Как экспортировать Excel в JSON: онлайн-инструменты и Python
Содержание
- Зачем экспортировать Excel в JSON?
- Как выглядят данные Excel в формате JSON?
- Метод 1: Экспорт Excel в JSON онлайн
- Метод 2: Экспорт Excel в JSON на Python с помощью Pandas
- Метод 3: Экспорт Excel в JSON на Python с помощью Spire.XLS
- Распространенные проблемы при преобразовании Excel в JSON
- Какой метод выбрать?
- Часто задаваемые вопросы
Если вам когда-либо приходилось загружать данные из электронной таблицы в веб-приложение, создавать REST API или мигрировать данные в базу данных NoSQL, вы, вероятно, сталкивались с распространенной проблемой: Excel не предоставляет встроенного способа сохранения данных в формате JSON.
К счастью, существует несколько способов экспортировать Excel в JSON, от быстрых онлайн-конвертеров до программных решений на Python. Лучший метод зависит от размера файла, требований к безопасности и от того, нужно ли вам сохранять структуру рабочей книги, такую как несколько листов или результаты формул.
В этом руководстве мы сравним наиболее практичные подходы и поможем вам выбрать правильное решение для вашего сценария.
Быстрая навигация
- Зачем экспортировать Excel в JSON?
- Как выглядят данные Excel в формате JSON?
- Метод 1: Экспорт Excel в JSON онлайн
- Метод 2: Экспорт Excel в JSON на Python с помощью Pandas
- Метод 3: Экспорт Excel в JSON на Python с помощью Spire.XLS
- Распространенные проблемы при преобразовании Excel в JSON
- Какой метод выбрать?
- Часто задаваемые вопросы
Зачем экспортировать Excel в JSON?
Excel — это наиболее широко используемый инструмент для хранения структурированных данных, но современные приложения обмениваются данными в формате JSON. Преобразование между этими форматами необходимо всякий раз, когда данные из электронной таблицы должны быть перемещены в веб-контекст.
Типичные сценарии использования включают:
- Отправка данных из электронных таблиц в веб-приложения
- Импорт данных в REST API
- Работа с JavaScript-фреймворками, такими как React, Vue или Angular
- Миграция данных в базы данных NoSQL, такие как MongoDB
- Обмен данными между системами в конвейерах интеграции
В Excel нет встроенной опции «Сохранить как JSON», поэтому вам потребуется внешний инструмент или библиотека для преодоления этого разрыва.
Как выглядят данные Excel в формате JSON?
Строки Excel обычно преобразуются в объекты JSON, а заголовки столбцов становятся ключами объектов.
Данные Excel:
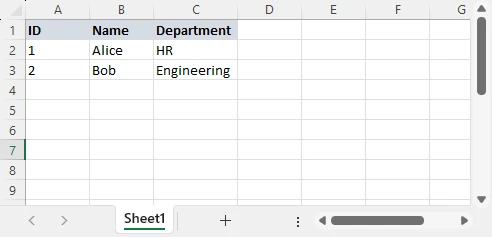
Вывод JSON:
[
{"ID": 1, "Name": "Alice", "Department": "HR"},
{"ID": 2, "Name": "Bob", "Department": "Engineering"}
]
Каждая строка становится объектом JSON, каждый заголовок столбца — ключом, а весь лист — массивом. Файлы XLS и XLSX следуют одному и тому же шаблону сопоставления.
Метод 1: Экспорт Excel в JSON онлайн
Онлайн-конвертеры Excel в JSON предоставляют самое быстрое решение для разовых преобразований, не требуя установки программного обеспечения или знаний программирования.
Шаги по преобразованию Excel в JSON онлайн
-
Загрузите файл Excel: Выберите файл .xlsx или .xls из локального хранилища. Большинство платформ поддерживают перетаскивание.
-
Настройте параметры: Укажите, включать ли заголовки, выберите конкретные листы или настройте формат вывода.
-
Конвертируйте и скачайте: Сервер обрабатывает ваш файл и генерирует вывод JSON. Получите преобразованный файл или скопируйте результат.
Рекомендуемые онлайн-конвертеры Excel в JSON
Различные инструменты хороши в разных сценариях:
| Инструмент | Лучше всего подходит для | Лимит размера файла | Специальные возможности |
|---|---|---|---|
| TableConvert | Табличные структуры JSON | 10 МБ | Пользовательский формат JSON, вложенные объекты |
| Data Formatter Pro | Быстрое преобразование в браузере | 5 МБ | Преобразование на стороне браузера, загрузка не требуется |
| JSON Editor Online | Визуальное редактирование после преобразования | 5 МБ | Встроенный валидатор и форматер JSON |
Преимущества и ограничения
Преимущества:
- Установка не требуется — доступ из любого браузера
- Быстро для небольших файлов до 5 МБ
- Простота для начинающих благодаря графическим интерфейсам
Ограничения:
- Лимиты размера файла: Большинство бесплатных конвертеров ограничивают загрузку до 5-10 МБ
- Проблемы конфиденциальности: Загрузка бизнес-данных на внешние серверы создает риски соответствия требованиям
- Обработка формул: Онлайн-конвертеры экспортируют результаты формул как статические значения
- Несколько листов: Многие инструменты экспортируют только активный лист или теряют структуру листа
Онлайн-конвертеры хорошо подходят для быстрых, неконфиденциальных преобразований. Для всего, что связано с большими файлами, конфиденциальными данными или сложными рабочими книгами, вам потребуется программное решение.
Метод 2: Экспорт Excel в JSON на Python с помощью Pandas
Pandas — самая популярная библиотека для анализа данных в Python, предлагающая простое преобразование Excel в JSON через свой API DataFrame. Этот метод подходит для специалистов по данным и аналитиков, которые уже используют Pandas для обработки данных.
Установка Pandas и зависимостей
pip install pandas openpyxl
Для устаревших файлов .xls также установите xlrd:
pip install xlrd
Чтение Excel и экспорт JSON
import pandas as pd
# Загрузка файла Excel в DataFrame
df = pd.read_excel("sales_report.xlsx")
# Экспорт DataFrame в JSON
df.to_json(
"sales_report.json",
orient="records",
indent=4
)
print("Данные Excel успешно экспортированы в JSON")
Ниже приведен пример листа Excel и вывода JSON:
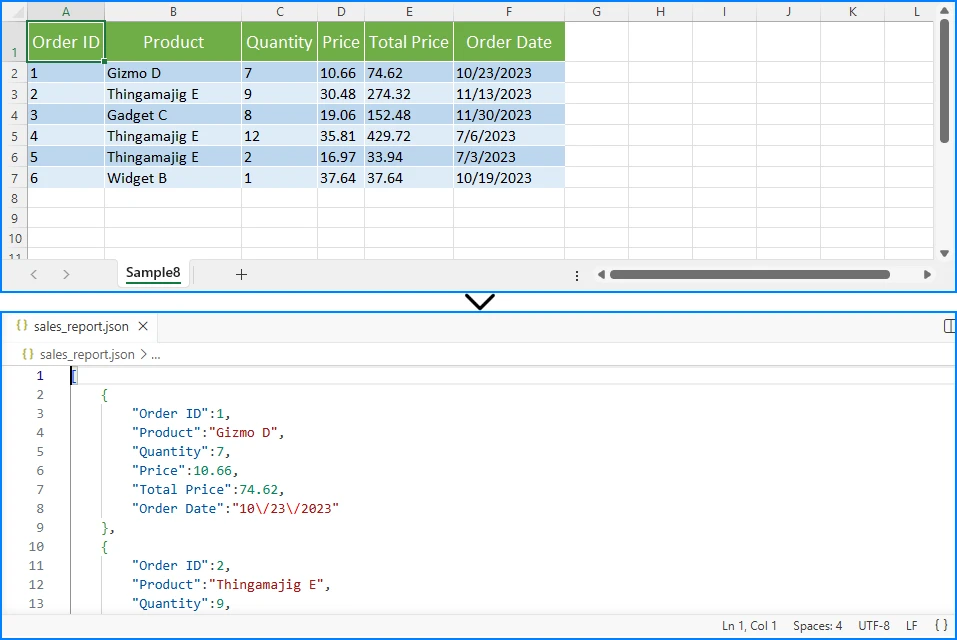
Ключевые параметры:
orient="records": Структурирует вывод как массив объектов (наиболее распространенный формат)indent=4: Форматирует JSON с отступом в 4 пробела
Понимание параметров вывода JSON
Pandas предоставляет несколько вариантов ориентации вывода через параметр orient:
orient="records" (Рекомендуется для API):
[
{"ID": 1, "Name": "Alice", "Department": "HR"},
{"ID": 2, "Name": "Bob", "Department": "Engineering"}
]
orient="index":
{
"0": {"ID": 1, "Name": "Alice", "Department": "HR"},
"1": {"ID": 2, "Name": "Bob", "Department": "Engineering"}
}
orient="split":
{
"columns": ["ID", "Name", "Department"],
"index": [0, 1],
"data": [[1, "Alice", "HR"], [2, "Bob", "Engineering"]]
}
Ориентация records является наиболее совместимым форматом для REST API и приложений JavaScript.
Обработка конкретных листов
import pandas as pd
# Чтение конкретного листа по имени
df = pd.read_excel("workbook.xlsx", sheet_name="Q4_Sales")
# Чтение конкретного листа по индексу (начиная с 0)
df = pd.read_excel("workbook.xlsx", sheet_name=0)
df.to_json("q4_sales.json", orient="records", indent=4)
Pandas отлично подходит для анализа данных, когда вам нужно фильтровать, агрегировать или преобразовывать данные перед экспортом. Однако он загружает целые файлы в память и не может сохранять логику формул, что делает его менее подходящим для больших файлов или корпоративных сценариев.
Преобразование Excel в JSON часто является лишь одним из шагов рабочего процесса обработки данных. Если вам нужно импортировать данные JSON обратно в электронные таблицы, ознакомьтесь с нашим руководством по преобразованию JSON в Excel для полного двустороннего обмена данными.
Метод 3: Экспорт Excel в JSON на Python с помощью Spire.XLS
Spire.XLS для Python предоставляет профессиональную библиотеку для обработки Excel, разработанную для сценариев, где Pandas не справляется. Она обрабатывает сложные структуры рабочих книг, сохраняет расчеты формул и эффективно обрабатывает большие файлы, не загружая целые наборы данных в память.
Установка Spire.XLS для Python
pip install Spire.XLS
Экспорт данных Excel в JSON
from spire.xls import Workbook
import json
# Создание экземпляра рабочей книги
workbook = Workbook()
workbook.LoadFromFile("sales_data.xlsx")
# Получение первого листа
sheet = workbook.Worksheets[0]
# Извлечение данных в структурированный формат
data = []
headers = []
# Чтение заголовков из первой строки
for col in range(sheet.AllocatedRange.Columns.Count):
cell = sheet.AllocatedRange.Rows[0].Cells[col]
headers.append(cell.Value)
# Чтение строк данных
for row_idx in range(1, sheet.AllocatedRange.Rows.Count):
row_data = {}
row = sheet.AllocatedRange.Rows[row_idx]
for col_idx in range(len(headers)):
cell = row.Cells[col_idx]
row_data[headers[col_idx]] = cell.Value
data.append(row_data)
# Экспорт в файл JSON
with open("sales_data.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=4, ensure_ascii=False)
print(f"Экспортировано {len(data)} записей в JSON")
workbook.Dispose()
Результат преобразования показан ниже:
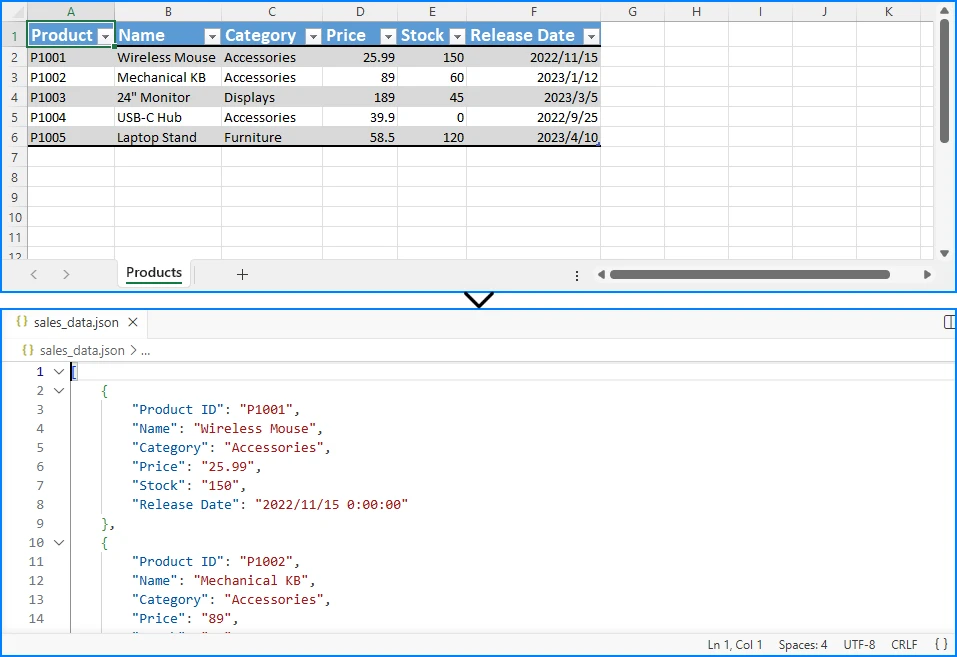
Ключевые моменты
-
Загрузка рабочей книги: Используйте
Workbook.LoadFromFile()для загрузки файла Excel в память. Этот метод поддерживает форматы XLS и XLSX. -
Доступ к листу: Получите конкретный лист с помощью
workbook.Worksheets[index], где индекс 0 относится к первому листу. -
Извлечение заголовков: Переберите первую строку выделенного диапазона (
sheet.AllocatedRange.Rows[0]) для сбора заголовков столбцов, которые будут служить ключами объектов JSON. -
Чтение строк данных: Пройдитесь по оставшимся строкам (начиная с индекса 1) и извлеките значения ячеек. Для каждой строки создайте словарь, сопоставляющий заголовки со значениями ячеек.
-
Экспорт в JSON: Используйте встроенную функцию
json.dump()Python для записи структуры данных в файл JSON с правильным форматированием (indent=4) и поддержкой Unicode (ensure_ascii=False).
