
Knowledgebase (2343)
Children categories
In MS Word, you can split a document by manually cutting the content from the original document and pasting it into a new document. Although the task is simple, it can also be quite tedious and time-consuming especially when dealing with a long document. This article will demonstrate how to programmatically split a Word document into multiple files using Spire.Doc for .NET .
Install Spire.Doc for .NET
To begin with, you need to add the DLL files included in the Spire.Doc for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.Doc
Split a Word Document by Page Break
A Word document can contain multiple pages separated by page breaks. To split a Word document by page break, you can refer to the below steps and code.
- Create a Document instance.
- Load a sample Word document using Document.LoadFromFile() method.
- Create a new Word document and add a section to it.
- Traverse through all body child objects of each section in the original document and determine whether the child object is a paragraph or a table.
- If the child object of the section is a table, directly add it to the section of new document using Section.Body.ChildObjects.Add() method.
- If the child object of the section is a paragraph, first add the paragraph object to the section of the new document. Then traverse through all child objects of the paragraph and determine whether the child object is a page break.
- If the child object of the paragraph is a page break, get its index and then remove the page break from its paragraph by index.
- Save the new Word document and then repeat the above processes.
- C#
- VB.NET
using System;
using Spire.Doc;
using Spire.Doc.Documents;
namespace SplitByPageBreak
{
class Program
{
static void Main(string[] args)
{
//Create a Document instance
Document original = new Document();
//Load a sample Word document
original.LoadFromFile(@"E:\Files\SplitByPageBreak.docx");
//Create a new Word document and add a section to it
Document newWord = new Document();
Section section = newWord.AddSection();
int index = 0;
//Traverse through all sections of the original document
foreach (Section sec in original.Sections)
{
//Traverse through all body child objects of each section
foreach (DocumentObject obj in sec.Body.ChildObjects)
{
if (obj is Paragraph)
{
Paragraph para = obj as Paragraph;
sec.CloneSectionPropertiesTo(section);
//Add paragraph object in the section of original document into section of new document
section.Body.ChildObjects.Add(para.Clone());
//Traverse through all child objects of each paragraph and determine whether the object is a page break
foreach (DocumentObject parobj in para.ChildObjects)
{
if (parobj is Break && (parobj as Break).BreakType == BreakType.PageBreak)
{
//Get the index of page break in paragraph
int i = para.ChildObjects.IndexOf(parobj);
//Remove the page break from its paragraph
section.Body.LastParagraph.ChildObjects.RemoveAt(i);
//Save the new Word document
newWord.SaveToFile(String.Format("result\out-{0}.docx", index), FileFormat.Docx);
index++;
//Create a new document and add a section
newWord = new Document();
section = newWord.AddSection();
//Add paragraph object in original section into section of new document
section.Body.ChildObjects.Add(para.Clone());
if (section.Paragraphs[0].ChildObjects.Count == 0)
{
//Remove the first blank paragraph
section.Body.ChildObjects.RemoveAt(0);
}
else
{
//Remove the child objects before the page break
while (i >= 0)
{
section.Paragraphs[0].ChildObjects.RemoveAt(i);
i--;
}
}
}
}
}
if (obj is Table)
{
//Add table object in original section into section of new document
section.Body.ChildObjects.Add(obj.Clone());
}
}
}
//Save to file
newWord.SaveToFile(String.Format("result/out-{0}.docx", index), FileFormat.Docx);
}
}
}
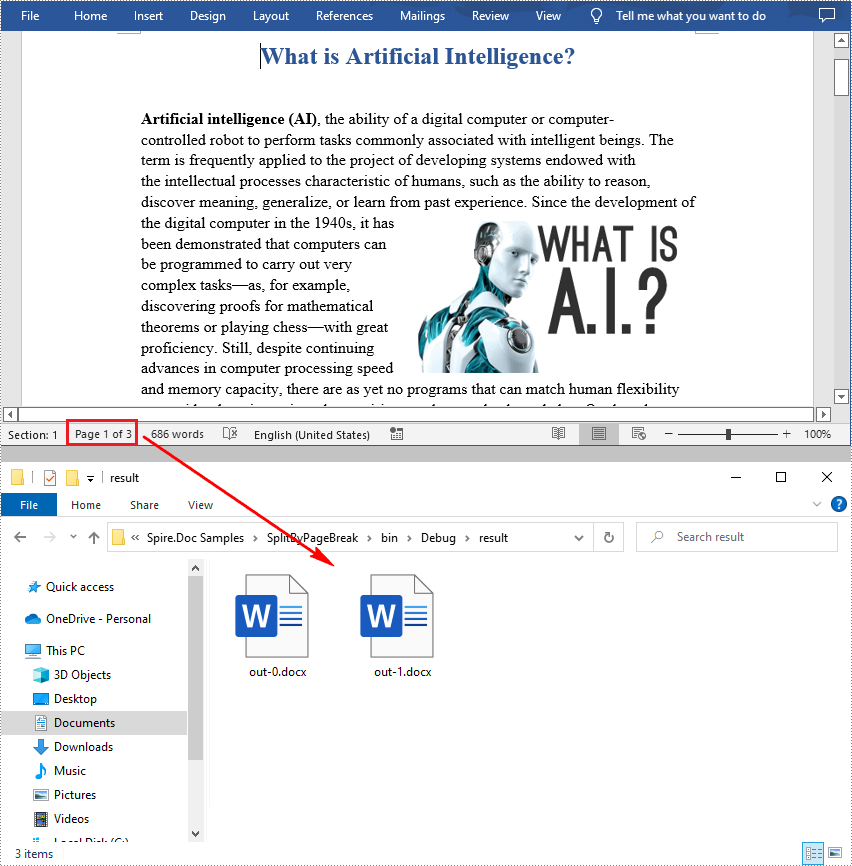
Split a Word Document by Section Break
In Word, a section is a part of a document that contains its own page formatting. For documents that contain multiple sections, Spire.Doc for .NET also supports splitting documents by section breaks. The detailed steps are as follows.
