
Knowledgebase (2344)
Children categories
A column chart in PowerPoint is a graphical representation of data that uses bars or columns to show comparisons between categories. It is commonly used to display financial data, statistics, and other quantitative information. Each column represents a category, and the height of the column corresponds to the value associated with that category. Column charts are easy to create and customize within PowerPoint, allowing users to quickly visualize their data.
In this article, you will learn how to programmatically create column charts in a PowerPoint document using Spire.Presentation for Python.
- Create a Clustered Column Chart in PowerPoint in Python
- Create a Stacked Column Chart in PowerPoint in Python
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Create a Clustered Column Chart in PowerPoint in Python
A clustered column chart is a type of bar graph where the bars (or columns) are grouped together in clusters or segments, with each cluster representing a category and the height of the columns within the cluster reflecting the value of a data point for that category.
To add a clustered column chart in PowerPoint using Spire.Prensetion for Python, you can use the ISlide.Shapes.AppendChartInit(type: ChartType, rectangle RectangleF, init bool) method and specify the chart type as ColumnClustered. This method returns an object of IChart class, which you can use to set the chart data, title, series labels, category labels, series values and other attributes.
The following are the steps to create a clustered column chart in PowerPoint in Python.
- Create a Presentation object.
- Get the first slide using Prenstion.Slides[] property.
- Add a clustered column chart to the side using ISlide.Shapes.AppendChartInit(type: ChartType, rectangle RectangleF, init bool).
- Add text and numbers to the chart sheet as chart data using IChart.ChartData property.
- Set series labels, category labels, series values and other attributes using the properties of the IChart class.
- Save the document to a PowerPoint file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Set slide size type
presentation.SlideSize.Type = SlideSizeType.Screen16x9
# Get the first slide
slide = presentation.Slides[0]
# Add clustered column chart
rect = RectangleF.FromLTRB(40, 80, 700, 450)
chart = slide.Shapes.AppendChartInit(ChartType.ColumnClustered, rect, False)
# Set chart title
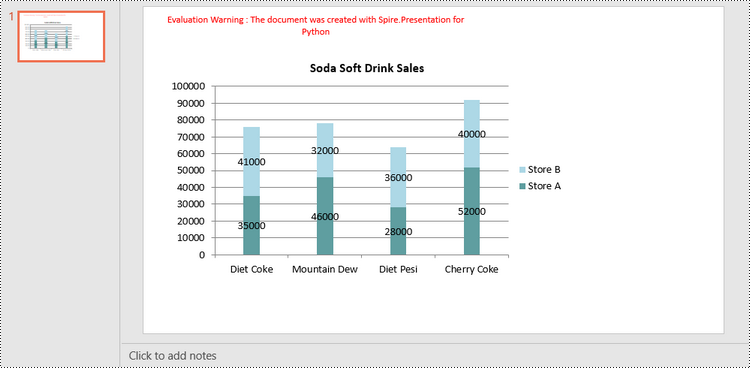
chart.ChartTitle.TextProperties.Text = "Soda Soft Drink Sales"
chart.ChartTitle.TextProperties.IsCentered = True
chart.ChartTitle.Height = 25
chart.HasTitle = True
# Insert text to chart as series labels
chart.ChartData[0,0].Text = "Product"
chart.ChartData[0,1].Text = "Store A"
chart.ChartData[0,2].Text = "Store B"
# Insert text to chart as category labels
chart.ChartData[1,0].Text = "Diet Coke"
chart.ChartData[2,0].Text = "Mountain Dew"
chart.ChartData[3,0].Text = "Diet Pesi"
chart.ChartData[4,0].Text = "Cherry Coke"
# Insert numbers to chart as values of series
Series1 = [35000, 46000, 28000, 52000]
Series2 = [41000, 32000, 36000, 40000]
i = 0
while i < len(Series1):
chart.ChartData[i + 1,1].NumberValue = Series1[i]
chart.ChartData[i + 1,2].NumberValue = Series2[i]
i += 1
# Set series labels
chart.Series.SeriesLabel = chart.ChartData["B1","C1"]
# Set category labels
chart.Categories.CategoryLabels = chart.ChartData["A2","A5"]
# Set values for series
chart.Series[0].Values = chart.ChartData["B2","B5"]
chart.Series[1].Values = chart.ChartData["C2","C5"]
# Set gap width
chart.GapWidth = 350
# Set overlap
chart.OverLap = -50
# Set fill color of each series
chart.Series[0].Fill.FillType = FillFormatType.Solid
chart.Series[0].Fill.SolidColor.Color = Color.get_CadetBlue()
chart.Series[1].Fill.FillType = FillFormatType.Solid
chart.Series[1].Fill.SolidColor.Color = Color.get_LightBlue()
# Add data labels
for i in range(len(Series1)):
chart.Series[0].DataLabels.Add()
chart.Series[1].DataLabels.Add()
# Save the document
presentation.SaveToFile("output/ClusteredColumnChart.pptx", FileFormat.Pptx2019)
presentation.Dispose()

Create a Stacked Column Chart in PowerPoint in Python
A stacked column chart is a variation of the standard column chart where each column represents a category, and the height of the column corresponds to the total value of the category.