JSON — не единственный формат, используемый для обмена данными. Если вам нужен более простой табличный формат для отчетности или интеграции систем, ознакомьтесь с нашим руководством по преобразованию Excel в CSV на Python.
Экспорт нескольких листов в JSON
Одним из ключевых преимуществ Spire.XLS является обработка многолистовых рабочих книг с сохранением структуры:
from spire.xls import Workbook
import json
workbook = Workbook()
workbook.LoadFromFile("quarterly_reports.xlsx")
workbook_data = {}
for sheet_index in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[sheet_index]
sheet_name = sheet.Name
sheet_data = []
headers = []
last_row = sheet.LastRow
last_col = sheet.LastColumn
if last_row > 0 and last_col > 0:
# Чтение заголовков
for col in range(1, last_col + 1):
cell_value = sheet.Range[1, col].Value
headers.append(cell_value if cell_value else f"Column{col}")
# Чтение строк данных
for row in range(2, last_row + 1):
row_data = {}
has_data = False
for col in range(1, last_col + 1):
cell = sheet.Range[row, col]
value = cell.Value
# Обработка ячеек с формулами - экспорт вычисленных результатов
if cell.HasFormula:
value = cell.FormulaValue
row_data[headers[col - 1]] = value
if value is not None and str(value).strip():
has_data = True
if has_data:
sheet_data.append(row_data)
workbook_data[sheet_name] = sheet_data
print(f"Обработано: {sheet_name} ({len(sheet_data)} строк)")
with open("quarterly_reports.json", "w", encoding="utf-8") as f:
json.dump(workbook_data, f, indent=4, ensure_ascii=False)
print(f"Экспортировано {workbook.Worksheets.Count} листов в JSON")
workbook.Dispose()
Структура вывода:
{
"Q1_Sales": [
{"Product": "Widget A", "Revenue": 15000, "Units": 500},
{"Product": "Widget B", "Revenue": 22000, "Units": 730}
],
"Q2_Sales": [
{"Product": "Widget A", "Revenue": 18000, "Units": 600},
{"Product": "Widget B", "Revenue": 25000, "Units": 830}
]
}
Преимущества использования Spire.XLS
- Сохранение структуры рабочей книги: Сохранение организации листов в выводе JSON
- Правильная обработка формул: Экспорт вычисленных значений из ячеек с формулами
- Эффективная обработка памяти: Обработка больших рабочих книг без загрузки целых файлов в память
- Отсутствие зависимости от Excel: Обработка файлов без необходимости установки Microsoft Excel
- Кроссплатформенность: Работает на Windows, Linux и macOS
Сравнение Pandas и Spire.XLS
| Функция | Pandas | Spire.XLS |
|---|---|---|
| Открытый исходный код | ✓ | ✗ |
| Анализ данных | ✓ | ✓ |
| Результаты формул | Ограничено | ✓ |
| Несколько листов | Базово | ✓ |
| Корпоративная автоматизация | Ограничено | ✓ |
| Эффективность памяти | Умеренно | ✓ |
| Поддержка больших файлов | Ограничено | ✓ |
Для систем, требующих иерархического или основанного на схеме обмена данными, вы также можете узнать, как преобразовать Excel в XML на Python.
Распространенные проблемы при преобразовании Excel в JSON
Несколько листов
Рабочие книги часто содержат несколько связанных листов. Экспорт всех листов как одного плоского массива теряет организационную структуру. Используйте библиотеку, такую как Spire.XLS, чтобы сохранить имена листов в качестве ключей верхнего уровня в выводе JSON.
Ячейки с формулами
Формулы Excel динамически вычисляют значения. При экспорте в JSON вы обычно хотите получить вычисленный результат, а не строку формулы. Spire.XLS предоставляет свойство FormulaValue для экспорта вычисленных значений, в то время как Pandas по умолчанию считывает отображаемые значения.
Форматирование дат
Excel хранит даты как числовые серийные даты. Без явной обработки даты могут экспортироваться как бессмысленные числа, такие как 45662, вместо "2026-05-01". Преобразуйте столбцы дат в строки ISO 8601 для совместимости с JSON.
Пустые ячейки и значения NULL
Пустые ячейки могут быть представлены как null, полностью опущены или экспортированы как пустые строки. Используйте null для отсутствующих значений и пустые строки для явно пустых ячеек, чтобы сохранить намерение данных.
Какой метод выбрать?
| Сценарий | Рекомендуемый метод | Обоснование |
|---|---|---|
| Быстрое разовое преобразование | Онлайн-конвертер | Без настройки, самое быстрое для периодического использования |
| Рабочие процессы анализа данных | Pandas | Интегрируется с конвейерами анализа |
| Сложные рабочие книги с несколькими листами | Spire.XLS | Сохраняет структуру, обрабатывает формулы |
| Большие файлы (>100 МБ) | Spire.XLS | Эффективная обработка памяти |
| Конфиденциальные/секретные данные | Spire.XLS (локально) | Без передачи на внешний сервер |
Часто задаваемые вопросы
Может ли Excel сохраняться напрямую в JSON?
Нет. Диалоговое окно «Сохранить как» в Excel поддерживает форматы XLSX, XLS, CSV, PDF и XML, но не JSON. Вам потребуется онлайн-конвертер, библиотека Python или пользовательский скрипт для экспорта данных Excel в JSON.
Как экспортировать данные Excel в файл JSON?
Выберите инструмент, загрузите файл Excel, извлеките данные листа, преобразуйте строки в объекты JSON с заголовками столбцов в качестве ключей и запишите вывод в файл .json.
С Pandas:
import pandas as pd
df = pd.read_excel("data.xlsx")
df.to_json("data.json", orient="records", indent=4)
Какая лучшая библиотека Python для преобразования Excel в JSON?
- Pandas: Лучше всего подходит для рабочих процессов анализа данных с мощными преобразованиями, но загружает целые файлы в память и не может сохранять формулы.
- Spire.XLS: Лучше всего подходит для корпоративных сценариев с большими файлами, несколькими листами и обработкой формул.
Как экспортировать несколько листов в JSON?
Используйте Spire.XLS для перебора листов и их организации в словаре с именами листов в качестве ключей:
from spire.xls import Workbook
import json
workbook = Workbook()
workbook.LoadFromFile("multi_sheet.xlsx")
result = {}
for sheet in workbook.Worksheets:
sheet_data = [] # Извлечение данных листа
# ... логика извлечения ...
result[sheet.Name] = sheet_data
with open("output.json", "w") as f:
json.dump(result, f, indent=4)
Можно ли сохранить формулы при преобразовании Excel в JSON?
Сами формулы не могут быть сохранены в JSON, поскольку JSON является статическим форматом данных. Однако вы можете экспортировать вычисленные результаты формул. Используйте свойство FormulaValue Spire.XLS для получения вычисленных значений вместо строк формул.
Как обрабатывать большие файлы Excel при экспорте в JSON?
Избегайте Pandas для больших файлов — он загружает все в память. Используйте Spire.XLS для эффективного доступа к ячейкам с низким потреблением памяти. Для очень больших наборов данных рассмотрите формат JSON с разделителями строк (JSONL), где каждая строка является отдельным объектом JSON, что позволяет обрабатывать потоки данных.
Заключение
Экспорт Excel в JSON устраняет разрыв между данными электронных таблиц и современными приложениями. Для быстрых преобразований онлайн-инструменты выполняют работу без какой-либо настройки. Когда вам нужны возможности анализа данных, Pandas предоставляет мощные преобразования. Для корпоративных сценариев с большими файлами, несколькими листами или обработкой формул Spire.XLS обеспечивает необходимый контроль и точность. Выбирайте в зависимости от размера файла, сложности и требований рабочего процесса.
Дополнительное чтение:
Como contar palavras em um PDF (O guia definitivo para 2026)

No nosso trabalho e vida diária, frequentemente nos deparamos com a necessidade de contar as palavras num documento PDF. Ao contrário do Microsoft Word, os ficheiros PDF não oferecem uma funcionalidade nativa de contagem de palavras, e a maioria dos leitores de PDF oferece apenas suporte limitado para contagem de palavras. Isto acontece porque os ficheiros PDF tratam o texto como elementos visuais fixos em vez de um fluxo contínuo de palavras. Se está a perguntar-se como contar palavras em documentos PDF facilmente, está no lugar certo. Este guia apresentará 3 soluções altamente eficazes para resolver este problema, cobrindo tudo, desde ferramentas online simples e diretas a scripts automatizados que podem lidar com centenas de documentos de uma só vez.
- Contar Palavras com Ferramentas Online
- Contar Palavras Usando Adobe Acrobat e MS Word
- Contagem de Palavras em PDF com Python
- Comparação de Métodos
Contar Palavras em PDF com Contador de Palavras Online
Quando se trata de obter uma contagem de palavras em PDF, os contadores online são geralmente a primeira solução que vem à mente. São incrivelmente leves, não requerem instalação e funcionam perfeitamente em todos os seus dispositivos. Em vez de sobrecarregar o seu computador com software pesado, pode obter uma resposta rápida diretamente no seu navegador web e passar para outras tarefas.
Como fazer:
- Passo 1. Abra o seu navegador web e procure uma ferramenta confiável e gratuita de contagem de palavras em PDF online.
- Passo 2. Arraste e solte o seu ficheiro PDF diretamente na caixa de upload.
- Passo 3. Após o ficheiro ser carregado e processado, o site exibirá a contagem total de palavras.
Resultado da contagem de palavras usando uma ferramenta PDF online: 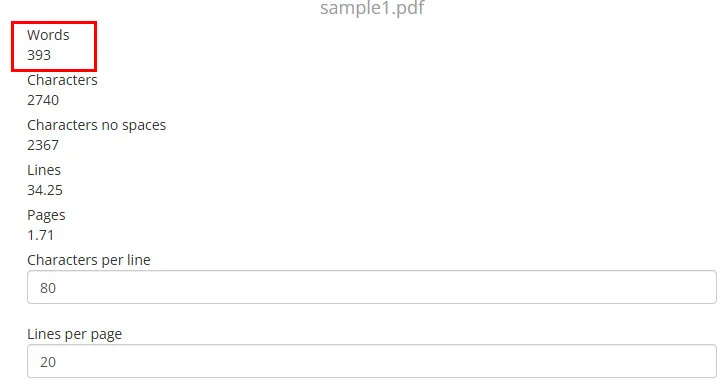
Aviso de Privacidade e Segurança: Não é recomendado carregar PDFs sensíveis para sites online gratuitos. Se o seu documento contiver segredos comerciais, identificações pessoais ou dados financeiros, ignore este método completamente. Ferramentas gratuitas só são seguras para artigos públicos e não sensíveis.
Contar Palavras num PDF Usando Adobe Acrobat e MS Word
Se está a trabalhar com documentos legais, projetos de tradução ou artigos académicos, a precisão é muitas vezes mais importante do que a velocidade. Nesses casos, um fluxo de trabalho baseado em desktop pode ser uma escolha mais segura e confiável do que depender de ferramentas online.
Ao contrário do Microsoft Word, o Adobe Acrobat não oferece uma funcionalidade dedicada de contagem de palavras em todas as edições. Uma solução comum é converter o PDF para Word e depois usar a funcionalidade integrada do Word para verificar a contagem de palavras.
Guia Passo a Passo:
- Passo 1. Abra o seu ficheiro PDF no Adobe Acrobat (ou use o conversor online oficial do Adobe Acrobat).
- Passo 2. Clique em Exportar PDF no painel direito e selecione Microsoft Word (.docx) como o seu formato de saída.
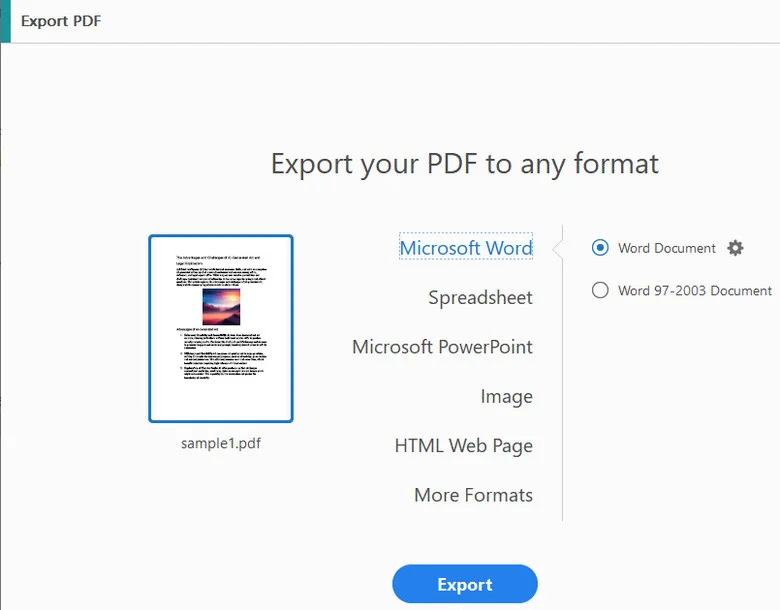
- Passo 3. Guarde o ficheiro recém-gerado no seu computador local.
- Passo 4. Abra o documento no Microsoft Word, navegue até ao separador Rever e clique em Contagem de Palavras.
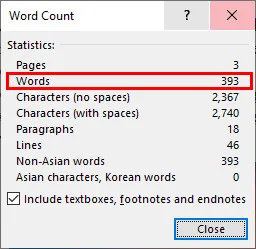
Nota: Não se preocupe com o seu ficheiro original, este processo simplesmente cria um novo documento Word, deixando o seu PDF original intocado.
Como Fazer Contagem de Palavras em PDF com Python Automaticamente
A conversão manual de ficheiros funciona bem para um ou dois documentos. Mas e se for um desenvolvedor ou analista de dados com uma pasta cheia de 500 relatórios? O processamento manual de um grande número de ficheiros pode ser demorado, tornando a automação uma solução mais prática.
Para desenvolvedores, extrair texto programaticamente é muitas vezes a forma mais eficiente de contar palavras em ficheiros PDF. Pode automatizar a contagem de palavras em PDF com um pequeno script Python. Com a ajuda do Free Spire.PDF for Python, pode extrair o texto bruto programaticamente e usar expressões regulares para contar as palavras instantaneamente.
