PowerPoint를 Word로 쉽게 변환하기 – Office, 온라인 도구 및 Python

PowerPoint 프레젠테이션은 시각적 스토리텔링에 적합하지만, 문서화, 편집 또는 유인물 인쇄를 위해 슬라이드의 Word 버전이 필요한 경우가 있습니다. PowerPoint(PPT/PPTX)를 Word로 변환하면 슬라이드를 편집 가능한 텍스트로 재사용하고, 주석을 추가하며, 보고서나 매뉴얼과 같은 더 큰 서면 자료에 통합할 수 있습니다.
이 튜토리얼에서는 도구 및 워크플로우에 따라 PowerPoint를 Word로 변환하는 세 가지 실용적인 방법을 안내합니다.
- PowerPoint의 내장 내보내기 기능 사용 — 추가 소프트웨어 없이 빠르고 간단합니다.
- 무료 온라인 PowerPoint-Word 변환기 사용 — 모든 브라우저에서 액세스할 수 있습니다.
- Python 자동화 사용 — 일괄 처리 및 전문적인 환경에 이상적입니다.
각 방법이 어떻게 작동하고 어떤 방법이 귀하의 요구에 가장 적합한지 살펴보겠습니다.
방법 1: Microsoft Office를 사용하여 PowerPoint를 Word로 변환
Microsoft PowerPoint와 Word가 이미 설치되어 있다면 추가 도구 없이 프레젠테이션을 Word로 직접 변환할 수 있습니다. 두 가지 접근 방식이 있습니다.
- "유인물 만들기" (인쇄 가능한 슬라이드 노트에는 유용하지만 편집 가능한 슬라이드에는 적합하지 않음)
- "PDF로 저장하고 Word에서 열기" (완전히 편집 가능한 문서에 권장됨)
두 가지 모두 살펴보겠습니다.
1.1 "유인물 만들기"를 사용하여 PowerPoint를 Word로 변환
이 내장된 PowerPoint 기능은 강의 노트나 유인물을 만들기 위해 슬라이드를 Word로 내보냅니다.
단계:
- PowerPoint 파일을 엽니다.
- 파일 → 내보내기 → 유인물 만들기로 이동합니다.
- 레이아웃 옵션(예: 슬라이드 아래 노트, 빈 줄, 개요만)을 선택합니다.
- 확인을 클릭하여 Word 파일을 생성합니다.
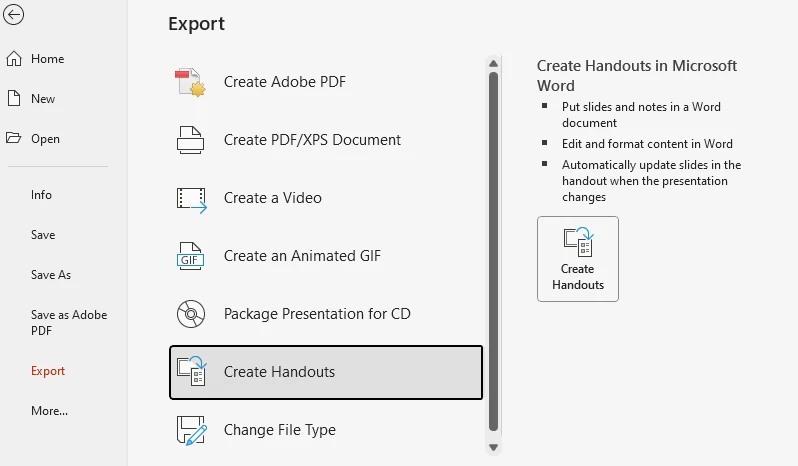
그러나 내보낸 슬라이드는 편집 가능한 개체가 아닌 정적 이미지로 Word에 나타납니다. 주변 텍스트(예: 노트, 댓글 또는 설명 추가)는 편집할 수 있지만 슬라이드 내부의 내용은 편집할 수 없습니다.
따라서 이 방법은 요약본을 인쇄하거나 배포하는 데는 좋지만 슬라이드 내용을 편집하는 데는 이상적이지 않습니다.
슬라이드를 정적 이미지로 직접 내보내려면 전용 접근 방식인 PowerPoint 슬라이드를 이미지로 내보내는 방법을 확인해 보세요.
1.2 PDF를 통해 PowerPoint를 편집 가능한 Word로 변환
완전히 편집 가능한 변환을 위한 가장 효과적인 접근 방식은 먼저 프레젠테이션을 PDF로 저장한 다음 Microsoft Word에서 여는 것입니다.
단계:
-
PowerPoint에서:
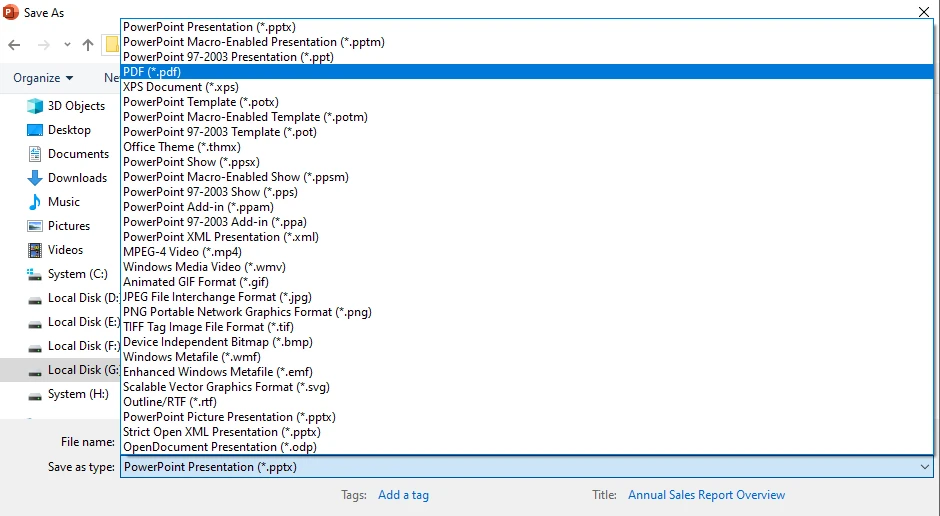
- 파일 → 다른 이름으로 저장 → PDF로 이동합니다.
- 출력 위치를 선택하고 저장을 클릭합니다.
-
Word에서:
- Microsoft Word를 엽니다.
- 파일 → 열기를 클릭하고 방금 만든 PDF를 선택합니다.
- 팝업 창에서 예를 클릭하면 Word가 자동으로 PDF를 편집 가능한 Word 문서로 변환합니다.
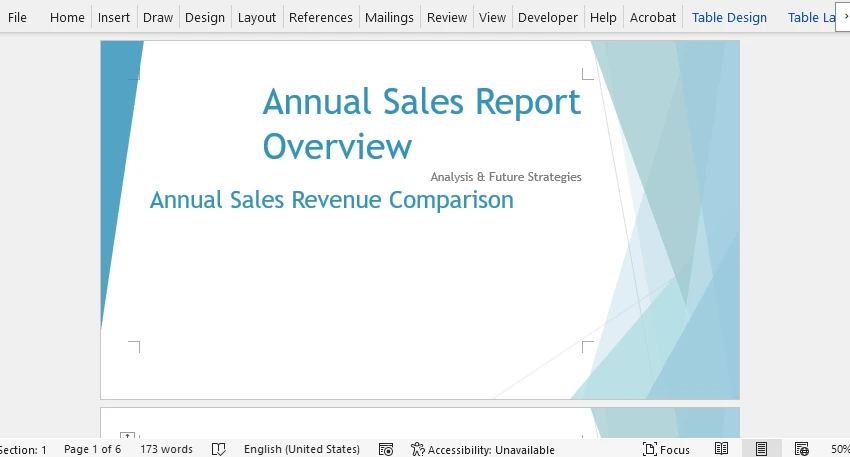
이제 원하는 대로 문서를 편집하거나 .docx 파일로 저장할 수 있습니다.
이 방법이 더 나은 이유:
- PowerPoint는 정확한 레이아웃과 벡터 그래픽으로 슬라이드를 PDF로 내보냅니다.
- Word의 내장 PDF 변환 엔진은 텍스트 상자, 이미지 및 서식을 편집 가능한 Word 개체로 재구성할 수 있습니다.
- 결과 문서는 시각적 충실도와 텍스트 접근성을 모두 유지하여 모든 것을 직접 편집할 수 있습니다.
더 나은 결과를 위한 팁:
- 선명한 이미지를 위해 고해상도 PDF 내보내기를 사용하세요.
- 지나치게 복잡한 전환이나 3D 효과는 피하세요. 평면적인 시각 자료로 나타납니다.
- 변환 후 글꼴 스타일과 단락 간격을 다시 확인하세요.
이 PowerPoint → PDF → Word 워크플로우는 모양과 편집 가능성 사이의 최상의 균형을 제공하여 문서화, 출판 및 보관에 이상적입니다.
방법 2: 온라인 도구를 사용하여 PowerPoint를 Word로 변환
Office가 설치되어 있지 않은 경우 온라인 PowerPoint-Word 변환기가 도움이 될 수 있습니다. 빠르고 접근성이 좋으며 플랫폼 독립적입니다.
온라인 변환기를 선택하는 이유
- 브라우저에서 직접 작동 — 설치가 필요 없습니다.
- 모든 시스템(Windows, macOS, Linux, ChromeOS)과 호환됩니다.
- 가끔 사용하는 사용자나 가벼운 작업에 편리합니다.
하지만 명심하세요:
- 많은 도구에는 파일 크기 또는 페이지 수 제한이 있습니다.
- 타사 서버에 기밀 파일을 업로드하면 개인 정보 보호 위험이 따릅니다.
추천 무료 도구
| 도구 | 파일 크기 제한 | 출력 형식 | 등록 | 일괄 지원 |
|---|---|---|---|---|
| FreeConvert | 1024MB | DOCX/DOC | 선택 사항 | 예 |
| Zamzar | 7MB | DOCX/DOC | 선택 사항 | 예 |
| Convertio | 100MB | DOCX/DOC | 선택 사항 | 예 |
참고: 민감한 자료를 업로드하기 전에 항상 각 사이트의 개인정보 보호정책을 읽어보세요.
예: FreeConvert 사용
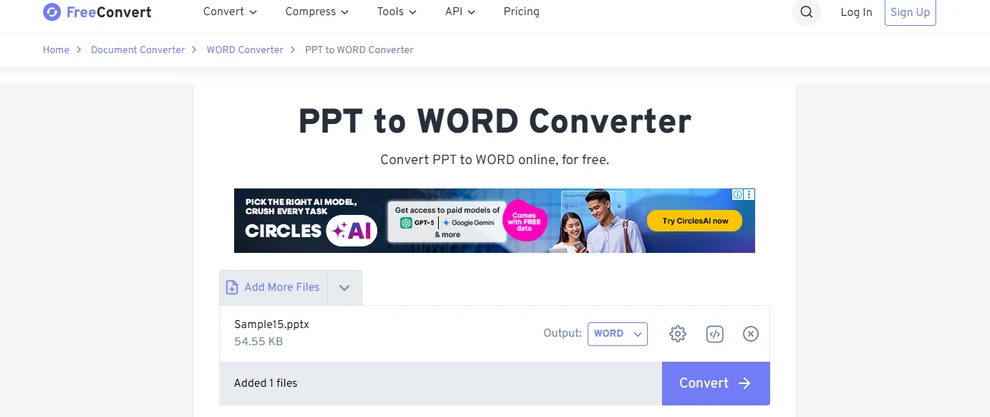
- FreeConvert PPT to Word Converter를 방문하세요.
- PowerPoint 파일을 업로드하고 변환을 클릭하세요.
- 변환이 완료될 때까지 기다리세요.
- 변환된 Word 문서를 다운로드하세요.
장점:
- 소프트웨어 설치 필요 없음
- 간단한 드래그 앤 드롭 인터페이스
- 우수한 서식 정확도
단점:
- 하루 무료 변환 횟수 제한
- 이미지를 약간 압축하거나 다시 포맷할 수 있음
온라인 변환기는 빠른 일회성 작업에 편리하지만, 정기적이거나 대규모 변환의 경우 데스크톱 또는 자동화된 솔루션이 더 효율적입니다.
더 광범위한 온라인 문서 변환을 위해 여러 파일 유형과 형식을 무료로 지원하는 CLOUDXDOCS 무료 온라인 문서 변환기를 탐색할 수 있습니다.
방법 3: Python으로 PowerPoint를 Word로 변환 자동화
대량으로 프레젠테이션을 처리해야 하는 개발자나 팀에게 자동화는 가장 빠르고 안정적인 솔루션을 제공합니다. 단 몇 줄의 Python 코드로 여러 PowerPoint 프레젠테이션을 Word 문서로 변환할 수 있습니다. 이 모든 과정은 파일 크기 제한이나 개인 정보 보호 문제 없이 사용자 컴퓨터에서 로컬로 처리됩니다.
이 예제에서는 단일 툴킷으로 전체 변환을 완료할 수 있게 해주는 올인원 라이브러리인 Free Spire.Office for Python을 사용합니다.
pip로 라이브러리를 설치하세요:
pip install spire.office.free
예: Python에서 PowerPoint를 Word로 변환
import os
from spire.presentation import Presentation, FileFormat
from spire.pdf import PdfDocument, FileFormat as PdfFileFormat
input_ppt = "G:/Documents/Sample14.pptx"
temp_pdf = "output/temp.pdf"
output_docx = "output/output.docx"
# 1단계: PowerPoint를 PDF로 변환
presentation = Presentation()
presentation.LoadFromFile(input_ppt)
presentation.SaveToFile(temp_pdf, FileFormat.PDF)
# 2단계: PDF를 Word로 변환
pdf = PdfDocument()
pdf.LoadFromFile(temp_pdf)
pdf.SaveToFile(output_docx, PdfFileFormat.DOCX)
# 3단계: 임시 PDF 파일 삭제
if os.path.exists(temp_pdf):
os.remove(temp_pdf)
print("PPTX가 Word로 성공적으로 변환되었습니다!")
아래 이미지는 Python을 사용하여 PowerPoint 프레젠테이션을 Word 문서로 변환한 결과를 보여줍니다.
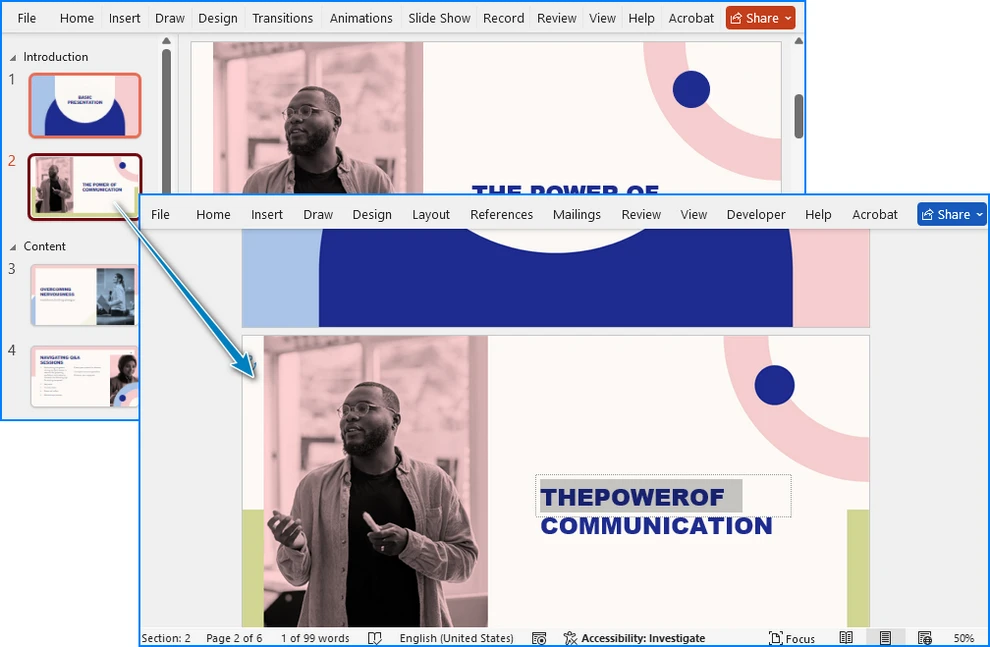
코드 설명
이 스크립트는 Free Spire.Office for Python을 사용하여 변환의 두 단계를 모두 처리합니다.
- Spire.Presentation은 PowerPoint 파일을 로드하여 고품질 PDF로 내보냅니다.
- Spire.PDF는 PDF를 완전히 편집 가능한 Word 문서(.docx)로 변환합니다.
- 변환 후 임시 PDF 파일은 작업 공간을 깨끗하게 유지하기 위해 자동으로 삭제됩니다.
이 워크플로우는 빠르고 안정적이며 모든 파일을 로컬에 보관하여 온라인 서비스를 사용하지 않고도 일관된 서식, 정확한 레이アウト 및 편집 가능한 텍스트를 보장합니다.
일괄 변환 예제
동일한 논리를 확장하여 폴더의 모든 PowerPoint 파일을 변환할 수 있습니다.
import os
from spire.presentation import Presentation, FileFormat
from spire.pdf import PdfDocument, FileFormat as PdfFileFormat
folder = "presentations"
for file in os.listdir(folder):
if file.endswith(".pptx"):
ppt_path = os.path.join(folder, file)
temp_pdf = os.path.join(folder, file.replace(".pptx", ".pdf"))
docx_path = os.path.join(folder, file.replace(".pptx", ".docx"))
# 1단계: PPTX를 PDF로 변환
presentation = Presentation()
presentation.LoadFromFile(ppt_path)
presentation.SaveToFile(temp_pdf, FileFormat.PDF)
# 2단계: PDF를 Word로 변환
pdf = PdfDocument()
pdf.LoadFromFile(temp_pdf)
pdf.SaveToFile(docx_path, PdfFileFormat.DOCX)
# 3단계: 임시 PDF 파일 삭제
if os.path.exists(temp_pdf):
os.remove(temp_pdf)
print("모든 PowerPoint 파일이 성공적으로 Word로 변환되었습니다!")
