- Personnalisation avancée de l'impression
- Adapté aux flux de travail d'entreprise
- Prend en charge l'impression silencieuse et par lots
Limites
- Nécessite des connaissances en programmation
- Nécessite la configuration d'un environnement de développement
En tant que bibliothèque PDF .NET professionnelle, Spire.PDF pour .NET prend non seulement en charge l'impression PDF, mais permet également aux développeurs de créer, modifier, convertir, diviser, fusionner, sécuriser et extraire du contenu de documents PDF par programmation. Il convient aux applications de bureau, aux projets ASP.NET, aux services cloud et aux systèmes de traitement automatisé de documents.
Tableau comparatif rapide
| Méthode | Idéal pour | Difficulté | Fonctionnalités avancées |
|---|---|---|---|
| Microsoft Edge | Impression PDF de base | Facile | Faible |
| Adobe Acrobat Reader | Impression professionnelle | Facile | Élevé |
| Google Chrome | Impression basée sur le navigateur | Facile | Moyen |
| Impression rapide de l'Explorateur de fichiers | Impression en un clic | Très facile | Faible |
| Programmation C# | Automatisation et flux de travail d'entreprise | Avancé | Très élevé |
Conclusion
Il existe plusieurs façons simples d'imprimer des PDF sous Windows, en fonction de vos besoins. Pour les utilisateurs occasionnels, les outils intégrés comme Microsoft Edge et Google Chrome offrent une impression rapide et pratique. Adobe Acrobat Reader offre des contrôles d'impression plus professionnels et une meilleure compatibilité avec les fichiers PDF complexes.
Pour les développeurs et les entreprises, l'impression programmatique en C# offre le plus haut niveau de flexibilité et d'automatisation. En utilisant des bibliothèques comme Spire.PDF pour .NET, vous pouvez intégrer l'impression PDF directement dans vos propres applications et flux de travail de documents avec un minimum de code.
FAQ
Q1. Windows peut-il imprimer des PDF sans Adobe Reader ?
Oui. Les utilisateurs de Windows peuvent imprimer des PDF en utilisant des outils intégrés comme Microsoft Edge ou des navigateurs Web tels que Google Chrome sans installer Adobe Reader.
Q2. Pourquoi mon PDF ne s'imprime-t-il pas correctement ?
Une mise à l'échelle incorrecte, des polices non prises en charge, des fichiers PDF corrompus ou des pilotes d'imprimante obsolètes peuvent tous causer des problèmes d'impression. Essayer un autre visualiseur PDF ou mettre à jour le pilote de l'imprimante aide souvent à résoudre le problème.
Q3. Comment imprimer uniquement des pages spécifiques d'un PDF ?
La plupart des visualiseurs PDF vous permettent de spécifier une plage de pages personnalisée dans la boîte de dialogue d'impression. Par exemple, vous pouvez imprimer les pages 1-3, 5 ou 7-10 au lieu du document entier.
Q4. Puis-je imprimer des PDF en noir et blanc ?
Oui. La plupart des outils d'impression PDF incluent une option de niveaux de gris ou monochrome dans les paramètres d'impression. Cela permet de réduire l'utilisation d'encre couleur.
Q5. Comment les développeurs peuvent-ils automatiser l'impression de PDF en C# ?
Les développeurs peuvent utiliser des bibliothèques PDF telles que Spire.PDF pour .NET pour automatiser l'impression de PDF avec des fonctionnalités telles que la sélection de l'imprimante, l'impression de plages de pages, le mode recto verso et l'impression silencieuse.
Cómo imprimir PDF en Windows: 5 formas fáciles y efectivas
Tabla de Contenidos
- Método 1: Imprimir PDFs usando Microsoft Edge
- Método 2: Imprimir PDFs con Adobe Acrobat Reader
- Método 3: Imprimir PDFs usando Google Chrome
- Método 4: Imprimir PDFs desde el Explorador de Archivos (Impresión Rápida)
- Método 5: Imprimir PDFs mediante programación en C#
- Tabla Comparativa Rápida
- Preguntas Frecuentes
- Conclusión
Imprimir archivos PDF en Windows es sencillo una vez que conoces las herramientas adecuadas. Ya sea que desees una forma rápida de imprimir un solo PDF, necesites configuraciones de impresión más avanzadas o quieras automatizar la impresión en tu propia aplicación, Windows ofrece varias opciones prácticas.
En esta guía, aprenderás 5 formas efectivas de imprimir PDFs en Windows, incluyendo soluciones integradas, métodos basados en navegador y un enfoque de programación en C# para desarrolladores.
