
Knowledgebase (2344)
Children categories
Content controls play an important role in Excel, providing powerful functionality for data input, display, and user interaction. These controls include text boxes, radio buttons, checkboxes, drop-down lists, and more. They offer users more efficient, intuitive, and flexible ways of handling data, making Excel a powerful tool for data management and analysis. This article will introduce how to use Spire.XLS for Python to add content controls to Excel documents or edit content controls in Excel documents using Python.
- Add Content Controls to an Excel document in Python
- Edit Content Controls in an Excel document in Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
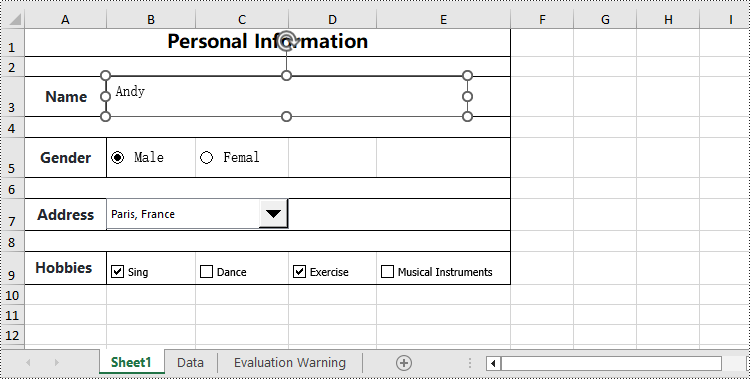
Add Content Controls to an Excel document in Python
Spire.XLS for Python allows you to add content controls supported by Excel, such as text boxes, radio buttons, drop-down lists (also known as combo boxes), checkboxes, and more. The following are the detailed steps:
- Create an object of the Workbook class.
- Use the Workbook.LoadFromFile() method to load an Excel data document.
- Use the Workbook.Worksheets[] property to retrieve the desired worksheet.
- Add a text box using the Worksheet.TextBoxes.AddTextBox() method.
- Add a radio button using the Worksheet.RadioButtons.Add() method.
- Add a combo box using the Worksheet.ComboBoxes.AddComboBox() method.
- Add a checkbox using the Worksheet.CheckBoxes.AddCheckBox() method.
- Use the Workbook.SaveToFile() method to save the resulting file.
- Python
from spire.xls.common import *
from spire.xls import *
# Create a new Workbook object
workbook = Workbook()
# Load an existing Excel file
workbook.LoadFromFile("Data/Sample01.xlsx")
# Select the first worksheet
worksheet = workbook.Worksheets[0]
# Set the height of the text box (unit: points)
height = 40
# Add a text box to the worksheet
textbox = worksheet.TextBoxes.AddTextBox(3, 2, height, 400)
textbox.Line.ForeKnownColor = ExcelColors.Black
textbox.Text = "Andy"
# Add radio buttons to the worksheet
radioButton1 = worksheet.RadioButtons.Add(5, 2, height, 60)
radioButton1.Text = "Male"
radioButton1.CheckState=CheckState.Checked
radioButton2 = worksheet.RadioButtons.Add(5, 3, height, 60)
radioButton2.Text = "Female"
# Assign a data range from another worksheet to a combo box
dataSheet = workbook.Worksheets[1]
comboBoxShape = worksheet.ComboBoxes.AddComboBox(7, 2, 30, 200)
comboBoxShape.ListFillRange = dataSheet.Range["A1:A7"]
comboBoxShape.SelectedIndex=1
# Add check boxes to the worksheet
checkBox = worksheet.CheckBoxes.AddCheckBox(9, 2, height, 60)
checkBox.CheckState = CheckState.Checked
checkBox.Text = "Sing"
checkBox = worksheet.CheckBoxes.AddCheckBox(9, 3, height, 60)
checkBox.CheckState = CheckState.Unchecked
checkBox.Text = "Dance"
checkBox = worksheet.CheckBoxes.AddCheckBox(9, 4, height, 60)
checkBox.CheckState = CheckState.Checked
checkBox.Text = "Exercise"
checkBox = worksheet.CheckBoxes.AddCheckBox(9, 5, height, 100)
checkBox.CheckState = CheckState.Unchecked
checkBox.Text = "Musical Instruments"
# Save the modified workbook to a new file
workbook.SaveToFile("AddContentControls.xlsx", ExcelVersion.Version2016)
# Clean up and release the workbook object
workbook.Dispose()
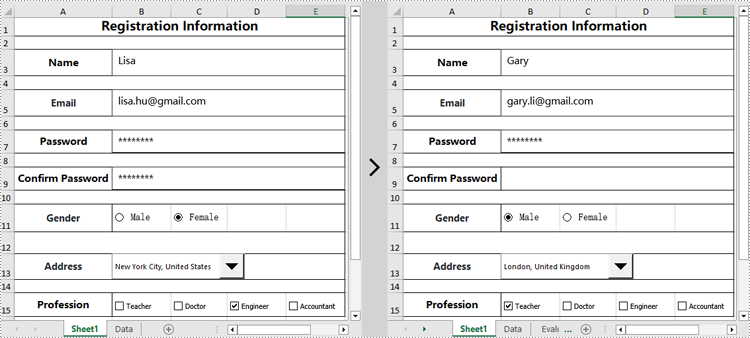
Edit Content Controls in an Excel document in Python
Spire.XLS for Python can also modify the properties of existing content controls in an Excel document, such as changing the text of a text box, resetting the selected item of a drop-down list, hiding a specific content control, and more. Here are the detailed steps:
- Create an object of the Workbook class.
