5 modi per inserire una pagina in Word (manualmente e tramite automazione Python)
Indice
- Inserire una pagina vuota in Word usando la barra degli strumenti
- Inserire istantaneamente una pagina in Word usando l'interruzione di pagina
- Inserire una pagina di copertina nei documenti Word
- Inserimento automatico di pagine usando l'interruzione di pagina prima
- Inserire una pagina in Word a livello di programmazione tramite Free Spire.Doc
- Domande frequenti (FAQ)

Quando scriviamo o modifichiamo un documento Word, spesso abbiamo bisogno di iniziare una nuova pagina, che sia tra due paragrafi esistenti o alla fine di una sezione. Tuttavia, premere ripetutamente il tasto Invio è solo una soluzione temporanea; una volta modificato il contenuto precedente, l'impaginazione può facilmente spostarsi.
Per evitare questo disordine nel layout, è necessario sapere come inserire una pagina in Word nel modo corretto. In questa guida, ti illustreremo ogni metodo professionale per aggiungere facilmente una pagina al tuo documento, inclusi tasti di scelta rapida, regole di layout automatiche e trucchi di programmazione per sviluppatori, assicurandoti che le tue pagine si dividano esattamente dove desideri senza modifiche di formattazione impreviste.
- Inserire una pagina vuota in Word usando la barra degli strumenti
- Inserire istantaneamente una pagina in Word usando l'interruzione di pagina
- Inserire una pagina di copertina nei documenti Word
- Inserimento automatico di pagine usando l'interruzione di pagina prima
- Inserire una pagina in Word a livello di programmazione tramite Free Spire.Doc
- Domande frequenti (FAQ)
Come inserire una pagina vuota in Word usando la barra degli strumenti
Se preferisci modificare i documenti utilizzando il menu principale, la barra multifunzione (Ribbon) è il metodo migliore per aggiungere una pagina a un file Word. Questo approccio ti consente di dividere il testo esattamente dove vuoi, garantendo una transizione fluida e senza interruzioni alla pagina successiva.
Usa questa opzione quando desideri inserire una pagina vuota nei documenti Word proprio nel mezzo di un contenuto esistente, ad esempio per creare una tela fresca e vuota per una nuova sezione o una galleria in arrivo.
- Passaggio 1. Posiziona il cursore esattamente dove vuoi che appaia il nuovo spazio vuoto.
- Passaggio 2. Vai alla scheda Inserisci sulla barra multifunzione in alto.
- Passaggio 3. Fai clic sul pulsante Pagina vuota nel gruppo Pagine.
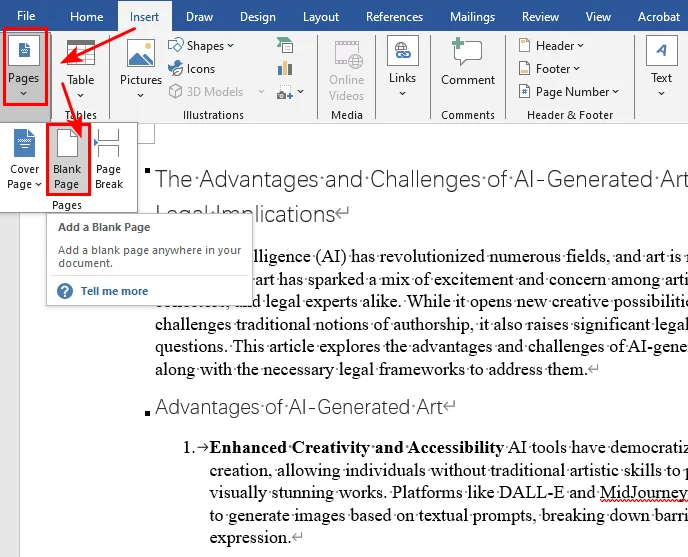
Microsoft Word inserirà istantaneamente una pagina pulita e vuota nel tuo documento in quel punto esatto, spingendo il testo esistente alla pagina successiva.
Come inserire istantaneamente una pagina in Word usando l'interruzione di pagina
In generale, un'interruzione di pagina singola viene utilizzata per dividere il contenuto e spingere un titolo o un paragrafo specifico all'inizio della pagina successiva. Due interruzioni di pagina consecutive creano solitamente una pagina vuota tra le sezioni di contenuto. Che tu preferisca utilizzare la barra degli strumenti o le scorciatoie da tastiera, padroneggiare questo metodo ti aiuterà a generare rapidamente pagine vuote in Word.
Metodo 1: Scorciatoia per inserire un'interruzione di pagina
Quando hai una scadenza ravvicinata, utilizzare una scorciatoia da tastiera è il modo più veloce per aggiungere un'interruzione di pagina a un documento Word.
- Passaggio 1. Fai clic per posizionare il cursore subito prima del testo che desideri spostare verso il basso.
- Passaggio 2. Premi Ctrl + Invio (Windows) o Cmd + Invio (Mac) una volta per spostare il testo verso il basso, oppure premilo due volte se desideri inserire una pagina vuota proprio lì.
Metodo 2: Inserire un'interruzione di pagina tramite la barra multifunzione
Se preferisci i menu visivi, puoi ottenere esattamente lo stesso risultato utilizzando la barra di navigazione principale di Microsoft Word per aggiungere interruzioni di pagina nei documenti Word:
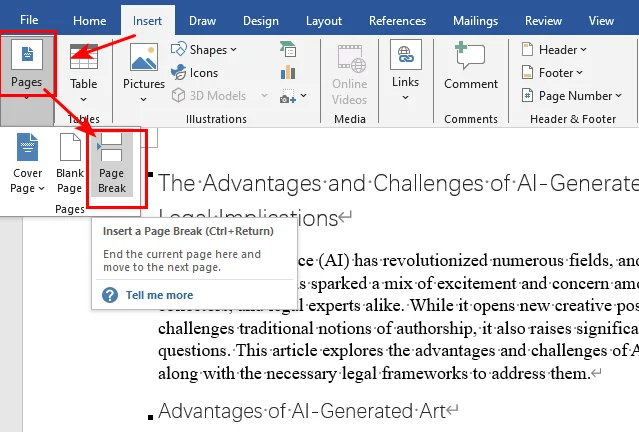
- Passaggio 1. Posiziona il cursore subito prima del testo o del titolo che deve essere spostato.
- Passaggio 2. Vai alla scheda Inserisci sulla barra multifunzione.
- Passaggio 3. Fai clic su Interruzione di pagina nel gruppo Pagine (fai clic due volte se desideri creare una pagina completamente vuota).
Potrebbe interessarti: Come rimuovere le interruzioni di pagina in Word (4 semplici metodi)
Come inserire una pagina di copertina nei documenti Word
Ogni rapporto professionale, proposta commerciale o saggio accademico ha bisogno di una prima pagina d'impatto. Invece di formattare manualmente, dovresti lasciare che Word gestisca il design e il lavoro strutturale pesante.
Se stai cercando come inserire una pagina di copertina in Word, il software fornisce una funzione integrata che imposta un layout introduttivo per te.
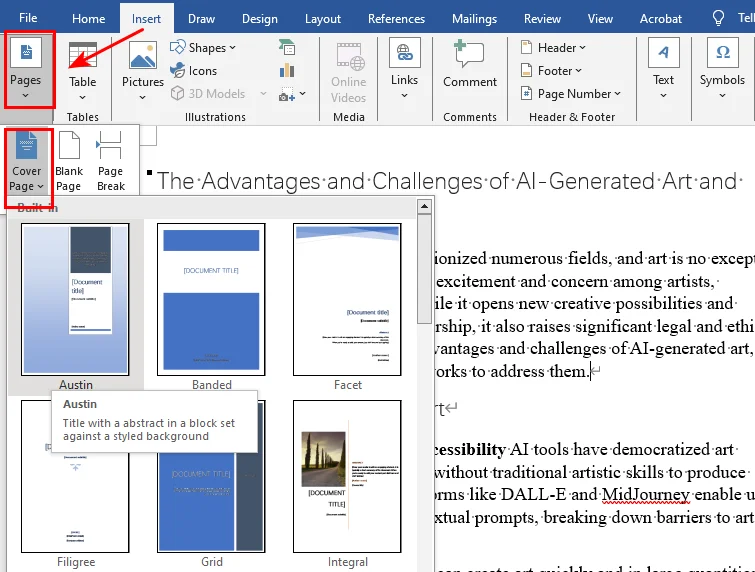
- Passaggio 1. Fai clic in un punto qualsiasi del documento.
- Passaggio 2. Vai alla scheda Inserisci sulla barra multifunzione.
- Passaggio 3. Fai clic su Pagina di copertina e seleziona il tuo layout preferito dalla galleria integrata.
Word gestisce le pagine di copertina in modo diverso rispetto al normale contenuto del documento. Quando inserisci una pagina di copertina integrata, Word la posiziona automaticamente all'inizio del documento e può evitare che la numerazione delle pagine appaia sulla pagina del titolo.
Inserimento automatico di pagine usando l'interruzione di pagina prima
Questa funzione è particolarmente utile in rapporti lunghi, manuali e libri in cui ogni capitolo dovrebbe iniziare su una nuova pagina. Invece di inserire le interruzioni di pagina manualmente, puoi utilizzare l'impostazione Interruzione di pagina prima di Word per assicurarti che titoli specifici inizino sempre su una nuova pagina.
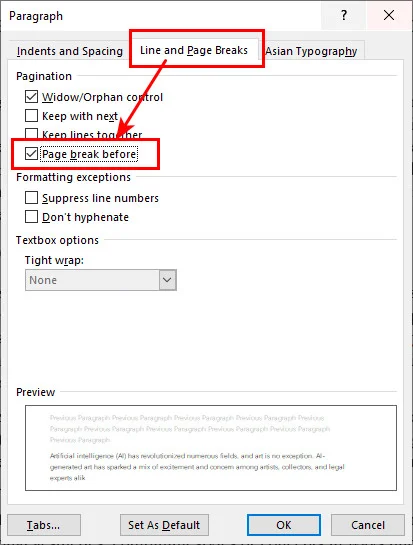
- Passaggio 1. Fai clic con il tasto destro sul titolo specifico o sullo stile Titolo 1 nella scheda Home, quindi seleziona Paragrafo.
- Passaggio 2. Vai alla scheda Distribuzione testo nella finestra di dialogo.
- Passaggio 3. Seleziona la casella accanto a Interruzione di pagina prima, quindi fai clic su OK.
Ora, ogni volta che applicherai quello stile di titolo, Word creerà automaticamente una nuova pagina per esso. Anche se elimini paragrafi nelle sezioni precedenti, i tuoi capitoli non saranno mai ammassati o disallineati.
Come inserire una pagina in Word a livello di programmazione tramite Free Spire.Doc
Quando si generano fatture, si raggruppano estratti conto mensili dei clienti o si assemblano contratti dinamici, è altamente consigliato automatizzare l'inserimento di pagine nei documenti Word per risparmiare tempo e fatica. L'utilizzo di Free Spire.Doc for Python rende facile semplificare l'intero processo. Rispecchiando la tecnica della doppia interruzione che abbiamo imparato nella sezione precedente, questa libreria ti consente di aggiungere interruzioni di pagina utilizzando il metodo AppendBreak. Iniettando due oggetti di interruzione di pagina consecutivi direttamente in un paragrafo o in un intervallo di testo, puoi aggiungere facilmente una pagina vuota nel tuo file di output senza aprire Microsoft Word.
Ecco l'esempio di codice che mostra come inserire una nuova pagina dopo il primo paragrafo:
from spire.doc import *
from spire.doc.common import *
# Crea un oggetto della classe Document
document = Document()
# Carica un file di esempio dal disco
document.LoadFromFile("/input/sample.docx")
# Ottieni la prima sezione del documento
section = document.Sections[0]
# Ottieni il primo paragrafo
paragraph = section.Paragraphs[0]
# Aggiungi la prima interruzione di pagina per terminare la pagina corrente
paragraph.AppendBreak(BreakType.PageBreak)
# Aggiungi la seconda interruzione di pagina per creare una pagina vuota
paragraph.AppendBreak(BreakType.PageBreak)
# Salva il file risultante
document.SaveToFile("/output/InsertBlankPage.docx", FileFormat.Docx2013)
document.Close()
Di seguito è riportata un'anteprima del documento risultante, puoi vedere che c'è una nuova pagina dopo il primo paragrafo: 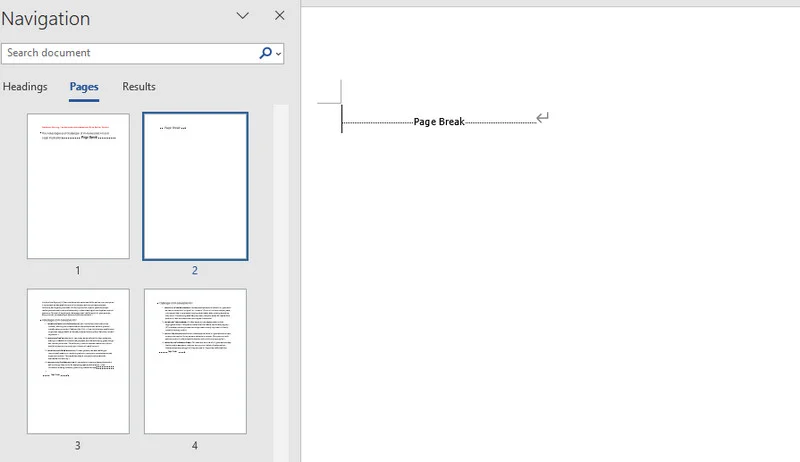
Conclusione
Questa guida copre cinque modi efficienti per inserire una pagina nei documenti Word, che spaziano da rapide correzioni manuali in Microsoft Word all'automazione programmatica utilizzando Free Spire.Doc for Python. Ogni metodo eccelle in scenari diversi: le opzioni manuali come pagine vuote o interruzioni di pagina sono perfette per modifiche singole, mentre Free Spire.Doc è la scelta ideale per integrare flussi di lavoro ed elaborazione di file ad alto volume. Scegliendo il metodo appropriato per il tuo scenario, puoi inserire pagine in modo efficiente mantenendo un layout del documento coerente.
Domande frequenti (FAQ) sull'inserimento di pagine in Word
D1: Come inserisco una pagina in orizzontale in Word?
Per inserire una pagina in orizzontale in Word, devi semplicemente isolare quella specifica sezione utilizzando un'interruzione di sezione e modificarne l'orientamento.
Per prima cosa, posiziona il cursore subito prima del contenuto che vuoi ruotare, vai su Layout > Interruzioni > Pagina successiva, quindi vai su Layout > Orientamento > Orizzontale. Questo ti consente di ruotare direttamente una pagina in Word da verticale a orizzontale senza modificare la formattazione del resto del documento.
D2: Qual è la differenza tra inserire una pagina vuota e un'interruzione di pagina?
Una pagina vuota inserisce una pagina bianca intatta tra le sezioni. Un'interruzione di pagina non crea spazio vuoto; è semplicemente un confine di formattazione invisibile che interrompe la riga corrente e sposta tutto il testo successivo direttamente all'inizio della pagina successiva, ma inserire due interruzioni di pagina può anche inserire una pagina vuota in Word.
D3: Perché la numerazione delle pagine si sballa dopo aver inserito una pagina di copertina?
I layout integrati di Word sono programmati per nascondere la numerazione sulle pagine del titolo, ma se i numeri appaiono ancora sulla copertina, fai doppio clic sull'area dell'intestazione o del piè di pagina per rivelare le opzioni di layout. Nella scheda Intestazione e piè di pagina sulla barra multifunzione, seleziona la casella Diversi per la prima pagina per iniziare la numerazione visibile in modo pulito dalla pagina due.
