
Knowledgebase (2344)
Children categories
Grouping rows and columns in Excel provides a more organized and structured view of data, making it easier to analyze and understand complex datasets. After grouping related rows or columns, you can collapse or expand them as needed to focus on specific subsets of information while hiding details. In this article, you will learn how to group or ungroup rows and columns , as well as how to collapse or expand groups in Excel in Python using Spire.XLS for Python.
- Group Rows and Columns in Excel in Python
- Ungroup Rows and Columns in Excel in Python
- Expand or Collapse Groups in Excel in Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Group Rows and Columns in Excel in Python
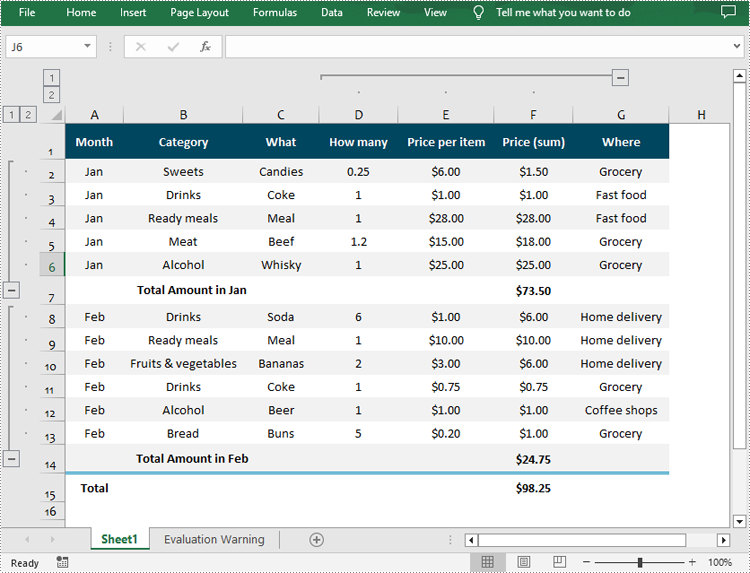
Spire.XLS for Python provides the Worksheet.GroupByRows() and Worksheet.GroupByColumns() methods to group specific rows and columns in an Excel worksheet. The following are the detailed steps:
- Create a Workbook object.
- Load a sample Excel file using Workbook.LoadFromFile() method.
- Get the specified worksheet using Workbook.Worksheets[] property.
- Group rows using Worksheet.GroupByRows() method.
- Group columns using Worksheet.GroupByColumns() method.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import * from spire.xls.common import * inputFile = "Data.xlsx" outputFile = "GroupRowsAndColumns.xlsx" # Create a Workbook object workbook = Workbook() # Load a sample Excel file workbook.LoadFromFile(inputFile) # Get the first worksheet sheet = workbook.Worksheets[0] # Group rows sheet.GroupByRows(2, 6, False) sheet.GroupByRows(8, 13, False) # Group columns sheet.GroupByColumns(4, 6, False) # Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2016) workbook.Dispose()
Ungroup Rows and Columns in Excel in Python
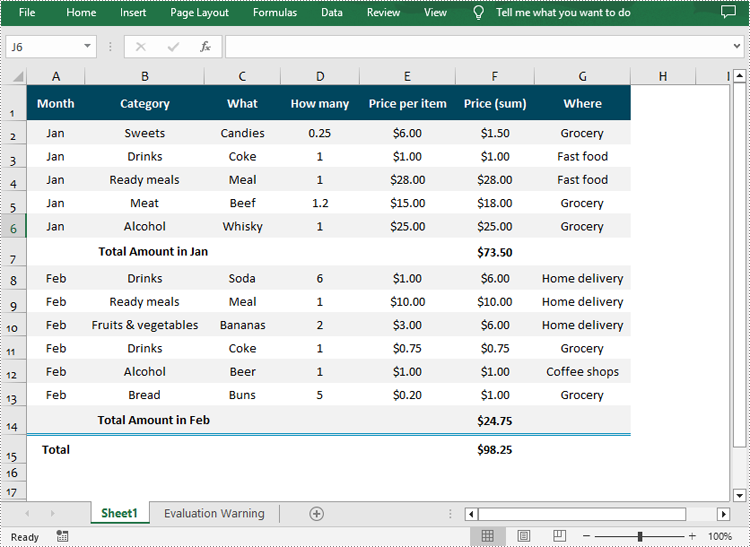
Ungrouping rows and columns in Excel refer to the process of reversing the grouping operation and restoring the individual rows or columns to their original state.