Exemplo de Código Python
O código abaixo mostra como contar palavras de múltiplos documentos PDF de uma só vez:
import os
import re
from spire.pdf.common import *
from spire.pdf import *
# 1. Definir o diretório da pasta de entrada
folder_path = "/input/pdfs/"
# 2. Configurar opções de extração de texto uma vez
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
print("--- Relatório de Contagem de Palavras ---")
# 3. Percorrer todos os ficheiros no diretório
for file_name in os.listdir(folder_path):
# Processar apenas ficheiros PDF
if file_name.lower().endswith('.pdf'):
file_path = os.path.join(folder_path, file_name)
# Inicializar o objeto Document e carregar o PDF atual
doc = PdfDocument()
doc.LoadFromFile(file_path)
# Extrair texto de todas as páginas do ficheiro atual
total_text = ""
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
textExtractor = PdfTextExtractor(page)
text = textExtractor.ExtractText(extractOptions)
if text:
total_text += text + "\n"
doc.Close()
# Contar palavras em inglês no texto extraído
word_count = len(re.findall(r"\b[a-zA-Z]+(?:['-][a-zA-Z]+)*\b", total_text))
# Imprimir o nome do ficheiro e a sua contagem de palavras correspondente
print(f"Ficheiro: {file_name} | Contagem de Palavras: {word_count}")
Abaixo está uma pré-visualização dos resultados da contagem de palavras em lote impressos pelo script:

Nota: A contagem de palavras é calculada usando correspondência de expressões regulares no texto extraído. Como diferentes aplicações usam regras diferentes para lidar com números, palavras hifenizadas, pontuação, cabeçalhos, rodapés e outro conteúdo especial, o resultado pode diferir ligeiramente da contagem de palavras reportada pelo Microsoft Word, Adobe Acrobat ou contadores de palavras de PDF online.
Porquê usar isto?
Este método é rápido e seguro porque os seus dados nunca saem do seu computador. Se está a lidar com projetos em larga escala, a utilização do Free Spire.PDF for Python traz várias vantagens técnicas sobre as ferramentas open-source padrão:
- Extração de Texto de Alta Fidelidade: Ao contrário de parsers de PDF básicos que frequentemente embaralham a ordem do texto ou misturam layouts de várias colunas, ele captura com precisão os fluxos de texto com base no layout visual, garantindo que a sua contagem final seja o mais próxima possível da leitura humana real.
- Excelente Desempenho em Ficheiros Grandes: Lida com documentos massivos e de várias páginas sem problemas, sem gastar muita memória do sistema, graças aos seus mecanismos otimizados de libertação de memória interna.
- Extensibilidade Tudo-em-Um: Se o seu fluxo de trabalho de processamento de PDF crescer no futuro, não precisará de mudar de ferramentas. Ele suporta totalmente funcionalidades avançadas como adicionar anotações, assinar documentos ou converter formatos de ficheiro sob uma base de código única e unificada.
Apenas note que se o seu PDF contiver imagens digitalizadas em vez de texto, precisará de adicionar uma etapa de OCR (Reconhecimento Ótico de Caracteres) para ler o texto primeiro.
Qual Contador de Palavras de PDF Deve Escolher?
A escolha do método certo depende da sua situação atual e do tipo de documento que tem. Aqui está um resumo rápido para o ajudar a escolher a melhor ferramenta para o trabalho:
| Método | Precisão | Velocidade | Segurança de Privacidade | Melhor Para |
|---|---|---|---|---|
| Ferramentas Online | Média | Rápida | Baixa | Artigos rápidos, públicos e não sensíveis |
| Adobe para Word | Alta | Média | Alta (100% Local) | Documentos oficiais, papéis legais e ficheiros altamente confidenciais |
| Script Python | Alta | Rápida (Em Lote) | Alta (100% Local) | Desenvolvedores, analistas de dados e processamento em lote automatizado |
Conclusão
Contar palavras em ficheiros PDF não precisa de ser complicado. Se precisa de uma resposta rápida de uma ferramenta online, uma contagem confiável através da conversão para Word, ou uma solução Python automatizada para processamento em lote, existe uma opção para cada cenário. Escolha a abordagem que corresponde às suas necessidades e comece a analisar os seus documentos PDF de forma mais eficiente.
Leia Também
PDF에서 단어 수를 세는 방법 (2026년 완벽 가이드)
일상 업무와 생활에서 PDF 문서의 단어 수를 세어야 하는 경우가 많습니다. Microsoft Word와 달리 PDF 파일은 기본 단어 수 세기 기능을 제공하지 않으며, 대부분의 PDF 리더는 단어 수 세기에 대한 제한적인 지원만 제공합니다. 이는 PDF 파일이 텍스트를 연속적인 단어 흐름이 아닌 고정된 시각적 요소로 취급하기 때문입니다. PDF 문서에서 단어 수를 쉽게 세는 방법이 궁금하다면 제대로 찾아오셨습니다. 이 가이드에서는 간단하고 직접적인 온라인 도구부터 한 번에 수백 개의 문서를 처리할 수 있는 자동화된 스크립트까지, 이 문제를 해결하는 3가지 매우 효과적인 솔루션을 소개합니다.
온라인 단어 카운터로 PDF 단어 수 세기
PDF 단어 수를 얻는 것에 관해서는 온라인 카운터가 일반적으로 가장 먼저 떠오르는 솔루션입니다. 매우 가볍고 설치가 전혀 필요 없으며 모든 장치에서 완벽하게 작동합니다. 컴퓨터에 무거운 소프트웨어를 설치하는 대신 웹 브라우저에서 직접 빠른 답변을 얻고 다른 작업으로 넘어갈 수 있습니다.
방법:
- 1단계. 웹 브라우저를 열고 신뢰할 수 있는 무료 온라인 PDF 단어 수 세기 도구를 검색합니다.
- 2단계. PDF 파일을 업로드 상자로 직접 드래그 앤 드롭합니다.
- 3단계. 파일이 업로드되고 처리된 후 웹사이트에서 총 단어 수를 표시합니다.
온라인 PDF 도구를 사용한 단어 수 결과:
개인 정보 보호 및 보안 경고: 민감한 PDF를 무료 온라인 웹사이트에 업로드하는 것은 권장되지 않습니다. 문서에 비즈니스 비밀, 개인 신분증 또는 금융 데이터가 포함되어 있다면 이 방법을 완전히 건너뛰십시오. 무료 도구는 공개적이고 민감하지 않은 기사에만 안전합니다.
Adobe Acrobat 및 MS Word를 사용하여 PDF에서 단어 수 세기
법률 문서, 번역 프로젝트 또는 학술 논문을 다루는 경우 속도보다 정확성이 더 중요할 수 있습니다. 이러한 경우 데스크톱 기반 워크플로우는 온라인 도구에 의존하는 것보다 더 안전하고 안정적인 선택이 될 수 있습니다.
Microsoft Word와 달리 Adobe Acrobat은 모든 에디션에서 전용 단어 수 세기 기능을 제공하지 않습니다. 일반적인 해결 방법은 PDF를 Word로 변환한 다음 Word의 내장 기능을 사용하여 단어 수를 확인하는 것입니다.
단계별 가이드:
- 1단계. Adobe Acrobat에서 PDF 파일을 엽니다(또는 공식 Adobe Acrobat 온라인 변환기를 사용합니다).
- 2단계. 오른쪽 창에서 PDF 내보내기를 클릭하고 출력 형식으로 Microsoft Word(.docx)를 선택합니다.
- 3단계. 새로 생성된 파일을 로컬 컴퓨터에 저장합니다.
- 4단계. Microsoft Word에서 문서를 열고 검토 탭으로 이동한 다음 단어 수를 클릭합니다.
참고: 원본 파일에 대해 걱정하지 마십시오. 이 프로세스는 새 Word 문서를 생성하고 원본 PDF는 그대로 유지합니다.
Python으로 PDF 단어 수 세기 자동화
파일을 수동으로 변환하는 것은 한두 개의 문서에는 괜찮습니다. 하지만 500개의 보고서가 담긴 폴더를 가진 개발자나 데이터 분석가라면 어떻게 해야 할까요? 많은 수의 파일을 수동으로 처리하는 것은 시간이 많이 걸리므로 자동화가 더 실용적인 솔루션이 됩니다.
개발자의 경우 프로그래밍 방식으로 텍스트를 추출하는 것이 PDF 파일의 단어 수를 세는 가장 효율적인 방법인 경우가 많습니다. 짧은 Python 스크립트로 PDF 단어 수를 자동화할 수 있습니다. Free Spire.PDF for Python의 도움으로 프로그래밍 방식으로 원시 텍스트를 추출하고 정규 표현식을 사용하여 단어를 즉시 셀 수 있습니다.
Python 코드 예제
아래 코드는 한 번에 여러 PDF 문서의 단어 수를 세는 방법을 보여줍니다:
import os
import re
from spire.pdf.common import *
from spire.pdf import *
# 1. 입력 폴더 디렉토리 정의
folder_path = "/input/pdfs/"
# 2. 텍스트 추출 옵션 한 번 구성
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
print("--- 단어 수 보고서 ---")
# 3. 디렉토리의 모든 파일을 반복
for file_name in os.listdir(folder_path):
# PDF 파일만 처리
if file_name.lower().endswith('.pdf'):
file_path = os.path.join(folder_path, file_name)
# Document 객체 초기화 및 현재 PDF 로드
doc = PdfDocument()
doc.LoadFromFile(file_path)
# 현재 파일의 모든 페이지에서 텍스트 추출
total_text = ""
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
textExtractor = PdfTextExtractor(page)
text = textExtractor.ExtractText(extractOptions)
if text:
total_text += text + "\n"
doc.Close()
# 추출된 텍스트에서 영어 단어 수 세기
word_count = len(re.findall(r"\b[a-zA-Z]+(?:['-][a-zA-Z]+)*\b", total_text))
# 파일 이름과 해당 단어 수 출력
print(f"파일: {file_name} | 단어 수: {word_count}")
아래는 스크립트에서 출력된 일괄 단어 수 결과 미리보기입니다:
참고: 단어 수는 추출된 텍스트에 대한 정규 표현식 일치를 사용하여 계산됩니다. 다른 애플리케이션은 숫자, 하이픈이 포함된 단어, 구두점, 머리글, 바닥글 및 기타 특수 콘텐츠를 처리하는 데 다른 규칙을 사용하므로 결과는 Microsoft Word, Adobe Acrobat 또는 온라인 PDF 단어 카운터에서 보고하는 단어 수와 약간 다를 수 있습니다.
이것을 사용하는 이유는 무엇인가요?
이 방법은 데이터가 컴퓨터를 벗어나지 않기 때문에 빠르고 안전합니다. 대규모 프로젝트를 다루는 경우 Free Spire.PDF for Python을 사용하면 표준 오픈 소스 도구에 비해 여러 가지 기술적 이점이 있습니다:
- 높은 충실도의 텍스트 추출: 텍스트 순서를 자주 엉망으로 만들거나 다단 레이아웃을 혼합하는 기본 PDF 파서와 달리 시각적 레이아웃을 기반으로 텍스트 스트림을 정확하게 캡처하여 최종 계산이 실제 사람의 읽기에 최대한 가깝도록 보장합니다.
- 대용량 파일에 대한 뛰어난 성능: 최적화된 내부 메모리 해제 메커니즘 덕분에 시스템 메모리를 많이 사용하지 않고도 대규모 다중 페이지 문서를 원활하게 처리합니다.
- 올인원 확장성: 향후 PDF 처리 워크플로우가 확장되더라도 도구를 변경할 필요가 없습니다. 단일 통합 코드베이스에서 주석 추가, 문서 서명 또는 파일 형식 변환과 같은 고급 기능을 완벽하게 지원합니다.
PDF에 텍스트 대신 스캔된 이미지가 포함된 경우 먼저 텍스트를 읽기 위해 OCR(광학 문자 인식) 단계를 추가해야 한다는 점에 유의하십시오.
어떤 PDF 단어 카운터를 선택해야 할까요?
올바른 방법을 선택하는 것은 현재 상황과 문서 유형에 따라 다릅니다. 다음은 작업을 위한 최상의 도구를 선택하는 데 도움이 되는 빠른 분석입니다:
| 방법 | 정확도 | 속도 | 개인 정보 보호 안전 | 가장 적합한 경우 |
|---|---|---|---|---|
| 온라인 도구 | 중간 | 빠름 | 낮음 | 빠르고 공개적이며 민감하지 않은 기사 |
| Adobe를 Word로 | 높음 | 중간 | 높음 (100% 로컬) | 공식 문서, 법률 서류 및 매우 기밀인 파일 |
| Python 스크립트 | 높음 | 빠름 (일괄) | 높음 (100% 로컬) | 개발자, 데이터 분석가 및 자동화된 일괄 처리 |
결론
PDF 파일에서 단어 수를 세는 것이 복잡할 필요는 없습니다. 온라인 도구에서 빠른 답변을 얻거나, Word 변환을 통해 안정적인 계산을 하거나, 일괄 처리를 위한 자동화된 Python 솔루션을 원하든 모든 시나리오에 대한 옵션이 있습니다. 요구 사항에 맞는 접근 방식을 선택하고 PDF 문서를 더 효율적으로 분석하십시오.
함께 읽어보기
Come contare le parole in un PDF (La guida definitiva per il 2026)
Nel nostro lavoro e nella vita quotidiana, ci troviamo spesso ad aver bisogno di contare le parole in un documento PDF. A differenza di Microsoft Word, i file PDF non forniscono una funzione nativa per il conteggio delle parole e la maggior parte dei lettori PDF offre solo un supporto limitato per il conteggio delle parole. Questo perché i file PDF trattano il testo come elementi visivi fissi piuttosto che come un flusso continuo di parole. Se ti stai chiedendo come contare le parole nei documenti PDF facilmente, sei nel posto giusto. Questa guida ti presenterà 3 soluzioni altamente efficaci per risolvere questo problema, coprendo tutto, da semplici strumenti online diretti a script automatizzati in grado di gestire centinaia di documenti contemporaneamente.