Resumen de los métodos cubiertos:
- Método 1: Imprimir PDFs usando Microsoft Edge
- Método 2: Imprimir PDFs con Adobe Acrobat Reader
- Método 3: Imprimir PDFs usando Google Chrome
- Método 4: Imprimir PDFs desde el Explorador de Archivos (Impresión Rápida)
- Método 5: Imprimir PDFs mediante programación en C#
Método 1: Imprimir PDFs usando Microsoft Edge
Ideal para: Usuarios cotidianos que desean una solución de impresión rápida y sencilla
Microsoft Edge viene preinstalado en Windows 10 y Windows 11, lo que lo convierte en una de las formas más accesibles de imprimir archivos PDF. El navegador incluye un visor de PDF integrado que admite funciones de impresión comunes sin necesidad de software de terceros. Para los usuarios que solo necesitan imprimir PDFs ocasionalmente, Edge ofrece una solución ligera y conveniente.
Pasos
- Haz clic derecho en tu archivo PDF.
- Selecciona Abrir con > Microsoft Edge .
- Presiona Ctrl + P o haz clic en el icono Imprimir en la barra de herramientas.
- Configura las opciones de impresión:
- Impresora
- Copias
- Rango de páginas
- Orientación
- Modo de color
- Escala
- Haz clic en Imprimir .
Ventajas
- No requiere instalación adicional
- Rápido y ligero
- Fácil para principiantes
Limitaciones
- Funciones de impresión avanzadas limitadas
- No ideal para diseños de impresión profesionales
Método 2: Imprimir PDFs con Adobe Acrobat Reader
Ideal para: Impresión precisa y configuraciones de impresión avanzadas
Adobe Acrobat Reader es una de las aplicaciones de PDF más utilizadas y es conocida por su motor de renderizado de PDF fiable. Proporciona capacidades de impresión más avanzadas que la mayoría de los visores integrados, lo que lo hace adecuado para documentos empresariales, formularios, presentaciones y archivos listos para imprimir. Si trabajas frecuentemente con PDFs complejos, Acrobat Reader generalmente ofrece los resultados más consistentes.
Pasos
- Abre el archivo PDF en Adobe Acrobat Reader.
- Presiona Ctrl + P .
- Ajusta las configuraciones de impresión como:
- Impresión a doble cara
- Impresión en escala de grises
- Impresión de póster
- Varias páginas por hoja
- Impresión de folletos
- Haz clic en Imprimir .
Ventajas
- Excelente compatibilidad con PDFs complejos
- Personalización avanzada de impresión
- Renderizado preciso de PDF
Limitaciones
- Tamaño de instalación mayor
- Puede consumir más recursos del sistema
Método 3: Imprimir PDFs usando Google Chrome
Ideal para: Usuarios que trabajan frecuentemente dentro de un navegador web
Google Chrome incluye un visor de PDF integrado que permite a los usuarios abrir e imprimir archivos PDF directamente desde la ventana del navegador. Dado que muchas personas ya usan Chrome a diario, este método es conveniente y requiere casi ninguna curva de aprendizaje. Es especialmente útil al descargar PDFs de sitios web o archivos adjuntos de correo electrónico e imprimirlos de inmediato.
Pasos
- Arrastra y suelta el PDF en Chrome.
- Presiona Ctrl + P .
- Configura las opciones de impresión.
- Haz clic en Imprimir .
Ventajas
- Conveniente y fácil de usar
- Inicio rápido
- No requiere software de PDF dedicado
Limitaciones
- Menos opciones de impresión profesional
- Menos adecuado para PDFs muy grandes
Método 4: Imprimir PDFs desde el Explorador de Archivos (Impresión Rápida)
Ideal para: Impresión de PDF con un solo clic
El Explorador de Archivos de Windows incluye un acceso directo "Imprimir" integrado que permite a los usuarios imprimir archivos PDF directamente desde el menú contextual del clic derecho. Este método es extremadamente rápido porque no necesitas abrir el documento manualmente primero. Funciona bien para tareas de impresión rápidas, especialmente al tratar con documentos sencillos o flujos de trabajo de oficina rutinarios.
Pasos
- Localiza el archivo PDF en tu computadora.
- Haz clic derecho en el archivo.
- Selecciona Imprimir .
Windows enviará automáticamente el PDF a tu impresora predeterminada utilizando la aplicación PDF predeterminada.
Ventajas
- Extremadamente rápido
- Flujo de trabajo simple de un clic
- Útil para tareas de impresión rápidas
Limitaciones
- Control mínimo sobre las configuraciones de impresión
- Depende del visor de PDF predeterminado
Método 5: Imprimir PDFs mediante programación en C#
Ideal para: Desarrolladores que crean flujos de trabajo de PDF automatizados
Si necesitas imprimir PDFs automáticamente dentro de aplicaciones de escritorio, sistemas empresariales o servicios backend, usar C# es una solución mucho más flexible.