To ungroup rows and columns in an Excel worksheet, you can use the Worksheet.UngroupByRows() and Worksheet.UngroupByColumns() methods. The following are the detailed steps:
- Create a Workbook object.
- Load a sample Excel file using Workbook.LoadFromFile() method.
- Get the specified worksheet using Workbook.Worksheets[] property.
- Ungroup rows using Worksheet.UngroupByRows() method.
- Ungroup columns using Worksheet.UngroupByColumns() method.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import * from spire.xls.common import * inputFile = "GroupRowsAndColumns.xlsx" outputFile = "UnGroupRowsAndColumns.xlsx" # Create a Workbook object workbook = Workbook() # Load a sample Excel file workbook.LoadFromFile(inputFile) # Get the first worksheet sheet = workbook.Worksheets[0] # UnGroup rows sheet.UngroupByRows(2, 6) sheet.UngroupByRows(8, 13) # UnGroup columns sheet.UngroupByColumns(4, 6) # Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2016) workbook.Dispose()
Expand or Collapse Groups in Excel in Python
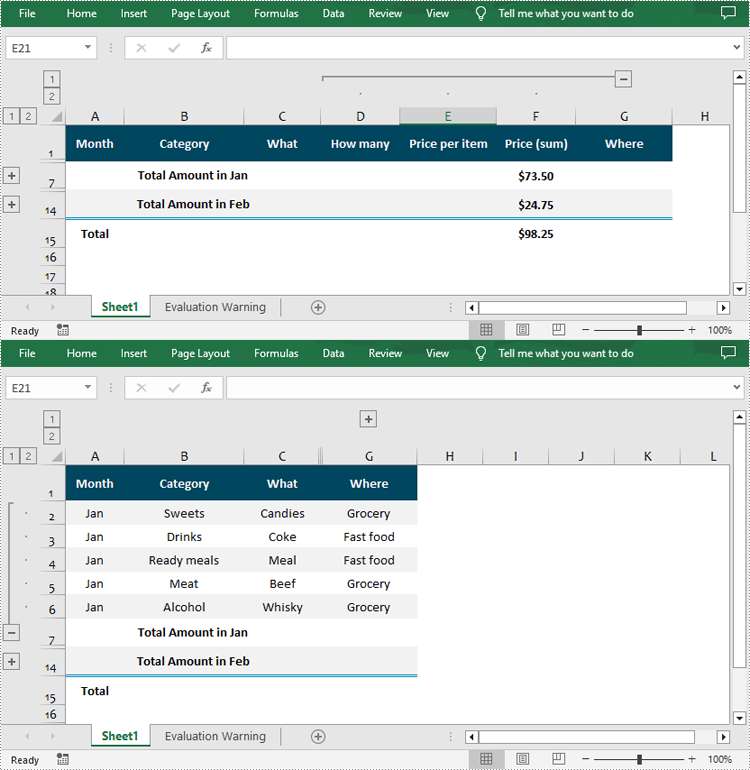
Expanding or collapsing groups in Excel refers to the action of showing or hiding the detailed information within a grouped section. With Spire.XLS for Python, you can expand or collapse groups through the Worksheet.Range[].ExpandGroup() or Worksheet.Range[].CollapseGroup() methods. The following are the detailed steps:
- Create a Workbook object.
- Load a sample Excel file using Workbook.LoadFromFile() method.
- Get the specified worksheet using Workbook.Worksheets[] property.
- Expand a specific group using the Worksheet.Range[].ExpandGroup() method.
