
Knowledgebase (2344)
Children categories
Locking cells is often used to protect the contents of specific cell ranges in a spreadsheet from accidental modification, which is useful in situations such as sharing a worksheet or protecting specific data. When you lock a cell, no one else can edit it unless they know the password or have the appropriate permissions. This feature is important for data security and integrity. In this article, we will show you how to lock specific cells, columns or rows in Excel on python platforms by using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
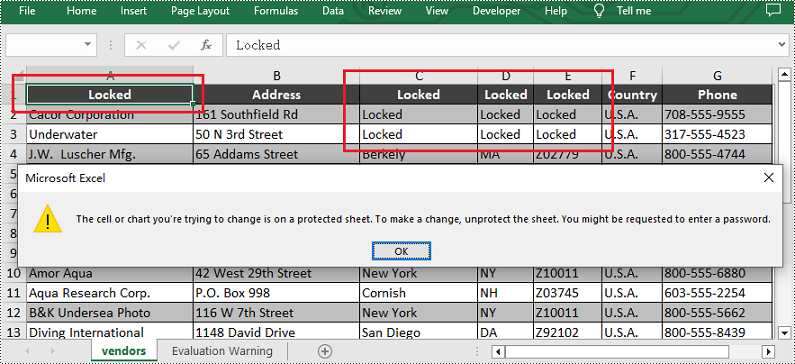
Lock Specific Cells in Python
Spire.XLS for Python supports users to lock a specified range of cells by setting the Worksheet.Range[].Style.Locked property to "True". Below are the detailed steps.
- Create a Workbook instance and load a sample excel file using Workbook.LoadFromFile() method.
- Get the first worksheet using Workbook.Worksheets[] property.
- Unlock all cells in the used range of the worksheet by setting the Worksheet.Range.Style.Locked property to "False".
- Set text for the specific cells using Worksheet.Range[].Text property and then lock them by setting the Worksheet.Range[].Style.Locked property to "True".
- Protect the worksheet using XlsWorksheetBase.Protect() method.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
inputFile = "C:/Users/Administrator/Desktop/Sample.xlsx"
outputFile = "C:/Users/Administrator/Desktop/LockSpecificCells.xlsx"
# Create a Workbook instance and load a sample file
workbook = Workbook()
workbook.LoadFromFile(inputFile)
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Unlock all cells in the used range of the worksheet
sheet.Range.Style.Locked = False
# Lock a specific cell in the sheet
sheet.Range["A1"].Text = "Locked"
sheet.Range["A1"].Style.Locked = True
# Lock a specific range of cells in the sheet
sheet.Range["C1:E3"].Text = "Locked"
sheet.Range["C1:E3"].Style.Locked = True
# Protect the worksheet with a password
sheet.Protect("123456", SheetProtectionType.All)
# Save the result file
workbook.SaveToFile(outputFile, ExcelVersion.Version2013)
workbook.Dispose()
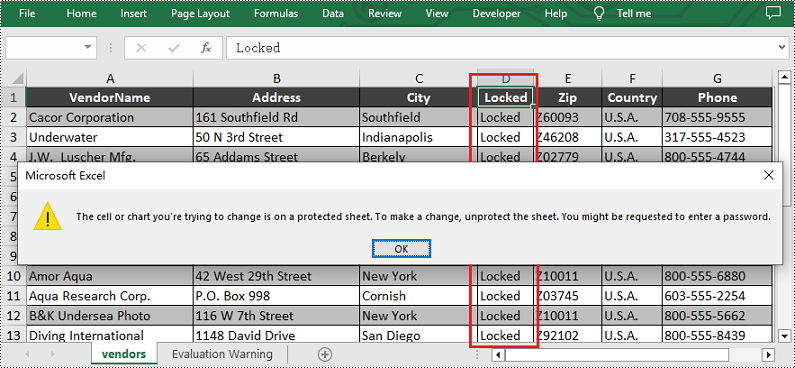
Lock a Specific Column in Python
If you want to lock a specific column in the worksheet, please set the Worksheet.Columns[].Style.Locked property to "True". Other steps are similar to the above method. Below are the detailed steps.
- Create a Workbook instance and load a sample excel file using Workbook.LoadFromFile() method.
- Get the first worksheet using Workbook.Worksheets[] property.
- Unlock all cells in the used range of the worksheet by setting the Worksheet.Range.Style.Locked property to "False".