이 접근 방식은 기업 아카이브, 교육 콘텐츠 라이브러리 또는 자동화된 보고 시스템에 적합하며, 남은 임시 파일 없이 수십 또는 수백 개의 프레젠테이션을 빠르고 안전하게 변환할 수 있습니다.
관심 있을 만한 다른 글: PowerPoint를 HTML로 변환하는 방법
모든 방법 비교
PowerPoint를 Word로 변환하는 데 가장 적합한 방법을 선택하는 데 도움이 되도록 사용 가능한 모든 접근 방식을 비교해 보겠습니다.
| 방법 | 필요한 도구 | 최적 대상 | 장점 | 단점 |
|---|---|---|---|---|
| PowerPoint + Word (PDF 방식) | Microsoft Office | 편집 가능한 문서 | 정확한 레이아웃, 완전 편집 가능 | 파일당 수동 단계 |
| PowerPoint 유인물 | PowerPoint | 유인물, 노트 | 내장 기능, 빠름 | 슬라이드 편집 불가 |
| 온라인 도구 | 브라우저 | 가끔 사용 | 쉬움, 크로스 플랫폼 | 개인 정보 보호 위험, 크기 제한 |
| Python 자동화 | Python, Spire SDK | 일괄 변환 | 완전 자동화, 유연함 | 설치 필요 |
PowerPoint를 Word로 변환하는 것에 대한 일반적인 질문
Q1: 서식을 잃지 않고 PowerPoint를 Word로 변환할 수 있나요?
예. PDF → Word 접근 방식은 텍스트 상자, 레이아웃 및 이미지를 높은 정확도로 보존합니다.
Q2: "유인물 만들기"를 사용할 때 슬라이드를 편집할 수 없는 이유는 무엇인가요?
PowerPoint가 슬라이드를 정적 이미지로 내보내기 때문입니다. 노트나 주변 텍스트는 편집할 수 있지만 슬라이드 내용 자체는 편집할 수 없습니다.
Q3: Word에서 애니메이션을 유지할 방법이 있나요?
아니요, Word는 애니메이션 효과를 지원하지 않습니다. 정적 콘텐츠만 전송됩니다.
Q4: 여러 PowerPoint 파일을 자동으로 변환하려면 어떻게 해야 하나요?
위에 표시된 Python 자동화 방법을 사용하세요. 폴더의 모든 .pptx 파일을 프로그래밍 방식으로 처리할 수 있습니다.
Q5: 어떤 방법이 가장 전문적으로 보이는 결과를 제공하나요?
온라인 도구와 Python 자동화 방법은 일반적으로 레이아웃 충실도와 편집 가능성 사이에서 최상의 균형을 제공합니다.
결론
PowerPoint를 Word로 변환하면 프레젠테이션 콘텐츠를 쉽게 편집, 주석 달기, 인쇄 및 용도 변경할 수 있는 유연성을 얻을 수 있습니다.
- 간단한 노트나 인쇄 가능한 개요에는 PowerPoint의 유in물 기능을 사용하세요.
- 완전히 편집 가능한 콘텐츠가 필요할 때는 PDF-Word 경로를 선택하세요.
- 대규모 또는 반복적인 변환을 위해 Python으로 프로세스를 자동화하세요.
각 방법은 보고서 준비, 교육 자료 인쇄 또는 자동화된 워크플로우에 변환 통합 등 다양한 목적을 수행합니다.
올바른 접근 방식을 사용하면 모든 프레젠테이션을 몇 분 안에 구조화되고 편집 가능하며 전문적인 Word 문서로 바꿀 수 있습니다.
관련 항목
Convertir facilement PowerPoint en Word – Office, outils en ligne et Python
Les présentations PowerPoint sont parfaites pour la narration visuelle, mais vous avez parfois besoin d'une version Word de vos diapositives — pour la documentation, l'édition ou l'impression de documents. La conversion de PowerPoint (PPT/PPTX) en Word vous permet de réutiliser vos diapositives sous forme de texte modifiable, d'ajouter des annotations et de les intégrer dans des documents écrits plus volumineux tels que des rapports ou des manuels.
Ce tutoriel vous présente trois façons pratiques de convertir PowerPoint en Word, en fonction de vos outils et de votre flux de travail :
- Utilisation de la fonctionnalité d'exportation intégrée de PowerPoint — rapide et simple, aucun logiciel supplémentaire n'est requis
- Utilisation de convertisseurs PowerPoint vers Word en ligne gratuits — accessibles depuis n'importe quel navigateur
- Utilisation de l'automatisation Python — idéale pour le traitement par lots et les environnements professionnels
Voyons comment chaque méthode fonctionne et laquelle répond le mieux à vos besoins.
Méthode 1 : Convertir PowerPoint en Word à l'aide de Microsoft Office
Si vous avez déjà installé Microsoft PowerPoint et Word, vous pouvez convertir des présentations en Word directement sans outils supplémentaires. Il existe deux approches :
- « Créer des documents » (utile pour les notes de diapositives imprimables mais pas pour les diapositives modifiables)
- « Enregistrer en tant que PDF et ouvrir dans Word » (recommandé pour les documents entièrement modifiables)
Examinons les deux.
1.1 Convertir PowerPoint en Word en utilisant « Créer des documents »
Cette fonctionnalité intégrée de PowerPoint exporte les diapositives dans Word pour créer des notes de cours ou des documents.
Étapes :
- Ouvrez votre fichier PowerPoint.
- Allez dans Fichier → Exporter → Créer des documents.
- Choisissez une option de mise en page (par exemple, Notes sous les diapositives, Lignes vierges, Plan uniquement).
- Cliquez sur OK pour générer un fichier Word.
Cependant, les diapositives exportées apparaissent dans Word sous forme d'images statiques, et non d'objets modifiables. Vous pouvez modifier le texte qui les entoure — par exemple, en ajoutant des notes, des commentaires ou des descriptions — mais pas le contenu à l'intérieur des diapositives.
Cette méthode est donc idéale pour imprimer ou distribuer des résumés, mais pas pour modifier le contenu des diapositives.
Si vous souhaitez exporter directement les diapositives sous forme d'images statiques, vous pouvez consulter comment exporter des diapositives PowerPoint en tant qu'images pour une approche dédiée.
1.2 Convertir PowerPoint en Word modifiable via PDF
Pour une conversion entièrement modifiable, l'approche la plus efficace consiste à d'abord enregistrer votre présentation au format PDF, puis à l'ouvrir dans Microsoft Word.
Étapes :
-
Dans PowerPoint :
- Allez dans Fichier → Enregistrer sous → PDF.
- Choisissez l'emplacement de sortie et cliquez sur Enregistrer.
-
Dans Word :
- Ouvrez Microsoft Word.
- Cliquez sur Fichier → Ouvrir, et sélectionnez le PDF que vous venez de créer.
- Cliquez sur Oui dans la fenêtre contextuelle, et Word convertira automatiquement le PDF en un document Word modifiable.
Vous pouvez maintenant modifier le document comme vous le souhaitez ou l'enregistrer en tant que fichier .docx.
Pourquoi cela fonctionne mieux :
- PowerPoint exporte les diapositives au format PDF avec une mise en page précise et des graphiques vectoriels.
- Le moteur de conversion PDF intégré de Word peut reconstruire les zones de texte, les images et la mise en forme en objets Word modifiables.
- Le document résultant conserve à la fois la fidélité visuelle et l'accessibilité du texte, vous permettant de tout modifier directement.
Conseils pour de meilleurs résultats :
- Utilisez une exportation PDF haute résolution pour des images nettes.
- Évitez les transitions ou les effets 3D trop complexes — ils apparaîtront comme des visuels plats.
- Après la conversion, revérifiez les styles de police et l'espacement des paragraphes.
Ce flux de travail PowerPoint → PDF → Word offre le meilleur équilibre entre l'apparence et la modifiabilité — idéal pour la documentation, la publication et l'archivage.
Méthode 2 : Convertir PowerPoint en Word à l'aide d'outils en ligne
Si vous n'avez pas Office installé, les convertisseurs PowerPoint vers Word en ligne peuvent vous aider. Ils sont rapides, accessibles et indépendants de la plate-forme.
Pourquoi choisir un convertisseur en ligne
- Fonctionne directement dans votre navigateur — aucune installation n'est requise.
- Compatible avec tous les systèmes (Windows, macOS, Linux, ChromeOS).
- Pratique pour les utilisateurs occasionnels ou les tâches légères.
Cependant, gardez à l'esprit :
- De nombreux outils ont des limites de taille de fichier ou de nombre de pages.
- Le téléchargement de fichiers confidentiels sur des serveurs tiers pose des risques de confidentialité.
Outils gratuits recommandés
| Outil | Limite de taille de fichier | Format de sortie | Inscription | Support par lots |
|---|---|---|---|---|
| FreeConvert | 1024MB | DOCX/DOC | Optionnel | Oui |
| Zamzar | 7MB | DOCX/DOC | Optionnel | Oui |
| Convertio | 100MB | DOCX/DOC | Optionnel | Oui |
Remarque : Lisez toujours la politique de confidentialité de chaque site avant de télécharger du matériel sensible.
Exemple : Utilisation de FreeConvert
- Visitez FreeConvert PPT to Word Converter.
- Téléchargez votre fichier PowerPoint et cliquez sur Convertir.
- Attendez la fin de la conversion.
- Téléchargez le document Word converti.
Avantages :
- Aucune installation de logiciel
- Interface simple par glisser-déposer
- Bonne précision de mise en forme
Inconvénients :
- Conversions gratuites limitées par jour
- Peut compresser ou reformater légèrement les images
Les convertisseurs en ligne sont pratiques pour les tâches ponctuelles rapides, mais pour les conversions régulières ou à grande échelle, une solution de bureau ou automatisée est plus efficace.
Pour une plus large gamme de conversions de documents en ligne, vous pouvez explorer CLOUDXDOCS Free Online Document Converter, qui prend en charge gratuitement plusieurs types et formats de fichiers.
Méthode 3 : Automatiser la conversion de PowerPoint en Word avec Python
Pour les développeurs ou les équipes qui ont besoin de gérer des présentations en masse, l'automatisation offre la solution la plus rapide et la plus fiable. Avec seulement quelques lignes de code Python, vous pouvez convertir plusieurs présentations PowerPoint en documents Word — le tout traité localement sur votre machine, sans limite de taille de fichier ni problème de confidentialité.
Cet exemple utilise Free Spire.Office for Python, une bibliothèque tout-en-un qui permet de réaliser l'intégralité de la conversion avec un seul toolkit.
Installez la bibliothèque avec pip :
pip install spire.office.free
Exemple : Convertir PowerPoint en Word en Python
import os
from spire.presentation import Presentation, FileFormat
from spire.pdf import PdfDocument, FileFormat as PdfFileFormat
input_ppt = "G:/Documents/Sample14.pptx"
temp_pdf = "output/temp.pdf"
output_docx = "output/output.docx"
# Étape 1 : Convertir PowerPoint en PDF
presentation = Presentation()
presentation.LoadFromFile(input_ppt)
presentation.SaveToFile(temp_pdf, FileFormat.PDF)
# Étape 2 : Convertir le PDF en Word
pdf = PdfDocument()
pdf.LoadFromFile(temp_pdf)
pdf.SaveToFile(output_docx, PdfFileFormat.DOCX)
# Étape 3 : Supprimer le fichier PDF temporaire
if os.path.exists(temp_pdf):
os.remove(temp_pdf)
print("Le PPTX a été converti avec succès en Word !")
L'image ci-dessous montre le résultat de la conversion d'une présentation PowerPoint en document Word à l'aide de Python.
Explication du code
Ce script utilise Free Spire.Office for Python pour gérer les deux étapes de la conversion :
- Spire.Presentation charge le fichier PowerPoint et l'exporte en tant que PDF de haute qualité.
- Spire.PDF convertit le PDF en un document Word entièrement modifiable (.docx).
- Après la conversion, le fichier PDF temporaire est supprimé automatiquement pour garder votre espace de travail propre.
Ce flux de travail est rapide, fiable et conserve tous les fichiers en local — garantissant une mise en forme cohérente, une mise en page précise et un texte modifiable sans utiliser de services en ligne.
Exemple de conversion par lots
Vous pouvez étendre la même logique pour convertir tous les fichiers PowerPoint dans un dossier :
import os
from spire.presentation import Presentation, FileFormat
from spire.pdf import PdfDocument, FileFormat as PdfFileFormat
folder = "presentations"
for file in os.listdir(folder):
if file.endswith(".pptx"):
ppt_path = os.path.join(folder, file)
temp_pdf = os.path.join(folder, file.replace(".pptx", ".pdf"))
docx_path = os.path.join(folder, file.replace(".pptx", ".docx"))
# Étape 1 : Convertir PPTX en PDF
presentation = Presentation()
presentation.LoadFromFile(ppt_path)
presentation.SaveToFile(temp_pdf, FileFormat.PDF)
# Étape 2 : Convertir le PDF en Word
pdf = PdfDocument()
pdf.LoadFromFile(temp_pdf)
pdf.SaveToFile(docx_path, PdfFileFormat.DOCX)
# Étape 3 : Supprimer le fichier PDF temporaire
if os.path.exists(temp_pdf):
os.remove(temp_pdf)
print("Tous les fichiers PowerPoint ont été convertis avec succès en Word !")
Cette approche est parfaite pour les archives d'entreprise, les bibliothèques de contenu éducatif ou les systèmes de reporting automatisés, permettant de convertir des dizaines ou des centaines de présentations rapidement et en toute sécurité, sans laisser de fichiers temporaires.
Vous aimerez peut-être aussi : Comment convertir PowerPoint en HTML
Comparaison de toutes les méthodes
Pour vous aider à choisir la méthode la plus appropriée pour convertir PowerPoint en Word, voici une comparaison de toutes les approches disponibles.
| Méthode | Outils nécessaires | Idéal pour | Avantages | Inconvénients |
|---|---|---|---|---|
| PowerPoint + Word (méthode PDF) | Microsoft Office | Documents modifiables | Mise en page précise, entièrement modifiable | Étapes manuelles par fichier |
| Documents PowerPoint | PowerPoint | Documents, notes | Intégré, rapide | Diapositives non modifiables |
| Outils en ligne | Navigateur | Utilisation occasionnelle | Facile, multiplateforme | Risque de confidentialité, taille limitée |
| Automatisation Python | Python, SDK Spire | Conversions par lots | Entièrement automatisé, flexible | Nécessite une configuration |
Questions fréquentes sur la conversion de PowerPoint en Word
Q1 : Puis-je convertir PowerPoint en Word sans perdre la mise en forme ?
Oui. L'approche PDF → Word préserve les zones de texte, les mises en page et les images avec une grande précision.
Q2 : Pourquoi ne puis-je pas modifier les diapositives lorsque j'utilise « Créer des documents » ?
Parce que PowerPoint exporte les diapositives sous forme d'images statiques. Vous pouvez modifier les notes ou le texte environnant, mais pas le contenu de la diapositive elle-même.
Q3 : Existe-t-il un moyen de conserver les animations dans Word ?
Non, Word ne prend pas en charge les effets d'animation — seul le contenu statique est transféré.
Q4 : Comment puis-je convertir plusieurs fichiers PowerPoint automatiquement ?
Utilisez la méthode d'automatisation Python présentée ci-dessus. Elle peut traiter tous les fichiers .pptx d'un dossier par programme.
Q5 : Quelle méthode donne le résultat le plus professionnel ?
Les Outils en ligne et la méthode d'automatisation Python offrent généralement le meilleur équilibre entre la fidélité de la mise en page et la modifiabilité.
Conclusion
La conversion de PowerPoint en Word vous donne la flexibilité de modifier, annoter, imprimer et réutiliser facilement le contenu de votre présentation.
- Utilisez la fonctionnalité de documents de PowerPoint pour des notes simples ou des plans imprimables.
- Choisissez la voie PDF vers Word lorsque vous avez besoin d'un contenu entièrement modifiable.
- Automatisez le processus avec Python pour les conversions à grande échelle ou récurrentes.
Chaque méthode a un objectif différent — que vous prépariez un rapport, imprimiez des supports de formation ou intégriez la conversion dans un flux de travail automatisé.
Avec la bonne approche, vous pouvez transformer n'importe quelle présentation en un document Word structuré, modifiable et professionnel en quelques minutes.
Voir aussi
Convertir PowerPoint a Word fácilmente – Office, herramientas en línea y Python
Tabla de Contenidos
Las presentaciones de PowerPoint son perfectas para la narración visual, pero a veces necesitas una versión de tus diapositivas en Word, para documentación, edición o impresión de folletos. Convertir PowerPoint (PPT/PPTX) a Word te permite reutilizar tus diapositivas como texto editable, agregar anotaciones e integrarlas en materiales escritos más grandes, como informes o manuales.
Este tutorial te guía a través de tres formas prácticas de convertir PowerPoint a Word, dependiendo de tus herramientas y flujo de trabajo:
- Usando la función de exportación integrada de PowerPoint — rápido y simple, no se necesita software adicional
- Usando conversores gratuitos en línea de PowerPoint a Word — accesibles desde cualquier navegador
- Usando automatización con Python — ideal para el procesamiento por lotes y entornos profesionales
Veamos cómo funciona cada método y cuál se adapta mejor a tus necesidades.