- Collapse a specific group using the Worksheet.Range[].CollapseGroup() method.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import * from spire.xls.common import * inputFile = "Grouped.xlsx" outputFile = "ExpandOrCollapseGroups.xlsx" # Create a Workbook object workbook = Workbook() # Load a sample Excel file workbook.LoadFromFile(inputFile) # Get the first worksheet sheet = workbook.Worksheets[0] # Expand a group sheet.Range["A2:G6"].ExpandGroup(GroupByType.ByRows) # Collapse a group sheet.Range["D1:F15"].CollapseGroup(GroupByType.ByColumns) # Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2016) workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
PDF bookmarks are navigational aids that allow users to quickly locate and jump to specific sections or pages in a PDF document. Through a simple click, users can arrive at the target location, which eliminates the need to manually scroll or search for specific content in a lengthy document. In this article, you will learn how to programmatically add, modify and delete bookmarks in PDF files using Spire.PDF for Python.
- Add Bookmarks to a PDF Document
- Edit Bookmarks in a PDF Document
- Delete Bookmarks from a PDF Document
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Add Bookmarks to a PDF Document in Python
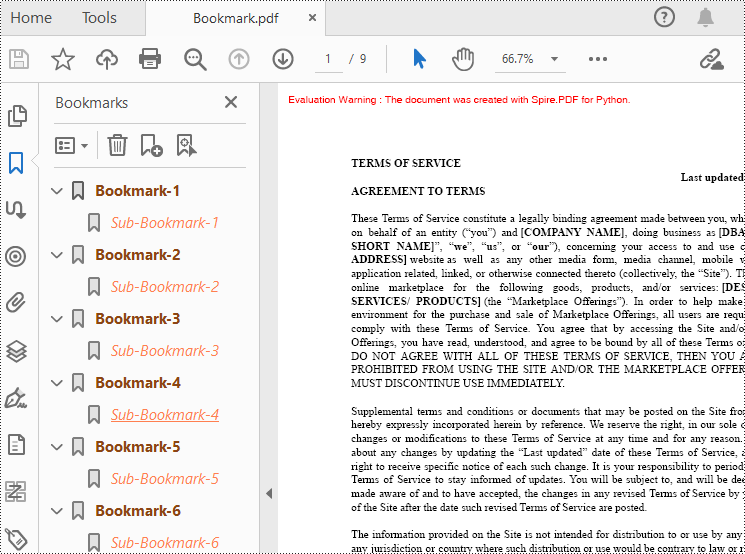
Spire.PDF for Python provides a method to add bookmarks to a PDF document: PdfDocument. Bookmarks.Add(). You can use this method to create primary bookmarks for the PDF document and use the PdfBookmarkCollection.Add() method to add sub-bookmarks to the primary bookmarks. Additionally, the PdfBookmark class offers other methods to set properties such as destination, text color, and text style for the bookmarks. The following are the detailed steps for adding bookmarks to a PDF document.
- Create a PdfDocument class instance.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Add a parent bookmark to the document using PdfDocument.Bookmarks.Add() method.
- Create a PdfDestination class object and set the destination of the parent bookmark using PdfBookmark.Action property.
- Set the text color and style of the parent bookmark.
- Create a PdfBookmarkCollection class object to add sub-bookmark to the parent bookmark using PdfBookmarkCollection.Add() method.