- Create a Document instance.
- Load a sample Word document using Document.LoadFromFile() method.
- Define a new Word document object.
- Traverse through all sections of the original Word document.
- Clone each section of the original document using Document.Sections.Clone() method.
- Add the cloned section to the new document as a new section using Document.Sections.Add() method.
- Save the result document using Document.SaveToFile() method.
- C#
- VB.NET
using System;
using Spire.Doc;
namespace SplitBySectionBreak
{
class Program
{
static void Main(string[] args)
{
//Create a Document instance
Document document = new Document();
//Load a sample Word document
document.LoadFromFile(@"E:\Files\SplitBySectionBreak.docx");
//Define a new Word document object
Document newWord;
//Traverse through all sections of the original Word document
for (int i = 0; i < document.Sections.Count; i++)
{
newWord = new Document();
//Clone each section of the original document and add it to the new document as new section
newWord.Sections.Add(document.Sections[i].Clone());
//Save the result document
newWord.SaveToFile(String.Format(@"test\out_{0}.docx", i));
}
}
}
}
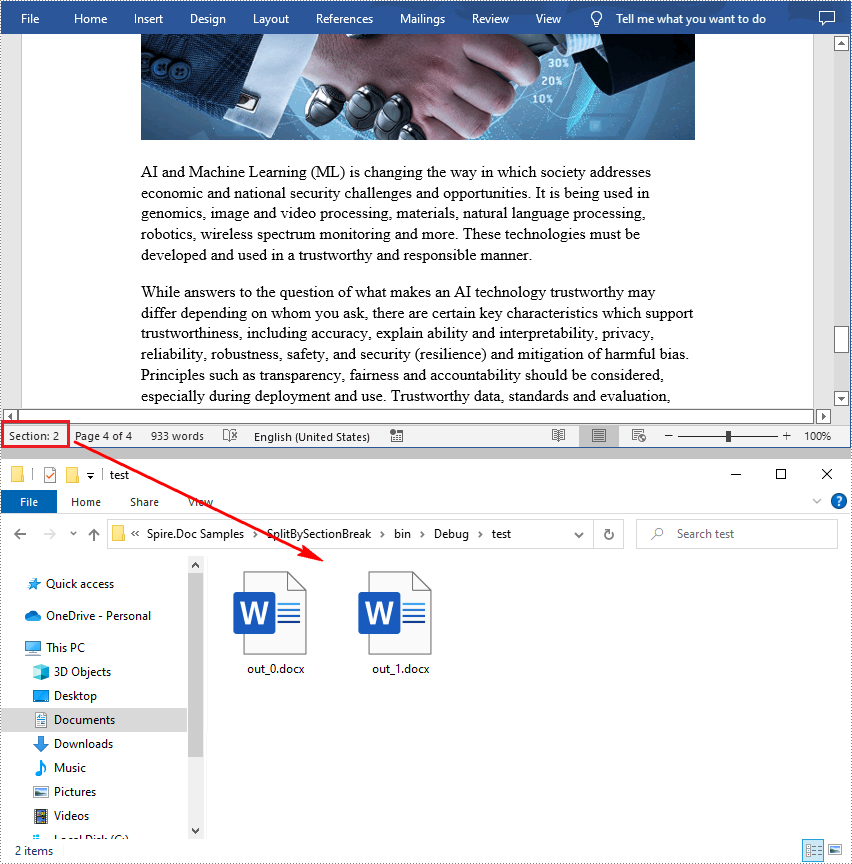
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
We have already demonstrated how to create the excel pivot table with Spire.XLS for .NET. It enables developers to set the property of PivotFieldFormatType to set format for the Data fields on pivot table. The following code sample will show you how to set display formats for data fields in C#.
Note: Before Start, please download the latest version of Spire.XLS and add Spire.Xls.dll in the bin folder as the reference of Visual Studio.