To add a stacked column chart in PowerPoint using Spire.Prensetion for Python, you use the ISlide.Shapes.AppendChartInit(type: ChartType, rectangle RectangleF, init bool) method and specify the chart type as ColumnStacked. Then, you can use to set the chart data, title, series labels, category labels, series values and other attributes using the properties of the IChart class.
The following are the steps to create a stacked column chart in PowerPoint in Python.
- Create a Presentation object.
- Get the first slide using Prenstion.Slides[] property.
- Add a stacked column chart to the side using ISlide.Shapes.AppendChartInit(type: ChartType, rectangle RectangleF, init bool).
- Add text and numbers to the chart sheet as chart data using IChart.ChartData property.
- Set series labels, category labels, series values and other attributes using the properties of the IChart class.
- Save the document to a PowerPoint file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Set slide size type
presentation.SlideSize.Type = SlideSizeType.Screen16x9
# Get the first slide
slide = presentation.Slides[0]
# Add a stacked column chart
rect = RectangleF.FromLTRB(40, 80, 700, 450)
chart = slide.Shapes.AppendChartInit(ChartType.ColumnStacked, rect, False)
# Set chart title
chart.ChartTitle.TextProperties.Text = "Soda Soft Drink Sales"
chart.ChartTitle.TextProperties.IsCentered = True
chart.ChartTitle.Height = 25
chart.HasTitle = True
# Insert text to chart as series labels
chart.ChartData[0,0].Text = "Product"
chart.ChartData[0,1].Text = "Store A"
chart.ChartData[0,2].Text = "Store B"
# Insert text to chart as category labels
chart.ChartData[1,0].Text = "Diet Coke"
chart.ChartData[2,0].Text = "Mountain Dew"
chart.ChartData[3,0].Text = "Diet Pesi"
chart.ChartData[4,0].Text = "Cherry Coke"
# Insert numbers to chart as values of series
Series1 = [35000, 46000, 28000, 52000]
Series2 = [41000, 32000, 36000, 40000]
i = 0
while i < len(Series1):
chart.ChartData[i + 1,1].NumberValue = Series1[i]
chart.ChartData[i + 1,2].NumberValue = Series2[i]
i += 1
# Set series labels
chart.Series.SeriesLabel = chart.ChartData["B1","C1"]
# Set category labels
chart.Categories.CategoryLabels = chart.ChartData["A2","A5"]
# Set values for series
chart.Series[0].Values = chart.ChartData["B2","B5"]
chart.Series[1].Values = chart.ChartData["C2","C5"]
# Set gap width
chart.GapWidth = 350
# Set fill color of each series
chart.Series[0].Fill.FillType = FillFormatType.Solid