- Use the Workbook.LoadFromFile() method to load an Excel document.
- Use the Workbook.Worksheets[] property to retrieve the desired worksheet.
- Modify the display content of a text box using the Worksheet.TextBoxes[].Text property.
- Set whether to display a specific text box using the Worksheet.TextBoxes[].Visible property.
- Set whether a radio button is checked using the Worksheet.RadioButtons[].CheckState property.
- Set the selected item of a combo box using the Worksheet.ComboBoxes[].SelectedIndex property.
- Set whether a checkbox is checked using the Worksheet.CheckBoxes[].CheckState property.
- Use the Workbook.SaveToFile() method to save the resulting file.
- Python
from spire.xls.common import *
from spire.xls import *
# Create a Workbook object
workbook = Workbook()
# Load Excel data from file
workbook.LoadFromFile("Data/Sample02.xlsx")
# Get the first worksheet
worksheet = workbook.Worksheets[0]
# Set the text content of the first textbox to "Gary"
worksheet.TextBoxes[0].Text = "Gary"
# Set the text content of the second textbox to "gary.li@gmail.com"
worksheet.TextBoxes[1].Text = "gary.li@gmail.com"
# Hide the fourth textbox
worksheet.TextBoxes[3].Visible = False
# Check the first radio button
worksheet.RadioButtons[0].CheckState = CheckState.Checked
# Set the selected index of the first combobox to 0 (the first option)
worksheet.ComboBoxes[0].SelectedIndex = 0
# Check the first checkbox
worksheet.CheckBoxes[0].CheckState = CheckState.Checked
# Uncheck the third checkbox
worksheet.CheckBoxes[2].CheckState = CheckState.Unchecked
# Save the modified workbook to a new file
workbook.SaveToFile("EditContentControls.xlsx", ExcelVersion.Version2016)
# Clean up and release the workbook object
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Sometimes, when dealing with PDF documents, there is a need to split a page into different sections based on content or layout. For instance, splitting a mixed-layout page with both horizontal and vertical content into two separate parts. This type of splitting is not commonly available in basic PDF management functions but can be important for academic papers, magazine ads, or mixed-layout designs. This article explains how to use Spire.PDF for Python to perform horizontal or vertical PDF page splitting.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Split PDF Page Horizontally or Vertically with Python
Spire.PDF for Python not only supports splitting a PDF document into multiple PDF documents, but also allows splitting a specific page within a PDF into two or more pages. Here are the detailed steps to split a page:
- Create an instance of the PdfDocument class.
- Load the source PDF document using the PdfDocument.LoadFromFile() method.
- Retrieve the page(s) to be split using PdfDocument.Pages[].
- Create a new PDF document and set its page margins to 0.
- Set the width or height of the new document to half of the source document.
- Add a page to the new PDF document using the PdfDocument.Pages.Add() method.
- Create a template for the source document's page using the PdfPageBase.CreateTemplate() method.
- Draw the content of the source page onto the new page using the PdfTemplate.Draw() method.