Método 1: Convertir PowerPoint a Word Usando Microsoft Office
Si ya tienes Microsoft PowerPoint y Word instalados, puedes convertir presentaciones a Word directamente sin herramientas adicionales. Hay dos enfoques:
- "Crear Documentos para Imprimir" (útil para notas de diapositivas imprimibles pero no para diapositivas editables)
- "Guardar como PDF y abrir en Word" (recomendado para documentos totalmente editables)
Veamos ambos.
1.1 Convertir PowerPoint a Word Usando "Crear Documentos para Imprimir"
Esta función integrada de PowerPoint exporta diapositivas a Word para crear notas de clase o documentos para imprimir.
Pasos:
- Abre tu archivo de PowerPoint.
- Ve a Archivo → Exportar → Crear Documentos para Imprimir.
- Elige una opción de diseño (p. ej., Notas debajo de las diapositivas, Líneas en blanco, Solo esquema).
- Haz clic en Aceptar para generar un archivo de Word.
Sin embargo, las diapositivas exportadas aparecen en Word como imágenes estáticas, no como objetos editables. Puedes editar el texto a su alrededor — por ejemplo, agregando notas, comentarios o descripciones — pero no el contenido dentro de las diapositivas.
Así que este método es excelente para imprimir o distribuir resúmenes, pero no es ideal para editar el contenido de las diapositivas.
Si deseas exportar directamente las diapositivas como imágenes estáticas, puedes consultar cómo exportar diapositivas de PowerPoint como imágenes para un enfoque dedicado.
1.2 Convertir PowerPoint a Word Editable a través de PDF
Para una conversión totalmente editable, el enfoque más efectivo es primero guardar tu presentación como PDF y luego abrirla en Microsoft Word.
Pasos:
-
En PowerPoint:
- Ve a Archivo → Guardar como → PDF.
- Elige la ubicación de salida y haz clic en Guardar.
-
En Word:
- Abre Microsoft Word.
- Haz clic en Archivo → Abrir, y selecciona el PDF que acabas de crear.
- Haz clic en Sí en la ventana emergente, y Word convertirá automáticamente el PDF en un documento de Word editable.
Ahora puedes editar el documento como desees o guardarlo como un archivo .docx.
Por Qué Esto Funciona Mejor:
- PowerPoint exporta las diapositivas a PDF con diseño preciso y gráficos vectoriales.
- El motor de conversión de PDF integrado de Word puede reconstruir cuadros de texto, imágenes y formato en objetos de Word editables.
- El documento resultante mantiene tanto la fidelidad visual como la accesibilidad del texto, lo que te permite editar todo directamente.
Consejos para Mejores Resultados:
- Usa una exportación a PDF de alta resolución para obtener imágenes nítidas.
- Evita transiciones o efectos 3D demasiado complejos — aparecerán como imágenes planas.
- Después de la conversión, vuelve a verificar los estilos de fuente y el espaciado de los párrafos.
Este flujo de trabajo PowerPoint → PDF → Word proporciona el mejor equilibrio entre apariencia y capacidad de edición — ideal para documentación, publicación y archivo.
Método 2: Convertir PowerPoint a Word Usando Herramientas en Línea
Si no tienes Office instalado, los conversores en línea de PowerPoint a Word pueden ayudar. Son rápidos, accesibles e independientes de la plataforma.
Por Qué Elegir un Conversor en Línea
- Funciona directamente en tu navegador — no se necesita instalación.
- Compatible con todos los sistemas (Windows, macOS, Linux, ChromeOS).
- Conveniente para usuarios ocasionales o tareas ligeras.
Sin embargo, ten en cuenta:
- Muchas herramientas tienen límites de tamaño de archivo o número de páginas.
- Subir archivos confidenciales a servidores de terceros plantea riesgos de privacidad.
Herramientas Gratuitas Recomendadas
| Herramienta | Límite de Tamaño de Archivo | Formato de Salida | Registro | Soporte por Lotes |
|---|---|---|---|---|
| FreeConvert | 1024MB | DOCX/DOC | Opcional | Sí |
| Zamzar | 7MB | DOCX/DOC | Opcional | Sí |
| Convertio | 100MB | DOCX/DOC | Opcional | Sí |
Nota: Lee siempre la política de privacidad de cada sitio antes de subir material sensible.
Ejemplo: Usando FreeConvert
- Visita FreeConvert PPT to Word Converter.
- Sube tu archivo de PowerPoint y haz clic en Convertir.
- Espera a que se complete la conversión.
- Descarga el documento de Word convertido.
Ventajas:
- Sin instalación de software
- Interfaz simple de arrastrar y soltar
- Buena precisión de formato
Desventajas:
- Conversiones gratuitas limitadas por día
- Puede comprimir o reformatear ligeramente las imágenes
Los conversores en línea son convenientes para tareas rápidas y únicas, pero para conversiones regulares o a gran escala, una solución de escritorio o automatizada es más eficiente.
Para una gama más amplia de conversiones de documentos en línea, puedes explorar CLOUDXDOCS Free Online Document Converter, que admite múltiples tipos de archivos y formatos de forma gratuita.
Método 3: Automatizar la Conversión de PowerPoint a Word con Python
Para desarrolladores o equipos que necesitan manejar presentaciones en masa, la automatización ofrece la solución más rápida y confiable. Con solo unas pocas líneas de código Python, puedes convertir múltiples presentaciones de PowerPoint en documentos de Word — todo procesado localmente en tu máquina, sin límites de tamaño de archivo ni preocupaciones de privacidad.
Este ejemplo utiliza Free Spire.Office for Python, una biblioteca todo en uno que permite completar toda la conversión con un único kit de herramientas.
Instala la biblioteca con pip:
pip install spire.office.free
Ejemplo: Convertir PowerPoint a Word en Python
import os
from spire.presentation import Presentation, FileFormat
from spire.pdf import PdfDocument, FileFormat as PdfFileFormat
input_ppt = "G:/Documents/Sample14.pptx"
temp_pdf = "output/temp.pdf"
output_docx = "output/output.docx"
# Step 1: Convert PowerPoint to PDF
presentation = Presentation()
presentation.LoadFromFile(input_ppt)
presentation.SaveToFile(temp_pdf, FileFormat.PDF)
# Step 2: Convert PDF to Word
pdf = PdfDocument()
pdf.LoadFromFile(temp_pdf)
pdf.SaveToFile(output_docx, PdfFileFormat.DOCX)
# Step 3: Delete the temporary PDF file
if os.path.exists(temp_pdf):
os.remove(temp_pdf)
print("¡PPTX se ha convertido exitosamente a Word!")
La imagen a continuación muestra el resultado de convertir una presentación de PowerPoint a un documento de Word usando Python.
Explicación del Código
Este script utiliza Free Spire.Office for Python para manejar ambos pasos de la conversión:
- Spire.Presentation carga el archivo de PowerPoint y lo exporta como un PDF de alta calidad.
- Spire.PDF convierte el PDF en un documento de Word (.docx) totalmente editable.
- Después de la conversión, el archivo PDF temporal se elimina automáticamente para mantener tu espacio de trabajo limpio.
Este flujo de trabajo es rápido, confiable y mantiene todos los archivos locales — asegurando un formato consistente, un diseño preciso y texto editable sin usar ningún servicio en línea.
Ejemplo de Conversión por Lotes
Puedes extender la misma lógica para convertir todos los archivos de PowerPoint en una carpeta:
import os
from spire.presentation import Presentation, FileFormat
from spire.pdf import PdfDocument, FileFormat as PdfFileFormat
folder = "presentations"
for file in os.listdir(folder):
if file.endswith(".pptx"):
ppt_path = os.path.join(folder, file)
temp_pdf = os.path.join(folder, file.replace(".pptx", ".pdf"))
docx_path = os.path.join(folder, file.replace(".pptx", ".docx"))
# Step 1: Convert PPTX to PDF
presentation = Presentation()
presentation.LoadFromFile(ppt_path)
presentation.SaveToFile(temp_pdf, FileFormat.PDF)
# Step 2: Convert PDF to Word
pdf = PdfDocument()
pdf.LoadFromFile(temp_pdf)
pdf.SaveToFile(docx_path, PdfFileFormat.DOCX)
# Step 3: Delete the temporary PDF file
if os.path.exists(temp_pdf):
os.remove(temp_pdf)
print("¡Todos los archivos de PowerPoint se han convertido exitosamente a Word!")
Este enfoque es perfecto para archivos corporativos, bibliotecas de contenido educativo o sistemas de informes automatizados, permitiendo que docenas o cientos de presentaciones se conviertan de manera rápida y segura, sin dejar archivos temporales.
También te puede interesar: Cómo Convertir PowerPoint a HTML
Comparación de Todos los Métodos
Para ayudarte a elegir el método más adecuado para convertir PowerPoint a Word, aquí tienes una comparación de todos los enfoques disponibles.
| Método | Herramientas Necesarias | Ideal Para | Pros | Contras |
|---|---|---|---|---|
| PowerPoint + Word (método PDF) | Microsoft Office | Documentos editables | Diseño preciso, totalmente editable | Pasos manuales por archivo |
| Documentos para Imprimir de PowerPoint | PowerPoint | Documentos para imprimir, notas | Integrado, rápido | Diapositivas no editables |
| Herramientas en Línea | Navegador | Uso ocasional | Fácil, multiplataforma | Riesgo de privacidad, tamaño limitado |
| Automatización con Python | Python, Spire SDKs | Conversiones por lotes | Totalmente automatizado, flexible | Requiere configuración |
Preguntas Comunes sobre la Conversión de PowerPoint a Word
P1: ¿Puedo convertir PowerPoint a Word sin perder el formato?
Sí. El enfoque PDF → Word preserva los cuadros de texto, diseños e imágenes con alta precisión.
P2: ¿Por qué no puedo editar las diapositivas al usar "Crear Documentos para Imprimir"?
Porque PowerPoint exporta las diapositivas como imágenes estáticas. Puedes editar notas o el texto circundante, pero no el contenido de la diapositiva en sí.
P3: ¿Hay alguna manera de mantener las animaciones en Word?
No, Word no admite efectos de animación — solo se transfiere el contenido estático.
P4: ¿Cómo convierto múltiples archivos de PowerPoint automáticamente?
Usa el método de automatización con Python que se muestra arriba. Puede procesar todos los archivos .pptx en una carpeta de forma programática.
P5: ¿Qué método ofrece el resultado de aspecto más profesional?
Las Herramientas en Línea y el método de automatización con Python generalmente proporcionan el mejor equilibrio entre la fidelidad del diseño y la capacidad de edición.
Conclusión
Convertir PowerPoint a Word te da la flexibilidad de editar, anotar, imprimir y reutilizar el contenido de tu presentación fácilmente.
- Usa la función de documentos para imprimir de PowerPoint para notas simples o esquemas imprimibles.
- Elige la ruta de PDF a Word cuando necesites contenido totalmente editable.
- Automatiza el proceso con Python para conversiones a gran escala o recurrentes.
Cada método sirve para un propósito diferente — ya sea que estés preparando un informe, imprimiendo materiales de capacitación o integrando la conversión en un flujo de trabajo automatizado.
Con el enfoque correcto, puedes convertir cualquier presentación en un documento de Word estructurado, editable y profesional en cuestión de minutos.
Ver También
PowerPoint einfach in Word umwandeln – Office, Online-Tools & Python
PowerPoint-Präsentationen eignen sich perfekt für visuelles Storytelling, aber manchmal benötigen Sie eine Word-Version Ihrer Folien – zur Dokumentation, Bearbeitung oder zum Drucken von Handouts. Das Konvertieren von PowerPoint (PPT/PPTX) in Word ermöglicht es Ihnen, Ihre Folien als bearbeitbaren Text wiederzuverwenden, Anmerkungen hinzuzufügen und sie in größere schriftliche Materialien wie Berichte oder Handbücher zu integrieren.
Dieses Tutorial führt Sie durch drei praktische Möglichkeiten, PowerPoint in Word zu konvertieren, abhängig von Ihren Tools und Ihrem Arbeitsablauf:
- Verwendung der integrierten Exportfunktion von PowerPoint – schnell und einfach, keine zusätzliche Software erforderlich
- Verwendung von kostenlosen Online-Konvertern von PowerPoint zu Word – von jedem Browser aus zugänglich
- Verwendung von Python-Automatisierung – ideal für die Stapelverarbeitung und professionelle Umgebungen
Schauen wir uns an, wie jede Methode funktioniert und welche am besten zu Ihren Bedürfnissen passt.
Methode 1: PowerPoint mit Microsoft Office in Word konvertieren
Wenn Sie bereits Microsoft PowerPoint und Word installiert haben, können Sie Präsentationen direkt ohne zusätzliche Tools in Word konvertieren. Es gibt zwei Ansätze:
- "Handzettel erstellen" (nützlich für druckbare Foliennotizen, aber nicht für bearbeitbare Folien)
- "Als PDF speichern und in Word öffnen" (empfohlen für vollständig bearbeitbare Dokumente)
Schauen wir uns beide an.
1.1 PowerPoint mit „Handzettel erstellen“ in Word konvertieren
Diese integrierte PowerPoint-Funktion exportiert Folien nach Word zum Erstellen von Vorlesungsnotizen oder Handouts.
Schritte:
- Öffnen Sie Ihre PowerPoint-Datei.
- Gehen Sie zu Datei → Exportieren → Handzettel erstellen.
- Wählen Sie eine Layoutoption (z. B. Notizen unter den Folien, Leere Zeilen, Nur Gliederung).
- Klicken Sie auf OK, um eine Word-Datei zu erstellen.
Die exportierten Folien erscheinen in Word jedoch als statische Bilder, nicht als bearbeitbare Objekte. Sie können Text um sie herum bearbeiten – zum Beispiel Notizen, Kommentare oder Beschreibungen hinzufügen – aber nicht den Inhalt innerhalb der Folien.
Diese Methode eignet sich also hervorragend zum Drucken oder Verteilen von Zusammenfassungen, ist aber nicht ideal für die Bearbeitung von Folieninhalten.
Wenn Sie die Folien direkt als statische Bilder exportieren möchten, können Sie sich wie man PowerPoint-Folien als Bilder exportiert für einen dedizierten Ansatz ansehen.
1.2 PowerPoint über PDF in bearbeitbares Word konvertieren
Für eine vollständig bearbeitbare Konvertierung ist der effektivste Ansatz, Ihre Präsentation zuerst als PDF zu speichern und sie dann in Microsoft Word zu öffnen.
Schritte:
-
In PowerPoint:
- Gehen Sie zu Datei → Speichern unter → PDF.
- Wählen Sie den Speicherort und klicken Sie auf Speichern.
-
In Word:
- Öffnen Sie Microsoft Word.
- Klicken Sie auf Datei → Öffnen und wählen Sie die gerade erstellte PDF-Datei aus.
- Klicken Sie im Popup-Fenster auf Ja, und Word konvertiert die PDF-Datei automatisch in ein bearbeitbares Word-Dokument.
Sie können das Dokument nun nach Belieben bearbeiten oder als .docx-Datei speichern.
Warum das besser funktioniert:
- PowerPoint exportiert die Folien als PDF mit präzisem Layout und Vektorgrafiken.
- Die integrierte PDF-Konvertierungs-Engine von Word kann Textfelder, Bilder und Formatierungen in bearbeitbare Word-Objekte rekonstruieren.
- Das resultierende Dokument behält sowohl die visuelle Wiedergabetreue als auch die Zugänglichkeit des Textes bei, sodass Sie alles direkt bearbeiten können.
Tipps für bessere Ergebnisse:
- Verwenden Sie einen hochauflösenden PDF-Export für saubere Bilder.
- Vermeiden Sie übermäßig komplexe Übergänge oder 3D-Effekte – sie werden als flache Grafiken angezeigt.
- Überprüfen Sie nach der Konvertierung die Schriftarten und den Absatzabstand.
Dieser PowerPoint → PDF → Word-Workflow bietet die beste Balance zwischen Erscheinungsbild und Bearbeitbarkeit – ideal für Dokumentation, Veröffentlichung und Archivierung.
Methode 2: PowerPoint mit Online-Tools in Word konvertieren
Wenn Sie Office nicht installiert haben, können Online-Konverter von PowerPoint zu Word helfen. Sie sind schnell, zugänglich und plattformunabhängig.
Warum einen Online-Konverter wählen
- Funktioniert direkt in Ihrem Browser – keine Installation erforderlich.
- Kompatibel mit allen Systemen (Windows, macOS, Linux, ChromeOS).
- Praktisch für gelegentliche Benutzer oder leichte Aufgaben.
Beachten Sie jedoch:
- Viele Tools haben Beschränkungen bei der Dateigröße oder Seitenzahl.
- Das Hochladen vertraulicher Dateien auf Server von Drittanbietern birgt Datenschutzrisiken.
Empfohlene kostenlose Tools
| Tool | Dateigrößenlimit | Ausgabeformat | Registrierung | Stapelverarbeitung |
|---|---|---|---|---|
| FreeConvert | 1024MB | DOCX/DOC | Optional | Ja |
| Zamzar | 7MB | DOCX/DOC | Optional | Ja |
| Convertio | 100MB | DOCX/DOC | Optional | Ja |
Hinweis: Lesen Sie immer die Datenschutzrichtlinie jeder Website, bevor Sie sensibles Material hochladen.
Beispiel: Verwendung von FreeConvert
- Besuchen Sie den FreeConvert PPT zu Word Konverter.
- Laden Sie Ihre PowerPoint-Datei hoch und klicken Sie auf Konvertieren.
