So drucken Sie mehrere Word-Dokumente gleichzeitig: 6 Methoden
Inhaltsverzeichnis
- Methode 1: Rechtsklick & Drucken über den Datei-Explorer
- Methode 2: Mehrere Word-Dateien per Drag & Drop über das Druckwarteschlangen-Fenster
- Methode 3: Word-Dateien für einen einheitlichen Druckauftrag zusammenführen
- Methode 4: Verwendung eines Word-Makros (VBA) zum Drucken aller Dokumente in einem Ordner
- Methode 5: Silent-Batch-Druck mit einem PowerShell-Skript
- Methode 6: Word-Dokumente in C# mit Spire.Doc drucken
- Kurzer Vergleich: Welche Batch-Druckmethode passt am besten zu Ihnen?
- Fazit
- Häufig gestellte Fragen (FAQs)

Das Drucken von Dutzenden von Verträgen, Berichten oder Rechnungen einzeln ist eine mühsame Zeitverschwendung. Egal, ob Sie Handouts für ein Meeting vorbereiten, juristische Dokumente erstellen oder einfach nur Ihren Büro-Schriftverkehr organisieren – die Möglichkeit, einen ganzen Ordner mit Word-Dateien auf einmal an den Drucker zu senden, kann Ihnen Stunden sparen.
Dieser Artikel führt Sie durch sechs praktische Methoden zum Batch-Druck von .doc- und .docx-Dateien – von mühelosen Rechtsklick-Tricks bis hin zu einer leistungsstarken, entwicklerorientierten Lösung mit Spire.Doc in C#. Wählen Sie die Methode, die zu Ihrem Arbeitsablauf passt, und drucken Sie ab heute intelligenter.
Überblick über die behandelten Methoden:
- Methode 1: Rechtsklick & Drucken über den Datei-Explorer
- Methode 2: Mehrere Word-Dateien per Drag & Drop über das Druckwarteschlangen-Fenster
- Methode 3: Word-Dateien für einen einheitlichen Druckauftrag zusammenführen
- Methode 4: Verwendung eines Word-Makros (VBA) zum Drucken aller Dokumente in einem Ordner
- Methode 5: Silent-Batch-Druck mit einem PowerShell-Skript
- Methode 6: Word-Dokumente in C# mit Spire.Doc drucken
Methode 1: Rechtsklick & Drucken über den Datei-Explorer
Die einfachste Methode erfordert keine zusätzlichen Tools und funktioniert sofort auf jedem Windows-PC. Sie ist perfekt geeignet, um schnell eine Handvoll Dokumente zu drucken, ohne Software installieren zu müssen. Wählen Sie einfach Ihre Dateien aus und lassen Sie Windows den Rest erledigen.
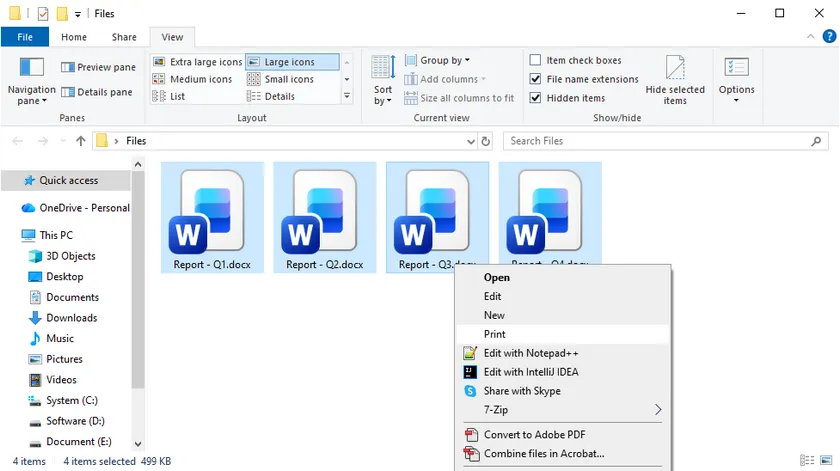
Schritte:
- Öffnen Sie den Datei-Explorer und navigieren Sie zu dem Ordner mit Ihren Word-Dokumenten.
- Wählen Sie die Dateien aus, die Sie drucken möchten: Halten Sie die Strg-Taste gedrückt und klicken Sie jede Datei einzeln an, oder drücken Sie Strg + A, um alle auszuwählen.
- Klicken Sie mit der rechten Maustaste auf eine der markierten Dateien und wählen Sie Drucken aus dem Kontextmenü.
Windows öffnet automatisch jedes Dokument in Microsoft Word, sendet es an Ihren Standarddrucker und schließt Word nach Abschluss des Vorgangs wieder. Beachten Sie, dass der Prozess bei Word-Sicherheitseinstellungen, die Makrowarnungen oder die geschützte Ansicht anzeigen, pausieren kann, bis Sie diese manuell bestätigen. Dennoch ist diese Methode für schnelle, gelegentliche Aufgaben kaum zu schlagen.
Methode 2: Mehrere Word-Dateien per Drag & Drop über das Druckwarteschlangen-Fenster
Dieser native Windows-Workflow per Drag & Drop ermöglicht den Batch-Druck mehrerer Word-Dokumente – ziehen Sie Ihre Dateien einfach auf eine Desktop-Verknüpfung Ihres Druckers. Dieser Ansatz erleichtert den Wechsel zwischen verschiedenen Druckern und ist ideal für Büroumgebungen mit mehreren Druckgeräten.
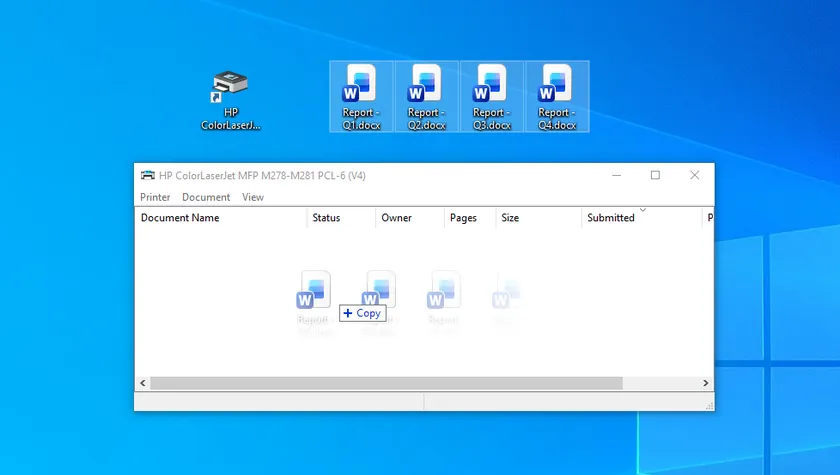
Schritte:
- Drücken Sie Win + R, geben Sie control printers ein und drücken Sie Enter, um das Fenster „Geräte und Drucker“ zu öffnen.
- Doppelklicken Sie auf das Symbol Ihres Zieldruckers, um dessen Druckwarteschlangen-Fenster zu öffnen.
- Wählen Sie alle gewünschten Word-Dateien aus und ziehen Sie diese per Drag & Drop direkt in den leeren Bereich des geöffneten Druckwarteschlangen-Fensters.
Die Dateien werden automatisch in die Liste der Druckaufträge aufgenommen. Windows öffnet, druckt und schließt jedes Dokument nacheinander.
Profi-Tipp: Sie können auch eine Desktop-Verknüpfung für den Drucker erstellen, um schneller darauf zuzugreifen, wobei das Ziehen in das Druckwarteschlangen-Fenster bei Batch-Aufgaben zuverlässigere Ergebnisse liefert.
Methode 3: Word-Dateien für einen einheitlichen Druckauftrag zusammenführen
Wenn Sie möchten, dass alle separaten Word-Dateien als ein kontinuierliches, geordnetes Dokument gedruckt werden, ist dieser Zusammenführungs-Workflow die optimale Lösung. Er funktioniert hervorragend für Handouts, formelle Berichte und Broschüren, die eine konsistente Seitennummerierung erfordern. Das Zusammenführen der Dateien vor dem Drucken erspart Ihnen das mühsame manuelle Sortieren der Seiten nach dem Druck.
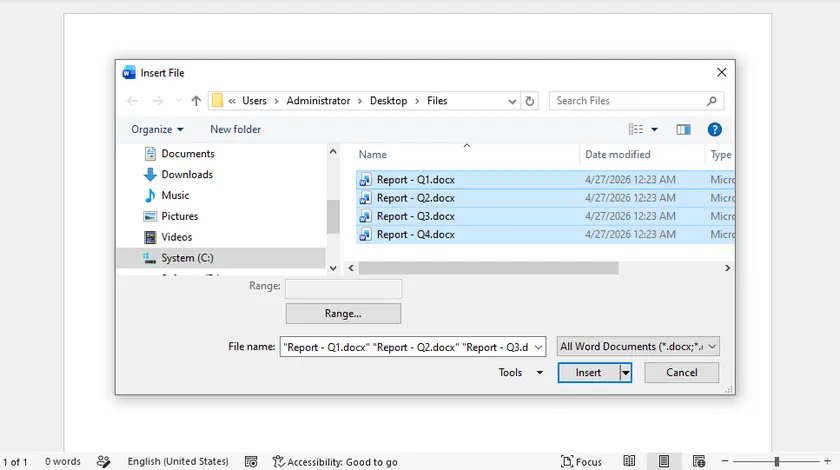
Schritte:
- Starten Sie Microsoft Word und erstellen Sie ein leeres neues Dokument.
- Navigieren Sie zu Einfügen > Objekt > Text aus Datei (alternative Pfade: Einfügen > Datei oder erweitern Sie das Dropdown-Menü „Objekt“ in bestimmten Word-Versionen).
- Markieren Sie alle DOCX-Dateien, die zusammengeführt werden sollen, und klicken Sie auf Einfügen. Die Dateien werden in der von Ihnen gewählten Reihenfolge zusammengefügt.
- Drücken Sie Strg + P, um das Druckmenü zu öffnen. Wählen Sie entweder Ihren physischen Drucker oder Microsoft Print to PDF und bestätigen Sie den Druckvorgang.
Sie erhalten ein zusammenhängendes Dokument mit ununterbrochenem Seitenfluss. Obwohl das Zusammenführen etwas zusätzliche Zeit in Anspruch nimmt, verhindert es falsch sortierte Seiten und macht das manuelle Zusammenstellen überflüssig – ideal für gebundene Dokumente und gedruckte Handouts.
Methode 4: Verwendung eines Word-Makros (VBA) zum Drucken aller Dokumente in einem Ordner
Wenn Sie häufig Stapel von Dokumenten aus demselben Ordner drucken, kann ein einfaches VBA-Makro den Prozess vollständig automatisieren. Diese Methode läuft direkt in Microsoft Word, erfordert keine zusätzliche Software und kann für den Druck mit einem Klick eingerichtet werden. Es ist ein ideales integriertes Automatisierungstool für regelmäßige, wiederkehrende Druckaufgaben.
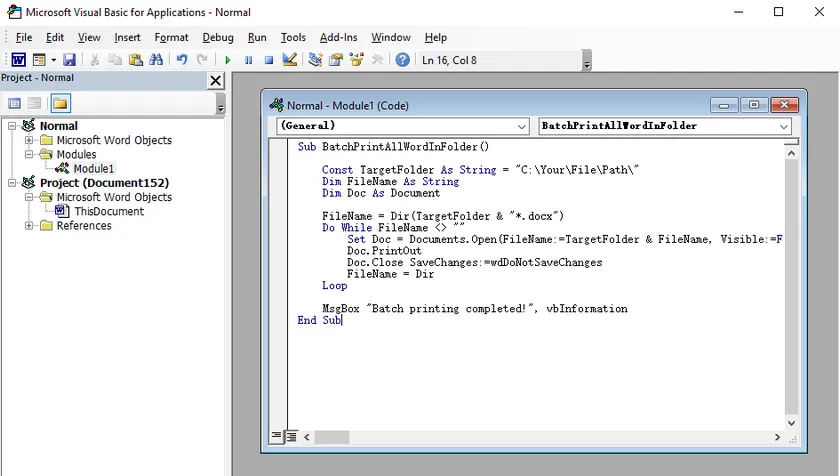
Schritte:
- Öffnen Sie Microsoft Word und drücken Sie Alt + F11, um den VBA-Editor zu öffnen.
- Gehen Sie zu Einfügen > Modul und fügen Sie den unten bereitgestellten, gebrauchsfertigen VBA-Code ein.
- Ersetzen Sie den Ordnerpfad im Code durch Ihr eigenes Verzeichnis.
- Drücken Sie F5, um das Makro auszuführen, oder weisen Sie es der Symbolleiste für den Schnellzugriff zu, um mit einem Klick zu drucken.
VBA-Code:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Ihr\Datei\Pfad\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "Batch-Druck abgeschlossen!", vbInformation
End Sub
Diese Methode druckt Dateien im Hintergrund, ohne Fenster zu öffnen. Die einzigen Voraussetzungen sind das Aktivieren von Makros und die Installation von Word – perfekt für den zuverlässigen Einsatz im persönlichen oder bürointernen Bereich.
Methode 5: Silent-Batch-Druck mit einem PowerShell-Skript
PowerShell bietet eine schnelle, leichtgewichtige und skriptbasierte Möglichkeit, mehrere Word-Dokumente im Hintergrund zu drucken – ohne Fenster, ohne Pop-ups und ohne manuelle Interaktion. Diese Methode ist ideal für Benutzer, die einen vollautomatischen Druck wünschen, und kann sogar mit der Windows-Aufgabenplanung für automatische, zeitgesteuerte Aufträge geplant werden.
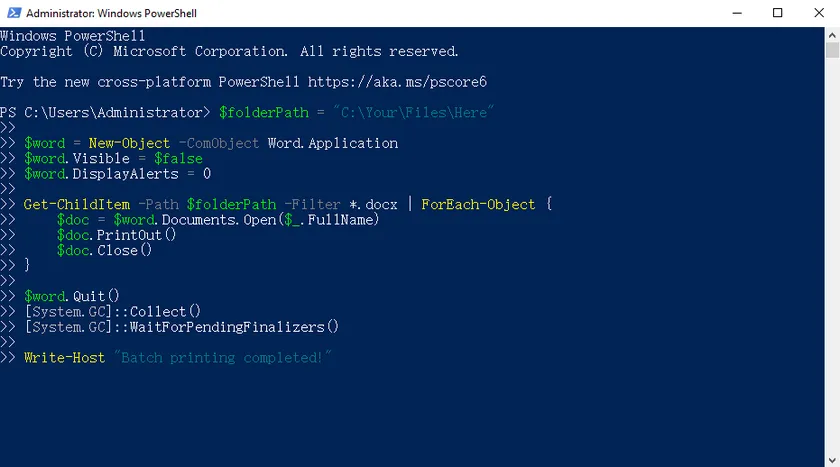
Schritte:
- Öffnen Sie PowerShell über das Startmenü (für grundlegendes Drucken sind keine Administratorrechte erforderlich).
- Kopieren Sie das unten bereitgestellte einfache Batch-Druck-Skript und fügen Sie es ein.
- Ändern Sie den Wert
$folderPathin Ihren Ziel-Dokumentenordner. - Führen Sie das Skript aus. Word läuft im Hintergrund, druckt alle Ihre Dokumente automatisch und schließt sich nach Abschluss sauber.
PowerShell-Skript:
$folderPath = "C:\Ihre\Dateien\Hier"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "Batch-Druck abgeschlossen!"
Diese Methode funktioniert ohne zusätzliche Software, unterstützt alle Word-Formate und liefert zuverlässigen, lautlosen Batch-Druck für den persönlichen und geschäftlichen Gebrauch.
Methode 6: Word-Dokumente in C# mit Spire.Doc drucken
Wenn Sie eine vollautomatisierte, leistungsstarke Batch-Drucklösung benötigen, die auf einem Server ohne Microsoft Office läuft, ist Spire.Doc for .NET die erste Wahl. Es bietet Ihnen die vollständige programmatische Kontrolle über den Dokumentendruck, was es ideal für Webanwendungen, Hintergrunddienste oder Dokumentenmanagementsysteme macht.
Warum Spire.Doc für den Batch-Druck verwenden?
Spire.Doc ist eine eigenständige .NET-Bibliothek, die Word-Dateien liest, erstellt und manipuliert, ohne von Word selbst abhängig zu sein. Für den Batch-Druck bedeutet dies, dass Sie Tausende von Dokumenten zuverlässig auf einem Server verarbeiten, einen bestimmten Drucker auswählen, Seitenbereiche festlegen und sogar beidseitigen Druck steuern können – alles durch sauberen C#-Code.
Einrichten von Spire.Doc in Ihrem .NET-Projekt
Installieren Sie das Paket über den NuGet Package Manager:
Install-Package Spire.Doc
Oder verwenden Sie die .NET CLI: dotnet add package Spire.Doc. Das ist alles – keine zusätzlichen Office-Lizenzen oder Installationen erforderlich.
C#-Codebeispiel: Alle Word-Dateien aus einem Verzeichnis drucken
Unten sehen Sie eine vollständige Konsolenanwendung, die alle .docx- und .doc-Dateien aus einem Ordner liest und sie lautlos mit einem Standard-Druckcontroller (ohne Pop-up-Dialog) druckt. Der Code zeigt auch, wie man mögliche Ausnahmen elegant behandelt.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\ZuDruckendeDokumente";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Drucke: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Unterdrückt den Druckdialog für lautloses Drucken
printDoc.PrintController = new StandardPrintController();
// Optional: Druckername und Kopien festlegen
// printDoc.PrinterSettings.PrinterName = "Mein Drucker";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Fehler beim Drucken von {filePath}: {ex.Message}");
}
}
}
Console.WriteLine("Batch-Druck abgeschlossen.");
}
}
Die Logik ist einfach: Alle Dateien aus dem Verzeichnis abrufen, die Erweiterung prüfen, jede in ein Spire.Doc-Document-Objekt laden, auf dessen PrintDocument zugreifen, den StandardPrintController festlegen, um den Windows-Druckdialog zu vermeiden, und Print() aufrufen. Die Schleife stellt sicher, dass jedes gültige Word-Dokument nacheinander gedruckt wird.
Die Eigenschaft PrintDocument.PrinterSettings ermöglicht eine präzise Steuerung. Sie können den genauen Drucker mit PrinterName angeben, die Anzahl der Kopien festlegen, einen Seitenbereich auswählen oder den beidseitigen Druck aktivieren. Weitere Informationen finden Sie unter Wie man Word-Dokumente in C# druckt.
Kurzer Vergleich: Welche Batch-Druckmethode passt am besten zu Ihnen?
| Methode | Erfordert Word? | Lautlos / Keine Pop-ups | Am besten geeignet für |
|---|---|---|---|
| Rechtsklick & Drucken | Ja | Mögliche Unterbrechungen | Gelegentliche Einzelaufgaben |
| Drag & Drop auf Drucker | Ja | Mögliche Unterbrechungen | Visuelle, schnelle tägliche Nutzung |
| Zusammenführen & als PDF drucken | Ja | Ja (nach Zusammenführung) | Erstellung eines geordneten Ausdrucks |
| VBA-Makro | Ja | Ja, falls konfiguriert | Persönliche, wiederkehrende Ordner |
| PowerShell-Skript | Ja (COM) | Ja | Geplante serverseitige Aufgaben |
| Spire.Doc mit C# | Nein | Ja, vollkommen lautlos | Server-Automatisierung & Integration |
Fazit
Das Stapeldrucken von Word-Dokumenten muss keine lästige Pflicht sein. Beginnen Sie mit den schnellen integrierten Tricks, nutzen Sie ein Skript, wenn Sie Wiederholbarkeit benötigen, und steigen Sie auf eine dedizierte Bibliothek wie Spire.Doc um, wenn Ihr Projekt eine robuste, Office-freie Lösung erfordert. Welchen Weg Sie auch wählen, die Minuten, die Sie sparen, summieren sich schnell zu Stunden gewonnener Produktivität. Wählen Sie jetzt eine Methode, laden Sie Ihren Ordner und lassen Sie den Drucker die Arbeit erledigen.
Häufig gestellte Fragen (FAQs)
Kann ich Word-Dokumente drucken, ohne jedes einzeln zu öffnen?
Ja. Die Methoden 4, 5 und 6 unterdrücken die Word-Oberfläche oder funktionieren ganz ohne sie. Das PowerShell-Skript und Spire.Doc drucken beide lautlos im Hintergrund, während das VBA-Makro das Anwendungsfenster ausblenden kann.
Funktioniert der Batch-Druck mit .doc- und .docx-Dateien?
Absolut. Jede hier beschriebene Methode verarbeitet sowohl ältere .doc- als auch moderne .docx-Formate. Bei der Verwendung von Spire.Doc liest die Bibliothek beide Formate nahtlos ohne Konvertierung.
Wie wähle ich einen bestimmten Drucker aus, wenn ich mehrere Dateien drucke?
Bei den manuellen Methoden legen Sie vor dem Start Ihren gewünschten Drucker als Standard fest. Beim PowerShell-Skript und dem C#-Spire.Doc-Beispiel können Sie den Druckernamen programmatisch im Code festlegen, was Ihnen eine präzise Kontrolle ermöglicht, ohne die Systemeinstellungen zu ändern.
Siehe auch
Как распечатать несколько документов Word одновременно: 6 способов
Оглавление
- Способ 1: Правая кнопка мыши и печать из Проводника
- Способ 2: Перетаскивание нескольких файлов Word в окно очереди печати
- Способ 3: Объединение файлов Word для единого задания на печать
- Способ 4: Использование макроса Word (VBA) для печати всех документов в папке
- Способ 5: Фоновая пакетная печать с помощью скрипта PowerShell
- Способ 6: Печать документов Word на C# с использованием Spire.Doc
- Краткое сравнение: какой метод пакетной печати подходит вам лучше всего?
- Заключение
- Часто задаваемые вопросы
Печать десятков контрактов, отчетов или счетов по одному — это утомительная трата времени. Готовите ли вы раздаточные материалы для встречи, создаете юридические документы или просто наводите порядок в офисных бумагах, возможность отправить целую папку файлов Word на принтер за один раз может сэкономить вам часы работы.