Leggi anche
5 façons d'insérer une page dans Word (manuellement et par automatisation Python)
Table des matières
- Insérer une page vierge dans Word via la barre d'outils
- Insérer instantanément une page dans Word à l'aide d'un saut de page
- Insérer une page de garde dans des documents Word
- Insertion automatique de page avec l'option « Saut de page avant »
- Insérer une page dans Word par programmation via Free Spire.Doc
- FAQ
Lors de la rédaction ou de la modification d'un document Word, nous avons souvent besoin de commencer une nouvelle page, que ce soit entre deux paragraphes existants ou à la toute fin d'une section. Cependant, appuyer plusieurs fois sur la touche Entrée n'est qu'une solution temporaire ; une fois que vous modifiez le contenu au-dessus, la mise en page peut facilement se décaler.
Pour éviter ce désordre de mise en page, vous devez savoir comment insérer une page dans Word de la bonne manière. Dans ce guide, nous vous présenterons toutes les méthodes professionnelles pour ajouter une page à votre document de manière transparente, y compris des raccourcis rapides, des règles de mise en page automatisées et des astuces de codage pour développeurs, garantissant que vos pages se séparent exactement là où vous le souhaitez sans changements de formatage inattendus.
- Insérer une page vierge dans Word via la barre d'outils
- Insérer instantanément une page dans Word à l'aide d'un saut de page
- Insérer une page de garde dans des documents Word
- Insertion automatique de page avec l'option « Saut de page avant »
- Insérer une page dans Word par programmation via Free Spire.Doc
- FAQ
Comment insérer une page vierge dans Word via la barre d'outils
Si vous préférez modifier vos documents à l'aide du menu principal, le ruban est la meilleure méthode pour ajouter une page à un fichier Word. Cette approche vous permet de diviser votre texte exactement là où vous le souhaitez, assurant une transition fluide vers la page suivante.
Utilisez cette option lorsque vous souhaitez insérer une page vierge dans des documents Word au milieu d'un contenu existant, par exemple pour créer une nouvelle page vide pour une section ou une galerie à venir.
- Étape 1. Placez votre curseur exactement là où vous souhaitez que le nouvel espace vide apparaisse.
- Étape 2. Allez dans l'onglet Insertion sur le ruban supérieur.
- Étape 3. Cliquez sur le bouton Page vierge dans le groupe Pages.
Microsoft Word insérera instantanément une page propre et vide dans votre document à cet endroit précis, repoussant le texte existant vers la page suivante.
Comment insérer instantanément une page dans Word à l'aide d'un saut de page
De manière générale, un saut de page unique est utilisé pour diviser votre contenu et pousser un titre ou un paragraphe spécifique vers le haut de la page suivante. Deux sauts de page consécutifs créent généralement une page vide entre deux sections de contenu. Que vous préfériez utiliser la barre d'outils ou les raccourcis clavier, maîtriser cette méthode vous aide à générer rapidement des pages vierges dans Word.
Méthode 1 : Raccourci pour insérer un saut de page
Lorsque vous êtes pressé par le temps, l'utilisation d'un raccourci clavier est le moyen le plus rapide d'ajouter un saut de page à un document Word.
- Étape 1. Cliquez pour placer votre curseur juste avant le texte que vous souhaitez déplacer vers le bas.
- Étape 2. Appuyez sur Ctrl + Entrée (Windows) ou Cmd + Retour (Mac) une fois pour déplacer le texte, ou appuyez deux fois si vous souhaitez insérer une page vierge à cet endroit.
Méthode 2 : Insérer un saut de page via le ruban
Si vous préférez les menus visuels, vous pouvez obtenir exactement le même résultat en utilisant la barre de navigation principale de Microsoft Word pour ajouter des sauts de page dans vos documents :
- Étape 1. Placez votre curseur juste avant le texte ou le titre qui doit être déplacé.
- Étape 2. Accédez à l'onglet Insertion sur le ruban.
- Étape 3. Cliquez sur Saut de page dans le groupe Pages (cliquez deux fois si vous souhaitez créer une page entièrement vierge).
Vous pourriez aimer : Comment supprimer les sauts de page dans Word (4 méthodes simples)
Comment insérer une page de garde dans des documents Word
Chaque rapport professionnel, proposition commerciale ou essai académique nécessite une page de couverture solide. Au lieu d'un formatage manuel, laissez Word gérer la conception et le travail structurel.
Si vous cherchez comment insérer une page de garde dans Word, le logiciel fournit une fonctionnalité intégrée qui met en place une mise en page d'introduction pour vous.
- Étape 1. Cliquez n'importe où dans votre document.
- Étape 2. Allez dans l'onglet Insertion sur le ruban.
- Étape 3. Cliquez sur Page de garde et sélectionnez votre mise en page préférée dans la galerie intégrée.
Word traite les pages de garde différemment du contenu habituel du document. Lorsque vous insérez une page de garde intégrée, Word la place automatiquement au début du document et peut empêcher la numérotation des pages d'apparaître sur la page de titre.
Insertion automatique de page avec l'option « Saut de page avant »
Cette fonctionnalité est particulièrement utile dans les longs rapports, manuels et livres où chaque chapitre doit commencer sur une nouvelle page. Au lieu d'insérer des sauts de page manuellement, vous pouvez utiliser le paramètre Saut de page avant de Word pour vous assurer que des titres spécifiques commencent toujours sur une nouvelle page.
- Étape 1. Faites un clic droit sur le titre spécifique ou sur le style « Titre 1 » dans votre onglet Accueil, puis sélectionnez Paragraphe.
- Étape 2. Allez dans l'onglet Enchaînements dans la fenêtre de dialogue.
- Étape 3. Cochez la case Saut de page avant, puis cliquez sur OK.
Désormais, chaque fois que vous appliquerez ce style de titre, Word créera automatiquement une nouvelle page pour celui-ci. Même si vous supprimez des paragraphes dans les sections précédentes, vos chapitres ne seront jamais entassés ou mal alignés.
Comment insérer une page dans Word par programmation via Free Spire.Doc
Lors de la génération de factures, du regroupement de relevés clients mensuels ou de l'assemblage de contrats dynamiques, il est fortement recommandé d'automatiser l'insertion de pages dans les documents Word pour gagner du temps et des efforts. L'utilisation de Free Spire.Doc for Python facilite la rationalisation de tout ce processus. En reproduisant la technique du double saut de page apprise dans la section précédente, cette bibliothèque vous permet d' ajouter des sauts de page en utilisant la méthode AppendBreak. En injectant deux objets de saut de page consécutifs directement dans un paragraphe ou une plage de texte, vous pouvez ajouter sans effort une page vide dans votre fichier de sortie sans ouvrir Microsoft Word.
Voici l'exemple de code montrant comment insérer une nouvelle page après le premier paragraphe :
from spire.doc import *
from spire.doc.common import *
# Créer un objet de la classe Document
document = Document()
# Charger un fichier exemple depuis le disque
document.LoadFromFile("/input/sample.docx")
# Obtenir la première section du document
section = document.Sections[0]
# Obtenir le premier paragraphe
paragraph = section.Paragraphs[0]
# Ajouter le premier saut de page pour terminer la page actuelle
paragraph.AppendBreak(BreakType.PageBreak)
# Ajouter le deuxième saut de page pour créer une page vide
paragraph.AppendBreak(BreakType.PageBreak)
# Enregistrer le fichier résultat
document.SaveToFile("/output/InsertBlankPage.docx", FileFormat.Docx2013)
document.Close()
Voici un aperçu du document résultant, vous pouvez voir qu'il y a une nouvelle page après le premier paragraphe :
Conclusion
Ce guide couvre cinq méthodes efficaces pour insérer une page dans des documents Word, allant des corrections manuelles rapides dans Microsoft Word à l'automatisation par programmation utilisant Free Spire.Doc for Python. Chaque méthode brille dans différents scénarios : les options manuelles comme les pages vierges ou les sauts de page sont parfaites pour des modifications ponctuelles, tandis que Free Spire.Doc est le choix idéal pour l'intégration de flux de travail et le traitement de fichiers en volume. En choisissant la méthode appropriée à votre scénario, vous pouvez insérer des pages efficacement tout en maintenant une mise en page cohérente.
FAQ sur l'insertion de pages dans Word
Q1 : Comment insérer une page en mode paysage dans Word ?
Pour insérer une page en mode paysage dans Word, il vous suffit d'isoler cette section spécifique à l'aide d'un saut de section et de modifier son orientation.
Tout d'abord, placez votre curseur juste avant le contenu que vous souhaitez faire pivoter, allez dans Mise en page > Sauts de page > Page suivante, puis accédez à Mise en page > Orientation > Paysage. Cela vous permet de faire pivoter une page dans Word directement du portrait au paysage sans modifier le formatage du reste de votre document.
Q2 : Quelle est la différence entre l'insertion d'une page vierge et un saut de page ?
Une page vierge insère une page vide intacte entre deux sections. Un saut de page ne crée pas d'espace vide ; c'est simplement une limite de formatage invisible qui coupe la ligne actuelle et pousse tout texte suivant directement vers le haut de la page suivante, mais l'insertion de deux sauts de page peut également insérer une page vierge dans Word.
Q3 : Pourquoi ma numérotation de page est-elle décalée après l'insertion d'une page de garde ?
Les mises en page intégrées de Word sont programmées pour masquer la numérotation sur les pages de titre, mais si les numéros apparaissent toujours sur votre couverture, double-cliquez sur la zone d'en-tête ou de pied de page pour révéler les options de mise en page. Dans l'onglet En-tête et pied de page du ruban, cochez la case Première page différente pour commencer votre numérotation visible proprement à partir de la page deux.
À lire également
- Supprimer rapidement les lignes vides dans Word : Manuel & VBA/Python
- Python : Insérer ou supprimer des sauts de section dans Word
- 5 méthodes simples pour diviser un document Word en plusieurs fichiers (Manuel & Automatisé)
- Ajouter des bordures de page dans Word (n'importe quelle page) : 4 méthodes simples
5 formas de insertar una página en Word (manual y automatización con Python)
Tabla de contenidos
- Insertar una página en blanco en Word usando la barra de herramientas
- Insertar una página en Word al instante usando un salto de página
- Insertar una página de portada en documentos de Word
- Inserción automática de páginas usando "Salto de página antes"
- Insertar una página en Word mediante programación con Free Spire.Doc
- Preguntas frecuentes
Al escribir o editar un documento de Word, a menudo necesitamos comenzar una página nueva, ya sea entre dos párrafos existentes o al final de una sección. Sin embargo, presionar repetidamente la tecla Enter es solo una solución temporal; una vez que editas el contenido anterior, el diseño puede desplazarse fácilmente.
Para evitar este desorden en el diseño, necesitas saber cómo insertar una página en Word de la manera correcta. En esta guía, te mostraremos todos los métodos profesionales para añadir una página a tu documento sin problemas, incluyendo atajos rápidos, reglas de diseño automatizadas y trucos de programación para desarrolladores, asegurando que tus páginas se dividan exactamente donde deseas sin cambios de formato inesperados.
- Insertar una página en blanco en Word usando la barra de herramientas
- Insertar una página en Word al instante usando un salto de página
- Insertar una página de portada en documentos de Word
- Inserción automática de páginas usando "Salto de página antes"
- Insertar una página en Word mediante programación con Free Spire.Doc
- Preguntas frecuentes
Cómo insertar una página en blanco en Word usando la barra de herramientas
Si prefieres editar documentos usando el menú principal, la cinta de opciones (Ribbon) es el mejor método para añadir una página a un archivo de Word. Este enfoque te permite dividir tu texto exactamente donde quieras, asegurando una transición fluida a la siguiente página.
Usa esta opción cuando desees insertar una página en blanco en documentos de Word justo en medio del contenido existente, como al crear un lienzo nuevo y vacío para una sección nueva o una próxima galería.
- Paso 1. Coloca el cursor exactamente donde quieras que aparezca el nuevo espacio vacío.
- Paso 2. Ve a la pestaña Insertar en la cinta de opciones superior.
- Paso 3. Haz clic en el botón Página en blanco en el grupo Páginas.
Microsoft Word insertará instantáneamente una página limpia y vacía en tu documento en ese punto exacto, desplazando el texto existente a la página siguiente.
Cómo insertar una página en Word al instante usando un salto de página
En términos generales, un salto de página simple se utiliza para dividir tu contenido y enviar un encabezado o párrafo específico al inicio de la siguiente página. Dos saltos de página consecutivos suelen crear una página vacía entre secciones de contenido. Ya sea que prefieras usar la barra de herramientas o atajos de teclado, dominar este método te ayudará a generar rápidamente páginas en blanco en Word.
Método 1: Atajo para insertar un salto de página
Cuando tienes una fecha límite ajustada, usar un atajo de teclado es la forma más rápida de añadir un salto de página a un documento de Word.
- Paso 1. Haz clic para colocar el cursor justo antes del texto que deseas desplazar hacia abajo.
- Paso 2. Presiona Ctrl + Enter (Windows) o Cmd + Return (Mac) una vez para desplazar el texto, o presiónalo dos veces si deseas insertar una página en blanco en ese lugar.
Método 2: Insertar un salto de página a través de la cinta de opciones
Si prefieres los menús visuales, puedes lograr exactamente el mismo resultado usando la barra de navegación principal de Microsoft Word para añadir saltos de página en documentos de Word:
- Paso 1. Coloca el cursor justo antes del texto o encabezado que necesita moverse.
- Paso 2. Navega a la pestaña Insertar en la cinta de opciones.
- Paso 3. Haz clic en Salto de página en el grupo Páginas (haz clic dos veces si deseas crear una página en blanco completa).
Quizás te interese: Cómo eliminar saltos de página en Word (4 métodos sencillos)
Cómo insertar una página de portada en documentos de Word
Todo informe profesional, propuesta de negocios o ensayo académico necesita una página frontal sólida. En lugar de formatear manualmente, deberías dejar que Word se encargue del diseño y el trabajo pesado estructural.
Si buscas cómo insertar una página de portada en Word, el software proporciona una función integrada que configura un diseño introductorio para ti.
- Paso 1. Haz clic en cualquier lugar dentro de tu documento.
- Paso 2. Ve a la pestaña Insertar en la cinta de opciones.
- Paso 3. Haz clic en Portada y selecciona tu diseño favorito de la galería integrada.
Word maneja las portadas de manera diferente al contenido regular del documento. Cuando insertas una portada integrada, Word la coloca automáticamente al principio del documento y puede evitar que la numeración de páginas aparezca en la página de título.
Inserción automática de páginas usando "Salto de página antes"
Esta función es especialmente útil en informes largos, manuales y libros donde cada capítulo debe comenzar en una página nueva. En lugar de insertar saltos de página manualmente, puedes usar la configuración Salto de página antes de Word para asegurar que encabezados específicos siempre comiencen en una página nueva.
- Paso 1. Haz clic derecho en el encabezado específico o en el estilo Título 1 en tu pestaña Inicio, luego selecciona Párrafo.
- Paso 2. Ve a la pestaña Líneas y saltos de página en la ventana de diálogo.
- Paso 3. Marca la casilla junto a Salto de página anterior, luego haz clic en Aceptar.
Ahora, cada vez que apliques ese estilo de encabezado, Word creará automáticamente una página nueva para él. Incluso si eliminas párrafos en secciones anteriores, tus capítulos nunca se amontonarán ni se desalinearán.