- Use the above methods to set the destination, text color, and text style of the sub-bookmark.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Terms of service.pdf")
# Loop through the pages in the PDF file
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
# Set the title and destination for the bookmark
bookmarkTitle = "Bookmark-{0}".format(i+1)
bookmarkDest = PdfDestination(page, PointF(0.0, 0.0))
# Create and configure the bookmark
bookmark = doc.Bookmarks.Add(bookmarkTitle)
bookmark.Color = PdfRGBColor(Color.get_SaddleBrown())
bookmark.DisplayStyle = PdfTextStyle.Bold
bookmark.Action = PdfGoToAction(bookmarkDest)
# Create a collection to hold child bookmarks
bookmarkColletion = PdfBookmarkCollection(bookmark)
# Set the title and destination for the child bookmark
childBookmarkTitle = "Sub-Bookmark-{0}".format(i+1)
childBookmarkDest = PdfDestination(page, PointF(0.0, 100.0))
# Create and configure the child bookmark
childBookmark = bookmarkColletion.Add(childBookmarkTitle)
childBookmark.Color = PdfRGBColor(Color.get_Coral())
childBookmark.DisplayStyle = PdfTextStyle.Italic
childBookmark.Action = PdfGoToAction(childBookmarkDest)
# Save the PDF file
outputFile = "Bookmark.pdf"
doc.SaveToFile(outputFile)
# Close the document
doc.Close()
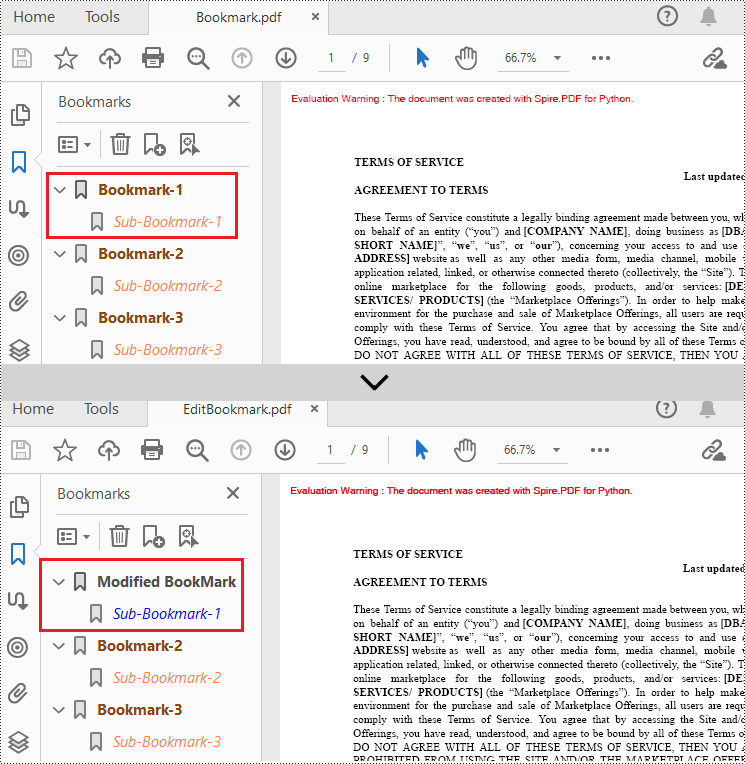
Edit Bookmarks in a PDF Document
If you need to update the existing bookmarks, you can use the methods of PdfBookmark class to rename the bookmarks and change their text color, text style. The following are the detailed steps.
- Create a PdfDocument class instance.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get a specified bookmark using PdfDocument.Bookmarks[] property.
- Change the title of the bookmark using PdfBookmark.Title property.
- Change the font color of the bookmark using PdfBookmark.Color property.
- Change the text style of the bookmark using PdfBookmark.DisplayStyle property.
- Change the text color and style of the sub-bookmark using the above methods.
- Save the result document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Bookmark.pdf")
# Get the first bookmark
bookmark = doc.Bookmarks.get_Item(0)
# Change the title of the bookmark
bookmark.Title = "Modified BookMark"
# Set the color of the bookmark
bookmark.Color = PdfRGBColor(Color.get_Black())
# Set the outline text style of the bookmark
bookmark.DisplayStyle = PdfTextStyle.Bold
# Edit child bookmarks of the parent bookmark
pBookmark = PdfBookmarkCollection(bookmark)
for i in range(pBookmark.Count):
childBookmark = pBookmark.get_Item(i)
childBookmark.Color = PdfRGBColor(Color.get_Blue())