- Warten Sie, bis die Konvertierung abgeschlossen ist.
- Laden Sie das konvertierte Word-Dokument herunter.
Vorteile:
- Keine Softwareinstallation
- Einfache Drag-and-Drop-Oberfläche
- Gute Formatierungsgenauigkeit
Nachteile:
- Begrenzte kostenlose Konvertierungen pro Tag
- Kann Bilder leicht komprimieren oder neu formatieren
Online-Konverter sind praktisch für schnelle einmalige Aufgaben, aber für regelmäßige oder umfangreiche Konvertierungen ist eine Desktop- oder automatisierte Lösung effizienter.
Für eine breitere Palette von Online-Dokumentkonvertierungen können Sie den CLOUDXDOCS Free Online Document Converter erkunden, der mehrere Dateitypen und -formate kostenlos unterstützt.
Methode 3: Automatisieren der Konvertierung von PowerPoint in Word mit Python
Für Entwickler oder Teams, die Präsentationen in großen Mengen verarbeiten müssen, bietet die Automatisierung die schnellste und zuverlässigste Lösung. Mit nur wenigen Zeilen Python-Code können Sie mehrere PowerPoint-Präsentationen in Word-Dokumente konvertieren – alles lokal auf Ihrem Computer verarbeitet, mit keine Dateigrößenbeschränkungen oder Datenschutzbedenken.
Dieses Beispiel verwendet Free Spire.Office for Python, eine All-in-One-Bibliothek, die es ermöglicht, die gesamte Konvertierung mit einem einzigen Toolkit abzuschließen.
Installieren Sie die Bibliothek mit pip:
pip install spire.office.free
Beispiel: PowerPoint in Word mit Python konvertieren
import os
from spire.presentation import Presentation, FileFormat
from spire.pdf import PdfDocument, FileFormat as PdfFileFormat
input_ppt = "G:/Documents/Sample14.pptx"
temp_pdf = "output/temp.pdf"
output_docx = "output/output.docx"
# Schritt 1: PowerPoint in PDF konvertieren
presentation = Presentation()
presentation.LoadFromFile(input_ppt)
presentation.SaveToFile(temp_pdf, FileFormat.PDF)
# Schritt 2: PDF in Word konvertieren
pdf = PdfDocument()
pdf.LoadFromFile(temp_pdf)
pdf.SaveToFile(output_docx, PdfFileFormat.DOCX)
# Schritt 3: Die temporäre PDF-Datei löschen
if os.path.exists(temp_pdf):
os.remove(temp_pdf)
print("PPTX wurde erfolgreich in Word konvertiert!")
Das folgende Bild zeigt das Ergebnis der Konvertierung einer PowerPoint-Präsentation in ein Word-Dokument mit Python.
Code-Erklärung
Dieses Skript verwendet Free Spire.Office for Python, um beide Schritte der Konvertierung durchzuführen:
- Spire.Presentation lädt die PowerPoint-Datei und exportiert sie als hochwertige PDF.
- Spire.PDF konvertiert die PDF-Datei in ein vollständig bearbeitbares Word-Dokument (.docx).
- Nach der Konvertierung wird die temporäre PDF-Datei automatisch gelöscht, um Ihren Arbeitsbereich sauber zu halten.
Dieser Workflow ist schnell, zuverlässig und hält alle Dateien lokal – was eine konsistente Formatierung, ein genaues Layout und bearbeitbaren Text ohne die Nutzung von Online-Diensten gewährleistet.
Beispiel für Stapelkonvertierung
Sie können dieselbe Logik erweitern, um alle PowerPoint-Dateien in einem Ordner zu konvertieren:
import os
from spire.presentation import Presentation, FileFormat
from spire.pdf import PdfDocument, FileFormat as PdfFileFormat
folder = "presentations"
for file in os.listdir(folder):
if file.endswith(".pptx"):
ppt_path = os.path.join(folder, file)
temp_pdf = os.path.join(folder, file.replace(".pptx", ".pdf"))
docx_path = os.path.join(folder, file.replace(".pptx", ".docx"))
# Schritt 1: PPTX in PDF konvertieren
presentation = Presentation()
presentation.LoadFromFile(ppt_path)
presentation.SaveToFile(temp_pdf, FileFormat.PDF)
# Schritt 2: PDF in Word konvertieren
pdf = PdfDocument()
pdf.LoadFromFile(temp_pdf)
pdf.SaveToFile(docx_path, PdfFileFormat.DOCX)
# Schritt 3: Die temporäre PDF-Datei löschen
if os.path.exists(temp_pdf):
os.remove(temp_pdf)
print("Alle PowerPoint-Dateien wurden erfolgreich in Word konvertiert!")
Dieser Ansatz ist perfekt für Unternehmensarchive, Bibliotheken mit Bildungsinhalten oder automatisierte Berichtssysteme und ermöglicht die schnelle und sichere Konvertierung von Dutzenden oder Hunderten von Präsentationen ohne verbleibende temporäre Dateien.
Das könnte Ihnen auch gefallen: So konvertieren Sie PowerPoint in HTML
Vergleich aller Methoden
Um Ihnen bei der Auswahl der am besten geeigneten Methode zur Konvertierung von PowerPoint in Word zu helfen, finden Sie hier einen Vergleich aller verfügbaren Ansätze.
| Methode | Benötigte Tools | Am besten für | Vorteile | Nachteile |
|---|---|---|---|---|
| PowerPoint + Word (PDF-Methode) | Microsoft Office | Bearbeitbare Dokumente | Genaues Layout, vollständig bearbeitbar | Manuelle Schritte pro Datei |
| PowerPoint-Handzettel | PowerPoint | Handzettel, Notizen | Integriert, schnell | Folien nicht bearbeitbar |
| Online-Tools | Browser | Gelegentliche Nutzung | Einfach, plattformübergreifend | Datenschutzrisiko, begrenzte Größe |
| Python-Automatisierung | Python, Spire SDKs | Stapelkonvertierungen | Vollautomatisch, flexibel | Erfordert Einrichtung |
Häufig gestellte Fragen zur Konvertierung von PowerPoint in Word
F1: Kann ich PowerPoint in Word konvertieren, ohne die Formatierung zu verlieren?
Ja. Der PDF → Word-Ansatz bewahrt Textfelder, Layouts und Bilder mit hoher Genauigkeit.
F2: Warum kann ich Folien bei Verwendung von „Handzettel erstellen“ nicht bearbeiten?
Weil PowerPoint Folien als statische Bilder exportiert. Sie können Notizen oder umgebenden Text bearbeiten, aber nicht den Folieninhalt selbst.
F3: Gibt es eine Möglichkeit, Animationen in Word beizubehalten?
Nein, Word unterstützt keine Animationseffekte – es werden nur statische Inhalte übertragen.
F4: Wie konvertiere ich mehrere PowerPoint-Dateien automatisch?
Verwenden Sie die Python-Automatisierungsmethode oben gezeigt. Sie kann alle .pptx-Dateien in einem Ordner programmgesteuert verarbeiten.
F5: Welche Methode liefert das professionellste Ergebnis?
Die Online-Tools und die Python-Automatisierungsmethode bieten im Allgemeinen die beste Balance zwischen Layouttreue und Bearbeitbarkeit.
Fazit
Die Konvertierung von PowerPoint in Word gibt Ihnen die Flexibilität, Ihre Präsentationsinhalte einfach zu bearbeiten, mit Anmerkungen zu versehen, zu drucken und wiederzuverwenden.
- Verwenden Sie die Handzettelfunktion von PowerPoint für einfache Notizen oder druckbare Gliederungen.
- Wählen Sie den PDF-zu-Word-Weg, wenn Sie vollständig bearbeitbare Inhalte benötigen.
- Automatisieren Sie den Prozess mit Python für umfangreiche oder wiederkehrende Konvertierungen.
Jede Methode dient einem anderen Zweck – ob Sie einen Bericht vorbereiten, Schulungsmaterialien drucken oder die Konvertierung in einen automatisierten Arbeitsablauf integrieren.
Mit dem richtigen Ansatz können Sie jede Präsentation innerhalb von Minuten in ein strukturiertes, bearbeitbares und professionelles Word-Dokument umwandeln.
Siehe auch
Легко конвертируйте PowerPoint в Word – Office, онлайн-инструменты и Python
Презентации PowerPoint идеально подходят для визуального повествования, но иногда вам нужна версия ваших слайдов в формате Word — для документации, редактирования или печати раздаточных материалов. Преобразование PowerPoint (PPT/PPTX) в Word позволяет повторно использовать ваши слайды в виде редактируемого текста, добавлять аннотации и интегрировать их в более крупные письменные материалы, такие как отчеты или руководства.
В этом руководстве рассматриваются три практических способа преобразования PowerPoint в Word в зависимости от ваших инструментов и рабочего процесса:
- Использование встроенной функции экспорта PowerPoint — быстро и просто, не требуется дополнительное программное обеспечение
- Использование бесплатных онлайн-конвертеров PowerPoint в Word — доступно из любого браузера
- Использование автоматизации с помощью Python — идеально для пакетной обработки и профессиональной среды
Давайте рассмотрим, как работает каждый метод и какой из них лучше всего соответствует вашим потребностям.
Метод 1: Преобразование PowerPoint в Word с помощью Microsoft Office
Если у вас уже установлены Microsoft PowerPoint и Word, вы можете преобразовывать презентации в Word напрямую без дополнительных инструментов. Существует два подхода:
- «Создать раздаточные материалы» (полезно для печати заметок к слайдам, но не для редактируемых слайдов)
- «Сохранить как PDF и открыть в Word» (рекомендуется для полностью редактируемых документов)
Давайте рассмотрим оба варианта.
1.1 Преобразование PowerPoint в Word с помощью «Создать раздаточные материалы»
Эта встроенная функция PowerPoint экспортирует слайды в Word для создания конспектов лекций или раздаточных материалов.
Шаги:
- Откройте файл PowerPoint.
- Перейдите в Файл → Экспорт → Создать раздаточные материалы.
- Выберите вариант макета (например, Заметки под слайдами, Пустые строки, Только структура).
- Нажмите OK, чтобы создать файл Word.
Однако экспортированные слайды отображаются в Word как статические изображения, а не как редактируемые объекты. Вы можете редактировать текст вокруг них — например, добавлять заметки, комментарии или описания — но не содержимое самих слайдов.
Таким образом, этот метод отлично подходит для печати или распространения кратких содержаний, но не идеален для редактирования содержимого слайдов.
Если вы хотите напрямую экспортировать слайды как статические изображения, вы можете ознакомиться со статьей как экспортировать слайды PowerPoint как изображения для специального подхода.
1.2 Преобразование PowerPoint в редактируемый Word через PDF
Для полностью редактируемого преобразования наиболее эффективным подходом является сначала сохранить презентацию в формате PDF, а затем открыть ее в Microsoft Word.
Шаги:
-
В PowerPoint:
- Перейдите в Файл → Сохранить как → PDF.
- Выберите место сохранения и нажмите Сохранить.
-
В Word:
- Откройте Microsoft Word.
- Нажмите Файл → Открыть и выберите только что созданный PDF-файл.
- Нажмите Да во всплывающем окне, и Word автоматически преобразует PDF в редактируемый документ Word.
Теперь вы можете редактировать документ по своему усмотрению или сохранить его как файл .docx.
Почему это работает лучше:
- PowerPoint экспортирует слайды в PDF с точным макетом и векторной графикой.
- Встроенный механизм преобразования PDF в Word может восстанавливать текстовые поля, изображения и форматирование в редактируемые объекты Word.
- Полученный документ сохраняет как визуальную точность, так и доступность текста, позволяя редактировать все напрямую.
Советы для лучших результатов:
- Используйте экспорт в PDF с высоким разрешением для получения четких изображений.
- Избегайте слишком сложных переходов или 3D-эффектов — они будут отображаться как плоские изображения.
- После преобразования проверьте стили шрифтов и межстрочные интервалы.
Этот рабочий процесс PowerPoint → PDF → Word обеспечивает наилучший баланс между внешним видом и возможностью редактирования — идеально для документации, публикации и архивирования.
Метод 2: Преобразование PowerPoint в Word с помощью онлайн-инструментов
Если у вас не установлен Office, вам могут помочь онлайн-конвертеры PowerPoint в Word. Они быстрые, доступные и не зависят от платформы.
Почему стоит выбрать онлайн-конвертер
- Работает прямо в браузере — установка не требуется.
- Совместим со всеми системами (Windows, macOS, Linux, ChromeOS).
- Удобно для нерегулярных пользователей или легких задач.
Однако имейте в виду:
- Многие инструменты имеют ограничения по размеру файла или количеству страниц.
- Загрузка конфиденциальных файлов на сторонние серверы сопряжена с рисками для конфиденциальности.
Рекомендуемые бесплатные инструменты
| Инструмент | Ограничение размера файла | Выходной формат | Регистрация | Пакетная поддержка |
|---|---|---|---|---|
| FreeConvert | 1024MB | DOCX/DOC | Необязательно | Да |
| Zamzar | 7MB | DOCX/DOC | Необязательно | Да |
| Convertio | 100MB | DOCX/DOC | Необязательно | Да |
Примечание: Всегда читайте политику конфиденциальности каждого сайта перед загрузкой конфиденциальных материалов.
Пример: Использование FreeConvert
- Посетите Конвертер PPT в Word от FreeConvert.
- Загрузите свой файл PowerPoint и нажмите «Конвертировать».
- Дождитесь завершения преобразования.
- Загрузите преобразованный документ Word.
Преимущества:
- Не требуется установка программного обеспечения
- Простой интерфейс с перетаскиванием
- Хорошая точность форматирования
Недостатки:
- Ограниченное количество бесплатных преобразований в день
- Может незначительно сжимать или переформатировать изображения
Онлайн-конвертеры удобны для быстрых разовых задач, но для регулярных или крупномасштабных преобразований более эффективным является настольное или автоматизированное решение.
Для более широкого спектра онлайн-преобразований документов вы можете изучить Бесплатный онлайн-конвертер документов CLOUDXDOCS, который поддерживает множество типов и форматов файлов бесплатно.
Метод 3: Автоматизация преобразования PowerPoint в Word с помощью Python
Для разработчиков или команд, которым необходимо обрабатывать презентации в больших объемах, автоматизация предлагает самое быстрое и надежное решение. Всего несколькими строками кода на Python вы можете преобразовать несколько презентаций PowerPoint в документы Word — все обрабатывается локально на вашем компьютере, без ограничений по размеру файла или проблем с конфиденциальностью.
В этом примере используется Free Spire.Office for Python, универсальная библиотека, которая позволяет выполнить все преобразование с помощью одного набора инструментов.
Установите библиотеку с помощью pip:
pip install spire.office.free
Пример: Преобразование PowerPoint в Word на Python
import os
from spire.presentation import Presentation, FileFormat
from spire.pdf import PdfDocument, FileFormat as PdfFileFormat
input_ppt = "G:/Documents/Sample14.pptx"
temp_pdf = "output/temp.pdf"
output_docx = "output/output.docx"
# Шаг 1: Преобразование PowerPoint в PDF
presentation = Presentation()
presentation.LoadFromFile(input_ppt)
presentation.SaveToFile(temp_pdf, FileFormat.PDF)
# Шаг 2: Преобразование PDF в Word
pdf = PdfDocument()
pdf.LoadFromFile(temp_pdf)
pdf.SaveToFile(output_docx, PdfFileFormat.DOCX)
# Шаг 3: Удаление временного PDF-файла
if os.path.exists(temp_pdf):
os.remove(temp_pdf)
print("PPTX успешно преобразован в Word!")
На изображении ниже показан результат преобразования презентации PowerPoint в документ Word с помощью Python.
Объяснение кода
Этот скрипт использует Free Spire.Office for Python для выполнения обоих шагов преобразования:
- Spire.Presentation загружает файл PowerPoint и экспортирует его в высококачественный PDF.
- Spire.PDF преобразует PDF в полностью редактируемый документ Word (.docx).
- После преобразования временный PDF-файл автоматически удаляется, чтобы ваше рабочее пространство оставалось чистым.
Этот рабочий процесс быстрый, надежный и сохраняет все файлы локально, обеспечивая последовательное форматирование, точный макет и редактируемый текст без использования каких-либо онлайн-сервисов.
Пример пакетного преобразования
Вы можете расширить ту же логику для преобразования всех файлов PowerPoint в папке:
import os
from spire.presentation import Presentation, FileFormat
from spire.pdf import PdfDocument, FileFormat as PdfFileFormat
folder = "presentations"
for file in os.listdir(folder):
if file.endswith(".pptx"):
ppt_path = os.path.join(folder, file)
temp_pdf = os.path.join(folder, file.replace(".pptx", ".pdf"))
docx_path = os.path.join(folder, file.replace(".pptx", ".docx"))
# Шаг 1: Преобразование PPTX в PDF
presentation = Presentation()
presentation.LoadFromFile(ppt_path)
presentation.SaveToFile(temp_pdf, FileFormat.PDF)
# Шаг 2: Преобразование PDF в Word
pdf = PdfDocument()
pdf.LoadFromFile(temp_pdf)
pdf.SaveToFile(docx_path, PdfFileFormat.DOCX)
# Шаг 3: Удаление временного PDF-файла
if os.path.exists(temp_pdf):
os.remove(temp_pdf)
print("Все файлы PowerPoint были успешно преобразованы в Word!")
Этот подход идеально подходит для корпоративных архивов, библиотек образовательного контента или автоматизированных систем отчетности, позволяя быстро и безопасно преобразовывать десятки или сотни презентаций без оставшихся временных файлов.