В этой статье мы рассмотрим шесть практических методов пакетной печати файлов .doc и .docx — от простых приемов с правой кнопкой мыши до мощного решения для разработчиков на C# с использованием Spire.Doc. Выберите тот, который лучше всего подходит для вашего рабочего процесса, и начните печатать эффективнее уже сегодня.
Обзор рассматриваемых методов:
- Способ 1: Правая кнопка мыши и печать из Проводника
- Способ 2: Перетаскивание нескольких файлов Word в окно очереди печати
- Способ 3: Объединение файлов Word для единого задания на печать
- Способ 4: Использование макроса Word (VBA) для печати всех документов в папке
- Способ 5: Фоновая пакетная печать с помощью скрипта PowerShell
- Способ 6: Печать документов Word на C# с использованием Spire.Doc
Способ 1: Правая кнопка мыши и печать из Проводника
Самый простой метод, не требующий дополнительных инструментов и работающий мгновенно на любом ПК с Windows. Он идеально подходит для быстрой печати нескольких документов без установки какого-либо программного обеспечения. Просто выделите файлы, а остальное сделает Windows.
Шаги:
- Откройте Проводник и перейдите в папку с вашими документами Word.
- Выберите файлы, которые хотите распечатать: удерживайте клавишу Ctrl и щелкайте по каждому файлу отдельно или нажмите Ctrl + A, чтобы выбрать все.
- Нажмите правой кнопкой мыши на любой выделенный файл и выберите Печать в контекстном меню.
Windows автоматически откроет каждый документ в Microsoft Word, отправит его на принтер по умолчанию и закроет Word после завершения. Имейте в виду, что если настройки безопасности Word отображают предупреждения о макросах или защищенный просмотр, процесс может приостановиться до вашего подтверждения. Тем не менее, для быстрой разовой печати этот метод незаменим.
Способ 2: Перетаскивание нескольких файлов Word в окно очереди печати
Этот встроенный рабочий процесс Windows позволяет выполнять пакетную печать нескольких документов Word путем перетаскивания файлов на ярлык принтера. Такой подход упрощает переключение между разными принтерами, что идеально подходит для офисов, оснащенных несколькими печатающими устройствами.
Шаги:
- Нажмите Win + R, введите control printers и нажмите Enter, чтобы открыть окно «Устройства и принтеры».
- Дважды щелкните значок нужного принтера, чтобы открыть окно очереди печати.
- Выберите все нужные файлы Word и перетащите их прямо в пустую область открытого окна очереди печати.
Файлы автоматически добавятся в список заданий на печать. Windows будет открывать, печатать и закрывать каждый документ последовательно.
Совет: Вы также можете создать ярлык принтера на рабочем столе для быстрого доступа, хотя перетаскивание непосредственно в окно очереди печати дает более надежные результаты для пакетных задач.
Способ 3: Объединение файлов Word для единого задания на печать
Если вы хотите, чтобы все отдельные файлы Word были напечатаны как один непрерывный документ, этот метод объединения — оптимальное решение. Он отлично подходит для раздаточных материалов, официальных отчетов и брошюр, требующих последовательной нумерации страниц. Объединение файлов перед печатью избавляет от утомительной ручной сортировки страниц после вывода.
Шаги:
- Запустите Microsoft Word и создайте новый пустой документ.
- Перейдите в Вставка > Объект > Текст из файла (альтернативные пути: Вставка > Файл или разверните выпадающее меню «Объект» в некоторых версиях Word).
- Выделите все файлы DOCX для объединения и нажмите Вставка. Файлы соберутся в выбранном вами порядке.
- Нажмите Ctrl + P, чтобы открыть панель печати. Выберите ваш физический принтер или Microsoft Print to PDF, затем подтвердите печать.
Вы получите один связный документ с непрерывной нумерацией страниц. Хотя объединение занимает немного больше времени, оно предотвращает нарушение порядка страниц и исключает ручную сортировку — идеально для сброшюрованных документов и раздаточных материалов.
Способ 4: Использование макроса Word (VBA) для печати всех документов в папке
Если вы часто печатаете пакеты документов из одной и той же папки, простой VBA-макрос может полностью автоматизировать этот процесс. Этот метод работает непосредственно внутри Microsoft Word, не требует дополнительного ПО и может быть настроен для печати в один клик. Это идеальный встроенный инструмент автоматизации для регулярных повторяющихся задач печати.
Шаги:
- Откройте Microsoft Word и нажмите Alt + F11, чтобы открыть редактор VBA.
- Перейдите в Вставка > Модуль и вставьте готовый код VBA, приведенный ниже.
- Замените путь к папке в коде на свой собственный каталог.
- Нажмите F5 для запуска макроса или добавьте его на панель быстрого доступа для печати в один клик.
Код VBA:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Ваш\Путь\К\Файлу\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "Пакетная печать завершена!", vbInformation
End Sub
Этот метод печатает файлы в фоновом режиме без открытия окон. Единственные требования — включение макросов и установленный Word. Идеально подходит для надежного использования дома или в офисе.
Способ 5: Фоновая пакетная печать с помощью скрипта PowerShell
PowerShell предлагает быстрый и легкий способ печати нескольких документов Word в фоновом режиме — без окон, всплывающих сообщений и ручного взаимодействия. Этот метод идеален для пользователей, которым нужна полная автоматизация, и его даже можно запланировать через «Планировщик заданий Windows» для автоматического выполнения по расписанию.
Шаги:
- Откройте PowerShell из меню «Пуск» (права администратора для базовой печати не требуются).
- Скопируйте и вставьте приведенный ниже простой скрипт пакетной печати.
- Измените значение
$folderPathна путь к вашей папке с документами. - Запустите скрипт. Word будет работать в фоновом режиме, автоматически распечатает все документы и корректно закроется после завершения.
Скрипт PowerShell:
$folderPath = "C:\Ваши\Файлы\Здесь"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "Пакетная печать завершена!"
Этот метод работает без дополнительного ПО, поддерживает все форматы Word и обеспечивает надежную фоновую печать как для личного, так и для офисного использования.
Способ 6: Печать документов Word на C# с использованием Spire.Doc
Когда вам нужно полностью автоматизированное высокопроизводительное решение для пакетной печати, работающее на сервере без установленного Microsoft Office, Spire.Doc for .NET — это идеальная библиотека. Она дает полный программный контроль над печатью документов, что делает ее идеальной для веб-приложений, фоновых служб или систем управления документами.
Почему стоит использовать Spire.Doc для пакетной печати?
Spire.Doc — это автономная библиотека .NET, которая читает, создает и редактирует файлы Word без какой-либо зависимости от самого Word. Для пакетной печати это означает, что вы можете надежно обрабатывать тысячи документов на сервере, выбирать конкретный принтер, задавать диапазоны страниц и даже настраивать двустороннюю печать — и все это с помощью чистого кода C#.
Настройка Spire.Doc в вашем проекте .NET
Установите пакет через NuGet Package Manager:
Install-Package Spire.Doc
Или используйте .NET CLI: dotnet add package Spire.Doc. Это все — никаких дополнительных лицензий или установок Office.
Пример кода на C#: Печать всех файлов Word из каталога
Ниже представлено консольное приложение, которое считывает все файлы .docx и .doc из папки и печатает их в фоновом режиме с использованием стандартного контроллера печати (без всплывающих диалоговых окон). Код также показывает, как корректно обрабатывать возможные исключения.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\ДокументыДляПечати";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
// Фильтр только для .docx и .doc
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Печать: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Отключение диалогового окна печати для фоновой печати
printDoc.PrintController = new StandardPrintController();
// Опционально: установка имени принтера и количества копий
// printDoc.PrinterSettings.PrinterName = "Мой Принтер";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Ошибка печати {filePath}: {ex.Message}");
}
}
}
Console.WriteLine("Пакетная печать завершена.");
}
}
Логика проста: получить все файлы из каталога, проверить расширение, загрузить каждый в объект Document библиотеки Spire.Doc, получить доступ к его PrintDocument, установить StandardPrintController, чтобы избежать появления окна печати Windows, и вызвать Print(). Цикл гарантирует, что каждый корректный документ Word будет напечатан последовательно.
Свойство PrintDocument.PrinterSettings открывает доступ к тонкой настройке. Вы можете указать конкретный принтер через PrinterName, задать количество копий, выбрать диапазон страниц или включить двустороннюю печать. Для более подробного ознакомления обратитесь к руководству Как печатать документы Word на C#.
Краткое сравнение: какой метод пакетной печати подходит вам лучше всего?
| Метод | Требуется Word? | Фоновый режим / Без окон | Лучше всего подходит для |
|---|---|---|---|
| Правая кнопка мыши | Да | Возможны прерывания | Разовые задачи |
| Перетаскивание на ярлык | Да | Возможны прерывания | Визуальное, ежедневное использование |
| Объединение и печать в PDF | Да | Да (после объединения) | Создание одного упорядоченного документа |
| VBA Макрос | Да | Да, если настроено | Личные повторяющиеся задачи |
| Скрипт PowerShell | Да (COM) | Да | Серверные задачи по расписанию |
| Spire.Doc на C# | Нет | Да, полностью фоновый | Серверная автоматизация и интеграция |
Заключение
Пакетная печать документов Word не обязательно должна быть рутиной. Начните с простых встроенных приемов, перейдите к скриптам, когда потребуется повторяемость, и используйте специализированную библиотеку, такую как Spire.Doc, когда ваш проект требует надежного решения без зависимости от Office. Какой бы путь вы ни выбрали, сэкономленные минуты быстро сложатся в часы продуктивной работы. Выберите метод, подготовьте папку и позвольте принтеру сделать всю тяжелую работу.
Часто задаваемые вопросы
Можно ли печатать документы Word, не открывая каждый из них?
Да. Методы 4, 5 и 6 либо подавляют интерфейс Word, либо работают без него вовсе. Скрипт PowerShell и Spire.Doc печатают в фоновом режиме, а макрос VBA может скрыть окно приложения.
Работает ли пакетная печать с файлами .doc и .docx?
Безусловно. Каждый описанный здесь метод поддерживает как старые форматы .doc, так и современные .docx. При использовании Spire.Doc библиотека бесшовно читает оба формата без необходимости конвертации.
Как выбрать конкретный принтер при печати нескольких файлов?
Для ручных методов установите нужный принтер по умолчанию перед началом работы. В скрипте PowerShell и примере на C# со Spire.Doc вы можете программно задать имя принтера внутри кода, что дает точный контроль без изменения системных настроек.
Смотрите также
Como converter tabelas do Word para CSV (DOC/DOCX para CSV)
Índice

CSV (Comma-Separated Values) é um formato leve e universalmente compatível para dados tabulares. Documentos do Word (DOC e DOCX), por outro lado, são documentos de texto rico que contêm parágrafos, imagens, cabeçalhos, formatação e tabelas. Como o CSV suporta apenas linhas e colunas, converter Word para CSV ou DOCX para CSV quase sempre significa extrair dados de tabelas do documento.
As organizações frequentemente precisam converter tabelas do Word ou DOCX para CSV ao mover dados estruturados para planilhas, bancos de dados, sistemas de CRM, ferramentas de análise ou fluxos de trabalho automatizados.
Este guia abrange dois métodos práticos para converter tabelas do Word para CSV, além de contexto importante sobre por que o Word não pode exportar CSV diretamente e quando os conversores online são apropriados.
Navegação Rápida
- Por que o Word não pode ser salvo diretamente como CSV
- Método 1 – Converter tabelas do Word para CSV usando software de planilha
- Você pode usar um conversor online de Word para CSV?
- Método 2 – Converter tabelas do Word para CSV automaticamente com Python
- FAQ
Qual Método Escolher?
| Método | Facilidade de Uso | Processamento em Lote | Privacidade | Melhor Para |
|---|---|---|---|---|
| Software de Planilha | Alta | Não | Alta | Conversões ocasionais, revisão manual |
| Python (Spire.Doc) | Média | Sim | Alta | Automação, processamento em lote, tarefas recorrentes |
1. Por que o Word não pode ser salvo diretamente como CSV
O Microsoft Word não oferece uma opção de "Salvar como CSV". Isso não é uma falha — reflete uma incompatibilidade fundamental de formato:
- Documentos do Word contêm conteúdo misto: parágrafos, imagens, cabeçalhos, rodapés, texto estilizado e tabelas. Um único documento pode ter várias seções, colunas e elementos aninhados.
- Arquivos CSV contêm apenas dados tabulares planos: linhas e colunas de texto simples separadas por vírgulas.
O Word não consegue determinar automaticamente como achatar um documento de texto rico em um layout tabular. Um documento com três parágrafos, uma imagem e uma tabela não se mapeia claramente em linhas e colunas. A única parte de um documento do Word que tem uma representação CSV natural é dados de tabela estruturados.
É por isso que todas as abordagens práticas para converter Word para CSV se concentram em extrair tabelas do documento — seja por meio de software de planilha, ferramentas online ou métodos programáticos.
2. Método 1 – Converter tabelas do Word para CSV usando software de planilha
A maneira mais direta de converter tabelas do Word para CSV é copiar a tabela para um aplicativo de planilha e exportá-la. Tanto o Microsoft Excel quanto o Google Sheets suportam este fluxo de trabalho.
O Fluxo de Trabalho
- Copie a tabela do Word para uma planilha — Selecione a tabela no Word, copie-a e cole-a em uma nova planilha
- Verifique os dados importados — Verifique se as linhas, colunas e valores das células estão corretamente separados. Observe as células mescladas, que podem causar desalinhamento
- Exporte como CSV — Salve ou baixe a planilha no formato CSV
Opção A – Microsoft Office
- Abra o documento do Word e copie a tabela que deseja exportar.
- Cole a tabela em uma planilha do Excel e verifique se as linhas e colunas foram importadas corretamente.
- Revise células mescladas, quebras de linha ou outros problemas de formatação que possam afetar a estrutura do CSV.
- Escolha Arquivo > Salvar como e salve a planilha como um arquivo CSV.
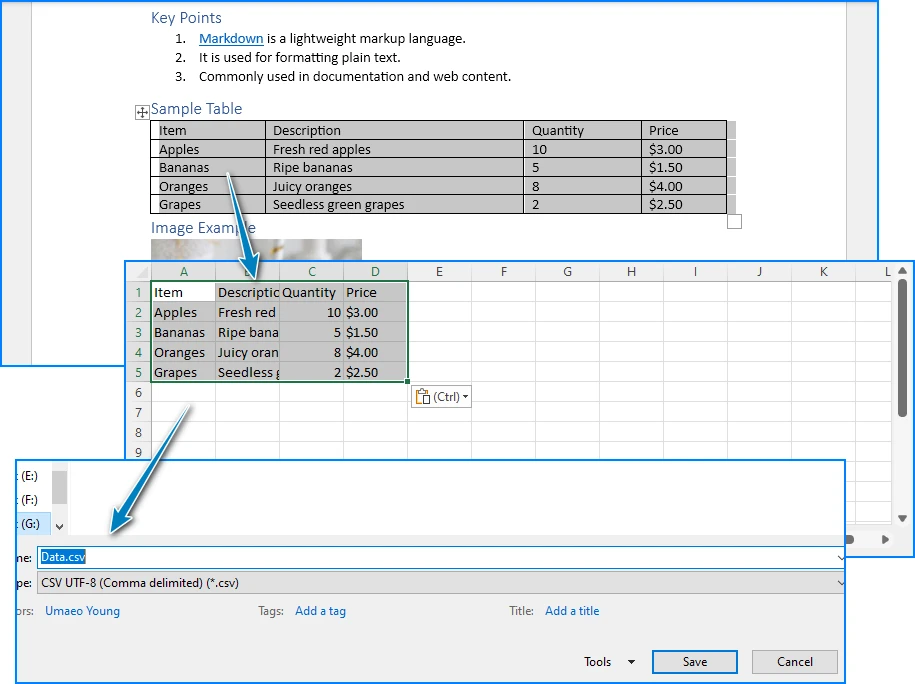
O Excel preserva bem a estrutura da tabela do Word — linhas e colunas se mapeiam corretamente na maioria dos casos. Se o seu documento contiver várias tabelas, você pode colar cada uma em uma planilha separada e salvar cada uma como um arquivo CSV individual.
Considerações:
- Células mescladas na tabela do Word podem causar desalinhamento após a colagem
- O Excel é executado localmente, portanto seus dados permanecem em sua máquina
- O processo é manual e não é prático para conversões frequentes ou em larga escala
Opção B – Google Sheets
- Copie a tabela do documento do Word (no Google Docs ou outros visualizadores de documentos).
- Cole-a em uma nova planilha do Google Sheets.
- Verifique a estrutura da tabela importada e ajuste quaisquer dados desalinhados.
- Baixe a planilha como um arquivo CSV usando Arquivo > Download > Valores Separados por Vírgula (.csv).
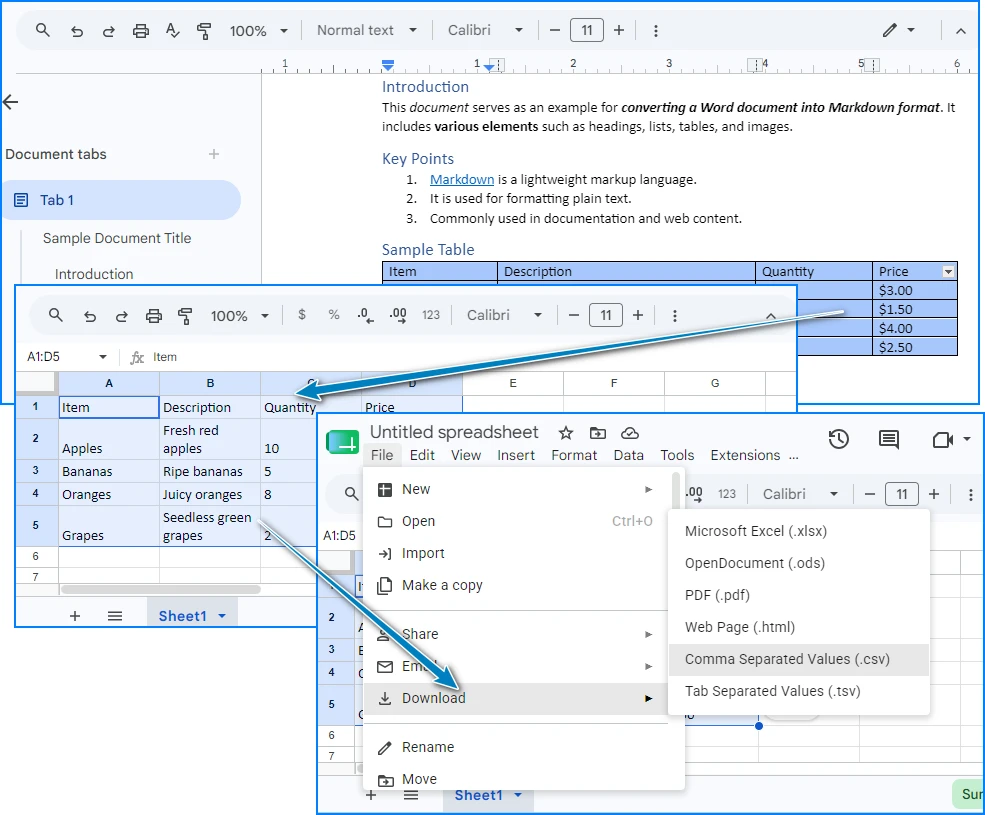
O Google Sheets é gratuito e requer apenas uma conta Google. Ele também facilita o compartilhamento e a revisão de dados com colaboradores antes de exportar para CSV.
Considerações:
- Os dados são armazenados nos servidores do Google durante a edição — considere isso para informações confidenciais
- Nenhuma instalação de software necessária
- Assim como o Excel, este é um processo manual sem suporte de automação
Quando Usar Este Método
A conversão baseada em planilha funciona bem quando você precisa ocasionalmente exportar dados de tabelas do Word para CSV e deseja revisar os dados antes de salvar. Para conversões recorrentes, vários documentos ou fluxos de trabalho automatizados, o método Python abaixo é mais eficiente.
Se você também precisar converter DOCX (documentos do Word) para XLSX, pode consultar nosso guia de conversão de Docx para XLSX para um fluxo de trabalho de planilha estruturado.
3. Você pode usar um conversor online de Word para CSV?
Sim. Vários sites oferecem ferramentas de conversor de Word para CSV que permitem fazer upload de um arquivo DOC ou DOCX e baixar um arquivo CSV. Estes são adequados para conversões rápidas e únicas quando você não quer instalar nenhum software.
No entanto, os conversores online têm limitações notáveis:
- Privacidade — Seu documento é carregado em um servidor de terceiros, o que pode não ser aceitável para dados confidenciais ou proprietários
- Limites de tamanho de arquivo — A maioria das ferramentas gratuitas restringe uploads a 5–10 MB
- Reconhecimento de tabela — Alguns conversores extraem apenas a primeira tabela; outros podem interpretar mal a estrutura do documento
- Sem processamento em lote — Você pode converter apenas um arquivo por vez
Para dados confidenciais, conversões recorrentes ou processamento em lote, métodos locais (software de planilha ou Python) são preferíveis.
4. Método 2 – Converter tabelas do Word para CSV automaticamente com Python
Se você precisar converter arquivos do Word para CSV regularmente, automatizar o processamento de documentos ou lidar com um grande número de arquivos, o Python oferece uma solução mais eficiente. Com o Spire.Doc for Python, você pode ler documentos do Word, extrair dados de tabelas e exportá-los diretamente para o formato CSV — tudo sem o Microsoft Word instalado.
Instalar Spire.Doc for Python
Instale a biblioteca via pip:
pip install spire.doc
Importe as classes necessárias em seu script Python:
from spire.doc import *
from spire.doc.common import *
Alternativamente, você pode baixar Spire.Doc for Python e integrá-lo manualmente.