Firstly please check the original DataField format on PivotTable:
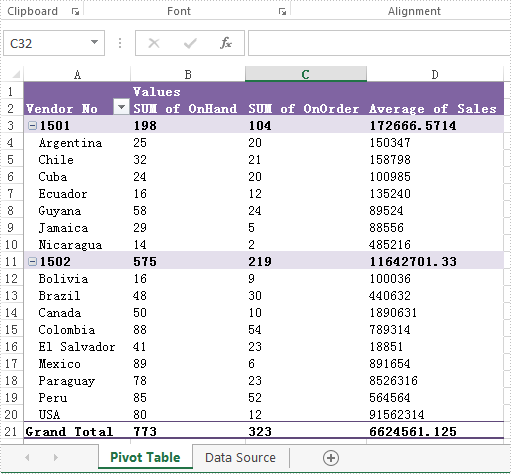
Step 1: Create a new Excel workbook and load from file.
Workbook workbook = new Workbook();
workbook.LoadFromFile("Sample.xlsx");
Step 2: Get the first worksheet from the workbook.
Worksheet sheet = workbook.Worksheets[0];
Step 3: Accessing the first Pivot table from the first worksheet.
XlsPivotTable pt = sheet.PivotTables[0] as XlsPivotTable;
Step 4: Accessing the Data Field.
PivotDataField pivotDataField = pt.DataFields[0];
Step 5: Setting data display format by setting the property of PivotFieldFormatType as PercentageOfColumn.
pivotDataField.ShowDataAs = PivotFieldFormatType.PercentageOfColumn;
Step 6: Save the document to file.
workbook.SaveToFile("Result.xlsx", ExcelVersion.Version2010);
The effective screenshot after setting the Datafield format in PivotTable:
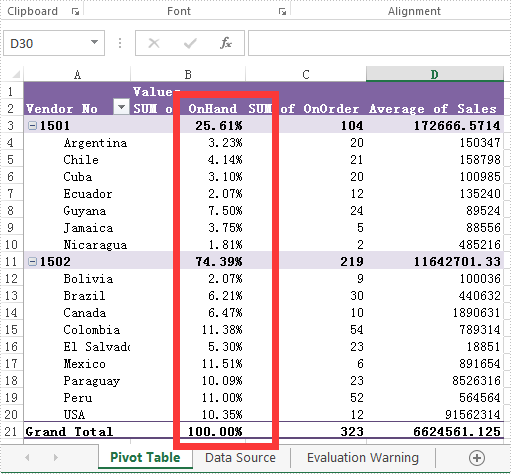
Full codes of how to set the Datafields type in Excel Pivot Table.
using Spire.Xls;
using Spire.Xls.Core.Spreadsheet.PivotTables;
namespace SetDataFieldsformat
{
class Program
{
static void Main(string[] args)
{
Workbook workbook = new Workbook();
workbook.LoadFromFile("Sample.xlsx");
Worksheet sheet = workbook.Worksheets[0];
XlsPivotTable pt = sheet.PivotTables[0] as XlsPivotTable;
PivotDataField pivotDataField = pt.DataFields[0];
pivotDataField.ShowDataAs = PivotFieldFormatType.PercentageOfColumn;
workbook.SaveToFile("Result.xlsx", ExcelVersion.Version2010);
}
}
}
A PDF document encrypted with a user password legally cannot be opened without the password. We’d better detect if a document is password protected or not before we try to open it. This article presents how to determine if a PDF document is encrypted with password using Spire.PDF in C#, VB.NET.
Code Snippet:
Step 1: Initialize an instance of PdfDocument class.
PdfDocument doc = new PdfDocument();
Step 2: Load a sample PDF document.
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Encrypted.pdf");
Step 3: Detect whether the document is encrypted with password or not.
bool isEncrypted = doc.IsEncrypted; Console.WriteLine(isEncrypted);
Result:
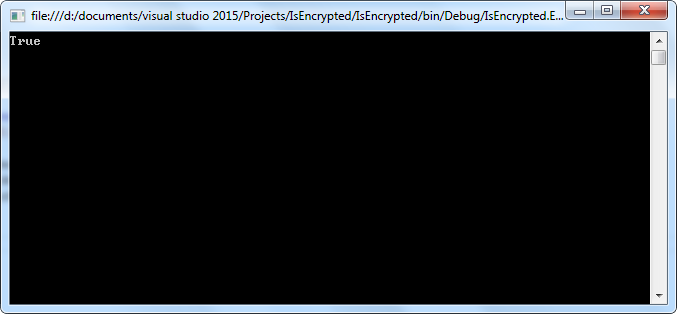
Full Code:
using Spire.Pdf;
using System;
namespace Detect
{
class Program
{
static void Main(string[] args)
{
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Encrypted.pdf");
bool isEncrypted = doc.IsEncrypted;
Console.WriteLine(isEncrypted);
Console.Read();
}
}
}
Imports Spire.Pdf
Namespace Detect
Class Program
Private Shared Sub Main(args As String())
Dim doc As New PdfDocument()
doc.LoadFromFile("C:\Users\Administrator\Desktop\Encrypted.pdf")
Dim isEncrypted As Boolean = doc.IsEncrypted
Console.WriteLine(isEncrypted)
Console.Read()
End Sub
End Class
End Namespace