Con Spire.PDF para .NET, los desarrolladores pueden imprimir archivos PDF con configuraciones avanzadas como rangos de páginas, impresión a doble cara, impresión en escala de grises, selección de impresora y procesamiento por lotes.
Instalar la Biblioteca
Install-Package Spire.PDF
Ejemplo de C#: Imprimir un archivo PDF
using Spire.Pdf;
using System.Drawing.Printing;
namespace PrintPdf
{
class Program
{
static void Main(string[] args)
{
// Cargar un archivo pdf
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("Input.pdf");
// Especificar el nombre de la impresora
doc.PrintSettings.PrinterName = "Tu Nombre de Impresora";
// Seleccionar un rango de páginas para imprimir
doc.PrintSettings.SelectPageRange(1, 5);
// O seleccionar páginas discontinuas
// doc.PrintSettings.SelectSomePages(new int[] { 1, 3, 5, 7 });
// Especificar copias
doc.PrintSettings.Copies = 1;
// Habilitar impresión a doble cara
doc.PrintSettings.Duplex = Duplex.Default;
// Habilitar impresión en escala de grises
doc.PrintSettings.Color = false;
// Ejecutar la impresión
doc.Print();
// Liberar recursos
doc.Dispose();
}
}
}
Ejemplo de C#: Imprimir archivos PDF en lote
using Spire.Pdf;
using System.IO;
namespace BatchPrintPdf
{
class Program
{
static void Main(string[] args)
{
// Especificar la carpeta que contiene los archivos PDF
string folderPath = @"C:\PDFs\";
// Obtener todos los archivos PDF en la carpeta
string[] files = Directory.GetFiles(folderPath, "*.pdf");
// Recorrer cada archivo PDF
foreach (string file in files)
{
// Cargar el documento PDF
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(file);
// Especificar el nombre de la impresora
doc.PrintSettings.PrinterName = "Tu Nombre de Impresora";
// Imprimir el PDF
doc.Print();
// Liberar recursos
doc.Dispose();
}
}
}
}
Leer más: Cómo imprimir documentos PDF en C# (sin Adobe)
Ventajas
- Soporte completo de automatización
- Personalización avanzada de impresión
- Adecuado para flujos de trabajo empresariales
- Soporta impresión silenciosa y por lotes
Limitaciones
- Requiere conocimientos de programación
- Necesita configuración del entorno de desarrollo
Como biblioteca profesional de PDF para .NET, Spire.PDF para .NET no solo admite la impresión de PDF, sino que también permite a los desarrolladores crear, editar, convertir, dividir, fusionar, proteger y extraer contenido de documentos PDF mediante programación. Es adecuado para aplicaciones de escritorio, proyectos ASP.NET, servicios en la nube y sistemas de procesamiento de documentos automatizados.
Tabla Comparativa Rápida
| Método | Ideal para | Dificultad | Funciones Avanzadas |
|---|---|---|---|
| Microsoft Edge | Impresión básica de PDF | Fácil | Baja |
| Adobe Acrobat Reader | Impresión profesional | Fácil | Alta |
| Google Chrome | Impresión basada en navegador | Fácil | Media |
| Impresión Rápida del Explorador de Archivos | Impresión con un clic | Muy Fácil | Baja |
| Programación en C# | Automatización y flujos de trabajo empresariales | Avanzado | Muy Alta |
Conclusión
Hay varias formas sencillas de imprimir PDFs en Windows, dependiendo de tus necesidades. Para usuarios ocasionales, herramientas integradas como Microsoft Edge y Google Chrome proporcionan una impresión rápida y conveniente. Adobe Acrobat Reader ofrece controles de impresión más profesionales y una mejor compatibilidad con archivos PDF complejos.
Para desarrolladores y empresas, la impresión programática en C# proporciona el mayor nivel de flexibilidad y automatización. Utilizando bibliotecas como Spire.PDF para .NET, puedes integrar la impresión de PDF directamente en tus propias aplicaciones y flujos de trabajo de documentos con un mínimo de código.
Preguntas Frecuentes
P1. ¿Puede Windows imprimir PDFs sin Adobe Reader?
Sí. Los usuarios de Windows pueden imprimir PDFs utilizando herramientas integradas como Microsoft Edge o navegadores web como Google Chrome sin necesidad de instalar Adobe Reader.
P2. ¿Por qué mi PDF no se imprime correctamente?
El escalado incorrecto, las fuentes no compatibles, los archivos PDF corruptos o los controladores de impresora obsoletos pueden causar problemas de impresión. Intentar con otro visor de PDF o actualizar el controlador de la impresora a menudo ayuda a resolver el problema.
P3. ¿Cómo imprimo solo páginas específicas de un PDF?
La mayoría de los visores de PDF te permiten especificar un rango de páginas personalizado en el cuadro de diálogo de impresión. Por ejemplo, puedes imprimir las páginas 1-3, 5 o 7-10 en lugar del documento completo.