Converter uma Tabela do Word para CSV
O exemplo a seguir carrega um documento do Word, extrai a primeira tabela, lê suas linhas e células e grava os dados em um arquivo CSV.
import csv
from spire.doc import *
from spire.doc.common import *
document = Document()
document.LoadFromFile("Sample.docx")
section = document.Sections.get_Item(0)
for t in range(section.Tables.Count):
table = section.Tables.get_Item(t)
csv_data = []
for r in range(table.Rows.Count):
row = table.Rows.get_Item(r)
row_data = []
for c in range(row.Cells.Count):
cell = row.Cells.get_Item(c)
paragraphs = []
for p in range(cell.Paragraphs.Count):
text = cell.Paragraphs.get_Item(p).Text.strip()
if text:
paragraphs.append(text)
row_data.append(" ".join(paragraphs))
csv_data.append(row_data)
csv_path = f"table_{t + 1}.csv"
with open(csv_path, "w", newline="", encoding="utf-8-sig") as f:
csv.writer(f).writerows(csv_data)
document.Close()
Como Funciona
Document.LoadFromFile()carrega o documento do Word na memória.section.Tables.get_Item(table_index)seleciona a tabela a ser exportada.- O script percorre cada linha e célula da tabela usando as coleções Rows e Cells.
- Cada célula da tabela pode conter um ou mais parágrafos. O script lê todos os parágrafos usando
cell.Paragraphse extrai seu conteúdo de texto. - O texto do parágrafo extraído é limpo com
.strip()e combinado em uma única string para o valor da célula CSV. csv.writer()exporta os dados da tabela coletados para um arquivo CSV padrão que pode ser aberto no Excel, Google Sheets, bancos de dados ou outras ferramentas de processamento de dados.
Resultado da Saída
Abaixo está uma prévia da tabela do Word e do arquivo CSV gerado:
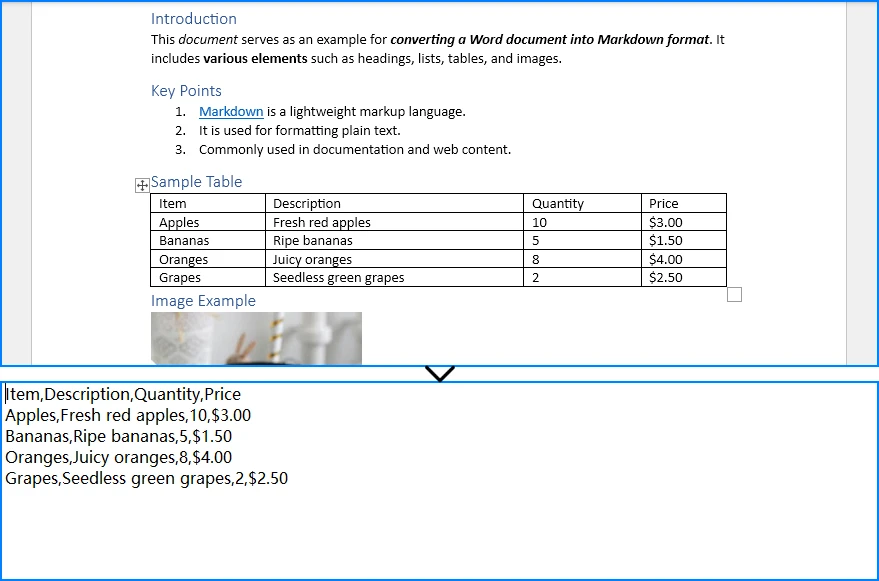
A saída é um arquivo .csv formatado corretamente contendo os dados da tabela do Word, pronto para importação no Excel, bancos de dados ou qualquer sistema que aceite entrada CSV.
Extrair Múltiplas Tabelas de um Documento do Word
Se o seu documento do Word contiver várias tabelas, itere por section.Tables e salve cada uma como um arquivo CSV separado:
for t in range(section.Tables.Count):
word_table_to_csv(
word_path,
f"table_{t + 1}.csv",
table_index=t
)
Converter em Lote Vários Arquivos do Word
Para processar uma pasta inteira de documentos do Word, itere pelos arquivos e extraia a primeira tabela de cada um:
for filename in os.listdir(input_folder):
if filename.lower().endswith((".doc", ".docx")):
word_table_to_csv(
os.path.join(input_folder, filename),
os.path.join(
output_folder,
os.path.splitext(filename)[0] + ".csv"
)
)
Por que Usar Python para Conversão de Word para CSV?
A automação com Python e Spire.Doc for Python oferece vantagens claras quando você precisa converter tabelas do Word para CSV em escala:
| Vantagem | Detalhes |
|---|---|
| Conversão em lote | Processe dezenas ou centenas de arquivos do Word em um único script |
| Automação | Agende conversões para serem executadas automaticamente — diariamente, semanalmente ou sob demanda |
| Grandes conjuntos de dados | Lide com documentos do Word com tabelas grandes que são impraticáveis de converter manualmente |
| Integração de fluxo de trabalho | Integre a conversão de Word para CSV em pipelines de dados, processos ETL ou fluxos de trabalho CI/CD |
| Sem dependência do Microsoft Word | Spire.Doc for Python funciona sem o Microsoft Word instalado |
| Precisão dos dados | A extração programática elimina erros de copiar e colar e garante resultados consistentes |
Para uso mais avançado, você também pode consultar nosso guia sobre extrair tabelas de documentos do Word usando Python.
5. FAQ
Posso converter Word para CSV diretamente?
Não. O Microsoft Word não tem uma opção integrada para salvar ou exportar documentos como CSV. A caixa de diálogo "Salvar como" do Word suporta formatos como DOCX, PDF, RTF, HTML e texto simples — mas não CSV. Para converter Word para CSV, você precisa extrair dados de tabelas do documento e gravá-los em um arquivo CSV usando software de planilha ou automação Python.
Por que o Word não pode salvar diretamente como CSV?
O Word é um formato de documento de texto rico que suporta parágrafos, imagens, cabeçalhos, estilos e conteúdo misto. CSV é um formato tabular plano que armazena apenas linhas e colunas de texto separadas por vírgulas. O Word não consegue determinar automaticamente como achatar uma estrutura de documento complexa em um layout tabular, portanto, não oferece CSV como opção de exportação. Apenas dados estruturados — tipicamente dados em tabelas do Word — podem ser convertidos significativamente para CSV.
Como converto uma tabela do Word para CSV?
Você tem duas opções principais: (1) Software de planilha — Copie a tabela do Word para o Excel ou Google Sheets, verifique os dados e salve ou baixe como CSV. Esta é a abordagem mais comum para uso ocasional. (2) Python — Use Spire.Doc for Python para ler o documento do Word, acessar a tabela programaticamente, extrair valores de células e gravá-los em um arquivo CSV. Isso é ideal para automação, processamento em lote e conversões recorrentes.
Posso converter DOCX para CSV sem o Excel?
Sim. Você pode converter DOCX para CSV sem o Excel usando: (1) Google Sheets — Cole os dados da tabela do Word em uma planilha do Google Sheets e baixe como CSV. (2) Ferramentas online — Faça upload do seu arquivo DOCX para um site conversor de Word para CSV e baixe o resultado. (3) Python — Use Spire.Doc for Python para ler o arquivo DOCX, extrair dados de tabelas e gravá-los em CSV. Isso funciona sem nenhum software do Microsoft Office instalado.
Existe um conversor gratuito de Word para CSV?
Sim. Existem opções gratuitas em duas categorias: (1) Conversores online — Muitos sites oferecem conversão gratuita de Word para CSV, embora geralmente tenham limites de tamanho de arquivo e levantem preocupações de privacidade, pois seus dados são carregados em um servidor de terceiros. (2) Scripts Python — Você pode escrever um script de conversão local e gratuito usando Spire.Doc for Python (que oferece uma versão gratuita) e o módulo csv integrado do Python. Isso mantém seus dados privados e não tem restrições de tamanho de arquivo.
Como extraio dados de um documento do Word para CSV em Python?
Use Spire.Doc for Python para carregar o documento do Word, acessar a tabela através das coleções Sections e Tables, iterar por linhas e células para ler o texto de cada célula e gravar os dados em um arquivo CSV usando o csv.writer padrão do Python. O exemplo de código completo é fornecido no Método 2 acima.
O Spire.Doc for Python requer que o Microsoft Word seja instalado?
Não. Spire.Doc for Python é uma biblioteca independente que cria, lê e manipula documentos do Word de forma independente. Ele não requer que o Microsoft Word ou qualquer componente do Office seja instalado em seu sistema. Isso o torna adequado para ambientes de servidor, fluxos de trabalho automatizados e máquinas onde o Office não está disponível.
Conclusão
Converter Word para CSV significa extrair dados de tabelas estruturadas de documentos DOC ou DOCX e salvá-los em um formato tabular. Software de planilha (Excel ou Google Sheets) fornece uma abordagem manual simples — copie a tabela do Word, verifique os dados e exporte como CSV. Isso funciona bem para conversões ocasionais, mas não escala para processamento em lote ou fluxos de trabalho recorrentes.
Automação com Python com Spire.Doc for Python oferece uma solução confiável para converter tabelas do Word para CSV programaticamente. Ele lê arquivos DOC e DOCX, extrai dados de tabelas com precisão e grava a saída CSV — tudo sem exigir o Microsoft Word. Para desenvolvedores e organizações que convertem regularmente arquivos DOC ou DOCX para CSV, Spire.Doc for Python oferece uma maneira confiável de automatizar todo o processo, preservando os dados da tabela com precisão.
Você pode solicitar uma licença gratuita de 30 dias para avaliar todos os recursos do Spire.Doc for Python.
Veja Também
Word 표를 CSV로 변환하는 방법 (DOC/DOCX를 CSV로)
CSV(쉼표로 구분된 값)는 표 형식 데이터를 위한 가볍고 보편적으로 호환되는 형식입니다. 반면에 Word 문서(DOC 및 DOCX)는 단락, 이미지, 머리글, 서식 및 표를 포함하는 서식 있는 텍스트 문서입니다. CSV는 행과 열만 지원하므로, Word를 CSV 또는 DOCX를 CSV로 변환하는 것은 거의 항상 문서에서 표 데이터를 추출하는 것을 의미합니다.
조직은 구조화된 데이터를 스프레드시트, 데이터베이스, CRM 시스템, 분석 도구 또는 자동화된 워크플로로 이동할 때 종종 Word 또는 DOCX 표를 CSV로 변환해야 합니다.
이 가이드에서는 Word 표를 CSV로 변환하는 두 가지 실용적인 방법과 Word가 CSV를 직접 내보낼 수 없는 이유 및 온라인 변환기가 적절한 시기에 대한 중요한 맥락을 다룹니다.
빠른 탐색
- Word를 CSV로 직접 저장할 수 없는 이유
- 방법 1 – 스프레드시트 소프트웨어를 사용하여 Word 표를 CSV로 변환
- 온라인 Word-CSV 변환기를 사용할 수 있나요?
- 방법 2 – Python으로 Word 표를 CSV로 자동 변환
- 자주 묻는 질문
어떤 방법을 선택해야 할까요?
| 방법 | 사용 편의성 | 일괄 처리 | 개인 정보 보호 | 가장 적합한 경우 |
|---|---|---|---|---|
| 스프레드시트 소프트웨어 | 높음 | 아니요 | 높음 | 간헐적 변환, 수동 검토 |
| Python (Spire.Doc) | 중간 | 예 | 높음 | 자동화, 일괄 처리, 반복 작업 |
1. Word를 CSV로 직접 저장할 수 없는 이유
Microsoft Word에는 "CSV로 저장" 옵션이 없습니다. 이는 간과가 아니라 형식의 근본적인 불일치를 반영합니다:
- Word 문서에는 단락, 이미지, 머리글, 바닥글, 스타일이 지정된 텍스트 및 표와 같은 혼합 콘텐츠가 포함되어 있습니다. 단일 문서에는 여러 섹션, 열 및 중첩된 요소가 있을 수 있습니다.
- CSV 파일에는 쉼표로 구분된 평면 표 형식 데이터(행 및 열)만 포함됩니다.
Word는 서식 있는 텍스트 문서를 표 형식 레이아웃으로 평탄화하는 방법을 자동으로 결정할 수 없습니다. 세 개의 단락, 이미지 및 표가 있는 문서는 행과 열에 깔끔하게 매핑되지 않습니다. Word 문서에서 CSV로 자연스럽게 표현될 수 있는 유일한 부분은 구조화된 표 데이터입니다.
이것이 Word를 CSV로 변환하는 모든 실용적인 접근 방식이 문서에서 표를 추출하는 데 중점을 두는 이유입니다. 스프레드시트 소프트웨어, 온라인 도구 또는 프로그래밍 방식을 통해서든 말입니다.
2. 방법 1 – 스프레드시트 소프트웨어를 사용하여 Word 표를 CSV로 변환
Word 표를 CSV로 변환하는 가장 간단한 방법은 표를 스프레드시트 애플리케이션에 복사하여 내보내는 것입니다. Microsoft Excel과 Google Sheets 모두 이 워크플로를 지원합니다.
워크플로
- Word 표 복사하여 스프레드시트에 붙여넣기 — Word에서 표를 선택하고 복사한 다음 새 스프레드시트에 붙여넣습니다.
- 가져온 데이터 확인 — 행, 열 및 셀 값이 올바르게 구분되었는지 확인합니다. 병합된 셀은 정렬 불량을 유발할 수 있으므로 주의하십시오.
- CSV로 내보내기 — 스프레드시트를 CSV 형식으로 저장하거나 다운로드합니다.
옵션 A – Microsoft Office
- Word 문서를 열고 내보낼 표를 복사합니다.
- 표를 Excel 워크시트에 붙여넣고 행과 열이 올바르게 가져와졌는지 확인합니다.
- CSV 구조에 영향을 줄 수 있는 병합된 셀, 줄 바꿈 또는 기타 서식 문제를 검토합니다.
- 파일 > 다른 이름으로 저장을 선택하고 워크시트를 CSV 파일로 저장합니다.
Excel은 대부분의 경우 행과 열이 올바르게 매핑되므로 Word 표 구조를 잘 유지합니다. 문서에 여러 표가 포함된 경우 각 표를 별도의 워크시트에 붙여넣고 각 표를 개별 CSV 파일로 저장할 수 있습니다.
고려 사항:
- Word 표의 병합된 셀은 붙여넣은 후 정렬 불량을 유발할 수 있습니다.
- Excel은 로컬에서 실행되므로 데이터는 컴퓨터에 유지됩니다.
- 이 프로세스는 수동이며 빈번하거나 대규모 변환에는 실용적이지 않습니다.
옵션 B – Google Sheets
- Word 문서(Google Docs 또는 기타 문서 뷰어)에서 표를 복사합니다.
- 새 Google Sheets 스프레드시트에 붙여넣습니다.
- 가져온 표 구조를 확인하고 잘못 정렬된 데이터를 조정합니다.
- 파일 > 다운로드 > 쉼표로 구분된 값(.csv)을 사용하여 스프레드시트를 CSV 파일로 다운로드합니다.
Google Sheets는 무료이며 Google 계정만 있으면 됩니다. 또한 CSV로 내보내기 전에 공동 작업자와 데이터를 공유하고 검토하기 쉽습니다.
고려 사항:
- 데이터는 편집 중에 Google 서버에 저장됩니다. 민감한 정보의 경우 이를 고려하십시오.
- 소프트웨어 설치가 필요하지 않습니다.
- Excel과 마찬가지로 이 프로세스는 수동이며 자동화 지원이 없습니다.
이 방법을 사용해야 하는 경우
스프레드시트 기반 변환은 Word 표 데이터를 CSV로 내보내야 하는 경우와 저장하기 전에 데이터를 검토하려는 경우에 잘 작동합니다. 반복적인 변환, 여러 문서 또는 자동화된 워크플로의 경우 아래의 Python 방법이 더 효율적입니다.
DOCX(Word 문서)를 XLSX로 변환해야 하는 경우 구조화된 스프레드시트 워크플로에 대한 Docx를 XLSX로 변환하는 가이드를 참조할 수 있습니다.
3. 온라인 Word-CSV 변환기를 사용할 수 있나요?
예. 여러 웹사이트에서 Word-CSV 변환기 도구를 제공하여 DOC 또는 DOCX 파일을 업로드하고 CSV 파일을 다운로드할 수 있습니다. 소프트웨어를 설치하고 싶지 않을 때 빠르고 일회성 변환에 적합합니다.
그러나 온라인 변환기에는 다음과 같은 주목할 만한 제한 사항이 있습니다:
- 개인 정보 보호 — 문서가 타사 서버에 업로드되므로 민감하거나 독점적인 데이터에는 허용되지 않을 수 있습니다.
- 파일 크기 제한 — 대부분의 무료 도구는 업로드를 5-10MB로 제한합니다.
- 표 인식 — 일부 변환기는 첫 번째 표만 추출하고, 다른 변환기는 문서 구조를 잘못 해석할 수 있습니다.
- 일괄 처리 없음 — 한 번에 하나의 파일만 변환할 수 있습니다.
민감한 데이터, 반복적인 변환 또는 일괄 처리를 위해서는 로컬 방법(스프레드시트 소프트웨어 또는 Python)이 선호됩니다.
4. 방법 2 – Python으로 Word 표를 CSV로 자동 변환
Word 파일을 CSV로 정기적으로 변환하거나, 문서 처리를 자동화하거나, 대량의 파일을 처리해야 하는 경우 Python은 더 효율적인 솔루션을 제공합니다. Spire.Doc for Python을 사용하면 Microsoft Word를 설치하지 않고도 Word 문서를 읽고, 표 데이터를 추출하고, CSV 형식으로 직접 내보낼 수 있습니다.
Spire.Doc for Python 설치
pip를 통해 라이브러리를 설치합니다:
pip install spire.doc
Python 스크립트에서 필요한 클래스를 가져옵니다:
from spire.doc import *
from spire.doc.common import *
또는 Spire.Doc for Python을 다운로드하여 수동으로 통합할 수 있습니다.
Word 표를 CSV로 변환
다음 예제는 Word 문서를 로드하고, 첫 번째 표를 추출하고, 행과 셀을 읽고, 데이터를 CSV 파일에 씁니다.
import csv
from spire.doc import *
from spire.doc.common import *
document = Document()
document.LoadFromFile("Sample.docx")
section = document.Sections.get_Item(0)
for t in range(section.Tables.Count):
table = section.Tables.get_Item(t)
csv_data = []
for r in range(table.Rows.Count):
row = table.Rows.get_Item(r)
row_data = []
for c in range(row.Cells.Count):
cell = row.Cells.get_Item(c)
paragraphs = []
for p in range(cell.Paragraphs.Count):
text = cell.Paragraphs.get_Item(p).Text.strip()
if text:
paragraphs.append(text)
row_data.append(" ".join(paragraphs))
csv_data.append(row_data)
csv_path = f"table_{t + 1}.csv"
with open(csv_path, "w", newline="", encoding="utf-8-sig") as f:
csv.writer(f).writerows(csv_data)
document.Close()
작동 방식
Document.LoadFromFile()은 Word 문서를 메모리로 로드합니다.section.Tables.get_Item(table_index)은 내보낼 표를 선택합니다.- 스크립트는 Rows 및 Cells 컬렉션을 사용하여 표의 모든 행과 셀을 반복합니다.
- 각 표 셀에는 하나 이상의 단락이 포함될 수 있습니다. 스크립트는
cell.Paragraphs를 사용하여 모든 단락을 읽고 텍스트 콘텐츠를 추출합니다. - 추출된 단락 텍스트는
.strip()으로 정리되고 CSV 셀 값에 대한 단일 문자열로 결합됩니다. csv.writer()는 수집된 표 데이터를 Excel, Google Sheets, 데이터베이스 또는 기타 데이터 처리 도구에서 열 수 있는 표준 CSV 파일로 내보냅니다.
결과
아래는 Word 표와 생성된 CSV 파일의 미리 보기입니다:
결과는 Word 표 데이터를 포함하는 올바르게 형식화된 .csv 파일로, Excel, 데이터베이스 또는 CSV 입력을 허용하는 모든 시스템으로 가져올 준비가 되었습니다.
Word 문서에서 여러 표 추출
Word 문서에 여러 표가 포함된 경우 section.Tables를 반복하고 각 표를 별도의 CSV 파일로 저장합니다:
for t in range(section.Tables.Count):
word_table_to_csv(
word_path,
f"table_{t + 1}.csv",
table_index=t
)
여러 Word 파일 일괄 변환
Word 문서 폴더 전체를 처리하려면 파일을 반복하고 각 파일에서 첫 번째 표를 추출합니다:
for filename in os.listdir(input_folder):
if filename.lower().endswith((".doc", ".docx")):
word_table_to_csv(
os.path.join(input_folder, filename),
os.path.join(
output_folder,
os.path.splitext(filename)[0] + ".csv"
)
)
Word를 CSV로 변환하는 데 Python을 사용하는 이유
Spire.Doc for Python을 사용한 Python 자동화는 대규모로 Word 표를 CSV로 변환해야 할 때 명확한 이점을 제공합니다:
| 이점 | 세부 정보 |
|---|---|
| 일괄 변환 | 단일 스크립트로 수십 또는 수백 개의 Word 파일 처리 |
| 자동화 | 변환을 예약하여 자동으로 실행 — 매일, 매주 또는 필요에 따라 |
| 대규모 데이터 세트 | 수동으로 변환하기 어려운 대규모 표가 있는 Word 문서 처리 |
| 워크플로 통합 | 데이터 파이프라인, ETL 프로세스 또는 CI/CD 워크플로에 Word-CSV 변환 통합 |
| Microsoft Word 종속성 없음 | Spire.Doc for Python은 Microsoft Word 없이 작동합니다. |
| 데이터 정확성 | 프로그래밍 방식 추출은 복사-붙여넣기 오류를 제거하고 일관된 결과를 보장합니다. |
더 고급 사용법은 Python을 사용하여 Word 문서에서 표 추출에 대한 가이드도 확인할 수 있습니다.
5. 자주 묻는 질문
Word를 CSV로 직접 변환할 수 있나요?