childBookmark.DisplayStyle = PdfTextStyle.Regular
# Save the PDF document
outputFile = "EditBookmark.pdf"
# Close the document
doc.SaveToFile(outputFile)
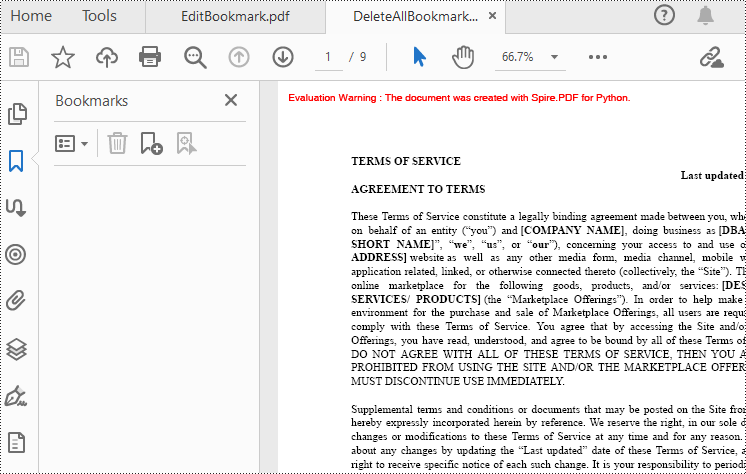
Delete Bookmarks from a PDF Document
Spire.PDF for Python also provides methods to delete any bookmark in a PDF document. PdfDocument.Bookmarks.RemoveAt() method is used to remove a specific primary bookmark, PdfDocument.Bookmarks.Clear() method is used to remove all bookmarks, and PdfBookmarkCollection.RemoveAt() method is used to remove a specific sub-bookmark of a primary bookmark. The detailed steps of removing bookmarks form a PDF document are as follows.
- Create a PdfDocument class instance.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the first bookmark using PdfDocument.Bookmarks[] property.
- Remove a specified sub-bookmark of the first bookmark using PdfBookmarkCollection.RemoveAt() method.
- Remove a specified bookmark including its sub-bookmarks using PdfDocument.Bookmarks.RemoveAt() method.
- Remove all bookmarks in the PDF file using PdfDocument.Bookmarks.Clear() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Bookmark.pdf")
# # Delete the first bookmark
# doc.Bookmarks.RemoveAt(0)
# # Get the first bookmark
# bookmark = doc.Bookmarks.get_Item(0)
# # Remove the first child bookmark from first parent bookmark
# pBookmark = PdfBookmarkCollection(bookmark)
# pBookmark.RemoveAt(0)
#Remove all bookmarks
doc.Bookmarks.Clear()
# Save the PDF document
output = "DeleteAllBookmarks.pdf"
doc.SaveToFile(output)
# Close the document
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
The conversion from HTML to image allows you to capture the appearance and layout of the HTML content as a static image file. It can be useful for various purposes, such as generating website previews, creating screenshots, archiving web pages, or integrating HTML content into applications that primarily deal with images. In this article, you will learn how to convert an HTML file or an HTML string to an image in Python using Spire.Doc for Python.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
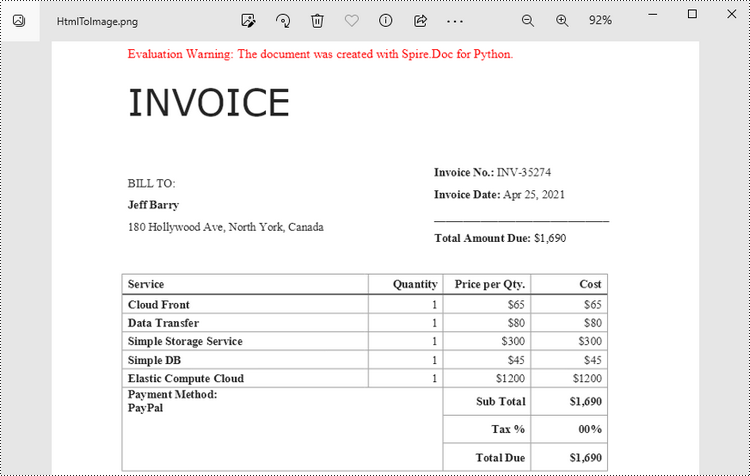
Convert an HTML File to an Image in Python
When an HTML file is loaded into the Document object using the Document.LoadFromFile() method, its contents are automatically rendered as the contents of a Word page. Then, a specific page can be saved as an image stream using the Document.SaveImageToStreams() method.
The following are the steps to convert an HTML file to an image with Python.
- Create a Document object.
- Load a HTML file using Document.LoadFromFile() method.