- Set text for the fourth column using the Worksheet.Columns[].Text property and then lock it by setting the Worksheet.Columns[].Style.Locked property to "True".
- Protect the worksheet with a password by calling XlsWorksheetBase.Protect() method.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
inputFile = "C:/Users/Administrator/Desktop/Sample.xlsx"
outputFile = "C:/Users/Administrator/Desktop/LockSpecificColumn.xlsx"
# Create a Workbook instance and load a sample file
workbook = Workbook()
workbook.LoadFromFile(inputFile)
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Unlock all cells in the used range of the worksheet
sheet.Range.Style.Locked = False
# Lock the fourth column in the sheet
sheet.Columns[3].Text = "Locked"
sheet.Columns[3].Style.Locked = True
# Protect the worksheet with a password
sheet.Protect("123456", SheetProtectionType.All)
# Save the result file
workbook.SaveToFile(outputFile, ExcelVersion.Version2013)
workbook.Dispose()
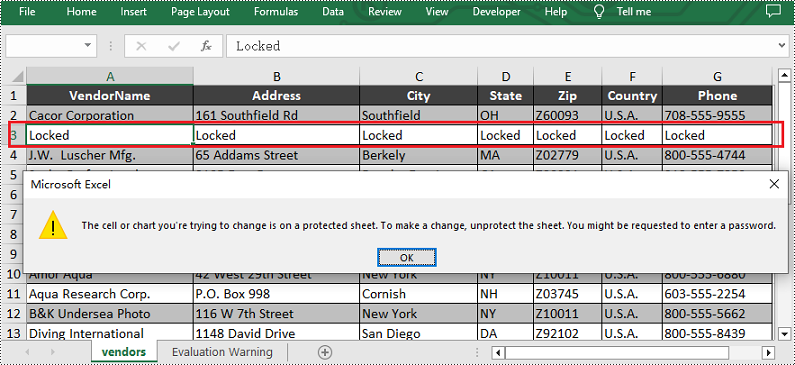
Lock a Specific Row in Python
Similarly, if you want to lock a certain row, please set the Worksheet.Rows[].Style.Locked property to "True". Here are the detailed steps.
- Create a Workbook instance and load a sample excel file using Workbook.LoadFromFile() method.
- Get the first worksheet using Workbook.Worksheets[] property.
- Unlock all cells in the used range of the worksheet by setting the Worksheet.Range.Style.Locked property to "False".
- Set text for the third row using the Worksheet.Rows[].Text property and then lock it by setting the Worksheet.Rows[].Style.Locked property to "True".
- Protect the worksheet with a password using XlsWorksheetBase.Protect() method.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
inputFile = "C:/Users/Administrator/Desktop/Sample.xlsx"
outputFile = "C:/Users/Administrator/Desktop/LockSpecificRow.xlsx"
# Create a Workbook instance and load a sample file
workbook = Workbook()
workbook.LoadFromFile(inputFile)
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Unlock all cells in the used range of the worksheet
sheet.Range.Style.Locked = False
# Lock the third row in the worksheet
sheet.Rows[2].Text = "Locked"
sheet.Rows[2].Style.Locked = True
# Protect the worksheet with a password
sheet.Protect("123456", SheetProtectionType.All)
# Save the result file
workbook.SaveToFile(outputFile, ExcelVersion.Version2013)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
PDF files are designed to preserve the formatting and layout of the original document, making them ideal for sharing and printing. However, they are typically not editable without specialized software. Converting a PDF to a Word document allows you to make changes, add or delete text, modify formatting, and customize content as needed. This is particularly useful when you want to update or revise existing PDF files. In this article, we will explain how to convert PDF to Word DOC or DOCX formats in Python using Spire.PDF for Python.