- Save the split document using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load the PDF document
pdf.LoadFromFile("Terms of service.pdf")
# Get the first page
page = doc.Pages.get_Item(0)
# Create a new PDF document and remove the page margins
newpdf = PdfDocument()
newpdf.PageSettings.Margins.All=0
# Horizontal splitting: Set the width of the new document's page to be the same as the width of the first page of the original document, and the height to half of the first page's height
newpdf.PageSettings.Width=page.Size.Width
newpdf.PageSettings.Height=page.Size.Height/2
'''
# Vertical splitting: Set the width of the new document's page to be half of the width of the first page of the original document, and the height to the same as the first page's height
newpdf.PageSettings.Width=page.Size.Width/2
newpdf.PageSettings.Height=page.Size.Height
'''
# Add a new page to the new PDF document
newPage = newpdf.Pages.Add()
# Set the text layout format
format = PdfTextLayout()
format.Break=PdfLayoutBreakType.FitPage
format.Layout=PdfLayoutType.Paginate
# Create a template based on the first page of the original document and draw it onto the new page of the new document, automatically paginating when the page is filled
page.CreateTemplate().Draw(newPage, PointF(0.0, 0.0), format)
# Save the document
newpdf.SaveToFile("HorizontalSplitting.pdf")
# Close the objects
newpdf.Close()
pdf.Close()
The result of horizontal splitting is as follows:
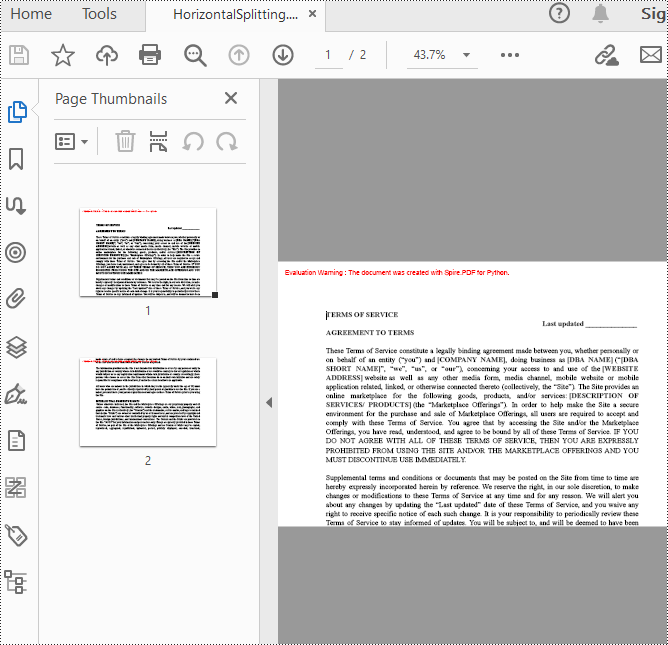
The result of vertical splitting is as follows:
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Using lists in PowerPoint allows you to present information in a structured and visually appealing way. They help break down complex ideas into digestible points, making it easier for your audience to understand and retain key concepts. Whether you're creating a slide deck for a business presentation, educational workshop, or conference talk, incorporating lists can enhance the visual appeal and effectiveness of your content. In this article, we will demonstrate how to create numbered lists and bulleted lists in PowerPoint presentations in Python using Spire.Presentation for Python.
- Create a Numbered List in PowerPoint in Python
- Create a Bulleted List with Symbol Bullets in PowerPoint in Python
- Create a Bulleted List with Image Bullets in PowerPoint in Python
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Create a Numbered List in PowerPoint in Python
Spire.Presentation supports adding numerals or bullet points in front of paragraphs to create a numbered or bulleted list. To specify the bullet type, you can use the ParagraphProperties.BulletType property. The following are the steps to create a numbered list in a PowerPoint slide using Spire.Presentation for Python.
- Create a Presentation object.
- Get the first slide using Presentation.Slides[0] property.
- Append a shape to the slide using ISlide.Shapes.AppendShape() method and set the shape style.
- Specify the items of the numbered list inside a list.
- Create paragraphs based on the list items, and set the bullet type of these paragraphs to Numbered using ParagraphProperties.BulletType property.
- Set the numbered bullet style of these paragraphs using ParagraphProperties.BulletStyle property.
- Add these paragraphs to the shape using IAutoShape.TextFrame.Paragraphs.Append() method.