P4. ¿Puedo imprimir PDFs en blanco y negro?
Sí. La mayoría de las herramientas de impresión de PDF incluyen una opción de escala de grises o monocromática en la configuración de impresión. Esto ayuda a reducir el uso de tinta de color.
P5. ¿Cómo pueden los desarrolladores automatizar la impresión de PDF en C#?
Los desarrolladores pueden usar bibliotecas de PDF como Spire.PDF para .NET para automatizar la impresión de PDF con funciones como selección de impresora, impresión de rangos de páginas, modo dúplex e impresión silenciosa.
PDFs unter Windows drucken: 5 einfache und effektive Wege
Inhaltsverzeichnis
Das Drucken von PDF-Dateien unter Windows ist einfach, wenn Sie die richtigen Werkzeuge kennen. Egal, ob Sie eine schnelle Möglichkeit zum Drucken einer einzelnen PDF-Datei benötigen, erweiterte Druckeinstellungen wünschen oder das Drucken in Ihrer eigenen Anwendung automatisieren möchten, Windows bietet mehrere praktische Optionen.
In dieser Anleitung lernen Sie 5 effektive Möglichkeiten zum Drucken von PDFs unter Windows kennen, darunter integrierte Lösungen, browserbasierte Methoden und ein C#-Programmieransatz für Entwickler.
Übersicht über die behandelten Methoden:
- Methode 1: PDFs mit Microsoft Edge drucken
- Methode 2: PDFs mit Adobe Acrobat Reader drucken
- Methode 3: PDFs mit Google Chrome drucken
- Methode 4: PDFs aus dem Datei-Explorer drucken (Schnelldruck)
- Methode 5: PDFs programmatisch in C# drucken
Methode 1: PDFs mit Microsoft Edge drucken
Am besten geeignet für: Alltägliche Benutzer, die eine schnelle und einfache Drucklösung suchen
Microsoft Edge ist auf Windows 10 und Windows 11 vorinstalliert und somit eine der zugänglichsten Möglichkeiten zum Drucken von PDF-Dateien. Der Browser verfügt über einen integrierten PDF-Viewer, der gängige Druckfunktionen unterstützt, ohne dass eine Software von Drittanbietern erforderlich ist. Für Benutzer, die nur gelegentlich PDFs drucken müssen, bietet Edge eine leichte und praktische Lösung.
Schritte
- Klicken Sie mit der rechten Maustaste auf Ihre PDF-Datei.
- Wählen Sie Öffnen mit > Microsoft Edge .
- Drücken Sie Strg + P oder klicken Sie auf das Symbol Drucken in der Symbolleiste.
- Konfigurieren Sie die Druckeinstellungen:
- Drucker
- Kopien
- Seitenbereich
- Ausrichtung
- Farbmodus
- Skalierung
- Klicken Sie auf Drucken .
Vorteile
- Keine zusätzliche Installation erforderlich
- Schnell und leichtgewichtig
- Einfach für Anfänger
Einschränkungen
- Begrenzte erweiterte Druckfunktionen
- Nicht ideal für professionelle Drucklayouts
Methode 2: PDFs mit Adobe Acrobat Reader drucken
Am besten geeignet für: Genaues Drucken und erweiterte Druckeinstellungen
Adobe Acrobat Reader ist eine der am weitesten verbreiteten PDF-Anwendungen und bekannt für seine zuverlässige PDF-Rendering-Engine. Es bietet erweiterte Druckfunktionen als die meisten integrierten Viewer und eignet sich daher für Geschäftsdokumente, Formulare, Präsentationen und druckfertige Dateien. Wenn Sie häufig mit komplexen PDFs arbeiten, liefert Acrobat Reader in der Regel die konsistentesten Ergebnisse.
Schritte
- Öffnen Sie die PDF-Datei in Adobe Acrobat Reader.
- Drücken Sie Strg + P .
- Passen Sie die Druckeinstellungen an, wie z. B.:
- Duplexdruck
- Graustufendruck
- Poster-Druck
- Mehrere Seiten pro Blatt
- Broschürendruck
- Klicken Sie auf Drucken .
Vorteile
- Hervorragende Kompatibilität mit komplexen PDFs
- Erweiterte Druckanpassung
- Genaue PDF-Darstellung
Einschränkungen
- Größere Installationsgröße
- Kann mehr Systemressourcen verbrauchen
Methode 3: PDFs mit Google Chrome drucken
Am besten geeignet für: Benutzer, die häufig in einem Webbrowser arbeiten
Google Chrome verfügt über einen integrierten PDF-Viewer, mit dem Benutzer PDF-Dateien direkt aus dem Browserfenster öffnen und drucken können. Da viele Leute Chrome bereits täglich nutzen, ist diese Methode praktisch und erfordert kaum Lernaufwand. Sie ist besonders nützlich, wenn Sie PDFs von Websites oder E-Mail-Anhängen herunterladen und sofort ausdrucken.