- Convert PDF to Word DOC or DOCX in Python
- Setting Document Properties While Converting PDF to Word in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to Word DOC or DOCX in Python
Spire.PDF for Python provides the PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method to convert PDF documents to a wide range of file formats, including Word DOC, DOCX, and more. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Convert the PDF document to a Word DOCX or DOC file using PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Sample.pdf")
# Convert the PDF document to a Word DOCX file
doc.SaveToFile("ToDocx.docx", FileFormat.DOCX)
# Or convert the PDF document to a Word DOC file
doc.SaveToFile("ToDoc.doc", FileFormat.DOC)
# Close the PdfDocument object
doc.Close()
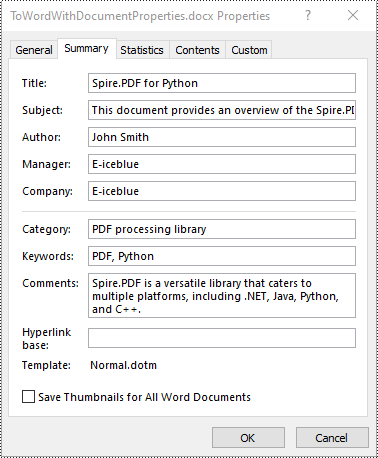
Setting Document Properties While Converting PDF to Word in Python
Document properties are attributes or information associated with a document that provide additional details about the file. These properties offer insights into various aspects of the document, such as its author, title, subject, version, keywords, category, and more.
Spire.PDF for Python provides the PdfToDocConverter class which allows developers to convert a PDF document to a Word DOCX file and set document properties for the file. The detailed steps are as follows.
- Create an object of the PdfToDocConverter class.
- Set document properties, such as title, subject, comment and author, for the converted Word DOCX file using the properties of the PdfToDocConverter class.
- Convert the PDF document to a Word DOCX file using PdfToDocConverter.SaveToDocx() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfToDocConverter class
converter = PdfToDocConverter("Sample.pdf")
# Set document properties such as title, subject, author and keywords for the converted .DOCX file
converter.DocxOptions.Title = "Spire.PDF for Python"
converter.DocxOptions.Subject = "This document provides an overview of the Spire.PDF for Python product."
converter.DocxOptions.Tags = "PDF, Python"
converter.DocxOptions.Categories = "PDF processing library"
converter.DocxOptions.Commments = "Spire.PDF is a versatile library that caters to multiple platforms, including .NET, Java, Python, and C++."
converter.DocxOptions.Authors = "John Smith"
converter.DocxOptions.LastSavedBy = "Alexander Johnson"
converter.DocxOptions.Revision = 8
converter.DocxOptions.Version = "V4.0"
converter.DocxOptions.ProgramName = "Spire.PDF for Python"
converter.DocxOptions.Company = "E-iceblue"
converter.DocxOptions.Manager = "E-iceblue"
# Convert the PDF document to a Word DOCX file
converter.SaveToDocx("ToWordWithDocumentProperties.docx")
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
OLE enables users to incorporate diverse file types-such as images, charts, documents, and multimedia-directly into Excel workbooks, fostering a more dynamic and comprehensive representation of information. By inserting OLE objects, users can create interactive and engaging spreadsheets that integrate a variety of data formats to simplify analyses and presentations in a single Excel environment. In this article, you will learn how to insert linked or embedded OLE objects to Excel in Python as well as how to extract OLE objects from Excel in Python using Spire.XLS for Python.
- Insert a Linked OLE Object to Excel in Python
- Insert an Embedded Object to Excel in Python
- Extract OLE Objects from Excel in Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Insert a Linked OLE Object to Excel in Python
To insert an OLE object to a worksheet, you use the Worksheet.OleObjects.Add(fileName, image, linkType) method, in which:
- the fileName parameter specifies the path of an external file to be inserted,
- the image parameter specifies a thumbnail of the first page or a document icon that the OLE object will be displayed as,
- the linkType parameter determines whether the OLE object is inserted to the document as an embedded source or a linked source.
The following are the steps to insert a linked OEL object to Excel using Spire.XLS for Python.
- Create a Workbook object.
- Get the first worksheet through Workbook.Worksheet[index] property.
- Load an image using Image.FromFile() method.
- Insert an OLE object to the worksheet using Worksheet.OleObjects.Add() method, and specify the link type as OleLinkType.Link.
- Specify the OLE object location through IOleObject.Location property.
- Specify the OLE object type through IOleObject.ObjectType property.
- Save the workbook to an Excel file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Add text to A1
sheet.Range["A1"].Text = "Here is an OLE Object."