chart.Series[0].Fill.SolidColor.Color = Color.get_CadetBlue()
chart.Series[1].Fill.FillType = FillFormatType.Solid
chart.Series[1].Fill.SolidColor.Color = Color.get_LightBlue()
# Add data labels
for i in range(len(Series1)):
chart.Series[0].DataLabels.Add()
chart.Series[1].DataLabels.Add()
# Save the document
presentation.SaveToFile("output/StackedColumnChart.pptx", FileFormat.Pptx2019)
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
SVG (Scalable Vector Graphics) is a flexible file format widely used on the web. Unlike traditional image formats, SVG files are not based on pixels. Instead, they use mathematical equations to define shapes, lines, and colors. This unique characteristic allows SVG files to be scaled up or down without any loss of quality, making them an excellent choice for creating interactive and visually appealing graphics. By converting Excel files to SVG, you can seamlessly embed the resulting SVG files into web pages, ensuring smooth integration and display of your Excel data on the web. In this article, we will demonstrate how to convert Excel to SVG format in Python using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Convert a Worksheet in Excel to SVG in Python
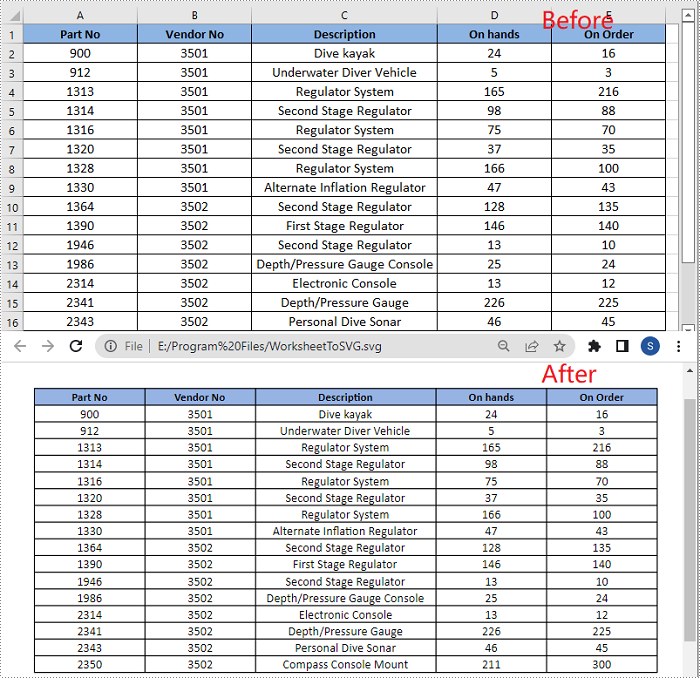
Spire.XLS for Python provides the Worksheet.ToSVGStream() method to convert an Excel worksheet to SVG. The detailed steps are as follows:
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet by its index through Workbook.Worksheets[] property.
- Create an object of the Stream class.
- Save the worksheet to an SVG using Worksheet.ToSVGStream() method.
- Python
from spire.xls.common import *
from spire.xls import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample1.xlsx")
# Get the first worksheet
worksheet = workbook.Worksheets[0]
# Save the worksheet to an SVG
stream = Stream("WorksheetToSVG.svg")
worksheet.ToSVGStream(stream, 0, 0, 0, 0)
stream.Flush()
stream.Close()
workbook.Dispose()
Convert a Chart Sheet in Excel to SVG in Python
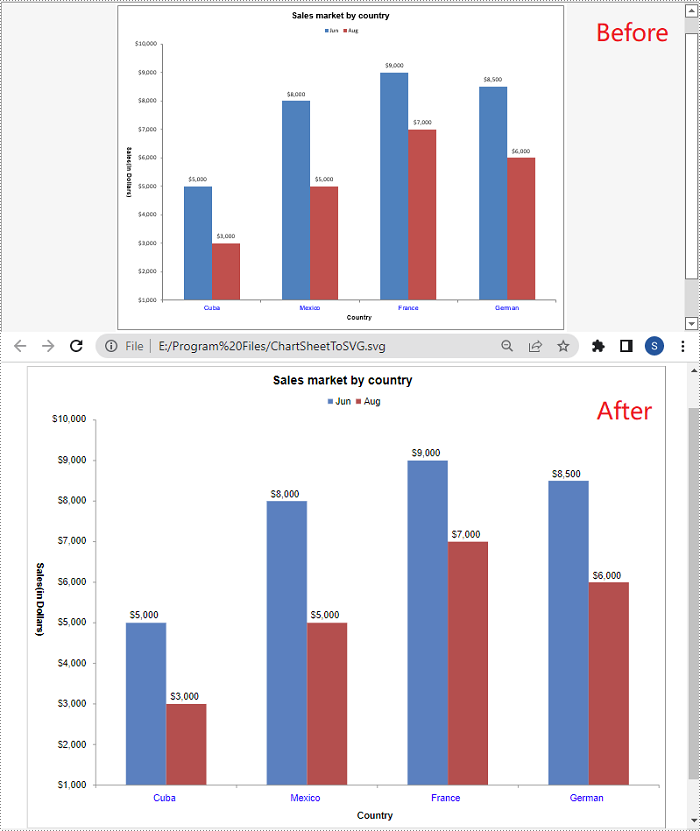
A chart sheet in Excel is a separate sheet within an Excel workbook that is dedicated to displaying a chart. Spire.XLS for Python allows you to convert a chart sheet to SVG by using the ChartSheet.ToSVGStream() method. The detailed steps are as follows:
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific chart sheet using Workbook.GetChartSheetByName() method.