- Conta parole con strumenti online
- Conta parole utilizzando Adobe Acrobat e MS Word
- Conteggio parole in PDF con Python
- Confronto dei metodi
Conta parole in PDF con contatore di parole online
Quando si tratta di ottenere un conteggio di parole PDF, i contatori online sono solitamente la prima soluzione che viene in mente. Sono incredibilmente leggeri, non richiedono alcuna installazione e funzionano perfettamente su tutti i tuoi dispositivi. Invece di ingombrare il tuo computer con software pesanti, puoi ottenere una risposta rapida direttamente nel tuo browser web e passare ad altre attività.
Come fare:
- Passaggio 1. Apri il tuo browser web e cerca uno strumento affidabile e gratuito per il conteggio delle parole PDF online.
- Passaggio 2. Trascina e rilascia il tuo file PDF direttamente nell'area di caricamento.
- Passaggio 3. Dopo che il file è stato caricato ed elaborato, il sito web visualizzerà il conteggio totale delle parole.
Risultato del conteggio parole utilizzando uno strumento PDF online:
Avviso sulla privacy e sicurezza: Non è consigliabile caricare PDF sensibili su siti web online gratuiti. Se il tuo documento contiene segreti aziendali, ID personali o dati finanziari, salta completamente questo metodo. Gli strumenti gratuiti sono sicuri solo per articoli pubblici e non sensibili.
Conta parole in un PDF utilizzando Adobe Acrobat e MS Word
Se stai lavorando con documenti legali, progetti di traduzione o documenti accademici, l'accuratezza è spesso più importante della velocità. In questi casi, un flusso di lavoro basato su desktop può essere una scelta più sicura e affidabile rispetto all'affidarsi a strumenti online.
A differenza di Microsoft Word, Adobe Acrobat non fornisce una funzione dedicata per il conteggio delle parole in tutte le edizioni. Una soluzione comune è convertire il PDF in Word e quindi utilizzare la funzione integrata di Word per verificare il conteggio delle parole.
Guida passo passo:
- Passaggio 1. Apri il tuo file PDF in Adobe Acrobat (o usa il convertitore online ufficiale di Adobe Acrobat).
- Passaggio 2. Fai clic su Esporta PDF nel riquadro destro e seleziona Microsoft Word (.docx) come formato di output.
- Passaggio 3. Salva il file appena generato sul tuo computer locale.
- Passaggio 4. Apri il documento in Microsoft Word, vai alla scheda Revisione e fai clic su Conteggio parole.
Nota: non preoccuparti del tuo file originale, questo processo crea semplicemente un nuovo documento Word, lasciando intatto il tuo PDF originale.
Come fare il conteggio parole in PDF con Python automaticamente
La conversione manuale dei file va bene per uno o due documenti. Ma cosa succede se sei uno sviluppatore o un analista di dati con una cartella piena di 500 report? L'elaborazione manuale di un gran numero di file può richiedere tempo, rendendo l'automazione una soluzione più pratica.
Per gli sviluppatori, l'estrazione di testo a livello di codice è spesso il modo più efficiente per contare le parole nei file PDF. Puoi automatizzare il conteggio delle parole PDF con un breve script Python. Con l'aiuto di Free Spire.PDF per Python, puoi estrarre il testo grezzo a livello di codice e utilizzare espressioni regolari per contare le parole istantaneamente.
Esempio di codice Python
Il codice seguente mostra come contare le parole di più documenti PDF in una sola volta:
import os
import re
from spire.pdf.common import *
from spire.pdf import *
# 1. Definisci la directory della cartella di input
folder_path = "/input/pdfs/"
# 2. Configura le opzioni di estrazione del testo una sola volta
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
print("--- Report Conteggio Parole ---")
# 3. Scorri tutti i file nella directory
for file_name in os.listdir(folder_path):
# Elabora solo i file PDF
if file_name.lower().endswith('.pdf'):
file_path = os.path.join(folder_path, file_name)
# Inizializza l'oggetto Document e carica il PDF corrente
doc = PdfDocument()
doc.LoadFromFile(file_path)
# Estrai il testo da tutte le pagine del file corrente
total_text = ""
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
textExtractor = PdfTextExtractor(page)
text = textExtractor.ExtractText(extractOptions)
if text:
total_text += text + "\n"
doc.Close()
# Conta le parole inglesi nel testo estratto
word_count = len(re.findall(r"\b[a-zA-Z]+(?:['-][a-zA-Z]+)*\b", total_text))
# Stampa il nome del file e il suo conteggio parole corrispondente
print(f"File: {file_name} | Conteggio parole: {word_count}")
Di seguito è riportata un'anteprima dei risultati del conteggio parole batch stampati dallo script:
Nota: Il conteggio delle parole viene calcolato utilizzando la corrispondenza di espressioni regolari sul testo estratto. Poiché diverse applicazioni utilizzano regole diverse per la gestione di numeri, parole con trattino, punteggiatura, intestazioni, piè di pagina e altri contenuti speciali, il risultato potrebbe differire leggermente dal conteggio parole riportato da Microsoft Word, Adobe Acrobat o dai contatori di parole PDF online.
Perché usarlo?
Questo metodo è veloce e sicuro perché i tuoi dati non lasciano mai il tuo computer. Se hai a che fare con progetti su larga scala, l'utilizzo di Free Spire.PDF per Python offre diversi vantaggi tecnici rispetto agli strumenti open-source standard:
- Estrazione di testo ad alta fedeltà: A differenza dei parser PDF di base che spesso mescolano l'ordine del testo o confondono layout a più colonne, cattura accuratamente i flussi di testo in base al layout visivo, garantendo che il conteggio finale sia il più vicino possibile alla lettura umana reale.
- Eccellenti prestazioni su file di grandi dimensioni: Gestisce documenti di grandi dimensioni e multipagina senza problemi, senza consumare molta memoria di sistema, grazie ai suoi meccanismi ottimizzati di rilascio della memoria interna.
- Estensibilità all-in-one: Se il tuo flusso di lavoro di elaborazione PDF crescerà in futuro, non avrai bisogno di cambiare strumenti. Supporta pienamente funzionalità avanzate come l'aggiunta di annotazioni, la firma di documenti o la conversione di formati di file sotto un'unica base di codice unificata.
Tieni presente che se il tuo PDF contiene immagini scansionate invece di testo, dovrai aggiungere un passaggio OCR (Optical Character Recognition) per leggere prima il testo.
Quale contatore di parole PDF dovresti scegliere?
La scelta del metodo giusto dipende dalla tua situazione attuale e dal tipo di documento che hai. Ecco una rapida panoramica per aiutarti a scegliere lo strumento migliore per il lavoro:
| Metodo | Accuratezza | Velocità | Sicurezza della privacy | Ideale per |
|---|---|---|---|---|
| Strumenti online | Media | Veloce | Bassa | Articoli rapidi, pubblici e non sensibili |
| Adobe a Word | Alta | Media | Alta (100% locale) | Documenti ufficiali, documenti legali e file altamente riservati |
| Script Python | Alta | Veloce (batch) | Alta (100% locale) | Sviluppatori, analisti di dati ed elaborazione batch automatizzata |
Conclusione
Contare le parole nei file PDF non deve essere complicato. Sia che tu abbia bisogno di una risposta rapida da uno strumento online, di un conteggio affidabile tramite conversione Word o di una soluzione Python automatizzata per l'elaborazione batch, esiste un'opzione per ogni scenario. Scegli l'approccio che soddisfa le tue esigenze e inizia ad analizzare i tuoi documenti PDF in modo più efficiente.
Leggi anche
Comment compter les mots dans un PDF (Le guide ultime pour 2026)
Dans notre travail et notre vie quotidienne, nous avons souvent besoin de compter les mots d'un document PDF. Contrairement à Microsoft Word, les fichiers PDF ne fournissent pas de fonctionnalité native de comptage de mots, et la plupart des lecteurs PDF n'offrent qu'un support limité pour le comptage de mots. En effet, les fichiers PDF traitent le texte comme des éléments visuels fixes plutôt que comme un flux continu de mots. Si vous vous demandez comment compter les mots dans des documents PDF facilement, vous êtes au bon endroit. Ce guide vous présentera 3 solutions très efficaces pour résoudre ce problème, couvrant tout, des outils en ligne simples et directs aux scripts automatisés qui peuvent traiter des centaines de documents à la fois.
- Compter les mots avec des outils en ligne
- Compter les mots à l'aide d'Adobe Acrobat et de MS Word
- Nombre de mots dans un PDF avec Python
- Comparaison des méthodes
Compter les mots dans un PDF avec un compteur de mots en ligne
Quand il s'agit d'obtenir un compte de mots d'un PDF, les compteurs en ligne sont généralement la première solution qui vient à l'esprit. Ils sont incroyablement légers, ne nécessitent aucune installation et fonctionnent parfaitement sur tous vos appareils. Au lieu d'encombrer votre ordinateur avec des logiciels lourds, vous pouvez obtenir une réponse rapide directement dans votre navigateur Web et passer à d'autres tâches.
Comment faire :
- Étape 1. Ouvrez votre navigateur Web et recherchez un outil de comptage de mots PDF gratuit et fiable en ligne.
- Étape 2. Faites glisser et déposez votre fichier PDF directement dans la zone de téléchargement.
- Étape 3. Une fois le fichier téléchargé et traité, le site Web affichera le nombre total de mots.
Résultat du comptage de mots à l'aide d'un outil PDF en ligne :
Avertissement sur la confidentialité et la sécurité : Il n'est pas recommandé de télécharger des PDF sensibles sur des sites Web gratuits en ligne. Si votre document contient des secrets commerciaux, des identifiants personnels ou des données financières, ignorez complètement cette méthode. Les outils gratuits ne sont sûrs que pour les articles publics et non sensibles.
Compter les mots dans un PDF à l'aide d'Adobe Acrobat et de MS Word
Si vous travaillez avec des documents juridiques, des projets de traduction ou des articles universitaires, la précision est souvent plus importante que la rapidité. Dans ces cas, un flux de travail basé sur le bureau peut être un choix plus sûr et plus fiable que de s'appuyer sur des outils en ligne.
Contrairement à Microsoft Word, Adobe Acrobat ne fournit pas de fonctionnalité dédiée de comptage de mots dans toutes ses éditions. Une solution de contournement courante consiste à convertir le PDF en Word, puis à utiliser la fonctionnalité intégrée de Word pour vérifier le nombre de mots.
Guide étape par étape :
- Étape 1. Ouvrez votre fichier PDF dans Adobe Acrobat (ou utilisez le convertisseur officiel en ligne Adobe Acrobat).
- Étape 2. Cliquez sur Exporter le PDF dans le volet de droite et sélectionnez Microsoft Word (.docx) comme format de sortie.
- Étape 3. Enregistrez le fichier nouvellement généré sur votre ordinateur local.
- Étape 4. Ouvrez le document dans Microsoft Word, accédez à l'onglet Révision et cliquez sur Nombre de mots.
Remarque : Ne vous inquiétez pas pour votre fichier d'origine, ce processus crée simplement un tout nouveau document Word, laissant votre PDF d'origine intact.
Comment faire le comptage de mots dans un PDF avec Python automatiquement
La conversion manuelle de fichiers fonctionne bien pour un ou deux documents. Mais que faire si vous êtes un développeur ou un analyste de données avec un dossier contenant 500 rapports ? Le traitement manuel d'un grand nombre de fichiers peut prendre du temps, faisant de l'automatisation une solution plus pratique.
Pour les développeurs, l'extraction de texte par programmation est souvent le moyen le plus efficace de compter les mots dans les fichiers PDF. Vous pouvez automatiser le comptage de mots PDF avec un court script Python. Avec l'aide de Free Spire.PDF pour Python, vous pouvez extraire le texte brut par programmation et utiliser des expressions régulières pour compter les mots instantanément.
Exemple de code Python
Le code ci-dessous montre comment compter les mots de plusieurs documents PDF en une seule fois :
import os
import re
from spire.pdf.common import *
from spire.pdf import *
# 1. Définir le répertoire du dossier d'entrée
folder_path = "/input/pdfs/"
# 2. Configurer les options d'extraction de texte une seule fois
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
print("--- Rapport de comptage de mots ---")
# 3. Parcourir tous les fichiers du répertoire
for file_name in os.listdir(folder_path):
# Traiter uniquement les fichiers PDF
if file_name.lower().endswith('.pdf'):
file_path = os.path.join(folder_path, file_name)
# Initialiser l'objet Document et charger le PDF actuel
doc = PdfDocument()
doc.LoadFromFile(file_path)
# Extraire le texte de toutes les pages du fichier actuel
total_text = ""
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
textExtractor = PdfTextExtractor(page)
text = textExtractor.ExtractText(extractOptions)
if text:
total_text += text + "\n"
doc.Close()
# Compter les mots anglais dans le texte extrait
word_count = len(re.findall(r"\b[a-zA-Z]+(?:['-][a-zA-Z]+)*\b", total_text))
# Afficher le nom du fichier et son nombre de mots correspondant
print(f"Fichier : {file_name} | Nombre de mots : {word_count}")
Ci-dessous, un aperçu des résultats du comptage de mots par lots imprimés par le script :
Remarque : Le nombre de mots est calculé à l'aide de la correspondance d'expressions régulières sur le texte extrait. Comme différentes applications utilisent des règles différentes pour gérer les nombres, les mots avec trait d'union, la ponctuation, les en-têtes, les pieds de page et d'autres contenus spéciaux, le résultat peut différer légèrement du nombre de mots signalé par Microsoft Word, Adobe Acrobat ou les compteurs de mots PDF en ligne.
Pourquoi utiliser ceci ?
Cette méthode est à la fois rapide et sécurisée car vos données ne quittent jamais votre ordinateur. Si vous traitez des projets à grande échelle, l'utilisation de Free Spire.PDF pour Python offre plusieurs avantages techniques par rapport aux outils open-source standards :
- Extraction de texte haute fidélité : Contrairement aux analyseurs PDF de base qui mélangent souvent l'ordre du texte ou confondent les mises en page multicolonnes, il capture avec précision les flux de texte en fonction de la mise en page visuelle, garantissant que votre comptage final est aussi proche que possible de la lecture humaine réelle.
- Excellentes performances sur les fichiers volumineux : Il gère les documents massifs de plusieurs pages en douceur sans consommer beaucoup de mémoire système, grâce à ses mécanismes optimisés de libération de mémoire interne.