# Load an image to be displayed as an icon of ole object
image = Image.FromFile("C:/Users/Administrator/Desktop/word_icon.png")
with Stream() as stream:
image.Save(stream,ImageFormat.get_Png())
# Add an ole object to the worksheet that links to an external file
oleObject = sheet.OleObjects.Add("C:/Users/Administrator/Desktop/invoice.docx", stream, OleLinkType.Link)
# Specify ole object location
oleObject.Location = sheet.Range["B3"]
# Specify ole object type
oleObject.ObjectType = OleObjectType.WordDocument
# Save to file
workbook.SaveToFile("output/OleObject.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Insert an Embedded OLE Object to Excel in Python
To insert an embedded OEL object to Excel, you specify the link type as OleLinkType.Embed while invoking the Worksheet.OleObjects.Add() method. The detailed steps are as follows.
- Create a Workbook object.
- Get the first worksheet through Workbook.Worksheet[index] property.
- Load an image using Image.FromFile() method.
- Insert an OLE object to the worksheet using Worksheet.OleObjects.Add() method, and specify the link type as OleLinkType.Embed.
- Specify the OLE object location through IOleObject.Location property.
- Specify the OLE object type through IOleObject.ObjectType property.
- Save the workbook to an Excel file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Add text to A1
sheet.Range["A1"].Text = "Here is an OLE Object."
# Load an image that represents ole object
image = Image.FromFile("C:/Users/Administrator/Desktop/screenshot.png")
with Stream() as stream:
image.Save(stream,ImageFormat.get_Png())
# Add an ole object to the worksheet as embedded source
oleObject = sheet.OleObjects.Add("C:/Users/Administrator/Desktop/invoice.docx", stream, OleLinkType.Embed)
# Specify ole object location
oleObject.Location = sheet.Range["B3"]
# Specify ole object type
oleObject.ObjectType = OleObjectType.WordDocument
# Save to file
workbook.SaveToFile("output/OleObject.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
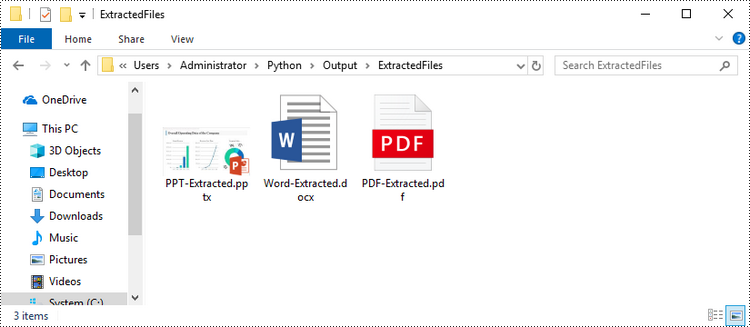
Extract OLE Objects from Excel in Python
Spire.XLS for Python provides the Worksheet.HasOleObjects property to determine whether a worksheet has OLE objects. If it does, get all the objects through the Worksheet.OleObjects property. Then, determine the type of a particular OEL object and save the OEL as a file of the appropriate document type. The following are the steps to extract OLE objects from Excel using Spire.XLS for Python.
- Create a Workbook object.
- Get a specific worksheet through Workbook.Worksheet[index] property.
- Determine if the worksheet contains OLE objects through Worksheet.HasOleObjects property.
- Get all the OLE objects from the worksheet through Worksheet.OleObjects property.
- Determine the type of a particular OEL object and save the OEL as a file of the appropriate document type.
- Python
from spire.xls import *
from spire.xls.common import *
# Write data to file
def WriteAllBytes(fname:str,data):
fp = open(fname,"wb")
for d in data:
fp.write(d)
fp.close()
# Create a Workbook object
workbook = Workbook()
# Load an Excel document
workbook.LoadFromFile("C:\\Users\\Administrator\\Desktop\\OleObjects.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Determine if the worksheet has ole objects
if sheet.HasOleObjects:
# Iterate through the found objects
for obj in sheet.OleObjects:
# If the object type is a Word document, save it to a .docx file
type = obj.ObjectType
if type is OleObjectType.WordDocument:
WriteAllBytes("output/ExtractedFiles/Word-Extracted.docx", obj.OleData)
# If the object type is an Adobe Acrobat document, save it to a .pdf file
if type is OleObjectType.AdobeAcrobatDocument:
WriteAllBytes("output/ExtractedFiles/PDF-Extracted.pdf", obj.OleData)
# If the object type is a PowerPoint document, save it to a .pptx file
if type is OleObjectType.PowerPointPresentation:
WriteAllBytes("output/ExtractedFiles/PPT-Extracted.pptx", obj.OleData)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