- Convert a specific page to an image stream using Document.SaveImageToStreams() method.
- Save the image stream as a PNG file using BufferedWriter.write() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load an HTML file
document.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Sample.html", FileFormat.Html, XHTMLValidationType.none)
# Save the first page as an image stream
imageStream = document.SaveImageToStreams(0, ImageType.Bitmap)
# Convert the image stream as a PNG file
with open("output/HtmlToImage.png",'wb') as imageFile:
imageFile.write(imageStream.ToArray())
document.Close()
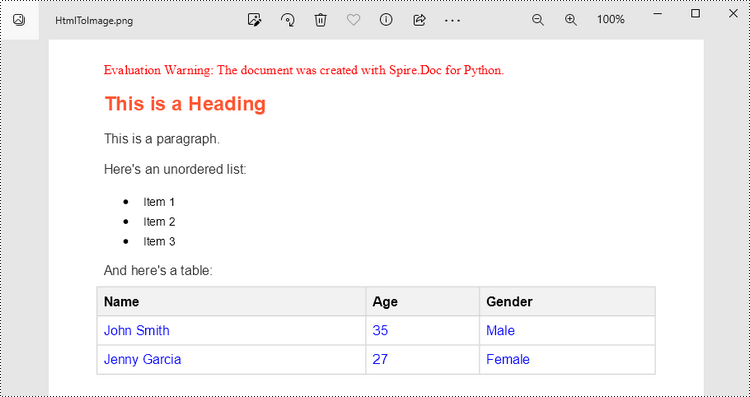
Convert an HTML String to an Image in Python
To render uncomplicated HTML strings (typically text and its formatting) as a Word page, you can utilize the Paragraph.AppendHTML() method. Afterwards, you can convert it to an image stream using the Document.SaveImageToStreams() method.
The following are the steps to convert an HTML string to an image in Python.
- Create a Document object.
- Add a section using Document.AddSection() method.
- Add a paragraph using Section.AddParagraph() method.
- Specify the HTML string, and add the it to the paragraph using Paragraph.AppendHTML() method.
- Convert a specific page to an image stream using Document.SaveImageToStreams() method.
- Save the image stream as a PNG file using BufferedWriter.write() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Add a section to the document
sec = document.AddSection()
# Add a paragraph to the section
paragraph = sec.AddParagraph()
# Specify the HTML string
htmlString = """
<html>
<head>
<title>HTML to Word Example</title>
<style>
body {
font-family: Arial, sans-serif;
}
h1 {
color: #FF5733;
font-size: 24px;
margin-bottom: 20px;
}
p {
color: #333333;
font-size: 16px;
margin-bottom: 10px;
}
ul {
list-style-type: disc;
margin-left: 20px;
margin-bottom: 15px;
}
li {
font-size: 14px;
margin-bottom: 5px;
}
table {
border-collapse: collapse;
width: 100%;
margin-bottom: 20px;
}
th, td {
border: 1px solid #CCCCCC;
padding: 8px;
text-align: left;
}
th {
background-color: #F2F2F2;
font-weight: bold;
}
td {
color: #0000FF;
}
</style>
</head>
<body>
<h1>This is a Heading</h1>
<p>This is a paragraph.</p>
<p>Here's an unordered list:</p>
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
<p>And here's a table:</p>
<table>
<tr>
<th>Name</th>
<th>Age</th>
<th>Gender</th>
</tr>
<tr>
<td>John Smith</td>
<td>35</td>
<td>Male</td>
</tr>
<tr>
<td>Jenny Garcia</td>
<td>27</td>
<td>Female</td>
</tr>
</table>
</body>
</html>
"""
# Append the HTML string to the paragraph
paragraph.AppendHTML(htmlString)
# Save the first page as an image stream
imageStream = document.SaveImageToStreams(0, ImageType.Bitmap)
# Convert the image stream as a PNG file
with open("output/HtmlToImage2.png",'wb') as imageFile:
imageFile.write(imageStream.ToArray())
document.Close()
Get a Free License
To fully experience the capabilities of Spire.Doc for Python without any evaluation limitations, you can request a free 30-day trial license.