Вам также может понравиться: Как преобразовать PowerPoint в HTML
Сравнение всех методов
Чтобы помочь вам выбрать наиболее подходящий метод преобразования PowerPoint в Word, вот сравнение всех доступных подходов.
| Метод | Необходимые инструменты | Лучше всего для | Плюсы | Минусы |
|---|---|---|---|---|
| PowerPoint + Word (метод PDF) | Microsoft Office | Редактируемые документы | Точный макет, полностью редактируемый | Ручные шаги для каждого файла |
| Раздаточные материалы PowerPoint | PowerPoint | Раздаточные материалы, заметки | Встроенный, быстрый | Слайды не редактируются |
| Онлайн-инструменты | Браузер | Нерегулярное использование | Простой, кроссплатформенный | Риск конфиденциальности, ограниченный размер |
| Автоматизация с помощью Python | Python, Spire SDKs | Пакетные преобразования | Полностью автоматизированный, гибкий | Требуется настройка |
Часто задаваемые вопросы о преобразовании PowerPoint в Word
В1: Могу ли я преобразовать PowerPoint в Word без потери форматирования?
Да. Подход PDF → Word сохраняет текстовые поля, макеты и изображения с высокой точностью.
В2: Почему я не могу редактировать слайды при использовании «Создать раздаточные материалы»?
Потому что PowerPoint экспортирует слайды как статические изображения. Вы можете редактировать заметки или окружающий текст, но не само содержимое слайда.
В3: Есть ли способ сохранить анимацию в Word?
Нет, Word не поддерживает эффекты анимации — передается только статическое содержимое.
В4: Как мне автоматически преобразовать несколько файлов PowerPoint?
Используйте метод автоматизации с помощью Python, показанный выше. Он может программно обрабатывать все файлы .pptx в папке.
В5: Какой метод дает наиболее профессионально выглядящий результат?
Онлайн-инструменты и метод автоматизации с помощью Python обычно обеспечивают наилучший баланс между точностью макета и возможностью редактирования.
Заключение
Преобразование PowerPoint в Word дает вам гибкость для редактирования, аннотирования, печати и повторного использования содержимого вашей презентации.
- Используйте функцию раздаточных материалов PowerPoint для простых заметок или печатных конспектов.
- Выберите путь PDF-в-Word, когда вам нужен полностью редактируемый контент.
- Автоматизируйте процесс с помощью Python для крупномасштабных или повторяющихся преобразований.
Каждый метод служит своей цели — будь то подготовка отчета, печать учебных материалов или интеграция преобразования в автоматизированный рабочий процесс.
С правильным подходом вы можете превратить любую презентацию в структурированный, редактируемый и профессиональный документ Word за считанные минуты.
Смотрите также
Rimuovere una tabella in Excel (Converti in intervallo, Cancella formattazione, VBA e Python)
Indice
- Comprendere cosa succede quando si rimuove una tabella in Excel
- Come rimuovere una tabella in Excel convertendola in un intervallo
- Come rimuovere la formattazione della tabella in Excel
- Come rimuovere completamente una tabella in Excel
- Come rimuovere più tabelle in Excel contemporaneamente utilizzando VBA
- Come rimuovere tabelle in Excel utilizzando l'automazione Python
- Suggerimenti professionali per la rimozione di una tabella in Excel
- Conclusione
- Domande frequenti: Rimuovere una tabella in Excel

La rimozione di una tabella in Excel è un'operazione semplice ma essenziale per semplificare i dati. Sebbene le tabelle siano utili per organizzare e gestire le informazioni, ci sono momenti in cui potresti volerle rimuovere, sia per snellire la formattazione, esportare dati grezzi o smettere di usare funzionalità strutturate.
In questa guida, esploreremo vari metodi per rimuovere una tabella in Excel, inclusa la conversione in un intervallo, la cancellazione della formattazione e l'eliminazione completa. Inoltre, dimostreremo come automatizzare il processo utilizzando VBA e Python, aiutandoti a risparmiare tempo quando lavori con più tabelle.
Panoramica dei contenuti
- Comprendere cosa succede quando si rimuove una tabella in Excel
- Come rimuovere una tabella in Excel convertendola in un intervallo
- Come rimuovere la formattazione della tabella in Excel
- Come rimuovere completamente una tabella in Excel
- Come rimuovere più tabelle in Excel contemporaneamente utilizzando VBA
- Come rimuovere tabelle in Excel utilizzando l'automazione Python
- Suggerimenti professionali per la rimozione di una tabella in Excel
- Conclusione
- Domande frequenti: Rimuovere una tabella in Excel
Comprendere cosa succede quando si rimuove una tabella in Excel
La rimozione di una tabella in Excel può avere risultati diversi a seconda del metodo scelto:
- Converti in intervallo: Mantiene tutti i dati e qualsiasi formattazione applicata alla tabella come formattazione statica delle celle, ma rimuove le funzionalità della tabella come filtri e riferimenti strutturati.
- Cancella formattazione tabella: Mantiene i dati ma rimuove tutti i colori, i bordi e gli stili della tabella.
- Elimina intera tabella: Rimuove permanentemente sia la tabella che i suoi dati.
Esploriamo queste opzioni in dettaglio e vediamo come influenzano i tuoi dati di Excel.
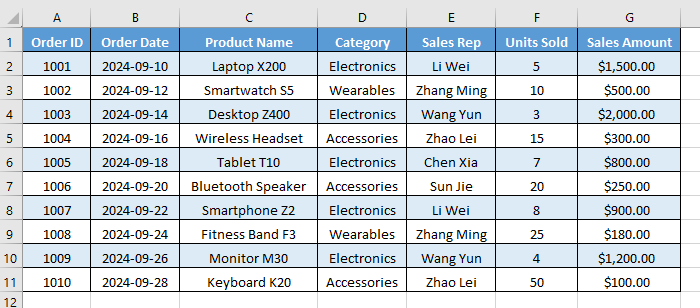
Come rimuovere una tabella in Excel convertendola in un intervallo?
Il metodo più semplice e affidabile per rimuovere una tabella in Excel è convertirla in un intervallo regolare, che mantiene intatti i dati e la formattazione. Puoi scegliere tra due opzioni principali per questa conversione: utilizzando la barra multifunzione di Excel o il menu contestuale.
Opzione 1. Utilizzando la barra multifunzione di Excel
Segui i passaggi seguenti per convertire una tabella in un intervallo tramite la barra multifunzione di Excel:
-
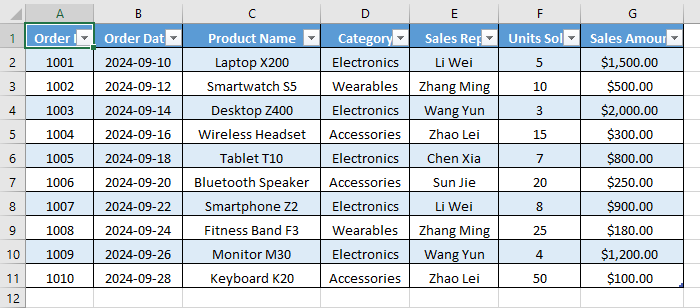
Seleziona una cella qualsiasi all'interno della tabella: Fai clic su una cella qualsiasi (come "A1") all'interno della tabella che desideri rimuovere. Non è necessario selezionare l'intera tabella.
-
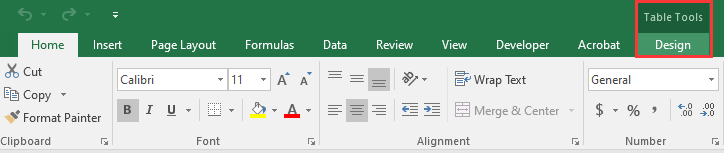
Vai alla scheda Progettazione: Non appena selezioni una cella della tabella, la scheda contestuale Progettazione apparirà sulla barra multifunzione di Excel, sotto Strumenti tabella. Fai clic su di essa.
-
Fai clic su "Converti in intervallo": Nel gruppo Strumenti all'estrema sinistra, troverai il pulsante "Converti in intervallo". Fai clic su di esso.

-
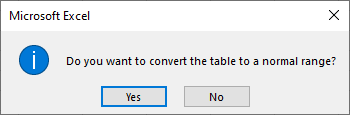
Conferma l'azione: Excel mostrerà una finestra di dialogo che chiede: "Convertire la tabella in un intervallo normale?" Fai clic su Sì.
Dopo la conversione, la struttura della tabella viene rimossa e i filtri non sono più disponibili. Tuttavia, qualsiasi formattazione della tabella (come righe alternate e stili di intestazione) rimane, ma l'intervallo diventa statico anziché dinamico.
Opzione 2. Utilizzando il menu contestuale
Per coloro che preferiscono i menu contestuali, l'utilizzo del menu contestuale è altrettanto efficace e un po' più veloce:
-
Seleziona una cella qualsiasi all'interno della tabella: Proprio come nel primo metodo, fai clic in un punto qualsiasi all'interno dei dati della tabella.
-
Fai clic con il pulsante destro del mouse per aprire il menu contestuale: Fai clic con il pulsante destro del mouse sulla cella selezionata.
-
Naviga nel menu: Nel menu contestuale, passa il mouse sopra (o fai clic su) Tabella.
-
Seleziona "Converti in intervallo": Dal sottomenu che appare, seleziona Converti in intervallo.
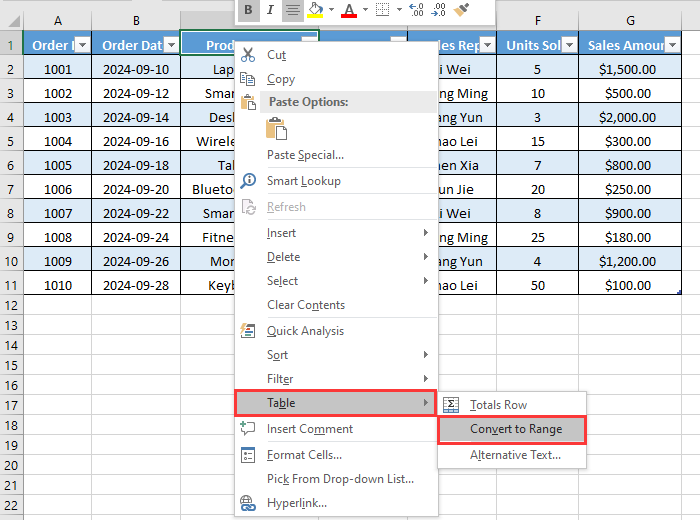
-
Conferma l'azione: Fai clic su Sì nella finestra di dialogo di conferma.
Questo metodo produce lo stesso risultato dell'utilizzo della barra multifunzione ma offre un approccio più rapido e basato sul mouse.
Come rimuovere la formattazione della tabella in Excel?
In alcuni casi, potresti voler rimuovere la formattazione della tabella in Excel, inclusi elementi come filtri, colori e bordi. Segui i passaggi seguenti per cancellare la formattazione e riportare i dati a un layout più semplice:
-
Converti la tabella in un intervallo: Innanzitutto, converti la tabella in un intervallo normale utilizzando la barra multifunzione di Excel o il menu contestuale descritto sopra.
-
Cancella la formattazione della tabella
Ora che i dati sono un semplice intervallo, puoi rimuovere la formattazione residua.-
Seleziona l'intero intervallo di dati: Fai clic e trascina per selezionare tutte le celle che facevano parte della tabella originale, inclusa l'intestazione.
-
Vai alla scheda Home: Sulla barra multifunzione di Excel, vai alla scheda Home.
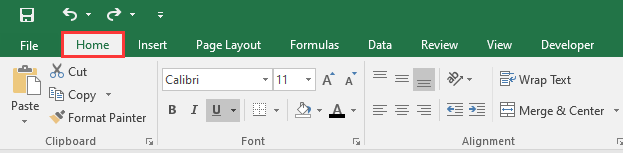
-
Cancella i formati:
-
Nel gruppo Modifica, fai clic sul pulsante Cancella (sembra una gomma rosa).
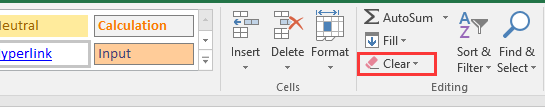
-
Dal menu a discesa, seleziona Cancella formati.
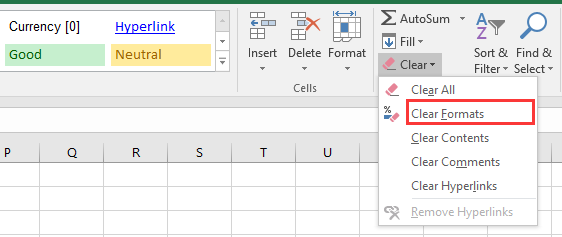
-
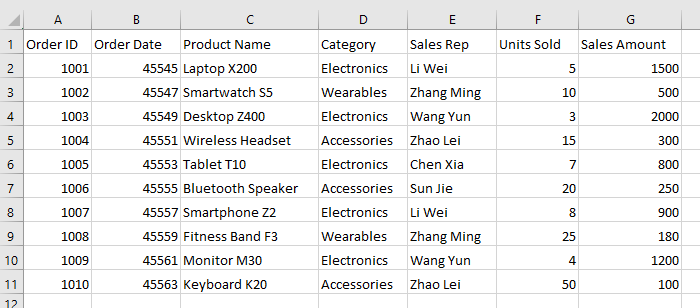
-
Ora, tutta la formattazione specifica della tabella viene rimossa, ma i dati rimangono intatti. Le celle tornano al carattere, al colore e ai bordi predefiniti di Excel, offrendoti un blocco di dati pulito e non formattato, pronto per una nuova formattazione o analisi.
Come rimuovere completamente una tabella in Excel
Se devi rimuovere sia la tabella che tutti i dati che contiene, questo metodo ti aiuterà. Assicurati di essere certo di non aver più bisogno delle informazioni prima di procedere. Per eliminare completamente una tabella, segui questi passaggi:
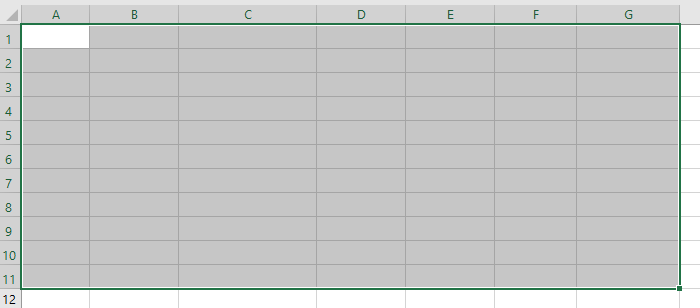
-
Seleziona l'intera tabella: Fai clic in un punto qualsiasi all'interno della tabella e premi Ctrl + A (Windows) o Cmd + A (Mac) per selezionare l'intera tabella, inclusa l'intestazione e le righe totali.
-
Cancella tutti i dati e la formattazione: Vai alla scheda Home e trova il gruppo Modifica. Fai clic su Cancella, quindi seleziona Cancella tutto dal menu a discesa.
Questa azione rimuove permanentemente tutti i dati, la formattazione e la struttura della tabella. Le celle verranno cancellate, senza lasciare traccia della tabella originale.
Come rimuovere più tabelle in Excel contemporaneamente utilizzando VBA
Se il tuo file Excel contiene più tabelle, rimuoverle manualmente una per una può richiedere molto tempo. Puoi utilizzare VBA (Visual Basic for Applications) per automatizzare il processo.
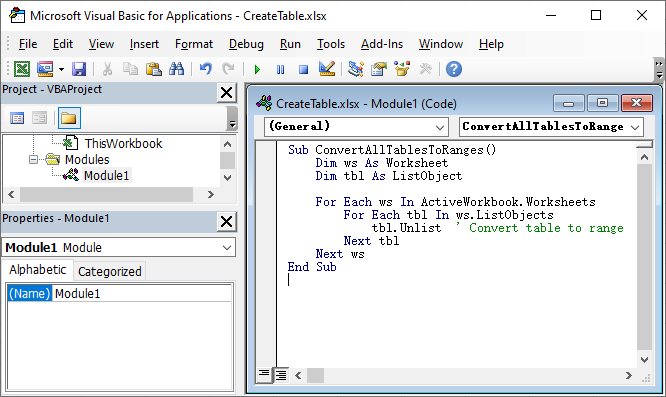
Ecco come rimuovere tutte le tabelle in un file Excel mantenendo i dati utilizzando uno script VBA:
-
Premi Alt + F11 per aprire l'editor VBA.
-
Fai clic su Inserisci → Modulo.
-
Copia e incolla il seguente codice VBA:
Sub ConvertAllTablesToRanges() Dim ws As Worksheet Dim tbl As ListObject For Each ws In ActiveWorkbook.Worksheets For Each tbl In ws.ListObjects tbl.Unlist ' Converti tabella in intervallo Next tbl Next ws End Sub -
Premi F5 per eseguire la macro.
Questa macro scorre ogni foglio di lavoro nel file Excel, trova tutti i ListObjects (tabelle) e li converte in intervalli normali, preservando i dati ma rimuovendo la funzionalità della tabella.
Per maggiori dettagli sul metodo Unlist utilizzato in questo script VBA, consulta la documentazione ufficiale di Microsoft: Metodo Excel ListObject.Unlist.
Come rimuovere tabelle in Excel utilizzando l'automazione Python?
Se lavori con Python per l'elaborazione dei dati, la creazione di report automatizzati o applicazioni backend, puoi rimuovere tabelle in Excel utilizzando una libreria come Spire.XLS for Python.
Spire.XLS for Python è una popolare libreria Excel che consente agli sviluppatori di creare, leggere e manipolare file Excel direttamente tramite codice senza richiedere Microsoft Excel. Oltre a rimuovere le tabelle, ti consente di leggere e scrivere valori e formule di celle, applicare o cancellare la formattazione, gestire fogli di lavoro, inserire grafici o immagini e persino convertire file Excel in PDF o altri formati.