- Extensibilité tout-en-un : Si votre flux de travail de traitement PDF évolue à l'avenir, vous n'aurez pas besoin de changer d'outils. Il prend entièrement en charge les fonctionnalités avancées telles que l'ajout d'annotations, la signature de documents ou la conversion de formats de fichiers sous une base de code unique et unifiée.
Notez simplement que si votre PDF contient des images numérisées au lieu de texte, vous devrez ajouter une étape OCR (reconnaissance optique de caractères) pour lire le texte d'abord.
Quel compteur de mots PDF choisir ?
Choisir la bonne méthode dépend de votre situation actuelle et du type de document que vous avez. Voici un résumé rapide pour vous aider à choisir le meilleur outil pour le travail :
| Méthode | Précision | Vitesse | Sécurité de la confidentialité | Idéal pour |
|---|---|---|---|---|
| Outils en ligne | Moyenne | Rapide | Faible | Articles rapides, publics et non sensibles |
| Adobe vers Word | Élevée | Moyenne | Élevée (100 % local) | Documents officiels, papiers juridiques et fichiers hautement confidentiels |
| Script Python | Élevée | Rapide (en masse) | Élevée (100 % local) | Développeurs, analystes de données et traitement par lots automatisé |
Conclusion
Compter les mots dans les fichiers PDF ne doit pas être compliqué. Que vous ayez besoin d'une réponse rapide d'un outil en ligne, d'un compte fiable via la conversion Word ou d'une solution Python automatisée pour le traitement par lots, il existe une option pour chaque scénario. Choisissez l'approche qui correspond à vos besoins et commencez à analyser vos documents PDF plus efficacement.
À lire également
Cómo contar palabras en un PDF (La guía definitiva para 2026)
Tabla de Contenidos
En nuestro trabajo y vida diaria, a menudo nos encontramos con la necesidad de contar las palabras en un documento PDF. A diferencia de Microsoft Word, los archivos PDF no proporcionan una función nativa de conteo de palabras, y la mayoría de los lectores de PDF ofrecen un soporte limitado para contar palabras. Esto se debe a que los archivos PDF tratan el texto como elementos visuales fijos en lugar de un flujo continuo de palabras. Si te preguntas cómo contar palabras en documentos PDF fácilmente, estás en el lugar correcto. Esta guía presentará 3 soluciones altamente efectivas para resolver este problema, cubriendo todo, desde herramientas en línea simples y directas hasta scripts automatizados que pueden manejar cientos de documentos a la vez.
- Contar Palabras con Herramientas en Línea
- Contar Palabras Usando Adobe Acrobat y MS Word
- Conteo de Palabras en PDF con Python
- Comparación de Métodos
Contar Palabras en PDF con un Contador de Palabras en Línea
Cuando se trata de obtener un conteo de palabras en PDF, los contadores en línea suelen ser la primera solución que viene a la mente. Son increíblemente ligeros, no requieren ninguna instalación y funcionan perfectamente en todos tus dispositivos. En lugar de llenar tu computadora con software pesado, puedes obtener una respuesta rápida directamente en tu navegador web y pasar a otras tareas.
Cómo hacerlo:
- Paso 1. Abre tu navegador web y busca una herramienta gratuita y confiable en línea para contar palabras en PDF.
- Paso 2. Arrastra y suelta tu archivo PDF directamente en el cuadro de carga.
- Paso 3. Después de que el archivo se cargue y se procese, el sitio web mostrará el conteo total de palabras.
Resultado del conteo de palabras usando una herramienta PDF en línea:
Advertencia de Privacidad y Seguridad: No se recomienda subir PDFs confidenciales a sitios web gratuitos en línea. Si tu documento contiene secretos comerciales, identificaciones personales o datos financieros, omite este método por completo. Las herramientas gratuitas solo son seguras para artículos públicos y no confidenciales.
Contar Palabras en un PDF Usando Adobe Acrobat y MS Word
Si estás trabajando con documentos legales, proyectos de traducción o trabajos académicos, la precisión a menudo es más importante que la velocidad. En estos casos, un flujo de trabajo basado en escritorio puede ser una opción más segura y confiable que depender de herramientas en línea.
A diferencia de Microsoft Word, Adobe Acrobat no proporciona una función dedicada de conteo de palabras en todas sus ediciones. Una solución común es convertir el PDF a Word y luego usar la función integrada de Word para verificar el conteo de palabras.
Guía Paso a Paso:
- Paso 1. Abre tu archivo PDF en Adobe Acrobat (o usa el convertidor oficial en línea de Adobe Acrobat).
- Paso 2. Haz clic en Exportar PDF en el panel derecho y selecciona Microsoft Word (.docx) como tu formato de salida.
- Paso 3. Guarda el archivo recién generado en tu computadora local.
- Paso 4. Abre el documento en Microsoft Word, navega a la pestaña Revisar y haz clic en Conteo de palabras.
Nota: No te preocupes por tu archivo original, este proceso simplemente crea un documento de Word completamente nuevo, dejando tu PDF original intacto.
Cómo Hacer el Conteo de Palabras en PDF con Python Automáticamente
Convertir archivos manualmente funciona bien para uno o dos documentos. ¿Pero qué pasa si eres un desarrollador o un analista de datos con una carpeta llena de 500 informes? Procesar manualmente una gran cantidad de archivos puede llevar mucho tiempo, haciendo de la automatización una solución más práctica.
Para los desarrolladores, extraer texto programáticamente es a menudo la forma más eficiente de contar palabras en archivos PDF. Puedes automatizar el conteo de palabras en PDF con un script corto de Python. Con la ayuda de Free Spire.PDF para Python, puedes extraer el texto sin procesar programáticamente y usar expresiones regulares para contar las palabras al instante.
Ejemplo de Código Python
El siguiente código muestra cómo contar palabras de múltiples documentos PDF de una sola vez:
import os
import re
from spire.pdf.common import *
from spire.pdf import *
# 1. Define el directorio de la carpeta de entrada
folder_path = "/input/pdfs/"
# 2. Configura las opciones de extracción de texto una vez
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
print("--- Informe de Conteo de Palabras ---")
# 3. Itera sobre todos los archivos en el directorio
for file_name in os.listdir(folder_path):
# Procesa solo archivos PDF
if file_name.lower().endswith('.pdf'):
file_path = os.path.join(folder_path, file_name)
# Inicializa el objeto Document y carga el PDF actual
doc = PdfDocument()
doc.LoadFromFile(file_path)
# Extrae texto de todas las páginas del archivo actual
total_text = ""
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
textExtractor = PdfTextExtractor(page)
text = textExtractor.ExtractText(extractOptions)
if text:
total_text += text + "\n"
doc.Close()
# Cuenta las palabras en inglés en el texto extraído
word_count = len(re.findall(r"\b[a-zA-Z]+(?:['-][a-zA-Z]+)*\b", total_text))
# Imprime el nombre del archivo y su conteo de palabras correspondiente
print(f"Archivo: {file_name} | Conteo de Palabras: {word_count}")
A continuación se muestra una vista previa de los resultados del conteo de palabras por lotes impresos por el script:
Nota: El conteo de palabras se calcula utilizando la coincidencia de expresiones regulares en el texto extraído. Dado que diferentes aplicaciones utilizan reglas diferentes para manejar números, palabras con guiones, puntuación, encabezados, pies de página y otro contenido especial, el resultado puede diferir ligeramente del conteo de palabras informado por Microsoft Word, Adobe Acrobat o los contadores de palabras de PDF en línea.
¿Por qué usar esto?
Este método es rápido y seguro porque tus datos nunca salen de tu computadora. Si estás lidiando con proyectos a gran escala, utilizar Free Spire.PDF para Python ofrece varias ventajas técnicas sobre las herramientas de código abierto estándar:
- Extracción de Texto de Alta Fidelidad: A diferencia de los analizadores básicos de PDF que a menudo mezclan el orden del texto o confunden los diseños multicolumna, captura con precisión los flujos de texto basándose en el diseño visual, asegurando que tu conteo final sea lo más cercano posible a la lectura humana real.
- Excelente Rendimiento en Archivos Grandes: Maneja documentos masivos de varias páginas sin problemas sin consumir mucha memoria del sistema, gracias a sus mecanismos optimizados de liberación de memoria interna.
- Extensibilidad Todo en Uno: Si tu flujo de trabajo de procesamiento de PDF crece en el futuro, no necesitarás cambiar de herramientas. Admite completamente funciones avanzadas como agregar anotaciones, firmar documentos o convertir formatos de archivo bajo una base de código unificada.
Solo ten en cuenta que si tu PDF contiene imágenes escaneadas en lugar de texto, necesitarás agregar un paso de OCR (Reconocimiento Óptico de Caracteres) para leer el texto primero.
¿Qué Contador de Palabras en PDF Deberías Elegir?
Elegir el método correcto depende de tu situación actual y del tipo de documento que tengas. Aquí tienes un resumen rápido para ayudarte a elegir la mejor herramienta para el trabajo:
| Método | Precisión | Velocidad | Seguridad de Privacidad | Mejor Para |
|---|---|---|---|---|
| Herramientas en Línea | Media | Rápida | Baja | Artículos rápidos, públicos y no confidenciales |
| Adobe a Word | Alta | Media | Alta (100% Local) | Documentos oficiales, papeles legales y archivos altamente confidenciales |
| Script de Python | Alta | Rápida (Lotes) | Alta (100% Local) | Desarrolladores, analistas de datos y procesamiento automático por lotes |
Conclusión
Contar palabras en archivos PDF no tiene por qué ser complicado. Ya sea que necesites una respuesta rápida de una herramienta en línea, un conteo confiable a través de la conversión a Word o una solución automatizada de Python para el procesamiento por lotes, hay una opción para cada escenario. Elige el enfoque que se ajuste a tus necesidades y comienza a analizar tus documentos PDF de manera más eficiente.
También Lee
Wie man Wörter in einer PDF-Datei zählt (Der ultimative Leitfaden für 2026)
Inhaltsverzeichnis
In unserer täglichen Arbeit und im Leben müssen wir oft die Wörter in einem PDF-Dokument zählen. Im Gegensatz zu Microsoft Word bieten PDF-Dateien keine native Funktion zum Zählen von Wörtern, und die meisten PDF-Reader bieten nur begrenzte Unterstützung für das Zählen von Wörtern. Dies liegt daran, dass PDF-Dateien Text als feste visuelle Elemente und nicht als kontinuierlichen Wortfluss behandeln. Wenn Sie sich fragen, wie Sie Wörter in PDF-Dokumenten zählen können, sind Sie hier genau richtig. Dieser Leitfaden stellt 3 äußerst effektive Lösungen vor, um dieses Problem zu lösen, und deckt alles ab, von einfachen, direkten Online-Tools bis hin zu automatisierten Skripten, die Hunderte von Dokumenten auf einmal verarbeiten können.
- Wörter zählen mit Online-Tools
- Wörter zählen mit Adobe Acrobat und MS Word
- Wortanzahl in PDF mit Python
- Vergleich der Methoden
Wörter in PDF mit Online-Wortzähler zählen
Wenn es darum geht, die Wortanzahl eines PDFs zu ermitteln, sind Online-Zähler normalerweise die erste Lösung, die einem in den Sinn kommt. Sie sind unglaublich leichtgewichtig, erfordern keine Installation und funktionieren perfekt auf all Ihren Geräten. Anstatt Ihren Computer mit schwerer Software zu überladen, können Sie eine schnelle Antwort direkt in Ihrem Webbrowser erhalten und sich anderen Aufgaben widmen.
So geht's:
- Schritt 1. Öffnen Sie Ihren Webbrowser und suchen Sie nach einem vertrauenswürdigen, kostenlosen Online-Tool zum Zählen von Wörtern in PDFs.
- Schritt 2. Ziehen Sie Ihre PDF-Datei per Drag & Drop direkt in das Upload-Feld.
- Schritt 3. Nachdem die Datei hochgeladen und verarbeitet wurde, zeigt die Website die Gesamtzahl der Wörter an.
Ergebnis der Wortzählung mit einem Online-PDF-Tool:
Warnung zu Datenschutz & Sicherheit: Es wird nicht empfohlen, sensible PDFs auf kostenlose Online-Websites hochzuladen. Wenn Ihr Dokument Geschäftsgeheimnisse, persönliche Ausweise oder Finanzdaten enthält, überspringen Sie diese Methode vollständig. Kostenlose Tools sind nur für öffentliche, nicht sensible Artikel sicher.
Wörter in einem PDF mit Adobe Acrobat und MS Word zählen
Wenn Sie mit juristischen Dokumenten, Übersetzungsprojekten oder akademischen Arbeiten arbeiten, ist Genauigkeit oft wichtiger als Geschwindigkeit. In diesen Fällen kann ein Desktop-basierter Workflow eine sicherere und zuverlässigere Wahl sein, als sich auf Online-Tools zu verlassen.
Im Gegensatz zu Microsoft Word bietet Adobe Acrobat nicht in allen Editionen eine spezielle Funktion zum Zählen von Wörtern. Eine gängige Umgehungslösung ist die Konvertierung des PDFs in Word und die anschließende Verwendung der integrierten Funktion von Word, um die Wortanzahl zu überprüfen.
Schritt-für-Schritt-Anleitung:
- Schritt 1. Öffnen Sie Ihre PDF-Datei in Adobe Acrobat (oder verwenden Sie den offiziellen Adobe Acrobat Online-Konverter).
- Schritt 2. Klicken Sie im rechten Bereich auf PDF exportieren und wählen Sie Microsoft Word (.docx) als Ausgabeformat.
- Schritt 3. Speichern Sie die neu generierte Datei auf Ihrem lokalen Computer.
- Schritt 4. Öffnen Sie das Dokument in Microsoft Word, navigieren Sie zur Registerkarte Überprüfen und klicken Sie auf Wörter zählen.
Hinweis: Machen Sie sich keine Sorgen um Ihre Originaldatei, dieser Prozess erstellt lediglich ein brandneues Word-Dokument, während Ihr ursprüngliches PDF unverändert bleibt.
So zählen Sie Wörter in PDF mit Python automatisch
Das manuelle Konvertieren von Dateien funktioniert für ein oder zwei Dokumente gut. Aber was ist, wenn Sie ein Entwickler oder Datenanalyst mit einem Ordner voller 500 Berichte sind? Die manuelle Verarbeitung einer großen Anzahl von Dateien kann zeitaufwendig sein, was die Automatisierung zu einer praktikableren Lösung macht.