Cómo insertar una página en Word mediante programación con Free Spire.Doc
Al generar facturas, agrupar estados de cuenta mensuales de clientes o ensamblar contratos dinámicos, es altamente recomendable automatizar la inserción de páginas en documentos de Word para ahorrar tiempo y esfuerzo. Usar Free Spire.Doc for Python facilita la optimización de todo este proceso. Reflejando la técnica de doble salto que aprendimos en la sección anterior, esta biblioteca te permite añadir saltos de página usando el método AppendBreak. Al inyectar dos objetos de salto de página consecutivos directamente en un párrafo o rango de texto, puedes añadir sin esfuerzo una página vacía en tu archivo de salida sin abrir Microsoft Word.
Aquí tienes el ejemplo de código que muestra cómo insertar una página nueva después del primer párrafo:
from spire.doc import *
from spire.doc.common import *
# Crear un objeto de la clase Document
document = Document()
# Cargar un archivo de muestra desde el disco
document.LoadFromFile("/input/sample.docx")
# Obtener la primera sección del documento
section = document.Sections[0]
# Obtener el primer párrafo
paragraph = section.Paragraphs[0]
# Añadir el primer salto de página para finalizar la página actual
paragraph.AppendBreak(BreakType.PageBreak)
# Añadir el segundo salto de página para crear una página vacía
paragraph.AppendBreak(BreakType.PageBreak)
# Guardar el archivo resultante
document.SaveToFile("/output/InsertBlankPage.docx", FileFormat.Docx2013)
document.Close()
A continuación se muestra una vista previa del documento resultante, puedes ver que hay una página nueva después del primer párrafo:
Conclusión
Esta guía cubre cinco formas eficientes de insertar una página en documentos de Word, que van desde soluciones manuales rápidas en Microsoft Word hasta la automatización programática usando Free Spire.Doc for Python. Cada método destaca en diferentes escenarios: las opciones manuales como páginas en blanco o saltos de página son perfectas para ediciones únicas, mientras que Free Spire.Doc es la opción ideal para integrar flujos de trabajo y procesamiento de archivos de gran volumen. Al elegir el método apropiado para tu escenario, puedes insertar páginas de manera eficiente mientras mantienes un diseño de documento consistente.
Preguntas frecuentes sobre la inserción de páginas en Word
P1: ¿Cómo inserto una página en orientación horizontal en Word?
Para insertar una página horizontal en Word, simplemente necesitas aislar esa sección específica usando un salto de sección y cambiar su orientación.
Primero, coloca el cursor justo antes del contenido que deseas girar, ve a Disposición > Saltos > Página siguiente, y luego navega a Disposición > Orientación > Horizontal. Esto te permite rotar una página en Word directamente de vertical a horizontal sin cambiar el formato del resto de tu documento.
P2: ¿Cuál es la diferencia entre insertar una página en blanco y un salto de página?
Una página en blanco inserta una página vacía intacta entre secciones. Un salto de página no crea espacio vacío; es simplemente un límite de formato invisible que corta la línea actual y envía cualquier texto siguiente directamente al inicio de la página siguiente, pero insertar dos saltos de página también puede insertar una página en blanco en Word.
P3: ¿Por qué mi numeración de páginas se desordena después de insertar una portada?
Los diseños integrados de Word están programados para ocultar la numeración en las páginas de título, pero si los números siguen apareciendo en tu portada, haz doble clic en el área del encabezado o pie de página para revelar las opciones de diseño. En la pestaña Encabezado y pie de página de la cinta de opciones, marca la casilla Primera página diferente para comenzar tu numeración visible limpiamente desde la página dos.
Leer también
insert-a-page-in-word
Inhaltsverzeichnis
Beim Schreiben oder Bearbeiten eines Word-Dokuments müssen wir häufig eine neue Seite beginnen – sei es direkt zwischen zwei bestehenden Absätzen oder am Ende eines Abschnitts. Das wiederholte Drücken der Eingabetaste ist jedoch nur eine vorübergehende Lösung; sobald Sie den Inhalt darüber bearbeiten, kann sich das Layout leicht verschieben.
Um dieses Layout-Chaos zu vermeiden, müssen Sie wissen, wie man in Word richtig eine Seite einfügt. In dieser Anleitung führen wir Sie durch alle professionellen Methoden, um Ihrem Dokument nahtlos eine Seite hinzuzufügen, einschließlich schneller Tastenkombinationen, automatisierter Layout-Regeln und Programmier-Tricks für Entwickler. So stellen Sie sicher, dass Ihre Seiten genau dort umbrechen, wo Sie es beabsichtigen, ohne unerwartete Formatierungsänderungen.
- Einfügen einer leeren Seite in Word über die Symbolleiste
- Sofortiges Einfügen einer Seite in Word mittels Seitenumbruch
- Einfügen eines Deckblatts in Word-Dokumente
- Automatisches Einfügen von Seiten mit „Seitenumbruch davor“
- Programmgesteuertes Einfügen einer Seite in Word mit Free Spire.Doc
- FAQs
Einfügen einer leeren Seite in Word über die Symbolleiste
Wenn Sie Dokumente lieber über das Hauptmenü bearbeiten, ist das Menüband (Ribbon) die beste Methode, um eine Seite in eine Word-Datei einzufügen. Dieser Ansatz ermöglicht es Ihnen, Ihren Text genau dort zu trennen, wo Sie es möchten, und sorgt für einen reibungslosen Übergang zur nächsten Seite.
Verwenden Sie diese Option, wenn Sie eine leere Seite mitten in bestehenden Inhalten einfügen möchten, z. B. um eine frische, leere Fläche für einen neuen Abschnitt oder eine kommende Galerie zu schaffen.
- Schritt 1. Platzieren Sie Ihren Cursor genau an der Stelle, an der der neue, leere Bereich erscheinen soll.
- Schritt 2. Gehen Sie auf die Registerkarte Einfügen im oberen Menüband.
- Schritt 3. Klicken Sie in der Gruppe Seiten auf die Schaltfläche Leere Seite.
Microsoft Word fügt sofort eine saubere, leere Seite an dieser Stelle ein und schiebt den bestehenden Text auf die folgende Seite.
Sofortiges Einfügen einer Seite in Word mittels Seitenumbruch
Im Allgemeinen wird ein einzelner Seitenumbruch verwendet, um Inhalte zu trennen und eine bestimmte Überschrift oder einen Absatz an den Anfang der nächsten Seite zu schieben. Zwei aufeinanderfolgende Seitenumbrüche erzeugen normalerweise eine leere Seite zwischen Inhaltsabschnitten. Egal, ob Sie die Symbolleiste oder Tastenkombinationen bevorzugen, die Beherrschung dieser Methode hilft Ihnen, schnell leere Seiten in Word zu generieren.
Methode 1: Tastenkombination zum Einfügen eines Seitenumbruchs
Wenn Sie unter Zeitdruck stehen, ist die Verwendung einer Tastenkombination der schnellste Weg, um einen Seitenumbruch in ein Word-Dokument einzufügen.
- Schritt 1. Klicken Sie, um Ihren Cursor direkt vor den Text zu setzen, den Sie nach unten verschieben möchten.
- Schritt 2. Drücken Sie einmal Strg + Eingabetaste (Windows) oder Cmd + Return (Mac), um den Text nach unten zu schieben, oder drücken Sie die Kombination zweimal, wenn Sie direkt dort eine leere Seite einfügen möchten.
Methode 2: Einfügen eines Seitenumbruchs über das Menüband
Wenn Sie visuelle Menüs bevorzugen, können Sie genau das gleiche Ergebnis über die Hauptnavigationsleiste von Microsoft Word erzielen:
- Schritt 1. Platzieren Sie Ihren Cursor direkt vor den Text oder die Überschrift, die verschoben werden soll.
- Schritt 2. Navigieren Sie zur Registerkarte Einfügen im Menüband.
- Schritt 3. Klicken Sie in der Gruppe Seiten auf Seitenumbruch (klicken Sie zweimal darauf, wenn Sie eine vollständige leere Seite erstellen möchten).
Das könnte Sie auch interessieren: Wie man Seitenumbrüche in Word entfernt (4 einfache Methoden)
Einfügen eines Deckblatts in Word-Dokumente
Jeder professionelle Bericht, Geschäftsvorschlag oder akademische Aufsatz benötigt eine aussagekräftige Titelseite. Anstatt manuell zu formatieren, sollten Sie Word die Design- und Strukturarbeit überlassen.
Wenn Sie wissen möchten, wie man ein Deckblatt in Word einfügt, bietet die Software eine integrierte Funktion, die ein einleitendes Layout für Sie erstellt.
- Schritt 1. Klicken Sie an eine beliebige Stelle in Ihrem Dokument.
- Schritt 2. Gehen Sie auf die Registerkarte Einfügen im Menüband.
- Schritt 3. Klicken Sie auf Deckblatt und wählen Sie Ihr bevorzugtes Layout aus der integrierten Galerie aus.
Word behandelt Deckblätter anders als den regulären Dokumentinhalt. Wenn Sie ein integriertes Deckblatt einfügen, platziert Word es automatisch am Anfang des Dokuments und kann verhindern, dass die Seitennummerierung auf der Titelseite erscheint.
Automatisches Einfügen von Seiten mit „Seitenumbruch davor“
Diese Funktion ist besonders nützlich bei langen Berichten, Handbüchern und Büchern, bei denen jedes Kapitel auf einer neuen Seite beginnen sollte. Anstatt Seitenumbrüche manuell einzufügen, können Sie die Einstellung Seitenumbruch davor in Word verwenden, um sicherzustellen, dass bestimmte Überschriften immer auf einer neuen Seite beginnen.
- Schritt 1. Klicken Sie mit der rechten Maustaste auf die spezifische Überschrift oder die Formatvorlage „Überschrift 1“ auf der Registerkarte „Start“ und wählen Sie Absatz.
- Schritt 2. Gehen Sie im Dialogfenster auf die Registerkarte Zeilen- und Seitenumbruch.
- Schritt 3. Aktivieren Sie das Kontrollkästchen neben Seitenumbruch davor und klicken Sie auf OK.
Jetzt erstellt Word jedes Mal, wenn Sie diese Überschriften-Formatvorlage anwenden, automatisch eine neue Seite dafür. Selbst wenn Sie Absätze in früheren Abschnitten löschen, werden Ihre Kapitel nie zusammenrücken oder falsch ausgerichtet sein.
Programmgesteuertes Einfügen einer Seite in Word mit Free Spire.Doc
Beim Erstellen von Rechnungen, Zusammenstellen monatlicher Kundenabrechnungen oder Erstellen dynamischer Verträge ist es sehr empfehlenswert, das Einfügen von Seiten in Word-Dokumente zu automatisieren, um Zeit und Mühe zu sparen. Die Verwendung von Free Spire.Doc for Python macht es einfach, diesen gesamten Prozess zu optimieren. In Anlehnung an die Technik mit zwei Umbrüchen, die wir im vorherigen Abschnitt gelernt haben, ermöglicht diese Bibliothek das Hinzufügen von Seitenumbrüchen mit der Methode AppendBreak. Durch das Einfügen von zwei aufeinanderfolgenden Seitenumbruch-Objekten direkt in einen Absatz oder Textbereich können Sie mühelos eine leere Seite in Ihrer Ausgabedatei hinzufügen, ohne Microsoft Word öffnen zu müssen.
Hier ist das Codebeispiel, das zeigt, wie man nach dem ersten Absatz eine neue Seite einfügt:
from spire.doc import *
from spire.doc.common import *
# Erstellen eines Objekts der Document-Klasse
document = Document()
# Laden einer Beispieldatei von der Festplatte
document.LoadFromFile("/input/sample.docx")
# Abrufen des ersten Abschnitts des Dokuments
section = document.Sections[0]
# Abrufen des ersten Absatzes
paragraph = section.Paragraphs[0]
# Anfügen des ersten Seitenumbruchs, um die aktuelle Seite zu beenden
paragraph.AppendBreak(BreakType.PageBreak)
# Anfügen des zweiten Seitenumbruchs, um eine leere Seite zu erstellen
paragraph.AppendBreak(BreakType.PageBreak)
# Speichern der Ergebnisdatei
document.SaveToFile("/output/InsertBlankPage.docx", FileFormat.Docx2013)
document.Close()
Unten sehen Sie eine Vorschau des Ergebnisdokuments; Sie können sehen, dass nach dem ersten Absatz eine neue Seite vorhanden ist:
Fazit
Dieser Leitfaden deckt fünf effiziente Möglichkeiten ab, eine Seite in Word-Dokumente einzufügen, von schnellen manuellen Korrekturen in Microsoft Word bis hin zur programmgesteuerten Automatisierung mit Free Spire.Doc for Python. Jede Methode glänzt in unterschiedlichen Szenarien: Manuelle Optionen wie leere Seiten oder Seitenumbrüche sind perfekt für einmalige Bearbeitungen, während Free Spire.Doc die ideale Wahl für die Integration von Arbeitsabläufen und die Verarbeitung großer Dateimengen ist. Durch die Wahl der geeigneten Methode für Ihr Szenario können Sie Seiten effizient einfügen und gleichzeitig ein konsistentes Dokumentlayout beibehalten.
FAQs zum Einfügen von Seiten in Word
F1: Wie füge ich eine Seite im Querformat in Word ein?
Um eine Seite im Querformat in Word einzufügen, müssen Sie diesen spezifischen Abschnitt einfach mit einem Abschnittsumbruch isolieren und dessen Ausrichtung ändern.
Platzieren Sie zuerst Ihren Cursor direkt vor den Inhalt, den Sie drehen möchten, gehen Sie auf Layout > Umbrüche > Nächste Seite und navigieren Sie dann zu Layout > Ausrichtung > Querformat. Dies ermöglicht es Ihnen, eine Seite in Word direkt zu drehen, vom Hoch- ins Querformat, ohne die Formatierung des restlichen Dokuments zu ändern.
F2: Was ist der Unterschied zwischen dem Einfügen einer leeren Seite und einem Seitenumbruch?
Eine leere Seite fügt eine unberührte leere Seite zwischen Abschnitten ein. Ein Seitenumbruch erzeugt keinen leeren Raum; er ist lediglich eine unsichtbare Formatierungsgrenze, die die aktuelle Zeile vorzeitig beendet und jeden folgenden Text direkt an den Anfang der nächsten Seite schiebt. Das Einfügen von zwei Seitenumbrüchen kann jedoch auch eine leere Seite in Word erzeugen.
F3: Warum stimmt meine Seitennummerierung nicht mehr, nachdem ich ein Deckblatt eingefügt habe?
Die integrierten Layouts von Word sind so programmiert, dass die Nummerierung auf Titelseiten ausgeblendet wird. Wenn jedoch trotzdem Nummern auf Ihrem Deckblatt erscheinen, doppelklicken Sie auf den Kopf- oder Fußzeilenbereich, um die Layout-Optionen anzuzeigen. Aktivieren Sie auf der Registerkarte Kopf- und Fußzeile im Menüband das Kontrollkästchen Erste Seite anders, damit Ihre sichtbare Nummerierung sauber ab Seite zwei beginnt.
Lesen Sie auch
5 способов вставки страницы в Word (вручную и с помощью автоматизации Python)
Оглавление
- Вставка пустой страницы в Word с помощью панели инструментов
- Мгновенная вставка страницы в Word с помощью разрыва страницы
- Вставка титульной страницы в документы Word
- Автоматическая вставка страницы с помощью функции «Разрыв страницы перед»
- Программная вставка страницы в Word через Free Spire.Doc
- Часто задаваемые вопросы
При написании или редактировании документа Word нам часто требуется начать новую страницу — будь то прямо между двумя существующими абзацами или в самом конце раздела. Однако многократное нажатие клавиши Enter — это лишь временное решение; как только вы отредактируете текст выше, верстка может легко «поехать».