아니요. Microsoft Word에는 문서를 CSV로 저장하거나 내보내는 내장 옵션이 없습니다. Word의 "다른 이름으로 저장" 대화 상자는 DOCX, PDF, RTF, HTML 및 일반 텍스트와 같은 형식을 지원하지만 CSV는 지원하지 않습니다. Word를 CSV로 변환하려면 문서에서 표 데이터를 추출하고 스프레드시트 소프트웨어 또는 Python 자동화를 사용하여 CSV 파일에 써야 합니다.
Word가 직접 CSV로 저장되지 않는 이유는 무엇인가요?
Word는 단락, 이미지, 머리글, 스타일 및 혼합 콘텐츠를 지원하는 서식 있는 텍스트 문서 형식입니다. CSV는 쉼표로 구분된 텍스트 행과 열만 저장하는 평면 표 형식입니다. Word는 복잡한 문서 구조를 표 형식 레이아웃으로 평탄화하는 방법을 자동으로 결정할 수 없으므로 CSV를 내보내기 옵션으로 제공하지 않습니다. 구조화된 데이터, 즉 일반적으로 Word 표의 데이터만 의미 있게 CSV로 변환할 수 있습니다.
Word 표를 CSV로 변환하는 방법은 무엇인가요?
두 가지 주요 옵션이 있습니다. (1) 스프레드시트 소프트웨어 — Word 표를 Excel 또는 Google Sheets에 복사하고 데이터를 확인한 다음 CSV로 저장하거나 내보냅니다. 이는 간헐적인 사용에 가장 일반적인 접근 방식입니다. (2) Python — Spire.Doc for Python을 사용하여 Word 문서를 읽고, 프로그래밍 방식으로 표에 액세스하고, 셀 값을 추출하고, CSV 파일에 씁니다. 이는 자동화, 일괄 처리 및 반복 변환에 이상적입니다.
Excel 없이 DOCX를 CSV로 변환할 수 있나요?
예. 다음을 사용하여 Excel 없이 DOCX를 CSV로 변환할 수 있습니다. (1) Google Sheets — Word 표 데이터를 Google Sheets 스프레드시트에 붙여넣고 CSV로 다운로드합니다. (2) 온라인 도구 — Word-CSV 변환기 웹사이트에 DOCX 파일을 업로드하고 결과를 다운로드합니다. (3) Python — Spire.Doc for Python을 사용하여 DOCX 파일을 읽고, 표 데이터를 추출하고, CSV로 씁니다. 이는 Microsoft Office 소프트웨어를 설치하지 않고도 작동합니다.
무료 Word-CSV 변환기가 있나요?
예. 두 가지 범주에 무료 옵션이 있습니다. (1) 온라인 변환기 — 많은 웹사이트에서 무료 Word-CSV 변환을 제공하지만 일반적으로 파일 크기 제한이 있고 데이터가 타사 서버에 업로드되므로 개인 정보 보호 문제가 발생합니다. (2) Python 스크립트 — Spire.Doc for Python(무료 버전 제공)과 Python의 내장 csv 모듈을 사용하여 무료 로컬 변환 스크립트를 작성할 수 있습니다. 이렇게 하면 데이터가 비공개로 유지되고 파일 크기 제한이 없습니다.
Python에서 Word 문서의 데이터를 CSV로 추출하는 방법은 무엇인가요?
Spire.Doc for Python을 사용하여 Word 문서를 로드하고, Sections 및 Tables 컬렉션을 통해 표에 액세스하고, 행과 셀을 반복하여 각 셀의 텍스트를 읽고, Python의 표준 csv.writer를 사용하여 데이터를 CSV 파일에 씁니다. 전체 코드 예제는 위의 방법 2에 제공됩니다.
Spire.Doc for Python은 Microsoft Word 설치가 필요하나요?
아니요. Spire.Doc for Python은 Word 문서를 독립적으로 생성, 읽기 및 조작하는 독립 실행형 라이브러리입니다. Microsoft Word 또는 Office 구성 요소가 시스템에 설치되어 있을 필요가 없습니다. 따라서 서버 환경, 자동화된 워크플로 및 Office를 사용할 수 없는 컴퓨터에 적합합니다.
결론
Word를 CSV로 변환하는 것은 DOC 또는 DOCX 문서에서 구조화된 표 데이터를 추출하여 표 형식으로 저장하는 것을 의미합니다. 스프레드시트 소프트웨어(Excel 또는 Google Sheets)는 간단한 수동 접근 방식을 제공합니다. Word 표를 복사하고, 데이터를 확인하고, CSV로 내보냅니다. 이는 간헐적인 변환에 잘 작동하지만 일괄 처리 또는 반복 워크플로에는 확장되지 않습니다.
Python 자동화와 Spire.Doc for Python은 Word 표를 프로그래밍 방식으로 CSV로 변환하는 안정적인 솔루션을 제공합니다. DOC 및 DOCX 파일을 읽고, 표 데이터를 정확하게 추출하고, CSV 출력을 작성합니다. 이 모든 과정은 Microsoft Word가 필요하지 않습니다. 정기적으로 DOC 또는 DOCX 파일을 CSV로 변환하는 개발자 및 조직의 경우 Spire.Doc for Python은 전체 프로세스를 자동화하는 안정적인 방법을 제공하는 동시에 표 데이터를 정확하게 보존합니다.
30일 무료 라이선스를 신청하여 Spire.Doc for Python의 모든 기능을 평가할 수 있습니다.
참고 자료
Come convertire tabelle Word in CSV (DOC/DOCX in CSV)
Indice
CSV (Comma-Separated Values) è un formato leggero e universalmente compatibile per dati tabulari. I documenti Word (DOC e DOCX), d'altra parte, sono documenti di testo ricco che contengono paragrafi, immagini, intestazioni, formattazione e tabelle. Poiché CSV supporta solo righe e colonne, la conversione da Word a CSV o da DOCX a CSV significa quasi sempre estrarre dati tabulari dal documento.
Le organizzazioni spesso necessitano di convertire tabelle Word o DOCX in CSV quando spostano dati strutturati in fogli di calcolo, database, sistemi CRM, strumenti di analisi o flussi di lavoro automatizzati.
Questa guida copre due metodi pratici per convertire tabelle Word in CSV, oltre a un contesto importante sul perché Word non può esportare CSV direttamente e quando i convertitori online sono appropriati.
Navigazione rapida
- Perché Word non può essere salvato direttamente come CSV
- Metodo 1 – Convertire tabelle Word in CSV utilizzando software di fogli di calcolo
- È possibile utilizzare un convertitore online da Word a CSV?
- Metodo 2 – Convertire tabelle Word in CSV automaticamente con Python
- FAQ
Quale metodo scegliere?
| Metodo | Facilità d'uso | Elaborazione batch | Privacy | Ideale per |
|---|---|---|---|---|
| Software di fogli di calcolo | Alta | No | Alta | Conversioni occasionali, revisione manuale |
| Python (Spire.Doc) | Media | Sì | Alta | Automazione, elaborazione batch, attività ricorrenti |
1. Perché Word non può essere salvato direttamente come CSV
Microsoft Word non offre un'opzione "Salva con nome CSV". Questo non è un errore – riflette una discrepanza fondamentale tra i formati:
- Documenti Word contengono contenuti misti: paragrafi, immagini, intestazioni, piè di pagina, testo stilizzato e tabelle. Un singolo documento può avere più sezioni, colonne e elementi annidati.
- File CSV contengono solo dati tabulari piatti: righe e colonne di testo semplice separate da virgole.
Word non può determinare automaticamente come appiattire un documento di testo ricco in un layout tabulare. Un documento con tre paragrafi, un'immagine e una tabella non si mappa chiaramente in righe e colonne. L'unica parte di un documento Word che ha una rappresentazione CSV naturale sono i dati tabulari strutturati.
Ecco perché ogni approccio pratico per convertire Word in CSV si concentra sull'estrazione di tabelle dal documento – sia tramite software di fogli di calcolo, strumenti online o metodi programmatici.
2. Metodo 1 – Convertire tabelle Word in CSV utilizzando software di fogli di calcolo
Il modo più semplice per convertire tabelle Word in CSV è copiare la tabella in un'applicazione per fogli di calcolo ed esportarla. Sia Microsoft Excel che Google Sheets supportano questo flusso di lavoro.
Il flusso di lavoro
- Copia la tabella Word in un foglio di calcolo – Seleziona la tabella in Word, copiala e incollala in un nuovo foglio di calcolo
- Verifica i dati importati – Controlla che righe, colonne e valori delle celle siano separati correttamente. Fai attenzione alle celle unite, che potrebbero causare disallineamenti
- Esporta come CSV – Salva o scarica il foglio di calcolo in formato CSV
Opzione A – Microsoft Office
- Apri il documento Word e copia la tabella che desideri esportare.
- Incolla la tabella in un foglio di lavoro Excel e verifica che righe e colonne siano importate correttamente.
- Rivedi le celle unite, le interruzioni di riga o altri problemi di formattazione che potrebbero influire sulla struttura CSV.
- Scegli File > Salva con nome e salva il foglio di lavoro come file CSV.
Excel preserva bene la struttura delle tabelle Word – righe e colonne si mappano correttamente nella maggior parte dei casi. Se il tuo documento contiene più tabelle, puoi incollarle ciascuna in un foglio di lavoro separato e salvarle singolarmente come file CSV.
Considerazioni:
- Le celle unite nella tabella Word potrebbero causare disallineamenti dopo l'incollatura
- Excel viene eseguito localmente, quindi i tuoi dati rimangono sulla tua macchina
- Il processo è manuale e non pratico per conversioni frequenti o su larga scala
Opzione B – Google Sheets
- Copia la tabella dal documento Word (in Google Docs o altri visualizzatori di documenti).
- Incollala in un nuovo foglio di calcolo Google Sheets.
- Verifica la struttura della tabella importata e correggi eventuali dati disallineati.
- Scarica il foglio di calcolo come file CSV utilizzando File > Scarica > Valori separati da virgola (.csv).
Google Sheets è gratuito e richiede solo un account Google. Rende anche facile condividere e rivedere i dati con i collaboratori prima di esportare in CSV.
Considerazioni:
- I dati vengono archiviati sui server di Google durante la modifica – considera questo per informazioni sensibili
- Nessuna installazione di software richiesta
- Come Excel, questo è un processo manuale senza supporto di automazione
Quando usare questo metodo
La conversione basata su fogli di calcolo funziona bene quando hai bisogno occasionalmente di esportare dati di tabelle Word in CSV e desideri rivedere i dati prima di salvarli. Per conversioni ricorrenti, più documenti o flussi di lavoro automatizzati, il metodo Python di seguito è più efficiente.
Se hai anche bisogno di convertire DOCX (documenti Word) in XLSX, puoi fare riferimento alla nostra guida alla conversione da Docx a XLSX per un flusso di lavoro strutturato di fogli di calcolo.
3. È possibile utilizzare un convertitore online da Word a CSV?
Sì. Diversi siti web offrono strumenti convertitore da Word a CSV che ti permettono di caricare un file DOC o DOCX e scaricare un file CSV. Questi sono adatti per conversioni rapide e una tantum quando non vuoi installare alcun software.
Tuttavia, i convertitori online hanno limitazioni notevoli:
- Privacy – Il tuo documento viene caricato su un server di terze parti, il che potrebbe non essere accettabile per dati sensibili o proprietari
- Limiti di dimensione del file – La maggior parte degli strumenti gratuiti limita i caricamenti a 5-10 MB
- Riconoscimento tabelle – Alcuni convertitori estraggono solo la prima tabella; altri potrebbero interpretare erroneamente la struttura del documento
- Nessuna elaborazione batch – Puoi convertire solo un file alla volta
Per dati sensibili, conversioni ricorrenti o elaborazione batch, i metodi locali (software di fogli di calcolo o Python) sono preferibili.
4. Metodo 2 – Convertire tabelle Word in CSV automaticamente con Python
Se hai bisogno di convertire file Word in CSV regolarmente, automatizzare l'elaborazione dei documenti o gestire un gran numero di file, Python offre una soluzione più efficiente. Con Spire.Doc per Python, puoi leggere documenti Word, estrarre dati tabulari ed esportarli direttamente in formato CSV – tutto senza avere Microsoft Word installato.
Installa Spire.Doc per Python
Installa la libreria tramite pip:
pip install spire.doc
Importa le classi necessarie nel tuo script Python:
from spire.doc import *
from spire.doc.common import *
In alternativa, puoi scaricare Spire.Doc per Python e integrarlo manualmente.
Convertire una tabella Word in CSV
L'esempio seguente carica un documento Word, estrae la prima tabella, legge le sue righe e celle e scrive i dati in un file CSV.
import csv
from spire.doc import *
from spire.doc.common import *
document = Document()
document.LoadFromFile("Sample.docx")
section = document.Sections.get_Item(0)
for t in range(section.Tables.Count):
table = section.Tables.get_Item(t)
csv_data = []
for r in range(table.Rows.Count):
row = table.Rows.get_Item(r)
row_data = []
for c in range(row.Cells.Count):
cell = row.Cells.get_Item(c)
paragraphs = []
for p in range(cell.Paragraphs.Count):
text = cell.Paragraphs.get_Item(p).Text.strip()
if text:
paragraphs.append(text)
row_data.append(" ".join(paragraphs))
csv_data.append(row_data)
csv_path = f"table_{t + 1}.csv"
with open(csv_path, "w", newline="", encoding="utf-8-sig") as f:
csv.writer(f).writerows(csv_data)
document.Close()
Come funziona
Document.LoadFromFile()carica il documento Word in memoria.section.Tables.get_Item(table_index)seleziona la tabella da esportare.- Lo script scorre ogni riga e cella della tabella utilizzando le collezioni Rows e Cells.
- Ogni cella della tabella può contenere uno o più paragrafi. Lo script legge tutti i paragrafi utilizzando
cell.Paragraphsed estrae il loro contenuto testuale. - Il testo del paragrafo estratto viene pulito con
.strip()e combinato in un'unica stringa per il valore della cella CSV. csv.writer()esporta i dati tabulari raccolti in un file CSV standard che può essere aperto in Excel, Google Sheets, database o altri strumenti di elaborazione dati.
Risultato dell'output
Di seguito è riportata un'anteprima della tabella Word e del file CSV generato:
L'output è un file .csv correttamente formattato contenente i dati della tabella Word, pronto per l'importazione in Excel, database o qualsiasi sistema che accetti input CSV.
Estrarre più tabelle da un documento Word
Se il tuo documento Word contiene più tabelle, scorri section.Tables e salva ciascuna come file CSV separato:
for t in range(section.Tables.Count):
word_table_to_csv(
word_path,
f"table_{t + 1}.csv",
table_index=t
)
Convertire in batch più file Word
Per elaborare un'intera cartella di documenti Word, scorri i file ed estrai la prima tabella da ciascuno:
for filename in os.listdir(input_folder):
if filename.lower().endswith((".doc", ".docx")):
word_table_to_csv(
os.path.join(input_folder, filename),
os.path.join(
output_folder,
os.path.splitext(filename)[0] + ".csv"
)
)
Perché usare Python per la conversione da Word a CSV?
L'automazione Python con Spire.Doc per Python offre chiari vantaggi quando è necessario convertire tabelle Word in CSV su larga scala:
| Vantaggio | Dettagli |
|---|---|
| Conversione batch | Elabora decine o centinaia di file Word in un unico script |
| Automazione | Pianifica conversioni per l'esecuzione automatica – giornaliera, settimanale o su richiesta |
| Grandi set di dati | Gestisci documenti Word con tabelle di grandi dimensioni che sono impraticabili da convertire manualmente |
| Integrazione del flusso di lavoro | Integra la conversione da Word a CSV in pipeline di dati, processi ETL o flussi di lavoro CI/CD |
| Nessuna dipendenza da Microsoft Word | Spire.Doc per Python funziona senza Microsoft Word installato |
| Accuratezza dei dati | L'estrazione programmatica elimina gli errori di copia-incolla e garantisce risultati coerenti |
Per un uso più avanzato, puoi anche consultare la nostra guida su estrarre tabelle da documenti Word usando Python.
5. FAQ
Posso convertire Word in CSV direttamente?
No. Microsoft Word non ha un'opzione integrata per salvare o esportare documenti come CSV. La finestra di dialogo "Salva con nome" di Word supporta formati come DOCX, PDF, RTF, HTML e testo semplice – ma non CSV. Per convertire Word in CSV, devi estrarre i dati tabulari dal documento e scriverli in un file CSV utilizzando software di fogli di calcolo o automazione Python.
Perché Word non può salvare direttamente come CSV?
Word è un formato di documento di testo ricco che supporta paragrafi, immagini, intestazioni, stili e contenuti misti. CSV è un formato tabulare piatto che memorizza solo righe e colonne di testo separate da virgole. Word non può determinare automaticamente come appiattire una struttura di documento complessa in un layout tabulare, quindi non offre CSV come opzione di esportazione. Solo i dati strutturati – tipicamente dati nelle tabelle Word – possono essere convertiti in modo significativo in CSV.
Come converto una tabella Word in CSV?
Hai due opzioni principali: (1) Software di fogli di calcolo – Copia la tabella Word in Excel o Google Sheets, verifica i dati e salva o scarica come CSV. Questo è l'approccio più comune per un uso occasionale. (2) Python – Usa Spire.Doc per Python per leggere il documento Word, accedere alla tabella programmaticamente, estrarre i valori delle celle e scriverli in un file CSV. Questo è ideale per l'automazione, l'elaborazione batch e le conversioni ricorrenti.
Posso convertire DOCX in CSV senza Excel?
Sì. Puoi convertire DOCX in CSV senza Excel utilizzando: (1) Google Sheets – Incolla i dati della tabella Word in un foglio di calcolo Google Sheets e scarica come CSV. (2) Strumenti online – Carica il tuo file DOCX su un sito web convertitore da Word a CSV e scarica il risultato. (3) Python – Usa Spire.Doc per Python per leggere il file DOCX, estrarre i dati tabulari e scriverli in CSV. Questo funziona senza alcun software Microsoft Office installato.
Esiste un convertitore gratuito da Word a CSV?
Sì. Ci sono opzioni gratuite in due categorie: (1) Convertitori online – Molti siti web offrono conversioni gratuite da Word a CSV, anche se di solito hanno limiti di dimensione del file e sollevano preoccupazioni sulla privacy poiché i tuoi dati vengono caricati su un server di terze parti. (2) Script Python – Puoi scrivere uno script di conversione gratuito e locale utilizzando Spire.Doc per Python (che offre una versione gratuita) e il modulo csv integrato di Python. Questo mantiene i tuoi dati privati e non ha limiti di dimensione del file.
Come estraggo dati da un documento Word in CSV in Python?
Usa Spire.Doc per Python per caricare il documento Word, accedere alla tabella tramite le collezioni Sections e Tables, scorrere righe e celle per leggere il testo di ogni cella e scrivere i dati in un file CSV utilizzando il csv.writer standard di Python. L'esempio di codice completo è fornito nella Metodo 2 sopra.
Spire.Doc per Python richiede l'installazione di Microsoft Word?
No. Spire.Doc per Python è una libreria autonoma che crea, legge e manipola documenti Word in modo indipendente. Non richiede l'installazione di Microsoft Word o di alcun componente di Office sul tuo sistema. Questo lo rende adatto per ambienti server, flussi di lavoro automatizzati e macchine dove Office non è disponibile.
Conclusione
Convertire Word in CSV significa estrarre dati tabulari strutturati da documenti DOC o DOCX e salvarli in un formato tabulare. Il software di fogli di calcolo (Excel o Google Sheets) fornisce un semplice approccio manuale: copia la tabella Word, verifica i dati ed esporta come CSV. Questo funziona bene per conversioni occasionali ma non scala all'elaborazione batch o ai flussi di lavoro ricorrenti.
L'automazione Python con Spire.Doc per Python offre una soluzione affidabile per convertire tabelle Word in CSV programmaticamente. Legge file DOC e DOCX, estrae accuratamente i dati tabulari e genera output CSV – tutto senza richiedere Microsoft Word. Per sviluppatori e organizzazioni che convertono regolarmente file DOC o DOCX in CSV, Spire.Doc per Python offre un modo affidabile per automatizzare l'intero processo preservando accuratamente i dati tabulari.
Puoi richiedere una licenza gratuita di 30 giorni per valutare tutte le funzionalità di Spire.Doc per Python.
Vedi anche
Comment convertir des tableaux Word en CSV (DOC/DOCX en CSV)
Table des matières
CSV (Comma-Separated Values) est un format léger et universellement compatible pour les données tabulaires. Les documents Word (DOC et DOCX), en revanche, sont des documents texte enrichi contenant des paragraphes, des images, des en-têtes, des mises en forme et des tableaux. Comme le CSV ne prend en charge que les lignes et les colonnes, la conversion de Word en CSV ou de DOCX en CSV signifie presque toujours l'extraction des données tabulaires du document.
Les organisations ont souvent besoin de convertir des tableaux Word ou DOCX en CSV lors du transfert de données structurées vers des tableurs, des bases de données, des systèmes CRM, des outils d'analyse ou des flux de travail automatisés.
Ce guide couvre deux méthodes pratiques pour convertir des tableaux Word en CSV, ainsi que des informations importantes sur la raison pour laquelle Word ne peut pas exporter directement en CSV et quand les convertisseurs en ligne sont appropriés.
Navigation rapide
- Pourquoi Word ne peut pas être enregistré directement en CSV
- Méthode 1 – Convertir des tableaux Word en CSV à l'aide d'un logiciel tableur
- Pouvez-vous utiliser un convertisseur Word en CSV en ligne ?
- Méthode 2 – Convertir automatiquement des tableaux Word en CSV avec Python
- FAQ
Quelle méthode choisir ?
| Méthode | Facilité d'utilisation | Traitement par lots | Confidentialité | Idéal pour |
|---|---|---|---|---|
| Logiciel tableur | Élevée | Non | Élevée | Conversions occasionnelles, revue manuelle |
| Python (Spire.Doc) | Moyenne | Oui | Élevée | Automatisation, traitement par lots, tâches récurrentes |
1. Pourquoi Word ne peut pas être enregistré directement en CSV
Microsoft Word n'offre pas d'option "Enregistrer sous CSV". Ce n'est pas un oubli — cela reflète une incompatibilité fondamentale des formats :
- Les documents Word contiennent un contenu mixte : paragraphes, images, en-têtes, pieds de page, texte stylisé et tableaux. Un seul document peut avoir plusieurs sections, colonnes et éléments imbriqués.