Ecco come puoi rimuovere tabelle in Excel utilizzando Python con Spire.XLS for Python:
-
Installa Spire.XLS for Python: Esegui il seguente comando nel tuo terminale per installarlo direttamente tramite PyPI:
pip install Spire.XLS -
Rimuovi tabelle con codice Python: Una volta installata la libreria, aggiungi il seguente codice per rimuovere le tabelle nel tuo file Excel utilizzando Python:
from spire.xls import * # Carica la cartella di lavoro workbook = Workbook() workbook.LoadFromFile("CreateTable.xlsx") # Scansiona tutti i fogli di lavoro per indice for ws_index in range(len(workbook.Worksheets)): sheet = workbook.Worksheets[ws_index] # Scansiona dall'ultima tabella alla prima per rimuovere in sicurezza per indice for tbl_index in range(len(sheet.ListObjects) - 1, -1, -1): sheet.ListObjects.RemoveAt(tbl_index) # Salva la cartella di lavoro workbook.SaveToFile("DeleteAllTables.xlsx", ExcelVersion.Version2016) workbook.Dispose()
Questo codice rimuove tutte le tabelle nel file Excel, mantenendo i dati intatti e pronti per ulteriori elaborazioni.
Leggi la guida ufficiale completa: Aggiungere o rimuovere tabelle in Excel in Python.
Suggerimenti professionali per la rimozione di una tabella in Excel
Quando si rimuove una tabella in Excel, i seguenti suggerimenti possono aiutarti a evitare problemi comuni e a mantenere l'integrità dei dati:
- Esegui sempre il backup della cartella di lavoro prima di eseguire script VBA o di automazione.
- Controlla due volte le formule per riferimenti interrotti dopo la conversione.
- Riapplica i filtri manualmente se necessario dopo la conversione in un intervallo.
- Mantieni un formato coerente applicando stili di cella personalizzati dopo aver rimosso la formattazione della tabella.
- Usa intervalli denominati invece delle tabelle se hai solo bisogno di riferimenti fissi senza comportamento strutturato.
Conclusione
La rimozione di una tabella in Excel non deve essere complicata. Seguendo questa guida su come rimuovere una tabella in Excel, puoi mantenere in sicurezza i tuoi dati e la formattazione intatti. Che tu preferisca i passaggi manuali, l'automazione VBA o lo scripting Python con Spire.XLS, questi metodi rendono la rimozione della tabella rapida, affidabile e senza stress. Provali oggi per ripulire i tuoi fogli di calcolo e snellire il tuo flusso di lavoro!
Domande frequenti: Rimuovere una tabella in Excel
D1: Come convertire una tabella in un intervallo normale in Excel ma mantenere i dati?
R1: Seleziona una cella qualsiasi nella tabella → Fai clic con il pulsante destro del mouse su Tabella → Converti in intervallo o vai a Progettazione → Converti in intervallo → Fai clic su Sì. I tuoi dati rimangono, ma le funzionalità della tabella vengono rimosse.
D2: Come rimuovo solo la formattazione della tabella in Excel?
R2: Innanzitutto, converti la tabella in un intervallo normale. Quindi seleziona tutte le celle → vai a Home → fai clic su Cancella → Cancella formati.
D3: Posso rimuovere più tabelle in Excel contemporaneamente?
R3: Sì. Usa una macro VBA per convertire tutte le tabelle in intervalli.
D4: Posso rimuovere una tabella in Excel usando Python?
R4: Sì. Puoi utilizzare librerie come Spire.XLS for Python per rimuovere tabelle in Excel con Python.
Leggi anche
Remover uma tabela no Excel (Converter em intervalo, Limpar formatação, VBA e Python)
Índice
- Entendendo o Que Acontece Quando Você Remove uma Tabela no Excel
- Como Remover uma Tabela no Excel Convertendo-a para um Intervalo
- Como Remover a Formatação de Tabela no Excel
- Como Remover uma Tabela no Excel Completamente
- Como Remover Tabelas no Excel de uma Vez Usando VBA
- Como Remover Tabelas no Excel usando Automação com Python
- Dicas Profissionais para Remover uma Tabela no Excel
- Conclusão
- Perguntas Frequentes: Remover Tabela no Excel
Remover uma tabela no Excel é uma tarefa simples, mas essencial para simplificar seus dados. Embora as tabelas sejam úteis para organizar e gerenciar informações, há momentos em que você pode querer removê-las - seja para otimizar a formatação, exportar dados brutos ou parar de usar recursos estruturados.
Neste guia, exploraremos vários métodos para remover uma tabela no Excel, incluindo convertê-la para um intervalo, limpar sua formatação e excluí-la completamente. Além disso, demonstraremos como automatizar o processo usando VBA e Python, ajudando você a economizar tempo ao trabalhar com várias tabelas.
Visão Geral do Conteúdo
- Entendendo o Que Acontece Quando Você Remove uma Tabela no Excel
- Como Remover uma Tabela no Excel Convertendo-a para um Intervalo
- Como Remover a Formatação de Tabela no Excel
- Como Remover uma Tabela no Excel Completamente
- Como Remover Tabelas no Excel de uma Vez Usando VBA
- Como Remover Tabelas no Excel usando Automação com Python
- Dicas Profissionais para Remover uma Tabela no Excel
- Conclusão
- Perguntas Frequentes: Remover Tabela no Excel
Entendendo o Que Acontece Quando Você Remove uma Tabela no Excel
Remover uma tabela no Excel pode ter resultados diferentes dependendo do método que você escolher:
- Converter para Intervalo: Mantém todos os seus dados e qualquer formatação aplicada à tabela como formatação de célula estática, mas remove recursos da tabela como filtros e referências estruturadas.
- Limpar Formatação da Tabela: Mantém os dados, mas remove todas as cores, bordas e estilos da tabela.
- Excluir Tabela Inteira: Remove permanentemente tanto a tabela quanto seus dados.
Vamos explorar essas opções em detalhes e ver como elas afetam seus dados no Excel.
Como Remover uma Tabela no Excel Convertendo-a para um Intervalo?
O método mais simples e confiável para remover uma tabela no Excel é convertê-la para um intervalo regular, o que mantém seus dados e formatação intactos. Você pode escolher entre duas opções principais para essa conversão: usar a faixa de opções do Excel ou o menu de clique com o botão direito.
Opção 1. Usando a Faixa de Opções do Excel
Siga os passos abaixo para converter uma tabela em um intervalo através da faixa de opções do Excel:
-
Selecione Qualquer Célula Dentro da Sua Tabela: Clique em qualquer célula (como "A1") dentro da tabela que você deseja remover. Você não precisa selecionar a tabela inteira.
-
Navegue até a Aba Design: Assim que você selecionar uma célula da tabela, a aba contextual Design aparecerá na faixa de opções do Excel, em Ferramentas de Tabela. Clique nela.
-
Clique em "Converter em Intervalo": No grupo Ferramentas, na extrema esquerda, você encontrará o botão "Converter em Intervalo". Clique nele.
-
Confirme a Ação: O Excel exibirá uma caixa de diálogo perguntando: "Deseja converter a tabela em um intervalo normal?" Clique em Sim.
Após a conversão, a estrutura da tabela é removida e os filtros não estão mais disponíveis. No entanto, qualquer formatação da tabela (como linhas em tiras e estilos de cabeçalho) permanece, mas o intervalo se torna estático em vez de dinâmico.
Opção 2. Usando o Menu de Clique com o Botão Direito
Para aqueles que preferem menus de contexto, usar o menu de clique com o botão direito é igualmente eficaz e um pouco mais rápido:
-
Selecione Qualquer Célula Dentro da Tabela: Assim como no primeiro método, clique em qualquer lugar dentro dos dados da sua tabela.
-
Clique com o Botão Direito para Abrir o Menu de Contexto: Clique com o botão direito na célula selecionada.
-
Navegue no Menu: No menu de clique com o botão direito, passe o mouse sobre (ou clique em) Tabela.
-
Selecione "Converter em Intervalo": No submenu que aparece, selecione Converter em Intervalo.
-
Confirme a Ação: Clique em Sim na caixa de diálogo de confirmação.
Este método produz o mesmo resultado que usar a faixa de opções, mas oferece uma abordagem mais rápida e orientada pelo mouse.
Como Remover a Formatação de Tabela no Excel?
Em alguns casos, você pode querer remover a formatação da tabela no Excel, incluindo elementos como filtros, cores e bordas. Siga os passos abaixo para limpar a formatação e retornar seus dados a um layout mais simples:
-
Converta a Tabela para um Intervalo: Primeiro, converta a tabela para um intervalo normal usando a faixa de opções do Excel ou o menu de clique com o botão direito descrito acima.
-
Limpe a Formatação da Tabela
Agora que os dados são um intervalo simples, você pode remover a formatação restante.-
Selecione Todo o Intervalo de Dados: Clique e arraste para selecionar todas as células que faziam parte da tabela original, incluindo o cabeçalho.
-
Vá para a Aba Página Inicial: Na faixa de opções do Excel, navegue até a aba Página Inicial.
-
Limpe os Formatos:
-
No grupo Edição, clique no botão Limpar (parece uma borracha rosa).
-
No menu suspenso, selecione Limpar Formatos.
-
-
Agora, toda a formatação específica da tabela foi removida, mas seus dados permanecem intactos. As células revertem para a fonte, cor e bordas padrão do Excel, fornecendo um bloco de dados limpo e não formatado, pronto para nova formatação ou análise.
Como Remover uma Tabela no Excel Completamente
Se você precisa remover tanto a tabela quanto todos os dados que ela contém, este método ajudará. Certifique-se de que não precisa mais das informações antes de prosseguir. Para excluir completamente uma tabela, siga estes passos:
-
Selecione a Tabela Inteira: Clique em qualquer lugar dentro da tabela e pressione Ctrl + A (Windows) ou Cmd + A (Mac) para selecionar a tabela inteira, incluindo o cabeçalho e as linhas de totais.
-
Limpar Todos os Dados e Formatação: Vá para a aba Página Inicial e encontre o grupo Edição. Clique em Limpar, depois selecione Limpar Tudo no menu suspenso.
Esta ação remove permanentemente todos os dados, formatação e a estrutura da tabela. As células serão limpas, não deixando vestígios da tabela original.
Como Remover Tabelas no Excel de uma Vez Usando VBA
Se o seu arquivo Excel contém várias tabelas, remover cada uma manualmente pode ser demorado. Você pode usar o VBA (Visual Basic for Applications) para automatizar o processo.
Veja como remover todas as tabelas em um arquivo Excel, mantendo os dados, usando um Script VBA:
-
Pressione Alt + F11 para abrir o Editor do VBA.
-
Clique em Inserir → Módulo.
-
Copie e cole o seguinte código VBA:
Sub ConvertAllTablesToRanges() Dim ws As Worksheet Dim tbl As ListObject For Each ws In ActiveWorkbook.Worksheets For Each tbl In ws.ListObjects tbl.Unlist ' Converte tabela em intervalo Next tbl Next ws End Sub -
Pressione F5 para executar a macro.
Esta macro percorre cada planilha no arquivo Excel, encontra todos os ListObjects (tabelas) e os converte em intervalos normais - preservando os dados, mas removendo a funcionalidade da tabela.
Para mais detalhes sobre o método Unlist usado neste script VBA, consulte a documentação oficial da Microsoft: Método Excel ListObject.Unlist.
Como Remover Tabelas no Excel usando Automação com Python?
Se você está trabalhando com Python para processamento de dados, relatórios automatizados ou aplicativos de backend, pode remover tabelas no Excel usando uma biblioteca como o Spire.XLS for Python.
O Spire.XLS for Python é uma biblioteca popular para Excel que permite aos desenvolvedores criar, ler e manipular arquivos Excel diretamente através de código, sem a necessidade do Microsoft Excel. Além de remover tabelas, ele permite ler e escrever valores e fórmulas de células, aplicar ou limpar formatação, gerenciar planilhas, inserir gráficos ou imagens e até mesmo converter arquivos Excel para PDF ou outros formatos.
Veja como você pode remover tabelas no Excel usando Python com o Spire.XLS for Python:
-
Instale o Spire.XLS for Python: Execute o seguinte comando no seu terminal para instalá-lo diretamente via PyPI:
pip install Spire.XLS -
Remova Tabelas com Código Python: Uma vez que a biblioteca esteja instalada, adicione o seguinte código para remover tabelas no seu arquivo Excel usando Python:
from spire.xls import * # Carregue a pasta de trabalho workbook = Workbook() workbook.LoadFromFile("CreateTable.xlsx") # Percorra todas as planilhas pelo índice for ws_index in range(len(workbook.Worksheets)): sheet = workbook.Worksheets[ws_index] # Percorra da última tabela para a primeira para remover com segurança pelo índice for tbl_index in range(len(sheet.ListObjects) - 1, -1, -1): sheet.ListObjects.RemoveAt(tbl_index) # Salve a pasta de trabalho workbook.SaveToFile("DeleteAllTables.xlsx", ExcelVersion.Version2016) workbook.Dispose()
Este código remove todas as tabelas do arquivo Excel, mantendo seus dados intactos e prontos para processamento posterior.
Leia o guia oficial completo: Adicionar ou Remover Tabelas no Excel em Python.
Dicas Profissionais para Remover uma Tabela no Excel
Ao remover uma tabela no Excel, as dicas a seguir podem ajudá-lo a evitar problemas comuns e a manter a integridade dos dados:
- Sempre faça backup da sua pasta de trabalho antes de executar scripts de VBA ou automação.
- Verifique novamente as fórmulas em busca de referências quebradas após a conversão.
- Reaplique os filtros manualmente, se necessário, após converter para um intervalo.
- Mantenha um formato consistente aplicando estilos de célula personalizados após remover a formatação da tabela.
- Use intervalos nomeados em vez de tabelas se você precisar apenas de referências fixas sem comportamento estruturado.
Conclusão
Remover uma tabela no Excel não precisa ser complicado. Seguindo este guia sobre como remover uma tabela no Excel, você pode manter seus dados e formatação intactos com segurança. Quer você prefira passos manuais, automação com VBA ou scripts em Python com Spire.XLS, esses métodos tornam a remoção de tabelas rápida, confiável e sem estresse. Experimente-os hoje para limpar suas planilhas e otimizar seu fluxo de trabalho!
Perguntas Frequentes: Remover Tabela no Excel
P1: Como converter uma tabela para um intervalo normal no Excel, mas manter os dados?
R1: Selecione qualquer célula na tabela → Clique com o botão direito em Tabela → Converter em Intervalo ou vá para Design → Converter em Intervalo → Clique em Sim. Seus dados permanecem, mas os recursos da tabela são removidos.
P2: Como removo apenas a formatação da tabela no Excel?
R2: Primeiro, converta a tabela para um intervalo normal. Em seguida, selecione todas as células → vá para Página Inicial → clique em Limpar → Limpar Formatos.
P3: Posso remover várias tabelas no Excel de uma vez?
R3: Sim. Use uma macro VBA para converter todas as tabelas em intervalos.
P4: Posso remover uma tabela no Excel usando Python?
R4: Sim. Você pode utilizar bibliotecas como o Spire.XLS for Python para remover tabelas no Excel com Python.
Leia Também
Excel에서 표 제거 (범위로 변환, 서식 지우기, VBA & Python)
Excel에서 표를 제거하는 것은 데이터를 단순화하는 간단하면서도 필수적인 작업입니다. 표는 정보를 구성하고 관리하는 데 유용하지만, 서식을 간소화하거나 원시 데이터를 내보내거나 구조화된 기능 사용을 중단하려는 등 여러 이유로 표를 제거하고 싶을 때가 있습니다.
이 가이드에서는 Excel에서 표를 제거하는 다양한 방법을 살펴보겠습니다. 여기에는 표를 범위로 변환하거나, 서식을 지우거나, 완전히 삭제하는 방법이 포함됩니다. 또한 VBA와 Python을 사용하여 프로세스를 자동화하는 방법을 시연하여 여러 표로 작업할 때 시간을 절약할 수 있도록 도와드립니다.
콘텐츠 개요
- Excel에서 표를 제거할 때 발생하는 일 이해하기
- Excel에서 표를 범위로 변환하여 제거하는 방법
- Excel에서 표 서식을 제거하는 방법
- Excel에서 표를 완전히 제거하는 방법
- VBA를 사용하여 Excel에서 한 번에 표를 제거하는 방법
- Python 자동화를 사용하여 Excel에서 표를 제거하는 방법
- Excel에서 표를 제거하기 위한 전문가 팁
- 결론
- 자주 묻는 질문: Excel에서 표 제거
Excel에서 표를 제거할 때 발생하는 일 이해하기
Excel에서 표를 제거하면 선택한 방법에 따라 다른 결과가 나타날 수 있습니다.
- 범위로 변환: 모든 데이터와 표에 적용된 서식을 정적 셀 서식으로 유지하지만 필터 및 구조적 참조와 같은 표 기능은 제거합니다.
- 표 서식 지우기: 데이터는 유지하지만 모든 표 색상, 테두리 및 스타일을 제거합니다.
- 전체 표 삭제: 표와 해당 데이터를 영구적으로 제거합니다.
이러한 옵션을 자세히 살펴보고 Excel 데이터에 어떤 영향을 미치는지 알아보겠습니다.
Excel에서 표를 범위로 변환하여 제거하는 방법은?