Чтобы избежать беспорядка в макете, необходимо знать, как правильно вставлять страницу в Word. В этом руководстве мы расскажем обо всех профессиональных методах добавления страницы в документ, включая быстрые клавиши, правила автоматической верстки и приемы программирования, которые гарантируют, что страницы будут разделены именно там, где вам нужно, без неожиданных изменений форматирования.
- Вставка пустой страницы в Word с помощью панели инструментов
- Мгновенная вставка страницы в Word с помощью разрыва страницы
- Вставка титульной страницы в документы Word
- Автоматическая вставка страницы с помощью функции «Разрыв страницы перед»
- Программная вставка страницы в Word через Free Spire.Doc
- Часто задаваемые вопросы
Как вставить пустую страницу в Word с помощью панели инструментов
Если вы предпочитаете редактировать документы с помощью главного меню, лента (Ribbon) — лучший способ добавить страницу в файл Word. Этот подход позволяет разделить текст именно там, где вы хотите, обеспечивая плавный и аккуратный переход на следующую страницу.
Используйте этот вариант, если хотите вставить пустую страницу в документ Word прямо посреди существующего контента, например, чтобы создать чистое пространство для нового раздела или галереи.
- Шаг 1. Установите курсор именно в то место, где должно появиться новое пустое пространство.
- Шаг 2. Перейдите на вкладку Вставка (Insert) на верхней ленте.
- Шаг 3. Нажмите кнопку Пустая страница (Blank Page) в группе Страницы (Pages).
Microsoft Word мгновенно вставит чистую пустую страницу в документ в указанном месте, переместив существующий текст на следующую страницу.
Как мгновенно вставить страницу в Word с помощью разрыва страницы
Как правило, один разрыв страницы используется для разделения контента и переноса определенного заголовка или абзаца в начало следующей страницы. Два последовательных разрыва страницы обычно создают пустую страницу между разделами документа. Независимо от того, предпочитаете ли вы панель инструментов или сочетания клавиш, освоение этого метода поможет вам быстро создавать пустые страницы в Word.
Метод 1: Сочетание клавиш для вставки разрыва страницы
Когда сроки поджимают, использование сочетания клавиш — самый быстрый способ добавить разрыв страницы в документ Word.
- Шаг 1. Установите курсор прямо перед текстом, который нужно перенести вниз.
- Шаг 2. Нажмите Ctrl + Enter (в Windows) или Cmd + Return (на Mac) один раз, чтобы перенести текст, или дважды, если хотите вставить пустую страницу прямо в этом месте.
Метод 2: Вставка разрыва страницы через ленту меню
Если вы предпочитаете визуальные меню, вы можете добиться того же результата, используя главную панель навигации Microsoft Word:
- Шаг 1. Установите курсор прямо перед текстом или заголовком, который нужно переместить.
- Шаг 2. Перейдите на вкладку Вставка (Insert) на ленте.
- Шаг 3. Нажмите Разрыв страницы (Page Break) в группе Страницы (нажмите дважды, если хотите создать полноценную пустую страницу).
Вам может быть интересно: Как удалить разрывы страниц в Word (4 простых метода)
Как вставить титульную страницу в документы Word
Любой профессиональный отчет, бизнес-предложение или академическая работа нуждаются в качественной обложке. Вместо ручного форматирования позвольте Word взять на себя дизайн и структурную работу.
Если вы ищете способ вставки титульной страницы в Word, программа предоставляет встроенную функцию, которая создаст для вас вводный макет.
- Шаг 1. Щелкните в любом месте вашего документа.
- Шаг 2. Перейдите на вкладку Вставка (Insert) на ленте.
- Шаг 3. Нажмите Титульная страница (Cover Page) и выберите понравившийся макет из встроенной галереи.
Word обрабатывает титульные страницы иначе, чем остальной контент документа. Когда вы вставляете встроенную титульную страницу, Word автоматически помещает ее в начало документа и позволяет скрыть нумерацию страниц на титульном листе.
Автоматическая вставка страницы с помощью функции «Разрыв страницы перед»
Эта функция особенно полезна в длинных отчетах, руководствах и книгах, где каждая глава должна начинаться с новой страницы. Вместо того чтобы вставлять разрывы страниц вручную, вы можете использовать настройку Word Разрыв страницы перед (Page break before), чтобы определенные заголовки всегда начинались с новой страницы.
- Шаг 1. Щелкните правой кнопкой мыши по нужному заголовку или стилю «Заголовок 1» на вкладке «Главная» и выберите Абзац (Paragraph).
- Шаг 2. Перейдите на вкладку Положение на странице (Line and Page Breaks) в открывшемся окне.
- Шаг 3. Установите флажок рядом с пунктом С новой страницы (Page break before) и нажмите ОК.
Теперь каждый раз, когда вы применяете этот стиль заголовка, Word будет автоматически создавать для него новую страницу. Даже если вы удалите абзацы в предыдущих разделах, ваши главы никогда не «съедут» и не сместятся.
Как программно вставить страницу в Word через Free Spire.Doc
При создании счетов, формировании ежемесячных отчетов для клиентов или подготовке динамических контрактов настоятельно рекомендуется автоматизировать вставку страниц в документы Word, чтобы сэкономить время и силы. Использование Free Spire.Doc for Python позволяет легко оптимизировать весь этот процесс. Повторяя технику двойного разрыва, которую мы изучили в предыдущем разделе, эта библиотека позволяет добавлять разрывы страниц с помощью метода AppendBreak. Вставляя два последовательных объекта разрыва страницы прямо в абзац или диапазон текста, вы можете легко добавить пустую страницу в выходной файл, не открывая Microsoft Word.
Вот пример кода, показывающий, как вставить новую страницу после первого абзаца:
from spire.doc import *
from spire.doc.common import *
# Создаем объект класса Document
document = Document()
# Загружаем образец файла с диска
document.LoadFromFile("/input/sample.docx")
# Получаем первый раздел документа
section = document.Sections[0]
# Получаем первый абзац
paragraph = section.Paragraphs[0]
# Добавляем первый разрыв страницы, чтобы завершить текущую страницу
paragraph.AppendBreak(BreakType.PageBreak)
# Добавляем второй разрыв страницы, чтобы создать пустую страницу
paragraph.AppendBreak(BreakType.PageBreak)
# Сохраняем результат
document.SaveToFile("/output/InsertBlankPage.docx", FileFormat.Docx2013)
document.Close()
Ниже представлен предварительный просмотр результирующего документа, где видно, что после первого абзаца появилась новая страница:
Заключение
В этом руководстве рассмотрены пять эффективных способов вставки страницы в документы Word, от быстрых ручных исправлений в Microsoft Word до программной автоматизации с использованием Free Spire.Doc for Python. Каждый метод хорош в своих сценариях: ручные варианты, такие как вставка пустой страницы или разрыва, идеально подходят для разовых правок, в то время как Free Spire.Doc — идеальный выбор для интеграции в рабочие процессы и обработки большого объема файлов. Выбирая подходящий метод, вы сможете эффективно вставлять страницы, сохраняя при этом целостность макета документа.
Часто задаваемые вопросы о вставке страниц в Word
В1: Как вставить страницу с альбомной ориентацией в Word?
Чтобы вставить страницу с альбомной ориентацией в Word, вам просто нужно изолировать этот конкретный раздел с помощью разрыва раздела и изменить его ориентацию.
Сначала установите курсор прямо перед контентом, который нужно повернуть, перейдите в Макет > Разрывы > Следующая страница, а затем перейдите в Макет > Ориентация > Альбомная. Это позволит вам напрямую повернуть страницу в Word из книжной в альбомную, не меняя форматирование остальной части документа.
В2: В чем разница между вставкой пустой страницы и разрывом страницы?
Пустая страница добавляет нетронутую пустую страницу между разделами. Разрыв страницы не создает пустого пространства; это просто невидимая граница форматирования, которая обрывает текущую строку и переносит весь последующий текст в начало следующей страницы. Однако вставка двух разрывов страниц подряд также может создать пустую страницу в Word.
В3: Почему нумерация страниц сбивается после вставки титульной страницы?
Встроенные макеты Word запрограммированы так, чтобы скрывать нумерацию на титульных листах. Но если номера все же отображаются на обложке, дважды щелкните область верхнего или нижнего колонтитула, чтобы открыть параметры макета. На вкладке Конструктор (Header & Footer) на ленте установите флажок Особый колонтитул для первой страницы (Different First Page), чтобы нумерация начиналась со второй страницы.
Читайте также
Como imprimir vários documentos do Word de uma só vez: 6 maneiras
Índice
- Método 1: Clicar com o botão direito e imprimir no Explorador de Arquivos
- Método 2: Arrastar e soltar vários arquivos do Word via janela da fila de impressão
- Método 3: Mesclar arquivos do Word primeiro para um trabalho de impressão unificado
- Método 4: Usar uma macro do Word (VBA) para imprimir todos os documentos em uma pasta
- Método 5: Impressão em lote silenciosa com um script PowerShell
- Método 6: Imprimir documentos do Word em C# usando Spire.Doc
- Comparação rápida: Qual método de impressão em lote é o melhor para você?
- Considerações finais
- Perguntas frequentes

Imprimir dezenas de contratos, relatórios ou faturas um por um é uma perda de tempo entediante. Esteja você preparando folhetos para uma reunião, produzindo documentos legais ou simplesmente organizando a papelada do seu escritório, a capacidade de enviar uma pasta inteira de arquivos do Word para a impressora de uma só vez pode economizar horas.
Este artigo apresenta seis métodos práticos para imprimir em lote arquivos .doc e .docx — desde truques simples com o botão direito até uma solução poderosa orientada para desenvolvedores usando o Spire.Doc em C#. Escolha o que melhor se adapta ao seu fluxo de trabalho e comece a imprimir de forma mais inteligente hoje mesmo.
Visão geral dos métodos abordados:
- Método 1: Clicar com o botão direito e imprimir no Explorador de Arquivos
- Método 2: Arrastar e soltar vários arquivos do Word via janela da fila de impressão
- Método 3: Mesclar arquivos do Word primeiro para um trabalho de impressão unificado
- Método 4: Usar uma macro do Word (VBA) para imprimir todos os documentos em uma pasta
- Método 5: Impressão em lote silenciosa com um script PowerShell
- Método 6: Imprimir documentos do Word em C# usando Spire.Doc
Método 1: Clicar com o botão direito e imprimir no Explorador de Arquivos
O método mais simples não requer ferramentas extras e funciona instantaneamente em qualquer PC com Windows. É perfeito para imprimir rapidamente alguns documentos sem instalar nenhum software. Basta selecionar seus arquivos e deixar o Windows cuidar do resto.
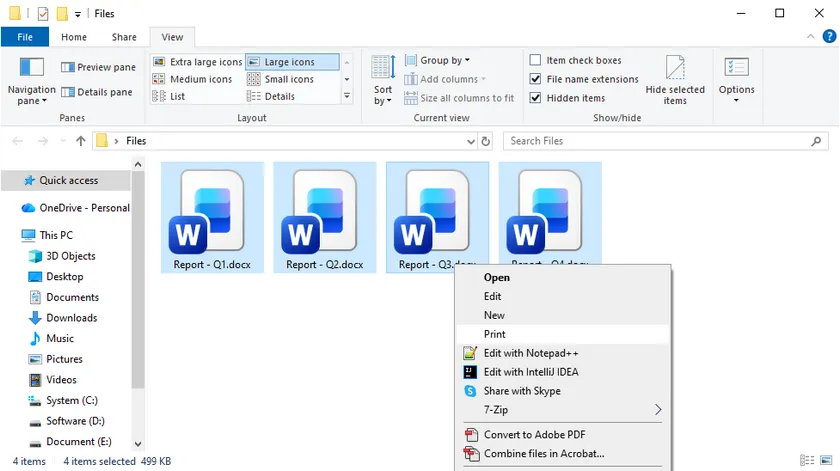
Passos:
- Abra o Explorador de Arquivos e navegue até a pasta que contém seus documentos do Word.
- Selecione os arquivos que deseja imprimir: mantenha pressionada a tecla Ctrl e clique em cada um individualmente, ou pressione Ctrl + A para selecionar todos.
- Clique com o botão direito em qualquer arquivo destacado e escolha Imprimir no menu de contexto.
O Windows abrirá automaticamente cada documento no Microsoft Word, enviará para a impressora padrão e fechará o Word ao terminar. Lembre-se de que, se as configurações de segurança do Word exibirem avisos de macro ou avisos de Modo de Exibição Protegido, o processo poderá pausar até que você os confirme manualmente. Ainda assim, para trabalhos rápidos e ocasionais, este método é imbatível.
Método 2: Arrastar e soltar vários arquivos do Word via janela da fila de impressão
Este fluxo de trabalho nativo de arrastar e soltar do Windows permite a impressão em lote de vários documentos do Word — basta arrastar seus arquivos para um atalho da impressora na área de trabalho. Essa abordagem facilita a alternância entre diferentes impressoras, tornando-a ideal para ambientes de escritório equipados com vários dispositivos de impressão.
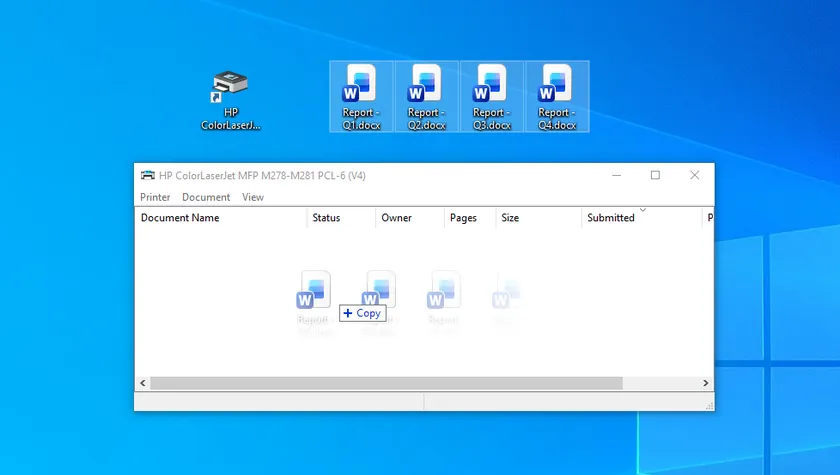
Passos:
- Pressione Win + R, digite control printers e pressione Enter para abrir a janela Dispositivos e Impressoras.
- Clique duas vezes no ícone da impressora desejada para abrir a janela da fila de impressão.
- Selecione todos os arquivos do Word desejados e arraste-os diretamente para a área em branco da janela da fila de impressão aberta.
Os arquivos preencherão a lista de trabalhos de impressão automaticamente. O Windows abrirá, imprimirá e fechará cada documento sequencialmente.
Dica profissional: Você também pode criar um atalho de impressora na área de trabalho para acesso rápido, embora arrastar para a janela da fila de impressão ofereça resultados mais confiáveis para tarefas em lote.
Método 3: Mesclar arquivos do Word primeiro para um trabalho de impressão unificado
Se você deseja que todos os arquivos separados do Word sejam impressos como um documento contínuo e ordenado, este fluxo de trabalho de mesclagem é a sua solução ideal. Ele funciona excepcionalmente bem para folhetos, relatórios formais e livretos que exigem uma sequência de páginas consistente. Mesclar arquivos antes da impressão elimina a tediosa classificação manual de páginas após a saída.