- Les fichiers CSV ne contiennent que des données tabulaires plates : lignes et colonnes de texte brut séparées par des virgules.
Word ne peut pas déterminer automatiquement comment aplatir un document texte enrichi dans une disposition tabulaire. Un document avec trois paragraphes, une image et un tableau ne se mappe pas proprement en lignes et colonnes. La seule partie d'un document Word qui a une représentation CSV naturelle est les données tabulaires structurées.
C'est pourquoi chaque approche pratique pour convertir Word en CSV se concentre sur l'extraction des tableaux du document — que ce soit par le biais de logiciels tableurs, d'outils en ligne ou de méthodes programmatiques.
2. Méthode 1 – Convertir des tableaux Word en CSV à l'aide d'un logiciel tableur
La manière la plus simple de convertir des tableaux Word en CSV est de copier le tableau dans une application tableur et de l'exporter. Microsoft Excel et Google Sheets prennent en charge ce flux de travail.
Le flux de travail
- Copier le tableau Word dans un tableur — Sélectionnez le tableau dans Word, copiez-le et collez-le dans un nouveau tableur
- Vérifier les données importées — Vérifiez que les lignes, les colonnes et les valeurs des cellules sont correctement séparées. Faites attention aux cellules fusionnées, qui peuvent causer un désalignement
- Exporter en CSV — Enregistrez ou téléchargez le tableur au format CSV
Option A – Microsoft Office
- Ouvrez le document Word et copiez le tableau que vous souhaitez exporter.
- Collez le tableau dans une feuille de calcul Excel et vérifiez que les lignes et les colonnes sont importées correctement.
- Vérifiez les cellules fusionnées, les sauts de ligne ou d'autres problèmes de mise en forme qui pourraient affecter la structure CSV.
- Choisissez Fichier > Enregistrer sous et enregistrez la feuille de calcul en tant que fichier CSV.
Excel préserve bien la structure des tableaux Word — les lignes et les colonnes se mappent correctement dans la plupart des cas. Si votre document contient plusieurs tableaux, vous pouvez coller chacun d'eux sur une feuille de calcul distincte et enregistrer chacun comme un fichier CSV individuel.
Considérations :
- Les cellules fusionnées dans le tableau Word peuvent causer un désalignement après le collage
- Excel s'exécute localement, vos données restent donc sur votre machine
- Le processus est manuel et peu pratique pour des conversions fréquentes ou à grande échelle
Option B – Google Sheets
- Copiez le tableau du document Word (dans Google Docs ou d'autres visionneuses de documents).
- Collez-le dans une nouvelle feuille de calcul Google Sheets.
- Vérifiez la structure du tableau importé et ajustez les données mal alignées.
- Téléchargez la feuille de calcul au format CSV en utilisant Fichier > Télécharger > Valeurs séparées par des virgules (.csv).
Google Sheets est gratuit et ne nécessite qu'un compte Google. Il permet également de partager et de réviser facilement les données avec des collaborateurs avant de les exporter en CSV.
Considérations :
- Les données sont stockées sur les serveurs de Google pendant l'édition — tenez-en compte pour les informations sensibles
- Aucune installation de logiciel requise
- Comme Excel, il s'agit d'un processus manuel sans prise en charge de l'automatisation
Quand utiliser cette méthode
La conversion basée sur un tableur fonctionne bien lorsque vous avez besoin d'exporter occasionnellement des données de tableaux Word en CSV et que vous souhaitez examiner les données avant de les enregistrer. Pour les conversions récurrentes, les documents multiples ou les flux de travail automatisés, la méthode Python ci-dessous est plus efficace.
Si vous avez également besoin de convertir DOCX (documents Word) en XLSX, vous pouvez consulter notre guide de conversion Docx en XLSX pour un flux de travail de tableur structuré.
3. Pouvez-vous utiliser un convertisseur Word en CSV en ligne ?
Oui. Plusieurs sites Web proposent des outils de convertisseur Word en CSV qui vous permettent de télécharger un fichier DOC ou DOCX et de télécharger un fichier CSV. Ceux-ci conviennent aux conversions rapides et ponctuelles lorsque vous ne souhaitez pas installer de logiciel.
Cependant, les convertisseurs en ligne présentent des limitations notables :
- Confidentialité — Votre document est téléchargé sur un serveur tiers, ce qui peut ne pas être acceptable pour des données sensibles ou propriétaires
- Limites de taille de fichier — La plupart des outils gratuits limitent les téléchargements à 5–10 Mo
- Reconnaissance des tableaux — Certains convertisseurs n'extraient que le premier tableau ; d'autres peuvent mal interpréter la structure du document
- Pas de traitement par lots — Vous ne pouvez convertir qu'un seul fichier à la fois
Pour les données sensibles, les conversions récurrentes ou le traitement par lots, les méthodes locales (logiciel tableur ou Python) sont préférables.
4. Méthode 2 – Convertir automatiquement des tableaux Word en CSV avec Python
Si vous devez convertir régulièrement des fichiers Word en CSV, automatiser le traitement des documents ou gérer un grand nombre de fichiers, Python offre une solution plus efficace. Avec Spire.Doc pour Python, vous pouvez lire des documents Word, extraire des données tabulaires et les exporter directement au format CSV — le tout sans avoir Microsoft Word installé.
Installer Spire.Doc pour Python
Installez la bibliothèque via pip :
pip install spire.doc
Importez les classes requises dans votre script Python :
from spire.doc import *
from spire.doc.common import *
Alternativement, vous pouvez télécharger Spire.Doc pour Python et l'intégrer manuellement.
Convertir un tableau Word en CSV
L'exemple suivant charge un document Word, extrait le premier tableau, lit ses lignes et ses cellules, et écrit les données dans un fichier CSV.
import csv
from spire.doc import *
from spire.doc.common import *
document = Document()
document.LoadFromFile("Sample.docx")
section = document.Sections.get_Item(0)
for t in range(section.Tables.Count):
table = section.Tables.get_Item(t)
csv_data = []
for r in range(table.Rows.Count):
row = table.Rows.get_Item(r)
row_data = []
for c in range(row.Cells.Count):
cell = row.Cells.get_Item(c)
paragraphs = []
for p in range(cell.Paragraphs.Count):
text = cell.Paragraphs.get_Item(p).Text.strip()
if text:
paragraphs.append(text)
row_data.append(" ".join(paragraphs))
csv_data.append(row_data)
csv_path = f"table_{t + 1}.csv"
with open(csv_path, "w", newline="", encoding="utf-8-sig") as f:
csv.writer(f).writerows(csv_data)
document.Close()
Comment ça marche
Document.LoadFromFile()charge le document Word en mémoire.section.Tables.get_Item(table_index)sélectionne le tableau à exporter.- Le script parcourt chaque ligne et chaque cellule du tableau à l'aide des collections Rows et Cells.
- Chaque cellule de tableau peut contenir un ou plusieurs paragraphes. Le script lit tous les paragraphes à l'aide de
cell.Paragraphset extrait leur contenu textuel. - Le texte des paragraphes extrait est nettoyé avec
.strip()et combiné en une seule chaîne pour la valeur de la cellule CSV. csv.writer()exporte les données tabulaires collectées vers un fichier CSV standard qui peut être ouvert dans Excel, Google Sheets, des bases de données ou d'autres outils de traitement de données.
Résultat
Ci-dessous, un aperçu du tableau Word et du fichier CSV généré :
Le résultat est un fichier .csv correctement formaté contenant les données du tableau Word, prêt à être importé dans Excel, des bases de données ou tout système acceptant des entrées CSV.
Extraire plusieurs tableaux d'un document Word
Si votre document Word contient plusieurs tableaux, itérez sur section.Tables et enregistrez chacun d'eux dans un fichier CSV séparé :
for t in range(section.Tables.Count):
word_table_to_csv(
word_path,
f"table_{t + 1}.csv",
table_index=t
)
Convertir par lots plusieurs fichiers Word
Pour traiter un dossier entier de documents Word, parcourez les fichiers et extrayez le premier tableau de chacun :
for filename in os.listdir(input_folder):
if filename.lower().endswith((".doc", ".docx")):
word_table_to_csv(
os.path.join(input_folder, filename),
os.path.join(
output_folder,
os.path.splitext(filename)[0] + ".csv"
)
)
Pourquoi utiliser Python pour la conversion Word en CSV ?
L'automatisation Python avec Spire.Doc pour Python offre des avantages clairs lorsque vous avez besoin de convertir des tableaux Word en CSV à grande échelle :
| Avantage | Détails |
|---|---|
| Conversion par lots | Traitez des dizaines ou des centaines de fichiers Word en un seul script |
| Automatisation | Planifiez les conversions pour qu'elles s'exécutent automatiquement — quotidiennement, hebdomadairement ou à la demande |
| Grands ensembles de données | Traitez des documents Word avec de grands tableaux qui sont impraticables à convertir manuellement |
| Intégration du flux de travail | Intégrez la conversion Word vers CSV dans des pipelines de données, des processus ETL ou des flux de travail CI/CD |
| Aucune dépendance à Microsoft Word | Spire.Doc pour Python fonctionne sans Microsoft Word installé |
| Précision des données | L'extraction programmatique élimine les erreurs de copier-coller et garantit des résultats cohérents |
Pour une utilisation plus avancée, vous pouvez également consulter notre guide sur l'extraction de tableaux de documents Word à l'aide de Python.
5. FAQ
Puis-je convertir Word en CSV directement ?
Non. Microsoft Word n'a pas d'option intégrée pour enregistrer ou exporter des documents au format CSV. La boîte de dialogue "Enregistrer sous" de Word prend en charge des formats tels que DOCX, PDF, RTF, HTML et texte brut — mais pas CSV. Pour convertir Word en CSV, vous devez extraire les données tabulaires du document et les écrire dans un fichier CSV à l'aide d'un logiciel tableur ou de l'automatisation Python.
Pourquoi Word ne peut-il pas enregistrer directement en CSV ?
Word est un format de document texte enrichi qui prend en charge les paragraphes, les images, les en-têtes, les styles et le contenu mixte. CSV est un format tabulaire plat qui ne stocke que des lignes et des colonnes de texte séparées par des virgules. Word ne peut pas déterminer automatiquement comment aplatir une structure de document complexe dans une disposition tabulaire, il n'offre donc pas le CSV comme option d'exportation. Seules les données structurées — généralement les données dans les tableaux Word — peuvent être converties de manière significative en CSV.
Comment convertir un tableau Word en CSV ?
Vous avez deux options principales : (1) Logiciel tableur — Copiez le tableau Word dans Excel ou Google Sheets, vérifiez les données et enregistrez ou téléchargez en CSV. C'est l'approche la plus courante pour une utilisation occasionnelle. (2) Python — Utilisez Spire.Doc pour Python pour lire le document Word, accéder au tableau par programme, extraire les valeurs des cellules et les écrire dans un fichier CSV. C'est idéal pour l'automatisation, le traitement par lots et les conversions récurrentes.
Puis-je convertir DOCX en CSV sans Excel ?
Oui. Vous pouvez convertir DOCX en CSV sans Excel en utilisant : (1) Google Sheets — Collez les données du tableau Word dans une feuille de calcul Google Sheets et téléchargez en CSV. (2) Outils en ligne — Téléchargez votre fichier DOCX sur un site Web de convertisseur Word en CSV et téléchargez le résultat. (3) Python — Utilisez Spire.Doc pour Python pour lire le fichier DOCX, extraire les données tabulaires et les écrire en CSV. Cela fonctionne sans aucun logiciel Microsoft Office installé.
Existe-t-il un convertisseur Word en CSV gratuit ?
Oui. Il existe des options gratuites dans deux catégories : (1) Convertisseurs en ligne — De nombreux sites Web proposent une conversion gratuite de Word en CSV, bien qu'ils aient généralement des limites de taille de fichier et soulèvent des préoccupations en matière de confidentialité car vos données sont téléchargées sur un serveur tiers. (2) Scripts Python — Vous pouvez écrire un script de conversion gratuit et local en utilisant Spire.Doc pour Python (qui offre une version gratuite) et le module csv intégré de Python. Cela maintient la confidentialité de vos données et n'a aucune restriction de taille de fichier.
Comment extraire des données d'un document Word vers CSV en Python ?
Utilisez Spire.Doc pour Python pour charger le document Word, accéder au tableau via les collections Sections et Tables, itérer sur les lignes et les cellules pour lire le texte de chaque cellule, et écrire les données dans un fichier CSV à l'aide du csv.writer standard de Python. L'exemple de code complet est fourni dans la Méthode 2 ci-dessus.
Spire.Doc pour Python nécessite-t-il Microsoft Word installé ?
Non. Spire.Doc pour Python est une bibliothèque autonome qui crée, lit et manipule des documents Word indépendamment. Il ne nécessite pas que Microsoft Word ou tout autre composant Office soit installé sur votre système. Cela le rend adapté aux environnements serveur, aux flux de travail automatisés et aux machines où Office n'est pas disponible.
Conclusion
Convertir Word en CSV signifie extraire des données tabulaires structurées des documents DOC ou DOCX et les enregistrer dans un format tabulaire. Les logiciels tableurs (Excel ou Google Sheets) offrent une approche manuelle simple — copiez le tableau Word, vérifiez les données et exportez en CSV. Cela fonctionne bien pour les conversions occasionnelles mais ne convient pas au traitement par lots ou aux flux de travail récurrents.
L'automatisation Python avec Spire.Doc pour Python fournit une solution fiable pour convertir des tableaux Word en CSV par programme. Il lit les fichiers DOC et DOCX, extrait les données tabulaires avec précision et génère une sortie CSV — le tout sans nécessiter Microsoft Word. Pour les développeurs et les organisations qui convertissent régulièrement des fichiers DOC ou DOCX en CSV, Spire.Doc pour Python offre un moyen fiable d'automatiser l'ensemble du processus tout en préservant les données tabulaires avec précision.
Vous pouvez demander une licence gratuite de 30 jours pour évaluer toutes les fonctionnalités de Spire.Doc pour Python.
Voir aussi
Cómo convertir tablas de Word a CSV (DOC/DOCX a CSV)
Tabla de Contenidos
CSV (Comma-Separated Values) es un formato ligero y universalmente compatible para datos tabulares. Los documentos de Word (DOC y DOCX), por otro lado, son documentos de texto enriquecido que contienen párrafos, imágenes, encabezados, formato y tablas. Dado que CSV solo admite filas y columnas, convertir Word a CSV o DOCX a CSV casi siempre significa extraer datos de tablas del documento.
Las organizaciones a menudo necesitan convertir tablas de Word o DOCX a CSV al mover datos estructurados a hojas de cálculo, bases de datos, sistemas CRM, herramientas de análisis o flujos de trabajo automatizados.
Esta guía cubre dos métodos prácticos para convertir tablas de Word a CSV, además de contexto importante sobre por qué Word no puede exportar CSV directamente y cuándo son apropiados los convertidores en línea.
Navegación Rápida
- Por qué Word no se puede guardar directamente como CSV
- Método 1: Convertir tablas de Word a CSV usando software de hoja de cálculo
- ¿Se puede usar un convertidor en línea de Word a CSV?
- Método 2: Convertir tablas de Word a CSV automáticamente con Python
- Preguntas frecuentes
¿Qué método deberías elegir?
| Método | Facilidad de uso | Procesamiento por lotes | Privacidad | Ideal para |
|---|---|---|---|---|
| Software de hoja de cálculo | Alta | No | Alta | Conversiones ocasionales, revisión manual |
| Python (Spire.Doc) | Media | Sí | Alta | Automatización, procesamiento por lotes, tareas recurrentes |
1. Por qué Word no se puede guardar directamente como CSV
Microsoft Word no ofrece una opción de "Guardar como CSV". Esto no es un descuido, sino que refleja una incompatibilidad fundamental de formato:
- Documentos de Word contienen contenido mixto: párrafos, imágenes, encabezados, pies de página, texto con estilo y tablas. Un solo documento puede tener múltiples secciones, columnas y elementos anidados.
- Archivos CSV solo contienen datos tabulares planos: filas y columnas de texto plano separadas por comas.
Word no puede determinar automáticamente cómo aplanar un documento de texto enriquecido en un diseño tabular. Un documento con tres párrafos, una imagen y una tabla no se mapea limpiamente a filas y columnas. La única parte de un documento de Word que tiene una representación CSV natural es los datos de tablas estructuradas.
Es por eso que cada enfoque práctico para convertir Word a CSV se centra en extraer tablas del documento, ya sea a través de software de hoja de cálculo, herramientas en línea o métodos programáticos.
2. Método 1: Convertir tablas de Word a CSV usando software de hoja de cálculo
La forma más sencilla de convertir tablas de Word a CSV es copiar la tabla a una aplicación de hoja de cálculo y exportarla. Tanto Microsoft Excel como Google Sheets admiten este flujo de trabajo.
El Flujo de Trabajo
- Copiar la tabla de Word a una hoja de cálculo: Selecciona la tabla en Word, cópiala y pégala en una nueva hoja de cálculo.
- Verificar los datos importados: Comprueba que las filas, columnas y valores de las celdas estén correctamente separados. Presta atención a las celdas combinadas, que pueden causar desalineación.
- Exportar como CSV: Guarda o descarga la hoja de cálculo en formato CSV.
Opción A – Microsoft Office
- Abre el documento de Word y copia la tabla que deseas exportar.
- Pega la tabla en una hoja de cálculo de Excel y verifica que las filas y columnas se importen correctamente.
- Revisa las celdas combinadas, saltos de línea u otros problemas de formato que puedan afectar la estructura del CSV.
- Selecciona Archivo > Guardar como y guarda la hoja de cálculo como un archivo CSV.
Excel conserva bien la estructura de las tablas de Word: las filas y columnas se mapean correctamente en la mayoría de los casos. Si tu documento contiene varias tablas, puedes pegar cada una en una hoja de cálculo separada y guardar cada una como un archivo CSV individual.
Consideraciones:
- Las celdas combinadas en la tabla de Word pueden causar desalineación después de pegarlas.
- Excel se ejecuta localmente, por lo que tus datos permanecen en tu máquina.
- El proceso es manual y no es práctico para conversiones frecuentes o a gran escala.
Opción B – Google Sheets
- Copia la tabla del documento de Word (en Google Docs u otros visores de documentos).
- Pégala en una nueva hoja de cálculo de Google Sheets.
- Verifica la estructura de la tabla importada y ajusta cualquier dato desalineado.
- Descarga la hoja de cálculo como un archivo CSV usando Archivo > Descargar > Valores separados por comas (.csv).
Google Sheets es gratuito y solo requiere una cuenta de Google. También facilita compartir y revisar datos con colaboradores antes de exportar a CSV.
Consideraciones:
- Los datos se almacenan en los servidores de Google durante la edición; ten esto en cuenta para información confidencial.
- No se requiere instalación de software.
- Al igual que Excel, este es un proceso manual sin soporte de automatización.
¿Cuándo usar este método?
La conversión basada en hojas de cálculo funciona bien cuando necesitas exportar datos de tablas de Word a CSV ocasionalmente y quieres revisar los datos antes de guardarlos. Para conversiones recurrentes, múltiples documentos o flujos de trabajo automatizados, el método de Python a continuación es más eficiente.
Si también necesitas convertir DOCX (documentos de Word) a XLSX, puedes consultar nuestra guía de conversión de Docx a XLSX para un flujo de trabajo de hoja de cálculo estructurado.
3. ¿Se puede usar un convertidor en línea de Word a CSV?
Sí. Varios sitios web ofrecen herramientas convertidoras de Word a CSV que te permiten subir un archivo DOC o DOCX y descargar un archivo CSV. Estos son adecuados para conversiones rápidas y únicas cuando no quieres instalar ningún software.
Sin embargo, los convertidores en línea tienen limitaciones notables:
- Privacidad: Tu documento se sube a un servidor de terceros, lo que puede no ser aceptable para datos confidenciales o propietarios.
- Límites de tamaño de archivo: La mayoría de las herramientas gratuitas restringen las cargas a 5-10 MB.
- Reconocimiento de tablas: Algunos convertidores solo extraen la primera tabla; otros pueden interpretar mal la estructura del documento.
- Sin procesamiento por lotes: Solo puedes convertir un archivo a la vez.
Para datos confidenciales, conversiones recurrentes o procesamiento por lotes, los métodos locales (software de hoja de cálculo o Python) son preferibles.
4. Método 2: Convertir tablas de Word a CSV automáticamente con Python
Si necesitas convertir archivos de Word a CSV regularmente, automatizar el procesamiento de documentos o manejar un gran número de archivos, Python ofrece una solución más eficiente. Con Spire.Doc para Python, puedes leer documentos de Word, extraer datos de tablas y exportarlos directamente a formato CSV, todo sin necesidad de tener Microsoft Word instalado.
Instalar Spire.Doc para Python
Instala la biblioteca a través de pip:
pip install spire.doc
Importa las clases necesarias en tu script de Python:
from spire.doc import *
from spire.doc.common import *
Alternativamente, puedes descargar Spire.Doc para Python e integrarlo manualmente.
Convertir una tabla de Word a CSV
El siguiente ejemplo carga un documento de Word, extrae la primera tabla, lee sus filas y celdas, y escribe los datos en un archivo CSV.
import csv
from spire.doc import *
from spire.doc.common import *
document = Document()
document.LoadFromFile("Sample.docx")
section = document.Sections.get_Item(0)
for t in range(section.Tables.Count):
table = section.Tables.get_Item(t)
csv_data = []
for r in range(table.Rows.Count):
row = table.Rows.get_Item(r)
row_data = []
for c in range(row.Cells.Count):
cell = row.Cells.get_Item(c)
paragraphs = []
for p in range(cell.Paragraphs.Count):
text = cell.Paragraphs.get_Item(p).Text.strip()
if text:
paragraphs.append(text)
row_data.append(" ".join(paragraphs))
csv_data.append(row_data)
csv_path = f"table_{t + 1}.csv"
with open(csv_path, "w", newline="", encoding="utf-8-sig") as f:
csv.writer(f).writerows(csv_data)
document.Close()
Cómo funciona
Document.LoadFromFile()carga el documento de Word en memoria.section.Tables.get_Item(table_index)selecciona la tabla a exportar.- El script recorre cada fila y celda de la tabla utilizando las colecciones Rows y Cells.