- Create an object of the Stream class.
- Save the chart sheet to an SVG using ChartSheet.ToSVGStream() method.
- Python
from spire.xls.common import *
from spire.xls import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample2.xlsx")
# Get a specific chart sheet
chartSheet = workbook.GetChartSheetByName("Chart1")
# Save the chart sheet to an SVG
stream = Stream("ChartSheetToSVG.svg")
chartSheet.ToSVGStream(stream)
stream.Flush()
stream.Close()
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
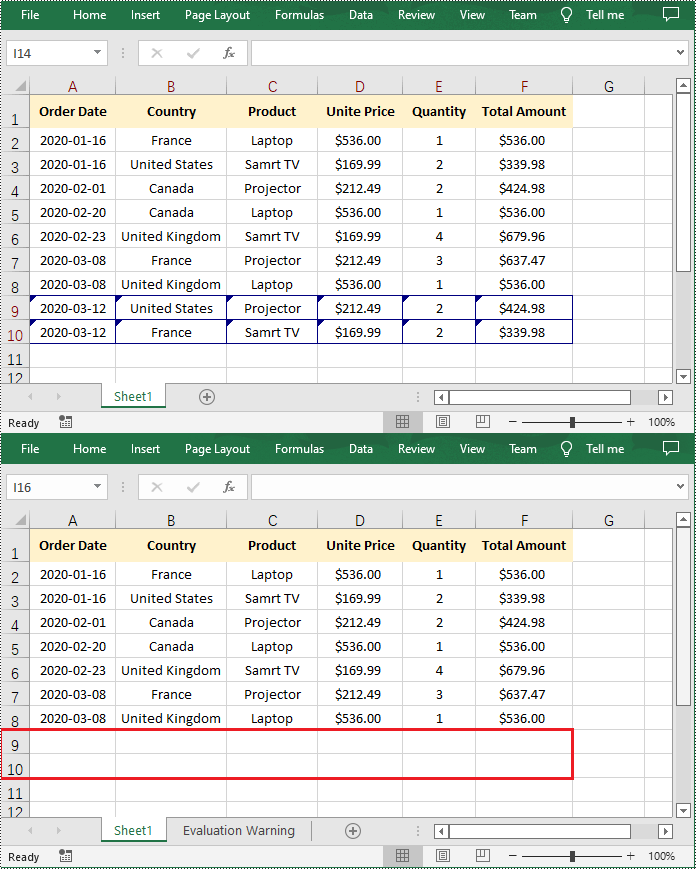
Accepting and rejecting tracked changes in Excel are essential features that empower users to effectively manage and control modifications made by multiple contributors. Accepting changes allows users to include modifications in the spreadsheet, facilitating collaboration and ensuring that the final version reflects collective input. Conversely, rejecting changes enables users to maintain the original content and avoid incorporating incorrect or unnecessary modifications. These functions provide users with the ability to maintain data integrity, ensure document accuracy, and streamline the collaborative process in Excel. In this article, we will demonstrate how to accept and reject tracked changes in Excel in Python using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Accept Tracked Changes in Excel in Python
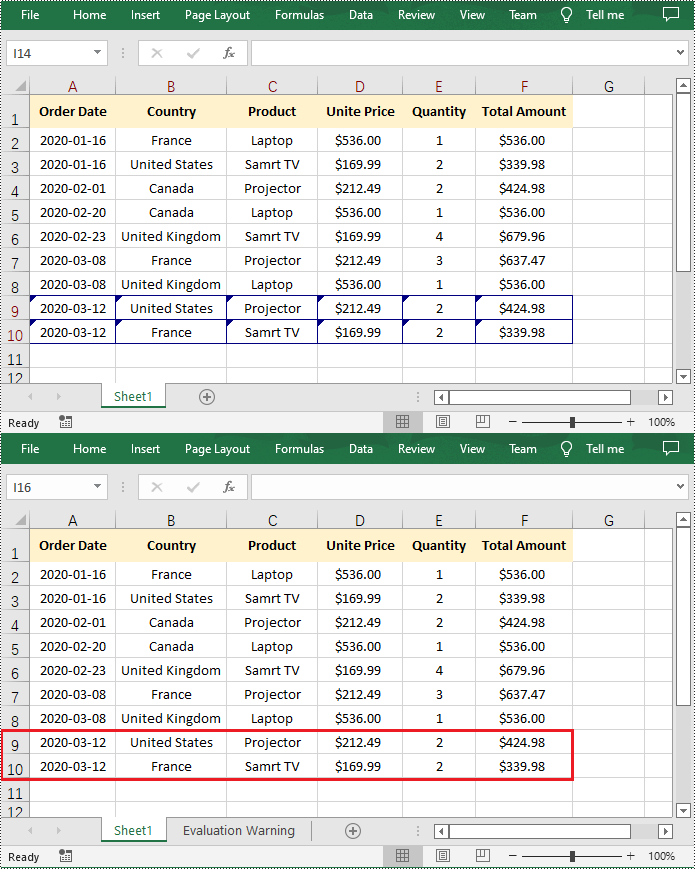
Spire.XLS for Python provides the Workbook.HasTrackedChanges property to determine whether an Excel workbook has tracked changes or not. If the property returns True, you can use the Workbook.AcceptAllTrackedChanges() method to accept these changes at once.
The following steps explain how to accept all tracked changes in an Excel workbook using Spire.XLS for Python:
- Create a Workbook object.
- Load a sample Excel workbook using Workbook.LoadFromFile() method.