Für Entwickler ist die programmatische Extraktion von Text oft der effizienteste Weg, um Wörter in PDF-Dateien zu zählen. Sie können die PDF-Wortzählung mit einem kurzen Python-Skript automatisieren. Mit Hilfe von Free Spire.PDF for Python können Sie den Rohtext programmatisch extrahieren und reguläre Ausdrücke verwenden, um die Wörter sofort zu zählen.
Python-Codebeispiel
Der folgende Code zeigt, wie Sie die Wörter mehrerer PDF-Dokumente auf einmal zählen:
import os
import re
from spire.pdf.common import *
from spire.pdf import *
# 1. Definieren Sie das Eingabeordnerverzeichnis
folder_path = "/input/pdfs/"
# 2. Konfigurieren Sie die Textextraktionsoptionen einmal
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
print("--- Wortzählbericht ---")
# 3. Schleife durch alle Dateien im Verzeichnis
for file_name in os.listdir(folder_path):
# Verarbeiten Sie nur PDF-Dateien
if file_name.lower().endswith('.pdf'):
file_path = os.path.join(folder_path, file_name)
# Initialisieren Sie das Document-Objekt und laden Sie das aktuelle PDF
doc = PdfDocument()
doc.LoadFromFile(file_path)
# Extrahieren Sie Text aus allen Seiten der aktuellen Datei
total_text = ""
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
textExtractor = PdfTextExtractor(page)
text = textExtractor.ExtractText(extractOptions)
if text:
total_text += text + "\n"
doc.Close()
# Zählen Sie englische Wörter im extrahierten Text
word_count = len(re.findall(r"\b[a-zA-Z]+(?:['-][a-zA-Z]+)*\b", total_text))
# Drucken Sie den Dateinamen und seine entsprechende Wortanzahl
print(f"Datei: {file_name} | Wortanzahl: {word_count}")
Unten sehen Sie eine Vorschau der Batch-Wortzählungsergebnisse, die vom Skript gedruckt werden:
Hinweis: Die Wortanzahl wird mithilfe von regulären Ausdrücken auf dem extrahierten Text berechnet. Da verschiedene Anwendungen unterschiedliche Regeln für die Behandlung von Zahlen, mit Bindestrichen verbundenen Wörtern, Satzzeichen, Kopf- und Fußzeilen sowie anderen speziellen Inhalten verwenden, kann das Ergebnis leicht von der Wortanzahl abweichen, die von Microsoft Word, Adobe Acrobat oder Online-PDF-Wortzählern gemeldet wird.
Warum dies verwenden?
Diese Methode ist sowohl schnell als auch sicher, da Ihre Daten Ihren Computer niemals verlassen. Wenn Sie sich mit großen Projekten befassen, bietet die Verwendung von Free Spire.PDF für Python mehrere technische Vorteile gegenüber herkömmlichen Open-Source-Tools:
- Hochwertige Textextraktion: Im Gegensatz zu einfachen PDF-Parsern, die oft die Textreihenfolge durcheinanderbringen oder mehrspaltige Layouts vermischen, erfasst sie Textströme genau basierend auf dem visuellen Layout, um sicherzustellen, dass Ihre endgültige Zählung so nah wie möglich an der tatsächlichen menschlichen Lesung liegt.
- Hervorragende Leistung bei großen Dateien: Sie verarbeitet riesige, mehrseitige Dokumente reibungslos, ohne viel Systemspeicher zu verbrauchen, dank ihrer optimierten internen Speicherfreigabemechanismen.
- All-in-One-Erweiterbarkeit: Wenn Ihr PDF-Verarbeitungsworkflow in Zukunft wächst, müssen Sie keine Tools wechseln. Sie unterstützt vollständig erweiterte Funktionen wie das Hinzufügen von Anmerkungen, das Signieren von Dokumenten oder die Konvertierung von Dateiformaten unter einer einzigen, einheitlichen Codebasis.
Beachten Sie nur, dass Sie, wenn Ihr PDF gescannte Bilder anstelle von Text enthält, einen OCR-Schritt (Optical Character Recognition) hinzufügen müssen, um den Text zuerst zu lesen.
Welchen PDF-Wortzähler sollten Sie wählen?
Die Wahl der richtigen Methode hängt von Ihrer aktuellen Situation und der Art des Dokuments ab, das Sie haben. Hier ist eine kurze Übersicht, die Ihnen hilft, das beste Werkzeug für die jeweilige Aufgabe auszuwählen:
| Methode | Genauigkeit | Geschwindigkeit | Datenschutz | Am besten geeignet für |
|---|---|---|---|---|
| Online-Tools | Mittel | Schnell | Niedrig | Schnelle, öffentliche und nicht sensible Artikel |
| Adobe zu Word | Hoch | Mittel | Hoch (100 % lokal) | Offizielle Dokumente, juristische Papiere und hochvertrauliche Dateien |
| Python-Skript | Hoch | Schnell (Stapelverarbeitung) | Hoch (100 % lokal) | Entwickler, Datenanalysten und automatisierte Stapelverarbeitung |
Fazit
Das Zählen von Wörtern in PDF-Dateien muss nicht kompliziert sein. Ob Sie eine schnelle Antwort von einem Online-Tool, eine zuverlässige Zählung durch Word-Konvertierung oder eine automatisierte Python-Lösung für die Stapelverarbeitung benötigen, es gibt eine Option für jedes Szenario. Wählen Sie den Ansatz, der Ihren Bedürfnissen entspricht, und beginnen Sie, Ihre PDF-Dokumente effizienter zu analysieren.
Auch lesen
Как подсчитать количество слов в PDF (Полное руководство на 2026 год)
В нашей повседневной работе и жизни мы часто сталкиваемся с необходимостью подсчитать слова в документе PDF. В отличие от Microsoft Word, файлы PDF не имеют встроенной функции подсчета слов, а большинство программ для чтения PDF предлагают лишь ограниченную поддержку подсчета слов. Это связано с тем, что файлы PDF рассматривают текст как фиксированные визуальные элементы, а не как непрерывный поток слов. Если вы задаетесь вопросом, как легко подсчитать слова в документах PDF, вы попали по адресу. Это руководство представит 3 высокоэффективных решения этой проблемы, охватывающих все: от простых, прямых онлайн-инструментов до автоматизированных скриптов, которые могут обрабатывать сотни документов одновременно.
- Подсчет слов с помощью онлайн-инструментов
- Подсчет слов с помощью Adobe Acrobat и MS Word
- Подсчет слов в PDF с помощью Python
- Сравнение методов
Подсчет слов в PDF с помощью онлайн-счетчика слов
Когда дело доходит до подсчета слов в PDF, онлайн-счетчики обычно являются первым решением, которое приходит на ум. Они невероятно легкие, не требуют установки и отлично работают на всех ваших устройствах. Вместо того чтобы загромождать свой компьютер тяжелым программным обеспечением, вы можете быстро получить ответ прямо в веб-браузере и перейти к другим задачам.
Как это сделать:
- Шаг 1. Откройте веб-браузер и найдите надежный бесплатный онлайн-инструмент для подсчета слов в PDF.
- Шаг 2. Перетащите ваш PDF-файл прямо в поле загрузки.
- Шаг 3. После загрузки и обработки файла веб-сайт отобразит общее количество слов.
Результат подсчета слов с помощью онлайн-инструмента для PDF:
Предупреждение о конфиденциальности и безопасности: Не рекомендуется загружать конфиденциальные PDF-файлы на бесплатные онлайн-сайты. Если ваш документ содержит коммерческие тайны, личные удостоверения или финансовые данные, полностью пропустите этот метод. Бесплатные инструменты безопасны только для общедоступных, неконфиденциальных статей.
Подсчет слов в PDF с помощью Adobe Acrobat и MS Word
Если вы работаете с юридическими документами, переводческими проектами или академическими работами, точность часто важнее скорости. В этих случаях настольный рабочий процесс может быть более безопасным и надежным выбором, чем полагаться на онлайн-инструменты.
В отличие от Microsoft Word, Adobe Acrobat не предоставляет выделенной функции подсчета слов во всех своих версиях. Распространенным обходным путем является преобразование PDF в Word, а затем использование встроенной функции Word для проверки количества слов.
Пошаговое руководство:
- Шаг 1. Откройте ваш PDF-файл в Adobe Acrobat (или используйте официальный онлайн-конвертер Adobe Acrobat).
- Шаг 2. Нажмите Экспорт PDF в правой панели и выберите Microsoft Word (.docx) в качестве формата вывода.
- Шаг 3. Сохраните вновь созданный файл на свой локальный компьютер.
- Шаг 4. Откройте документ в Microsoft Word, перейдите на вкладку Рецензирование и нажмите Число слов.
Примечание: Не беспокойтесь о своем исходном файле, этот процесс просто создает совершенно новый документ Word, оставляя ваш исходный PDF нетронутым.
Как автоматически подсчитать слова в PDF с помощью Python
Ручное преобразование файлов подходит для одного или двух документов. Но что, если вы разработчик или аналитик данных с папкой, содержащей 500 отчетов? Ручная обработка большого количества файлов может занять много времени, что делает автоматизацию более практичным решением.
Для разработчиков программное извлечение текста часто является наиболее эффективным способом подсчета слов в PDF-файлах. Вы можете автоматизировать подсчет слов в PDF с помощью короткого скрипта Python. С помощью бесплатного Spire.PDF для Python вы можете программно извлекать необработанный текст и использовать регулярные выражения для мгновенного подсчета слов.
Пример кода Python
Приведенный ниже код показывает, как подсчитать слова в нескольких PDF-документах за один раз:
import os
import re
from spire.pdf.common import *
from spire.pdf import *
# 1. Определите каталог входной папки
folder_path = "/input/pdfs/"
# 2. Настройте параметры извлечения текста один раз
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
print("--- Отчет о подсчете слов ---")
# 3. Переберите все файлы в каталоге
for file_name in os.listdir(folder_path):
# Обрабатывайте только PDF-файлы
if file_name.lower().endswith('.pdf'):
file_path = os.path.join(folder_path, file_name)
# Инициализируйте объект Document и загрузите текущий PDF
doc = PdfDocument()
doc.LoadFromFile(file_path)
# Извлеките текст со всех страниц текущего файла
total_text = ""
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
textExtractor = PdfTextExtractor(page)
text = textExtractor.ExtractText(extractOptions)
if text:
total_text += text + "\n"
doc.Close()
# Подсчитайте английские слова в извлеченном тексте
word_count = len(re.findall(r"\b[a-zA-Z]+(?:['-][a-zA-Z]+)*\b", total_text))
# Выведите имя файла и соответствующее количество слов
print(f"Файл: {file_name} | Количество слов: {word_count}")
Ниже представлен предварительный просмотр результатов пакетного подсчета слов, выведенных скриптом:
Примечание: Подсчет слов выполняется с помощью сопоставления регулярных выражений с извлеченным текстом. Поскольку разные приложения используют разные правила для обработки чисел, слов с дефисами, знаков препинания, колонтитулов и другого специального содержимого, результат может незначительно отличаться от количества слов, сообщаемого Microsoft Word, Adobe Acrobat или онлайн-счетчиками слов PDF.
Зачем это использовать?
Этот метод быстр и безопасен, поскольку ваши данные никогда не покидают ваш компьютер. Если вы имеете дело с крупномасштабными проектами, использование бесплатного Spire.PDF для Python дает несколько технических преимуществ по сравнению со стандартными инструментами с открытым исходным кодом:
- Высокоточное извлечение текста: В отличие от базовых парсеров PDF, которые часто перемешивают порядок текста или путают многоколоночные макеты, он точно захватывает текстовые потоки на основе визуального макета, гарантируя, что ваш окончательный подсчет будет максимально приближен к реальному человеческому чтению.
- Отличная производительность на больших файлах: Он плавно обрабатывает огромные многостраничные документы, не расходуя много системной памяти, благодаря оптимизированным механизмам освобождения внутренней памяти.
- Расширяемость «все в одном»: Если ваш рабочий процесс обработки PDF расширится в будущем, вам не придется менять инструменты. Он полностью поддерживает расширенные функции, такие как добавление аннотаций, подписание документов или преобразование форматов файлов в рамках единой унифицированной кодовой базы.
Просто имейте в виду, что если ваш PDF содержит отсканированные изображения вместо текста, вам потребуется добавить шаг OCR (оптическое распознавание символов) для предварительного чтения текста.
Какой счетчик слов в PDF выбрать?
Выбор правильного метода зависит от вашей текущей ситуации и типа документа. Вот краткий обзор, который поможет вам выбрать лучший инструмент для вашей задачи:
| Метод | Точность | Скорость | Безопасность конфиденциальности | Лучше всего подходит для |
|---|---|---|---|---|
| Онлайн-инструменты | Средняя | Быстро | Низкая | Быстрые, общедоступные и неконфиденциальные статьи |
| Adobe в Word | Высокая | Средняя | Высокая (100% локально) | Официальные документы, юридические документы и файлы с высокой степенью конфиденциальности |
| Скрипт Python | Высокая | Быстро (пакетная обработка) | Высокая (100% локально) | Разработчики, аналитики данных и автоматизированная пакетная обработка |
Заключение
Подсчет слов в файлах PDF не обязательно должен быть сложным. Независимо от того, нужен ли вам быстрый ответ от онлайн-инструмента, надежный подсчет путем преобразования в Word или автоматизированное решение Python для пакетной обработки, существует вариант для каждого сценария. Выберите подход, который соответствует вашим потребностям, и начните анализировать свои PDF-документы более эффективно.
Также читайте
Alterar fonte em PDF: Adobe, online e automação em C#

O PDF tem sido há muito tempo o padrão universal para compartilhar documentos profissionais de formato fixo em todo o mundo. No entanto, seu design estático muitas vezes traz um ponto de dor comum: você não pode alterar facilmente tamanhos, estilos ou cores de fonte em um PDF sem as ferramentas certas.
Seja para corrigir formatação de texto inconsistente, atualizar fontes de marca, ajustar tamanhos de fonte para legibilidade ou refinar a tipografia para impressão e apresentações, dominar como alterar fontes em PDF é uma habilidade essencial para estudantes, profissionais e proprietários de empresas.