- Cada celda de la tabla puede contener uno o más párrafos. El script lee todos los párrafos usando
cell.Paragraphsy extrae su contenido de texto. - El texto de los párrafos extraído se limpia con
.strip()y se combina en una sola cadena para el valor de la celda CSV. csv.writer()exporta los datos de la tabla recopilados a un archivo CSV estándar que se puede abrir en Excel, Google Sheets, bases de datos u otras herramientas de procesamiento de datos.
Resultado de la Salida
A continuación, se muestra una vista previa de la tabla de Word y el archivo CSV generado:
La salida es un archivo .csv correctamente formateado que contiene los datos de la tabla de Word, listo para importar a Excel, bases de datos o cualquier sistema que acepte entrada CSV.
Extraer Múltiples Tablas de un Documento de Word
Si tu documento de Word contiene varias tablas, itera a través de section.Tables y guarda cada una como un archivo CSV separado:
for t in range(section.Tables.Count):
word_table_to_csv(
word_path,
f"table_{t + 1}.csv",
table_index=t
)
Procesar por Lotes Múltiples Archivos de Word
Para procesar una carpeta completa de documentos de Word, itera a través de los archivos y extrae la primera tabla de cada uno:
for filename in os.listdir(input_folder):
if filename.lower().endswith((".doc", ".docx")):
word_table_to_csv(
os.path.join(input_folder, filename),
os.path.join(
output_folder,
os.path.splitext(filename)[0] + ".csv"
)
)
¿Por qué usar Python para la conversión de Word a CSV?
La automatización con Python y Spire.Doc para Python ofrece ventajas claras cuando necesitas convertir tablas de Word a CSV a escala:
| Ventaja | Detalles |
|---|---|
| Conversión por lotes | Procesa docenas o cientos de archivos de Word en un solo script. |
| Automatización | Programa conversiones para que se ejecuten automáticamente: a diario, semanalmente o bajo demanda. |
| Grandes conjuntos de datos | Maneja documentos de Word con tablas grandes que son poco prácticas de convertir manualmente. |
| Integración de flujos de trabajo | Integra la conversión de Word a CSV en canalizaciones de datos, procesos ETL o flujos de trabajo CI/CD. |
| Sin dependencia de Microsoft Word | Spire.Doc para Python funciona sin Microsoft Word instalado. |
| Precisión de los datos | La extracción programática elimina errores de copiar y pegar y garantiza resultados consistentes. |
Para un uso más avanzado, también puedes consultar nuestra guía sobre cómo extraer tablas de documentos de Word usando Python.
5. Preguntas frecuentes
¿Puedo convertir Word a CSV directamente?
No. Microsoft Word no tiene una opción integrada para guardar o exportar documentos como CSV. El cuadro de diálogo "Guardar como" de Word admite formatos como DOCX, PDF, RTF, HTML y texto plano, pero no CSV. Para convertir Word a CSV, necesitas extraer los datos de la tabla del documento y escribirlos en un archivo CSV usando software de hoja de cálculo o automatización con Python.
¿Por qué Word no puede guardar directamente como CSV?
Word es un formato de documento de texto enriquecido que admite párrafos, imágenes, encabezados, estilos y contenido mixto. CSV es un formato tabular plano que almacena solo filas y columnas de texto separadas por comas. Word no puede determinar automáticamente cómo aplanar una estructura de documento compleja en un diseño tabular, por lo que no ofrece CSV como opción de exportación. Solo los datos estructurados, típicamente datos en tablas de Word, se pueden convertir significativamente a CSV.
¿Cómo convierto una tabla de Word a CSV?
Tienes dos opciones principales: (1) Software de hoja de cálculo: Copia la tabla de Word a Excel o Google Sheets, verifica los datos y guarda o descarga como CSV. Este es el enfoque más común para uso ocasional. (2) Python: Usa Spire.Doc para Python para leer el documento de Word, acceder a la tabla mediante programación, extraer los valores de las celdas y escribirlos en un archivo CSV. Esto es ideal para automatización, procesamiento por lotes y conversiones recurrentes.
¿Puedo convertir DOCX a CSV sin Excel?
Sí. Puedes convertir DOCX a CSV sin Excel usando: (1) Google Sheets: Pega los datos de la tabla de Word en una hoja de cálculo de Google Sheets y descarga como CSV. (2) Herramientas en línea: Sube tu archivo DOCX a un sitio web convertidor de Word a CSV y descarga el resultado. (3) Python: Usa Spire.Doc para Python para leer el archivo DOCX, extraer los datos de la tabla y escribirlos en CSV. Esto funciona sin necesidad de tener instalado ningún software de Microsoft Office.
¿Existe un convertidor gratuito de Word a CSV?
Sí. Hay opciones gratuitas en dos categorías: (1) Convertidores en línea: Muchos sitios web ofrecen conversión gratuita de Word a CSV, aunque generalmente tienen límites de tamaño de archivo y plantean preocupaciones de privacidad, ya que tus datos se suben a un servidor de terceros. (2) Scripts de Python: Puedes escribir un script de conversión gratuito y local usando Spire.Doc para Python (que ofrece una versión gratuita) y el módulo csv integrado de Python. Esto mantiene tus datos privados y no tiene restricciones de tamaño de archivo.
¿Cómo extraigo datos de un documento de Word a CSV en Python?
Usa Spire.Doc para Python para cargar el documento de Word, acceder a la tabla a través de las colecciones Sections y Tables, iterar a través de filas y celdas para leer el texto de cada celda y escribir los datos en un archivo CSV usando el csv.writer estándar de Python. El ejemplo de código completo se proporciona en el Método 2 anterior.
¿Spire.Doc para Python requiere que Microsoft Word esté instalado?
No. Spire.Doc para Python es una biblioteca independiente que crea, lee y manipula documentos de Word de forma independiente. No requiere que Microsoft Word ni ningún componente de Office esté instalado en tu sistema. Esto lo hace adecuado para entornos de servidor, flujos de trabajo automatizados y máquinas donde Office no está disponible.
Conclusión
Convertir Word a CSV significa extraer datos de tablas estructuradas de documentos DOC o DOCX y guardarlos en un formato tabular. El software de hoja de cálculo (Excel o Google Sheets) proporciona un enfoque manual sencillo: copia la tabla de Word, verifica los datos y exporta como CSV. Esto funciona bien para conversiones ocasionales, pero no escala para procesamiento por lotes o flujos de trabajo recurrentes.
La automatización con Python y Spire.Doc para Python ofrece una solución confiable para convertir tablas de Word a CSV mediante programación. Lee archivos DOC y DOCX, extrae datos de tablas con precisión y genera salida CSV, todo sin requerir Microsoft Word. Para desarrolladores y organizaciones que convierten regularmente archivos DOC o DOCX a CSV, Spire.Doc para Python ofrece una forma confiable de automatizar todo el proceso mientras conserva los datos de la tabla con precisión.
Puedes solicitar una licencia gratuita de 30 días para evaluar todas las funciones de Spire.Doc para Python.
Ver también
So konvertieren Sie Word-Tabellen in CSV (DOC/DOCX in CSV)
Inhaltsverzeichnis
CSV (Comma-Separated Values) ist ein leichtgewichtiges, universell kompatibles Format für tabellarische Daten. Word-Dokumente (DOC und DOCX) hingegen sind Rich-Text-Dokumente, die Absätze, Bilder, Kopfzeilen, Formatierungen und Tabellen enthalten. Da CSV nur Zeilen und Spalten unterstützt, bedeutet die Konvertierung von Word in CSV oder DOCX in CSV fast immer die Extraktion von Tabellendaten aus dem Dokument.
Organisationen müssen Word- oder DOCX-Tabellen häufig in CSV konvertieren, wenn sie strukturierte Daten in Tabellenkalkulationen, Datenbanken, CRM-Systemen, Analysetools oder automatisierte Workflows übertragen.
Diese Anleitung behandelt zwei praktische Methoden zur Konvertierung von Word-Tabellen in CSV sowie wichtige Hintergründe dazu, warum Word CSV nicht direkt exportieren kann und wann Online-Konverter geeignet sind.
Schnellnavigation
- Warum Word nicht direkt als CSV gespeichert werden kann
- Methode 1 – Word-Tabellen mit Tabellenkalkulationssoftware in CSV konvertieren
- Kann man einen Online-Word-zu-CSV-Konverter verwenden?
- Methode 2 – Word-Tabellen automatisch mit Python in CSV konvertieren
- FAQ
Welche Methode sollten Sie wählen?
| Methode | Benutzerfreundlichkeit | Stapelverarbeitung | Datenschutz | Am besten geeignet für |
|---|---|---|---|---|
| Tabellenkalkulationssoftware | Hoch | Nein | Hoch | Gelegentliche Konvertierungen, manuelle Überprüfung |
| Python (Spire.Doc) | Mittel | Ja | Hoch | Automatisierung, Stapelverarbeitung, wiederkehrende Aufgaben |
1. Warum Word nicht direkt als CSV gespeichert werden kann
Microsoft Word bietet keine Option zum "Speichern unter CSV". Dies ist kein Versehen – es spiegelt eine grundlegende Formatinkongruenz wider:
- Word-Dokumente enthalten gemischte Inhalte: Absätze, Bilder, Kopfzeilen, Fußzeilen, formatierter Text und Tabellen. Ein einzelnes Dokument kann mehrere Abschnitte, Spalten und verschachtelte Elemente enthalten.
- CSV-Dateien enthalten nur flache tabellarische Daten: Zeilen und Spalten von reinem Text, getrennt durch Kommas.
Word kann nicht automatisch bestimmen, wie ein Rich-Text-Dokument in ein tabellarisches Layout umgewandelt werden soll. Ein Dokument mit drei Absätzen, einem Bild und einer Tabelle lässt sich nicht sauber in Zeilen und Spalten abbilden. Der einzige Teil eines Word-Dokuments, der eine natürliche CSV-Darstellung hat, sind strukturierte Tabellendaten.
Aus diesem Grund konzentriert sich jeder praktische Ansatz zur Konvertierung von Word in CSV auf die Extraktion von Tabellen aus dem Dokument – sei es über Tabellenkalkulationssoftware, Online-Tools oder programmatische Methoden.
2. Methode 1 – Word-Tabellen mit Tabellenkalkulationssoftware in CSV konvertieren
Der einfachste Weg, Word-Tabellen in CSV zu konvertieren, ist das Kopieren der Tabelle in eine Tabellenkalkulationsanwendung und der Export daraus. Sowohl Microsoft Excel als auch Google Sheets unterstützen diesen Workflow.
Der Workflow
- Kopieren Sie die Word-Tabelle in eine Tabellenkalkulation – Wählen Sie die Tabelle in Word aus, kopieren Sie sie und fügen Sie sie in eine neue Tabellenkalkulation ein.
- Überprüfen Sie die importierten Daten – Stellen Sie sicher, dass Zeilen, Spalten und Zellwerte korrekt getrennt sind. Achten Sie auf zusammengeführte Zellen, die zu Fehlausrichtungen führen können.
- Als CSV exportieren – Speichern oder laden Sie die Tabellenkalkulation im CSV-Format herunter.
Option A – Microsoft Office
- Öffnen Sie das Word-Dokument und kopieren Sie die zu exportierende Tabelle.
- Fügen Sie die Tabelle in ein Excel-Arbeitsblatt ein und überprüfen Sie, ob Zeilen und Spalten korrekt importiert wurden.
- Überprüfen Sie zusammengeführte Zellen, Zeilenumbrüche oder andere Formatierungsprobleme, die die CSV-Struktur beeinträchtigen könnten.
- Wählen Sie Datei > Speichern unter und speichern Sie das Arbeitsblatt als CSV-Datei.
Excel behält die Struktur von Word-Tabellen gut bei – Zeilen und Spalten werden in den meisten Fällen korrekt zugeordnet. Wenn Ihr Dokument mehrere Tabellen enthält, können Sie jede auf ein separates Arbeitsblatt kopieren und jede als einzelne CSV-Datei speichern.
Überlegungen:
- Zusammengeführte Zellen in der Word-Tabelle können nach dem Einfügen zu Fehlausrichtungen führen.
- Excel läuft lokal, sodass Ihre Daten auf Ihrem Computer bleiben.
- Der Prozess ist manuell und für häufige oder groß angelegte Konvertierungen nicht praktikabel.
Option B – Google Sheets
- Kopieren Sie die Tabelle aus dem Word-Dokument (in Google Docs oder anderen Dokumentenanzeigen).
- Fügen Sie sie in eine neue Google Sheets-Tabellenkalkulation ein.
- Überprüfen Sie die Struktur der importierten Tabelle und passen Sie fehlerhafte Daten an.
- Laden Sie die Tabellenkalkulation als CSV-Datei herunter, indem Sie Datei > Herunterladen > Kommagetrennte Werte (.csv) wählen.
Google Sheets ist kostenlos und erfordert nur ein Google-Konto. Es erleichtert auch das Teilen und Überprüfen von Daten mit Mitarbeitern, bevor sie in CSV exportiert werden.
Überlegungen:
- Daten werden während der Bearbeitung auf den Servern von Google gespeichert – berücksichtigen Sie dies bei sensiblen Informationen.
- Keine Softwareinstallation erforderlich.
- Wie Excel ist dies ein manueller Prozess ohne Automatisierungsunterstützung.
Wann diese Methode verwenden?
Die tabellenbasierte Konvertierung eignet sich gut, wenn Sie gelegentlich Word-Tabellendaten in CSV exportieren müssen und die Daten vor dem Speichern überprüfen möchten. Für wiederkehrende Konvertierungen, mehrere Dokumente oder automatisierte Workflows ist die unten beschriebene Python-Methode effizienter.
Wenn Sie auch DOCX (Word-Dokumente) in XLSX konvertieren müssen, können Sie sich auf unseren Leitfaden zur Konvertierung von Docx in XLSX für einen strukturierten Tabellenkalkulations-Workflow beziehen.
3. Kann man einen Online-Word-zu-CSV-Konverter verwenden?
Ja. Mehrere Websites bieten Word-zu-CSV-Konverter-Tools an, mit denen Sie eine DOC- oder DOCX-Datei hochladen und eine CSV-Datei herunterladen können. Diese eignen sich für schnelle, einmalige Konvertierungen, wenn Sie keine Software installieren möchten.
Online-Konverter haben jedoch bemerkenswerte Einschränkungen:
- Datenschutz – Ihr Dokument wird auf einen Server eines Drittanbieters hochgeladen, was für sensible oder proprietäre Daten möglicherweise nicht akzeptabel ist.
- Dateigrößenbeschränkungen – Die meisten kostenlosen Tools beschränken Uploads auf 5–10 MB.
- Tabellenerkennung – Einige Konverter extrahieren nur die erste Tabelle; andere interpretieren die Dokumentstruktur möglicherweise falsch.
- Keine Stapelverarbeitung – Sie können nur eine Datei nach der anderen konvertieren.
Für sensible Daten, wiederkehrende Konvertierungen oder Stapelverarbeitung sind lokale Methoden (Tabellenkalkulationssoftware oder Python) vorzuziehen.
4. Methode 2 – Word-Tabellen automatisch mit Python in CSV konvertieren
Wenn Sie Word-Dateien regelmäßig in CSV konvertieren, die Dokumentenverarbeitung automatisieren oder eine große Anzahl von Dateien verarbeiten müssen, bietet Python eine effizientere Lösung. Mit Spire.Doc for Python können Sie Word-Dokumente lesen, Tabellendaten extrahieren und sie direkt in das CSV-Format exportieren – und das alles ohne installiertes Microsoft Word.
Spire.Doc for Python installieren
Installieren Sie die Bibliothek über pip:
pip install spire.doc
Importieren Sie die erforderlichen Klassen in Ihr Python-Skript:
from spire.doc import *
from spire.doc.common import *
Alternativ können Sie Spire.Doc for Python herunterladen und manuell integrieren.
Eine Word-Tabelle in CSV konvertieren
Das folgende Beispiel lädt ein Word-Dokument, extrahiert die erste Tabelle, liest ihre Zeilen und Zellen und schreibt die Daten in eine CSV-Datei.
import csv
from spire.doc import *
from spire.doc.common import *
document = Document()
document.LoadFromFile("Sample.docx")
section = document.Sections.get_Item(0)
for t in range(section.Tables.Count):
table = section.Tables.get_Item(t)
csv_data = []
for r in range(table.Rows.Count):
row = table.Rows.get_Item(r)
row_data = []
for c in range(row.Cells.Count):
cell = row.Cells.get_Item(c)
paragraphs = []
for p in range(cell.Paragraphs.Count):
text = cell.Paragraphs.get_Item(p).Text.strip()
if text:
paragraphs.append(text)
row_data.append(" ".join(paragraphs))
csv_data.append(row_data)
csv_path = f"table_{t + 1}.csv"
with open(csv_path, "w", newline="", encoding="utf-8-sig") as f:
csv.writer(f).writerows(csv_data)
document.Close()
Wie es funktioniert
Document.LoadFromFile()lädt das Word-Dokument in den Speicher.section.Tables.get_Item(table_index)wählt die zu exportierende Tabelle aus.- Das Skript durchläuft jede Zeile und jede Zelle in der Tabelle mithilfe der Sammlungen Rows und Cells.
- Jede Tabellenzelle kann einen oder mehrere Absätze enthalten. Das Skript liest alle Absätze mithilfe von
cell.Paragraphsund extrahiert deren Textinhalt. - Der extrahierte Absatztext wird mit
.strip()bereinigt und zu einer einzigen Zeichenkette für den CSV-Zellwert kombiniert. csv.writer()exportiert die gesammelten Tabellendaten in eine Standard-CSV-Datei, die in Excel, Google Sheets, Datenbanken oder anderen Datenverarbeitungstools geöffnet werden kann.
Ergebnis
Unten sehen Sie eine Vorschau der Word-Tabelle und der generierten CSV-Datei:
Das Ergebnis ist eine korrekt formatierte .csv-Datei, die die Word-Tabellendaten enthält und für den Import in Excel, Datenbanken oder jedes System, das CSV-Eingaben akzeptiert, bereit ist.
Mehrere Tabellen aus einem Word-Dokument extrahieren
Wenn Ihr Word-Dokument mehrere Tabellen enthält, durchlaufen Sie section.Tables und speichern Sie jede als separate CSV-Datei:
for t in range(section.Tables.Count):
word_table_to_csv(
word_path,
f"table_{t + 1}.csv",
table_index=t
)
Mehrere Word-Dateien im Stapelverfahren konvertieren
Um einen ganzen Ordner mit Word-Dokumenten zu verarbeiten, durchlaufen Sie die Dateien und extrahieren Sie die erste Tabelle aus jeder:
for filename in os.listdir(input_folder):
if filename.lower().endswith((".doc", ".docx")):
word_table_to_csv(
os.path.join(input_folder, filename),
os.path.join(
output_folder,
os.path.splitext(filename)[0] + ".csv"
)
)
Warum Python für die Word-zu-CSV-Konvertierung verwenden?
Die Python-Automatisierung mit Spire.Doc for Python bietet klare Vorteile, wenn Sie Word-Tabellen im großen Stil in CSV konvertieren müssen:
| Vorteil | Details |
|---|---|
| Stapelkonvertierung | Verarbeiten Sie Dutzende oder Hunderte von Word-Dateien in einem einzigen Skript. |
| Automatisierung | Planen Sie Konvertierungen, die automatisch ausgeführt werden – täglich, wöchentlich oder nach Bedarf. |
| Große Datensätze | Verarbeiten Sie Word-Dokumente mit großen Tabellen, die manuell zu konvertieren unpraktisch sind. |
| Workflow-Integration | Integrieren Sie die Word-zu-CSV-Konvertierung in Datenpipelines, ETL-Prozesse oder CI/CD-Workflows. |
| Keine Abhängigkeit von Microsoft Word | Spire.Doc for Python funktioniert ohne installiertes Microsoft Word. |
| Datengenauigkeit | Die programmatische Extraktion eliminiert Kopier-/Einfügefehler und gewährleistet konsistente Ergebnisse. |
Für fortgeschrittenere Anwendungsfälle können Sie auch unseren Leitfaden zum Extrahieren von Tabellen aus Word-Dokumenten mit Python konsultieren.
5. FAQ
Kann ich Word direkt in CSV konvertieren?
Nein. Microsoft Word verfügt nicht über eine integrierte Option zum Speichern oder Exportieren von Dokumenten als CSV. Der Dialog "Speichern unter" von Word unterstützt Formate wie DOCX, PDF, RTF, HTML und Nur-Text – aber nicht CSV. Um Word in CSV zu konvertieren, müssen Sie Tabellendaten aus dem Dokument extrahieren und sie mithilfe von Tabellenkalkulationssoftware oder Python-Automatisierung in eine CSV-Datei schreiben.
Warum kann Word nicht direkt als CSV gespeichert werden?
Word ist ein Rich-Text-Dokumentformat, das Absätze, Bilder, Kopfzeilen, Stile und gemischte Inhalte unterstützt. CSV ist ein flaches Tabellenformat, das nur Zeilen und Spalten von Text speichert, die durch Kommas getrennt sind. Word kann nicht automatisch bestimmen, wie eine komplexe Dokumentstruktur in ein tabellarisches Layout umgewandelt werden soll, daher bietet es CSV nicht als Exportoption an. Nur strukturierte Daten – typischerweise Daten in Word-Tabellen – können sinnvoll in CSV konvertiert werden.
Wie konvertiere ich eine Word-Tabelle in CSV?