Excel에서 표를 제거하는 가장 간단하고 신뢰할 수 있는 방법은 데이터와 서식을 그대로 유지하는 일반 범위로 변환하는 것입니다. 이 변환에는 Excel 리본을 사용하거나 마우스 오른쪽 클릭 메뉴를 사용하는 두 가지 주요 옵션 중에서 선택할 수 있습니다.
옵션 1. Excel 리본 사용
아래 단계에 따라 Excel 리본을 통해 표를 범위로 변환합니다.
-
표 안의 아무 셀이나 선택: 제거하려는 표 안의 아무 셀("A1" 등)이나 클릭합니다. 전체 표를 선택할 필요는 없습니다.
-
디자인 탭으로 이동: 표 셀을 선택하자마자 Excel 리본의 표 도구 아래에 상황별 디자인 탭이 나타납니다. 클릭합니다.
-
"범위로 변환" 클릭: 맨 왼쪽에 있는 도구 그룹에서 "범위로 변환" 버튼을 찾을 수 있습니다. 클릭합니다.
-
작업 확인: Excel에서 "표를 일반 범위로 변환하시겠습니까?"라는 대화 상자가 나타납니다. 예를 클릭합니다.
변환 후에는 표 구조가 제거되고 필터를 더 이상 사용할 수 없습니다. 그러나 줄무늬 행 및 머리글 스타일과 같은 모든 표 서식은 유지되지만 범위는 동적이 아닌 정적이 됩니다.
옵션 2. 마우스 오른쪽 클릭 메뉴 사용
상황에 맞는 메뉴를 선호하는 사람들에게는 마우스 오른쪽 클릭 메뉴를 사용하는 것이 똑같이 효과적이고 조금 더 빠릅니다.
-
표 안의 아무 셀이나 선택: 첫 번째 방법과 마찬가지로 표 데이터 안의 아무 곳이나 클릭합니다.
-
마우스 오른쪽 클릭하여 상황에 맞는 메뉴 열기: 선택한 셀을 마우스 오른쪽 버튼으로 클릭합니다.
-
메뉴 탐색: 마우스 오른쪽 클릭 메뉴에서 표 위로 마우스를 가져가거나 클릭합니다.
-
"범위로 변환" 선택: 나타나는 하위 메뉴에서 범위로 변환을 선택합니다.
-
작업 확인: 확인 대화 상자에서 예를 클릭합니다.
이 방법은 리본을 사용하는 것과 동일한 결과를 생성하지만 더 빠르고 마우스 중심적인 접근 방식을 제공합니다.
Excel에서 표 서식을 제거하는 방법은?
경우에 따라 필터, 색상 및 테두리와 같은 요소를 포함하여 Excel에서 표 서식을 제거하고 싶을 수 있습니다. 아래 단계에 따라 서식을 지우고 데이터를 더 간단한 레이아웃으로 되돌립니다.
-
표를 범위로 변환: 먼저 위에서 설명한 Excel 리본 또는 마우스 오른쪽 클릭 메뉴를 사용하여 표를 일반 범위로 변환합니다.
-
표 서식 지우기
이제 데이터가 간단한 범위이므로 남은 서식을 제거할 수 있습니다.-
전체 데이터 범위 선택: 머리글을 포함하여 원래 표의 일부였던 모든 셀을 클릭하고 드래그하여 선택합니다.
-
홈 탭으로 이동: Excel 리본에서 홈 탭으로 이동합니다.
-
서식 지우기:
-
편집 그룹에서 지우기 버튼(분홍색 지우개 모양)을 클릭합니다.
-
드롭다운 메뉴에서 서식 지우기를 선택합니다.
-
-
이제 모든 표 관련 서식이 제거되었지만 데이터는 그대로 유지됩니다. 셀은 Excel의 기본 글꼴, 색상 및 테두리로 되돌아가 새 서식이나 분석을 위해 준비된 깨끗하고 서식이 지정되지 않은 데이터 블록을 제공합니다.
Excel에서 표를 완전히 제거하는 방법
표와 표에 포함된 모든 데이터를 모두 제거해야 하는 경우 이 방법이 도움이 됩니다. 계속하기 전에 정보가 더 이상 필요하지 않은지 확인하십시오. 표를 완전히 삭제하려면 다음 단계를 따르십시오.
-
전체 표 선택: 표 안의 아무 곳이나 클릭하고 Ctrl + A(Windows) 또는 Cmd + A(Mac)를 눌러 머리글 및 합계 행을 포함한 전체 표를 선택합니다.
-
모든 데이터 및 서식 지우기: 홈 탭으로 이동하여 편집 그룹을 찾습니다. 지우기를 클릭한 다음 드롭다운 메뉴에서 모두 지우기를 선택합니다.
이 작업은 모든 데이터, 서식 및 표 구조를 영구적으로 제거합니다. 셀이 지워져 원래 표의 흔적이 남지 않습니다.
VBA를 사용하여 Excel에서 한 번에 표를 제거하는 방법
Excel 파일에 여러 표가 포함된 경우 각 표를 수동으로 제거하는 것은 시간이 많이 걸릴 수 있습니다. VBA(Visual Basic for Applications)를 사용하여 프로세스를 자동화할 수 있습니다.
VBA 스크립트를 사용하여 데이터를 유지하면서 Excel 파일의 모든 표를 제거하는 방법은 다음과 같습니다.
-
Alt + F11을 눌러 VBA 편집기를 엽니다.
-
삽입 → 모듈을 클릭합니다.
-
다음 VBA 코드를 복사하여 붙여넣습니다.
Sub ConvertAllTablesToRanges() Dim ws As Worksheet Dim tbl As ListObject For Each ws In ActiveWorkbook.Worksheets For Each tbl In ws.ListObjects tbl.Unlist ' 표를 범위로 변환 Next tbl Next ws End Sub -
F5를 눌러 매크로를 실행합니다.
이 매크로는 Excel 파일의 모든 워크시트를 반복하고 모든 ListObjects(표)를 찾아 일반 범위로 변환하여 데이터는 보존하지만 표 기능은 제거합니다.
이 VBA 스크립트에서 사용된 Unlist 메서드에 대한 자세한 내용은 공식 Microsoft 설명서를 참조하십시오. Excel ListObject.Unlist 메서드.
Python 자동화를 사용하여 Excel에서 표를 제거하는 방법은?
데이터 처리, 자동화된 보고 또는 백엔드 애플리케이션을 위해 Python으로 작업하는 경우 Spire.XLS for Python과 같은 라이브러리를 사용하여 Excel에서 표를 제거할 수 있습니다.
Spire.XLS for Python은 개발자가 Microsoft Excel 없이 코드를 통해 직접 Excel 파일을 생성, 읽기 및 조작할 수 있게 해주는 인기 있는 Excel 라이브러리입니다. 표 제거 외에도 셀 값 및 수식 읽기 및 쓰기, 서식 적용 또는 지우기, 워크시트 관리, 차트 또는 이미지 삽입, 심지어 Excel 파일을 PDF로 변환 또는 다른 형식으로 변환할 수 있습니다.
Spire.XLS for Python을 사용하여 Python으로 Excel에서 표를 제거하는 방법은 다음과 같습니다.
-
Spire.XLS for Python 설치: 터미널에서 다음 명령을 실행하여 PyPI를 통해 직접 설치합니다.
pip install Spire.XLS -
Python 코드로 표 제거: 라이브러리가 설치되면 다음 코드를 추가하여 Python을 사용하여 Excel 파일에서 표를 제거합니다.
from spire.xls import * # 통합 문서 로드 workbook = Workbook() workbook.LoadFromFile("CreateTable.xlsx") # 인덱스로 모든 워크시트 반복 for ws_index in range(len(workbook.Worksheets)): sheet = workbook.Worksheets[ws_index] # 인덱스로 안전하게 제거하기 위해 마지막 표부터 첫 번째 표까지 반복 for tbl_index in range(len(sheet.ListObjects) - 1, -1, -1): sheet.ListObjects.RemoveAt(tbl_index) # 통합 문서 저장 workbook.SaveToFile("DeleteAllTables.xlsx", ExcelVersion.Version2016) workbook.Dispose()
이 코드는 Excel 파일의 모든 표를 제거하여 데이터를 그대로 유지하고 추가 처리를 위해 준비합니다.
전체 공식 가이드 읽기: Python에서 Excel에 표 추가 또는 제거.
Excel에서 표를 제거하기 위한 전문가 팁
Excel에서 표를 제거할 때 다음 팁을 따르면 일반적인 문제를 피하고 데이터 무결성을 유지하는 데 도움이 될 수 있습니다.
- VBA 또는 자동화 스크립트를 실행하기 전에 항상 통합 문서를 백업하십시오.
- 변환 후 깨진 참조가 있는지 수식을 다시 확인하십시오.
- 범위로 변환한 후 필요한 경우 필터를 수동으로 다시 적용하십시오.
- 표 서식을 제거한 후 사용자 지정 셀 스타일을 적용하여 일관된 형식을 유지하십시오.
- 구조화된 동작 없이 고정된 참조만 필요한 경우 표 대신 명명된 범위를 사용하십시오.
결론
Excel에서 표를 제거하는 것이 복잡할 필요는 없습니다. Excel에서 표를 제거하는 방법에 대한 이 가이드를 따르면 데이터와 서식을 안전하게 유지할 수 있습니다. 수동 단계, VBA 자동화 또는 Spire.XLS를 사용한 Python 스크립팅을 선호하든 이러한 방법을 사용하면 표 제거를 빠르고 안정적이며 스트레스 없이 수행할 수 있습니다. 오늘 시도하여 스프레드시트를 정리하고 워크플로를 간소화하십시오!
자주 묻는 질문: Excel에서 표 제거
Q1: Excel에서 표를 일반 범위로 변환하되 데이터는 유지하는 방법은 무엇입니까?
A1: 표의 아무 셀이나 선택 → 마우스 오른쪽 클릭 표 → 범위로 변환 또는 디자인 → 범위로 변환 → 예를 클릭합니다. 데이터는 유지되지만 표 기능은 제거됩니다.
Q2: Excel에서 표 서식만 제거하려면 어떻게 해야 합니까?
A2: 먼저 표를 일반 범위로 변환합니다. 그런 다음 모든 셀을 선택 → 홈 → 지우기 클릭 → 서식 지우기.
Q3: Excel에서 여러 표를 한 번에 제거할 수 있습니까?
A3: 예. VBA 매크로를 사용하여 모든 표를 범위로 변환합니다.
Q4: Python을 사용하여 Excel에서 표를 제거할 수 있습니까?
A4: 예. Spire.XLS for Python과 같은 라이브러리를 활용하여 Python으로 Excel에서 표를 제거할 수 있습니다.
또한 읽기
Supprimer un tableau dans Excel (Convertir en plage, Effacer la mise en forme, VBA et Python)
Table des matières
- Comprendre ce qui se passe lorsque vous supprimez un tableau dans Excel
- Comment supprimer un tableau dans Excel en le convertissant en plage
- Comment supprimer la mise en forme d'un tableau dans Excel
- Comment supprimer complètement un tableau dans Excel
- Comment supprimer plusieurs tableaux dans Excel à la fois en utilisant VBA
- Comment supprimer des tableaux dans Excel en utilisant l'automatisation Python
- Conseils de pro pour supprimer un tableau dans Excel
- Conclusion
- FAQ : Supprimer un tableau dans Excel
La suppression d'un tableau dans Excel est une tâche simple mais essentielle pour simplifier vos données. Bien que les tableaux soient utiles pour organiser et gérer les informations, il peut arriver que vous souhaitiez les supprimer, que ce soit pour rationaliser la mise en forme, exporter des données brutes ou cesser d'utiliser des fonctionnalités structurées.
Dans ce guide, nous explorerons différentes méthodes pour supprimer un tableau dans Excel, notamment en le convertissant en plage, en effaçant sa mise en forme et en le supprimant complètement. De plus, nous montrerons comment automatiser le processus à l'aide de VBA et de Python, ce qui vous aidera à gagner du temps lorsque vous travaillez avec plusieurs tableaux.
Aperçu du contenu
- Comprendre ce qui se passe lorsque vous supprimez un tableau dans Excel
- Comment supprimer un tableau dans Excel en le convertissant en plage
- Comment supprimer la mise en forme d'un tableau dans Excel
- Comment supprimer complètement un tableau dans Excel
- Comment supprimer plusieurs tableaux dans Excel à la fois en utilisant VBA
- Comment supprimer des tableaux dans Excel en utilisant l'automatisation Python
- Conseils de pro pour supprimer un tableau dans Excel
- Conclusion
- FAQ : Supprimer un tableau dans Excel
Comprendre ce qui se passe lorsque vous supprimez un tableau dans Excel
La suppression d'un tableau dans Excel peut avoir des résultats différents selon la méthode que vous choisissez :
- Convertir en plage : Conserve toutes vos données et toute la mise en forme appliquée au tableau en tant que mise en forme de cellule statique, mais supprime les fonctionnalités du tableau telles que les filtres et les références structurées.
- Effacer la mise en forme du tableau : Conserve les données mais supprime toutes les couleurs, bordures et styles du tableau.
- Supprimer le tableau entier : Supprime définitivement le tableau et ses données.
Explorons ces options en détail et voyons comment elles affectent vos données Excel.
Comment supprimer un tableau dans Excel en le convertissant en plage ?
La méthode la plus simple et la plus fiable pour supprimer un tableau dans Excel consiste à le convertir en une plage normale, ce qui préserve vos données et votre mise en forme. Vous pouvez choisir parmi deux options principales pour cette conversion : utiliser le ruban Excel ou le menu contextuel.
Option 1. Utilisation du ruban Excel
Suivez les étapes ci-dessous pour convertir un tableau en plage via le ruban Excel :
-
Sélectionnez n'importe quelle cellule à l'intérieur de votre tableau : Cliquez sur n'importe quelle cellule (telle que "A1") dans le tableau que vous souhaitez supprimer. Vous n'avez pas besoin de sélectionner tout le tableau.
-
Accédez à l'onglet Création : Dès que vous sélectionnez une cellule de tableau, l'onglet contextuel Création apparaît sur le ruban Excel, sous Outils de tableau. Cliquez dessus.
-
Cliquez sur "Convertir en plage" : Dans le groupe Outils à l'extrême gauche, vous trouverez le bouton "Convertir en plage". Cliquez dessus.
-
Confirmez l'action : Excel affichera une boîte de dialogue vous demandant : "Voulez-vous convertir le tableau en une plage normale ?" Cliquez sur Oui.
Après la conversion, la structure du tableau est supprimée et les filtres ne sont plus disponibles. Cependant, toute mise en forme du tableau (comme les lignes à bandes et les styles d'en-tête) est conservée, mais la plage devient statique au lieu de dynamique.
Option 2. Utilisation du menu contextuel
Pour ceux qui préfèrent les menus contextuels, l'utilisation du menu contextuel est tout aussi efficace et un peu plus rapide :
-
Sélectionnez n'importe quelle cellule à l'intérieur du tableau : Tout comme dans la première méthode, cliquez n'importe où à l'intérieur des données de votre tableau.
-
Faites un clic droit pour ouvrir le menu contextuel : Faites un clic droit sur la cellule sélectionnée.
-
Naviguez dans le menu : Dans le menu contextuel, survolez (ou cliquez sur) Tableau.
-
Sélectionnez "Convertir en plage" : Dans le sous-menu qui apparaît, sélectionnez Convertir en plage.
-
Confirmez l'action : Cliquez sur Oui dans la boîte de dialogue de confirmation.
Cette méthode produit le même résultat que l'utilisation du ruban mais offre une approche plus rapide, pilotée par la souris.
Comment supprimer la mise en forme d'un tableau dans Excel ?
Dans certains cas, vous souhaiterez peut-être supprimer la mise en forme du tableau dans Excel, y compris des éléments tels que les filtres, les couleurs et les bordures. Suivez les étapes ci-dessous pour effacer la mise en forme et redonner à vos données une disposition plus simple :
-
Convertir le tableau en plage : Tout d'abord, convertissez le tableau en une plage normale en utilisant soit le ruban Excel, soit le menu contextuel décrit ci-dessus.
-
Effacer la mise en forme du tableau
Maintenant que les données sont une simple plage, vous pouvez supprimer la mise en forme restante.-
Sélectionnez toute la plage de données : Cliquez et faites glisser pour sélectionner toutes les cellules qui faisaient partie du tableau d'origine, y compris l'en-tête.
-
Allez à l'onglet Accueil : Sur le ruban Excel, accédez à l'onglet Accueil.
-
Effacer les formats :
-
Dans le groupe Édition, cliquez sur le bouton Effacer (il ressemble à une gomme rose).
-
Dans le menu déroulant, sélectionnez Effacer les formats.
-
-
Désormais, toute la mise en forme spécifique au tableau est supprimée, mais vos données restent intactes. Les cellules retrouvent la police, la couleur et les bordures par défaut d'Excel, vous offrant un bloc de données propre et non formaté, prêt pour une nouvelle mise en forme ou une nouvelle analyse.
Comment supprimer complètement un tableau dans Excel
Si vous devez supprimer à la fois le tableau et toutes les données qu'il contient, cette méthode vous aidera. Assurez-vous d'être certain de ne plus avoir besoin des informations avant de continuer. Pour supprimer complètement un tableau, suivez ces étapes :
-
Sélectionnez le tableau entier: Cliquez n'importe où à l'intérieur du tableau et appuyez sur Ctrl + A (Windows) ou Cmd + A (Mac) pour sélectionner le tableau entier, y compris l'en-tête et les lignes de total.
-
Effacer toutes les données et la mise en forme: Allez à l'onglet Accueil et trouvez le groupe Édition. Cliquez sur Effacer, puis sélectionnez Effacer tout dans le menu déroulant.