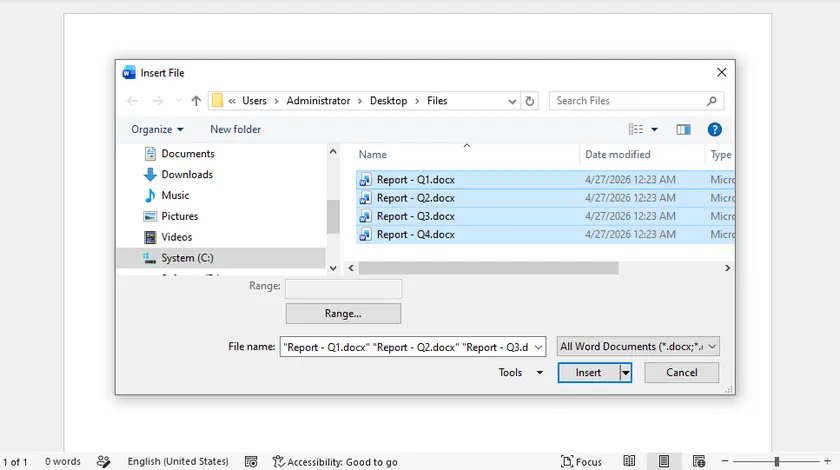
Passos:
- Abra o Microsoft Word e crie um novo documento em branco.
- Navegue até Inserir > Objeto > Texto do Arquivo (caminhos alternativos: Inserir > Arquivo ou expanda o menu suspenso Objeto em certas edições do Word).
- Destaque todos os arquivos DOCX a serem mesclados e clique em Inserir. Os arquivos serão montados seguindo a ordem selecionada.
- Pressione Ctrl + P para abrir o painel de impressão. Selecione sua impressora física ou Microsoft Print to PDF e confirme a impressão.
Você receberá um documento coeso com fluxo de página ininterrupto. Embora a mesclagem leve um pouco mais de tempo, ela evita páginas fora de ordem e elimina a colação manual — ideal para documentos encadernados e folhetos impressos.
Método 4: Usar uma macro do Word (VBA) para imprimir todos os documentos em uma pasta
Se você imprime frequentemente lotes de documentos da mesma pasta, uma simples macro VBA pode automatizar totalmente o processo. Este método é executado diretamente no Microsoft Word, não requer software extra e pode ser configurado para impressão com um clique. É uma ferramenta de automação integrada ideal para tarefas de impressão regulares e repetidas.
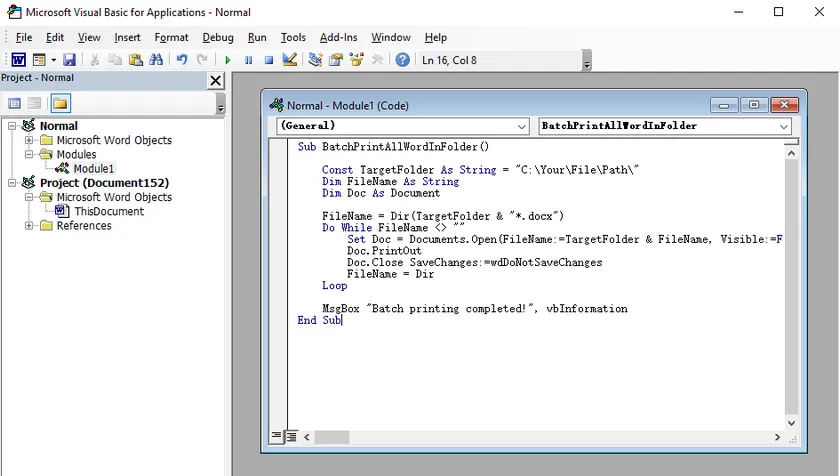
Passos:
- Abra o Microsoft Word e pressione Alt + F11 para abrir o editor VBA.
- Vá para Inserir > Módulo e cole o código VBA pronto para uso fornecido abaixo.
- Substitua o caminho da pasta no código pelo seu próprio diretório.
- Pressione F5 para executar a macro ou atribua-a à Barra de Ferramentas de Acesso Rápido para impressão com um clique.
Código VBA:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Seu\Caminho\De\Arquivo\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "Impressão em lote concluída!", vbInformation
End Sub
Este método imprime arquivos silenciosamente em segundo plano sem abrir janelas. Os únicos requisitos são habilitar macros e ter o Word instalado — perfeito para uso pessoal ou de escritório confiável.
Método 5: Impressão em lote silenciosa com um script PowerShell
PowerShell oferece uma maneira rápida, leve e baseada em script para imprimir vários documentos do Word em segundo plano — sem janelas, sem pop-ups e sem interação manual. Este método é ideal para usuários que desejam impressão totalmente automatizada e pode até ser agendado com o Agendador de Tarefas do Windows para trabalhos cronometrados automaticamente.
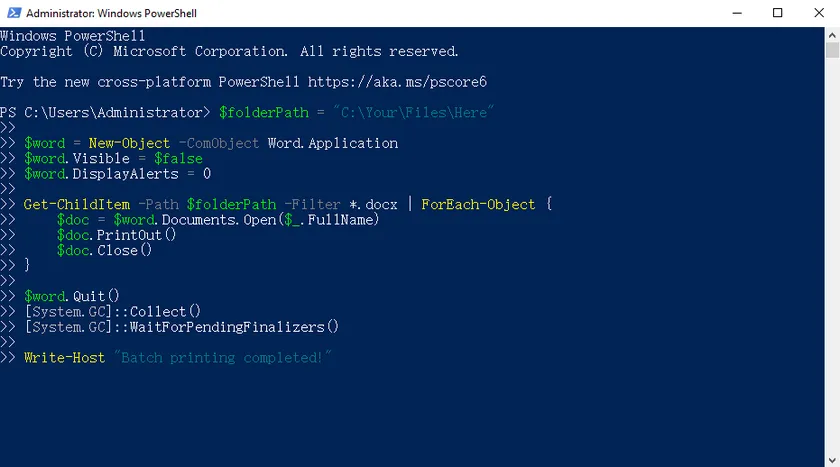
Passos:
- Abra o PowerShell no Menu Iniciar (não são necessários direitos de administrador para impressão básica).
- Copie e cole o script de impressão em lote simples fornecido abaixo.
- Altere o valor
$folderPathpara a pasta de documentos de destino. - Execute o script. O Word será executado silenciosamente em segundo plano, imprimirá todos os seus documentos automaticamente e fechará corretamente ao terminar.
Script PowerShell:
$folderPath = "C:\Seus\Arquivos\Aqui"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "Impressão em lote concluída!"
Este método funciona sem software extra, suporta todos os formatos do Word e oferece impressão em lote silenciosa e confiável para uso pessoal e de escritório.
Método 6: Imprimir documentos do Word em C# usando Spire.Doc
Quando você precisa de uma solução de impressão em lote de alto desempenho e totalmente automatizada que seja executada em um servidor sem o Microsoft Office, o Spire.Doc for .NET é a biblioteca ideal. Ele oferece controle programático completo sobre a impressão de documentos, tornando-o ideal para aplicativos da web, serviços em segundo plano ou sistemas de gerenciamento de documentos.
Por que usar o Spire.Doc para impressão em lote?
O Spire.Doc é uma biblioteca .NET independente que lê, cria e manipula arquivos do Word sem qualquer dependência do próprio Word. Para impressão em lote, isso significa que você pode processar milhares de documentos de forma confiável em um servidor, selecionar uma impressora específica, definir intervalos de páginas e até mesmo lidar com impressão duplex — tudo através de código C# limpo.
Configurando o Spire.Doc em seu projeto .NET
Instale o pacote via NuGet Package Manager:
Install-Package Spire.Doc
Ou use a CLI do .NET: dotnet add package Spire.Doc. É isso — sem licenças ou instalações adicionais do Office.
Exemplo de código C#: Imprimir todos os arquivos do Word de um diretório
Abaixo está um aplicativo de console completo que lê todos os arquivos .docx e .doc de uma pasta e os imprime silenciosamente com um controlador de impressão padrão (sem caixa de diálogo pop-up). O código também mostra como lidar com possíveis exceções com elegância.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\DocumentosParaImprimir";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
// Filtrar apenas para .docx e .doc
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Imprimindo: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Suprimir a caixa de diálogo de impressão para impressão silenciosa
printDoc.PrintController = new StandardPrintController();
// Opcionalmente, defina o nome da impressora e as cópias
// printDoc.PrinterSettings.PrinterName = "Minha Impressora Específica";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Falha ao imprimir {filePath}: {ex.Message}");
}
}
}
Console.WriteLine("Impressão em lote concluída.");
}
}
A lógica é direta: obtenha todos os arquivos do diretório, verifique a extensão, carregue cada um em um objeto Document do Spire.Doc, acesse seu PrintDocument, defina StandardPrintController para evitar a caixa de diálogo de impressão do Windows e chame Print(). O loop garante que cada documento do Word válido seja impresso sequencialmente.
A propriedade PrintDocument.PrinterSettings abre as portas para um controle refinado. Você pode especificar a impressora exata com PrinterName, definir o número de cópias, escolher um intervalo de páginas ou habilitar a impressão duplex. Para uma introdução mais detalhada, consulte Como imprimir documentos do Word em C#.
Comparação rápida: Qual método de impressão em lote é o melhor para você?
| Método | Requer Word? | Silencioso / Sem pop-ups | Melhor para |
|---|---|---|---|
| Clicar com o botão direito e imprimir | Sim | Possíveis interrupções | Tarefas ocasionais |
| Arrastar para atalho da impressora | Sim | Possíveis interrupções | Uso diário visual e rápido |
| Mesclar e imprimir em PDF | Sim | Sim (após mesclado) | Produzir uma única impressão ordenada |
| Macro VBA | Sim | Sim, se configurado | Pastas pessoais repetitivas |
| Script PowerShell | Sim (COM) | Sim | Tarefas agendadas no servidor |
| Spire.Doc com C# | Não | Sim, totalmente silencioso | Automação de servidor e integração |
Considerações finais
A impressão em lote de documentos do Word não precisa ser uma tarefa árdua. Comece com os truques integrados rápidos, adote um script quando precisar de repetibilidade e mude para uma biblioteca dedicada como o Spire.Doc quando seu projeto exigir uma solução robusta e sem Office. Qualquer que seja o caminho escolhido, os minutos que você economizar se somarão rapidamente a horas de produtividade recuperada. Agora escolha um método, carregue sua pasta e deixe a impressora fazer o trabalho pesado.
Perguntas frequentes
Posso imprimir documentos do Word sem abrir cada um?
Sim. Os métodos 4, 5 e 6 suprimem a interface do Word ou funcionam sem ela inteiramente. O script PowerShell e o Spire.Doc imprimem silenciosamente em segundo plano, enquanto a macro VBA pode ocultar a janela do aplicativo.
A impressão em lote funciona com arquivos .doc e .docx?
Com certeza. Todos os métodos descritos aqui lidam com formatos .doc legados e .docx modernos. Ao usar o Spire.Doc, a biblioteca lê perfeitamente ambos os formatos sem qualquer conversão.
Como seleciono uma impressora específica ao imprimir vários arquivos?
Para os métodos manuais, defina a impressora desejada como padrão antes de começar. Com o script PowerShell e o exemplo C# do Spire.Doc, você pode definir programaticamente o nome da impressora no código, dando a você controle preciso sem alterar os padrões do sistema.
Veja também
한 번에 여러 Word 문서를 인쇄하는 방법: 6가지 방법
수십 개의 계약서, 보고서 또는 청구서를 하나씩 인쇄하는 것은 매우 번거롭고 시간 낭비입니다. 회의용 유인물을 준비하든, 법률 문서를 작성하든, 단순히 사무실 서류를 정리하든, 폴더 전체의 Word 파일을 한 번에 프린터로 보낼 수 있다면 몇 시간을 절약할 수 있습니다.
이 기사에서는 .doc 및 .docx 파일을 일괄 인쇄하는 6가지 실용적인 방법을 안내합니다. 간단한 우클릭 방식부터 C#에서 Spire.Doc을 사용하는 강력한 개발자용 솔루션까지 다룹니다. 워크플로에 맞는 방법을 선택하여 오늘부터 더 스마트하게 인쇄해 보세요.
다루는 방법 개요:
- 방법 1: 파일 탐색기에서 우클릭 후 인쇄
- 방법 2: 인쇄 대기열 창을 통해 여러 Word 파일 드래그 앤 드롭
- 방법 3: Word 파일을 먼저 병합하여 통합 인쇄 작업 수행
- 방법 4: Word 매크로(VBA)를 사용하여 폴더 내 모든 문서 인쇄
- 방법 5: PowerShell 스크립트로 자동 일괄 인쇄
- 방법 6: Spire.Doc을 사용하여 C#에서 Word 문서 인쇄
방법 1: 파일 탐색기에서 우클릭 후 인쇄
가장 간단한 방법으로 별도의 도구가 필요 없으며 모든 Windows PC에서 즉시 작동합니다. 소프트웨어를 설치하지 않고 소량의 문서를 빠르게 인쇄할 때 적합합니다. 파일을 선택하기만 하면 Windows가 나머지를 처리합니다.
단계:
- 파일 탐색기를 열고 Word 문서가 있는 폴더로 이동합니다.
- 인쇄할 파일을 선택합니다. Ctrl 키를 누른 상태에서 각 파일을 개별적으로 클릭하거나, Ctrl + A를 눌러 전체를 선택합니다.
- 강조 표시된 파일 중 하나를 우클릭하고 컨텍스트 메뉴에서 인쇄를 선택합니다.
Windows가 자동으로 각 문서를 Microsoft Word에서 열고 기본 프린터로 보낸 뒤 완료되면 Word를 닫습니다. Word 보안 설정에 따라 매크로 경고나 보호된 보기 메시지가 표시되면 수동으로 확인해야 할 수도 있습니다. 하지만 가끔씩 빠르게 인쇄해야 할 때 이보다 좋은 방법은 없습니다.
방법 2: 인쇄 대기열 창을 통해 여러 Word 파일 드래그 앤 드롭
이 Windows 기본 드래그 앤 드롭 워크플로를 사용하면 여러 Word 문서를 일괄 인쇄할 수 있습니다. 파일을 특정 프린터 바탕 화면 바로 가기로 드래그하기만 하면 됩니다. 이 방식은 여러 프린터를 사용하는 사무실 환경에서 프린터를 쉽게 전환할 수 있어 매우 유용합니다.
단계:
- Win + R을 누르고 control printers를 입력한 뒤 Enter를 눌러 '장치 및 프린터' 창을 엽니다.
- 대상 프린터 아이콘을 더블 클릭하여 인쇄 대기열 창을 엽니다.
- 대상 Word 파일을 모두 선택한 다음, 열려 있는 인쇄 대기열 창의 빈 영역으로 직접 드래그 앤 드롭합니다.
파일이 자동으로 인쇄 작업 목록에 추가됩니다. Windows가 각 문서를 순차적으로 열고 인쇄한 뒤 닫습니다.
전문가 팁: 바탕 화면에 프린터 바로 가기를 만들어 빠르게 액세스할 수도 있지만, 인쇄 대기열 창으로 드래그하는 것이 일괄 작업 시 더 안정적인 결과를 제공합니다.
방법 3: Word 파일을 먼저 병합하여 통합 인쇄 작업 수행
모든 개별 Word 파일을 하나의 연속된 순서로 인쇄하려면 병합 워크플로가 최적의 솔루션입니다. 일관된 페이지 순서가 필요한 유인물, 공식 보고서 및 소책자에 매우 효과적입니다. 인쇄 전 파일을 병합하면 출력 후 수동으로 페이지를 정리하는 번거로움이 사라집니다.
단계:
- Microsoft Word를 실행하고 새 빈 문서를 만듭니다.
- 삽입 > 개체 > 파일의 텍스트로 이동합니다(Word 버전에 따라 삽입 > 파일 또는 개체 드롭다운 메뉴 확장).