Neste guia, detalhamos métodos passo a passo para alterar a fonte do PDF usando:
- Software profissional (Adobe Acrobat Pro)
- Solução alternativa de desktop (Microsoft Word)
- Editores de PDF online gratuitos
- Automação programática (C#/.NET)
Também elaboramos sobre as limitações de fontes em PDF, as melhores práticas do setor e FAQs para resolver todos os seus problemas de edição de fontes em PDF de uma vez por todas.
Entendendo os Desafios das Fontes em PDF
Antes de modificar as fontes de PDF, é fundamental entender por que os PDFs são difíceis de editar:
| Desafio | Explicação |
|---|---|
| Fontes incorporadas vs. não incorporadas | Alguns PDFs incorporam apenas subconjuntos de fontes, limitando as opções de edição. |
| PDFs digitalizados (baseados em imagem) | Estes não têm uma camada de texto editável, e OCR é necessário para converter imagens em texto editável. |
| Fontes de sistema ausentes | Se uma fonte não estiver instalada em seu dispositivo, o texto pode aparecer corrompido ou ser substituído automaticamente. |
| Caixas de texto fixas | O texto do PDF é dividido em blocos de texto independentes. Alterar o tamanho da fonte em PDF pode causar quebras de linha, transbordamento de texto ou alteração de layout. |
| Restrições de permissão | Alguns PDFs são bloqueados pelo criador; você pode precisar remover permissões antes de editar. |
Método 1: Editar Fonte de PDF com Adobe Acrobat Pro
O Adobe Acrobat Pro é a ferramenta mais confiável para editar fontes de PDF nativas. Ele oferece personalização de fonte sem perdas, controle tipográfico completo e OCR integrado para documentos digitalizados, compatível com Windows e Mac.
Passos para alterar a fonte no Adobe Acrobat:
(1) Abra seu PDF no Adobe Acrobat Pro.
(2) Entre no Modo de Edição: Clique no botão “Editar” na barra global superior para ativar o painel de edição de PDF.
(3) Selecione seu texto: Selecione o bloco de texto específico que você deseja reformatar com o cursor do mouse.
(4) Altere a fonte: Na seção “FORMATAR TEXTO” no painel esquerdo:
- Escolha uma nova fonte na lista suspensa
- Ajuste o tamanho da fonte (valores predefinidos ou entrada personalizada)
- Altere a cor da fonte do PDF através do seletor de cores
- Alterne estilos de texto em negrito, itálico, sublinhado
- Defina o alinhamento do texto: esquerda, centro, direita, justificado
- Personalize o espaçamento entre linhas e o espaçamento entre caracteres
(5) Clique fora da caixa de texto para aplicar suas alterações e salvar o PDF.

Dica Profissional para PDFs Digitalizados
Se o seu PDF veio de um documento digitalizado, o Acrobat executa automaticamente o OCR (Reconhecimento Óptico de Caracteres) para criar uma camada de texto editável. Isso é crucial para alterar fontes em documentos PDF digitalizados.
Método 2: Alterar Fonte de PDF com Microsoft Word
Se você não possui software de PDF premium, use o Microsoft Word como uma solução alternativa para alterar a fonte em um documento PDF no Windows e Mac. Ele converte PDFs em documentos do Word editáveis, suporta edição completa de fontes e reexporta para PDF.
(1) Abra o Microsoft Word e clique em “Arquivo” > “Abrir” para selecionar seu arquivo PDF.
(2) Uma janela pop-up aparecerá confirmando a conversão do PDF. Clique em “OK” para converter o PDF em um documento do Word editável.
(3) Selecione o texto e use a barra de ferramentas de fonte superior do Word para alterar a família da fonte, tamanho, cor e estilo negrito/itálico.
(4) Corrija quaisquer alterações de layout (observe que elementos complexos podem ser perdidos ou desalinhados. O Word funciona melhor com PDFs simples baseados em texto).
(5) Vá para “Arquivo” > “Salvar como” e escolha “PDF” como o formato de exportação para salvar seu arquivo atualizado.
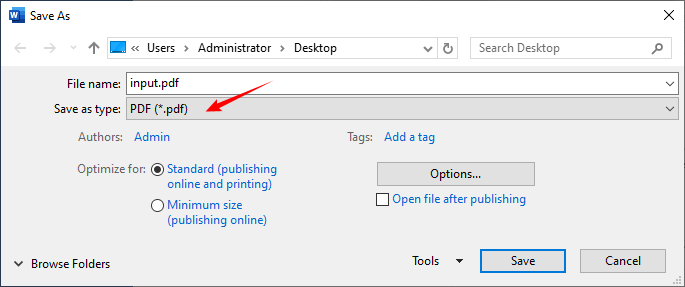
Após refinar as fontes e a formatação do PDF, você pode compactar o tamanho do arquivo PDF finalizado preservando a integridade da fonte e do layout.
Método 3: Editores de PDF Online Gratuitos
Para alterações de fonte únicas e simples, editores de PDF online gratuitos permitem que você edite a fonte em PDF diretamente no seu navegador. Recomendamos Soda PDF e Sejda, duas ferramentas confiáveis que oferecem recursos gratuitos de edição de fontes em PDF.
Alterar Fonte em PDF Online Usando Soda PDF
O Soda PDF oferece uma ferramenta de edição baseada na web que facilita a edição de fontes de PDF online. Sem nenhuma instalação, você pode receber um arquivo PDF com a fonte desejada.
(1) Abra a ferramenta Editar PDF do Soda PDF e carregue seu PDF.
(2) Selecione o texto existente para modificar a família da fonte, ajustar o tamanho da fonte, definir estilos negrito/itálico ou alterar a cor da fonte no PDF.
(3) Após a edição, salve e baixe seu arquivo PDF final.
Método 4: Alterar Fonte de PDF Programaticamente com C#
Para desenvolvedores, equipes de TI ou usuários que precisam realizar processamento em lote, o Free Spire.PDF for .NET é uma biblioteca gratuita que permite alterar todas as fontes em um PDF com apenas algumas linhas de código C#.
Principais Benefícios
- Gratuito para uso comercial e não comercial
- Altere em lote TODAS as fontes em um PDF em segundos
- Sem edição manual; ideal para fluxos de trabalho automatizados
- Preserva o layout e a formatação do PDF
Exemplo de Código C# Passo a Passo
O código a seguir carrega um PDF, recupera todas as fontes usadas no documento e as substitui por uma nova fonte (Calibri, Itálico, 11pt).
using Spire.Pdf;
using Spire.Pdf.Graphics;
using Spire.Pdf.Graphics.Fonts;
namespace Replace_font_in_PDF
{
class Program
{
static void Main(string[] args)
{
// 1. Carregar o documento PDF
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile(@"C:\SimpleDocument.pdf");
// 2. Obter todas as fontes usadas no PDF
PdfUsedFont[] fonts = pdf.UsedFonts;
// 3. Criar uma nova fonte TrueType
PdfTrueTypeFont newfont = new PdfTrueTypeFont("Calibri", 11f, PdfFontStyle.Italic, true);
// 4. Substituir cada fonte existente pela nova fonte
foreach (PdfUsedFont font in fonts)
{
font.Replace(newfont);
}
// 5. Salvar o PDF modificado
pdf.SaveToFile("ChangePdfFont.pdf");
}
}
}
O código usa dois membros principais:
- pdf.UsedFonts: Recupera uma matriz de cada fonte usada no PDF (incluindo subconjuntos).
- font.Replace(newfont): Substitui a fonte original pela nova fonte.
Exemplo de Saída:
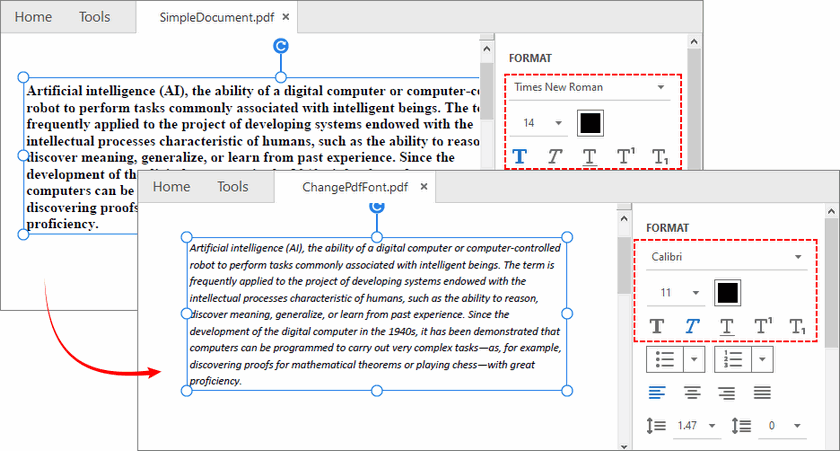
⚠️ Observação: O Free Spire.PDF atualmente suporta apenas a substituição de fontes Type‑1 padrão e fontes TrueType não incorporadas.
Preservando Tamanho e Estilo da Fonte
Em cenários do mundo real, substituir fontes de PDF com um tamanho ou estilo fixo geralmente causa problemas de layout, como sobreposição de texto, truncamento de conteúdo e quebras de linha quebradas. Para evitar distorção do documento, você pode reter o tamanho e o estilo da fonte originais, apenas trocando a família da fonte.
// Substituir cada fonte preservando seu tamanho e estilo originais
PdfUsedFont[] fonts = pdf.UsedFonts;
foreach (PdfUsedFont font in fonts)
{
float originalSize = font.Size; // Manter o tamanho original da fonte
PdfFontStyle originalStyle = font.Style; // Manter o estilo original (negrito, itálico, etc.)
// Criar uma nova fonte TrueType com o mesmo tamanho e estilo
PdfTrueTypeFont newfont = new PdfTrueTypeFont("Calibri", originalSize, originalStyle, true);
// Substituir a fonte antiga pela nova
font.Replace(newfont);
}
Personalizando a Fonte do PDF
Você pode modificar o construtor de fonte para atender às suas necessidades:
// usando diferentes famílias de fontes
PdfFont newfont = new PdfFont(PdfFontFamily.Helvetica, 12f, PdfFontStyle.Bold);
PdfFont newfont = new PdfFont(PdfFontFamily.Courier, 10f, PdfFontStyle.Regular);
// Usando uma fonte de sistema específica por nome (TrueType)
PdfTrueTypeFont newfont = new PdfTrueTypeFont("Arial", 11f, PdfFontStyle.Regular, true);
Com base na substituição de fontes em lote, você também pode pesquisar e substituir strings de texto em PDF usando C# com Free Spire.PDF.
Melhores Práticas para Alterar Fontes de PDF
- Use fontes seguras para a web: Use Arial, Calibri, Helvetica ou Times New Roman para garantir a exibição consistente em todos os dispositivos e sistemas operacionais.
- Evite editar excessivamente PDFs digitalizados: Para alterações tipográficas pesadas, recrie o documento no Word/Google Docs e exporte para PDF para obter resultados mais limpos.
- Incorpore fontes personalizadas: Se estiver usando fontes específicas da marca, ative a incorporação de fontes ao salvar para evitar erros de fonte ausente em outros dispositivos.
- Use ferramentas de desktop/programáticas para documentos profissionais: Para PDFs comerciais, legais ou em lote, priorize Adobe Acrobat, Word ou C# (Free Spire.PDF) em vez de ferramentas online gratuitas para melhor controle de qualidade.
Conclusão
Aprender como alterar fonte em PDF elimina as limitações da formatação estática de PDF, permitindo que você aprimore documentos para uso profissional, branding de negócios ou fluxos de trabalho automatizados. Para resultados profissionais, o Adobe Acrobat Pro continua sendo o padrão ouro. Se você já possui o Microsoft Word, ele oferece uma solução alternativa gratuita e inteligente para usuários do Word. Para edições rápidas baseadas em navegador, editores online gratuitos funcionam bem.
E para desenvolvedores e usuários avançados, o Free Spire.PDF for .NET abre um mundo de automação. Com apenas algumas linhas de código C#, você pode substituir todas as fontes em um PDF com consistência e precisão. Sempre confirme se o seu PDF é editável ou digitalizado primeiro para escolher o método de edição mais rápido e eficaz.
Perguntas Frequentes Sobre Alteração de Fontes em PDFs
P: Posso alterar a fonte em um PDF gratuitamente?
R: Sim. Você pode usar o Microsoft Word, ferramentas online gratuitas ou o método C# Free Spire.PDF para alterar fontes de PDF sem custo. Ferramentas premium são necessárias apenas para edições avançadas/ilimitadas.
P: Por que não consigo editar texto no meu PDF?
R: Seu arquivo é muito provavelmente um PDF digitalizado/baseado em imagem. Esses arquivos não têm uma camada de texto editável — você precisa de software OCR para converter a imagem em texto editável antes de modificar as fontes.
P: Alterar a fonte em um PDF afeta o layout do documento?
R: Sim, potencialmente. Fontes diferentes têm larguras de caracteres diferentes, o que pode alterar as quebras de linha e os layouts das páginas. Cada caixa de texto é independente, portanto, o texto não flui automaticamente para a próxima página.
P: Posso usar fontes personalizadas para edição de PDF?
R: Sim. Instale a fonte personalizada em seu dispositivo Windows/Mac primeiro; então você pode selecioná-la no Acrobat, Word, editores online ou referenciá-la por caminho de arquivo no código C# do Free Spire.PDF. Lembre-se de incorporar a fonte ao salvar para evitar erros de exibição em outros dispositivos.
P: Alterar uma fonte aumentará o tamanho do arquivo PDF?
R: Possivelmente. Se você substituir uma fonte não incorporada por uma incorporada, os dados da fonte serão adicionados ao PDF, aumentando o tamanho do arquivo. Para evitar arquivos PDF maiores, use fontes seguras para a web padrão e ative a incorporação apenas quando necessário.
Veja Também
PDF에서 글꼴 변경하기: Adobe, 온라인 및 C# 자동화
PDF는 오랫동안 전 세계적으로 고정 형식의 전문 문서를 공유하는 보편적인 표준이었습니다. 그러나 정적인 디자인은 종종 일반적인 문제점을 야기합니다. 올바른 도구 없이는 PDF에서 글꼴 크기, 스타일 또는 색상을 쉽게 변경할 수 없습니다.