Schritte
- Ziehen Sie die PDF-Datei per Drag & Drop in Chrome.
- Drücken Sie Strg + P .
- Konfigurieren Sie die Druckeinstellungen.
- Klicken Sie auf Drucken .
Vorteile
- Bequem und einfach zu bedienen
- Schneller Start
- Keine dedizierte PDF-Software erforderlich
Einschränkungen
- Weniger professionelle Druckoptionen
- Weniger geeignet für sehr große PDFs
Methode 4: PDFs aus dem Datei-Explorer drucken (Schnelldruck)
Am besten geeignet für: Ein-Klick-PDF-Druck
Der Windows-Datei-Explorer enthält eine integrierte „Drucken“-Verknüpfung, mit der Benutzer PDF-Dateien direkt aus dem Kontextmenü per Rechtsklick drucken können. Diese Methode ist extrem schnell, da Sie das Dokument nicht zuerst manuell öffnen müssen. Sie eignet sich gut für schnelle Druckaufgaben, insbesondere bei einfachen Dokumenten oder routinemäßigen Büroabläufen.
Schritte
- Suchen Sie die PDF-Datei auf Ihrem Computer.
- Klicken Sie mit der rechten Maustaste auf die Datei.
- Wählen Sie Drucken .
Windows sendet die PDF-Datei automatisch an Ihren Standarddrucker, wobei die Standard-PDF-Anwendung verwendet wird.
Vorteile
- Extrem schnell
- Einfacher Ein-Klick-Workflow
- Nützlich für schnelle Druckaufgaben
Einschränkungen
- Minimale Kontrolle über die Druckeinstellungen
- Verlässt sich auf den Standard-PDF-Viewer
Methode 5: PDFs programmatisch in C# drucken
Am besten geeignet für: Entwickler, die automatisierte PDF-Workflows erstellen
Wenn Sie PDFs automatisch in Desktop-Anwendungen, Unternehmenssystemen oder Backend-Diensten drucken müssen, ist die Verwendung von C# eine flexiblere Lösung.
Mit Spire.PDF for .NET können Entwickler PDF-Dateien mit erweiterten Einstellungen wie Seitenbereichen, Duplexdruck, Graustufendruck, Druckerauswahl und Stapelverarbeitung drucken.
Bibliothek installieren
Install-Package Spire.PDF
C#-Beispiel: Eine PDF-Datei drucken
using Spire.Pdf;
using System.Drawing.Printing;
namespace PrintPdf
{
class Program
{
static void Main(string[] args)
{
// Eine PDF-Datei laden
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("Input.pdf");
// Druckernamen angeben
doc.PrintSettings.PrinterName = "Ihr Druckername";
// Einen zu druckenden Seitenbereich auswählen
doc.PrintSettings.SelectPageRange(1, 5);
// Oder einzelne Seiten auswählen
// doc.PrintSettings.SelectSomePages(new int[] { 1, 3, 5, 7 });
// Anzahl der Kopien angeben
doc.PrintSettings.Copies = 1;
// Duplexdruck aktivieren
doc.PrintSettings.Duplex = Duplex.Default;
// Graustufendruck aktivieren
doc.PrintSettings.Color = false;
// Drucken ausführen
doc.Print();
// Ressourcen freigeben
doc.Dispose();
}
}
}
C#-Beispiel: PDF-Dateien stapelweise drucken
using Spire.Pdf;
using System.IO;
namespace BatchPrintPdf
{
class Program
{
static void Main(string[] args)
{
// Ordner mit PDF-Dateien angeben
string folderPath = @"C:\PDFs\";
// Alle PDF-Dateien im Ordner abrufen
string[] files = Directory.GetFiles(folderPath, "*.pdf");
// Jede PDF-Datei durchlaufen
foreach (string file in files)
{
// PDF-Dokument laden
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(file);
// Druckernamen angeben
doc.PrintSettings.PrinterName = "Ihr Druckername";
// PDF drucken
doc.Print();
// Ressourcen freigeben
doc.Dispose();
}
}
}
}
Weiterlesen: So drucken Sie PDF-Dokumente in C# (ohne Adobe)
Vorteile
- Vollständige Automatisierungsunterstützung
- Erweiterte Druckanpassung
- Geeignet für Unternehmens-Workflows
- Unterstützt leisen und Stapeldruck
Einschränkungen
- Erfordert Programmierkenntnisse
- Benötigt Einrichtung der Entwicklungsumgebung
Als professionelle .NET-PDF-Bibliothek unterstützt Spire.PDF for .NET nicht nur den PDF-Druck, sondern ermöglicht Entwicklern auch, PDF-Dokumente programmatisch zu erstellen, zu bearbeiten, zu konvertieren, aufzuteilen, zusammenzuführen, zu sichern und Inhalte daraus zu extrahieren. Es eignet sich für Desktop-Anwendungen, ASP.NET-Projekte, Cloud-Dienste und automatisierte Dokumentenverarbeitungssysteme.