- 병합할 모든 DOCX 파일을 강조 표시한 다음 삽입을 클릭합니다. 파일이 선택한 순서대로 결합됩니다.
- Ctrl + P를 눌러 인쇄 패널을 엽니다. 실제 프린터 또는 Microsoft Print to PDF를 선택하고 인쇄를 확인합니다.
페이지 흐름이 끊기지 않는 하나의 응집력 있는 문서를 얻게 됩니다. 병합하는 데 약간의 시간이 더 걸리지만, 페이지 순서가 뒤바뀌는 것을 방지하고 수동 분류 작업을 없애주므로 제본 문서나 인쇄된 유인물에 이상적입니다.
방법 4: Word 매크로(VBA)를 사용하여 폴더 내 모든 문서 인쇄
같은 폴더에서 문서를 자주 일괄 인쇄하는 경우, 간단한 VBA 매크로를 통해 프로세스를 완전히 자동화할 수 있습니다. 이 방법은 Microsoft Word 내에서 직접 실행되며 추가 소프트웨어가 필요 없고, 원클릭 인쇄로 설정할 수 있습니다. 반복적인 인쇄 작업을 위한 이상적인 내장 자동화 도구입니다.
단계:
- Microsoft Word를 열고 Alt + F11을 눌러 VBA 편집기를 엽니다.
- 삽입 > 모듈로 이동하여 아래 제공된 VBA 코드를 붙여넣습니다.
- 코드의 폴더 경로를 자신의 디렉터리로 바꿉니다.
- F5를 눌러 매크로를 실행하거나, 빠른 실행 도구 모음에 할당하여 원클릭 인쇄를 설정합니다.
VBA 코드:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Your\File\Path\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "일괄 인쇄가 완료되었습니다!", vbInformation
End Sub
이 방법은 창을 열지 않고 백그라운드에서 조용히 파일을 인쇄합니다. 매크로를 활성화하고 Word가 설치되어 있기만 하면 되므로 개인 또는 사무실 데스크톱용으로 매우 안정적입니다.
방법 5: PowerShell 스크립트로 자동 일괄 인쇄
PowerShell은 창이나 팝업, 수동 조작 없이 백그라운드에서 여러 Word 문서를 인쇄할 수 있는 빠르고 가벼운 스크립트 기반 방식을 제공합니다. 이 방법은 완전히 자동화된 인쇄를 원하는 사용자에게 이상적이며, Windows 작업 스케줄러를 사용하여 예약된 시간에 자동으로 인쇄하도록 설정할 수도 있습니다.
단계:
- 시작 메뉴에서 PowerShell을 엽니다(기본 인쇄에는 관리자 권한이 필요하지 않음).
- 아래 제공된 간단한 일괄 인쇄 스크립트를 복사하여 붙여넣습니다.
$folderPath값을 대상 문서 폴더로 변경합니다.- 스크립트를 실행합니다. Word가 백그라운드에서 조용히 실행되어 모든 문서를 자동으로 인쇄하고 완료되면 깔끔하게 종료됩니다.
PowerShell 스크립트:
$folderPath = "C:\Your\Files\Here"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "일괄 인쇄가 완료되었습니다!"
이 방법은 추가 소프트웨어 없이도 모든 Word 형식을 지원하며, 개인 및 사무실 용도로 안정적인 자동 일괄 인쇄를 제공합니다.
방법 6: Spire.Doc을 사용하여 C#에서 Word 문서 인쇄
Microsoft Office가 설치되지 않은 서버에서 실행되는 완전히 자동화된 고성능 일괄 인쇄 솔루션이 필요하다면 Spire.Doc for .NET이 최고의 라이브러리입니다. 문서 인쇄에 대한 완전한 프로그래밍 제어 권한을 제공하므로 웹 애플리케이션, 백그라운드 서비스 또는 문서 관리 시스템에 이상적입니다.
일괄 인쇄에 Spire.Doc을 사용하는 이유
Spire.Doc은 Word 자체에 대한 의존성 없이 Word 파일을 읽고, 만들고, 조작하는 독립형 .NET 라이브러리입니다. 일괄 인쇄의 경우, 서버에서 수천 개의 문서를 안정적으로 처리하고, 특정 프린터를 선택하고, 페이지 범위를 설정하고, 양면 인쇄까지 처리할 수 있습니다. 이 모든 것이 깔끔한 C# 코드로 가능합니다.
.NET 프로젝트에서 Spire.Doc 설정
NuGet 패키지 관리자를 통해 패키지를 설치합니다:
Install-Package Spire.Doc
또는 .NET CLI 사용: dotnet add package Spire.Doc. 추가적인 Office 라이선스나 설치가 필요 없습니다.
C# 코드 예제: 디렉터리의 모든 Word 파일 인쇄
아래는 폴더에서 모든 .docx 및 .doc 파일을 읽어 표준 인쇄 컨트롤러(팝업 대화 상자 없음)를 사용하여 조용히 인쇄하는 전체 콘솔 애플리케이션입니다. 또한 예외 처리를 우아하게 수행하는 방법도 보여줍니다.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\DocumentsToPrint";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"인쇄 중: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// 자동 인쇄를 위해 인쇄 대화 상자 표시 안 함
printDoc.PrintController = new StandardPrintController();
// 선택적으로 프린터 이름 및 복사본 설정
// printDoc.PrinterSettings.PrinterName = "My Specific Printer";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"{filePath} 인쇄 실패: {ex.Message}");
}
}
}
Console.WriteLine("일괄 인쇄가 완료되었습니다.");
}
}
논리는 간단합니다. 디렉터리에서 모든 파일을 가져오고, 확장자를 확인하고, 각 파일을 Spire.Doc Document 객체로 로드한 뒤 PrintDocument에 액세스합니다. StandardPrintController를 설정하여 Windows 인쇄 대화 상자를 피하고 Print()를 호출합니다. 루프는 모든 유효한 Word 문서가 순차적으로 인쇄되도록 보장합니다.
PrintDocument.PrinterSettings 속성을 사용하면 세밀한 제어가 가능합니다. PrinterName으로 정확한 프린터를 지정하고, 복사본 수를 설정하고, 페이지 범위를 선택하거나 양면 인쇄를 활성화할 수 있습니다. 자세한 내용은 C#에서 Word 문서 인쇄 방법을 참조하세요.
빠른 비교: 나에게 가장 적합한 일괄 인쇄 방법은?
| 방법 | Word 필요 여부 | 자동/팝업 없음 | 용도 |
|---|---|---|---|
| 우클릭 후 인쇄 | 예 | 중단 가능성 있음 | 가끔 수행하는 일회성 작업 |
| 프린터 바로 가기로 드래그 | 예 | 중단 가능성 있음 | 시각적이고 빠른 일상적 사용 |
| 병합 후 PDF로 인쇄 | 예 | 예 (병합 후) | 단일 순서 인쇄물 생성 |
| VBA 매크로 | 예 | 예 (설정 시) | 개인적인 반복 폴더 작업 |
| PowerShell 스크립트 | 예 (COM) | 예 | 예약된 서버 측 작업 |
| Spire.Doc (C#) | 아니요 | 예, 완전 자동 | 서버 자동화 및 통합 |
결론
Word 문서 일괄 인쇄가 반드시 힘든 작업일 필요는 없습니다. 빠른 내장 기능을 시작으로, 반복성이 필요할 때는 스크립트를 사용하고, 프로젝트에 강력하고 Office가 필요 없는 솔루션이 요구될 때는 Spire.Doc과 같은 전용 라이브러리를 사용하세요. 어떤 방법을 선택하든 절약한 시간은 생산성 향상으로 이어질 것입니다. 이제 방법을 선택하고 폴더를 준비하여 프린터가 힘든 일을 대신하게 하세요.
자주 묻는 질문(FAQ)
각 문서를 열지 않고 Word 문서를 인쇄할 수 있나요?
네. 방법 4, 5, 6은 모두 Word 인터페이스를 숨기거나 아예 사용하지 않습니다. PowerShell 스크립트와 Spire.Doc은 모두 백그라운드에서 조용히 인쇄하며, VBA 매크로는 애플리케이션 창을 숨길 수 있습니다.
일괄 인쇄가 .doc 및 .docx 파일 모두에서 작동하나요?
물론입니다. 여기에 설명된 모든 방법은 레거시 .doc 및 최신 .docx 형식을 모두 처리합니다. Spire.Doc을 사용할 경우 라이브러리가 변환 없이 두 형식을 원활하게 읽습니다.
여러 파일을 인쇄할 때 특정 프린터를 선택하려면 어떻게 하나요?
수동 방법의 경우 시작하기 전에 원하는 프린터를 기본값으로 설정하세요. PowerShell 스크립트와 C# Spire.Doc 예제에서는 코드 내에서 프로그래밍 방식으로 프린터 이름을 설정할 수 있으므로 시스템 기본값을 변경하지 않고도 정밀하게 제어할 수 있습니다.
참고 항목
Come stampare più documenti Word contemporaneamente: 6 metodi
Indice
- Metodo 1: Tasto destro e Stampa da Esplora file
- Metodo 2: Trascinamento di più file Word nella finestra della coda di stampa
- Metodo 3: Unire prima i file Word per un unico processo di stampa
- Metodo 4: Utilizzare una macro di Word (VBA) per stampare tutti i documenti in una cartella
- Metodo 5: Stampa batch silenziosa con uno script PowerShell
- Metodo 6: Stampare documenti Word in C# utilizzando Spire.Doc
- Confronto rapido: Quale metodo di stampa batch è più adatto a te?
- Considerazioni finali
- Domande frequenti (FAQ)
Stampare decine di contratti, report o fatture uno alla volta è una perdita di tempo noiosa. Che tu stia preparando materiale per una riunione, producendo documenti legali o semplicemente organizzando le scartoffie del tuo ufficio, la capacità di inviare un'intera cartella di file Word alla stampante in una sola volta può farti risparmiare ore.
Questo articolo ti guida attraverso sei metodi pratici per stampare in batch file .doc e .docx, dai semplici trucchi con il tasto destro a una potente soluzione orientata agli sviluppatori che utilizza Spire.Doc in C#. Scegli quello più adatto al tuo flusso di lavoro e inizia a stampare in modo più intelligente oggi stesso.
Panoramica dei metodi trattati:
- Metodo 1: Tasto destro e Stampa da Esplora file
- Metodo 2: Trascinamento di più file Word nella finestra della coda di stampa
- Metodo 3: Unire prima i file Word per un unico processo di stampa
- Metodo 4: Utilizzare una macro di Word (VBA) per stampare tutti i documenti in una cartella
- Metodo 5: Stampa batch silenziosa con uno script PowerShell
- Metodo 6: Stampare documenti Word in C# utilizzando Spire.Doc
Metodo 1: Tasto destro e Stampa da Esplora file
Il metodo più semplice non richiede strumenti aggiuntivi e funziona istantaneamente su qualsiasi PC Windows. È perfetto per stampare rapidamente una manciata di documenti senza installare alcun software. Basta selezionare i file e lasciare che Windows faccia il resto.
Passaggi:
- Apri Esplora file e vai alla cartella contenente i tuoi documenti Word.
- Seleziona i file che desideri stampare: tieni premuto il tasto Ctrl e fai clic su ciascuno di essi singolarmente, oppure premi Ctrl + A per selezionarli tutti.
- Fai clic con il tasto destro su uno qualsiasi dei file evidenziati e scegli Stampa dal menu contestuale.
Windows aprirà automaticamente ogni documento in Microsoft Word, lo invierà alla stampante predefinita e chiuderà Word al termine. Tieni presente che se le impostazioni di sicurezza di Word visualizzano avvisi sulle macro o messaggi di Visualizzazione protetta, il processo potrebbe interrompersi finché non li confermi manualmente. Tuttavia, per lavori rapidi e occasionali, questo metodo è difficile da battere.
Metodo 2: Trascinamento di più file Word nella finestra della coda di stampa
Questo flusso di lavoro nativo di Windows basato sul trascinamento consente la stampa batch di più documenti Word: basta trascinare i file su un collegamento desktop della stampante dedicato. Questo approccio rende facile passare da una stampante all'altra a piacimento, rendendolo ideale per ambienti d'ufficio dotati di diversi dispositivi di stampa.
Passaggi:
- Premi Win + R, digita control printers, quindi premi Invio per avviare la finestra Dispositivi e stampanti.
- Fai doppio clic sull'icona della stampante desiderata per aprire la finestra della coda di stampa.
- Seleziona tutti i file Word di destinazione, quindi trascinali direttamente nell'area vuota della finestra della coda di stampa aperta.
I file popoleranno automaticamente l'elenco dei processi di stampa. Windows aprirà, stamperà e chiuderà ogni documento in sequenza.
Consiglio dell'esperto: Puoi anche creare un collegamento alla stampante sul desktop per un accesso rapido, sebbene il trascinamento nella finestra della coda di stampa offra risultati più affidabili per le attività batch.
Metodo 3: Unire prima i file Word per un unico processo di stampa
Se desideri che tutti i file Word separati vengano stampati come un unico documento continuo e ordinato, questo flusso di lavoro di unione è la soluzione ottimale. Funziona eccezionalmente bene per dispense, report formali e opuscoli che richiedono una sequenza di pagine coerente. Unire i file prima della stampa elimina la noiosa operazione manuale di ordinamento delle pagine dopo la stampa.
Passaggi:
- Avvia Microsoft Word e crea un nuovo documento vuoto.
- Vai su Inserisci > Oggetto > Testo da file (percorsi alternativi: Inserisci > File o espandi il menu a discesa Oggetto in alcune versioni di Word).
- Evidenzia tutti i file DOCX da unire, quindi fai clic su Inserisci. I file verranno assemblati seguendo l'ordine selezionato.
- Premi Ctrl + P per aprire il pannello di stampa. Seleziona la tua stampante fisica o Microsoft Print to PDF, quindi conferma la stampa.
Riceverai un documento coeso con un flusso di pagine ininterrotto. Sebbene l'unione richieda un po' di tempo extra, previene l'ordine errato delle pagine ed elimina l'assemblaggio manuale: ideale per documenti rilegati e dispense stampate.
Metodo 4: Utilizzare una macro di Word (VBA) per stampare tutti i documenti in una cartella
Se stampi spesso batch di documenti dalla stessa cartella, una semplice macro VBA può automatizzare completamente il processo. Questo metodo viene eseguito direttamente all'interno di Microsoft Word, non richiede software aggiuntivo e può essere configurato per la stampa con un solo clic. È uno strumento di automazione integrato ideale per attività di stampa regolari e ripetute.
Passaggi:
- Apri Microsoft Word e premi Alt + F11 per aprire l'editor VBA.
- Vai su Inserisci > Modulo e incolla il codice VBA pronto all'uso fornito di seguito.
- Sostituisci il percorso della cartella nel codice con la tua directory.
- Premi F5 per eseguire la macro, oppure assegnala alla barra di accesso rapido per la stampa con un clic.
Codice VBA:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Il\Tuo\Percorso\File\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "Stampa batch completata!", vbInformation
End Sub
Questo metodo stampa i file silenziosamente in background senza aprire finestre. Gli unici requisiti sono abilitare le macro e avere Word installato: perfetto per un uso affidabile su desktop personale o in ufficio.
Metodo 5: Stampa batch silenziosa con uno script PowerShell
PowerShell offre un modo veloce, leggero e basato su script per stampare più documenti Word in background: nessuna finestra, nessun pop-up e nessuna interazione manuale. Questo metodo è ideale per gli utenti che desiderano una stampa completamente automatizzata e può persino essere pianificato con l'Utilità di pianificazione di Windows per attività automatiche e programmate.