- Save the document to a PowerPoint file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an object of the Presentation class
presentation = Presentation()
# Get the first slide
slide = presentation.Slides[0]
# Add a shape to the slide and set the shape style
shape = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF(50.0, 50.0, 300.0, 200.0))
shape.Fill.FillType = FillFormatType.none
shape.Line.FillType= FillFormatType.none
# Add text to the default paragraph
paragraph = shape.TextFrame.Paragraphs[0]
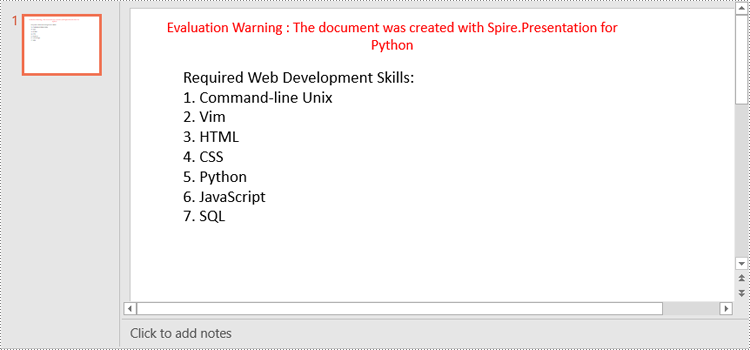
paragraph.Text = "Required Web Development Skills:"
paragraph.Alignment = TextAlignmentType.Left
paragraph.TextRanges[0].Fill.FillType = FillFormatType.Solid
paragraph.TextRanges[0].Fill.SolidColor.Color = Color.get_Black()
# Specify the list items
listItems = [
" Command-line Unix",
" Vim",
" HTML",
" CSS",
" Python",
" JavaScript",
" SQL"
]
# Create a numbered list
for item in listItems:
textParagraph = TextParagraph()
textParagraph.Text = item
textParagraph.Alignment = TextAlignmentType.Left
textParagraph.TextRanges[0].Fill.FillType = FillFormatType.Solid
textParagraph.TextRanges[0].Fill.SolidColor.Color = Color.get_Black()
textParagraph.BulletType = TextBulletType.Numbered
textParagraph.BulletStyle = NumberedBulletStyle.BulletArabicPeriod
shape.TextFrame.Paragraphs.Append(textParagraph)
# Save the result document
presentation.SaveToFile("NumberedList.pptx", FileFormat.Pptx2013)
presentation.Dispose()
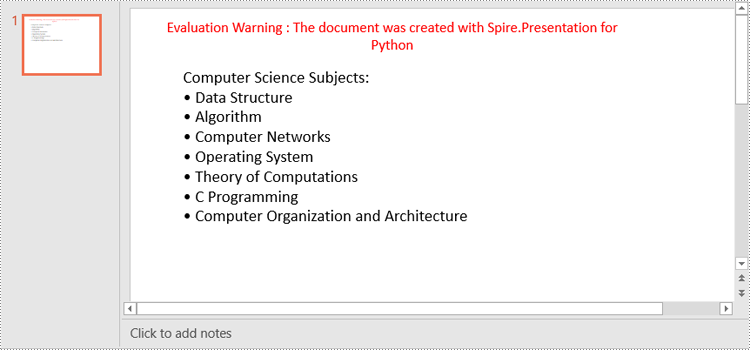
Create a Bulleted List with Symbol Bullets in PowerPoint in Python
The process of creating a bulleted list with symbol bullets is very similar to that of creating a numbered list. The only difference is that you need to set the bullet type of the paragraphs to Symbol. The following are the steps.
- Create a Presentation object.
- Get the first slide using Presentation.Slides[0] property.
- Append a shape to the slide using ISlide.Shapes.AppendShape() method and set the shape style.
- Specify the items of the bulleted list inside a list.
- Create paragraphs based on the list items, and set the bullet type of these paragraphs to Symbol using ParagraphProperties.BulletType property.
- Add these paragraphs to the shape using IAutoShape.TextFrame.Paragraphs.Append() method.