Vergleichstabelle
| Methode | Am besten geeignet für | Schwierigkeit | Erweiterte Funktionen |
|---|---|---|---|
| Microsoft Edge | Einfacher PDF-Druck | Einfach | Gering |
| Adobe Acrobat Reader | Professioneller Druck | Einfach | Hoch |
| Google Chrome | Browserbasierter Druck | Einfach | Mittel |
| Schnelldruck im Datei-Explorer | Ein-Klick-Druck | Sehr einfach | Gering |
| C#-Programmierung | Automatisierung & Unternehmens-Workflows | Fortgeschritten | Sehr hoch |
Fazit
Es gibt mehrere einfache Möglichkeiten, PDFs unter Windows zu drucken, je nach Ihren Bedürfnissen. Für Gelegenheitsnutzer bieten integrierte Tools wie Microsoft Edge und Google Chrome schnelles und bequemes Drucken. Adobe Acrobat Reader bietet professionellere Drucksteuerungen und eine bessere Kompatibilität mit komplexen PDF-Dateien.
Für Entwickler und Unternehmen bietet der programmatische Druck in C# ein Höchstmaß an Flexibilität und Automatisierung. Mit Bibliotheken wie Spire.PDF for .NET können Sie den PDF-Druck mit minimalem Code direkt in Ihre eigenen Anwendungen und Dokumenten-Workflows integrieren.
FAQs
F1. Kann Windows PDFs ohne Adobe Reader drucken?
Ja. Windows-Benutzer können PDFs mit integrierten Tools wie Microsoft Edge oder Webbrowsern wie Google Chrome drucken, ohne Adobe Reader installieren zu müssen.
F2. Warum wird mein PDF nicht korrekt gedruckt?
Falsche Skalierung, nicht unterstützte Schriftarten, beschädigte PDF-Dateien oder veraltete Druckertreiber können zu Druckproblemen führen. Der Versuch, einen anderen PDF-Viewer zu verwenden oder den Druckertreiber zu aktualisieren, hilft oft, das Problem zu lösen.
F3. Wie drucke ich nur bestimmte Seiten aus einem PDF?
Die meisten PDF-Viewer ermöglichen es Ihnen, einen benutzerdefinierten Seitenbereich im Druckdialogfeld anzugeben. Sie können beispielsweise die Seiten 1-3, 5 oder 7-10 anstelle des gesamten Dokuments drucken.
F4. Kann ich PDFs in Schwarzweiß drucken?
Ja. Die meisten PDF-Drucktools enthalten in den Druckeinstellungen eine Option für Graustufen oder Monochrom. Dies hilft, den Verbrauch von Farb-Tinte zu reduzieren.
F5. Wie können Entwickler den PDF-Druck in C# automatisieren?
Entwickler können PDF-Bibliotheken wie Spire.PDF for .NET verwenden, um den PDF-Druck mit Funktionen wie Druckerauswahl, Seitenbereichsdruck, Duplexmodus und stillem Druck zu automatisieren.
Как печатать PDF на Windows: 5 простых и эффективных способов
Оглавление
- Способ 1: Печать PDF-файлов с помощью Microsoft Edge
- Способ 2: Печать PDF-файлов с помощью Adobe Acrobat Reader
- Способ 3: Печать PDF-файлов с помощью Google Chrome
- Способ 4: Печать PDF-файлов из Проводника (Быстрая печать)
- Способ 5: Программная печать PDF-файлов в C#
- Сравнительная таблица
- Часто задаваемые вопросы
- Заключение
Печать PDF-файлов в Windows проста, если вы знаете правильные инструменты. Хотите ли вы быстрый способ печати одного PDF-файла, нуждаетесь в более расширенных настройках печати или хотите автоматизировать печать в своем собственном приложении, Windows предлагает несколько практических вариантов.
В этом руководстве вы узнаете о 5 эффективных способах печати PDF-файлов в Windows, включая встроенные решения, методы на основе браузера и подход к программированию на C# для разработчиков.
Обзор рассматриваемых методов:
- Способ 1: Печать PDF-файлов с помощью Microsoft Edge
- Способ 2: Печать PDF-файлов с помощью Adobe Acrobat Reader
- Способ 3: Печать PDF-файлов с помощью Google Chrome
- Способ 4: Печать PDF-файлов из Проводника (Быстрая печать)
- Способ 5: Программная печать PDF-файлов в C#
Способ 1: Печать PDF-файлов с помощью Microsoft Edge
Лучше всего подходит для: Обычных пользователей, которым нужно быстрое и простое решение для печати
Microsoft Edge предустановлен в Windows 10 и Windows 11, что делает его одним из самых доступных способов печати PDF-файлов. Браузер включает встроенный просмотрщик PDF, который поддерживает распространенные функции печати без необходимости установки стороннего программного обеспечения. Для пользователей, которым требуется только периодическая печать PDF, Edge предлагает легкое и удобное решение.