Passaggi:
- Apri PowerShell dal menu Start (non sono necessari diritti di amministratore per la stampa di base).
- Copia e incolla il semplice script di stampa batch fornito di seguito.
- Modifica il valore
$folderPathcon la cartella dei documenti di destinazione. - Esegui lo script. Word verrà eseguito silenziosamente in background, stamperà automaticamente tutti i documenti e si chiuderà correttamente al termine.
Script PowerShell:
$folderPath = "C:\I\Tuoi\File\Qui"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "Stampa batch completata!"
Questo metodo funziona senza software aggiuntivo, supporta tutti i formati Word e offre una stampa batch silenziosa e affidabile sia per uso personale che in ufficio.
Metodo 6: Stampare documenti Word in C# utilizzando Spire.Doc
Quando hai bisogno di una soluzione di stampa batch completamente automatizzata e ad alte prestazioni che funzioni su un server senza Microsoft Office, Spire.Doc for .NET è la libreria di riferimento. Ti offre un controllo programmatico completo sulla stampa dei documenti, rendendola ideale per applicazioni web, servizi in background o sistemi di gestione documentale.
Perché utilizzare Spire.Doc per la stampa batch?
Spire.Doc è una libreria .NET autonoma che legge, crea e manipola file Word senza alcuna dipendenza da Word stesso. Per la stampa batch, ciò significa che puoi elaborare migliaia di documenti in modo affidabile su un server, selezionare una stampante specifica, impostare intervalli di pagine e persino gestire la stampa fronte-retro, tutto tramite un codice C# pulito.
Configurazione di Spire.Doc nel tuo progetto .NET
Installa il pacchetto tramite NuGet Package Manager:
Install-Package Spire.Doc
Oppure usa la CLI .NET: dotnet add package Spire.Doc. Tutto qui: nessuna licenza o installazione di Office aggiuntiva.
Esempio di codice C#: Stampare tutti i file Word da una directory
Di seguito è riportata un'applicazione console completa che legge tutti i file .docx e .doc da una cartella e li stampa silenziosamente con un controller di stampa standard (nessuna finestra di dialogo pop-up). Il codice mostra anche come gestire correttamente le possibili eccezioni.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\DocumentiDaStampare";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
// Filtra solo per .docx e .doc
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Stampa in corso: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Sopprime la finestra di dialogo di stampa per una stampa silenziosa
printDoc.PrintController = new StandardPrintController();
// Opzionalmente imposta il nome della stampante e le copie
// printDoc.PrinterSettings.PrinterName = "La Mia Stampante";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Impossibile stampare {filePath}: {ex.Message}");
}
}
}
Console.WriteLine("Stampa batch completata.");
}
}
La logica è semplice: ottieni tutti i file dalla directory, controlla l'estensione, carica ciascuno in un oggetto Document di Spire.Doc, accedi al suo PrintDocument, imposta StandardPrintController per evitare la finestra di dialogo di stampa di Windows e chiama Print(). Il ciclo garantisce che ogni documento Word valido venga stampato in sequenza.
La proprietà PrintDocument.PrinterSettings apre la porta a un controllo granulare. Puoi specificare la stampante esatta con PrinterName, impostare il numero di copie, scegliere un intervallo di pagine o abilitare la stampa fronte-retro. Per un'introduzione più dettagliata, fai riferimento a Come stampare documenti Word in C#.
Confronto rapido: Quale metodo di stampa batch è più adatto a te?
| Metodo | Richiede Word? | Silenzioso / Nessun pop-up | Ideale per |
|---|---|---|---|
| Tasto destro e Stampa | Sì | Possibili interruzioni | Attività occasionali |
| Trascina su collegamento stampante | Sì | Possibili interruzioni | Uso quotidiano rapido e visivo |
| Unisci e stampa in PDF | Sì | Sì (una volta uniti) | Produrre un unico stampato ordinato |
| Macro VBA | Sì | Sì, se configurato | Cartelle personali ripetitive |
| Script PowerShell | Sì (COM) | Sì | Attività pianificate lato server |
| Spire.Doc con C# | No | Sì, completamente silenzioso | Automazione server e integrazione |
Considerazioni finali
La stampa batch di documenti Word non deve essere un lavoro gravoso. Inizia con i rapidi trucchi integrati, adotta uno script quando hai bisogno di ripetibilità e passa a una libreria dedicata come Spire.Doc quando il tuo progetto richiede una soluzione robusta e priva di Office. Qualunque strada tu scelga, i minuti risparmiati si sommeranno rapidamente in ore di produttività recuperata. Ora scegli un metodo, carica la tua cartella e lascia che la stampante faccia il lavoro pesante.
Domande frequenti (FAQ)
Posso stampare documenti Word senza aprirli uno per uno?
Sì. I metodi 4, 5 e 6 sopprimono l'interfaccia di Word o funzionano senza di essa. Lo script PowerShell e Spire.Doc stampano entrambi silenziosamente in background, mentre la macro VBA può nascondere la finestra dell'applicazione.
La stampa batch funziona con file .doc e .docx?
Assolutamente sì. Ogni metodo descritto qui gestisce sia i formati legacy .doc che quelli moderni .docx. Quando si utilizza Spire.Doc, la libreria legge perfettamente entrambi i formati senza alcuna conversione.
Come seleziono una stampante specifica durante la stampa di più file?
Per i metodi manuali, imposta la stampante desiderata come predefinita prima di iniziare. Con lo script PowerShell e l'esempio C# di Spire.Doc, puoi impostare programmaticamente il nome della stampante all'interno del codice, offrendoti un controllo preciso senza modificare le impostazioni predefinite del sistema.
Vedi anche
Comment imprimer plusieurs documents Word à la fois : 6 méthodes
Table des matières
- Méthode 1 : Clic droit et imprimer depuis l'Explorateur de fichiers
- Méthode 2 : Glisser-déposer plusieurs fichiers Word via la fenêtre de file d'attente d'impression
- Méthode 3 : Fusionner d'abord les fichiers Word pour une impression unifiée
- Méthode 4 : Utiliser une macro Word (VBA) pour imprimer tous les documents d'un dossier
- Méthode 5 : Impression par lots silencieuse avec un script PowerShell
- Méthode 6 : Imprimer des documents Word en C# avec Spire.Doc
- Comparaison rapide : quelle méthode d'impression par lots vous convient le mieux ?
- Réflexions finales
- FAQ
Imprimer des dizaines de contrats, rapports ou factures un par un est une perte de temps fastidieuse. Que vous prépariez des documents pour une réunion, produisiez des documents juridiques ou organisiez simplement vos dossiers de bureau, la capacité d'envoyer tout un dossier de fichiers Word à l'imprimante en une seule fois peut vous faire gagner des heures.
Cet article vous présente six méthodes pratiques pour imprimer par lots des fichiers .doc et .docx, allant d'astuces simples par clic droit à une solution puissante destinée aux développeurs utilisant Spire.Doc en C#. Choisissez celle qui correspond à votre flux de travail et commencez à imprimer plus intelligemment dès aujourd'hui.
Aperçu des méthodes couvertes :
- Méthode 1 : Clic droit et imprimer depuis l'Explorateur de fichiers
- Méthode 2 : Glisser-déposer plusieurs fichiers Word via la fenêtre de file d'attente d'impression
- Méthode 3 : Fusionner d'abord les fichiers Word pour une impression unifiée
- Méthode 4 : Utiliser une macro Word (VBA) pour imprimer tous les documents d'un dossier
- Méthode 5 : Impression par lots silencieuse avec un script PowerShell
- Méthode 6 : Imprimer des documents Word en C# avec Spire.Doc
Méthode 1 : Clic droit et imprimer depuis l'Explorateur de fichiers
La méthode la plus simple ne nécessite aucun outil supplémentaire et fonctionne instantanément sur n'importe quel PC Windows. Elle est parfaite pour imprimer rapidement quelques documents sans installer de logiciel. Sélectionnez simplement vos fichiers et laissez Windows gérer le reste.
Étapes :
- Ouvrez l'Explorateur de fichiers et accédez au dossier contenant vos documents Word.
- Sélectionnez les fichiers que vous souhaitez imprimer : maintenez la touche Ctrl enfoncée et cliquez sur chaque fichier individuellement, ou appuyez sur Ctrl + A pour tout sélectionner.
- Faites un clic droit sur n'importe quel fichier sélectionné et choisissez Imprimer dans le menu contextuel.
Windows ouvrira automatiquement chaque document dans Microsoft Word, l'enverra à votre imprimante par défaut et fermera Word une fois terminé. Gardez à l'esprit que si vos paramètres de sécurité Word affichent des avertissements de macro ou des invites de mode protégé, le processus peut s'interrompre jusqu'à ce que vous les confirmiez manuellement. Néanmoins, pour des tâches rapides et occasionnelles, cette méthode est difficile à battre.
Méthode 2 : Glisser-déposer plusieurs fichiers Word via la fenêtre de file d'attente d'impression
Ce flux de travail natif de Windows permet l'impression par lots de plusieurs documents Word : il suffit de faire glisser vos fichiers sur un raccourci de bureau dédié à l'imprimante. Cette approche facilite le basculement entre différentes imprimantes, ce qui la rend idéale pour les environnements de bureau équipés de plusieurs périphériques d'impression.
Étapes :
- Appuyez sur Win + R, tapez control printers, puis appuyez sur Entrée pour lancer la fenêtre Périphériques et imprimantes.
- Double-cliquez sur l'icône de votre imprimante cible pour afficher sa fenêtre de file d'attente d'impression.
- Sélectionnez tous les fichiers Word cibles, puis faites-les glisser directement dans la zone vide de la fenêtre de file d'attente d'impression ouverte.
Les fichiers seront automatiquement ajoutés à la liste des travaux d'impression. Windows ouvrira, imprimera et fermera chaque document séquentiellement.
Conseil d'expert : Vous pouvez également créer un raccourci d'imprimante sur le bureau pour un accès rapide, bien que le glisser-déposer dans la fenêtre de file d'attente d'impression donne des résultats plus fiables pour les tâches par lots.
Méthode 3 : Fusionner d'abord les fichiers Word pour une impression unifiée
Si vous souhaitez que tous les fichiers Word séparés soient imprimés sous forme d'un seul document continu et ordonné, ce flux de travail de fusion est votre solution optimale. Il fonctionne exceptionnellement bien pour les documents distribués, les rapports officiels et les livrets qui nécessitent une séquence de pages cohérente. Fusionner les fichiers avant l'impression évite le tri manuel fastidieux des pages après la sortie.
Étapes :
- Lancez Microsoft Word et créez un nouveau document vierge.
- Accédez à Insertion > Objet > Texte d'un fichier (chemins alternatifs : Insertion > Fichier ou développez le menu déroulant Objet sur certaines éditions de Word).
- Mettez en surbrillance tous les fichiers DOCX à fusionner, puis cliquez sur Insérer. Les fichiers s'assembleront selon l'ordre sélectionné.
- Appuyez sur Ctrl + P pour ouvrir le panneau d'impression. Sélectionnez votre imprimante physique ou Microsoft Print to PDF, puis confirmez l'impression.
Vous obtiendrez un document cohérent avec un flux de pages ininterrompu. Bien que la fusion prenne un peu plus de temps, elle évite les pages mal ordonnées et élimine le tri manuel, ce qui est idéal pour les documents reliés et les supports imprimés.
Méthode 4 : Utiliser une macro Word (VBA) pour imprimer tous les documents d'un dossier
Si vous imprimez fréquemment des lots de documents à partir du même dossier, une simple macro VBA peut automatiser entièrement le processus. Cette méthode s'exécute directement dans Microsoft Word, ne nécessite aucun logiciel supplémentaire et peut être configurée pour une impression en un clic. C'est un outil d'automatisation intégré idéal pour les tâches d'impression répétitives.
Étapes :
- Ouvrez Microsoft Word et appuyez sur Alt + F11 pour ouvrir l'éditeur VBA.
- Allez dans Insertion > Module et collez le code VBA prêt à l'emploi fourni ci-dessous.
- Remplacez le chemin du dossier dans le code par votre propre répertoire.
- Appuyez sur F5 pour exécuter la macro, ou assignez-la à la barre d'outils Accès rapide pour une impression en un clic.
Code VBA :
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Votre\Chemin\De\Fichier\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "Impression par lots terminée !", vbInformation
End Sub
Cette méthode imprime les fichiers silencieusement en arrière-plan sans ouvrir de fenêtres. Les seules exigences sont l'activation des macros et l'installation de Word — parfait pour une utilisation fiable sur un ordinateur personnel ou de bureau.
Méthode 5 : Impression par lots silencieuse avec un script PowerShell
PowerShell offre un moyen rapide, léger et basé sur des scripts pour imprimer plusieurs documents Word en arrière-plan — sans fenêtres, sans pop-ups et sans interaction manuelle. Cette méthode est idéale pour les utilisateurs qui souhaitent une impression entièrement automatisée, et elle peut même être planifiée avec le Planificateur de tâches Windows pour des travaux automatiques et programmés.
Étapes :
- Ouvrez PowerShell depuis le menu Démarrer (aucun droit d'administrateur requis pour l'impression de base).
- Copiez et collez le script d'impression par lots simple fourni ci-dessous.
- Modifiez la valeur
$folderPathpar le dossier contenant vos documents cibles. - Exécutez le script. Word s'exécutera silencieusement en arrière-plan, imprimera tous vos documents automatiquement et se fermera proprement une fois terminé.
Script PowerShell :
$folderPath = "C:\Vos\Fichiers\Ici"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "Impression par lots terminée !"
Cette méthode fonctionne sans logiciel supplémentaire, prend en charge tous les formats Word et offre une impression par lots silencieuse et fiable pour un usage personnel et professionnel.
Méthode 6 : Imprimer des documents Word en C# avec Spire.Doc
Lorsque vous avez besoin d'une solution d'impression par lots entièrement automatisée et haute performance qui s'exécute sur un serveur sans Microsoft Office, Spire.Doc for .NET est la bibliothèque de référence. Elle vous donne un contrôle programmatique complet sur l'impression de documents, ce qui la rend idéale pour les applications web, les services en arrière-plan ou les systèmes de gestion documentaire.
Pourquoi utiliser Spire.Doc pour l'impression par lots ?
Spire.Doc est une bibliothèque .NET autonome qui lit, crée et manipule des fichiers Word sans aucune dépendance à Word lui-même. Pour l'impression par lots, cela signifie que vous pouvez traiter des milliers de documents de manière fiable sur un serveur, sélectionner une imprimante spécifique, définir des plages de pages et même gérer l'impression recto verso — le tout via un code C# propre.
Configuration de Spire.Doc dans votre projet .NET
Installez le package via le gestionnaire de packages NuGet :
Install-Package Spire.Doc
Ou utilisez l'interface de ligne de commande .NET : dotnet add package Spire.Doc. C'est tout — aucune licence ou installation Office supplémentaire n'est requise.
Exemple de code C# : Imprimer tous les fichiers Word d'un répertoire
Voici une application console complète qui lit tous les fichiers .docx et .doc d'un dossier et les imprime silencieusement avec un contrôleur d'impression standard (sans boîte de dialogue contextuelle). Le code montre également comment gérer les exceptions potentielles avec élégance.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\DocumentsAImprimer";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
// Filtrer uniquement pour .docx et .doc
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Impression : {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Supprimer la boîte de dialogue d'impression pour une impression silencieuse
printDoc.PrintController = new StandardPrintController();
// Optionnellement définir le nom de l'imprimante et le nombre de copies
// printDoc.PrinterSettings.PrinterName = "Mon imprimante spécifique";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Échec de l'impression de {filePath} : {ex.Message}");
}
}
}
Console.WriteLine("Impression par lots terminée.");
}
}
La logique est simple : obtenir tous les fichiers du répertoire, vérifier l'extension, charger chacun dans un objet Document de Spire.Doc, accéder à son PrintDocument, définir StandardPrintController pour éviter la boîte de dialogue d'impression Windows, et appeler Print(). La boucle garantit que chaque document Word valide est imprimé séquentiellement.