- Save the document to a PowerPoint file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an object of the Presentation class
presentation = Presentation()
# Get the first slide
slide = presentation.Slides[0]
# Add a shape to the slide and set the shape style
shape = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF(50.0, 50.0, 350.0, 200.0))
shape.Fill.FillType = FillFormatType.none
shape.Line.FillType = FillFormatType.none
# Add text to the default paragraph
paragraph = shape.TextFrame.Paragraphs[0]
paragraph.Text = "Computer Science Subjects:"
paragraph.Alignment = TextAlignmentType.Left
paragraph.TextRanges[0].Fill.FillType = FillFormatType.Solid
paragraph.TextRanges[0].Fill.SolidColor.Color = Color.get_Black()
# Specify the list items
listItems = [
" Data Structure",
" Algorithm",
" Computer Networks",
" Operating System",
" Theory of Computations",
" C Programming",
" Computer Organization and Architecture"
]
# Create a symbol bulleted list
for item in listItems:
textParagraph = TextParagraph()
textParagraph.Text = item
textParagraph.Alignment = TextAlignmentType.Left
textParagraph.TextRanges[0].Fill.FillType = FillFormatType.Solid
textParagraph.TextRanges[0].Fill.SolidColor.Color = Color.get_Black()
textParagraph.BulletType = TextBulletType.Symbol
shape.TextFrame.Paragraphs.Append(textParagraph)
# Save the result document
presentation.SaveToFile("SymbolBulletedList.pptx", FileFormat.Pptx2013)
presentation.Dispose()
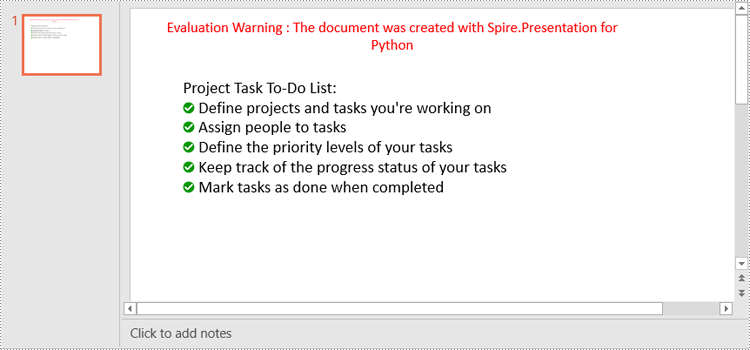
Create a Bulleted List with Image Bullets in PowerPoint in Python
To use an image as bullets, you need to set the bullet type of the paragraphs to Picture and then set the image as bullet points using the ParagraphProperties.BulletPicture.EmbedImage property. The following are the detailed steps.
- Create a Presentation object.
- Get the first slide using Presentation.Slides[0] property.
- Append a shape to the slide using ISlide.Shapes.AppendShape() method and set the shape style.
- Specify the items of the bulleted list inside a list.
- Create paragraphs based on the list items, and set the bullet type of these paragraphs to Picture using ParagraphProperties.BulletType property.
- Set an image as bullet points using ParagraphProperties.BulletPicture.EmbedImage property.
- Add these paragraphs to the shape using IAutoShape.TextFrame.Paragraphs.Append() method.
- Save the document to a PowerPoint file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an object of the Presentation class
presentation = Presentation()
# Get the first slide
slide = presentation.Slides[0]
# Add a shape to the slide and set the shape style
shape = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF(50.0, 50.0, 400.0, 180.0))
shape.Fill.FillType = FillFormatType.none
shape.Line.FillType = FillFormatType.none
# Add text to the default paragraph
paragraph = shape.TextFrame.Paragraphs[0]
paragraph.Text = "Project Task To-Do List:"
paragraph.Alignment = TextAlignmentType.Left
paragraph.TextRanges[0].Fill.FillType = FillFormatType.Solid
paragraph.TextRanges[0].Fill.SolidColor.Color = Color.get_Black()
# Specify the list items
listItems = [
" Define projects and tasks you're working on",
" Assign people to tasks",
" Define the priority levels of your tasks",
" Keep track of the progress status of your tasks",
" Mark tasks as done when completed"
]
# Create an image bulleted list
for item in listItems:
textParagraph = TextParagraph()
textParagraph.Text = item
textParagraph.Alignment = TextAlignmentType.Left
textParagraph.TextRanges[0].Fill.FillType = FillFormatType.Solid
textParagraph.TextRanges[0].Fill.SolidColor.Color = Color.get_Black()
textParagraph.BulletType = TextBulletType.Picture
stream = Stream("icon.png")
imageData = presentation.Images.AppendStream(stream)
textParagraph.BulletPicture.EmbedImage = imageData
shape.TextFrame.Paragraphs.Append(textParagraph)
stream.Close()
# Save the result document
presentation.SaveToFile("ImageBulletedList.pptx", FileFormat.Pptx2013)
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