Шаги
- Щелкните правой кнопкой мыши по вашему PDF-файлу.
- Выберите Открыть с помощью > Microsoft Edge .
- Нажмите Ctrl + P или щелкните значок Печать на панели инструментов.
- Настройте параметры печати:
- Принтер
- Копии
- Диапазон страниц
- Ориентация
- Цветовой режим
- Масштаб
- Нажмите Печать .
Преимущества
- Не требуется дополнительная установка
- Быстрый и легкий
- Прост для начинающих
Ограничения
- Ограниченные расширенные функции печати
- Не подходит для профессионального макета печати
Способ 2: Печать PDF-файлов с помощью Adobe Acrobat Reader
Лучше всего подходит для: Точной печати и расширенных настроек печати
Adobe Acrobat Reader — одно из наиболее широко используемых приложений для работы с PDF, известное своим надежным механизмом рендеринга PDF. Он предоставляет более расширенные возможности печати, чем большинство встроенных просмотрщиков, что делает его подходящим для деловых документов, форм, презентаций и файлов, готовых к печати. Если вы часто работаете со сложными PDF-файлами, Acrobat Reader обычно обеспечивает наиболее стабильные результаты.
Шаги
- Откройте PDF-файл в Adobe Acrobat Reader.
- Нажмите Ctrl + P .
- Настройте параметры печати, такие как:
- Двусторонняя печать
- Печать в оттенках серого
- Печать постеров
- Несколько страниц на листе
- Печать брошюры
- Нажмите Печать .
Преимущества
- Отличная совместимость со сложными PDF-файлами
- Расширенная настройка печати
- Точный рендеринг PDF
Ограничения
- Большой размер установки
- Может потреблять больше системных ресурсов
Способ 3: Печать PDF-файлов с помощью Google Chrome
Лучше всего подходит для: Пользователей, которые часто работают в веб-браузере
Google Chrome включает встроенный просмотрщик PDF, который позволяет пользователям открывать и печатать PDF-файлы непосредственно из окна браузера. Поскольку многие люди уже ежедневно используют Chrome, этот метод удобен и практически не требует обучения. Он особенно полезен при загрузке PDF-файлов с веб-сайтов или вложений электронной почты и их немедленной печати.
Шаги
- Перетащите PDF в Chrome.
- Нажмите Ctrl + P .
- Настройте параметры печати.
- Нажмите Печать .
Преимущества
- Удобно и просто в использовании
- Быстрый запуск
- Не требуется специальное программное обеспечение для PDF
Ограничения
- Меньше профессиональных опций печати
- Менее подходит для очень больших PDF-файлов
Способ 4: Печать PDF-файлов из Проводника (Быстрая печать)
Лучше всего подходит для: Печати PDF одним щелчком мыши
Проводник Windows включает встроенную функцию «Печать», которая позволяет пользователям печатать PDF-файлы непосредственно из контекстного меню правой кнопки мыши. Этот метод чрезвычайно быстр, потому что вам не нужно вручную открывать документ. Он хорошо подходит для быстрых задач печати, особенно при работе с простыми документами или обычными офисными рабочими процессами.
Шаги
- Найдите PDF-файл на своем компьютере.
- Щелкните правой кнопкой мыши по файлу.
- Выберите Печать .
Windows автоматически отправит PDF на ваш принтер по умолчанию, используя приложение PDF по умолчанию.
Преимущества
- Чрезвычайно быстро
- Простой рабочий процесс в один клик
- Полезно для быстрых задач печати
Ограничения
- Минимальный контроль над настройками печати
- Зависит от программы просмотра PDF по умолчанию
Способ 5: Программная печать PDF-файлов в C#
Лучше всего подходит для: Разработчиков, создающих автоматизированные рабочие процессы для PDF
Если вам нужно автоматически печатать PDF-файлы в настольных приложениях, корпоративных системах или серверных службах, использование C# является гораздо более гибким решением.
С помощью Spire.PDF for .NET разработчики могут печатать PDF-файлы с расширенными настройками, такими как диапазоны страниц, двусторонняя печать, печать в оттенках серого, выбор принтера и пакетная обработка.