- Check if the workbook has tracked changes using Workbook.HasTrackedChanges property.
- Accept all tracked changes in the workbook using Workbook.AcceptAllTrackedChanges() method.
- Save the result workbook using Workbook.SaveToFile() method.
- Python
from spire.xls.common import *
from spire.xls import *
# Specify the input and output file paths
inputFile = "Sample.xlsx"
outputFile = "AcceptChanges.xlsx"
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile(inputFile)
# Check if the file has tracked changes
if workbook.HasTrackedChanges:
# Accept all tracked changes in the file
workbook.AcceptAllTrackedChanges()
# Save the result file
workbook.SaveToFile(outputFile, FileFormat.Version2013)
workbook.Dispose()
Reject Tracked Changes in Excel in Python
If the changes made to a workbook compromise the integrity of the data, such as introducing errors, inconsistencies, or inaccuracies, you can reject these changes by using the Workbook.RejectAllTrackedChanges() method.
The following steps explain how to reject all tracked changes in an Excel workbook using Spire.XLS for Python:
- Create a Workbook object.
- Load a sample Excel workbook using Workbook.LoadFromFile() method.
- Check if the workbook has tracked changes using Workbook.HasTrackedChanges property.
- Reject all tracked changes in the workbook using Workbook.RejectAllTrackedChanges() method.
- Save the result workbook using Workbook.SaveToFile() method.
- Python
from spire.xls.common import *
from spire.xls import *
# Specify the input and output file paths
inputFile = "Sample.xlsx"
outputFile = "RejectChanges.xlsx"
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile(inputFile)
# Check if the file has tracked changes
if workbook.HasTrackedChanges:
# Reject all tracked changes in the file
workbook.RejectAllTrackedChanges()
# Save the result file
workbook.SaveToFile(outputFile, FileFormat.Version2013)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