일관되지 않은 텍스트 서식을 수정하거나, 브랜드 글꼴을 업데이트하거나, 가독성을 위해 글꼴 크기를 조정하거나, 인쇄 및 프레젠테이션을 위해 타이포그래피를 개선해야 하는 경우, PDF에서 글꼴을 변경하는 방법을 마스터하는 것은 학생, 전문가 및 사업주 모두에게 필수적인 기술입니다.
이 가이드에서는 다음을 사용하여 PDF 글꼴을 변경하는 단계별 방법을 자세히 설명합니다.
또한 PDF 글꼴 제한 사항, 업계 모범 사례 및 FAQ를 자세히 설명하여 PDF 글꼴 편집 문제를 완전히 해결합니다.
PDF 글꼴 문제 이해
PDF 글꼴을 수정하기 전에 PDF가 편집하기 어려운 이유를 이해하는 것이 중요합니다.
| 문제 | 설명 |
|---|---|
| 포함된 글꼴 vs. 포함되지 않은 글꼴 | 일부 PDF는 글꼴의 하위 집합만 포함하여 편집 옵션을 제한합니다. |
| 스캔된 PDF (이미지 기반) | 편집 가능한 텍스트 계층이 없으며, 이미지를 편집 가능한 텍스트로 변환하려면 OCR이 필요합니다. |
| 누락된 시스템 글꼴 | 장치에 글꼴이 설치되어 있지 않으면 텍스트가 손상되거나 자동으로 대체될 수 있습니다. |
| 고정 텍스트 상자 | PDF 텍스트는 독립적인 텍스트 블록으로 나뉩니다. PDF에서 글꼴 크기를 변경하면 줄 바꿈, 텍스트 넘침 또는 레이아웃 변경이 발생할 수 있습니다. |
| 권한 제한 | 일부 PDF는 작성자가 잠금 처리합니다. 편집하기 전에 권한을 제거해야 할 수 있습니다. |
방법 1: Adobe Acrobat Pro로 PDF 글꼴 편집
Adobe Acrobat Pro는 네이티브 PDF 글꼴을 편집하는 가장 안정적인 도구입니다. 손실 없는 글꼴 사용자 지정, 전체 타이포그래피 제어 및 스캔된 문서용 내장 OCR을 제공하며 Windows 및 Mac 모두와 호환됩니다.
Adobe Acrobat에서 글꼴을 변경하는 단계:
(1) Adobe Acrobat Pro에서 PDF를 엽니다.
(2) 편집 모드 진입: 상단 전역 바에서 “편집” 버튼을 클릭하여 PDF 편집 패널을 활성화합니다.
(3) 텍스트 선택: 마우스 커서로 다시 서식을 지정하려는 특정 텍스트 블록을 선택합니다.
(4) 글꼴 변경: 왼쪽 패널의 “텍스트 서식” 섹션에서:
- 드롭다운 목록에서 새 글꼴 선택
- 글꼴 크기 조정 (사전 설정 값 또는 사용자 지정 입력)
- 색상 선택기를 통해 PDF 글꼴 색상 변경
- 굵게, 기울임꼴, 밑줄 텍스트 스타일 토글
- 텍스트 정렬 설정: 왼쪽, 가운데, 오른쪽, 양쪽 맞춤
- 줄 간격 및 문자 간격 사용자 지정
(5) 텍스트 상자 외부를 클릭하여 변경 사항을 적용하고 PDF를 저장합니다.
스캔된 PDF를 위한 팁
PDF가 스캔된 문서에서 온 경우 Acrobat은 자동으로 OCR(광학 문자 인식)을 실행하여 편집 가능한 텍스트 계층을 생성합니다. 이는 스캔된 PDF 문서에서 글꼴을 변경하는 데 중요합니다.
방법 2: Microsoft Word로 PDF 글꼴 변경
프리미엄 PDF 소프트웨어가 없는 경우 Microsoft Word를 해결 방법으로 사용하여 Windows 및 Mac에서 PDF 문서의 글꼴을 변경할 수 있습니다. PDF를 편집 가능한 Word 문서로 변환하고, 전체 글꼴 편집을 지원하며, PDF로 다시 내보냅니다.
(1) Microsoft Word를 실행하고 “파일” > “열기”를 클릭하여 PDF 파일을 선택합니다.
(2) PDF 변환을 확인하는 팝업이 나타납니다. “확인”을 클릭하여 PDF를 편집 가능한 Word 문서로 변환합니다.
(3) 텍스트를 선택하고 Word 상단 글꼴 도구 모음을 사용하여 글꼴 모음, 크기, 색상 및 굵게/기울임꼴 스타일을 변경합니다.
(4) 레이아웃 변경 사항을 수정합니다 (복잡한 요소가 손실되거나 정렬되지 않을 수 있습니다. Word는 간단한 텍스트 기반 PDF에서 가장 잘 작동합니다).
(5) “파일” > “다른 이름으로 저장”으로 이동하여 내보내기 형식으로 “PDF”를 선택하여 업데이트된 파일을 저장합니다.
PDF 글꼴 및 서식을 다듬은 후에는 글꼴 및 레이아웃 무결성을 유지하면서 최종 PDF 파일 크기를 압축할 수 있습니다.
방법 3: 무료 온라인 PDF 편집기
일회성으로 간단한 글꼴 변경의 경우, 무료 온라인 PDF 편집기를 사용하면 브라우저에서 직접 PDF의 글꼴을 편집할 수 있습니다. 저희는 무료 PDF 글꼴 편집 기능을 제공하는 두 가지 신뢰할 수 있는 도구인 Soda PDF와 Sejda를 추천합니다.
Soda PDF를 사용하여 온라인에서 PDF 글꼴 변경
Soda PDF는 온라인에서 PDF 글꼴을 쉽게 편집할 수 있는 웹 기반 편집 도구를 제공합니다. 설치 없이도 원하는 글꼴이 포함된 PDF 파일을 받을 수 있습니다.
(1) Soda PDF의 PDF 편집 도구를 열고 PDF를 업로드합니다.
(2) 기존 텍스트를 선택하여 글꼴 모음, 글꼴 크기 조정, 굵게/기울임꼴 스타일 설정 또는 PDF에서 글꼴 색상 변경을 수정합니다.
(3) 편집 후 최종 PDF 파일을 저장하고 다운로드합니다.
방법 4: C#로 프로그래밍 방식 PDF 글꼴 변경
개발자, IT 팀 또는 일괄 처리를 수행해야 하는 사용자의 경우, Free Spire.PDF for .NET은 몇 줄의 C# 코드로 PDF의 모든 글꼴을 변경할 수 있는 무료 라이브러리입니다.
주요 이점
- 상업용 및 비상업용으로 무료 사용
- 몇 초 만에 PDF의 모든 글꼴 일괄 변경
- 수동 편집 불필요; 자동화된 워크플로우에 이상적
- PDF 레이아웃 및 서식 유지
단계별 C# 코드 예제
다음 코드는 PDF를 로드하고, 문서에 사용된 모든 글꼴을 검색하고, 모두 새 글꼴(Calibri, 기울임꼴, 11pt)로 바꿉니다.
using Spire.Pdf;
using Spire.Pdf.Graphics;
using Spire.Pdf.Graphics.Fonts;
namespace Replace_font_in_PDF
{
class Program
{
static void Main(string[] args)
{
// 1. PDF 문서 로드
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile(@"C:\SimpleDocument.pdf");
// 2. PDF에 사용된 모든 글꼴 가져오기
PdfUsedFont[] fonts = pdf.UsedFonts;
// 3. 새 TrueType 글꼴 생성
PdfTrueTypeFont newfont = new PdfTrueTypeFont("Calibri", 11f, PdfFontStyle.Italic, true);
// 4. 기존 글꼴을 새 글꼴로 모두 바꾸기
foreach (PdfUsedFont font in fonts)
{
font.Replace(newfont);
}
// 5. 수정된 PDF 저장
pdf.SaveToFile("ChangePdfFont.pdf");
}
}
}
이 코드는 두 가지 핵심 멤버를 사용합니다.
- pdf.UsedFonts: PDF에 사용된 모든 글꼴(하위 집합 포함)의 배열을 검색합니다.
- font.Replace(newfont): 원본 글꼴을 새 글꼴로 바꿉니다.
예제 출력:
⚠️ 참고: Free Spire.PDF는 현재 표준 Type‑1 글꼴 및 포함되지 않은 TrueType 글꼴만 바꾸는 것을 지원합니다.
글꼴 크기 및 스타일 유지
실제 시나리오에서는 고정된 크기나 스타일로 PDF 글꼴을 바꾸면 텍스트 겹침, 내용 잘림, 줄 바꿈 깨짐과 같은 레이아웃 문제가 발생하는 경우가 많습니다. 문서 왜곡을 방지하려면 글꼴 패밀리만 바꾸면서 원래 글꼴 크기와 스타일을 유지할 수 있습니다.
// 원래 크기와 스타일을 유지하면서 각 글꼴 바꾸기
PdfUsedFont[] fonts = pdf.UsedFonts;
foreach (PdfUsedFont font in fonts)
{
float originalSize = font.Size; // 원본 글꼴 크기 유지
PdfFontStyle originalStyle = font.Style; // 원본 스타일 (굵게, 기울임꼴 등) 유지
// 동일한 크기와 스타일로 새 TrueType 글꼴 생성
PdfTrueTypeFont newfont = new PdfTrueTypeFont("Calibri", originalSize, originalStyle, true);
// 이전 글꼴을 새 글꼴로 바꾸기
font.Replace(newfont);
}
PDF 글꼴 사용자 지정
필요에 맞게 글꼴 생성자를 수정할 수 있습니다.
// 다른 글꼴 패밀리 사용
PdfFont newfont = new PdfFont(PdfFontFamily.Helvetica, 12f, PdfFontStyle.Bold);
PdfFont newfont = new PdfFont(PdfFontFamily.Courier, 10f, PdfFontStyle.Regular);
// 특정 시스템 글꼴을 이름으로 사용 (TrueType)
PdfTrueTypeFont newfont = new PdfTrueTypeFont("Arial", 11f, PdfFontStyle.Regular, true);
일괄 글꼴 바꾸기를 기반으로 Free Spire.PDF를 사용하여 C#으로 PDF에서 텍스트 문자열을 검색하고 바꿀 수도 있습니다. 찾아서 바꾸기.
PDF 글꼴 변경 모범 사례
- 웹 안전 글꼴 사용: Arial, Calibri, Helvetica 또는 Times New Roman을 사용하여 모든 장치 및 운영 체제에서 일관된 표시를 보장합니다.
- 스캔된 PDF 과도 편집 방지: 복잡한 타이포그래피 변경의 경우, Word/Google Docs에서 문서를 다시 만들고 PDF로 내보내 더 깔끔한 결과를 얻으십시오.
- 사용자 지정 글꼴 포함: 브랜드별 글꼴을 사용하는 경우, 저장 중에 글꼴 포함을 활성화하여 다른 장치에서 글꼴 누락 오류를 방지하십시오.
- 전문 문서에는 데스크톱/프로그래밍 도구 사용: 비즈니스, 법률 또는 일괄 PDF의 경우, 더 나은 품질 관리를 위해 무료 온라인 도구보다 Adobe Acrobat, Word 또는 C# (Free Spire.PDF)을 우선적으로 사용하십시오.
마무리
PDF에서 글꼴을 변경하는 방법을 배우면 정적 PDF 서식의 제한 사항을 제거하여 전문적인 사용, 비즈니스 브랜딩 또는 자동화된 워크플로우를 위해 문서를 다듬을 수 있습니다. 전문적인 결과를 위해 Adobe Acrobat Pro는 여전히 최고입니다. 이미 Microsoft Word를 가지고 있다면, Word 사용자를 위한 영리한 무료 해결 방법을 제공합니다. 빠르고 브라우저 기반 편집의 경우 무료 온라인 편집기가 잘 작동합니다.
개발자와 파워 유저의 경우, Free Spire.PDF for .NET은 자동화의 세계를 열어줍니다. 몇 줄의 C# 코드로 PDF의 모든 글꼴을 일관성과 정확성으로 바꿀 수 있습니다. 가장 빠르고 효과적인 편집 방법을 선택하려면 항상 PDF가 편집 가능한지 또는 스캔된 것인지 먼저 확인하십시오.
PDF 글꼴 변경에 대한 FAQ
Q: PDF 글꼴을 무료로 변경할 수 있나요?
A: 예. Microsoft Word, 무료 온라인 도구 또는 C# Free Spire.PDF 방법을 사용하여 비용 없이 PDF 글꼴을 변경할 수 있습니다. 프리미엄 도구는 고급/무제한 편집에만 필요합니다.
Q: PDF에서 텍스트를 편집할 수 없는 이유는 무엇인가요?
A: 파일이 스캔/이미지 기반 PDF일 가능성이 높습니다. 이러한 파일에는 편집 가능한 텍스트 계층이 없습니다. 글꼴을 수정하기 전에 이미지를 편집 가능한 텍스트로 변환하려면 OCR 소프트웨어가 필요합니다.
Q: PDF에서 글꼴을 변경하면 문서 레이아웃에 영향을 미치나요?
A: 예, 잠재적으로 영향을 미칠 수 있습니다. 다른 글꼴은 다른 문자 너비를 가지므로 줄 바꿈과 페이지 레이아웃이 변경될 수 있습니다. 각 텍스트 상자는 독립적이므로 텍스트가 다음 페이지로 자동으로 흐르지 않습니다.
Q: PDF 편집에 사용자 지정 글꼴을 사용할 수 있나요?
A: 예. 먼저 Windows/Mac 장치에 사용자 지정 글꼴을 설치한 다음 Acrobat, Word, 온라인 편집기에서 선택하거나 Free Spire.PDF C# 코드에서 파일 경로를 통해 참조할 수 있습니다. 다른 장치에서 표시 오류를 방지하려면 저장 시 글꼴을 포함하는 것을 잊지 마십시오.
Q: 글꼴을 변경하면 PDF 파일 크기가 늘어나나요?
A: 가능합니다. 포함되지 않은 글꼴을 포함된 글꼴로 바꾸면 글꼴 데이터가 PDF에 추가되어 파일 크기가 늘어납니다. 더 큰 PDF 파일을 피하려면 표준 웹 안전 글꼴을 사용하고 필요한 경우에만 포함을 활성화하십시오.