Установка библиотеки
Install-Package Spire.PDF
Пример кода на C#: Печать PDF-файла
using Spire.Pdf;
using System.Drawing.Printing;
namespace PrintPdf
{
class Program
{
static void Main(string[] args)
{
// Загрузка PDF-файла
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("Input.pdf");
// Указание имени принтера
doc.PrintSettings.PrinterName = "Имя вашего принтера";
// Выбор диапазона страниц для печати
doc.PrintSettings.SelectPageRange(1, 5);
// Или выбор отдельных страниц
// doc.PrintSettings.SelectSomePages(new int[] { 1, 3, 5, 7 });
// Указание количества копий
doc.PrintSettings.Copies = 1;
// Включение двусторонней печати
doc.PrintSettings.Duplex = Duplex.Default;
// Включение печати в оттенках серого
doc.PrintSettings.Color = false;
// Выполнение печати
doc.Print();
// Освобождение ресурсов
doc.Dispose();
}
}
}
Пример кода на C#: Пакетная печать PDF-файлов
using Spire.Pdf;
using System.IO;
namespace BatchPrintPdf
{
class Program
{
static void Main(string[] args)
{
// Указание папки, содержащей PDF-файлы
string folderPath = @"C:\PDFs\";
// Получение всех PDF-файлов в папке
string[] files = Directory.GetFiles(folderPath, "*.pdf");
// Перебор каждого PDF-файла
foreach (string file in files)
{
// Загрузка PDF-документа
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(file);
// Указание имени принтера
doc.PrintSettings.PrinterName = "Имя вашего принтера";
// Печать PDF
doc.Print();
// Освобождение ресурсов
doc.Dispose();
}
}
}
}
Читать далее: Как печатать PDF-документы на C# (без Adobe)
Преимущества
- Полная поддержка автоматизации
- Расширенная настройка печати
- Подходит для корпоративных рабочих процессов
- Поддерживает тихую и пакетную печать
Ограничения
- Требует знаний программирования
- Требует настройки среды разработки
Как профессиональная библиотека .NET для работы с PDF, Spire.PDF for .NET не только поддерживает печать PDF, но и позволяет разработчикам создавать, редактировать, конвертировать, разделять, объединять, защищать и извлекать контент из PDF-документов программно. Она подходит для настольных приложений, проектов ASP.NET, облачных сервисов и систем автоматизированной обработки документов.
Сравнительная таблица
| Способ | Лучше всего подходит для | Сложность | Расширенные функции |
|---|---|---|---|
| Microsoft Edge | Базовая печать PDF | Легко | Низкий |
| Adobe Acrobat Reader | Профессиональная печать | Легко | Высокий |
| Google Chrome | Печать из браузера | Легко | Средний |
| Быстрая печать из Проводника | Печать одним щелчком | Очень легко | Низкий |
| Программирование на C# | Автоматизация и корпоративные рабочие процессы | Сложно | Очень высокий |
Заключение
Существует несколько простых способов печати PDF-файлов в Windows, в зависимости от ваших потребностей. Для обычных пользователей встроенные инструменты, такие как Microsoft Edge и Google Chrome, обеспечивают быструю и удобную печать. Adobe Acrobat Reader предлагает более профессиональные элементы управления печатью и лучшую совместимость со сложными PDF-файлами.
Для разработчиков и предприятий программная печать в C# обеспечивает высочайший уровень гибкости и автоматизации. Используя библиотеки, такие как Spire.PDF for .NET, вы можете интегрировать печать PDF непосредственно в свои собственные приложения и рабочие процессы обработки документов с минимальным количеством кода.
Часто задаваемые вопросы
В1. Может ли Windows печатать PDF-файлы без Adobe Reader?
Да. Пользователи Windows могут печатать PDF-файлы, используя встроенные инструменты, такие как Microsoft Edge, или веб-браузеры, такие как Google Chrome, без установки Adobe Reader.
В2. Почему мой PDF-файл не печатается должным образом?
Неправильное масштабирование, неподдерживаемые шрифты, поврежденные PDF-файлы или устаревшие драйверы принтера могут вызвать проблемы с печатью. Попытка использовать другую программу для просмотра PDF или обновление драйвера принтера часто помогает решить проблему.
В3. Как распечатать только определенные страницы из PDF?
Большинство программ для просмотра PDF позволяют указать пользовательский диапазон страниц в диалоговом окне печати. Например, вы можете распечатать страницы 1-3, 5 или 7-10 вместо всего документа.
В4. Могу ли я печатать PDF-файлы в черно-белом режиме?
Да. Большинство инструментов для печати PDF включают опцию «оттенки серого» или «монохромный» в настройках печати. Это помогает снизить расход цветных чернил.
В5. Как разработчики могут автоматизировать печать PDF в C#?
Разработчики могут использовать библиотеки для работы с PDF, такие как Spire.PDF for .NET, для автоматизации печати PDF с такими функциями, как выбор принтера, печать диапазона страниц, режим двусторонней печати и тихая печать.