Cette action supprime définitivement toutes les données, la mise en forme et la structure du tableau. Les cellules seront effacées, ne laissant aucune trace du tableau d'origine.
Comment supprimer plusieurs tableaux dans Excel à la fois en utilisant VBA
Si votre fichier Excel contient plusieurs tableaux, la suppression manuelle de chacun d'entre eux peut prendre beaucoup de temps. Vous pouvez utiliser VBA (Visual Basic for Applications) pour automatiser le processus.
Voici comment supprimer tous les tableaux d'un fichier Excel tout en conservant les données à l'aide d'un script VBA :
-
Appuyez sur Alt + F11 pour ouvrir l'éditeur VBA.
-
Cliquez sur Insertion → Module.
-
Copiez et collez le code VBA suivant :
Sub ConvertAllTablesToRanges() Dim ws As Worksheet Dim tbl As ListObject For Each ws In ActiveWorkbook.Worksheets For Each tbl In ws.ListObjects tbl.Unlist ' Convert table to range Next tbl Next ws End Sub -
Appuyez sur F5 pour exécuter la macro.
Cette macro parcourt chaque feuille de calcul du fichier Excel, trouve tous les ListObjects (tableaux) et les convertit en plages normales, préservant ainsi les données mais supprimant les fonctionnalités du tableau.
Pour plus de détails sur la méthode Unlist utilisée dans ce script VBA, consultez la documentation officielle de Microsoft : Méthode Excel ListObject.Unlist.
Comment supprimer des tableaux dans Excel en utilisant l'automatisation Python ?
Si vous travaillez avec Python pour le traitement de données, les rapports automatisés ou les applications backend, vous pouvez supprimer des tableaux dans Excel à l'aide d'une bibliothèque comme Spire.XLS for Python.
Spire.XLS for Python est une bibliothèque Excel populaire qui permet aux développeurs de créer, lire et manipuler des fichiers Excel directement via le code sans nécessiter Microsoft Excel. En plus de la suppression de tableaux, il vous permet de lire et d'écrire des valeurs et des formules de cellules, d'appliquer ou d'effacer la mise en forme, de gérer des feuilles de calcul, d'insérer des graphiques ou des images, et même de convertir des fichiers Excel en PDF ou d'autres formats.
Voici comment vous pouvez supprimer des tableaux dans Excel en utilisant Python avec Spire.XLS for Python :
-
Installez Spire.XLS for Python: Exécutez la commande suivante dans votre terminal pour l'installer directement via PyPI :
pip install Spire.XLS -
Supprimer des tableaux avec du code Python: Une fois la bibliothèque installée, ajoutez le code suivant pour supprimer des tableaux dans votre fichier Excel à l'aide de Python :
from spire.xls import * # Load the workbook workbook = Workbook() workbook.LoadFromFile("CreateTable.xlsx") # Loop through all worksheets by index for ws_index in range(len(workbook.Worksheets)): sheet = workbook.Worksheets[ws_index] # Loop from last table to first to safely remove by index for tbl_index in range(len(sheet.ListObjects) - 1, -1, -1): sheet.ListObjects.RemoveAt(tbl_index) # Save the workbook workbook.SaveToFile("DeleteAllTables.xlsx", ExcelVersion.Version2016) workbook.Dispose()
Ce code supprime tous les tableaux du fichier Excel, en gardant vos données intactes et prêtes pour un traitement ultérieur.
Lisez le guide officiel complet : Ajouter ou supprimer des tableaux dans Excel en Python.
Conseils de pro pour supprimer un tableau dans Excel
Lors de la suppression d'un tableau dans Excel, les conseils suivants peuvent vous aider à éviter les problèmes courants et à maintenir l'intégrité des données :
- Sauvegardez toujours votre classeur avant d'exécuter des scripts VBA ou d'automatisation.
- Vérifiez les formules pour les références rompues après la conversion.
- Réappliquez les filtres manuellement si nécessaire après la conversion en plage.
- Conservez un format cohérent en appliquant des styles de cellule personnalisés après avoir supprimé la mise en forme du tableau.
- Utilisez des plages nommées au lieu de tableaux si vous n'avez besoin que de références fixes sans comportement structuré.
Conclusion
La suppression d'un tableau dans Excel n'a pas à être compliquée. En suivant ce guide sur la façon de supprimer un tableau dans Excel, vous pouvez conserver en toute sécurité vos données et votre mise en forme. Que vous préfériez les étapes manuelles, l'automatisation VBA ou les scripts Python avec Spire.XLS, ces méthodes rendent la suppression de tableau rapide, fiable et sans stress. Essayez-les dès aujourd'hui pour nettoyer vos feuilles de calcul et rationaliser votre flux de travail !
FAQ : Supprimer un tableau dans Excel
Q1 : Comment convertir un tableau en une plage normale dans Excel tout en conservant les données ?
R1 : Sélectionnez n'importe quelle cellule du tableau → Clic droit sur Tableau → Convertir en plage ou allez dans Création → Convertir en plage → Cliquez sur Oui. Vos données sont conservées, mais les fonctionnalités du tableau sont supprimées.
Q2 : Comment supprimer uniquement la mise en forme du tableau dans Excel ?
R2 : Tout d'abord, convertissez le tableau en une plage normale. Ensuite, sélectionnez toutes les cellules → allez dans Accueil → cliquez sur Effacer → Effacer les formats.
Q3 : Puis-je supprimer plusieurs tableaux dans Excel à la fois ?
R3 : Oui. Utilisez une macro VBA pour convertir tous les tableaux en plages.
Q4 : Puis-je supprimer un tableau dans Excel en utilisant Python ?
R4 : Oui. Vous pouvez utiliser des bibliothèques comme Spire.XLS for Python pour supprimer des tableaux dans Excel avec Python.
À lire également
Quitar una tabla en Excel (Convertir a rango, Borrar formato, VBA y Python)
Tabla de Contenidos
- Entender lo que Sucede al Eliminar una Tabla en Excel
- Cómo Eliminar una Tabla en Excel Convirtiéndola en un Rango
- Cómo Eliminar el Formato de Tabla en Excel
- Cómo Eliminar una Tabla en Excel por Completo
- Cómo Eliminar Varias Tablas en Excel a la Vez Usando VBA
- Cómo Eliminar Tablas en Excel usando Automatización con Python
- Consejos Profesionales para Eliminar una Tabla en Excel
- Conclusión
- Preguntas Frecuentes: Eliminar Tabla en Excel
Eliminar una tabla en Excel es una tarea sencilla pero esencial para simplificar tus datos. Aunque las tablas son útiles para organizar y gestionar información, hay momentos en los que es posible que desees eliminarlas, ya sea para optimizar el formato, exportar datos sin procesar o dejar de usar funciones estructuradas.
En esta guía, exploraremos varios métodos para eliminar una tabla en Excel, incluyendo convertirla en un rango, borrar su formato y eliminarla por completo. Además, demostraremos cómo automatizar el proceso usando VBA y Python, ayudándote a ahorrar tiempo al trabajar con múltiples tablas.
Resumen de Contenidos
- Entender lo que Sucede al Eliminar una Tabla en Excel
- Cómo Eliminar una Tabla en Excel Convirtiéndola en un Rango
- Cómo Eliminar el Formato de Tabla en Excel
- Cómo Eliminar una Tabla en Excel por Completo
- Cómo Eliminar Varias Tablas en Excel a la Vez Usando VBA
- Cómo Eliminar Tablas en Excel usando Automatización con Python
- Consejos Profesionales para Eliminar una Tabla en Excel
- Conclusión
- Preguntas Frecuentes: Eliminar Tabla en Excel
Entender lo que Sucede al Eliminar una Tabla en Excel
Eliminar una tabla en Excel puede tener diferentes resultados dependiendo del método que elijas:
- Convertir a Rango: Mantiene todos tus datos y cualquier formato aplicado por la tabla como formato de celda estático, pero elimina las características de la tabla como filtros y referencias estructuradas.
- Borrar Formato de Tabla: Mantiene los datos pero elimina todos los colores, bordes y estilos de la tabla.
- Eliminar Tabla Completa: Elimina permanentemente tanto la tabla como sus datos.
Exploremos estas opciones en detalle y veamos cómo afectan tus datos de Excel.
¿Cómo Eliminar una Tabla en Excel Convirtiéndola en un Rango?
El método más simple y fiable para eliminar una tabla en Excel es convertirla en un rango normal, lo que mantiene tus datos y formato intactos. Puedes elegir entre dos opciones principales para esta conversión: usar la cinta de opciones de Excel o el menú contextual.
Opción 1. Usando la Cinta de Opciones de Excel
Sigue los pasos a continuación para convertir una tabla en un rango a través de la cinta de opciones de Excel:
-
Selecciona Cualquier Celda Dentro de tu Tabla: Haz clic en cualquier celda (como "A1") dentro de la tabla que deseas eliminar. No necesitas seleccionar toda la tabla.
-
Ve a la Pestaña de Diseño: Tan pronto como selecciones una celda de la tabla, aparecerá la pestaña contextual de Diseño en la cinta de opciones de Excel, bajo Herramientas de tabla. Haz clic en ella.
-
Haz clic en "Convertir en Rango": En el grupo Herramientas en el extremo izquierdo, encontrarás el botón "Convertir en Rango". Haz clic en él.
-
Confirma la Acción: Excel mostrará un cuadro de diálogo preguntando, "¿Desea convertir la tabla en un rango normal?" Haz clic en Sí.
Después de la conversión, la estructura de la tabla se elimina y los filtros ya no están disponibles. Sin embargo, cualquier formato de tabla (como filas con bandas y estilos de encabezado) permanece, pero el rango se vuelve estático en lugar de dinámico.
Opción 2. Usando el Menú Contextual
Para aquellos que prefieren los menús contextuales, usar el menú contextual es igual de efectivo y un poco más rápido:
-
Selecciona Cualquier Celda Dentro de la Tabla: Al igual que en el primer método, haz clic en cualquier parte dentro de los datos de tu tabla.
-
Haz Clic Derecho para Abrir el Menú Contextual: Haz clic derecho en la celda seleccionada.
-
Navega por el Menú: En el menú contextual, pasa el cursor sobre (o haz clic en) Tabla.
-
Selecciona "Convertir en Rango": En el submenú que aparece, selecciona Convertir en Rango.
-
Confirma la Acción: Haz clic en Sí en el cuadro de diálogo de confirmación.
Este método produce el mismo resultado que usar la cinta de opciones, pero ofrece un enfoque más rápido y manejado por el ratón.
¿Cómo Eliminar el Formato de Tabla en Excel?
En algunos casos, es posible que desees eliminar el formato de la tabla en Excel, incluyendo elementos como filtros, colores y bordes. Sigue los pasos a continuación para borrar el formato y devolver tus datos a un diseño más simple:
-
Convierte la Tabla en un Rango: Primero, convierte la tabla en un rango normal usando la cinta de opciones de Excel o el menú contextual descrito anteriormente.
-
Borra el Formato de la Tabla
Ahora que los datos son un rango simple, puedes eliminar el formato restante.-
Selecciona Todo el Rango de Datos: Haz clic y arrastra para seleccionar todas las celdas que formaban parte de la tabla original, incluido el encabezado.
-
Ve a la Pestaña de Inicio: En la cinta de opciones de Excel, ve a la pestaña Inicio.
-
Borra los Formatos:
-
En el grupo Edición, haz clic en el botón Borrar (parece una goma de borrar rosa).
-
En el menú desplegable, selecciona Borrar Formatos.
-
-
Ahora, todo el formato específico de la tabla se ha eliminado, pero tus datos permanecen intactos. Las celdas vuelven a la fuente, color y bordes predeterminados de Excel, dejándote un bloque de datos limpio y sin formato, listo para un nuevo formato o análisis.
Cómo Eliminar una Tabla en Excel por Completo
Si necesitas eliminar tanto la tabla como todos los datos que contiene, este método te ayudará. Asegúrate de que ya no necesitas la información antes de proceder. Para eliminar una tabla por completo, sigue estos pasos:
-
Selecciona la Tabla Completa: Haz clic en cualquier lugar dentro de la tabla y presiona Ctrl + A (Windows) o Cmd + A (Mac) para seleccionar toda la tabla, incluyendo el encabezado y las filas de totales.
-
Borrar Todos los Datos y Formato: Ve a la pestaña Inicio y busca el grupo Edición. Haz clic en Borrar, luego selecciona Borrar todo en el menú desplegable.
Esta acción elimina permanentemente todos los datos, el formato y la estructura de la tabla. Las celdas se borrarán, sin dejar rastro de la tabla original.
Cómo Eliminar Varias Tablas en Excel a la Vez Usando VBA
Si tu archivo de Excel contiene varias tablas, eliminarlas una por una manualmente puede llevar mucho tiempo. Puedes usar VBA (Visual Basic para Aplicaciones) para automatizar el proceso.
A continuación se explica cómo eliminar todas las tablas de un archivo de Excel manteniendo los datos mediante un Script de VBA:
-
Presiona Alt + F11 para abrir el Editor de VBA.
-
Haz clic en Insertar → Módulo.
-
Copia y pega el siguiente código VBA:
Sub ConvertAllTablesToRanges() Dim ws As Worksheet Dim tbl As ListObject For Each ws In ActiveWorkbook.Worksheets For Each tbl In ws.ListObjects tbl.Unlist ' Convert table to range Next tbl Next ws End Sub -
Presiona F5 para ejecutar la macro.
Esta macro recorre cada hoja de cálculo en el archivo de Excel, encuentra todos los ListObjects (tablas) y los convierte en rangos normales, conservando los datos pero eliminando la funcionalidad de la tabla.
Para obtener más detalles sobre el método Unlist utilizado en este script de VBA, consulta la documentación oficial de Microsoft: Método ListObject.Unlist de Excel.
¿Cómo Eliminar Tablas en Excel usando Automatización con Python?
Si trabajas con Python para el procesamiento de datos, informes automatizados o aplicaciones de backend, puedes eliminar tablas en Excel utilizando una biblioteca como Spire.XLS para Python.
Spire.XLS para Python es una popular biblioteca de Excel que permite a los desarrolladores crear, leer y manipular archivos de Excel directamente a través del código sin necesidad de Microsoft Excel. Además de eliminar tablas, te permite leer y escribir valores y fórmulas de celdas, aplicar o borrar formato, gestionar hojas de cálculo, insertar gráficos o imágenes, e incluso convertir archivos de Excel a PDF u otros formatos.
A continuación se explica cómo puedes eliminar tablas en Excel usando Python con Spire.XLS para Python:
-
Instala Spire.XLS para Python: Ejecuta el siguiente comando en tu terminal para instalarlo directamente a través de PyPI:
pip install Spire.XLS -
Elimina Tablas con Código Python: Una vez instalada la biblioteca, añade el siguiente código para eliminar tablas en tu archivo de Excel usando Python:
from spire.xls import * # Load the workbook workbook = Workbook() workbook.LoadFromFile("CreateTable.xlsx") # Loop through all worksheets by index for ws_index in range(len(workbook.Worksheets)): sheet = workbook.Worksheets[ws_index] # Loop from last table to first to safely remove by index for tbl_index in range(len(sheet.ListObjects) - 1, -1, -1): sheet.ListObjects.RemoveAt(tbl_index) # Save the workbook workbook.SaveToFile("DeleteAllTables.xlsx", ExcelVersion.Version2016) workbook.Dispose()
Este código elimina todas las tablas del archivo de Excel, manteniendo tus datos intactos y listos para su posterior procesamiento.
Lee la guía oficial completa: Añadir o Eliminar Tablas en Excel en Python.
Consejos Profesionales para Eliminar una Tabla en Excel
Al eliminar una tabla en Excel, los siguientes consejos pueden ayudarte a evitar problemas comunes y a mantener la integridad de los datos:
- Haz siempre una copia de seguridad de tu libro de trabajo antes de ejecutar scripts de VBA o de automatización.
- Verifica dos veces las fórmulas en busca de referencias rotas después de la conversión.
- Vuelve a aplicar los filtros manualmente si es necesario después de convertir a un rango.
- Mantén un formato coherente aplicando estilos de celda personalizados después de eliminar el formato de la tabla.
- Usa rangos con nombre en lugar de tablas si solo necesitas referencias fijas sin comportamiento estructurado.
Conclusión
Eliminar una tabla en Excel no tiene por qué ser complicado. Siguiendo esta guía sobre cómo eliminar una tabla en Excel, puedes mantener tus datos y formato intactos de forma segura. Ya sea que prefieras los pasos manuales, la automatización con VBA o los scripts de Python con Spire.XLS, estos métodos hacen que la eliminación de tablas sea rápida, fiable y sin estrés. ¡Pruébalos hoy para limpiar tus hojas de cálculo y optimizar tu flujo de trabajo!
Preguntas Frecuentes: Eliminar Tabla en Excel
P1: ¿Cómo convertir una tabla a un rango normal en Excel pero mantener los datos?
R1: Selecciona cualquier celda de la tabla → Haz clic derecho en Tabla → Convertir en Rango o ve a Diseño → Convertir en Rango → Haz clic en Sí. Tus datos permanecen, pero las características de la tabla se eliminan.
P2: ¿Cómo elimino solo el formato de la tabla en Excel?
R2: Primero, convierte la tabla en un rango normal. Luego selecciona todas las celdas → ve a Inicio → haz clic en Borrar → Borrar Formatos.
P3: ¿Puedo eliminar varias tablas en Excel a la vez?
R3: Sí. Usa una macro de VBA para convertir todas las tablas en rangos.
P4: ¿Puedo eliminar una tabla en Excel usando Python?
R4: Sí. Puedes utilizar bibliotecas como Spire.XLS para Python para eliminar tablas en Excel con Python.