Sie haben zwei Hauptoptionen: (1) Tabellenkalkulationssoftware – Kopieren Sie die Word-Tabelle in Excel oder Google Sheets, überprüfen Sie die Daten und speichern Sie sie als CSV. Dies ist der gängigste Ansatz für gelegentliche Nutzung. (2) Python – Verwenden Sie Spire.Doc for Python, um das Word-Dokument zu lesen, programmgesteuert auf die Tabelle zuzugreifen, Zellwerte zu extrahieren und sie in eine CSV-Datei zu schreiben. Dies ist ideal für Automatisierung, Stapelverarbeitung und wiederkehrende Konvertierungen.
Kann ich DOCX ohne Excel in CSV konvertieren?
Ja. Sie können DOCX ohne Excel konvertieren, indem Sie: (1) Google Sheets – Fügen Sie die Word-Tabellendaten in eine Google Sheets-Tabellenkalkulation ein und laden Sie sie als CSV herunter. (2) Online-Tools – Laden Sie Ihre DOCX-Datei auf eine Word-zu-CSV-Konverter-Website hoch und laden Sie das Ergebnis herunter. (3) Python – Verwenden Sie Spire.Doc for Python, um die DOCX-Datei zu lesen, Tabellendaten zu extrahieren und sie in CSV zu schreiben. Dies funktioniert ohne installierte Microsoft Office-Software.
Gibt es einen kostenlosen Word-zu-CSV-Konverter?
Ja. Es gibt kostenlose Optionen in zwei Kategorien: (1) Online-Konverter – Viele Websites bieten kostenlose Word-zu-CSV-Konvertierung an, obwohl sie in der Regel Dateigrößenbeschränkungen haben und Datenschutzbedenken aufwerfen, da Ihre Daten auf einen Server eines Drittanbieters hochgeladen werden. (2) Python-Skripte – Sie können ein kostenloses, lokales Konvertierungsskript mit Spire.Doc for Python (das eine kostenlose Version anbietet) und dem integrierten csv-Modul von Python schreiben. Dies schützt Ihre Daten und hat keine Dateigrößenbeschränkungen.
Wie extrahiere ich Daten aus einem Word-Dokument in CSV in Python?
Verwenden Sie Spire.Doc for Python, um das Word-Dokument zu laden, über die Sammlungen Sections und Tables auf die Tabelle zuzugreifen, Zeilen und Zellen zu durchlaufen, um den Text jeder Zelle zu lesen, und die Daten mithilfe des Standard-csv.writer von Python in eine CSV-Datei zu schreiben. Das vollständige Codebeispiel finden Sie in Methode 2 oben.
Benötigt Spire.Doc for Python Microsoft Word zur Installation?
Nein. Spire.Doc for Python ist eine eigenständige Bibliothek, die Word-Dokumente unabhängig erstellt, liest und bearbeitet. Sie erfordert keine Installation von Microsoft Word oder einer Office-Komponente auf Ihrem System. Dies macht sie für Serverumgebungen, automatisierte Workflows und Maschinen geeignet, auf denen Office nicht verfügbar ist.
Fazit
Die Konvertierung von Word in CSV bedeutet die Extraktion strukturierter Tabellendaten aus DOC- oder DOCX-Dokumenten und deren Speicherung in einem tabellarischen Format. Tabellenkalkulationssoftware (Excel oder Google Sheets) bietet einen einfachen manuellen Ansatz – kopieren Sie die Word-Tabelle, überprüfen Sie die Daten und exportieren Sie sie als CSV. Dies funktioniert gut für gelegentliche Konvertierungen, skaliert aber nicht für Stapelverarbeitung oder wiederkehrende Workflows.
Python-Automatisierung mit Spire.Doc for Python bietet eine zuverlässige Lösung für die programmatische Konvertierung von Word-Tabellen in CSV. Sie liest DOC- und DOCX-Dateien, extrahiert Tabellendaten genau und schreibt CSV-Ausgaben – und das alles ohne Microsoft Word. Für Entwickler und Organisationen, die regelmäßig DOC- oder DOCX-Dateien in CSV konvertieren, bietet Spire.Doc for Python eine zuverlässige Möglichkeit, den gesamten Prozess zu automatisieren und gleichzeitig Tabellendaten genau zu erhalten.
Sie können eine kostenlose 30-Tage-Lizenz beantragen, um alle Funktionen von Spire.Doc for Python zu evaluieren.
Siehe auch
Как преобразовать таблицы Word в CSV (DOC/DOCX в CSV)
Оглавление
CSV (Comma-Separated Values) — это легкий, универсально совместимый формат для табличных данных. Документы Word (DOC и DOCX), напротив, являются документами с расширенным форматированием, которые содержат абзацы, изображения, заголовки, форматирование и таблицы. Поскольку CSV поддерживает только строки и столбцы, преобразование Word в CSV или DOCX в CSV почти всегда означает извлечение табличных данных из документа.
Организациям часто требуется преобразовывать таблицы Word или DOCX в CSV при переносе структурированных данных в электронные таблицы, базы данных, системы CRM, аналитические инструменты или автоматизированные рабочие процессы.
В этом руководстве рассматриваются два практических метода преобразования таблиц Word в CSV, а также важный контекст о том, почему Word не может экспортировать CSV напрямую и когда подходят онлайн-конвертеры.
Быстрая навигация
- Почему Word не может быть сохранен напрямую как CSV
- Метод 1 – Преобразование таблиц Word в CSV с помощью табличных редакторов
- Можно ли использовать онлайн-конвертер Word в CSV?
- Метод 2 – Автоматическое преобразование таблиц Word в CSV с помощью Python
- Часто задаваемые вопросы
Какой метод выбрать?
| Метод | Простота использования | Пакетная обработка | Конфиденциальность | Лучше всего подходит для |
|---|---|---|---|---|
| Табличные редакторы | Высокая | Нет | Высокая | Периодические преобразования, ручная проверка |
| Python (Spire.Doc) | Средняя | Да | Высокая | Автоматизация, пакетная обработка, повторяющиеся задачи |
1. Почему Word не может быть сохранен напрямую как CSV
Microsoft Word не предлагает опцию «Сохранить как CSV». Это не упущение — это отражение фундаментального несоответствия форматов:
- Документы Word содержат смешанный контент: абзацы, изображения, заголовки, нижние колонтитулы, стилизованный текст и таблицы. Один документ может иметь несколько разделов, столбцов и вложенных элементов.
- Файлы CSV содержат только плоские табличные данные: строки и столбцы обычного текста, разделенные запятыми.
Word не может автоматически определить, как преобразовать документ с расширенным форматированием в табличный макет. Документ с тремя абзацами, изображением и таблицей не может быть легко преобразован в строки и столбцы. Единственная часть документа Word, которая имеет естественное представление в формате CSV, — это структурированные табличные данные.
Именно поэтому каждый практический подход к преобразованию Word в CSV фокусируется на извлечении таблиц из документа — будь то с помощью табличных редакторов, онлайн-инструментов или программных методов.
2. Метод 1 – Преобразование таблиц Word в CSV с помощью табличных редакторов
Самый простой способ преобразовать таблицы Word в CSV — скопировать таблицу в приложение для работы с электронными таблицами и экспортировать ее. Как Microsoft Excel, так и Google Sheets поддерживают этот рабочий процесс.
Рабочий процесс
- Скопируйте таблицу Word в электронную таблицу — Выделите таблицу в Word, скопируйте ее и вставьте в новую электронную таблицу.
- Проверьте импортированные данные — Убедитесь, что строки, столбцы и значения ячеек правильно разделены. Обратите внимание на объединенные ячейки, которые могут вызвать смещение.
- Экспортируйте в формате CSV — Сохраните или загрузите электронную таблицу в формате CSV.
Вариант A – Microsoft Office
- Откройте документ Word и скопируйте таблицу, которую хотите экспортировать.
- Вставьте таблицу в лист Excel и убедитесь, что строки и столбцы импортированы правильно.
- Проверьте объединенные ячейки, переносы строк или другие проблемы форматирования, которые могут повлиять на структуру CSV.
- Выберите Файл > Сохранить как и сохраните рабочий лист в виде файла CSV.
Excel хорошо сохраняет структуру таблиц Word — строки и столбцы в большинстве случаев отображаются правильно. Если ваш документ содержит несколько таблиц, вы можете вставить каждую на отдельный рабочий лист и сохранить каждую как отдельный файл CSV.
Соображения:
- Объединенные ячейки в таблице Word могут вызвать смещение после вставки.
- Excel работает локально, поэтому ваши данные остаются на вашем компьютере.
- Процесс ручной и непрактичен для частых или крупномасштабных преобразований.
Вариант B – Google Sheets
- Скопируйте таблицу из документа Word (в Google Docs или других программах просмотра документов).
- Вставьте ее в новую электронную таблицу Google Sheets.
- Проверьте структуру импортированной таблицы и скорректируйте любые смещенные данные.
- Загрузите электронную таблицу в виде файла CSV, используя Файл > Загрузить > Значения, разделенные запятыми (.csv).
Google Sheets бесплатен и требует только учетной записи Google. Он также позволяет легко делиться данными и просматривать их с коллегами перед экспортом в CSV.
Соображения:
- Данные хранятся на серверах Google во время редактирования — учитывайте это при работе с конфиденциальной информацией.
- Установка программного обеспечения не требуется.
- Как и Excel, это ручной процесс без поддержки автоматизации.
Когда использовать этот метод
Преобразование на основе электронных таблиц хорошо работает, когда вам иногда нужно экспортировать данные таблиц Word в CSV и вы хотите просмотреть данные перед сохранением. Для повторяющихся преобразований, нескольких документов или автоматизированных рабочих процессов метод Python, описанный ниже, более эффективен.
Если вам также нужно преобразовать DOCX (документы Word) в XLSX, вы можете обратиться к нашему руководству по преобразованию Docx в XLSX для структурированного рабочего процесса с электронными таблицами.
3. Можно ли использовать онлайн-конвертер Word в CSV?
Да. Существует несколько веб-сайтов, предлагающих инструменты конвертера Word в CSV, которые позволяют загрузить файл DOC или DOCX и скачать файл CSV. Они подходят для быстрых, одноразовых преобразований, когда вы не хотите устанавливать какое-либо программное обеспечение.
Однако онлайн-конвертеры имеют существенные ограничения:
- Конфиденциальность — Ваш документ загружается на сторонний сервер, что может быть неприемлемо для конфиденциальных или проприетарных данных.
- Ограничения размера файла — Большинство бесплатных инструментов ограничивают загрузку до 5–10 МБ.
- Распознавание таблиц — Некоторые конвертеры извлекают только первую таблицу; другие могут неправильно интерпретировать структуру документа.
- Отсутствие пакетной обработки — Вы можете конвертировать только один файл за раз.
Для конфиденциальных данных, повторяющихся преобразований или пакетной обработки предпочтительны локальные методы (табличные редакторы или Python).
4. Метод 2 – Автоматическое преобразование таблиц Word в CSV с помощью Python
Если вам нужно регулярно преобразовывать файлы Word в CSV, автоматизировать обработку документов или работать с большим количеством файлов, Python предоставляет более эффективное решение. С помощью Spire.Doc для Python вы можете читать документы Word, извлекать табличные данные и экспортировать их непосредственно в формат CSV — все это без установленного Microsoft Word.
Установка Spire.Doc для Python
Установите библиотеку через pip:
pip install spire.doc
Импортируйте необходимые классы в ваш скрипт Python:
from spire.doc import *
from spire.doc.common import *
В качестве альтернативы вы можете скачать Spire.Doc для Python и интегрировать его вручную.
Преобразование таблицы Word в CSV
Следующий пример загружает документ Word, извлекает первую таблицу, считывает ее строки и ячейки и записывает данные в файл CSV.
import csv
from spire.doc import *
from spire.doc.common import *
document = Document()
document.LoadFromFile("Sample.docx")
section = document.Sections.get_Item(0)
for t in range(section.Tables.Count):
table = section.Tables.get_Item(t)
csv_data = []
for r in range(table.Rows.Count):
row = table.Rows.get_Item(r)
row_data = []
for c in range(row.Cells.Count):
cell = row.Cells.get_Item(c)
paragraphs = []
for p in range(cell.Paragraphs.Count):
text = cell.Paragraphs.get_Item(p).Text.strip()
if text:
paragraphs.append(text)
row_data.append(" ".join(paragraphs))
csv_data.append(row_data)
csv_path = f"table_{t + 1}.csv"
with open(csv_path, "w", newline="", encoding="utf-8-sig") as f:
csv.writer(f).writerows(csv_data)
document.Close()
Как это работает
Document.LoadFromFile()загружает документ Word в память.section.Tables.get_Item(table_index)выбирает таблицу для экспорта.- Скрипт проходит по каждой строке и ячейке таблицы, используя коллекции Rows и Cells.
- Каждая ячейка таблицы может содержать один или несколько абзацев. Скрипт считывает все абзацы с помощью
cell.Paragraphsи извлекает их текстовое содержимое. - Извлеченный текст абзаца очищается с помощью
.strip()и объединяется в одну строку для значения ячейки CSV. csv.writer()экспортирует собранные табличные данные в стандартный файл CSV, который можно открыть в Excel, Google Sheets, базах данных или других инструментах обработки данных.
Результат
Ниже представлен предварительный просмотр таблицы Word и сгенерированного файла CSV:
Результатом является правильно отформатированный файл .csv, содержащий данные таблицы Word, готовый для импорта в Excel, базы данных или любую систему, принимающую ввод в формате CSV.
Извлечение нескольких таблиц из документа Word
Если ваш документ Word содержит несколько таблиц, пройдитесь по section.Tables и сохраните каждую как отдельный файл CSV:
for t in range(section.Tables.Count):
word_table_to_csv(
word_path,
f"table_{t + 1}.csv",
table_index=t
)
Пакетное преобразование нескольких файлов Word
Чтобы обработать всю папку документов Word, пройдитесь по файлам и извлеките первую таблицу из каждого:
for filename in os.listdir(input_folder):
if filename.lower().endswith((".doc", ".docx")):
word_table_to_csv(
os.path.join(input_folder, filename),
os.path.join(
output_folder,
os.path.splitext(filename)[0] + ".csv"
)
)
Почему использовать Python для преобразования Word в CSV?
Автоматизация Python с помощью Spire.Doc для Python предлагает явные преимущества, когда вам нужно преобразовывать таблицы Word в CSV в больших масштабах:
| Преимущество | Подробности |
|---|---|
| Пакетное преобразование | Обработка десятков или сотен файлов Word в одном скрипте |
| Автоматизация | Планирование преобразований для автоматического запуска — ежедневно, еженедельно или по запросу |
| Большие наборы данных | Работа с документами Word с большими таблицами, которые непрактично преобразовывать вручную |
| Интеграция рабочего процесса | Интеграция преобразования Word в CSV в конвейеры данных, процессы ETL или рабочие процессы CI/CD |
| Отсутствие зависимости от Microsoft Word | Spire.Doc для Python работает без установленного Microsoft Word |
| Точность данных | Программное извлечение устраняет ошибки копирования-вставки и обеспечивает согласованные результаты |
Для более продвинутого использования вы также можете ознакомиться с нашим руководством по извлечению таблиц из документов Word с помощью Python.
5. Часто задаваемые вопросы
Могу ли я преобразовать Word в CSV напрямую?
Нет. Microsoft Word не имеет встроенной опции для сохранения или экспорта документов в формате CSV. Диалоговое окно «Сохранить как» Word поддерживает такие форматы, как DOCX, PDF, RTF, HTML и простой текст — но не CSV. Чтобы преобразовать Word в CSV, вам нужно извлечь табличные данные из документа и записать их в файл CSV с помощью табличного редактора или автоматизации Python.
Почему Word не может сохраняться напрямую как CSV?
Word — это формат документа с расширенным форматированием, который поддерживает абзацы, изображения, заголовки, стили и смешанный контент. CSV — это плоский табличный формат, который хранит только строки и столбцы текста, разделенные запятыми. Word не может автоматически определить, как преобразовать сложную структуру документа в табличный макет, поэтому он не предлагает CSV в качестве опции экспорта. Только структурированные данные — как правило, данные в таблицах Word — могут быть осмысленно преобразованы в CSV.
Как преобразовать таблицу Word в CSV?
У вас есть два основных варианта: (1) Табличные редакторы — Скопируйте таблицу Word в Excel или Google Sheets, проверьте данные и сохраните или загрузите в формате CSV. Это наиболее распространенный подход для периодического использования. (2) Python — Используйте Spire.Doc для Python для чтения документа Word, доступа к таблице программно, извлечения значений ячеек и записи их в файл CSV. Это идеально подходит для автоматизации, пакетной обработки и повторяющихся преобразований.
Могу ли я преобразовать DOCX в CSV без Excel?
Да. Вы можете преобразовать DOCX в CSV без Excel, используя: (1) Google Sheets — Вставьте данные таблицы Word в электронную таблицу Google Sheets и загрузите в формате CSV. (2) Онлайн-инструменты — Загрузите свой файл DOCX на веб-сайт конвертера Word в CSV и скачайте результат. (3) Python — Используйте Spire.Doc для Python для чтения файла DOCX, извлечения табличных данных и записи их в CSV. Это работает без установленного программного обеспечения Microsoft Office.
Существует ли бесплатный конвертер Word в CSV?
Да. Существуют бесплатные варианты в двух категориях: (1) Онлайн-конвертеры — Многие веб-сайты предлагают бесплатное преобразование Word в CSV, хотя они обычно имеют ограничения по размеру файла и вызывают опасения по поводу конфиденциальности, поскольку ваши данные загружаются на сторонний сервер. (2) Скрипты Python — Вы можете написать бесплатный локальный скрипт преобразования, используя Spire.Doc для Python (который предлагает бесплатную версию) и встроенный модуль csv Python. Это сохраняет конфиденциальность ваших данных и не имеет ограничений по размеру файла.
Как извлечь данные из документа Word в CSV с помощью Python?
Используйте Spire.Doc для Python для загрузки документа Word, доступа к таблице через коллекции Sections и Tables, прохода по строкам и ячейкам для чтения текста каждой ячейки и записи данных в файл CSV с помощью стандартного csv.writer Python. Полный пример кода приведен в Методе 2 выше.
Требуется ли установка Microsoft Word для Spire.Doc для Python?
Нет. Spire.Doc для Python — это автономная библиотека, которая создает, читает и манипулирует документами Word независимо. Она не требует установки Microsoft Word или каких-либо компонентов Office в вашей системе. Это делает ее подходящей для серверных сред, автоматизированных рабочих процессов и машин, где Office недоступен.
Заключение
Преобразование Word в CSV означает извлечение структурированных табличных данных из документов DOC или DOCX и сохранение их в табличном формате. Табличные редакторы (Excel или Google Sheets) предоставляют простой ручной подход — скопируйте таблицу Word, проверьте данные и экспортируйте в формате CSV. Это хорошо работает для периодических преобразований, но не подходит для пакетной обработки или повторяющихся рабочих процессов.
Автоматизация Python с помощью Spire.Doc для Python предоставляет надежное решение для программного преобразования таблиц Word в CSV. Он читает файлы DOC и DOCX, точно извлекает табличные данные и записывает вывод в формате CSV — все это без необходимости установки Microsoft Word. Для разработчиков и организаций, которые регулярно преобразуют файлы DOC или DOCX в CSV, Spire.Doc для Python предлагает надежный способ автоматизировать весь процесс, сохраняя при этом табличные данные с высокой точностью.
Вы можете подать заявку на бесплатную 30-дневную лицензию для оценки всех функций Spire.Doc для Python.
См. также
Como converter CSV para Word (métodos manuais e Python)
Índice
- Por que converter CSV para Word?
- Método 1 – Copiar e Colar Dados CSV no Word
- Método 2 – Converter CSV para uma Tabela do Word usando Texto para Tabela
- Método 3 – Usar um Conversor Online de CSV para Word
- Limitações da Conversão Manual e Online de CSV para Word
- Método 4 – Converter CSV para Word Automaticamente com Python
- Exemplo Completo de Python para Converter CSV para Word
- Por que usar Spire.Doc para Conversão de CSV para Word?
- Métodos de Conversão de CSV para Word Comparados
- FAQ

Arquivos CSV são amplamente utilizados para armazenar e trocar dados tabulares, mas nem sempre são o melhor formato para compartilhar informações. Quando você precisa incluir dados de planilhas em um relatório, proposta, documento de projeto ou entrega para o cliente, converter um arquivo CSV para um documento Word geralmente oferece melhores opções de apresentação e formatação.
Existem várias maneiras de converter CSV para Word, desde técnicas manuais simples até conversores dedicados de CSV para Word e soluções automatizadas. O melhor método depende do seu fluxo de trabalho, do tamanho dos seus dados e da frequência com que você precisa realizar a conversão.
Neste guia, você aprenderá quatro maneiras práticas de converter CSV para documentos Word, incluindo métodos manuais, conversores online de CSV para Word e uma abordagem baseada em Python para converter dados CSV em documentos DOCX automaticamente. Se você precisa de uma conversão rápida única ou uma solução escalável para tarefas recorrentes, encontrará uma opção que atenda às suas necessidades.
Navegação Rápida
- Por que converter CSV para Word?
- Método 1 – Copiar e Colar Dados CSV no Word
- Método 2 – Converter CSV para uma Tabela do Word usando Texto para Tabela
- Método 3 – Usar um Conversor Online de CSV para Word
- Limitações da Conversão Manual e Online de CSV para Word
- Método 4 – Converter CSV para Word Automaticamente com Python
- Exemplo Completo de Python para Converter CSV para Word
- Por que usar Spire.Doc para Conversão de CSV para Word?
- Métodos de Conversão de CSV para Word Comparados
- FAQ
1. Por que converter CSV para Word?
Você pode se perguntar: por que não usar o Excel? Afinal, arquivos CSV abrem nativamente em aplicativos de planilhas. Embora o Excel seja ótimo para análise de dados e cálculos, os documentos Word servem a propósitos diferentes. O Word oferece formatação superior para relatórios narrativos, entregas para clientes e documentos prontos para impressão onde os dados precisam aparecer ao lado de texto explicativo, cabeçalhos e layouts estilizados.