La propriété PrintDocument.PrinterSettings ouvre la porte à un contrôle précis. Vous pouvez spécifier l'imprimante exacte avec PrinterName, définir le nombre de copies, choisir une plage de pages ou activer l'impression recto verso. Pour une introduction plus détaillée, reportez-vous à Comment imprimer des documents Word en C#.
Comparaison rapide : quelle méthode d'impression par lots vous convient le mieux ?
| Méthode | Nécessite Word ? | Silencieux / Sans pop-ups | Idéal pour |
|---|---|---|---|
| Clic droit & Imprimer | Oui | Interruptions possibles | Tâches occasionnelles |
| Glisser vers raccourci imprimante | Oui | Interruptions possibles | Usage quotidien rapide et visuel |
| Fusionner & Imprimer en PDF | Oui | Oui (une fois fusionné) | Produire une seule impression ordonnée |
| Macro VBA | Oui | Oui, si configuré | Dossiers répétitifs personnels |
| Script PowerShell | Oui (COM) | Oui | Tâches planifiées côté serveur |
| Spire.Doc avec C# | Non | Oui, totalement silencieux | Automatisation serveur & intégration |
Réflexions finales
L'impression par lots de documents Word ne doit pas être une corvée. Commencez par les astuces intégrées rapides, adoptez un script lorsque vous avez besoin de répétabilité, et passez à une bibliothèque dédiée comme Spire.Doc lorsque votre projet exige une solution robuste et sans Office. Quelle que soit la voie choisie, les minutes que vous économiserez s'additionneront rapidement pour devenir des heures de productivité retrouvée. Choisissez maintenant une méthode, chargez votre dossier et laissez l'imprimante faire le gros du travail.
FAQ
Puis-je imprimer des documents Word sans ouvrir chacun d'eux ?
Oui. Les méthodes 4, 5 et 6 suppriment toutes l'interface Word ou fonctionnent sans elle. Le script PowerShell et Spire.Doc impriment tous deux silencieusement en arrière-plan, tandis que la macro VBA peut masquer la fenêtre de l'application.
L'impression par lots fonctionne-t-elle avec les fichiers .doc et .docx ?
Absolument. Chaque méthode décrite ici gère à la fois les anciens formats .doc et les formats modernes .docx. Lors de l'utilisation de Spire.Doc, la bibliothèque lit de manière transparente les deux formats sans aucune conversion.
Comment sélectionner une imprimante spécifique lors de l'impression de plusieurs fichiers ?
Pour les méthodes manuelles, définissez l'imprimante souhaitée comme imprimante par défaut avant de commencer. Avec le script PowerShell et l'exemple C# Spire.Doc, vous pouvez définir par programmation le nom de l'imprimante dans le code, vous offrant un contrôle précis sans modifier les paramètres par défaut du système.
Voir aussi
Cómo imprimir varios documentos de Word a la vez: 6 formas
Tabla de contenidos
- Método 1: Clic derecho e imprimir desde el Explorador de archivos
- Método 2: Arrastrar y soltar múltiples archivos de Word a través de la ventana de cola de impresión
- Método 3: Combinar archivos de Word primero para un trabajo de impresión unificado
- Método 4: Usar una macro de Word (VBA) para imprimir todos los documentos de una carpeta
- Método 5: Impresión por lotes silenciosa con un script de PowerShell
- Método 6: Imprimir documentos de Word en C# usando Spire.Doc
- Comparación rápida: ¿Qué método de impresión por lotes se adapta mejor a usted?
- Reflexiones finales
- Preguntas frecuentes
Imprimir docenas de contratos, informes o facturas uno por uno es una pérdida de tiempo tediosa. Ya sea que esté preparando folletos para una reunión, produciendo documentos legales o simplemente organizando el papeleo de su oficina, la capacidad de enviar una carpeta completa de archivos de Word a la impresora de una sola vez puede ahorrarle horas.
Este artículo le guía a través de seis métodos prácticos para imprimir por lotes archivos .doc y .docx, desde trucos sencillos de clic derecho hasta una potente solución orientada a desarrolladores utilizando Spire.Doc en C#. Elija el que mejor se adapte a su flujo de trabajo y comience a imprimir de forma más inteligente hoy mismo.
Resumen de los métodos cubiertos:
- Método 1: Clic derecho e imprimir desde el Explorador de archivos
- Método 2: Arrastrar y soltar múltiples archivos de Word a través de la ventana de cola de impresión
- Método 3: Combinar archivos de Word primero para un trabajo de impresión unificado
- Método 4: Usar una macro de Word (VBA) para imprimir todos los documentos de una carpeta
- Método 5: Impresión por lotes silenciosa con un script de PowerShell
- Método 6: Imprimir documentos de Word en C# usando Spire.Doc
Método 1: Clic derecho e imprimir desde el Explorador de archivos
El método más sencillo no requiere herramientas adicionales y funciona al instante en cualquier PC con Windows. Es perfecto para imprimir rápidamente un puñado de documentos sin instalar ningún software. Simplemente seleccione sus archivos y deje que Windows haga el resto.
Pasos:
- Abra el Explorador de archivos y navegue hasta la carpeta que contiene sus documentos de Word.
- Seleccione los archivos que desea imprimir: mantenga presionada la tecla Ctrl y haga clic en cada uno individualmente, o presione Ctrl + A para seleccionarlos todos.
- Haga clic derecho en cualquier archivo resaltado y elija Imprimir en el menú contextual.
Windows abrirá automáticamente cada documento en Microsoft Word, lo enviará a su impresora predeterminada y cerrará Word al finalizar. Tenga en cuenta que si la configuración de seguridad de Word muestra advertencias de macros o avisos de Vista protegida, el proceso puede pausarse hasta que los confirme manualmente. Aun así, para trabajos rápidos y ocasionales, este método es difícil de superar.
Método 2: Arrastrar y soltar múltiples archivos de Word a través de la ventana de cola de impresión
Este flujo de trabajo nativo de arrastrar y soltar de Windows permite la impresión por lotes de múltiples documentos de Word; simplemente arrastre sus archivos a un acceso directo de escritorio de la impresora. Este enfoque facilita el cambio entre diferentes impresoras a voluntad, lo que lo hace ideal para entornos de oficina equipados con varios dispositivos de impresión.
Pasos:
- Presione Win + R, escriba control printers y luego presione Enter para abrir la ventana de Dispositivos e impresoras.
- Haga doble clic en el icono de su impresora de destino para abrir su ventana de cola de impresión.
- Seleccione todos los archivos de Word de destino y luego arrástrelos y suéltelos directamente en el área en blanco de la ventana de cola de impresión abierta.
Los archivos se añadirán a la lista de trabajos de impresión automáticamente. Windows abrirá, imprimirá y cerrará cada documento secuencialmente.
Consejo profesional: También puede crear un acceso directo de impresora en el escritorio para un acceso rápido, aunque arrastrar a la ventana de cola de impresión ofrece resultados más fiables para tareas por lotes.
Método 3: Combinar archivos de Word primero para un trabajo de impresión unificado
Si desea que todos los archivos de Word separados se impriman como un documento continuo y ordenado, este flujo de trabajo de combinación es su solución óptima. Funciona excepcionalmente bien para folletos, informes formales y cuadernillos que requieren una secuencia de páginas coherente. Combinar archivos antes de imprimir elimina la tediosa clasificación manual de páginas después de la salida.
Pasos:
- Inicie Microsoft Word y cree un nuevo documento en blanco.
- Navegue a Insertar > Objeto > Texto de archivo (rutas alternativas: Insertar > Archivo o expanda el menú desplegable Objeto en ciertas ediciones de Word).
- Resalte todos los archivos DOCX que se van a combinar y luego haga clic en Insertar. Los archivos se ensamblarán siguiendo el orden seleccionado.
- Presione Ctrl + P para abrir el panel de impresión. Seleccione su impresora física o Microsoft Print to PDF y luego confirme la impresión.
Recibirá un documento cohesivo con un flujo de páginas ininterrumpido. Aunque la combinación requiere un poco de tiempo adicional, evita el desorden de páginas y elimina la clasificación manual, ideal para documentos encuadernados y folletos impresos.
Método 4: Usar una macro de Word (VBA) para imprimir todos los documentos de una carpeta
Si imprime frecuentemente lotes de documentos de la misma carpeta, una sencilla macro de VBA puede automatizar completamente el proceso. Este método se ejecuta directamente dentro de Microsoft Word, no requiere software adicional y se puede configurar para imprimir con un solo clic. Es una herramienta de automatización integrada ideal para tareas de impresión regulares y repetitivas.
Pasos:
- Abra Microsoft Word y presione Alt + F11 para abrir el editor de VBA.
- Vaya a Insertar > Módulo y pegue el código VBA listo para usar que se proporciona a continuación.
- Reemplace la ruta de la carpeta en el código con su propio directorio.
- Presione F5 para ejecutar la macro, o asígnela a la Barra de herramientas de acceso rápido para imprimir con un solo clic.
Código VBA:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Tu\Ruta\De\Archivo\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "¡Impresión por lotes completada!", vbInformation
End Sub
Este método imprime archivos silenciosamente en segundo plano sin abrir ventanas. Los únicos requisitos son habilitar las macros y tener Word instalado; perfecto para un uso fiable en escritorio personal o de oficina.
Método 5: Impresión por lotes silenciosa con un script de PowerShell
PowerShell ofrece una forma rápida, ligera y basada en scripts para imprimir múltiples documentos de Word en segundo plano: sin ventanas, sin ventanas emergentes y sin interacción manual. Este método es ideal para usuarios que desean una impresión totalmente automatizada, e incluso se puede programar con el Programador de tareas de Windows para trabajos automáticos y programados.
Pasos:
- Abra PowerShell desde el menú Inicio (no se requieren derechos de administrador para la impresión básica).
- Copie y pegue el sencillo script de impresión por lotes que se proporciona a continuación.
- Cambie el valor de
$folderPatha su carpeta de documentos de destino. - Ejecute el script. Word se ejecutará silenciosamente en segundo plano, imprimirá todos sus documentos automáticamente y se cerrará limpiamente al finalizar.
Script de PowerShell:
$folderPath = "C:\Sus\Archivos\Aqui"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "¡Impresión por lotes completada!"
Este método funciona sin software adicional, admite todos los formatos de Word y ofrece una impresión por lotes silenciosa y fiable tanto para uso personal como de oficina.
Método 6: Imprimir documentos de Word en C# usando Spire.Doc
Cuando necesita una solución de impresión por lotes de alto rendimiento y totalmente automatizada que se ejecute en un servidor sin Microsoft Office, Spire.Doc for .NET es la biblioteca de referencia. Le brinda un control programático completo sobre la impresión de documentos, lo que la hace ideal para aplicaciones web, servicios en segundo plano o sistemas de gestión de documentos.
¿Por qué usar Spire.Doc para la impresión por lotes?
Spire.Doc es una biblioteca .NET independiente que lee, crea y manipula archivos de Word sin ninguna dependencia de Word en sí. Para la impresión por lotes, esto significa que puede procesar miles de documentos de forma fiable en un servidor, seleccionar una impresora específica, establecer rangos de páginas e incluso manejar la impresión a doble cara, todo a través de código C# limpio.
Configuración de Spire.Doc en su proyecto .NET
Instale el paquete a través del Administrador de paquetes NuGet:
Install-Package Spire.Doc
O use la CLI de .NET: dotnet add package Spire.Doc. Eso es todo: no se requieren licencias ni instalaciones adicionales de Office.
Ejemplo de código C#: Imprimir todos los archivos de Word de un directorio
A continuación se muestra una aplicación de consola completa que lee todos los archivos .docx y .doc de una carpeta y los imprime silenciosamente con un controlador de impresión estándar (sin cuadro de diálogo emergente). El código también muestra cómo manejar posibles excepciones con elegancia.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\DocumentosParaImprimir";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
// Filtrar solo a .docx y .doc
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Imprimiendo: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Suprimir el cuadro de diálogo de impresión para una impresión silenciosa
printDoc.PrintController = new StandardPrintController();
// Opcionalmente establecer el nombre de la impresora y las copias
// printDoc.PrinterSettings.PrinterName = "Mi Impresora Especifica";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Error al imprimir {filePath}: {ex.Message}");
}
}
}
Console.WriteLine("Impresión por lotes completada.");
}
}
La lógica es sencilla: obtener todos los archivos del directorio, verificar la extensión, cargar cada uno en un objeto Document de Spire.Doc, acceder a su PrintDocument, establecer StandardPrintController para evitar el cuadro de diálogo de impresión de Windows y llamar a Print(). El bucle asegura que cada documento de Word válido se imprima secuencialmente.
La propiedad PrintDocument.PrinterSettings abre la puerta a un control detallado. Puede especificar la impresora exacta con PrinterName, establecer el número de copias, elegir un rango de páginas o habilitar la impresión a doble cara. Para una introducción más detallada, consulte Cómo imprimir documentos de Word en C#.
Comparación rápida: ¿Qué método de impresión por lotes se adapta mejor a usted?
| Método | ¿Requiere Word? | Silencioso / Sin ventanas emergentes | Mejor para |
|---|---|---|---|
| Clic derecho e imprimir | Sí | Posibles interrupciones | Tareas ocasionales |
| Arrastrar a acceso directo de impresora | Sí | Posibles interrupciones | Uso diario visual y rápido |
| Combinar e imprimir a PDF | Sí | Sí (una vez combinado) | Producir una sola impresión ordenada |
| Macro VBA | Sí | Sí, si está configurado | Carpetas personales repetitivas |
| Script de PowerShell | Sí (COM) | Sí | Tareas programadas del lado del servidor |
| Spire.Doc con C# | No | Sí, totalmente silencioso | Automatización e integración de servidores |
Reflexiones finales
La impresión por lotes de documentos de Word no tiene por qué ser una tarea pesada. Comience con los trucos integrados rápidos, adopte un script cuando necesite repetibilidad y pase a una biblioteca dedicada como Spire.Doc cuando su proyecto exija una solución robusta y sin Office. Cualquiera que sea la ruta que tome, los minutos que ahorre se sumarán rápidamente a horas de productividad recuperada. Ahora elija un método, cargue su carpeta y deje que la impresora haga el trabajo pesado.
Preguntas frecuentes
¿Puedo imprimir documentos de Word sin abrir cada uno?
Sí. Los métodos 4, 5 y 6 suprimen la interfaz de Word o funcionan sin ella por completo. Tanto el script de PowerShell como Spire.Doc imprimen silenciosamente en segundo plano, mientras que la macro VBA puede ocultar la ventana de la aplicación.
¿La impresión por lotes funciona con archivos .doc y .docx?
Absolutamente. Todos los métodos descritos aquí manejan tanto los formatos .doc heredados como los modernos .docx. Al usar Spire.Doc, la biblioteca lee sin problemas ambos formatos sin ninguna conversión.
¿Cómo selecciono una impresora específica al imprimir varios archivos?
Para los métodos manuales, establezca la impresora deseada como predeterminada antes de comenzar. Con el script de PowerShell y el ejemplo de C# de Spire.Doc, puede establecer programáticamente el nombre de la impresora dentro del código, lo que le brinda un control preciso sin cambiar los valores predeterminados del sistema.