Casos de Uso Comuns
| Caso de Uso | Por que Word em vez de Excel |
|---|---|
| Relatórios de negócios | Combine tabelas de dados com análise narrativa e resumos executivos |
| Documentação de projetos | Incorpore dados em documentos estruturados que incluem instruções e contexto |
| Entregas para clientes | Apresente dados em documentos formatados profissionalmente e com marca |
| Artigos acadêmicos | Siga diretrizes de formatação específicas (APA, MLA) com dados integrados ao texto |
| Preparação para mala direta | Use dados CSV como fonte para cartas e etiquetas personalizadas no Word |
Quando você precisa converter um arquivo CSV para um documento Word, o método correto depende da frequência com que você o faz e do controle de formatação que você precisa.
2. Método 1 – Copiar e Colar Dados CSV no Word
A maneira mais simples de trazer dados CSV para o Word é copiá-los de uma planilha e colá-los diretamente. Este método funciona bem para conjuntos de dados pequenos e tarefas únicas.
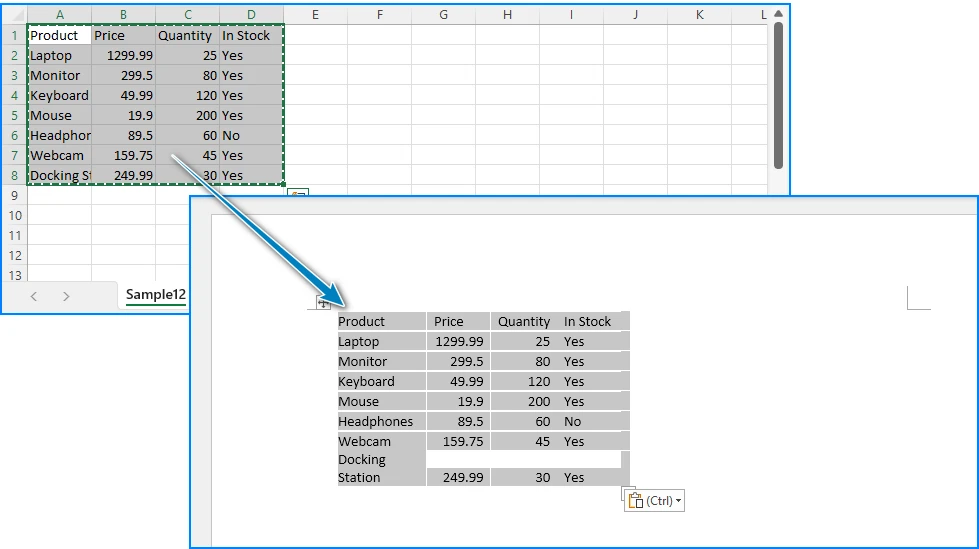
Passo 1: Abrir o Arquivo CSV no Excel
Clique duas vezes no seu arquivo .csv, ou abra o Excel e use Arquivo > Abrir para carregar o CSV. O Excel analisará automaticamente os valores separados por vírgula em colunas.
Passo 2: Selecionar os Dados
Destaque as células que você deseja incluir no seu documento Word. Você pode selecionar a planilha inteira pressionando Ctrl + A, ou selecionar um intervalo específico.
Passo 3: Colar no Word
Abra o Microsoft Word, posicione o cursor onde você deseja os dados e pressione Ctrl + V. O Word converterá automaticamente os dados tabulares em uma tabela do Word.
Passo 4: Aplicar Formatação de Tabela
Use a guia Design da Tabela do Word para aplicar um estilo, ajustar larguras de coluna e formatar cabeçalhos.
Prós e Contras
| Aspecto | Avaliação |
|---|---|
| Facilidade de uso | Muito fácil — nenhuma ferramenta especial necessária |
| Velocidade | Rápido para conjuntos de dados pequenos |
| Controle de formatação | Limitado — a formatação pode falhar com dados grandes |
| Escalabilidade | Não adequado para arquivos com centenas ou milhares de linhas |
| Reprodutibilidade | Processo manual — difícil de repetir consistentemente |
Se você também trabalha com fluxos de trabalho de planilhas, pode achar nosso guia sobre converter arquivos CSV para Excel útil.
3. Método 2 – Converter CSV para uma Tabela do Word usando Texto para Tabela
O Word possui um recurso integrado que pode converter texto delimitado diretamente em uma tabela — sem necessidade de Excel. Este método é particularmente relevante se você estiver procurando como converter CSV para uma tabela do Word, pois usa a conversão nativa Texto para Tabela do Word.
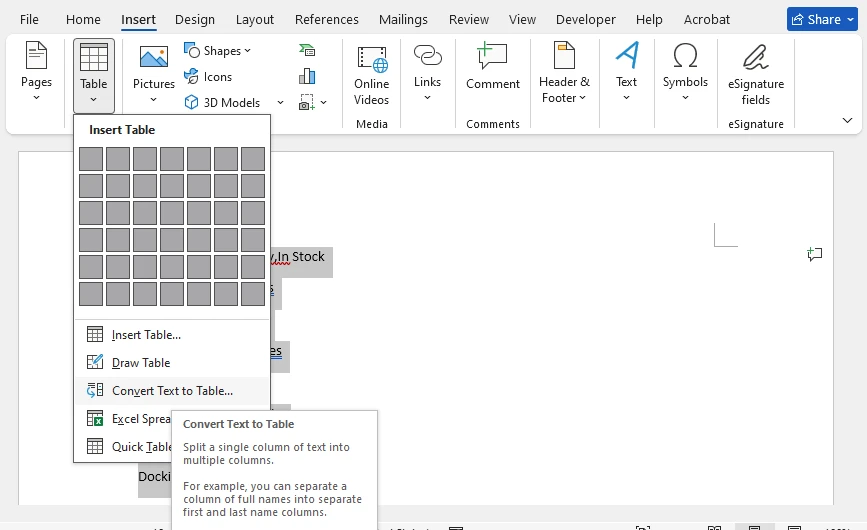
Passo 1: Abrir o Arquivo CSV em um Editor de Texto
Abra seu arquivo .csv no Bloco de Notas, Notepad++ ou qualquer editor de texto simples. Você verá os valores brutos separados por vírgula.
Passo 2: Copiar o Conteúdo CSV
Selecione todo o texto (Ctrl + A) e copie-o (Ctrl + C).
Passo 3: Colar no Word como Texto Simples
No Word, cole o conteúdo. Ele aparecerá como texto simples com vírgulas separando os valores.
Passo 4: Usar a Conversão Texto para Tabela
Selecione o texto colado, vá para Inserir > Tabela > Converter Texto em Tabela. Na caixa de diálogo:
- Defina Separar texto em para Vírgulas
- Ajuste o número de colunas, se necessário
- Clique em OK
O Word converterá o texto separado por vírgula em uma tabela devidamente estruturada.
Passo 5: Formatar a Tabela
Aplique um estilo de tabela da guia Design da Tabela, formate a linha de cabeçalho e ajuste as larguras das colunas conforme necessário.
Prós e Contras
| Aspecto | Avaliação |
|---|---|
| Facilidade de uso | Fácil — sem necessidade de Excel, funciona inteiramente dentro do Word |
| Controle de formatação | Médio — o Word lida com a estrutura da tabela automaticamente |
| Escalabilidade | Funciona para arquivos de tamanho moderado; arquivos muito grandes podem ser lentos |
| Precisão | Boa — o Word analisa corretamente os delimitadores de vírgula na maioria dos casos |
| Limitação | Pode interpretar mal vírgulas dentro de campos entre aspas (por exemplo, "Smith, John") |
Se seus dados já estiverem armazenados em pastas de trabalho do Excel em vez de arquivos CSV, consulte nosso guia sobre converter planilhas do Excel em documentos Word.
4. Método 3 – Usar um Conversor Online de CSV para Word
Se você não tem Excel ou Word instalado, ou apenas precisa de uma conversão rápida única, um conversor online de CSV para Word pode fazer o trabalho em segundos. Várias ferramentas gratuitas permitem que você carregue um arquivo CSV e baixe um documento Word.
Como Funciona
- Procure por "conversor online de CSV para Word" no seu navegador
- Carregue seu arquivo
.csvno site do conversor - Aguarde a conclusão da conversão
- Baixe o arquivo
.docxgerado
O que Procurar em um Conversor Online
Ao escolher um conversor online de CSV para Word, considere:
- Limites de tamanho de arquivo
- Formatos de saída suportados (DOC vs DOCX)
- Políticas de privacidade de dados
- Qualidade da formatação da tabela
- Suporte à conversão em lote
Prós e Contras
| Aspecto | Avaliação |
|---|---|
| Facilidade de uso | Muito fácil — nenhuma instalação de software necessária |
| Velocidade | Rápido para arquivos pequenos a médios |
| Controle de formatação | Baixo — você obtém o que a ferramenta produz |
| Privacidade | Preocupação — seus dados são carregados em um servidor de terceiros |
| Limites de tamanho de arquivo | A maioria das ferramentas impõe restrições de tamanho de upload |
| Processamento em lote | Não suportado — um arquivo por vez |
Quando Usar um Conversor Online
Conversores online são uma escolha razoável quando você tem um único arquivo CSV não sensível e só precisa de uma conversão rápida. No entanto, se seus dados contêm informações pessoais, registros financeiros ou conteúdo crítico para os negócios, carregá-los em um serviço de terceiros pode não ser apropriado.
Se você precisa de conversões repetíveis ou em larga escala, a automação é geralmente uma solução melhor a longo prazo.
5. Limitações da Conversão Manual e Online de CSV para Word
Métodos manuais e ferramentas online funcionam para uso ocasional, mas falham quando você precisa processar arquivos CSV regularmente ou em escala. Aqui estão os desafios comuns:
Desafios Comuns
- Trabalho repetitivo — Se você converte CSV para Word toda semana ou todo dia, o copiar e colar manual se torna tedioso e propenso a erros.
- Grandes conjuntos de dados — O Word tem dificuldade em lidar com tabelas com milhares de linhas coladas do Excel. O desempenho degrada e a formatação falha.
- Processamento em lote — Quando você precisa converter vários arquivos CSV para documentos Word, fazê-los um por um é impraticável.
- Consistência de formatação — A formatação manual varia a cada vez. Cabeçalhos, fontes e estilos de tabela podem parecer diferentes entre os documentos.
- Preocupações com privacidade — Conversores online exigem o upload de seus dados para servidores externos, o que pode não ser aceitável para informações confidenciais.
- Geração automatizada de relatórios — Se os relatórios precisam ser gerados em um cronograma (diário, semanal), a conversão manual não consegue acompanhar.
Para essas situações, a automação com Python oferece um caminho prático — e a próxima seção mostra exatamente como implementá-la.
6. Método 4 – Converter CSV para Word Automaticamente com Python
Python é uma escolha natural para automatizar a conversão de CSV para Word. Ele tem um módulo csv integrado para ler dados e, com Spire.Doc for Python, você pode criar e formatar documentos Word sem exigir que o Microsoft Word esteja instalado.
Esta seção detalha a implementação completa: instalação da biblioteca, leitura de dados CSV, construção de uma tabela do Word e salvamento do resultado como DOCX.
Instalar Spire.Doc for Python
Instale a biblioteca via pip:
pip install spire.doc
Importe as classes necessárias no seu script Python:
from spire.doc import *
from spire.doc.common import *
Passo 1: Ler Dados CSV
O módulo csv integrado do Python lê arquivos CSV em uma lista de linhas:
import csv
csv_data = []
with open("sales_data.csv", "r", encoding="utf-8-sig") as file:
reader = csv.reader(file)
for row in reader:
csv_data.append(row)
A primeira linha geralmente contém os cabeçalhos das colunas e as linhas subsequentes contêm os dados.
Passo 2: Criar um Documento e Tabela do Word
Crie um novo documento Word, adicione uma seção e inicialize uma tabela com as dimensões dos seus dados CSV:
document = Document()
section = document.AddSection()
num_rows = len(csv_data)
num_cols = len(csv_data[0]) if csv_data else 0
table = section.AddTable(True)
table.ResetCells(num_rows, num_cols)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, 100)
Passo 3: Preencher a Tabela com Dados CSV
Itere pelas linhas CSV e escreva cada valor na célula correspondente. Formate a linha de cabeçalho com um estilo distinto:
for r in range(num_rows):
row = table.Rows[r]
row.Height = 22
row.HeightType = TableRowHeightType.Exactly
for c in range(num_cols):
cell = row.Cells[c]
paragraph = cell.AddParagraph()
text_range = paragraph.AppendText(csv_data[r][c])
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
if r == 0:
row.IsHeader = True
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_DarkBlue()
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.TextColor = Color.get_White()
text_range.CharacterFormat.FontSize = 11
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
else:
text_range.CharacterFormat.FontSize = 10
if r % 2 == 0:
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_LightGray()
else:
cell.CellFormat.Shading.BackgroundPatternColor = Color.Empty()
Este código formata a primeira linha como um cabeçalho com fundo azul escuro e texto branco em negrito, e aplica cores alternadas às linhas para legibilidade.
Passo 4: Salvar como DOCX
Salve o documento Word gerado:
document.SaveToFile("SalesReport.docx", FileFormat.Docx)
document.Close()
Abaixo está uma prévia dos dados CSV e do documento Word gerado:
A saída é um arquivo .docx devidamente formatado contendo seus dados CSV em uma tabela do Word.
Para opções de personalização de tabela mais avançadas, confira nosso guia sobre criação e formatação de tabelas do Word com Python.
7. Exemplo Completo de Python para Converter CSV para Word
Aqui está o script completo e executável que lê um arquivo CSV e o converte em um documento Word com um título, tabela formatada, cores alternadas de linha e bordas de tabela.
import csv
from spire.doc import *
from spire.doc.common import *
def csv_to_word(csv_path, output_path, title="Data Report"):
csv_data = []
with open(csv_path, "r", encoding="utf-8-sig") as file:
reader = csv.reader(file)
for row in reader:
csv_data.append(row)
if not csv_data:
print("CSV file is empty.")
return
num_rows = len(csv_data)
num_cols = len(csv_data[0])
document = Document()
section = document.AddSection()
title_para = section.AddParagraph()
title_range = title_para.AppendText(title)
title_range.CharacterFormat.FontSize = 18
title_range.CharacterFormat.Bold = True
title_para.Format.HorizontalAlignment = HorizontalAlignment.Center
title_para.Format.AfterSpacing = 12
table = section.AddTable(True)
table.ResetCells(num_rows, num_cols)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, 100)
for r in range(num_rows):
row = table.Rows[r]
row.Height = 22
row.HeightType = TableRowHeightType.Exactly
for c in range(num_cols):
cell = row.Cells[c]
paragraph = cell.AddParagraph()
text_range = paragraph.AppendText(csv_data[r][c])
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
if r == 0:
row.IsHeader = True
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_DarkBlue()
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.TextColor = Color.get_White()
text_range.CharacterFormat.FontSize = 11
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
else:
text_range.CharacterFormat.FontSize = 10
if r % 2 == 0:
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_LightGray()
else:
cell.CellFormat.Shading.BackgroundPatternColor = Color.Empty()
table.Format.Borders.Vertical.BorderType = BorderStyle.Single
table.Format.Borders.Vertical.LineWidth = 0.5
table.Format.Borders.Horizontal.BorderType = BorderStyle.Single
table.Format.Borders.Horizontal.LineWidth = 0.5
document.SaveToFile(output_path, FileFormat.Docx)
document.Close()
print(f"Word document saved to: {output_path}")
csv_to_word("sales_data.csv", "SalesReport.docx", "Q4 Sales Report")
Como Funciona
csv.readerlê o arquivo CSV linha por linha, lidando com diferentes codificações viautf-8-sig(que lida com marcadores BOM).Document()cria um documento Word em branco.AddSection()adiciona uma seção (página) ao documento.AddTable(True)cria uma nova tabela com ajuste automático ativado.ResetCells()define as dimensões exatas.AppendText()escreve cada valor CSV na célula correspondente como um intervalo de texto.- Formatação do cabeçalho aplica um fundo azul escuro, texto branco em negrito e alinhamento central à primeira linha.
- Cores alternadas de linha usam cinza claro para linhas pares e sem preenchimento para linhas ímpares, melhorando a legibilidade.
SaveToFile()exporta o documento como um arquivo.docx.
8. Por que usar Spire.Doc para Conversão de CSV para Word?
Spire.Doc for Python oferece várias vantagens técnicas para desenvolvedores que precisam gerar documentos Word a partir de dados CSV programaticamente.
Vantagens
| Vantagem | Detalhes |
|---|---|
| Sem dependência do Microsoft Word | Crie e manipule arquivos DOCX sem instalar o Microsoft Word no servidor ou máquina |
| Formatação abrangente de tabelas | Controle de sombreamento de células, bordas, alinhamento, alturas de linha, larguras de coluna e estilos de tabela |
| Geração automatizada de relatórios | Crie scripts que convertem CSV para Word em um cronograma, integrando-se a pipelines de dados |
| Processamento de documentos em lote | Processe vários arquivos CSV em um loop, gerando documentos Word separados para cada um |
| Integração com Python | Funciona perfeitamente com o módulo csv padrão do Python e outras bibliotecas de processamento de dados |
| Suporte completo a DOCX | Gere documentos compatíveis com Microsoft Word, LibreOffice e Google Docs |
Classes de API Principais
Document— Representa um documento Word. Use-o para criar novos documentos ou carregar os existentes.Section— Representa uma seção (página) dentro de um documento. Contém parágrafos, tabelas e outros conteúdos.Table— Representa uma tabela em um documento Word. Suporta manipulação de linhas/colunas, estilização e bordas.TableRow/TableCell— Fornecem acesso a linhas e células individuais para formatação e inserção de conteúdo.Paragraph/TextRange— Lidam com o conteúdo de texto dentro das células, incluindo fonte, tamanho, cor e alinhamento.
9. Métodos de Conversão de CSV para Word Comparados
| Método | Facilidade de Uso | Processamento em Lote | Controle de Formatação | Privacidade | Melhor Para |
|---|---|---|---|---|---|
| Copiar e Colar | ★★★★★ | ✗ | Baixo | ✓ | Tarefas únicas, conjuntos de dados pequenos |
| Texto para Tabela | ★★★★☆ | ✗ | Médio | ✓ | Fluxos de trabalho sem Excel, dados moderados |
| Conversor Online | ★★★★★ | ✗ | Baixo | ✗ | Conversões rápidas únicas |
| Python + Spire.Doc | ★★★☆☆ | ✓ | Alto | ✓ | Tarefas recorrentes, processamento em lote, automação |
Resumo: Métodos manuais e ferramentas online são rápidos e acessíveis, mas não escalam. A automação com Python e Spire.Doc requer um pequeno investimento de configuração, mas compensa quando você precisa de conversão de CSV para Word consistente, repetível ou em lote.
10. FAQ
Como faço para converter um arquivo CSV para um documento Word?
Você pode converter um arquivo CSV para um documento Word usando vários métodos: (1) Abra o CSV no Excel, copie os dados e cole-os no Word; (2) Use o recurso Texto para Tabela do Word para converter texto separado por vírgula diretamente em uma tabela; (3) Use um conversor online de CSV para Word para uma conversão rápida única; (4) Use Python com Spire.Doc for Python para automatizar a conversão programaticamente. A abordagem Python é a melhor para tarefas recorrentes ou processamento em lote.
Posso converter CSV para DOCX automaticamente?
Sim. Você pode automatizar a conversão de CSV para DOCX usando Python. Leia os dados CSV com o módulo csv integrado do Python, em seguida, use Spire.Doc for Python para criar um documento Word, preencher uma tabela com os dados CSV e salvá-lo como um arquivo .docx. Essa abordagem funciona sem o Microsoft Word instalado e pode ser agendada para ser executada automaticamente.
Como insiro dados CSV em uma tabela do Word?
Para inserir dados CSV em uma tabela do Word manualmente, você pode usar o recurso Inserir > Tabela > Converter Texto em Tabela do Word — cole o texto CSV e, em seguida, converta-o usando vírgulas como delimitador. Para inserção programática, use Python: leia o CSV com o módulo csv, crie uma tabela em um documento Word usando Spire.Doc for Python e itere pelas linhas CSV para preencher cada célula.
Existe um conversor gratuito de CSV para Word online?
Sim, vários sites oferecem conversão gratuita de CSV para Word. No entanto, conversores online têm limitações: restrições de tamanho de arquivo, controle de formatação limitado e preocupações com privacidade, pois seus dados são carregados em um servidor de terceiros. Para dados sensíveis ou conversões recorrentes, uma solução local em Python com Spire.Doc for Python é uma alternativa mais confiável e privada.
O Python pode converter arquivos CSV em documentos Word?
Sim, Python pode converter arquivos CSV em documentos Word. Usando Spire.Doc for Python, você pode ler dados CSV com o módulo csv padrão, criar um documento Word, adicionar uma tabela formatada, preenchê-la com o conteúdo CSV e salvar o resultado como um arquivo DOCX. Isso funciona sem o Microsoft Word e suporta o processamento em lote de vários arquivos CSV.
O Spire.Doc for Python requer que o Microsoft Word esteja instalado?
Não. Spire.Doc for Python é uma biblioteca independente que cria e manipula documentos Word de forma independente. Ele não requer que o Microsoft Word ou qualquer componente do Office seja instalado em seu sistema. Isso o torna adequado para ambientes de servidor e fluxos de trabalho automatizados.
Conclusão
Converter CSV para Word é uma tarefa comum com várias abordagens. Métodos manuais — copiar e colar e o recurso Texto para Tabela do Word — funcionam bem para uso ocasional com conjuntos de dados pequenos. Conversores online oferecem conveniência para tarefas rápidas e únicas, mas levantam preocupações com privacidade e carecem de controle de formatação. Nenhuma dessas opções escala para processamento em lote, geração de relatórios agendada ou cenários que exigem formatação consistente em muitos documentos.
Automação com Python usando Spire.Doc for Python fornece uma solução confiável para converter CSV para DOCX programaticamente. Ele lê dados CSV, cria tabelas formatadas do Word e gera documentos profissionais sem exigir o Microsoft Word — tornando-o ideal para fluxos de trabalho automatizados, processamento em lote e geração de documentos do lado do servidor.
Você pode solicitar uma licença gratuita de 30 dias para avaliar todos os recursos do Spire.Doc for Python.